
1. نظرة عامة
في سوق البيع بالتجزئة التنافسي اليوم، من الضروري تمكين العملاء من العثور على ما يبحثون عنه بالضبط، وبسرعة وسهولة. غالبًا ما تعجز عمليات البحث التقليدية المستندة إلى الكلمات الرئيسية عن ملاحظة الفروق الدقيقة في طلبات البحث وقوائم المنتجات الكبيرة. يكشف هذا الدرس التطبيقي حول الترميز عن تطبيق بحث متطوّر للبيع بالتجزئة تم إنشاؤه على AlloyDB وAlloyDB AI، ويستفيد من أحدث التقنيات، مثل "البحث المتّجه" وفهرسة scaNN والفلاتر المتعدّدة الأوجه و"الفلترة التكيّفية" الذكية وإعادة الترتيب لتقديم تجربة بحث ديناميكية مختلطة على مستوى المؤسسة.
لدينا الآن فهم أساسي لثلاثة أمور:
- ما هو البحث السياقي بالنسبة إلى الوكيل وكيفية تنفيذه باستخدام "البحث المتّجه"
- تحدّثنا أيضًا بالتفصيل عن إمكانية استخدام Vector Search ضمن نطاق بياناتك، أي داخل قاعدة البيانات نفسها (تتيح جميع قواعد بيانات Google Cloud هذه الإمكانية، إذا لم تكن على علم بذلك).
- لقد ذهبنا إلى أبعد من ذلك في إطلاعك على كيفية تحقيق إمكانية البحث المتّجه الخفيف الوزن هذه مع أداء وجودة عاليتَين باستخدام إمكانية البحث المتّجه في AlloyDB المستندة إلى فهرس ScaNN.
إذا لم تكن قد اطّلعت على تجارب RAG الأساسية والمتوسطة والمتقدّمة قليلاً، أنصحك بقراءة هذه التجارب الثلاث هنا وهنا وهنا بالترتيب المذكور.
التحدّي
تجاوز الفلاتر والكلمات الرئيسية والمطابقة السياقية: قد يؤدي البحث البسيط عن كلمة رئيسية إلى عرض آلاف النتائج، العديد منها غير ذي صلة. يجب أن يفهم الحلّ المثالي الغرض من طلب البحث، وأن يجمعه مع معايير فلترة دقيقة (مثل العلامة التجارية أو المادة أو السعر)، وأن يعرض العناصر الأكثر صلة في غضون أجزاء من الثانية. يتطلّب ذلك بنية أساسية قوية ومرنة وقابلة للتوسّع للبحث. بالتأكيد، لقد قطعنا شوطًا طويلاً من البحث عن الكلمات الرئيسية إلى المطابقات السياقية وعمليات البحث عن التشابه. تخيّل أنّ أحد العملاء يبحث عن "سترة مريحة وأنيقة ومقاومة للماء ومناسبة للتنزه في الربيع"، ويطبّق في الوقت نفسه فلاتر، ولا يعرض تطبيقك ردودًا عالية الجودة فحسب، بل يتميّز أيضًا بأداء عالٍ، ويتم اختيار تسلسل كل ذلك بشكل ديناميكي من خلال قاعدة البيانات.
الهدف
لمعالجة ذلك من خلال دمج
- البحث السياقي (البحث المستند إلى المتّجهات): فهم المعنى الدلالي لطلبات البحث وأوصاف المنتجات
- الفلترة المتعدّدة الأوجه: تتيح للمستخدمين تحسين النتائج باستخدام سمات معيّنة
- النهج المختلط: دمج البحث السياقي مع الفلترة المنظَّمة بسلاسة
- التحسين المتقدّم: الاستفادة من الفهرسة المتخصّصة والفلترة التكيّفية وإعادة الترتيب لتحسين السرعة والملاءمة
- مراقبة الجودة المستندة إلى الذكاء الاصطناعي التوليدي: دمج عملية التحقّق من صحة النماذج اللغوية الكبيرة للحصول على نتائج عالية الجودة
لنستعرض بالتفصيل بنية عملية التنفيذ ومراحلها.
ما ستنشئه
تطبيق بحث للبيع بالتجزئة
في إطار ذلك، عليك إجراء ما يلي:
- إنشاء مثيل وجدول AlloyDB لمجموعة بيانات التجارة الإلكترونية
- إعداد عمليات التضمين وVector Search
- إنشاء فهرس البيانات الوصفية وفهرس ScaNN
- تنفيذ "البحث المتّجه" المتقدّم في AlloyDB باستخدام طريقة الفلترة المضمّنة في ScaNN
- إعداد "الفلاتر المتعدّدة الأوجه" و"البحث المختلط" في طلب بحث واحد
- تحسين مدى صلة طلب البحث بالنتائج من خلال إعادة الترتيب والاسترجاع (اختياري)
- تقييم ردّ طلب البحث باستخدام Gemini (اختياري)
- MCP Toolbox for Databases وطبقة التطبيق
- تطوير التطبيقات (Java) باستخدام ميزة "البحث المتعدّد الأوجه"
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: اتّبِع الرابط وفعِّل واجهات برمجة التطبيقات.
بدلاً من ذلك، يمكنك استخدام أمر gcloud لهذا الغرض. راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة البيانات
في هذا التمرين العملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات التجارة الإلكترونية. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة بيانات التجارة الإلكترونية فيها.
إنشاء مجموعة ومثيل
- انتقِل إلى صفحة AlloyDB في Cloud Console. تتمثّل إحدى الطرق السهلة للعثور على معظم الصفحات في Cloud Console في البحث عنها باستخدام شريط البحث في وحدة التحكّم.
- انقر على إنشاء مجموعة من تلك الصفحة:

- ستظهر لك شاشة مشابهة للشاشة أدناه. أنشئ مجموعة ومثيل بالقيم التالية (تأكَّد من تطابق القيم في حال استنساخ الرمز البرمجي للتطبيق من المستودع):
- معرّف المجموعة: "
vector-cluster" - كلمة المرور: "
alloydb" - PostgreSQL 15 / أحدث إصدار يُنصح به
- المنطقة: "
us-central1" - الشبكات: "
default"
- عند اختيار الشبكة التلقائية، ستظهر لك شاشة مثل الشاشة أدناه.
انقر على إعداد الاتصال.
- بعد ذلك، اختَر "استخدام نطاق عناوين IP يتم تخصيصه تلقائيًا" وانقر على "متابعة". بعد مراجعة المعلومات، انقر على "إنشاء ربط".
- بعد إعداد شبكتك، يمكنك مواصلة إنشاء مجموعتك. انقر على إنشاء مجموعة لإكمال إعداد المجموعة كما هو موضّح أدناه:
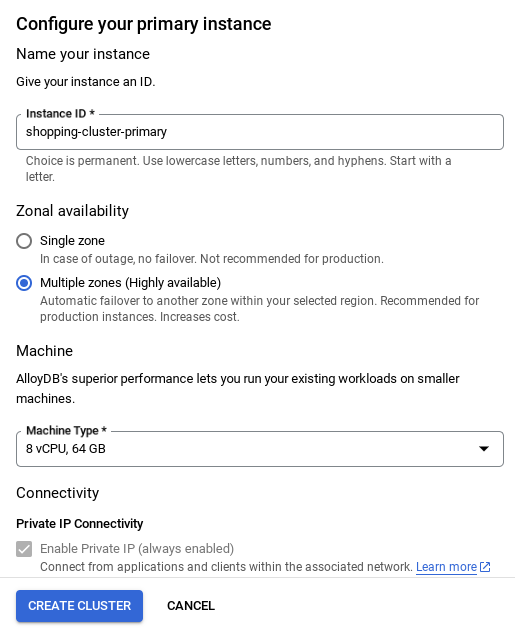
ملاحظة مهمة:
- احرص على تغيير معرّف المثيل (الذي يمكنك العثور عليه عند إعداد المجموعة أو المثيل) إلى **
vector-instance**. إذا لم تتمكّن من تغييره، تذكَّر استخدام معرّف المثيل في جميع المراجع القادمة. - يُرجى العِلم أنّ عملية إنشاء المجموعة ستستغرق حوالي 10 دقائق. بعد إتمام العملية بنجاح، من المفترض أن تظهر لك شاشة تعرض نظرة عامة على المجموعة التي أنشأتها للتو.
4. نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتقِل إلى AlloyDB، واختَر المجموعة الأساسية، ثم AlloyDB Studio:
قد تحتاج إلى الانتظار إلى حين اكتمال عملية إنشاء الجهاز الظاهري. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb"
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration وظائف يمكنك استخدامها للوصول إلى نقاط نهاية التوقّع في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إذا أردت التحقّق من الإضافات التي تم تفعيلها في قاعدة البيانات، نفِّذ أمر SQL التالي:
select extname, extversion from pg_extension;
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
سيسمح عمود التضمين بتخزين قيم المتجهات للنص.
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
تحميل البيانات إلى قاعدة البيانات
- انسخ عبارات طلب البحث
insertمنinsert scripts sqlفي ورقة البيانات إلى المحرّر كما هو موضّح أعلاه. يمكنك نسخ 10 إلى 50 عبارة إدراج للحصول على عرض توضيحي سريع لحالة الاستخدام هذه. تتضمّن علامة التبويب "العبارات المحدّدة 25-30 صفًا" قائمة محدّدة من العبارات.
يمكن العثور على رابط البيانات في ملف مستودع github هذا.
- انقر على تشغيل. تظهر نتائج طلب البحث في جدول النتائج.
ملاحظة مهمة:
احرص على نسخ 25 إلى 50 سجلاً فقط لإدراجها، وتأكَّد من أنّها من نطاق الفئة والفئة الفرعية واللون وأنواع الجنس.
5- إنشاء تضمينات للبيانات
يكمن الابتكار الحقيقي في محركات البحث الحديثة في فهم المعنى، وليس فقط الكلمات الرئيسية. وهنا يأتي دور التضمينات والبحث المتّجه.
حوّلنا أوصاف المنتجات وطلبات بحث المستخدمين إلى تمثيلات رقمية عالية الأبعاد تُعرف باسم "التضمينات" باستخدام نماذج لغوية مُدرَّبة مسبقًا. تتضمّن عمليات التضمين هذه المعنى الدلالي، ما يسمح لنا بالعثور على منتجات "متشابهة في المعنى" بدلاً من مجرد العثور على كلمات متطابقة. في البداية، أجرينا تجربة على البحث المباشر عن التشابه بين المتجهات في عمليات التضمين هذه لتحديد خط أساس، ما يوضّح قوة الفهم الدلالي حتى قبل تحسين الأداء.
سيتيح عمود التضمين تخزين قيم المتجهات لنص وصف المنتج. سيسمح عمود img_embeddings بتخزين تضمينات الصور (متعددة الوسائط). بهذه الطريقة، يمكنك أيضًا استخدام البحث المستند إلى المسافة بين النص والصورة. لكنّنا سنستخدم تضمينات نصية فقط في هذا الدرس التطبيقي.
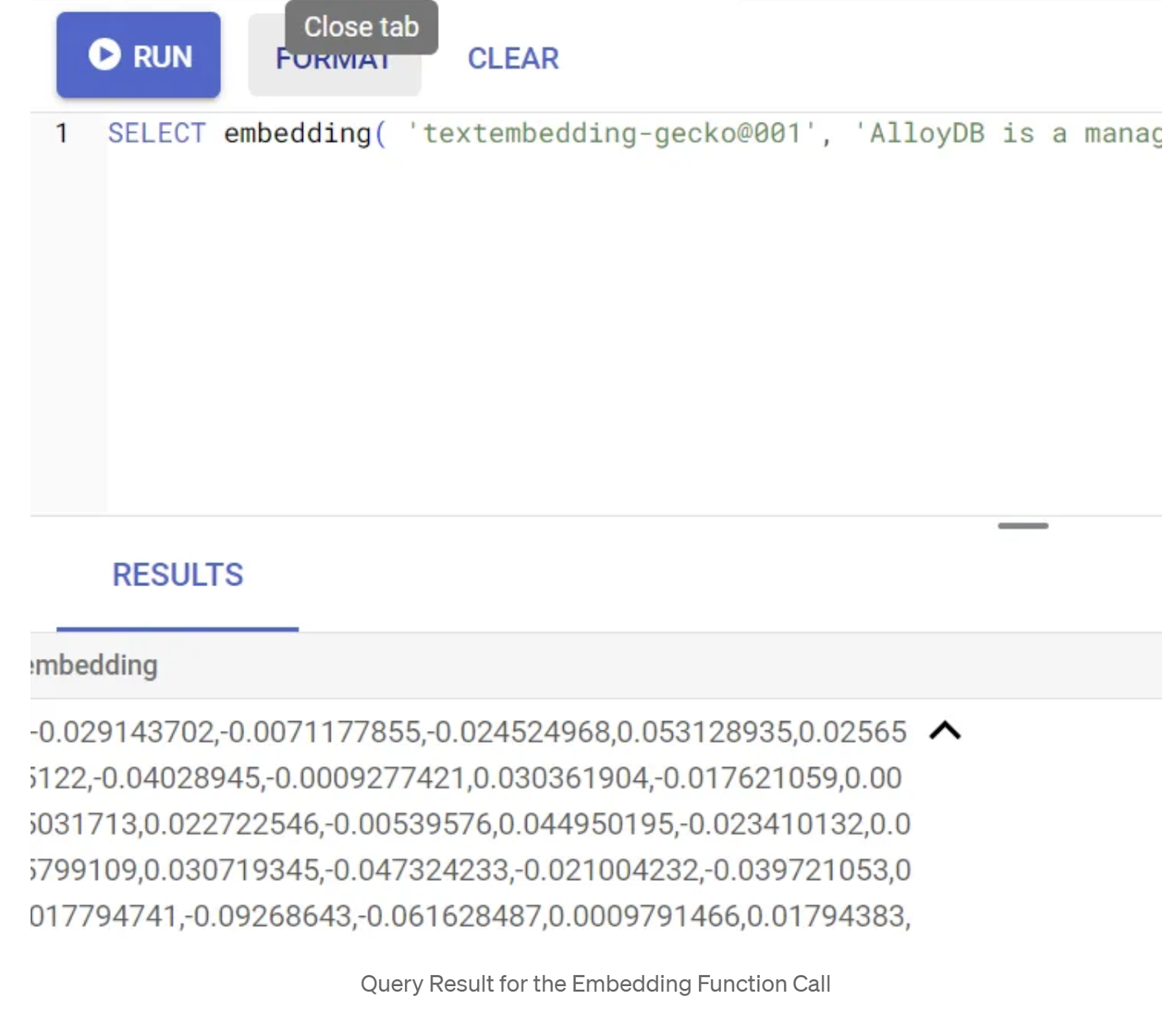
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
من المفترض أن يعرض هذا الطلب متجه التضمينات، الذي يبدو كصفيف من الأرقام العشرية، للنص النموذجي في الطلب. يبدو على النحو التالي:
تعديل حقل "المتّجه" abstract_embeddings
نفِّذ لغة معالجة البيانات (DML) أدناه لتعديل وصف المحتوى في الجدول باستخدام عمليات التضمين المقابلة:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
قد تواجه مشكلة في إنشاء أكثر من عدد قليل من التضمينات (20 إلى 25 كحد أقصى) إذا كنت تستخدم حساب فوترة تجريبيًا في Google Cloud. لذا، يجب الحدّ من عدد الصفوف في نص الإدراج.
إذا أردت إنشاء تضمينات صور (لإجراء بحث سياقي متعدد الوسائط)، نفِّذ التحديث أدناه أيضًا:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. إجراء عملية توليد معزّز بالاسترجاع (RAG) متقدّمة باستخدام ميزات AlloyDB الجديدة
بعد أن أصبح الجدول والبيانات والتضمينات جاهزة، لننفّذ الآن عملية "البحث المتّجهي" في الوقت الفعلي عن نص بحث المستخدم. يمكنك اختبار ذلك من خلال تنفيذ طلب البحث أدناه:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
في طلب البحث هذا، نقارن تضمين النص الخاص بعبارة البحث التي أدخلها المستخدم "تي شيرت بياقة دائرية" مع عمليات تضمين النص لجميع أوصاف المنتجات في جدول الملابس (المخزّنة في العمود المسمّى "التضمين") باستخدام دالة مسافة التشابه الجيب التمام (الممثّلة بالرمز "<=>"). ونحوّل نتيجة طريقة التضمين إلى نوع متّجه لجعلها متوافقة مع المتّجهات المخزّنة في قاعدة البيانات. يشير LIMIT 10 إلى أنّنا نختار 10 نتائج مطابقة لنص البحث.
