
۱. 🏰 هکاتون تحلیل دادههای دیزنیلند (دوره دوم - ۳ دسامبر) 🏰
خلاصه | در این هکاتون، شما یک خط لوله تحلیل داده سرتاسری با استفاده از قابلیتهای هوش مصنوعی/یادگیری ماشین در گوگل کلود خواهید ساخت. دادهها را در AlloyDB ، یک پایگاه داده کاملاً مدیریتشده و سازگار با PostgreSQL که برای حجم کاری بالا بهینه شده است، بارگذاری خواهید کرد، سپس از Datastream ، یک سرویس ثبت دادههای تغییر (CDC) بدون سرور، برای انتقال آن به BigQuery ، انبار داده بدون سرور گوگل کلود، استفاده خواهید کرد. در BigQuery، از BigQuery ML استفاده خواهید کرد که به شما امکان میدهد مدلهای یادگیری ماشین را مستقیماً در BigQuery با استفاده از SQL استاندارد، برای تحلیل بررسی و پیشبینی حضور و غیاب ایجاد و اجرا کنید. در نهایت، با عاملها کار خواهید کرد، یا از طریق Conversational Analytics & Data Agents به صورت آماده، یا یک عامل سفارشی، با استفاده از Agent Development Kit و جعبه ابزار MCP برای تعامل زبان طبیعی با دادههای خود ایجاد خواهید کرد. |
دستهها | نوع سند: Codelab، محصول: Bigquery |
نویسنده | ریحانه رزگی، مت کورنیلون |
طرح بندی | پیمایش |
رباتها | نوایندکس |
۲. مقدمه
خوش آمدید، جادوگران داده آینده دیزنی!🪄
راهنماهای سفر خستهکننده و پیمایش بیپایان انجمنها را فراموش کنید. تصور کنید که در حال برنامهریزی یک سفر بینظیر به دیزنیلند هستید، مجهز به بینشهای مبتنی بر داده. کدام پارک بهترین تجربه را ارائه میدهد؟ چه زمانی جمعیت کمتر است؟ آیا میتوانید بهترین زمان برای فتح آن صف طولانی و بدنام را پیشبینی کنید؟
در این هکاتون، شما در حال ساخت ابزار نهایی برنامهریزی دیزنیلند خود هستید. ما دادهها را داریم: نظرات بازدیدکنندگان در شعب جهانی، زمانهای انتظار تاریخی و آمار حضور. ماموریت شما؟ تبدیل این دادههای خام به بینشهای عملی:
- جمعآوری دادهها: نظرات مختلف در مورد دیزنیلند، زمان انتظار و آمار حضور و غیاب را در AlloyDB، پایگاه دادهی با کارایی بالای سازگار با PostgreSQL ما، بارگذاری کنید.
- جابجایی یکپارچه: با استفاده از Datastream، سرویس ثبت دادههای تغییر بدون سرور ما، این اطلاعات پویا را به راحتی به BigQuery، انبار داده قدرتمند بدون سرور Google Cloud، منتقل کنید.
- جادو را پیشبینی کنید: از BigQuery ML برای تجزیه و تحلیل نظرات و پیشبینی زمان انتظار مستقیماً با SQL استفاده کنید. کشف کنید کدام شعب به طور مداوم رضایت مشتریان را جلب میکنند و زمان بهینه برای مراجعه شما چیست.
- با دادههایتان صحبت کنید - به معنای واقعی کلمه!: از ابزارهای از پیش ساخته شده استفاده کنید که به شما امکان میدهند با کشیدن یک چوب، بینشهایی کسب کنید.
- تعامل هوشمند: ساخته خود را با یک عامل هوشمند، که توسط جعبه ابزار MCP برای پایگاههای داده و ADK (کیت توسعه عامل) پشتیبانی میشود، تاجگذاری کنید. بپرسید: "بهترین جاذبه دیزنیلند پاریس برای دوستداران فضا چیست و بهترین زمان برای پیوستن به صف چه زمانی است؟" و پاسخهای فوری و مبتنی بر داده دریافت کنید.
آماده شوید تا اسرار جادوییترین مکانهای روی زمین را کشف کنید و یک خط لوله تجزیه و تحلیل دادهها بسازید که باعث افتخار میکی شود!
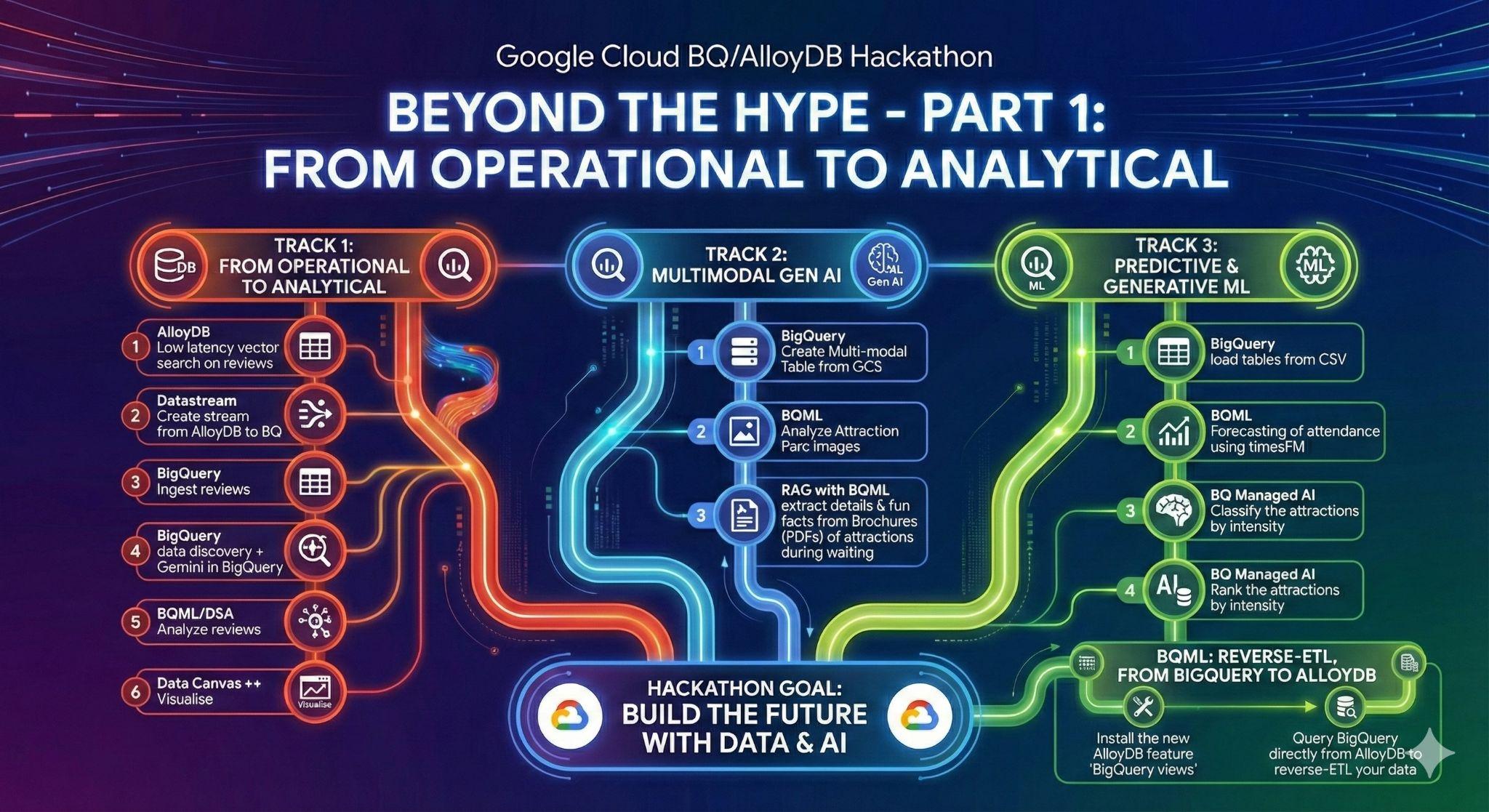
۳. وظیفه ۱: از عملیاتی به تحلیلی؛ نقدهای دیزنیلند را با Gemini تحلیل کنید
برای این مرحله اولیه، دادهها را از پایگاه داده عملیاتی AlloyDB خود بازیابی کرده و برای تجزیه و تحلیل دادههای بعدی، آنها را در BigQuery بارگذاری خواهید کرد.
