
1. はじめに
データがさまざまな物理ストレージ システムに分散されている最新のエンタープライズ データクラウドでは、セキュリティの断片化という大きなアーキテクチャ上の課題があります。
データが Google Cloud Storage の Parquet などのオープンソース形式で物理的に保存され、BigQuery SQL や Apache Spark などの複数の異なるエンジンによってクエリされる場合、センシティブ データ(金融取引額など)が常に保護されるようにするにはどうすればよいですか?
この Codelab では、Apache Iceberg テーブル、BigQuery、Knowledge Catalog を使用してこれらの問題を解決する、ガバナンスされたデータ レイクハウス アーキテクチャを構築します。Infrastructure as Code(IaC)を使用して、ゼロトラスト セキュリティ ポリシーと、さまざまなコンピューティング エンジンで動的に適用される方法を定義します。
前提条件
- 課金を有効にした Google Cloud プロジェクト
- SQL、IAM、Cloud Storage のコンセプトの基本的な理解。
学習内容
- Cloud Storage がデータをネイティブに保持する BigQuery の Apache Iceberg 用 Google Cloud Lakehouse テーブルを作成する方法。
- 列レベルのセキュリティとデータ マスキングに ポリシータグを使用して、一元化されたデータポリシーを適用する方法。
- Cloud リソース接続を使用して、物理ストレージ アクセスと論理データ アクセスを分離する方法。
- Managed Service for Apache Spark を使用してゼロトラスト コンピューティング委任を適用し、オープンソース エンジンがガバナンスをバイパスできないようにする方法。
- 自動化されたデータリネージを可視化する方法。
アーキテクチャの概要: Iceberg のユニバーサル ガバナンス
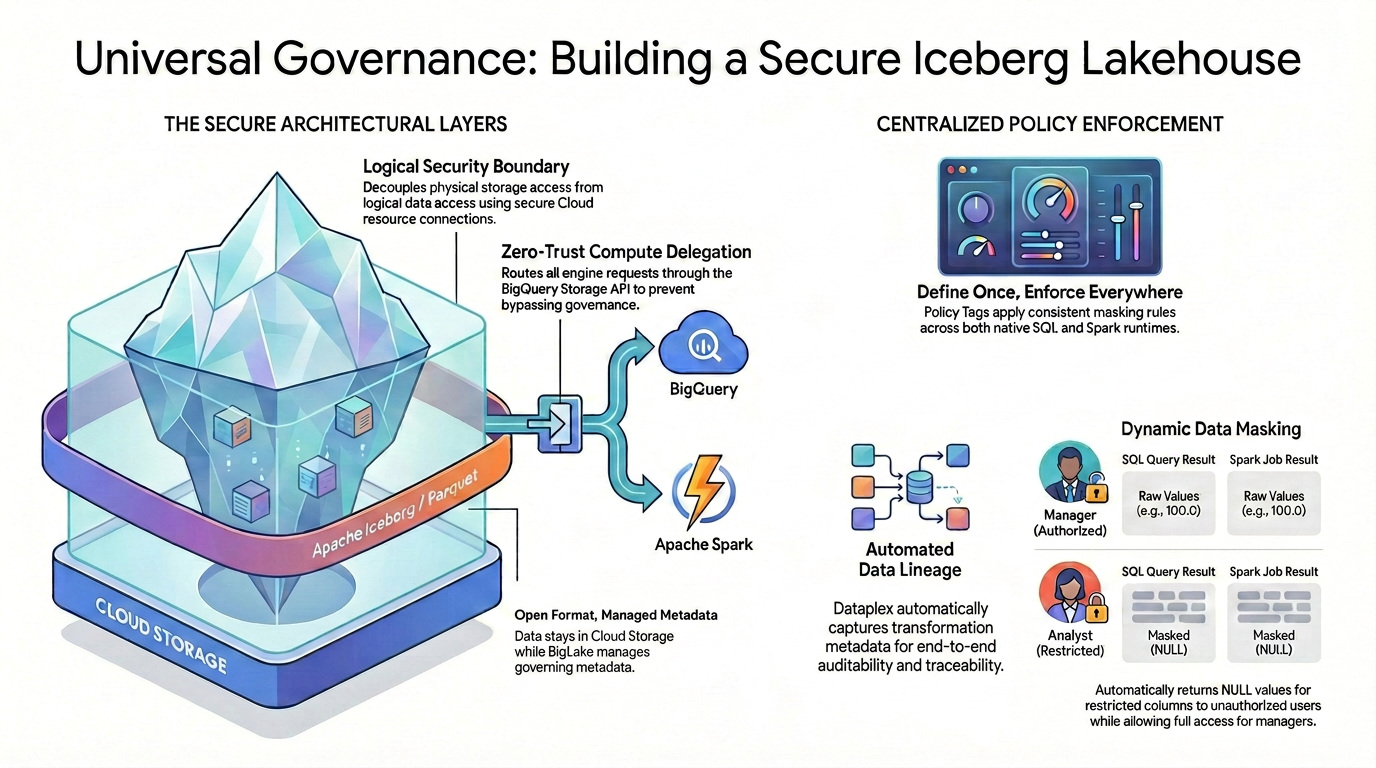
オープンソースのデータ形式で、きめ細かいアクセス制御(列レベルのセキュリティやデータ マスキングなど)を実現するには、厳格で統一されたセキュリティ アーキテクチャを確立する必要があります。
図に示すように、このガバナンスされたレイクハウス パターンは、セキュリティの断片化という課題を解決するために、次の 2 つの主要な柱に依存しています。
🛡️ 安全なアーキテクチャ レイヤ(左)
ユーザーや外部エンジンが Cloud Storage に直接アクセスできるようにするのではなく、バケットレベルの広範なセキュリティのみをサポートする安全な基盤を構築します。
- オープン フォーマット、マネージド メタデータ: データはオープン Apache Iceberg(Parquet)形式を使用して Cloud Storage に物理的に保存され、Lakehouse はガバナンス メタデータをシームレスに管理します。
- 論理的セキュリティ境界: 安全な Cloud リソース接続を使用して、物理ストレージ アクセスと論理データ アクセスを分離します。エンドユーザーに、未加工の GCS ファイルに対する直接的な物理 IAM アクセス権が付与されることはありません。
- ゼロトラスト コンピューティング委任: 実行エンジンがガバナンス ルールをバイパスできないように、すべてのデータ読み取りリクエストは BigQuery Storage API を介して厳密にルーティングされます。これは、クエリがネイティブの BigQuery SQL から発生したか、オープンソースの Apache Spark から発生したかに関係なく適用されます。
🎯 ポリシーの一元適用(右)
安全な基盤が整っているため、Knowledge Catalog はガバナンスの統合された頭脳として機能します。
- 一度定義すれば、どこでも適用できる: Knowledge Catalog でポリシータグを一度定義するだけで、アーキテクチャはサポートされているすべての実行ランタイムに一貫したマスキング ルールを適用します。
- 動的データ マスキング: データがクエリされると、システムはユーザーの ID をオンザフライで評価します。承認されたユーザーは、SQL と Spark の両方で未加工のマスクされていない値(100.0 など)を確認できますが、制限されたユーザーは、両方のエンジンで制限された列に対してマスクされた NULL 値を自動的に受け取ります。
