
1. Übersicht
Im heutigen wettbewerbsorientierten Einzelhandel ist es von entscheidender Bedeutung, dass Kunden schnell und intuitiv genau das finden, wonach sie suchen. Die herkömmliche Suche mit Suchbegriffen stößt oft an ihre Grenzen, da sie mit komplexen Anfragen und riesigen Produktkatalogen zu kämpfen hat. In diesem Codelab wird eine ausgereifte Einzelhandelssuchanwendung vorgestellt, die auf AlloyDB und AlloyDB AI basiert und modernste Vektorsuche, scaNN-Indexierung, Facettenfilter und intelligentes adaptives Filtern und Neusortieren nutzt, um eine dynamische, hybride Suche auf Unternehmensebene zu ermöglichen.
Wir haben jetzt bereits ein grundlegendes Verständnis von drei Dingen:
- Was die kontextbezogene Suche für Ihren Agenten bedeutet und wie Sie sie mithilfe der Vektorsuche umsetzen können.
- Wir haben uns auch eingehend damit beschäftigt, wie Sie die Vektorsuche im Rahmen Ihrer Daten, also in Ihrer Datenbank selbst, erreichen können. Alle Google Cloud-Datenbanken unterstützen dies, falls Sie es noch nicht wussten.
- Wir sind einen Schritt weiter gegangen als der Rest der Welt und haben Ihnen gezeigt, wie Sie eine solche schlanke RAG-Funktion für die Vektorsuche mit hoher Leistung und Qualität mit der AlloyDB-Vektorsuche auf Basis des ScaNN-Index erreichen können.
Wenn Sie diese grundlegenden, fortgeschrittenen und leicht fortgeschrittenen RAG-Tests noch nicht durchlaufen haben, empfehlen wir Ihnen, sie in der angegebenen Reihenfolge hier, hier und hier zu lesen.
Die Herausforderung
Über Filter, Keywords und kontextbezogene Übereinstimmung hinaus: Eine einfache Keyword-Suche kann Tausende von Ergebnissen liefern, von denen viele irrelevant sind. Die ideale Lösung muss die Intention hinter der Anfrage verstehen, sie mit präzisen Filterkriterien (z. B. Marke, Material oder Preis) kombinieren und die relevantesten Artikel in Millisekunden präsentieren. Dafür ist eine leistungsstarke, flexible und skalierbare Suchinfrastruktur erforderlich. Wir haben uns von der Keyword-Suche über kontextbezogene Übereinstimmungen bis hin zur Ähnlichkeitssuche weiterentwickelt. Stellen Sie sich aber vor, ein Kunde sucht nach „einer bequemen, stilvollen, wasserdichten Jacke zum Wandern im Frühling“ und wendet gleichzeitig Filter an. Ihre Anwendung liefert nicht nur hochwertige Antworten, sondern ist auch leistungsstark und die Reihenfolge all dessen wird dynamisch von Ihrer Datenbank ausgewählt.
Ziel
Um dieses Problem durch die Integration von
- Kontextbezogene Suche (Vektorsuche): Semantische Bedeutung von Anfragen und Produktbeschreibungen verstehen
- Faceted Filtering: Nutzer können Ergebnisse mit bestimmten Attributen eingrenzen
- Hybridansatz: Kontextbezogene Suche und strukturierte Filterung nahtlos kombinieren
- Erweiterte Optimierung: Nutzung von spezialisierter Indexierung, adaptiver Filterung und Neuberechnung des Rangs für Geschwindigkeit und Relevanz
- Generative KI-basierte Qualitätskontrolle: LLM-Validierung für eine höhere Ergebnisqualität.
Sehen wir uns die Architektur und die Implementierung genauer an.
Aufgaben
Eine Retail Search-Anwendung
Dabei gehen Sie so vor:
- AlloyDB-Instanz und -Tabelle für das E-Commerce-Dataset erstellen
- Einbettungen und Vektorsuche einrichten
- Metadatenindex und ScaNN-Index erstellen
- Erweiterte Vektorsuche in AlloyDB mit der Inline-Filterungsmethode von ScaNN implementieren
- Facettenfilter und Hybridsuche in einer einzigen Anfrage einrichten
- Relevanz von Anfragen mit Reranking und Recall optimieren (optional)
- Antwort auf Anfrage mit Gemini bewerten (optional)
- MCP Toolbox for Databases und Anwendungsebene
- Application Development (Java) with Faceted Search
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, können Sie mit dem folgenden Befehl prüfen, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die E-Commerce-Daten. Dazu werden Cluster verwendet, in denen alle Ressourcen wie Datenbanken und Logs enthalten sind. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine Tabelle, in die das E-Commerce-Dataset geladen wird.
