
1. Введение
В современном корпоративном облаке данных, где данные хранятся в различных физических системах хранения, возникает масштабная архитектурная проблема фрагментированной безопасности.
Как обеспечить надежную защиту конфиденциальных данных (например, сумм финансовых транзакций) при физическом хранении данных в форматах с открытым исходным кодом, таких как Parquet, в хранилище Google Cloud и запросах к ним со стороны различных движков, таких как BigQuery SQL или Apache Spark?
В этом практическом занятии вы создадите архитектуру управляемого хранилища данных (Governed Data Lakehouse), которая решает эти проблемы с помощью таблиц Apache Iceberg , BigQuery и Knowledge Catalog . Вы будете использовать концепцию «инфраструктура как код» (IaC) для определения политик безопасности с нулевым доверием и способов их динамического применения в различных вычислительных системах.
Предварительные требования
- Проект Google Cloud с включенной функцией выставления счетов.
- Базовое понимание концепций SQL, IAM и облачного хранилища.
Что вы узнаете
- Как создать таблицы Google Cloud Lakehouse для Apache Iceberg в BigQuery, где данные хранятся непосредственно в Cloud Storage.
- Как обеспечить соблюдение централизованных политик данных с помощью тегов политик для обеспечения безопасности на уровне столбцов и маскирования данных.
- Как отделить физический доступ к хранилищу от логического доступа к данным с помощью подключения к облачным ресурсам .
- Как обеспечить делегирование вычислительных ресурсов по принципу «нулевого доверия» с использованием управляемых сервисов для Apache Spark , чтобы гарантировать, что механизмы с открытым исходным кодом не смогут обойти правила управления.
- Как визуализировать автоматизированную отслеживание происхождения данных .
Обзор архитектуры: Универсальное управление на айсберге
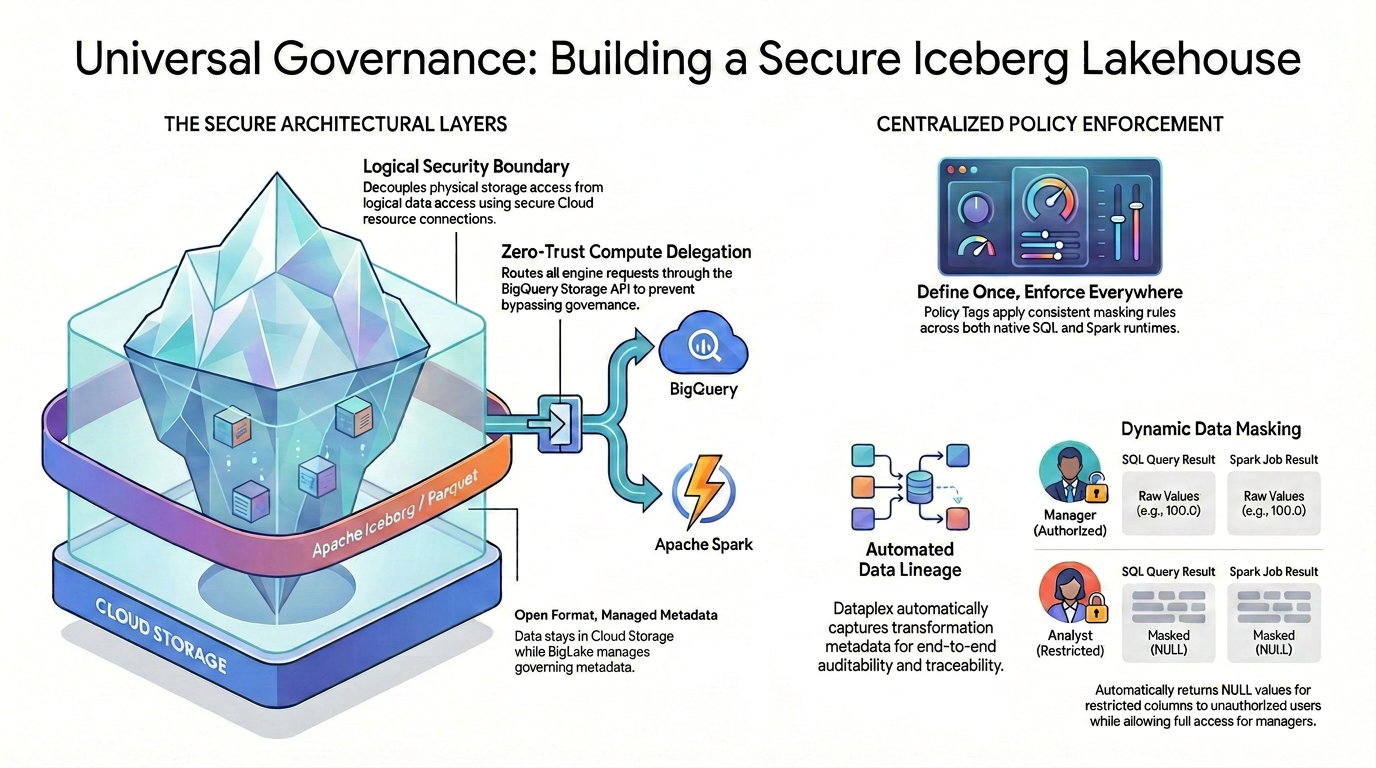
Для обеспечения детального контроля доступа (например, на уровне столбцов и маскирования данных) к данным в форматах с открытым исходным кодом необходимо создать строгую и унифицированную архитектуру безопасности.
