
1. 🏰 디즈니랜드 데이터 분석 해커톤 (2판 - 12월 3일) 🏰
요약 | 이 해커톤에서는 Google Cloud의 AI/ML 기능을 활용하여 엔드 투 엔드 데이터 분석 파이프라인을 빌드합니다. 까다로운 워크로드에 최적화된 완전 관리형 PostgreSQL 호환 데이터베이스인 AlloyDB에 데이터를 로드한 다음 서버리스 변경 데이터 캡처 (CDC) 서비스인 Datastream을 사용하여 Google Cloud의 서버리스 데이터 웨어하우스인 BigQuery로 데이터를 이동합니다. BigQuery에서는 표준 SQL을 사용하여 BigQuery에서 직접 머신러닝 모델을 만들고 실행할 수 있는 BigQuery ML을 적용하여 리뷰 분석 및 출석 예측을 수행합니다. 마지막으로 대화형 분석 및 데이터 에이전트를 통해 기본적으로 제공되는 에이전트를 사용하거나 에이전트 개발 키트 및 MCP 도구 상자를 사용하여 데이터와 자연어로 상호작용하는 맞춤 에이전트를 만듭니다. |
categories | docType:Codelab, product:Bigquery |
저자 | Rayhane Rezgui, Matt Cornillon |
레이아웃 | 스크롤 |
로봇 | NOINDEX |
2. 소개
미래의 디즈니 데이터 마법사 여러분, 환영합니다!🪄
지루한 여행 가이드와 끝없는 포럼 스크롤은 잊으세요. 데이터 기반 통계를 활용하여 완벽한 디즈니랜드 여행을 계획한다고 가정해 보겠습니다. 어느 공원이 가장 좋은 경험을 제공하나요? 언제 가장 한산한가요? 악명 높은 긴 대기열을 뚫을 최적의 시간을 예측해 줄 수 있어?
이 해커톤에서는 최고의 디즈니랜드 계획 도구를 빌드합니다. 전 세계 지점의 방문자 리뷰, 이전 대기 시간, 출석률 등 다양한 데이터를 확인할 수 있습니다. 너의 임무는? 이 원시 데이터를 활용 가능한 인사이트로 변환해 줘.
- 데이터 수집: 고성능 PostgreSQL 호환 데이터베이스인 AlloyDB에 다양한 디즈니랜드 리뷰, 대기 시간, 출석률을 로드합니다.
- 원활한 이동: Google Cloud의 강력한 서버리스 데이터 웨어하우스인 BigQuery로 이 동적 정보를 간편하게 이동하려면 Google의 서버리스 변경 데이터 캡처 서비스인 Datastream을 사용하세요.
- 마법 예측: BigQuery ML을 활용하여 SQL로 직접 리뷰 감정을 분석하고 대기 시간을 예측하세요. 지점별로 고객에게 미소를 선사하는 곳과 방문하기에 가장 좋은 시간을 알아보세요.
- 데이터와 대화하기: 지팡이를 휘두르는 것만으로도 통계를 얻을 수 있는 사전 빌드 도구를 사용하세요.
- 지능형 상호작용: 데이터베이스용 MCP 도구 상자 및 ADK (에이전트 개발 키트)로 구동되는 지능형 에이전트로 창작물을 완성하세요. '우주를 좋아하는 사람에게 디즈니랜드 파리에서 가장 좋은 어트랙션은 뭐야? 줄을 서기에 가장 좋은 시간은 언제야?'라고 물어보면 데이터 기반의 답변을 즉시 얻을 수 있습니다.
지구상에서 가장 마법 같은 장소의 비밀을 풀고 미키가 자랑스러워할 데이터 분석 파이프라인을 구축해 보세요.
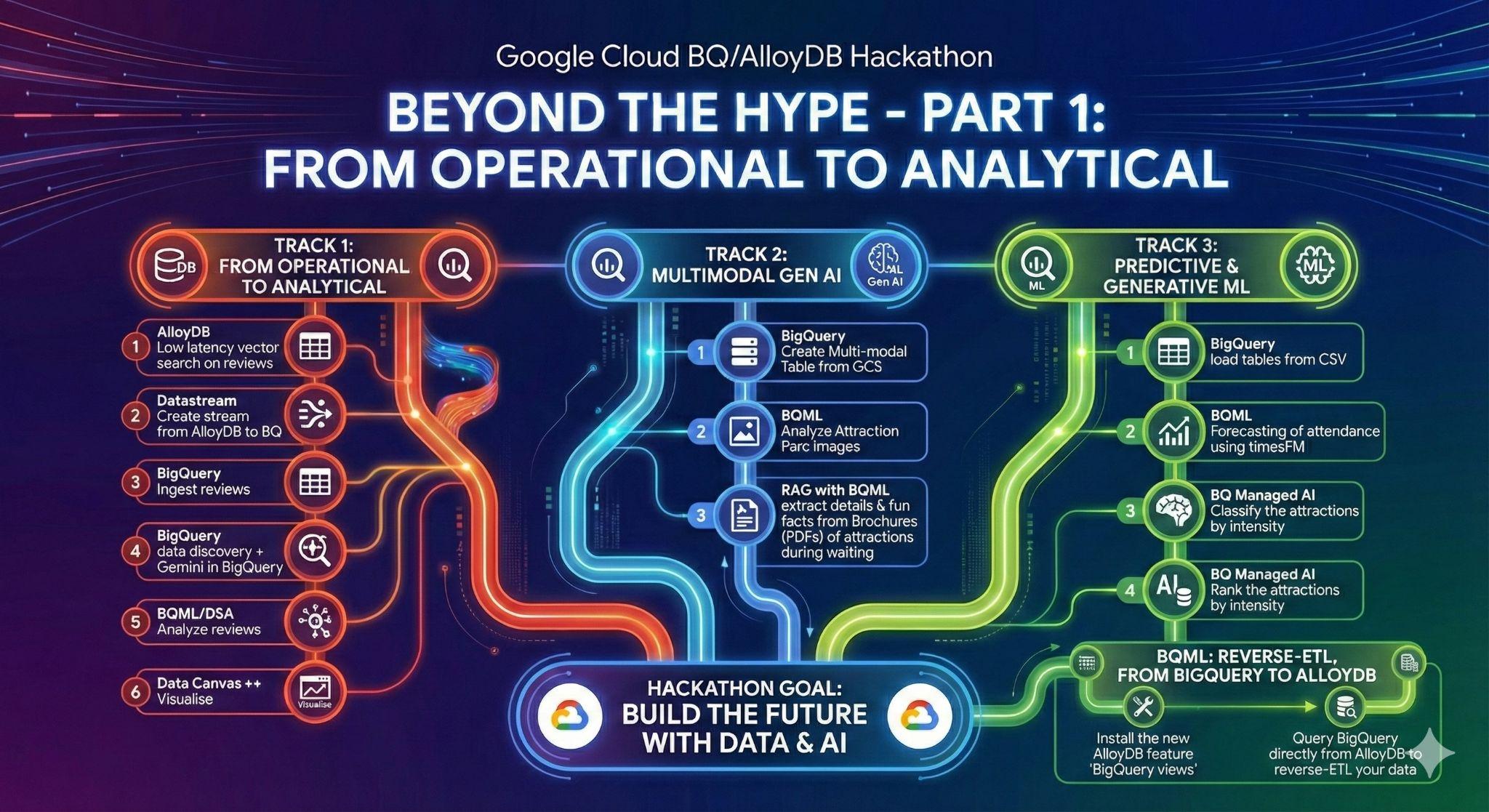
3. 작업 1: 운영에서 분석으로 전환하기: Gemini로 디즈니랜드 리뷰 분석하기
이 초기 단계에서는 AlloyDB 운영 데이터베이스에서 데이터를 가져와 후속 데이터 분석을 위해 BigQuery에 로드합니다.