Cluster und Instanz erstellen
- Rufen Sie in der Cloud Console die AlloyDB-Seite auf. Die meisten Seiten in der Cloud Console lassen sich ganz einfach über die Suchleiste der Console finden.
- Wählen Sie auf dieser Seite CLUSTER ERSTELLEN aus:

- Sie sehen dann einen Bildschirm wie den folgenden. Erstellen Sie einen Cluster und eine Instanz mit den folgenden Werten. Achten Sie darauf, dass die Werte übereinstimmen, wenn Sie den Anwendungscode aus dem Repository klonen:
- Cluster-ID: „
vector-cluster“ - password: "
alloydb" - PostgreSQL 15 / neueste empfohlene Version
- Region: "
us-central1" - Netzwerk: „
default“
- Wenn Sie das Standardnetzwerk auswählen, wird ein Bildschirm wie der unten stehende angezeigt.
Wählen Sie Verbindung einrichten aus.
- Wählen Sie dort Automatisch zugewiesenen IP-Bereich verwenden aus und klicken Sie auf „Weiter“. Nachdem Sie die Informationen geprüft haben, wählen Sie „VERBINDUNG ERSTELLEN“ aus.
- Nachdem Sie Ihr Netzwerk eingerichtet haben, können Sie mit der Erstellung Ihres Clusters fortfahren. Klicken Sie auf CLUSTER ERSTELLEN, um die Einrichtung des Clusters abzuschließen (siehe unten):
WICHTIGER HINWEIS:
- Achten Sie darauf, die Instanz-ID zu ändern (die Sie bei der Konfiguration des Clusters / der Instanz finden) in**
vector-instance**. Wenn Sie sie nicht ändern können, verwenden Sie Ihre Instanz-ID in allen nachfolgenden Referenzen. - Die Clustererstellung dauert etwa 10 Minuten. Nach erfolgreicher Ausführung sollte ein Bildschirm mit der Übersicht des gerade erstellten Clusters angezeigt werden.
4. Datenaufnahme
Jetzt ist es an der Zeit, eine Tabelle mit den Daten zum Geschäft hinzuzufügen. Rufen Sie AlloyDB auf, wählen Sie den primären Cluster und dann AlloyDB Studio aus:
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Wenn Sie prüfen möchten, welche Erweiterungen für Ihre Datenbank aktiviert wurden, führen Sie diesen SQL-Befehl aus:
select extname, extversion from pg_extension;
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
In der Einbettungsspalte können die Vektorwerte des Texts gespeichert werden.
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Dem AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Daten in die Datenbank laden
- Kopieren Sie die
insert-Abfrageanweisungen aus derinsert scripts sqlim Tabellenblatt in den Editor. Sie können 10 bis 50 INSERT-Anweisungen kopieren, um diesen Anwendungsfall schnell zu demonstrieren. Eine ausgewählte Liste von Einfügungen finden Sie auf dem Tab Ausgewählte Einfügungen (25–30 Zeilen).
Links zu den Daten finden Sie in dieser Datei im GitHub-Repository.
- Klicken Sie auf Ausführen. Die Ergebnisse Ihrer Abfrage werden in der Tabelle Ergebnisse angezeigt.
WICHTIGER HINWEIS:
Kopieren Sie nur 25 bis 50 Datensätze zum Einfügen und achten Sie darauf, dass sie aus einem Bereich von Kategorie-, Unterkategorie-, Farb- und Geschlechtstypen stammen.
5. Einbettungen für die Daten erstellen
Die eigentliche Innovation bei der modernen Suche liegt darin, dass nicht nur Keywords, sondern auch die Bedeutung verstanden wird. Hier kommen Einbettungen und Vektorsuche ins Spiel.
Wir haben Produktbeschreibungen und Nutzeranfragen mithilfe vortrainierter Sprachmodelle in hochdimensionale numerische Darstellungen, sogenannte „Embeddings“, umgewandelt. Diese Einbettungen erfassen die semantische Bedeutung, sodass wir Produkte finden können, die „ähnlich in der Bedeutung“ sind, anstatt nur übereinstimmende Wörter zu enthalten. Zuerst haben wir mit der direkten Suche nach Vektorähnlichkeiten für diese Einbettungen experimentiert, um eine Baseline zu erstellen. So konnten wir die Leistungsfähigkeit des semantischen Verständnisses bereits vor Leistungsoptimierungen demonstrieren.
