
1. 🏰 Sự kiện hackathon về phân tích dữ liệu tại Disneyland (Lần thứ 2 – ngày 3 tháng 12) 🏰
Tóm tắt | Trong cuộc thi Hackathon này, bạn sẽ xây dựng một quy trình phân tích dữ liệu từ đầu đến cuối, tận dụng các chức năng AI/ML trên Google Cloud. Bạn sẽ tải dữ liệu vào AlloyDB, một cơ sở dữ liệu hoàn toàn được quản lý, tương thích với PostgreSQL và được tối ưu hoá cho các tải công việc đòi hỏi nhiều tài nguyên, sau đó sử dụng Datastream, một dịch vụ chụp dữ liệu thay đổi (CDC) không máy chủ, để di chuyển dữ liệu đó sang BigQuery, kho dữ liệu không máy chủ của Google Cloud. Trong BigQuery, bạn sẽ áp dụng BigQuery ML, cho phép bạn tạo và thực thi các mô hình học máy ngay trong BigQuery bằng cách sử dụng SQL chuẩn để phân tích bài đánh giá và dự đoán số người tham dự. Cuối cùng, bạn sẽ khám phá các tác nhân, có thể là tác nhân có sẵn thông qua Phân tích đàm thoại và Data Agents hoặc tạo một tác nhân tuỳ chỉnh bằng Bộ công cụ phát triển tác nhân và bộ công cụ MCP để tương tác với dữ liệu bằng ngôn ngữ tự nhiên. |
danh mục | docType:Codelab, product:Bigquery |
Tác giả | Rayhane Rezgui, Matt Cornillon |
Bố cục | cuộn |
Robot | noindex |
2. Giới thiệu
Chào mừng các chuyên gia dữ liệu tương lai của Disney!🪄
Không cần phải xem hướng dẫn du lịch nhàm chán và cuộn chuột mãi trên diễn đàn. Hãy tưởng tượng bạn đang lên kế hoạch cho một chuyến đi hoàn hảo đến Disneyland, được trang bị những thông tin chi tiết dựa trên dữ liệu. Công viên nào mang lại trải nghiệm tốt nhất? Khi nào lượng khách tham quan ít nhất? Bạn có thể dự đoán thời điểm thích hợp nhất để vượt qua hàng đợi dài khét tiếng đó không?
Trong cuộc thi Hackathon này, bạn sẽ xây dựng công cụ lập kế hoạch tối ưu cho Disneyland. Chúng tôi có dữ liệu: bài đánh giá của khách tham quan tại các chi nhánh trên toàn cầu, thời gian chờ đợi trong quá khứ và số liệu về lượt tham dự. Sứ mệnh của bạn là gì? Chuyển đổi dữ liệu thô này thành thông tin chi tiết hữu ích:
- Thu thập dữ liệu: Tải nhiều đánh giá, thời gian chờ và số liệu về lượng khách tham quan Disneyland vào AlloyDB, cơ sở dữ liệu hiệu suất cao, tương thích với PostgreSQL của chúng tôi.
- Di chuyển liền mạch: Sử dụng Datastream (dịch vụ ghi nhận dữ liệu thay đổi không máy chủ của chúng tôi) để dễ dàng di chuyển thông tin động này vào BigQuery (kho dữ liệu không máy chủ mạnh mẽ của Google Cloud).
- Dự đoán điều kỳ diệu: Khai thác BigQuery ML để phân tích cảm xúc trong bài đánh giá và dự báo thời gian chờ trực tiếp bằng SQL. Khám phá những chi nhánh luôn mang đến sự hài lòng và thời điểm thích hợp nhất để bạn ghé thăm.
- Trò chuyện với dữ liệu của bạn theo đúng nghĩa đen! Sử dụng các công cụ dựng sẵn để thu thập thông tin chi tiết chỉ bằng một lần vuốt đũa phép.
- Tương tác thông minh: Hoàn thiện tác phẩm của bạn bằng một tác nhân thông minh, được hỗ trợ bởi bộ công cụ MCP cho cơ sở dữ liệu và ADK (Bộ công cụ phát triển tác nhân). Đặt câu hỏi "Điểm tham quan nào ở Disneyland Paris phù hợp nhất với những người yêu thích vũ trụ và thời điểm nào là phù hợp nhất để xếp hàng?" và nhận được câu trả lời tức thì dựa trên dữ liệu.
Chuẩn bị sẵn sàng khám phá những bí mật của những nơi kỳ diệu nhất trên Trái Đất và xây dựng một quy trình phân tích dữ liệu mà ngay cả Mickey cũng phải tự hào!
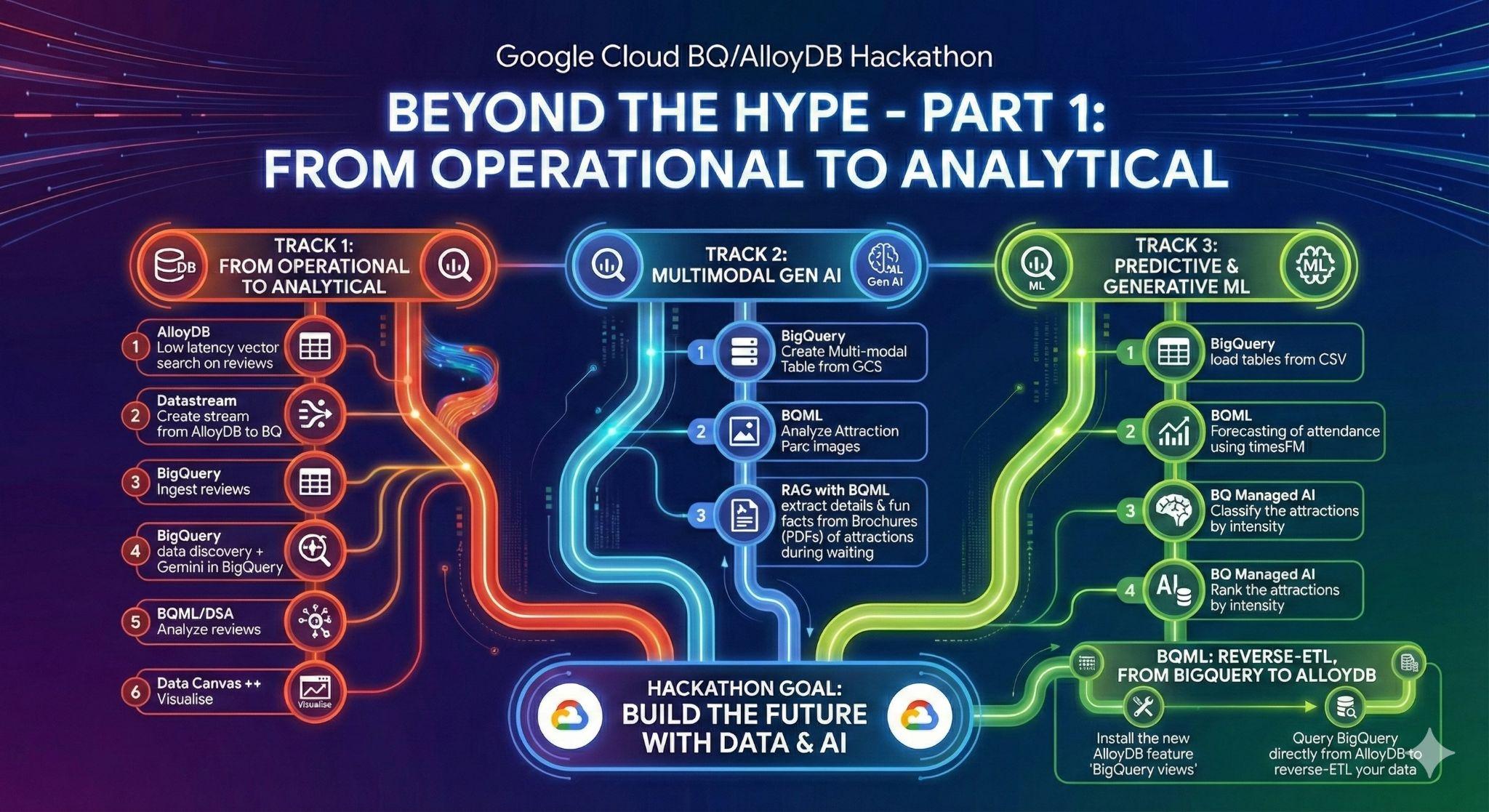
3. Việc cần làm 1: Từ hoạt động đến phân tích; Phân tích các bài đánh giá về Disneyland bằng Gemini
Trong giai đoạn ban đầu này, bạn sẽ truy xuất dữ liệu từ cơ sở dữ liệu hoạt động AlloyDB và tải dữ liệu đó vào BigQuery để phân tích dữ liệu sau này.
