
1. परिचय
आजकल, कंपनियां डेटा क्लाउड का इस्तेमाल करती हैं. इसमें डेटा, अलग-अलग फ़िज़िकल स्टोरेज सिस्टम में सेव होता है. ऐसे में, सुरक्षा को लेकर एक बड़ी चुनौती होती है, क्योंकि डेटा अलग-अलग जगहों पर सेव होने की वजह से, उसे सुरक्षित रखने के लिए अलग-अलग तरीके अपनाने पड़ते हैं.
सेंसिटिव डेटा (जैसे, फ़ाइनेंशियल ट्रांज़ैक्शन की रकम) को लगातार सुरक्षित रखने के लिए, क्या किया जा सकता है? ऐसा तब ज़रूरी होता है, जब डेटा को Google Cloud Storage पर Parquet जैसे ओपन-सोर्स फ़ॉर्मैट में सेव किया गया हो और BigQuery SQL या Apache Spark जैसे कई अलग-अलग इंजन से क्वेरी की गई हो.
इस कोडलैब में, डेटा को सुरक्षित रखने के लिए, एक ऐसा आर्किटेक्चर बनाया जाएगा जो इन समस्याओं को हल करता है. इसके लिए, Apache Iceberg टेबल, BigQuery, और Knowledge Catalog का इस्तेमाल किया जाएगा. इसमें, Infrastructure as Code (IaC) का इस्तेमाल करके, ज़ीरो-ट्रस्ट सुरक्षा नीतियां तय की जाएंगी. साथ ही, यह भी बताया जाएगा कि अलग-अलग कंप्यूट इंजन पर इन नीतियों को डाइनैमिक तरीके से कैसे लागू किया जाता है.
ज़रूरी शर्तें
- बिलिंग की सुविधा वाला Google क्लाउड प्रोजेक्ट.
- एसक्यूएल, आईएएम, और Cloud Storage के कॉन्सेप्ट की बुनियादी जानकारी.
आपको क्या सीखने को मिलेगा
- BigQuery में Apache Iceberg के लिए, Google Cloud Lakehouse टेबल बनाने का तरीका. इसमें डेटा, Cloud Storage में सेव होता है.
- कॉलम-लेवल की सुरक्षा और डेटा मास्किंग के लिए, पॉलिसी टैग का इस्तेमाल करके, सेंट्रलाइज़ डेटा नीतियां लागू करने का तरीका.
