
1. Introdução
Em uma Data Cloud empresarial moderna, em que os dados residem em vários sistemas de armazenamento físico, há um grande desafio arquitetônico de segurança fragmentada.
Como garantir que dados sensíveis (como valores de transações financeiras) sejam protegidos de maneira consistente quando armazenados fisicamente em formatos de código aberto, como o Parquet, no armazenamento do Google Cloud e consultados por vários mecanismos diferentes, como o SQL do BigQuery ou o Apache Spark?
Neste codelab, você vai criar uma arquitetura de lakehouse de dados governados que resolve esses problemas usando tabelas do Apache Iceberg, BigQuery e Knowledge Catalog. Você vai usar a infraestrutura como código (IaC) para definir políticas de segurança de confiança zero e como elas são aplicadas dinamicamente em diferentes mecanismos de computação.
Pré-requisitos
- Ter um projeto do Google Cloud com o faturamento ativado.
- Entendimento básico dos conceitos de SQL, IAM e Cloud Storage.
O que você vai aprender
- Como criar tabelas do Google Cloud Lakehouse para Apache Iceberg no BigQuery, em que o Cloud Storage armazena os dados de forma nativa.
- Como aplicar políticas de dados centralizadas usando tags de política para segurança no nível da coluna e mascaramento de dados.
- Como separar o acesso ao armazenamento físico do acesso lógico aos dados usando a conexão de recursos do Cloud.
- Como aplicar a delegação de computação de confiança zero usando o Serviço Gerenciado para Apache Spark para garantir que os mecanismos de código aberto não possam ignorar a governança.
- Como visualizar a linhagem de dados automatizada.
Visão geral da arquitetura: governança universal no Iceberg
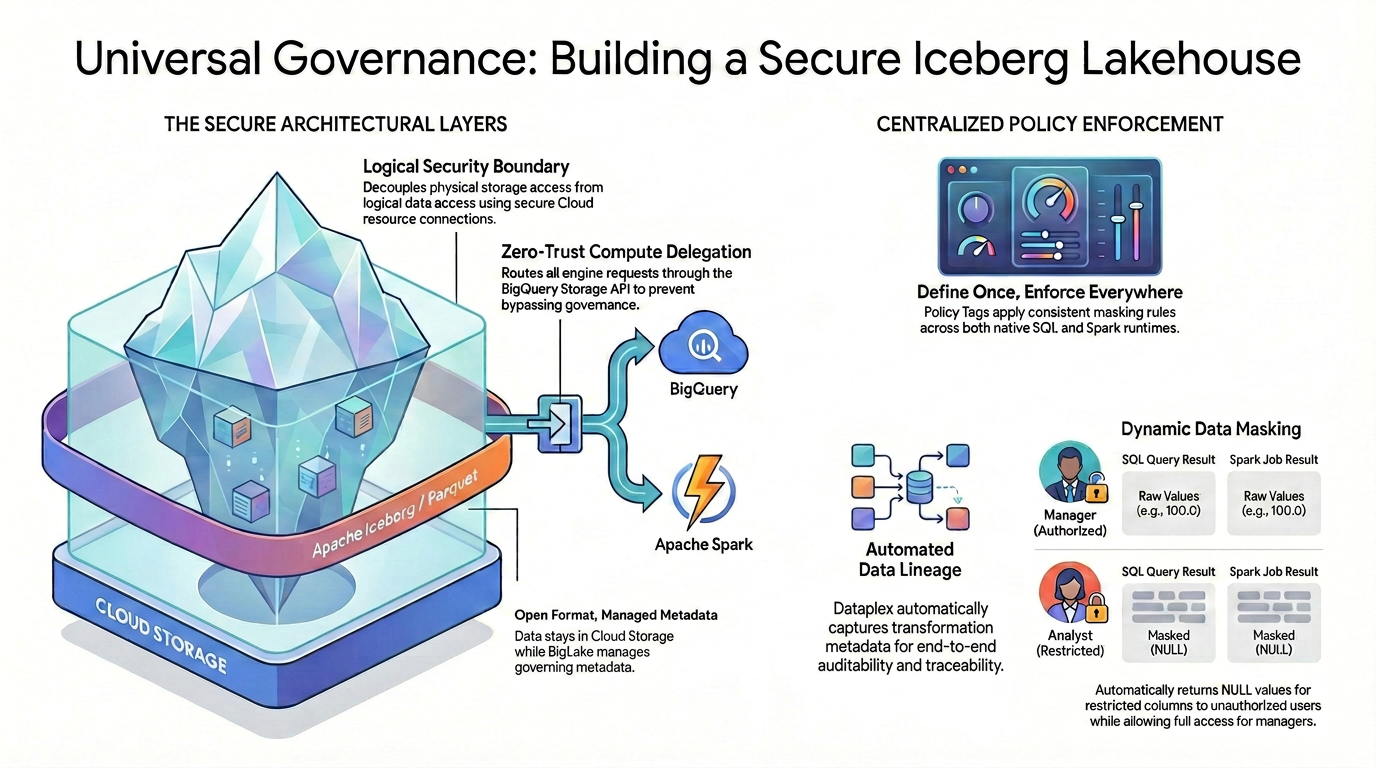
Para ter um controle de acesso refinado (como segurança no nível da coluna e mascaramento de dados) em formatos de dados de código aberto, é necessário estabelecer uma arquitetura de segurança rigorosa e unificada.