In der Einbettungsspalte können die Vektorwerte des Produktbeschreibungstexts gespeichert werden. In der Spalte „img_embeddings“ können Bildeinbettungen (multimodal) gespeichert werden. So können Sie auch die Suche auf Grundlage der Distanz zwischen Text und Bild verwenden. In diesem Lab verwenden wir jedoch nur Texteinbettungen.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dadurch sollte der Einbettungsvektor zurückgegeben werden, der wie ein Array von Gleitkommazahlen aussieht. Das sieht so aus:
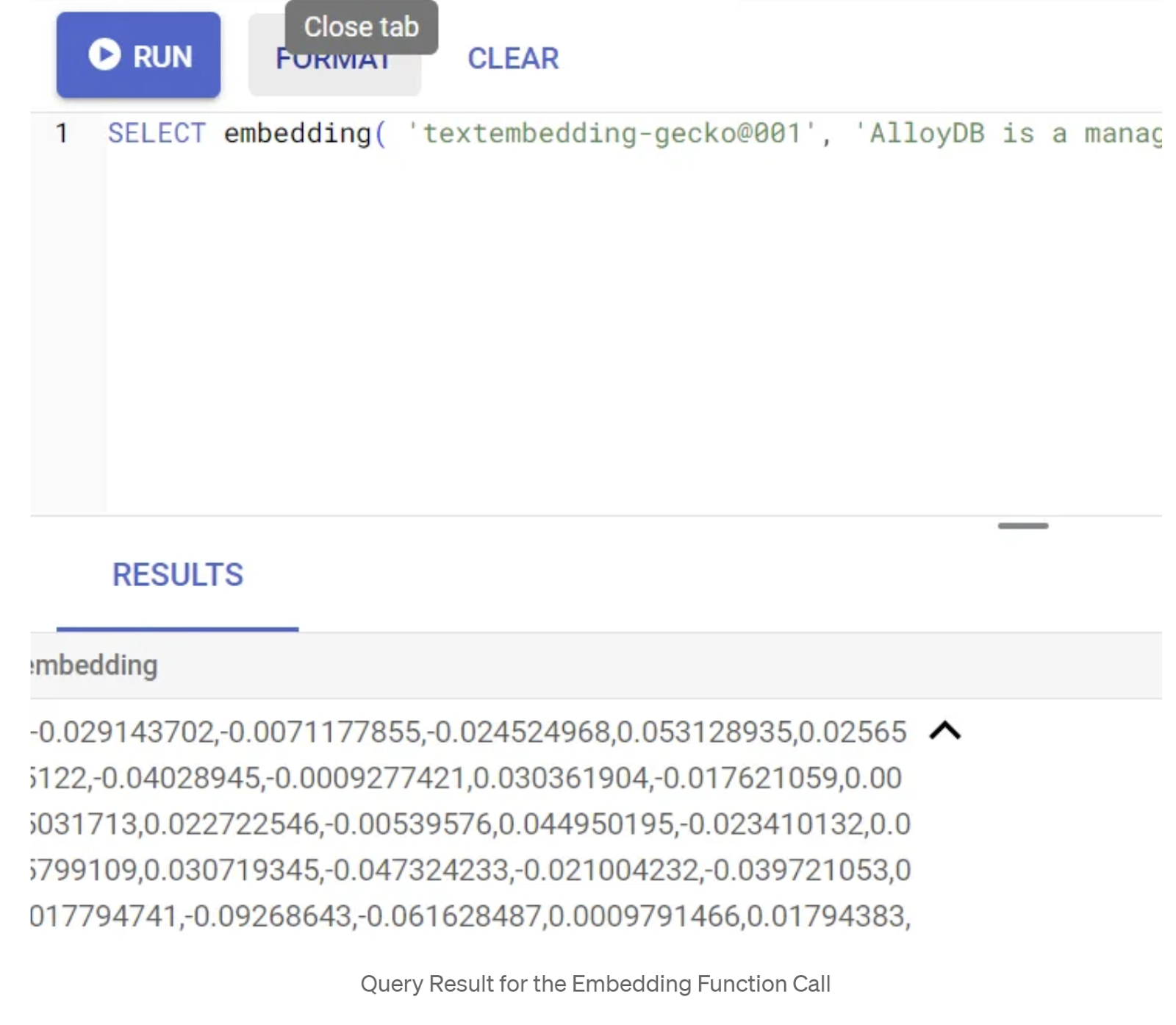
Vektorfeld „abstract_embeddings“ aktualisieren
Führen Sie die folgende DML aus, um die Inhaltsbeschreibung in der Tabelle mit den entsprechenden Einbettungen zu aktualisieren:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Wenn Sie ein Abrechnungskonto mit Testguthaben für Google Cloud verwenden, kann es sein, dass Sie nicht mehr als etwa 20 bis 25 Einbettungen generieren können. Begrenzen Sie daher die Anzahl der Zeilen im Einfügeskript.