- Cloud resource connection का इस्तेमाल करके, फ़िज़िकल स्टोरेज ऐक्सेस को लॉजिकल डेटा ऐक्सेस से अलग करने का तरीका.
- ओपन-सोर्स इंजन, गवर्नेंस को बायपास न कर पाएं, इसके लिए Apache Spark के लिए मैनेज की जा रही सेवा का इस्तेमाल करके, ज़ीरो-ट्रस्ट कंप्यूट डेलिगेशन लागू करने का तरीका.
- डेटा लीनिएज को अपने-आप विज़ुअलाइज़ करने का तरीका.
आर्किटेक्चर की खास जानकारी: Iceberg पर यूनिवर्सल गवर्नेंस
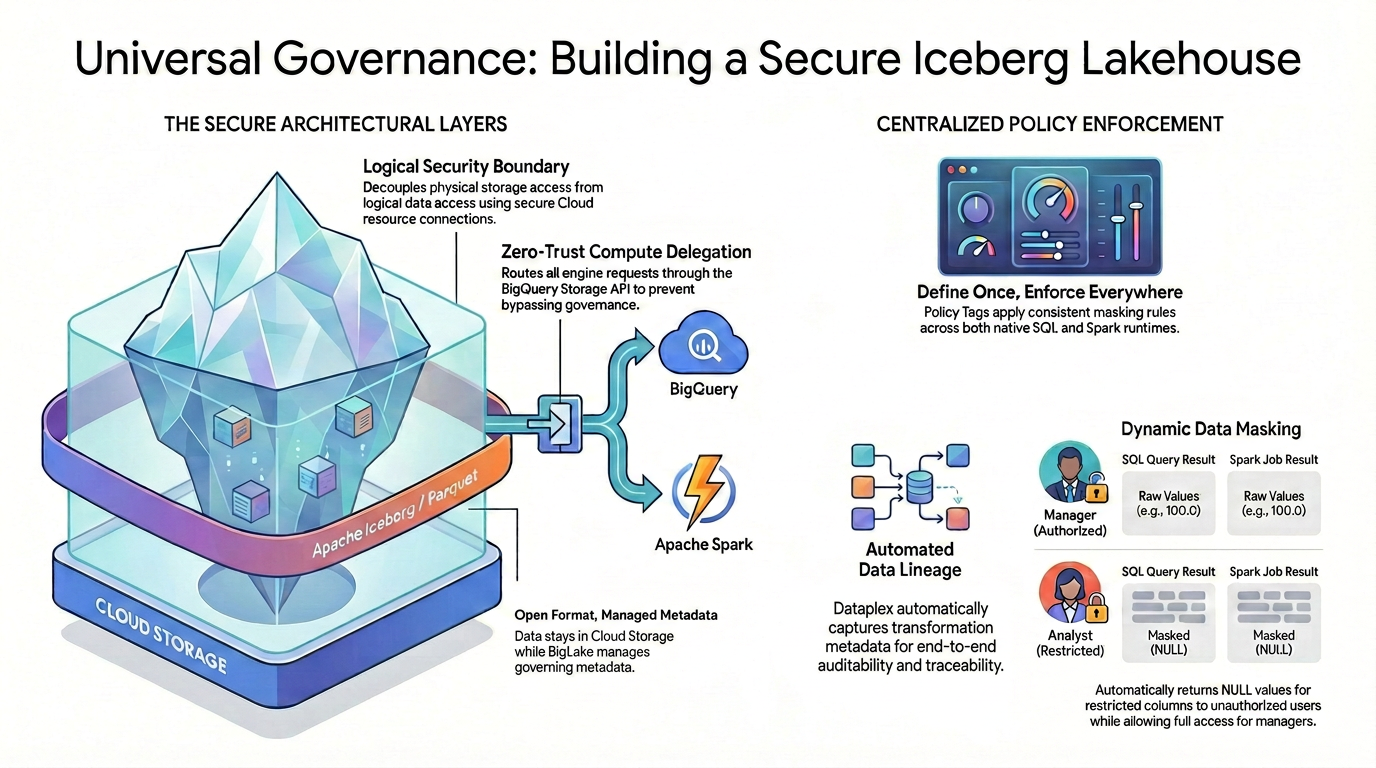
ओपन-सोर्स डेटा फ़ॉर्मैट पर, फ़ाइन-ग्रेन्ड ऐक्सेस कंट्रोल (जैसे, कॉलम-लेवल की सुरक्षा और डेटा मास्किंग) पाने के लिए, आपको सुरक्षा का एक सख्त और यूनिफ़ाइड आर्किटेक्चर बनाना होगा.
जैसा कि डायग्राम में दिखाया गया है, डेटा को अलग-अलग जगहों पर सेव होने की वजह से, सुरक्षा से जुड़ी चुनौती को हल करने के लिए, इस गवर्नेंस वाले लेकहाउस पैटर्न में दो मुख्य पिलर का इस्तेमाल किया जाता है:
🛡️ सुरक्षित आर्किटेक्चरल लेयर (बाईं ओर)
उपयोगकर्ताओं या बाहरी इंजन को Cloud Storage को सीधे तौर पर ऐक्सेस करने की अनुमति देने के बजाय, एक सुरक्षित फ़ाउंडेशन बनाएं. Cloud Storage में सिर्फ़ बकेट-लेवल की सुरक्षा की सुविधा मिलती है.
- ओपन फ़ॉर्मैट, मैनेज किया गया मेटाडेटा: डेटा, Cloud Storage में Apache Iceberg (Parquet) के ओपन फ़ॉर्मैट का इस्तेमाल करके सेव होता है. वहीं, Lakehouse, गवर्नेंस वाले मेटाडेटा को आसानी से मैनेज करता है.
- लॉजिकल सुरक्षा बाउंड्री: सुरक्षित Cloud resource connection का इस्तेमाल करके, फ़िज़िकल स्टोरेज ऐक्सेस को लॉजिकल डेटा ऐक्सेस से अलग करें. एंड यूज़र को, GCS की रॉ फ़ाइलों का सीधे तौर पर फ़िज़िकल आईएएम ऐक्सेस कभी नहीं दिया जाता.
