
1. 🏰 Хакатон по анализу данных в Диснейленде (2-й выпуск - 3 декабря) 🏰
Краткое содержание | На этом хакатоне вы создадите комплексный конвейер анализа данных, используя возможности ИИ/машинного обучения в Google Cloud. Вы загрузите данные в AlloyDB — полностью управляемую базу данных, совместимую с PostgreSQL и оптимизированную для ресурсоемких задач, а затем с помощью Datastream — бессерверного сервиса захвата изменений данных (CDC) — переместите их в BigQuery , бессерверное хранилище данных Google Cloud. В BigQuery вы примените BigQuery ML , который позволяет создавать и выполнять модели машинного обучения непосредственно в BigQuery с использованием стандартного SQL для анализа отзывов и прогнозирования посещаемости. Наконец, вы поэкспериментируете с агентами, используя либо готовые решения Conversational Analytics & Data Agents, либо создадите собственного агента на базе Agent Development Kit и MCP toolbox для взаимодействия с данными на естественном языке. |
категории | docType:Codelab, product:Bigquery |
Автор | Райхан Резги, Мэтт Корниллон |
Макет | прокрутка |
Роботы | noindex |
2. Введение
Добро пожаловать, будущие гении обработки данных Disney! 🪄
Забудьте о скучных путеводителях и бесконечном пролистывании форумов. Представьте себе планирование идеальной поездки в Диснейленд, основанное на данных. Какой парк предлагает лучшие впечатления? Когда меньше всего народу? Можете ли вы предсказать лучшее время, чтобы преодолеть печально известную длинную очередь?
В этом хакатоне вы создадите свой идеальный инструмент планирования посещения Диснейленда. У нас есть данные: отзывы посетителей из разных филиалов по всему миру, история времени ожидания и статистика посещаемости. Ваша задача? Преобразовать эти необработанные данные в полезные аналитические выводы:
- Сбор данных: Загрузите разнообразные отзывы о Диснейленде, время ожидания и данные о посещаемости в AlloyDB, нашу высокопроизводительную базу данных, совместимую с PostgreSQL.
- Бесперебойное перемещение: используйте Datastream, наш бессерверный сервис для отслеживания изменений данных, чтобы без труда перемещать эту динамическую информацию в BigQuery, мощное бессерверное хранилище данных Google Cloud.
- Предскажите чудо: используйте возможности машинного обучения BigQuery для анализа настроений в отзывах и прогнозирования времени ожидания непосредственно с помощью SQL. Узнайте, какие филиалы неизменно дарят улыбки и когда лучше всего посетить отделение.
- Обращайтесь к своим данным — в прямом смысле!: используйте готовые инструменты, которые позволят вам получать ценные аналитические данные одним движением волшебной палочки.
- Интеллектуальное взаимодействие: Дополните свое творение интеллектуальным агентом, работающим на основе инструментария MCP для баз данных и ADK (Agent Development Kit). Спросите: «Какой аттракцион в парижском Диснейленде лучше всего подходит для любителей космоса, и в какое время лучше всего встать в очередь?» — и получите мгновенные ответы, основанные на данных.
Приготовьтесь раскрыть секреты самых волшебных мест на Земле и создать систему анализа данных, которой бы гордился сам Микки!
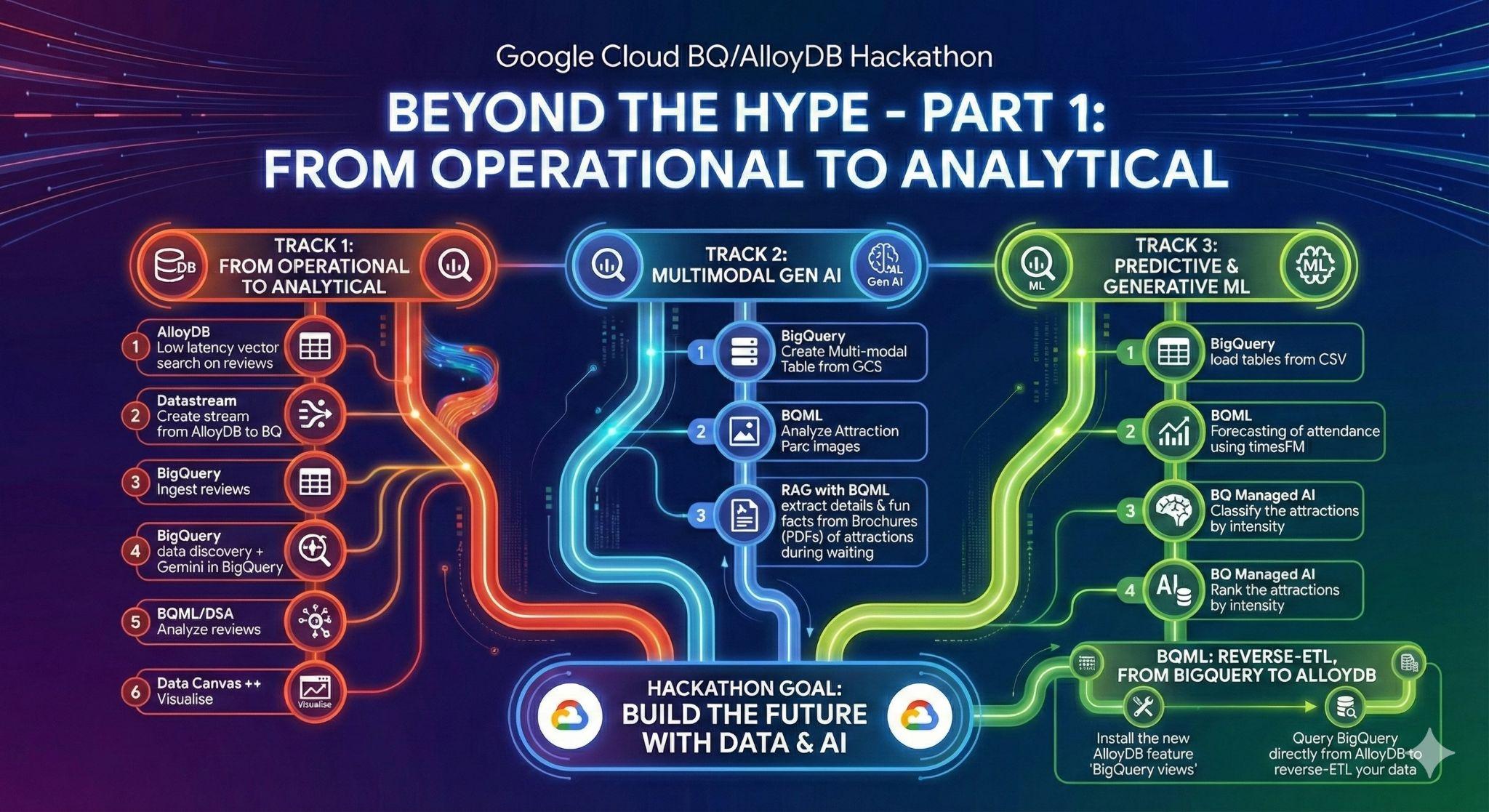
3. Задание 1: От операционного подхода к аналитическому; анализ отзывов о Диснейленде с помощью Gemini.