تتيح لك AlloyDB إمكانات جديدة في التوليد المعزّز بالاسترجاع (RAG) باستخدام "البحث المتّجه":
بالنسبة إلى الحلول على مستوى المؤسسة، لا يكفي البحث عن المتجهات الأولية. الأداء مهم للغاية.
فهرس ScaNN (الجيران الأقرب القابل للتوسيع)
لتحقيق سرعة فائقة في البحث التقريبي عن أقرب الجيران (ANN)، فعّلنا فهرس scaNN في AlloyDB. تم تصميم ScaNN، وهي خوارزمية بحث متطوّرة عن الجيران الأقرب تقريبًا، طوّرها فريق أبحاث Google، لإجراء عمليات بحث فعّالة عن التشابه بين المتجهات على نطاق واسع. تؤدي هذه الطريقة إلى تسريع الاستعلامات بشكل كبير من خلال تقليل مساحة البحث بكفاءة واستخدام تقنيات التكميم، ما يتيح تنفيذ استعلامات المتجهات أسرع بما يصل إلى 4 مرات من طرق الفهرسة الأخرى مع تقليل مساحة الذاكرة المستخدَمة. يمكنك الاطّلاع على مزيد من المعلومات حول هذا الموضوع هنا وهنا.
لنفعّل الإضافة وننشئ الفهارس:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
إنشاء فهارس لكل من حقول تضمين النص وتضمين الصور (في حال أردت استخدام تضمين الصور في البحث):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
فهارس البيانات الوصفية
في حين أنّ scaNN يتعامل مع فهرسة المتجهات، تم إعداد فهارس B-tree أو GIN التقليدية بدقة على السمات المنظَّمة (مثل الفئة والفئة الفرعية والتصميم واللون وما إلى ذلك). تُعدّ هذه الفهارس ضرورية لفعالية البحث المتعدّد الأوجه. نفِّذ العبارات أدناه لإعداد فهارس البيانات الوصفية:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
ملاحظة مهمة:
بما أنّه من المحتمل أنّك أدرجت 25 إلى 50 سجلاً فقط، لن تكون الفهارس (ScaNN أو أي فهرس آخر) فعّالة.
التصفية المضمّنة
من التحديات الشائعة في البحث المتّجه هو دمجه مع فلاتر منظَّمة (مثل "أحذية حمراء"). تعمل ميزة الفلترة المضمّنة في AlloyDB على تحسين ذلك. بدلاً من فلترة النتائج بعد إجراء بحث واسع النطاق عن المتجهات، تطبِّق الفلترة المضمّنة شروط الفلترة أثناء عملية البحث عن المتجهات نفسها، ما يؤدي إلى تحسين الأداء والدقة بشكل كبير في عمليات البحث عن المتجهات التي تمّت فلترتها.
يُرجى الرجوع إلى هذه المستندات لمعرفة المزيد من المعلومات حول الحاجة إلى ميزة "الفلترة المضمّنة". يمكنك أيضًا الاطّلاع على معلومات حول البحث المتّجه المفلتر لتحسين أداء البحث المتّجه هنا. الآن، إذا أردت تفعيل الفلترة المضمّنة لتطبيقك، شغِّل العبارة التالية من المحرّر:
SET scann.enable_inline_filtering = on;
تكون الفلترة المضمّنة هي الأفضل في الحالات التي تتضمّن انتقائية متوسطة. أثناء بحث AlloyDB في فهرس المتجهات، لا يحتسب المسافات إلا للمتجهات التي تتطابق مع شروط فلترة البيانات الوصفية (الفلاتر الوظيفية في الاستعلام التي يتم التعامل معها عادةً في عبارة WHERE). يؤدي ذلك إلى تحسين الأداء بشكل كبير لهذه الطلبات، ما يكمّل مزايا الفلترة اللاحقة أو الفلترة المسبقة.
التصفية التكيّفية
لتحسين الأداء بشكلٍ أكبر، تختار ميزة "الفلترة التكيّفية" في AlloyDB بشكلٍ ديناميكي استراتيجية الفلترة الأكثر فعالية (الفلترة المضمّنة أو المسبقة) أثناء تنفيذ طلب البحث. ويحلّل أنماط الطلبات وتوزيعات البيانات لضمان الأداء الأمثل بدون تدخّل يدوي، وهو مفيد بشكل خاص لعمليات البحث المتّجهية المفلترة حيث يتم التبديل تلقائيًا بين استخدام فهرس المتّجهات وفهرس البيانات الوصفية. لتفعيل الفلترة التكيّفية، استخدِم العلامة scann.enable_preview_features.
عندما تؤدي الفلترة التكيّفية إلى التبديل من الفلترة المضمّنة إلى الفلترة المسبقة أثناء التنفيذ، تتغيّر خطة طلب البحث بشكلٍ ديناميكي.
SET scann.enable_preview_features = on;
ملاحظة مهمة: قد لا تتمكّن من تنفيذ العبارة أعلاه بدون إعادة تشغيل المثيل، وفي حال مواجهة خطأ، من الأفضل تفعيل العلامة enable_preview_features من قسم علامات قاعدة البيانات في مثيلك.
فلاتر متعدّدة الأوجه تستخدم جميع الفهارس
يتيح البحث المتعدّد الأوجه للمستخدمين تحسين النتائج من خلال تطبيق فلاتر متعدّدة استنادًا إلى سمات أو "أوجه" محدّدة (مثل العلامة التجارية أو السعر أو الحجم أو تقييم العملاء). يدمج تطبيقنا هذه التصنيفات بسلاسة مع البحث المتّجه. يمكن لطلب بحث واحد الآن الجمع بين اللغة الطبيعية (البحث السياقي) وعدة خيارات محدّدة الأوجه، والاستفادة بشكل ديناميكي من كلّ من الفهارس المتجهة والتقليدية. يوفّر ذلك إمكانية بحث مختلط ديناميكي حقًا، ما يتيح للمستخدمين التوغّل في النتائج بدقة.
في تطبيقنا، بما أنّنا أنشأنا جميع فهارس البيانات الوصفية، أصبحنا جاهزين لاستخدام الفلتر المتعدّد الأوجه على الويب من خلال معالجة ذلك مباشرةً باستخدام طلبات بحث SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
في طلب البحث هذا، نجري بحثًا مختلطًا يتضمّن
- الفلترة المتعدّدة الأوجه في عبارة WHERE
- البحث المتّجهي في عبارة ORDER BY باستخدام طريقة التشابه الجيب التمامي
تمثّل القيم 1 و2 و3 و4 قيم الفلتر المتعدّد الأوجه في مصفوفة، وتمثّل القيمة 5 نص بحث المستخدم. استبدِل $1 إلى $4 بقيم الفلتر المتعدّد الأوجه التي تختارها كما يلي:
category = ANY([‘Apparel', ‘Footwear'])
استبدِل 5 دولار أمريكي بنص بحث من اختيارك، مثلاً "قمصان بولو".
ملاحظة مهمة: إذا لم تكن لديك الفهارس بسبب المجموعة المحدودة من السجلات التي أدرجتها، لن يظهر لك تأثير الأداء. ولكن في مجموعة بيانات إنتاج كاملة، ستلاحظ أنّ وقت التنفيذ ينخفض بشكل كبير عند استخدام "البحث المتّجه" نفسه، وذلك بفضل استخدام فهرس ScaNN المضمّن في "البحث المتّجه" مع ميزة "الفلترة المضمّنة".
بعد ذلك، لنقيّم معدّل الاسترجاع لعملية "البحث المتّجهي" هذه التي تم تفعيل ScaNN فيها.
إعادة الترتيب
حتى مع استخدام ميزة "البحث المتقدّم"، قد تحتاج النتائج الأولية إلى بعض التحسينات النهائية. وهي خطوة مهمة تعيد ترتيب نتائج البحث الأولية لتحسين مدى صلتها بطلب البحث. بعد أن يقدّم البحث المختلط الأولي مجموعة من المنتجات المرشّحة، يطبّق نموذج أكثر تطورًا (وغالبًا ما يكون أكثر تعقيدًا من الناحية الحسابية) درجة ملاءمة أكثر دقة. يضمن ذلك أنّ النتائج الأولى المعروضة للمستخدم هي الأنسب، ما يؤدي إلى تحسين جودة البحث بشكل كبير. نقيّم باستمرار معدّل الاسترجاع لقياس مدى جودة النظام في استرداد جميع العناصر ذات الصلة بطلب بحث معيّن، ونعمل على تحسين نماذجنا لزيادة احتمالية عثور العميل على ما يحتاج إليه.
