
1. 🏰 Hackathon de análise de dados da Disneylândia (2ª edição – 3 de dezembro) 🏰
Resumo | Neste hackathon, você vai criar um pipeline de análise de dados completo usando recursos de IA/ML no Google Cloud. Você vai carregar dados no AlloyDB, um banco de dados totalmente gerenciado e compatível com PostgreSQL otimizado para cargas de trabalho exigentes. Em seguida, use o Datastream, um serviço sem servidor de captura de dados alterados (CDC), para movê-los para o BigQuery, o data warehouse sem servidor do Google Cloud. No BigQuery, você vai usar o BigQuery ML, que permite criar e executar modelos de machine learning diretamente no BigQuery usando SQL padrão para análise de avaliações e previsão de presença. Por fim, você vai testar agentes, seja usando os recursos prontos para uso das Análises de conversação e dos agentes de dados, ou criando um agente personalizado com o Kit de Desenvolvimento de Agentes e a MCP Toolbox para interagir com seus dados em linguagem natural. |
categories | docType:Codelab, product:Bigquery |
Author | Rayhane Rezgui, Matt Cornillon |
Layout | rolagem |
Robôs | noindex |
2. Introdução
Olá, futuros magos de dados da Disney!🪄
Esqueça os guias de viagem chatos e a rolagem infinita de fóruns. Imagine planejar a viagem perfeita à Disneylândia com insights baseados em dados. Qual parque oferece a melhor experiência? Quando há menos pessoas? Você pode prever o melhor horário para enfrentar aquela fila notoriamente longa?
Nesta hackathon, você vai criar a ferramenta de planejamento definitiva da Disneylândia. Temos os dados: avaliações de visitantes de filiais em todo o mundo, tempos de espera históricos e números de visitantes. Sua missão? Transforme esses dados brutos em insights úteis:
- Coletar dados:carregue diversas avaliações, tempos de espera e números de visitantes da Disneyland no AlloyDB, nosso banco de dados de alto desempenho compatível com PostgreSQL.
- Movimentação integrada:use o Datastream, nosso serviço de captura de dados alterados sem servidor, para mover essas informações dinâmicas com facilidade para o BigQuery, o data warehouse sem servidor avançado do Google Cloud.
- Preveja a magia:use o BigQuery ML para analisar o sentimento das avaliações e prever tempos de espera diretamente com SQL. Descubra quais filiais sempre oferecem sorrisos e qual é o melhor horário para sua visita.
- Converse com seus dados, literalmente! Use ferramentas pré-criadas que permitem receber insights com um toque de varinha.
- Interação inteligente:crie um agente inteligente com a caixa de ferramentas MCP para bancos de dados e o ADK (Kit de Desenvolvimento de Agente). Pergunte: "Qual é a melhor atração da Disneyland Paris para quem ama o espaço, e qual é o melhor horário para entrar na fila?" e receba respostas instantâneas baseadas em dados.
Planeje e prepare-se para descobrir os segredos dos lugares mais mágicos da Terra e crie um pipeline de análise de dados que deixaria o Mickey orgulhoso!
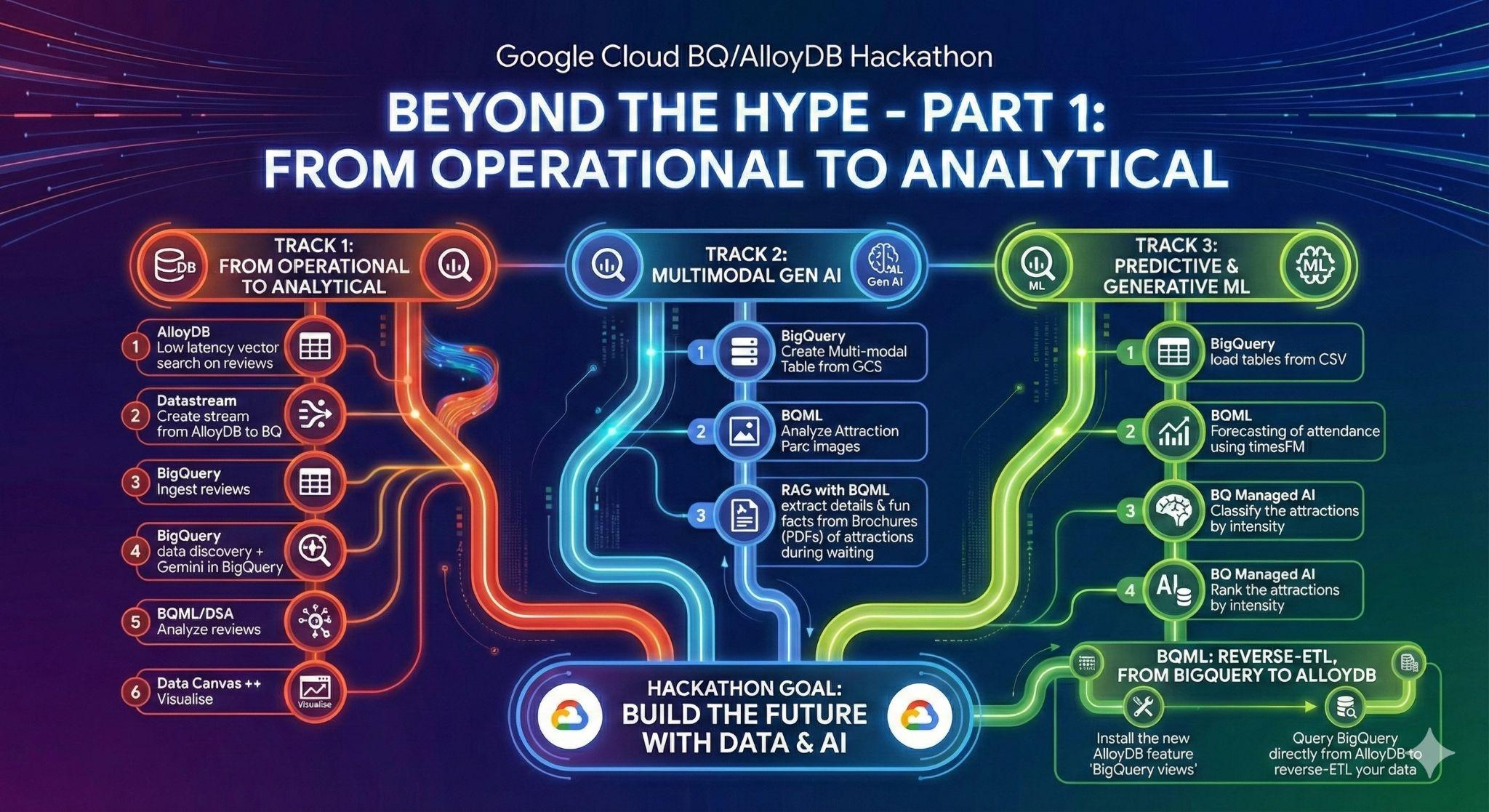
3. Tarefa 1: de operacional a analítico; analise as avaliações da Disneylândia com o Gemini
Nesta etapa inicial, você vai extrair os dados do banco de dados operacional do AlloyDB e carregá-los no BigQuery para análise de dados posterior.