На начальном этапе вы получите данные из вашей операционной базы данных AlloyDB и загрузите их в BigQuery для последующего анализа данных.
Вам также потребуется настроить все необходимое в AlloyDB для вашего будущего агента!
Загрузка данных в AlloyDB
Для начала давайте импортируем данные в наш кластер AlloyDB для PostgreSQL !
Мы собираемся обработать 20 000 отзывов о парках развлечений Диснейленд и составить список аттракций.
Вам необходимо предпринять следующие шаги:
Создание таблиц:
- Создайте таблицу disneyland_reviews с 6 столбцами: review_id и rating (целое число), year_month, reviewer_location, review_text, branch (текст).
- Создайте таблицу disneyland_attractions с 4 столбцами: attraction_id (целое число), branch, name и description (текст).
Используя выбранный вами инструмент, импортируйте данные из CSV-файлов:
- Для просмотра таблицы отзывов
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv -
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvдля таблицы аттракционов
Для предоставления рекомендаций по достопримечательностям нам необходимо создать векторные представления описаний достопримечательностей:
- Установите расширение pgvector в AlloyDB.
- Добавьте в таблицу столбец с векторным изображением под названием «встраивание».
- Сгенерируйте и заполните встраивание описаний, используя встроенную интеграцию AlloyDB и Vertex AI.
От операционного к аналитическому аспектам с Datastream.
Для потоковой передачи данных из AlloyDB в BigQuery мы будем использовать Google Datastream. Это мощное бессерверное решение, которое будет отслеживать все изменения в исходных таблицах (с помощью функции Change Data Capture) и отправлять их в BigQuery.
Для репликации изменений из AlloyDB в Datastream необходимо создать так называемый слот публикации и репликации в PostgreSQL.
Выполните следующие запросы в вашем кластере AlloyDB (их необходимо запускать по одному):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
В своей трансляции вы будете использовать слоты для публикации и воспроизведения, поэтому запомните их названия!
Вот и всё, теперь мы можем создать трансляцию!
В Datastream вам необходимо выполнить следующие действия:
- Создайте профиль источника для вашего кластера AlloyDB (используйте публичный IP-адрес).
- Создайте профиль назначения для BigQuery.
- Создать поток данных из AlloyDB в BigQuery.
Данные должны появиться в BigQuery через несколько минут.
Обнаружение данных в BigQuery
Теперь, когда наши данные загружены в BigQuery, давайте убедимся, что мы знакомы с новыми улучшениями в интерфейсе, прежде чем приступать к работе!
У нас появились 3 новые функции, которые вы уже можете увидеть на панели просмотра BigQuery.
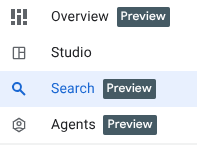
- Обзор: содержит информацию о возможностях BigQuery, ознакомительные туры для начала анализа и другие варианты.
- Поиск: выполните семантический поиск по вашим данным.
- Агенты: Тсс! Мы оставим это на потом 🤫
Ищите данные семантически в BigQuery.
В панели поиска BigQuery перейдите на вкладку «Поиск» и поэкспериментируйте с терминами, связанными с Диснеем, например, «аттракционы» или «филиал».
Визуализируйте свои данные в BigQuery.
Теперь вы можете визуализировать и обрабатывать свои данные в BigQuery. Для этого вы можете выполнить следующий запрос в новой вкладке запросов:
SELECT
*
FROM
[dataset_name].[table_name];
Получите аналитические данные из таблицы отзывов.
В этом задании вам нужно будет включить функцию анализа данных для таблицы disneyland_reviews в наборе данных disney .
Data Insights — это инструмент для всех, кто хочет анализировать свои данные и получать ценные выводы без написания сложных SQL-запросов.
Это может занять несколько минут.
Запрос к таблице disneyland_reviews без использования SQL-запросов.
Полученные вами в предыдущем разделе данные готовы. В этом задании вы будете использовать сгенерированную на основе этих данных подсказку для запроса к таблице disneyland_reviews без использования кода.
Выберите аналитический вывод и выполните связанный с ним запрос. Например, найдите запрос, который вычисляет разницу в среднем рейтинге между последовательными месяцами для каждого филиала. Он будет выглядеть примерно так:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Используйте систему обмена знаниями BigQuery для лучшего понимания данных.
Для начала давайте посмотрим на вкладку «Аналитика» на уровне набора данных; это даст нам представление о скрытых взаимосвязях между таблицами в наборе данных Disney. Затем,
- Сгенерируйте описание набора данных с помощью Gemini и добавьте его в сведения о наборе данных.
- Создайте описание для таблиц с отзывами и достопримечательностями, а также для всех отдельных столбцов в этих таблицах и сохраните его.
