
1. 🏰 Disneyland Data Analytics Hackathon (2ª edizione - 3 dicembre) 🏰
Riepilogo | In questo hackathon, creerai una pipeline di analisi dei dati end-to-end sfruttando le funzionalità di AI/ML su Google Cloud. Caricherai i dati in AlloyDB, un database completamente gestito e compatibile con PostgreSQL ottimizzato per carichi di lavoro impegnativi, poi utilizzerai Datastream, un servizio serverless di acquisizione dei dati di modifica (CDC), per spostarli in BigQuery, il data warehouse serverless di Google Cloud. In BigQuery, applicherai BigQuery ML, che ti consente di creare ed eseguire modelli di machine learning direttamente in BigQuery utilizzando SQL standard, per l'analisi delle recensioni e la previsione della partecipazione. Infine, potrai sperimentare con gli agenti, pronti all'uso tramite Analisi conversazionale e Agenti di dati, oppure creare un agente personalizzato, basato su Agent Development Kit e MCP Toolbox per l'interazione in linguaggio naturale con i tuoi dati. |
categorie | docType:Codelab, product:Bigquery |
Autore | Rayhane Rezgui, Matt Cornillon |
Layout | scorrimento |
Robot | noindex |
2. Introduzione
Benvenuti, futuri maghi dei dati Disney!🪄
Dimentica le noiose guide di viaggio e lo scorrimento infinito dei forum. Immagina di pianificare il viaggio perfetto a Disneyland, con informazioni basate sui dati. Quale parco offre la migliore esperienza? Quando c'è meno gente? Riesci a prevedere il momento migliore per affrontare quella coda notoriamente lunga?
In questo hackathon, creerai lo strumento definitivo per pianificare la tua visita a Disneyland. Abbiamo i dati: recensioni dei visitatori delle filiali di tutto il mondo, tempi di attesa storici e cifre relative alle presenze. La tua missione? Trasforma questi dati non elaborati in insight strategici:
- Raccogli dati:carica diverse recensioni, tempi di attesa e cifre di affluenza di Disneyland in AlloyDB, il nostro database compatibile con PostgreSQL ad alte prestazioni.
- Spostamento senza interruzioni:utilizza Datastream, il nostro servizio serverless di acquisizione delle modifiche ai dati, per spostare facilmente queste informazioni dinamiche in BigQuery, il potente data warehouse serverless di Google Cloud.
- Prevedi la magia: utilizza BigQuery ML per analizzare il sentiment delle recensioni e prevedere i tempi di attesa direttamente con SQL. Scopri quali filiali offrono sempre un servizio impeccabile e qual è l'orario migliore per la tua visita.
- Parla con i tuoi dati, letteralmente: Utilizza strumenti predefiniti che ti consentono di ottenere approfondimenti con un semplice tocco della bacchetta.
- Interazione intelligente:completa la tua creazione con un agente intelligente, basato su MCP Toolbox per database e ADK (Agent Development Kit). Chiedi "Qual è l'attrazione migliore di Disneyland Paris per gli amanti dello spazio e qual è il momento migliore per fare la fila?" e ricevi risposte immediate basate sui dati.
Preparati a scoprire i segreti dei luoghi più magici della Terra e a creare una pipeline di analisi dei dati che renderebbe orgoglioso Topolino.
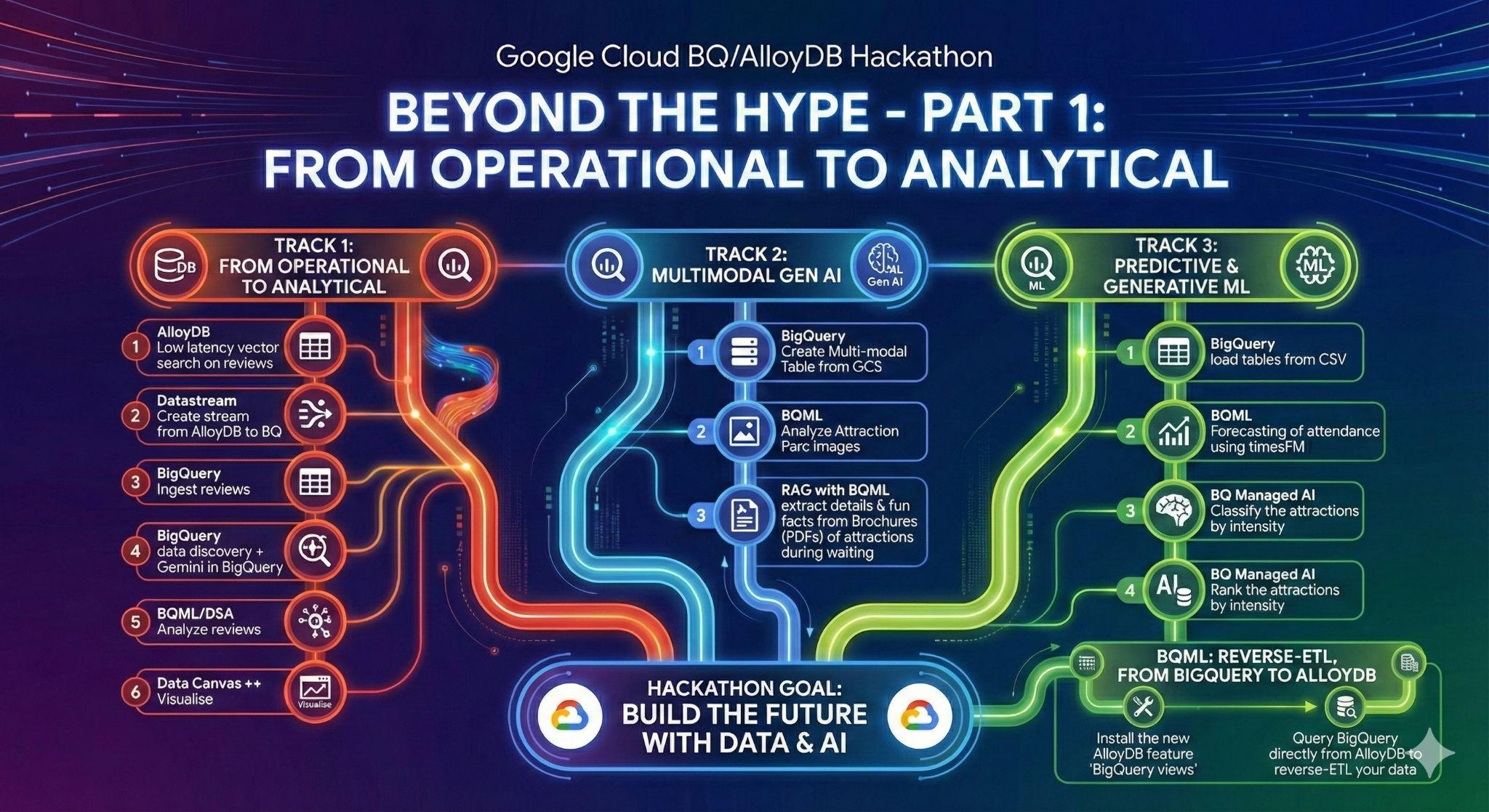
3. Attività 1: da operativo ad analitico; analizza le recensioni di Disneyland con Gemini
Per questa fase iniziale, recupererai i dati dal database operativo AlloyDB e li caricherai in BigQuery per l'analisi successiva.