또한 향후 에이전트에 필요한 모든 것을 AlloyDB에서 설정합니다.
AlloyDB의 데이터 로드
먼저 PostgreSQL용 AlloyDB 클러스터로 데이터를 가져와 보겠습니다.
디즈니랜드 놀이공원의 리뷰 2만 개와 놀이기구 목록을 수집할 예정입니다.
다음 단계를 따르세요.
표 만들기:
- 6개의 열(review_id 및 rating은 정수, year_month, reviewer_location, review_text, branch는 텍스트)이 있는 테이블 disneyland_reviews를 만듭니다.
- attraction_id(정수), branch, name, description(텍스트)의 4개 열이 있는 disneyland_attractions 테이블을 만듭니다.
원하는 도구를 사용하여 CSV에서 데이터를 가져옵니다.
- 리뷰 테이블의
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv - 관광명소 테이블의
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csv
명소 추천을 제공하려면 명소 설명의 임베딩을 만들어야 합니다.
- AlloyDB에 pgvector 확장 프로그램 설치
- 테이블 attraction에 'embedding'이라는 벡터 열을 추가합니다.
- AlloyDB와 Vertex AI 간의 기본 통합을 사용하여 설명의 임베딩 생성 및 채우기
Datastream을 사용하여 운영 데이터에서 분석 데이터로
AlloyDB에서 BigQuery로 데이터를 스트리밍하려면 Google Datastream을 사용합니다. 변경 데이터 캡처를 사용하여 소스 테이블의 모든 변경사항을 수신하고 BigQuery로 전송하는 강력한 서버리스 솔루션입니다.
Datastream으로 AlloyDB의 변경사항을 복제하려면 Postgres에서 게시 및 복제 슬롯을 만들어야 합니다.
AlloyDB 클러스터에서 다음 쿼리를 실행합니다 (한 번에 하나씩 실행해야 함).
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
스트림에서 간행물과 복제 슬롯을 사용하므로 이름을 기억하세요.
이제 스트림을 만들 수 있습니다.
Datastream에서 수행해야 하는 단계는 다음과 같습니다.
- AlloyDB 클러스터의 소스 프로필 만들기 (공개 IP 주소 사용)
- BigQuery용 대상 프로필 만들기
- AlloyDB에서 BigQuery로 스트림을 만듭니다.
몇 분 안에 BigQuery에서 데이터를 사용할 수 있습니다.
BigQuery의 데이터 검색
이제 BigQuery에 데이터가 있으니 작업을 시작하기 전에 인터페이스의 새로운 개선사항을 알아두세요.
BigQuery 탐색 패널에서 이미 확인할 수 있는 3가지 새로운 함수가 있습니다.
- 개요: BigQuery 기능, 분석을 시작하기 위한 둘러보기 등 다양한 정보가 포함되어 있습니다.
- 검색: 데이터 애셋에 대한 시맨틱 검색을 실행합니다.
- 상담사: 조용히 하세요. 나중에 사용할 수 있도록 저장해 두겠습니다 🤫
BigQuery에서 데이터의 의미 검색하기
BigQuery 탐색 패널의 검색 탭으로 이동하여 'attractions' 또는 'branch'와 같은 Disney 관련 용어를 사용해 보세요.
BigQuery에서 데이터 시각화하기
이제 BigQuery에서 데이터를 시각화하고 조작할 수 있습니다. 이를 위해 새 쿼리 탭에서 이 쿼리를 실행할 수 있습니다.
SELECT
*
FROM
[dataset_name].[table_name];
리뷰 테이블에서 데이터 인사이트 생성
이 작업에서는 disney 데이터 세트 안의 disneyland_reviews 테이블에 대한 데이터 인사이트를 사용 설정합니다.
데이터 인사이트는 복잡한 SQL 쿼리를 작성할 필요 없이 간편하게 데이터를 탐색하고 인사이트를 수집하기 원하는 모든 사람을 위한 도구입니다.
몇 분 정도 걸릴 수 있습니다.
SQL 없이 disneyland_reviews 테이블 쿼리하기
이전 섹션에서 생성한 인사이트가 준비되어 있습니다. 이 작업에서는 코드를 사용하지 않고 이 인사이트에서 생성한 프롬프트를 사용하여 disneyland_reviews 테이블을 쿼리해 보겠습니다.
인사이트를 선택하고 관련 쿼리를 실행합니다. 예를 들어 각 지점의 연속된 월 간 평균 평점 차이를 계산하는 쿼리를 찾습니다. 다음과 같이 표시됩니다.
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
BigQuery 지식 엔진을 사용하여 데이터 더 잘 이해하기
먼저 데이터 세트 수준에서 통계 탭을 살펴보겠습니다. 이렇게 하면 disney 데이터 세트의 테이블 간 숨겨진 관계를 파악할 수 있습니다. 그런 다음 다음 단계를 따르세요.