قبل استخدام هذه الميزة في تطبيقك، تأكَّد من استيفاء جميع المتطلبات الأساسية:
- تأكَّد من تثبيت إضافة google_ml_integration.
- تأكَّد من ضبط العلامة google_ml_integration.enable_model_support على "مفعَّل".
- الدمج مع Vertex AI
- فعِّل واجهة برمجة التطبيقات Discovery Engine API.
- الحصول على الأدوار المطلوبة لاستخدام نماذج الترتيب
بعد ذلك، يمكنك استخدام طلب البحث التالي في تطبيقنا لإعادة ترتيب مجموعة نتائج البحث المختلط:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
في هذا الاستعلام، نعيد ترتيب مجموعة نتائج المنتجات الخاصة بالبحث السياقي التي يتم تناولها في عبارة ORDER BY باستخدام طريقة التشابه الجيب التمامي. "قميص وردي" هو النص الذي يبحث عنه المستخدم.
ملاحظة مهمة: قد لا تتوفّر ميزة "إعادة الترتيب" للبعض منكم بعد، لذا استبعدتها من الرمز البرمجي للتطبيق، ولكن إذا أردت تضمينها، يمكنك اتّباع النموذج الذي تناولناه أعلاه.
Recall Evaluator
في البحث المشابه، يشير التذكّر إلى النسبة المئوية للحالات ذات الصلة التي تم استرجاعها من عملية بحث، أي عدد النتائج الموجبة الصحيحة. هذا هو المقياس الأكثر شيوعًا المستخدَم لقياس جودة البحث. أحد أسباب فقدان الاسترجاع هو الفرق بين البحث عن الجيران الأقرب التقريبي، أو aNN، والبحث عن الجيران الأقرب k (التام)، أو kNN. تنفّذ فهارس المتجهات، مثل ScaNN في AlloyDB، خوارزميات aNN، ما يتيح لك تسريع البحث عن المتجهات في مجموعات البيانات الكبيرة مقابل التنازل قليلاً عن الدقة. تتيح لك AlloyDB الآن إمكانية قياس هذا التوازن مباشرةً في قاعدة البيانات للاستعلامات الفردية والتأكّد من ثباته بمرور الوقت. يمكنك تعديل مَعلمات الطلب والفهرس استجابةً لهذه المعلومات لتحقيق نتائج وأداء أفضل.
ما هو المنطق الذي يستند إليه استرجاع نتائج البحث؟
في سياق البحث المتّجهي، يشير الاسترجاع إلى النسبة المئوية للمتّجهات التي يعرضها الفهرس والتي تمثّل أقرب الجيران الحقيقيين. على سبيل المثال، إذا كان طلب البحث عن الجيران الأقرب لـ 20 جارًا أقرب يعرض 19 من الجيران الأقرب الحقيقيين، تكون نسبة الاسترجاع 19/20x100 = %95. الاسترجاع هو المقياس المستخدَم لجودة البحث، ويتم تعريفه على أنّه النسبة المئوية للنتائج التي تم عرضها والتي تكون الأقرب موضوعيًا إلى متجهات طلب البحث.
يمكنك العثور على مقياس الاسترجاع لاستعلام متّجه في فهرس متّجه لإعدادات معيّنة باستخدام الدالة evaluate_query_recall. تتيح لك هذه الدالة ضبط المَعلمات للحصول على نتائج استرجاع طلبات البحث المتجهة التي تريدها.
ملاحظة مهمة:
إذا واجهت خطأ "تم رفض الإذن" في فهرس HNSW في الخطوات التالية، يمكنك تخطّي قسم تقييم الاسترجاع بالكامل في الوقت الحالي. قد يكون السبب مرتبطًا بقيود الوصول في هذه المرحلة لأنّها قد تم إصدارها للتوّ عند إنشاء مستندات هذا الدرس التطبيقي حول الترميز.
- اضبط العلامة Enable Index Scan على فهرس ScaNN وفهرس HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- نفِّذ طلب البحث التالي في AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
تتلقّى الدالة evaluate_query_recall طلب البحث كمَعلمة وتعرض مدى صحة النتائج. أستخدم طلب البحث نفسه الذي استخدمته للتحقّق من الأداء كطلب بحث إدخال للدالة. لقد أضفتُ SCaNN كطريقة فهرسة. لمزيد من خيارات المَعلمات، يُرجى الرجوع إلى المستندات.
في ما يلي مقياس الاسترجاع لطلب البحث هذا في "البحث المتجهي" الذي كنا نستخدمه:
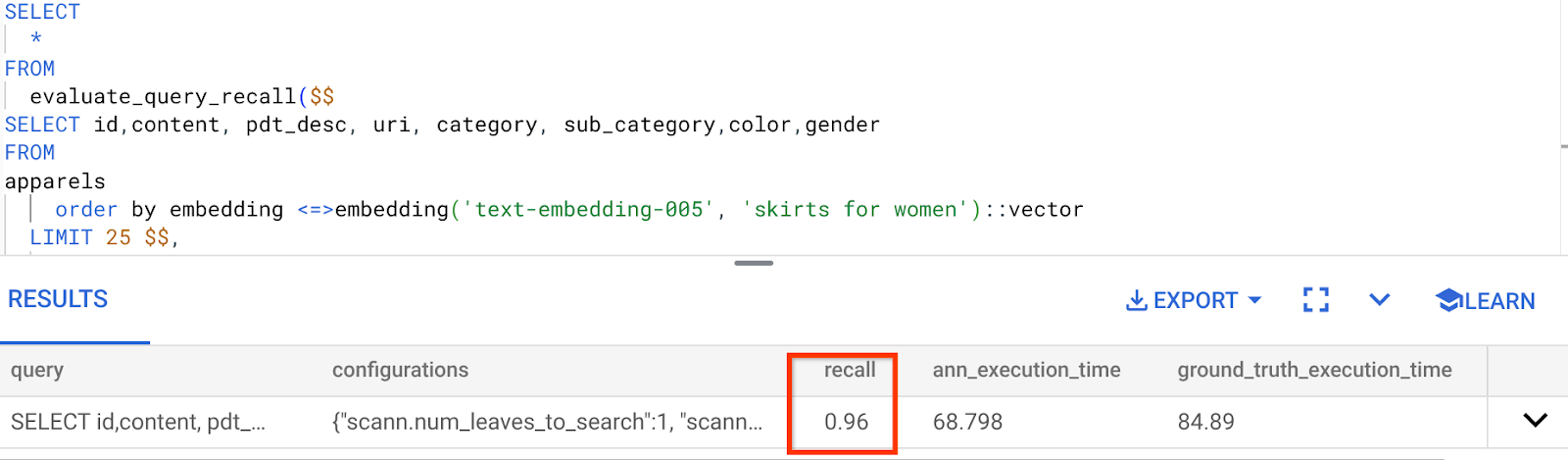
أرى أنّ معدّل الاسترجاع هو %96. في هذه الحالة، يكون الاسترجاع جيدًا جدًا. ولكن إذا كانت القيمة غير مقبولة، يمكنك استخدام هذه المعلومات لتغيير مَعلمات الفهرس والطُرق ومَعلمات طلب البحث وتحسين استرجاع المعلومات في "البحث المتّجه".
اختبارها باستخدام مَعلمات طلب البحث والفهرس المعدَّلة
لنختبر الآن طلب البحث من خلال تعديل مَعلمات طلب البحث استنادًا إلى الاستدعاء الذي تم تلقّيه.
- تعديل مَعلمات الفهرس:
في هذا الاختبار، سأستخدم "مسافة L2" بدلاً من دالة قياس التشابه "جيب التمام".
ملاحظة مهمة جدًا: قد تسأل "كيف نعرف أنّ طلب البحث هذا يستخدم التشابه الجيب التمامي؟". يمكنك تحديد دالة المسافة باستخدام "<=>" لتمثيل مسافة جيب التمام.