Как показано на диаграмме, эта модель управляемого дома у озера опирается на два основных столпа для решения проблемы разрозненной безопасности:
🛡️ Уровни защищенной архитектуры (слева)
Вместо того чтобы позволять пользователям или внешним механизмам напрямую получать доступ к облачному хранилищу — что обеспечивает лишь общую безопасность на уровне отдельных сегментов — вы создаете надежную основу.
- Открытый формат, управляемые метаданные: данные физически хранятся в Cloud Storage в открытом формате Apache Iceberg (Parquet), а Lakehouse обеспечивает бесперебойное управление основными метаданными.
- Граница логической безопасности: вы отделяете доступ к физическому хранилищу от доступа к логическим данным, используя защищенное соединение с облачным ресурсом. Конечным пользователям никогда не предоставляется прямой физический доступ IAM к необработанным файлам GCS.
- Делегирование вычислительных ресурсов по принципу нулевого доверия: чтобы гарантировать, что ни один механизм выполнения не сможет обойти правила управления, все запросы на чтение данных направляются строго через API хранилища BigQuery. Это относится как к запросам, исходящим из собственного SQL-кода BigQuery, так и к запросам с открытым исходным кодом Apache Spark.
🎯 Централизованное обеспечение соблюдения политики (справа)
Благодаря надежной основе, Каталог знаний выступает в качестве единого центра управления:
- Определите один раз, применяйте везде: вы определяете свои теги политик в каталоге знаний всего один раз, и архитектура применяет согласованные правила маскирования повсеместно во всех поддерживаемых средах выполнения.
- Динамическое маскирование данных: при запросе данных система в режиме реального времени определяет личность пользователя. Авторизованные пользователи будут видеть исходные, незамаскированные значения (например, 100.0) как в SQL, так и в Spark, а пользователи с ограниченными правами автоматически будут получать замаскированные значения NULL для столбцов с ограниченным доступом в обоих механизмах.
- Автоматизированная отслеживаемость происхождения данных: по мере передачи и преобразования данных Knowledge Catalog автоматически фиксирует метаданные преобразований, обеспечивая встроенную сквозную возможность аудита и отслеживания без необходимости написания специального кода для ведения журналов.
2. Настройка и требования
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
Инициализация среды
Откройте Cloud Shell и настройте переменные проекта, чтобы все команды были направлены на правильную инфраструктуру.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Затем определим наших двух персонажей.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Включить API
Включите необходимые сервисы Google Cloud.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Скачайте исходный код Codelab.
Чтобы избежать перегрузки вашей оболочки Cloud Shell, вам потребуется выполнить разреженное извлечение (sparse checkout) , чтобы загрузить из репозитория Google Cloud DevRel только необходимые для этого практического занятия скрипты Python.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Создать хранилище
Создайте хранилище для высокозащищенных управляемых данных Iceberg.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Подготовка идентификационных данных и обеспечение безопасности
Настройте подключение к облачному ресурсу. Это единственный объект, который хранит постоянные физические ключи IAM для чтения необработанных файлов Iceberg.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Далее настройте профили пользователей. Пользователям предоставляется логический доступ, а не доступ к физическому хранилищу. Чтобы избежать ошибок, вызванных задержками распространения IAM, сначала создайте учетные записи, подождите несколько секунд, а затем назначьте им роли.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Создавайте собственные таблицы Iceberg с помощью Lakehouse.
