
1. Giới thiệu
Trong Đám mây dữ liệu doanh nghiệp hiện đại, nơi dữ liệu nằm trên nhiều hệ thống lưu trữ vật lý, có một thách thức lớn về kiến trúc liên quan đến bảo mật phân mảnh.
Làm cách nào để đảm bảo rằng dữ liệu nhạy cảm (như số tiền giao dịch tài chính) được bảo vệ một cách nhất quán khi dữ liệu được lưu trữ vật lý ở các định dạng nguồn mở như Parquet trên bộ nhớ Google Cloud và được truy vấn bởi nhiều công cụ khác nhau, chẳng hạn như BigQuery SQL hoặc Apache Spark?
Trong lớp học lập trình này, bạn sẽ xây dựng một kiến trúc Lakehouse dữ liệu được quản lý giúp giải quyết những vấn đề này bằng cách sử dụng các bảng Apache Iceberg, BigQuery và Knowledge Catalog. Bạn sẽ sử dụng Cơ sở hạ tầng dưới dạng mã (IaC) để xác định các chính sách bảo mật theo mô hình không tin tưởng và cách các chính sách này được thực thi một cách linh hoạt trên nhiều công cụ tính toán.
Điều kiện tiên quyết
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- Hiểu biết cơ bản về các khái niệm SQL, IAM và Cloud Storage.
Kiến thức bạn sẽ học được
- Cách tạo bảng Google Cloud Lakehouse cho Apache Iceberg trong BigQuery, nơi Cloud Storage lưu trữ dữ liệu một cách tự nhiên.
- Cách thực thi các chính sách dữ liệu tập trung bằng cách sử dụng Thẻ chính sách để bảo mật ở cấp cột và che giấu dữ liệu.
- Cách tách quyền truy cập vào bộ nhớ vật lý khỏi quyền truy cập dữ liệu logic bằng cách sử dụng kết nối tài nguyên trên Cloud.
- Cách thực thi tính năng uỷ quyền tính toán theo mô hình không tin tưởng bằng cách sử dụng Dịch vụ được quản lý cho Apache Spark để đảm bảo các công cụ nguồn mở không thể bỏ qua quy trình quản trị.
- Cách trực quan hoá Dòng dõi dữ liệu tự động .
Tổng quan về kiến trúc: Quản trị phổ quát trên Iceberg
