
1. บทนำ
ใน Data Cloud ขององค์กรสมัยใหม่ซึ่งข้อมูลอยู่ทั่วทั้งระบบพื้นที่เก็บข้อมูลจริงต่างๆ ความท้าทายด้านสถาปัตยกรรมที่สำคัญคือการรักษาความปลอดภัยที่กระจัดกระจาย
คุณจะมั่นใจได้อย่างไรว่าข้อมูลที่ละเอียดอ่อน (เช่น จำนวนธุรกรรมทางการเงิน) จะได้รับการปกป้องอย่างสม่ำเสมอเมื่อจัดเก็บข้อมูลจริงในรูปแบบโอเพนซอร์ส เช่น Parquet ใน Google Cloud Storage และเครื่องมือต่างๆ เช่น BigQuery SQL หรือ Apache Spark จะค้นหาข้อมูลดังกล่าว
ใน Codelab นี้ คุณจะได้สร้างสถาปัตยกรรม Governed Data Lakehouse ที่แก้ปัญหาเหล่านี้โดยใช้ตาราง Apache Iceberg, BigQuery และแคตตาล็อกความรู้ คุณจะใช้โครงสร้างพื้นฐานเป็นโค้ด (IaC) เพื่อกำหนดนโยบายความปลอดภัยแบบ Zero Trust และวิธีบังคับใช้นโยบายแบบไดนามิกในเครื่องมือประมวลผลต่างๆ
ข้อกำหนดเบื้องต้น
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- ความเข้าใจพื้นฐานเกี่ยวกับแนวคิด SQL, IAM และ Cloud Storage
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างตาราง Google Cloud Lakehouse สำหรับ Apache Iceberg ใน BigQuery ซึ่ง Cloud Storage จัดเก็บข้อมูลโดยกำเนิด
- วิธีบังคับใช้นโยบายข้อมูลแบบรวมศูนย์โดยใช้แท็กนโยบายสำหรับการรักษาความปลอดภัยระดับคอลัมน์และการปกปิดข้อมูล
- วิธีแยกการเข้าถึงพื้นที่เก็บข้อมูลจริงจากการเข้าถึงข้อมูลเชิงตรรกะโดยใช้การเชื่อมต่อทรัพยากรระบบคลาวด์
- วิธีบังคับใช้การมอบสิทธิ์การประมวลผลแบบ Zero-Trust โดยใช้บริการที่มีการจัดการสำหรับ Apache Spark เพื่อให้มั่นใจว่าเครื่องมือโอเพนซอร์สจะไม่สามารถข้ามการกำกับดูแลได้
- วิธีแสดงภาพแหล่งที่มาของข้อมูลอัตโนมัติ
ภาพรวมสถาปัตยกรรม: การกํากับดูแลแบบสากลใน Iceberg
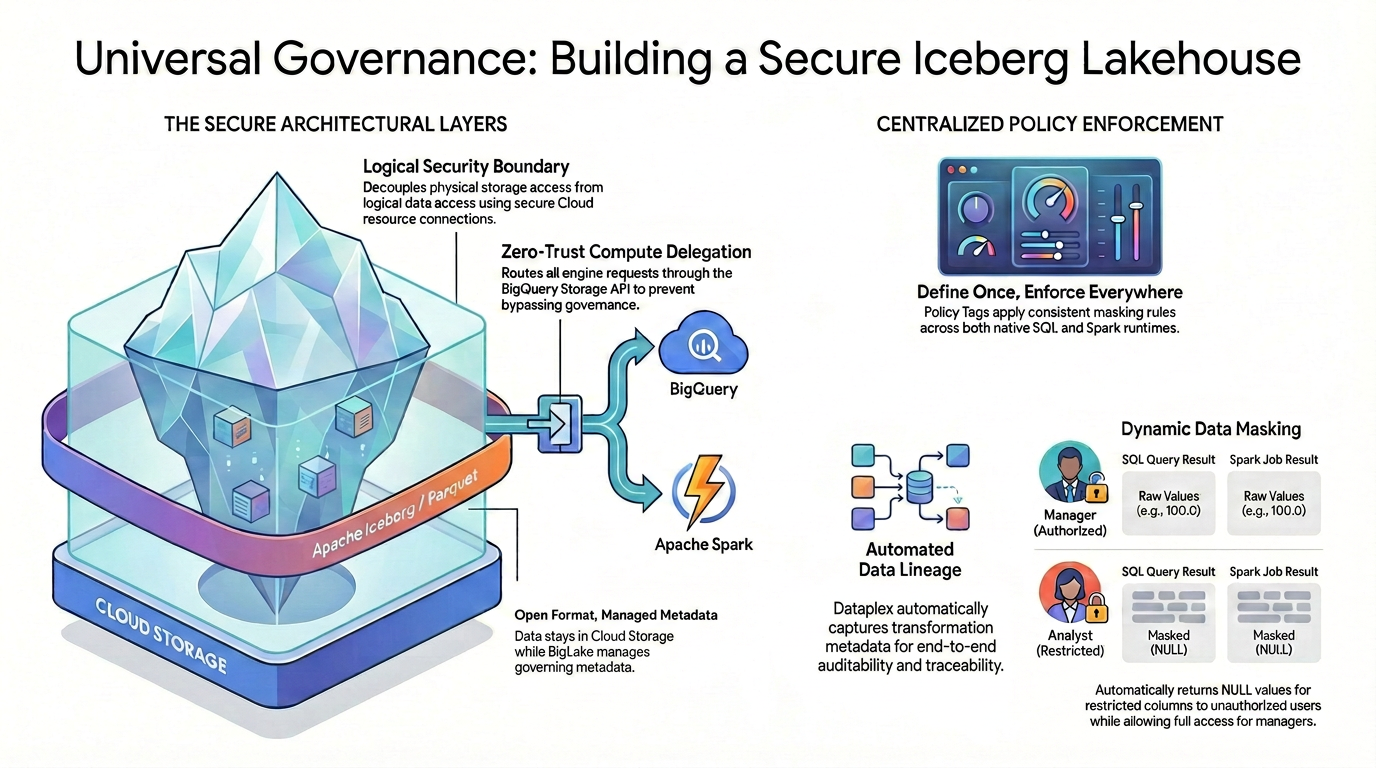
หากต้องการควบคุมการเข้าถึงแบบละเอียด (เช่น การรักษาความปลอดภัยระดับคอลัมน์และการปกปิดข้อมูล) ในรูปแบบข้อมูลโอเพนซอร์ส คุณต้องสร้างสถาปัตยกรรมการรักษาความปลอดภัยที่เข้มงวดและเป็นหนึ่งเดียว
ดังที่แสดงในแผนภาพ รูปแบบ Lakehouse ที่มีการควบคุมนี้อาศัยเสาหลัก 2 เสาในการแก้ปัญหาความท้าทายด้านความปลอดภัยที่กระจัดกระจาย ดังนี้
🛡️ เลเยอร์สถาปัตยกรรมที่ปลอดภัย (ซ้าย)
แทนที่จะอนุญาตให้ผู้ใช้หรือเครื่องมือภายนอกเข้าถึง Cloud Storage โดยตรง ซึ่งรองรับเฉพาะการรักษาความปลอดภัยระดับ Bucket ในวงกว้าง คุณควรสร้างรากฐานที่ปลอดภัย
