
1. 🏰 Disneyland Data Analytics Hackathon (2nd Edition - 3rd Dec) 🏰
खास जानकारी | इस हैकथॉन में, आपको Google Cloud पर एआई/मशीन लर्निंग की सुविधाओं का इस्तेमाल करके, एंड-टू-एंड डेटा विश्लेषण पाइपलाइन बनानी होगी. आपको डेटा को AlloyDB में लोड करना होगा. यह पूरी तरह से मैनेज किया जाने वाला, PostgreSQL के साथ काम करने वाला डेटाबेस है. इसे ज़्यादा वर्कलोड के लिए ऑप्टिमाइज़ किया गया है. इसके बाद, आपको Datastream का इस्तेमाल करना होगा. यह सर्वरलेस चेंज डेटा कैप्चर (सीडीसी) सेवा है. इसकी मदद से, डेटा को BigQuery में ट्रांसफ़र किया जा सकता है. BigQuery, Google Cloud का सर्वरलेस डेटा वेयरहाउस है. BigQuery में, BigQuery ML का इस्तेमाल किया जाएगा. इससे, स्टैंडर्ड एसक्यूएल का इस्तेमाल करके, सीधे तौर पर BigQuery में मशीन लर्निंग मॉडल बनाए और लागू किए जा सकते हैं. इनका इस्तेमाल, समीक्षा के विश्लेषण और उपस्थिति का अनुमान लगाने के लिए किया जाएगा. आखिर में, आपको एजेंट के साथ काम करना होगा. इसके लिए, Conversational Analytics और डेटा एजेंट के ज़रिए, आउट ऑफ़ द बॉक्स एजेंट का इस्तेमाल करें या Agent Development Kit और MCP toolbox की मदद से, कस्टम एजेंट बनाएं. इससे आपको अपने डेटा के साथ नैचुरल लैंग्वेज में इंटरैक्ट करने में मदद मिलेगी. |
categories | docType:Codelab, product:Bigquery |
लेखक | रेहान रेज़गुई, मैट कॉर्निलॉन |
लेआउट | स्क्रोल करना |
रोबोट | noindex |
2. परिचय
डेटा विज़र्ड, आपका स्वागत है!🪄
अब आपको लंबी-चौड़ी ट्रैवल गाइड पढ़ने और फ़ोरम को बार-बार स्क्रोल करने की ज़रूरत नहीं है. कल्पना करें कि आपको डेटा पर आधारित अहम जानकारी के साथ, Disneyland की यात्रा की योजना बनानी है. किस पार्क में सबसे अच्छा अनुभव मिलता है? यहां सबसे कम भीड़ कब होती है? क्या तुम यह अनुमान लगा सकते हो कि लंबी कतार से बचने के लिए, सबसे सही समय क्या होगा?
इस हैकथॉन में, आपको Disneyland की यात्रा प्लान करने वाला एक बेहतरीन टूल बनाना है. हमारे पास यह डेटा है: दुनिया भर की शाखाओं में आने वाले लोगों की समीक्षाएं, इंतज़ार करने का पुराना समय, और उपस्थिति के आंकड़े. आपका मिशन क्या है? इस रॉ डेटा को काम की अहम जानकारी में बदलें:
- डेटा इकट्ठा करना: Disneyland के बारे में अलग-अलग तरह की समीक्षाएं, इंतज़ार का समय, और लोगों की मौजूदगी से जुड़े आंकड़े, AlloyDB में लोड किए जाते हैं. यह PostgreSQL के साथ काम करने वाला, हाई-परफ़ॉर्मेंस डेटाबेस है.
- आसानी से डेटा ट्रांसफ़र करना: हमारी बिना सर्वर वाली डेटा कैप्चर सेवा, Datastream का इस्तेमाल करके इस डाइनैमिक जानकारी को आसानी से BigQuery में ट्रांसफ़र करें. BigQuery, Google Cloud का बिना सर्वर वाला पावरफ़ुल डेटा वेयरहाउस है.
- जादुई अनुमान लगाएं: BigQuery ML का इस्तेमाल करके, समीक्षाओं की भावना का विश्लेषण करें. साथ ही, सीधे तौर पर SQL की मदद से इंतज़ार के समय का अनुमान लगाएं. जानें कि कौनसी ब्रांच में आपको सबसे अच्छा अनुभव मिला और वहां जाने का सबसे सही समय क्या है.
- अपने डेटा से बात करें - सच में!: पहले से बने ऐसे टूल का इस्तेमाल करें जिनसे आपको एक स्वाइप में अहम जानकारी मिल सके.
- इंटेलिजेंट इंटरैक्शन: अपने क्रिएशन को एक इंटेलिजेंट एजेंट के साथ बेहतर बनाएं. यह एजेंट, डेटाबेस के लिए एमसीपी टूलबॉक्स और एडीके (Agent Development Kit) की मदद से काम करता है. "अंतरिक्ष में दिलचस्पी रखने वालों के लिए, डिज़्नीलैंड पेरिस में सबसे अच्छी राइड कौनसी है और लाइन में लगने का सबसे सही समय क्या है?" पूछें और डेटा पर आधारित जवाब तुरंत पाएं.
पृथ्वी की सबसे बेहतरीन जगहों के बारे में जानने के लिए तैयार हो जाएं. साथ ही, डेटा विश्लेषण की ऐसी पाइपलाइन बनाएं जिस पर मिकी को गर्व हो!
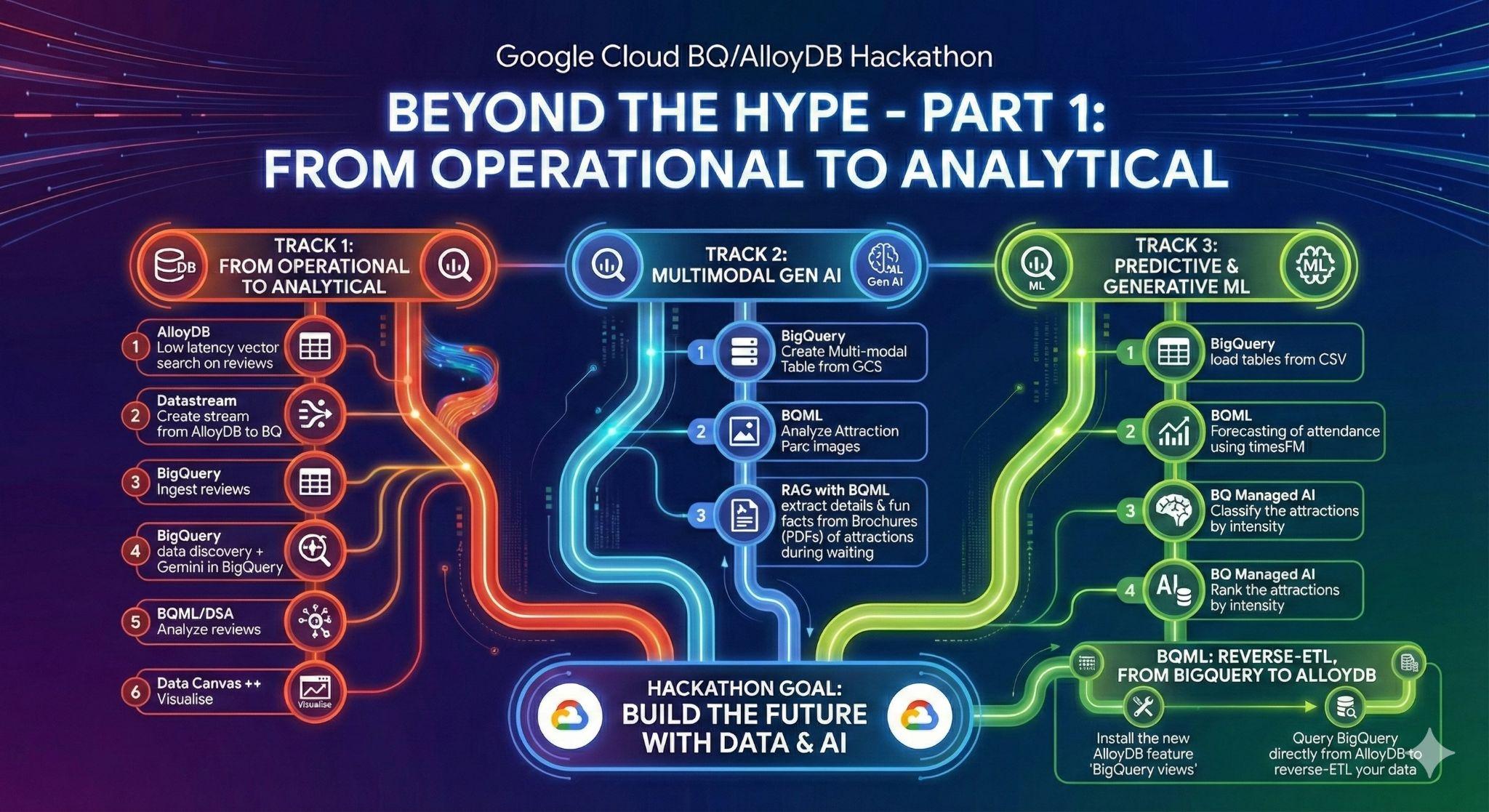
3. पहला टास्क: ऑपरेशनल से लेकर विश्लेषण तक; Gemini की मदद से Disneyland की समीक्षाओं का विश्लेषण करना
शुरुआती चरण में, आपको अपने AlloyDB ऑपरेशनल डेटाबेस से डेटा वापस पाना होगा. इसके बाद, डेटा का विश्लेषण करने के लिए उसे BigQuery में लोड करना होगा.