Выполните сканирование профиля ваших данных.
Цель этого раздела — очистить и подготовить ваши данные. Однако вы не очень хорошо знакомы с распределением значений в каждом столбце. Вам необходимо провести анализ ваших данных, чтобы понять, какие преобразования необходимо выполнить.
Универсальный каталог Dataplex от Google Cloud автоматизирует сканирование профилирования для получения согласованных показателей качества данных. Ключевые статистические данные включают количество нулевых значений, уникальных значений, диапазоны данных и распределение значений. Активировать сканирование профилирования можно через интерфейс BigQuery.
Это может занять пару минут, поэтому вы можете посмотреть следующий раздел, пока ждете.
Ответьте на следующие вопросы:
- Каков средний рейтинг Диснейленда?
- Где чаще всего находятся рецензенты?
- Все отзывы уникальны?
- Какой процент пропущенных данных в столбце Year_Month?
Проведите проверку качества ваших данных.
Автоматическая проверка качества данных в Dataplex Universal Catalog позволяет определять и измерять качество данных в таблицах BigQuery. Вы можете автоматизировать сканирование данных, проверять их на соответствие заданным правилам и регистрировать оповещения, если ваши данные не соответствуют требованиям качества. Вы можете управлять правилами и развертыванием проверки качества данных как кодом, повышая целостность производственных конвейеров обработки данных.
На основе анализа профиля определите проверку качества (используя не более 10% ваших данных в качестве выборки), которая:
- Проверяет наличие нулевых значений в столбце " ветка ".
- Выполняет проверку корректности " рейтинга ", поскольку он может принадлежать только к набору: 1, 2, 3, 4, 5.
- Проверяет уникальность " review_id ".
Убедитесь, что результаты сканирования экспортируются в таблицу BigQuery quality_scan_results.
Подумайте обо всех потенциальных преобразованиях, которые вам необходимо применить к вашим данным.
Подготовьте свои данные с помощью функции подготовки данных Gemini.
После проведенных вами проверок качества данных и профилирования, настало время очистить данные перед их анализом.
Подготовка данных — это ресурсы BigQuery , которые используют Gemini в BigQuery для анализа ваших данных и предоставления интеллектуальных рекомендаций по их очистке, преобразованию и обогащению. Вы можете значительно сократить время и усилия, необходимые для выполнения задач по ручной подготовке данных.
В этом разделе вы будете использовать функцию подготовки данных для выполнения следующих операций с таблицей disneyland_reviews:
- Отфильтруйте строки, в которых значение столбца Branch равно NULL или пустой строке.
- Замените "missing" в Year_Month на Null.
- Заменяет символы подчеркивания пробелами в столбце "ветка" для улучшения читаемости.
- Экспорт в преобразованную таблицу disneyland_reviews_cleaned
Анализируйте отзывы с помощью Gemini
Теперь, когда вы очистили данные, вы можете начать их анализ с помощью моделей машинного обучения BigQuery и Gemini. У вас две задачи:
- Извлечение категорий из отзывов
- Анализ настроений в отзывах о Диснейленде
BigQuery ML позволяет создавать и запускать модели машинного обучения (ML) с помощью запросов GoogleSQL. Модели BigQuery ML хранятся в наборах данных BigQuery, аналогично таблицам и представлениям. BigQuery ML также предоставляет доступ к моделям Vertex AI и API Cloud AI для выполнения задач искусственного интеллекта (ИИ), таких как генерация текста или машинный перевод. Gemini для Google Cloud также предоставляет помощь на основе ИИ для задач BigQuery.
Для моделей Gemini Pro и Flash можно выбрать использование ML.GENERATE_TEXT или AI.GENERATE (предварительная версия).
Следующие шаги помогут вам использовать ML.GENERATE_TEXT.
Создайте подключение к облачному ресурсу и предоставьте роль IAM.
Для работы с моделями Gemini Pro и Gemini Flash необходимо создать подключение к облачному ресурсу в BigQuery. Также необходимо предоставить учетной записи службы, подключенной к облачному ресурсу, права доступа по IAM через роль, чтобы обеспечить ей доступ к сервисам Vertex AI.
Предоставьте учетной записи службы подключения роль пользователя Vertex AI.
Разрешите учетной записи службы подключения использовать выбранную вами модель (например, gemini-2.5-flash ), предоставив ей роль пользователя Vertex AI. Для распространения разрешения потребуется 1 минута.
Создайте модели Gemini в BigQuery.
Создайте свою модель, используя указанное выше соединение. Используйте, например, конечную точку gemini-2.5-flash.
Предложите Gemini проанализировать отзывы клиентов по категориям и настроениям.
В этом задании вы будете использовать модель Gemini для анализа каждого отзыва клиента по категориям и уровню тональности, как положительного, так и отрицательного.
Проанализируйте отзывы покупателей по категориям.
Примечание: В дальнейшем для анализа мы будем использовать только 100 строк , поскольку обработка 20 000 строк в Gemini может занять некоторое время.
-
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Этот запрос извлекает отзывы клиентов из таблицы disneyland_reviews , формирует подсказки для модели gemini , чтобы определить категории в каждом отзыве. Результаты должны быть сохранены в новой таблице reviews_categories
Пожалуйста , подождите. На обработку отзывов клиентов и отображение результатов в выходной таблице модели требуется приблизительно 30 секунд.
Отобразить результаты:
SELECT * FROM [dataset_name].[results_table_name];
Уделите время ознакомлению с некоторыми из категорий.
Проанализируйте отзывы покупателей, чтобы выявить положительные и отрицательные мнения.
На основе SQL-запроса для извлечения ключевых слов напишите запрос, который анализирует отзывы, разделяя их на положительные, отрицательные и нейтральные, в столбце с названием "sentiment".