Você também vai configurar tudo o que é necessário no AlloyDB para seu futuro agente.
Carregamento de dados no AlloyDB
Primeiro, vamos importar alguns dados para nosso cluster do AlloyDB para PostgreSQL.
Vamos ingerir 20 mil avaliações dos parques de diversões da Disneyland e uma lista de atrações.
As etapas que você precisa seguir são as seguintes:
Criação de tabelas:
- Crie uma tabela disneyland_reviews com seis colunas: review_id e rating como número inteiro, year_month, reviewer_location, review_text, branch como texto.
- Crie uma tabela disneyland_attractions com quatro colunas: attraction_id como número inteiro, branch, name e description como texto.
Usando a ferramenta de sua escolha, importe dados dos arquivos CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvpara a tabela de avaliaçõesgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvpara a tabela de atrações
Para oferecer recomendações de atrações, precisamos criar incorporações da descrição delas:
- Instalar a extensão pgvector no AlloyDB
- Adicione uma coluna de vetor chamada "embedding" à sua tabela "attraction".
- Gerar e preencher o embedding das descrições usando a integração nativa entre o AlloyDB e a Vertex AI
De operacional a analítico com o Datastream
Para fazer streaming dos nossos dados do AlloyDB para o BigQuery, vamos usar o Google Datastream. É uma solução sem servidor avançada que detecta todas as mudanças nas tabelas de origem (usando a captura de dados alterados) e as envia para o BigQuery.
Para replicar mudanças do AlloyDB com o Datastream, é necessário criar o que chamamos de publicação e slot de replicação no Postgres.
Execute as consultas a seguir no cluster do AlloyDB (uma de cada vez):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Você vai usar a publicação e o slot de replicação no seu stream. Por isso, lembre-se dos nomes.
E é só isso. Agora podemos criar um stream.
As etapas que você precisa seguir no Datastream são as seguintes:
- Crie um perfil de origem para seu cluster do AlloyDB (use o endereço IP público).
- Criar um perfil de destino para o BigQuery
- Crie um stream do AlloyDB para o BigQuery.
Os dados vão estar disponíveis no BigQuery em alguns minutos.
Descoberta de dados no BigQuery
Agora que temos nossos dados no BigQuery, vamos conferir as novas melhorias na interface antes de começar a trabalhar.
Temos três novas funções que já estão disponíveis no painel de análise detalhada do BigQuery.

- Visão geral:contém informações sobre recursos do BigQuery, tutoriais para começar a fazer análises e outras possibilidades.
- Pesquisa:faça uma pesquisa semântica nos seus recursos de dados.
- Agentes:shhh! Vamos deixar isso para depois 🤫
Pesquisar seus dados semanticamente no BigQuery
Acesse a guia "Pesquisar" no painel de análise detalhada do BigQuery e teste termos relacionados à Disney, como "atrações" ou "filial".
Visualizar seus dados no BigQuery
Agora você pode visualizar e manipular seus dados no BigQuery. Para isso, execute esta consulta em uma nova guia de consulta:
SELECT
*
FROM
[dataset_name].[table_name];
Gerar insights de dados na tabela de avaliações
Nesta tarefa, você vai ativar os Insights de dados na tabela disneyland_reviews no conjunto de dados disney.
Insights de dados é uma ferramenta para quem quer analisar e entender os dados sem precisar escrever consultas SQL complexas.
Isso pode levar alguns minutos.
Consultar a tabela "disneyland_reviews" sem SQL
Os insights que você gerou na seção anterior estão prontos. Nesta tarefa, você vai usar um comando gerado com esses insights para consultar a tabela disneyland_reviews sem usar código.
Selecione um insight e execute a consulta associada a ele. Por exemplo, encontre a consulta que calcula a diferença na classificação média entre meses consecutivos para cada filial. Ele vai ficar assim:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Usar o mecanismo de conhecimento do BigQuery para entender melhor os dados
Primeiro, vamos analisar a guia Insights em um nível de conjunto de dados. Isso vai nos dar uma ideia das relações ocultas entre as tabelas no conjunto de dados da Disney. Em seguida,
- Gere uma descrição do conjunto de dados usando o Gemini e adicione aos detalhes dele.
- Gere uma descrição das avaliações e atrações das tabelas, bem como de todas as colunas individuais dessas tabelas, e salve.
