
1. Introduzione
In un cloud di dati aziendale moderno, in cui i dati risiedono in vari sistemi di archiviazione fisica, esiste un'enorme sfida architettonica di sicurezza frammentata.
Come fai a garantire che i dati sensibili (come gli importi delle transazioni finanziarie) siano protetti in modo coerente quando i dati vengono archiviati fisicamente in formati open source come Parquet su Google Cloud Storage e sottoposti a query da più motori diversi, come BigQuery SQL o Apache Spark?
In questa codelab, creerai un'architettura di data lakehouse gestita che risolve questi problemi utilizzando tabelle Apache Iceberg, BigQuery e Knowledge Catalog. Utilizzerai Infrastructure as Code (IaC) per definire le policy di sicurezza Zero Trust e il modo in cui vengono applicate dinamicamente su diversi motori di calcolo.
Prerequisiti
- Un progetto Google Cloud con la fatturazione abilitata.
- Comprensione di base dei concetti di SQL, IAM e Cloud Storage.
Cosa imparerai a fare
- Come creare tabelle Google Cloud Lakehouse per Apache Iceberg in BigQuery, dove Cloud Storage contiene i dati in modo nativo.
- Come applicare policy dei dati centralizzate utilizzando i tag di policy per la sicurezza a livello di colonna e il mascheramento dei dati.
- Come disaccoppiare l'accesso allo spazio di archiviazione fisico dall'accesso logico ai dati utilizzando la connessione alla risorsa Cloud.
- Come applicare la delega di calcolo Zero Trust utilizzando Managed Service for Apache Spark per garantire che i motori open source non possano bypassare la governance.
- Come visualizzare la derivazione dei dati automatizzata Data Lineage.
Panoramica dell'architettura: governance universale su Iceberg
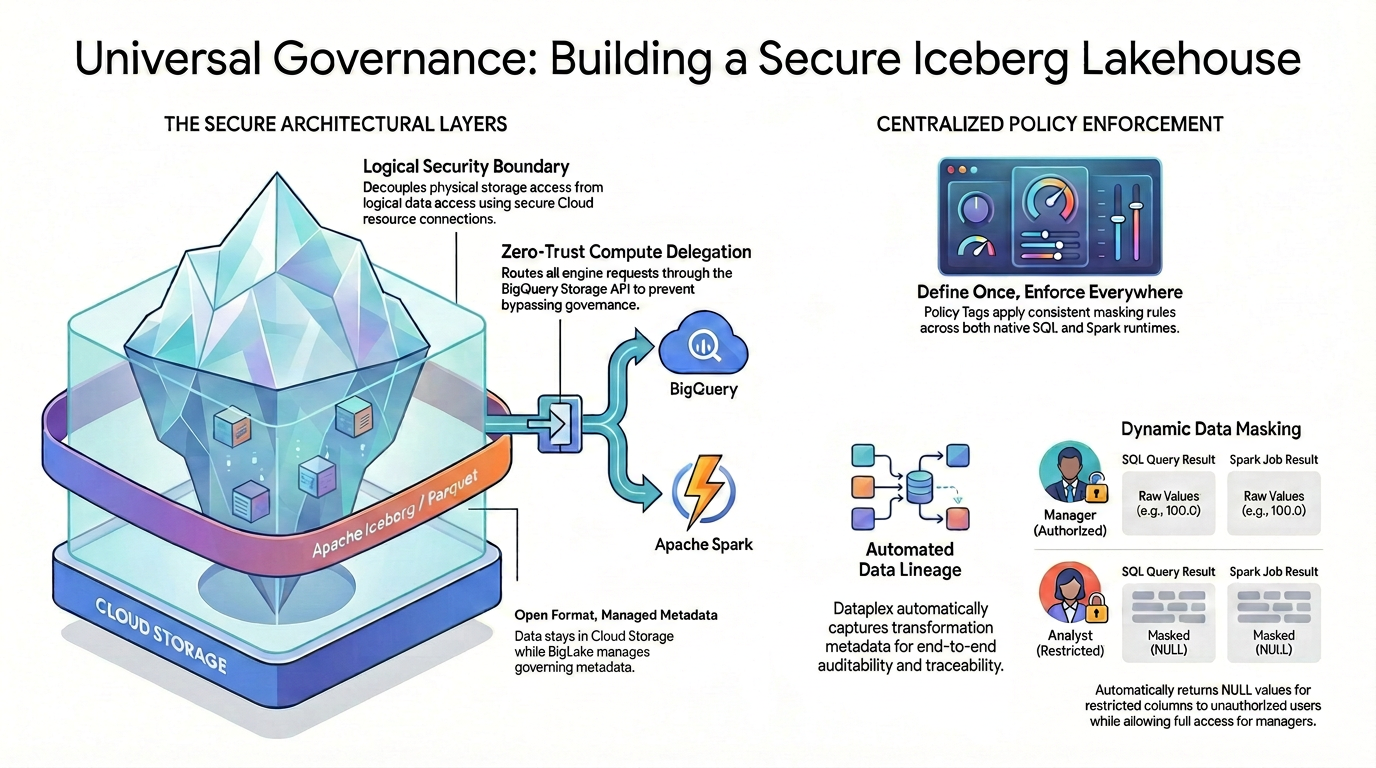
Per ottenere un controllo dell'accesso granulare (come la sicurezza a livello di colonna e il mascheramento dei dati) sui formati di dati open source, devi stabilire un'architettura di sicurezza rigorosa e unificata.