- Gemini를 사용하여 데이터 세트 설명을 생성하고 데이터 세트 세부정보에 추가합니다.
- 테이블 리뷰 및 명소와 해당 테이블의 모든 개별 열에 대한 설명을 생성하고 저장합니다.
데이터 프로필 스캔 실행
이 섹션의 목표는 데이터를 정리하고 준비하는 것입니다. 하지만 각 열의 값 분포에 익숙하지 않습니다. 데이터에 어떤 종류의 변환 단계를 수행해야 하는지 알기 위해서는 데이터의 프로필을 만들어야 합니다.
Google Cloud의 Dataplex Universal Catalog는 일관된 데이터 품질 측정항목을 제공하기 위해 프로파일링 스캔을 자동화합니다. 확인된 주요 통계에는 null 수, 고유 값, 데이터 범위, 값 분포가 포함됩니다. BigQuery 인터페이스를 통해 프로필 스캔을 활성화할 수 있습니다.
몇 분 정도 걸릴 수 있으니 기다리는 동안 다음 섹션을 살펴보세요.
다음 질문에 답변합니다.
- 디즈니랜드의 평균 평점은 얼마인가요?
- 리뷰어는 어디에 가장 많이 있나요?
- 모든 리뷰가 고유한가요?
- Year_Month 열에서 누락된 데이터의 비율은 얼마인가요?
데이터 품질 스캔 실행
Dataplex Universal Catalog의 자동 데이터 품질을 사용하면 BigQuery 테이블의 데이터 품질을 정의하고 측정할 수 있습니다. 데이터 스캔을 자동화하고 정의된 규칙에 따라 데이터를 검증하며 데이터가 품질 요구사항을 충족하지 않으면 알림을 로깅할 수 있습니다. 데이터 품질 규칙과 배포를 코드로 관리하여 데이터 프로덕션 파이프라인의 무결성을 향상시킬 수 있습니다.
프로필 스캔을 기반으로 다음을 충족하는 품질 스캔 (샘플 크기로 데이터의 10% 이하)을 정의합니다.
- 'branch' 열의 null 값을 확인합니다.
- 'rating'이 1, 2, 3, 4, 5 집합에만 있을 수 있으므로 유효성 검사를 실행합니다.
- 'review_id'의 고유성을 확인합니다.
스캔 결과가 BigQuery 테이블 quality_scan_results로 내보내지는지 확인합니다.
데이터에 적용해야 하는 모든 잠재적 변환을 생각해 보세요.
Gemini의 데이터 준비를 사용하여 데이터 준비
데이터 품질 및 프로파일링 스캔을 수행한 후에는 데이터를 분석하기 전에 정리해야 합니다.
데이터 준비는 BigQuery 리소스로, BigQuery의 Gemini를 사용하여 데이터를 분석하고 데이터 정리, 변환, 보강을 위한 지능형 추천을 제공합니다. 수동 데이터 준비 작업에 필요한 시간과 노력을 크게 줄일 수 있습니다.
이 섹션에서는 데이터 준비를 사용하여 disneyland_reviews 테이블에서 다음 작업을 실행합니다.
- '지점' 열이 NULL이거나 빈 문자열인 행을 필터링합니다.
- Year_Month에서 'missing'을 Null로 바꿉니다.
- 가독성을 높이기 위해 브랜치 열에서 밑줄을 공백으로 바꿉니다.
- 변환된 테이블 disneyland_reviews_cleaned로 내보내기
Gemini로 리뷰 분석
데이터를 정리했으므로 BigQuery ML 및 Gemini 모델을 사용하여 데이터를 분석할 수 있습니다. 다음 두 가지 목표가 있습니다.
- 리뷰에서 카테고리 추출
- disneyland_reviews의 감정 분석
BigQuery ML을 사용하면 GoogleSQL 쿼리를 사용하여 머신러닝 (ML) 모델을 만들고 실행할 수 있습니다. BigQuery ML 모델은 테이블 및 뷰와 유사한 BigQuery 데이터 세트에 저장됩니다. BigQuery ML을 사용하면 Vertex AI 모델 및 Cloud AI API에 액세스하여 텍스트 생성 또는 기계 번역과 같은 인공지능 (AI) 작업을 수행할 수 있습니다. 또한 Google Cloud를 위한 Gemini는 BigQuery 태스크에 AI 기반 지원을 제공합니다.
Gemini Pro 또는 Flash 모델과 함께 ML.GENERATE_TEXT 또는 AI.GENERATE (프리뷰)를 사용할 수 있습니다.
ML.GENERATE_TEXT를 사용하려면 다음 단계를 따르세요.
클라우드 리소스 연결을 생성하고 IAM 역할 부여하기
Gemini Pro 및 Gemini Flash 모델로 작업할 수 있도록 BigQuery에서 Vertex AI 모델로 Cloud 리소스 연결을 만들어야 합니다. 또한 역할을 통해 클라우드 리소스 연결의 서비스 계정에 IAM 권한을 부여하여 Vertex AI 서비스에 액세스할 수 있도록 합니다.
연결의 서비스 계정에 Vertex AI 사용자 역할 부여
Vertex AI 사용자 역할을 부여하여 연결의 서비스 계정이 선택한 모델 (예: gemini-2.5-flash)을 사용할 수 있도록 허용합니다. 권한이 전파되는 데 1분이 걸립니다.
BigQuery에서 Gemini 모델 만들기
위의 연결을 사용하여 모델을 만듭니다. 예를 들어 엔드포인트 gemini-2.5-flash.를 사용합니다.
고객 리뷰에서 카테고리와 감정을 분석하도록 Gemini에 프롬프트 입력하기
이 태스크에서는 Gemini 모델을 사용하여 각 고객 리뷰에서 카테고리 및 감정(긍정 또는 부정)을 분석합니다.
고객 리뷰를 분석하여 카테고리 추출하기
참고: 이제부터 분석을 위해 100개의 행만 사용합니다. 20,000개의 행에 대한 Gemini 호출은 시간이 오래 걸릴 수 있기 때문입니다.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
이 쿼리는 disneyland_reviews 테이블에서 고객 리뷰를 가져와 gemini 모델에 각 리뷰 내의 카테고리를 식별하도록 요청하는 프롬프트를 구성합니다. 결과는 새 테이블 reviews_categories에 저장되어야 합니다.
