
1. Wprowadzenie
W nowoczesnej chmurze danych dla przedsiębiorstw, w której dane znajdują się w różnych fizycznych systemach przechowywania, ogromnym wyzwaniem architektonicznym jest rozproszone bezpieczeństwo.
Jak zapewnić spójną ochronę danych wrażliwych (takich jak kwoty transakcji finansowych), gdy dane są fizycznie przechowywane w formatach open source, takich jak Parquet, w usłudze Google Cloud Storage i są odpytywane przez wiele różnych silników, takich jak BigQuery SQL czy Apache Spark?
W tym ćwiczeniu utworzysz architekturę zarządzanej architektury lakehouse, która rozwiązuje te problemy za pomocą tabel Apache Iceberg, BigQuery i Knowledge Catalog. Użyjesz infrastruktury jako kodu (IaC), aby zdefiniować zasady bezpieczeństwa oparte na zasadzie zerowego zaufania oraz sposób ich dynamicznego egzekwowania w różnych silnikach obliczeniowych.
Wymagania wstępne
- Projekt Google Cloud z włączonymi płatnościami.
- Podstawowa wiedza na temat SQL, IAM i Cloud Storage.
Czego się nauczysz
- Jak tworzyć tabele Google Cloud Lakehouse dla Apache Iceberg w BigQuery, w których dane są natywnie przechowywane w Cloud Storage.
- Jak egzekwować scentralizowane zasady dotyczące danych za pomocą tagów zasad w celu zapewnienia bezpieczeństwa na poziomie kolumny i maskowania danych.
- Jak oddzielić dostęp do fizycznego magazynu od logicznego dostępu do danych za pomocą połączenia zasobu Cloud.
- Jak egzekwować delegowanie obliczeń oparte na zasadzie zerowego zaufania za pomocą usługi zarządzanej dla Apache Spark, aby zapewnić, że silniki open source nie mogą obejść zarządzania.
- Jak wizualizować automatyczną historię danych.
Omówienie architektury: uniwersalne zarządzanie w Iceberg
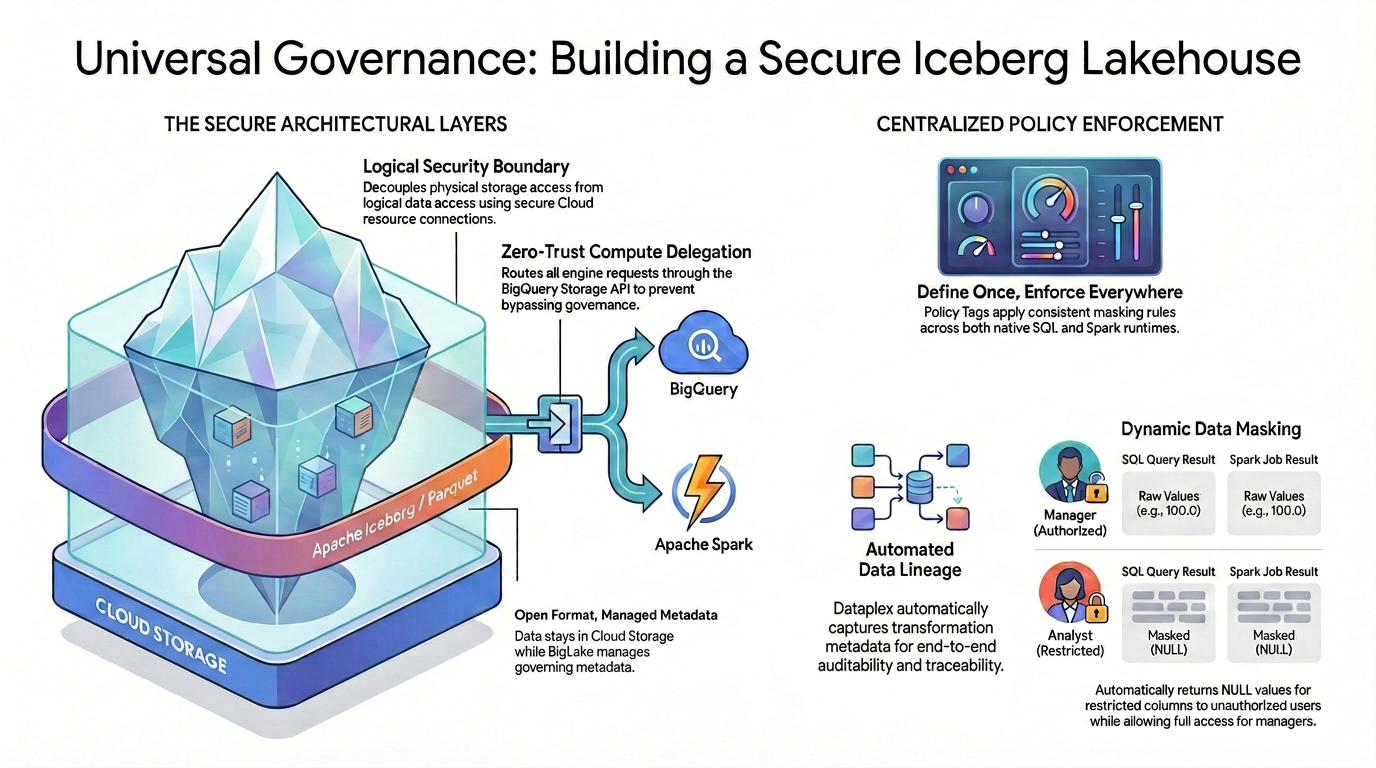
Aby uzyskać szczegółową kontrolę dostępu (np. bezpieczeństwo na poziomie kolumny i maskowanie danych) w formatach danych open source, musisz ustanowić ścisłą i ujednoliconą architekturę bezpieczeństwa.
Jak pokazano na diagramie, ten wzorzec zarządzanej architektury lakehouse opiera się na 2 głównych filarach, które rozwiązują problem rozproszonego bezpieczeństwa:
🛡️ Bezpieczne warstwy architektury (po lewej)
Zamiast zezwalać użytkownikom lub silnikom zewnętrznym na bezpośredni dostęp do Cloud Storage, który obsługuje tylko szerokie zabezpieczenia na poziomie zasobnika, tworzysz bezpieczny fundament.
- Format otwarty, zarządzane metadane: dane fizycznie pozostają w Cloud Storage w otwartym formacie Apache Iceberg (Parquet), a Lakehouse bezproblemowo zarządza metadanymi.
- Logiczna granica bezpieczeństwa: oddzielasz dostęp do fizycznego magazynu od logicznego dostępu do danych za pomocą bezpiecznego połączenia z zasobem Cloud. Użytkownicy końcowi nigdy nie otrzymują bezpośredniego fizycznego dostępu IAM do nieprzetworzonych plików GCS.
- Delegowanie obliczeń oparte na zasadzie zerowego zaufania: aby zapewnić, że żaden silnik wykonawczy nie może obejść reguł zarządzania, wszystkie żądania odczytu danych są ściśle kierowane przez interfejs BigQuery Storage API. Dotyczy to zarówno zapytań pochodzących z natywnego BigQuery SQL, jak i Apache Spark open source.
🎯 Scentralizowane egzekwowanie zasad (po prawej)
Dzięki bezpiecznemu fundamentowi Knowledge Catalog pełni rolę ujednoliconego centrum zarządzania:
- Zdefiniuj raz, egzekwuj wszędzie: tagi zasad definiujesz w Knowledge Catalog tylko raz, a architektura stosuje spójne reguły maskowania we wszystkich obsługiwanych środowiskach wykonawczych.
- Dynamiczne maskowanie danych: gdy dane są odpytywane, system na bieżąco ocenia tożsamość użytkownika. Użytkownicy autoryzowani będą widzieć nieprzetworzone, niezasłonięte wartości (np. 100.0) zarówno w SQL, jak i Spark, a użytkownicy z ograniczeniami będą automatycznie otrzymywać zamaskowane wartości NULL w przypadku kolumn z ograniczeniami w obu silnikach.
- Automatyczna historia danych: gdy dane przepływają i są przekształcane, Knowledge Catalog automatycznie rejestruje metadane przekształceń, zapewniając wbudowaną możliwość audytu i śledzenia bez konieczności stosowania niestandardowego kodu logowania.