साथ ही, आपको अपने आने वाले समय के एजेंट के लिए, AlloyDB में सभी ज़रूरी चीज़ें सेट अप करनी होंगी!
AlloyDB में डेटा लोड करना
सबसे पहले, अपने AlloyDB for PostgreSQL क्लस्टर में कुछ डेटा इंपोर्ट करते हैं !
हम Disneyland के मनोरंजन पार्कों और घूमने की जगहों के लिए 20 हज़ार समीक्षाएं शामिल करेंगे.
इसके लिए, यह तरीका अपनाएं:
टेबल बनाने की सुविधा:
- छह कॉलम वाली disneyland_reviews टेबल बनाएं: review_id और rating को पूर्णांक के तौर पर, year_month, reviewer_location, review_text, branch को टेक्स्ट के तौर पर.
- चार कॉलम वाली disneyland_attractions टेबल बनाएं: attraction_id को पूर्णांक के तौर पर, branch, name, और description को टेक्स्ट के तौर पर सेट करें.
अपनी पसंद के टूल का इस्तेमाल करके, CSV फ़ाइलों से डेटा इंपोर्ट करें:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvसमीक्षाओं की टेबल के लिएgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvआकर्षण की टेबल के लिए
आकर्षणों के सुझाव देने के लिए, हमें आकर्षणों के ब्यौरे की एम्बेडिंग बनानी होगी:
- AlloyDB में pgvector एक्सटेंशन इंस्टॉल करना
- अपनी टेबल अट्रैक्शन में "embedding" नाम का एक वेक्टर कॉलम जोड़ें
- AlloyDB और Vertex AI के बीच नेटिव इंटिग्रेशन का इस्तेमाल करके, ब्यौरों की एम्बेडिंग जनरेट करना और उन्हें पॉप्युलेट करना
Datastream की मदद से, ऑपरेशनल डेटा को ऐनलिटिकल डेटा में बदलना
AlloyDB से BigQuery में डेटा स्ट्रीम करने के लिए, हम Google Datastream का इस्तेमाल करेंगे. यह सर्वरलेस समाधान है. यह सोर्स टेबल में होने वाले सभी बदलावों को सुनेगा (बदलाव किए गए डेटा को कैप्चर करने की सुविधा का इस्तेमाल करके) और उन्हें BigQuery को भेजेगा.
Datastream की मदद से AlloyDB में किए गए बदलावों को दोहराने के लिए, हमें Postgres पर पब्लिकेशन और रेप्लिकेशन स्लॉट बनाना होगा.
अपने AlloyDB क्लस्टर पर यहां दी गई क्वेरी चलाएं. आपको इन्हें एक-एक करके चलाना होगा:
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
आपको अपनी स्ट्रीम में पब्लिकेशन और रेप्लिकेशन स्लॉट का इस्तेमाल करना होगा. इसलिए, इनके नाम याद रखें!
बस इतना ही, अब हम स्ट्रीम बना सकते हैं!
Datastream में आपको ये चरण पूरे करने होंगे:
- अपने AlloyDB क्लस्टर के लिए सोर्स प्रोफ़ाइल बनाएं. इसके लिए, सार्वजनिक आईपी पते का इस्तेमाल करें
- BigQuery के लिए डेस्टिनेशन प्रोफ़ाइल बनाना
- AlloyDB से BigQuery में स्ट्रीम बनाएं.
डेटा, कुछ ही मिनटों में BigQuery में उपलब्ध हो जाएगा.
BigQuery में डेटा डिस्कवरी
अब हमारे पास BigQuery में डेटा है. इसलिए, काम शुरू करने से पहले, आइए इंटरफ़ेस में हुए नए सुधारों के बारे में जान लें!
हमने तीन नए फ़ंक्शन जोड़े हैं. इन्हें BigQuery के एक्सप्लोरेशन पैनल में देखा जा सकता है.
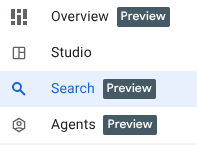
- खास जानकारी: इसमें BigQuery की सुविधाओं के बारे में जानकारी होती है. साथ ही, विश्लेषण शुरू करने के लिए टूर और अन्य संभावनाएं भी होती हैं.
- खोजें: अपनी डेटा ऐसेट पर सिमैंटिक सर्च करें.
- Agents: Shhh! हम इसे बाद के लिए सेव कर लेंगे 🤫
BigQuery में अपने डेटा को सिमैंटिक तरीके से खोजना
BigQuery एक्सप्लोरेशन पैनल में मौजूद 'खोजें' टैब पर जाएं. इसके बाद, "आकर्षण" या "शाखा" जैसे Disney से जुड़े शब्दों का इस्तेमाल करें.
BigQuery में अपने डेटा को विज़ुअलाइज़ करना
अब BigQuery में अपने डेटा को विज़ुअलाइज़ और बेहतर बनाया जा सकता है. इसके लिए, इस क्वेरी को नए क्वेरी टैब में चलाया जा सकता है;
SELECT
*
FROM
[dataset_name].[table_name];
समीक्षाओं की टेबल में डेटा इनसाइट जनरेट करना
इस टास्क में, आपको disney डेटासेट में मौजूद disneyland_reviews टेबल पर डेटा इनसाइट की सुविधा चालू करनी होगी.
डेटा इनसाइट एक ऐसा टूल है जो अपने डेटा को एक्सप्लोर करना चाहता है और जटिल एसक्यूएल क्वेरी लिखे बिना अहम जानकारी पाना चाहता है.
इसमें कुछ मिनट लग सकते हैं.
SQL का इस्तेमाल किए बिना disneyland_reviews टेबल को क्वेरी करो
पिछले सेक्शन में जनरेट की गई अहम जानकारी अब तैयार है. इस टास्क में, आपको इन अहम जानकारी से जनरेट हुए प्रॉम्प्ट का इस्तेमाल करके, disneyland_reviews टेबल से कोड का इस्तेमाल किए बिना क्वेरी करनी होगी.