رابط المستندات لوظائف المسافة في "البحث عن المتّجهات"
يستخدم الاستعلام السابق دالة المسافة "تشابه جيب التمام"، بينما سنحاول الآن استخدام "مسافة L2". ولكن يجب أيضًا التأكّد من أنّ فهرس ScaNN الأساسي يستخدم دالة مسافة L2. لننشئ الآن فهرسًا باستخدام طلب بحث مختلف لدالة المسافة: مسافة L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
عبارة drop index هي فقط لضمان عدم وجود فهرس غير ضروري في الجدول.
يمكنني الآن تنفيذ الاستعلام التالي لتقييم RECALL بعد تغيير دالة المسافة في وظيفة "البحث المتّجه".
[بعد] طلب البحث الذي يستخدم دالة المسافة L2:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
يمكنك الاطّلاع على الفرق أو التحويل في قيمة الاسترجاع للفهرس المعدَّل.
هناك مَعلمات أخرى يمكنك تغييرها في الفهرس، مثل num_leaves وما إلى ذلك، استنادًا إلى قيمة الاسترجاع المطلوبة ومجموعة البيانات التي يستخدمها تطبيقك.
التحقّق من صحة نتائج البحث عن المتّجهات باستخدام النماذج اللغوية الكبيرة
لتحقيق أعلى جودة في البحث الخاضع للرقابة، أضفنا طبقة اختيارية للتحقّق من صحة نتائج البحث باستخدام نماذج اللغات الكبيرة. يمكن استخدام نماذج اللغات الكبيرة لتقييم مدى صلة نتائج البحث بالموضوع ومدى اتساقها، خاصةً في ما يتعلق بطلبات البحث المعقّدة أو الغامضة. يمكن أن يشمل ذلك:
التحقّق الدلالي:
نموذج لغوي كبير (LLM) يربط النتائج بموضوع البحث.
الفلترة المنطقية:
استخدام نموذج لغوي كبير لتطبيق قواعد أو منطق عمل معقّد يصعب ترميزه في الفلاتر التقليدية، ما يؤدي إلى تحسين قائمة المنتجات بشكل أكبر استنادًا إلى معايير دقيقة
ضمان الجودة:
تحديد النتائج الأقل صلة بالموضوع والإبلاغ عنها تلقائيًا لكي يراجعها فريقنا أو يتم تحسين النموذج
إليك كيف حقّقنا ذلك في ميزات AlloyDB AI:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
طلب البحث الأساسي هو طلب البحث نفسه الذي رأيناه في أقسام البحث المتعدّد الأوجه والبحث المختلط وإعادة الترتيب. في هذا الاستعلام، أضفنا مستوى تقييم GEMINI لمجموعة النتائج التي تمّت إعادة ترتيبها والممثّلة ببنية ml_predict_row. لقد علّقت على الفلاتر المتعدّدة الأوجه، ولكن يمكنك تضمين العناصر التي تختارها في مصفوفة للعناصر النائبة من $1 إلى $4. استبدِل 5 دولار أمريكي بالنص الذي تريد البحث عنه، مثلاً "قميص وردي بدون نقش زهور".
7. MCP Toolbox for Databases وطبقة التطبيق
وراء الكواليس، تضمن الأدوات القوية والتطبيق المنظَّم جيدًا التشغيل السلس.
تُبسّط أداة MCP (بروتوكول سياق النموذج) لقواعد البيانات عملية دمج أدوات الذكاء الاصطناعي التوليدي والذكاء الاصطناعي الوكيل مع AlloyDB. يعمل هذا الخادم كمصدر مفتوح يسهّل تجميع الاتصالات والمصادقة وعرض وظائف قاعدة البيانات بشكل آمن لوكلاء الذكاء الاصطناعي أو التطبيقات الأخرى.
في تطبيقنا، استخدمنا MCP Toolbox for Databases كطبقة تجريدية لجميع طلبات البحث الذكية المختلطة.
اتّبِع الخطوات التالية لإعداد "مجموعة الأدوات" ونشرها لحالة الاستخدام:
يمكنك ملاحظة أنّ إحدى قواعد البيانات المتوافقة مع MCP Toolbox for Databases هي AlloyDB، وبما أنّنا قد وفّرناها في القسم السابق، لننتقل إلى إعداد Toolbox.
- انتقِل إلى "وحدة Cloud Shell" وتأكَّد من اختيار مشروعك وعرضه في طلب الوحدة. نفِّذ الأمر التالي من "وحدة Cloud Shell الطرفية" للانتقال إلى دليل مشروعك:
mkdir toolbox-tools
cd toolbox-tools
- نفِّذ الأمر أدناه لتنزيل مجموعة الأدوات وتثبيتها في مجلدك الجديد:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- انتقِل إلى "محرّر Cloud Shell" (لوضع تعديل الرمز) وأضِف ملفًا باسم "tools.yaml" في مجلد جذر المشروع.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
تأكَّد من استبدال النص البرمجي Tools.yaml بالشفرة من ملف المستودع هذا.
دعونا نتعرّف على ملف tools.yaml:
تمثّل المصادر مصادر البيانات المختلفة التي يمكن أن تتفاعل معها إحدى الأدوات. يمثّل المصدر مصدر بيانات يمكن للأداة التفاعل معه. يمكنك تعريف المصادر كخريطة في قسم المصادر ضمن ملف tools.yaml. عادةً، يحتوي إعداد المصدر على أي معلومات مطلوبة للاتصال بقاعدة البيانات والتفاعل معها.
تحدِّد الأدوات الإجراءات التي يمكن أن يتّخذها الوكيل، مثل القراءة والكتابة إلى مصدر. تمثّل الأداة إجراءً يمكن أن يتّخذه الوكيل، مثل تنفيذ عبارة SQL. يمكنك تعريف "الأدوات" كخريطة في قسم الأدوات في ملف tools.yaml. عادةً، تتطلّب الأداة مصدرًا لتنفيذ الإجراءات.
لمزيد من التفاصيل حول ضبط ملف tools.yaml، يُرجى الرجوع إلى هذه المستندات.
- نفِّذ الأمر التالي (من مجلد mcp-toolbox) لبدء الخادم:
./toolbox --tools-file "tools.yaml"
إذا فتحت الخادم الآن في وضع المعاينة على الويب على السحابة الإلكترونية، من المفترض أن تتمكّن من رؤية خادم "مجموعة الأدوات" يعمل مع أداتك الجديدة التي تحمل الاسم get-order-data.
يتم تشغيل خادم MCP Toolbox تلقائيًا على المنفذ 5000. لنستخدم Cloud Shell لاختبار ذلك.
انقر على "معاينة الويب" في Cloud Shell كما هو موضّح أدناه:
انقر على "تغيير المنفذ" (Change port) واضبط المنفذ على 5000 كما هو موضّح أدناه، ثم انقر على "تغيير ومعاينة" (Change and Preview).
من المفترض أن يؤدي ذلك إلى ظهور الناتج التالي:
- لننشُر Toolbox على Cloud Run:
أولاً، يمكننا البدء بخادم MCP Toolbox واستضافته على Cloud Run. سيمنحنا ذلك نقطة نهاية عامة يمكننا دمجها مع أي تطبيق آخر و/أو تطبيقات "الوكيل" أيضًا. تتوفر تعليمات استضافة هذا التطبيق على Cloud Run هنا. سنستعرض الخطوات الرئيسية الآن.
- ابدأ تشغيل "وحدة طرفية Cloud Shell" جديدة أو استخدِم "وحدة طرفية Cloud Shell" حالية. انتقِل إلى مجلد المشروع الذي يتضمّن ملف toolbox الثنائي وملف tools.yaml، وهو في هذه الحالة toolbox-tools، إذا لم تكن فيه:
cd toolbox-tools
- اضبط المتغيّر PROJECT_ID للإشارة إلى رقم تعريف مشروع Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- تفعيل خدمات Google Cloud التالية
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- لننشئ حساب خدمة منفصلاً سيعمل كمعرّف لخدمة Toolbox التي سننشرها على Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- نحرص أيضًا على أن يكون لحساب الخدمة هذا الأدوار الصحيحة، أي القدرة على الوصول إلى Secret Manager والتواصل مع AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- سنحمّل ملف tools.yaml كمفتاح سرّي:
gcloud secrets create tools --data-file=tools.yaml
إذا كان لديك رمز سري حالي وأردت تعديل إصدار الرمز السري، نفِّذ ما يلي:
gcloud secrets versions add tools --data-file=tools.yaml
- اضبط متغيّر بيئة على صورة الحاوية التي تريد استخدامها في Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- الخطوة الأخيرة في أمر النشر المألوف إلى Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
من المفترض أن تبدأ هذه الخطوة عملية نشر Toolbox Server باستخدام ملف tools.yaml الذي تم إعداده على Cloud Run. عند اكتمال عملية النشر بنجاح، من المفترض أن تظهر لك رسالة مشابهة لما يلي:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
أصبحت جاهزًا لاستخدام أداتك التي تم نشرها حديثًا في تطبيقك المستند إلى الذكاء الاصطناعي التوليدي!!!