Для создания управляемых таблиц Iceberg вы будете использовать встроенные возможности Lakehouse.
Создайте набор данных BigQuery.
Сначала создайте набор данных BigQuery для логической группировки наших таблиц Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Создайте таблицы «Айсберг».
Далее выполните следующие команды для создания таблиц. Обратите внимание на блок OPTIONS , где мы указываем table_format = 'ICEBERG' и напрямую сопоставляем его с нашим сегментом Cloud Storage и подключением.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Заполните таблицы данными.
Наконец, вставьте примеры данных в только что созданные таблицы Iceberg.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Теперь у вас есть две полностью функционирующие таблицы Iceberg. Lakehouse управляет метаданными, но физические файлы Parquet надежно хранятся в вашем хранилище GCS!
Имитация конвейера ETL
В реальных условиях необработанные данные часто агрегируются в сводные таблицы для бизнес-отчетности. Давайте представим себя инженером данных и создадим ежедневную сводную таблицу продаж на основе наших необработанных данных о транзакциях.
(Примечание: выполните этот шаг сейчас, чтобы у Google Cloud было достаточно времени для обработки фоновых метаданных. Вы узнаете, почему это важно, позже в практическом задании!)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Централизованное управление: определение политик с помощью Python.
В производственной среде настройка политик управления через пользовательский интерфейс затруднительна с точки зрения масштабируемости и поддержки. Вместо этого настоятельно рекомендуется использовать инфраструктуру как код (IaC).
В этом разделе вы будете использовать SDK Google Cloud Python для программного создания и поэтапного обеспечения соблюдения правил управления на основе концепции «нулевого доверия».
Настройте среду Python.
Для начала давайте настроим изолированную среду Python ( venv ), чтобы избежать конфликтов библиотек, и установим необходимые SDK Google Cloud.
Выполните следующие команды в Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Создайте тег таксономии и политики.
Таксономия — это логический контейнер, а тег политики — это конкретная метка, которую вы присвоите нашему столбцу с конфиденциальной информацией. Для обеспечения безопасности на уровне столбца вам сначала нужен логический контейнер (таксономия) и конкретная метка (тег политики).
Если вы заглянете внутрь 1_create_taxonomy.py , вы увидите следующую основную логику:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Явно задав тип политики FINE_GRAINED_ACCESS_CONTROL , вы преобразуете стандартный тег метаданных в строгую границу безопасности с нулевым доверием. Любой столбец с этим тегом по умолчанию будет иметь запрещенный доступ для всех пользователей.
Запустите скрипт для создания ресурсов:
python 1_create_taxonomy.py
Настройте правило маскирования (политику данных).
Теперь определите, что произойдет, если кто-то без привилегий запросит данные из помеченного столбца. Вы создадите политику данных , которая будет принудительно возвращать значение NULL , и прикрепите это правило к учетной записи аналитика .
Внутри файла 2_create_masking.py скрипт динамически находит идентификатор тега политики, который вы только что создали, и применяет политику данных:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Этот код программно создает правило, которое заставляет базовые значения возвращать значение NULL. Затем он назначает роль IAM maskedReader конкретному пользователю Analyst, гарантируя, что он будет видеть только замаскированную версию данных.
Запустите скрипт, чтобы настроить правило маскирования:
python 2_create_masking.py
Предоставить детальный доступ
Из-за нашей системы нулевого доверия никто сейчас не может прочитать помеченный столбец. Вам необходимо явно предоставить доступ менеджеру и своему личному кабинету.
Внутри 3_grant_access.py вы изменяете политику IAM самого тега Policy Tag:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Добавление роли categoryFineGrainedReader позволяет этим конкретным субъектам обходить правила маскирования и считывать необработанные, незамаскированные данные.
Запустите скрипт, чтобы предоставить доступ:
python 3_grant_access.py
Прикрепите тег политики к таблице BigQuery.
Наконец, вам необходимо прикрепить этот логический тег политики к нашей физической схеме таблицы Iceberg.
Взгляните на 4_attach_tag.py . Этот скрипт получает схему таблицы BigQuery, перебирает поля и прикрепляет тег непосредственно к столбцу amount :
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
После применения этого обновления схемы Lakehouse мгновенно сопоставляет логические теги нашего каталога знаний с физическими файлами Parquet, хранящимися в вашем хранилище Cloud Storage.