- ज़ीरो-ट्रस्ट कंप्यूट डेलिगेशन: यह पक्का करने के लिए कि कोई भी एक्ज़ीक्यूशन इंजन, गवर्नेंस के नियमों को बायपास न कर पाए, डेटा पढ़ने के सभी अनुरोधों को BigQuery Storage API के ज़रिए ही भेजा जाता है. यह नियम तब भी लागू होता है, जब क्वेरी, BigQuery SQL या ओपन-सोर्स Apache Spark से की जाती है.
🎯 सेंट्रलाइज़ पॉलिसी एनफ़ोर्समेंट (दाईं ओर)
सुरक्षित फ़ाउंडेशन बनाने के बाद, Knowledge Catalog, गवर्नेंस के लिए यूनिफ़ाइड ब्रेन के तौर पर काम करता है:
- एक बार तय करें, हर जगह लागू करें: Knowledge Catalog में, पॉलिसी टैग सिर्फ़ एक बार तय करें. इसके बाद, आर्किटेक्चर, सभी काम करने वाले रनटाइम पर, मास्किंग के एक जैसे नियम लागू करता है.
- डाइनैमिक डेटा मास्किंग: जब डेटा के लिए क्वेरी की जाती है, तो सिस्टम, उपयोगकर्ता की पहचान का आकलन तुरंत करता है. अनुमति वाले उपयोगकर्ताओं को, एसक्यूएल और Spark, दोनों में रॉ और बिना मास्क की गई वैल्यू (जैसे, 100.0) दिखेंगी. वहीं, प्रतिबंधित उपयोगकर्ताओं को, दोनों इंजन में प्रतिबंधित कॉलम के लिए, मास्क की गई NULL वैल्यू अपने-आप मिलेंगी.
- डेटा लीनिएज अपने-आप ट्रैक होना: डेटा के फ़्लो और ट्रांसफ़ॉर्म होने पर, Knowledge Catalog, ट्रांसफ़ॉर्मेशन मेटाडेटा को अपने-आप कैप्चर करता है. इससे, कस्टम लॉगिंग कोड की ज़रूरत के बिना, एंड-टू-एंड ऑडिट और ट्रेस करने की सुविधा मिलती है.
2. सेटअप और ज़रूरी शर्तें
Cloud Shell लॉन्च करना
Google Cloud को लैपटॉप से रिमोट ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में, Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं टूलबार पर मौजूद, Cloud Shell आइकॉन पर क्लिक करें:
एनवायरमेंट को प्रोविज़न करने और उससे कनेक्ट होने में कुछ सेकंड लगेंगे. जब यह प्रोसेस पूरी हो जाएगी, तो आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल लोड होते हैं. इसमें 5 जीबी की परसिस्टेंट होम डायरेक्ट्री मिलती है. साथ ही, यह Google Cloud पर चलती है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में, सारा काम ब्राउज़र में किया जा सकता है. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
एनवायरमेंट शुरू करना
Cloud Shell खोलें और अपने प्रोजेक्ट के वैरिएबल सेट करें, ताकि सभी कमांड सही इन्फ़्रास्ट्रक्चर को टारगेट करें.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
इसके बाद, अपने दो पर्सोना तय करें.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
एपीआई चालू करें
ज़रूरी Google Cloud सेवाएं चालू करें.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
कोडलैब का सोर्स कोड डाउनलोड करना
Cloud Shell को व्यवस्थित रखने के लिए, स्पार्स चेकआउट करें. इससे, Google Cloud DevRel रिपॉज़िटरी से, इस कोडलैब के लिए ज़रूरी Python स्क्रिप्ट ही डाउनलोड होंगी.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
स्टोरेज बनाना
सुरक्षित तरीके से मैनेज किए गए Iceberg डेटा को सेव करने के लिए, बकेट बनाएं.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
पहचान और सुरक्षा की तैयारी करना
Cloud resource connection कॉन्फ़िगर करें. यह सिर्फ़ ऐसी इकाई है जिसके पास, Iceberg की रॉ फ़ाइलों को पढ़ने के लिए, परमानेंट फ़िज़िकल आईएएम कुंजियां होती हैं.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
इसके बाद, उपयोगकर्ता के पर्सोना सेट अप करें. उपयोगकर्ताओं को लॉजिकल ऐक्सेस दिया जाता है, न कि फ़िज़िकल स्टोरेज ऐक्सेस. आईएएम के लागू होने में होने वाली देरी की वजह से होने वाली गड़बड़ियों से बचने के लिए, पहले खाते बनाएं. इसके बाद, कुछ सेकंड इंतज़ार करें. फिर उन्हें भूमिकाएं असाइन करें.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Lakehouse की मदद से, Iceberg की नेटिव टेबल बनाना
मैनेज की गई Iceberg टेबल बनाने के लिए, Lakehouse की नेटिव सुविधाओं का इस्तेमाल किया जाएगा.
