
১. সংক্ষিপ্ত বিবরণ
আজকের প্রতিযোগিতামূলক রিটেইল জগতে, গ্রাহকদেরকে তারা যা খুঁজছেন তা দ্রুত এবং স্বতঃস্ফূর্তভাবে খুঁজে পেতে সাহায্য করা অত্যন্ত গুরুত্বপূর্ণ। প্রচলিত কীওয়ার্ড-ভিত্তিক সার্চ প্রায়শই সূক্ষ্ম কোয়েরি এবং বিশাল প্রোডাক্ট ক্যাটালগের সাথে তাল মেলাতে ব্যর্থ হয়। এই কোডল্যাবটি AlloyDB ও AlloyDB AI-এর উপর ভিত্তি করে নির্মিত একটি অত্যাধুনিক রিটেইল সার্চ অ্যাপ্লিকেশন উন্মোচন করে, যা এন্টারপ্রাইজ স্কেলে একটি ডাইনামিক ও হাইব্রিড সার্চ অভিজ্ঞতা প্রদানের জন্য অত্যাধুনিক ভেক্টর সার্চ, scaNN ইনডেক্সিং, ফেসেটেড ফিল্টার এবং ইন্টেলিজেন্ট অ্যাডাপটিভ ফিল্টারিং ও রির্যাঙ্কিং প্রযুক্তি ব্যবহার করে।
এখন আমাদের তিনটি বিষয় সম্পর্কে প্রাথমিক ধারণা রয়েছে:
- আপনার এজেন্টের জন্য কনটেক্সচুয়াল সার্চের অর্থ কী এবং ভেক্টর সার্চ ব্যবহার করে কীভাবে তা সম্পন্ন করা যায়।
- আমরা আপনার ডেটার পরিধির মধ্যে, অর্থাৎ আপনার ডেটাবেসের মধ্যেই ভেক্টর সার্চ অর্জনের বিষয়টি নিয়েও গভীরভাবে আলোচনা করেছি (যদি আপনি আগে থেকে না জেনে থাকেন, তবে বলে রাখি, গুগল ক্লাউডের সমস্ত ডেটাবেসই এটি সমর্থন করে!)।
- ScaNN ইনডেক্স দ্বারা চালিত AlloyDB ভেক্টর সার্চ ক্ষমতার মাধ্যমে কীভাবে উচ্চ পারফরম্যান্স ও গুণমান সহ এমন একটি হালকা ভেক্টর সার্চ RAG সক্ষমতা অর্জন করা যায়, তা আপনাদের জানাতে আমরা বিশ্বের বাকিদের চেয়ে এক ধাপ এগিয়ে গিয়েছি।
আপনি যদি সেই প্রাথমিক, মধ্যবর্তী এবং কিছুটা উন্নত RAG পরীক্ষাগুলো না করে থাকেন, তাহলে আমি আপনাকে এখানে , এখানে এবং এখানে তালিকাভুক্ত ক্রমানুসারে ওই তিনটি পড়ার জন্য উৎসাহিত করব।
চ্যালেঞ্জ
ফিল্টার, কীওয়ার্ড এবং প্রাসঙ্গিক মিলের বাইরে: একটি সাধারণ কীওয়ার্ড সার্চে হাজার হাজার ফলাফল আসতে পারে, যার মধ্যে অনেকগুলোই অপ্রাসঙ্গিক। আদর্শ সমাধানটির কাজ হলো অনুসন্ধানের পেছনের উদ্দেশ্য বোঝা, সেটিকে সুনির্দিষ্ট ফিল্টার শর্তের (যেমন ব্র্যান্ড, উপাদান বা মূল্য) সাথে মেলানো এবং মিলিসেকেন্ডের মধ্যে সবচেয়ে প্রাসঙ্গিক আইটেমগুলো উপস্থাপন করা। এর জন্য একটি শক্তিশালী, নমনীয় এবং সম্প্রসারণযোগ্য সার্চ পরিকাঠামো প্রয়োজন। এটা ঠিক যে আমরা কীওয়ার্ড সার্চ থেকে প্রাসঙ্গিক মিল এবং সাদৃশ্য অনুসন্ধানের দিকে অনেক দূর এগিয়ে এসেছি। কিন্তু কল্পনা করুন, একজন গ্রাহক "বসন্তে হাইকিং করার জন্য একটি আরামদায়ক, স্টাইলিশ, জলরোধী জ্যাকেট" খুঁজছেন এবং একই সাথে ফিল্টার প্রয়োগ করছেন, আর আপনার অ্যাপ্লিকেশনটি শুধু মানসম্মত ফলাফলই দিচ্ছে না, বরং এটি উচ্চ-কার্যক্ষমও এবং এই সবকিছুর ক্রম আপনার ডেটাবেস দ্বারা গতিশীলভাবে নির্বাচিত হচ্ছে।
উদ্দেশ্য
এর সমাধান করতে সমন্বয়ের মাধ্যমে
- প্রাসঙ্গিক অনুসন্ধান (ভেক্টর অনুসন্ধান): কোয়েরি এবং পণ্যের বিবরণের শব্দার্থগত অর্থ বোঝা
- ফেসেটেড ফিল্টারিং: ব্যবহারকারীদের নির্দিষ্ট বৈশিষ্ট্য ব্যবহার করে ফলাফল পরিমার্জন করার সুযোগ দেওয়া।
- হাইব্রিড পদ্ধতি: প্রাসঙ্গিক অনুসন্ধানের সাথে কাঠামোগত ফিল্টারিংয়ের নির্বিঘ্ন সংমিশ্রণ
- উন্নত অপ্টিমাইজেশন: গতি এবং প্রাসঙ্গিকতার জন্য বিশেষায়িত ইনডেক্সিং, অ্যাডাপ্টিভ ফিল্টারিং এবং রির্যাঙ্কিং-এর ব্যবহার।
- জেনারেটিভ এআই-চালিত গুণমান নিয়ন্ত্রণ: উন্নততর ফলাফলের জন্য এলএলএম ভ্যালিডেশন অন্তর্ভুক্তিকরণ।
চলুন এর স্থাপত্য এবং বাস্তবায়ন প্রক্রিয়াটি বিশদভাবে আলোচনা করা যাক।
আপনি যা তৈরি করবেন
একটি খুচরা অনুসন্ধান অ্যাপ্লিকেশন
এর অংশ হিসেবে, আপনাকে যা করতে হবে তা হলো:
- ইকমার্স ডেটাসেটের জন্য একটি AlloyDB ইনস্ট্যান্স এবং টেবিল তৈরি করুন
- এমবেডিং এবং ভেক্টর সার্চ সেট আপ করুন
- মেটাডেটা সূচক এবং স্ক্যান সূচক তৈরি করুন
- ScaNN-এর ইনলাইন ফিল্টারিং পদ্ধতি ব্যবহার করে AlloyDB-তে উন্নত ভেক্টর সার্চ বাস্তবায়ন করুন।
- একটিমাত্র কোয়েরিতে ফেসেটেড ফিল্টার এবং হাইব্রিড সার্চ সেট আপ করুন
- রির্যাঙ্কিং এবং রিকলের মাধ্যমে কোয়েরির প্রাসঙ্গিকতা পরিমার্জন করুন (ঐচ্ছিক)
- জেমিনি দিয়ে কোয়েরির উত্তর মূল্যায়ন করুন (ঐচ্ছিক)
- ডেটাবেস এবং অ্যাপ্লিকেশন লেয়ারের জন্য এমসিপি টুলবক্স
- ফেসেটেড সার্চ সহ অ্যাপ্লিকেশন ডেভেলপমেন্ট (জাভা)
প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন: লিঙ্কটি অনুসরণ করুন এবং এপিআইগুলো সক্রিয় করুন।
বিকল্পভাবে আপনি এর জন্য gcloud কমান্ড ব্যবহার করতে পারেন। gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
৩. ডাটাবেস সেটআপ
এই ল্যাবে আমরা ই-কমার্স ডেটার ডেটাবেস হিসেবে অ্যালয়ডিবি (AlloyDB) ব্যবহার করব। এটি ডেটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে প্রকৃত ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে ইকমার্স ডেটাসেটটি লোড করা হবে।
একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন
- ক্লাউড কনসোলে AlloyDB পেজটিতে যান। ক্লাউড কনসোলের বেশিরভাগ পেজ খুঁজে পাওয়ার একটি সহজ উপায় হলো কনসোলের সার্চ বার ব্যবহার করে সেগুলোর জন্য অনুসন্ধান করা।
- সেই পৃষ্ঠা থেকে CREATE CLUSTER নির্বাচন করুন:

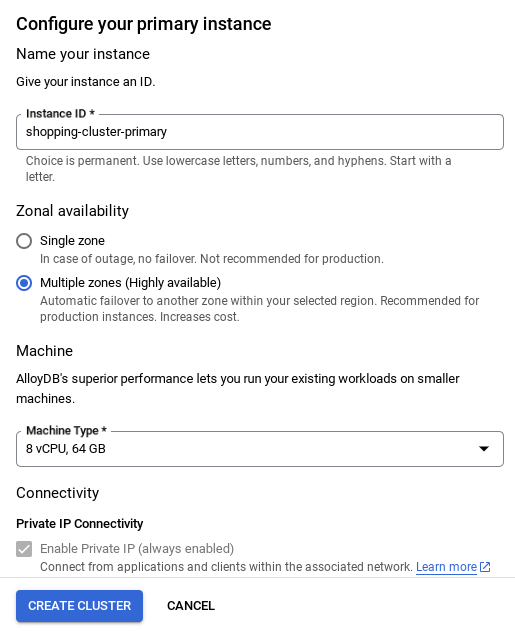
- আপনি নীচেরটির মতো একটি স্ক্রিন দেখতে পাবেন। নিম্নলিখিত মানগুলি দিয়ে একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন (আপনি যদি রিপো থেকে অ্যাপ্লিকেশন কোড ক্লোন করেন তবে নিশ্চিত করুন যে মানগুলি মিলে যায়):
- ক্লাস্টার আইডি : "
vector-cluster" - পাসওয়ার্ড : "
alloydb" - PostgreSQL 15 / সর্বশেষ সংস্করণ সুপারিশ করা হচ্ছে
- অঞ্চল : "
us-central1" - নেটওয়ার্কিং : "
default"
- আপনি যখন ডিফল্ট নেটওয়ার্ক নির্বাচন করবেন, তখন নিচের স্ক্রিনের মতো একটি স্ক্রিন দেখতে পাবেন।
সংযোগ স্থাপন নির্বাচন করুন।
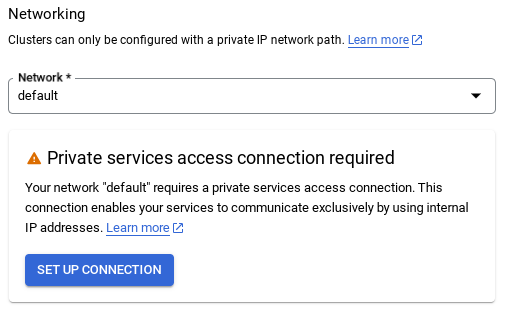
- সেখান থেকে, " Use an automatically allocated IP range " নির্বাচন করুন এবং Continue নির্বাচন করুন। তথ্য পর্যালোচনা করার পর, CREATE CONNECTION নির্বাচন করুন।