- 自動データリネージ: データがフローして変換されると、Knowledge Catalog は変換メタデータを自動的にキャプチャし、カスタム ロギング コードを必要とせずに、エンドツーエンドの監査可能性とトレーサビリティを組み込みで提供します。
2. 設定と要件
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソールで、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
環境を初期化する
Cloud Shell を開き、プロジェクト変数を設定して、すべてのコマンドが正しいインフラストラクチャをターゲットにしていることを確認します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
次に、2 つのペルソナを定義します。
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
API を有効にする
必要な Google Cloud サービスを有効にします。
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Codelab のソースコードをダウンロードする
Cloud Shell が煩雑にならないように、スパース チェックアウトを実行して、この Codelab に必要な Python スクリプトのみを Google Cloud DevRel リポジトリからダウンロードします。
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
ストレージを作成する
高度に安全な管理対象 Iceberg データを保持するバケットを作成します。
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
ID とセキュリティを準備する
クラウド リソース接続を構成します。これは、未加工の Iceberg ファイルを読み取るための永続的な物理 IAM 鍵を保持する唯一のエンティティです。
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
次に、ユーザー ペルソナを設定します。ユーザーには物理ストレージ アクセスではなく、論理アクセスが付与されます。IAM 伝播の遅延によるエラーを防ぐため、最初にアカウントを作成し、数秒待ってからロールを割り当てます。
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Lakehouse を介してネイティブ Iceberg テーブルを作成する
Lakehouse のネイティブ機能を使用して、マネージド Iceberg テーブルを作成します。
BigQuery データセットを作成する
まず、Iceberg テーブルを論理的にグループ化する BigQuery データセットを作成します。
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg テーブルを作成する
次に、次のコマンドを実行してテーブルを作成します。table_format = 'ICEBERG' を指定し、Cloud Storage バケットと接続に直接マッピングする OPTIONS ブロックに注目してください。
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
テーブルにデータを入力する
最後に、新しく作成した Iceberg テーブルにサンプルデータを挿入します。
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
これで、完全に機能する Iceberg テーブルが 2 つ作成されました。Lakehouse はメタデータを管理しますが、物理的な Parquet ファイルは GCS バケットに安全に保存されます。
ETL パイプラインをシミュレートする
実際のシナリオでは、多くの場合、元データはビジネス レポート用に集計されて概要テーブルにまとめられます。データ エンジニアとして、元トランザクション データから毎日の売上概要テーブルを作成してみましょう。
(注: このステップを今すぐ実行して、Google Cloud がバックグラウンド メタデータを処理するのに十分な時間を確保してください。このステップの重要性については、この Codelab の後半で説明します)。
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. 一元化されたガバナンス: Python を使用してポリシーを定義する