Realizar uma verificação de perfil dos seus dados
O objetivo desta seção é limpar e preparar seus dados. No entanto, você não conhece muito bem a distribuição dos valores de cada coluna. É necessário criar um perfil dos dados para saber quais tipos de etapas de transformação precisam ser realizadas.
O Dataplex Universal Catalog do Google Cloud automatiza verificações de criação de perfil para oferecer métricas de qualidade de dados consistentes. As principais estatísticas identificadas incluem contagens nulas, valores distintos, intervalos de dados e distribuições de valores. É possível ativar uma verificação do perfil na interface do BigQuery.
Isso pode levar alguns minutos. Enquanto espera, você pode ler a próxima seção.
Responda às seguintes perguntas:
- Qual é a classificação média da Disneyland?
- Onde os avaliadores estão localizados com mais frequência?
- Todas as avaliações são únicas?
- Qual é a porcentagem de dados ausentes na coluna "Year_Month"?
Fazer uma verificação de qualidade dos seus dados
Com a qualidade de dados automática do Dataplex Universal Catalog, é possível definir e medir a qualidade dos dados nas suas tabelas do BigQuery. É possível automatizar a verificação de dados, validar os dados em relação às regras definidas e registrar alertas se eles não atenderem aos requisitos de qualidade. É possível gerenciar regras e implantações de qualidade de dados como código, melhorando a integridade dos pipelines de produção de dados.
Com base na verificação do perfil, defina uma verificação de qualidade (em não mais de 10% dos seus dados como tamanho da amostra) que:
- Verifica valores nulos na coluna "branch"
- Realiza uma verificação de validade para a classificação, já que ela só pode estar no conjunto de : 1,2,3,4,5
- Verifica a exclusividade de "review_id"
Verifique se a verificação exporta os resultados para uma tabela do BigQuery quality_scan_results.
Pense em todas as transformações que você precisa aplicar aos seus dados.
Preparar seus dados usando a preparação de dados do Gemini
Depois das verificações de qualidade de dados e verificação do perfil que você realizou, é hora de limpar os dados antes de analisá-los.
As preparações de dados são recursos do BigQuery que usam o Gemini no BigQuery para analisar seus dados e oferecer sugestões inteligentes de limpeza, transformação e enriquecimento. Você pode reduzir significativamente o tempo e o esforço necessários para tarefas manuais de preparação de dados.
Nesta seção, você vai usar o Data Preparation para realizar estas operações na tabela "disneyland_reviews":
- Filtre as linhas em que a coluna "Branch" é NULL ou uma string vazia.
- Substitua "missing" em Year_Month por Null.
- Substitui sublinhados por espaços na coluna "Branch" para melhorar a legibilidade.
- Exportar para a tabela transformada disneyland_reviews_cleaned
Analisar avaliações com o Gemini
Agora que você limpou seus dados, pode começar a analisá-los usando o BigQuery ML e os modelos do Gemini. Você tem dois objetivos:
- Extrair categorias das avaliações
- Análise de sentimento de disneyland_reviews
Com o BigQuery ML, é possível criar e executar modelos de machine learning (ML) usando consultas do GoogleSQL. Os modelos do BigQuery ML são armazenados em conjuntos de dados da ferramenta, semelhantes a tabelas e visualizações. O BigQuery ML também permite acessar modelos da Vertex AI e APIs de IA do Google Cloud para realizar tarefas de inteligência artificial (IA), como geração de texto ou tradução automática. O Gemini para Google Cloud também oferece assistência com tecnologia de IA para tarefas do BigQuery.
Você pode usar ML.GENERATE_TEXT ou AI.GENERATE (pré-lançamento) com os modelos Gemini Pro ou Flash.
As etapas a seguir mostram como usar ML.GENERATE_TEXT.
Criar a conexão a recursos do Cloud e conceder o papel do IAM
Você precisa criar uma conexão a recursos do Cloud no BigQuery com os modelos da Vertex AI para trabalhar com os modelos Gemini Pro e Gemini Flash. Você também vai conceder permissões do IAM à conta de serviço da conexão do recurso do Cloud usando um papel para permitir que ela acesse os serviços da Vertex AI.
Conceder a função de usuário da Vertex AI à conta de serviço da conexão
Conceda à conta de serviço da conexão o papel de usuário da Vertex AI para permitir que ela use o modelo escolhido (por exemplo, gemini-2.5-flash). A propagação da permissão leva um minuto.
Criar os modelos do Gemini no BigQuery
Crie seu modelo usando a conexão acima. Use, por exemplo, o endpoint gemini-2.5-flash.
Pedir que o Gemini analise as avaliações dos clientes em busca de categorias e sentimentos
Nesta tarefa, você vai usar o modelo do Gemini para analisar cada avaliação do cliente em busca de categorias e sentimentos positivos ou negativos.
Analisar as avaliações de clientes por categorias
Observação: daqui em diante, para a análise, vamos usar apenas 100 linhas, já que a chamada do Gemini em 20 mil linhas pode levar algum tempo.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Essa consulta usa as avaliações dos clientes da tabela disneyland_reviews para criar comandos a fim de que o modelo gemini identifique categorias em cada avaliação. Os resultados precisam ser armazenados em uma nova tabela reviews_categories
. Aguarde. O modelo leva cerca de 30 segundos para processar os registros das avaliações dos clientes e ter os resultados na tabela de saída.
Mostrar os resultados:
SELECT * FROM [dataset_name].[results_table_name];
Leia algumas das categorias.
Analisar as avaliações dos clientes em busca de sentimentos positivos e negativos
Com base na consulta SQL para extração de palavras-chave, escreva uma consulta que analise a avaliação como positiva, negativa e neutra em uma coluna chamada "sentimento".
