
1. 🏰 Disneyland Data Analytics Hackathon (2. Auflage – 3. Dezember) 🏰
Zusammenfassung | In diesem Hackathon entwickeln Sie eine End-to-End-Datenanalyse-Pipeline, die KI/ML-Funktionen in Google Cloud nutzt. Sie laden Daten in AlloyDB, eine vollständig verwaltete, PostgreSQL-kompatible Datenbank, die für anspruchsvolle Arbeitslasten optimiert ist, und verwenden dann Datastream, einen serverlosen CDC-Dienst (Change Data Capture), um die Daten in BigQuery, das serverlose Data Warehouse von Google Cloud, zu verschieben. In BigQuery wenden Sie BigQuery ML an, mit dem Sie Modelle für maschinelles Lernen direkt in BigQuery mit Standard-SQL erstellen und ausführen können, um Rezensionen zu analysieren und die Teilnehmerzahl zu prognostizieren. Schließlich können Sie mit Agents arbeiten, entweder sofort über konversationelle Analyse und Daten-Agents oder indem Sie einen benutzerdefinierten Agenten erstellen, der auf dem Agent Development Kit und der MCP Toolbox basiert und eine Interaktion in natürlicher Sprache mit Ihren Daten ermöglicht. |
Kategorien | docType:Codelab, product:Bigquery |
Author | Rayhane Rezgui, Matt Cornillon |
Layout | Scrollen |
Roboter | noindex |
2. Einführung
Willkommen, zukünftige Disney-Datenexperten! 🪄
Vergessen Sie mühsame Reiseführer und endloses Scrollen in Foren. Stellen Sie sich vor, Sie planen den perfekten Disneyland-Trip und haben dabei datengestützte Statistiken zur Verfügung. Welcher Park bietet die besten Erlebnisse? Wann sind die Menschenmassen am geringsten? Kannst du vorhersagen, wann die beste Zeit ist, um die berüchtigte lange Warteschlange zu überwinden?
Bei diesem Hackathon entwickeln Sie das ultimative Disneyland-Planungstool. Wir haben die Daten: Rezensionen von Besuchern in allen Niederlassungen weltweit, historische Wartezeiten und Besucherzahlen. Ihre Aufgabe? Verwandeln Sie diese Rohdaten in umsetzbare Informationen:
- Daten erfassen:Laden Sie verschiedene Disneyland-Rezensionen, Wartezeiten und Besucherzahlen in AlloyDB, unsere leistungsstarke, PostgreSQL-kompatible Datenbank.
- Nahtlose Übertragung:Mit Datastream, unserem serverlosen Change Data Capture-Dienst, können Sie diese dynamischen Informationen mühelos in BigQuery, das leistungsstarke serverlose Data Warehouse von Google Cloud, übertragen.
- Predict the Magic:Mit BigQuery ML können Sie die Stimmung in Rezensionen analysieren und Wartezeiten direkt mit SQL vorhersagen. Finden Sie heraus, in welchen Filialen Sie am häufigsten lächeln und wann der beste Zeitpunkt für einen Besuch ist.
- Daten auf natürliche Weise verbinden: Nutzen Sie vorgefertigte Tools, mit denen Sie im Handumdrehen Erkenntnisse gewinnen können.
- Intelligente Interaktion:Mit einem intelligenten Agenten, der auf der MCP Toolbox for Databases und dem ADK (Agent Development Kit) basiert, können Sie Ihre Kreation noch weiter optimieren. Fragen Sie: „Was ist die beste Attraktion im Disneyland Paris für Weltraumfans und wann ist die beste Zeit, sich in die Warteschlange einzureihen?“ und erhalten Sie sofort datengestützte Antworten.
Machen Sie sich bereit, die Geheimnisse der magischsten Orte der Welt zu lüften und eine Datenanalyse-Pipeline zu erstellen, die Mickey stolz machen würde.
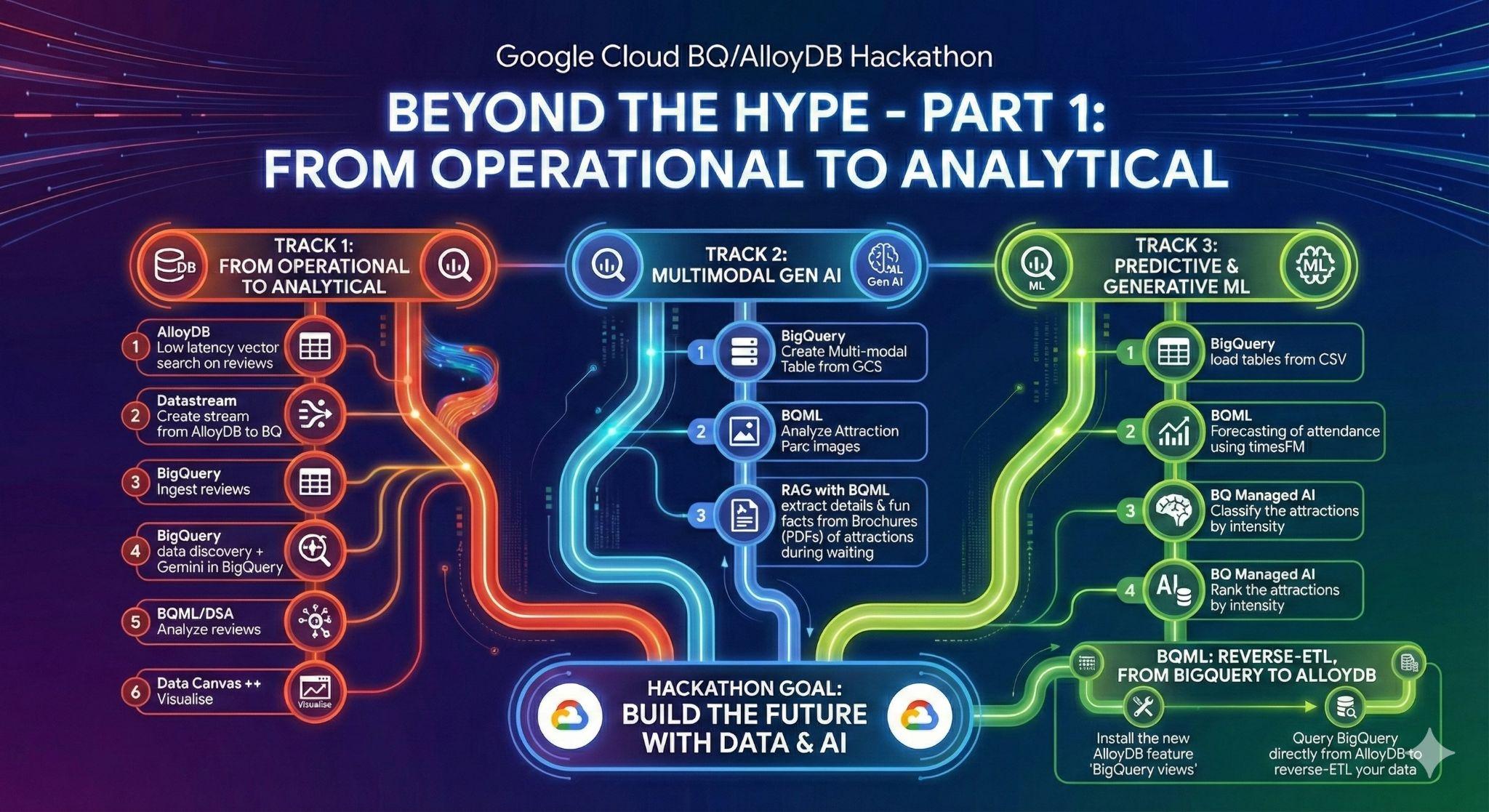
3. Aufgabe 1: Von operativ zu analytisch – Disneyland-Rezensionen mit Gemini analysieren
In dieser ersten Phase rufen Sie die Daten aus Ihrer AlloyDB-Betriebsdatenbank ab und laden sie zur anschließenden Datenanalyse in BigQuery.
