
1. 简介
在现代企业数据云中,数据分布在各种物理存储系统中,因此存在安全碎片化这一巨大的架构挑战。
当数据以 Parquet 等开源格式实际存储在 Google Cloud Storage 中,并由 BigQuery SQL 或 Apache Spark 等多个不同引擎查询时,如何确保敏感数据(例如金融交易金额)受到一致的保护?
在此 Codelab 中,您将构建一个受管控的数据湖仓一体架构,该架构使用 Apache Iceberg 表、BigQuery 和 Knowledge Catalog 来解决这些问题。您将使用基础设施即代码 (IaC) 来定义零信任安全政策,以及这些政策如何在不同的计算引擎中动态强制执行。
前提条件
- 启用了结算功能的 Google Cloud 项目。
- 对 SQL、IAM 和 Cloud Storage 概念有基本的了解。
学习内容
- 如何在 BigQuery 中为 Apache Iceberg 创建 Google Cloud Lakehouse 表,其中 Cloud Storage 原生保存数据。
- 如何使用政策标记强制执行集中式数据政策,以实现列级安全性和数据遮盖。
- 如何使用 Cloud 资源连接将物理存储访问与逻辑数据访问权限分离。
- 如何使用 Managed Service for Apache Spark 强制执行零信任计算委托,以确保开源引擎无法绕过治理。
- 如何直观呈现自动化的数据沿袭。
架构概览:Iceberg 上的通用治理
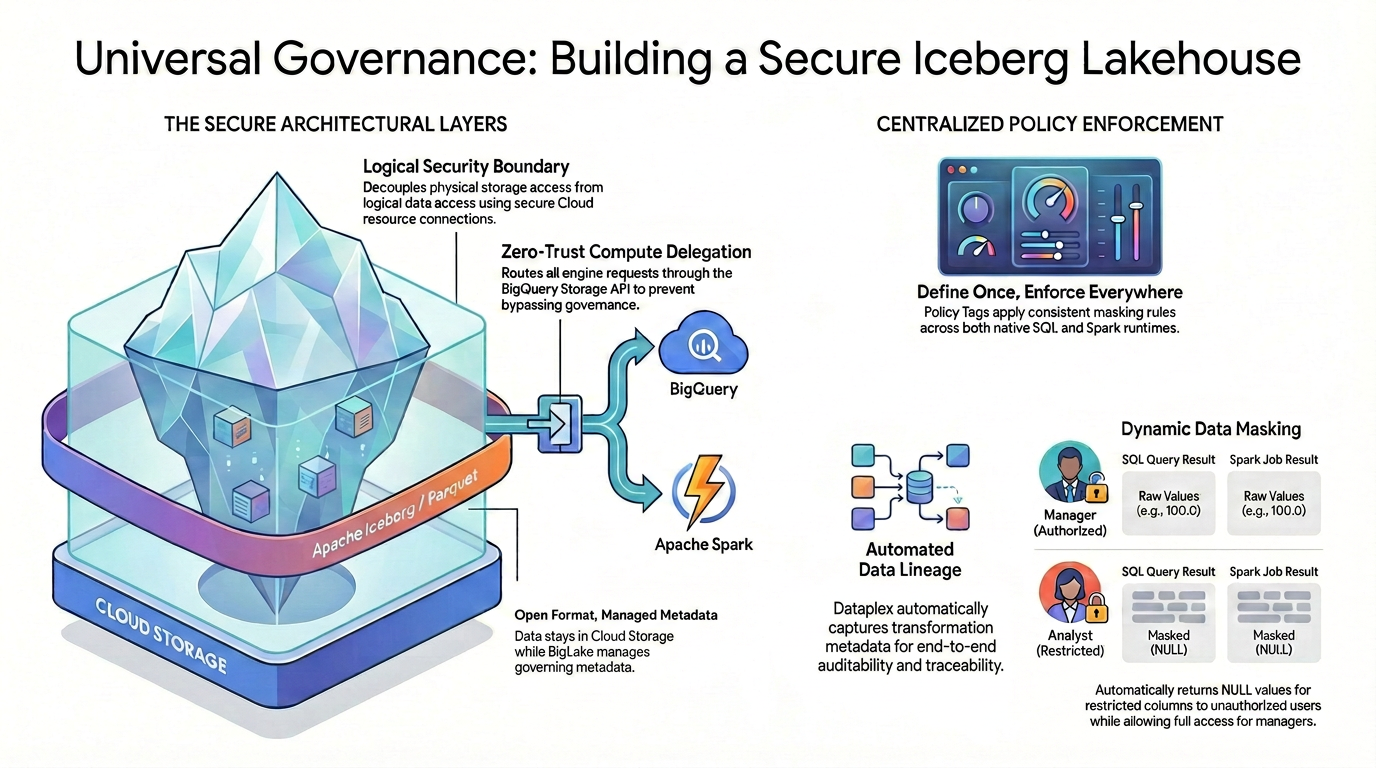
如需对开放源代码数据格式实现精细的访问权限控制(例如列级安全性和数据遮盖),您必须建立严格且统一的安全架构。
如图所示,这种受监管的数据湖仓模式依赖于两大支柱来解决碎片化的安全挑战:
🛡️ 安全架构层(左侧)
您无需允许用户或外部引擎直接访问 Cloud Storage(仅支持广泛的存储分区级安全性),而是可以构建安全的基础。
- 开放格式,托管元数据:数据以开放的 Apache Iceberg (Parquet) 格式实际存储在 Cloud Storage 中,而 Lakehouse 可无缝管理治理元数据。
- 逻辑安全边界:您可以使用安全的 Cloud 资源连接将物理存储访问与逻辑数据访问权限分离。最终用户永远不会获得对原始 GCS 文件的直接物理 IAM 访问权限。
- 零信任计算委托:为确保没有执行引擎可以绕过治理规则,所有数据读取请求都严格通过 BigQuery Storage API 路由。无论查询是源自原生 BigQuery SQL 还是开源 Apache Spark,此规则都适用。
🎯 集中式政策实施(右)
在安全的基础之上,Knowledge Catalog 可充当统一的治理大脑:
- 一次定义,处处强制执行:您只需在 Knowledge Catalog 中定义一次政策标记,该架构便会在所有受支持的执行运行时中普遍应用一致的遮盖规则。
- 动态数据遮盖:查询数据时,系统会动态评估用户身份。获得授权的用户将在 SQL 和 Spark 中看到原始的未遮盖值(例如 100.0),而受限用户将自动收到两个引擎中受限列的遮盖 NULL 值。