Essa consulta usa as avaliações dos clientes da tabela disneyland_reviews para criar comandos a fim de que o modelo gemini classifique o sentimento de cada avaliação. Em seguida, os resultados são armazenados em uma nova tabela reviews_analysis para uso em análises futuras. Aguarde. O modelo leva alguns segundos para processar os registros das avaliações de clientes. Quando o modelo for concluído, o resultado vai estar na tabela reviews_analysis criada.
Confira os resultados:
SELECT * FROM [...];
A tabela reviews_analysis tem a coluna Sentiment com a análise de sentimento, além das colunas social_media_source, review_text, customer_id, location_id e review_datetime. Confira alguns dos registros. Observe que alguns dos resultados positivos e negativos podem não estar formatados corretamente. Eles têm caracteres estranhos, como pontos ou espaços extras. Você pode limpar os registros usando a visualização abaixo.
Criar uma visualização para limpar os registros
Crie uma visualização que higienize os valores do sentimento da coluna fazendo o seguinte:
- Usando LOWER para garantir que todos os valores estejam em minúsculas.
- Remover pontuação (ponto , vírgula e espaço) usando REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
A consulta cria a visualização cleaned_data_view e inclui os resultados do sentimento, o texto da avaliação e Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Em seguida, ele analisa o resultado do sentimento (positivo ou negativo) para garantir que todas as letras sejam minúsculas e que caracteres estranhos, como pontos ou espaços extras, sejam removidos. A visualização resultante vai facilitar as análises em outras etapas deste laboratório.
- Use a consulta abaixo com a visualização para conferir as linhas criadas.
SELECT * FROM [view_name];
Criar um relatório que conta avaliações positivas e negativas com a tela de dados
Agora é hora de analisar os resultados. Vamos começar fazendo isso diretamente no BigQuery, usando a tela de dados. É uma ferramenta que permite pesquisar dados (semânticos ou por palavra-chave), consultar e unir tabelas, criar gráficos e receber insights criando um fluxo de tela.
Seu objetivo final é criar um gráfico de sua escolha com as porcentagens de avaliações positivas e negativas . Veja um exemplo:
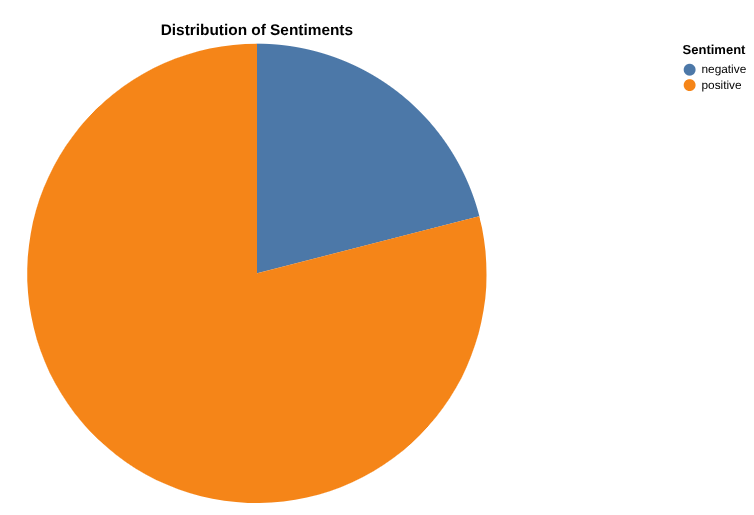
Crie um gráfico do número de avaliações por categoria, bem como a distribuição de avaliações positivas e negativas para cada categoria
Dica: ative e use a Análise avançada da Tela de dados, que executa um notebook Python em uma tela.
4. Tarefa 2: analisar imagens de parques de atrações para identificar fotos da Disneylândia e extrair curiosidades dos folhetos do parque
Análise de imagens no BigQuery
Você tem acesso a algumas fotos emocionantes e atraentes do Attraction parc que os visitantes tiraram ao longo dos anos. Você está muito animado com a próxima viagem! No entanto, você não sabe quais são fotos reais da Disneyland. Sua tarefa é identificar esses problemas. As imagens estão localizadas em gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland::False

Is_disneyland::True
Para realizar essa análise rapidamente. Use as tabelas de objetos do BigQuery e o Gemini pelo BigQuery ML (ML.GENERATE_TEXT).
Você pode verificar a saída do Gemini conferindo algumas fotos?
Crie seu próprio sistema de RAG com o BigQuery em folhetos da Disneylândia
Enquanto espera na fila, você quer saber algumas curiosidades ou detalhes técnicos sobre a atração.
Em gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,, você encontra arquivos PDF com folhetos de todos os parques do mundo.
Objetivo:criar um sistema de geração aumentada por recuperação (RAG) totalmente no BigQuery para permitir que os usuários façam perguntas complexas sobre o parque com base em alguns documentos PDF.
Para isso, você precisa:
- Criar uma tabela de objetos de arquivos PDF
- Crie uma UDF em Python para dividir arquivos PDF em partes. Confira um exemplo que você pode usar:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Analise o arquivo PDF em partes
- Gerar embeddings depois de criar um modelo remoto
- Executar uma pesquisa vetorial para encontrar "
Ou manger un repas tex-mex à volonté?" ou "where to eat a tex-mex meal buffet-style?" - Gerar uma resposta aprimorada pelos resultados da pesquisa vetorial da pergunta "
Ou manger un repas tex-mex à volonté?" ou "where to eat a tex-mex meal buffet-style?"
5. Tarefa 3: machine learning em grande escala com o BigQuery: previsão, classificação e ranking
Previsão de tempos de espera
As fotos são muito legais! Não deixe para depois! Para saber quais atrações escolher e quais evitar, você precisa saber os tempos de espera reais de algumas atrações entre Paris e a Califórnia. Sua tarefa é prever os waiting_times de cada atração usando machine learning (Arima plus ou TimesFM) a cada 30 minutos em 2025.