. 잠시 기다려 주세요. 모델이 고객 리뷰 레코드를 처리하고 결과를 출력 테이블에 표시하는 데 약 30초가 소요됩니다.
결과를 표시합니다.
SELECT * FROM [dataset_name].[results_table_name];
시간을 내어 카테고리를 읽어보세요.
고객 리뷰를 분석하여 긍정적 및 부정적 감정 분류하기
키워드 추출을 위한 SQL 쿼리를 기반으로 'sentiment'이라는 열 아래에 리뷰를 긍정, 부정, 중립으로 분석하는 쿼리를 작성해 줘.
이 쿼리는 disneyland_reviews 테이블에서 고객 리뷰를 가져와 gemini 모델에 각 리뷰에 담긴 감정을 분류하도록 요청하는 프롬프트를 구성합니다. 결과는 새 테이블 reviews_analysis에 저장되므로 나중에 추가 분석에 사용할 수 있습니다. 기다려 주세요. 모델이 고객 리뷰 레코드를 처리하는 데 몇 초가 소요됩니다. 모델이 완료되면 생성된 reviews_analysis 테이블에 결과가 표시됩니다.
결과를 살펴봅니다.
SELECT * FROM [...];
reviews_analysis 테이블에는 감정 분석이 포함된 Sentiment 열과 social_media_source, review_text, customer_id, location_id, review_datetime 열이 포함되어 있습니다. 레코드를 살펴봅니다. 마침표, 여분의 공백과 같은 불필요한 문자로 인해 긍정적 및 부정적 감정에 대한 일부 결과의 형식이 올바르게 지정되지 않았을 수 있습니다. 아래의 뷰를 사용하여 레코드를 정리하세요.
레코드를 정리할 뷰 만들기
다음과 같이 열 감정의 값을 정리하는 뷰를 만듭니다.
- LOWER를 사용하여 모든 값이 소문자인지 확인합니다.
- REPLACE를 사용하여 문장 부호 (. 및 , 및 공백) 삭제
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
이 쿼리는 cleaned_data_view 뷰를 생성하며 감정 결과, 리뷰 텍스트, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch를 포함합니다. 그런 다음 감정 결과 (긍정 또는 부정)를 가져와 모든 문자를 소문자로 만들고 마침표, 여분의 공백과 같은 불필요한 문자를 삭제합니다. 이렇게 생성된 뷰를 사용하면 이 실습의 후반부에서 추가 분석을 더 쉽게 수행할 수 있습니다.
- 아래의 쿼리를 사용하여 뷰를 쿼리하면 생성된 행을 볼 수 있습니다.
SELECT * FROM [view_name];
데이터 캔버스로 긍정적 리뷰와 부정적 리뷰의 개수에 대한 보고서 만들기
이제 결과를 분석할 차례입니다. 데이터 캔버스를 통해 BigQuery에서 직접 시작해 보겠습니다. 데이터를 검색 (의미론적 또는 키워드)하고, 테이블을 쿼리하고 조인하고, 캔버스 흐름을 만들어 그래프를 만들고 통계를 얻을 수 있는 도구입니다.
최종 목표는 긍정적 리뷰와 부정적 리뷰의 비율을 원하는 그래프로 만드는 것입니다 . 예를 들면 다음과 같습니다.
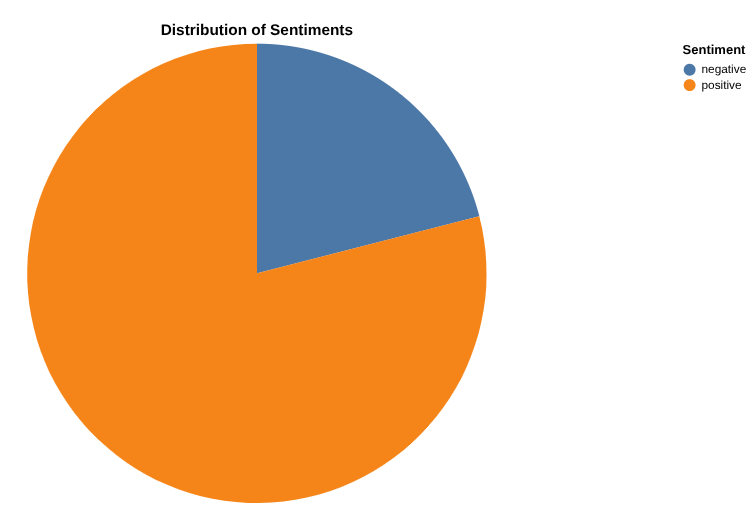
카테고리별 리뷰 수와 각 카테고리의 긍정적 리뷰 및 부정적 리뷰 분포를 그래프로 표시해 줘.
도움말: 캔버스 내에서 Python 노트북을 실행하는 데이터 캔버스의 고급 분석을 활성화하고 사용하세요.
4. 과제 2: 놀이공원 이미지를 분석하여 디즈니랜드 사진을 식별하고 공원 브로셔에서 재미있는 사실 추출
BigQuery의 이미지 분석
방문객이 수년에 걸쳐 촬영한 스릴 있고 매력적인 어트랙션 파르크 사진을 볼 수 있습니다. 다가오는 여행에 무척 설레고 있습니다. 하지만 어떤 사진이 디즈니랜드의 실제 사진인지 알 수 없습니다. 이러한 항목을 식별해야 합니다. 사진은 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/에 있습니다.

Is_disneyland: False

Is_disneyland: True
이 분석을 신속하게 실행하기 위해 BigQuery ML (ML.GENERATE_TEXT)을 통해 BigQuery의 객체 테이블과 Gemini를 사용해야 합니다.
사진을 확인하여 Gemini의 출력을 검증할 수 있나요?
디즈니랜드 브로셔에 대한 BigQuery로 자체 RAG 시스템 만들기
줄을 서서 기다리는 동안 기다리는 어트랙션에 관한 재미있는 사실/기술적 세부정보를 알고 싶습니다.
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,에는 전 세계 모든 공원의 브로셔가 포함된 PDF 파일이 있습니다.
목표: 사용자가 일부 PDF 문서를 기반으로 공원에 관한 복잡한 질문을 할 수 있도록 BigQuery 내에서 검색 증강 생성 (RAG) 시스템을 만듭니다.
이를 위해 다음 단계를 따라야 합니다.