الوصول إلى الأدوات في خادم Toolbox
بعد نشر Toolbox، سننشئ طبقة وسيطة (shim) لوظائف Python Cloud Run للتفاعل مع خادم Toolbox الذي تم نشره. يعود السبب إلى أنّ Toolbox لا تتضمّن حاليًا حزمة تطوير برامج (SDK) بلغة Java، لذا أنشأنا طبقة وسيطة (shim) بلغة Python للتفاعل مع الخادم. في ما يلي رمز المصدر لوظيفة Cloud Run هذه.
عليك إنشاء Cloud Run Function ونشره لتتمكّن من الوصول إلى أدوات مجموعة الأدوات التي أنشأناها ونشرناها في الخطوات السابقة:
- في Google Cloud Console، انتقِل إلى صفحة Cloud Run.
- انقر على "كتابة دالة".
- في حقل "اسم الخدمة"، أدخِل اسمًا لوصف الدالة. يجب أن تبدأ أسماء الخدمات بحرف فقط، وأن تحتوي على 49 حرفًا أو أقل، بما في ذلك الأحرف أو الأرقام أو الواصلات. لا يمكن أن تنتهي أسماء الخدمات بشرطات، ويجب أن تكون فريدة لكل منطقة ومشروع. لا يمكن تغيير اسم الخدمة لاحقًا، وهو يظهر للجميع. (Enter retail-product-search-quality)
- في قائمة "المنطقة"، استخدِم القيمة التلقائية أو اختَر المنطقة التي تريد نشر الدالة فيها. (اختَر us-central1)
- في قائمة "وقت التشغيل" (Runtime)، استخدِم القيمة التلقائية أو اختَر إصدارًا لوقت التشغيل. (اختَر Python 3.11)
- في قسم "المصادقة"، اختَر "السماح بالوصول العام".
- انقر على الزر "إنشاء"
- يتم إنشاء الدالة وتحميلها باستخدام نموذج main.py وrequirements.txt.
- استبدِل ذلك بالملفَين: main.py و requirements.txt من مستودع هذا المشروع
- انشر الدالة، وسيظهر لك نقطة نهاية لدالة Cloud Run.
يجب أن تبدو نقطة النهاية على النحو التالي (أو شيء مشابه):
نقطة نهاية دالة Cloud Run للوصول إلى مجموعة الأدوات: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
لتسهيل إكمال المشروع خلال الجدول الزمني (لجلسات التدريب العملي بإشراف مدرّب)، سيتم مشاركة رقم المشروع لنقطة النهاية في وقت جلسة التدريب العملي.
ملاحظة مهمة:
بدلاً من ذلك، يمكنك أيضًا تنفيذ جزء قاعدة البيانات مباشرةً كجزء من الرمز البرمجي لتطبيقك أو دالة Cloud Run.
8. تطوير التطبيقات (Java) باستخدام ميزة "البحث المتعدّد الأوجه"
أخيرًا، يتم إتاحة كل هذه المكوّنات الفعّالة في الخلفية من خلال طبقة التطبيق. تم تطوير التطبيق بلغة Java، وهو يوفّر واجهة المستخدم للتفاعل مع نظام البحث. تنسّق هذه الخدمة طلبات البحث إلى AlloyDB، وتتعامل مع عرض الفلاتر المتعدّدة الأوجه، وتدير اختيارات المستخدمين، وتعرض نتائج البحث التي تم التحقّق من صحتها وإعادة ترتيبها بطريقة سلسة وبديهية.
- يمكنك البدء بالانتقال إلى "وحدة طرفية Cloud Shell" واستنساخ المستودع:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- انتقِل إلى "محرّر Cloud Shell"، حيث يمكنك الاطّلاع على المجلد الذي تم إنشاؤه حديثًا باسم faceted_searching_retail.
- احذف ما يلي لأنّ هذه الخطوات مكتملة في الأقسام السابقة:
- احذف المجلد Cloud_Run_Function.
- احذف الملف db_script.sql.
- احذف الملف tools.yaml.
- انتقِل إلى مجلد المشروع retail-faceted-search، وستظهر لك بنية المشروع على النحو التالي:
- في الملف ProductRepository.java، عليك تعديل المتغيّر TOOLBOX_ENDPOINT باستخدام نقطة النهاية من دالة Cloud Run (التي تم نشرها) أو الحصول على نقطة النهاية من المتحدث الذي يقدّم التدريب العملي.
ابحث عن سطر الرمز التالي واستبدِله بنقطة النهاية:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- تأكَّد من أنّ ملفَي Dockerfile وpom.xml متوافقان مع إعدادات مشروعك (لا يلزم إجراء أي تغيير إلا إذا غيّرت أي إصدار أو إعدادات بشكل صريح).
- في "وحدة Cloud Shell الطرفية"، تأكَّد من أنّك داخل المجلد الرئيسي وضمن مجلد المشروع (faceted_searching_retail / retail-faceted-search). استخدِم الأوامر التالية للتأكّد من أنّك في المجلد الصحيح في الوحدة الطرفية:
cd faceted_searching_retail
cd retail-faceted-search
- حزِّم تطبيقك وأنشئه واختبِره على جهازك:
mvn package
mvn spring-boot:run
من المفترض أن تتمكّن من عرض تطبيقك من خلال النقر على "معاينة على المنفذ 8080" (Preview on port 8080) في "وحدة Cloud Shell الطرفية" (Cloud Shell Terminal) كما هو موضّح أدناه:
9. النشر على Cloud Run: ***خطوة مهمة
في "وحدة Cloud Shell الطرفية"، تأكَّد من أنّك داخل المجلد الرئيسي وضمن مجلد المشروع (faceted_searching_retail / retail-faceted-search). استخدِم الأوامر التالية للتأكّد من أنّك في المجلد الصحيح في الوحدة الطرفية:
cd faceted_searching_retail
cd retail-faceted-search
بعد التأكّد من أنّك في مجلّد المشروع، نفِّذ الأمر التالي:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
بعد النشر، من المفترض أن تتلقّى نقطة نهاية Cloud Run تم نشرها على النحو التالي:
https://retail-search-**********-uc.a.run.app/
10. عرض توضيحي
لنطّلِع على مثال عمليّ:
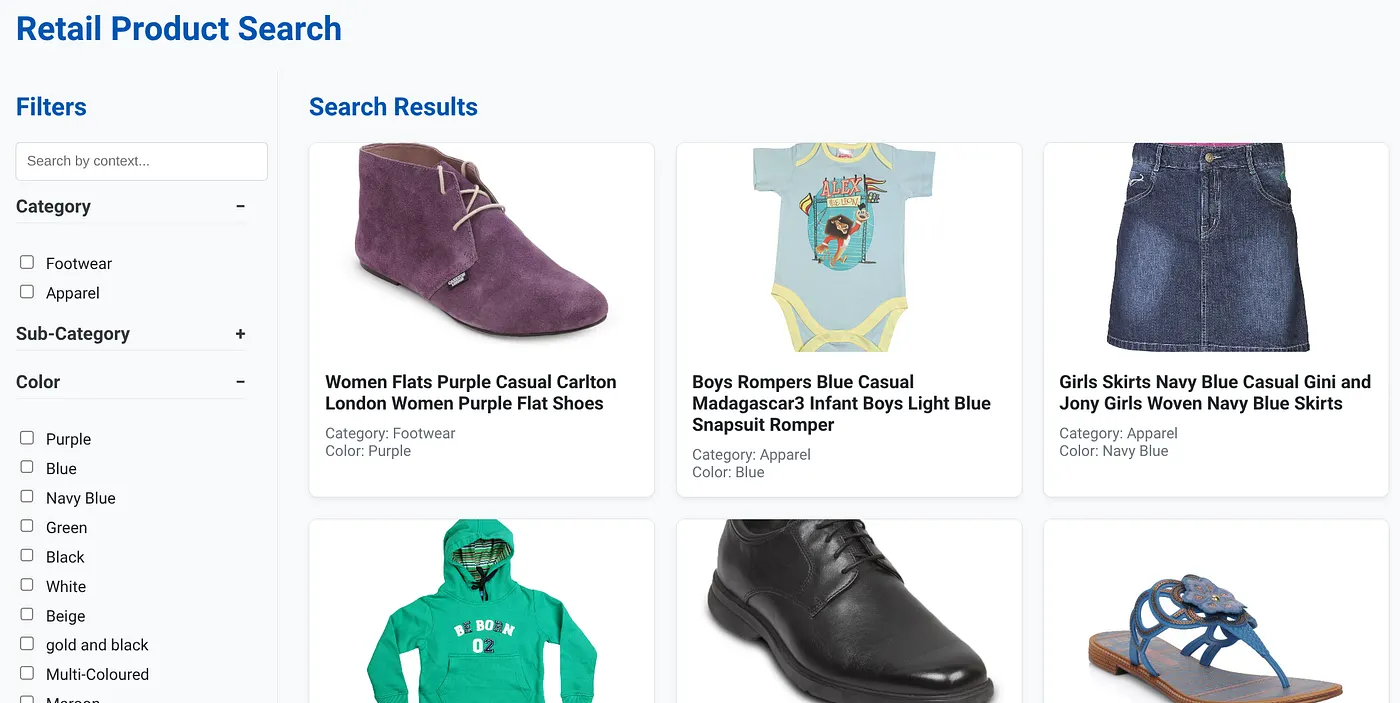
تعرض الصورة أعلاه الصفحة المقصودة لتطبيق البحث الديناميكي المختلط.