Os dados que você vai usar estão neste arquivo CSV: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
As etapas da sua tarefa são:
- Carregue o arquivo no conjunto de dados do BigQuery em uma tabela chamada "waiting_times".
- Treine um modelo de previsão nos seus dados (Arima_Plus) ou faça previsões diretamente usando AI.Forecast
- Avalie a performance do modelo ou compare os dados previstos com os de entrada.
Classificar as atividades por intensidade
Você está visitando a Disneylândia com amigos, e embora o parque seja geralmente adequado para famílias, algumas atrações podem ser muito intensas para algumas pessoas. Vamos usar as funções de IA gerenciadas do BigQuery para classificar e classificar as atrações por nível de emoção e intensidade, sem viés humano, para que possamos atender a todos.
- Use
AI.CLASSIFYpara categorizar passeios com base nas descrições em uma das três categorias mágicas: [easy-peasy, thrilling, extreme]
Classificar atrações por nível de emoção
- Use
AI.SCOREpara comparar e ordenar atrações com base em um nível de emoção, em que a classificação 10 é a mais extrema e a 1 é a menos.
6. Tarefa 3 (bônus): ETL reverso do BigQuery para o AlloyDB
Você aproveitou os recursos avançados do BigQuery para gerar insights sobre grandes quantidades de dados. Agora você quer que esses insights sejam acionáveis pelos seus aplicativos operacionais (e agentes de IA).
Mas como? Fazendo o contrário! O AlloyDB para PostgreSQL é excelente para disponibilizar dados com baixa latência e alta velocidade, perfeito para seus aplicativos críticos voltados ao usuário. Vamos fazer a ETL reversa dos dados que acabamos de gerar.
Para isso, vamos usar um recurso totalmente novo, ainda em prévia privada, chamado "Visualizações do BigQuery" no AlloyDB. Com esse recurso, é possível consultar dados do BigQuery diretamente no banco de dados do Postgres.
Primeiro, conceda à conta de serviço do cluster do AlloyDB os privilégios necessários para consultar o BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
A saída contém um campo "serviceAccountEmail", que é a conta de serviço desse cluster.
No console do Google Cloud, acesse a página "IAM" e conceda as seguintes permissões a essa principal:
- Leitor de dados do BigQuery (roles/bigquery.dataViewer)
- Usuário de sessão de leitura do BigQuery (roles/bigquery.readSessionUser)
Agora, acesse o AlloyDB Studio no console e conecte-se ao banco de dados "postgres".
Execute as consultas a seguir para instalar e configurar o novo recurso:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Agora é possível criar uma "tabela externa" que será mapeada para uma tabela atual no BigQuery. Use qualquer tabela que você criou na Tarefa 3. Confira um exemplo de sintaxe:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Tudo pronto, vamos consultar a tabela! Execute um primeiro SELECT para validar o link entre o AlloyDB e o BigQuery e, por fim, crie uma nova tabela no AlloyDB para ingerir os dados da sua tabela externa.
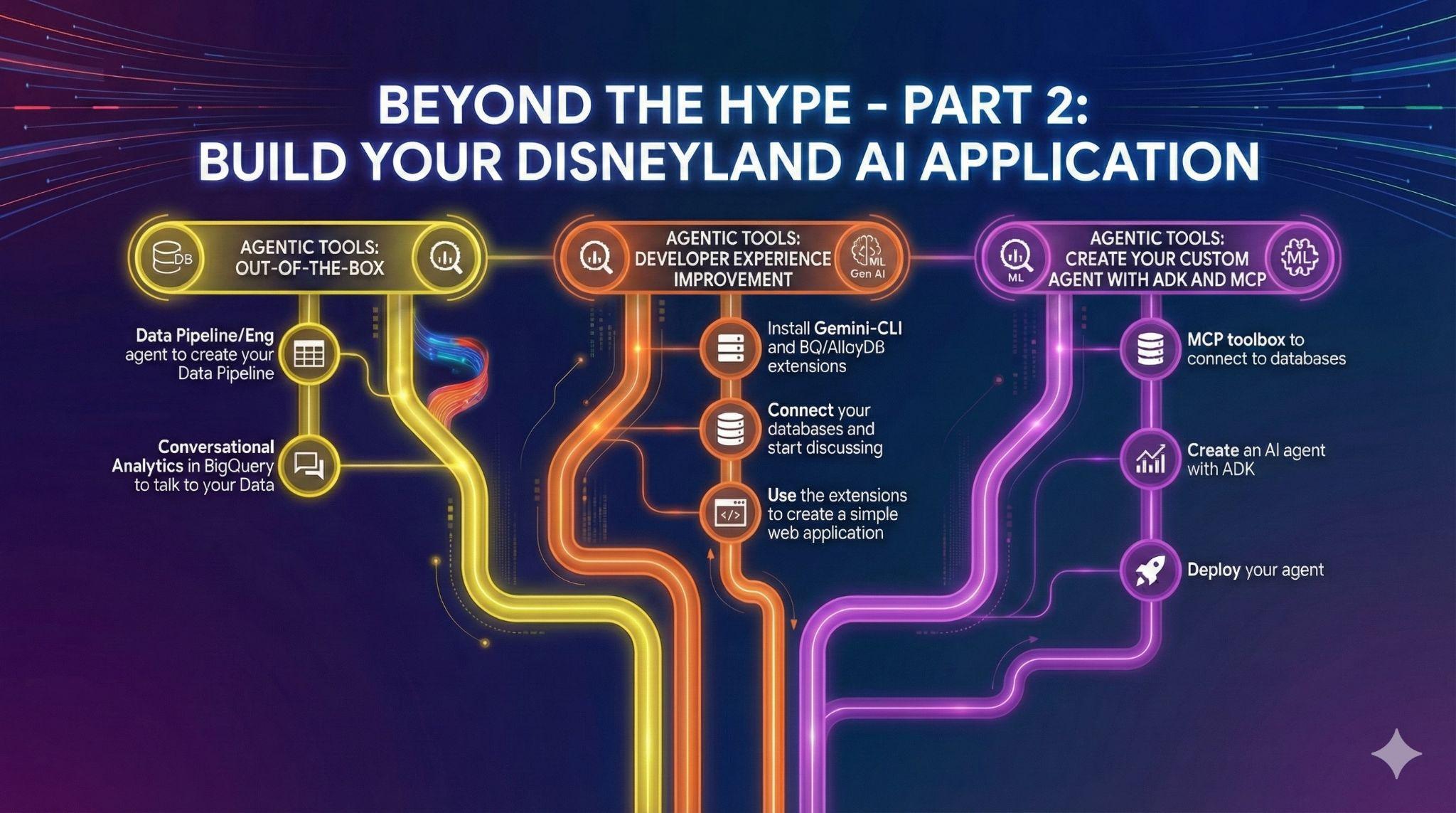
7. Tarefa 4: agentes de dados prontos para uso
Você tem amigos que querem contribuir com o projeto do aplicativo da Disneyland. Eles têm acesso aos dados no BigQuery, mas têm níveis variados de conhecimento em SQL e engenharia de dados. Você quer aproveitar os anúncios recentes do BigQuery sobre agentes de dados já integrados à interface para ajudar seus amigos:
- Criar pipelines de dados.