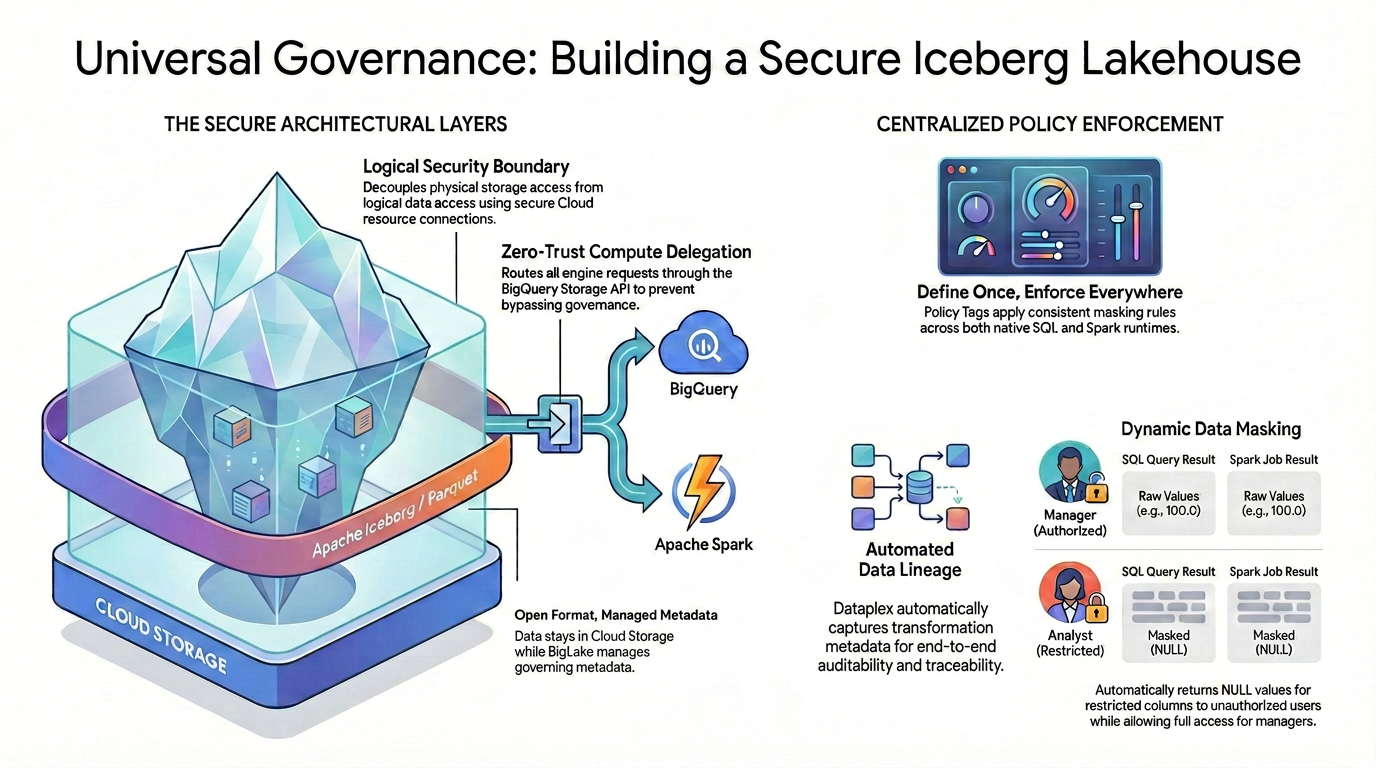
Để đạt được khả năng kiểm soát quyền truy cập chi tiết (như bảo mật ở cấp cột và che giấu dữ liệu) trên các định dạng dữ liệu nguồn mở, bạn phải thiết lập một kiến trúc bảo mật nghiêm ngặt và thống nhất.
Như minh hoạ trong sơ đồ, mẫu lakehouse được quản lý này dựa vào hai trụ cột chính để giải quyết thách thức về bảo mật phân mảnh:
🛡️ Các lớp kiến trúc bảo mật (Bên trái)
Thay vì cho phép người dùng hoặc các công cụ bên ngoài truy cập trực tiếp vào Cloud Storage (chỉ hỗ trợ bảo mật rộng ở cấp bộ chứa), bạn sẽ xây dựng một nền tảng bảo mật.
- Định dạng mở, siêu dữ liệu được quản lý: Dữ liệu vẫn nằm trong Cloud Storage ở định dạng Apache Iceberg (Parquet) mở, trong khi Lakehouse quản lý siêu dữ liệu quản trị một cách liền mạch.
- Ranh giới bảo mật logic: Bạn tách quyền truy cập vào bộ nhớ vật lý khỏi quyền truy cập dữ liệu bằng cách sử dụng kết nối tài nguyên trên Cloud bảo mật. Người dùng cuối không bao giờ được cấp quyền truy cập IAM vật lý trực tiếp vào các tệp GCS thô.
- Uỷ quyền tính toán theo mô hình không tin tưởng: Để đảm bảo không có công cụ thực thi nào có thể bỏ qua các quy tắc quản trị, tất cả các yêu cầu đọc dữ liệu đều được định tuyến nghiêm ngặt thông qua BigQuery Storage API. Điều này áp dụng cho cả trường hợp truy vấn bắt nguồn từ SQL gốc của BigQuery hoặc Apache Spark nguồn mở.
🎯 Thực thi chính sách tập trung (Bên phải)
Với nền tảng bảo mật đã được thiết lập, Knowledge Catalog đóng vai trò là bộ não thống nhất cho quy trình quản trị:
- Xác định một lần, thực thi ở mọi nơi: Bạn chỉ cần xác định Thẻ chính sách một lần trong Knowledge Catalog và kiến trúc sẽ áp dụng các quy tắc che giấu nhất quán trên toàn bộ thời gian chạy thực thi được hỗ trợ.