Wenn Sie Image-Einbettungen generieren möchten (um eine multimodale kontextbezogene Suche durchzuführen), führen Sie auch das folgende Update aus:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Erweitertes RAG mit den neuen Funktionen von AlloyDB ausführen
Nachdem die Tabelle, die Daten und die Einbettungen bereit sind, führen wir die Echtzeit-Vektorsuche für den Suchtext des Nutzers durch. Sie können dies testen, indem Sie die folgende Abfrage ausführen:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
In dieser Abfrage vergleichen wir die Texteinbettung der vom Nutzer eingegebenen Suchanfrage „T-Shirt mit Rundhalsausschnitt“ mit den Texteinbettungen aller Produktbeschreibungen in der Tabelle „apparel“ (gespeichert in der Spalte „embedding“) mithilfe der Kosinus-Ähnlichkeitsdistanzfunktion (dargestellt durch das Symbol „<=>“). Wir wandeln das Ergebnis der Einbettungsmethode in den Vektortyp um, damit es mit den in der Datenbank gespeicherten Vektoren kompatibel ist. LIMIT 10 bedeutet, dass die zehn am besten passenden Ergebnisse für den Suchtext ausgewählt werden.
AlloyDB bringt Vector Search RAG auf ein neues Niveau:
Für eine Lösung auf Unternehmensniveau reicht die reine Vektorsuche nicht aus. Die Leistung ist entscheidend.
ScaNN-Index (Scalable Nearest Neighbors)
Um eine ultraschnelle Suche nach dem ungefähren nächsten Nachbarn (Approximate Nearest Neighbor, ANN) zu ermöglichen, haben wir den ScaNN-Index in AlloyDB aktiviert. ScaNN ist ein hochmoderner ANN-Algorithmus (Approximate Nearest Neighbor, geschätzter nächster Nachbar), der vom Google Research-Team entwickelt wurde und für die effiziente Suche nach Vektorähnlichkeiten in großem Maßstab konzipiert ist. Er beschleunigt Abfragen erheblich, indem er den Suchraum effizient reduziert und Quantisierungstechniken verwendet. So sind Vektorabfragen bis zu viermal schneller als bei anderen Indexierungsmethoden und der Speicherbedarf ist geringer. Weitere Informationen und weitere Informationen
Aktivieren wir die Erweiterung und erstellen wir die Indexe:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Indexe für Texteinbettungs- und Bildeinbettungsfelder erstellen (falls Sie Bildeinbettungen in Ihrer Suche verwenden möchten):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Metadatenindexe
Während scaNN die Vektorindexierung übernimmt, wurden herkömmliche B-Baum- oder GIN-Indizes sorgfältig für strukturierte Attribute wie Kategorie, Unterkategorie, Stil und Farbe eingerichtet. Diese Indexe sind entscheidend für die Effizienz der facettierten Filterung. Führen Sie die folgenden Anweisungen aus, um Metadatenindexe einzurichten:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
WICHTIGER HINWEIS:
Da Sie möglicherweise nur 25 bis 50 Datensätze eingefügt haben, sind Indexe (ScaNN oder andere Indexe) nicht effektiv.
Inline-Filterung
Eine häufige Herausforderung bei der Vektorsuche ist die Kombination mit strukturierten Filtern (z.B. „rote Schuhe“). Die Inline-Filterung von AlloyDB optimiert diesen Prozess. Anstatt Ergebnisse nach einer umfassenden Vektorsuche zu filtern, werden beim Inline-Filtern Filterbedingungen während der Vektorsuche angewendet. Dadurch werden Leistung und Genauigkeit gefilterter Vektorsuchen erheblich verbessert.