- รูปแบบเปิด ข้อมูลเมตาที่มีการจัดการ: ข้อมูลจะยังคงอยู่ใน Cloud Storage โดยใช้รูปแบบ Apache Iceberg (Parquet) แบบเปิด ขณะที่ Lakehouse จะจัดการข้อมูลเมตาที่ควบคุมได้อย่างราบรื่น
- ขอบเขตความปลอดภัยแบบลอจิคัล: คุณแยกการเข้าถึงพื้นที่เก็บข้อมูลจริงจากการเข้าถึงข้อมูลแบบลอจิคัลโดยใช้การเชื่อมต่อทรัพยากรระบบคลาวด์ที่ปลอดภัย ผู้ใช้ปลายทางจะไม่ได้รับสิทธิ์เข้าถึง IAM ทางกายภาพโดยตรงไปยังไฟล์ GCS ดิบ
- การมอบสิทธิ์การประมวลผลแบบ Zero-Trust: เพื่อให้มั่นใจว่าไม่มีเครื่องมือการดำเนินการใดที่สามารถข้ามกฎการกำกับดูแลได้ ระบบจะกำหนดเส้นทางการอ่านข้อมูลทั้งหมดผ่าน BigQuery Storage API อย่างเคร่งครัด ไม่ว่าการค้นหาจะมาจาก BigQuery SQL ดั้งเดิมหรือ Apache Spark แบบโอเพนซอร์ส
🎯 การบังคับใช้นโยบายแบบรวมศูนย์ (ขวา)
เมื่อมีรากฐานที่มั่นคงและปลอดภัยแล้ว แคตตาล็อกความรู้จะทำหน้าที่เป็นศูนย์กลางการกำกับดูแล
- กำหนดครั้งเดียว บังคับใช้ได้ทุกที่: คุณกำหนดแท็กนโยบายในแคตตาล็อกความรู้เพียงครั้งเดียว และสถาปัตยกรรมจะใช้กฎการมาสก์ที่สอดคล้องกันในรันไทม์การดำเนินการที่รองรับทั้งหมด
- การมาสก์ข้อมูลแบบไดนามิก: เมื่อมีการค้นหาข้อมูล ระบบจะประเมินข้อมูลระบุตัวตนของผู้ใช้แบบเรียลไทม์ แม้ว่าผู้ใช้ที่ได้รับอนุญาตจะเห็นค่าดิบที่ไม่ได้มาสก์ (เช่น 100.0) ทั้งใน SQL และ Spark แต่ผู้ใช้ที่ถูกจำกัดจะได้รับค่า NULL ที่มาสก์โดยอัตโนมัติสำหรับคอลัมน์ที่ถูกจำกัดในทั้ง 2 เครื่องมือ
- แหล่งที่มาของข้อมูลอัตโนมัติ: เมื่อข้อมูลไหลและเปลี่ยนรูปแบบ แคตตาล็อกความรู้จะบันทึกข้อมูลเมตาของการเปลี่ยนรูปแบบโดยอัตโนมัติ ซึ่งจะช่วยให้ตรวจสอบและติดตามได้ตั้งแต่ต้นจนจบในตัวโดยไม่ต้องใช้โค้ดการบันทึกที่กำหนดเอง
2. การตั้งค่าและข้อกำหนด
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลในแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก คอนโซล Google Cloud ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหน้าแรกขนาด 5 GB ที่คงอยู่ถาวรและทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์โดยไม่ต้องติดตั้งอะไรเลย
เริ่มต้นสภาพแวดล้อม
เปิด Cloud Shell แล้วตั้งค่าตัวแปรโปรเจ็กต์เพื่อให้แน่ใจว่าคำสั่งทั้งหมดจะกำหนดเป้าหมายไปยังโครงสร้างพื้นฐานที่ถูกต้อง
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
จากนั้นกำหนดลักษณะตัวตน 2 แบบ
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