- আপনার নেটওয়ার্ক সেট আপ হয়ে গেলে, আপনি আপনার ক্লাস্টার তৈরি করা চালিয়ে যেতে পারেন। নিচে দেখানো অনুযায়ী ক্লাস্টার সেট আপ সম্পন্ন করতে CREATE CLUSTER-এ ক্লিক করুন:
গুরুত্বপূর্ণ দ্রষ্টব্য:
- ক্লাস্টার / ইনস্ট্যান্স কনফিগার করার সময় আপনি যে ইনস্ট্যান্স আইডিটি পাবেন, সেটি অবশ্যই **
vector-instance**- এ পরিবর্তন করুন। যদি আপনি এটি পরিবর্তন করতে না পারেন, তবে পরবর্তী সমস্ত রেফারেন্সে আপনার ইনস্ট্যান্স আইডি ব্যবহার করতে মনে রাখবেন। - মনে রাখবেন, ক্লাস্টার তৈরি হতে প্রায় ১০ মিনিট সময় লাগবে। এটি সফল হলে, আপনি আপনার তৈরি করা ক্লাস্টারের একটি সার্বিক চিত্র দেখতে পাবেন।
৪. ডেটা গ্রহণ
এখন স্টোর সম্পর্কিত ডেটা সহ একটি টেবিল যোগ করার সময় এসেছে। AlloyDB-তে যান, প্রাইমারি ক্লাস্টার নির্বাচন করুন এবং তারপর AlloyDB Studio-তে যান:
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb"
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
আপনার ডাটাবেসে কোন এক্সটেনশনগুলো সক্রিয় করা হয়েছে তা পরীক্ষা করতে চাইলে, এই SQL কমান্ডটি চালান:
select extname, extversion from pg_extension;
একটি টেবিল তৈরি করুন
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
এমবেডিং কলামটি টেক্সটের ভেক্টর মানগুলো সংরক্ষণের সুযোগ দেবে।
অনুমতি প্রদান করুন
'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
ডাটাবেসে ডেটা লোড করুন
- শীটে থাকা
insert scripts sqlথেকেinsertকোয়েরি স্টেটমেন্টগুলো উপরে উল্লিখিত এডিটরে কপি করুন। এই ব্যবহারের ক্ষেত্রটির একটি দ্রুত ডেমোর জন্য আপনি ১০-৫০টি ইনসার্ট স্টেটমেন্ট কপি করতে পারেন। এখানে 'Selected Inserts 25-30 rows' ট্যাবে ইনসার্টগুলোর একটি নির্বাচিত তালিকা রয়েছে।
ডেটার লিঙ্ক এই গিটহাব রিপো ফাইলে পাওয়া যাবে ।
- রান-এ ক্লিক করুন। আপনার কোয়েরির ফলাফল রেজাল্টস টেবিলে প্রদর্শিত হবে।
গুরুত্বপূর্ণ দ্রষ্টব্য:
ইনসার্ট করার জন্য শুধু ২৫-৫০টি রেকর্ড কপি করুন এবং নিশ্চিত করুন যে সেগুলো ক্যাটাগরি, সাব-ক্যাটাগরি, রঙ ও লিঙ্গ ধরনের একটি নির্দিষ্ট পরিসর থেকে নেওয়া হয়েছে।
৫. ডেটার জন্য এমবেডিং তৈরি করুন
আধুনিক অনুসন্ধানের প্রকৃত উদ্ভাবন শুধু কীওয়ার্ড বোঝার মধ্যে নয়, বরং অর্থ অনুধাবন করার মধ্যে নিহিত। এখানেই এমবেডিং এবং ভেক্টর সার্চের ভূমিকা শুরু হয়।
আমরা প্রি-ট্রেইনড ল্যাঙ্গুয়েজ মডেল ব্যবহার করে পণ্যের বিবরণ এবং ব্যবহারকারীর কোয়েরিগুলোকে 'এম্বেডিংস' নামক উচ্চ-মাত্রিক সাংখ্যিক উপস্থাপনায় রূপান্তরিত করেছি। এই এম্বেডিংসগুলো শব্দার্থগত অর্থ ধারণ করে, যা আমাদেরকে শুধুমাত্র একই রকম শব্দ থাকার পরিবর্তে 'অর্থে সাদৃশ্যপূর্ণ' পণ্য খুঁজে পেতে সাহায্য করে। প্রাথমিকভাবে, আমরা একটি বেসলাইন স্থাপনের জন্য এই এম্বেডিংসগুলোর উপর সরাসরি ভেক্টর সিমিলারিটি সার্চ নিয়ে পরীক্ষা চালিয়েছি, যা পারফরম্যান্স অপটিমাইজেশনের আগেও শব্দার্থগত উপলব্ধির শক্তি প্রদর্শন করে।
'embedding' কলামটি পণ্যের বিবরণের টেক্সটের ভেক্টর মান সংরক্ষণের সুযোগ দেবে। 'img_embeddings' কলামটি ইমেজ এমবেডিং (মাল্টিমোডাল) সংরক্ষণের সুযোগ দেবে। এভাবে আপনি টেক্সট ও ইমেজের দূরত্বের ওপর ভিত্তি করে সার্চও করতে পারবেন। কিন্তু এই ল্যাবে আমরা শুধু টেক্সট এমবেডিং ব্যবহার করব।
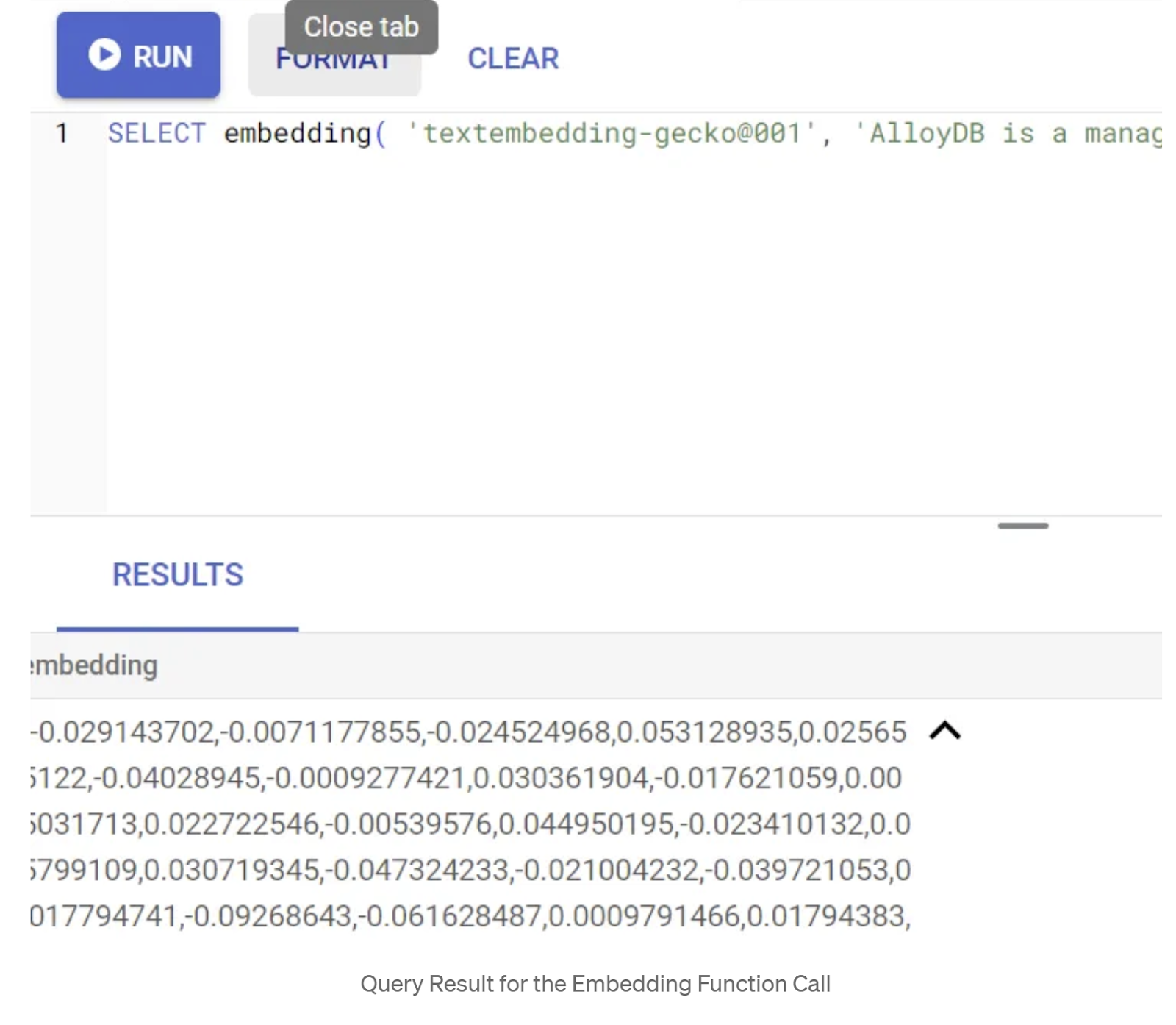
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
এটি কোয়েরিতে থাকা নমুনা টেক্সটের জন্য এমবেডিংস ভেক্টরটি রিটার্ন করবে, যা ফ্লোট সংখ্যার একটি অ্যারের মতো দেখতে। এটি দেখতে এইরকম:
abstract_embeddings ভেক্টর ফিল্ডটি আপডেট করুন
টেবিলের বিষয়বস্তুর বিবরণ সংশ্লিষ্ট এমবেডিং দিয়ে আপডেট করতে নিচের DML-টি চালান:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
আপনি যদি গুগল ক্লাউডের জন্য একটি ট্রায়াল ক্রেডিট বিলিং অ্যাকাউন্ট ব্যবহার করেন, তাহলে কয়েকটি এমবেডিং (ধরুন সর্বোচ্চ ২০-২৫টি) তৈরি করতে আপনার সমস্যা হতে পারে। তাই ইনসার্ট স্ক্রিপ্টে সারির সংখ্যা সীমিত রাখুন।
আপনি যদি ইমেজ এমবেডিং তৈরি করতে চান (মাল্টিমোডাল কনটেক্সচুয়াল সার্চ করার জন্য), তাহলে নিচের আপডেটটিও চালান:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
৬. AlloyDB-এর নতুন বৈশিষ্ট্যগুলির সাহায্যে উন্নত RAG সম্পাদন করুন
এখন যেহেতু টেবিল, ডেটা, এমবেডিং সবই প্রস্তুত, চলুন ব্যবহারকারীর সার্চ টেক্সটের জন্য রিয়েল টাইম ভেক্টর সার্চটি সম্পাদন করা যাক। নিচের কোয়েরিটি চালিয়ে আপনি এটি পরীক্ষা করতে পারেন:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
এই কোয়েরিতে, আমরা ব্যবহারকারীর দেওয়া সার্চ "T-shirt with round neck"-এর টেক্সট এমবেডিং-কে, অ্যাপারেলস টেবিলের (যা "embedding" নামের কলামে সংরক্ষিত) সমস্ত প্রোডাক্ট ডেসক্রিপশনের টেক্সট এমবেডিং-এর সাথে, কোসাইন সিমিলারিটি ডিসটেন্স ফাংশন (যা "<=>" চিহ্ন দ্বারা নির্দেশিত) ব্যবহার করে তুলনা করছি। ডেটাবেসে সংরক্ষিত ভেক্টরগুলোর সাথে সামঞ্জস্যপূর্ণ করার জন্য আমরা এমবেডিং পদ্ধতির ফলাফলকে ভেক্টর টাইপে রূপান্তর করছি। LIMIT 10 বোঝায় যে আমরা সার্চ টেক্সটটির সবচেয়ে কাছের ১০টি ম্যাচ নির্বাচন করছি।
AlloyDB ভেক্টর সার্চ RAG-কে পরবর্তী স্তরে নিয়ে যায়:
এন্টারপ্রাইজ-স্কেল সলিউশনের জন্য সাধারণ ভেক্টর সার্চ যথেষ্ট নয়। পারফরম্যান্স অত্যন্ত গুরুত্বপূর্ণ।
স্ক্যানএন (স্কেলেবল নিয়ারেস্ট নেইবারস) সূচক
অত্যন্ত দ্রুত অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার (ANN) সার্চ অর্জনের জন্য, আমরা AlloyDB-তে scaNN ইনডেক্সটি সক্রিয় করেছি। ScaNN হলো গুগল রিসার্চ দ্বারা বিকশিত একটি অত্যাধুনিক অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার সার্চ অ্যালগরিদম, যা বৃহৎ পরিসরে কার্যকর ভেক্টর সিমিলারিটি সার্চের জন্য ডিজাইন করা হয়েছে। এটি সার্চ স্পেসকে দক্ষতার সাথে প্রুনিং করে এবং কোয়ান্টাইজেশন কৌশল ব্যবহার করে কোয়েরির গতি উল্লেখযোগ্যভাবে বাড়িয়ে দেয়, যা অন্যান্য ইনডেক্সিং পদ্ধতির তুলনায় ৪ গুণ পর্যন্ত দ্রুততর ভেক্টর কোয়েরি এবং কম মেমরি ফুটপ্রিন্ট প্রদান করে। এ সম্পর্কে আরও জানতে এখানে এবং এখানে পড়ুন।