Weitere Informationen zur Notwendigkeit von Inline-Filtern finden Sie in dieser Dokumentation. Weitere Informationen zur gefilterten Vektorsuche zur Leistungsoptimierung der Vektorsuche Wenn Sie die Inline-Filterung für Ihre Anwendung aktivieren möchten, führen Sie die folgende Anweisung in Ihrem Editor aus:
SET scann.enable_inline_filtering = on;
Inline-Filter eignen sich am besten für Fälle mit mittlerer Selektivität. Wenn AlloyDB den Vektorindex durchsucht, werden Distanzen nur für Vektoren berechnet, die den Bedingungen für die Metadatenfilterung entsprechen (Ihre funktionalen Filter in einer Abfrage, die normalerweise in der WHERE-Klausel verarbeitet werden). Dadurch wird die Leistung dieser Abfragen erheblich verbessert, was die Vorteile von Post-Filter oder Pre-Filter ergänzt.
Adaptive Filterung
Um die Leistung weiter zu optimieren, wählt das adaptive Filtern von AlloyDB während der Abfrageausführung dynamisch die effizienteste Filterstrategie (Inline- oder Vorfilterung) aus. Es analysiert Abfragemuster und Datenverteilungen, um ohne manuellen Eingriff eine optimale Leistung zu erzielen. Das ist besonders bei gefilterten Vektorsuchen von Vorteil, da automatisch zwischen der Verwendung von Vektor- und Metadatenindex gewechselt wird. Verwenden Sie das Flag „scann.enable_preview_features“, um die adaptive Filterung zu aktivieren.
Wenn durch adaptives Filtern während der Ausführung ein Wechsel von Inline-Filtern zu Vorfiltern ausgelöst wird, ändert sich der Abfrageplan dynamisch.
SET scann.enable_preview_features = on;
WICHTIGER HINWEIS: Möglicherweise können Sie die oben genannte Anweisung nicht ausführen, ohne die Instanz neu zu starten. Wenn ein Fehler auftritt, aktivieren Sie das Flag „enable_preview_features“ besser im Abschnitt „Datenbank-Flags“ Ihrer Instanz.
Faceted Filters using all the Indexes (Facettenfilter mit allen Indexen)
Mit der facettierten Suche können Nutzer die Ergebnisse eingrenzen, indem sie mehrere Filter basierend auf bestimmten Attributen oder „Facetten“ (z.B. Marke, Preis, Größe, Kundenbewertung) anwenden. In unserer Anwendung werden diese Facetten nahtlos in die Vektorsuche integriert. In einer einzelnen Abfrage kann jetzt natürliche Sprache (kontextbezogene Suche) mit mehreren facettierten Auswahlmöglichkeiten kombiniert werden. Dabei werden sowohl Vektor- als auch herkömmliche Indexe dynamisch genutzt. So können Nutzer die Ergebnisse präzise eingrenzen.
Da wir in unserer Anwendung bereits alle Metadatenindexe erstellt haben, können wir die facettierte Filterung im Web direkt mit SQL-Abfragen verwenden:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
In dieser Anfrage führen wir eine hybride Suche durch, bei der sowohl
- Facettenfilterung in der WHERE-Klausel und
- Vektorsuche in der ORDER BY-Klausel mit der Kosinus-Ähnlichkeitsmethode.
$1, $2, $3 und $4 stehen für die Werte der Facettenfilter in einem Array und $5 für den Suchtext des Nutzers. Ersetzen Sie $1 bis $4 durch die gewünschten Werte für facettierte Filter, z. B.:
category = ANY([‘Apparel', ‘Footwear'])
Ersetzen Sie „$5“ durch einen Suchtext Ihrer Wahl, z. B. „Poloshirts“.
WICHTIGER HINWEIS: Wenn Sie die Indexe aufgrund der begrenzten Anzahl der eingefügten Datensätze nicht haben, sehen Sie keine Auswirkungen auf die Leistung. Bei einem vollständigen Produktionsdatensatz wird die Ausführungszeit jedoch deutlich verkürzt. Das ist möglich, weil der ScaNN-Index mit Inline-Filterung für die Vektorsuche verwendet wird.
Als Nächstes sehen wir uns den Recall für diese ScaNN-basierte Vektorsuche an.
Reranking
Auch bei der erweiterten Suche müssen die ersten Ergebnisse möglicherweise noch überarbeitet werden. Dieser wichtige Schritt ordnet die ursprünglichen Suchergebnisse neu an, um die Relevanz zu verbessern. Nachdem die erste hybride Suche eine Reihe von infrage kommenden Produkten geliefert hat, wird ein anspruchsvolleres (und oft rechenintensiveres) Modell angewendet, um einen detaillierteren Relevanzwert zu ermitteln. So wird sichergestellt, dass die dem Nutzer präsentierten Top-Ergebnisse die relevantesten sind, was die Suchqualität deutlich verbessert. Wir bewerten den Recall kontinuierlich, um zu messen, wie gut das System alle relevanten Elemente für eine bestimmte Anfrage abruft. Außerdem optimieren wir unsere Modelle, um die Wahrscheinlichkeit zu maximieren, dass ein Kunde findet, was er sucht.