- Colaborar no código SQL.
- Converse com os dados deles.
Agentes de engenharia de dados para automatizar seus pipelines de dados
Crie uma nova visualização average_waiting_time que une a tabela waiting time e attractions e calcula o average waiting_time por atração usando o Agente de engenharia de dados.
Criar seu agente de análise de conversação no BigQuery
E se você pudesse criar um agente para conversar com seus dados, sem programação, sem SQL, sem implantação e na interface do BigQuery? Seria incrível, não é? Isso já é possível com a guia "Agentes" no BigQuery.
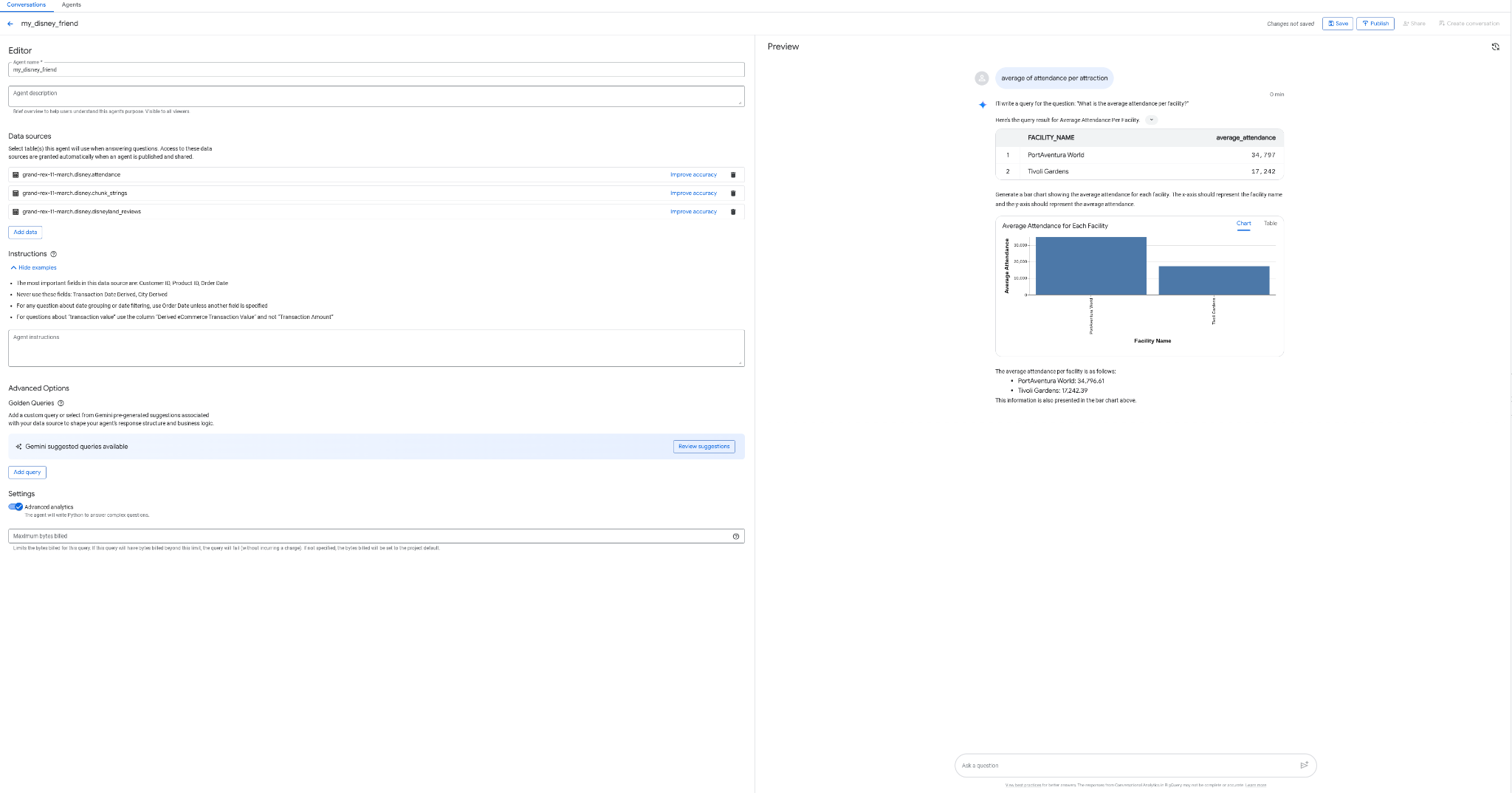
- Crie um agente my_disney_friend que se conecte às suas tabelas da Disney. Você pode melhorar a performance do agente preenchendo as instruções dele. Faça perguntas como "qual é a porcentagem de avaliações positivas e negativas, qual é o tempo médio de espera por atração etc.?"