कोई अहम जानकारी चुनें और उससे जुड़ी क्वेरी चलाएं. उदाहरण के लिए, वह क्वेरी ढूंढें जिससे हर ब्रांच के लिए, लगातार दो महीनों की औसत रेटिंग के बीच के अंतर का हिसाब लगाया जा सके. यह कुछ ऐसा दिखेगा:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
डेटा को बेहतर तरीके से समझने के लिए, BigQuery नॉलेज इंजन का इस्तेमाल करना
सबसे पहले, डेटासेट लेवल पर अहम जानकारी टैब देखते हैं. इससे हमें Disney डेटासेट में मौजूद टेबल के बीच छिपे हुए संबंधों के बारे में पता चलेगा. इसके बाद,
- Gemini का इस्तेमाल करके, डेटासेट के बारे में जानकारी जनरेट करें और उसे डेटासेट की जानकारी में जोड़ें.
- टेबल में मौजूद समीक्षाओं और आकर्षणों के बारे में जानकारी जनरेट करें. साथ ही, उन टेबल में मौजूद सभी कॉलम के बारे में जानकारी जनरेट करके सेव करें.
अपने डेटा की प्रोफ़ाइल स्कैन करना
इस सेक्शन का मकसद, आपके डेटा को साफ़ करना और तैयार करना है. हालांकि, आपको हर कॉलम की वैल्यू के डिस्ट्रिब्यूशन के बारे में ज़्यादा जानकारी नहीं है. आपको अपने डेटा की प्रोफ़ाइल बनानी होगी, ताकि यह पता चल सके कि आपको अपने डेटा पर किस तरह के बदलाव करने हैं.
Google Cloud का Dataplex Universal Catalog, प्रोफ़ाइलिंग स्कैन को अपने-आप करता है, ताकि डेटा की क्वालिटी से जुड़ी मेट्रिक एक जैसी रहें. पहचान किए गए मुख्य आंकड़ों में, शून्य की संख्या, अलग-अलग वैल्यू, डेटा रेंज, और वैल्यू डिस्ट्रिब्यूशन शामिल हैं. BigQuery इंटरफ़ेस की मदद से, प्रोफ़ाइल स्कैन की सुविधा चालू की जा सकती है.
इसमें कुछ मिनट लग सकते हैं. इसलिए, इंतज़ार करते समय अगला सेक्शन देखें.
इन सवालों के जवाब दें:
- Disneyland की औसत रेटिंग कितनी है?
- समीक्षा करने वाले लोग सबसे ज़्यादा कहाँ के हैं?
- क्या सभी समीक्षाएं यूनीक हैं?
- Year_Month कॉलम में मौजूद डेटा का कितना प्रतिशत मौजूद नहीं है?
अपने डेटा की क्वालिटी स्कैन करना
Dataplex Universal Catalog की डेटा क्वालिटी अपने-आप तय होने की सुविधा की मदद से, BigQuery टेबल में मौजूद डेटा की क्वालिटी तय की जा सकती है और उसका आकलन किया जा सकता है. डेटा को स्कैन करने की प्रोसेस को अपने-आप होने वाली प्रोसेस के तौर पर सेट अप किया जा सकता है. साथ ही, तय किए गए नियमों के हिसाब से डेटा की पुष्टि की जा सकती है. इसके अलावा, अगर आपका डेटा क्वालिटी की ज़रूरी शर्तों को पूरा नहीं करता है, तो सूचनाएं लॉग की जा सकती हैं. डेटा क्वालिटी के नियमों और डिप्लॉयमेंट को कोड के तौर पर मैनेज किया जा सकता है. इससे डेटा प्रोडक्शन पाइपलाइन की इंटिग्रिटी बेहतर होती है.
प्रोफ़ाइल स्कैन के आधार पर, क्वालिटी स्कैन तय करें. यह स्कैन, आपके डेटा के 10% से ज़्यादा हिस्से पर नहीं होना चाहिए. इसमें ये बातें शामिल हों:
- यह "branch" कॉलम के लिए, शून्य वैल्यू की जांच करता है
- यह "rating" की वैल्यू की जांच करता है, क्योंकि इसकी वैल्यू सिर्फ़ 1,2,3,4,5 हो सकती है
- यह कुकी, "review_id" की यूनीकनेस की जांच करती है
पक्का करें कि स्कैन के नतीजे, BigQuery टेबल quality_scan_results में एक्सपोर्ट किए गए हों.
सोचें कि आपको अपने डेटा पर कौन-कौनसे ट्रांसफ़ॉर्मेशन लागू करने हैं.
Gemini की डेटा तैयार करने की सुविधा का इस्तेमाल करके अपना डेटा तैयार करना
डेटा क्वालिटी और प्रोफ़ाइलिंग स्कैन करने के बाद, अब डेटा का विश्लेषण करने से पहले उसे साफ़ करने का समय है.
डेटा की तैयारी, BigQuery संसाधन हैं. ये आपके डेटा का विश्लेषण करने के लिए, BigQuery में Gemini का इस्तेमाल करते हैं. साथ ही, डेटा को साफ़ करने, ट्रांसफ़ॉर्म करने, और बेहतर बनाने के लिए, सुझाव देते हैं. इससे, मैन्युअल तरीके से डेटा तैयार करने में लगने वाला समय और मेहनत काफ़ी कम हो जाती है.
इस सेक्शन में, डेटा तैयारी की सुविधा का इस्तेमाल करके, disneyland_reviews टेबल पर ये कार्रवाइयां की जाएंगी:
- उन पंक्तियों को फ़िल्टर करके हटा दें जिनमें Branch कॉलम की वैल्यू NULL है या कोई स्ट्रिंग खाली है.
- Year_Month में "missing" को Null से बदलें.
- यह फ़ंक्शन, ब्रांच कॉलम में अंडरस्कोर की जगह स्पेस का इस्तेमाल करता है, ताकि उसे आसानी से पढ़ा जा सके
- डेटा को बदली गई टेबल disneyland_reviews_cleaned में एक्सपोर्ट करें
Gemini की मदद से समीक्षाओं का विश्लेषण करना
डेटा को साफ़ करने के बाद, BigQuery ML और Gemini मॉडल का इस्तेमाल करके उसका विश्लेषण किया जा सकता है. आपके दो मकसद हैं:
- समीक्षाओं से कैटगरी निकालना
- disneyland_reviews के बारे में लोगों की भावनाओं का विश्लेषण
BigQuery ML की मदद से, GoogleSQL क्वेरी का इस्तेमाल करके मशीन लर्निंग (एमएल) मॉडल बनाए और चलाए जा सकते हैं. BigQuery ML मॉडल, BigQuery डेटासेट में सेव किए जाते हैं. ये मॉडल, टेबल और व्यू की तरह होते हैं. BigQuery ML की मदद से, Vertex AI मॉडल और Cloud AI API को भी ऐक्सेस किया जा सकता है. इससे, आर्टिफ़िशियल इंटेलिजेंस (एआई) से जुड़े टास्क किए जा सकते हैं. जैसे, टेक्स्ट जनरेट करना या मशीन ट्रांसलेशन करना. Gemini for Google Cloud, BigQuery के टास्क के लिए एआई की मदद से सहायता भी उपलब्ध कराता है.
Gemini Pro या Flash मॉडल के साथ, ML.GENERATE_TEXT या AI.GENERATE (प्रीव्यू) का इस्तेमाल किया जा सकता है.
अगर आपको ML.GENERATE_TEXT का इस्तेमाल करना है, तो यहां दिया गया तरीका अपनाएं.
क्लाउड रिसॉर्स कनेक्शन बनाना और आईएएम की भूमिका असाइन करना
आपको BigQuery में Vertex AI मॉडल से Cloud संसाधन कनेक्शन बनाना होगा, ताकि Gemini Pro और Gemini Flash मॉडल का इस्तेमाल किया जा सके. आपको क्लाउड संसाधन कनेक्शन के सेवा खाते को आईएएम अनुमतियां भी देनी होंगी. इसके लिए, आपको उसे कोई भूमिका असाइन करनी होगी, ताकि वह Vertex AI की सेवाओं को ऐक्सेस कर सके.