- PDF 파일의 객체 테이블 만들기
- PDF 파일을 청크하는 Python UDF를 만듭니다. 다음은 사용할 수 있는 예입니다.
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- PDF 파일을 청크로 파싱
- 원격 모델을 만든 후 임베딩 생성
- 벡터 검색을 실행하여 '
Ou manger un repas tex-mex à volonté?' 또는 'where to eat a tex-mex meal buffet-style?' 찾기 - '
Ou manger un repas tex-mex à volonté?' 또는 'where to eat a tex-mex meal buffet-style?' 질문의 벡터 검색 결과로 보강된 답변 생성
5. 작업 3: BigQuery를 사용한 대규모 머신러닝: 예측, 분류, 순위 지정
예상 대기 시간
사진이 정말 멋지네요. 기다릴 수 없어요! 이제 어떤 어트랙션을 선택하고 어떤 어트랙션을 피해야 하는지 알기 위해 파리와 캘리포니아의 일부 어트랙션의 실제 대기 시간을 알아야 합니다. 2025년의 30분마다 머신러닝 (Arima plus 또는 TimesFM)을 사용하여 모든 어트랙션의 waiting_times를 예측해야 합니다.
사용할 데이터는 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv CSV 파일에 있습니다.
작업의 단계는 다음과 같습니다.
- waiting_times라는 테이블 아래의 BigQuery 데이터 세트에 파일을 로드합니다.
- 데이터 (Arima_Plus)로 예측 모델을 학습시키거나 AI.Forecast를 사용하여 직접 예측
- 모델 성능을 평가하거나 예측된 데이터를 입력 데이터와 비교합니다.
강도별로 라이드 분류
친구들과 디즈니랜드를 방문했는데, 이 놀이공원은 일반적으로 가족 친화적이지만 일부 놀이기구는 일부 사람들에게 너무 강렬할 수 있습니다. BigQuery 관리형 AI 기능을 사용하여 사람의 편견 없이 스릴과 강도 수준에 따라 명소를 분류하고 순위를 매겨 모든 사람을 만족시킬 수 있도록 해 줘.
AI.CLASSIFY를 사용하여 설명에 따라 놀이기구를 [easy-peasy, thrilling, extreme]의 세 가지 마법 카테고리 중 하나로 분류해 줘.
스릴 수준에 따라 놀이기구 순위 지정
AI.SCORE를 사용하여 스릴 수준에 따라 어트랙션을 비교하고 순위를 지정합니다. 여기서 10위가 가장 극단적이고 1위가 가장 낮습니다.
6. 작업 3-보너스: BigQuery에서 AlloyDB로 역방향 ETL
BigQuery의 강력한 기능을 활용하여 대량의 데이터에 대한 유용한 정보를 생성했습니다. 이제 운영 애플리케이션 (및 AI 에이전트)에서 이러한 통계를 활용할 수 있어야 합니다.
하지만 어떻게 할 수 있을까요? 반대로 하면 됩니다. Postgres용 AlloyDB는 짧은 지연 시간과 빠른 속도로 데이터를 제공하는 데 탁월하므로 중요한 사용자 대상 애플리케이션에 적합합니다. 방금 생성한 데이터를 역방향 ETL해 보겠습니다.
이를 위해 AlloyDB의 'BigQuery 뷰'라는 아직 비공개 프리뷰 단계에 있는 새로운 기능을 사용합니다. 이 기능을 사용하면 Postgres 데이터베이스에서 바로 BigQuery 데이터를 쿼리할 수 있습니다.
먼저 AlloyDB 클러스터 서비스 계정에 BigQuery를 쿼리하는 데 필요한 권한을 부여해야 합니다.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
출력에는 이 클러스터의 서비스 계정인 serviceAccountEmail 필드가 포함됩니다.
Google Cloud 콘솔에서 IAM 페이지로 이동하여 이 보안 주체에게 다음 권한을 부여합니다.
- BigQuery 데이터 뷰어 (roles/bigquery.dataViewer)
- BigQuery 읽기 세션 사용자 (roles/bigquery.readSessionUser)
이제 콘솔에서 AlloyDB Studio로 이동하여 'postgres' 데이터베이스에 연결합니다.
다음 쿼리를 실행하여 새 기능을 설치하고 구성합니다.
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
이제 BigQuery의 현재 테이블에 매핑되는 '외부 테이블'을 만들 수 있습니다. 작업 3에서 만든 테이블을 사용합니다. 다음은 구문의 예입니다.
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
준비가 끝났으니 테이블을 쿼리해 보겠습니다. 첫 번째 SELECT를 실행하여 AlloyDB와 BigQuery 간의 링크를 검증하고 마지막으로 AlloyDB에 새 테이블을 만들어 외부 테이블의 데이터를 수집합니다.
7. 작업 4: 기본 제공 데이터 에이전트
Disneyland Application 프로젝트에 참여하고 싶어 하는 친구가 있습니다. BigQuery의 데이터에 액세스할 수 있지만 SQL 및 데이터 엔지니어링 수준은 다양합니다. UI에 이미 통합되어 있는 데이터 에이전트에 관한 BigQuery의 최근 발표를 활용하여 친구를 지원하고 싶습니다.
- 데이터 파이프라인을 만듭니다.
- SQL 코드 공동작업
- 데이터와 대화하기
데이터 파이프라인 자동화를 위한 데이터 엔지니어링 에이전트
Data Engineering Agent를 사용하여 테이블 waiting_time과 attractions를 조인하고 어트랙션별 평균 waiting_time을 계산하는 새 뷰 average_waiting_time을 만듭니다.
BigQuery에서 대화형 분석 에이전트 만들기
코딩, SQL, 배포 없이 BigQuery 인터페이스에서 데이터와 대화하는 에이전트를 만들 수 있다면 얼마나 멋질까요? BigQuery의 '에이전트' 탭을 사용하면 오늘날에도 가능합니다.
