
1. Giriş
Verilerin çeşitli fiziksel depolama sistemlerinde bulunduğu modern bir kurumsal veri bulutunda, parçalanmış güvenlik nedeniyle büyük bir mimari zorluk yaşanır.
Veriler Google Cloud Storage'da Parquet gibi açık kaynak biçimlerinde fiziksel olarak depolandığında ve BigQuery SQL veya Apache Spark gibi birden fazla farklı motor tarafından sorgulandığında hassas verilerin (ör. finansal işlem tutarları) tutarlı bir şekilde korunmasını nasıl sağlarsınız?
Bu codelab'de, Apache Iceberg tabloları, BigQuery ve Knowledge Catalog kullanarak bu sorunları çözen yönetilen bir veri gölü ambarı mimarisi oluşturacaksınız. Sıfır güven güvenlik politikalarını ve bunların farklı işlem motorlarında nasıl dinamik olarak uygulandığını tanımlamak için Kod Olarak Altyapı (IaC) kullanacaksınız.
Ön koşullar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- SQL, IAM ve Cloud Storage kavramları hakkında temel bilgi sahibi olmanız gerekir.
Neler öğreneceksiniz?
- Cloud Storage'ın verileri yerel olarak tuttuğu BigQuery'de Apache Iceberg için Google Cloud Lakehouse tabloları oluşturma
- Sütun düzeyinde güvenlik ve veri maskeleme için politika etiketlerini kullanarak merkezi veri politikalarını nasıl zorunlu kılabilirsiniz?
- Cloud kaynak bağlantısı kullanarak fiziksel depolama erişimini mantıksal veri erişiminden ayırma
- Açık kaynak motorlarının yönetimi atlayamayacağından emin olmak için Managed Service for Apache Spark kullanarak sıfır güvenli bilgi işlem delegasyonunu nasıl zorunlu kılabilirsiniz?
- Otomatik veri soyunu görselleştirme
Mimarisine genel bakış: Iceberg'de evrensel yönetim
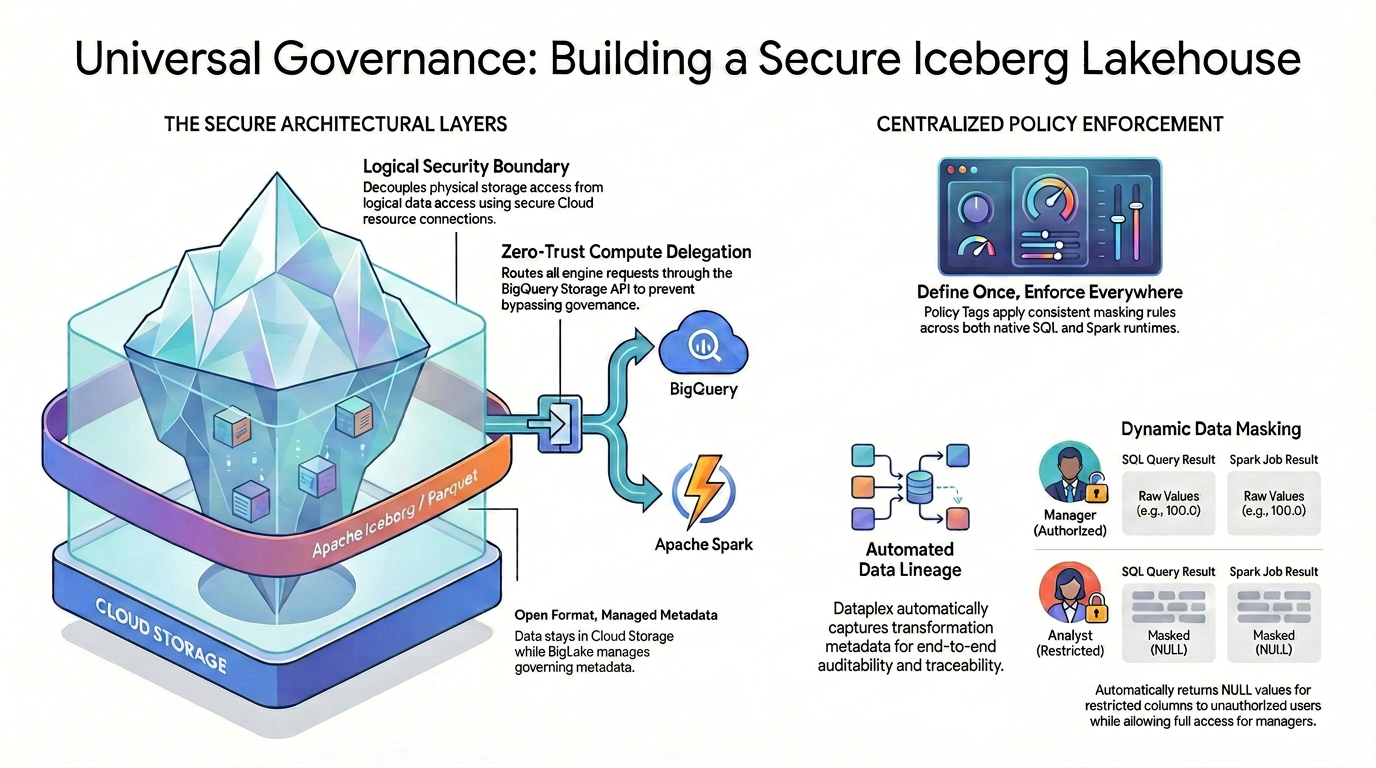
Açık kaynaklı veri biçimlerinde ayrıntılı erişim denetimi (ör. sütun düzeyinde güvenlik ve veri maskeleme) elde etmek için katı ve birleşik bir güvenlik mimarisi oluşturmanız gerekir.