कनेक्शन के सेवा खाते को Vertex AI के उपयोगकर्ता की भूमिका असाइन करना
कनेक्शन के सेवा खाते को, चुने गए मॉडल (उदाहरण के लिए, gemini-2.5-flash) का इस्तेमाल करने की अनुमति दें. इसके लिए, उसे Vertex AI User की भूमिका असाइन करें. अनुमति लागू होने में एक मिनट लगता है.
BigQuery में Gemini मॉडल बनाना
ऊपर दिए गए कनेक्शन का इस्तेमाल करके, अपना मॉडल बनाएं. उदाहरण के लिए, gemini-2.5-flash. एंडपॉइंट का इस्तेमाल करें
Gemini को प्रॉम्प्ट देकर, कैटगरी और भावना के हिसाब से खरीदारों की समीक्षाओं का विश्लेषण करना
इस टास्क में, आपको Gemini मॉडल का इस्तेमाल करके, हर ग्राहक की समीक्षा का विश्लेषण करना होगा. इसके लिए, आपको समीक्षा को कैटगरी में बांटना होगा और यह तय करना होगा कि समीक्षा सकारात्मक है या नकारात्मक.
कैटगरी के लिए खरीदारों की समीक्षाओं का विश्लेषण करना
ध्यान दें: अब से, विश्लेषण के लिए हम सिर्फ़ 100 लाइनें लेंगे, क्योंकि 20 हज़ार लाइनों पर Gemini को कॉल करने में समय लग सकता है.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
यह क्वेरी, disneyland_reviews टेबल से ग्राहक समीक्षाएं लेती है. साथ ही, gemini मॉडल के लिए प्रॉम्प्ट बनाती है, ताकि हर समीक्षा में कैटगरी की पहचान की जा सके. नतीजों को नई टेबल reviews_categories में सेव किया जाना चाहिए
. कृपया इंतज़ार करें. मॉडल को ग्राहक की समीक्षाओं के रिकॉर्ड को प्रोसेस करने में करीब 30 सेकंड लगते हैं. इसके बाद, आउटपुट टेबल में नतीजे दिखते हैं.
नतीजे दिखाएं:
SELECT * FROM [dataset_name].[results_table_name];
कुछ समय निकालकर, कुछ कैटगरी के बारे में पढ़ें.
सकारात्मक और नकारात्मक भावनाओं के लिए, ग्राहकों की समीक्षाओं का विश्लेषण करना
कीवर्ड निकालने के लिए एसक्यूएल क्वेरी के आधार पर, एक ऐसी क्वेरी लिखें जो "भावना" नाम के कॉलम में, समीक्षा को पॉज़िटिव, नेगेटिव, और सामान्य कैटगरी में बांटकर विश्लेषण करे.
इस क्वेरी में, disneyland_reviews टेबल से ग्राहक की समीक्षाएं ली जाती हैं. साथ ही, gemini मॉडल के लिए प्रॉम्प्ट बनाए जाते हैं, ताकि हर समीक्षा के बारे में पता चल सके कि वह सकारात्मक है, नकारात्मक है या सामान्य है. इसके बाद, नतीजों को नई टेबल reviews_analysis में सेव कर दिया जाता है, ताकि बाद में उनका इस्तेमाल किया जा सके. कृपया इंतज़ार करें. मॉडल को ग्राहक की समीक्षाओं के रिकॉर्ड को प्रोसेस करने में कुछ सेकंड लगते हैं. मॉडल तैयार होने के बाद, नतीजे को बनाई गई reviews_analysis टेबल में देखा जा सकता है.
नतीजे एक्सप्लोर करें:
SELECT * FROM [...];
reviews_analysis टेबल में, Sentiment कॉलम में भावना का विश्लेषण किया गया है. इसमें social_media_source, review_text, customer_id, location_id, और review_datetime कॉलम शामिल हैं. कुछ रिकॉर्ड देखें. ऐसा हो सकता है कि पॉज़िटिव और नेगेटिव के कुछ नतीजे सही फ़ॉर्मैट में न हों. साथ ही, उनमें फ़ुल स्टॉप या अतिरिक्त स्पेस जैसे गैर-ज़रूरी वर्ण मौजूद हों. नीचे दिए गए व्यू का इस्तेमाल करके, रिकॉर्ड को सैनिटाइज़ किया जा सकता है.
रिकॉर्ड को सुरक्षित करने के लिए व्यू बनाना
ऐसा व्यू बनाएं जो कॉलम की भावना की वैल्यू को इस तरह से सुरक्षित करे:
- LOWER फ़ंक्शन का इस्तेमाल करके, यह पक्का किया जाता है कि सभी वैल्यू लोअरकेस में हों.
- REPLACE फ़ंक्शन का इस्तेमाल करके, विराम चिह्न (. और , और स्पेस) हटाना
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
क्वेरी, cleaned_data_view व्यू बनाती है. इसमें, भावना के विश्लेषण के नतीजे, समीक्षा का टेक्स्ट, और Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch शामिल होता है. इसके बाद, यह भावना के आधार पर मिले नतीजे (सकारात्मक या नकारात्मक) को लेता है. साथ ही, यह पक्का करता है कि सभी अक्षर छोटे हों और अतिरिक्त वर्ण हटा दिए गए हों. जैसे, अतिरिक्त स्पेस या अवधि. इस व्यू से, इस लैब में बाद के चरणों में ज़्यादा विश्लेषण करना आसान हो जाएगा.
- बनाई गई पंक्तियां देखने के लिए, नीचे दी गई क्वेरी का इस्तेमाल करके व्यू को क्वेरी किया जा सकता है.
SELECT * FROM [view_name];
Data Canvas की मदद से, सकारात्मक और नकारात्मक समीक्षाओं की संख्या की रिपोर्ट बनाना
अब, अपने नतीजों का विश्लेषण करें. आइए, डेटा कैनवस की मदद से सीधे BigQuery में डेटा एक्सप्लोर करना शुरू करें. यह एक ऐसा टूल है जिसकी मदद से, डेटा को खोजा जा सकता है (सिमेंटिक या कीवर्ड के हिसाब से). साथ ही, टेबल को क्वेरी और जॉइन किया जा सकता है. इसके अलावा, कैनवस का फ़्लो बनाकर ग्राफ़ बनाए जा सकते हैं और अहम जानकारी पाई जा सकती है.
आपका मुख्य लक्ष्य, सकारात्मक और नकारात्मक समीक्षाओं के प्रतिशत का अपनी पसंद का ग्राफ़ बनाना है . यहां एक उदाहरण दिया गया है:
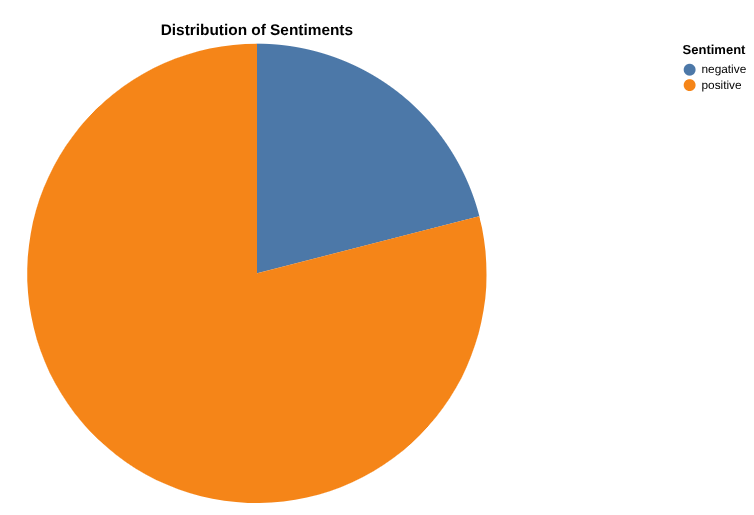
हर कैटगरी के लिए, समीक्षाओं की संख्या का ग्राफ़ बनाएं. साथ ही, हर कैटगरी के लिए पॉज़िटिव और नेगेटिव समीक्षाओं का डिस्ट्रिब्यूशन दिखाएं
अहम जानकारी: डेटा कैनवस की बेहतर विश्लेषण सुविधा को चालू करें और उसका इस्तेमाल करें. यह सुविधा, कैनवस में Python नोटबुक चलाती है.