Bevor Sie diese Funktion in Ihrer Anwendung verwenden, müssen Sie alle Voraussetzungen erfüllen:
- Prüfen Sie, ob die Erweiterung „google_ml_integration“ installiert ist.
- Prüfen Sie, ob das Flag „google_ml_integration.enable_model_support“ auf „on“ gesetzt ist.
- In Vertex AI einbinden:
- Aktivieren Sie die Discovery Engine API.
- Erforderliche Rollen zum Verwenden von Ranking-Modellen abrufen
Anschließend können Sie die folgende Abfrage in unserer Anwendung verwenden, um die Ergebnisse der Hybridsuche neu zu ranken:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
In dieser Abfrage wird das Produktresultset der kontextbezogenen Suche, das in der ORDER BY-Klausel angesprochen wird, mit der Methode der Kosinusähnlichkeit neu gerankt. „Pinkes Top“ ist der Text, nach dem der Nutzer sucht.
WICHTIGER HINWEIS: Einige von Ihnen haben möglicherweise noch keinen Zugriff auf das Reranking. Daher habe ich es aus dem Anwendungscode ausgeschlossen. Wenn Sie es einfügen möchten, können Sie dem oben beschriebenen Beispiel folgen.
Recall-Bewerter
Der Recall bei der Ähnlichkeitssuche ist der Prozentsatz der relevanten Instanzen, die bei einer Suche abgerufen wurden, d.h. die Anzahl der korrekt positiven Ergebnisse. Dies ist der gängigste Messwert zur Messung der Suchqualität. Eine Quelle für den Verlust der Trefferquote ist der Unterschied zwischen der Suche nach dem ungefähren nächsten Nachbarn (Approximate Nearest Neighbor, aNN) und der Suche nach dem k (exakten) nächsten Nachbarn (kNN). Vektorindizes wie ScaNN von AlloyDB implementieren ANN-Algorithmen, mit denen Sie die Vektorsuche in großen Datasets beschleunigen können. Dies geht jedoch mit einem geringen Verlust an Recall einher. Mit AlloyDB können Sie diesen Kompromiss jetzt direkt in der Datenbank für einzelne Abfragen messen und dafür sorgen, dass er im Laufe der Zeit stabil bleibt. Sie können Abfrage- und Indexparameter auf Grundlage dieser Informationen aktualisieren, um bessere Ergebnisse und eine bessere Leistung zu erzielen.
Welche Logik steckt hinter dem Abrufen von Suchergebnissen?
Im Kontext der Vektorsuche bezieht sich der Recall bzw. die Trefferquote auf den Prozentsatz der Vektoren, die vom Index zurückgegeben werden und die tatsächlichen nächsten Nachbarn sind. Wenn z. B. eine Abfrage nach 20 nächsten Nachbarn 19 der „grundlegend echten“ nächsten Nachbarn zurückgibt, beträgt der Recall 19/20 × 100 = 95%. Recall ist der Messwert für die Suchqualität und wird als Prozentsatz der zurückgegebenen Ergebnisse definiert, die den Anfragevektoren objektiv am nächsten sind.
Mit der Funktion evaluate_query_recall können Sie den Recall für eine Vektoranfrage für einen Vektorindex für eine bestimmte Konfiguration ermitteln. Mit dieser Funktion können Sie Ihre Parameter so anpassen, dass Sie die gewünschten Recall-Ergebnisse für Vektorabfragen erzielen.
WICHTIGER HINWEIS:
Wenn Sie in den folgenden Schritten einen Fehler vom Typ „Permission denied“ für den HNSW-Index erhalten, überspringen Sie diesen gesamten Abschnitt zur Recall-Bewertung vorerst. Das kann mit Zugriffsbeschränkungen zusammenhängen, da es zum Zeitpunkt der Dokumentation dieses Codelabs gerade erst veröffentlicht wurde.
