
1. 🏰 Disneyland Data Analytics Hackathon(第 2 版 - 12 月 3 日)🏰
摘要 | 在此黑客马拉松中,您将利用 Google Cloud 上的 AI/机器学习功能构建端到端数据分析流水线。您将数据加载到 AlloyDB(一种与 PostgreSQL 兼容的全托管式数据库,专为要求严苛的工作负载而优化),然后使用 Datastream(一种无服务器变更数据捕获 [CDC] 服务)将数据迁移到 BigQuery(Google Cloud 的无服务器数据仓库)。在 BigQuery 中,您将应用 BigQuery ML,该工具可让您使用标准 SQL 直接在 BigQuery 中创建和执行机器学习模型,以进行评价分析和出席情况预测。最后,您将体验智能体,既可以通过对话式分析和数据代理直接使用,也可以创建由智能体开发套件和 MCP Toolbox 提供支持的自定义智能体,以便使用自然语言与数据互动。 |
类别 | docType:Codelab、product:Bigquery |
Author | Rayhane Rezgui、Matt Cornillon |
布局 | 滚动 |
机器人 | noindex |
2. 简介
欢迎各位未来的迪士尼数据向导!🪄
告别枯燥的旅游指南和无休止的论坛浏览。想象一下,您在规划完美的迪士尼乐园之旅时,可以利用数据驱动的洞见。哪个公园的体验最好?何时人最少?您能预测征服那条出了名的长队的最佳时间吗?
在此黑客马拉松中,您将打造自己的终极迪士尼乐园规划工具。我们拥有丰富的数据:来自全球各分店游客的评价、历史等待时间和出席人数。您的使命是什么?将这些原始数据转化为富有实用价值的分析洞见:
- 收集数据:将各种迪士尼乐园评价、等待时间和入园人数数据加载到 AlloyDB(一款与 PostgreSQL 兼容的高性能数据库)中。
- 无缝移动:使用我们的无服务器变更数据捕获服务 Datastream,轻松将这些动态信息移动到 BigQuery(Google Cloud 的强大无服务器数据仓库)。
- 预测魔力:利用 BigQuery ML 直接通过 SQL 分析评价情感并预测等待时间。了解哪些分店始终能让顾客满意,以及您前往的最佳时间。
- 与数据对话 - 真正意义上的对话!使用预构建的工具,只需挥动魔杖即可获得数据洞见。
- 智能互动:使用 MCP Toolbox for Databases 和 ADK(智能体开发套件)打造智能代理,为您的作品锦上添花。询问“巴黎迪士尼乐园最适合太空爱好者的景点是什么?排队的最佳时间是什么?”,即可获得即时、数据驱动的回答。
做好准备,探索地球上最神奇的地方的秘密,并构建一条让米奇感到自豪的数据分析流水线!
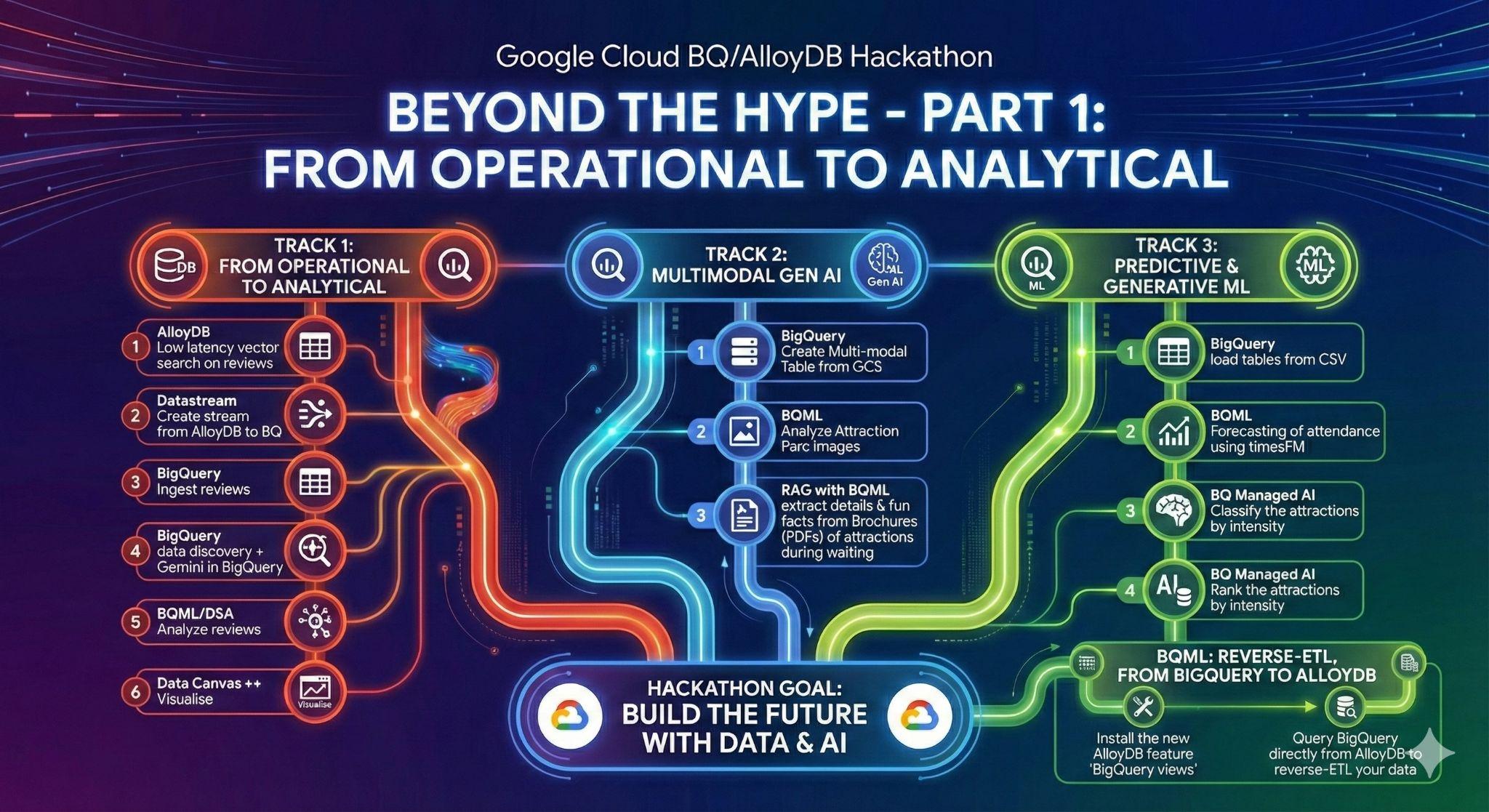
3. 任务 1:从运营到分析;使用 Gemini 分析 Disneyland 评价
在此初始阶段,您将从 AlloyDB 运营数据库中检索数据,并将其加载到 BigQuery 中以进行后续数据分析。
您还将设置 AlloyDB 中未来代理所需的一切!