همچنین هر آنچه را که برای نماینده آینده خود در AlloyDB نیاز دارید، تنظیم خواهید کرد!
بارگذاری دادهها در AlloyDB
اول از همه، بیایید مقداری داده به کلاستر AlloyDB for PostgreSQL خود وارد کنیم!
ما قرار است ۲۰ هزار نقد و بررسی برای پارکهای تفریحی دیزنیلند و فهرستی از جاذبههای آن دریافت کنیم.
مراحلی که باید انجام دهید به شرح زیر است:
ایجاد جداول:
- یک جدول به نام disneyland_reviews با ۶ ستون ایجاد کنید: review_id و rating به عنوان عدد صحیح، year_month، reviewer_location، review_text و branch به عنوان متن.
- یک جدول به نام disneyland_attractions با ۴ ستون ایجاد کنید: attraction_id به عنوان عدد صحیح، شاخه، نام و توضیحات به عنوان متن.
با استفاده از ابزار مورد نظر خود، دادهها را از CSVها وارد کنید:
- برای جدول نظرات
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv -
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvبرای جدول جاذبهها
برای ارائه توصیههای جاذبهها، باید جاسازیهایی از توضیحات جاذبهها ایجاد کنیم:
- افزونه pgvector را در AlloyDB نصب کنید
- یک ستون برداری به نام "جاسازی" به جاذبه میز خود اضافه کنید
- با استفاده از ادغام بومی بین AlloyDB و Vertex AI، جاسازی توضیحات را تولید و پر کنید.
از عملیات تا تحلیل با Datastream
برای انتقال دادهها از AlloyDB به BigQuery، از Google Datastream استفاده خواهیم کرد. این یک راهکار قدرتمند بدون نیاز به سرویس است که به تمام تغییرات در جداول منبع (با استفاده از Change Data Capture) گوش میدهد و آنها را به BigQuery ارسال میکند.
برای اینکه بتوانیم تغییرات AlloyDB را با Datastream تکرار کنیم، باید چیزی به نام «اسلات انتشار و تکرار» (publication and replication slot) در Postgres ایجاد کنیم.
کوئریهای زیر را روی کلاستر AlloyDB خود اجرا کنید (باید آنها را یکی یکی اجرا کنید):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
شما از اسلات انتشار و تکثیر در جریان خود استفاده خواهید کرد، بنابراین نامها را به خاطر بسپارید!
و این همه، حالا میتوانیم یک جریان ایجاد کنیم!
مراحلی که باید در Datastream انجام دهید به شرح زیر است:
- یک پروفایل منبع برای کلاستر AlloyDB خود ایجاد کنید (از آدرس IP عمومی استفاده کنید)
- یک پروفایل مقصد برای BigQuery ایجاد کنید
- یک جریان از AlloyDB به BigQuery ایجاد کنید.
دادهها باید ظرف چند دقیقه در BigQuery در دسترس باشند.
کشف دادهها در BigQuery
حالا که دادههایمان را در BigQuery داریم، بیایید قبل از شروع کار، مطمئن شویم که با پیشرفتهای جدید رابط کاربری آشنا هستیم!
ما ۳ تابع جدید داریم که میتوانید آنها را در پنل کاوش BigQuery مشاهده کنید.
- مرور کلی: شامل اطلاعاتی در مورد ویژگیهای BigQuery، تورهایی برای شروع تجزیه و تحلیل و سایر امکانات است.
- جستجو: جستجوی معنایی را روی داراییهای داده خود انجام دهید.
- مامورها: هیس! اینو برای بعد میذاریم 🤫
جستجوی معنایی دادهها در BigQuery
به برگه جستجو در پنل کاوش BigQuery بروید و با اصطلاحات مرتبط با دیزنی مانند «جاذبهها» یا «شاخه» بازی کنید.
دادههای خود را در BigQuery مصورسازی کنید
اکنون میتوانید دادههای خود را در BigQuery تجسم و دستکاری کنید. برای این کار، میتوانید این پرسوجو را در یک برگه پرسوجوی جدید اجرا کنید.
SELECT
*
FROM
[dataset_name].[table_name];
ایجاد بینشهای دادهای در جدول نظرات
در این کار، شما بینشهای دادهای را در جدول disneyland_reviews در مجموعه داده disney فعال خواهید کرد.
بینشهای داده ابزاری برای هر کسی است که میخواهد دادههای خود را بررسی کند و بدون نوشتن کوئریهای پیچیده SQL، بینشهایی کسب کند.
این ممکن است چند دقیقه طول بکشد.
پرس و جو از جدول disneyland_reviews بدون SQL
بینشهایی که در بخش قبل ایجاد کردید اکنون آماده هستند. در این کار، شما از یک اعلان تولید شده از این بینشها برای پرس و جو از جدول disneyland_reviews بدون استفاده از کد استفاده خواهید کرد.
یک بینش انتخاب کنید و پرسوجوی مرتبط با آن را اجرا کنید. برای مثال، پرسوجویی را پیدا کنید که تفاوت میانگین رتبهبندی بین ماههای متوالی برای هر شعبه را محاسبه میکند. این پرسوجو به این شکل خواهد بود:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
استفاده از موتور دانش BigQuery برای درک بهتر دادهها
اول از همه؛ بیایید با نگاهی به تب Insights در سطح مجموعه داده شروع کنیم؛ این به ما ایدهای در مورد روابط پنهان بین جداول در مجموعه داده دیزنی میدهد. سپس،
- با استفاده از Gemini توصیفی از مجموعه دادهها ایجاد کنید و آن را به جزئیات مجموعه دادهها اضافه کنید.