- 自动数据沿袭:随着数据流动和转换,Knowledge Catalog 会自动捕获转换元数据,从而提供内置的端到端可审核性和可追溯性,而无需自定义日志记录代码。
2. 设置和要求
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
初始化环境
打开 Cloud Shell 并设置项目变量,以确保所有命令都指向正确的基础设施。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
然后,定义我们的两个买家角色。
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
启用 API
启用必要的 Google Cloud 服务。
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
下载 Codelab 源代码
为避免 Cloud Shell 杂乱无章,您将执行稀疏检出,仅从 Google Cloud DevRel 代码库下载此 Codelab 所需的 Python 脚本。
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
创建存储空间
创建存储分区以存储高度安全且受治理的 Iceberg 数据。
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
准备身份验证与安全
配置云资源连接。这是唯一持有永久性物理 IAM 密钥以读取原始 Iceberg 文件的实体。
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
接下来,设置用户角色。系统会向用户授予逻辑访问权限,而不是物理存储访问权限。为防止因 IAM 传播延迟而导致错误,您将先创建账号,等待几秒钟,然后分配角色。
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. 通过 Lakehouse 创建原生 Iceberg 表
您将使用 Lakehouse 的原生功能来创建受管理的 Iceberg 表。
创建 BigQuery 数据集
首先,创建一个 BigQuery 数据集,以便从逻辑上对 Iceberg 表进行分组。
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
创建 Iceberg 表
接下来,运行以下命令来创建表。请注意 OPTIONS 块,我们在其中指定了 table_format = 'ICEBERG' 并将其直接映射到我们的 Cloud Storage 存储分区和连接。
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
用数据填充表格
最后,将示例数据插入到新创建的 Iceberg 表中。
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
现在,您已拥有两个功能齐全的 Iceberg 表。湖仓一体架构会管理元数据,但实际的 Parquet 文件会安全地存储在您的 GCS 存储分区中!