Come illustrato nel diagramma, questo pattern di lakehouse gestito si basa su due pilastri principali per risolvere la sfida della sicurezza frammentata:
🛡️ I livelli di architettura sicura (a sinistra)
Anziché consentire agli utenti o ai motori esterni di accedere direttamente a Cloud Storage, che supporta solo la sicurezza a livello di bucket, crei una base sicura.
- Formato aperto, metadati gestiti: i dati rimangono fisicamente in Cloud Storage utilizzando il formato Apache Iceberg (Parquet) aperto, mentre Lakehouse gestisce senza problemi i metadati di governance.
- Limite di sicurezza logico: disaccoppi l'accesso allo spazio di archiviazione fisico dall'accesso ai dati logico utilizzando una connessione alle risorse Cloud sicura. Agli utenti finali non viene mai concesso l'accesso IAM fisico diretto ai file GCS non elaborati.
- Delega di calcolo Zero Trust: per garantire che nessun motore di esecuzione possa bypassare le regole di governance, tutte le richieste di lettura dei dati vengono instradate rigorosamente tramite l'API BigQuery Storage. Questo vale sia che la query provenga da BigQuery SQL nativo sia da Apache Spark open source.
🎯 Applicazione centralizzata delle policy (a destra)
Con la base sicura, Knowledge Catalog funge da cervello unificato per la governance:
- Definisci una volta, applica ovunque: definisci i tag di policy in Knowledge Catalog una sola volta e l'architettura applica regole di mascheramento coerenti a livello universale in tutti i runtime di esecuzione supportati.
- Mascheramento dinamico dei dati: quando viene eseguita una query sui dati, il sistema valuta l'identità dell'utente in tempo reale. Mentre gli utenti autorizzati vedranno i valori non elaborati e non mascherati (ad es. 100.0) sia in SQL che in Spark, gli utenti con limitazioni riceveranno automaticamente valori NULL mascherati per le colonne con limitazioni in entrambi i motori.
- Derivazione dei dati automatizzata: man mano che i dati scorrono e si trasformano, Knowledge Catalog acquisisce automaticamente i metadati di trasformazione, fornendo auditabilità e tracciabilità end-to-end integrate senza richiedere codice di logging personalizzato.
2. Configurazione e requisiti
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questa codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere qualcosa di simile a questo:

Questa macchina virtuale è dotata di tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questa codelab può essere svolto all'interno di un browser. Non è necessario installare nulla.
Inizializza l'ambiente
Apri Cloud Shell e imposta le variabili del progetto per assicurarti che tutti i comandi siano destinati all'infrastruttura corretta.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Quindi, definiamo le nostre due persone.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Abilita le API
Abilita i servizi Google Cloud necessari.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Scarica il codice sorgente della codelab
Per evitare di ingombrare Cloud Shell, eseguirai un checkout sparso per scaricare solo gli script Python necessari per questa codelab dal repository Google Cloud DevRel.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Crea spazio di archiviazione
Crea il bucket per contenere i dati Iceberg gestiti altamente sicuri.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Prepara identità e sicurezza
Configura la connessione alla risorsa cloud. Questa è l'unica entità che contiene le chiavi IAM fisiche permanenti per leggere i file Iceberg non elaborati.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Quindi, configura le persone utente. Agli utenti viene concesso l'accesso logico, non l'accesso allo spazio di archiviazione fisico. Per evitare errori causati da ritardi di propagazione IAM, crea prima gli account, attendi qualche secondo e poi assegna i relativi ruoli.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Crea tabelle Iceberg native tramite Lakehouse
Utilizzerai le funzionalità native di Lakehouse per creare le tabelle Iceberg gestite.