- توضیحی از نظرات و جاذبههای جداول و همچنین تمام ستونهای جداگانه در آن جداول ایجاد کنید و آن را ذخیره کنید.
اسکن پروفایل دادههای خود را انجام دهید
هدف این بخش، پاکسازی و آمادهسازی دادههای شماست. با این حال، شما با توزیع مقادیر هر ستون خیلی آشنا نیستید. برای اینکه بدانید چه نوع مراحل تبدیلی را باید روی دادههای خود انجام دهید، باید دادههای خود را پروفایل کنید.
کاتالوگ جهانی Dataplex گوگل کلود ، اسکنهای پروفایلینگ را خودکار میکند تا معیارهای کیفیت دادهی ثابتی را ارائه دهد. آمارهای کلیدی شناساییشده شامل تعداد تهی، مقادیر متمایز، محدودههای داده و توزیع مقادیر است. فعالسازی اسکن پروفایل از طریق رابط BigQuery امکانپذیر است.
ممکن است چند دقیقه طول بکشد، بنابراین میتوانید در حین انتظار، بخش بعدی را نیز مشاهده کنید.
به سوالات زیر پاسخ دهید:
- میانگین امتیاز دیزنیلند چقدر است؟
- منتقدان بیشتر کجا مستقر هستند؟
- آیا همه نقدها منحصر به فرد هستند؟
- درصد دادههای از دست رفته در ستون Year_Month چقدر است؟
اسکن با کیفیتی از دادههای خود انجام دهید
کیفیت خودکار دادههای Dataplex Universal Catalog به شما امکان میدهد کیفیت دادههای موجود در جداول BigQuery خود را تعریف و اندازهگیری کنید. میتوانید اسکن دادهها را خودکار کنید، دادهها را با قوانین تعریفشده اعتبارسنجی کنید و در صورت عدم رعایت الزامات کیفیت توسط دادههایتان، هشدارها را ثبت کنید. میتوانید قوانین کیفیت دادهها و استقرارها را به صورت کد مدیریت کنید و یکپارچگی خطوط تولید دادهها را بهبود بخشید.
بر اساس اسکن پروفایل، یک اسکن با کیفیت (حداکثر بر روی 10٪ از دادههای خود به عنوان حجم نمونه) تعریف کنید که:
- مقادیر تهی را برای ستون " شاخه " بررسی میکند
- بررسی اعتبار « امتیاز » را انجام میدهد، زیرا فقط میتواند در مجموعهی ۱،۲،۳،۴،۵ باشد.
- منحصر به فرد بودن " review_id " را بررسی میکند
مطمئن شوید که اسکن نتایج را به جدول BigQuery با نام quality_scan_results ارسال میکند.
به تمام تبدیلهای بالقوهای که باید روی دادههایتان اعمال کنید فکر کنید.
دادههای خود را با استفاده از آمادهسازی دادههای Gemini آماده کنید
پس از اسکنهای کیفیت و پروفایلبندی دادهها که انجام دادید، زمان آن رسیده است که دادهها را قبل از تجزیه و تحلیل، پاکسازی کنید.
آمادهسازی دادهها ، منابع BigQuery هستند که از Gemini در BigQuery برای تجزیه و تحلیل دادههای شما و ارائه پیشنهادهای هوشمند برای تمیز کردن، تبدیل و غنیسازی آن استفاده میکنند. شما میتوانید زمان و تلاش مورد نیاز برای کارهای دستی آمادهسازی دادهها را به میزان قابل توجهی کاهش دهید.
در این بخش، از آمادهسازی دادهها برای انجام این عملیات روی جدول disneyland_reviews خود استفاده خواهید کرد:
- ردیفهایی را که ستون Branch آنها NULL یا یک رشته خالی است، فیلتر کنید.
- عبارت "missing" در Year_Month را با Null جایگزین کنید.
- برای بهبود خوانایی، زیرخطها را با فاصله در ستون شاخه جایگزین میکند
- خروجی گرفتن به جدول تبدیلشده disneyland_reviews_cleaned
تحلیل نظرات با Gemini
حالا که دادههایتان را پاکسازی کردهاید، میتوانید با استفاده از مدلهای BigQuery ML و Gemini شروع به تجزیه و تحلیل آنها کنید. شما دو هدف دارید:
- استخراج دستهها از نظرات
- تحلیل احساسات disneyland_reviews
BigQuery ML به شما امکان میدهد مدلهای یادگیری ماشین (ML) را با استفاده از کوئریهای GoogleSQL ایجاد و اجرا کنید . مدلهای BigQuery ML در مجموعه دادههای BigQuery، مشابه جداول و نماها، ذخیره میشوند. BigQuery ML همچنین به شما امکان میدهد به مدلهای هوش مصنوعی Vertex و APIهای هوش مصنوعی ابری دسترسی داشته باشید تا وظایف هوش مصنوعی (AI) مانند تولید متن یا ترجمه ماشینی را انجام دهید. Gemini برای Google Cloud نیز کمک مبتنی بر هوش مصنوعی را برای وظایف BigQuery ارائه میدهد.
شما میتوانید از ML.GENERATE_TEXT یا AI.GENERATE (پیشنمایش) با مدلهای Gemini pro یا Flash استفاده کنید.
اگر میخواهید از ML.GENERATE_TEXT استفاده کنید، مراحل زیر شما را راهنمایی میکنند.
اتصال منابع ابری را ایجاد کنید و نقش IAM را اعطا کنید
شما باید یک اتصال منابع ابری در BigQuery به مدلهای Vertex AI ایجاد کنید تا بتوانید با مدلهای Gemini Pro و Gemini Flash کار کنید. همچنین از طریق یک نقش، مجوزهای IAM حساب سرویس اتصال منابع ابری را به آن اعطا خواهید کرد تا به سرویسهای Vertex AI دسترسی داشته باشد.
اعطای نقش کاربری Vertex AI به حساب سرویس اتصال
با اعطای نقش کاربری Vertex AI به حساب کاربری سرویس اتصال، به آن اجازه دهید از مدل انتخابی شما (برای مثال gemini-2.5-flash ) استفاده کند. انتشار این مجوز ۱ دقیقه طول میکشد.
مدلهای Gemini را در BigQuery ایجاد کنید
مدل خود را با استفاده از اتصال بالا ایجاد کنید. برای مثال از endpoint gemini-2.5-flash.
Gemini را وادار کنید تا نظرات مشتریان را از نظر دستهبندیها و احساسات تجزیه و تحلیل کند.
در این تکلیف، شما از مدل Gemini برای تجزیه و تحلیل هر نظر مشتری از نظر دستهبندیها و احساسات، چه مثبت و چه منفی، استفاده خواهید کرد.