Configurerai anche tutto il necessario in AlloyDB per il tuo futuro agente.
Caricamento dei dati in AlloyDB
Innanzitutto, importiamo alcuni dati nel nostro cluster AlloyDB per PostgreSQL.
Inseriremo 20.000 recensioni per i parchi divertimento Disneyland e un elenco di attrazioni.
Ecco i passaggi da seguire:
Creazione di tabelle:
- Crea una tabella disneyland_reviews con 6 colonne: review_id e rating come numeri interi, year_month, reviewer_location, review_text, branch come testo.
- Crea una tabella disneyland_attractions con 4 colonne: attraction_id come numero intero, branch, name e description come testo.
Utilizzando lo strumento che preferisci, importa i dati dai file CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvper la tabella delle recensionigs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvper la tabella delle attrazioni
Per fornire consigli sulle attrazioni, dobbiamo creare incorporamenti della descrizione delle attrazioni:
- Installa l'estensione pgvector in AlloyDB
- Aggiungi una colonna vettoriale chiamata "embedding" alla tabella Attrazione
- Genera e compila l'embedding delle descrizioni utilizzando l'integrazione nativa tra AlloyDB e Vertex AI
Da operativi ad analitici con Datastream
Per trasmettere i nostri dati da AlloyDB a BigQuery, utilizzeremo Google Datastream. Si tratta di una potente soluzione serverless che rileva tutte le modifiche nelle tabelle di origine (utilizzando Change Data Capture (CDC)) e le invia a BigQuery.
Per poter replicare le modifiche da AlloyDB con Datastream, dobbiamo creare una pubblicazione e uno slot di replica su Postgres.
Esegui le seguenti query sul tuo cluster AlloyDB (devi eseguirle una alla volta):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Utilizzerai lo slot di pubblicazione e replica nel tuo stream, quindi ricorda i nomi.
È tutto, ora possiamo creare uno stream.
I passaggi da seguire in Datastream sono i seguenti:
- Crea un profilo di origine per il tuo cluster AlloyDB (utilizza l'indirizzo IP pubblico)
- Crea un profilo di destinazione per BigQuery
- Crea un flusso di dati da AlloyDB a BigQuery.
I dati dovrebbero essere disponibili in BigQuery in pochi minuti.
Individuazione dei dati in BigQuery
Ora che abbiamo i dati in BigQuery, assicuriamoci di conoscere i nuovi miglioramenti dell'interfaccia prima di iniziare a lavorare.
Abbiamo tre nuove funzioni che puoi già vedere nel riquadro di esplorazione di BigQuery.
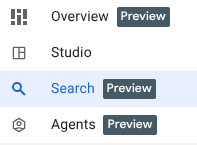
- Panoramica:contiene informazioni sulle funzionalità di BigQuery, tour per iniziare l'analisi e altre possibilità.
- Cerca:esegui la ricerca semantica nelle tue risorse di dati.
- Agenti: shhh! Lo lasciamo per un altro momento 🤫
Eseguire ricerche semantiche nei dati in BigQuery
Vai alla scheda Cerca nel riquadro di esplorazione di BigQuery e prova i termini correlati a Disney, come "attrazioni" o "filiale".
Visualizzare i dati in BigQuery
Ora puoi visualizzare e manipolare i tuoi dati in BigQuery. Per farlo, puoi eseguire questa query in una nuova scheda di query:
SELECT
*
FROM
[dataset_name].[table_name];
Generare approfondimenti sui dati nella tabella delle recensioni
In questa attività, abiliterai gli approfondimenti sui dati nella tabella disneyland_reviews all'interno del set di dati disney.
Data Insights è uno strumento per chiunque voglia esplorare i propri dati e ottenere informazioni approfondite senza scrivere query SQL complesse.
L'operazione potrebbe richiedere alcuni minuti.
Esegui query sulla tabella disneyland_reviews senza SQL
Gli approfondimenti che hai generato nella sezione precedente sono ora pronti. In questa attività, utilizzerai un prompt generato da questi approfondimenti per eseguire query sulla tabella disneyland_reviews senza utilizzare codice.
Seleziona un approfondimento ed esegui la query associata. Ad esempio, trova la query che calcola la differenza nella valutazione media tra mesi consecutivi per ogni filiale. Avrà questo aspetto:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Utilizzare BigQuery Knowledge Engine per comprendere meglio i dati
Per prima cosa, esaminiamo la scheda Approfondimenti a livello di set di dati. In questo modo, avremo un'idea delle relazioni nascoste tra le tabelle nel set di dati Disney. A questo punto:
- Genera una descrizione del set di dati utilizzando Gemini e aggiungila ai dettagli del set di dati.