- Legen Sie das Flag „Enable Index Scan“ für den ScaNN-Index und den HNSW-Index fest:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Führen Sie die folgende Abfrage in AlloyDB Studio aus:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Die Funktion „evaluate_query_recall“ verwendet die Abfrage als Parameter und gibt den entsprechenden Recall zurück. Ich verwende dieselbe Abfrage, mit der ich die Leistung geprüft habe, als Funktionseingabeabfrage. Ich habe SCaNN als Indexmethode hinzugefügt. Weitere Parameteroptionen finden Sie in der Dokumentation.
Der Recall für diese Vektorsuche-Abfrage, die wir verwendet haben:
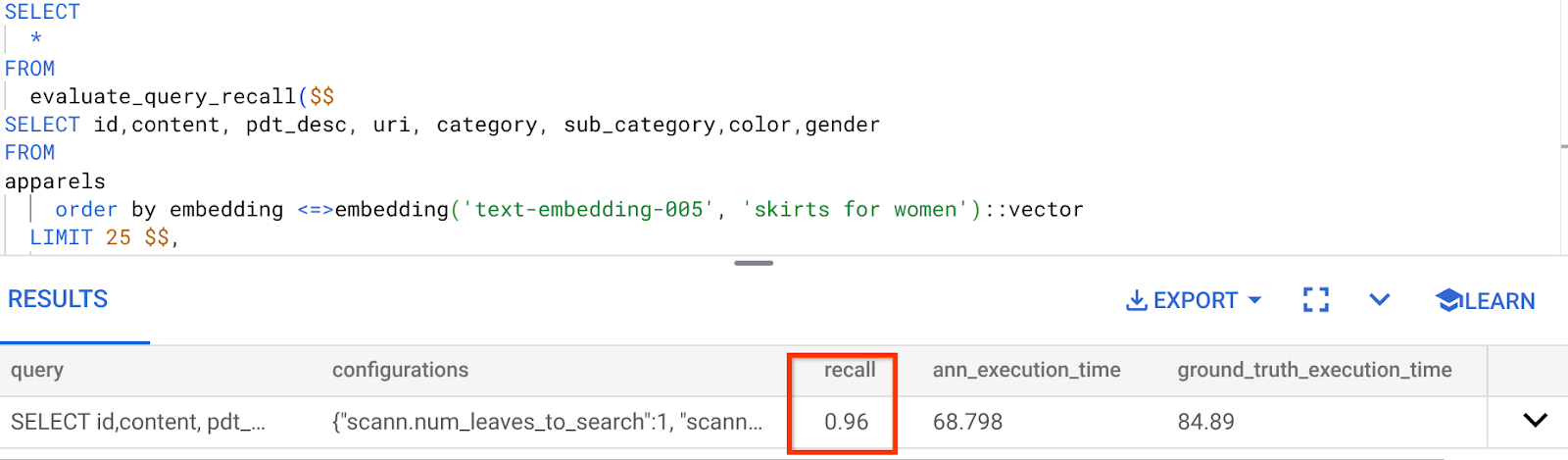
Der RECALL liegt bei 96%. In diesem Fall ist der Recall wirklich gut. Wenn es sich jedoch um einen inakzeptablen Wert handelte, können Sie diese Informationen verwenden, um die Indexparameter, Methoden und Suchparameter zu ändern und die Erinnerung für diese Vektorsuche zu verbessern.
Mit geänderten Abfrage- und Indexparametern testen
Jetzt testen wir die Abfrage, indem wir die Suchparameter auf Grundlage des erhaltenen Rückrufs ändern.
- So ändern Sie die Indexparameter:
Für diesen Test verwende ich die Ähnlichkeitsdistanzfunktion L2-Distanz anstelle von Kosinus.
Sehr wichtiger Hinweis: „Woher wissen wir, dass in dieser Anfrage die KOSINUS-Ähnlichkeit verwendet wird?“, fragen Sie sich vielleicht. Sie können die Distanzfunktion anhand der Verwendung von „<=>“ zur Darstellung der Kosinusdistanz erkennen.
Docs-Link für Distanzfunktionen der Vektorsuche
In der vorherigen Abfrage wurde die Kosinusähnlichkeitsdistanzfunktion verwendet. Jetzt probieren wir die L2-Distanz aus. Dazu müssen wir aber auch dafür sorgen, dass der zugrunde liegende ScaNN-Index die L2-Distanzfunktion verwendet. Erstellen wir nun einen Index mit einer anderen Distanzfunktionsabfrage: L2-Distanz: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
Die Anweisung „DROP INDEX“ dient nur dazu, sicherzustellen, dass kein unnötiger Index für die Tabelle vorhanden ist.