AlloyDB 中的数据加载
首先,我们将一些数据导入 AlloyDB for PostgreSQL 集群!
我们将提取 2 万条迪士尼乐园的游乐园评价和一份景点列表。
您需要采取的步骤如下:
创建表格:
- 创建一个包含 6 列的表 disneyland_reviews:review_id 和 rating 为整数,year_month、reviewer_location、review_text、branch 为文本。
- 创建一个名为 disneyland_attractions 的表,其中包含 4 列:attraction_id(整数)、branch、name 和 description(文本)。
使用您选择的工具,从 CSV 文件导入数据:
- 评价表的
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv - 景点表的
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csv
为了提供景点推荐,我们需要创建景点说明的嵌入:
- 在 AlloyDB 中安装 pgvector 扩展程序
- 向您的“attraction”表中添加一个名为“embedding”的向量列
- 使用 AlloyDB 与 Vertex AI 之间的原生集成,生成并填充说明的嵌入
利用 Datastream 将运营数据转化为分析数据
为了将数据从 AlloyDB 流式传输到 BigQuery,我们将使用 Google Datastream。它是一种强大的无服务器解决方案,可监听源表中的所有更改(使用变更数据捕获),并将这些更改发送到 BigQuery。
为了能够使用 Datastream 复制 AlloyDB 中的更改,我们需要在 Postgres 上创建发布和复制槽。
在 AlloyDB 集群上执行以下查询(您需要一次运行一个查询):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
您将在流中使用发布和复制槽,因此请记住这些名称!
这样就完成了,现在我们可以创建直播了!
您需要在 Datastream 中执行的步骤如下:
- 为 AlloyDB 集群创建源配置文件(使用公共 IP 地址)
- 为 BigQuery 创建目标配置文件
- 创建从 AlloyDB 到 BigQuery 的数据流。
数据应会在几分钟内出现在 BigQuery 中。
BigQuery 中的数据发现
现在,我们已将数据导入 BigQuery,在开始工作之前,我们先来了解一下界面中的新增强功能!
我们新增了 3 个函数,您现在可以在 BigQuery 探索面板中看到这些函数。
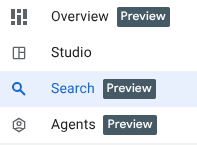
- 概览:包含有关 BigQuery 功能的信息、开始分析的导览以及其他可能性。
- 搜索:对数据资产执行语义搜索。
- 客服人员:嘘!我们稍后会介绍这一点🤫
在 BigQuery 中进行语义化数据搜索
前往 BigQuery 探索面板中的“搜索”标签页,尝试使用与迪士尼相关的字词,例如“景点”或“分支”。
在 BigQuery 中直观呈现数据
现在,您可以在 BigQuery 中直观呈现和处理数据。为此,您可以在新的查询标签页中运行此查询;
SELECT
*
FROM
[dataset_name].[table_name];
根据评价表生成数据分析
在此任务中,您将对 disney 数据集中的 disneyland_reviews 表执行数据分析。
数据分析这项工具适合以下这样的用户:想要探索其数据并获取洞见,但又不想编写复杂的 SQL 查询。
这可能需要几分钟时间。
在不使用 SQL 的情况下查询 disneyland_reviews 表
您在上一部分中生成的数据分析现已可供使用。在此任务中,您将使用基于这些数据分析生成的提示,在不编写代码的情况下对 disneyland_reviews 表运行查询。
选择一条数据分析并运行与其相关的查询。例如,找到可计算每个分店在相邻月份之间的平均评分差异的查询。它看起来会像这样:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
使用 BigQuery 知识引擎更好地了解数据
首先,我们先从数据集级别的数据分析标签页开始,了解迪士尼数据集中的各个表之间隐藏的关系。然后进行以下操作:
- 使用 Gemini 生成数据集的说明,并将其添加到数据集详细信息中。
- 生成有关 reviews 表和 attractions 表以及这些表中所有单独列的说明,然后保存。
对数据执行数据分析扫描
本部分的目标是清理和准备数据。不过,您不太熟悉每个列的值的分布情况。您需要对数据进行分析,以了解需要对数据执行哪些类型的转换步骤。
Google Cloud 的 Dataplex Universal Catalog 可自动执行 分析扫描,以提供一致的数据质量指标。系统会识别关键统计信息,包括 null 值数量、不同值、数据范围和值分布。您可以通过 BigQuery 界面启动数据分析扫描。
这可能需要几分钟时间,您可以在等待时查看下一部分。
请回答以下问题:
- Disneyland 的平均评分是多少?