Şemada gösterildiği gibi, bu yönetilen lakehouse kalıbı, parçalanmış güvenlik sorununu çözmek için iki temel unsura dayanır:
🛡️ Güvenli Mimari Katmanlar (Sol)
Kullanıcıların veya harici motorların Cloud Storage'a doğrudan erişmesine izin vermek yerine (yalnızca geniş paket düzeyinde güvenliği destekler) güvenli bir temel oluşturursunuz.
- Açık biçim, yönetilen meta veriler: Veriler, açık Apache Iceberg (Parquet) biçiminde Cloud Storage'da fiziksel olarak kalır. Lakehouse ise yönetici meta verilerini sorunsuz bir şekilde yönetir.
- Mantıksal güvenlik sınırı: Güvenli bir Cloud kaynağı bağlantısı kullanarak fiziksel depolama erişimini mantıksal veri erişiminden ayırırsınız. Son kullanıcılara, ham GCS dosyalarına doğrudan fiziksel IAM erişimi hiçbir zaman verilmez.
- Sıfır güvenli işlem yetkilendirmesi: Hiçbir yürütme motorunun yönetim kurallarını atlayamaması için tüm veri okuma istekleri kesinlikle BigQuery Storage API üzerinden yönlendirilir. Bu durum, sorgunun kaynağı yerel BigQuery SQL veya açık kaynaklı Apache Spark olsa da geçerlidir.
🎯 Merkezi politika yaptırımı (doğru)
Güvenli temel oluşturulduktan sonra Knowledge Catalog, yönetim için birleşik beyin görevi görür:
- Bir kez tanımlayın, her yerde uygulayın: Politika Etiketlerinizi Bilgi Kataloğu'nda yalnızca bir kez tanımlarsınız ve mimari, desteklenen tüm yürütme çalışma zamanlarında tutarlı maskeleme kuralları uygular.
- Dinamik veri maskeleme: Veriler sorgulandığında sistem, kullanıcının kimliğini anında değerlendirir. Yetkili kullanıcılar hem SQL hem de Spark'ta ham, maskelenmemiş değerleri (ör. 100,0) görürken kısıtlanmış kullanıcılar her iki motorda da kısıtlanmış sütunlar için otomatik olarak maskelenmiş NULL değerleri alır.
- Otomatik veri sırası: Veriler akıp dönüştürülürken Knowledge Catalog, dönüşüm meta verilerini otomatik olarak yakalar. Böylece özel günlük kaydı kodu gerektirmeden yerleşik uçtan uca denetlenebilirlik ve izlenebilirlik sağlanır.