Crea il set di dati BigQuery
Innanzitutto, crea un set di dati BigQuery per raggruppare logicamente le tabelle Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Crea le tabelle Iceberg
Quindi, esegui i seguenti comandi per creare le tabelle. Nota il blocco OPTIONS in cui specifichiamo table_format = 'ICEBERG' e lo mappiamo direttamente al nostro bucket Cloud Storage e alla nostra connessione.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Compila le tabelle con i dati
Infine, inserisci i dati di esempio nelle tabelle Iceberg appena create.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Ora hai due tabelle Iceberg completamente funzionanti. Lakehouse gestisce i metadati, ma i file Parquet fisici risiedono in modo sicuro nel tuo bucket GCS.
Simula una pipeline ETL
In uno scenario reale, i dati non elaborati vengono spesso aggregati in tabelle di riepilogo per i report aziendali. Agiamo come data engineer e creiamo una tabella di riepilogo delle vendite giornaliere dai nostri dati delle transazioni non elaborati.
(Nota: esegui questo passaggio ora in modo che Google Cloud abbia abbastanza tempo per elaborare i metadati in background. Scoprirai perché è importante più avanti nella codelab.)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Governance centralizzata: definisci le policy utilizzando Python
In un ambiente di produzione, la configurazione delle policy di governance tramite l'interfaccia utente è difficile da scalare e gestire. Al contrario, è consigliabile utilizzare Infrastructure as Code (IaC).
In questa sezione, utilizzerai l'SDK Google Cloud Python per creare e applicare in modo programmatico le regole di governance Zero Trust passo dopo passo.
Configura l'ambiente Python
Innanzitutto, configuriamo un ambiente Python isolato (venv) per evitare conflitti tra le librerie e installiamo gli SDK Google Cloud richiesti.
Esegui questi comandi in Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Crea la tassonomia e il tag di policy
Una tassonomia è un container logico e un tag di policy è l'etichetta specifica che collegherai alla nostra colonna sensibile. Per applicare la sicurezza a livello di colonna, devi prima avere un container logico (una tassonomia) e un'etichetta specifica (un tag di policy).
Se esamini 1_create_taxonomy.py, vedrai la seguente logica di base:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Impostando esplicitamente il tipo di policy FINE_GRAINED_ACCESS_CONTROL, trasformi un tag di metadati standard in un limite di sicurezza Zero Trust rigoroso. Per impostazione predefinita, qualsiasi colonna con questo tag negherà l'accesso a tutti gli utenti.
Esegui lo script per creare le risorse:
python 1_create_taxonomy.py
Configura la regola di mascheramento (policy dei dati)
Ora definisci cosa succede quando qualcuno senza privilegi esegue una query sulla colonna con tag. Creerai una policy dei dati che forza il valore a restituire NULL e collegherai questa regola alla persona analista.
All'interno di 2_create_masking.py, lo script cerca dinamicamente l'ID del tag di policy appena creato e applica una policy dei dati:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Questo codice crea in modo programmatico una regola che forza i valori sottostanti a restituire NULL. Quindi, assegna il ruolo IAM maskedReader specificamente alla persona analista, assicurandosi che veda solo la versione mascherata dei dati.
Esegui lo script per configurare la regola di mascheramento:
python 2_create_masking.py
Concedi l'accesso granulare
A causa della nostra configurazione Zero Trust, al momento nessuno può leggere la colonna con tag. Devi concedere esplicitamente l'accesso al responsabile e al tuo account personale.
All'interno di 3_grant_access.py, modifichi la policy IAM del tag di policy stesso:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
L'aggiunta del ruolo categoryFineGrainedReader consente a queste entità specifiche di bypassare le regole di mascheramento e leggere i dati non elaborati e non mascherati.
Esegui lo script per concedere l'accesso:
python 3_grant_access.py
Collega il tag di policy alla tabella BigQuery
Infine, devi collegare questo tag di policy logico allo schema della tabella Iceberg fisica.
Dai un'occhiata a 4_attach_tag.py. Lo script recupera lo schema della tabella BigQuery, scorre i campi e collega il tag in modo specifico alla colonna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Quando viene applicato questo aggiornamento dello schema, Lakehouse collega immediatamente i tag logici di Knowledge Catalog ai file Parquet fisici archiviati nel bucket Cloud Storage.