Bạn cũng sẽ thiết lập mọi thứ cần thiết trong AlloyDB cho tác nhân của mình trong tương lai!
Đang tải dữ liệu trong AlloyDB
Trước hết, hãy nhập một số dữ liệu vào cụm AlloyDB cho PostgreSQL của chúng ta!
Chúng ta sẽ nhập 20.000 bài đánh giá về các công viên giải trí của Disneyland và danh sách các điểm tham quan.
Sau đây là các bước bạn cần thực hiện:
Tạo bảng:
- Tạo một bảng disneyland_reviews có 6 cột: review_id và điểm xếp hạng dưới dạng số nguyên, year_month, reviewer_location, review_text, branch dưới dạng văn bản.
- Tạo một bảng disneyland_attractions có 4 cột: attraction_id là số nguyên, branch, name và description là văn bản.
Sử dụng công cụ bạn chọn để nhập dữ liệu từ các tệp CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvcho bảng bài đánh giágs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvcho bảng địa điểm tham quan
Để đưa ra đề xuất về các điểm tham quan, chúng ta cần tạo các mục nhúng cho phần mô tả về các điểm tham quan:
- Cài đặt tiện ích pgvector trong AlloyDB
- Thêm một cột vectơ có tên là "embedding" vào bảng attraction
- Tạo và điền giá trị nhúng cho nội dung mô tả bằng cách sử dụng chế độ tích hợp gốc giữa AlloyDB và Vertex AI
Từ dữ liệu vận hành đến dữ liệu phân tích bằng Datastream
Để truyền trực tuyến dữ liệu từ AlloyDB sang BigQuery, chúng ta sẽ sử dụng Google Datastream. Đây là một giải pháp mạnh mẽ không cần máy chủ, có thể theo dõi mọi thay đổi trong các bảng nguồn (bằng cách sử dụng tính năng Ghi nhận thay đổi dữ liệu) và gửi các thay đổi đó đến BigQuery.
Để có thể sao chép các thay đổi từ AlloyDB bằng Datastream, chúng ta cần tạo một cái gọi là vị trí xuất bản và nhân bản trên Postgres.
Thực thi các truy vấn sau trên cụm AlloyDB (bạn cần chạy từng truy vấn một):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Bạn sẽ sử dụng vị trí xuất bản và sao chép trong luồng của mình, vì vậy hãy nhớ tên của các vị trí này!
Vậy là xong, giờ đây chúng ta có thể tạo một sự kiện phát trực tiếp!
Sau đây là các bước bạn cần thực hiện trong Datastream:
- Tạo hồ sơ nguồn cho cụm AlloyDB (sử dụng địa chỉ IP công khai)
- Tạo hồ sơ đích cho BigQuery
- Tạo luồng dữ liệu từ AlloyDB đến BigQuery.
Dữ liệu sẽ có trong BigQuery sau vài phút.
Khám phá dữ liệu trong BigQuery
Bây giờ chúng ta đã có dữ liệu trong BigQuery, hãy đảm bảo rằng chúng ta biết các điểm cải tiến mới trong giao diện trước khi bắt đầu làm việc!
Chúng tôi có 3 chức năng mới mà bạn có thể thấy trong bảng khám phá BigQuery.
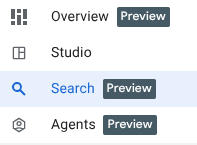
- Tổng quan: chứa thông tin về các tính năng của BigQuery, hướng dẫn để bắt đầu phân tích và nhiều khả năng khác.
- Tìm kiếm: thực hiện tìm kiếm ngữ nghĩa trên tài sản dữ liệu của bạn.
- Nhân viên hỗ trợ: Suỵt! Chúng ta sẽ lưu lại phần này để xem sau 🤫
Tìm kiếm dữ liệu theo ngữ nghĩa trong BigQuery
Chuyển đến thẻ Tìm kiếm trong bảng khám phá BigQuery và thử nghiệm với các cụm từ liên quan đến Disney như "điểm tham quan" hoặc "chi nhánh".
Trực quan hoá dữ liệu trong BigQuery
Giờ đây, bạn có thể trực quan hoá và xử lý dữ liệu của mình trong BigQuery. Để làm việc này, bạn có thể chạy truy vấn này trong một thẻ truy vấn mới;
SELECT
*
FROM
[dataset_name].[table_name];
Tạo thông tin chi tiết về dữ liệu trên bảng đánh giá
Trong nhiệm vụ này, bạn sẽ bật thông tin chi tiết về dữ liệu trên bảng disneyland_reviews trong tập dữ liệu disney.
Thông tin chi tiết về dữ liệu là một công cụ dành cho những người muốn khám phá dữ liệu và thu thập thông tin chi tiết mà không cần viết các truy vấn SQL phức tạp.
Quá trình này có thể mất vài phút.
Truy vấn bảng disneyland_reviews mà không cần SQL
Thông tin chi tiết mà bạn đã tạo trong phần trước hiện đã sẵn sàng. Trong nhiệm vụ này, bạn sẽ sử dụng một câu lệnh được tạo từ những thông tin chi tiết này để truy vấn bảng disneyland_reviews mà không cần dùng mã.