4. टास्क 2: डिज़्नीलैंड की फ़ोटो की पहचान करने के लिए, आकर्षण वाले पार्क की इमेज का विश्लेषण करना. साथ ही, पार्क के ब्रोशर से मज़ेदार जानकारी निकालना
BigQuery में इमेज का विश्लेषण करना
आपके पास Attraction parc की कुछ रोमांचक और आकर्षक तस्वीरें देखने का विकल्प है. ये तस्वीरें, यहां आने वाले लोगों ने समय-समय पर ली हैं. आप अपनी आने वाली यात्रा के लिए बहुत उत्साहित हैं! हालांकि, आपको यह नहीं पता कि इनमें से कौनसी फ़ोटो Disneyland की हैं. आपको उन लोगों की पहचान करनी है. ये फ़ोटो gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/ में मौजूद हैं.

Is_disneyland: False

Is_disneyland: True
इस विश्लेषण को तुरंत पूरा करने के लिए. आपको BigQuery की ऑब्जेक्ट टेबल और BigQuery ML (ML.GENERATE_TEXT) के ज़रिए Gemini का इस्तेमाल करना चाहिए.
क्या कुछ फ़ोटो देखकर, Gemini के जवाब की पुष्टि की जा सकती है?
Disneyland के ब्रोशर पर BigQuery की मदद से, अपना RAG सिस्टम बनाना
लाइन में इंतज़ार करते समय, आपको उस जगह के बारे में कुछ मज़ेदार बातें/तकनीकी जानकारी चाहिए जहां जाने के लिए इंतज़ार किया जा रहा है.
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, में, आपको दुनिया भर के सभी पार्कों के ब्रोशर वाली PDF फ़ाइलें मिलेंगी.
लक्ष्य: BigQuery में पूरी तरह से रिट्रीवल-ऑगमेंटेड जनरेशन (आरएजी) सिस्टम बनाना, ताकि उपयोगकर्ता कुछ पीडीएफ़ दस्तावेज़ों के आधार पर पार्क के बारे में मुश्किल सवाल पूछ सकें.
इसके लिए, आपको ये काम करने होंगे:
- PDF फ़ाइलों की ऑब्जेक्ट टेबल बनाना
- PDF फ़ाइलों को हिस्सों में बांटने के लिए, Python UDF बनाएं. यहां एक उदाहरण दिया गया है, जिसका इस्तेमाल किया जा सकता है:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- PDF फ़ाइल को हिस्सों में पार्स करना
- रिमोट मॉडल बनाने के बाद, एम्बेडिंग जनरेट करना
- "
Ou manger un repas tex-mex à volonté?" या "where to eat a tex-mex meal buffet-style?" ढूंढने के लिए, वेक्टर सर्च की सुविधा का इस्तेमाल करना - "
Ou manger un repas tex-mex à volonté?" या ""where to eat a tex-mex meal buffet-style?" सवाल के वेक्टर सर्च के नतीजों के आधार पर जवाब जनरेट करो
5. तीसरा टास्क: BigQuery की मदद से बड़े पैमाने पर मशीन लर्निंग: पूर्वानुमान, क्लासिफ़िकेशन, और रैंकिंग
अनुमानित इंतज़ार का समय
तस्वीरें बहुत अच्छी हैं! मुझसे इंतज़ार नहीं हो रहा! अब आपको यह जानना है कि पेरिस और कैलिफ़ोर्निया के बीच मौजूद किन जगहों पर जाना चाहिए और किन जगहों पर नहीं. इसके लिए, आपको कुछ जगहों पर लगने वाले इंतज़ार के समय के बारे में जानना है. आपका काम, साल 2025 में हर 30 मिनट के लिए, हर जगह पर लगने वाले इंतज़ार के समय का अनुमान लगाना है. इसके लिए, मशीन लर्निंग (Arima plus या TimesFM) का इस्तेमाल करें.
आपको इस csv फ़ाइल में मौजूद डेटा का इस्तेमाल करना है: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
आपके टास्क के चरण ये हैं:
- फ़ाइल को waiting_times नाम की टेबल के तहत, अपने BigQuery डेटासेट में लोड करें.
- अपने डेटा (Arima_Plus) पर अनुमान लगाने वाले मॉडल को ट्रेन करें या AI.Forecast का इस्तेमाल करके सीधे तौर पर अनुमान लगाएं
- मॉडल की परफ़ॉर्मेंस का आकलन करना या अनुमानित डेटा की तुलना इनपुट डेटा से करना
राइड को इंटेंसिटी के हिसाब से कैटगरी में बांटना
आपको अपने दोस्तों के साथ डिज़्नीलैंड जाना है. आम तौर पर, यह पार्क परिवार के साथ घूमने के लिए अच्छा है. हालांकि, कुछ राइड कुछ लोगों के लिए बहुत मुश्किल हो सकती हैं. आइए, BigQuery के मैनेज किए गए एआई फ़ंक्शन का इस्तेमाल करके, रोमांच और इंटेंसिटी लेवल के हिसाब से आकर्षणों को क्लासिफ़ाई और रैंक करें. इससे हम सभी को शामिल कर पाएंगे.
AI.CLASSIFYका इस्तेमाल करके, राइड को उनके ब्यौरे के आधार पर तीन कैटगरी में से किसी एक में बांटें: [easy-peasy, thrilling, extreme]
राइड की रैंक, रोमांच के लेवल पर निर्भर करती है
AI.SCOREका इस्तेमाल करके, थ्रिल लेवल के आधार पर आकर्षणों की तुलना करें और उन्हें क्रम में लगाएं. इसमें रैंक 10 सबसे ज़्यादा और रैंक 1 सबसे कम थ्रिल लेवल को दिखाता है.
6. तीसरा टास्क बोनस: BigQuery से AlloyDB में रिवर्स-ईटीएल
आपने बड़ी मात्रा में मौजूद डेटा से अहम जानकारी जनरेट करने के लिए, BigQuery की दमदार सुविधाओं का इस्तेमाल किया हो. अब आपको यह जानकारी अपने ऑपरेशनल ऐप्लिकेशन (और एआई एजेंट!) के लिए उपलब्ध करानी है, ताकि वे इस पर कार्रवाई कर सकें.
लेकिन कैसे? उल्टा करके! AlloyDB for Postgres, कम समय में तेज़ी से डेटा उपलब्ध कराने के लिए सबसे अच्छा है. यह उपयोगकर्ताओं के लिए उपलब्ध कराए जाने वाले आपके ज़रूरी ऐप्लिकेशन के लिए सबसे सही है. इसलिए, आइए अभी जनरेट किए गए डेटा को रिवर्स-ईटीएल करें.
इसके लिए, हम एक नई सुविधा का इस्तेमाल करेंगे. यह सुविधा अब भी प्राइवेट प्रीव्यू में है. इसे AlloyDB में "BigQuery व्यू" कहा जाता है. इस सुविधा की मदद से, सीधे Postgres डेटाबेस में BigQuery डेटा को क्वेरी किया जा सकता है.
सबसे पहले, आपको अपने AlloyDB क्लस्टर के सेवा खाते को BigQuery से क्वेरी करने के लिए ज़रूरी अनुमतियां देनी होंगी.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
आउटपुट में serviceAccountEmail फ़ील्ड होता है. यह इस क्लस्टर के लिए सेवा खाता होता है.
Google Cloud Console में, IAM पेज पर जाएं और इस प्रिंसिपल को ये अनुमतियां दें:
- BigQuery डेटा व्यूअर (roles/bigquery.dataViewer)
- BigQuery Read Session User (roles/bigquery.readSessionUser)
अब Console में AlloyDB Studio पर जाएं और "postgres" डेटाबेस से कनेक्ट करें.