Esegui lo script per aggiornare lo schema della tabella:
python 4_attach_tag.py
5. Verifica le policy di Knowledge Catalog
È il momento di verificare se la nostra governance centralizzata funziona. Lo testerai su due motori diversi per dimostrare che le policy di Knowledge Catalog vengono applicate a livello universale.
Verifica utilizzando BigQuery SQL nativo
Innanzitutto, utilizzerai Cloud Shell per assumere l'identità delle nostre due persone ed eseguire una query sulla tabella utilizzando il motore SQL nativo di BigQuery.
Test come responsabile (utente con privilegi):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Poiché il responsabile ha il ruolo di lettore granulare, verranno visualizzati i valori dell'importo non elaborati.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Test come analista (utente con limitazioni):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
A causa della regola di mascheramento di Knowledge Catalog, la colonna dell'importo restituisce NULL per ogni riga.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Ripristina la tua identità
Pulisci lo stato di autenticazione di Cloud Shell per tornare al tuo utente amministratore.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Verifica utilizzando Apache Spark (delega di calcolo)
Cosa succede se un data scientist utilizza Apache Spark per leggere questa tabella? Se Spark legge direttamente i file Parquet GCS fisici, le regole di mascheramento di Knowledge Catalog vengono completamente bypassate perché Cloud Storage comprende solo le autorizzazioni a livello di bucket.
Per evitare questo problema, applichi la delega di calcolo utilizzando il connettore Spark-BigQuery. Questo connettore funge da bridge sicuro, instradando le richieste di lettura di Spark tramite l'API BigQuery Storage in modo che le regole di governance di Knowledge Catalog vengano valutate dinamicamente prima che i dati vengano inviati al cluster Spark.
Dai un'occhiata alla logica di base all'interno dello script read_transactions.py che hai scaricato:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Tieni presente che non stiamo indirizzando Spark al percorso gs:// dei file Iceberg. Specificando .format("bigquery"), l'API BigQuery Storage intercetta la richiesta di lettura, controlla l'identità dell'utente che esegue il job Spark, applica le regole di mascheramento di Knowledge Catalog e restituisce solo i dati autorizzati al DataFrame Spark.
Carica questo script PySpark nel bucket Cloud Storage in modo che Managed Apache Spark possa accedervi:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Esegui Spark come responsabile:
Utilizzerai Managed Apache Spark. Questo servizio gestito ti consente di eseguire i workload Spark direttamente senza dover eseguire il provisioning, la configurazione o la gestione di cluster dedicati.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Esamina i log di output del job nel terminale. Poiché il responsabile ha il ruolo di lettore granulare, Spark recupera correttamente gli importi non elaborati e non mascherati.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Esegui Spark come analista:
Ora, invia esattamente lo stesso job Spark, ma questa volta impersona la persona analista.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Controlla di nuovo i log. Anche se l'analista ha eseguito esattamente lo stesso codice Spark, l'API BigQuery Storage ha intercettato la richiesta e applicato la policy di Knowledge Catalog. Il DataFrame Spark dell'analista mostra null per gli importi.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Compromessi architettonici: BigQuery SQL vs. Spark
Hai appena dimostrato che il risultato è identico indipendentemente dal motore. La policy di Knowledge Catalog è stata applicata correttamente. Ma in produzione, quale dovresti utilizzare?
- BigQuery SQL: ideale per i flussi di lavoro in cui SQL è il motore desiderato ed esegue i calcoli direttamente in loco. È ideale per l'analisi rapida e la business intelligence.
- Apache Spark: consente workload più complessi grazie all'utilizzo di Python, il che lo rende adatto a pipeline di machine learning avanzate o codice Hadoop legacy.
Il punto chiave: indipendentemente dal motore utilizzato, applicando la delega di calcolo, il livello di governance Zero Trust centralizzato non può mai essere bypassato.
6. Derivazione dei dati automatizzata
In qualsiasi architettura di dati aziendale, sapere esattamente da dove provengono i dati e come sono stati modificati è fondamentale per la conformità, il debug e la creazione di fiducia. Questo concetto è noto come derivazione dei dati. Risponde a domande fondamentali come: "Se un responsabile sta esaminando un report sulle vendite giornaliere, quali tabelle non elaborate sono state utilizzate per calcolare questi numeri?"
In genere, il monitoraggio di questo ciclo di vita richiede ai data engineer di scrivere manualmente codice di logging personalizzato o di utilizzare strumenti di terze parti complessi per analizzare gli script SQL. Tuttavia, in un data lakehouse Google Cloud gestito, questo monitoraggio è integrato e completamente automatico.