نظرات مشتریان را برای دسته بندی ها تجزیه و تحلیل کنید
توجه: از این به بعد، برای تجزیه و تحلیل، فقط ۱۰۰ ردیف را در نظر میگیریم ، زیرا فراخوانی Gemini روی ۲۰ هزار ردیف میتواند مدتی طول بکشد.
-
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
این کوئری نظرات مشتریان را از جدول disneyland_reviews میگیرد و برای مدل gemini پیامهایی میسازد تا دستهبندیهای درون هر نقد را شناسایی کند. نتایج باید در جدول جدیدی reviews_categories ذخیره شوند.
لطفاً صبر کنید. پردازش سوابق نظرات مشتریان و نمایش نتایج در جدول خروجی، تقریباً 30 ثانیه طول میکشد.
نمایش نتایج:
SELECT * FROM [dataset_name].[results_table_name];
کمی وقت بگذارید و برخی از دستهبندیها را بخوانید.
نظرات مشتریان را برای یافتن نظرات مثبت و منفی تجزیه و تحلیل کنید
بر اساس کوئری SQL برای استخراج کلمات کلیدی، کوئریای بنویسید که نظرات را در ستونی به نام «احساسات» به مثبت، منفی و خنثی تجزیه و تحلیل کند.
این پرسوجو، نظرات مشتریان را از جدول disneyland_reviews دریافت میکند، و برای مدل gemini ، دستورالعملهایی برای طبقهبندی احساسات هر نظر ایجاد میکند. سپس نتایج در جدول جدیدی reviews_analysis ذخیره میشوند تا بتوانید بعداً از آن برای تحلیل بیشتر استفاده کنید. لطفاً صبر کنید. پردازش سوابق نظرات مشتریان توسط مدل، چند ثانیه طول میکشد. پس از اتمام مدل، نتیجه در جدول reviews_analysis ایجاد شده قرار میگیرد.
نتایج را بررسی کنید:
SELECT * FROM [...];
جدول reviews_analysis دارای ستون Sentiment است که شامل تحلیل احساسات است و ستونهای social_media_source ، review_text ، customer_id ، location_id و review_datetime نیز در آن گنجانده شدهاند. به برخی از رکوردها نگاهی بیندازید. ممکن است متوجه شوید که برخی از نتایج مثبت و منفی به درستی قالببندی نشدهاند و دارای کاراکترهای اضافی مانند نقطه یا فضای اضافی هستند. میتوانید با استفاده از نمای زیر، رکوردها را پاکسازی کنید.
ایجاد یک نما برای پاکسازی رکوردها
یک view ایجاد کنید که مقادیر ستون sentiment را به صورت زیر پاکسازی کند:
- با استفاده از LOWER مطمئن شوید که همه مقادیر با حروف کوچک نوشته شدهاند.
- حذف علائم نگارشی (. و ، و فاصله) با استفاده از REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
این کوئری، view مربوط به cleaned_data_view را ایجاد میکند و شامل نتایج احساسات، متن نقد، Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch میشود. سپس نتیجه احساسات (مثبت یا منفی) را دریافت کرده و اطمینان حاصل میکند که همه حروف با حروف کوچک نوشته شدهاند و کاراکترهای اضافی مانند فاصله یا نقطه اضافی حذف شدهاند. view حاصل، انجام تجزیه و تحلیل بیشتر در مراحل بعدی این آزمایش را آسانتر میکند.
- شما میتوانید با استفاده از کوئری زیر، به view مورد نظر کوئری بزنید تا ردیفهای ایجاد شده را ببینید.
SELECT * FROM [view_name];
با استفاده از Data Canvas گزارشی از تعداد نظرات مثبت و منفی ایجاد کنید
حالا وقت آن رسیده که نتایج خود را تجزیه و تحلیل کنید. بیایید با انجام این کار به طور مستقیم در BigQuery، از طریق Data Canvas شروع کنیم. این ابزاری است که به شما امکان میدهد دادهها را (به صورت معنایی یا کلمه کلیدی) جستجو کنید، جداول را پرس و جو و به هم متصل کنید، نمودار ایجاد کنید و با ایجاد جریانی از بوم، بینش کسب کنید.
هدف نهایی شما ایجاد نموداری از درصد نظرات مثبت در مقابل نظرات منفی انتخابی شماست. در اینجا مثالی آورده شده است:
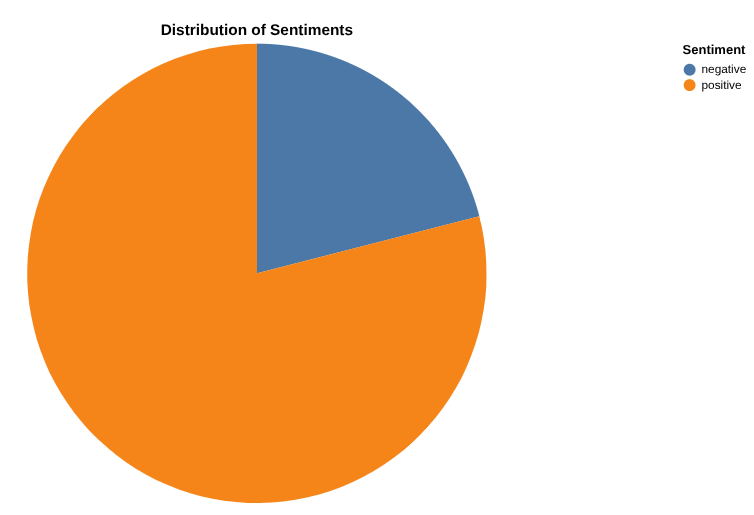
نموداری از تعداد نظرات در هر دسته و همچنین توزیع نظرات مثبت و منفی برای هر دسته ایجاد کنید.
نکته: تحلیل پیشرفتهی Data Canvas را فعال کنید و از آن استفاده کنید، که یک دفترچه یادداشت پایتون را درون یک بوم اجرا میکند.
۴. وظیفه ۲: تصاویر پارکهای تفریحی را تجزیه و تحلیل کنید تا عکسهای دیزنیلند را شناسایی کرده و حقایق جالب را از بروشورهای پارک استخراج کنید
تحلیل تصویر در BigQuery
شما به برخی از عکسهای هیجانانگیز و جذاب پارک جاذبه که بازدیدکنندگان در طول سالها گرفتهاند، دسترسی دارید. شما برای سفر پیش رو بسیار هیجانزده هستید! با این حال، نمیدانید کدام یک از آنها عکسهای واقعی دیزنیلند هستند. وظیفه شما شناسایی آنها است. تصاویر در gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/ قرار دارند.

Is_disneyland: غلط

Is_disneyland: درست است
برای انجام سریع این تحلیل، باید از جداول شیء BigQuery و Gemini از طریق BigQuery ML ( ML.GENERATE_TEXT ) استفاده کنید.