- Genera una descrizione delle recensioni e delle attrazioni delle tabelle, nonché di tutte le singole colonne di queste tabelle, e salvala.
Eseguire una scansione di profilazione dei dati
L'obiettivo di questa sezione è pulire e preparare i dati. Tuttavia, non hai molta familiarità con la distribuzione dei valori di ogni colonna. Devi profilare i dati per sapere quali tipi di passaggi di trasformazione devi eseguire.
Il Catalogo universale Dataplex di Google Cloud automatizza le scansioni di profilazione per fornire metriche di qualità dei dati coerenti. Le statistiche chiave identificate includono conteggi nulli, valori distinti, intervalli di dati e distribuzioni di valori. È possibile attivare una scansione di profilazione tramite l'interfaccia BigQuery.
L'operazione può richiedere alcuni minuti, quindi puoi leggere la sezione successiva durante l'attesa.
Rispondi alle seguenti domande:
- Qual è la valutazione media di Disneyland?
- Dove si trovano la maggior parte dei recensori?
- Tutte le recensioni sono uniche?
- Qual è la percentuale di dati mancanti nella colonna Year_Month?
Esegui una scansione della qualità dei dati
La qualità dei dati automatica di Dataplex Universal Catalog ti consente di definire e misurare la qualità dei dati nelle tabelle BigQuery. Puoi automatizzare la scansione dei dati, convalidarli in base a regole definite e registrare avvisi se i dati non soddisfano i requisiti di qualità. Puoi gestire le regole e le implementazioni della qualità dei dati come codice, migliorando l'integrità delle pipeline di produzione dei dati.
In base alla scansione di profilazione, definisci una scansione della qualità (su non più del 10% dei tuoi dati come dimensione del campione) che:
- Verifica la presenza di valori nulli per la colonna "branch"
- Esegue un controllo di validità per "rating", in quanto può essere solo nell'insieme : 1,2,3,4,5
- Verifica l'unicità di "review_id"
Assicurati che la scansione esporti i risultati in una tabella BigQuery quality_scan_results.
Pensa a tutte le potenziali trasformazioni che devi applicare ai tuoi dati.
Preparare i dati utilizzando la preparazione dei dati di Gemini
Dopo le scansioni della qualità dei dati e della profilazione che hai eseguito, è il momento di pulire i dati prima di analizzarli.
Le preparazioni dei dati sono risorse BigQuery che utilizzano Gemini in BigQuery per analizzare i tuoi dati e fornire suggerimenti intelligenti per la pulizia, la trasformazione e l'arricchimento. Puoi ridurre notevolmente il tempo e l'impegno necessari per le attività manuali di preparazione dei dati.
In questa sezione utilizzerai la preparazione dei dati per eseguire queste operazioni sulla tabella disneyland_reviews:
- Filtra le righe in cui la colonna Filiale è NULL o una stringa vuota.
- Sostituisci "missing" in Year_Month con Null.
- Sostituisce i trattini bassi con spazi nella colonna del ramo per migliorare la leggibilità
- Esporta nella tabella trasformata disneyland_reviews_cleaned
Analizzare le recensioni con Gemini
Ora che hai pulito i dati, puoi iniziare ad analizzarli utilizzando BigQuery ML e i modelli Gemini. Hai due obiettivi:
- Estrarre le categorie dalle recensioni
- Analisi del sentiment di disneyland_reviews
BigQuery ML ti consente di creare ed eseguire modelli di machine learning (ML) utilizzando query GoogleSQL. I modelli BigQuery ML vengono archiviati nei set di dati BigQuery, in modo simile a tabelle e viste. BigQuery ML ti consente anche di accedere ai modelli Vertex AI e alle API Cloud AI per eseguire attività di intelligenza artificiale (AI) come la generazione di testo o la traduzione automatica. Gemini in Google Cloud fornisce anche assistenza basata sull'AI per le attività BigQuery.
Puoi scegliere di utilizzare ML.GENERATE_TEXT o AI.GENERATE (anteprima) con i modelli Gemini Pro o Flash.
I seguenti passaggi ti guidano se vuoi utilizzare ML.GENERATE_TEXT.
Crea la connessione alla risorsa cloud e concedi il ruolo IAM
Devi creare una connessione alle risorse Cloud in BigQuery ai modelli Vertex AI per poter lavorare con i modelli Gemini Pro e Gemini Flash. Concederai anche le autorizzazioni IAM del service account della connessione alla risorsa cloud, tramite un ruolo, per consentirgli di accedere ai servizi Vertex AI.
Concedi il ruolo Utente Vertex AI al service account della connessione
Consenti al service account della connessione di utilizzare il modello scelto (ad esempio gemini-2.5-flash) concedendogli il ruolo Utente Vertex AI. La propagazione dell'autorizzazione richiede 1 minuto.
Crea i modelli Gemini in BigQuery
Crea il modello utilizzando la connessione sopra indicata. Utilizza ad esempio l'endpoint gemini-2.5-flash.
Chiedere a Gemini di analizzare le recensioni dei clienti per categorie e sentiment
In questa attività, utilizzerai il modello Gemini per analizzare ogni recensione del cliente in base a categorie e sentiment, positivo o negativo.
Analizzare le recensioni dei clienti per le categorie
Nota: d'ora in poi, per l'analisi, prenderemo in considerazione solo 100 righe, poiché la chiamata di Gemini su 20.000 righe può richiedere un po' di tempo.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Questa query prende le recensioni dei clienti dalla tabella disneyland_reviews, crea prompt per il modello gemini per identificare le categorie all'interno di ogni recensione. I risultati devono essere archiviati in una nuova tabella reviews_categories
. Attendi. Il modello impiega circa 30 secondi per elaborare i record delle recensioni dei clienti e per avere i risultati nella tabella di output.