চলুন এক্সটেনশনটি সক্রিয় করি এবং ইনডেক্সগুলো তৈরি করি:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
টেক্সট এমবেডিং এবং ইমেজ এমবেডিং উভয় ফিল্ডের জন্য ইনডেক্স তৈরি করা (যদি আপনি আপনার সার্চে ইমেজ এমবেডিং ব্যবহার করতে চান):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
মেটাডেটা সূচক
যদিও scaNN ভেক্টর ইনডেক্সিং পরিচালনা করে, ঐতিহ্যবাহী B-tree বা GIN ইনডেক্সগুলি কাঠামোগত অ্যাট্রিবিউটের (যেমন ক্যাটাগরি, সাব-ক্যাটাগরি, স্টাইলিং, কালার, ইত্যাদি) উপর অত্যন্ত যত্ন সহকারে সেট আপ করা হতো। ফেসেটেড ফিল্টারিংয়ের কার্যকারিতার জন্য এই ইনডেক্সগুলি অত্যন্ত গুরুত্বপূর্ণ। মেটাডেটা ইনডেক্স সেট আপ করতে নিচের স্টেটমেন্টগুলো চালান:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
গুরুত্বপূর্ণ দ্রষ্টব্য:
যেহেতু আপনি হয়তো মাত্র ২৫-৫০টি রেকর্ড যোগ করেছেন, তাই ইনডেক্সগুলো (ScaNN বা অন্য যেকোনো ইনডেক্স) কার্যকর হবে না।
ইনলাইন ফিল্টারিং
ভেক্টর সার্চের একটি সাধারণ চ্যালেঞ্জ হলো এটিকে স্ট্রাকচার্ড ফিল্টারের (যেমন, "লাল জুতো") সাথে সমন্বয় করা। AlloyDB-এর ইনলাইন ফিল্টারিং এই সমস্যাটি সমাধান করে। একটি বিস্তৃত ভেক্টর সার্চের ফলাফল পরে ফিল্টার করার পরিবর্তে, ইনলাইন ফিল্টারিং ভেক্টর সার্চ প্রক্রিয়া চলাকালীনই ফিল্টারের শর্তাবলী প্রয়োগ করে, যা ফিল্টার করা ভেক্টর সার্চের পারফরম্যান্স এবং নির্ভুলতা ব্যাপকভাবে উন্নত করে।
ইনলাইন ফিল্টারিং-এর প্রয়োজনীয়তা সম্পর্কে আরও জানতে এই ডকুমেন্টেশনটি দেখুন। এছাড়াও, ভেক্টর সার্চের পারফরম্যান্স অপটিমাইজেশনের জন্য ফিল্টারড ভেক্টর সার্চ সম্পর্কে এখানে জানুন। এখন যদি আপনি আপনার অ্যাপ্লিকেশনের জন্য ইনলাইন ফিল্টারিং চালু করতে চান, তাহলে আপনার এডিটর থেকে নিম্নলিখিত স্টেটমেন্টটি রান করুন:
SET scann.enable_inline_filtering = on;
মাঝারি সিলেক্টিভিটির ক্ষেত্রে ইনলাইন ফিল্টারিং সবচেয়ে ভালো। AlloyDB যখন ভেক্টর ইনডেক্সে অনুসন্ধান করে, তখন এটি শুধুমাত্র সেইসব ভেক্টরের দূরত্ব গণনা করে যা মেটাডেটা ফিল্টারিং শর্তের সাথে মেলে (একটি কোয়েরিতে আপনার ফাংশনাল ফিল্টার, যা সাধারণত WHERE ক্লজে পরিচালনা করা হয়)। এটি পোস্ট-ফিল্টার বা প্রি-ফিল্টারের সুবিধার পরিপূরক হিসেবে এই কোয়েরিগুলির পারফরম্যান্স ব্যাপকভাবে উন্নত করে।
অভিযোজিত ফিল্টারিং
পারফরম্যান্স আরও অপ্টিমাইজ করার জন্য, AlloyDB-এর অ্যাডাপ্টিভ ফিল্টারিং কোয়েরি এক্সিকিউশনের সময় ডাইনামিকভাবে সবচেয়ে কার্যকর ফিল্টারিং স্ট্র্যাটেজি (ইনলাইন বা প্রি-ফিল্টারিং) বেছে নেয়। এটি ম্যানুয়াল হস্তক্ষেপ ছাড়াই সর্বোত্তম পারফরম্যান্স নিশ্চিত করতে কোয়েরি প্যাটার্ন এবং ডেটা ডিস্ট্রিবিউশন বিশ্লেষণ করে, যা বিশেষত ফিল্টারড ভেক্টর সার্চের জন্য উপকারী, যেখানে এটি স্বয়ংক্রিয়ভাবে ভেক্টর এবং মেটাডেটা ইনডেক্স ব্যবহারের মধ্যে সুইচ করে। অ্যাডাপ্টিভ ফিল্টারিং সক্রিয় করতে, scann.enable_preview_features ফ্ল্যাগটি ব্যবহার করুন।
এক্সিকিউশন চলাকালীন অ্যাডাপ্টিভ ফিল্টারিং যখন ইনলাইন ফিল্টারিং থেকে প্রি-ফিল্টারিং-এ পরিবর্তন ঘটায়, তখন কোয়েরি প্ল্যান গতিশীলভাবে পরিবর্তিত হয়।
SET scann.enable_preview_features = on;
গুরুত্বপূর্ণ দ্রষ্টব্য: ইনস্ট্যান্সটি রিস্টার্ট না করে আপনি হয়তো উপরের স্টেটমেন্টটি চালাতে পারবেন না। যদি কোনো ত্রুটি দেখা দেয়, তবে আপনার ইনস্ট্যান্সের ডাটাবেস ফ্ল্যাগস সেকশন থেকে enable_preview_features ফ্ল্যাগটি সক্রিয় করে নেওয়া ভালো।
সমস্ত সূচক ব্যবহার করে ফেসেটেড ফিল্টার
ফেসেটেড সার্চ ব্যবহারকারীদের নির্দিষ্ট অ্যাট্রিবিউট বা 'ফ্যাসেট' (যেমন, ব্র্যান্ড, মূল্য, আকার, গ্রাহক রেটিং)-এর উপর ভিত্তি করে একাধিক ফিল্টার প্রয়োগ করে ফলাফল পরিমার্জন করার সুযোগ দেয়। আমাদের অ্যাপ্লিকেশনটি এই ফ্যাসেটগুলোকে ভেক্টর সার্চের সাথে নির্বিঘ্নে একীভূত করে। এখন একটিমাত্র কোয়েরিই স্বাভাবিক ভাষা (কনটেক্সচুয়াল সার্চ)-এর সাথে একাধিক ফেসেটেড নির্বাচনকে একত্রিত করতে পারে, যা ভেক্টর এবং প্রচলিত উভয় ইনডেক্সকেই গতিশীলভাবে কাজে লাগায়। এটি একটি সত্যিকারের গতিশীল হাইব্রিড সার্চিং সক্ষমতা প্রদান করে, যা ব্যবহারকারীদের ফলাফলকে নির্ভুলভাবে আরও গভীরে গিয়ে বিশ্লেষণ করার সুযোগ দেয়।
আমাদের অ্যাপ্লিকেশনে, যেহেতু আমরা ইতিমধ্যেই সমস্ত মেটাডেটা ইনডেক্স তৈরি করে ফেলেছি, তাই SQL কোয়েরি ব্যবহার করে সরাসরি ওয়েবে ফেসেটেড ফিল্টার ব্যবহারের জন্য আমরা সম্পূর্ণ প্রস্তুত:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
এই কোয়েরিতে আমরা হাইব্রিড সার্চ করছি — যেখানে উভয়কেই অন্তর্ভুক্ত করা হয়েছে।
- WHERE ক্লজে ফেসেটেড ফিল্টারিং এবং
- কোসাইন সাদৃশ্য পদ্ধতি ব্যবহার করে ORDER BY ক্লজে ভেক্টর অনুসন্ধান।
$1, $2, $3 এবং $4 একটি অ্যারেতে থাকা ফেসেটেড ফিল্টার ভ্যালুগুলোকে নির্দেশ করে এবং $5 ব্যবহারকারীর সার্চ টেক্সটকে নির্দেশ করে। নিচের মতো করে $1 থেকে $4 পর্যন্ত আপনার পছন্দের ফেসেটেড ফিল্টার ভ্যালু দিয়ে প্রতিস্থাপন করুন:
বিভাগ = যেকোনো(['পোশাক', 'জুতা'])
$5-এর জায়গায় আপনার পছন্দের একটি সার্চ টেক্সট বসান, যেমন, "পোলো টি-শার্ট"।
গুরুত্বপূর্ণ দ্রষ্টব্য: আপনি যদি সীমিত সংখ্যক রেকর্ড সন্নিবেশ করার কারণে ইনডেক্সগুলো না পান, তাহলে আপনি পারফরম্যান্সে এর প্রভাব দেখতে পাবেন না। কিন্তু একটি সম্পূর্ণ প্রোডাকশন ডেটাসেটে আপনি লক্ষ্য করবেন যে, একই ভেক্টর সার্চের এক্সিকিউশন টাইম উল্লেখযোগ্যভাবে কমে গেছে। ভেক্টর সার্চের উপর ইনলাইন ফিল্টারিং যুক্ত ScaNN ইনডেক্স ব্যবহার করার ফলেই এটি সম্ভব হয়েছে!!!