- 评价者主要位于哪些国家/地区?
- 所有评价是否都是独一无二的?
- “Year_Month”列中缺失数据的百分比是多少?
对数据执行质量扫描
借助 Dataplex Universal Catalog 自动化数据质量功能,您可以定义和衡量 BigQuery 表中数据的质量。您可以自动扫描数据,根据定义的规则验证数据,并在数据不符合质量要求时记录提醒。您可以将数据质量规则和部署作为代码进行管理,从而提高数据生产流水线的完整性。
根据数据分析扫描结果,定义一个质量扫描(样本量不超过数据量的 10%),该扫描应:
- 检查“branch”列是否存在 null 值
- 对“评分”执行有效性检查,因为该值只能是以下集合中的一个:1、2、3、4、5
- 检查“review_id”的唯一性review_id
确保扫描将结果导出到 BigQuery 表 quality_scan_results。
考虑您需要对数据应用的所有潜在转换。
使用 Gemini 的数据准备功能准备数据
在执行数据质量和分析扫描后,接下来需要清理数据,然后才能进行分析。
数据准备是 BigQuery 资源,可使用 Gemini in BigQuery 分析数据,并提供智能建议来清理、转换和丰富数据。您可以大幅减少手动数据准备任务所需的时间和精力。
在本部分中,您将使用数据准备功能对 disneyland_reviews 表执行以下操作:
- 过滤掉“Branch”(分支)列为 NULL 或空字符串的行。
- 将 Year_Month 中的“missing”替换为 Null。
- 将分支列中的下划线替换为空格,以提高可读性
- 导出到转换后的表 disneyland_reviews_cleaned
使用 Gemini 分析评价
现在,您已清理完数据,可以开始使用 BigQuery ML 和 Gemini 模型来分析数据了。您有两个目标:
- 从评价中提取类别
- disneyland_reviews 的情感分析
利用 BigQuery ML,您可以使用 GoogleSQL 查询创建和运行机器学习 (ML) 模型。BigQuery ML 模型存储在 BigQuery 数据集中,类似于表和视图。您还可以通过 BigQuery ML 来访问 Vertex AI 模型和 云 AI API 执行人工智能 (AI) 任务,例如文本生成或机器翻译。Gemini for Google Cloud 还为 BigQuery 任务提供依托 AI 技术的辅助功能。
您可以选择将 ML.GENERATE_TEXT 或 AI.GENERATE(预览版)与 Gemini Pro 或 Flash 模型搭配使用。
如果您想使用 ML.GENERATE_TEXT,请按照以下步骤操作。
创建 Cloud 资源连接并授予 IAM 角色
您需要在 BigQuery 中创建与 Vertex AI 模型的 Cloud 资源连接,以便使用 Gemini Pro 和 Gemini Flash 模型。您还将通过角色为 Cloud 资源连接的服务账号授予 IAM 权限,使其能够访问 Vertex AI 服务。
向连接的服务账号授予 Vertex AI User 角色
向连接的服务账号授予 Vertex AI User 角色,使其能够使用您选择的模型(例如 gemini-2.5-flash)。权限需要 1 分钟才能传播完毕。
在 BigQuery 中创建 Gemini 模型
使用上述连接创建模型。例如,使用端点 gemini-2.5-flash.