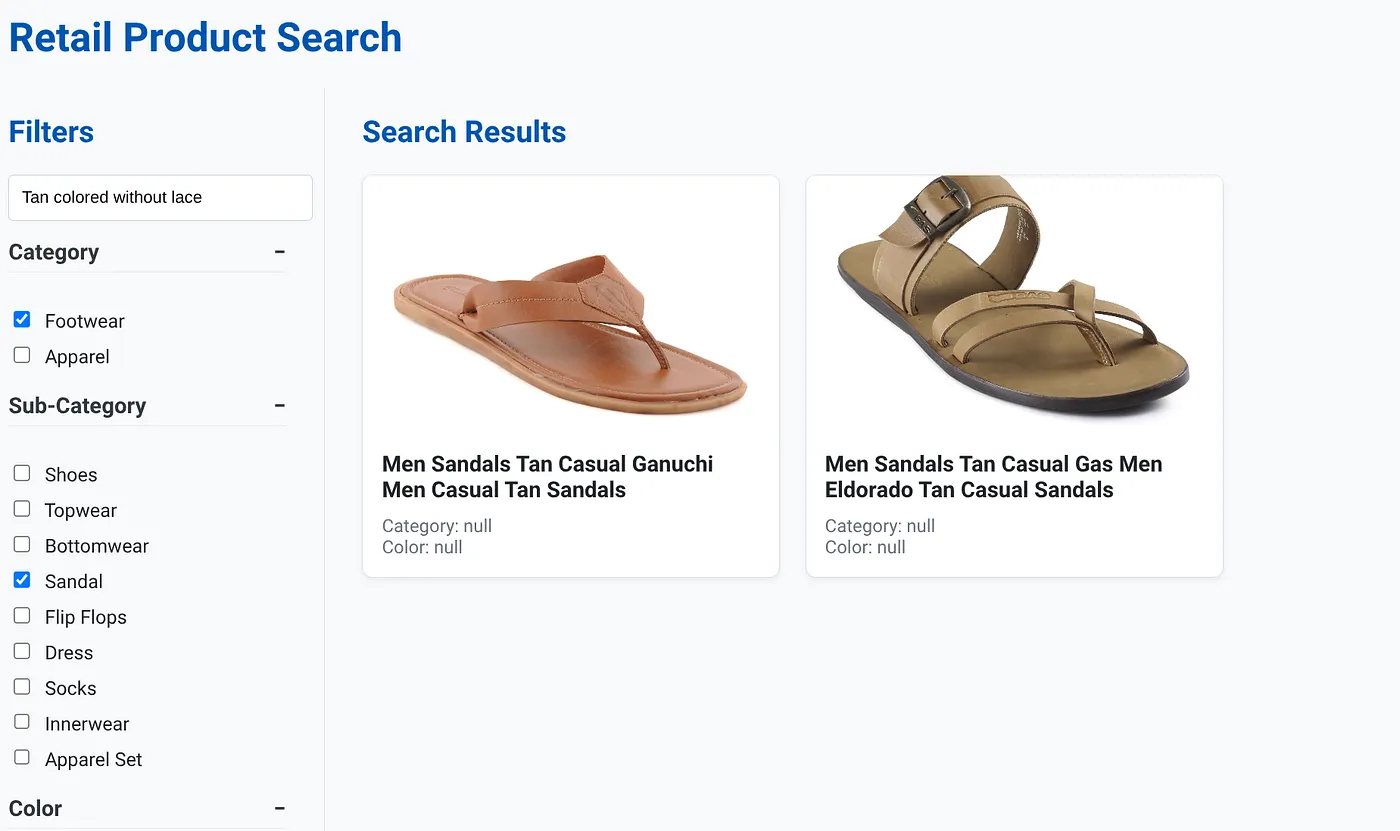
تعرض الصورة أعلاه نتائج البحث عن "حذاء بلون أسمر بدون رباط" . الفلاتر المتعدّدة الأوجه التي تم اختيارها هي: أحذية، صنادل.
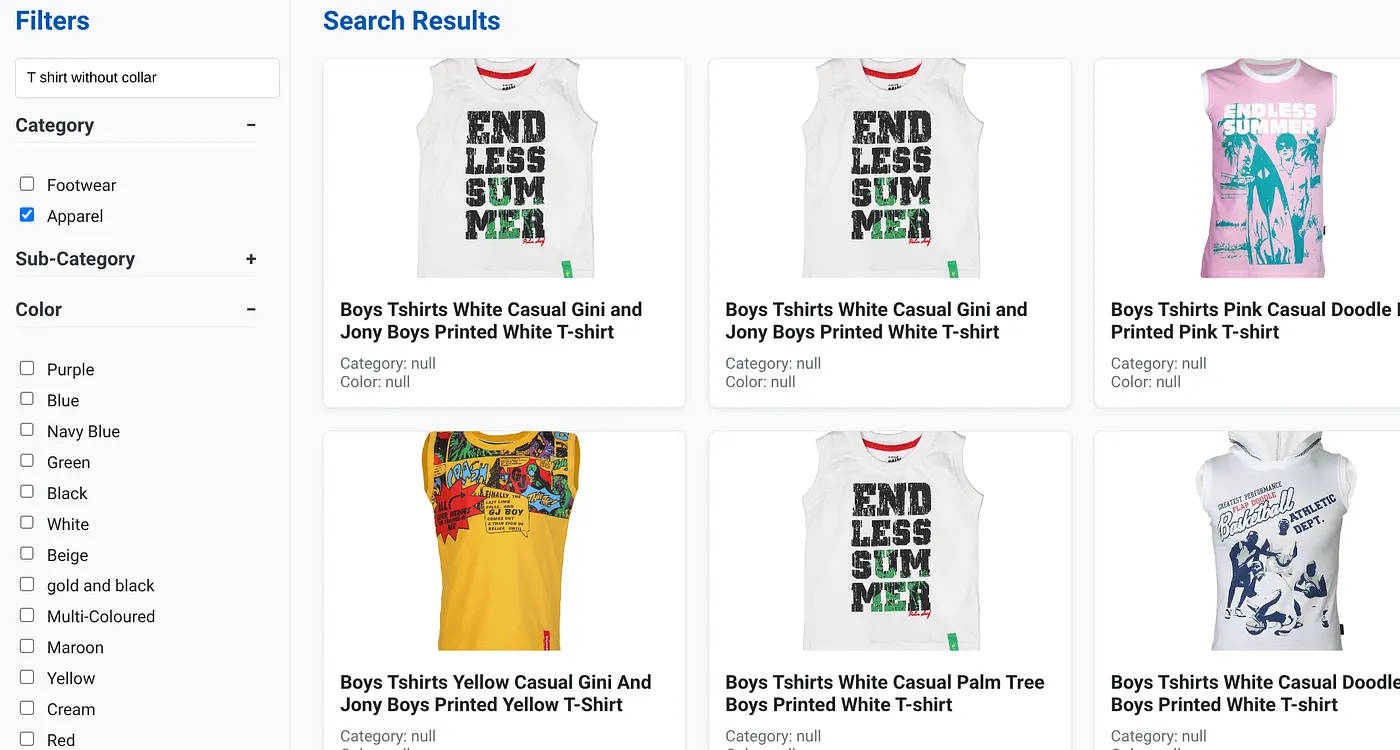
تعرض الصورة أعلاه نتائج البحث عن "قميص بدون ياقة" . الفلاتر المتعدّدة الأوجه: الملابس
يمكنك الآن دمج المزيد من الميزات التوليدية والمستندة إلى الوكلاء لجعل هذا التطبيق قابلاً للتنفيذ.