BigQuery डेटासेट बनाना
सबसे पहले, BigQuery डेटासेट बनाएं, ताकि Iceberg टेबल को लॉजिकल तरीके से ग्रुप किया जा सके.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg टेबल बनाना
इसके बाद, टेबल बनाने के लिए ये कमांड चलाएं. OPTIONS ब्लॉक देखें. इसमें, हमने table_format = 'ICEBERG' तय किया है और इसे सीधे तौर पर अपने Cloud Storage बकेट और कनेक्शन पर मैप किया है.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
टेबल में डेटा डालना
आखिर में, नई बनाई गई Iceberg टेबल में, सैंपल डेटा डालें.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
अब आपके पास, पूरी तरह से काम करने वाली दो Iceberg टेबल हैं. Lakehouse, मेटाडेटा को मैनेज करता है. हालांकि, Parquet की फ़िज़िकल फ़ाइलें, आपकी GCS बकेट में सुरक्षित तरीके से सेव रहती हैं!
ईटीएल पाइपलाइन की प्रोसेस को सिम्युलेट करना
असल दुनिया में, रॉ डेटा को अक्सर कारोबार की रिपोर्टिंग के लिए, खास जानकारी वाली टेबल में इकट्ठा किया जाता है. आइए, डेटा इंजीनियर के तौर पर काम करें और ट्रांज़ैक्शन के रॉ डेटा से, रोज़ाना की बिक्री की खास जानकारी वाली टेबल बनाएं.
(ध्यान दें: यह चरण अभी पूरा करें, ताकि Google Cloud को बैकग्राउंड मेटाडेटा प्रोसेस करने के लिए काफ़ी समय मिल सके. आपको कोडलैब में बाद में पता चलेगा कि यह क्यों ज़रूरी है!)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. सेंट्रलाइज़ गवर्नेंस: Python का इस्तेमाल करके नीतियां तय करना
प्रोडक्शन एनवायरमेंट में, यूज़र इंटरफ़ेस (यूआई) के ज़रिए गवर्नेंस की नीतियां कॉन्फ़िगर करना, मुश्किल होता है. साथ ही, इसे स्केल और मेंटेन करना भी मुश्किल होता है. इसलिए, Infrastructure as Code (IaC) का इस्तेमाल करने का सुझाव दिया जाता है.
इस सेक्शन में, Google Cloud Python SDK का इस्तेमाल करके, ज़ीरो-ट्रस्ट गवर्नेंस के नियमों को प्रोग्राम के ज़रिए, सिलसिलेवार तरीके से बनाया और लागू किया जाएगा.
Python एनवायरमेंट सेट अप करना
सबसे पहले, लाइब्रेरी के टकराव से बचने और ज़रूरी Google Cloud SDK इंस्टॉल करने के लिए, आइसोलेटेड Python एनवायरमेंट (venv) सेट अप करें.
Cloud Shell में ये कमांड चलाएं:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
टैक्सोनॉमी और पॉलिसी टैग बनाना
टैक्सोनॉमी एक लॉजिकल कंटेनर है. वहीं, पॉलिसी टैग वह खास लेबल है जिसे सेंसिटिव कॉलम से जोड़ा जाएगा. कॉलम-लेवल की सुरक्षा लागू करने के लिए, सबसे पहले आपको एक लॉजिकल कंटेनर (टैक्सोनॉमी) और एक खास लेबल (पॉलिसी टैग) की ज़रूरत होगी.
1_create_taxonomy.py में, आपको यह मुख्य लॉजिक दिखेगा:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
FINE_GRAINED_ACCESS_CONTROL नीति का टाइप साफ़ तौर पर सेट करके, स्टैंडर्ड मेटाडेटा टैग को सख्त ज़ीरो-ट्रस्ट सुरक्षा बाउंड्री में बदला जा सकता है. इस टैग वाले किसी भी कॉलम को डिफ़ॉल्ट रूप से, किसी भी उपयोगकर्ता के लिए ऐक्सेस नहीं किया जा सकेगा.