Этот запрос извлекает отзывы клиентов из таблицы disneyland_reviews , формирует подсказки для модели gemini , чтобы классифицировать тональность каждого отзыва. Затем результаты сохраняются в новой таблице reviews_analysis , чтобы вы могли использовать их позже для дальнейшего анализа. Пожалуйста, подождите. Модели требуется несколько секунд для обработки записей отзывов клиентов. После завершения работы модели результат будет сохранен в созданной таблице reviews_analysis .
Ознакомьтесь с результатами:
SELECT * FROM [...];
В таблице reviews_analysis есть столбец Sentiment , содержащий результаты анализа тональности, а также столбцы social_media_source , review_text , customer_id , location_id и review_datetime . Взгляните на некоторые записи. Вы можете заметить, что некоторые результаты для положительных и отрицательных отзывов могут быть отформатированы неправильно, содержать лишние символы, такие как точки или пробелы. Вы можете очистить записи, используя представление ниже.
Создайте представление для очистки записей.
Создайте представление, которое очищает значения столбца «Сентябрь» следующим образом:
- Используйте LOWER, чтобы убедиться, что все значения написаны строчными буквами.
- Удаление знаков препинания (. и , и пробелов) с помощью команды REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
Запрос создает представление cleaned_data_view , которое включает результаты анализа тональности, текст отзыва, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch . Затем он обрабатывает результат анализа тональности (положительный или отрицательный) и гарантирует, что все буквы будут переведены в нижний регистр, а лишние символы, такие как пробелы или точки, будут удалены. Полученное представление упростит дальнейший анализ на последующих этапах этой лабораторной работы.
- Вы можете выполнить запрос к представлению с помощью приведенного ниже запроса, чтобы увидеть созданные строки.
SELECT * FROM [view_name];
Создайте отчет о количестве положительных и отрицательных отзывов с помощью Data Canvas.
Теперь пришло время проанализировать результаты. Начнем с того, что сделаем это непосредственно в BigQuery, используя Data Canvas. Это инструмент, который позволяет искать данные (семантически или по ключевым словам), запрашивать и объединять таблицы, создавать графики и получать аналитические данные, формируя поток данных на основе Data Canvas.
Ваша конечная цель — построить график, отображающий процентное соотношение положительных и отрицательных отзывов по вашему выбору. Вот пример:
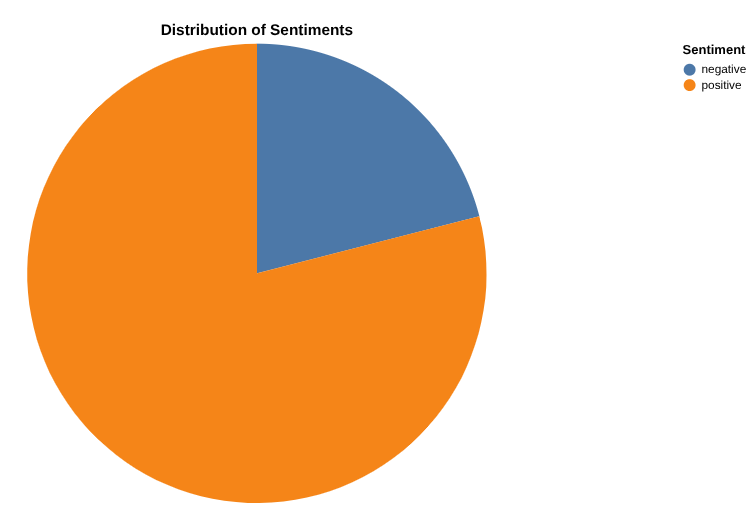
Создайте график количества отзывов по категориям, а также распределение положительных и отрицательных отзывов для каждой категории.
Совет: Активируйте и используйте функцию расширенного анализа Data Canvas, которая запускает блокнот Python внутри холста.
4. Задание 2: Проанализируйте изображения аттракционов, чтобы определить фотографии Диснейленда и извлечь интересные факты из брошюр парка.
Анализ изображений в BigQuery
У вас есть доступ к захватывающим и привлекательным фотографиям парка аттракционов, сделанным посетителями за эти годы. Вы в восторге от предстоящей поездки! Однако вы не знаете, какие из них являются подлинными фотографиями Диснейленда. Вам поручено определить, какие именно. Фотографии находятся по адресу gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/ .

Is_disneyland: False

Is_disneyland: True
Для быстрого проведения этого анализа следует использовать объектные таблицы BigQuery и Gemini через BigQuery ML ( ML.GENERATE_TEXT ).
Можете ли вы проверить работу Gemini, посмотрев несколько фотографий?
Создайте свою собственную систему RAG с помощью BigQuery на основе брошюр Диснейленда.
Ожидая в очереди, вам наверняка захочется узнать интересные факты или технические подробности о аттракционе, который вы собираетесь посетить.
В gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, вы найдете PDF-файлы, содержащие брошюры всех парков по всему миру.
Цель: Создать систему генерации информации с расширенными возможностями поиска (Retrieval-Augmented Generation, RAG), полностью интегрированную в BigQuery, которая позволит пользователям задавать сложные вопросы о парке на основе PDF-документов.
Для достижения этой цели вам необходимо:
- Создайте таблицу объектов PDF-файлов.
- Создайте пользовательскую функцию на Python для разбивки PDF-файлов на части. Вот пример, который вы можете использовать:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Разбейте PDF-файл на фрагменты.
- Сгенерируйте эмбеддинги после создания удаленной модели.
- Выполните векторный поиск, чтобы найти "
Ou manger un repas tex-mex à volonté?" или "where to eat a tex-mex meal buffet-style?". - Сгенерируйте ответ, дополненный результатами векторного поиска по вопросу "
Ou manger un repas tex-mex à volonté?" или "where to eat a tex-mex meal buffet-style?".
5. Задание 3: Машинное обучение в масштабе с использованием BigQuery: прогнозирование, классификация и ранжирование
Прогнозируемое время ожидания
Фотографии просто потрясающие! Не терпится! Теперь, чтобы понять, какие достопримечательности выбрать, а какие избегать, вам нужно узнать фактическое время ожидания на некоторых из них на маршруте между Парижем и Калифорнией. Ваша задача — спрогнозировать время ожидания на каждой достопримечательности, используя машинное обучение (Arima plus или TimesFM), каждые 30 минут в 2025 году.