Außerdem richten Sie alles ein, was Sie in AlloyDB für Ihren zukünftigen Agent benötigen.
Daten in AlloyDB laden
Zuerst importieren wir einige Daten in unseren AlloyDB for PostgreSQL-Cluster.
Wir werden 20.000 Rezensionen für Disneyland-Freizeitparks und eine Liste von Attraktionen aufnehmen.
Gehen Sie dazu so vor:
Tabellen erstellen:
- Erstelle eine Tabelle mit dem Namen disneyland_reviews mit sechs Spalten: „review_id“ und „rating“ als Ganzzahl, „year_month“, „reviewer_location“, „review_text“ und „branch“ als Text.
- Erstelle eine Tabelle mit dem Namen disneyland_attractions mit vier Spalten: „attraction_id“ als Ganzzahl, „branch“, „name“ und „description“ als Text.
Daten aus den CSV-Dateien mit dem gewünschten Tool importieren:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvfür die Rezensionstabellegs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvfür die Tabelle „Sehenswürdigkeiten“
Um Empfehlungen für Sehenswürdigkeiten zu geben, müssen wir Einbettungen der Beschreibungen von Sehenswürdigkeiten erstellen:
- pgvector-Erweiterung in AlloyDB installieren
- Fügen Sie der Tabelle „attraction“ eine Vektorspalte mit dem Namen „embedding“ hinzu.
- Einbettungen der Beschreibungen mit der nativen Integration zwischen AlloyDB und Vertex AI generieren und einfügen
Von Betriebsdaten zu Analysedaten mit Datastream
Um unsere Daten aus AlloyDB in BigQuery zu streamen, verwenden wir Google Datastream. Es handelt sich um eine leistungsstarke serverlose Lösung, die alle Änderungen in Quelltabellen (mithilfe von Change Data Capture) erfasst und an BigQuery sendet.
Damit Änderungen aus AlloyDB mit Datastream repliziert werden können, müssen wir in Postgres eine sogenannte Publikation und einen Replikationsslot erstellen.
Führen Sie die folgenden Abfragen in Ihrem AlloyDB-Cluster aus (Sie müssen sie einzeln ausführen):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Du verwendest den Publikations- und Replikations-Slot in deinem Stream. Merke dir also die Namen.
Das war's auch schon. Jetzt können wir einen Stream erstellen.
Folgende Schritte sind in Datastream erforderlich:
- Quellprofil für Ihren AlloyDB-Cluster erstellen (öffentliche IP-Adresse verwenden)
- Zielprofil für BigQuery erstellen
- Stream von AlloyDB zu BigQuery erstellen
Die Daten sollten in wenigen Minuten in BigQuery verfügbar sein.
Datenermittlung in BigQuery
Nachdem wir unsere Daten in BigQuery haben, sollten wir uns die neuen Verbesserungen in der Benutzeroberfläche ansehen, bevor wir mit der Arbeit beginnen.
Es gibt drei neue Funktionen, die Sie bereits im BigQuery-Explorationsbereich sehen können.
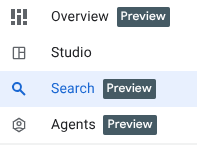
- Übersicht:Enthält Informationen zu BigQuery-Funktionen, Anleitungen für den Einstieg in die Analyse und andere Möglichkeiten.
- Suchen:Führen Sie eine semantische Suche in Ihren Datenassets durch.
- Kundenservicemitarbeiter:Pssst! Das heben wir uns für später auf. 🤫
Daten in BigQuery semantisch durchsuchen
Rufen Sie den Tab „Suche“ im BigQuery-Untersuchungsbereich auf und probieren Sie Begriffe im Zusammenhang mit Disney aus, z. B. „Attraktionen“ oder „Niederlassung“.
Daten in BigQuery visualisieren
Sie können Ihre Daten jetzt in BigQuery visualisieren und bearbeiten. Dazu können Sie diese Abfrage auf einem neuen Tab ausführen.
SELECT
*
FROM
[dataset_name].[table_name];
Datenstatistiken für die Tabelle „reviews“ erstellen
In dieser Aufgabe aktivieren Sie Data Insights für die Tabelle disneyland_reviews im Dataset disney.
Data Insights ist ein Tool zum Analysieren von Daten und zum Erstellen von Statistiken ohne komplexe SQL-Abfragen.
Das kann einige Minuten dauern.
Tabelle „disneyland_reviews“ ohne SQL abfragen
Die im vorherigen Abschnitt generierten Insights sind jetzt verfügbar. In dieser Aufgabe verwenden Sie einen aus diesen Insights generierten Prompt, um die Tabelle disneyland_reviews ohne Code abzufragen.
Wählen Sie einen Insight aus und führen Sie die zugehörige Abfrage aus. Suchen Sie beispielsweise nach der Abfrage, mit der die Differenz der durchschnittlichen Bewertung zwischen aufeinanderfolgenden Monaten für jede Filiale berechnet wird. Das würde so aussehen:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
BigQuery Knowledge Engine verwenden, um Daten besser zu verstehen
Sehen wir uns zuerst den Tab Statistiken auf Dataset-Ebene an. So erhalten wir einen Eindruck von den verborgenen Beziehungen zwischen den Tabellen im Disney-Dataset. Danach geht es so weiter:
- Mit Gemini eine Beschreibung des Datasets generieren und den Dataset-Details hinzufügen.