Como ilustrado no diagrama, esse padrão de lakehouse governado depende de dois pilares principais para resolver o desafio da segurança fragmentada:
🛡️ As camadas arquitetônicas seguras (à esquerda)
Em vez de permitir que usuários ou mecanismos externos acessem o Cloud Storage diretamente, que só oferece suporte a segurança ampla no nível do bucket, você cria uma base segura.
- Formato aberto, metadados gerenciados:os dados permanecem fisicamente no Cloud Storage usando o formato aberto Apache Iceberg (Parquet), enquanto o Lakehouse gerencia perfeitamente os metadados de governança.
- Limite de segurança lógica:você separa o acesso ao armazenamento físico do acesso aos dados usando uma conexão a recursos do Cloud segura. Os usuários finais nunca recebem acesso físico direto do IAM aos arquivos brutos do GCS.
- Delegação de computação de confiança zero:para garantir que nenhum mecanismo de execução possa ignorar as regras de governança, todas as solicitações de leitura de dados são estritamente encaminhadas pela API BigQuery Storage. Isso se aplica se a consulta for originada do SQL nativo do BigQuery ou do Apache Spark de código aberto.
🎯 Aplicação centralizada de políticas (direita)
Com essa base segura, o Knowledge Catalog atua como o cérebro unificado da governança:
- Definir uma vez, aplicar em todos os lugares:você define as tags de política no Knowledge Catalog apenas uma vez, e a arquitetura aplica regras de mascaramento consistentes em todos os tempos de execução compatíveis.
- Mascaramento dinâmico de dados:quando os dados são consultados, o sistema avalia a identidade do usuário em tempo real. Os usuários autorizados vão ver os valores brutos e sem máscara (por exemplo, 100,0) em SQL e Spark, enquanto os usuários restritos vão receber automaticamente valores NULL mascarados para colunas restritas nos dois mecanismos.
- Linhagem de dados automatizada:à medida que os dados fluem e são transformados, o Knowledge Catalog captura automaticamente os metadados de transformação, oferecendo capacidade de auditoria e rastreamento de ponta a ponta integradas sem exigir código de geração de registros personalizado.
2. Configuração e requisitos
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
Inicializar o ambiente
Abra o Cloud Shell e defina as variáveis do projeto para garantir que todos os comandos sejam direcionados à infraestrutura correta.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Em seguida, defina nossas duas personas.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Ativar APIs
Ative os serviços necessários do Google Cloud.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Faça o download do código-fonte do codelab
Para evitar poluir o Cloud Shell, faça um checkout esparso para baixar apenas os scripts Python necessários para este codelab do repositório DevRel do Google Cloud.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Criar armazenamento
Crie o bucket para armazenar os dados do Iceberg altamente seguros e governados.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Preparar identidades e segurança
Configure a conexão a recursos do Cloud. Essa é a única entidade que tem as chaves físicas permanentes do IAM para ler os arquivos brutos do Iceberg.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Em seguida, configure os perfis de usuários. Os usuários recebem acesso lógico, não acesso ao armazenamento físico. Para evitar erros causados por atrasos na propagação do IAM, primeiro crie as contas, aguarde alguns segundos e atribua as funções.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Criar tabelas nativas do Iceberg usando o Lakehouse
Você vai usar os recursos nativos do Lakehouse para criar as tabelas gerenciadas do Iceberg.