เปิดใช้ API
เปิดใช้บริการ Google Cloud ที่จำเป็น
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
ดาวน์โหลดซอร์สโค้ดของ Codelab
คุณจะทำการชำระเงินแบบกระจายเพื่อดาวน์โหลดเฉพาะสคริปต์ Python ที่จำเป็นสำหรับ Codelab นี้จากที่เก็บ DevRel ของ Google Cloud เพื่อไม่ให้ Cloud Shell รก
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
สร้างพื้นที่เก็บข้อมูล
สร้างที่เก็บข้อมูลเพื่อจัดเก็บข้อมูล Iceberg ที่มีการควบคุมและมีความปลอดภัยสูง
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
เตรียมข้อมูลประจำตัวและความปลอดภัย
กำหนดค่าการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งเป็นเพียงเอนทิตีเดียวที่มีคีย์ IAM จริงแบบถาวรเพื่ออ่านไฟล์ Iceberg ดิบ
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
จากนั้นให้ตั้งค่ากลุ่มเป้าหมายผู้ใช้ โดยผู้ใช้จะได้รับสิทธิ์เข้าถึงเชิงตรรกะ ไม่ใช่สิทธิ์เข้าถึงพื้นที่เก็บข้อมูลจริง เพื่อป้องกันข้อผิดพลาดที่เกิดจากความล่าช้าในการเผยแพร่ IAM คุณจะต้องสร้างบัญชีก่อน รอสักครู่ แล้วจึงมอบหมายบทบาท
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. สร้างตาราง Iceberg แบบเนทีฟผ่าน Lakehouse
คุณจะใช้ความสามารถดั้งเดิมของ Lakehouse เพื่อสร้างตาราง Iceberg ที่มีการจัดการ
สร้างชุดข้อมูล BigQuery
ก่อนอื่น ให้สร้างชุดข้อมูล BigQuery เพื่อจัดกลุ่มตาราง Iceberg อย่างเป็นตรรกะ
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
สร้างตาราง Iceberg
จากนั้นเรียกใช้คำสั่งต่อไปนี้เพื่อสร้างตาราง สังเกตบล็อก OPTIONS ที่เรากำหนด table_format = 'ICEBERG' และแมปกับ Bucket ของ Cloud Storage และการเชื่อมต่อโดยตรง
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
ป้อนข้อมูลลงในตาราง
สุดท้าย ให้แทรกข้อมูลตัวอย่างลงในตาราง Iceberg ที่สร้างขึ้นใหม่
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
ตอนนี้คุณมีตาราง Iceberg ที่ทำงานได้อย่างเต็มรูปแบบ 2 ตารางแล้ว Lakehouse จะจัดการข้อมูลเมตา แต่ไฟล์ Parquet จริงจะอยู่ในที่เก็บข้อมูล GCS ของคุณอย่างปลอดภัย
จำลองไปป์ไลน์ ETL
ในสถานการณ์จริง ข้อมูลดิบมักจะได้รับการรวบรวมไว้ในตารางสรุปสำหรับการรายงานทางธุรกิจ ลองมาสวมบทบาทเป็นวิศวกรข้อมูลและสร้างตารางสรุปยอดขายรายวันจากข้อมูลธุรกรรมดิบกัน