- Generieren Sie eine Beschreibung der Tabellen „reviews“ und „attractions“ sowie aller einzelnen Spalten in diesen Tabellen und speichern Sie sie.
Profilscan Ihrer Daten durchführen
In diesem Abschnitt geht es darum, Ihre Daten zu bereinigen und vorzubereiten. Sie sind jedoch nicht sehr vertraut mit der Verteilung der Werte der einzelnen Spalten. Sie müssen Ihre Daten analysieren, um zu wissen, welche Transformationsschritte Sie darauf anwenden müssen.
Dataplex Universal Catalog von Google Cloud automatisiert Profilscans, um einheitliche Messwerte für die Datenqualität zu liefern. Zu den wichtigsten Statistiken gehören Nullwerte, eindeutige Werte, Datenbereiche und Werteverteilungen. Sie können einen Profilscan über die BigQuery-Oberfläche aktivieren.
Das kann ein paar Minuten dauern. In der Zwischenzeit können Sie sich gern schon den nächsten Abschnitt ansehen.
Beantworten Sie folgende Fragen:
- Wie ist die durchschnittliche Bewertung von Disneyland?
- Wo befinden sich die meisten Rezensenten?
- Sind alle Rezensionen einzigartig?
- Wie hoch ist der Prozentsatz der fehlenden Daten in der Spalte „Year_Month“?
Qualitätsscan Ihrer Daten durchführen
Mit automatischer Datenqualität in Dataplex Universal Catalog können Sie die Qualität der Daten in Ihren BigQuery-Tabellen definieren und messen. Sie können das Scannen von Daten automatisieren, Daten anhand definierter Regeln validieren und Benachrichtigungen protokollieren, wenn Ihre Daten nicht den Qualitätsanforderungen entsprechen. Sie können Datenqualitätsregeln und ‑bereitstellungen als Code verwalten und so die Integrität von Datenproduktionspipelines verbessern.
Definieren Sie auf Grundlage des Profilscans einen Qualitätsscan (mit einer Stichprobengröße von maximal 10% Ihrer Daten), der:
- Prüft auf Nullwerte für die Spalte branch.
- Führt eine Gültigkeitsprüfung für die Bewertung durch, da sie nur in der Menge 1,2,3,4,5 enthalten sein kann.
- Prüft die Eindeutigkeit von „review_id“
Achten Sie darauf, dass die Scanergebnisse in die BigQuery-Tabelle „quality_scan_results“ exportiert werden.
Überlegen Sie, welche Transformationen Sie auf Ihre Daten anwenden müssen.
Daten mit der Datenaufbereitung von Gemini vorbereiten
Nachdem Sie die Datenqualität und die Profilerstellung gescannt haben, ist es an der Zeit, die Daten vor der Analyse zu bereinigen.
Datenvorbereitungen sind BigQuery-Ressourcen, die Gemini in BigQuery verwenden, um Ihre Daten zu analysieren und intelligente Vorschläge zum Bereinigen, Transformieren und Anreichern zu machen. Sie können den Zeitaufwand und den Aufwand für manuelle Datenaufbereitungsaufgaben erheblich reduzieren.
In diesem Abschnitt verwenden Sie die Datenaufbereitung, um die folgenden Vorgänge für die Tabelle „disneyland_reviews“ auszuführen:
- Filtern Sie Zeilen heraus, in denen die Spalte „Branch“ entweder NULL oder ein leerer String ist.
- Ersetzen Sie „missing“ in „Year_Month“ durch „Null“.
- Unterstriche in der Spalte „Branch“ werden durch Leerzeichen ersetzt, um die Lesbarkeit zu verbessern.
- In die transformierte Tabelle „disneyland_reviews_cleaned“ exportieren
Rezensionen mit Gemini analysieren
Nachdem Sie Ihre Daten bereinigt haben, können Sie sie mit BigQuery ML und Gemini-Modellen analysieren. Sie haben zwei Ziele:
- Kategorien aus Rezensionen extrahieren
- Sentimentanalyse von „disneyland_reviews“
Mit BigQuery ML können Sie über GoogleSQL-Abfragen ML-Modelle erstellen und ausführen. BigQuery ML-Modelle werden in BigQuery-Datasets gespeichert, ähnlich wie Tabellen und Ansichten. Mit BigQuery ML haben Sie auch Zugriff auf Vertex AI-Modelle und Cloud AI APIs, um Aufgaben im Bereich künstliche Intelligenz (KI) wie Textgenerierung oder maschinelle Übersetzung auszuführen. Gemini für Google Cloud bietet auch KI-basierte Unterstützung für BigQuery-Aufgaben.
Sie können ML.GENERATE_TEXT oder AI.GENERATE (Vorschau) mit Gemini Pro- oder Flash-Modellen verwenden.
Die folgenden Schritte führen Sie durch die Verwendung von ML.GENERATE_TEXT.
Cloud-Ressourcenverbindung erstellen und IAM-Rolle zuweisen
Sie müssen eine Cloud-Ressourcenverbindung in BigQuery zu Vertex AI-Modellen erstellen, damit Sie mit Gemini Pro- und Gemini Flash-Modellen arbeiten können. Außerdem gewähren Sie dem Dienstkonto der Cloud-Ressourcenverbindung eine Rolle mit IAM-Berechtigungen, mit denen der Zugriff auf Vertex AI-Dienste möglich ist.
Dem Dienstkonto der Verbindung die Rolle „Vertex AI User“ gewähren
Erlauben Sie dem Dienstkonto der Verbindung, das ausgewählte Modell (z. B. gemini-2.5-flash) zu verwenden, indem Sie ihm die Rolle „Vertex AI-Nutzer“ zuweisen. Es dauert eine Minute, bis die Berechtigung wirksam wird.
Gemini-Modelle in BigQuery erstellen
Erstellen Sie Ihr Modell mit der oben genannten Verbindung. Verwenden Sie beispielsweise den Endpunkt gemini-2.5-flash..
Gemini auffordern, Kundenrezensionen in Bezug auf Kategorien und Sentiment zu analysieren
In dieser Aufgabe analysieren Sie mit dem Gemini-Modell Kundenrezensionen in Bezug auf Kategorien und positives sowie negatives Sentiment.
Kundenrezensionen nach Kategorien analysieren
Hinweis: Für die Analyse berücksichtigen wir ab sofort nur 100 Zeilen, da der Gemini-Aufruf für 20.000 Zeilen eine Weile dauern kann.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Diese Abfrage übernimmt Kundenrezensionen aus der Tabelle disneyland_reviews und erstellt Prompts für das Modell gemini, um Kategorien in den jeweiligen Rezensionen zu ermitteln. Die Ergebnisse sollten in einer neuen Tabelle reviews_categories gespeichert werden.