Visualizza i risultati:
SELECT * FROM [dataset_name].[results_table_name];
Leggi alcune categorie.
Analizza le recensioni dei clienti per individuare il sentiment positivo e negativo
In base alla query SQL per l'estrazione delle parole chiave, scrivi una query che analizzi la recensione in Positiva, Negativa e Neutra in una colonna denominata "sentiment".
Questa query prende le recensioni dei clienti dalla tabella disneyland_reviews, crea prompt per il modello gemini per classificare il sentiment di ogni recensione. I risultati vengono poi archiviati in una nuova tabella reviews_analysis, in modo da poterli utilizzare in un secondo momento per ulteriori analisi. Attendi. Il modello impiega alcuni secondi per elaborare i record delle recensioni dei clienti. Al termine dell'operazione, il risultato si trova nella tabella reviews_analysis creata.
Esplora i risultati:
SELECT * FROM [...];
La tabella reviews_analysis ha la colonna Sentiment contenente l'analisi del sentiment, con le colonne social_media_source, review_text, customer_id, location_id e review_datetime incluse. Dai un'occhiata ad alcuni dei record. Potresti notare che alcuni risultati positivi e negativi non sono formattati correttamente, con caratteri estranei come punti o spazi aggiuntivi. Puoi sanificare i record utilizzando la visualizzazione riportata di seguito.
Crea una visualizzazione per sanificare i record
Crea una visualizzazione che pulisce i valori della colonna Sentiment:
- Utilizzando LOWER per assicurarti che tutti i valori siano in minuscolo.
- Rimozione della punteggiatura (., , e spazio) utilizzando REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
La query crea la visualizzazione cleaned_data_view e include i risultati del sentiment, il testo della recensione, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Prende quindi il risultato del sentiment (positivo o negativo) e si assicura che tutte le lettere siano minuscole e che i caratteri estranei come spazi o punti aggiuntivi vengano rimossi. La visualizzazione risultante semplificherà l'ulteriore analisi nei passaggi successivi di questo lab.
- Puoi eseguire una query sulla visualizzazione con la query riportata di seguito per visualizzare le righe create.
SELECT * FROM [view_name];
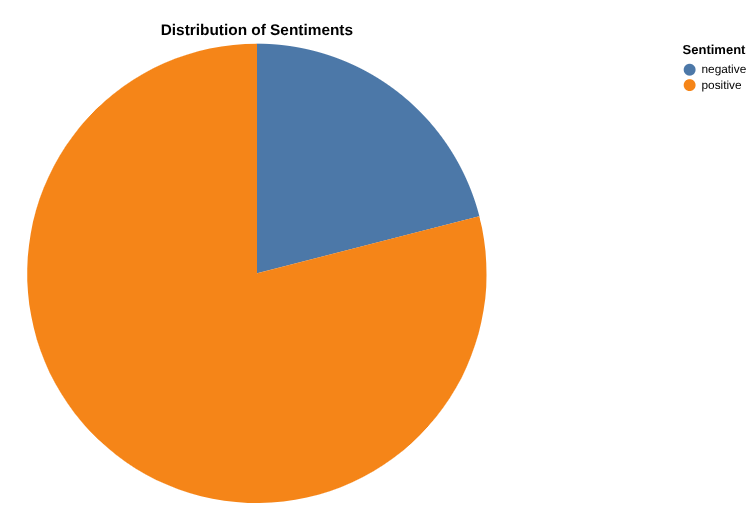
Creare un report dei conteggi delle recensioni positive e negative con Data Canvas
Ora è il momento di analizzare i risultati. Iniziamo a farlo direttamente in BigQuery, tramite il canvas di dati. Questo strumento ti consente di cercare dati (semanticamente o per parola chiave), eseguire query e unire tabelle, creare grafici e ottenere approfondimenti creando un flusso di canvas.
L'obiettivo finale è creare un grafico a tua scelta delle percentuali di recensioni positive e negative . Ecco un esempio:
Crea un grafico del numero di recensioni per categoria, nonché la distribuzione delle recensioni positive e negative per ciascuna categoria
Suggerimento: attiva e utilizza l'analisi avanzata di Data Canvas, che esegue un notebook Python all'interno di un canvas.
4. Attività 2: analizza le immagini del parco divertimenti per identificare le foto di Disneyland ed estrai curiosità dalle brochure del parco
Analisi delle immagini in BigQuery
Hai accesso ad alcune foto emozionanti e accattivanti del parco divertimenti scattate dai visitatori nel corso degli anni. Non vedi l'ora di partire per il tuo prossimo viaggio in programma. Tuttavia, non sai quali sono le foto reali di Disneyland. Il tuo compito è identificarli. Le immagini si trovano in gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: True
Per eseguire rapidamente questa analisi. Devi utilizzare le tabelle degli oggetti di BigQuery e Gemini tramite BigQuery ML (ML.GENERATE_TEXT).
Puoi verificare l'output di Gemini controllando alcune foto?
Crea il tuo sistema RAG con BigQuery sulle brochure di Disneyland
Mentre aspetti in coda, vuoi conoscere alcune curiosità o dettagli tecnici sull'attrazione che stai aspettando.
In gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, troverai i file PDF contenenti le brochure di tutti i parchi del mondo.
Obiettivo:creare un sistema Retrieval-Augmented Generation (RAG) interamente in BigQuery per consentire agli utenti di porre domande complesse sul parco in base ad alcuni documenti PDF.
A questo scopo, devi:
- Crea una tabella di oggetti di file PDF
- Crea una funzione definita dall'utente Python per dividere i file PDF in blocchi. Ecco un esempio che puoi utilizzare:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Analizza il file PDF in blocchi
- Generare embedding dopo aver creato un modello remoto
- Esegui una ricerca vettoriale per trovare "
Ou manger un repas tex-mex à volonté?" o "where to eat a tex-mex meal buffet-style?" - Genera una risposta arricchita dai risultati della ricerca vettoriale della domanda "
Ou manger un repas tex-mex à volonté?" o ""where to eat a tex-mex meal buffet-style?"