Запустите скрипт для обновления схемы таблицы:
python 4_attach_tag.py
5. Проверка политик каталога знаний.
Пришло время проверить, работает ли наша централизованная система управления. Вы проверите это на двух разных системах, чтобы доказать, что правила Каталога знаний применяются повсеместно.
Проверка с использованием встроенного SQL-запроса BigQuery.
Сначала вы воспользуетесь Cloud Shell, чтобы принять на себя роли двух наших персонажей и выполнить запрос к таблице, используя встроенный SQL-движок BigQuery.
Тестирование от имени менеджера (привилегированный пользователь):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Поскольку у менеджера есть роль "Внимательный читатель", будут отображаться исходные значения сумм.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Тестирование от имени аналитика (пользователь с ограниченными правами):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Из-за правила маскирования в каталоге знаний столбец «сумма» возвращает значение NULL для каждой строки.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Восстановите свою личность
Очистите состояние аутентификации Cloud Shell, чтобы вернуть права администратора.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Проверка с использованием Apache Spark (делегирование вычислительных ресурсов).
Что если специалист по анализу данных использует Apache Spark для чтения этой таблицы? Если Spark читает физические файлы Parquet из GCS напрямую, правила маскирования каталога знаний полностью игнорируются, поскольку Cloud Storage понимает только разрешения на уровне сегментов.
Чтобы предотвратить это, необходимо обеспечить делегирование вычислительных ресурсов с помощью коннектора Spark-BigQuery . Этот коннектор выступает в качестве защищенного моста, направляя запросы на чтение Spark через API хранилища BigQuery, так что правила управления каталогом знаний динамически оцениваются до отправки каких-либо данных в кластер Spark.
Ознакомьтесь с основной логикой скрипта read_transactions.py , который вы скачали:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Обратите внимание, что мы не указываем Spark путь gs:// к файлам Iceberg. Указав .format("bigquery") , API хранилища BigQuery перехватывает запрос на чтение, проверяет личность пользователя, запускающего задание Spark, применяет правила маскирования из каталога знаний и возвращает в DataFrame Spark только авторизованные данные.
Загрузите этот скрипт pySpark в свой сегмент Cloud Storage, чтобы управляемый Apache Spark мог получить к нему доступ:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Запустите Spark в качестве менеджера:
Вы будете использовать управляемый Apache Spark. Этот управляемый сервис позволяет запускать рабочие нагрузки Spark напрямую, без необходимости выделения, настройки или управления выделенными кластерами.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Посмотрите журналы выполнения заданий в терминале. Поскольку у менеджера есть роль «Подробный читатель», Spark успешно извлекает исходные, незамаскированные значения.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Запустите Spark от имени аналитика:
Теперь запустите точно такое же задание Spark, но на этот раз представьте себя в роли аналитика.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Проверьте журналы еще раз. Несмотря на то, что аналитик запускал тот же самый код Spark, API хранилища BigQuery перехватил запрос и применил политику каталога знаний. В DataFrame Spark аналитика для сумм отображается null !
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Архитектурные компромиссы: BigQuery SQL против Spark
Вы только что доказали, что результат одинаков независимо от используемого движка! Политика каталога знаний была успешно применена. Но в производственной среде, какой движок следует использовать?
- BigQuery SQL: Отлично подходит для рабочих процессов, где SQL является предпочтительным механизмом и выполняет вычисления непосредственно на месте. Идеально подходит для быстрой аналитики и бизнес-аналитики.
- Apache Spark: Благодаря использованию Python позволяет обрабатывать более сложные задачи, что делает его хорошо подходящим для сложных конвейеров машинного обучения или устаревшего кода Hadoop.
Главный вывод: независимо от используемого движка, благодаря принудительному делегированию вычислительных ресурсов, централизованный уровень управления на основе принципа нулевого доверия никогда не будет обойден!
6. Автоматизированная отслеживание происхождения данных
В любой корпоративной архитектуре данных крайне важно точно знать, откуда берутся ваши данные и как они были изменены, для обеспечения соответствия требованиям, отладки и установления доверия. Эта концепция известна как «происхождение данных ». Она отвечает на фундаментальные вопросы, такие как: «Если менеджер просматривает ежедневный отчет о продажах, какие исходные таблицы использовались для расчета этих цифр?»
Традиционно отслеживание этого жизненного цикла требует от инженеров данных вручную писать собственный код для логирования или использовать сложные сторонние инструменты для анализа SQL-скриптов. Однако в управляемой среде Google Cloud Lakehouse это отслеживание встроено и полностью автоматизировано.