. Bitte warten. Es kann ca. 30 Sekunden dauern, bis das Modell die Einträge der Kundenrezensionen verarbeitet hat und die Ergebnisse in der Ausgabetabelle verfügbar sind.
Ergebnisse anzeigen:
SELECT * FROM [dataset_name].[results_table_name];
Nehmen Sie sich etwas Zeit, um einige der Kategorien zu lesen.
Kundenrezensionen in Bezug auf positives und negatives Sentiment analysieren
Schreibe auf Grundlage der SQL-Abfrage für die Keyword-Extraktion eine Abfrage, mit der Rezensionen in die Kategorien „Positiv“, „Negativ“ und „Neutral“ unter der Spalte „sentiment“ analysiert werden.
Diese Abfrage übernimmt Kundenrezensionen aus der Tabelle disneyland_reviews und erstellt Prompts für das Modell gemini, um das Sentiment der Rezensionen zu klassifizieren. Die Ergebnisse werden in der neuen Tabelle reviews_analysis gespeichert und können später zur weiteren Analyse verwendet werden. Bitte warten. Es kann einige Sekunden dauern, bis das Modell die Einträge der Kundenrezensionen verarbeitet hat. Wenn die Verarbeitung abgeschlossen ist, sind die Ergebnisse in der Tabelle reviews_analysis verfügbar.
Ergebnisse ansehen:
SELECT * FROM [...];
Die Tabelle reviews_analysis enthält die Spalte Sentiment mit der Sentimentanalyse, einschließlich der Spalten social_media_source, review_text, customer_id, location_id und review_datetime. Werfen Sie einen Blick auf die Datensätze. Es kann sein, dass einige Ergebnisse für positiv und negativ nicht korrekt formatiert sind, da sie überflüssige Zeichen wie Punkte oder zusätzliche Leerzeichen enthalten. Anhand folgender Ansicht können Sie die Einträge bereinigen.
Ansicht zur Bereinigung der Datensätze erstellen
Erstellen Sie eine Ansicht, in der die Werte der Spalte „Sentiment“ bereinigt werden. Gehen Sie dazu so vor:
- Mit LOWER wird dafür gesorgt, dass alle Werte in Kleinbuchstaben angegeben werden.
- Entfernen von Satzzeichen (., und Leerzeichen) mit REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
Als Ergebnis der Abfrage wird die Ansicht cleaned_data_view mit den Sentimentergebnissen, dem Rezensionstext und Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch erstellt. Dann werden in den positiven und negativen Sentimentergebnissen alle Buchstaben in Kleinbuchstaben umgewandelt und überflüssige Zeichen, wie überflüssige Leerzeichen oder Punkte, entfernt. Mit der erstellten Ansicht lässt sich die Analyse in den späteren Schritten in diesem Lab einfacher durchführen.
- Mit folgender Abfrage lassen sich die erstellten Zeilen anzeigen:
SELECT * FROM [view_name];
Bericht mit der Anzahl positiver und negativer Rezensionen mit Data Canvas erstellen
Jetzt ist es an der Zeit, die Ergebnisse zu analysieren. Beginnen wir mit der direkten Ausführung in BigQuery über Data Canvas. Mit diesem Tool können Sie Daten semantisch oder nach Keyword durchsuchen, Tabellen abfragen und verknüpfen, Diagramme erstellen und Erkenntnisse gewinnen, indem Sie einen Canvas-Ablauf erstellen.
Ihr Ziel ist es, ein Diagramm Ihrer Wahl mit den Prozentsätzen der positiven und negativen Rezensionen zu erstellen . Beispiel:
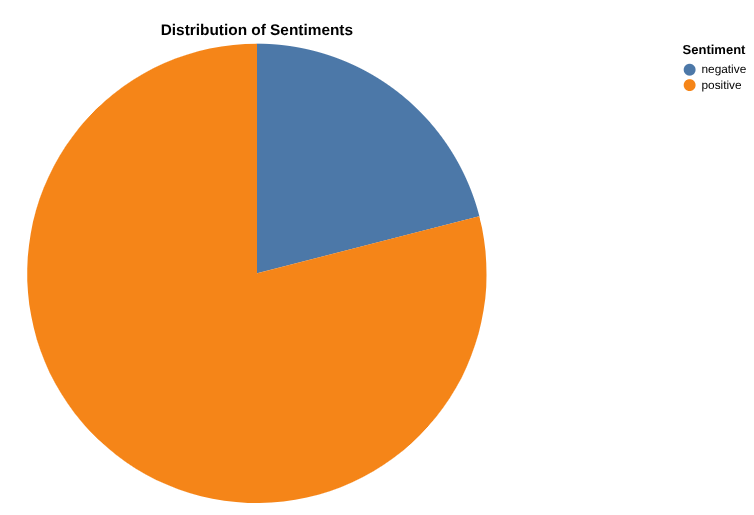
Diagramm mit der Anzahl der Rezensionen pro Kategorie sowie der Verteilung positiver und negativer Rezensionen für jede Kategorie erstellen
Tipp: Aktivieren und verwenden Sie die erweiterte Analyse von Data Canvas, bei der ein Python-Notebook in einem Canvas ausgeführt wird.
4. Aufgabe 2: Bilder von Freizeitparks analysieren, um Disneyland-Fotos zu identifizieren und interessante Fakten aus Parkbroschüren zu extrahieren
Bildanalyse in BigQuery
Sie haben Zugriff auf einige spannende und ansprechende Bilder des Freizeitparks, die Besucher im Laufe der Jahre aufgenommen haben. Sie freuen sich schon sehr auf Ihre bevorstehende Reise. Sie wissen jedoch nicht, welche davon tatsächliche Fotos von Disneyland sind. Ihre Aufgabe ist es, diese zu identifizieren. Die Bilder befinden sich in gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland::False

Is_disneyland::True
Um diese Analyse schnell durchzuführen. Sie sollten die Objekttabellen von BigQuery und Gemini über BigQuery ML (ML.GENERATE_TEXT) verwenden.
Können Sie die Ausgabe von Gemini überprüfen, indem Sie sich einige Fotos ansehen?
Eigenes RAG-System mit BigQuery für Disneyland-Broschüren erstellen
Während Sie in der Schlange stehen, möchten Sie einige interessante Fakten oder technische Details zur Attraktion erfahren, auf die Sie warten.
Unter gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, finden Sie PDF-Dateien mit Broschüren für alle Parks weltweit.