संसाधन बनाने के लिए स्क्रिप्ट चलाएं:
python 1_create_taxonomy.py
मास्किंग का नियम (डेटा नीति) कॉन्फ़िगर करना
अब यह तय करें कि टैग किए गए कॉलम के लिए, बिना अनुमति वाला कोई व्यक्ति क्वेरी करता है, तो क्या होगा. एक डेटा नीति बनाएं. इससे, वैल्यू NULL के तौर पर दिखेगी. साथ ही, इस नियम को ऐनलिस्ट पर्सोना पर लागू करें.
2_create_masking.py में, स्क्रिप्ट, आपके बनाए गए पॉलिसी टैग आईडी को डाइनैमिक तरीके से ढूंढती है और डेटा नीति लागू करती है:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
यह कोड, प्रोग्राम के ज़रिए एक ऐसा नियम बनाता है जिससे, वैल्यू NULL के तौर पर दिखती है. इसके बाद, यह मास्क किए गए रीडर की आईएएम भूमिका को खास तौर पर ऐनलिस्ट पर्सोना को असाइन करता है. इससे यह पक्का होता है कि उन्हें डेटा का सिर्फ़ मास्क किया गया वर्शन दिखे.
मास्किंग का नियम कॉन्फ़िगर करने के लिए स्क्रिप्ट चलाएं:
python 2_create_masking.py
फ़ाइन-ग्रेन्ड ऐक्सेस देना
ज़ीरो-ट्रस्ट सेटअप की वजह से, फ़िलहाल टैग किए गए कॉलम को कोई भी नहीं पढ़ सकता. आपको मैनेजर और अपने निजी खाते को साफ़ तौर पर ऐक्सेस देना होगा.
3_grant_access.py में, पॉलिसी टैग की आईएएम नीति में बदलाव करें:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
categoryFineGrainedReader भूमिका जोड़ने से, ये खास प्रिंसिपल, मास्किंग के नियमों को बायपास कर सकते हैं और रॉ, बिना मास्क किया गया डेटा पढ़ सकते हैं.
ऐक्सेस देने के लिए स्क्रिप्ट चलाएं:
python 3_grant_access.py
पॉलिसी टैग को BigQuery टेबल से जोड़ना
आखिर में, इस लॉजिकल पॉलिसी टैग को, Iceberg टेबल के फ़िज़िकल स्कीमा से जोड़ना होगा.
4_attach_tag.py देखें. स्क्रिप्ट, BigQuery टेबल स्कीमा फ़ेच करती है, फ़ील्ड के ज़रिए इटरेट करती है, और खास तौर पर amount कॉलम से टैग जोड़ती है:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
स्कीमा का यह अपडेट लागू होने पर, Lakehouse, Knowledge Catalog के लॉजिकल टैग को, Cloud Storage बकेट में सेव की गई Parquet की फ़िज़िकल फ़ाइलों से तुरंत जोड़ देता है.
टेबल स्कीमा अपडेट करने के लिए स्क्रिप्ट चलाएं:
python 4_attach_tag.py
5. Knowledge Catalog की नीतियों की पुष्टि करना
अब यह टेस्ट करने का समय है कि सेंट्रलाइज़ गवर्नेंस काम करता है या नहीं. यह टेस्ट दो अलग-अलग इंजन पर किया जाएगा, ताकि यह साबित किया जा सके कि Knowledge Catalog की नीतियां, हर जगह लागू होती हैं.
BigQuery के नेटिव एसक्यूएल का इस्तेमाल करके पुष्टि करना
सबसे पहले, Cloud Shell का इस्तेमाल करके, अपने दो पर्सोना की पहचान मान लें. इसके बाद, BigQuery के नेटिव एसक्यूएल इंजन का इस्तेमाल करके, टेबल के लिए क्वेरी करें.