آیا میتوانید با بررسی چند عکس، خروجی Gemini را تأیید کنید؟
با استفاده از BigQuery روی بروشورهای دیزنیلند، سیستم RAG خودتان را بسازید
در حالی که در صف منتظر هستید، میخواهید درباره جاذبهای که منتظرش هستید، اطلاعات جالب/جزئیات فنی کسب کنید.
در gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, فایلهای PDF حاوی بروشورهای مربوط به همه پارکهای جهان را خواهید یافت.
هدف: ایجاد یک سیستم بازیابی-تقویتشده (RAG) کاملاً درون BigQuery تا کاربران بتوانند بر اساس برخی اسناد PDF، سوالات پیچیدهای در مورد پارک بپرسند.
برای رسیدن به این هدف، شما باید:
- ایجاد جدول اشیاء از فایلهای pdf
- یک UDF پایتون برای تکه تکه کردن فایلهای PDF ایجاد کنید. در اینجا مثالی آورده شده است که میتوانید استفاده کنید:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- فایل PDF را به قطعات کوچک تجزیه کنید
- ایجاد جاسازیها پس از ایجاد یک مدل از راه دور
- یک جستجوی برداری انجام دهید تا عبارتهای «
Ou manger un repas tex-mex à volonté?» یا «where to eat a tex-mex meal buffet-style?» را پیدا کنید. - پاسخی تولید کنید که با نتایج جستجوی برداری برای سوال «
Ou manger un repas tex-mex à volonté?» یا «where to eat a tex-mex meal buffet-style?» تکمیل شده باشد.
۵. وظیفه ۳: یادگیری ماشین در مقیاس بزرگ با BigQuery: پیشبینی، طبقهبندی و رتبهبندی
پیشبینی زمان انتظار
عکسها خیلی باحالن! بیصبرانه منتظرید! حالا برای اینکه بدونید کدوم جاذبهها رو انتخاب کنید و از کدومها دوری کنید، میخواید زمان انتظار واقعی برای بعضی از جاذبههای بین پاریس و کالیفرنیا رو بدونید. وظیفه شما اینه که با استفاده از یادگیری ماشینی (Arima plus یا TimesFM) زمان انتظار هر جاذبه رو برای هر 30 دقیقه در سال 2025 پیشبینی کنید.
دادههایی که استفاده خواهید کرد در این فایل csv قرار دارند: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
مراحل کار شما عبارتند از:
- فایل را در مجموعه دادههای BigQuery خود، زیر جدولی به نام waiting_times بارگذاری کنید.
- یک مدل پیشبینی را روی دادههای خود آموزش دهید (Arima_Plus) یا مستقیماً با استفاده از AI.Forecast پیشبینی کنید
- ارزیابی عملکرد مدل یا مقایسه دادههای پیشبینیشده با دادههای ورودی
سواریها را بر اساس شدت دستهبندی کنید
شما با دوستانتان به دیزنیلند میروید و اگرچه این پارک عموماً مناسب خانواده است، اما برخی از وسایل بازی میتواند برای برخی افراد بیش از حد هیجانانگیز باشد. بیایید از توابع هوش مصنوعی مدیریتشدهی BigQuery برای طبقهبندی و رتبهبندی جاذبهها بر اساس سطح هیجان و شدت، بدون سوگیری انسانی، استفاده کنیم تا بتوانیم همه را در نظر بگیریم.
- از
AI.CLASSIFYبرای دستهبندی سواریها بر اساس توضیحاتشان در یکی از سه دسته جادویی استفاده کنید: [آسان، هیجانانگیز، فوقالعاده]
رتبه بندی در سطح هیجان
- از
AI.SCOREبرای مقایسه و مرتبسازی جاذبهها بر اساس سطح هیجان استفاده کنید، به طوری که رتبه ۱۰ شدیدترین و رتبه ۱ کمترین میزان هیجان را نشان میدهد.
۶. وظیفه ۳ - جایزه: ETL معکوس، از BigQuery به AlloyDB
شما از قابلیتهای قدرتمند BigQuery برای ایجاد بینش در مورد حجم زیادی از دادهها استفاده کردهاید. اکنون میخواهید این بینشها توسط برنامههای عملیاتی شما (و عوامل هوش مصنوعی!) قابل اجرا باشند.
اما چگونه؟ با حرکت به سمت دیگر! AlloyDB برای Postgres در ارائه دادهها با تأخیر کم و سرعت بالا، که برای برنامههای کاربردی حیاتی شما که با کاربر مواجه هستند، ایدهآل است، پیشرفت میکند. بنابراین بیایید دادههایی را که تولید کردهایم، ETL معکوس کنیم.
برای انجام این کار، ما از یک ویژگی کاملاً جدید، که هنوز در پیشنمایش خصوصی است، به نام "BigQuery views" در AlloyDB استفاده خواهیم کرد. این ویژگی به شما امکان میدهد دادههای BigQuery را مستقیماً در پایگاه داده Postgres خود جستجو کنید.
ابتدا، باید به حساب سرویس کلاستر AlloyDB خود، امتیازات لازم برای پرسوجو از BigQuery را اعطا کنید.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
خروجی شامل یک فیلد serviceAccountEmail است که حساب سرویس این کلاستر است.
در کنسول گوگل کلود، به صفحه IAM بروید و امتیازات زیر را به این مدیر اصلی اعطا کنید:
- نمایشگر دادههای BigQuery (roles/bigquery.dataViewer)
- کاربر جلسه خواندن BigQuery (roles/bigquery.readSessionUser)
حالا، در کنسول به AlloyDB Studio بروید و به پایگاه داده "postgres" متصل شوید.
برای نصب و پیکربندی ویژگی جدید، کوئریهای زیر را اجرا کنید:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
اکنون میتوانید یک «جدول خارجی» ایجاد کنید که به جدول فعلی در BigQuery نگاشت شود. از هر جدولی که در مرحله ۳ ایجاد کردهاید، استفاده کنید. در اینجا مثالی از نحو آن آمده است:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
همه چیز آماده است، بیایید جدول را جستجو کنیم! اولین SELECT را برای اعتبارسنجی پیوند بین AlloyDB و BigQuery اجرا کنید و در نهایت یک جدول جدید در AlloyDB ایجاد کنید تا دادهها را از جدول خارجی خود دریافت کنید.
۷. وظیفه ۴: عاملهای داده آماده به کار
شما دوستانی دارید که میخواهند در پروژه برنامه دیزنیلند مشارکت کنند. آنها به دادههای BigQuery دسترسی دارند، اما در SQL و مهندسی داده در سطوح مختلفی هستند. شما میخواهید از اطلاعیههای اخیر BigQuery در مورد عوامل دادهای که از قبل در رابط کاربری ادغام شدهاند، برای کمک به دوستانتان استفاده کنید:
- ایجاد خطوط لوله داده.
- همکاری در کد SQL
- با دادههایشان صحبت کنید.
عوامل مهندسی داده برای خودکارسازی خطوط لوله داده شما
یک نمای جدید به نام average_waiting_time ایجاد کنید که جدول زمان انتظار و جاذبهها را به هم متصل کند و با استفاده از Data Engineering Agent، میانگین زمان انتظار به ازای هر جاذبه را محاسبه کند.