(หมายเหตุ: ทำขั้นตอนนี้เลยเพื่อให้ Google Cloud มีเวลาเพียงพอในการประมวลผลข้อมูลเมตาเบื้องหลัง คุณจะทราบว่าเหตุใดขั้นตอนนี้จึงสำคัญในภายหลังใน Codelab)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. การกำกับดูแลแบบรวมศูนย์: กำหนดนโยบายโดยใช้ Python
ในสภาพแวดล้อมฮาร์ดแวร์และซอฟต์แวร์ การกำหนดค่านโยบายการกำกับดูแลผ่าน UI นั้นยากต่อการปรับขนาดและบำรุงรักษา แต่เราขอแนะนำอย่างยิ่งให้ใช้โครงสร้างพื้นฐานเป็นโค้ด (IaC) แทน
ในส่วนนี้ คุณจะได้ใช้ Google Cloud Python SDK เพื่อสร้างและบังคับใช้กฎการกำกับดูแลแบบ Zero-Trust โดยอัตโนมัติทีละขั้นตอน
ตั้งค่าสภาพแวดล้อม Python
ก่อนอื่น มาตั้งค่าสภาพแวดล้อม Python ที่แยกต่างหาก (venv) เพื่อหลีกเลี่ยงข้อขัดแย้งของไลบรารีและติดตั้ง Google Cloud SDK ที่จำเป็นกัน
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
สร้างการจัดหมวดหมู่และแท็กนโยบาย
การจัดหมวดหมู่คือคอนเทนเนอร์เชิงตรรกะ และแท็กนโยบายคือป้ายกำกับเฉพาะที่คุณจะแนบกับคอลัมน์ที่มีความละเอียดอ่อนของเรา หากต้องการบังคับใช้ความปลอดภัยระดับคอลัมน์ คุณต้องมีคอนเทนเนอร์เชิงตรรกะ (การจัดหมวดหมู่) และป้ายกำกับเฉพาะ (แท็กนโยบาย) ก่อน
หากดูภายใน 1_create_taxonomy.py คุณจะเห็นตรรกะหลักต่อไปนี้
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
การตั้งค่าFINE_GRAINED_ACCESS_CONTROLประเภทนโยบายอย่างชัดเจนจะเปลี่ยนแท็กข้อมูลเมตามาตรฐานให้เป็นขอบเขตความปลอดภัยแบบ Zero Trust ที่เข้มงวด คอลัมน์ใดก็ตามที่มีแท็กนี้จะปฏิเสธการเข้าถึงของผู้ใช้ทั้งหมดโดยค่าเริ่มต้น
เรียกใช้สคริปต์เพื่อสร้างทรัพยากร
python 1_create_taxonomy.py
กำหนดคือกฎการมาสก์ (นโยบายข้อมูล)
ตอนนี้คุณกําหนดสิ่งที่เกิดขึ้นเมื่อผู้ที่ไม่มีสิทธิ์ทําการสืบค้นคอลัมน์ที่ติดแท็กได้แล้ว คุณจะสร้างนโยบายข้อมูลที่บังคับให้ค่าแสดงเป็น NULL และแนบกฎนี้กับลักษณะตัวตนของนักวิเคราะห์
ภายใน 2_create_masking.py สคริปต์จะค้นหารหัสแท็กนโยบายที่คุณเพิ่งสร้างแบบไดนามิกและใช้นโยบายข้อมูล
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
โค้ดนี้จะสร้างกฎโดยอัตโนมัติซึ่งบังคับให้ค่าพื้นฐานแสดงเป็น NULL จากนั้นจะกำหนดบทบาท IAM ของ maskedReader ให้กับผู้ใช้ที่รับบทบาทนักวิเคราะห์โดยเฉพาะ เพื่อให้มั่นใจว่าผู้ใช้จะเห็นเฉพาะข้อมูลเวอร์ชันที่มาสก์
เรียกใช้สคริปต์เพื่อกำหนดคือกฎการมาสก์
python 2_create_masking.py
ให้สิทธิ์เข้าถึงแบบละเอียด