2. Konfiguracja i wymagania
Uruchamianie Cloud Shell
Chociaż Google Cloud można obsługiwać zdalnie z laptopa, w tym ćwiczeniu będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na prawym górnym pasku narzędzi:
Uzyskanie dostępu do środowiska i połączenie się z nim może zająć kilka chwil. Gdy to się skończy, zobaczysz coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym ćwiczeniu możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Inicjowanie środowiska
Otwórz Cloud Shell i ustaw zmienne projektu, aby wszystkie polecenia były kierowane do właściwej infrastruktury.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Następnie zdefiniuj 2 persony.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Włączanie interfejsów API
Włącz niezbędne usługi Google Cloud.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Pobieranie kodu źródłowego ćwiczenia
Aby nie zaśmiecać Cloud Shell, wykonasz sparse checkout, aby pobrać z repozytorium Google Cloud DevRel tylko niezbędne skrypty Pythona na potrzeby tego ćwiczenia.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Tworzenie miejsca na dane
Utwórz zasobnik, w którym będą przechowywane wysoce bezpieczne, zarządzane dane Iceberg.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Przygotowywanie tożsamości i zabezpieczeń
Skonfiguruj połączenie z zasobem Cloud. Jest to jedyny podmiot, który ma stałe fizyczne klucze IAM do odczytywania nieprzetworzonych plików Iceberg.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Następnie skonfiguruj persony użytkowników. Użytkownicy mają dostęp logiczny, a nie fizyczny do magazynu. Aby zapobiec błędom spowodowanym opóźnieniami w propagacji IAM, najpierw utworzysz konta, odczekasz kilka sekund, a następnie przypiszesz im role.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Tworzenie natywnych tabel Iceberg za pomocą Lakehouse
Do utworzenia zarządzanych tabel Iceberg użyjesz natywnych funkcji Lakehouse.
Tworzenie zbioru danych BigQuery
Najpierw utwórz zbiór danych BigQuery, aby logicznie pogrupować tabele Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Tworzenie tabel Iceberg
Następnie uruchom te polecenia, aby utworzyć tabele. Zwróć uwagę na blok OPTIONS, w którym określamy table_format = 'ICEBERG' i mapujemy go bezpośrednio na zasobnik Cloud Storage i połączenie.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Wypełnianie tabel danymi
Na koniec wstaw przykładowe dane do nowo utworzonych tabel Iceberg.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Masz teraz 2 w pełni funkcjonalne tabele Iceberg. Lakehouse zarządza metadanymi, ale fizyczne pliki Parquet są bezpiecznie przechowywane w zasobniku GCS.
Symulowanie potoku ETL
W rzeczywistym scenariuszu nieprzetworzone dane są często agregowane w tabele podsumowań na potrzeby raportowania biznesowego. Wciel się w rolę inżyniera danych i utwórz tabelę podsumowania dziennej sprzedaży na podstawie nieprzetworzonych danych transakcji.
(Uwaga: wykonaj ten krok teraz, aby Google Cloud miał wystarczająco dużo czasu na przetworzenie metadanych w tle. W dalszej części ćwiczenia dowiesz się, dlaczego jest to ważne).
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Scentralizowane zarządzanie: definiowanie zasad za pomocą Pythona
W środowisku produkcyjnym konfigurowanie zasad zarządzania za pomocą interfejsu użytkownika jest trudne do skalowania i utrzymania. Zamiast tego zdecydowanie zalecamy używanie infrastruktury jako kodu (IaC).
W tej sekcji użyjesz pakietu Google Cloud Python SDK, aby programowo tworzyć i egzekwować zasady zarządzania oparte na zasadzie zerowego zaufania.
Konfigurowanie środowiska Pythona
Najpierw skonfigurujmy izolowane środowisko Pythona (venv), aby uniknąć konfliktów bibliotek, i zainstalujmy wymagane pakiety Google Cloud SDK.
Uruchom te polecenia w Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Tworzenie taksonomii i tagu zasad
Taksonomia to kontener logiczny, a tag zasad to konkretna etykieta, którą przypiszesz do kolumny wrażliwych danych. Aby egzekwować bezpieczeństwo na poziomie kolumny, musisz najpierw mieć kontener logiczny (taksonomię) i konkretną etykietę (tag zasad).