मैनेजर के तौर पर टेस्ट करना (अनुमति वाला उपयोगकर्ता):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
मैनेजर के पास फ़ाइन-ग्रेन्ड रीडर की भूमिका है. इसलिए, उसे रकम की रॉ वैल्यू दिखेंगी
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
ऐनलिस्ट के तौर पर टेस्ट करना (प्रतिबंधित उपयोगकर्ता):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Knowledge Catalog के मास्किंग के नियम की वजह से, हर लाइन के लिए, रकम वाला कॉलम NULL के तौर पर दिखता है.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
अपनी पहचान वापस लाना
अपने एडमिन उपयोगकर्ता पर वापस जाने के लिए, Cloud Shell की पुष्टि करने की स्थिति को साफ़ करें.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Apache Spark (कंप्यूट डेलिगेशन) का इस्तेमाल करके पुष्टि करना
अगर कोई डेटा साइंटिस्ट, इस टेबल को पढ़ने के लिए Apache Spark का इस्तेमाल करता है, तो क्या होगा? अगर Spark, GCS की Parquet की फ़िज़िकल फ़ाइलों को सीधे तौर पर पढ़ता है, तो Knowledge Catalog के मास्किंग के नियम पूरी तरह से बायपास हो जाते हैं. ऐसा इसलिए होता है, क्योंकि Cloud Storage में सिर्फ़ बकेट-लेवल की अनुमतियां काम करती हैं.
इससे बचने के लिए, कंप्यूट डेलिगेशन लागू करने के लिए, Spark-BigQuery कनेक्टर का इस्तेमाल करें. यह कनेक्टर, एक सुरक्षित ब्रिज के तौर पर काम करता है. यह Spark के रीड अनुरोधों को BigQuery Storage API के ज़रिए भेजता है, ताकि Spark क्लस्टर को कोई भी डेटा भेजे जाने से पहले, Knowledge Catalog के गवर्नेंस के नियमों का आकलन डाइनैमिक तरीके से किया जा सके.
डाउनलोड की गई read_transactions.py स्क्रिप्ट में मौजूद मुख्य लॉजिक देखें:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
ध्यान दें कि हम Spark को, Iceberg की फ़ाइलों के gs:// पाथ पर पॉइंट नहीं कर रहे हैं. .format("bigquery") तय करने पर, BigQuery Storage API, रीड अनुरोध को इंटरसेप्ट करता है. इसके बाद, Spark जॉब चलाने वाले उपयोगकर्ता की पहचान की जांच करता है, Knowledge Catalog के मास्किंग के नियम लागू करता है, और सिर्फ़ अनुमति वाला डेटा, Spark DataFrame को वापस भेजता है.
इस PySpark स्क्रिप्ट को अपनी Cloud Storage बकेट में अपलोड करें, ताकि मैनेज किए जा रहे Apache Spark को इसे ऐक्सेस किया जा सके:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
मैनेजर के तौर पर Spark चलाना:
मैनेज किए जा रहे Apache Spark का इस्तेमाल किया जाएगा. इस मैनेज की जा रही सेवा की मदद से, Spark के वर्कलोड को सीधे तौर पर चलाया जा सकता है. इसके लिए, खास क्लस्टर को प्रोविज़न, कॉन्फ़िगर या मैनेज करने की ज़रूरत नहीं होती.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
टर्मिनल में, जॉब के आउटपुट लॉग देखें. मैनेजर के पास फ़ाइन-ग्रेन्ड रीडर की भूमिका है. इसलिए, Spark, रकम की रॉ और बिना मास्क की गई वैल्यू को सफलतापूर्वक वापस लाता है.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
ऐनलिस्ट के तौर पर Spark चलाना:
अब ठीक वही Spark जॉब सबमिट करें. हालांकि, इस बार ऐनलिस्ट पर्सोना के तौर पर काम करें.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
लॉग फिर से देखें. ऐनलिस्ट ने ठीक वही Spark कोड चलाया. इसके बावजूद, BigQuery Storage API ने अनुरोध को इंटरसेप्ट किया और Knowledge Catalog की नीति लागू की. ऐनलिस्ट के Spark DataFrame में, रकम के लिए null दिखता है!
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
आर्किटेक्चरल ट्रेड-ऑफ़: BigQuery SQL बनाम Spark
आपने अभी-अभी साबित किया है कि इंजन कोई भी हो, नतीजा एक जैसा ही होता है! Knowledge Catalog की नीति सफलतापूर्वक लागू की गई. हालांकि, प्रोडक्शन में किसका इस्तेमाल करना चाहिए?