Chọn một thông tin chi tiết và chạy truy vấn liên quan đến thông tin chi tiết đó. Ví dụ: tìm truy vấn tính toán mức chênh lệch về điểm xếp hạng trung bình giữa các tháng liên tiếp cho từng chi nhánh. URL sẽ có dạng như sau:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Sử dụng BigQuery Knowledge Engine để hiểu rõ hơn về dữ liệu
Trước tiên, hãy bắt đầu bằng cách xem thẻ Thông tin chi tiết ở cấp tập dữ liệu. Thẻ này sẽ giúp chúng ta nắm được các mối quan hệ ẩn giữa các bảng trong tập dữ liệu disney. Sau đó:
- Tạo nội dung mô tả về tập dữ liệu bằng Gemini và thêm nội dung đó vào phần thông tin chi tiết về tập dữ liệu.
- Tạo nội dung mô tả về các bảng đánh giá và địa điểm tham quan, cũng như tất cả các cột riêng lẻ trong những bảng đó rồi lưu lại.
Quét hồ sơ dữ liệu của bạn
Mục tiêu của phần này là làm sạch và chuẩn bị dữ liệu. Tuy nhiên, bạn không nắm rõ được sự phân phối các giá trị của từng cột. Bạn cần lập hồ sơ dữ liệu để biết loại bước chuyển đổi mà bạn cần thực hiện trên dữ liệu của mình.
Danh mục chung Dataplex của Google Cloud tự động hoá các lượt quét lập hồ sơ để cung cấp các chỉ số nhất quán về chất lượng dữ liệu. Các số liệu thống kê chính được xác định bao gồm số lượng giá trị rỗng, giá trị riêng biệt, dải ô dữ liệu và phân phối giá trị. Bạn có thể kích hoạt quá trình quét hồ sơ thông qua Giao diện BigQuery.
Quá trình này có thể mất vài phút, vì vậy bạn có thể xem phần tiếp theo trong khi chờ đợi.
Trả lời các câu hỏi sau:
- Điểm xếp hạng trung bình của Disneyland là bao nhiêu?
- Người đánh giá tập trung ở đâu nhiều nhất?
- Tất cả các bài đánh giá đều là nội dung riêng biệt?
- Tỷ lệ dữ liệu bị thiếu trong cột Year_Month là bao nhiêu?
Thực hiện quét chất lượng dữ liệu
Danh mục chung của Dataplex chất lượng dữ liệu tự động cho phép bạn xác định và đo lường chất lượng dữ liệu trong các bảng BigQuery. Bạn có thể tự động hoá việc quét dữ liệu, xác thực dữ liệu dựa trên các quy tắc đã xác định và ghi lại các cảnh báo nếu dữ liệu của bạn không đáp ứng các yêu cầu về chất lượng. Bạn có thể quản lý các quy tắc và việc triển khai chất lượng dữ liệu dưới dạng mã, giúp cải thiện tính toàn vẹn của quy trình sản xuất dữ liệu.
Dựa trên kết quả quét hồ sơ, hãy xác định một quy trình quét chất lượng (trên không quá 10% dữ liệu của bạn làm kích thước mẫu) để:
- Kiểm tra các giá trị rỗng cho cột "branch"
- Thực hiện kiểm tra tính hợp lệ cho "rating", vì giá trị này chỉ có thể nằm trong tập hợp : 1,2,3,4,5
- Kiểm tra tính duy nhất của "review_id"
Đảm bảo kết quả quét được xuất sang Bảng BigQuery quality_scan_results.
Hãy nghĩ về tất cả các phép biến đổi tiềm năng mà bạn cần áp dụng cho dữ liệu của mình.
Chuẩn bị dữ liệu bằng tính năng Chuẩn bị dữ liệu của Gemini
Sau khi thực hiện các lượt quét chất lượng dữ liệu và lập hồ sơ, bạn cần làm sạch dữ liệu trước khi phân tích.
Chuẩn bị dữ liệu là các tài nguyên BigQuery, sử dụng Gemini trong BigQuery để phân tích dữ liệu của bạn và đưa ra các đề xuất thông minh để làm sạch, biến đổi và làm phong phú dữ liệu. Bạn có thể giảm đáng kể thời gian và công sức cần thiết cho các công việc chuẩn bị dữ liệu theo cách thủ công.
Trong phần này, bạn sẽ sử dụng tính năng Chuẩn bị dữ liệu để thực hiện các thao tác sau trên bảng disneyland_reviews:
- Lọc ra những hàng có cột Chi nhánh là NULL hoặc một chuỗi trống.
- Thay thế "missing" trong Year_Month bằng Null.
- Thay thế dấu gạch dưới bằng dấu cách trong cột nhánh để cải thiện khả năng đọc
- Xuất sang bảng đã chuyển đổi disneyland_reviews_cleaned
Phân tích bài đánh giá bằng Gemini
Giờ đây, sau khi đã làm sạch dữ liệu, bạn có thể bắt đầu phân tích dữ liệu đó bằng cách sử dụng BigQuery ML và các mô hình Gemini. Bạn có 2 mục tiêu:
- Trích xuất danh mục từ bài đánh giá
- Phân tích cảm xúc của disneyland_reviews
BigQuery ML cho phép bạn tạo và chạy các mô hình học máy (ML) bằng cách sử dụng các truy vấn GoogleSQL. Các mô hình BigQuery ML được lưu trữ trong tập dữ liệu BigQuery, tương tự như bảng và chế độ xem. BigQuery ML cũng cho phép bạn truy cập vào các mô hình Vertex AI và Cloud AI API để thực hiện các tác vụ trí tuệ nhân tạo (AI) như tạo văn bản hoặc bản dịch máy. Gemini cho Google Cloud cũng cung cấp sự hỗ trợ dựa trên AI cho các tác vụ trên BigQuery.
Bạn có thể chọn sử dụng ML.GENERATE_TEXT hoặc AI.GENERATE (bản dùng thử) với các mô hình Gemini Pro hoặc Flash.
Các bước sau đây sẽ hướng dẫn bạn nếu bạn muốn sử dụng ML.GENERATE_TEXT.
Tạo kết nối tài nguyên trên đám mây và cấp vai trò IAM
Bạn cần tạo một kết nối tài nguyên trên đám mây trong BigQuery với các mô hình Vertex AI để có thể làm việc với các mô hình Gemini Pro và Gemini Flash. Bạn cũng sẽ cấp quyền IAM cho tài khoản dịch vụ của kết nối tài nguyên đám mây thông qua một vai trò để cho phép tài khoản này truy cập vào các dịch vụ Vertex AI.
Cấp vai trò Người dùng Vertex AI cho tài khoản dịch vụ của mối kết nối
Cho phép tài khoản dịch vụ của mối kết nối sử dụng mô hình bạn chọn (ví dụ: gemini-2.5-flash) bằng cách cấp cho tài khoản đó vai trò Người dùng Vertex AI. Quyền sẽ được áp dụng sau 1 phút.