عامل تجزیه و تحلیل مکالمهای خود را در BigQuery ایجاد کنید
چه میشد اگر میتوانستید یک عامل ایجاد کنید که با دادههای شما ارتباط برقرار کند، بدون کدنویسی، بدون SQL و بدون استقرار، و از طریق رابط BigQuery، چقدر جالب میشد؟ خب، این کار امروزه با تب "Agents" در BigQuery امکانپذیر است.
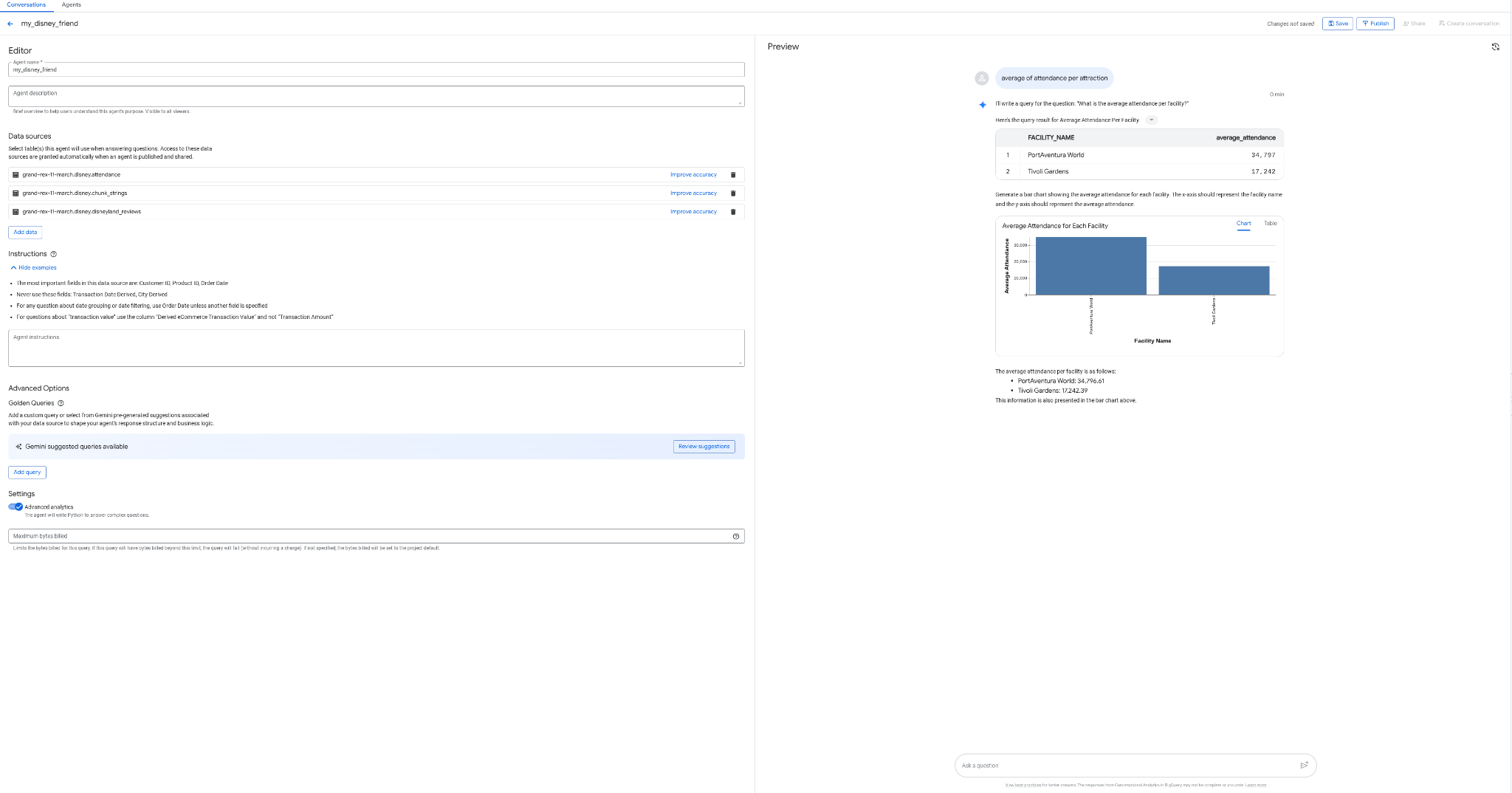
- یک نماینده به نام my_disney_friend ایجاد کنید که به میزهای دیزنی شما متصل شود. میتوانید با پر کردن دستورالعملهای نماینده، عملکرد نماینده را بهبود بخشید. سوالاتی مانند «درصد نظرات مثبت در مقابل منفی، میانگین زمان انتظار برای هر جاذبه چقدر است و غیره ...؟» بپرسید.
- عامل را در BigQuery و روی API منتشر کنید (بعداً از آن استفاده خواهید کرد).