এরপরে, এই ScaNN-সক্ষম ভেক্টর সার্চের রিকল মূল্যায়ন করা যাক।
পুনর্বিন্যাস
উন্নত সার্চের পরেও, প্রাথমিক ফলাফলগুলোর চূড়ান্ত পরিমার্জনের প্রয়োজন হতে পারে। এটি একটি গুরুত্বপূর্ণ ধাপ যা প্রাসঙ্গিকতা বাড়ানোর জন্য প্রাথমিক সার্চের ফলাফলগুলোকে পুনর্বিন্যাস করে। প্রাথমিক হাইব্রিড সার্চ যখন সম্ভাব্য পণ্যের একটি তালিকা প্রদান করে, তখন একটি আরও পরিশীলিত (এবং প্রায়শই গণনাগতভাবে ভারী) মডেল আরও সূক্ষ্ম স্তরের প্রাসঙ্গিকতা স্কোর প্রয়োগ করে। এটি নিশ্চিত করে যে ব্যবহারকারীর কাছে উপস্থাপিত শীর্ষ ফলাফলগুলোই সবচেয়ে প্রাসঙ্গিক, যা সার্চের মানকে উল্লেখযোগ্যভাবে উন্নত করে। একটি নির্দিষ্ট কোয়েরির জন্য সিস্টেমটি কতটা ভালোভাবে সমস্ত প্রাসঙ্গিক আইটেম খুঁজে বের করতে পারে তা পরিমাপ করার জন্য আমরা ক্রমাগত রিকল মূল্যায়ন করি এবং গ্রাহকের প্রয়োজনীয় জিনিস খুঁজে পাওয়ার সম্ভাবনা সর্বাধিক করার জন্য আমাদের মডেলগুলোকে পরিমার্জন করতে থাকি।
আপনার অ্যাপ্লিকেশনে এটি ব্যবহার করার আগে, নিশ্চিত করুন যে সমস্ত পূর্বশর্ত পূরণ করা হয়েছে:
- google_ml_integration এক্সটেনশনটি ইনস্টল করা আছে কিনা তা যাচাই করুন।
- যাচাই করুন যে google_ml_integration.enable_model_support ফ্ল্যাগটি 'on' এ সেট করা আছে।
- ভার্টেক্স এআই-এর সাথে একীভূত করুন।
- ডিসকভারি ইঞ্জিন এপিআই সক্রিয় করুন।
- র্যাঙ্কিং মডেল ব্যবহার করার জন্য প্রয়োজনীয় ভূমিকাগুলো অর্জন করুন।
এবং তারপরে আপনি আমাদের অ্যাপ্লিকেশনে হাইব্রিড-সার্চ করা ফলাফল সেটটিকে পুনরায় র্যাঙ্ক করতে নিম্নলিখিত কোয়েরিটি ব্যবহার করতে পারেন:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
এই কোয়েরিতে, আমরা কোসাইন সিমিলারিটি পদ্ধতি ব্যবহার করে ORDER BY ক্লজে উল্লিখিত কনটেক্সচুয়াল সার্চের প্রোডাক্ট রেজাল্ট সেটের রির্যাঙ্কিং করছি। 'Pink top' হলো সেই টেক্সট যা ব্যবহারকারী খুঁজছেন।
গুরুত্বপূর্ণ দ্রষ্টব্য: আপনাদের মধ্যে অনেকের কাছে হয়তো এখনও রির্যাঙ্কিং (Reranking) ব্যবহারের সুযোগ নেই, তাই আমি অ্যাপ্লিকেশন কোড থেকে এটি বাদ দিয়েছি। কিন্তু আপনি যদি এটি অন্তর্ভুক্ত করতে চান, তবে উপরে আলোচিত নমুনাটি অনুসরণ করতে পারেন।
প্রত্যাহার মূল্যায়নকারী
সিমিলারিটি সার্চে রিকল হলো একটি সার্চ থেকে প্রাপ্ত প্রাসঙ্গিক ইনস্ট্যান্সের শতাংশ, অর্থাৎ ট্রু পজিটিভের সংখ্যা। সার্চের মান পরিমাপের জন্য এটি সবচেয়ে প্রচলিত মেট্রিক। রিকল লসের একটি উৎস হলো অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার সার্চ (aNN) এবং কে (এক্সাক্ট) নিয়ারেস্ট নেইবার সার্চ (kNN)-এর মধ্যকার পার্থক্য। AlloyDB-এর ScaNN-এর মতো ভেক্টর ইনডেক্সগুলো aNN অ্যালগরিদম প্রয়োগ করে , যা রিকলের সামান্য ঘাটতির বিনিময়ে আপনাকে বড় ডেটাসেটে ভেক্টর সার্চের গতি বাড়াতে সাহায্য করে। এখন, AlloyDB আপনাকে প্রতিটি কোয়েরির জন্য সরাসরি ডেটাবেসে এই ঘাটতি পরিমাপ করার এবং সময়ের সাথে সাথে এর স্থিতিশীলতা নিশ্চিত করার ক্ষমতা প্রদান করে। আরও ভালো ফলাফল এবং পারফরম্যান্স অর্জনের জন্য আপনি এই তথ্যের ভিত্তিতে কোয়েরি এবং ইনডেক্স প্যারামিটার আপডেট করতে পারেন।
অনুসন্ধানের ফলাফল মনে রাখার পেছনের যুক্তি কী?
ভেক্টর সার্চের ক্ষেত্রে, রিকল বলতে ইনডেক্স দ্বারা ফেরত দেওয়া ভেক্টরগুলোর মধ্যে প্রকৃত নিকটতম প্রতিবেশী ভেক্টরের শতাংশকে বোঝায়। উদাহরণস্বরূপ, যদি ২০টি নিকটতম প্রতিবেশীর জন্য করা একটি কোয়েরি গ্রাউন্ড ট্রুথ নিকটতম প্রতিবেশীদের মধ্যে ১৯টি ফেরত দেয়, তাহলে রিকল হবে ১৯/২০x১০০ = ৯৫%। রিকল হলো সার্চের গুণমান পরিমাপের জন্য ব্যবহৃত একটি মেট্রিক, এবং এটিকে ফেরত আসা ফলাফলগুলোর সেই শতাংশ হিসাবে সংজ্ঞায়িত করা হয় যা বস্তুনিষ্ঠভাবে কোয়েরি ভেক্টরগুলোর সবচেয়ে কাছাকাছি।
আপনি evaluate_query_recall ফাংশনটি ব্যবহার করে একটি নির্দিষ্ট কনফিগারেশনের জন্য ভেক্টর ইনডেক্সের উপর করা ভেক্টর কোয়েরির রিকল খুঁজে পেতে পারেন। এই ফাংশনটি আপনাকে আপনার কাঙ্ক্ষিত ভেক্টর কোয়েরি রিকলের ফলাফল অর্জনের জন্য প্যারামিটারগুলো টিউন করার সুযোগ দেয়।
গুরুত্বপূর্ণ দ্রষ্টব্য:
যদি আপনি নিম্নলিখিত ধাপগুলিতে HNSW ইনডেক্সে 'permission denied' ত্রুটির সম্মুখীন হন, তাহলে আপাতত এই সম্পূর্ণ রিকল ইভ্যালুয়েশন অংশটি এড়িয়ে যান। এই কোডল্যাবটি ডকুমেন্ট করার সময় এটি সদ্য প্রকাশিত হওয়ায়, এই মুহূর্তে এর কারণ অ্যাক্সেস সীমাবদ্ধতা হতে পারে।
- ScanN ইনডেক্স এবং HNSW ইনডেক্সে Enable Index Scan ফ্ল্যাগটি সেট করুন:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio-তে নিম্নলিখিত কোয়েরিটি চালান:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall ফাংশনটি প্যারামিটার হিসেবে কোয়েরি গ্রহণ করে এবং এর রিকল রিটার্ন করে। আমি পারফরম্যান্স পরীক্ষা করার জন্য যে কোয়েরিটি ব্যবহার করেছিলাম, সেটিই ফাংশনের ইনপুট কোয়েরি হিসেবে ব্যবহার করছি। আমি ইনডেক্স মেথড হিসেবে SCaNN যুক্ত করেছি। আরও প্যারামিটার অপশনের জন্য ডকুমেন্টেশন দেখুন।
আমরা যে ভেক্টর সার্চ কোয়েরিটি ব্যবহার করে আসছি তার রিকল হলো:
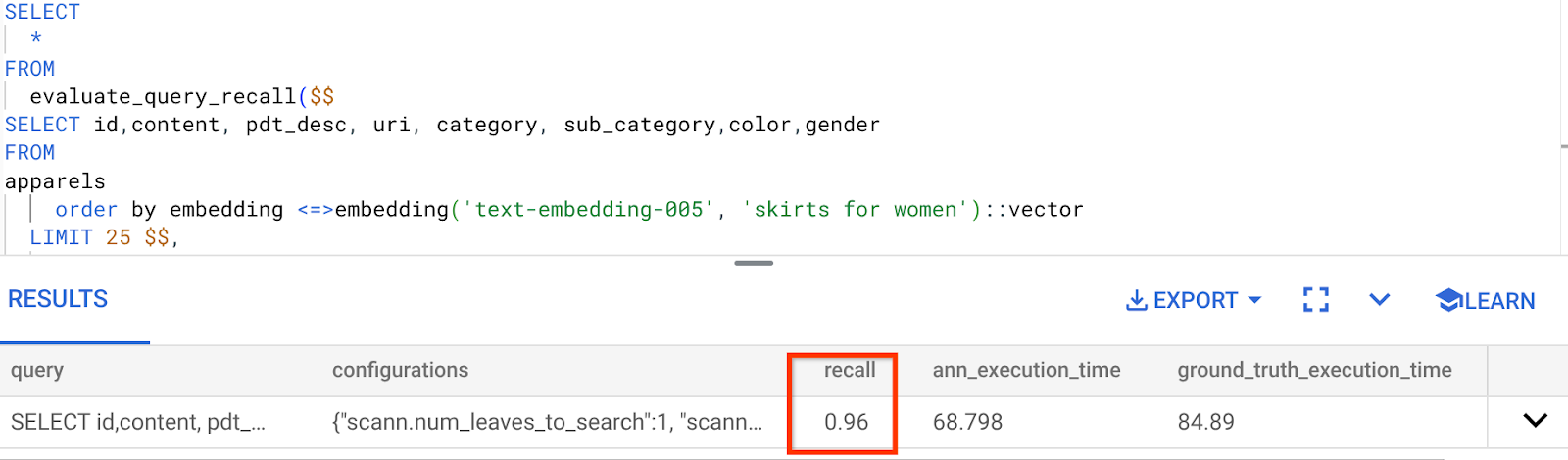
আমি দেখছি যে রিকল (RECALL) ৯৬%। এক্ষেত্রে রিকলটি সত্যিই খুব ভালো। কিন্তু যদি এটি একটি অগ্রহণযোগ্য মান হতো, তাহলে আপনি এই তথ্য ব্যবহার করে ইনডেক্স প্যারামিটার, মেথড এবং কোয়েরি প্যারামিটার পরিবর্তন করে এই ভেক্টর সার্চের জন্য আমার রিকল উন্নত করতে পারতেন!