- Che giấu dữ liệu linh hoạt: Khi dữ liệu được truy vấn, hệ thống sẽ đánh giá danh tính của người dùng ngay lập tức. Mặc dù người dùng được uỷ quyền sẽ thấy các giá trị thô, không được che giấu (ví dụ: 100.0) trong cả SQL và Spark, nhưng người dùng bị hạn chế sẽ tự động nhận được các giá trị NULL được che giấu cho các cột bị hạn chế trên cả hai công cụ.
- Dòng dõi dữ liệu tự động: Khi dữ liệu di chuyển và chuyển đổi, Knowledge Catalog sẽ tự động ghi lại siêu dữ liệu chuyển đổi, cung cấp khả năng kiểm tra và theo dõi từ đầu đến cuối mà không cần mã ghi nhật ký tuỳ chỉnh.
2. Thiết lập và yêu cầu
Khởi động Cloud Shell
Mặc dù bạn có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trong Cloud.
Trong Google Cloud Console, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Bạn chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi hoàn tất, bạn sẽ thấy một nội dung như sau:

Máy ảo này được tải tất cả các công cụ phát triển mà bạn cần. Máy ảo này cung cấp một thư mục chính 5 GB liên tục và chạy trên Google Cloud, giúp nâng cao đáng kể hiệu suất mạng và quy trình xác thực. Bạn có thể thực hiện tất cả công việc trong lớp học lập trình này trong một trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
Khởi chạy môi trường
Mở Cloud Shell và đặt các biến dự án để đảm bảo tất cả các lệnh đều nhắm đến cơ sở hạ tầng chính xác.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Sau đó, hãy xác định hai nhân vật của chúng ta.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Cho phép API
Cho phép các dịch vụ cần thiết của Google Cloud.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Tải mã nguồn của lớp học lập trình xuống
Để tránh làm lộn xộn Cloud Shell, bạn sẽ thực hiện thao tác thanh toán thưa thớt để chỉ tải các tập lệnh Python cần thiết cho lớp học lập trình này xuống từ kho lưu trữ Google Cloud DevRel.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Tạo bộ nhớ
Tạo bộ chứa để lưu trữ dữ liệu Iceberg được quản lý có tính bảo mật cao.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Chuẩn bị danh tính và bảo mật
Định cấu hình kết nối tài nguyên trên Cloud. Đây là thực thể duy nhất lưu giữ các khoá IAM vật lý vĩnh viễn để đọc các tệp Iceberg thô.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Tiếp theo, hãy thiết lập nhân vật người dùng. Người dùng được cấp quyền truy cập logic, không phải quyền truy cập vào bộ nhớ vật lý. Để tránh các lỗi do độ trễ trong quá trình truyền IAM, trước tiên, bạn sẽ tạo tài khoản, đợi vài giây rồi chỉ định vai trò cho các tài khoản đó.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Tạo bảng Iceberg gốc thông qua Lakehouse
Bạn sẽ sử dụng các tính năng gốc của Lakehouse để tạo các bảng Iceberg được quản lý.
Tạo tập dữ liệu BigQuery
Trước tiên, hãy tạo một tập dữ liệu BigQuery để nhóm các bảng Iceberg một cách logic.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Tạo bảng Iceberg
Tiếp theo, hãy chạy các lệnh sau để tạo bảng. Hãy lưu ý khối OPTIONS nơi chúng ta chỉ định table_format = 'ICEBERG' và liên kết trực tiếp khối này với bộ chứa và kết nối Cloud Storage.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Điền dữ liệu vào bảng
Cuối cùng, hãy chèn dữ liệu mẫu vào các bảng Iceberg mới tạo.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Bây giờ, bạn đã có hai bảng Iceberg hoạt động đầy đủ. Lakehouse quản lý siêu dữ liệu, nhưng các tệp Parquet vật lý được lưu trữ an toàn trong bộ chứa GCS của bạn!