Jeśli zajrzysz do pliku 1_create_taxonomy.py, zobaczysz tę podstawową logikę:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Jawnie ustawiając typ zasady FINE_GRAINED_ACCESS_CONTROL, przekształcasz standardowy tag metadanych w ścisłą granicę bezpieczeństwa opartą na zasadzie zerowego zaufania. Każda kolumna z tym tagiem domyślnie odmawia dostępu wszystkim użytkownikom.
Uruchom skrypt, aby utworzyć zasoby:
python 1_create_taxonomy.py
Konfigurowanie reguły maskowania (zasady dotyczące danych)
Teraz zdefiniuj, co się stanie, gdy ktoś bez uprawnień zapyta o kolumnę z tagiem. Utworzysz zasadę dotyczącą danych, która wymusza zwracanie wartości NULL, i przypiszesz tę regułę do persony analityka.
W pliku 2_create_masking.py skrypt dynamicznie wyszukuje utworzony przez Ciebie identyfikator tagu zasad i stosuje zasadę dotyczącą danych:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Ten kod programowo tworzy regułę, która wymusza zwracanie wartości NULL. Następnie przypisuje rolę IAM maskedReader konkretnie do persony analityka, dzięki czemu widzi on tylko zamaskowaną wersję danych.
Uruchom skrypt, aby skonfigurować regułę maskowania:
python 2_create_masking.py
Przyznawanie szczegółowego dostępu
Ze względu na konfigurację opartą na zasadzie zerowego zaufania nikt nie może teraz odczytać kolumny z tagiem. Musisz jawnie przyznać dostęp menedżerowi i swojemu kontu osobistemu.
W pliku 3_grant_access.py modyfikujesz uprawnienia samego tagu zasad:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Dodanie roli categoryFineGrainedReader umożliwia tym konkretnym podmiotom zabezpieczeń obejście reguł maskowania i odczytanie nieprzetworzonych, niezasłoniętych danych.
Uruchom skrypt, aby przyznać dostęp:
python 3_grant_access.py
Dołączanie tagu zasad do tabeli BigQuery
Na koniec musisz dołączyć ten logiczny tag zasad do fizycznego schematu tabeli Iceberg.
Spójrz na plik 4_attach_tag.py. Skrypt pobiera schemat tabeli BigQuery, iteruje po polach i dołącza tag konkretnie do kolumny amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Gdy ta aktualizacja schematu zostanie zastosowana, Lakehouse natychmiast połączy logiczne tagi Knowledge Catalog z fizycznymi plikami Parquet przechowywanymi w zasobniku Cloud Storage.
Uruchom skrypt, aby zaktualizować schemat tabeli:
python 4_attach_tag.py
5. Weryfikowanie zasad Knowledge Catalog
Czas sprawdzić, czy scentralizowane zarządzanie działa. Przetestujesz to w 2 różnych silnikach, aby udowodnić, że zasady Knowledge Catalog są egzekwowane uniwersalnie.
Weryfikowanie za pomocą natywnego SQL BigQuery
Najpierw użyjesz Cloud Shell, aby przyjąć tożsamość 2 person i wysłać zapytanie do tabeli za pomocą natywnego silnika SQL BigQuery.
Testowanie jako menedżer (użytkownik z uprawnieniami):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Ponieważ menedżer ma rolę odczytującego z uprawnieniami, będzie widzieć nieprzetworzone wartości kwot.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Testowanie jako analityk (użytkownik z ograniczeniami):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Ze względu na regułę maskowania Knowledge Catalog kolumna amount zwraca wartość NULL w każdym wierszu.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Przywracanie tożsamości
Zwolnij miejsce w stanie uwierzytelniania Cloud Shell, aby wrócić do użytkownika administracyjnego.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Weryfikowanie za pomocą Apache Spark (delegowanie obliczeń)
Co się stanie, jeśli analityk danych użyje Apache Spark do odczytania tej tabeli? Jeśli Spark odczytuje fizyczne pliki GCS Parquet bezpośrednio, reguły maskowania Knowledge Catalog są całkowicie pomijane, ponieważ Cloud Storage rozumie tylko uprawnienia na poziomie zasobnika.
Aby temu zapobiec, wymusisz delegowanie obliczeń za pomocą oprogramowania sprzęgającego Spark-BigQuery. To oprogramowanie sprzęgające działa jako bezpieczny most, kierując żądania odczytu Spark przez interfejs BigQuery Storage API, dzięki czemu reguły zarządzania Knowledge Catalog są dynamicznie oceniane, zanim jakiekolwiek dane zostaną wysłane do klastra Spark.