পরিবর্তিত কোয়েরি ও ইনডেক্স প্যারামিটার দিয়ে এটি পরীক্ষা করুন।
এখন প্রাপ্ত রিকলের উপর ভিত্তি করে কোয়েরি প্যারামিটারগুলো পরিবর্তন করে কোয়েরিটি পরীক্ষা করা যাক।
- সূচক পরামিতি পরিবর্তন করা:
এই পরীক্ষার জন্য, আমি 'কোসাইন' সাদৃশ্য দূরত্ব ফাংশনের পরিবর্তে 'এল২ ডিসটেন্স' ব্যবহার করব।
অত্যন্ত গুরুত্বপূর্ণ দ্রষ্টব্য: আপনি জিজ্ঞাসা করতে পারেন, "আমরা কীভাবে জানব যে এই কোয়েরিটি কোসাইন সিমিলারিটি ব্যবহার করে?"। কোসাইন ডিসটেন্স বোঝাতে "<=>" চিহ্নের ব্যবহার দেখে আপনি ডিসটেন্স ফাংশনটি শনাক্ত করতে পারেন।
ভেক্টর সার্চ দূরত্ব ফাংশনগুলোর জন্য ডকুমেন্টেশন লিঙ্ক ।
পূর্ববর্তী কোয়েরিতে কোসাইন সিমিলারিটি ডিসটেন্স ফাংশন ব্যবহার করা হয়েছে, যেখানে এখন আমরা L2 ডিসটেন্স ব্যবহার করে দেখব। কিন্তু তার জন্য আমাদের এটাও নিশ্চিত করতে হবে যে অন্তর্নিহিত ScaNN ইনডেক্সটিও L2 ডিসটেন্স ফাংশন ব্যবহার করছে। এখন চলুন একটি ভিন্ন ডিসটেন্স ফাংশন কোয়েরি দিয়ে একটি ইনডেক্স তৈরি করি: L2 ডিসটেন্স: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
টেবিলে কোনো অপ্রয়োজনীয় ইনডেক্স নেই, এটা নিশ্চিত করার জন্যই ড্রপ ইনডেক্স স্টেটমেন্টটি ব্যবহার করা হয়।
এখন, আমার ভেক্টর সার্চ ফাংশনালিটির ডিসট্যান্স ফাংশন পরিবর্তন করার পর RECALL মূল্যায়ন করতে আমি নিম্নলিখিত কোয়েরিটি চালাতে পারি।
[পরবর্তী] L2 ডিস্ট্যান্স ফাংশন ব্যবহার করে এমন কোয়েরি:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
আপডেট করা ইনডেক্সের ক্ষেত্রে রিকল ভ্যালুতে পার্থক্য বা পরিবর্তনটি আপনি দেখতে পারেন।
আপনার কাঙ্ক্ষিত রিকল ভ্যালু এবং আপনার অ্যাপ্লিকেশন যে ডেটাসেট ব্যবহার করে, তার উপর ভিত্তি করে ইনডেক্সে num_leaves ইত্যাদির মতো আরও অন্যান্য প্যারামিটার পরিবর্তন করা যায়।
ভেক্টর অনুসন্ধান ফলাফলের এলএলএম বৈধতা
সর্বোচ্চ মান নিয়ন্ত্রিত অনুসন্ধান অর্জনের জন্য, আমরা এলএলএম (LLM) যাচাইকরণের একটি ঐচ্ছিক স্তর অন্তর্ভুক্ত করেছি। বৃহৎ ভাষা মডেলগুলো অনুসন্ধানের ফলাফলের প্রাসঙ্গিকতা এবং সঙ্গতি মূল্যায়ন করতে ব্যবহার করা যেতে পারে, বিশেষ করে জটিল বা দ্ব্যর্থক কোয়েরির ক্ষেত্রে। এর মধ্যে অন্তর্ভুক্ত থাকতে পারে:
শব্দার্থিক যাচাইকরণ:
একটি এলএলএম কোয়েরির অভিপ্রায়ের সাথে ফলাফল মিলিয়ে দেখছে।
যৌক্তিক ফিল্টারিং:
প্রচলিত ফিল্টারে অন্তর্ভুক্ত করা কঠিন এমন জটিল ব্যবসায়িক যুক্তি বা নিয়ম প্রয়োগ করতে এলএলএম ব্যবহার করা হয়, যা সূক্ষ্ম মানদণ্ডের ভিত্তিতে পণ্যের তালিকাকে আরও পরিমার্জন করে।
গুণমান নিশ্চিতকরণ:
মানুষের পর্যালোচনা বা মডেল পরিমার্জনের জন্য কম প্রাসঙ্গিক ফলাফলগুলো স্বয়ংক্রিয়ভাবে শনাক্ত করে চিহ্নিত করা।
AlloyDB AI ফিচারগুলিতে আমরা এইভাবেই তা সম্পন্ন করেছি:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
মূল কোয়েরিটি সেই একই কোয়েরি যা আমরা ফেসেটেড সার্চ, হাইব্রিড সার্চ এবং রির্যাঙ্কিং সেকশনে দেখেছি। এখন এই কোয়েরিতে আমরা ml_predict_row কনস্ট্রাক্ট দ্বারা উপস্থাপিত রির্যাঙ্কড রেজাল্ট সেটের GEMINI ইভ্যালুয়েশনের একটি স্তর যুক্ত করেছি। আমি ফেসেটেড ফিল্টারগুলো কমেন্ট আউট করে দিয়েছি, কিন্তু $1 থেকে $4 প্লেসহোল্ডারগুলোর জন্য একটি অ্যারেতে আপনার পছন্দের আইটেমগুলো নির্দ্বিধায় অন্তর্ভুক্ত করতে পারেন। $5-এর জায়গায় আপনি যে টেক্সট দিয়ে সার্চ করতে চান তা লিখুন, যেমন, "Pink top, no floral pattern"।
৭. ডেটাবেস এবং অ্যাপ্লিকেশন লেয়ারের জন্য এমসিপি টুলবক্স
নেপথ্যে, শক্তিশালী টুলিং এবং একটি সুগঠিত অ্যাপ্লিকেশন মসৃণ কার্যক্রম নিশ্চিত করে।
ডেটাবেসের জন্য এমসিপি (মডেল কনটেক্সট প্রোটোকল) টুলবক্স অ্যালয়ডিবি-র সাথে জেনারেটিভ এআই এবং এজেন্টিক টুলগুলির ইন্টিগ্রেশনকে সহজ করে তোলে। এটি একটি ওপেন-সোর্স সার্ভার হিসেবে কাজ করে যা কানেকশন পুলিং, অথেনটিকেশন এবং এআই এজেন্ট বা অন্যান্য অ্যাপ্লিকেশনের কাছে ডেটাবেসের কার্যকারিতাগুলির নিরাপদ প্রকাশকে সুবিন্যস্ত করে।
আমাদের অ্যাপ্লিকেশনে, আমরা সকল ইন্টেলিজেন্ট হাইব্রিড সার্চ কোয়েরির জন্য একটি অ্যাবস্ট্রাকশন লেয়ার হিসেবে MCP টুলবক্স ফর ডেটাবেস ব্যবহার করেছি।
আমাদের ব্যবহারের জন্য টুলবক্স সেট আপ ও স্থাপন করতে নিচের ধাপগুলো অনুসরণ করুন:
আপনি দেখতে পাচ্ছেন যে, MCP Toolbox for Databases দ্বারা সমর্থিত ডেটাবেসগুলোর মধ্যে AlloyDB অন্যতম এবং যেহেতু আমরা পূর্ববর্তী বিভাগে এটি ইতিমধ্যে প্রস্তুত করে ফেলেছি, চলুন এবার টুলবক্সটি সেট আপ করা যাক।
- আপনার ক্লাউড শেল টার্মিনালে যান এবং নিশ্চিত করুন যে আপনার প্রজেক্টটি নির্বাচিত আছে এবং টার্মিনালের প্রম্পটে প্রদর্শিত হচ্ছে। আপনার প্রজেক্ট ডিরেক্টরিতে প্রবেশ করতে ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালান:
mkdir toolbox-tools
cd toolbox-tools
- আপনার নতুন ফোল্ডারে টুলবক্স ডাউনলোড ও ইনস্টল করতে নিচের কমান্ডটি চালান:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- ক্লাউড শেল এডিটর (কোড এডিট মোড)-এ যান এবং প্রজেক্টের রুট ফোল্ডারে 'tools.yaml' নামে একটি ফাইল যোগ করুন।