नई सुविधा को इंस्टॉल और कॉन्फ़िगर करने के लिए, यहां दी गई क्वेरी चलाएं:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
अब "फ़ॉरेन टेबल" बनाई जा सकती है. इसे BigQuery में मौजूद किसी टेबल से मैप किया जाएगा. टास्क 3 में बनाई गई किसी भी टेबल का इस्तेमाल करें. यहां सिंटैक्स का एक उदाहरण दिया गया है:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
सब तैयार है, अब टेबल से क्वेरी करते हैं! AlloyDB और BigQuery के बीच लिंक की पुष्टि करने के लिए, पहला SELECT स्टेटमेंट चलाएं. इसके बाद, फ़ॉरेन टेबल से डेटा पाने के लिए, AlloyDB में एक नई टेबल बनाएं.
7. टास्क 4: आउट-ऑफ़-द-बॉक्स डेटा एजेंट
आपके कुछ दोस्त हैं जो Disneyland Application प्रोजेक्ट में योगदान देना चाहते हैं. उनके पास BigQuery में मौजूद डेटा का ऐक्सेस है, लेकिन एसक्यूएल और डेटा इंजीनियरिंग में उनका लेवल अलग-अलग है. आपको BigQuery के डेटा एजेंट से जुड़े हाल ही के एलान का फ़ायदा उठाना है. ये डेटा एजेंट, यूज़र इंटरफ़ेस (यूआई) में पहले से ही इंटिग्रेट किए जा चुके हैं, ताकि आपके दोस्तों की मदद की जा सके:
- डेटा पाइपलाइन बनाएं.
- SQL कोड पर साथ मिलकर काम करें.
- उनके डेटा के बारे में सवाल पूछें.
डेटा पाइपलाइन को अपने-आप काम करने के लिए, डेटा इंजीनियरिंग एजेंट
Data Engineering Agent का इस्तेमाल करके, average_waiting_time नाम का एक नया व्यू बनाएं. इसमें waiting time और attractions टेबल को शामिल करें. साथ ही, हर attraction के लिए average waiting_time का हिसाब लगाएं.
BigQuery में कन्वर्सेशनल ऐनलिटिक्स एजेंट बनाना
अगर आपको कोडिंग, एसक्यूएल, और डिप्लॉयमेंट के बिना, अपने डेटा से बातचीत करने के लिए कोई एजेंट बनाने का विकल्प मिले, तो आपको कैसा लगेगा? साथ ही, अगर यह एजेंट BigQuery के इंटरफ़ेस से बनाया जा सके, तो यह कितना शानदार होगा? हालांकि, अब BigQuery में "एजेंट" टैब की मदद से ऐसा किया जा सकता है.
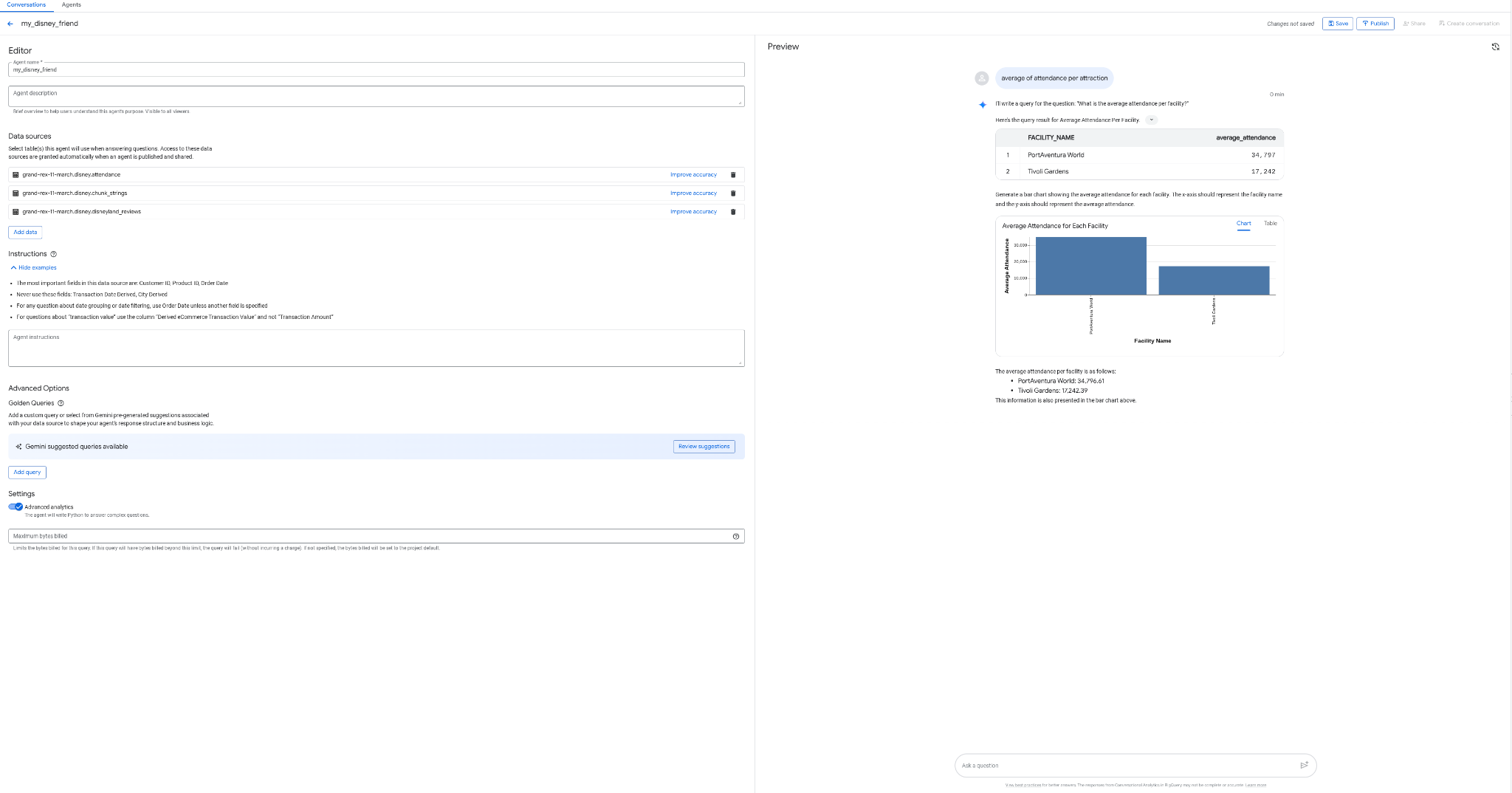
- my_disney_friend नाम का एक एजेंट बनाओ, जो तुम्हारी Disney टेबल से कनेक्ट हो. एजेंट के लिए निर्देश भरकर, एजेंट की परफ़ॉर्मेंस को बेहतर बनाया जा सकता है. "सकारात्मक और नकारात्मक समीक्षाओं का प्रतिशत कितना है, हर जगह पर इंतज़ार करने का औसत समय कितना है वगैरह ... ?" जैसे सवाल पूछें
- एजेंट को BigQuery और एपीआई में पब्लिश करें. इसका इस्तेमाल बाद में किया जाएगा.