Ziel:Ein RAG-System (Retrieval-Augmented Generation) vollständig in BigQuery erstellen, damit Nutzer komplexe Fragen zum Park auf Grundlage einiger PDF-Dokumente stellen können.
Dazu müssen Sie Folgendes tun:
- Objekttabelle mit PDF-Dateien erstellen
- Python-UDF zum Aufteilen von PDF-Dateien in Chunks erstellen Hier ist ein Beispiel, das Sie verwenden können:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- PDF-Datei in Abschnitte parsen
- Einbettungen nach dem Erstellen eines Remote-Modells generieren
- Vektorsuche ausführen, um „
Ou manger un repas tex-mex à volonté?“ oder „where to eat a tex-mex meal buffet-style?“ zu finden - Eine Antwort generieren, die durch Vektorsuchergebnisse der Frage „
Ou manger un repas tex-mex à volonté?“ oder „where to eat a tex-mex meal buffet-style?“ ergänzt wird
5. Aufgabe 3: Maschinelles Lernen im großen Maßstab mit BigQuery: Prognosen, Klassifizierung und Ranking
Wartezeiten vorhersagen
Die Bilder sind sehr cool! Sie können es kaum erwarten! Um zu wissen, welche Attraktionen Sie auswählen und welche Sie vermeiden sollten, möchten Sie die tatsächlichen Wartezeiten für einige der Attraktionen zwischen Paris und Kalifornien kennen. Ihre Aufgabe ist es, die Wartezeiten jeder Attraktion für jede 30-Minuten-Periode im Jahr 2025 mithilfe von Machine Learning (Arima Plus oder TimesFM) zu prognostizieren.
Die Daten, die Sie verwenden, befinden sich in dieser CSV-Datei: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
Die Schritte Ihrer Aufgabe sind:
- Laden Sie die Datei in Ihr BigQuery-Dataset in eine Tabelle namens „waiting_times“ hoch.
- Prognosemodell mit Ihren Daten trainieren (Arima_Plus) oder direkt mit AI.Forecast prognostizieren
- Modellleistung bewerten oder prognostizierte Daten mit den Eingabedaten vergleichen
Fahrten nach Intensität klassifizieren
Sie besuchen Disneyland mit Freunden. Der Park ist zwar im Allgemeinen familienfreundlich, aber einige Fahrgeschäfte sind für manche Personen zu intensiv. Wir verwenden verwaltete KI-Funktionen von BigQuery, um die Attraktionen nach Nervenkitzel und Intensität zu klassifizieren und zu bewerten. So können wir allen gerecht werden.
- Verwende
AI.CLASSIFY, um Fahrten anhand ihrer Beschreibungen in eine von drei magischen Kategorien einzuteilen: [easy-peasy, thrilling, extreme]
Fahrgeschäfte nach Nervenkitzel einstufen
- Verwenden Sie
AI.SCORE, um Attraktionen anhand des Nervenkitzels zu vergleichen und zu sortieren. Rang 10 ist dabei der höchste und Rang 1 der niedrigste.
6. Aufgabe 3 (Bonus): Umgekehrtes ETL von BigQuery zu AlloyDB
Sie haben die leistungsstarken Funktionen von BigQuery genutzt, um Erkenntnisse aus großen Datenmengen zu gewinnen. Jetzt sollen diese Erkenntnisse von Ihren operativen Anwendungen (und KI-Agents) genutzt werden können.
Wie funktioniert das? Indem du den anderen Weg gehst. AlloyDB for PostgreSQL eignet sich hervorragend für die Bereitstellung von Daten mit niedriger Latenz und hoher Geschwindigkeit und ist damit ideal für Ihre kritischen nutzerorientierten Anwendungen. Lassen Sie uns also die gerade generierten Daten per Reverse-ETL übertragen.
Dazu verwenden wir eine brandneue Funktion, die sich noch in der privaten Vorschau befindet: „BigQuery-Ansichten“ in AlloyDB. Mit dieser Funktion können Sie BigQuery-Daten direkt in Ihrer Postgres-Datenbank abfragen.
Zuerst müssen Sie dem Dienstkonto Ihres AlloyDB-Clusters die erforderlichen Berechtigungen zum Abfragen von BigQuery gewähren.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
Die Ausgabe enthält das Feld „serviceAccountEmail“, das das Dienstkonto für diesen Cluster ist.
Öffnen Sie in der Google Cloud Console die IAM-Seite und gewähren Sie diesem Prinzipal die folgenden Berechtigungen:
- BigQuery-Datenbetrachter (roles/bigquery.dataViewer)
- BigQuery-Lesesitzungsnutzer (roles/bigquery.readSessionUser)
Rufen Sie nun AlloyDB Studio in der Console auf und stellen Sie eine Verbindung zur Datenbank „postgres“ her.
Führen Sie die folgenden Abfragen aus, um die neue Funktion zu installieren und zu konfigurieren:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Sie können jetzt eine „fremde Tabelle“ erstellen, die einer aktuellen Tabelle in BigQuery zugeordnet wird. Verwenden Sie eine beliebige Tabelle, die Sie in Aufgabe 3 erstellt haben. Hier ein Beispiel für die Syntax:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Jetzt können wir die Tabelle abfragen. Führen Sie zuerst eine SELECT-Anweisung aus, um die Verknüpfung zwischen AlloyDB und BigQuery zu validieren. Erstellen Sie dann eine neue Tabelle in AlloyDB, um die Daten aus der externen Tabelle aufzunehmen.