- BigQuery SQL: उन वर्कफ़्लो के लिए बेहतर है जिनमें एसक्यूएल, पसंदीदा इंजन है और सीधे तौर पर कंप्यूटेशन करता है. यह तेज़ ऐनलिटिक्स और Business Intelligence के लिए सबसे सही है.
- Apache Spark: Python का इस्तेमाल करके, ज़्यादा जटिल वर्कलोड को मैनेज किया जा सकता है. इसलिए, यह मशीन लर्निंग की ऐडवांस पाइपलाइन या Hadoop के पुराने कोड के लिए सही है.
अहम जानकारी: कंप्यूट डेलिगेशन लागू करने पर, सेंट्रलाइज़ ज़ीरो-ट्रस्ट गवर्नेंस लेयर को बायपास नहीं किया जा सकता. भले ही, किसी भी इंजन का इस्तेमाल किया जाए!
6. डेटा लीनिएज अपने-आप ट्रैक होना
किसी भी एंटरप्राइज़ डेटा आर्किटेक्चर में, यह जानना ज़रूरी है कि आपका डेटा कहां से आता है और उसमें कैसे बदलाव किए गए हैं. इससे, कंप्लायंस, डीबग करने, और भरोसा कायम करने में मदद मिलती है. इस कॉन्सेप्ट को डेटा लीनिएज कहा जाता है. इससे इन बुनियादी सवालों के जवाब मिलते हैं: "अगर कोई मैनेजर, रोज़ाना की बिक्री की रिपोर्ट देख रहा है, तो उन नंबरों को कैलकुलेट करने के लिए, रॉ टेबल का इस्तेमाल किया गया था?"
आम तौर पर, इस लाइफ़साइकल को ट्रैक करने के लिए, डेटा इंजीनियर को कस्टम लॉगिंग कोड मैन्युअल तरीके से लिखना होता है या एसक्यूएल स्क्रिप्ट को पार्स करने के लिए, तीसरे पक्ष के जटिल टूल का इस्तेमाल करना होता है. हालांकि, Google Cloud Lakehouse में, यह ट्रैकिंग पहले से मौजूद होती है और इसे मैन्युअल तरीके से करने की ज़रूरत नहीं होती.
क्या आपको transactions_summary टेबल याद है? इसे कोडलैब में पहले, ट्रांज़ैक्शन की रॉ टेबल से बनाया गया था. जब BigQuery ने CREATE TABLE AS SELECT स्टेटमेंट को एक्ज़ीक्यूट किया, तो कंप्यूट इंजन ने ट्रांसफ़ॉर्मेशन मेटाडेटा को अपने-आप कैप्चर किया और उसे Knowledge Catalog को भेज दिया. आइए, नतीजा देखें.
लीनिएज को विज़ुअलाइज़ करना
- Google Cloud Console में, Knowledge Catalog > खोजें पर जाएं.
- खोज बार में
lakehouse_retail_demo.transactionsटाइप करें और टेबल पर क्लिक करें. - लीनिएज टैब पर क्लिक करें.
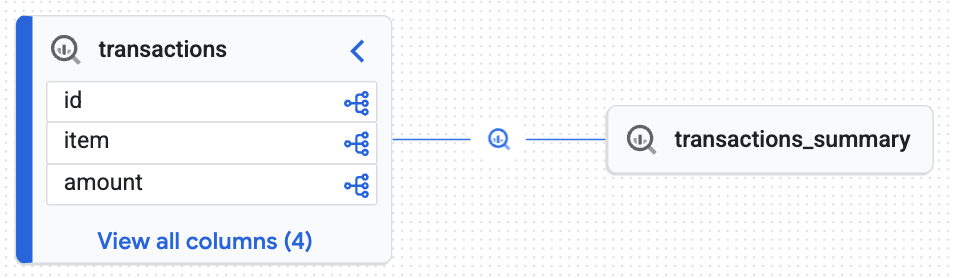
आपको Knowledge Engine से जनरेट किया गया एक इंटरैक्टिव ग्राफ़ दिखेगा. इससे यह साबित होता है कि टारगेट टेबल (transactions_summary), Iceberg की रॉ टेबल (transactions) से ली गई थी. आपने डेटा ऑडिट के लिए ज़रूरी, एंड-टू-एंड ट्रेस करने की सुविधा हासिल कर ली है.