เนื่องจากการตั้งค่าแบบ Zero-Trust จึงไม่มีใครอ่านคอลัมน์ที่ติดแท็กได้ในขณะนี้ คุณต้องให้สิทธิ์เข้าถึงบัญชีดูแลจัดการและบัญชีส่วนตัวอย่างชัดเจน
ใน 3_grant_access.py คุณจะแก้ไขนโยบาย IAM ของแท็กนโยบายได้โดยตรง
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
การเพิ่มcategoryFineGrainedReaderบทบาทจะช่วยให้ผู้ใช้ที่เฉพาะเจาะจงเหล่านี้ข้ามกฎการมาสก์และอ่านข้อมูลดิบที่ไม่ได้มาสก์ได้
เรียกใช้สคริปต์เพื่อให้สิทธิ์เข้าถึง
python 3_grant_access.py
แนบแท็กนโยบายกับตาราง BigQuery
สุดท้าย คุณต้องแนบแท็กนโยบายเชิงตรรกะนี้กับสคีมาตาราง Iceberg จริงของเรา
ดูที่ 4_attach_tag.py สคริปต์จะดึงข้อมูลสคีมาตาราง BigQuery วนซ้ำผ่านฟิลด์ และแนบแท็กกับคอลัมน์ amount โดยเฉพาะ
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
เมื่อใช้การอัปเดตสคีมานี้ Lakehouse จะเชื่อมโยงแท็กเชิงตรรกะของแคตตาล็อกความรู้กับไฟล์ Parquet จริงที่จัดเก็บไว้ใน Bucket ของ Cloud Storage โดยทันที
เรียกใช้สคริปต์เพื่ออัปเดตสคีมาของตาราง
python 4_attach_tag.py
5. ยืนยันนโยบายแคตตาล็อกความรู้
ถึงเวลาทดสอบว่าการกำกับดูแลแบบรวมศูนย์ของเราใช้งานได้หรือไม่ คุณจะทดสอบใน 2 เครื่องมือที่แตกต่างกันเพื่อพิสูจน์ว่านโยบายแคตตาล็อกความรู้มีผลบังคับใช้ในทุกที่
ยืนยันโดยใช้ SQL ดั้งเดิมของ BigQuery
ก่อนอื่น คุณจะใช้ Cloud Shell เพื่อสวมบทบาทเป็นผู้ใช้ 2 ประเภทของเรา และค้นหาตารางโดยใช้เครื่องมือ SQL ดั้งเดิมของ BigQuery
ทดสอบในฐานะผู้จัดการ (ผู้ใช้ที่มีสิทธิ์):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
เนื่องจากผู้จัดการมีบทบาทผู้อ่านแบบละเอียด จึงจะแสดงค่าจำนวนเงินดิบ
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
ทดสอบในฐานะนักวิเคราะห์ (ผู้ใช้ที่ถูกจำกัด)
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
เนื่องจากกฎการมาสก์แคตตาล็อกความรู้ คอลัมน์จำนวนจึงแสดงเป็น NULL สำหรับทุกแถว
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
กู้คืนข้อมูลประจำตัว
ล้างสถานะการตรวจสอบสิทธิ์ของ Cloud Shell เพื่อกลับไปใช้บัญชีผู้ดูแลระบบ
# Unset impersonation
gcloud config unset auth/impersonate_service_account
ยืนยันโดยใช้ Apache Spark (การมอบสิทธิ์การคำนวณ)