Помните таблицу transactions_summary которую вы создали ранее в практическом задании из исходной таблицы transactions? Когда BigQuery выполнил оператор CREATE TABLE AS SELECT , вычислительный движок автоматически получил метаданные преобразования и отправил их в Knowledge Catalog. Давайте посмотрим на результат.
Визуализируйте родословную
- В консоли Google Cloud перейдите в раздел «Каталог знаний» > «Поиск» .
- Введите в строку поиска
lakehouse_retail_demo.transactionsи щелкните по таблице. - Перейдите на вкладку «Происхождение» .
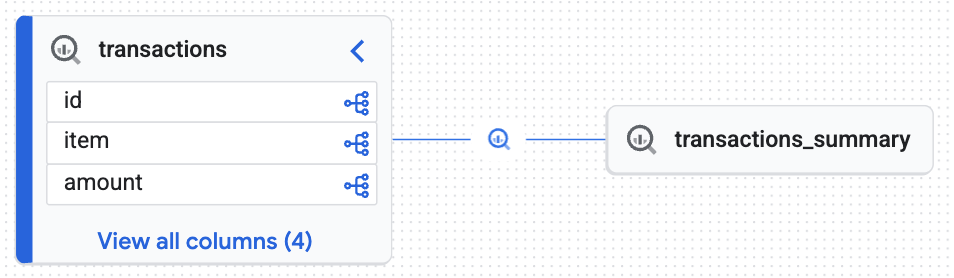
Вы увидите интерактивный график, сгенерированный механизмом знаний, доказывающий, что целевая таблица ( transactions_summary ) была получена из исходной управляемой таблицы Iceberg ( transactions ). Вы достигли сквозной прослеживаемости, необходимой для аудита данных.
7. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие шаги.
Удалить ресурсы управления каталогом знаний
Перед удалением набора данных BigQuery или хранилища Cloud Storage необходимо удалить правила логического управления. Если вы посмотрите содержимое скрипта cleanup_governance.py из репозитория, вы увидите следующую последовательность действий по удалению:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Порядок действий здесь имеет решающее значение. Сначала скрипт удаляет политику данных (правило маскирования), поскольку она зависит от тега политики. После удаления политики удаление родительской таксономии автоматически вызовет каскадное удаление всех нижележащих тегов политики без возникновения ошибок зависимости ресурсов.
Запустите скрипт очистки Python:
python cleanup_governance.py
Удалите учетные данные, хранилище и вычислительные ресурсы.
Теперь, когда уровень управления отключен, вы можете безопасно удалить таблицы BigQuery, сегменты Cloud Storage, учетные записи служб и локальную среду Python.
Скопируйте и запустите следующий блок комплексной очистки в вашей оболочке Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Выполнив эти шаги, вы гарантируете отсутствие в вашем проекте неиспользуемых ресурсов или скрытых политик.
8. Поздравляем!
Вы успешно внедрили полностью управляемое и доступное хранилище данных (Data Lakehouse).
Вы узнали, что:
- Встроенная интеграция с Iceberg: Lakehouse может управлять таблицами Iceberg с открытым исходным кодом, одновременно безопасно храня физические файлы в облачном хранилище.
- Делегирование вычислительных ресурсов для обеспечения безопасности: маршрутизация запросов через API хранилища BigQuery позволяет обеспечить детальное динамическое маскирование физических файлов, которые по своей природе не могут ограничивать частичный доступ.
- Управление, не зависящее от используемого движка: теги политик позволяют определить правила один раз и обеспечить их универсальное применение независимо от того, запрашиваются ли они через собственный SQL-запрос или среду выполнения Apache Spark.
- Обнаружение данных: Система управления знаниями автоматически отслеживает происхождение данных, обеспечивая необходимую возможность аудита на уровне предприятия.
Что дальше?
- Изучите расширенные возможности контроля доступа: для реализации более сложных сценариев безопасности ознакомьтесь с официальной документацией по настройке Lakehouse с помощью дополнительных функций .
- Управление неструктурированными данными для GenAI: обнаружение объектных таблиц . Расширьте этот шаблон безопасного моста на неструктурированные файлы (PDF, изображения) в облачном хранилище, создав безопасную, управляемую основу данных для Gemini Enterprise Agent Engine и конвейеров RAG.