Данные, которые вам понадобятся, находятся в этом CSV-файле: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
Этапы выполнения вашей задачи следующие:
- Загрузите файл в свой набор данных BigQuery в таблицу с именем waiting_times.
- Обучите модель прогнозирования на ваших данных (Arima_Plus) или прогнозируйте напрямую с помощью AI.Forecast.
- Оцените эффективность модели или сравните прогнозируемые данные с входными данными.
Классифицируйте аттракционы по интенсивности.
Вы посещаете Диснейленд с друзьями, и хотя парк в целом подходит для семейного отдыха, некоторые аттракционы могут показаться слишком экстремальными для некоторых людей. Давайте воспользуемся функциями управляемого ИИ BigQuery, чтобы классифицировать и ранжировать аттракционы по уровню экстремальности и интенсивности, без учета человеческого фактора, чтобы учесть потребности каждого.
- Используйте
AI.CLASSIFY, чтобы классифицировать аттракционы на основе их описаний по одной из трех волшебных категорий: [легко, захватывающе, экстремально].
Рейтинг зависит от уровня острых ощущений.
- Используйте
AI.SCOREдля сравнения и ранжирования аттракционов в зависимости от уровня экстремальности , где 10-й ранг означает самый высокий уровень, а 1-й — самый низкий.
6. Задание 3 — Бонус: Обратное ETL-преобразование, от BigQuery к AlloyDB.
Вы уже воспользовались мощными возможностями BigQuery для получения аналитических данных из больших объемов информации. Теперь вы хотите, чтобы эти данные можно было использовать в ваших операционных приложениях (и в работе ИИ-агентов!).
Но как? Сделав наоборот! AlloyDB для Postgres отлично подходит для предоставления данных с низкой задержкой и высокой скоростью, что идеально подходит для критически важных приложений, ориентированных на пользователей. Итак, давайте выполним обратное ETL-извлечение данных, которые мы только что сгенерировали.
Для этого мы воспользуемся совершенно новой функцией AlloyDB, которая пока находится в режиме закрытого предварительного просмотра и называется "Представления BigQuery". Эта функция позволяет запрашивать данные BigQuery прямо из вашей базы данных Postgres.
Во-первых, вам необходимо предоставить учетной записи службы кластера AlloyDB необходимые права для выполнения запросов к BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
В выходных данных содержится поле serviceAccountEmail, которое представляет собой учетную запись службы для данного кластера.