2. Kurulum ve şartlar
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir ancak bu codelab'de Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Ortamın temel hazırlığı ve bağlantı kurulması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir ekranla karşılaşırsınız:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarıyla birlikte gelir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
Ortamı başlatma
Cloud Shell'i açın ve tüm komutların doğru altyapıyı hedeflediğinden emin olmak için proje değişkenlerinizi ayarlayın.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Ardından iki karakterimizi tanımlayalım.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
API'leri etkinleştirme
Gerekli Google Cloud hizmetlerini etkinleştirin.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Codelab kaynak kodunu indirme
Cloud Shell'inizin karışmasını önlemek için Google Cloud DevRel deposundan yalnızca bu codelab için gerekli Python komut dosyalarını indirmek üzere seyrek ödeme işlemi yapacaksınız.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Depolama alanı oluşturma
Yüksek düzeyde güvenli, yönetilen Iceberg verilerini barındıracak paketi oluşturun.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Kimlikleri ve güvenliği hazırlama
Bulut kaynağı bağlantısını yapılandırın. Bu, ham Iceberg dosyalarını okumak için kalıcı fiziksel IAM anahtarlarını tutan tek varlıktır.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Ardından, kullanıcı kitlelerini ayarlayın. Kullanıcılara fiziksel depolama erişimi değil, mantıksal erişim verilir. IAM yayılımındaki gecikmelerden kaynaklanan hataları önlemek için önce hesapları oluşturacak, birkaç saniye bekleyecek ve ardından rollerini atayacaksınız.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Lakehouse aracılığıyla yerel Iceberg tabloları oluşturma
Yönetilen Iceberg tablolarını oluşturmak için Lakehouse'un yerel özelliklerini kullanacaksınız.
BigQuery veri kümesini oluşturma
Öncelikle Iceberg tablolarımızı mantıksal olarak gruplandırmak için bir BigQuery veri kümesi oluşturun.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg tablolarını oluşturma
Ardından, tabloları oluşturmak için aşağıdaki komutları çalıştırın. OPTIONS öğesini belirttiğimiz ve doğrudan Cloud Storage paketimize ve bağlantımıza eşlediğimiz table_format = 'ICEBERG' bloğuna dikkat edin.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Tabloları verilerle doldurma
Son olarak, yeni oluşturulan Iceberg tablolarına örnek veriler ekleyin.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Artık iki tam işlevli Iceberg tablonuz var. Lakehouse, meta verileri yönetir ancak fiziksel Parquet dosyaları GCS paketinizde güvenli bir şekilde bulunur.
ETL ardışık düzenini simüle etme
Gerçek hayattaki bir senaryoda, ham veriler genellikle işletme raporlaması için özet tablolarda toplanır. Veri mühendisi gibi davranıp ham işlem verilerimizden günlük satış özeti tablosu oluşturalım.
(Not: Google Cloud'un arka plan meta verilerini işlemesi için yeterli zamanı olması amacıyla bu adımı şimdi çalıştırın. Bunun neden önemli olduğunu daha sonra codelab'de öğreneceksiniz.)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Merkezi yönetim: Python kullanarak politikalar tanımlama
Üretim ortamında, yönetim politikalarını kullanıcı arayüzü üzerinden yapılandırmak ölçeklendirme ve sürdürme açısından zordur. Bunun yerine, kod olarak altyapı (IaC) kullanılması önemle tavsiye edilir.
Bu bölümde, Google Cloud Python SDK'yı kullanarak Sıfır Güven yönetim kurallarınızı adım adım programatik olarak oluşturacak ve uygulayacaksınız.
Python ortamını ayarlama
Öncelikle kitaplık çakışmalarını önlemek için izole bir Python ortamı (venv) oluşturalım ve gerekli Google Cloud SDK'larını yükleyelim.
Cloud Shell'de aşağıdaki komutları çalıştırın:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Sınıflandırma ve politika etiketini oluşturma
Taksonomi, mantıksal bir kapsayıcıdır. Politika Etiketi ise hassas sütunumuza ekleyeceğiniz etikettir. Sütun düzeyinde güvenliği zorunlu kılmak için öncelikle mantıksal bir kapsayıcı (bir sınıflandırma) ve belirli bir etiket (bir politika etiketi) gerekir.
1_create_taxonomy.py içine baktığınızda aşağıdaki temel mantığı görürsünüz:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
FINE_GRAINED_ACCESS_CONTROL politika türünü açıkça ayarlayarak standart bir meta veri etiketini katı bir sıfır güven güvenlik sınırına dönüştürürsünüz. Bu etikete sahip tüm sütunlar, varsayılan olarak tüm kullanıcıların erişimini engeller.