提示 Gemini 分析客户评价中的类别和情绪
在此任务中,您将使用 Gemini 模型分析每条顾客评价的类别以及情绪(正面或负面)。
按类别分析客户评价
注意:从现在开始,为了进行分析,我们将仅使用 100 行数据,因为对 2 万行数据进行 Gemini 调用可能需要一段时间。
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
此查询会从 disneyland_reviews 表中提取顾客评价,并为 gemini 模型构建提示以确定每条评价的类别。结果应存储在新表 reviews_categories 中
。请稍候。该模型大约需要 30 秒时间来处理客户评价记录,并将结果放入输出表中。
显示结果:
SELECT * FROM [dataset_name].[results_table_name];
花点时间阅读一些类别。
分析顾客评价的情绪(正面或负面)
根据用于提取关键字的 SQL 查询,编写一个查询,用于分析评价,并在名为“sentiment”的列下将评价分为正面、负面和中性。
此查询会从 disneyland_reviews 表中提取顾客评价,并为 gemini 模型构建提示以对每条评价的情绪进行分类。然后,生成的结果会存储在一个名为 reviews_analysis 的新表中,方便您稍后开展进一步分析。请稍候,该模型需要几秒钟时间来处理客户评价记录。模型完成处理后,结果会显示在创建的 reviews_analysis 表中。
探索结果:
SELECT * FROM [...];
reviews_analysis 表包含 Sentiment 列(包含情感分析结果),并包含 social_media_source、review_text、customer_id、location_id 和 review_datetime 列。请查看这些记录。您可能会注意到,其中一些正面或负面结果的格式不正确、包含多余的字符,例如英文句点或额外空格。您可以通过下面的视图来清理这些记录。
创建一个用于清理记录的视图
创建一个视图,通过以下方式清理列 sentiment 的值:
- 使用 LOWER 确保所有值均为小写。
- 使用 REPLACE 函数移除标点符号(句点、逗号和空格)
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
此查询将创建名为 cleaned_data_view 的视图,其中包含情绪评估结果、评价文本和 Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch。然后,它将提取情绪评估结果(正面或负面)并确保所有字母均为小写格式,且已移除多余的字符,例如额外的空格或英文句点。生成的视图便于您在本实验的稍后步骤中开展进一步分析。
- 您可以通过下方的查询来查询视图,以查看创建的行。
SELECT * FROM [view_name];
使用数据画布创建正面和负面评价数量报告
现在,您可以分析结果了。我们先来了解一下如何通过数据画布直接在 BigQuery 中执行操作。借助此工具,您可以通过创建画布流程来搜索数据(语义或关键字)、查询和联接表格、创建图表并获取数据洞见。
您的最终目标是创建一张图表,显示您选择的正面评价与负面评价百分比。示例如下:
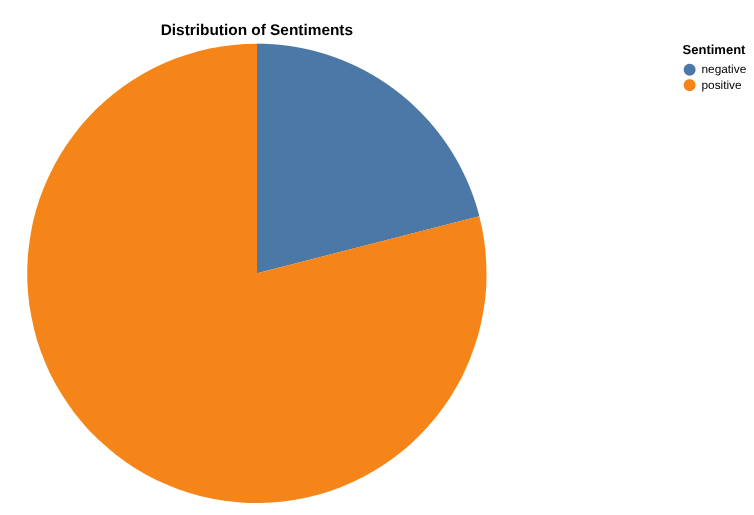
创建显示每个类别的评价数量以及每个类别的正面评价和负面评价分布情况的图表
提示:激活并使用数据画布的高级分析功能,该功能可在画布内运行 Python 笔记本。
4. 任务 2:分析游乐园图片,识别迪士尼乐园照片,并从乐园宣传册中提取有趣的事实
BigQuery 中的图片分析
您可以查看游客多年来拍摄的一些令人兴奋且极具吸引力的游乐园照片。您对即将开始的行程感到非常兴奋!不过,您不知道哪些是迪士尼乐园的真实照片。您的任务是识别这些问题。图片位于 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/ 中。

Is_disneyland: False

Is_disneyland: True
以便快速执行此分析。您应通过 BigQuery ML (ML.GENERATE_TEXT) 使用 BigQuery 的对象表和 Gemini。
您能否通过检查一些照片来验证 Gemini 的输出?
使用 BigQuery 基于迪士尼乐园宣传册创建自己的 RAG 系统
在排队等候时,您想了解有关所等候的景点的趣闻/技术细节。
在 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, 中,您会找到包含全球所有公园宣传册的 PDF 文件。
目标:完全在 BigQuery 中创建一个检索增强生成 (RAG) 系统,以便用户根据一些 PDF 文档提出有关公园的复杂问题。
如需实现此目的,您需要执行以下操作:
- 创建 PDF 文件的对象表
- 创建 Python UDF 以将 PDF 文件分块。您可以参照以下示例:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- 将 PDF 文件解析为块
- 创建远程模型后生成嵌入
- 运行向量搜索以查找“
Ou manger un repas tex-mex à volonté?”或“where to eat a tex-mex meal buffet-style?” - 生成由向量搜索结果增强的回答,问题为“
Ou manger un repas tex-mex à volonté?”或“where to eat a tex-mex meal buffet-style?”