Mô phỏng Quy trình ETL
Trong tình huống thực tế, dữ liệu thô thường được tổng hợp thành các bảng tóm tắt để báo cáo kinh doanh. Hãy đóng vai kỹ sư dữ liệu và tạo bảng tóm tắt doanh số hằng ngày từ dữ liệu giao dịch thô của chúng ta.
(Lưu ý: hãy chạy bước này ngay bây giờ để Google Cloud có đủ thời gian xử lý siêu dữ liệu nền. Bạn sẽ biết lý do tại sao bước này lại quan trọng trong phần sau của lớp học lập trình!)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Quản trị tập trung: Xác định chính sách bằng Python
Trong môi trường thực tế, việc định cấu hình các chính sách quản trị thông qua giao diện người dùng rất khó mở rộng và duy trì. Thay vào đó, bạn nên sử dụng Cơ sở hạ tầng dưới dạng mã (IaC).
Trong phần này, bạn sẽ sử dụng Google Cloud Python SDK để tạo và thực thi các quy tắc quản trị theo mô hình không tin tưởng từng bước theo phương thức lập trình.
Thiết lập môi trường Python
Trước tiên, hãy thiết lập một môi trường Python riêng biệt (venv) để tránh xung đột thư viện và cài đặt các Google Cloud SDK cần thiết.
Chạy các lệnh sau trong Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Tạo Phân loại và Thẻ chính sách
Phân loại là một vùng chứa logic và Thẻ chính sách là nhãn cụ thể mà bạn sẽ đính kèm vào cột nhạy cảm của chúng ta. Để thực thi bảo mật ở cấp cột, trước tiên, bạn cần có một vùng chứa logic (Phân loại) và một nhãn cụ thể (Thẻ chính sách).
Nếu bạn xem bên trong 1_create_taxonomy.py, bạn sẽ thấy logic cốt lõi sau:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Bằng cách đặt rõ ràng loại chính sách FINE_GRAINED_ACCESS_CONTROL, bạn sẽ chuyển đổi một thẻ siêu dữ liệu tiêu chuẩn thành một ranh giới bảo mật nghiêm ngặt theo mô hình không tin tưởng. Theo mặc định, mọi cột có thẻ này sẽ từ chối quyền truy cập đối với tất cả người dùng.
Chạy tập lệnh để tạo tài nguyên:
python 1_create_taxonomy.py
Định cấu hình Quy tắc che giấu (Chính sách dữ liệu)
Bây giờ, bạn sẽ xác định điều gì xảy ra khi một người không có đặc quyền truy vấn cột được gắn thẻ. Bạn sẽ tạo một Chính sách dữ liệu buộc giá trị trả về là NULL và đính kèm quy tắc này vào nhân vật Nhà phân tích.
Bên trong 2_create_masking.py, tập lệnh sẽ tra cứu linh hoạt Mã thẻ chính sách mà bạn vừa tạo và áp dụng chính sách dữ liệu:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Mã này sẽ tạo một quy tắc theo phương thức lập trình, buộc các giá trị cơ bản trả về là NULL. Sau đó, mã này sẽ chỉ định vai trò IAM maskedReader cụ thể cho nhân vật Nhà phân tích, đảm bảo họ chỉ thấy phiên bản dữ liệu được che giấu.
Chạy tập lệnh để định cấu hình quy tắc che giấu:
python 2_create_masking.py
Cấp quyền truy cập chi tiết
Do thiết lập theo mô hình không tin tưởng, nên hiện tại không ai có thể đọc cột được gắn thẻ. Bạn phải cấp quyền truy cập rõ ràng cho người quản lý và tài khoản cá nhân của mình.
Bên trong 3_grant_access.py, bạn sẽ sửa đổi chính sách IAM của chính Thẻ chính sách:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Việc thêm vai trò categoryFineGrainedReader cho phép các thực thể chính cụ thể này bỏ qua các quy tắc che giấu và đọc dữ liệu thô, không được che giấu.