Tạo các mô hình Gemini trong BigQuery
Tạo mô hình bằng cách sử dụng mối kết nối ở trên. Ví dụ: sử dụng điểm cuối gemini-2.5-flash.
Yêu cầu Gemini phân tích bài đánh giá của khách hàng theo danh mục và mức độ hài lòng
Trong nhiệm vụ này, bạn sẽ sử dụng mô hình Gemini để phân tích từng bài đánh giá của khách hàng theo danh mục và cảm xúc (tích cực hoặc tiêu cực).
Phân tích bài đánh giá của khách hàng cho các danh mục
Lưu ý: Kể từ bây giờ, để phân tích, chúng ta sẽ chỉ lấy 100 hàng, vì việc gọi Gemini trên 20.000 hàng có thể mất một lúc.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Truy vấn này lấy các bài đánh giá của khách hàng từ bảng disneyland_reviews, tạo câu lệnh cho mô hình gemini để xác định các danh mục trong từng bài đánh giá. Kết quả phải được lưu trữ trong một bảng mới reviews_categories
. Vui lòng chờ. Mô hình này mất khoảng 30 giây để xử lý các bản ghi bài đánh giá của khách hàng và đưa ra kết quả trong bảng đầu ra.
Hiển thị kết quả:
SELECT * FROM [dataset_name].[results_table_name];
Dành chút thời gian để đọc một số danh mục.
Phân tích bài đánh giá của khách hàng để xác định cảm xúc tích cực và tiêu cực
Dựa trên truy vấn SQL để trích xuất từ khoá, hãy viết một truy vấn phân tích bài đánh giá thành Tích cực, Tiêu cực và Trung lập trong một cột có tên là "sentiment" (cảm xúc).
Truy vấn này lấy bài đánh giá của khách hàng trong bảng disneyland_reviews, tạo câu lệnh cho mô hình gemini để phân loại tình cảm của từng bài đánh giá. Sau đó, kết quả sẽ được lưu trữ trong một bảng mới reviews_analysis để bạn có thể sử dụng sau này cho các hoạt động phân tích khác. Vui lòng đợi. Mô hình này mất vài giây để xử lý các bài đánh giá của khách hàng. Khi mô hình hoàn tất, kết quả sẽ nằm trong bảng reviews_analysis được tạo.
Khám phá kết quả:
SELECT * FROM [...];
Bảng reviews_analysis có cột Sentiment chứa thông tin phân tích cảm xúc, bao gồm các cột social_media_source, review_text, customer_id, location_id và review_datetime. Hãy xem một số bản ghi. Bạn có thể nhận thấy một số kết quả cho giá trị dương và giá trị âm có thể không được định dạng đúng, có các ký tự thừa như dấu chấm hoặc dấu cách thừa. Bạn có thể dọn dẹp các bản ghi bằng cách sử dụng chế độ xem bên dưới.
Tạo một khung hiển thị để dọn dẹp các bản ghi
Tạo một khung hiển thị giúp dọn dẹp các giá trị của cột cảm tính bằng cách:
- Sử dụng hàm LOWER để đảm bảo tất cả các giá trị đều là chữ thường.
- Xoá dấu chấm câu (. và , và dấu cách) bằng hàm REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
Truy vấn này tạo chế độ xem cleaned_data_view và bao gồm kết quả phân tích cảm xúc, văn bản đánh giá, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Sau đó, hàm này sẽ lấy kết quả về cảm xúc (tích cực hoặc tiêu cực) và đảm bảo rằng tất cả các chữ cái đều được viết thường, đồng thời các ký tự thừa như dấu cách hoặc dấu chấm thừa sẽ bị xoá. Chế độ xem kết quả sẽ giúp bạn dễ dàng phân tích thêm ở các bước sau trong phòng thí nghiệm này.
- Bạn có thể truy vấn khung hiển thị bằng truy vấn bên dưới để xem các hàng đã tạo.
SELECT * FROM [view_name];
Tạo báo cáo về số lượng đánh giá tích cực và tiêu cực bằng Data Canvas
Bây giờ là lúc bạn phân tích kết quả. Hãy bắt đầu bằng cách thực hiện trực tiếp trong BigQuery thông qua Canvas dữ liệu. Đây là một công cụ cho phép bạn tìm kiếm dữ liệu (theo ngữ nghĩa hoặc từ khoá), truy vấn và kết hợp các bảng, tạo biểu đồ và thu thập thông tin chi tiết bằng cách tạo một luồng trên canvas.
Mục tiêu cuối cùng của bạn là tạo một biểu đồ về tỷ lệ phần trăm bài đánh giá tích cực so với tiêu cực theo lựa chọn của bạn . Ví dụ:
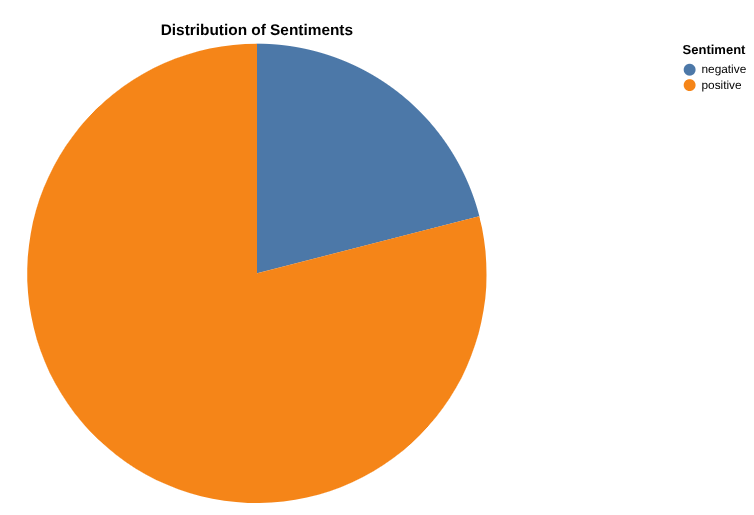
Tạo biểu đồ về số lượng bài đánh giá theo từng danh mục, cũng như mức độ phân bổ bài đánh giá tích cực và tiêu cực cho từng danh mục
Lưu ý: Kích hoạt và sử dụng tính năng Phân tích nâng cao của Data Canvas. Tính năng này chạy một Sổ tay Python bên trong canvas.
4. Việc 2: Phân tích hình ảnh công viên giải trí để xác định ảnh Disneyland và trích xuất thông tin thú vị từ Tờ rơi của công viên
Phân tích hình ảnh trong BigQuery
Bạn có thể xem một số bức ảnh hấp dẫn và thú vị về công viên giải trí do du khách chụp trong những năm qua. Bạn rất hào hứng với chuyến đi sắp tới! Tuy nhiên, bạn không biết bức ảnh nào là ảnh thực tế của Disneyland. Bạn có nhiệm vụ xác định những người đó. Các bức ảnh này nằm trong gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: True
Để nhanh chóng thực hiện phân tích này. Bạn nên sử dụng các bảng đối tượng của BigQuery và Gemini thông qua BigQuery ML (ML.GENERATE_TEXT).