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Tools.yaml স্ক্রিপ্টটি এই রিপো ফাইলের কোড দিয়ে প্রতিস্থাপন করতে ভুলবেন না ।
চলুন tools.yaml ফাইলটি বুঝি:
সোর্স হলো আপনার বিভিন্ন ডেটা সোর্স, যেগুলোর সাথে একটি টুল ইন্টারঅ্যাক্ট করতে পারে। একটি সোর্স এমন একটি ডেটা সোর্সকে বোঝায় যার সাথে একটি টুল ইন্টারঅ্যাক্ট করতে পারে। আপনি আপনার tools.yaml ফাইলের sources সেকশনে সোর্সগুলোকে একটি ম্যাপ হিসেবে সংজ্ঞায়িত করতে পারেন। সাধারণত, একটি সোর্স কনফিগারেশনে ডাটাবেসের সাথে সংযোগ স্থাপন এবং ইন্টারঅ্যাক্ট করার জন্য প্রয়োজনীয় সমস্ত তথ্য থাকে।
টুলগুলো এজেন্টের বিভিন্ন কাজ নির্ধারণ করে – যেমন কোনো সোর্স থেকে ডেটা পড়া বা তাতে লেখা। একটি টুল আপনার এজেন্টের একটি কাজকে বোঝায়, যেমন একটি SQL স্টেটমেন্ট চালানো। আপনি আপনার tools.yaml ফাইলের tools সেকশনে টুলগুলোকে একটি ম্যাপ হিসেবে সংজ্ঞায়িত করতে পারেন। সাধারণত, কোনো টুলের কাজ করার জন্য একটি সোর্সের প্রয়োজন হয়।
আপনার tools.yaml কনফিগার করার বিষয়ে আরও বিস্তারিত জানতে এই ডকুমেন্টেশনটি দেখুন।
- সার্ভারটি চালু করতে (mcp-toolbox ফোল্ডার থেকে) নিম্নলিখিত কমান্ডটি চালান:
./toolbox --tools-file "tools.yaml"
এখন আপনি যদি ক্লাউডে ওয়েব প্রিভিউ মোডে সার্ভারটি খোলেন, তাহলে আপনি টুলবক্স সার্ভারটি চালু এবং আপনার নতুন get-order-data নামের টুলটিসহ চলতে দেখতে পাবেন।
এমসিপি টুলবক্স সার্ভারটি ডিফল্টভাবে ৫০০০ পোর্টে চলে। চলুন, ক্লাউড শেল ব্যবহার করে এটি পরীক্ষা করে দেখি।
নিচে দেখানো অনুযায়ী ক্লাউড শেল-এ ওয়েব প্রিভিউ-তে ক্লিক করুন:
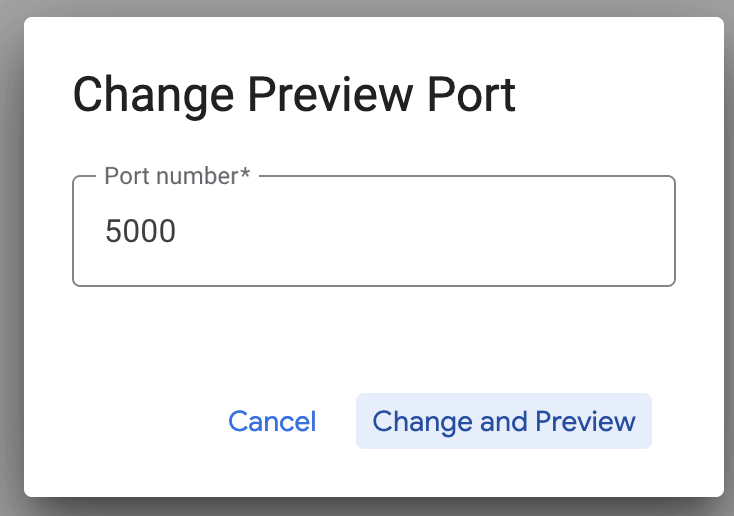
নিচে দেখানো অনুযায়ী Change port-এ ক্লিক করে পোর্টটি 5000 সেট করুন এবং Change and Preview-তে ক্লিক করুন।
এর ফলে যে আউটপুটটি আসবে তা হলো:
- চলুন আমাদের টুলবক্সটি ক্লাউড রান-এ ডেপ্লয় করি:
প্রথমেই, আমরা MCP টুলবক্স সার্ভারটি ক্লাউড রান-এ হোস্ট করতে পারি। এর ফলে আমরা একটি পাবলিক এন্ডপয়েন্ট পাব, যা আমরা অন্য যেকোনো অ্যাপ্লিকেশন এবং/অথবা এজেন্ট অ্যাপ্লিকেশনগুলোর সাথেও ইন্টিগ্রেট করতে পারব। ক্লাউড রান-এ এটি হোস্ট করার নির্দেশাবলী এখানে দেওয়া আছে। এখন আমরা মূল ধাপগুলো আলোচনা করব।
- একটি নতুন ক্লাউড শেল টার্মিনাল চালু করুন অথবা একটি বিদ্যমান ক্লাউড শেল টার্মিনাল ব্যবহার করুন। প্রজেক্ট ফোল্ডারে যান যেখানে টুলবক্স বাইনারি এবং tools.yaml রয়েছে, এই ক্ষেত্রে toolbox-tools, যদি আপনি ইতিমধ্যে এর ভিতরে না থাকেন:
cd toolbox-tools
- PROJECT_ID ভেরিয়েবলটি আপনার গুগল ক্লাউড প্রজেক্ট আইডি নির্দেশ করার জন্য সেট করুন।
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- এই Google Cloud পরিষেবাগুলি সক্রিয় করুন
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- চলুন একটি আলাদা সার্ভিস অ্যাকাউন্ট তৈরি করি, যেটি গুগল ক্লাউড রান-এ ডেপ্লয় করা টুলবক্স সার্ভিসটির আইডেন্টিটি হিসেবে কাজ করবে।
gcloud iam service-accounts create toolbox-identity
- আমরা এটাও নিশ্চিত করছি যে এই সার্ভিস অ্যাকাউন্টটির সঠিক ভূমিকা (role) রয়েছে, অর্থাৎ সিক্রেট ম্যানেজার (Secret Manager) অ্যাক্সেস করার এবং অ্যালয়ডিবি (AlloyDB)-র সাথে যোগাযোগ করার ক্ষমতা।
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- আমরা tools.yaml ফাইলটি একটি সিক্রেট হিসেবে আপলোড করব:
gcloud secrets create tools --data-file=tools.yaml
আপনার যদি আগে থেকেই একটি সিক্রেট থাকে এবং আপনি সেটির ভার্সন আপডেট করতে চান, তাহলে নিম্নলিখিতটি সম্পাদন করুন:
gcloud secrets versions add tools --data-file=tools.yaml
- ক্লাউড রানের জন্য আপনি যে কন্টেইনার ইমেজটি ব্যবহার করতে চান, সেটির জন্য একটি এনভায়রনমেন্ট ভেরিয়েবল সেট করুন:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- ক্লাউড রান-এর পরিচিত ডেপ্লয়মেন্ট কমান্ডের শেষ ধাপ:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
এর মাধ্যমে আমাদের কনফিগার করা tools.yaml সহ টুলবক্স সার্ভারটি ক্লাউড রান-এ ডেপ্লয় করার প্রক্রিয়া শুরু হবে। সফলভাবে ডেপ্লয়মেন্ট হলে, আপনি নিচের মতো একটি বার্তা দেখতে পাবেন:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
আপনি আপনার এজেন্টিক অ্যাপ্লিকেশনে সদ্য স্থাপন করা টুলটি ব্যবহার করার জন্য এখন সম্পূর্ণ প্রস্তুত!!!
টুলবক্স সার্ভারে টুলগুলি অ্যাক্সেস করা
টুলবক্সটি ডেপ্লয় করা হয়ে গেলে, আমরা ডেপ্লয় করা টুলবক্স সার্ভারের সাথে যোগাযোগ করার জন্য একটি পাইথন ক্লাউড রান ফাংশন শিম তৈরি করব। এর কারণ হলো, বর্তমানে টুলবক্সের কোনো জাভা এসডিকে নেই , তাই আমরা সার্ভারের সাথে যোগাযোগের জন্য একটি পাইথন শিম তৈরি করেছি। নিচে সেই ক্লাউড রান ফাংশনটির সোর্স কোড দেওয়া হলো।
পূর্ববর্তী ধাপগুলিতে আমরা যে টুলবক্স টুলগুলি তৈরি এবং স্থাপন করেছি, সেগুলি অ্যাক্সেস করতে সক্ষম হওয়ার জন্য আপনাকে এই ক্লাউড রান ফাংশনটি তৈরি এবং স্থাপন করতে হবে:
- Google Cloud কনসোলে, Cloud Run পৃষ্ঠায় যান
- একটি ফাংশন লিখুন-এ ক্লিক করুন।