Chạy tập lệnh để cấp quyền truy cập:
python 3_grant_access.py
Đính kèm Thẻ chính sách vào Bảng BigQuery
Cuối cùng, bạn phải đính kèm Thẻ chính sách logic này vào giản đồ bảng Iceberg vật lý của chúng ta.
Hãy xem 4_attach_tag.py. Tập lệnh sẽ tìm nạp giản đồ bảng BigQuery, lặp lại các trường và đính kèm thẻ cụ thể vào cột amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Khi bản cập nhật giản đồ này được áp dụng, Lakehouse sẽ liên kết ngay các thẻ logic của Knowledge Catalog xuống các tệp Parquet vật lý được lưu trữ trong bộ chứa Cloud Storage của bạn.
Chạy tập lệnh để cập nhật giản đồ bảng:
python 4_attach_tag.py
5. Xác minh các chính sách của Knowledge Catalog
Đã đến lúc kiểm tra xem quy trình quản trị tập trung của chúng ta có hoạt động hay không. Bạn sẽ kiểm tra quy trình này trên hai công cụ khác nhau để chứng minh rằng các chính sách của Knowledge Catalog được thực thi trên toàn cầu.
Xác minh bằng SQL gốc của BigQuery
Trước tiên, bạn sẽ sử dụng Cloud Shell để giả định danh tính của hai nhân vật và truy vấn bảng bằng công cụ SQL gốc của BigQuery.
Kiểm tra với tư cách là Người quản lý (Người dùng có đặc quyền):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Vì người quản lý có vai trò Người đọc chi tiết, nên hệ thống sẽ hiển thị các giá trị số tiền thô
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Kiểm tra với tư cách là nhà phân tích (Người dùng bị hạn chế):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Do quy tắc che giấu của Knowledge Catalog, cột số tiền sẽ trả về là NULL cho mọi hàng.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Khôi phục danh tính của bạn
Dọn dẹp trạng thái xác thực Cloud Shell để quay lại người dùng quản trị.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Xác minh bằng Apache Spark (Uỷ quyền tính toán)
Điều gì sẽ xảy ra nếu Nhà khoa học dữ liệu sử dụng Apache Spark để đọc bảng này? Nếu Spark đọc trực tiếp các tệp Parquet GCS vật lý, thì các quy tắc che giấu của Knowledge Catalog sẽ bị bỏ qua hoàn toàn vì Cloud Storage chỉ hiểu các quyền ở cấp bộ chứa.
Để ngăn chặn điều này, bạn sẽ thực thi tính năng uỷ quyền tính toán bằng cách sử dụng Trình kết nối Spark-BigQuery. Trình kết nối này đóng vai trò là cầu nối bảo mật, định tuyến các yêu cầu đọc Spark thông qua BigQuery Storage API để các quy tắc quản trị của Knowledge Catalog được đánh giá một cách linh hoạt trước khi bất kỳ dữ liệu nào được gửi đến cụm Spark.
Hãy xem logic cốt lõi bên trong tập lệnh read_transactions.py mà bạn đã tải xuống:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Xin lưu ý rằng chúng ta không trỏ Spark đến đường dẫn gs:// của các tệp Iceberg. Bằng cách chỉ định .format("bigquery"), BigQuery Storage API sẽ chặn yêu cầu đọc, kiểm tra danh tính của người dùng đang chạy công việc Spark, áp dụng các quy tắc che giấu của Knowledge Catalog và chỉ trả về dữ liệu được uỷ quyền cho Spark DataFrame.
Tải tập lệnh PySpark này lên bộ chứa Cloud Storage để Apache Spark được quản lý có thể truy cập vào tập lệnh này:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Chạy Spark với tư cách là người quản lý:
Bạn sẽ sử dụng Apache Spark được quản lý. Dịch vụ được quản lý này cho phép bạn chạy trực tiếp các tải công việc Spark mà không cần cung cấp, định cấu hình hoặc quản lý các cụm chuyên dụng.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Xem nhật ký đầu ra của công việc trong thiết bị đầu cuối. Vì người quản lý có vai trò Người đọc chi tiết, nên Spark đã truy xuất thành công các số tiền thô, không được che giấu.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Chạy Spark với tư cách là nhà phân tích:
Bây giờ, hãy gửi chính xác công việc Spark đó, nhưng lần này hãy mạo danh nhân vật nhà phân tích.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Kiểm tra lại nhật ký. Mặc dù nhà phân tích đã chạy chính xác cùng một mã Spark, nhưng BigQuery Storage API đã chặn yêu cầu và thực thi chính sách của Knowledge Catalog. Spark DataFrame của nhà phân tích hiển thị null cho các số tiền!