Bạn có thể xác minh kết quả của Gemini bằng cách kiểm tra một số bức ảnh không?
Tạo hệ thống RAG của riêng bạn bằng BigQuery trên tờ rơi của Disneyland
Trong khi chờ đợi, bạn muốn biết một số thông tin thú vị/chi tiết kỹ thuật về điểm tham quan mà bạn đang chờ.
Trong gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,, bạn sẽ tìm thấy các tệp PDF chứa tờ rơi của tất cả các công viên trên thế giới.
Mục tiêu: Tạo một hệ thống Tạo nội dung tăng cường khả năng truy xuất (RAG) hoàn toàn trong BigQuery để cho phép người dùng đặt các câu hỏi phức tạp về công viên dựa trên một số tài liệu PDF.
Để làm được điều này, bạn cần:
- Tạo bảng đối tượng gồm các tệp PDF
- Tạo UDF Python để chia tệp PDF thành các khối. Sau đây là một ví dụ bạn có thể sử dụng:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Phân tích cú pháp tệp PDF thành các đoạn
- Tạo embeddings sau khi tạo một mô hình từ xa
- Chạy một tìm kiếm vectơ để tìm "
Ou manger un repas tex-mex à volonté?" hoặc "where to eat a tex-mex meal buffet-style?" - Tạo câu trả lời được tăng cường bằng kết quả tìm kiếm vectơ của câu hỏi "
Ou manger un repas tex-mex à volonté?" hoặc "where to eat a tex-mex meal buffet-style?"
5. Bài tập 3: Học máy ở quy mô lớn bằng BigQuery: Dự báo, phân loại và xếp hạng
Dự đoán thời gian chờ
Những bức ảnh này rất tuyệt! Bạn không thể chờ đợi! Để biết nên chọn và nên tránh những điểm tham quan nào, bạn cần biết thời gian chờ thực tế của một số điểm tham quan giữa Paris và California. Nhiệm vụ của bạn là dự báo waiting_times của mọi điểm tham quan bằng cách sử dụng học máy (Arima plus hoặc TimesFM) cho mỗi 30 phút trong năm 2025.
Dữ liệu bạn sẽ sử dụng nằm trong tệp csv này: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
Các bước trong việc cần làm của bạn là:
- Tải tệp vào tập dữ liệu BigQuery của bạn trong một bảng có tên là waiting_times.
- Huấn luyện mô hình dự báo trên dữ liệu của bạn (Arima_Plus) hoặc dự báo trực tiếp bằng AI.Forecast
- Đánh giá hiệu suất của mô hình hoặc so sánh dữ liệu dự đoán với dữ liệu đầu vào
Phân loại các chuyến đi theo cường độ
Bạn đang tham quan Disneyland cùng bạn bè. Mặc dù công viên này thường dành cho gia đình, nhưng một số trò chơi có thể quá mạnh đối với một số người. Hãy sử dụng các hàm AI được quản lý của BigQuery để phân loại và xếp hạng các điểm tham quan theo mức độ hồi hộp và cường độ, không có sự thiên vị của con người, để chúng ta có thể đáp ứng mọi người.
- Sử dụng
AI.CLASSIFYđể phân loại các chuyến đi dựa trên nội dung mô tả thành một trong ba danh mục kỳ diệu: [easy-peasy, thrilling, extreme]
Xếp hạng các chuyến đi dựa trên mức độ mạo hiểm
- Sử dụng
AI.SCOREđể so sánh và sắp xếp các điểm tham quan dựa trên mức độ mạo hiểm, trong đó Hạng 10 là mạo hiểm nhất và Hạng 1 là ít mạo hiểm nhất.
6. Nhiệm vụ 3 – Bổ sung: ETL ngược, từ BigQuery sang AlloyDB
Bạn đã tận dụng các chức năng mạnh mẽ của BigQuery để tạo thông tin chi tiết về lượng lớn dữ liệu. Giờ đây, bạn muốn các thông tin chi tiết đó có thể được các ứng dụng vận hành (và các tác nhân AI!) của bạn thực hiện.
Nhưng làm cách nào? Bằng cách làm ngược lại! AlloyDB cho Postgres phát triển mạnh mẽ trong việc phân phát dữ liệu với độ trễ thấp và tốc độ cao, rất phù hợp cho các ứng dụng quan trọng mà người dùng sử dụng. Vậy hãy đảo ngược ETL dữ liệu mà chúng ta vừa tạo.
Để làm việc đó, chúng ta sẽ sử dụng một tính năng hoàn toàn mới (vẫn đang ở giai đoạn dùng thử riêng tư) có tên là "BigQuery views" trong AlloyDB. Tính năng này cho phép bạn truy vấn dữ liệu BigQuery ngay trong cơ sở dữ liệu Postgres.
Trước tiên, bạn cần cấp cho tài khoản dịch vụ của cụm AlloyDB các đặc quyền cần thiết để truy vấn BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
Đầu ra chứa trường serviceAccountEmail, là tài khoản dịch vụ cho cụm này.
Trong Google Cloud Console, hãy chuyển đến trang IAM rồi cấp cho chủ thể này các đặc quyền sau:
- Người xem dữ liệu BigQuery (roles/bigquery.dataViewer)
- Người dùng phiên đọc BigQuery (roles/bigquery.readSessionUser)
Bây giờ, hãy chuyển đến AlloyDB Studio trong Bảng điều khiển rồi kết nối với cơ sở dữ liệu "postgres".
Thực thi các truy vấn sau để cài đặt và định cấu hình tính năng mới:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Giờ đây, bạn có thể tạo một "bảng bên ngoài" sẽ được liên kết với một bảng hiện tại trong BigQuery. Sử dụng bảng bất kỳ mà bạn đã tạo trong Bài tập 3. Sau đây là một ví dụ về cú pháp:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Mọi thứ đã sẵn sàng, hãy truy vấn bảng! Thực thi một câu lệnh SELECT đầu tiên để xác thực mối liên kết giữa AlloyDB và BigQuery, sau đó tạo một bảng mới trong AlloyDB để nhận dữ liệu từ bảng bên ngoài.