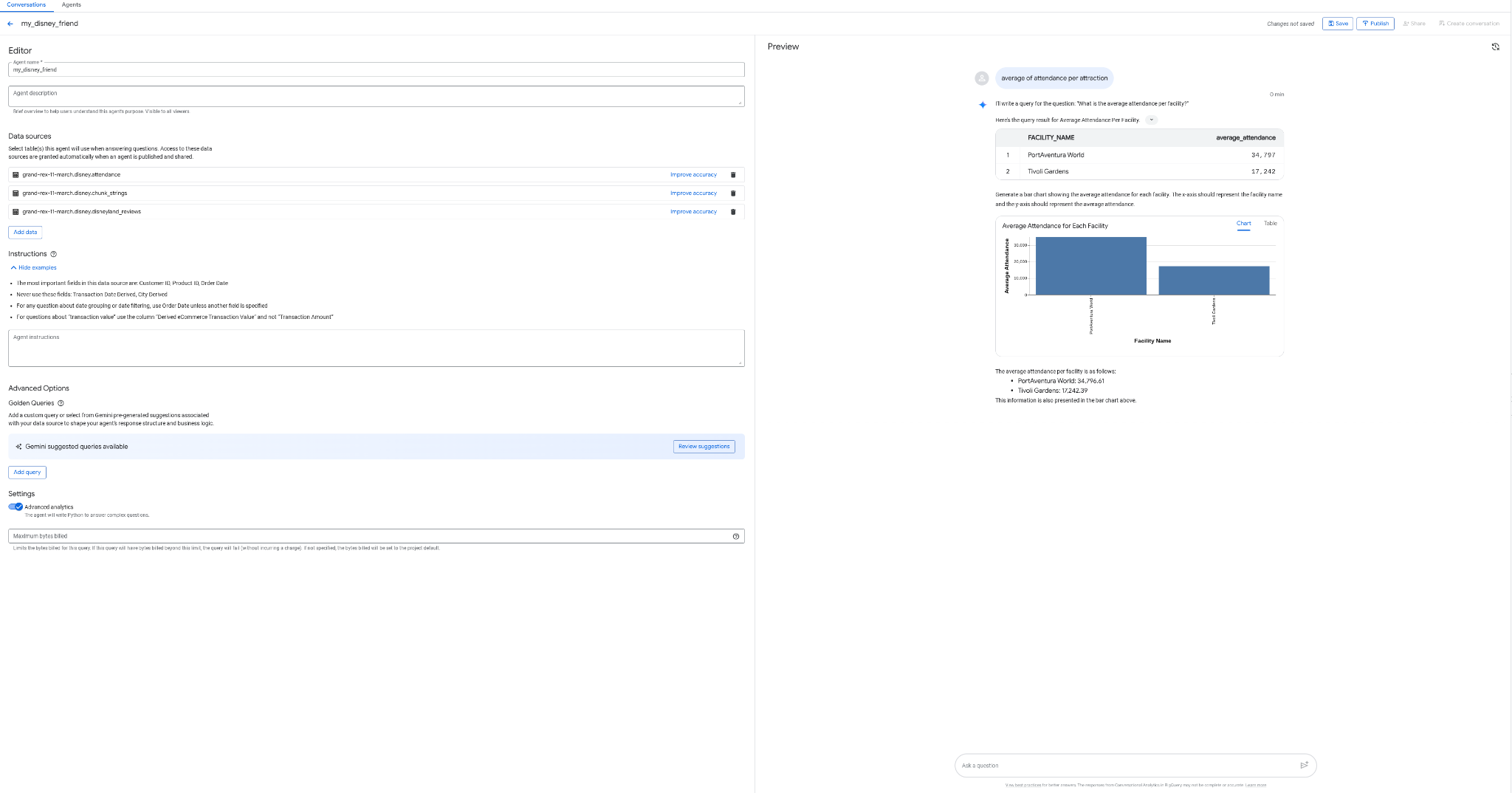
- 디즈니 테이블에 연결되는 에이전트 my_disney_friend를 만듭니다. 에이전트 요청 사항을 작성하여 에이전트 성능을 개선할 수 있습니다. '긍정적인 리뷰와 부정적인 리뷰의 비율은 얼마인가요? 어트랙션별 평균 대기 시간은 얼마인가요?'와 같은 질문을 합니다.
- BigQuery 및 API에 에이전트를 게시합니다 (나중에 사용됨).
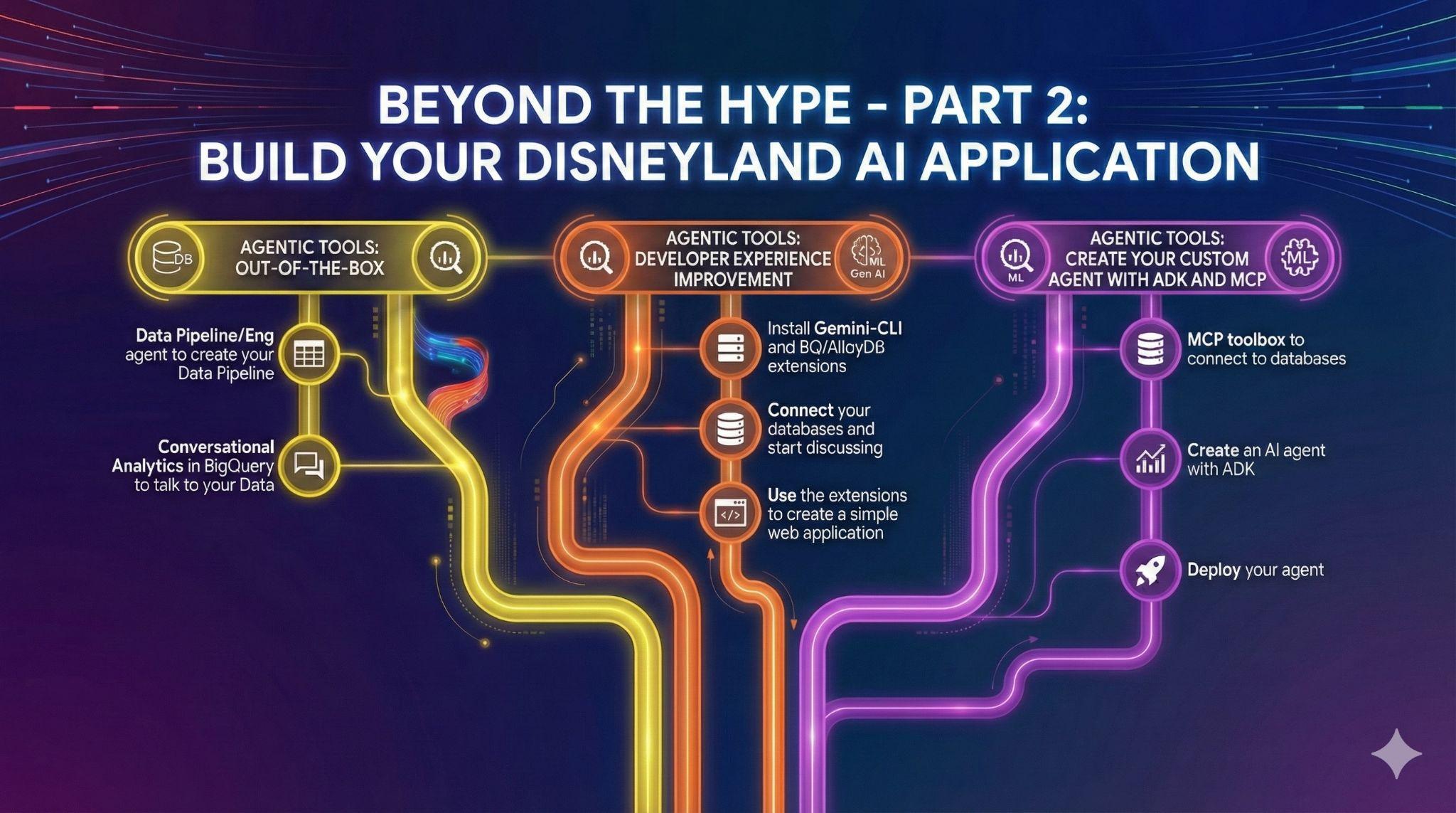
8. 작업 5: Gemini-CLI로 개발 환경 개선하기
AI 시대에 소프트웨어 빌드는 그 어느 때보다 쉬워졌습니다. 디즈니랜드 애플리케이션에 대한 아이디어가 수천 개 있으며 데이터를 최대한 활용하고 싶습니다. 데이터를 분석하는 것에서 더 나아가 이제 조치를 취해야 합니다.