Spójrz na podstawową logikę w pobranym skrypcie read_transactions.py:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Zwróć uwagę, że nie kierujemy Spark do ścieżki gs:// plików Iceberg. Określając .format("bigquery"), interfejs BigQuery Storage API przechwytuje żądanie odczytu, sprawdza tożsamość użytkownika uruchamiającego zadanie Spark, stosuje reguły maskowania Knowledge Catalog i zwraca tylko autoryzowane dane do Spark DataFrame.
Prześlij ten skrypt PySpark do zasobnika Cloud Storage, aby usługa zarządzana dla Apache Spark mogła uzyskać do niego dostęp:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Uruchamianie Spark jako menedżer:
Użyjesz usługi zarządzanej dla Apache Spark. Ta usługa zarządzana umożliwia uruchamianie zbiorów zadań Spark bezpośrednio bez konieczności udostępniania, konfigurowania ani zarządzania dedykowanymi klastrami.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Sprawdź logi danych wyjściowych zadania w terminalu. Ponieważ menedżer ma rolę odczytującego z uprawnieniami, Spark pomyślnie pobiera nieprzetworzone, niezasłonięte kwoty.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Uruchamianie Spark jako analityk:
Teraz prześlij dokładnie to samo zadanie Spark, ale tym razem wciel się w rolę analityka.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Ponownie sprawdź logi. Mimo że analityk uruchomił dokładnie ten sam kod Spark, interfejs BigQuery Storage API przechwycił żądanie i zastosował zasadę Knowledge Catalog. W Spark DataFrame analityka w przypadku kwot wyświetla się wartość null.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Kompromisy architektoniczne: BigQuery SQL a Spark
Właśnie udowodniłeś(-aś), że wynik jest identyczny niezależnie od silnika. Zasada Knowledge Catalog została pomyślnie zastosowana. Ale w środowisku produkcyjnym, którego silnika należy używać?
- BigQuery SQL: świetnie sprawdza się w przypadku przepływów pracy, w których SQL jest preferowanym silnikiem i wykonuje obliczenia bezpośrednio w miejscu. Idealnie nadaje się do szybkiej analizy i analityki biznesowej.
- Apache Spark: umożliwia bardziej złożone zbiory zadań dzięki użyciu Pythona, co sprawia, że dobrze nadaje się do zaawansowanych potoków uczenia maszynowego lub starszego kodu Hadoop.
Kluczowy wniosek: niezależnie od używanego silnika, dzięki wymuszeniu delegowania obliczeń nie można obejść scentralizowanej warstwy zarządzania opartej na zasadzie zerowego zaufania.
6. Automatyczna historia danych
W każdej architekturze danych przedsiębiorstwa kluczowe znaczenie dla zgodności, debugowania i budowania zaufania ma dokładna wiedza o tym, skąd pochodzą dane i jak zostały zmienione. To pojęcie jest znane jako historia danych. Odpowiada na podstawowe pytania, takie jak: „Jeśli menedżer przegląda raport dziennej sprzedaży, które tabele nieprzetworzonych danych zostały użyte do obliczenia tych liczb?”.
Tradycyjnie śledzenie tego cyklu życia wymaga od inżynierów danych ręcznego pisania niestandardowego kodu logowania lub używania złożonych narzędzi innych firm do analizowania skryptów SQL. Jednak w zarządzanej architekturze Google Cloud Lakehouse to śledzenie jest wbudowane i całkowicie automatyczne.
Pamiętasz tabelę transactions_summary, którą utworzyliśmy na podstawie tabeli nieprzetworzonych transakcji w dalszej części ćwiczenia? Gdy BigQuery wykonało instrukcję CREATE TABLE AS SELECT, silnik obliczeniowy automatycznie zarejestrował metadane przekształceń i wysłał je do Knowledge Catalog. Zobaczmy wynik.
Wizualizowanie historii danych
- W konsoli Google Cloud otwórz Knowledge Catalog > Wyszukiwanie.
- Wpisz
lakehouse_retail_demo.transactionsw pasku wyszukiwania i kliknij tabelę. - Kliknij kartę Historia danych.