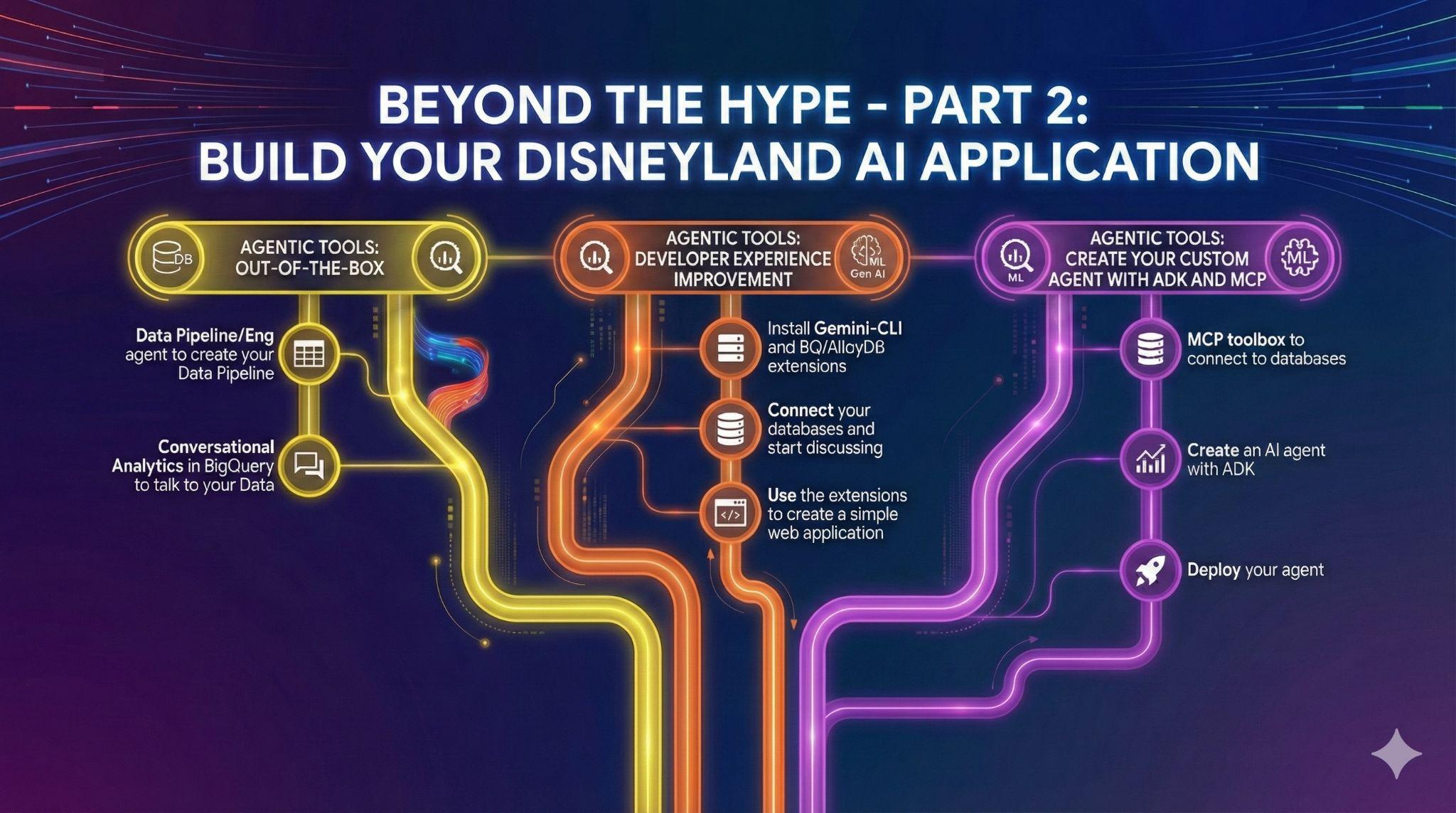
7. Aufgabe 4: Out-of-the-Box-Daten-Agents
Sie haben Freunde, die zum Disneyland-Anwendungsprojekt beitragen möchten. Sie haben Zugriff auf die Daten in BigQuery, aber unterschiedliche Kenntnisse in SQL und Data Engineering. Sie möchten die neuesten Ankündigungen von BigQuery zu Daten-Agents nutzen, die bereits in die Benutzeroberfläche integriert sind, um Ihren Freunden zu helfen:
- Datenpipelines erstellen
- Gemeinsam an SQL-Code arbeiten
- Mit Daten sprechen.
Data Engineering-Agents zum Automatisieren Ihrer Data Pipelines
Erstellen Sie mit dem Data Engineering Agent eine neue Ansicht „average_waiting_time“, in der die Tabelle „waiting_time“ und „attractions“ zusammengeführt und die durchschnittliche „waiting_time“ pro Attraktion berechnet wird.
KI-Agent für konversationelle Analysen in BigQuery erstellen
Stellen Sie sich vor, Sie könnten einen Agent erstellen, der mit Ihren Daten interagiert, ohne dass Sie programmieren, SQL verwenden oder den Agent bereitstellen müssen. Und das alles über die BigQuery-Oberfläche. Mit dem Tab „Agents“ in BigQuery ist das jetzt möglich.
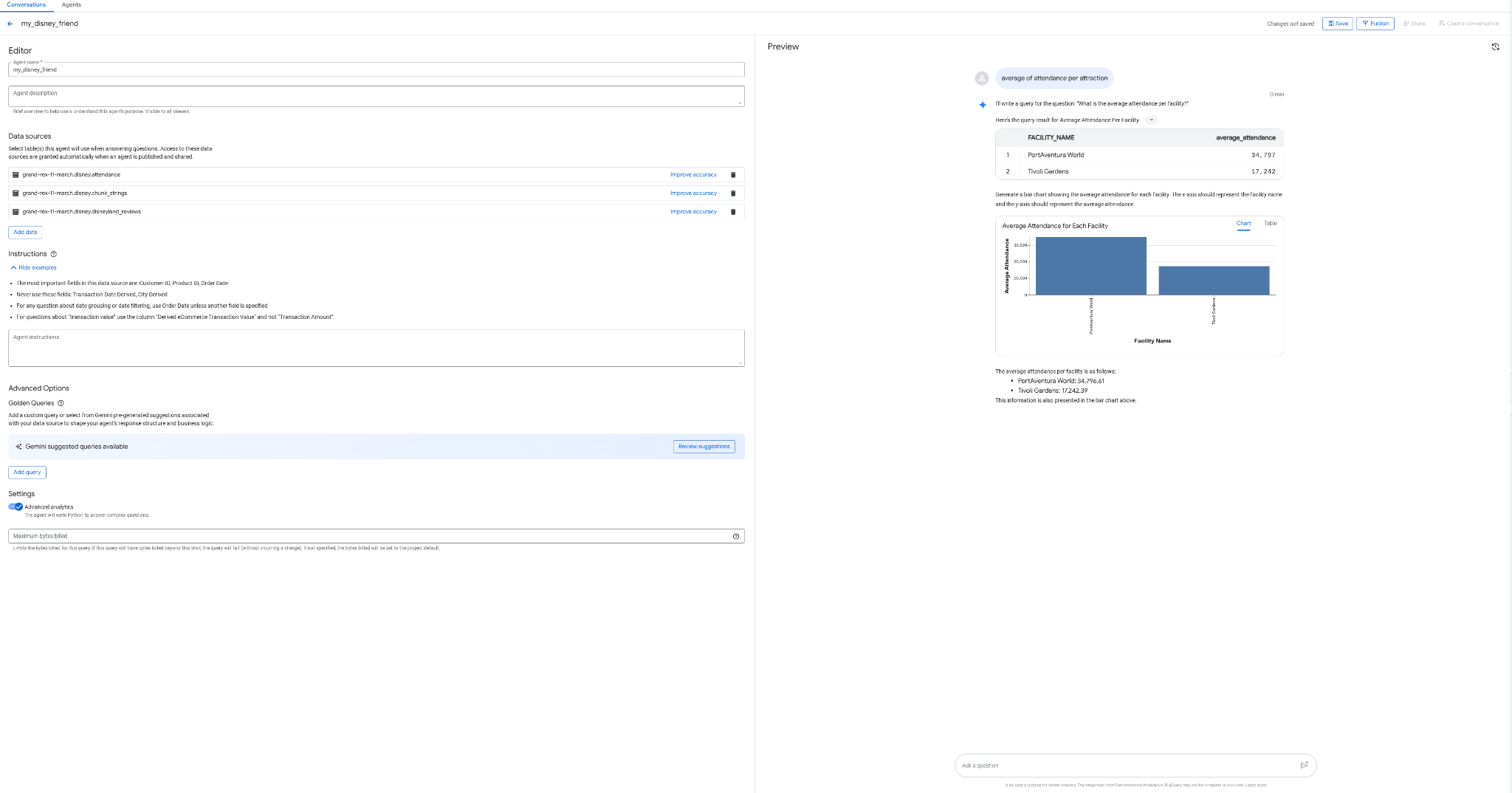
- Erstelle einen Agenten namens „my_disney_friend“, der eine Verbindung zu deinen Disney-Tabellen herstellt. Sie können die Leistung des Agents verbessern, indem Sie die Agent-Anweisungen ausfüllen. Stellen Sie Fragen wie „Wie viel Prozent der Rezensionen sind positiv bzw. negativ?“, „Wie lang ist die durchschnittliche Wartezeit pro Attraktion?“ usw.