Kaynakları oluşturmak için komut dosyasını çalıştırın:
python 1_create_taxonomy.py
Maskeleme kuralını (veri politikası) yapılandırma
Artık, ayrıcalıkları olmayan bir kullanıcı etiketli sütunu sorguladığında ne olacağını siz tanımlarsınız. Değerin NULL olarak döndürülmesini zorunlu kılan bir Veri Politikası oluşturacak ve bu kuralı Analist kişiliğine ekleyeceksiniz.
2_create_masking.py içinde komut dosyası, az önce oluşturduğunuz politika etiketi kimliğini dinamik olarak arar ve bir veri politikası uygular:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Bu kod, temel değerlerin NULL olarak döndürülmesini zorlayan bir kuralı programlı olarak oluşturur. Ardından, maskedReader IAM rolünü özellikle Analist karakterine atayarak verilerin yalnızca maskelenmiş sürümünü görmesini sağlar.
Maskeleme kuralını yapılandırmak için komut dosyasını çalıştırın:
python 2_create_masking.py
Ayrıntılı Erişim İzni Verme
Sıfır güven kurulumumuz nedeniyle, şu anda etiketlenmiş sütunu kimse okuyamıyor. Yöneticiye ve kişisel hesabınıza erişim izni vermeniz gerekir.
3_grant_access.py içinde, politika etiketinin IAM politikasını değiştirirsiniz:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
categoryFineGrainedReader rolünü eklediğinizde bu belirli asıl kullanıcılar maskeleme kurallarını atlayabilir ve maskelenmemiş ham verileri okuyabilir.
Erişim izni vermek için komut dosyasını çalıştırın:
python 3_grant_access.py
Politika etiketini BigQuery tablosuna ekleme
Son olarak, bu mantıksal politika etiketini fiziksel Iceberg tablo şemamıza eklemeniz gerekir.
4_attach_tag.py koduna göz atın. Bu komut dosyası, BigQuery tablo şemasını getirir, alanlarda yinelenir ve etiketi özellikle amount sütununa ekler:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Bu şema güncellemesi uygulandığında Lakehouse, Knowledge Catalog mantıksal etiketlerimizi Cloud Storage paketinize depolanan fiziksel Parquet dosyalarına anında bağlar.
Tablo şemasını güncellemek için komut dosyasını çalıştırın:
python 4_attach_tag.py
5. Bilgi Kataloğu Politikalarını Doğrulama
Merkezi yönetimimizin işe yarayıp yaramadığını test etme zamanı. Bilgi Kataloğu politikalarının evrensel olarak uygulandığını kanıtlamak için bu testi iki farklı motorda yapacaksınız.
BigQuery'nin kendi SQL'ini kullanarak doğrulama
İlk olarak, Cloud Shell'i kullanarak iki karakterimizin kimliğini üstlenecek ve BigQuery'nin yerel SQL motorunu kullanarak tabloyu sorgulayacaksınız.
Yönetici (ayrıcalıklı kullanıcı) olarak test etme:
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Yöneticinin ayrıntılı okuyucu rolü olduğundan, ham tutar değerleri gösterilir.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Analiz uzmanı olarak test etme (kısıtlanmış kullanıcı):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Bilgi Kataloğu maskeleme kuralı nedeniyle, tutar sütunu her satır için NULL olarak döndürülür.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Kimliğinizi geri yükleme
Yönetici kullanıcınıza dönmek için Cloud Shell kimlik doğrulama durumunuzu temizleyin.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Apache Spark ile doğrulama (işlem yetkilendirmesi)
Bir veri bilimcisi bu tabloyu okumak için Apache Spark'ı kullanırsa ne olur? Spark, fiziksel GCS Parquet dosyalarını doğrudan okursa Cloud Storage yalnızca paket düzeyindeki izinleri anladığından Knowledge Catalog maskeleme kuralları tamamen atlanır.
Bunu önlemek için Spark-BigQuery bağlayıcısını kullanarak işlem delegasyonunu zorunlu kılarsınız. Bu bağlayıcı, Spark okuma isteklerini BigQuery Storage API üzerinden yönlendirerek güvenli bir köprü görevi görür. Böylece, herhangi bir veri Spark kümesine gönderilmeden önce Knowledge Catalog yönetim kuralları dinamik olarak değerlendirilir.