جرِّب هذه الميزة لتستوحي أفكارًا جديدة!!!
11. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
- بدلاً من ذلك، يمكنك حذف مجموعة AlloyDB (غيِّر الموقع الجغرافي في هذا الرابط التشعّبي إذا لم تختر us-central1 للمجموعة في وقت الإعداد) التي أنشأناها للتو لهذا المشروع من خلال النقر على الزر DELETE CLUSTER (حذف المجموعة).
12. تهانينا
تهانينا! لقد نجحت في إنشاء تطبيق بحث مختلط ونشره باستخدام AlloyDB على Cloud Run.
أهمية هذه الميزة للأنشطة التجارية:
يقدّم تطبيق البحث الديناميكي المختلط هذا، المستنِد إلى AlloyDB AI، مزايا كبيرة لأنشطة البيع بالتجزئة والمؤسسات الأخرى، وهي:
ملاءمة فائقة: من خلال الجمع بين البحث السياقي (المستند إلى المتجهات) والفلترة الدقيقة المتعددة الأوجه وإعادة الترتيب الذكية، يحصل العملاء على نتائج ذات صلة عالية، ما يؤدي إلى زيادة الرضا والإحالات الناجحة.
قابلية التوسّع: تم تصميم بنية AlloyDB وفهرسة scaNN للتعامل مع فهارس المنتجات الضخمة وأحجام طلبات البحث الكبيرة، وهو أمر بالغ الأهمية لتطوير أنشطة التجارة الإلكترونية.
الأداء: تضمن الاستجابة الأسرع لطلبات البحث، حتى تلك المعقّدة التي تجمع بين البحث الدلالي والبحث عن الكلمات الرئيسية، تجربة مستخدم سلسة وتقليل معدلات التخلي عن البحث.
التوافق مع التكنولوجيا المستقبلية: يتيح دمج إمكانات الذكاء الاصطناعي (مثل التضمينات والتحقّق من صحة النماذج اللغوية الكبيرة) إمكانية الاستفادة من التطورات المستقبلية في الاقتراحات المخصّصة والتجارة الحوارية واكتشاف المنتجات الذكي.
بنية مبسطة: يغني دمج البحث المتّجه مباشرةً في AlloyDB عن الحاجة إلى قواعد بيانات متّجهة منفصلة أو مزامنة معقّدة، ما يسهّل عملية التطوير والصيانة.
لنفترض أنّ أحد المستخدِمين كتب طلب بحث بلغة طبيعية، مثل "أحذية رياضية صديقة للبيئة للنساء توفّر دعمًا عاليًا لقوس القدم".
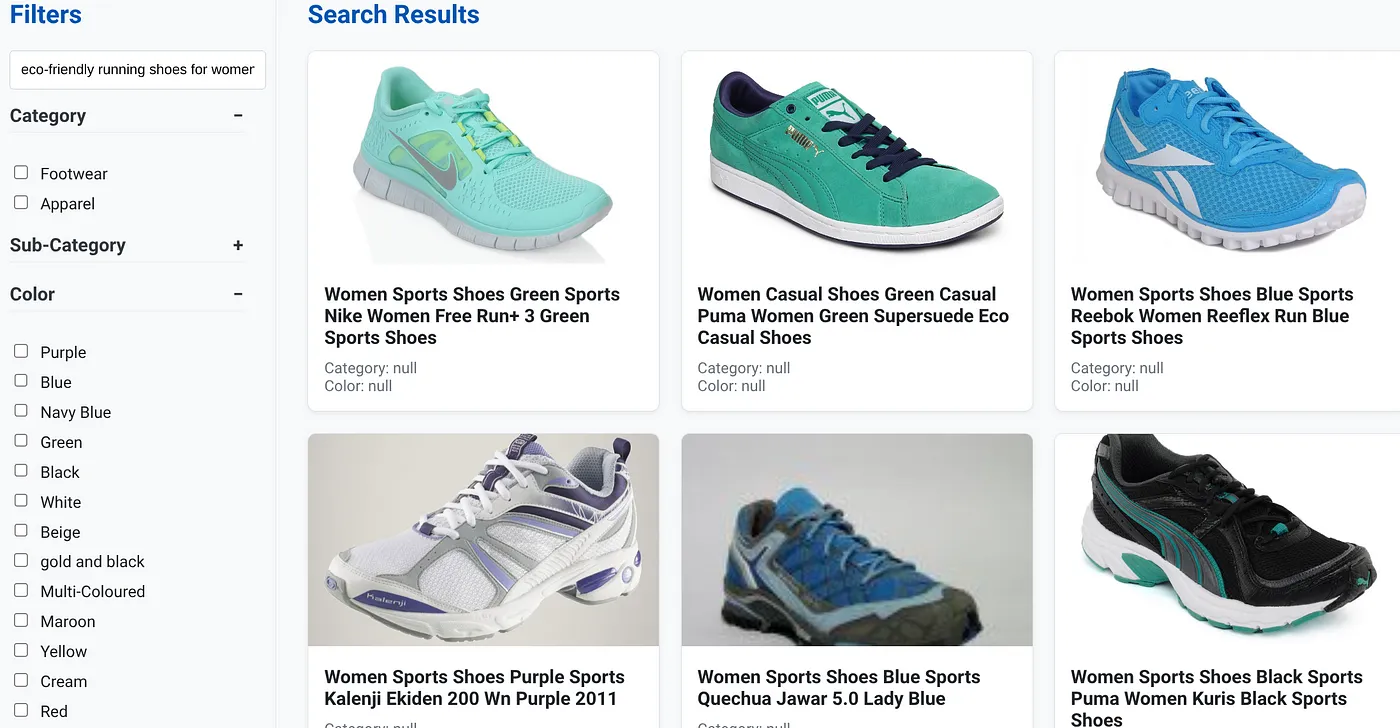
بينما يطبّق المستخدم في الوقت نفسه فلاتر متعددة الأوجه على "الفئة: <<>>" و"اللون: <<>>" و "السعر: من 100 إلى 150 دولار أمريكي":
- يعرض النظام على الفور قائمة منقّحة بالمنتجات، وتكون هذه المنتجات متوافقة دلاليًا مع اللغة الطبيعية وتتطابق بدقة مع الفلاتر المحدّدة.
- وراء الكواليس، يسرّع فهرس scaNN البحث المتّجه، وتضمن الفلترة المضمّنة والتكيّفية الأداء مع المعايير المجمّعة، وتعرض إعادة الترتيب النتائج المثالية في الأعلى.
- توضّح سرعة النتائج ودقتها قوة الجمع بين هاتين التقنيتين للحصول على تجربة بحث ذكية حقًا في مجال البيع بالتجزئة.
يتطلّب إنشاء تطبيق بحث من الجيل التالي في مجال البيع بالتجزئة تجاوز الطرق التقليدية، وباستخدام إمكانات AlloyDB وVertex AI وVector Search مع فهرسة scaNN والفلترة الديناميكية المتعدّدة الأوجه وإعادة الترتيب والتحقّق من صحة نموذج لغوي كبير (LLM)، يمكننا تقديم تجربة مستخدم لا مثيل لها تعزّز معدّل الاهتمام بالتطبيق وتزيد المبيعات. يوضّح هذا الحلّ القوي والقابل للتوسعة والذكي كيف تعيد إمكانات قواعد البيانات الحديثة، المزوّدة بالذكاء الاصطناعي، تشكيل مستقبل البيع بالتجزئة.