이 여정을 진행하려면 도움이 필요합니다. Google에서 지원해 드립니다.
Gemini CLI는 터미널에서 바로 Gemini의 기능을 사용할 수 있도록 지원하는 오픈소스 AI 에이전트입니다. 개발자는 강력한 애플리케이션을 빌드할 수 있으며 확장 프로그램을 통해 다양한 MCP (모델 컨텍스트 프로토콜) 서버와 상호작용할 수도 있습니다.
물론 AlloyDB 또는 BigQuery 데이터를 쿼리하는 확장 프로그램도 있습니다.
이 작업의 목표는 다음과 같습니다.
- Gemini-CLI 설치 (자체 터미널 또는 Cloud Shell)
- BigQuery 및 AlloyDB Gemini-CLI 확장 프로그램 설치
- Gemini-CLI가 BigQuery 및 AlloyDB 인스턴스에 연결할 수 있도록 환경 파일 만들기
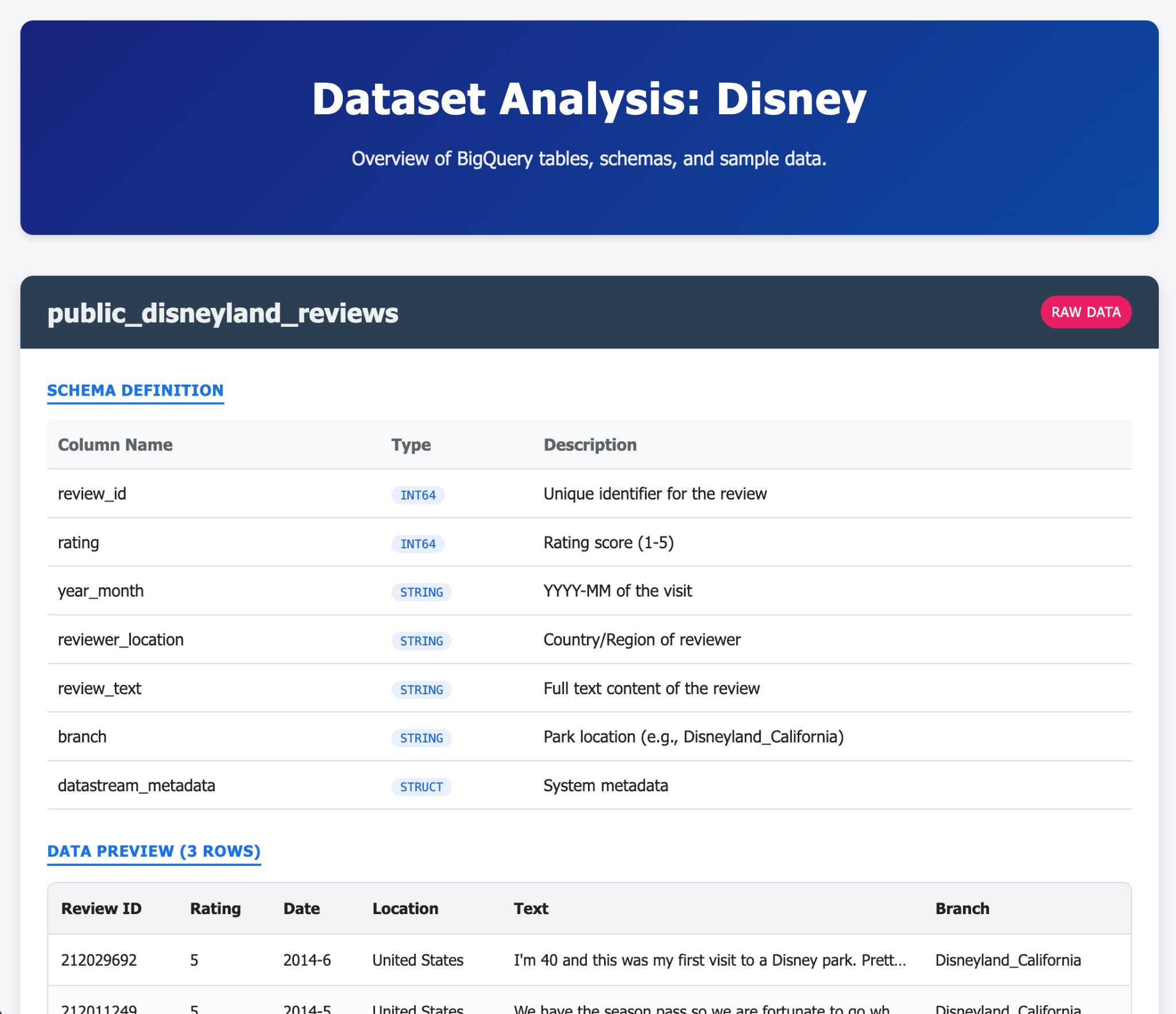
- Gemini-CLI에 AlloyDB 데이터베이스의 콘텐츠를 설명하는 멋진 단일 HTML 페이지를 생성해 달라고 요청하세요.