5. Attività 3: machine learning su larga scala con BigQuery: previsione, classificazione e ranking
Previsione dei tempi di attesa
Le foto sono molto belle. Non vedi l'ora! Ora, per sapere quali attrazioni scegliere e quali evitare, vuoi conoscere i tempi di attesa effettivi per alcune attrazioni tra Parigi e la California. Il tuo compito è prevedere i tempi di attesa di ogni attrazione utilizzando il machine learning (ARIMA_PLUS o TimesFM) ogni 30 minuti nel 2025.
I dati che utilizzerai si trovano in questo file CSV: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
I passaggi dell'attività sono:
- Carica il file nel set di dati BigQuery in una tabella chiamata waiting_times.
- Addestra un modello di previsione sui tuoi dati (Arima_Plus) o esegui la previsione direttamente utilizzando AI.Forecast
- Valuta le prestazioni del modello o confronta i dati previsti con i dati di input.
Classificare le corse in base all'intensità
Stai visitando Disneyland con gli amici e, anche se il parco è generalmente adatto alle famiglie, alcune giostre possono essere troppo intense per alcune persone. Utilizziamo le funzioni AI gestite di BigQuery per classificare le attrazioni in base al livello di brivido e intensità, senza pregiudizi umani, in modo da soddisfare tutti.
- Utilizza
AI.CLASSIFYper classificare le corse in base alle loro descrizioni in una delle tre categorie magiche: [easy-peasy, thrilling, extreme]
Classificare le giostre in base al livello di brivido
- Utilizza
AI.SCOREper confrontare e ordinare le attrazioni in base a un livello di brivido, dove il livello 10 è il più estremo e il livello 1 il meno.
6. Attività 3 - Bonus: ETL inverso, da BigQuery ad AlloyDB
Hai sfruttato le potenti funzionalità di BigQuery per generare approfondimenti su grandi quantità di dati. Ora vuoi che questi approfondimenti siano utilizzabili dalle tue applicazioni operative (e dagli agenti AI).
Ma come? Facendo il contrario. AlloyDB per PostgreSQL è ideale per pubblicare dati con bassa latenza e alta velocità, perfetto per le applicazioni critiche rivolte agli utenti. Quindi eseguiamo l'ETL inversa dei dati che abbiamo appena generato.
Per farlo, utilizzeremo una nuova funzionalità, ancora in anteprima privata, chiamata "Viste BigQuery" in AlloyDB. Questa funzionalità ti consente di eseguire query sui dati BigQuery direttamente nel tuo database Postgres.
Innanzitutto, devi concedere al service account del cluster AlloyDB i privilegi necessari per eseguire query su BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
L'output contiene un campo serviceAccountEmail, che è l'account di servizio per questo cluster.
Nella console Google Cloud, vai alla pagina IAM e concedi i seguenti privilegi a questa entità:
- Visualizzatore dati BigQuery (roles/bigquery.dataViewer)
- Utente sessione di lettura BigQuery (roles/bigquery.readSessionUser)
Ora vai ad AlloyDB Studio nella console e connettiti al database "postgres".
Esegui le seguenti query per installare e configurare la nuova funzionalità:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Ora puoi creare una "tabella esterna" che verrà mappata a una tabella corrente in BigQuery. Utilizza una delle tabelle che hai creato nell'attività 3. Ecco un esempio della sintassi:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Tutto pronto, eseguiamo una query sulla tabella. Esegui una prima istruzione SELECT per convalidare il collegamento tra AlloyDB e BigQuery e infine crea una nuova tabella in AlloyDB per importare i dati dalla tabella esterna.
7. Attività 4: agenti di dati predefiniti
Hai amici che vogliono contribuire al progetto dell'applicazione Disneyland. Hanno accesso ai dati in BigQuery, ma hanno livelli diversi di conoscenza di SQL e data engineering. Vuoi sfruttare gli annunci recenti di BigQuery relativi agli agenti di dati già integrati nell'interfaccia utente per aiutare i tuoi amici:
- Crea pipeline di dati.
- Collabora al codice SQL.
- Parlare con i loro dati.
Agenti di data engineering per automatizzare le pipeline di dati
Crea una nuova vista average_waiting_time che unisce la tabella waiting time e attractions e calcola la waiting_time media per attrazione utilizzando Data Engineering Agent.
Creare l'agente di analisi conversazionale in BigQuery
E se potessi creare un agente per interagire con i tuoi dati, senza programmazione, senza SQL e senza deployment, e dall'interfaccia di BigQuery? Non sarebbe fantastico? Oggi è possibile grazie alla scheda "Agenti" in BigQuery.