İndirdiğiniz read_transactions.py komut dosyasındaki temel mantığa göz atın:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Spark'ın, Iceberg dosyalarının gs:// yolunu göstermediğini unutmayın. .format("bigquery") belirtildiğinde BigQuery Storage API, okuma isteğini yakalar, Spark işini çalıştıran kullanıcının kimliğini kontrol eder, Knowledge Catalog maskeleme kurallarını uygular ve yalnızca yetkili verileri Spark DataFrame'e geri döndürür.
Yönetilen Apache Spark'ın erişebilmesi için bu PySpark komut dosyasını Cloud Storage paketinize yükleyin:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Spark'ı yönetici olarak çalıştırın:
Yönetilen Apache Spark'ı kullanacaksınız. Bu yönetilen hizmet sayesinde, özel kümeler sağlamanız, yapılandırmanız veya yönetmeniz gerekmeden Spark iş yüklerini doğrudan çalıştırabilirsiniz.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Terminaldeki iş çıkışı günlüklerine bakın. Yöneticinin ayrıntılı okuyucu rolü olduğundan Spark, maskelenmemiş ham tutarları başarıyla alır.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Spark'ı analist olarak çalıştırın:
Şimdi aynı Spark işini gönderin ancak bu kez analist kişiliğine bürünün.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Günlükleri tekrar kontrol edin. Analist tam olarak aynı Spark kodunu çalıştırmış olsa da BigQuery Storage API, isteği engelledi ve Knowledge Catalog politikasını uyguladı. Analistin Spark DataFrame'inde tutarlar için null gösteriliyor.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Mimari Değişkenler: BigQuery SQL ve Spark
Sonucun motordan bağımsız olarak aynı olduğunu kanıtladınız. Bilgi Kataloğu politikası başarıyla uygulandı. Ancak üretimde hangisini kullanmalısınız?
- BigQuery SQL: SQL'in istenen motor olduğu ve hesaplamaların doğrudan yerinde yapıldığı iş akışları için idealdir. Hızlı analiz ve iş zekası için idealdir.
- Apache Spark: Python kullandığı için daha karmaşık iş yüklerine olanak tanır. Bu nedenle, gelişmiş makine öğrenimi ardışık düzenleri veya eski Hadoop kodu için uygundur.
Önemli Not: Hangi motor kullanılırsa kullanılsın, işlem delegasyonu zorunlu kılındığında merkezi sıfır güven yönetimi katmanı asla atlanamaz.
6. Otomatik veri sırası
Herhangi bir kurumsal veri mimarisinde, verilerinizin tam olarak nereden geldiğini ve nasıl değiştirildiğini bilmek; uyumluluk, hata ayıklama ve güven oluşturma açısından kritik öneme sahiptir. Bu kavrama veri soyu adı verilir. "Bir yönetici günlük satış raporuna bakıyorsa bu sayıları hesaplamak için hangi ham tablolar kullanıldı?" gibi temel soruları yanıtlar.
Geleneksel olarak bu yaşam döngüsünün izlenmesi için veri mühendislerinin özel günlük kaydı kodunu manuel olarak yazması veya SQL komut dosyalarını ayrıştırmak için karmaşık üçüncü taraf araçlarını kullanması gerekir. Ancak yönetilen bir Google Cloud Lakehouse'da bu izleme yerleşiktir ve tamamen otomatik olarak yapılır.
Bu codelab'in önceki bölümlerinde ham işlemler tablosundan oluşturduğunuz transactions_summary tablosunu hatırlıyor musunuz? BigQuery bu CREATE TABLE AS SELECT ifadesini yürüttüğünde, bilgi işlem motoru dönüşüm meta verilerini otomatik olarak yakalayıp Knowledge Catalog'a gönderdi. Sonucu inceleyelim.
Soy ağacını görselleştirme
- Google Cloud Console'da Knowledge Catalog > Search'e gidin.
- Arama çubuğuna
lakehouse_retail_demo.transactionsyazın ve tabloyu tıklayın. - Soy sekmesini tıklayın.