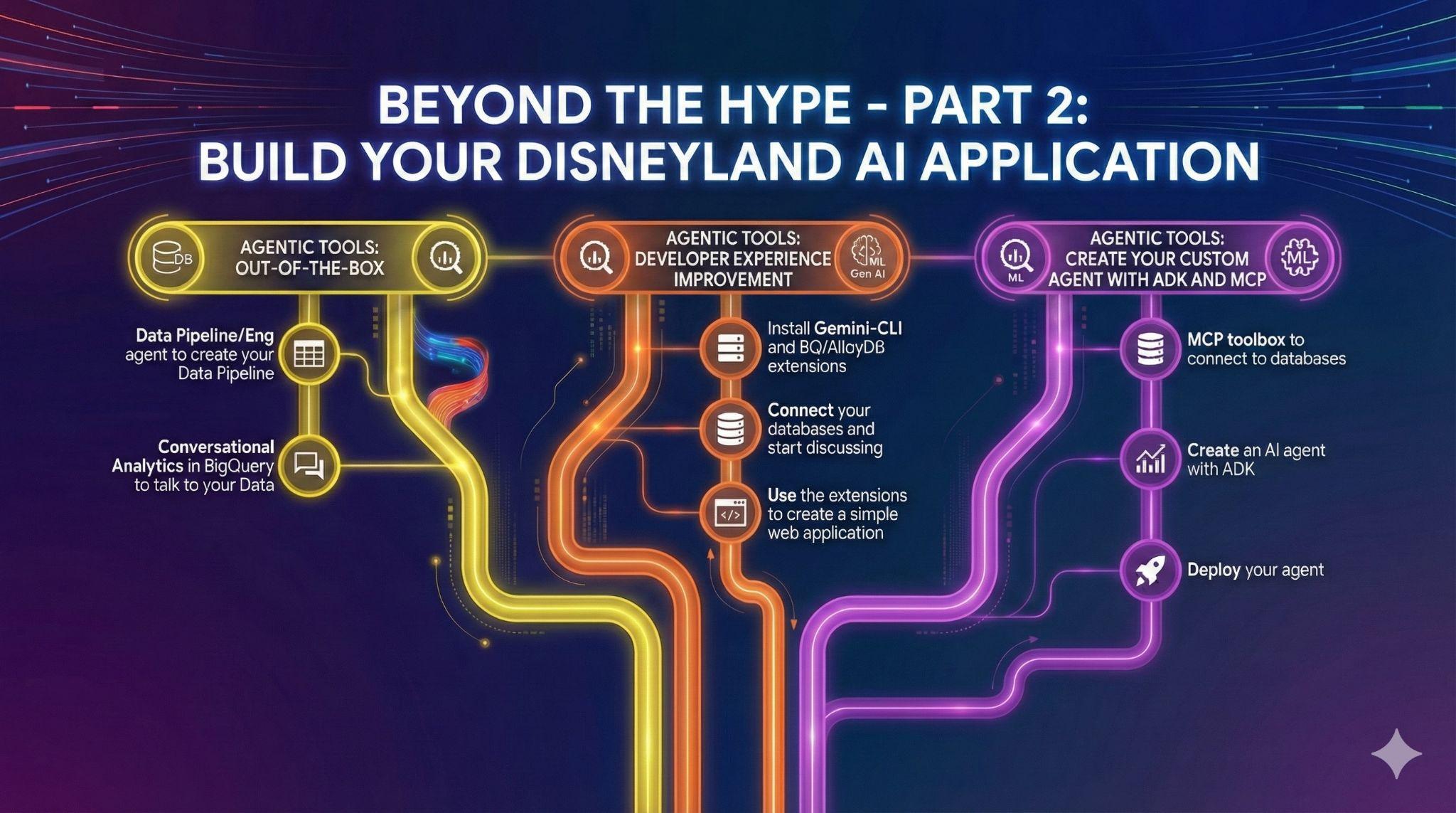
8. टास्क 5: Gemini-CLI की मदद से, डेवलपमेंट के अपने अनुभव को बेहतर बनाना
एआई के इस दौर में, सॉफ़्टवेयर बनाना पहले से ज़्यादा आसान हो गया है. आपके पास Disneyland ऐप्लिकेशन के लिए हज़ारों आइडिया हैं और आपको अपने डेटा का ज़्यादा से ज़्यादा इस्तेमाल करना है. आपको सिर्फ़ डेटा से बात नहीं करनी है, बल्कि अब आपको कार्रवाई करनी है!
इस काम में आपकी मदद करने के लिए, आपको सहायता की ज़रूरत होगी. हम आपको सारी जानकारी उपलब्ध कराएंगे.
Gemini CLI, एआई की मदद से काम करने वाला ओपन-सोर्स एजेंट है. इसकी मदद से, Gemini की सुविधा सीधे अपने टर्मिनल में पाई जा सकती है. डेवलपर, एक्सटेंशन की मदद से बेहतर ऐप्लिकेशन बना सकते हैं. साथ ही, अलग-अलग एमसीपी (मॉडल कॉन्टेक्स्ट प्रोटोकॉल) सर्वर के साथ इंटरैक्ट भी कर सकते हैं.
इनमें से, आपको AlloyDB या BigQuery डेटा की क्वेरी करने के लिए एक्सटेंशन भी मिल सकते हैं!
इस टास्क में, आपका लक्ष्य यह है:
- Gemini-CLI को अपने टर्मिनल या Cloud Shell में इंस्टॉल करें
- BigQuery और AlloyDB के Gemini-CLI एक्सटेंशन इंस्टॉल करना
- एक एनवायरमेंट फ़ाइल बनाएं, ताकि Gemini-CLI आपके BigQuery और AlloyDB इंस्टेंस से कनेक्ट हो सके
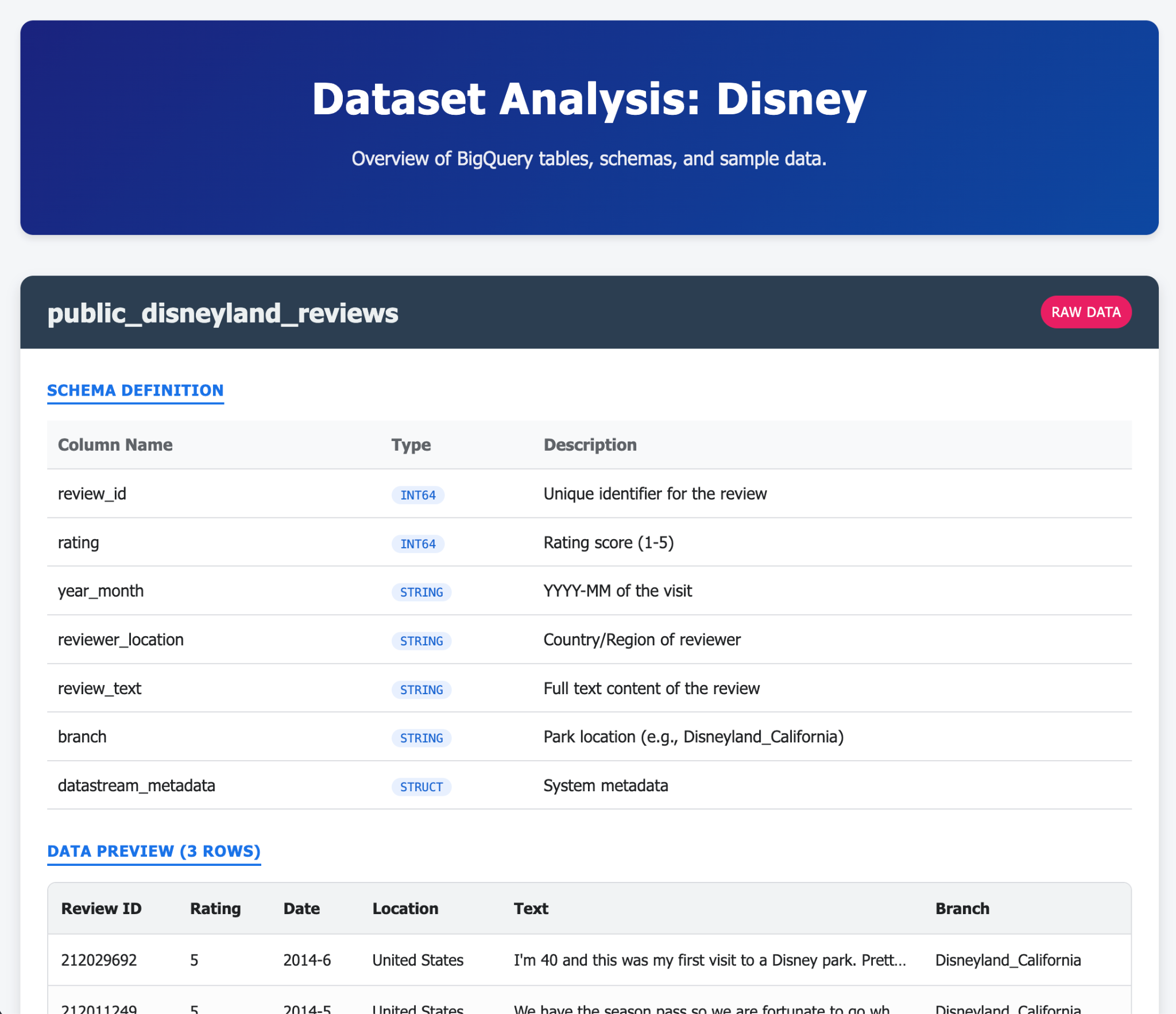
- Gemini-CLI से, एक ऐसा शानदार एचटीएमएल पेज जनरेट करने के लिए कहें जिसमें आपके AlloyDB डेटाबेस के कॉन्टेंट के बारे में बताया गया हो
- BigQuery के लिए भी ऐसा ही करें
यहाँ कुछ उदाहरण दिए गए हैं. इनमें बताया गया है कि Gemini-CLI और इसके एक्सटेंशन की मदद से, एक या कुछ प्रॉम्प्ट में क्या-क्या जनरेट किया जा सकता है. अब सोचें कि अगर आपको असल ज़िंदगी में भी ऐसा करने का मौका मिले, तो क्या होगा? 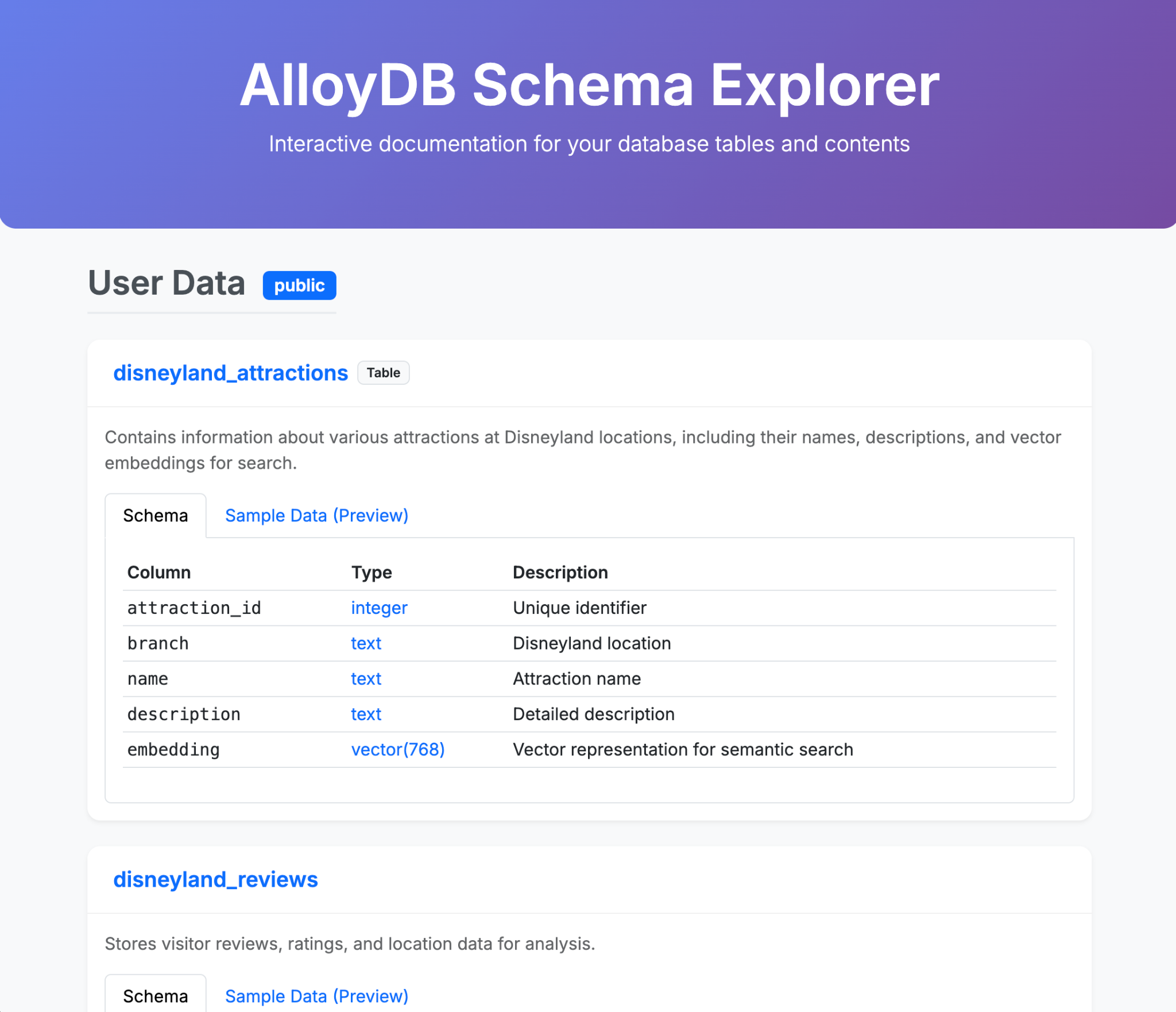