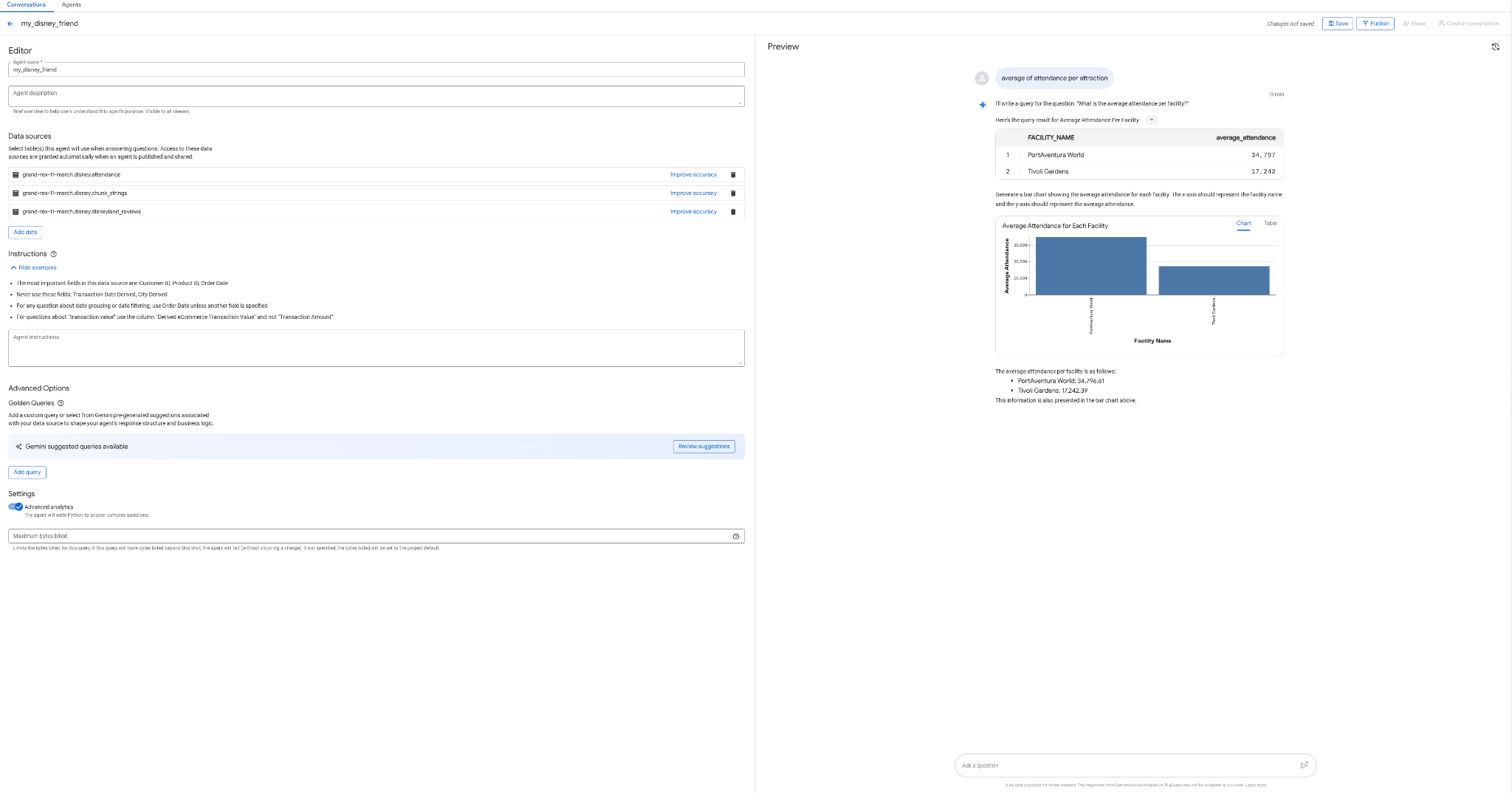
- Crea un agente my_disney_friend che si connette alle tue tabelle Disney. Puoi migliorare il rendimento dell'agente compilando le istruzioni dell'agente. Poni domande come "Qual è la percentuale di recensioni positive rispetto a quelle negative, qual è il tempo di attesa medio per attrazione e così via?"
- Pubblica l'agente in BigQuery e nell'API (lo utilizzerai in un secondo momento).
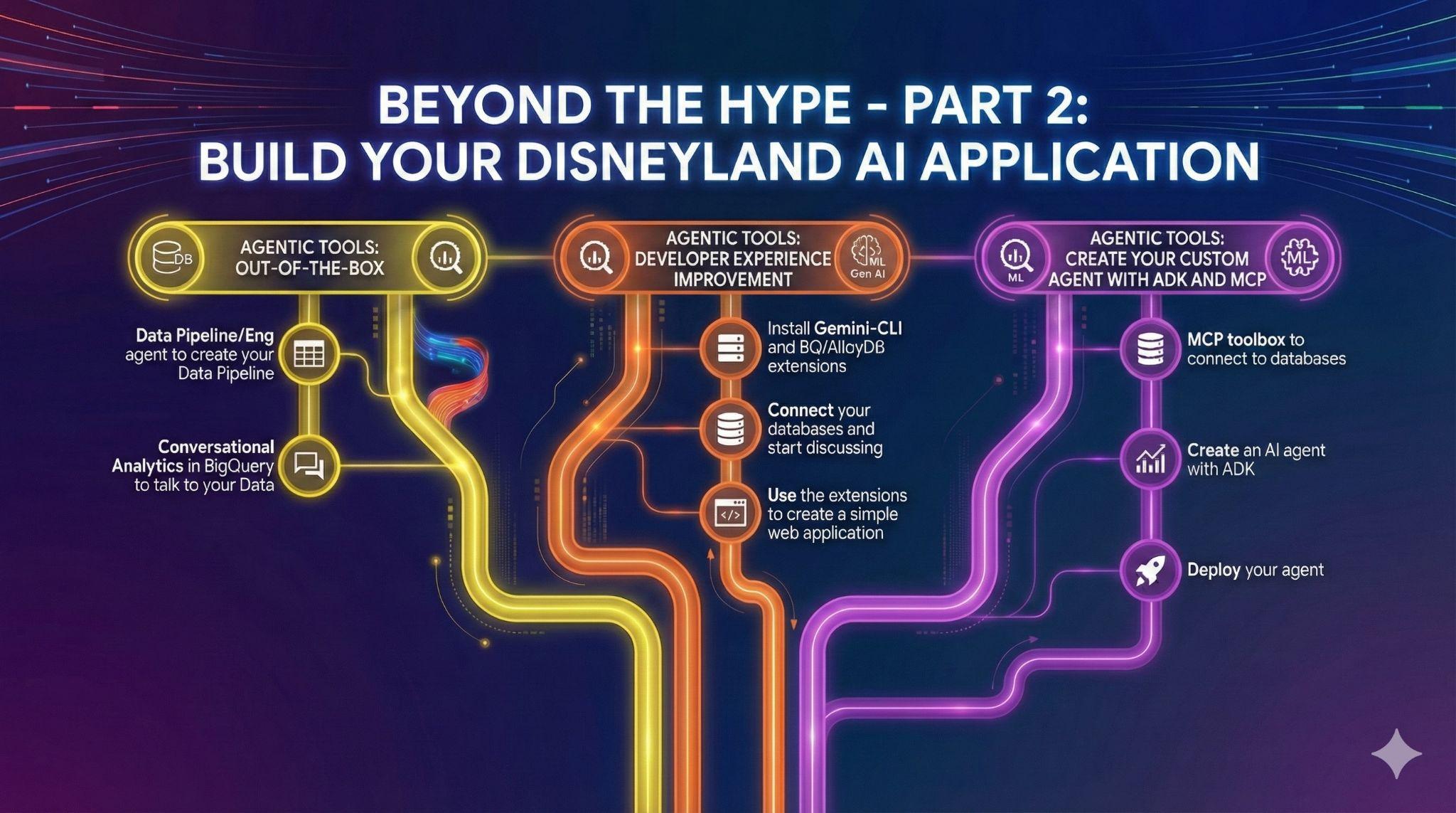
8. Attività 5: migliora la tua esperienza di sviluppo con Gemini CLI
In questa era dell'AI, creare software non è mai stato così accessibile. Hai migliaia di idee per la tua applicazione Disneyland e vuoi utilizzare i tuoi dati al massimo della loro capacità. Vuoi andare oltre la semplice analisi dei dati e passare all'azione.