5. 任务 3:使用 BigQuery 大规模进行机器学习:预测、分类和排名
预测等待时间
这些图片非常酷!您等不及了!现在,为了了解应该选择哪些景点,避开哪些景点,您需要知道巴黎和加利福尼亚之间一些景点的实际等待时间。您的任务是使用机器学习(Arima Plus 或 TimesFM)预测 2025 年每 30 分钟内每个景点的 waiting_times。
您将使用的数据位于以下 CSV 文件中:gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
任务步骤如下:
- 将文件加载到 BigQuery 数据集中名为“waiting_times”的表下。
- 根据您的数据训练预测模型 (Arima_Plus),或直接使用 AI.Forecast 进行预测
- 评估模型性能,或将预测数据与输入数据进行比较
按强度对骑行活动进行分类
您正与朋友一起游览迪士尼乐园,虽然乐园总体上适合全家出游,但有些游乐设施对某些人来说可能过于刺激。让我们使用 BigQuery 托管式 AI 函数,根据刺激程度和强度对景点进行分类和排名,避免人为偏见,以便满足所有人的需求。
- 使用
AI.CLASSIFY根据游乐设施的说明将其归入以下三个神奇类别之一:[easy-peasy, thrilling, extreme]
按刺激程度对游乐设施进行排名
- 使用
AI.SCORE可根据刺激程度比较和排序景点,其中 10 级最刺激,1 级最不刺激。
6. 任务 3-奖励:反向 ETL,从 BigQuery 到 AlloyDB
您已利用 BigQuery 的强大功能,从大量数据中生成了数据洞见。现在,您希望运营应用(和 AI 代理!)能够根据这些数据洞见采取行动。
但如何实现呢?反其道而行之!AlloyDB for PostgreSQL 非常适合以低延迟和高速度提供数据,是面向用户的关键应用的理想选择。现在,我们来对刚刚生成的数据进行反向 ETL。
为此,我们将使用 AlloyDB 中一项仍处于非公开预览阶段的全新功能,即“BigQuery 视图”。借助此功能,您可以直接在 Postgres 数据库中查询 BigQuery 数据。
首先,您需要向 AlloyDB 集群服务账号授予查询 BigQuery 所需的权限。
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
输出包含 serviceAccountEmail 字段,该字段是此集群的服务账号。
在 Google Cloud 控制台中,前往 IAM 页面,并向相应的正文授予以下权限:
- BigQuery Data Viewer (roles/bigquery.dataViewer)