В консоли Google Cloud перейдите на страницу IAM и предоставьте этому субъекту следующие права:
- BigQuery Data Viewer (roles/bigquery.dataViewer)
- Пользователь сессии чтения BigQuery (roles/bigquery.readSessionUser)
Теперь перейдите в консоль AlloyDB Studio и подключитесь к базе данных "postgres".
Выполните следующие запросы для установки и настройки новой функции:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Теперь вы можете создать «внешнюю таблицу», которая будет сопоставлена с существующей таблицей в BigQuery. Используйте любую таблицу, созданную вами в Задании 3. Вот пример синтаксиса:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Всё готово, давайте выполним запрос к таблице! Сначала выполним запрос SELECT, чтобы проверить связь между AlloyDB и BigQuery, а затем создадим новую таблицу в AlloyDB для импорта данных из вашей внешней таблицы.
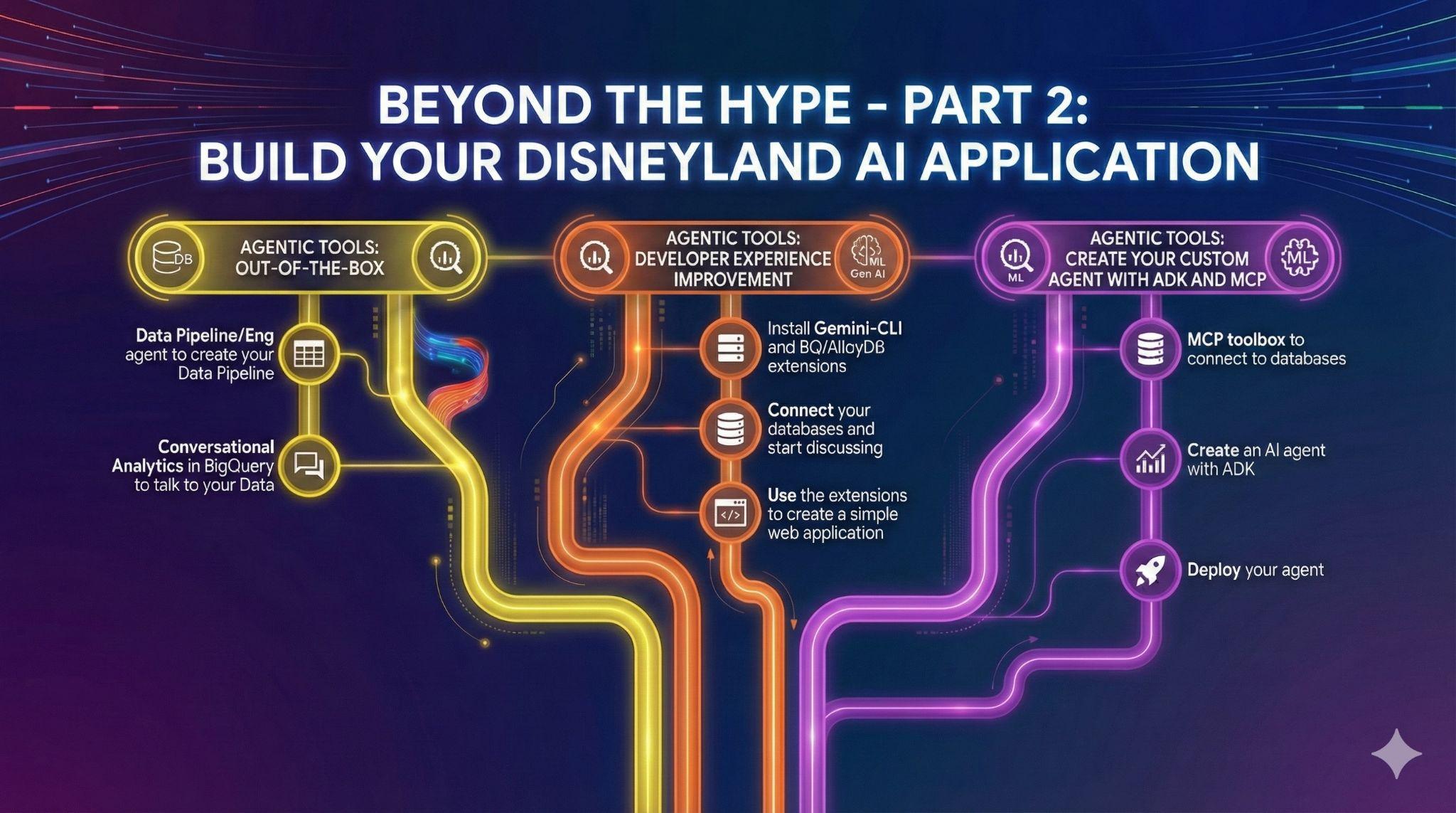
7. Задание 4: Готовые агенты обработки данных
У вас есть друзья, которые хотят внести свой вклад в проект приложения для Диснейленда. У них есть доступ к данным в BigQuery, но уровень их знаний SQL и работы с данными различается. Вы хотите использовать недавние анонсы BigQuery, касающиеся агентов данных, уже интегрированных в пользовательский интерфейс, чтобы помочь своим друзьям:
- Создание конвейеров данных.
- Совместная работа над SQL-кодом.
- Поговорите с их данными.
Агенты для автоматизации обработки данных в ваших конвейерах обработки данных.
Создайте новое представление average_waiting_time, которое объединяет таблицы waiting time и attractions и вычисляет среднее время ожидания для каждого аттракциона, используя агент Data Engineering Agent.
Создайте своего агента анализа диалогов в BigQuery.
А что если бы вы могли создать агента для взаимодействия с вашими данными без программирования, без SQL и без развертывания, прямо из интерфейса BigQuery? Как это было бы здорово! Сегодня это возможно благодаря вкладке «Агенты» в BigQuery.
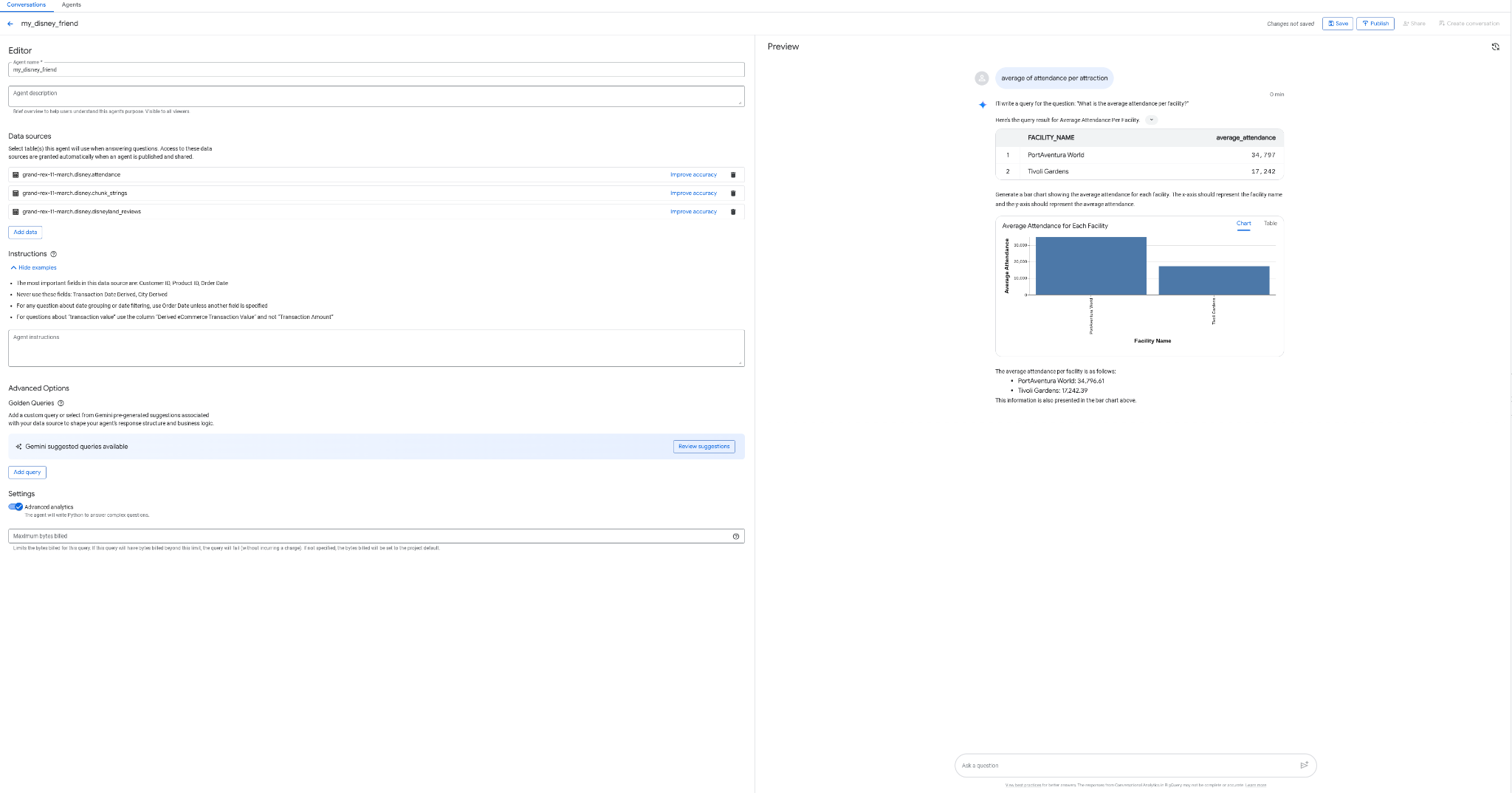
- Создайте агента my_disney_friend, который будет подключаться к вашим таблицам Disney Tables. Вы можете улучшить работу агента, заполнив инструкции для агента. Задавайте вопросы, например: «Какой процент положительных и отрицательных отзывов, каково среднее время ожидания на аттракционе и т. д.?»