Per aiutarti in questo percorso, avrai bisogno di aiuto. E abbiamo pensato a tutto.
Gemini CLI è un agente AI open source che porta la potenza di Gemini direttamente nel tuo terminale. Gli sviluppatori possono creare applicazioni potenti e, grazie alle estensioni, possono anche interagire con vari server MCP (Model Context Protocol).
Tra queste, puoi ovviamente trovare estensioni per eseguire query sui dati AlloyDB o BigQuery.
In questa attività, il tuo obiettivo è:
- Installa Gemini CLI (nel tuo terminale o in Cloud Shell)
- Installa le estensioni Gemini CLI di BigQuery e AlloyDB
- Crea un file di ambiente che consenta a Gemini-CLI di connettersi alle tue istanze BigQuery e AlloyDB
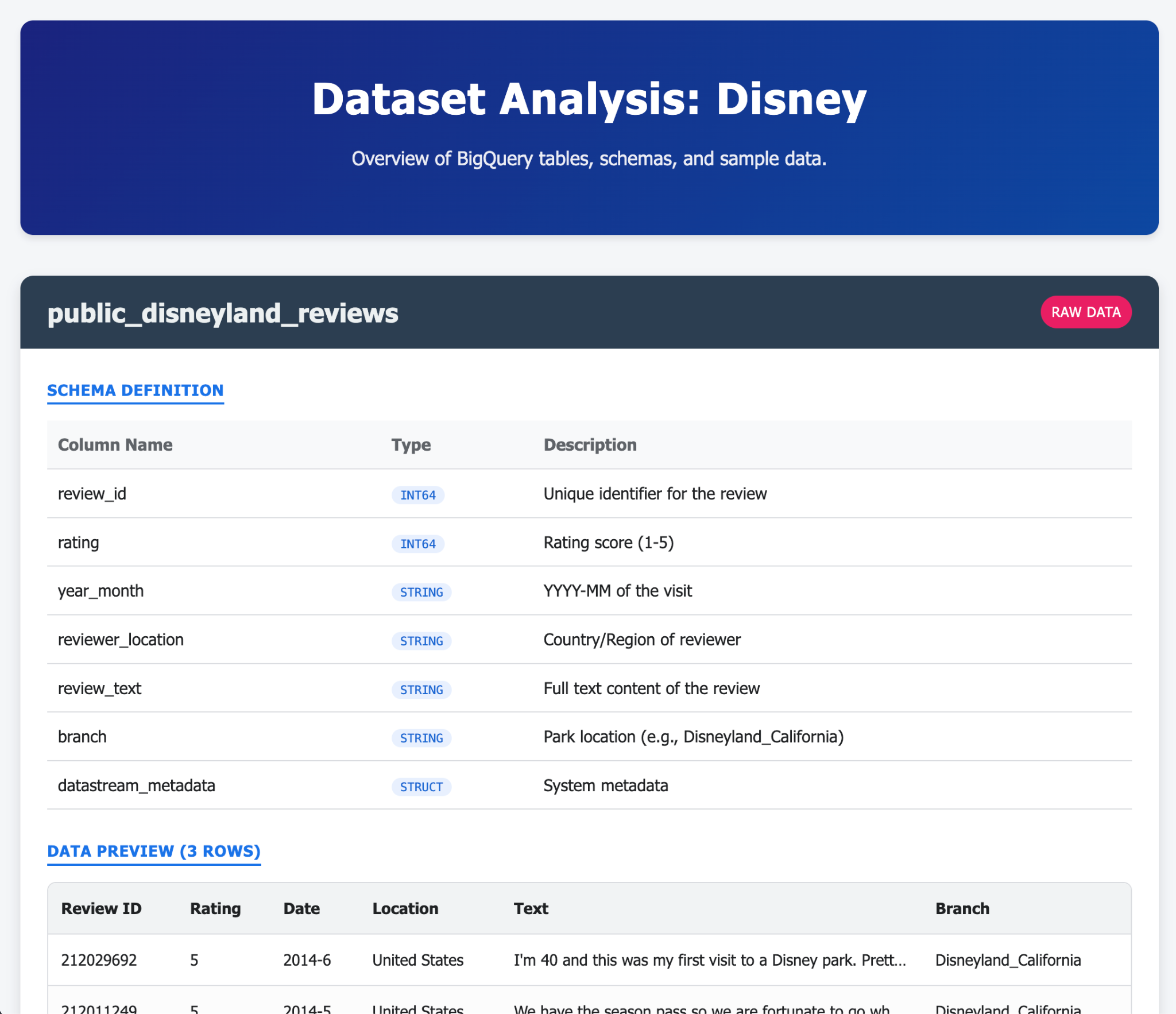
- Chiedi a Gemini-CLI di generare una singola pagina HTML elaborata che spieghi i contenuti del tuo database AlloyDB
- Fai lo stesso per BigQuery.