- BigQuery Read Session User (roles/bigquery.readSessionUser)
现在,前往控制台中的 AlloyDB Studio 并连接到“postgres”数据库。
执行以下查询以安装和配置新功能:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
您现在可以创建“外部表”,该表将映射到 BigQuery 中的当前表。使用您在任务 3 中创建的任何表。以下是语法示例:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
一切就绪,让我们查询表格吧!执行第一个 SELECT 语句来验证 AlloyDB 与 BigQuery 之间的链接,最后在 AlloyDB 中创建一个新表,以从外部表中提取数据。
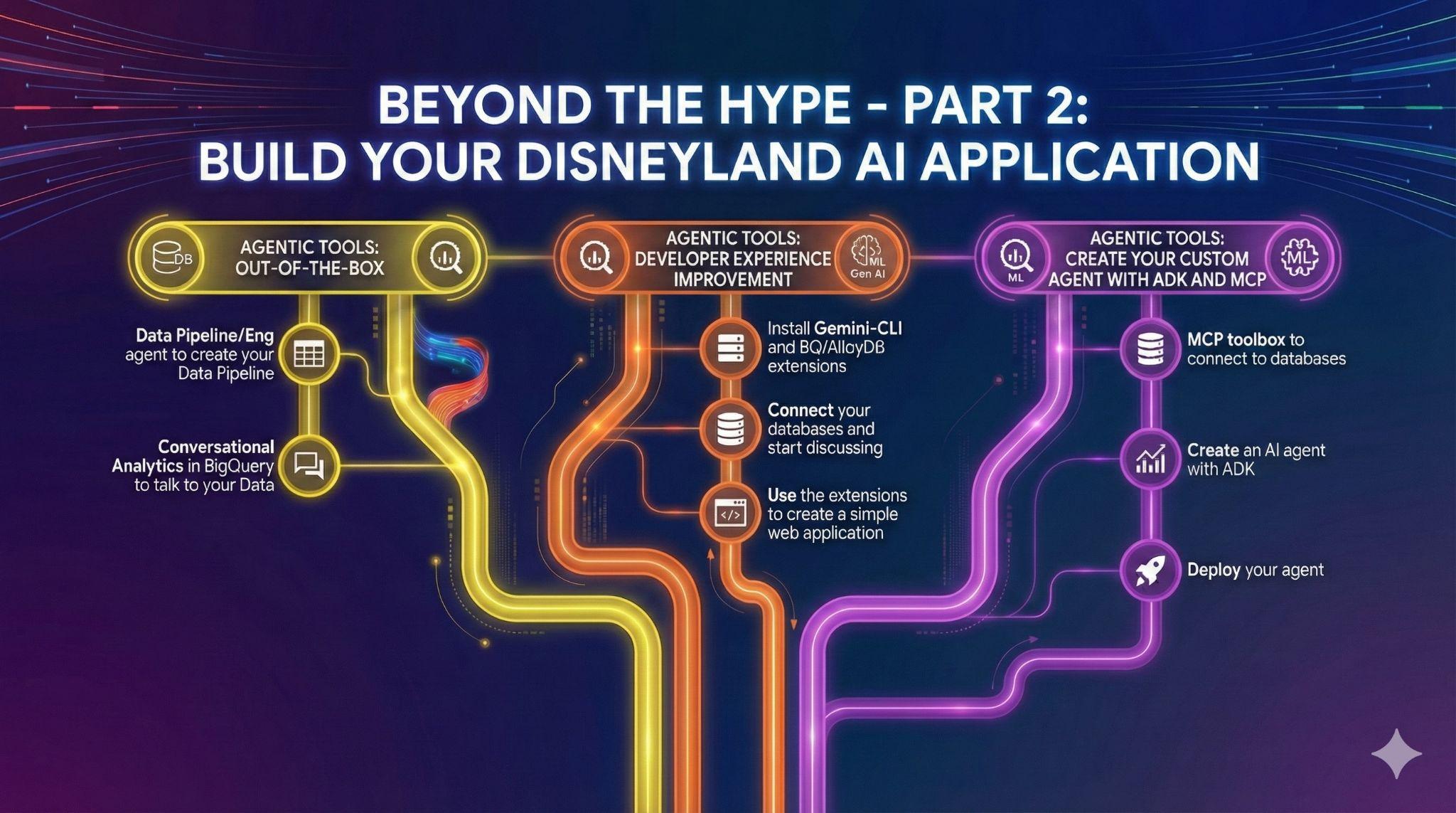
7. 任务 4:开箱即用的数据代理
您的好友想要为“Disneyland Application”项目做出贡献。他们可以访问 BigQuery 中的数据,但在 SQL 和数据工程方面的水平各不相同。您想利用 BigQuery 最近发布的有关已集成到界面中的数据智能体的公告来帮助您的朋友:
- 创建数据流水线。
- 协作处理 SQL 代码。
- 与数据对话。
用于自动执行数据流水线的数据工程智能体
使用 Data Engineering Agent 创建一个新视图 average_waiting_time,该视图联接了表 waiting_time 和 attractions,并计算了每个景点的平均 waiting_time。
在 BigQuery 中创建对话式分析代理
如果您无需编码、无需 SQL、无需部署,就能在 BigQuery 的界面中创建可与数据对话的代理,那会是多么酷的一件事?现在,您可以在 BigQuery 的“代理”标签页中实现这一点。
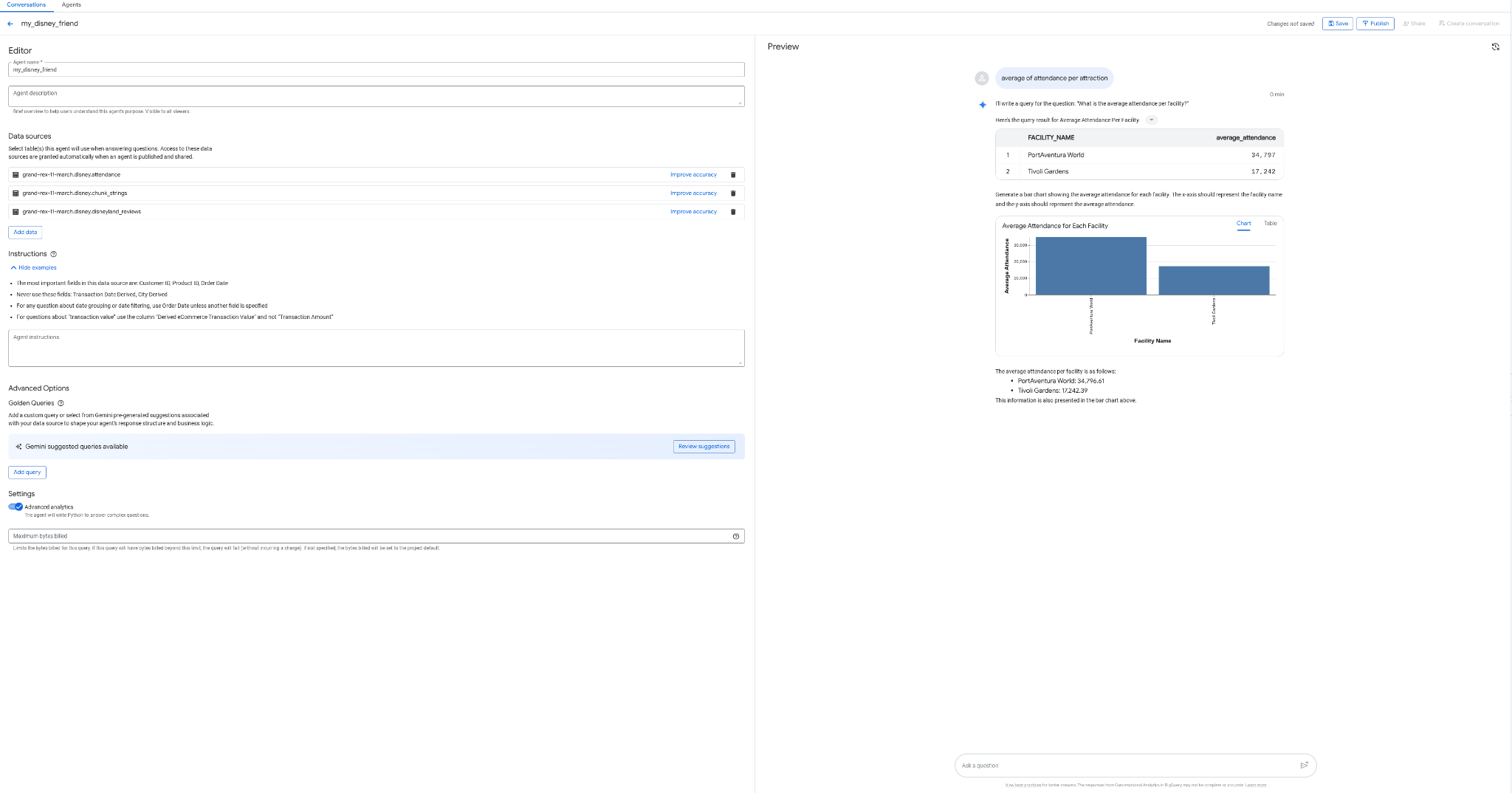
- 创建一个名为 my_disney_friend 的代理,该代理可连接到您的 Disney 表格。填写代理说明有助于提高代理性能。提出诸如“正面评价与负面评价的百分比是多少?每个景点的平均等待时间是多少?”等问题。
- 在 BigQuery 和 API 中发布代理(您稍后会用到)。
8. 任务 5:使用 Gemini-CLI 提升开发体验
在这个 AI 时代,构建软件从未如此简单。您为 Disneyland 应用构思了数千个创意,并希望最大限度地利用数据。您想做的不仅仅是分析数据,现在您需要采取行动!