- BigQuery에서도 동일한 작업을 실행합니다.
다음은 Gemini-CLI 및 확장 프로그램을 사용하여 단일 (또는 소수) 프롬프트로 생성할 수 있는 항목의 예입니다. 이제 실제 애플리케이션으로 이 작업을 할 수 있다고 상상해 보세요. 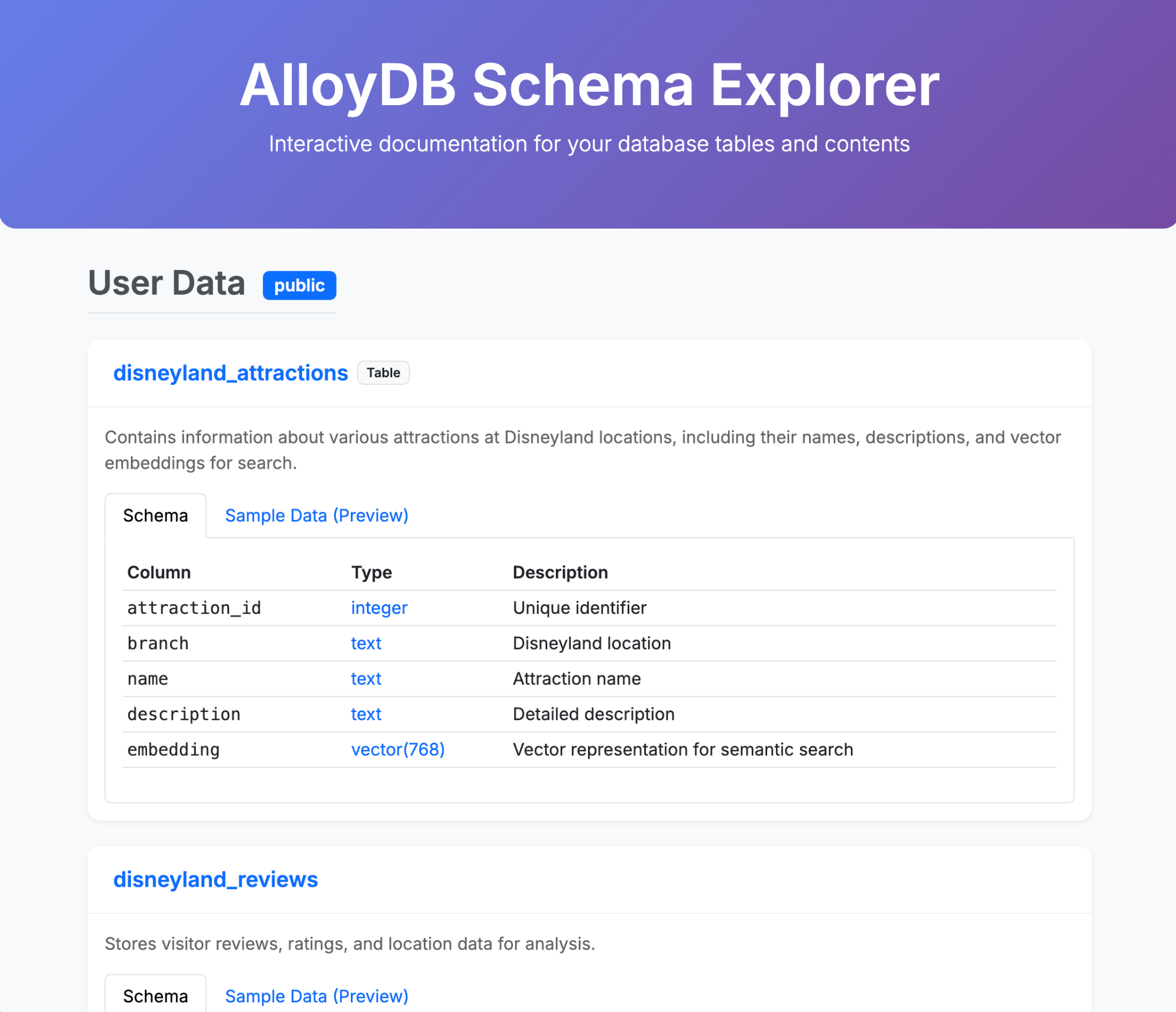
9. 작업 6: 데이터와 상호작용하는 AI 에이전트 만들기
디즈니랜드 방문자에게 완전히 새로운 사용자 환경을 제공하기 위해 여행 중에 방문자를 도울 수 있는 어시스턴트를 만듭니다. 상담사는 다음 작업을 할 수 있습니다.
- 공원에서 이용 가능한 모든 명소 나열
- 기대에 따라 명소 추천
- 명소 리뷰 추가
- 향후 몇 시간 동안의 어트랙션 대기 시간 추정치 제공
- 특정 명소의 리뷰 개요 제공
어시스턴트가 디즈니랜드와 관련된 질문에만 답변하고 사용자에게 친근한 어조를 유지하도록 합니다. 에이전트가 사용자의 요구사항에 맞는 올바른 도구를 선택하도록 에이전트 프롬프트를 조정하세요.
따라야 하는 단계는 다음과 같습니다.
- AlloyDB와 BigQuery를 소스로 사용하는 데이터베이스용 MCP 도구 상자 서버 배포
- AlloyDB 및 BigQuery를 쿼리하고 앞에서 나열된 에이전트 작업을 매핑하는 MCP 서버용 도구 5개를 선언합니다.
- MCP 도구 상자 UI를 사용하여 각 도구의 유효성을 검사합니다.
- MCP 도구 상자 서버에서 노출하는 도구를 사용할 수 있는 에이전트 개발 키트를 사용하여 에이전트 배포
- ADK 웹 인터페이스에 연결하고 사용 가능한 모든 도구를 포함하여 어시스턴트와의 전체 토론을 보여줍니다.
일찍 완료한 경우 보너스 단계:
에이전트가 준비되었나요? Agent Engine에 배포해 보겠습니다.