本番環境では、UI を介してガバナンス ポリシーを構成することは、スケーリングと維持が困難です。代わりに、Infrastructure as Code(IaC)を使用することを強くおすすめします。
このセクションでは、Google Cloud Python SDK を使用して、ゼロトラスト ガバナンス ルールをプログラムで段階的に作成して適用します。
Python 環境を設定する
まず、ライブラリの競合を回避し、必要な Google Cloud SDK をインストールするために、隔離された Python 環境(venv)を設定します。
Cloud Shell で次のコマンドを実行します。
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
分類とポリシータグを作成する
分類は論理コンテナであり、ポリシータグは機密性の高い列に付加する特定のラベルです。列レベルのセキュリティを適用するには、まず論理コンテナ(分類)と特定のラベル(ポリシータグ)が必要です。
1_create_taxonomy.py の内部を見ると、次のコアロジックが表示されます。
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
FINE_GRAINED_ACCESS_CONTROL ポリシータイプを明示的に設定すると、標準のメタデータタグが厳格なゼロトラスト セキュリティ境界に変換されます。このタグが付いた列は、デフォルトですべてのユーザーのアクセスを拒否します。
スクリプトを実行してリソースを作成します。
python 1_create_taxonomy.py
マスキング ルール(データポリシー)を構成する
次に、権限のないユーザーがタグ付きの列をクエリした場合の処理を定義します。値を NULL として返すように強制するデータポリシーを作成し、このルールをアナリスト ペルソナに適用します。
2_create_masking.py 内で、スクリプトは作成したポリシータグ ID を動的に検索し、データポリシーを適用します。
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
このコードは、基盤となる値を NULL として返すルールをプログラムで作成します。次に、マスクされたバージョンのデータのみが表示されるように、マスクされたリーダー IAM ロールをアナリスト ペルソナに割り当てます。
スクリプトを実行してマスキング ルールを構成します。
python 2_create_masking.py
きめ細かいアクセス権を付与する
ゼロトラスト設定のため、現在、タグ付けされた列を読み取れるユーザーはいません。マネージャーと個人アカウントに明示的にアクセス権を付与する必要があります。
3_grant_access.py 内で、ポリシータグ自体の IAM ポリシーを変更します。
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
categoryFineGrainedReader ロールを追加すると、これらの特定のプリンシパルはマスキング ルールをバイパスして、マスクされていない元のデータを読み取ることができます。
スクリプトを実行してアクセス権を付与します。
python 3_grant_access.py
ポリシータグを BigQuery テーブルに適用する
最後に、この論理ポリシータグを物理 Iceberg テーブル スキーマに添付する必要があります。
4_attach_tag.py をご覧ください。このスクリプトは、BigQuery テーブル スキーマを取得し、フィールドを反復処理して、amount 列にタグを付加します。
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
このスキーマ更新が適用されると、Lakehouse は Knowledge Catalog の論理タグを Cloud Storage バケットに保存されている物理 Parquet ファイルに即座にブリッジします。
スクリプトを実行してテーブル スキーマを更新します。
python 4_attach_tag.py
5. Knowledge Catalog ポリシーを確認する
集中型ガバナンスが機能するかどうかをテストします。2 つの異なるエンジンでテストを行い、Knowledge Catalog のポリシーが普遍的に適用されることを確認します。
BigQuery ネイティブ SQL を使用して検証する
まず、Cloud Shell を使用して 2 つのペルソナの ID を引き受け、BigQuery のネイティブ SQL エンジンを使用してテーブルにクエリを実行します。
管理者(権限のあるユーザー)としてテストする:
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
マネージャーにはきめ細かい読み取りのロールがあるため、未加工の金額値が表示されます。
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
アナリスト(制限付きユーザー)としてテストします。
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Knowledge Catalog のマスキング ルールにより、金額列はすべての行で NULL として返されます。
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
ID を復元する
Cloud Shell の認証状態をクリーンアップして、管理者ユーザーに戻ります。
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Apache Spark を使用して検証する(コンピューティング委任)
データ サイエンティストが Apache Spark を使用してこのテーブルを読み取るとどうなるでしょうか?Spark が物理 GCS Parquet ファイルを直接読み取ると、Cloud Storage はバケットレベルの権限しか認識しないため、Knowledge Catalog のマスキング ルールは完全にバイパスされます。
これを防ぐには、Spark-BigQuery コネクタを使用してコンピューティング委任を適用します。このコネクタは安全なブリッジとして機能し、Spark 読み取りリクエストを BigQuery Storage API 経由でルーティングします。これにより、データが Spark クラスタに送信される前に、Knowledge Catalog ガバナンス ルールが動的に評価されます。
ダウンロードした read_transactions.py スクリプト内のコアロジックを確認します。
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Spark で Iceberg ファイルの gs:// パスを指定していないことに注意してください。.format("bigquery") を指定すると、BigQuery Storage API は読み取りリクエストをインターセプトし、Spark ジョブを実行しているユーザーの ID を確認し、Knowledge Catalog のマスキング ルールを適用して、承認されたデータのみを Spark DataFrame に返します。
この PySpark スクリプトを Cloud Storage バケットにアップロードして、Managed Apache Spark がアクセスできるようにします。
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
マネージャーとして Spark を実行します。
Managed Apache Spark を使用します。このマネージド サービスを使用すると、専用クラスタのプロビジョニング、構成、管理を行うことなく、Spark ワークロードを直接実行できます。
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ターミナルのジョブ出力ログを確認します。マネージャーにはきめ細かい読み取りロールがあるため、Spark はマスクされていない未加工の金額を正常に取得します。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
アナリストとして Spark を実行します。
次に、まったく同じ Spark ジョブを送信しますが、今回はアナリスト ペルソナを偽装します。
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ログを再度確認します。アナリストがまったく同じ Spark コードを実行したにもかかわらず、BigQuery Storage API がリクエストをインターセプトし、Knowledge Catalog ポリシーを適用しました。アナリストの Spark DataFrame には、金額の代わりに null が表示されます。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
アーキテクチャ上のトレードオフ: BigQuery SQL と Spark
エンジンに関係なく結果が同じであることが証明されました。Knowledge Catalog ポリシーが適用されました。しかし、本番環境ではどちらを使用すべきでしょうか?