为了帮助您实现这一目标,您需要帮助。我们为您考虑周全。
Gemini CLI 是一款开源 AI 智能体,可将 Gemini 的强大功能直接引入您的终端。开发者可以构建强大的应用,并且借助扩展程序,还可以与各种 MCP(Model Context Protocol)服务器进行交互。
在这些扩展程序中,您当然可以找到用于查询 AlloyDB 或 BigQuery 数据的扩展程序!
在此任务中,您的目标是:
- 安装 Gemini-CLI(在您自己的终端中或在 Cloud Shell 中)
- 安装 BigQuery 和 AlloyDB Gemini-CLI 扩展程序
- 创建一个环境文件,使 Gemini-CLI 能够连接到您的 BigQuery 和 AlloyDB 实例
- 让 Gemini-CLI 生成一个精美的单 HTML 页面,用于说明 AlloyDB 数据库的内容
- 对 BigQuery 执行相同的操作
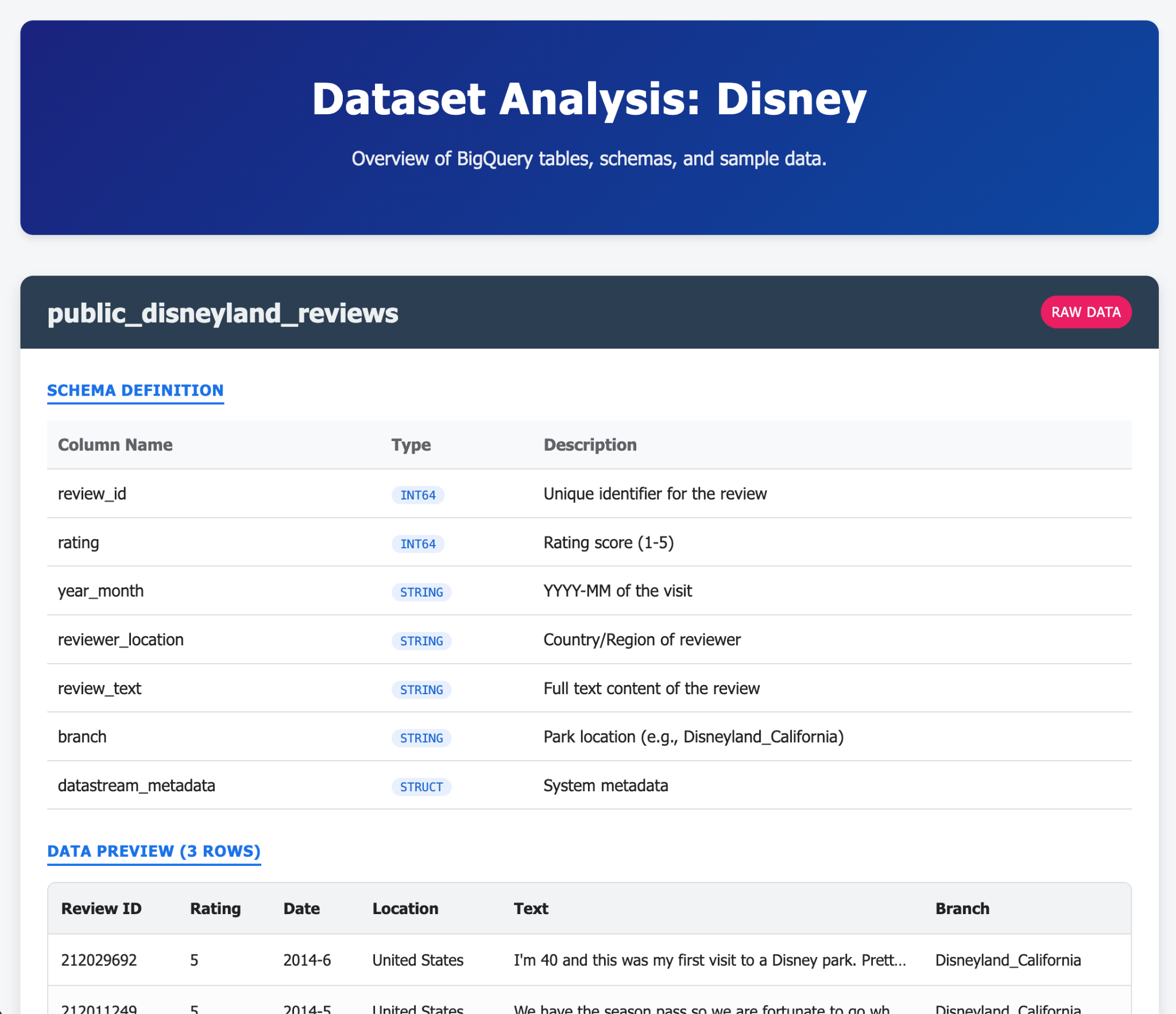
以下是一些示例,展示了如何通过 Gemini-CLI 及其扩展程序在单个(或少量)提示中生成内容。现在,想象一下,您可以在现实生活中的应用中实现这一点。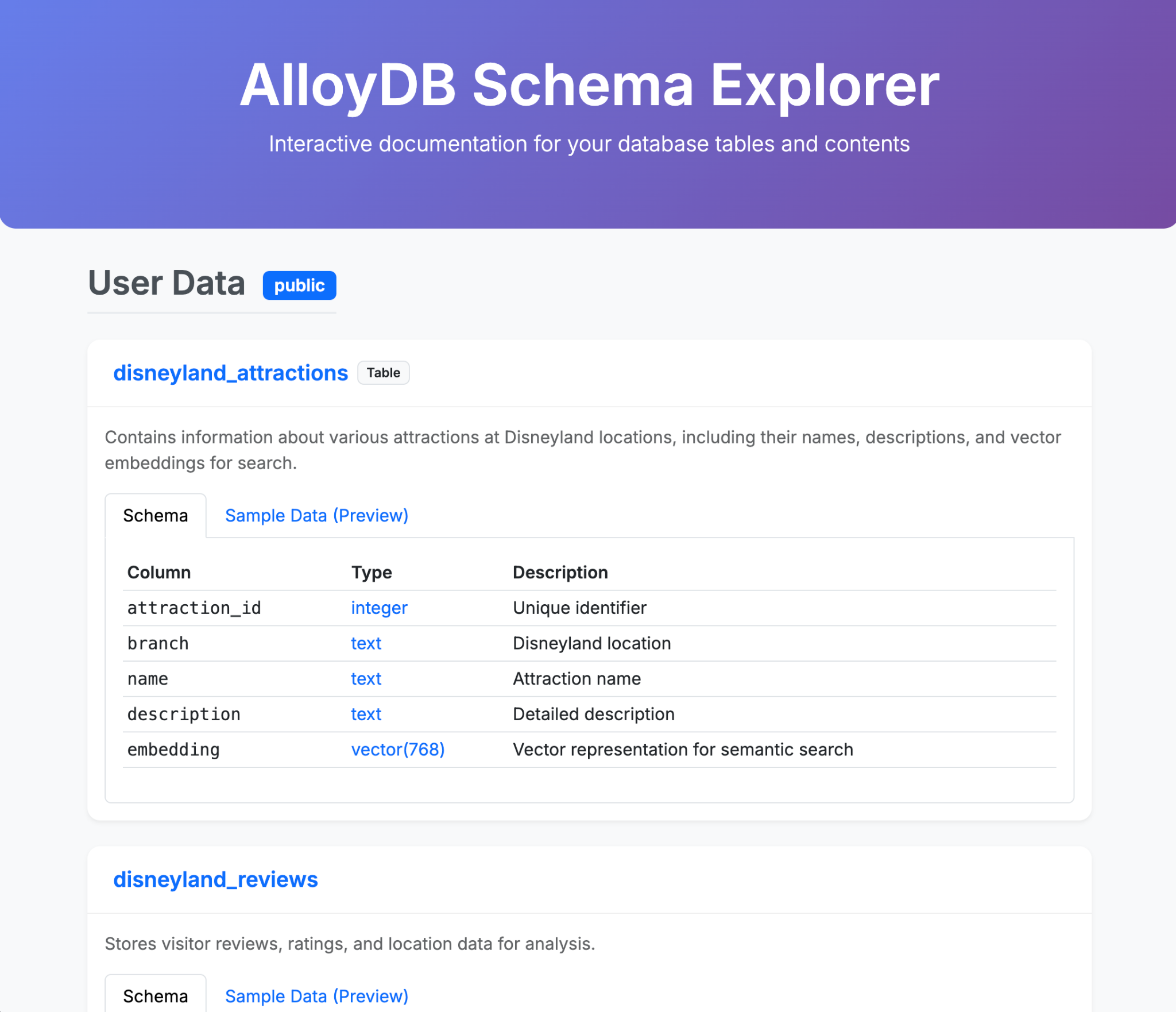
9. 任务 6:创建 AI 智能体以与数据互动
为了向迪士尼乐园游客提供全新的用户体验,您将创建一个可以在游客的旅途中为他们提供帮助的助理。您的代理将能够:
- 列出公园中的所有可用景点
- 根据预期推荐景点
- 添加对景点的评价
- 提供未来几小时内景点的等待时间估计值
- 提供特定景点的评价概览
您将确保助理只能回答与迪士尼乐园相关的问题,并以友好的语气与用户互动。调整智能体提示,确保智能体选择的工具能满足用户需求。
您需要按照以下步骤操作:
- 部署以 AlloyDB 和 BigQuery 为来源的 MCP Toolbox for Databases 服务器
- 为您的 MCP 服务器声明 5 种不同的工具,这些工具可查询 AlloyDB 和 BigQuery,并映射到前面列出的智能体操作
- 使用 MCP Toolbox 界面验证每个工具
- 使用智能体开发套件部署智能体,该智能体可以使用 MCP 工具箱服务器公开的工具
- 连接到 ADK 网页界面,并展示与助理的完整对话,包括所有可用的工具
如果您提前完成,可执行以下奖励步骤:
代理已准备就绪?我们将其部署到 Agent Engine!