7. स्टोरेज में जगह बनाएं
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं.
Knowledge Catalog के गवर्नेंस वाले संसाधन हटाना
BigQuery डेटासेट या Cloud Storage बकेट मिटाने से पहले, आपको गवर्नेंस के लॉजिकल नियम हटाने होंगे. अगर रिपॉज़िटरी में मौजूद cleanup_governance.py स्क्रिप्ट देखी जाए, तो आपको हटाने का यह क्रम दिखेगा:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
यहां क्रम ज़रूरी है. स्क्रिप्ट, सबसे पहले डेटा नीति (मास्किंग का नियम) मिटाती है, क्योंकि यह पॉलिसी टैग पर निर्भर करती है. नीति हटाने के बाद, पैरंट टैक्सोनॉमी को मिटाने पर, संसाधन की निर्भरता से जुड़ी गड़बड़ियां ट्रिगर किए बिना, सभी पॉलिसी टैग अपने-आप मिट जाएंगे.
Python क्लीनअप स्क्रिप्ट चलाएं:
python cleanup_governance.py
पहचान, स्टोरेज, और कंप्यूट ऐसेट हटाना
अब गवर्नेंस लेयर अलग हो गई है. इसलिए, BigQuery टेबल, Cloud Storage बकेट, सेवा खाते, और Python के लोकल एनवायरमेंट को सुरक्षित तरीके से मिटाया जा सकता है.
Cloud Shell में, व्यवस्थित करने के लिए यहां दिया गया पूरा ब्लॉक कॉपी करें और चलाएं:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
इन चरणों को पूरा करने के बाद, यह पक्का हो गया है कि आपके प्रोजेक्ट में, कोई भी अनाथ संसाधन या छिपी हुई नीतियां मौजूद नहीं हैं.
8. बधाई हो!
आपने डेटा को सुरक्षित रखने के लिए, एक ऐसा Data Lakehouse लागू किया है जिसमें डेटा को आसानी से खोजा जा सकता है.
आपने यह सीखा:
- Iceberg का नेटिव इंटिग्रेशन: Lakehouse, ओपन-सोर्स Iceberg टेबल को नेटिव तरीके से मैनेज कर सकता है. साथ ही, फ़िज़िकल फ़ाइलों को Cloud Storage में सुरक्षित तरीके से सेव कर सकता है.
- सुरक्षा के लिए कंप्यूट डेलिगेशन: क्वेरी को BigQuery Storage API के ज़रिए भेजकर, आपने फ़िज़िकल फ़ाइलों पर फ़ाइन-ग्रेन्ड डाइनैमिक मास्किंग लागू की. इन फ़ाइलों को नेटिव तरीके से, आंशिक ऐक्सेस को प्रतिबंधित नहीं किया जा सकता.
- इंजन-एग्नोस्टिक गवर्नेंस: पॉलिसी टैग की मदद से, नियम एक बार तय किए जा सकते हैं. इसके बाद, इन्हें नेटिव एसक्यूएल या Apache Spark रनटाइम के ज़रिए क्वेरी करने पर, हर जगह लागू किया जा सकता है.
- डेटा की खोज की जा सकती है: Knowledge Engine ने डेटा लीनिएज को अपने-आप ट्रैक किया. इससे, एंटरप्राइज़ ऑडिट की ज़रूरी सुविधा मिली.
आगे क्या करना है?
- ऐक्सेस कंट्रोल की ऐडवांस सुविधाओं के बारे में जानना: सुरक्षा के ज़्यादा जटिल परिदृश्य लागू करने के लिए, Lakehouse को अतिरिक्त सुविधाओं के साथ पसंद के मुताबिक बनाने के बारे में आधिकारिक दस्तावेज़ देखें.
- GenAI के लिए, अनस्ट्रक्चर्ड डेटा को सुरक्षित रखना: ऑब्जेक्ट टेबल के बारे में जानें. Cloud Storage में मौजूद अनस्ट्रक्चर्ड फ़ाइलों (पीडीएफ़, इमेज) के लिए, सुरक्षित ब्रिज के इस पैटर्न को बढ़ाएं. इससे, Gemini Enterprise Agent Engine और RAG पाइपलाइन के लिए, सुरक्षित और गवर्नेंस वाला डेटा फ़ाउंडेशन बनाया जा सकेगा.