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Đánh đổi về kiến trúc: BigQuery SQL so với Spark
Bạn vừa chứng minh rằng kết quả là giống hệt nhau bất kể công cụ nào được sử dụng! Chính sách của Knowledge Catalog đã được thực thi thành công. Nhưng trong quá trình sản xuất, bạn nên sử dụng công cụ nào?
- BigQuery SQL: Phù hợp với các quy trình làm việc mà SQL là công cụ mong muốn và chạy các phép tính trực tiếp tại chỗ. Công cụ này lý tưởng cho hoạt động phân tích nhanh và Thông tin kinh doanh.
- Apache Spark: Cho phép các tải công việc phức tạp hơn nhờ sử dụng Python, giúp công cụ này phù hợp với các quy trình Máy học nâng cao hoặc mã Hadoop cũ.
Điểm chính cần lưu ý: Bất kể công cụ nào được sử dụng, bằng cách thực thi tính năng uỷ quyền tính toán, bạn sẽ không bao giờ bỏ qua được lớp quản trị tập trung theo mô hình không tin tưởng!
6. Dòng dõi dữ liệu tự động
Trong mọi kiến trúc dữ liệu doanh nghiệp, việc biết chính xác nguồn gốc dữ liệu và cách dữ liệu đã được thay đổi là rất quan trọng để tuân thủ, gỡ lỗi và thiết lập độ tin cậy. Khái niệm này được gọi là Dòng dõi dữ liệu. Khái niệm này trả lời các câu hỏi cơ bản như: "Nếu người quản lý đang xem báo cáo doanh số hằng ngày, thì những bảng thô nào đã được sử dụng để tính toán các con số đó?"
Theo truyền thống, việc theo dõi vòng đời này đòi hỏi các kỹ sư dữ liệu phải tự viết mã ghi nhật ký tuỳ chỉnh hoặc sử dụng các công cụ phức tạp của bên thứ ba để phân tích cú pháp các tập lệnh SQL. Tuy nhiên, trong Google Cloud Lakehouse được quản lý, tính năng theo dõi này được tích hợp và hoàn toàn tự động.
Bạn có nhớ bảng transactions_summary mà bạn đã tạo từ bảng giao dịch thô ở phần trước trong lớp học lập trình không? Khi BigQuery thực thi câu lệnh CREATE TABLE AS SELECT đó, công cụ tính toán sẽ tự động ghi lại siêu dữ liệu chuyển đổi và gửi siêu dữ liệu đó đến Knowledge Catalog. Hãy xem kết quả.
Trực quan hoá dòng dõi
- Trong Google Cloud Console, hãy chuyển đến Knowledge Catalog > Tìm kiếm.
- Nhập
lakehouse_retail_demo.transactionsvào thanh tìm kiếm rồi nhấp vào bảng. - Nhấp vào thẻ Dòng dõi.
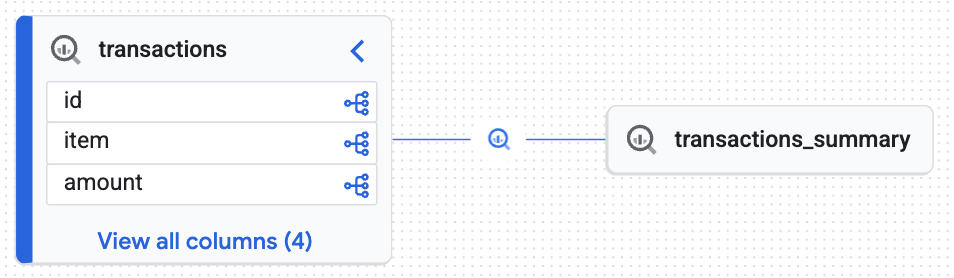
Bạn sẽ thấy một biểu đồ tương tác do Knowledge Engine tạo ra, chứng minh rằng bảng đích (transactions_summary) được lấy từ bảng Iceberg được quản lý thô (transactions). Bạn đã đạt được khả năng theo dõi từ đầu đến cuối, điều cần thiết cho việc kiểm tra dữ liệu.