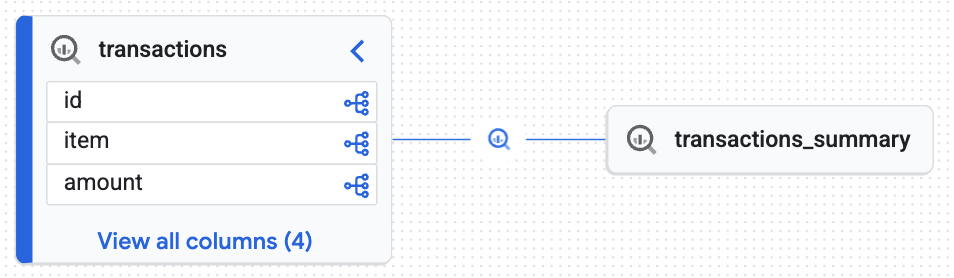
Hedef tablonun (transactions_summary) yönetilen ham Iceberg tablosundan (transactions) türetildiğini kanıtlayan, Knowledge Engine tarafından oluşturulmuş etkileşimli bir grafik görürsünüz. Veri denetimi için gerekli olan uçtan uca izlenebilirliği elde ettiniz.
7. Temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın.
Bilgi Kataloğu yönetim kaynaklarını kaldırma
BigQuery veri kümesini veya Cloud Storage paketini silmeden önce mantıksal yönetim kurallarını kaldırmanız gerekir. Depodaki cleanup_governance.py komut dosyasına bakarsanız aşağıdaki ayrıştırma sırasını görürsünüz:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Buradaki sıra önemlidir. Komut dosyası, politika etiketine bağlı olduğundan önce veri politikasını (maskeleme kuralı) siler. Politika kaldırıldıktan sonra üst sınıflandırmanın silinmesi otomatik olarak tüm temel politika etiketlerini basamaklandırır ve kaynak bağımlılığı hatalarını tetiklemeden siler.
Python temizleme komut dosyasını çalıştırın:
python cleanup_governance.py
Kimlikleri, depolama alanını ve bilgi işlem öğelerini kaldırma
Yönetim katmanı ayrıldığına göre artık BigQuery tablolarını, Cloud Storage paketlerini, hizmet hesaplarını ve yerel Python ortamını güvenle silebilirsiniz.
Aşağıdaki kapsamlı temizleme bloğunu kopyalayıp Cloud Shell'inizde çalıştırın:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Bu adımları tamamlayarak projenizde hiçbir yetim kaynağın veya gizli politikanın kalmadığından emin olursunuz.
8. Tebrikler!
Tümüyle yönetilen, keşfedilebilir bir veri gölü evi başarıyla uyguladınız.
Şunları öğrendiniz:
- Yerel Iceberg entegrasyonu: Veri gölü ambarı, fiziksel dosyaları Cloud Storage'da güvenli bir şekilde saklarken açık kaynaklı Iceberg tablolarını yerel olarak yönetebilir.
- Güvenlik için işlem yetkilendirmesi: Sorguları BigQuery Storage API üzerinden yönlendirerek, kısmi erişimi yerel olarak kısıtlayamayan fiziksel dosyalarda ayrıntılı dinamik maskeleme uyguladınız.
- Motordan Bağımsız Yönetim: Politika etiketleri, kuralları bir kez tanımlamanıza ve yerel SQL veya Apache Spark çalışma zamanları aracılığıyla sorgulanıp sorgulanmadığına bakılmaksızın evrensel olarak uygulanmasını sağlamanıza olanak tanır.
- Veri bulunabilirliği: Bilgi motoru, veri soyunu otomatik olarak izleyerek temel kurumsal denetlenebilirlik sağlar.
Yapabilecekleriniz
- Gelişmiş erişim denetimini keşfedin: Daha karmaşık güvenlik senaryoları uygulamak için Lakehouse'u ek özelliklerle özelleştirme hakkındaki resmi belgeleri inceleyin.
- Üretken yapay zeka için yapılandırılmamış verileri yönetme: Nesne Tabloları'nı keşfedin. Bu tam olarak aynı güvenli köprü modelini Cloud Storage'daki yapılandırılmamış dosyalara (PDF'ler, resimler) genişletin. Böylece Gemini Enterprise Agent Engine ve RAG işlem hatları için güvenli ve yönetilen bir veri temeli oluşturun.