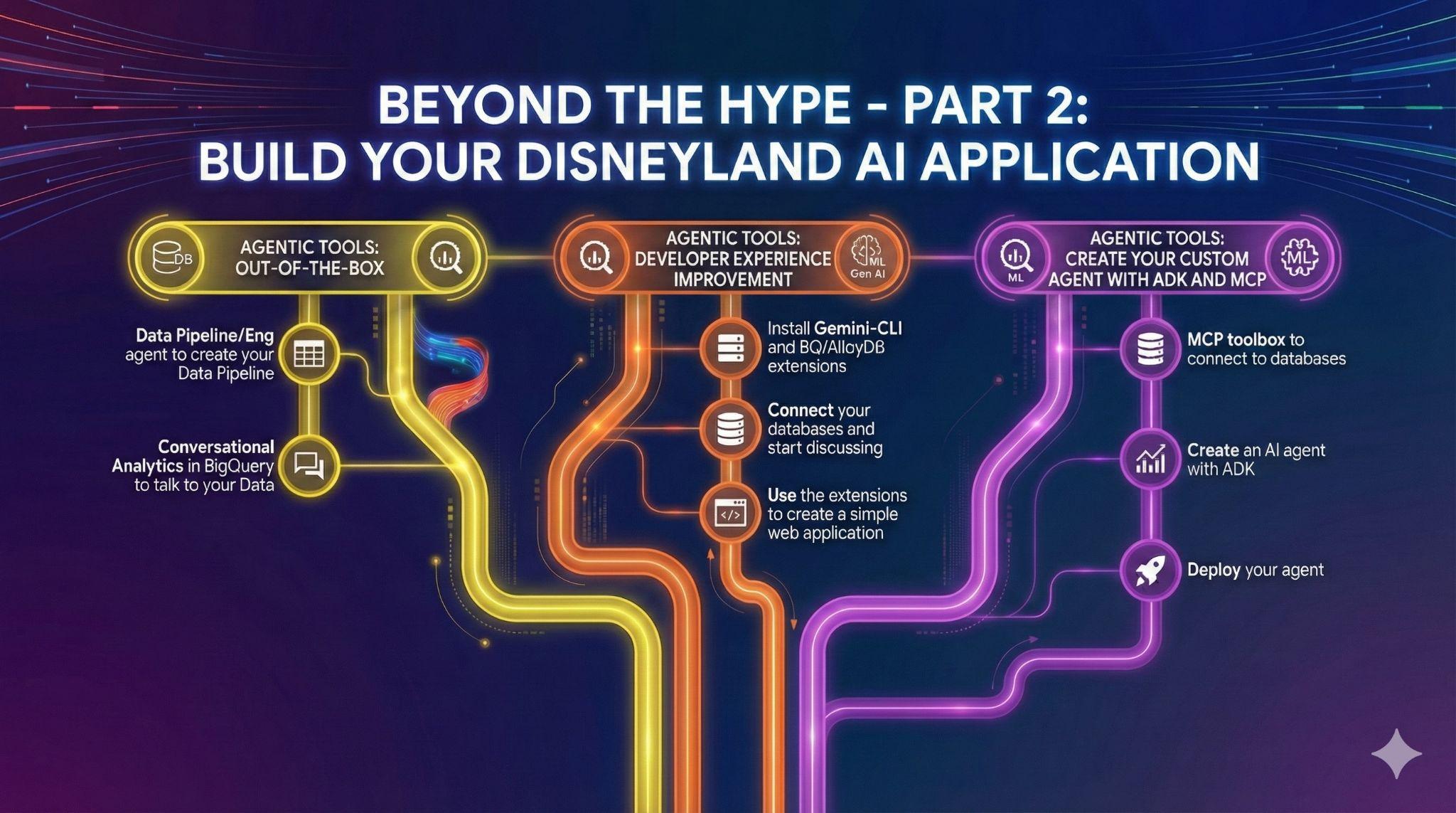
7. Tác vụ 4: Tác nhân dữ liệu có sẵn
Bạn có những người bạn muốn đóng góp cho dự án Ứng dụng Disneyland. Họ có quyền truy cập vào dữ liệu trong BigQuery, nhưng có trình độ khác nhau về SQL và kỹ thuật dữ liệu. Bạn muốn tận dụng những thông báo gần đây của BigQuery về các tác nhân dữ liệu đã được tích hợp vào giao diện người dùng để hỗ trợ bạn bè của mình:
- Tạo quy trình xử lý dữ liệu.
- Cộng tác trên mã SQL.
- Trò chuyện với dữ liệu của họ.
Tác nhân Kỹ thuật dữ liệu để tự động hoá Quy trình xử lý dữ liệu
Tạo một chế độ xem mới average_waiting_time kết hợp bảng thời gian chờ và các điểm tham quan, đồng thời tính toán average_waiting_time cho mỗi điểm tham quan bằng cách sử dụng Data Engineering Agent.
Tạo tác nhân Phân tích đàm thoại trong BigQuery
Nếu bạn có thể tạo một tác nhân để trò chuyện với dữ liệu của mình mà không cần viết mã, không cần SQL, không cần triển khai và ngay từ giao diện của BigQuery, thì điều đó sẽ tuyệt vời đến mức nào? Bạn có thể làm việc này ngay hôm nay bằng thẻ "Tác nhân" trong BigQuery.
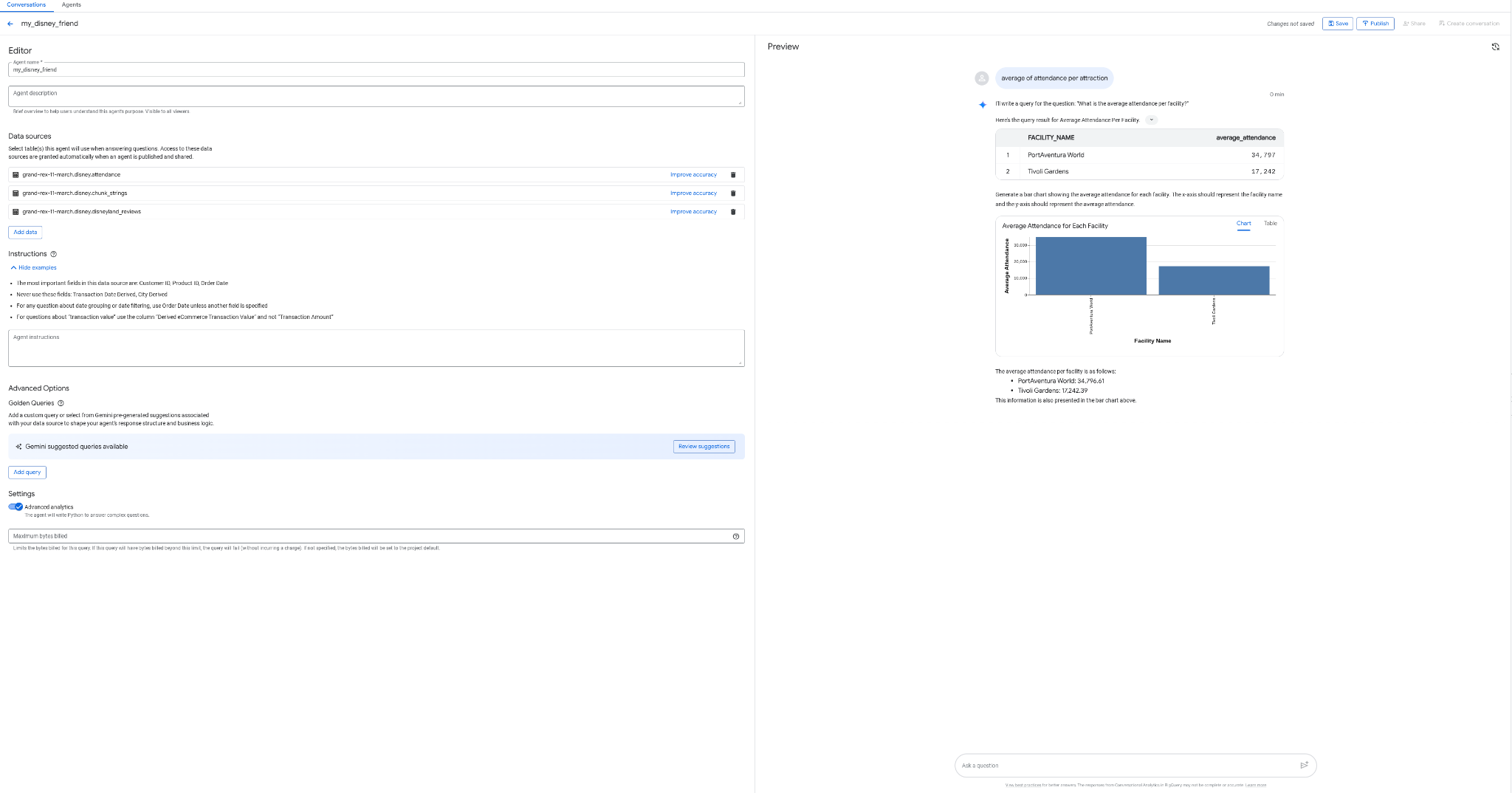
- Tạo một nhân viên hỗ trợ my_disney_friend, kết nối với các bảng disney của bạn. Bạn có thể cải thiện hiệu suất của nhân viên hỗ trợ bằng cách điền thông tin vào phần Hướng dẫn cho nhân viên hỗ trợ. Đặt các câu hỏi như "tỷ lệ bài đánh giá tích cực so với tiêu cực là bao nhiêu, thời gian chờ trung bình cho mỗi điểm tham quan là bao nhiêu,v.v.?"