模拟 ETL 流水线
在实际应用场景中,原始数据通常会汇总到摘要表中,以用于生成业务报告。我们来扮演数据工程师的角色,根据原始交易数据创建一个每日销售摘要表。
(注意:请立即运行此步骤,以便 Google Cloud 有足够的时间来处理后台元数据。您将在本 Codelab 的后面部分了解此设置的重要性!)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. 集中式治理:使用 Python 定义政策
在生产环境中,通过界面配置治理政策难以扩缩和维护。因此,强烈建议使用基础设施即代码 (IaC)。
在此部分中,您将使用 Google Cloud Python SDK 以编程方式逐步创建和强制执行零信任治理规则。
设置 Python 环境
首先,我们来设置一个独立的 Python 环境 (venv),以避免库冲突,并安装所需的 Google Cloud SDK。
在 Cloud Shell 中运行以下命令:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
创建分类和政策标记
分类是一个逻辑容器,而政策标记是您将附加到敏感列的具体标签。如需强制执行列级安全性,您首先需要一个逻辑容器(即分类)和一个特定标签(即政策标记)。
如果您查看 1_create_taxonomy.py 的内部,您会看到以下核心逻辑:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
通过显式设置 FINE_GRAINED_ACCESS_CONTROL 政策类型,您可以将标准元数据标记转换为严格的零信任安全边界。默认情况下,带有此标记的任何列都会拒绝所有用户的访问。
运行脚本以创建资源:
python 1_create_taxonomy.py
配置遮盖规则(数据政策)
现在,您需要定义当没有相应权限的用户查询带有标记的列时会发生什么情况。您将创建一个数据政策,强制将值返回为 NULL,并将此规则附加到 Analyst persona。
在 2_create_masking.py 内,脚本会动态查找您刚刚创建的政策标记 ID 并应用数据政策:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
此代码以编程方式创建了一条规则,用于强制将基础值返回为 NULL。然后,它专门为分析师角色分配了 maskedReader IAM 角色,确保他们只能看到经过遮盖的数据版本。
运行脚本以配置遮盖规则:
python 2_create_masking.py
授予精细访问权限
由于我们采用了零信任设置,因此目前无人可以读取标记的列。您必须明确授予经理账号和个人账号访问权限。
在 3_grant_access.py 中,您可以修改政策标记本身的 IAM 政策:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
添加 categoryFineGrainedReader 角色后,这些特定主账号就可以绕过遮盖规则,读取未经遮盖的原始数据。
运行脚本以授予访问权限:
python 3_grant_access.py
将政策标记附加到 BigQuery 表
最后,您必须将此逻辑政策标记附加到我们的物理 Iceberg 表架构。
您可以查看 4_attach_tag.py。该脚本会提取 BigQuery 表架构,遍历各个字段,并将标记专门附加到 amount 列:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
应用此架构更新后,Lakehouse 会立即将 Knowledge Catalog 逻辑标记桥接到存储在 Cloud Storage 存储分区中的物理 Parquet 文件。
运行脚本以更新表架构:
python 4_attach_tag.py
5. 验证 Knowledge Catalog 政策
现在,我们来测试一下集中式治理是否有效。您将通过两个不同的引擎进行测试,以证明 Knowledge Catalog 政策可普遍强制执行。
使用 BigQuery 原生 SQL 进行验证
首先,您将使用 Cloud Shell 假设两个角色的身份,并使用 BigQuery 的原生 SQL 引擎查询表。
以管理员(特权用户)身份进行测试:
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
由于经理拥有 Fine-Grained Reader 角色,因此系统会显示原始金额值
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
以分析师(受限用户)身份进行测试:
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
由于 Knowledge Catalog 屏蔽规则,金额列针对每一行都返回 NULL。
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
恢复您的身份
清理 Cloud Shell 身份验证状态,以返回到管理员用户。
# Unset impersonation
gcloud config unset auth/impersonate_service_account
使用 Apache Spark(计算委托)进行验证
如果数据科学家使用 Apache Spark 读取此表,会发生什么情况?如果 Spark 直接读取实际的 GCS Parquet 文件,则会完全绕过知识目录屏蔽规则,因为 Cloud Storage 只了解存储分区级权限。
为防止这种情况,您可以使用 Spark-BigQuery 连接器强制执行计算委托。此连接器充当安全桥梁,通过 BigQuery Storage API 路由 Spark 读取请求,以便在将任何数据发送到 Spark 集群之前动态评估知识目录治理规则。
查看您下载的 read_transactions.py 脚本中的核心逻辑:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
请注意,我们并未将 Spark 指向 Iceberg 文件的 gs:// 路径。通过指定 .format("bigquery"),BigQuery Storage API 会拦截读取请求,检查运行 Spark 作业的用户的身份,应用 Knowledge Catalog 屏蔽规则,并仅将授权的数据返回给 Spark DataFrame。
将此 PySpark 脚本上传到您的 Cloud Storage 存储分区,以便 Managed Apache Spark 可以访问它:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
以管理员身份运行 Spark:
您将使用托管式 Apache Spark。借助这项托管式服务,您可以直接运行 Spark 工作负载,而无需预配、配置或管理专用集群。
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
查看终端中的作业输出日志。由于经理具有 Fine-Grained Reader 角色,因此 Spark 成功检索到未经遮盖的原始金额。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
以分析师身份运行 Spark:
现在,提交完全相同的 Spark 作业,但这次要模拟分析师角色。
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
再次检查日志。尽管分析师运行的是完全相同的 Spark 代码,但 BigQuery Storage API 拦截了请求并强制执行了 Knowledge Catalog 政策。分析师的 Spark DataFrame 显示的金额为 null!