Criar o conjunto de dados do BigQuery
Primeiro, crie um conjunto de dados do BigQuery para agrupar logicamente as tabelas do Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Criar as tabelas Iceberg
Em seguida, execute os comandos abaixo para criar as tabelas. Observe o bloco OPTIONS, em que especificamos table_format = 'ICEBERG' e o mapeamos diretamente para nosso bucket do Cloud Storage e conexão.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Preencher as tabelas com dados
Por fim, insira dados de amostra nas tabelas Iceberg recém-criadas.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Agora você tem duas tabelas do Iceberg totalmente funcionais. O Lakehouse gerencia os metadados, mas os arquivos Parquet físicos ficam armazenados com segurança no seu bucket do GCS.
Simular um pipeline de ETL
Em um cenário real, os dados brutos geralmente são agregados em tabelas de resumo para relatórios comerciais. Vamos agir como um engenheiro de dados e criar uma tabela de resumo de vendas diárias com base nos nossos dados de transações brutas.
Observação: execute esta etapa agora para que o Google Cloud tenha tempo suficiente para processar os metadados em segundo plano. Você vai descobrir por que isso é importante mais adiante no codelab.)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Governança centralizada: defina políticas usando Python
Em um ambiente de produção, é difícil escalonar e manter a configuração de políticas de governança pela interface. Em vez disso, é altamente recomendável usar a infraestrutura como código (IaC).
Nesta seção, você vai usar o SDK do Python do Google Cloud para criar e aplicar de maneira programática as regras de governança de confiança zero, etapa por etapa.
Configurar o ambiente Python
Primeiro, vamos configurar um ambiente Python isolado (venv) para evitar conflitos de biblioteca e instalar os SDKs do Google Cloud necessários.
Execute os comandos a seguir no Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Criar a taxonomia e a tag de política
Uma taxonomia é um contêiner lógico, e uma tag de política é o rótulo específico que você vai anexar à coluna sensível. Para aplicar a segurança no nível da coluna, primeiro você precisa de um contêiner lógico (uma taxonomia) e um rótulo específico (uma tag de política).
Se você analisar 1_create_taxonomy.py, vai encontrar a seguinte lógica principal:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Ao definir explicitamente o tipo de política FINE_GRAINED_ACCESS_CONTROL, você transforma uma tag de metadados padrão em um limite de segurança estrito de confiança zero. Por padrão, qualquer coluna com essa tag nega o acesso a todos os usuários.
Execute o script para criar os recursos:
python 1_create_taxonomy.py
Configurar a regra de mascaramento (política de dados)
Agora, você define o que acontece quando alguém sem privilégios consulta a coluna marcada. Você vai criar uma política de dados que força o valor a retornar como NULL e anexar essa regra à persona do analista.
Dentro de 2_create_masking.py, o script procura dinamicamente o ID da tag de política que você acabou de criar e aplica uma política de dados:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Esse código cria programaticamente uma regra que força os valores subjacentes a serem retornados como NULL. Em seguida, ele atribui a função do IAM maskedReader especificamente à persona do analista, garantindo que ela veja apenas a versão mascarada dos dados.
Execute o script para configurar a regra de mascaramento:
python 2_create_masking.py
Conceder acesso granular
Devido à nossa configuração de confiança zero, ninguém pode ler a coluna marcada no momento. Você precisa conceder acesso explícito ao administrador e à sua conta pessoal.
Em 3_grant_access.py, modifique a política do IAM da própria tag de política:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Ao adicionar a função categoryFineGrainedReader, esses principais específicos podem ignorar as regras de mascaramento e ler os dados brutos não mascarados.
Execute o script para conceder acesso:
python 3_grant_access.py
Anexar a tag de política à tabela do BigQuery
Por fim, é necessário anexar essa tag de política lógica ao nosso esquema de tabela física do Iceberg.
Dê uma olhada no arquivo 4_attach_tag.py. O script busca o esquema da tabela do BigQuery, itera pelos campos e anexa a tag especificamente à coluna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Quando essa atualização de esquema é aplicada, o Lakehouse faz a ponte instantaneamente entre as tags lógicas do Knowledge Catalog e os arquivos Parquet físicos armazenados no bucket do Cloud Storage.