- Xuất bản tác nhân trong BigQuery và trên API (bạn sẽ sử dụng tác nhân này sau).
8. Việc cần làm 5: Cải thiện trải nghiệm phát triển bằng Gemini-CLI
Trong kỷ nguyên AI này, việc xây dựng phần mềm trở nên dễ dàng hơn bao giờ hết. Bạn có hàng nghìn ý tưởng cho ứng dụng Disneyland và muốn sử dụng dữ liệu của mình ở mức tối đa. Bạn muốn làm nhiều hơn là chỉ trò chuyện với dữ liệu, giờ bạn cần hành động!
Để đi trên con đường đó, bạn sẽ cần sự trợ giúp. Chúng tôi sẽ giúp bạn.
Gemini CLI là một tác nhân AI mã nguồn mở, giúp bạn khai thác sức mạnh của Gemini ngay trên cửa sổ dòng lệnh. Nhà phát triển có thể tạo các ứng dụng mạnh mẽ và nhờ các tiện ích, họ cũng có thể tương tác với nhiều máy chủ MCP (Giao thức ngữ cảnh mô hình).
Trong số đó, bạn có thể tìm thấy các tiện ích để truy vấn dữ liệu AlloyDB hoặc BigQuery!
Trong nhiệm vụ này, mục tiêu của bạn là:
- Cài đặt Gemini-CLI (trong cửa sổ dòng lệnh của riêng bạn hoặc trong Cloud Shell)
- Cài đặt các tiện ích Gemini-CLI của BigQuery và AlloyDB
- Tạo một tệp môi trường cho phép Gemini-CLI kết nối với các phiên bản BigQuery và AlloyDB
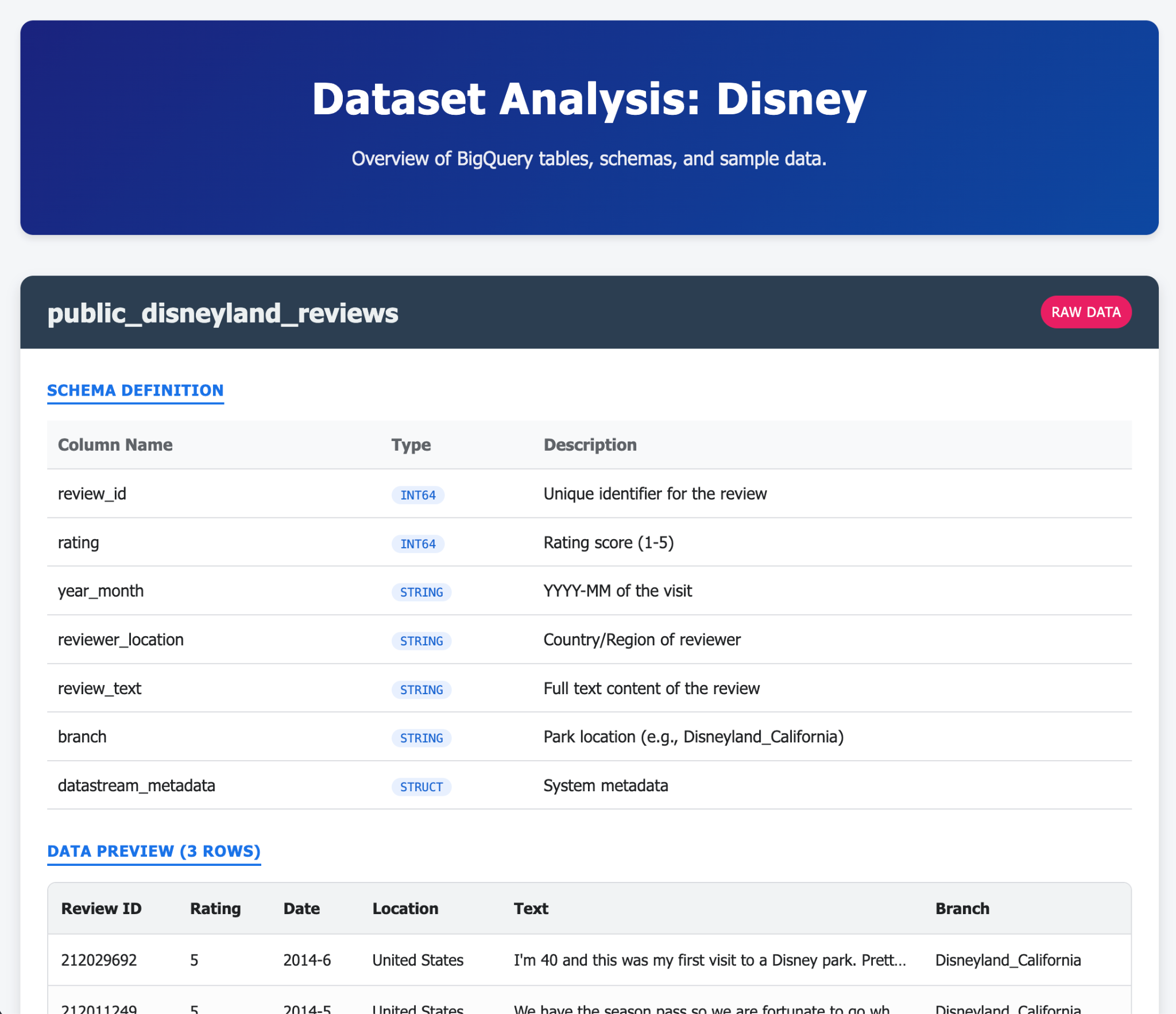
- Yêu cầu Gemini-CLI tạo một trang HTML đơn giản nhưng đẹp mắt để giải thích nội dung trong cơ sở dữ liệu AlloyDB của bạn
- Làm tương tự cho BigQuery
Sau đây là một số ví dụ về nội dung bạn có thể tạo trong một (hoặc vài) câu lệnh bằng Gemini-CLI và các tiện ích của công cụ này. Bây giờ, hãy tưởng tượng rằng bạn có thể làm điều đó với các ứng dụng trong thực tế. 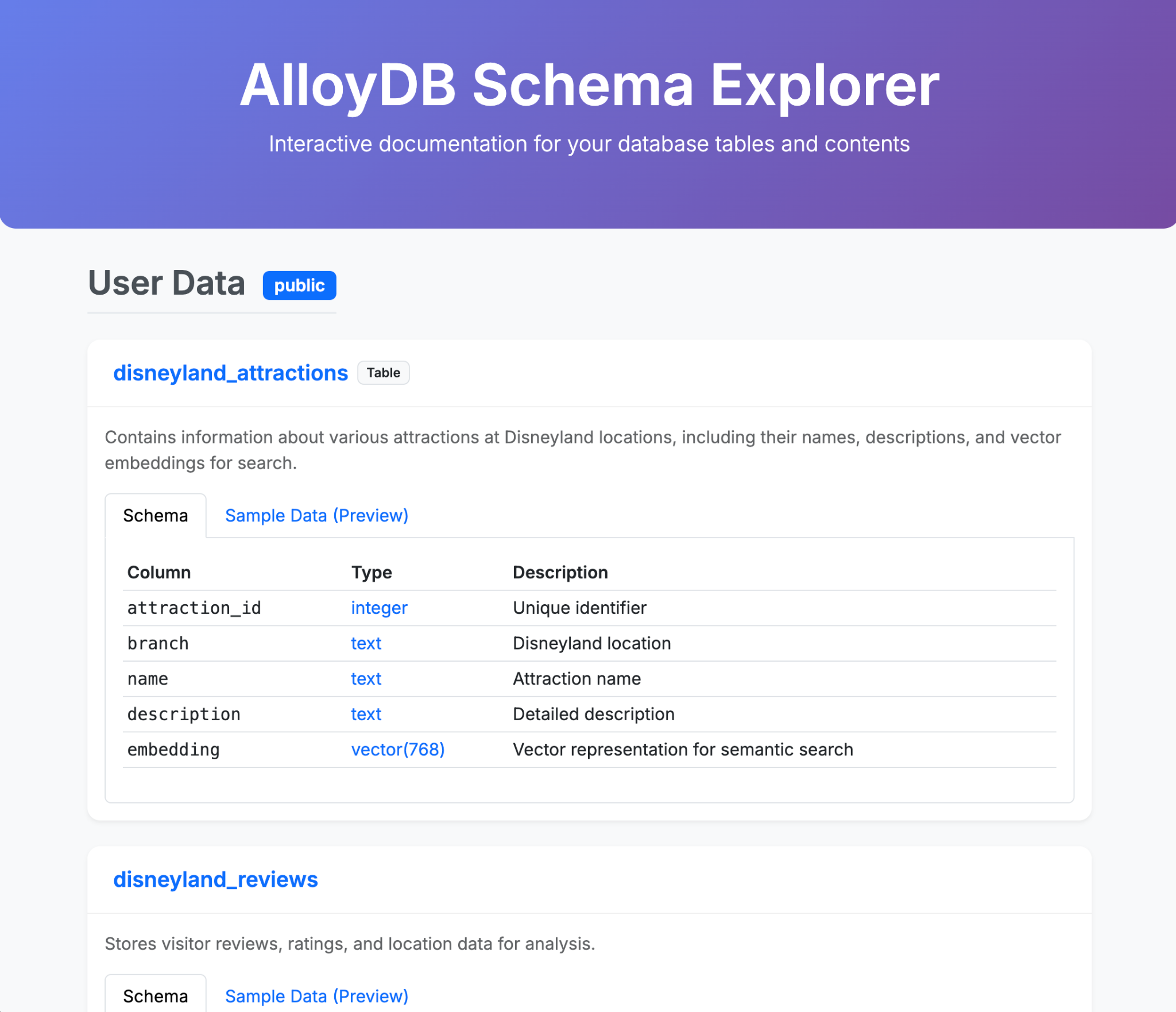