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
架构权衡:BigQuery SQL 与 Spark
您刚刚证明,无论使用哪个引擎,结果都是相同的!已成功强制执行 Knowledge Catalog 政策。但在正式版中,您应该使用哪个?
- BigQuery SQL:非常适合需要使用 SQL 作为引擎并直接在本地运行计算的工作流。非常适合快速分析和商业智能。
- Apache Spark:由于使用 Python,因此可以处理更复杂的工作负载,非常适合高级机器学习流水线或旧版 Hadoop 代码。
总结:无论使用哪个引擎,通过强制执行计算委托,集中式零信任治理层永远不会被绕过!
6. 自动数据沿袭
在任何企业数据架构中,准确了解数据的来源和更改方式对于合规性、调试和建立信任至关重要。此概念称为数据沿袭。它可以解答一些基本问题,例如:“如果经理查看每日销售报告,那么计算这些数字时使用了哪些原始表?”
传统上,跟踪此生命周期需要数据工程师手动编写自定义日志记录代码或使用复杂的第三方工具来解析 SQL 脚本。不过,在受监管的 Google Cloud Lakehouse 中,此跟踪功能是内置的,完全无需人工干预。
还记得您在本 Codelab 前面部分中根据原始交易表创建的 transactions_summary 表吗?当 BigQuery 执行该 CREATE TABLE AS SELECT 语句时,计算引擎会自动捕获转换元数据并将其发送到 Knowledge Catalog。我们来看看结果。
直观呈现沿袭
- 在 Google Cloud 控制台中,前往 Knowledge Catalog > 搜索。
- 在搜索栏中输入
lakehouse_retail_demo.transactions,然后点击表格。 - 点击沿袭标签页。
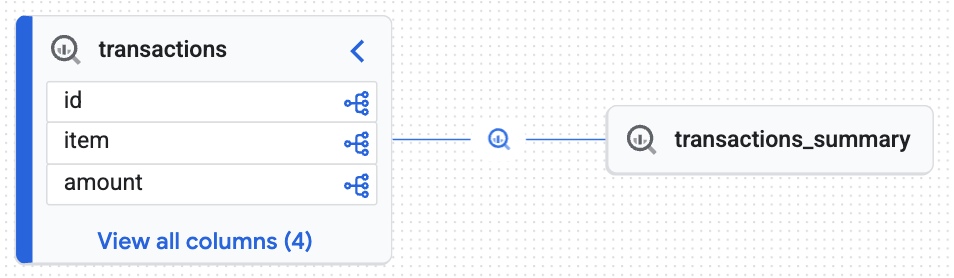
您将看到知识引擎生成的互动式图表,证明目标表 (transactions_summary) 是从原始受监管的 Iceberg 表 (transactions) 派生出来的。您实现了数据审核所需的端到端可追溯性。
7. 清理
为避免系统因本 Codelab 中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作。
移除 Knowledge Catalog 治理资源
在删除 BigQuery 数据集或 Cloud Storage 存储分区之前,您必须移除逻辑治理规则。如果您查看代码库中的 cleanup_governance.py 脚本,您会看到以下拆解序列:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
此处的顺序至关重要。该脚本首先删除数据政策(遮盖规则),因为它依赖于政策标记。移除政策后,删除父分类将自动级联并删除所有底层政策标记,而不会触发资源依赖性错误。
运行 Python 清理脚本:
python cleanup_governance.py
移除身份、存储和计算资产
现在,治理层已分离,您可以安全地删除 BigQuery 表、Cloud Storage 存储分区、服务账号和本地 Python 环境。
在 Cloud Shell 中复制并运行以下全面的清理代码块:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
完成这些步骤后,您已确保项目中不会再有孤立的资源或隐藏的政策。
8. 恭喜!
您已成功实现完全受监管且可发现的数据湖仓一体化。
您已了解:
- 原生 Iceberg 集成:Lakehouse 可以原生管理开源 Iceberg 表,同时将物理文件安全地存储在 Cloud Storage 中。
- 安全计算委托:通过 BigQuery Storage API 路由查询,您可以在无法限制部分访问权限的物理文件上强制执行精细的动态遮盖。
- 与引擎无关的治理:借助政策标记,您可以定义一次规则,无论通过原生 SQL 还是 Apache Spark 运行时进行查询,这些规则都会得到普遍强制执行。
- 数据可发现性:知识引擎会自动跟踪数据沿袭,从而提供必要的企业可审核性。
后续操作
- 探索高级访问权限控制:如需实现更复杂的安全方案,请查看有关使用其他功能自定义 Lakehouse 的官方文档。
- 针对生成式 AI 管理非结构化数据:探索对象表。将此确切的安全桥模式扩展到 Cloud Storage 中的非结构化文件(PDF、图片),为 Gemini Enterprise Agent Engine 和 RAG 流水线建立安全且受监管的数据基础。