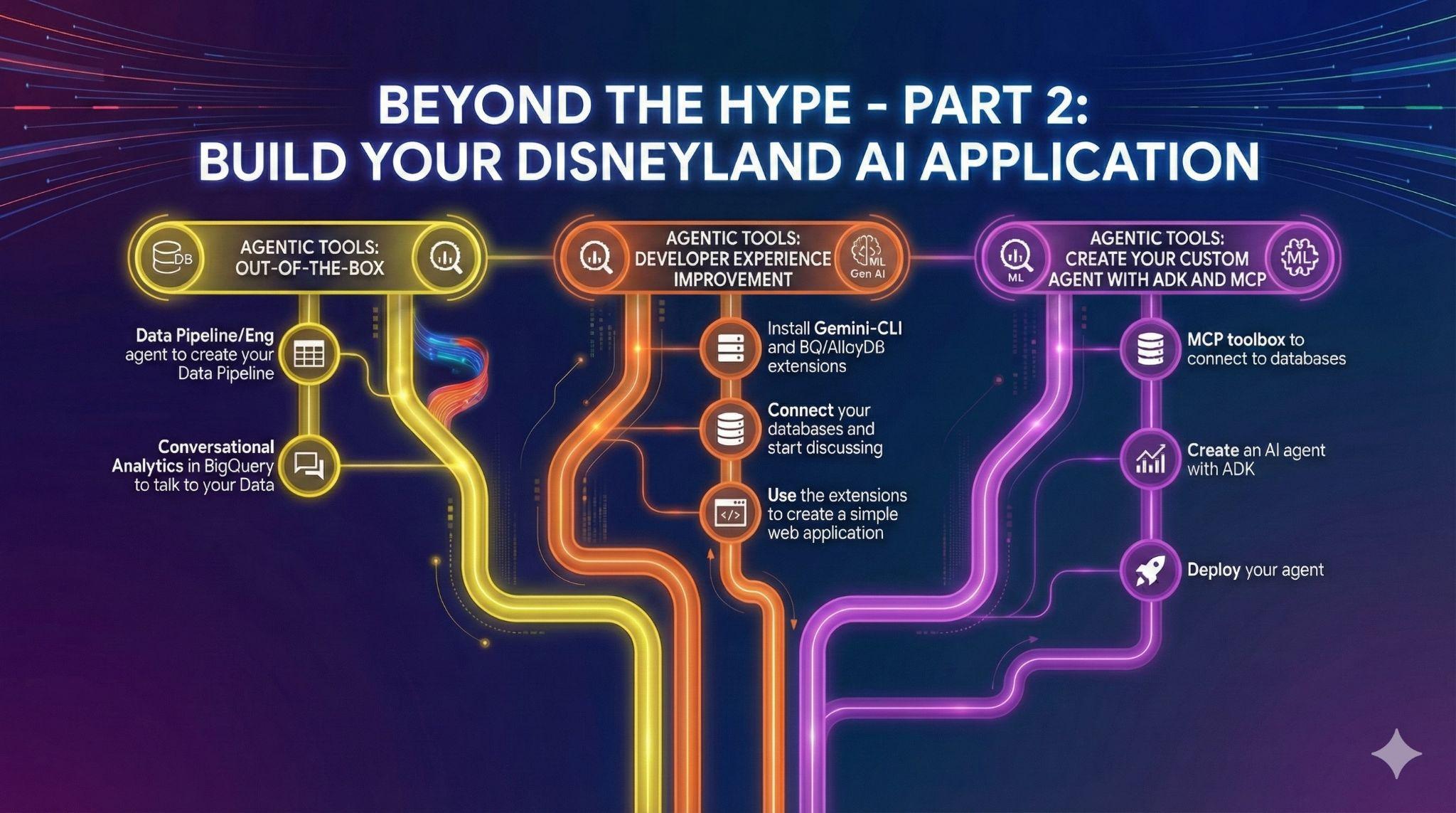
۸. وظیفه ۵: تجربه توسعه خود را با Gemini-CLI بهبود بخشید
در این عصر هوش مصنوعی، ساخت نرمافزار هرگز تا این حد در دسترس نبوده است. شما هزاران ایده برای برنامه دیزنیلند خود دارید و میخواهید از حداکثر ظرفیت دادههای خود استفاده کنید. شما میخواهید فراتر از صحبت کردن با دادهها بروید، اکنون به اقدام نیاز دارید!
برای کمک به شما در این مسیر، به کمک نیاز خواهید داشت. و ما شما را تحت پوشش قرار دادهایم.
رابط خط فرمان Gemini یک عامل هوش مصنوعی متنباز است که قدرت Gemini را مستقیماً به ترمینال شما میآورد. توسعهدهندگان میتوانند برنامههای قدرتمندی بسازند و به لطف افزونهها، میتوانند با سرورهای مختلف MCP (پروتکل زمینه مدل) نیز تعامل داشته باشند.
در میان آنها، مطمئناً میتوانید افزونههایی برای جستجوی دادههای AlloyDB یا BigQuery خود پیدا کنید!
در این تکلیف، هدف شما این است که:
- نصب Gemini-CLI (در ترمینال خودتان یا در Cloud Shell)
- افزونههای BigQuery و AlloyDB Gemini-CLI را نصب کنید
- یک فایل محیطی ایجاد کنید که به Gemini-CLI اجازه دهد به نمونههای BigQuery و AlloyDB شما متصل شود.
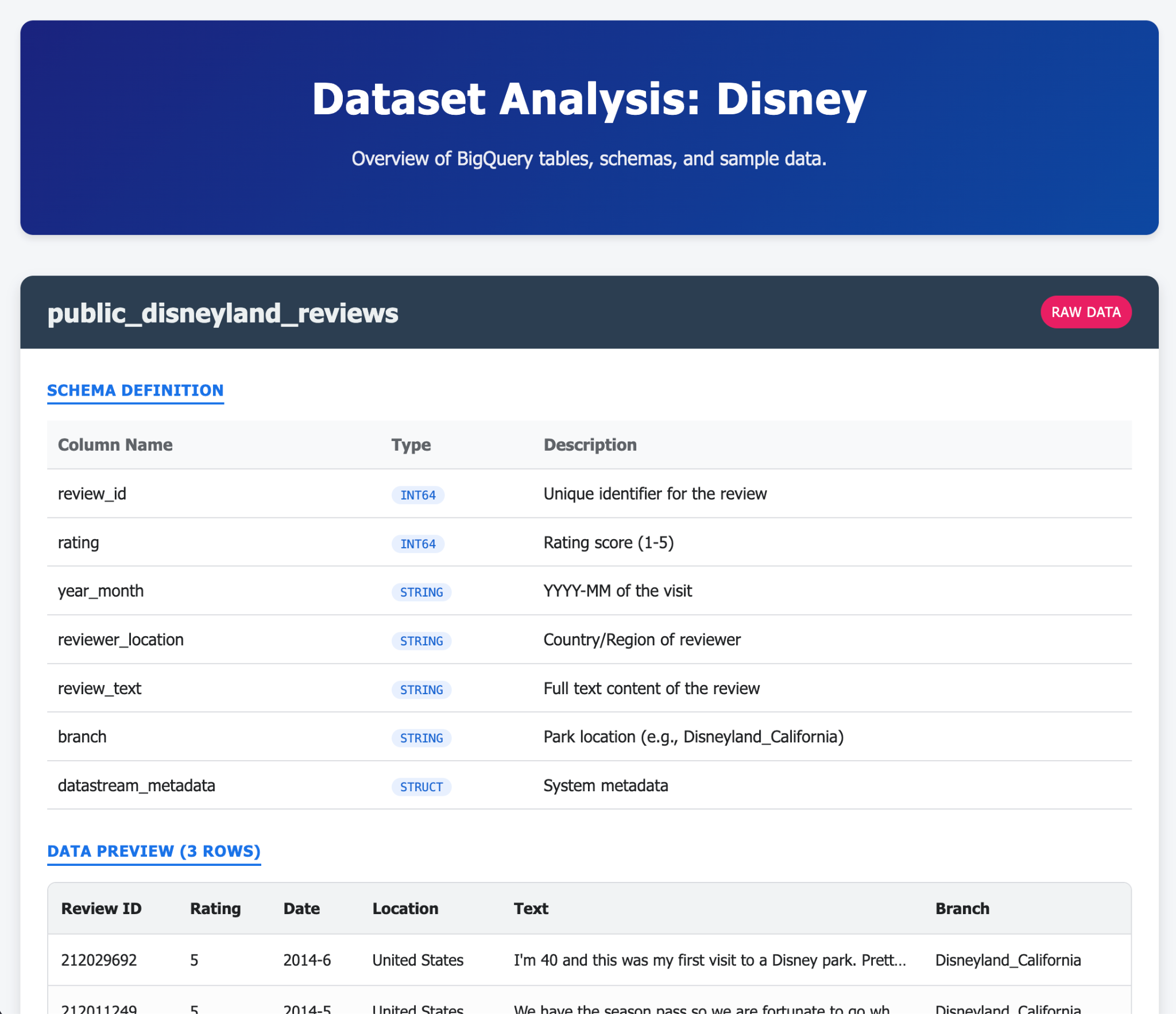
- از Gemini-CLI بخواهید یک صفحه HTML زیبا ایجاد کند که محتوای پایگاه داده AlloyDB شما را توضیح دهد.