- 'সার্ভিস নেম' ফিল্ডে, আপনার ফাংশন বর্ণনা করার জন্য একটি নাম লিখুন। সার্ভিসের নাম অবশ্যই একটি অক্ষর দিয়ে শুরু হতে হবে এবং এতে অক্ষর, সংখ্যা বা হাইফেন সহ সর্বোচ্চ ৪৯টি অক্ষর বা তার কম থাকতে হবে। সার্ভিসের নাম হাইফেন দিয়ে শেষ হতে পারবে না এবং প্রতিটি অঞ্চল ও প্রকল্পের জন্য এটি অবশ্যই অনন্য হতে হবে। সার্ভিসের নাম পরে পরিবর্তন করা যাবে না এবং এটি সর্বজনীনভাবে দৃশ্যমান থাকবে। (retail-product-search-quality লিখুন)
- অঞ্চল তালিকায়, ডিফল্ট মান ব্যবহার করুন, অথবা যে অঞ্চলে আপনি আপনার ফাংশনটি স্থাপন করতে চান তা নির্বাচন করুন। (us-central1 বেছে নিন)
- রানটাইম তালিকায় ডিফল্ট মান ব্যবহার করুন, অথবা একটি রানটাইম সংস্করণ নির্বাচন করুন। (পাইথন ৩.১১ বেছে নিন)
- প্রমাণীকরণ বিভাগে, "সর্বজনীন প্রবেশাধিকার অনুমতি দিন" নির্বাচন করুন।
- "তৈরি করুন" বোতামে ক্লিক করুন
- ফাংশনটি main.py এবং requirements.txt টেমপ্লেট দিয়ে তৈরি ও লোড করা হয়।
- ওটাকে এই প্রোজেক্টের রিপো থেকে main.py এবং requirements.txt ফাইল দুটি দিয়ে প্রতিস্থাপন করুন।
- ফাংশনটি ডিপ্লয় করুন এবং আপনি আপনার ক্লাউড রান ফাংশনের জন্য একটি এন্ডপয়েন্ট পেয়ে যাবেন।
আপনার এন্ডপয়েন্টটি দেখতে এইরকম (বা এর কাছাকাছি) হওয়া উচিত:
টুলবক্স অ্যাক্সেস করার জন্য ক্লাউড রান ফাংশন এন্ডপয়েন্ট: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
নির্ধারিত সময়সীমার মধ্যে সহজে কাজ শেষ করার জন্য (প্রশিক্ষক-পরিচালিত হাতে-কলমে সেশনগুলোর ক্ষেত্রে), চূড়ান্ত পর্যায়ের প্রজেক্ট নম্বরটি হ্যান্ডস-অন সেশনের সময় জানিয়ে দেওয়া হবে।
গুরুত্বপূর্ণ দ্রষ্টব্য:
বিকল্পভাবে, আপনি ডাটাবেস অংশটি সরাসরি আপনার অ্যাপ্লিকেশন কোড বা ক্লাউড রান ফাংশনের অংশ হিসেবেও প্রয়োগ করতে পারেন।
৮. ফেসেটেড সার্চ সহ অ্যাপ্লিকেশন ডেভেলপমেন্ট (জাভা)
অবশেষে, এই সমস্ত শক্তিশালী ব্যাকএন্ড উপাদানগুলো অ্যাপ্লিকেশন লেয়ারের মাধ্যমে জীবন্ত হয়ে ওঠে। জাভাতে তৈরি এই অ্যাপ্লিকেশনটি সার্চ সিস্টেমের সাথে যোগাযোগের জন্য ইউজার ইন্টারফেস প্রদান করে। এটি AlloyDB-তে কোয়েরিগুলো সমন্বয় করে, ফেসেটেড ফিল্টারগুলোর প্রদর্শন পরিচালনা করে, ব্যবহারকারীর নির্বাচনগুলো সামলায় এবং পুনর্বিন্যস্ত ও যাচাইকৃত সার্চ ফলাফলগুলো একটি নির্বিঘ্ন ও স্বজ্ঞাত পদ্ধতিতে উপস্থাপন করে।
- আপনি আপনার ক্লাউড শেল টার্মিনালে গিয়ে রিপোজিটরিটি ক্লোন করার মাধ্যমে শুরু করতে পারেন:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- ক্লাউড শেল এডিটর-এ যান , যেখানে আপনি নতুন তৈরি করা faceted_searching_retail ফোল্ডারটি দেখতে পাবেন।
- নিম্নলিখিতগুলি মুছে ফেলুন, কারণ সেই ধাপগুলি পূর্ববর্তী বিভাগগুলিতে ইতিমধ্যেই সম্পন্ন করা হয়েছে:
- Cloud_Run_Function ফোল্ডারটি মুছে ফেলুন
- db_script.sql ফাইলটি মুছে ফেলুন
- tools.yaml ফাইলটি মুছে ফেলুন
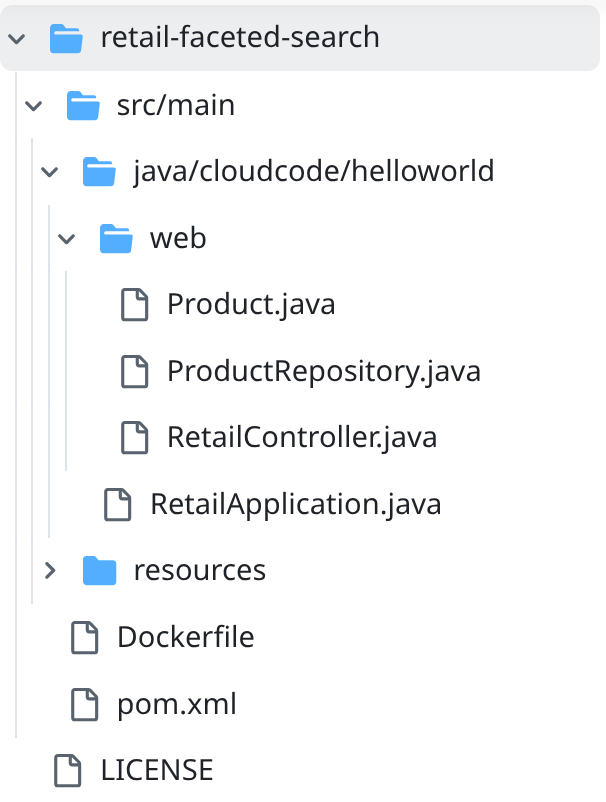
- retail-faceted-search প্রজেক্ট ফোল্ডারে প্রবেশ করুন এবং আপনি প্রজেক্টের কাঠামোটি দেখতে পাবেন:
- ProductRepository.java ফাইলে আপনাকে TOOLBOX_ENDPOINT ভেরিয়েবলটি আপনার ডেপ্লয় করা ক্লাউড রান ফাংশনের এন্ডপয়েন্ট দিয়ে পরিবর্তন করতে হবে অথবা হ্যান্ডস-অন স্পিকারের কাছ থেকে এন্ডপয়েন্টটি নিতে হবে।
নিচের কোড লাইনটি খুঁজুন এবং এটিকে আপনার এন্ডপয়েন্ট দিয়ে প্রতিস্থাপন করুন:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- নিশ্চিত করুন যে Dockerfile এবং pom.xml আপনার প্রোজেক্ট কনফিগারেশনের সাথে সামঞ্জস্যপূর্ণ (যদি না আপনি স্পষ্টভাবে কোনো ভার্সন বা কনফিগারেশন পরিবর্তন করে থাকেন, তবে কোনো পরিবর্তনের প্রয়োজন নেই)।
- ক্লাউড শেল টার্মিনালে নিশ্চিত করুন যে আপনি আপনার মূল ফোল্ডার এবং প্রজেক্ট ফোল্ডারের (faceted_searching_retail / retail-faceted-search) ভিতরে আছেন। আপনি যদি টার্মিনালে আগে থেকেই সঠিক ফোল্ডারে না থাকেন, তবে তা নিশ্চিত করতে নিম্নলিখিত কমান্ডগুলি ব্যবহার করুন:
cd faceted_searching_retail
cd retail-faceted-search
- আপনার অ্যাপ্লিকেশনটি স্থানীয়ভাবে প্যাকেজ, বিল্ড এবং পরীক্ষা করুন:
mvn package
mvn spring-boot:run
নীচে দেখানো অনুযায়ী, ক্লাউড শেল টার্মিনালে 'পোর্ট ৮০৮০-এ প্রিভিউ'-তে ক্লিক করে আপনি আপনার অ্যাপ্লিকেশনটি দেখতে পারবেন।
৯. ক্লাউড রান-এ ডেপ্লয় করুন: ***গুরুত্বপূর্ণ ধাপ***
ক্লাউড শেল টার্মিনালে নিশ্চিত করুন যে আপনি আপনার মূল ফোল্ডার এবং প্রজেক্ট ফোল্ডারের (faceted_searching_retail / retail-faceted-search) ভিতরে আছেন । আপনি যদি টার্মিনালে আগে থেকেই সঠিক ফোল্ডারে না থাকেন, তবে তা নিশ্চিত করতে নিম্নলিখিত কমান্ডগুলি ব্যবহার করুন:
cd faceted_searching_retail
cd retail-faceted-search
প্রজেক্ট ফোল্ডারে আছেন বলে নিশ্চিত হওয়ার পর, নিম্নলিখিত কমান্ডটি চালান:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
একবার ডেপ্লয় করা হয়ে গেলে, আপনি এইরকম দেখতে একটি ডেপ্লয় করা ক্লাউড রান এন্ডপয়েন্ট পাবেন:
https://retail-search-**********-uc.a.run.app/
১০. ডেমো
চলুন দেখি এই সবকিছু বাস্তবে কীভাবে কাজ করে:
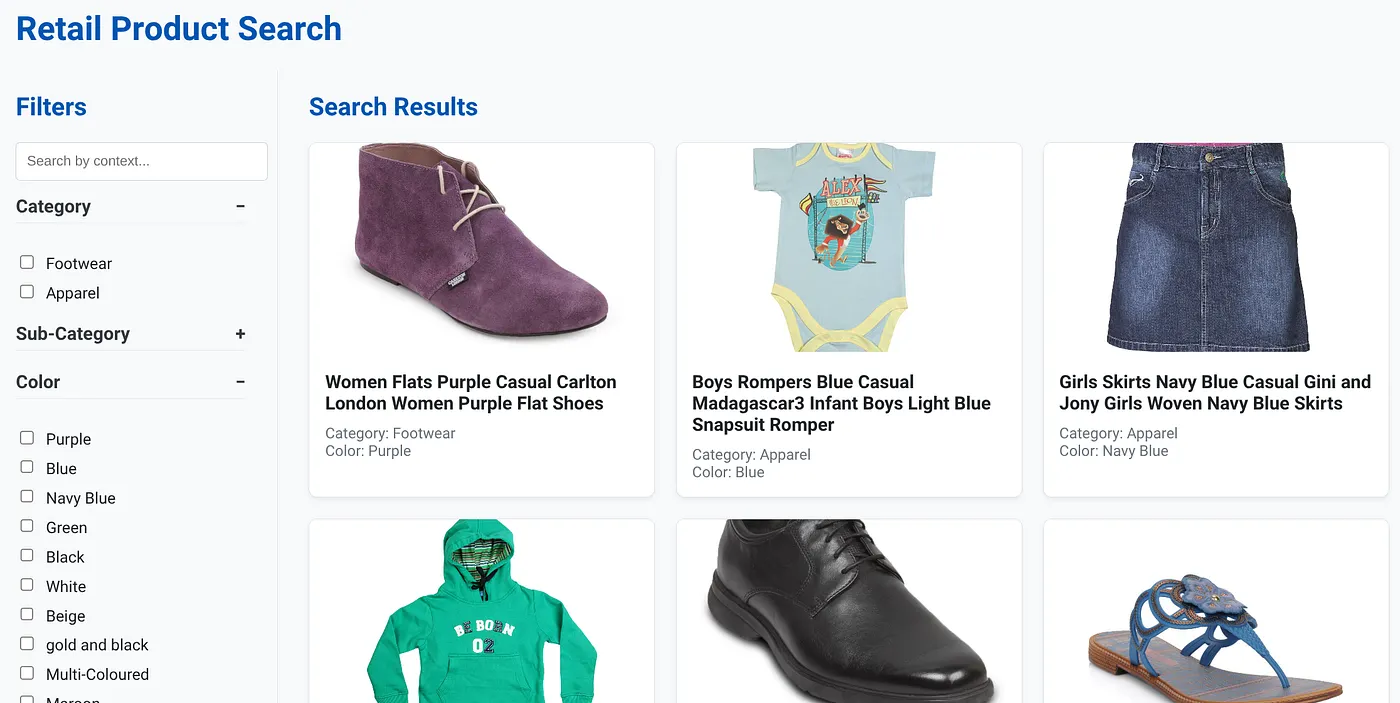
The above image shows the landing page for the dynamic hybrid search app.