Ecco alcuni esempi di ciò che potresti generare in un singolo prompt (o pochi) con Gemini CLI e le relative estensioni. Ora immagina di poterlo fare con applicazioni reali. 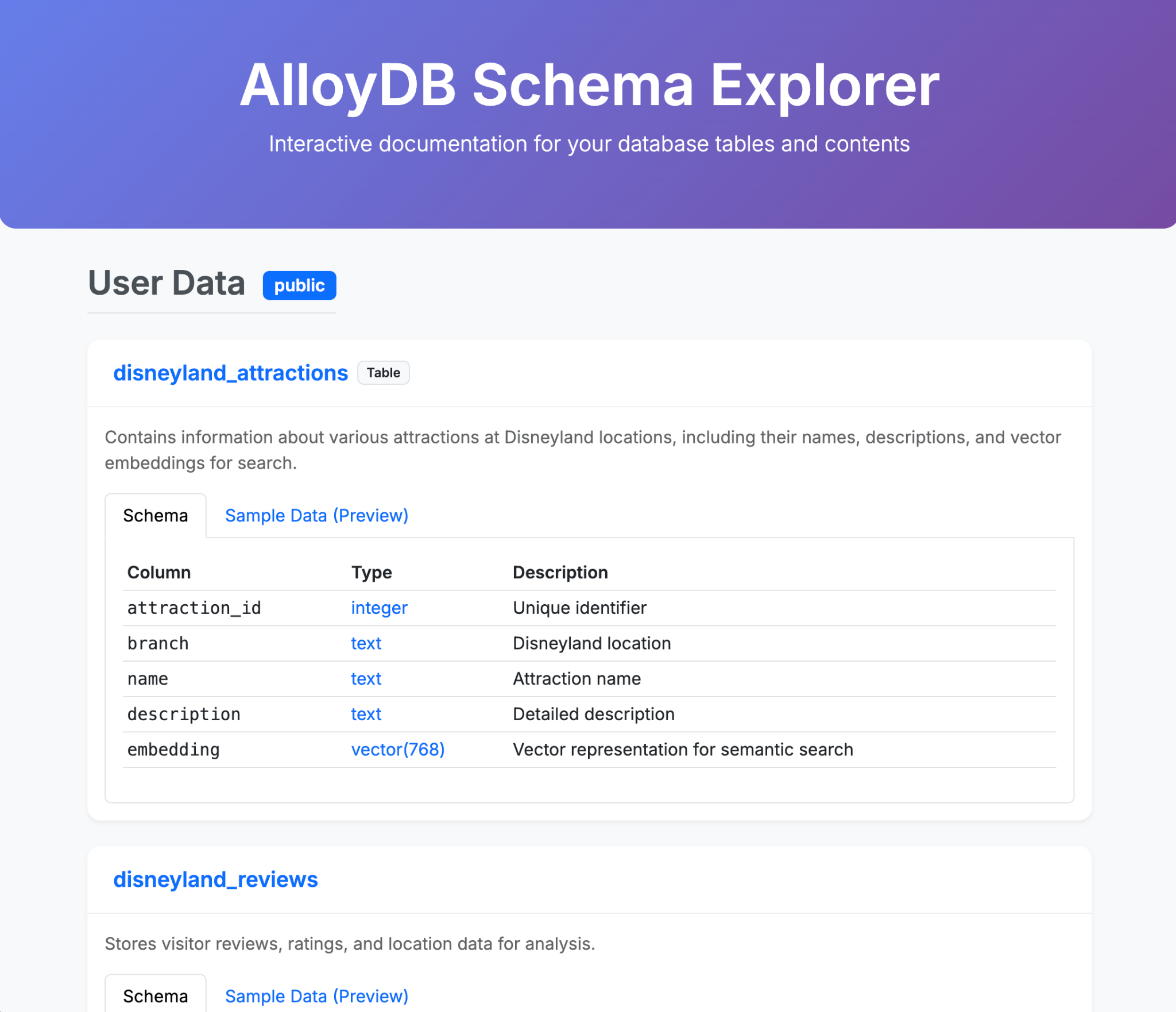
9. Attività 6: crea un agente AI per interagire con i tuoi dati
Per offrire una nuova esperienza utente ai visitatori di Disneyland, creerai un assistente che possa aiutarli durante il loro viaggio. Il tuo agente potrà:
- Elenca tutte le attrazioni disponibili nel parco
- Consigliare un'attrazione in base alle aspettative
- Aggiungere recensioni per un'attrazione
- Fornire una stima del tempo di attesa per un'attrazione nelle prossime ore
- Fornisci una panoramica delle recensioni per un'attrazione specifica
Assicurati che l'assistente possa rispondere solo a domande relative a Disneyland e che mantenga un tono amichevole con l'utente. Modifica il prompt dell'agente per assicurarti che scelga gli strumenti giusti per le esigenze dell'utente.
I passaggi da seguire sono:
- Esegui il deployment di un server MCP Toolbox for Databases che utilizza AlloyDB e BigQuery come origini
- Dichiara 5 strumenti diversi per il server MCP che eseguono query su AlloyDB e BigQuery e mappano le azioni dell'agente elencate in precedenza
- Utilizza l'interfaccia utente di MCP Toolbox per convalidare ciascuno dei tuoi strumenti
- Esegui il deployment di un agente utilizzando l'Agent Development Kit in grado di utilizzare gli strumenti esposti dal server MCP Toolbox
- Connettiti all'interfaccia web di ADK e mostra una discussione completa con l'assistente, inclusi tutti gli strumenti disponibili
Passaggio bonus se finisci in anticipo:
L'agente è pronto? Eseguiamo il deployment su Agent Engine.