9. छठा टास्क: अपने डेटा के साथ इंटरैक्ट करने के लिए, एआई एजेंट बनाना
DisneyLand आने वाले लोगों को नया अनुभव देने के लिए, आपको एक असिस्टेंट बनानी होगी. यह असिस्टेंट, यात्रा के दौरान लोगों की मदद कर सकती है. आपका एजेंट ये काम कर पाएगा:
- पार्क में मौजूद सभी जगहों की सूची
- उम्मीदों के आधार पर किसी जगह का सुझाव देना
- किसी जगह के बारे में समीक्षाएं जोड़ना
- अगले कुछ घंटों में किसी जगह पर जाने के लिए, इंतज़ार करने के समय का अनुमान बताओ
- किसी खास जगह के बारे में समीक्षाओं की खास जानकारी देना
आपको यह पक्का करना होगा कि आपकी असिस्टेंट सिर्फ़ Disneyland से जुड़े सवालों के जवाब दे सकती हो. साथ ही, वह उपयोगकर्ता के साथ दोस्ताना व्यवहार करे. अपने एजेंट के प्रॉम्प्ट को इस तरह से ट्यून करें कि एजेंट, उपयोगकर्ता की ज़रूरतों के हिसाब से सही टूल चुन सके.
इसके लिए, यह तरीका अपनाएं:
- AlloyDB और BigQuery को सोर्स के तौर पर इस्तेमाल करने वाले डेटाबेस के लिए एमसीपी टूलबॉक्स सर्वर को डिप्लॉय करना
- अपने एमसीपी सर्वर के लिए पांच अलग-अलग टूल के बारे में बताएं. ये टूल, AlloyDB और BigQuery से क्वेरी करते हैं. साथ ही, पहले से मौजूद एजेंट की कार्रवाइयों को मैप करते हैं
- अपने हर टूल की पुष्टि करने के लिए, एमसीपी टूलबॉक्स यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करें
- Agent Development Kit का इस्तेमाल करके, ऐसा एजेंट डिप्लॉय करें जो आपके एमसीपी टूलबॉक्स सर्वर से उपलब्ध कराए गए टूल का इस्तेमाल कर सके
- ADK के वेब इंटरफ़ेस से कनेक्ट करें और अपने असिस्टेंट के साथ पूरी बातचीत दिखाएं. इसमें उपलब्ध सभी टूल भी शामिल हों
अगर आपने टास्क को समय से पहले पूरा कर लिया है, तो यह बोनस चरण है:
क्या आपका एजेंट तैयार है? इसे एजेंट इंजन में डिप्लॉय करते हैं!