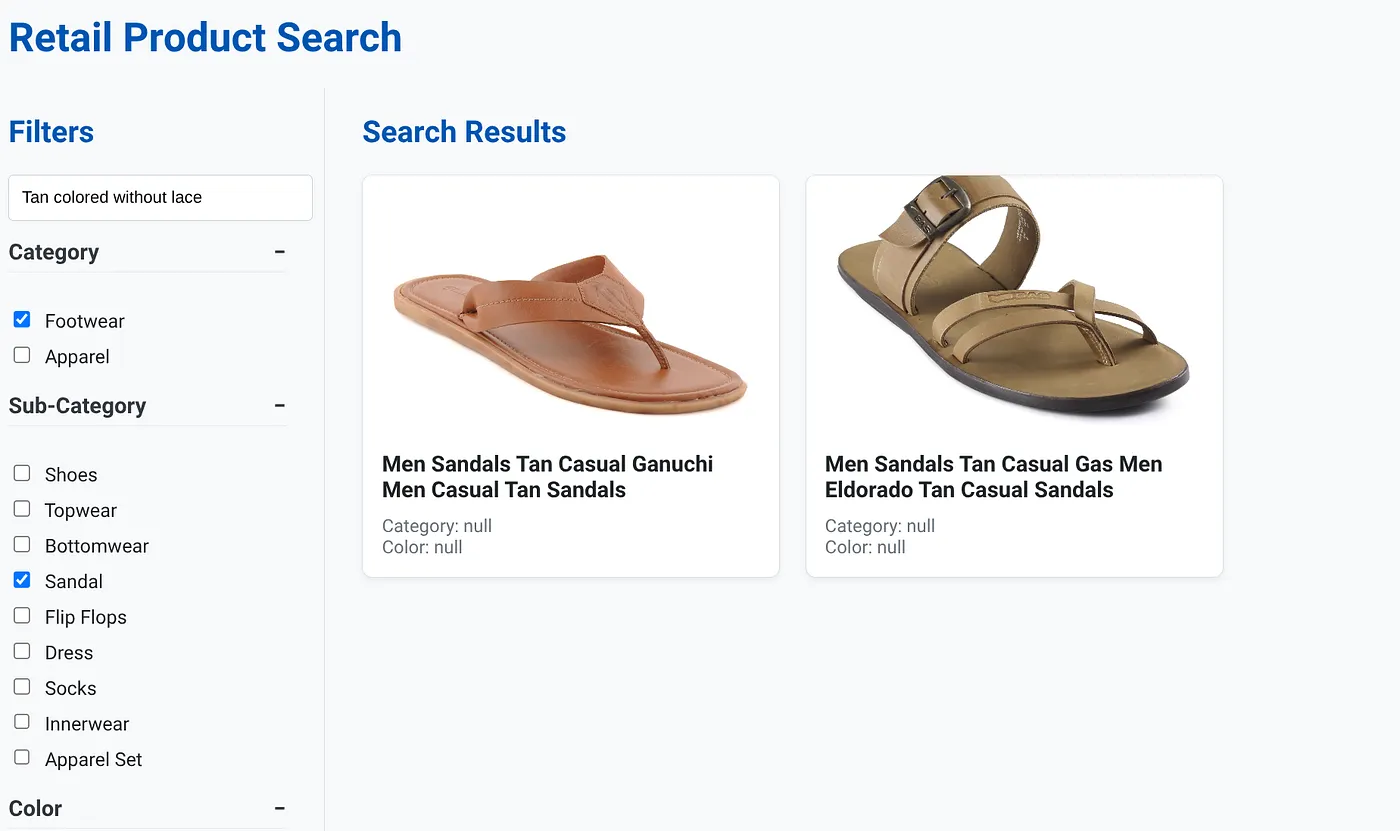
The above image has the search results for "Tan colored without lace" . The Faceted filters selected are: Footwear, Sandal.
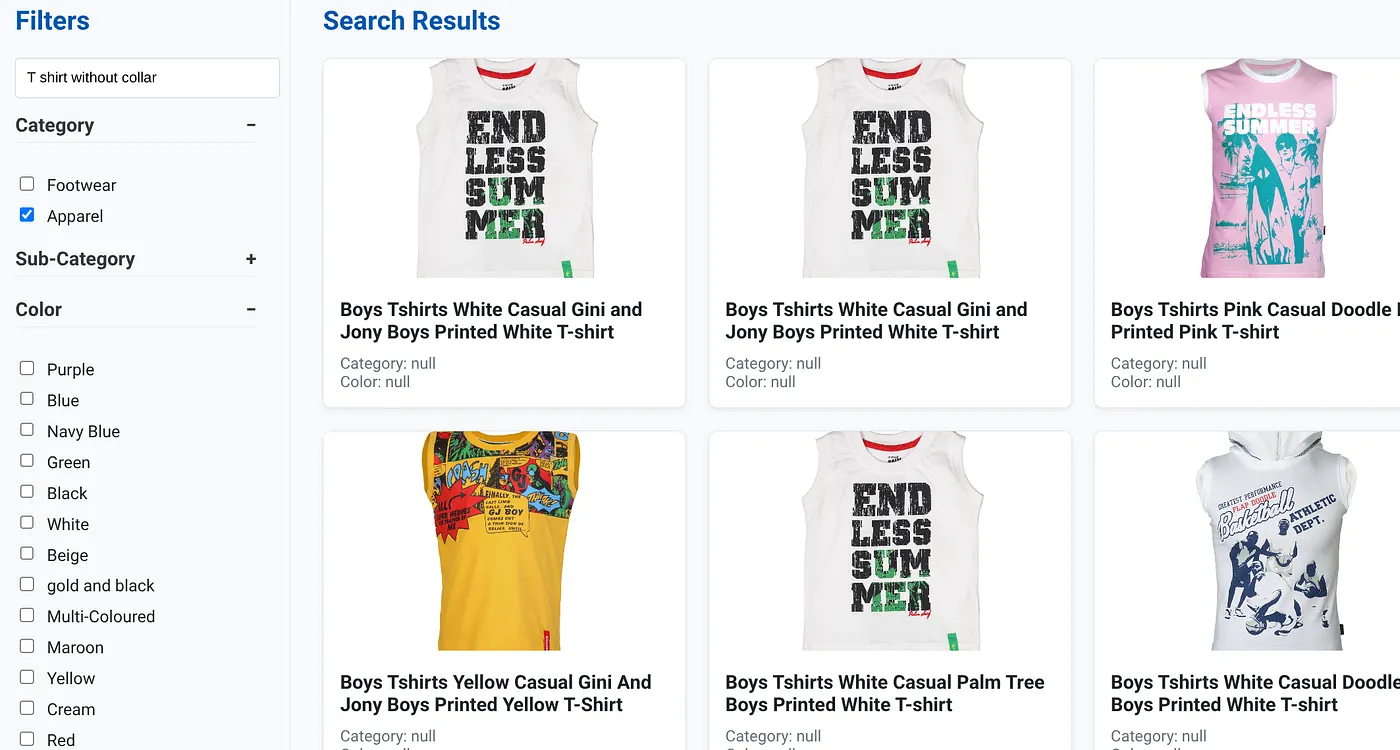
The above image shows the search results for "T shirt without collar" . Faceted filters: Apparel
You can now incorporate more generative and agentic features to make this application actionable.
Try it out so you're inspired to build on your own!!!
11. Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this post, follow these steps:
- In the Google Cloud console, go to the resource manager page.
- In the project list, select the project that you want to delete, and then click Delete .
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Alternatively, you can just delete the AlloyDB cluster (change the location in this hyperlink if you didn't choose us-central1 for the cluster at the time of configuration) that we just created for this project by clicking the DELETE CLUSTER button.
12. Congratulations
Congratulations! You have successfully built and deployed a HYBRID SEARCH APP with ALLOYDB on CLOUD RUN!!!
Why This Matters for businesses:
This dynamic hybrid search application, powered by AlloyDB AI, offers significant advantages for enterprise retail and other businesses:
Superior Relevance: By combining contextual (vector) search with precise faceted filtering and intelligent reranking, customers receive highly relevant results, leading to increased satisfaction and conversions.
Scalability: AlloyDB's architecture and scaNN indexing are designed to handle massive product catalogs and high query volumes, crucial for growing e-commerce businesses.
Performance: Faster query responses, even for complex hybrid searches, ensure a smooth user experience and minimize abandonment rates.
Future-Proofing: The integration of AI capabilities (embeddings, LLM validation) positions the application for future advancements in personalized recommendations, conversational commerce, and intelligent product discovery.
Simplified Architecture: Integrating vector search directly within AlloyDB eliminates the need for separate vector databases or complex synchronization, simplifying development and maintenance.
Let's say a user typed in a natural language query like "eco-friendly running shoes for women with high arch support."
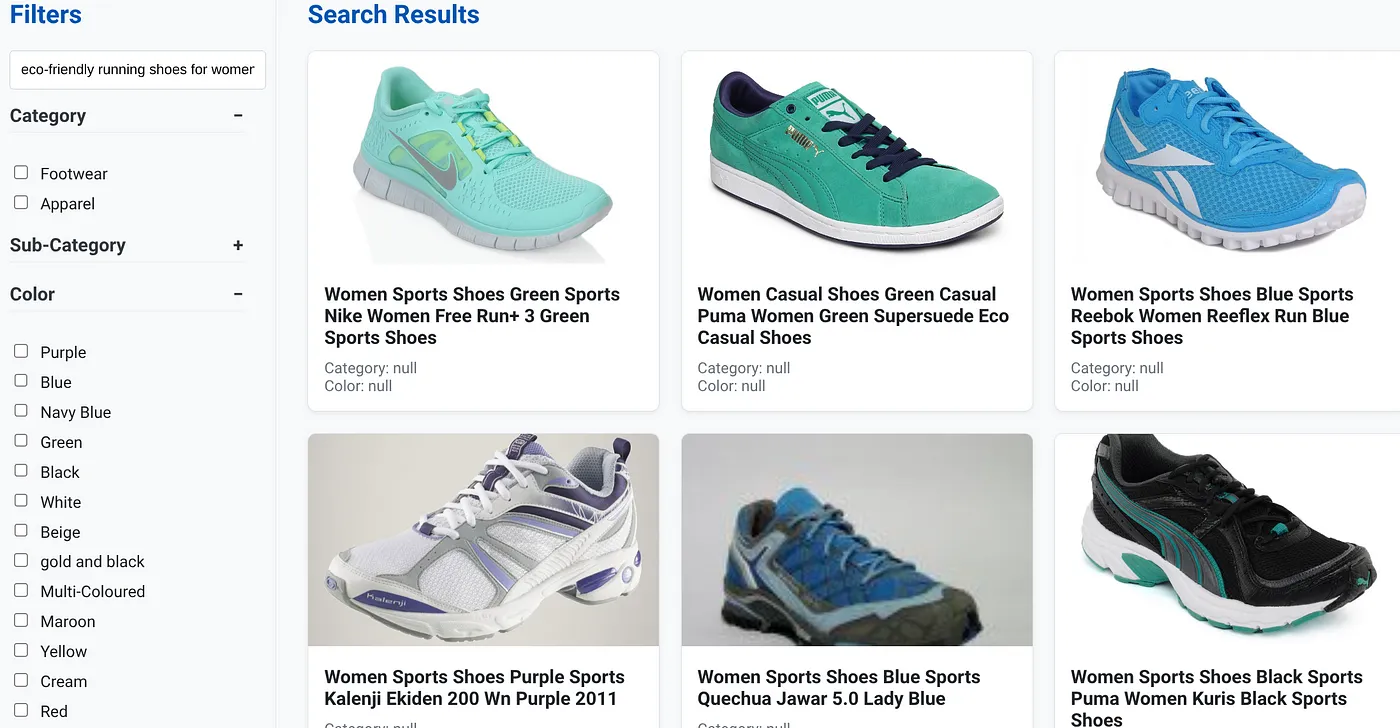
while simultaneously, the user applies faceted filters for "Category: <<>>" "Color: <<>>," and say "Price: $100-$150":
- The system instantly returns a refined list of products, semantically aligned with the natural language and precisely matching the chosen filters.
- Behind the scenes, the scaNN index accelerates the vector search, inline and adaptive filtering ensure performance with combined criteria, and reranking presents the optimal results at the top.
- The speed and accuracy of the results clearly illustrate the power of combining these technologies for a truly intelligent retail search experience.
Building a next-generation retail search application requires moving beyond conventional methods and by using the power of AlloyDB, Vertex AI, Vector Search with scaNN indexing, dynamic faceted filtering, reranking, and LLM validation, we can deliver an unparalleled customer experience that drives engagement and boosts sales. This robust, scalable, and intelligent solution demonstrates how modern database capabilities, infused with AI, are reshaping the future of retail!!!