- Опубликуйте агента в BigQuery и в API (вы будете использовать его позже).
8. Задание 5: Улучшите свой опыт разработки с помощью Gemini-CLI.
В эпоху искусственного интеллекта разработка программного обеспечения стала как никогда доступной. У вас тысячи идей для вашего приложения, посвященного Диснейленду, и вы хотите использовать свои данные на полную мощность. Вы хотите выйти за рамки простого взаимодействия с данными, теперь вам нужны действия!
Чтобы помочь вам на этом пути, вам понадобится помощь. И мы вам её предоставим.
Gemini CLI — это агент искусственного интеллекта с открытым исходным кодом, который переносит возможности Gemini непосредственно в ваш терминал. Разработчики могут создавать мощные приложения, а благодаря расширениям — взаимодействовать с различными серверами MCP (Model Context Protocol).
Среди них, конечно же, можно найти расширения для выполнения запросов к данным в AlloyDB или BigQuery!
В этом задании ваша цель состоит в следующем:
- Установите Gemini-CLI (в своем терминале или в Cloud Shell).
- Установите расширения Gemini-CLI для BigQuery и AlloyDB.
- Создайте файл среды, который позволит Gemini-CLI подключаться к вашим экземплярам BigQuery и AlloyDB.
- Воспользуйтесь Gemini-CLI, чтобы сгенерировать красивую единую HTML-страницу, которая объяснит содержимое вашей базы данных AlloyDB.
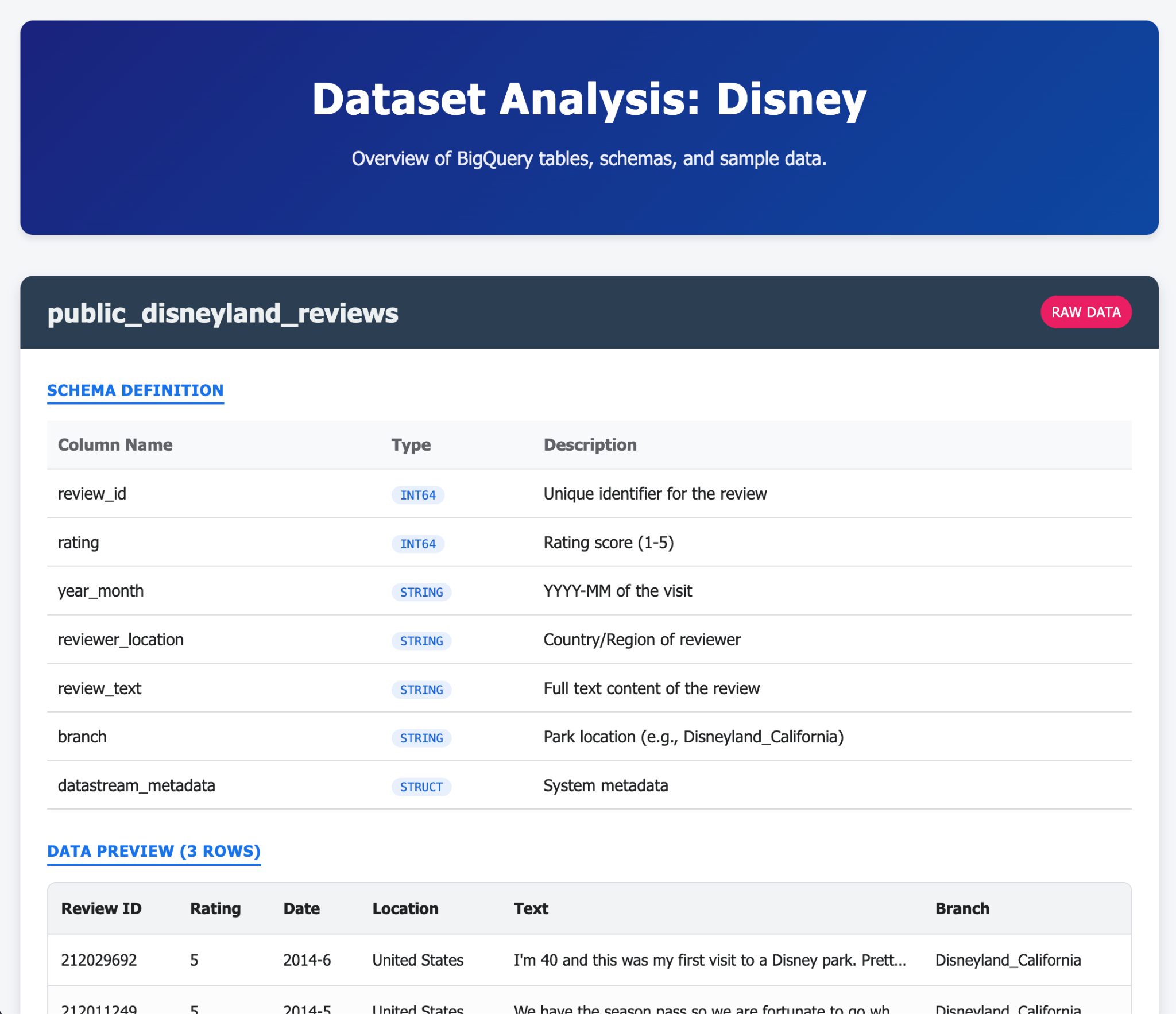
- Сделайте то же самое для BigQuery.