จะเกิดอะไรขึ้นหากนักวิทยาศาสตร์ข้อมูลใช้ Apache Spark เพื่ออ่านตารางนี้ หาก Spark อ่านไฟล์ Parquet ใน GCS จริงโดยตรง ระบบจะไม่สนใจกฎการมาสก์ของแคตตาล็อกความรู้โดยสิ้นเชิง เนื่องจาก Cloud Storage เข้าใจเฉพาะสิทธิ์ระดับ Bucket
หากต้องการป้องกันปัญหานี้ คุณต้องบังคับใช้การมอบสิทธิ์การคำนวณโดยใช้เครื่องมือเชื่อมต่อ Spark-BigQuery เครื่องมือเชื่อมต่อนี้ทำหน้าที่เป็นบริดจ์ที่ปลอดภัย โดยจะกำหนดเส้นทางการอ่านของ Spark ผ่าน BigQuery Storage API เพื่อให้ระบบประเมินกฎการกํากับดูแล Knowledge Catalog แบบไดนามิกก่อนที่จะส่งข้อมูลไปยังคลัสเตอร์ Spark
ดูตรรกะหลักภายในสคริปต์ read_transactions.py ที่คุณดาวน์โหลดมา
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
โปรดทราบว่าเราไม่ได้ชี้ Spark ไปยังเส้นทาง gs:// ของไฟล์ Iceberg เมื่อระบุ .format("bigquery") แล้ว BigQuery Storage API จะสกัดคำขออ่าน ตรวจสอบข้อมูลประจำตัวของผู้ใช้ที่เรียกใช้ Spark Job ใช้กฎการมาสก์ Knowledge Catalog และส่งคืนเฉพาะข้อมูลที่ได้รับอนุญาตไปยัง Spark DataFrame
อัปโหลดสคริปต์ PySpark นี้ไปยัง Bucket ของ Cloud Storage เพื่อให้ Managed Apache Spark เข้าถึงได้
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
เรียกใช้ Spark ในฐานะผู้จัดการ
คุณจะใช้ Apache Spark ที่มีการจัดการ บริการที่มีการจัดการนี้ช่วยให้คุณเรียกใช้ภาระงาน Spark ได้โดยตรงโดยไม่ต้องจัดสรร กำหนดค่า หรือจัดการคลัสเตอร์เฉพาะ
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ดูบันทึกเอาต์พุตของงานในเทอร์มินัล เนื่องจากผู้จัดการมีบทบาทผู้อ่านแบบละเอียด Spark จึงดึงข้อมูลจำนวนเงินดิบที่ไม่ได้มาสก์ได้สำเร็จ
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
เรียกใช้ Spark ในฐานะนักวิเคราะห์
ตอนนี้ให้ส่งงาน Spark เดียวกันทุกประการ แต่คราวนี้ให้แอบอ้างเป็นผู้ใช้ที่เป็นนักวิเคราะห์
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ตรวจสอบบันทึกอีกครั้ง แม้ว่านักวิเคราะห์จะเรียกใช้โค้ด Spark เดียวกันทุกประการ แต่ BigQuery Storage API จะสกัดกั้นคำขอและบังคับใช้นโยบายแคตตาล็อกความรู้ Spark DataFrame ของนักวิเคราะห์แสดง null สำหรับจำนวนเงิน
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
ข้อแลกเปลี่ยนด้านสถาปัตยกรรม: BigQuery SQL กับ Spark
คุณเพิ่งพิสูจน์ว่าผลลัพธ์จะเหมือนกันไม่ว่าจะเป็นเครื่องมือใดก็ตาม เราบังคับใช้นโยบายแคตตาล็อกความรู้เรียบร้อยแล้ว แต่ในเวอร์ชันที่ใช้งานจริง คุณควรใช้ตัวเลือกใด