- Publique o agente no BigQuery e na API (você vai usá-lo mais tarde).
8. Tarefa 5: melhore sua experiência de desenvolvimento com a CLI do Gemini
Nesta era da IA, criar software nunca foi tão acessível. Você tem milhares de ideias para seu aplicativo da Disneylândia e quer usar seus dados na capacidade máxima. Você quer ir além de apenas conversar com os dados, agora você precisa de ação!
Para ajudar você nessa jornada, você vai precisar de ajuda. E nós temos a solução.
A CLI do Gemini é um agente de IA de código aberto que traz o poder do Gemini diretamente para o seu terminal. Os desenvolvedores podem criar aplicativos avançados e, graças às extensões, também interagir com vários servidores MCP (Protocolo de Contexto de Modelo).
Entre elas, você encontra extensões para consultar seus dados do AlloyDB ou do BigQuery.
Nesta tarefa, seu objetivo é:
- Instalar a CLI do Gemini (no seu próprio terminal ou no Cloud Shell)
- Instalar as extensões da CLI do Gemini para BigQuery e AlloyDB
- Crie um arquivo de ambiente que permita que a Gemini-CLI se conecte às suas instâncias do BigQuery e do AlloyDB.
- Peça à CLI do Gemini para gerar uma página HTML única e sofisticada que explique o conteúdo do seu banco de dados do AlloyDB
- Faça o mesmo para o BigQuery
Confira alguns exemplos do que você pode gerar em um ou poucos comandos com a CLI do Gemini e as extensões dela. Agora imagine que você pode fazer isso com aplicativos da vida real. 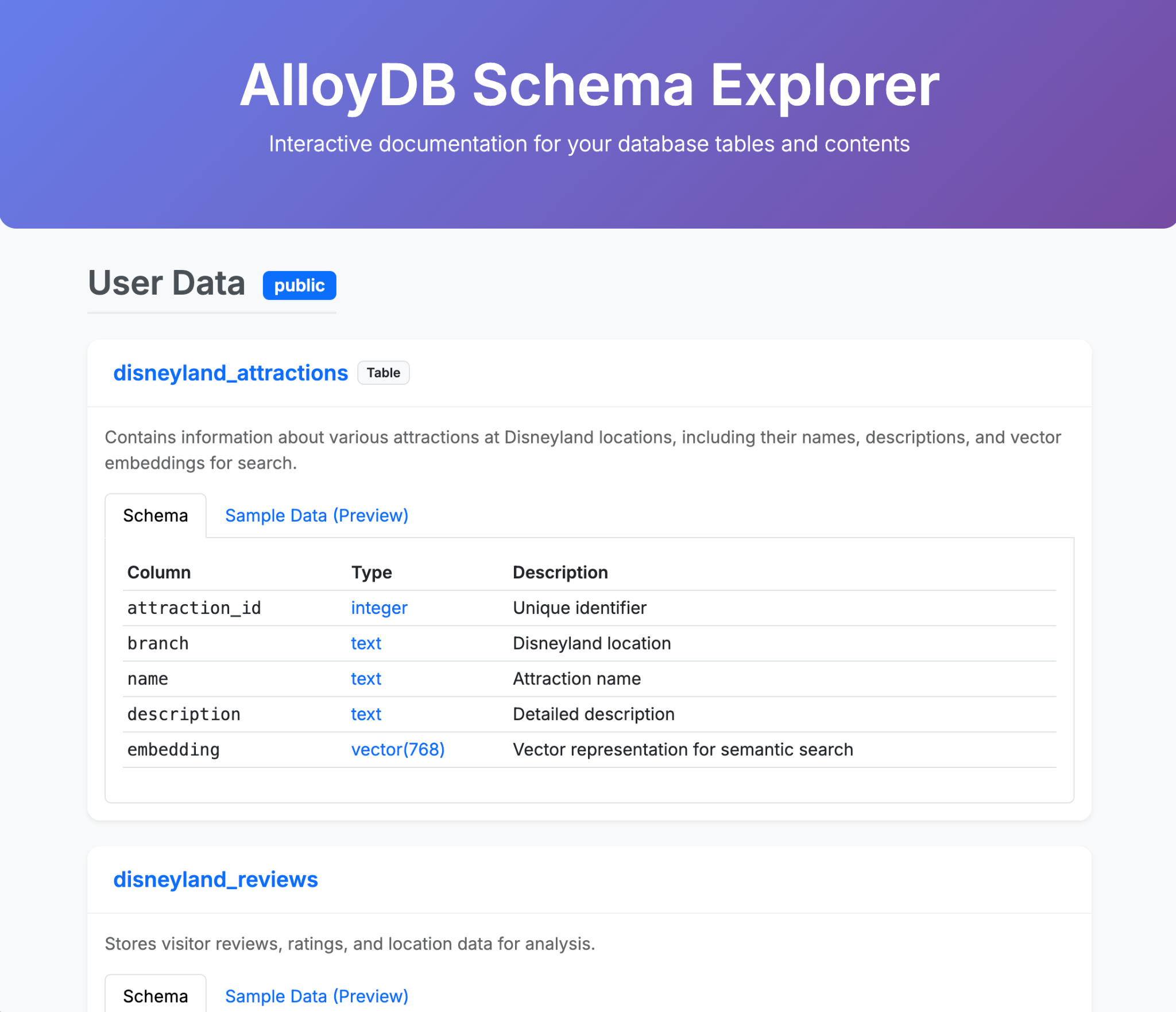
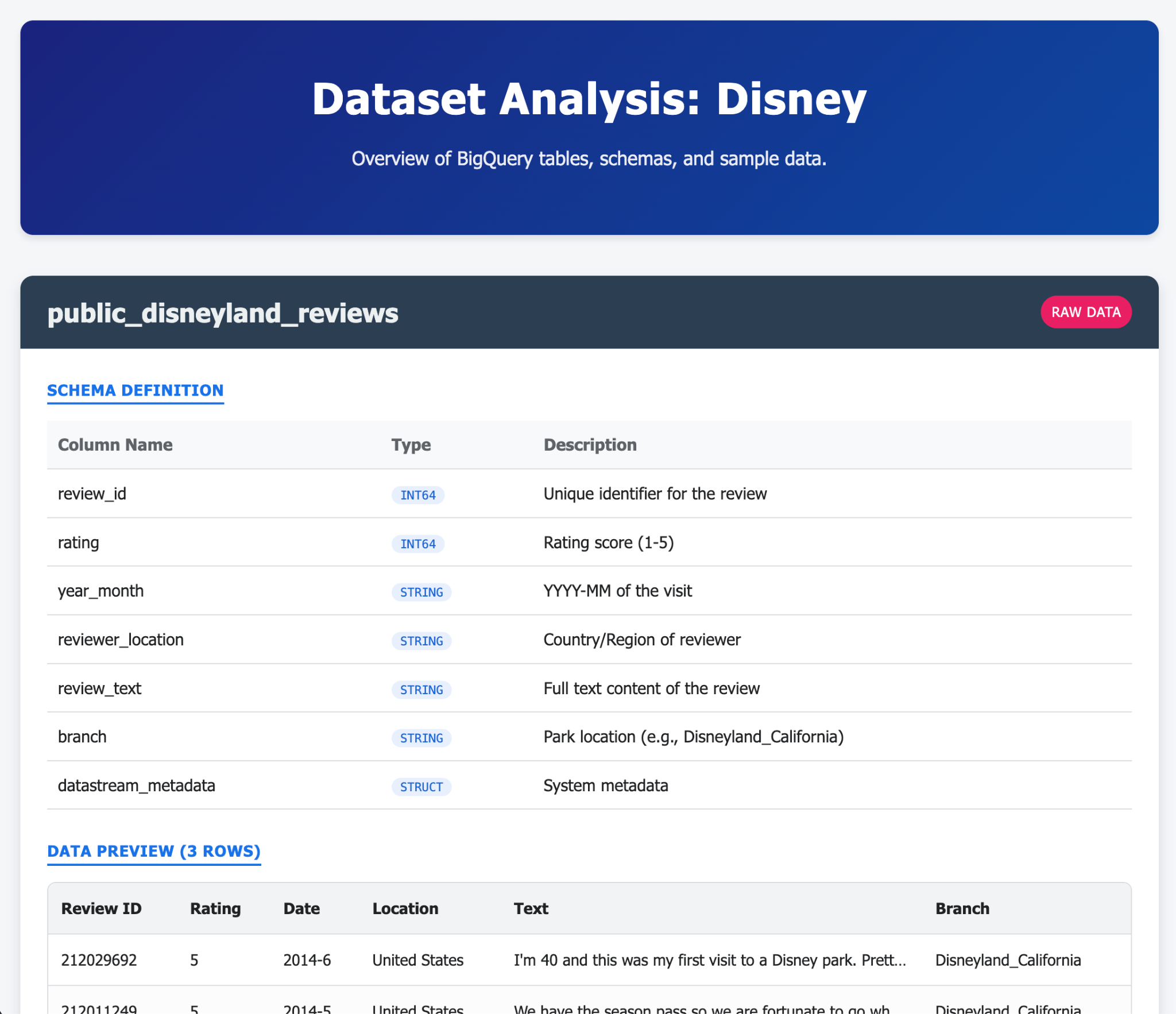