- BigQuery SQL: SQL が目的のエンジンであり、計算を直接実行するワークフローに最適です。高速分析とビジネス インテリジェンスに最適です。
- Apache Spark: Python を使用することで、より複雑なワークロードが可能になります。高度な ML パイプラインやレガシー Hadoop コードに適しています。
重要なポイント: どのエンジンを使用しても、コンピューティング委任を適用することで、一元化されたゼロトラスト ガバナンス レイヤをバイパスすることはできません。
6. 自動データリネージ
エンタープライズ データ アーキテクチャでは、データの出所と変更方法を正確に把握することが、コンプライアンス、デバッグ、信頼の確立に不可欠です。このコンセプトはデータリネージと呼ばれます。データリネージは、「マネージャーが日次売上レポートを見ている場合、その数値を計算するためにどの生テーブルが使用されたか」などの基本的な質問に答えます。
従来、このライフサイクルを追跡するには、データ エンジニアがカスタム ロギング コードを手動で作成するか、複雑なサードパーティ製ツールを使用して SQL スクリプトを解析する必要がありました。ただし、ガバナンスが適用された Google Cloud Lakehouse では、この追跡が組み込まれており、完全に自動化されています。
この Codelab の前半で作成した transactions_summary テーブルを思い出してください。BigQuery が CREATE TABLE AS SELECT ステートメントを実行すると、コンピューティング エンジンは変換メタデータを自動的にキャプチャして Knowledge Catalog に送信しました。結果を見てみましょう。
リネージを可視化する
- Google Cloud コンソールで、Knowledge Catalog > 検索 に移動します。
- 検索バーに「
lakehouse_retail_demo.transactions」と入力し、表をクリックします。 - [リネージ] タブをクリックします。
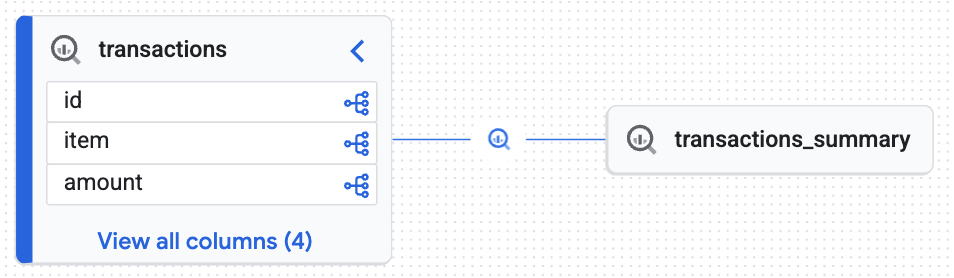
Knowledge Engine によって生成されたインタラクティブなグラフが表示され、ターゲット テーブル(transactions_summary)が未加工のガバナンス対象 Iceberg テーブル(transactions)から派生したことが証明されます。データ監査に不可欠なエンドツーエンドのトレーサビリティが実現しました。
7. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
Knowledge Catalog ガバナンス リソースを削除する
BigQuery データセットまたは Cloud Storage バケットを削除する前に、論理ガバナンス ルールを削除する必要があります。リポジトリの cleanup_governance.py スクリプトを見ると、次のクリーンアップ シーケンスが表示されます。
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
この順序は重要です。スクリプトは、ポリシータグに依存しているため、最初にデータポリシー(マスキング ルール)を削除します。ポリシーが削除されると、親分類を削除すると、リソース依存関係エラーをトリガーすることなく、基盤となるすべてのポリシータグが自動的にカスケード削除されます。
Python クリーンアップ スクリプトを実行します。
python cleanup_governance.py
ID、ストレージ、コンピューティング アセットを削除する
ガバナンス レイヤが切り離されたので、BigQuery テーブル、Cloud Storage バケット、サービス アカウント、ローカル Python 環境を安全に削除できます。
Cloud Shell で次の包括的なクリーンアップ ブロックをコピーして実行します。
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
これらの手順を完了すると、プロジェクトに孤立したリソースや非表示のポリシーが残っていないことを確認できます。
8. 完了
完全に管理され、検出可能なデータ レイクハウスが正常に実装されました。
学習した内容は次のとおりです。
- ネイティブ Iceberg インテグレーション: Lakehouse は、オープンソースの Iceberg テーブルをネイティブに管理しながら、物理ファイルを Cloud Storage に安全に保存できます。
- セキュリティのためのコンピューティング委任: BigQuery Storage API を介してクエリをルーティングすることで、部分アクセスをネイティブに制限できない物理ファイルにきめ細かい動的マスキングを適用しました。
- エンジンに依存しないガバナンス: ポリシータグを使用すると、ネイティブ SQL または Apache Spark ランタイムでクエリされたかどうかにかかわらず、ルールを一度定義して普遍的に適用できます。
- データの検出可能性: Knowledge Engine はデータリネージを自動的に追跡し、企業監査に不可欠な機能を提供します。
次のステップ
- 高度なアクセス制御について調べる: より複雑なセキュリティ シナリオを実装するには、追加機能で Lakehouse をカスタマイズするに関する公式ドキュメントをご覧ください。
- 生成 AI の非構造化データを管理する: オブジェクト テーブルについて説明します。このセキュア ブリッジ パターンを Cloud Storage の非構造化ファイル(PDF、画像)に拡張し、Gemini Enterprise Agent Engine と RAG パイプラインの安全で管理されたデータ基盤を確立します。