- همین کار را برای BigQuery انجام دهید
در اینجا چند نمونه از آنچه میتوانید در یک (یا چند) فرمان با Gemini-CLI و افزونههای آن تولید کنید، آورده شده است. حال تصور کنید که میتوانید این کار را با برنامههای کاربردی واقعی انجام دهید؟ 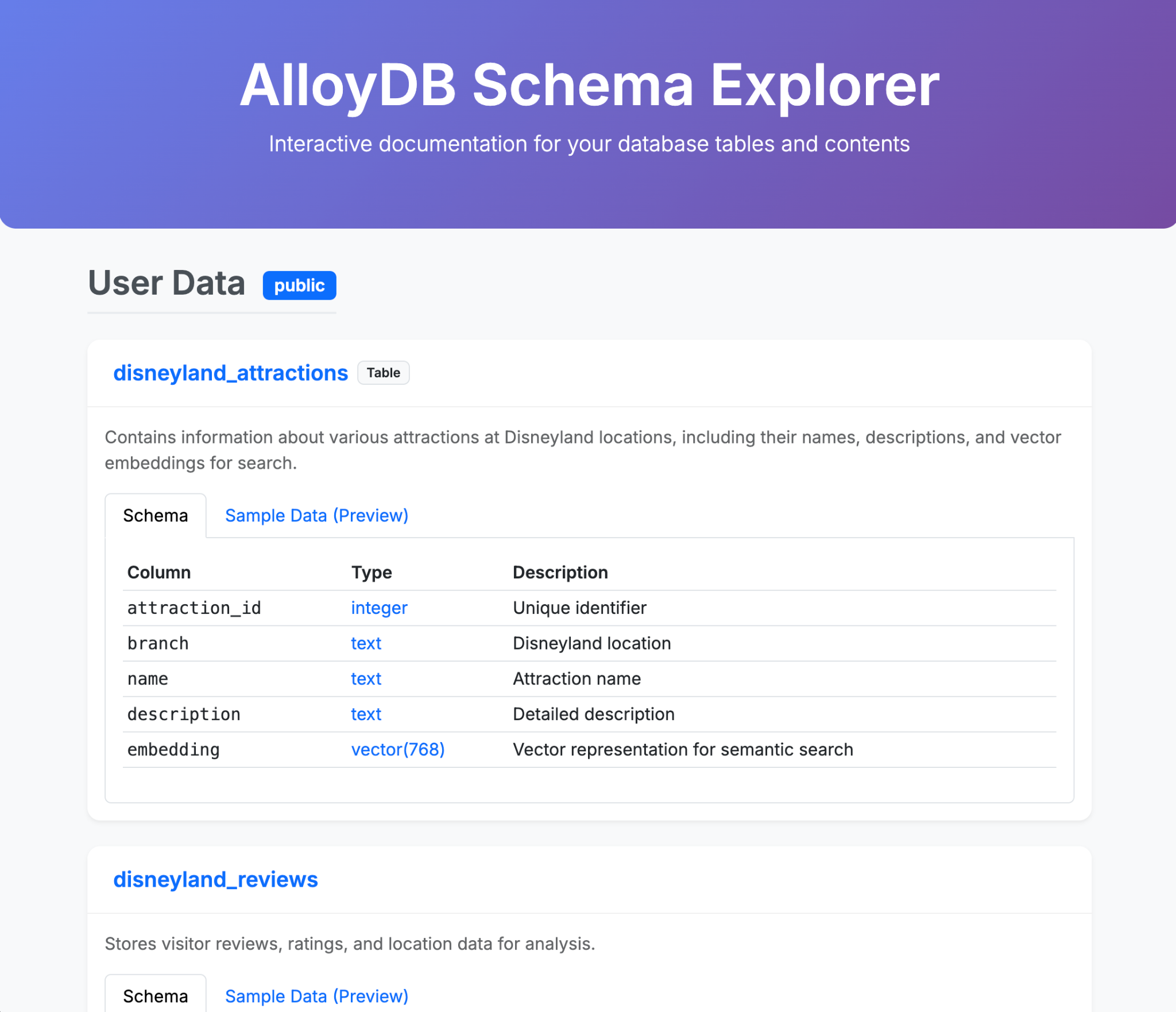
۹. وظیفه ۶: ایجاد یک عامل هوش مصنوعی برای تعامل با دادههای شما
برای ارائه یک تجربه کاربری کاملاً جدید به بازدیدکنندگان دیزنیلند، شما یک دستیار ایجاد خواهید کرد که میتواند در طول سفر به آنها کمک کند. نماینده شما قادر خواهد بود:
- تمام جاذبههای موجود در پارک را فهرست کنید
- بر اساس انتظارات، یک جاذبه گردشگری را پیشنهاد دهید
- افزودن نقد و بررسی برای یک جاذبه گردشگری
- تخمینی از زمان انتظار برای یک جاذبه در چند ساعت آینده ارائه دهید
- ارائه خلاصهای از نظرات مربوط به یک جاذبه خاص
شما مطمئن خواهید شد که دستیار شما فقط میتواند به سوالات مربوط به دیزنیلند پاسخ دهد و لحن دوستانهای با کاربر داشته باشد. پیام نماینده خود را تنظیم کنید تا مطمئن شوید که نماینده ابزارهای مناسبی را برای نیازهای کاربر انتخاب میکند.
مراحلی که باید دنبال کنید عبارتند از:
- یک جعبه ابزار MCP برای سرور پایگاههای دادهای که از AlloyDB و BigQuery به عنوان منبع استفاده میکنند، مستقر کنید.
- ۵ ابزار مختلف برای سرور MCP خود تعریف کنید که از AlloyDB و BigQuery پرسوجو میکنند و اقدامات عامل ذکر شده در بالا را نگاشت میکنند.
- برای اعتبارسنجی هر یک از ابزارهای خود از رابط کاربری جعبه ابزار MCP استفاده کنید
- با استفاده از کیت توسعه عامل، یک عامل مستقر کنید که بتواند از ابزارهای ارائه شده توسط سرور جعبه ابزار MCP شما استفاده کند.
- به رابط وب ADK خود متصل شوید و یک گفتگوی کامل با دستیار خود، شامل تمام ابزارهای موجود، را به نمایش بگذارید.
اگر زودتر تمام کنید، یک مرحله اضافی خواهید داشت:
آیا عامل شما آماده است؟ بیایید آن را در Agent Engine مستقر کنیم!