9. Tarefa 6: criar um agente de IA para interagir com seus dados
Para oferecer uma experiência do usuário totalmente nova aos visitantes da Disneyland, você vai criar um assistente que pode ajudar durante a viagem. O agente poderá:
- Listar todas as atrações disponíveis no parque
- Recomendar uma atração com base nas expectativas
- Adicionar avaliações de uma atração
- Fornecer uma estimativa do tempo de espera para uma atração nas próximas horas
- Fornecer uma visão geral das avaliações de uma atração específica
Você vai garantir que o assistente só responda a perguntas relacionadas à Disneyland e mantenha um tom amigável com o usuário. Ajuste o comando do agente para garantir que ele escolha as ferramentas certas para as necessidades do usuário.
As etapas que você precisa seguir são:
- Implante um servidor da MCP Toolbox for Databases que use o AlloyDB e o BigQuery como fontes.
- Declare cinco ferramentas diferentes para seu servidor MCP que consultam o AlloyDB e o BigQuery e mapeiam as ações do agente listadas anteriormente.
- Use a interface da MCP Toolbox para validar cada uma das suas ferramentas.
- Implante um agente usando o Kit de Desenvolvimento de Agente que pode usar as ferramentas expostas pelo servidor da caixa de ferramentas do MCP.
- Conecte-se à interface da Web do ADK e mostre uma discussão completa com seu assistente, incluindo todas as ferramentas disponíveis.
Etapa extra se você terminar antes:
Seu agente está pronto? Vamos implantar no Agent Engine!