Execute o script para atualizar o esquema da tabela:
python 4_attach_tag.py
5. Verificar as políticas do Knowledge Catalog
É hora de testar se nossa governança centralizada funciona. Você vai testar isso em dois mecanismos diferentes para provar que as políticas do Knowledge Catalog são aplicadas universalmente.
Verificar usando o SQL nativo do BigQuery
Primeiro, você vai usar o Cloud Shell para assumir a identidade das duas personas e consultar a tabela usando o mecanismo SQL nativo do BigQuery.
Teste como gerente (usuário com privilégios):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Como o gerente tem a função de leitor refinado, ele vai mostrar os valores brutos de quantidade.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Teste como o analista (usuário restrito):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Devido à regra de mascaramento do Knowledge Catalog, a coluna "Amount" retorna como NULL para todas as linhas.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Restaurar sua identidade
Limpe o estado de autenticação do Cloud Shell para voltar ao usuário administrador.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Verificar usando o Apache Spark (delegação de computação)
E se um cientista de dados usar o Apache Spark para ler essa tabela? Se o Spark ler os arquivos Parquet físicos do GCS diretamente, as regras de mascaramento do Knowledge Catalog serão totalmente ignoradas porque o Cloud Storage só entende as permissões no nível do bucket.
Para evitar isso, aplique a delegação de computação usando o conector Spark-BigQuery. Esse conector funciona como uma ponte segura, encaminhando as solicitações de leitura do Spark pela API BigQuery Storage para que as regras de governança do Knowledge Catalog sejam avaliadas dinamicamente antes que os dados sejam enviados ao cluster do Spark.
Confira a lógica principal no script read_transactions.py que você baixou:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Observe que não estamos apontando o Spark para o caminho gs:// dos arquivos do Iceberg. Ao especificar .format("bigquery"), a API BigQuery Storage intercepta a solicitação de leitura, verifica a identidade do usuário que está executando o job do Spark, aplica as regras de mascaramento do Knowledge Catalog e retorna apenas os dados autorizados ao DataFrame do Spark.
Faça upload do script do PySpark para o bucket do Cloud Storage para que o Apache Spark gerenciado possa acessá-lo:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Execute o Spark como gerente:
Você vai usar o Apache Spark gerenciado. Com esse serviço gerenciado, é possível executar cargas de trabalho do Spark diretamente, sem precisar provisionar, configurar ou gerenciar clusters dedicados.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Confira os registros de saída do job no terminal. Como o gerente tem o papel de Leitor refinado, o Spark recupera os valores brutos e não mascarados.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Execute o Spark como analista:
Agora, envie o mesmo job do Spark, mas desta vez se passando pela persona do analista.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Verifique os registros novamente. Mesmo que o analista tenha executado exatamente o mesmo código do Spark, a API BigQuery Storage interceptou a solicitação e aplicou a política do Knowledge Catalog. O DataFrame do Spark do analista mostra null para os valores.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Compensações arquitetônicas: SQL do BigQuery x Spark
Você acabou de provar que o resultado é idêntico, seja qual for o mecanismo. A política do Knowledge Catalog foi aplicada. Mas na produção, qual você deve usar?
- SQL do BigQuery:ideal para fluxos de trabalho em que o SQL é o mecanismo desejado e executa cálculos diretamente no local. É ideal para análises rápidas e Business Intelligence.
- Apache Spark:permite cargas de trabalho mais complexas usando Python, o que o torna adequado para pipelines avançados de machine learning ou código Hadoop legado.
O principal ponto:não importa qual mecanismo seja usado, ao aplicar a delegação de computação, a camada de governança centralizada de confiança zero nunca pode ser ignorada.
6. Linhagem de dados automatizada
Em qualquer arquitetura de dados corporativos, é fundamental saber exatamente de onde vêm os dados e como eles foram alterados para fins de compliance, depuração e estabelecimento de confiança. Esse conceito é conhecido como linhagem de dados. Ela responde a perguntas fundamentais, como: "Se um gerente estiver analisando um relatório de vendas diárias, quais tabelas brutas foram usadas para calcular esses números?"