- Veröffentlichen Sie den Agent in BigQuery und in der API (Sie werden ihn später verwenden).
8. Aufgabe 5: Entwicklung mit der Gemini CLI optimieren
In diesem KI-Zeitalter war es noch nie so einfach, Software zu entwickeln. Sie haben Tausende von Ideen für Ihre Disneyland-Anwendung und möchten Ihre Daten optimal nutzen. Sie möchten mehr als nur mit den Daten sprechen – jetzt sind Aktionen gefragt.
Dabei brauchst du Hilfe. Wir helfen Ihnen dabei.
Gemini CLI ist ein Open Source-KI-Agent, der die Leistungsfähigkeit von Gemini direkt in Ihr Terminal bringt. Entwickler können leistungsstarke Anwendungen erstellen und dank Erweiterungen auch mit verschiedenen MCP-Servern (Model Context Protocol) interagieren.
Dazu gehören natürlich auch Erweiterungen zum Abfragen Ihrer AlloyDB- oder BigQuery-Daten.
In dieser Aufgabe haben Sie folgende Ziele:
- Gemini CLI in Ihrem eigenen Terminal oder in Cloud Shell installieren
- Gemini CLI-Erweiterungen für BigQuery und AlloyDB installieren
- Umgebungsdatei erstellen, damit Gemini-CLI eine Verbindung zu Ihren BigQuery- und AlloyDB-Instanzen herstellen kann
- Gemini CLI bitten, eine ansprechende einzelne HTML-Seite zu generieren, auf der der Inhalt Ihrer AlloyDB-Datenbank erläutert wird
- Dasselbe für BigQuery tun
Hier sind einige Beispiele dafür, was Sie mit der Gemini CLI und ihren Erweiterungen in einem oder wenigen Prompts generieren können. Stellen Sie sich vor, Sie könnten das mit Anwendungen im echten Leben tun. 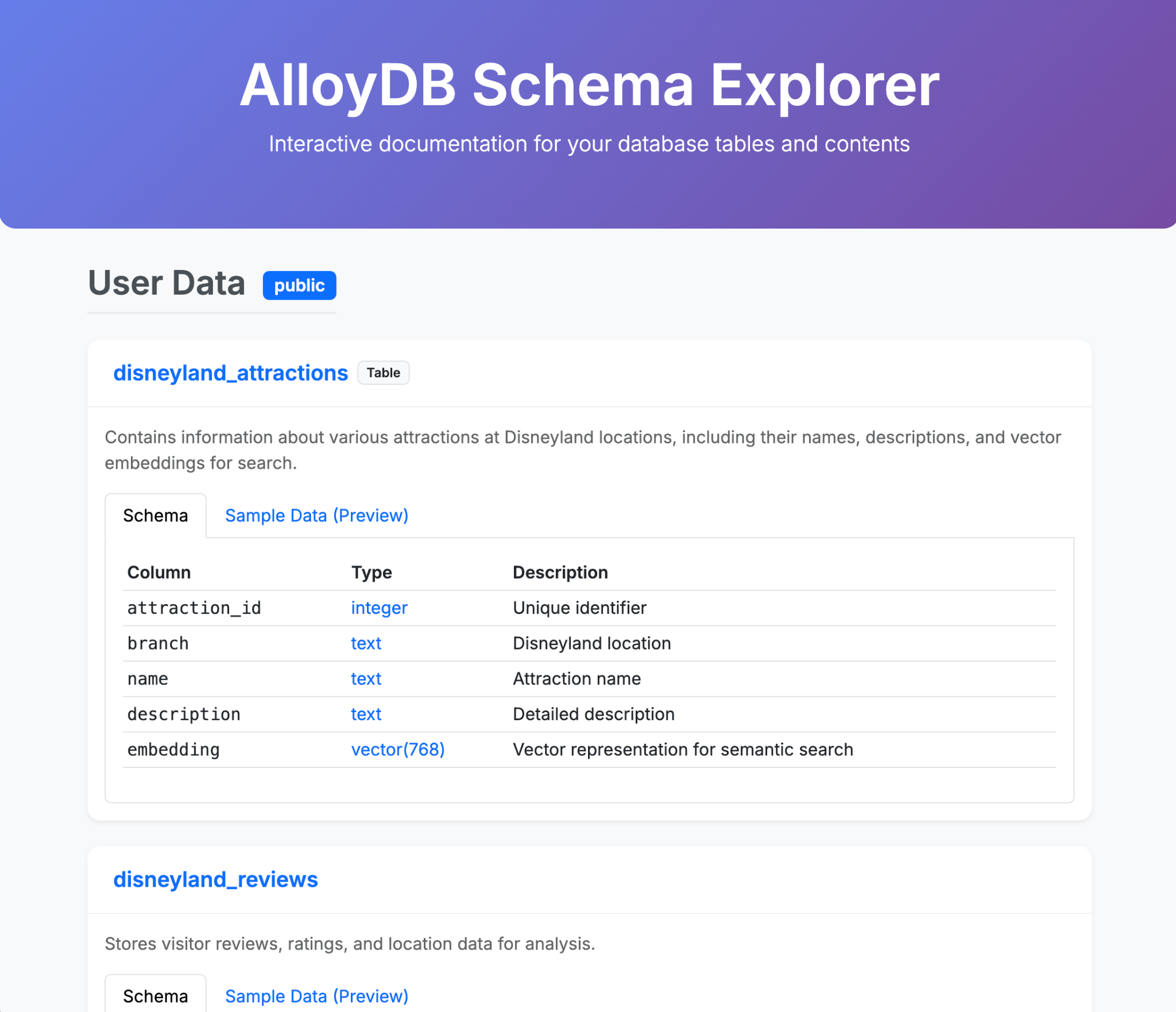
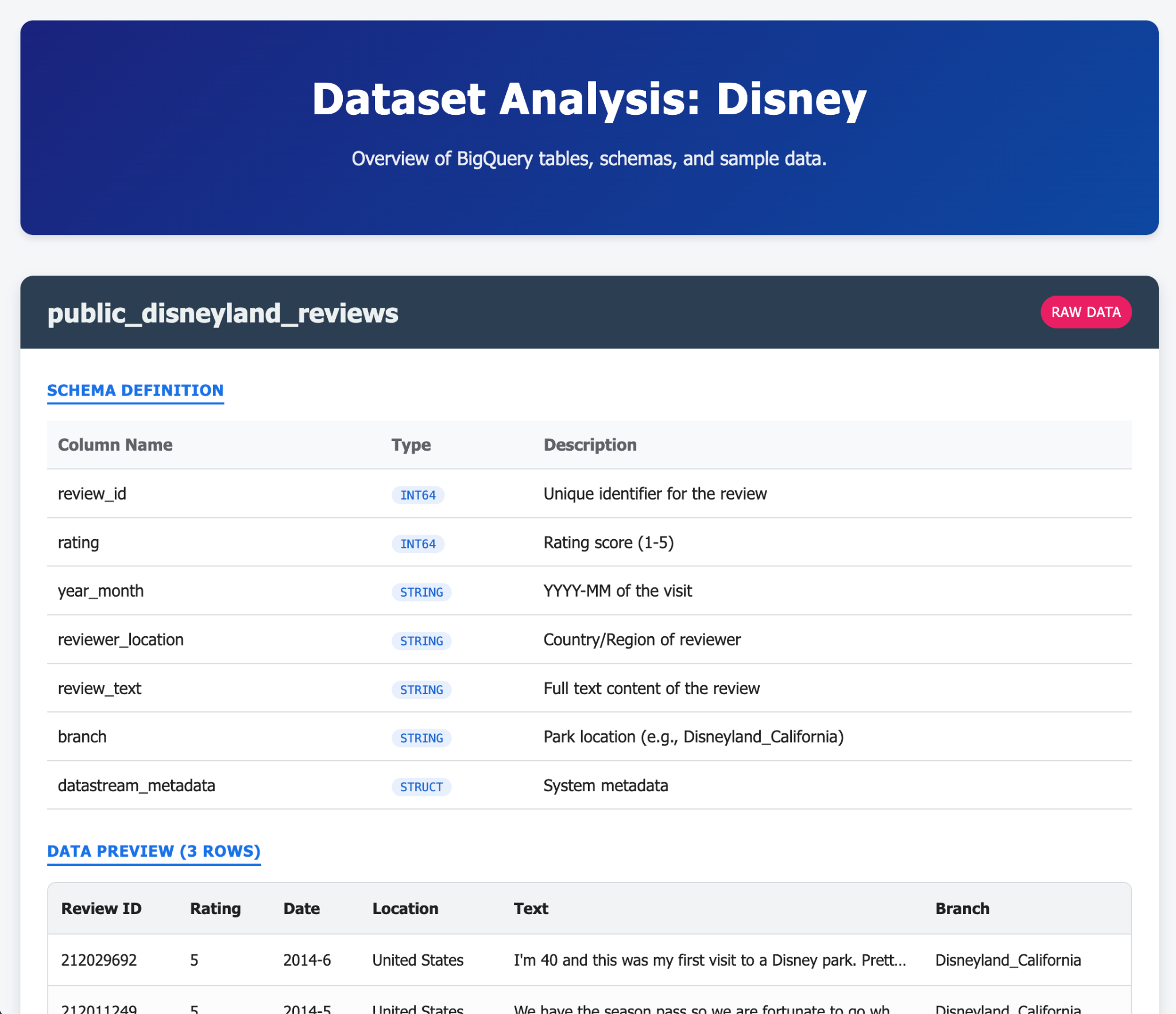