Ricordi la tabella transactions_summary che hai creato dalla tabella delle transazioni non elaborate in precedenza nella codelab? Quando BigQuery ha eseguito l'istruzione CREATE TABLE AS SELECT, il motore di calcolo ha acquisito automaticamente i metadati di trasformazione e li ha inviati a Knowledge Catalog. Vediamo il risultato.
Visualizza la derivazione
- Nella console Google Cloud, vai a Knowledge Catalog > Cerca.
- Digita
lakehouse_retail_demo.transactionsnella barra di ricerca e fai clic sulla tabella. - Fai clic sulla scheda Derivazione.
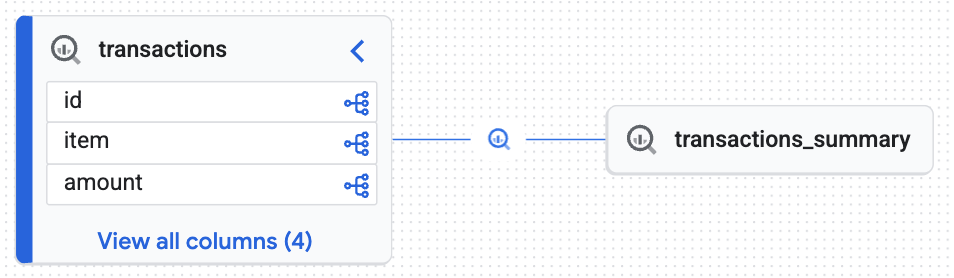
Verrà visualizzato un grafico interattivo generato dal motore di Knowledge che dimostra che la tabella di destinazione (transactions_summary) è stata derivata dalla tabella Iceberg gestita non elaborata (transactions). Hai ottenuto la tracciabilità end-to-end essenziale per l'audit dei dati.
7. Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa codelab, segui questi passaggi.
Rimuovi le risorse di governance di Knowledge Catalog
Prima di eliminare il set di dati BigQuery o il bucket Cloud Storage, devi rimuovere le regole di governance logiche. Se esamini lo script cleanup_governance.py dal repository, vedrai la seguente sequenza di eliminazione:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
L'ordine qui è fondamentale. Lo script elimina prima la policy dei dati (regola di mascheramento) perché si basa sul tag di policy. Una volta rimossa la policy, l'eliminazione della tassonomia principale verrà eseguita automaticamente a cascata ed eliminerà tutti i tag di policy sottostanti senza attivare errori di dipendenza delle risorse.
Esegui lo script di pulizia Python:
python cleanup_governance.py
Rimuovi identità, spazio di archiviazione e asset di calcolo
Ora che il livello di governance è scollegato, puoi eliminare in sicurezza le tabelle BigQuery, i bucket Cloud Storage, i service account e l'ambiente Python locale.
Copia ed esegui il seguente blocco di pulizia completo in Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Completando questi passaggi, ti sei assicurato che nel tuo progetto non rimangano risorse orfane o policy nascoste.
8. Complimenti!
Hai implementato correttamente un data lakehouse completamente gestito e rilevabile.
Hai imparato che:
- Integrazione nativa di Iceberg: Lakehouse può gestire in modo nativo le tabelle Iceberg open source archiviando i file fisici in modo sicuro in Cloud Storage.
- Delega di calcolo per la sicurezza: instradando le query tramite l'API BigQuery Storage, hai applicato il mascheramento dinamico granulare ai file fisici che non possono limitare l'accesso parziale in modo nativo.
- Governance indipendente dal motore: i tag di policy ti consentono di definire le regole una sola volta e di applicarle a livello universale, sia che vengano eseguite query tramite SQL nativo o runtime Apache Spark.
- Rilevabilità dei dati: il motore di Knowledge ha monitorato automaticamente la derivazione dei dati, fornendo un'audit aziendale essenziale.
Passaggi successivi
- Esplora il controllo dell'accesso avanzato: per implementare scenari di sicurezza più complessi, consulta la documentazione ufficiale sulla personalizzazione di Lakehouse con funzionalità aggiuntive.
- Gestisci i dati non strutturati per l'AI generativa: scopri le tabelle di oggetti. Estendi questo pattern di bridge sicuro ai file non strutturati (PDF, immagini) in Cloud Storage, stabilendo una base di dati sicura e gestita per Gemini Enterprise Agent Engine e le pipeline RAG.