9. Việc 6: Tạo một tác nhân AI để tương tác với dữ liệu của bạn
Để mang đến trải nghiệm người dùng hoàn toàn mới cho khách truy cập Disneyland, bạn sẽ tạo một trợ lý có thể giúp họ trong chuyến đi. Nhân viên hỗ trợ sẽ có thể:
- Liệt kê tất cả các điểm tham quan có trong công viên
- Đề xuất một điểm tham quan dựa trên kỳ vọng
- Thêm bài đánh giá cho một điểm tham quan
- Đưa ra thông tin ước tính về thời gian chờ của một điểm tham quan trong vài giờ tới
- Cung cấp thông tin tổng quan về các bài đánh giá cho một điểm tham quan cụ thể
Bạn sẽ đảm bảo rằng trợ lý của bạn chỉ có thể trả lời các câu hỏi liên quan đến Disneyland và giữ giọng điệu thân thiện với người dùng. Điều chỉnh câu lệnh cho trợ lý để đảm bảo trợ lý chọn đúng công cụ cho nhu cầu của người dùng.
Bạn cần làm theo các bước sau:
- Triển khai một máy chủ bộ công cụ MCP dành cho cơ sở dữ liệu sử dụng AlloyDB và BigQuery làm nguồn
- Khai báo 5 công cụ khác nhau cho máy chủ MCP của bạn để truy vấn AlloyDB và BigQuery, đồng thời lập bản đồ các hành động của tác nhân được liệt kê trước đó
- Sử dụng giao diện người dùng Hộp công cụ MCP để xác thực từng công cụ
- Triển khai một tác nhân bằng Bộ công cụ phát triển tác nhân có thể sử dụng các công cụ do máy chủ bộ công cụ MCP của bạn cung cấp
- Kết nối với giao diện web ADK và trình bày một cuộc thảo luận đầy đủ với trợ lý của bạn, bao gồm cả tất cả các công cụ có sẵn
Bước bổ sung nếu bạn hoàn thành sớm:
Nhân viên hỗ trợ của bạn đã sẵn sàng chưa? Hãy triển khai nó vào Agent Engine!