- SQL ของ BigQuery: เหมาะสำหรับเวิร์กโฟลว์ที่ต้องการใช้ SQL เป็นเครื่องมือและเรียกใช้การคำนวณในที่เดียว เหมาะอย่างยิ่งสำหรับการวิเคราะห์และ Business Intelligence ที่รวดเร็ว
- Apache Spark: ช่วยให้ปริมาณงานมีความซับซ้อนมากขึ้นได้ด้วยการใช้ Python จึงเหมาะสำหรับไปป์ไลน์แมชชีนเลิร์นนิงขั้นสูงหรือโค้ด Hadoop เดิม
ประเด็นสำคัญ: ไม่ว่าจะใช้เครื่องมือใดก็ตาม การบังคับใช้การมอบสิทธิ์การคำนวณจะทำให้ไม่สามารถข้ามเลเยอร์การกำกับดูแลแบบ Zero Trust ที่รวมศูนย์ได้
6. แหล่งที่มาของข้อมูลอัตโนมัติ
ในสถาปัตยกรรมข้อมูลขององค์กร การทราบแหล่งที่มาของข้อมูลและวิธีแก้ไขข้อมูลอย่างแม่นยำเป็นสิ่งสำคัญอย่างยิ่งสำหรับการปฏิบัติตามข้อกำหนด การแก้ไขข้อบกพร่อง และการสร้างความน่าเชื่อถือ แนวคิดนี้เรียกว่าแหล่งที่มาของข้อมูล ซึ่งจะตอบคำถามพื้นฐาน เช่น "หากผู้จัดการดูรายงานยอดขายรายวัน ระบบใช้ตารางดิบใดในการคำนวณตัวเลขเหล่านั้น"
โดยปกติแล้ว การติดตามวงจรนี้ต้องให้นักวิศวกรข้อมูลเขียนโค้ดการบันทึกที่กำหนดเองด้วยตนเอง หรือใช้เครื่องมือที่ซับซ้อนของบุคคลที่สามเพื่อแยกวิเคราะห์สคริปต์ SQL อย่างไรก็ตาม ใน Google Cloud Lakehouse ที่มีการควบคุม การติดตามนี้จะมาพร้อมกับระบบและไม่ต้องดำเนินการใดๆ
โปรดจำtransactions_summaryตารางที่คุณสร้างจากตารางธุรกรรมดิบก่อนหน้านี้ใน Codelab เมื่อ BigQuery ดำเนินการตามคำสั่ง CREATE TABLE AS SELECT นั้น Compute Engine จะบันทึกข้อมูลเมตาการเปลี่ยนรูปแบบโดยอัตโนมัติและส่งไปยังแคตตาล็อกความรู้ มาดูผลลัพธ์กัน
แสดงภาพที่มา
- ในคอนโซล Google Cloud ให้ไปที่แค็ตตาล็อกความรู้ > ค้นหา
- พิมพ์
lakehouse_retail_demo.transactionsในแถบค้นหา แล้วคลิกตาราง - คลิกแท็บแหล่งที่มา
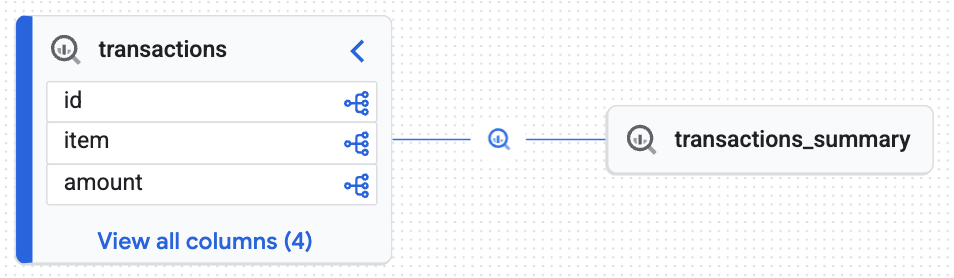
คุณจะเห็นกราฟแบบอินเทอร์แอกทีฟที่สร้างขึ้นโดย Knowledge Engine ซึ่งพิสูจน์ว่าตารางเป้าหมาย (transactions_summary) ได้มาจากตาราง Iceberg ที่มีการควบคุมแบบดิบ (transactions) คุณได้การตรวจสอบย้อนกลับแบบครบวงจรซึ่งจำเป็นสำหรับการตรวจสอบข้อมูล
7. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ใน Codelab นี้
นำทรัพยากรการกำกับดูแลแคตตาล็อกความรู้ออก
ก่อนที่จะลบชุดข้อมูล BigQuery หรือที่เก็บข้อมูล Cloud Storage คุณต้องนำกฎการกำกับดูแลเชิงตรรกะออก หากดูภายในสคริปต์ cleanup_governance.py จากที่เก็บ คุณจะเห็นลำดับการหยุดทำงานต่อไปนี้