Вот несколько примеров того, что можно сгенерировать в одном (или нескольких) запросах с помощью Gemini-CLI и его расширений. А теперь представьте, что это можно сделать в реальных приложениях? 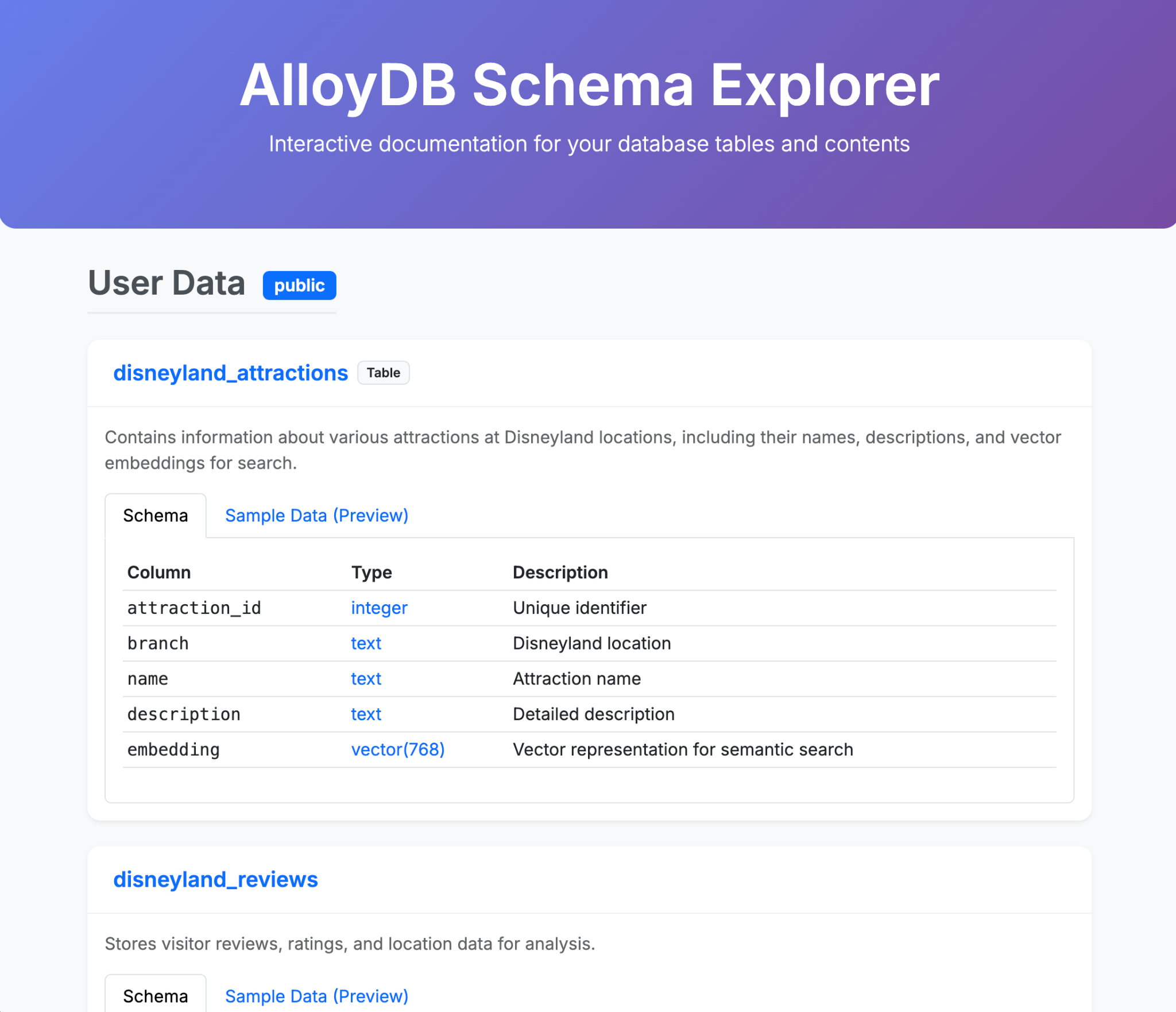
9. Задание 6: Создайте агента искусственного интеллекта для взаимодействия с вашими данными.
Чтобы предложить посетителям Диснейленда совершенно новый пользовательский опыт, вы создадите помощника, который сможет помочь им во время поездки. Ваш агент сможет:
- Перечислите все доступные достопримечательности в парке.
- Порекомендуйте достопримечательность, исходя из ожиданий.
- Добавить отзывы о достопримечательности
- Укажите приблизительное время ожидания у аттракциона в ближайшие несколько часов.
- Представьте обзор отзывов о конкретной достопримечательности.
Вы должны убедиться, что ваш ассистент может отвечать только на вопросы, связанные с Диснейлендом, и при этом сохраняет дружелюбный тон общения с пользователем. Настройте подсказки для агента, чтобы он выбирал подходящие инструменты в соответствии с потребностями пользователя.
Вам необходимо выполнить следующие шаги:
- Разверните набор инструментов MCP для серверов баз данных , использующих AlloyDB и BigQuery в качестве источников.
- Объявите 5 различных инструментов для вашего MCP-сервера, которые будут запрашивать данные из AlloyDB и BigQuery, и сопоставьте их с действиями агента, перечисленными ранее.
- Используйте пользовательский интерфейс MCP Toolbox для проверки каждого из ваших инструментов.
- Разверните агента с помощью Agent Development Kit , который может использовать инструменты, предоставляемые вашим сервером MCP Toolbox.
- Подключитесь к веб-интерфейсу ADK и продемонстрируйте полноценную беседу с вашим ассистентом, включая все доступные инструменты.
Дополнительный шаг, если вы закончите раньше:
Ваш агент готов? Давайте развернем его в Agent Engine!