Tradicionalmente, o rastreamento desse ciclo de vida exige que os engenheiros de dados escrevam manualmente um código de geração de registros personalizado ou usem ferramentas complexas de terceiros para analisar scripts SQL. No entanto, em um data lakehouse governado do Google Cloud, esse rastreamento é integrado e totalmente automático.
Lembra da tabela transactions_summary que você criou com base na tabela de transações brutas no início do codelab? Quando o BigQuery executou essa instrução CREATE TABLE AS SELECT, o mecanismo de computação capturou automaticamente os metadados de transformação e os enviou para o Knowledge Catalog. Vamos conferir o resultado.
Visualizar a linhagem
- No console do Google Cloud, acesse Knowledge Catalog > Pesquisar.
- Digite
lakehouse_retail_demo.transactionsna barra de pesquisa e clique na tabela. - Clique na guia Linhagem.
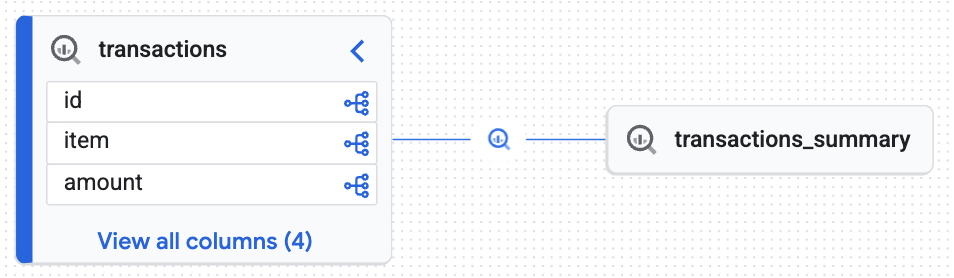
Você vai ver um gráfico interativo gerado pelo Knowledge Engine que prova que a tabela de destino (transactions_summary) foi derivada da tabela bruta gerenciada do Iceberg (transactions). Você alcançou a rastreabilidade de ponta a ponta essencial para a auditoria de dados.
7. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas.
Remover recursos de governança do Knowledge Catalog
Antes de excluir o conjunto de dados do BigQuery ou o bucket do Cloud Storage, remova as regras de governança lógica. Se você analisar o script cleanup_governance.py do repositório, vai encontrar a seguinte sequência de desmontagem:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
A ordem aqui é fundamental. Primeiro, o script exclui a política de dados (regra de mascaramento) porque ela depende da tag de política. Depois que a política é removida, a exclusão da taxonomia principal é propagada automaticamente e exclui todas as tags de política subjacentes sem acionar erros de dependência de recursos.
Execute o script de limpeza do Python:
python cleanup_governance.py
Remover identidades, armazenamento e recursos de computação
Agora que a camada de governança está separada, você pode excluir com segurança as tabelas do BigQuery, os buckets do Cloud Storage, as contas de serviço e o ambiente Python local.
Copie e execute o seguinte bloco de limpeza abrangente no Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Ao concluir essas etapas, você garante que não há recursos órfãos ou políticas ocultas no seu projeto.
8. Parabéns!
Você implementou um Data Lakehouse totalmente governado e detectável.
Você aprendeu que:
- Integração nativa do Iceberg:o Lakehouse pode gerenciar nativamente tabelas do Iceberg de código aberto enquanto armazena os arquivos físicos com segurança no Cloud Storage.
- Delegação de computação para segurança:ao encaminhar consultas pela API BigQuery Storage, você impôs uma máscara dinâmica refinada em arquivos físicos que não podem restringir o acesso parcial de forma nativa.
- Governança independente do mecanismo:com as tags de política, é possível definir regras uma vez e aplicá-las universalmente, seja por consultas com SQL nativo ou tempos de execução do Apache Spark.
- Capacidade de descoberta de dados:o Knowledge Engine rastreia automaticamente a linhagem de dados, oferecendo a capacidade de auditoria empresarial essencial.
Qual é a próxima etapa?
- Conheça o controle de acesso avançado:para implementar cenários de segurança mais complexos, consulte a documentação oficial sobre como personalizar o Lakehouse com outros recursos.
- Governe dados não estruturados para a IA generativa:descubra as tabelas de objetos. Estenda esse padrão exato de ponte segura a arquivos não estruturados (PDFs, imagens) no Cloud Storage, estabelecendo uma base de dados segura e governada para o Gemini Enterprise Agent Engine e os pipelines de RAG.