9. Aufgabe 6: KI-Agenten erstellen, um mit Ihren Daten zu interagieren
Um Besuchern von Disneyland ein völlig neues Nutzererlebnis zu bieten, erstellen Sie einen Assistenten, der ihnen während ihres Aufenthalts helfen kann. Ihr Agent kann:
- Alle verfügbaren Attraktionen im Park auflisten
- Eine Attraktion basierend auf Erwartungen empfehlen
- Rezensionen für eine Sehenswürdigkeit hinzufügen
- Eine Schätzung der Wartezeit für eine Attraktion in den nächsten Stunden
- Einen Überblick über die Rezensionen für eine bestimmte Sehenswürdigkeit geben
Du sorgst dafür, dass dein Assistent nur Fragen zu Disneyland beantworten kann und einen freundlichen Ton gegenüber dem Nutzer beibehält. Passen Sie den Prompt für Ihren Agenten an, damit er die richtigen Tools für die Anforderungen des Nutzers auswählt.
So gehen Sie vor:
- MCP Toolbox for Databases-Server bereitstellen, der AlloyDB und BigQuery als Quellen verwendet
- Fünf verschiedene Tools für Ihren MCP-Server deklarieren, die AlloyDB und BigQuery abfragen und die oben aufgeführten Agent-Aktionen zuordnen
- Jedes Ihrer Tools über die Benutzeroberfläche der MCP Toolbox validieren
- Einen Agenten mit dem Agent Development Kit bereitstellen, der die von Ihrem MCP-Toolbox-Server bereitgestellten Tools verwenden kann
- Stellen Sie eine Verbindung zur ADK-Weboberfläche her und zeigen Sie eine vollständige Unterhaltung mit Ihrem Assistenten, einschließlich aller verfügbaren Tools.
Bonus-Schritt, wenn Sie früher fertig sind:
Ist Ihr KI-Agent bereit? Stellen wir ihn in Agent Engine bereit.