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
ลำดับที่ระบุไว้ที่นี่มีความสำคัญอย่างยิ่ง สคริปต์จะลบนโยบายข้อมูล (กฎการมาสก์) ก่อนเนื่องจากต้องอาศัยแท็กนโยบาย เมื่อนำนโยบายออกแล้ว การลบการจัดการหมวดหมู่ระดับบนจะทำให้ระบบลบแท็กนโยบายที่เกี่ยวข้องทั้งหมดโดยอัตโนมัติโดยไม่ทำให้เกิดข้อผิดพลาดในการขึ้นต่อกันของทรัพยากร
เรียกใช้สคริปต์การล้างข้อมูล Python
python cleanup_governance.py
นำข้อมูลประจำตัว พื้นที่เก็บข้อมูล และทรัพยากรการประมวลผลออก
ตอนนี้เลเยอร์การกํากับดูแลแยกออกแล้ว คุณสามารถลบตาราง BigQuery, บัคเก็ต Cloud Storage, บัญชีบริการ และสภาพแวดล้อม Python ในเครื่องได้อย่างปลอดภัย
คัดลอกและเรียกใช้บล็อกการล้างข้อมูลที่ครอบคลุมต่อไปนี้ใน Cloud Shell
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
การทำตามขั้นตอนเหล่านี้จะช่วยให้มั่นใจได้ว่าไม่มีทรัพยากรที่ไม่มีเจ้าของหรือนโยบายที่ซ่อนอยู่ในโปรเจ็กต์
8. ยินดีด้วย
คุณได้ติดตั้งใช้งาน Data Lakehouse ที่มีการกำกับดูแลอย่างเต็มรูปแบบและค้นพบได้เรียบร้อยแล้ว
คุณได้เรียนรู้ว่า
- การผสานรวม Iceberg มาให้ตั้งแต่แรก: Lakehouse สามารถจัดการตาราง Iceberg แบบโอเพนซอร์สได้โดยตรงในขณะที่จัดเก็บไฟล์จริงอย่างปลอดภัยใน Cloud Storage
- การมอบสิทธิ์การคำนวณเพื่อความปลอดภัย: การกำหนดเส้นทางการค้นหาผ่าน BigQuery Storage API ทำให้คุณบังคับใช้การมาสก์แบบไดนามิกอย่างละเอียดกับไฟล์จริงซึ่งโดยปกติแล้วจะจำกัดการเข้าถึงบางส่วนไม่ได้
- การกํากับดูแลที่ไม่ขึ้นกับเครื่องมือ: แท็กนโยบายช่วยให้คุณกําหนดกฎได้ครั้งเดียวและบังคับใช้ได้ทั่วถึงไม่ว่าจะค้นหาผ่าน SQL ดั้งเดิมหรือรันไทม์ Apache Spark
- การค้นพบข้อมูล: Knowledge Engine ติดตามแหล่งที่มาของข้อมูลโดยอัตโนมัติ ซึ่งช่วยให้องค์กรตรวจสอบได้อย่างจำเป็น
สิ่งต่อไปที่ควรทำ
- สำรวจการควบคุมการเข้าถึงขั้นสูง: หากต้องการใช้สถานการณ์ด้านความปลอดภัยที่ซับซ้อนยิ่งขึ้น โปรดอ่านเอกสารประกอบอย่างเป็นทางการเกี่ยวกับการปรับแต่ง Lakehouse ด้วยฟีเจอร์เพิ่มเติม
- ควบคุมข้อมูลที่ไม่มีโครงสร้างสำหรับ GenAI: ค้นพบตารางออบเจ็กต์ ขยายรูปแบบบริดจ์ที่ปลอดภัยนี้ไปยังไฟล์ที่ไม่มีโครงสร้าง (PDF, รูปภาพ) ใน Cloud Storage เพื่อสร้างรากฐานข้อมูลที่ปลอดภัยและมีการควบคุมสำหรับ Gemini Enterprise Agent Engine และไปป์ไลน์ RAG