7. Dọn dẹp
Để tránh bị tính phí cho tài khoản Google Cloud đối với các tài nguyên được sử dụng trong lớp học lập trình này, hãy làm theo các bước sau.
Xoá tài nguyên quản trị Knowledge Catalog
Trước khi xoá tập dữ liệu BigQuery hoặc bộ chứa Cloud Storage, bạn phải xoá các quy tắc quản trị logic. Nếu bạn xem bên trong tập lệnh cleanup_governance.py trong kho lưu trữ, bạn sẽ thấy trình tự xoá sau:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Thứ tự ở đây rất quan trọng. Tập lệnh sẽ xoá Chính sách dữ liệu (quy tắc che giấu) trước vì chính sách này dựa vào Thẻ chính sách. Sau khi chính sách bị xoá, việc xoá Phân loại mẹ sẽ tự động xoá tất cả các Thẻ chính sách cơ bản mà không gây ra lỗi phụ thuộc tài nguyên.
Chạy tập lệnh dọn dẹp Python:
python cleanup_governance.py
Xoá danh tính, bộ nhớ và thành phần tính toán
Bây giờ, lớp quản trị đã được tách ra, bạn có thể xoá các bảng BigQuery, bộ chứa Cloud Storage, Tài khoản dịch vụ và môi trường Python cục bộ một cách an toàn.
Sao chép và chạy khối dọn dẹp toàn diện sau trong Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Bằng cách hoàn tất các bước này, bạn đã đảm bảo không còn tài nguyên bị bỏ rơi hoặc chính sách ẩn trong dự án của mình.
8. Xin chúc mừng!
Bạn đã triển khai thành công một Lakehouse dữ liệu có thể phát hiện và được quản lý đầy đủ.
Bạn đã tìm hiểu rằng:
- Tích hợp Iceberg gốc: Lakehouse có thể quản lý các bảng Iceberg nguồn mở một cách tự nhiên trong khi lưu trữ các tệp vật lý một cách an toàn trong Cloud Storage.
- Uỷ quyền tính toán để bảo mật: Bằng cách định tuyến các truy vấn thông qua BigQuery Storage API, bạn đã thực thi tính năng che giấu linh hoạt chi tiết trên các tệp vật lý mà theo mặc định không thể hạn chế quyền truy cập một phần.
- Quản trị độc lập với công cụ: Thẻ chính sách cho phép bạn xác định các quy tắc một lần và thực thi các quy tắc đó trên toàn cầu cho dù được truy vấn thông qua thời gian chạy SQL gốc hay Apache Spark.
- Khả năng phát hiện dữ liệu: Knowledge Engine tự động theo dõi dòng dõi dữ liệu, cung cấp khả năng kiểm tra doanh nghiệp cần thiết.
Tiếp theo là gì?
- Khám phá tính năng kiểm soát quyền truy cập nâng cao: Để triển khai các tình huống bảo mật phức tạp hơn, hãy xem tài liệu chính thức về cách tuỳ chỉnh Lakehouse bằng các tính năng bổ sung.
- Quản trị dữ liệu phi cấu trúc cho GenAI: Khám phá Bảng đối tượng. Mở rộng chính xác mẫu Cầu nối bảo mật này cho các tệp phi cấu trúc (PDF, hình ảnh) trong Cloud Storage, thiết lập nền tảng dữ liệu được quản lý và bảo mật cho Gemini Enterprise Agent Engine và các quy trình RAG.