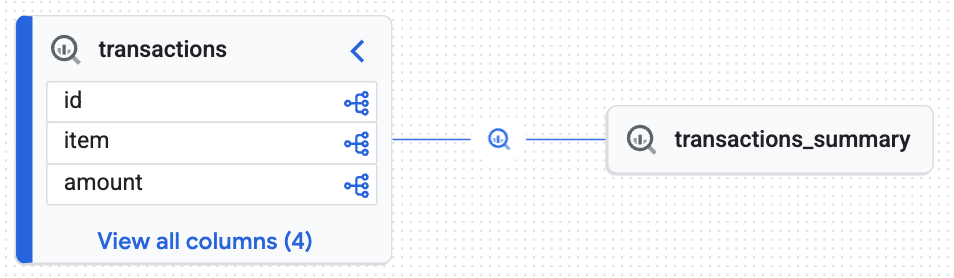
Zobaczysz interaktywny wykres wygenerowany przez Knowledge Engine, który potwierdza, że tabela docelowa (transactions_summary) została utworzona na podstawie nieprzetworzonej, zarządzanej tabeli Iceberg (transactions). Uzyskasz możliwość śledzenia od początku do końca, co jest niezbędne do audytu danych.
7. Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym ćwiczeniu, wykonaj te czynności.
Usuwanie zasobów zarządzania Knowledge Catalog
Zanim usuniesz zbiór danych BigQuery lub zasobnik Cloud Storage, musisz usunąć logiczne reguły zarządzania. Jeśli zajrzysz do skryptu cleanup_governance.py z repozytorium, zobaczysz tę sekwencję usuwania:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Kolejność jest tu kluczowa. Skrypt najpierw usuwa zasadę dotyczącą danych (regułę maskowania), ponieważ opiera się ona na tagu zasad. Po usunięciu zasady usunięcie taksonomii nadrzędnej spowoduje automatyczne usunięcie wszystkich tagów zasad bez wywoływania błędów zależności zasobów.
Uruchom skrypt czyszczenia w Pythonie:
python cleanup_governance.py
Usuwanie tożsamości, miejsca na dane i zasobów obliczeniowych
Teraz, gdy warstwa zarządzania jest odłączona, możesz bezpiecznie usunąć tabele BigQuery, zasobniki Cloud Storage, konta usługi i lokalne środowisko Pythona.
Skopiuj i uruchom w Cloud Shell ten kompleksowy blok czyszczenia:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Wykonanie tych czynności zapewni, że w projekcie nie pozostaną żadne osierocone zasoby ani ukryte zasady.
8. Gratulacje!
Udało Ci się wdrożyć w pełni zarządzaną, wykrywalną architekturę lakehouse.
Wiesz już, że:
- Natywna integracja z Iceberg: Lakehouse może natywnie zarządzać tabelami Iceberg open source, przechowując fizyczne pliki bezpiecznie w Cloud Storage.
- Delegowanie obliczeń na potrzeby bezpieczeństwa: kierując zapytania przez interfejs BigQuery Storage API, wymuszasz szczegółowe dynamiczne maskowanie plików fizycznych, które natywnie nie mogą ograniczać częściowego dostępu.
- Zarządzanie niezależne od silnika: tagi zasad umożliwiają zdefiniowanie reguł raz i egzekwowanie ich uniwersalnie, niezależnie od tego, czy zapytanie jest wysyłane za pomocą natywnego SQL, czy środowiska wykonawczego Apache Spark.
- Wykrywalność danych: Knowledge Engine automatycznie śledzi historię danych, zapewniając niezbędną możliwość audytu w przedsiębiorstwie.
Co dalej?
- Poznaj zaawansowaną kontrolę dostępu: aby wdrożyć bardziej złożone scenariusze bezpieczeństwa, zapoznaj się z oficjalną dokumentacją dotyczącą dostosowywania Lakehouse za pomocą dodatkowych funkcji.
- Zarządzaj danymi nieustrukturyzowanymi na potrzeby generatywnej AI: poznaj tabele obiektów. Rozszerz ten sam wzorzec bezpiecznego mostu na pliki nieustrukturyzowane (PDF, obrazy) w Cloud Storage, tworząc bezpieczny, zarządzany fundament danych dla silnika agenta Gemini Enterprise i potoków RAG.