Jetzt kann ich die folgende Abfrage ausführen, um den RECALL zu bewerten, nachdem ich die Distanzfunktion meiner Vektorsuchfunktion geändert habe.
[AFTER] Abfrage mit der Funktion L2-Distanz:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Die Differenz bzw. Transformation ist am Recall-Wert für den aktualisierten Index zu erkennen.
Es gibt weitere Parameter, die Sie im Index ändern können, z. B. „num_leaves“, basierend auf dem gewünschten Recall-Wert und dem Dataset, das von Ihrer Anwendung verwendet wird.
LLM-Validierung von Vektorsuchergebnissen
Um die höchste Qualität bei der kontrollierten Suche zu erreichen, haben wir eine optionale Ebene für die LLM-Validierung eingeführt. Large Language Models können verwendet werden, um die Relevanz und Kohärenz von Suchergebnissen zu bewerten, insbesondere bei komplexen oder mehrdeutigen Anfragen. Dazu kann Folgendes gehören:
Semantische Überprüfung:
Ein LLM, das Ergebnisse mit der Abfrageabsicht abgleicht.
Logische Filterung:
Ein LLM kann komplexe Geschäftslogik oder Regeln anwenden, die sich nur schwer in herkömmlichen Filtern codieren lassen. So lässt sich die Produktliste anhand differenzierter Kriterien weiter verfeinern.
Qualitätssicherung:
Weniger relevante Ergebnisse werden automatisch identifiziert und zur manuellen Überprüfung oder zur Optimierung des Modells gekennzeichnet.
So haben wir das in den AlloyDB AI-Funktionen umgesetzt:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
Die zugrunde liegende Abfrage ist dieselbe, die wir in den Abschnitten zur facettierten Suche, zur hybriden Suche und zum Reranking gesehen haben. In dieser Abfrage haben wir nun eine Ebene der GEMINI-Bewertung des neu gerankten Ergebnissatzes eingefügt, die durch das Konstrukt „ml_predict_row“ dargestellt wird. Ich habe die Facettenfilter auskommentiert. Sie können jedoch Elemente Ihrer Wahl in ein Array für die Platzhalter $1 bis $4 einfügen. Ersetzen Sie „$5“ durch den gewünschten Suchtext, z. B. „Pinkes Top ohne Blumenmuster“.
7. MCP Toolbox for Databases und Anwendungsebene
Hinter den Kulissen sorgen robuste Tools und eine gut strukturierte Anwendung für einen reibungslosen Betrieb.
Die Toolbox für Datenbanken des MCP (Model Context Protocol) vereinfacht die Integration von generativer KI und agentischen Tools in AlloyDB. Er fungiert als Open-Source-Server, der die Verbindungspooling, die Authentifizierung und die sichere Bereitstellung von Datenbankfunktionen für KI-Agents oder andere Anwendungen optimiert.
In unserer Anwendung haben wir die MCP Toolbox for Databases als Abstraktionsebene für alle unsere intelligenten Hybrid-Suchanfragen verwendet.
Gehen Sie so vor, um Toolbox für unseren Anwendungsfall einzurichten und bereitzustellen:
Sie sehen, dass AlloyDB eine der von der MCP-Toolbox für Datenbanken unterstützten Datenbanken ist. Da wir sie bereits im vorherigen Abschnitt bereitgestellt haben, können wir jetzt die Toolbox einrichten.
- Rufen Sie Ihr Cloud Shell-Terminal auf und prüfen Sie, ob Ihr Projekt ausgewählt ist und im Prompt des Terminals angezeigt wird. Führen Sie den folgenden Befehl im Cloud Shell-Terminal aus, um das Projektverzeichnis zu öffnen:
mkdir toolbox-tools
cd toolbox-tools
- Führen Sie den folgenden Befehl aus, um die Toolbox in Ihren neuen Ordner herunterzuladen und zu installieren:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Rufen Sie den Cloud Shell-Editor (für den Codebearbeitungsmodus) auf und fügen Sie im Stammordner des Projekts eine Datei mit dem Namen „tools.yaml“ hinzu.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Ersetzen Sie das Tools.yaml-Skript durch den Code aus dieser Repo-Datei.
Informationen zu „tools.yaml“:
Quellen stellen die verschiedenen Datenquellen dar, mit denen ein Tool interagieren kann. Eine Quelle ist eine Datenquelle, mit der ein Tool interagieren kann. Sie können Quellen als Map im Abschnitt „sources“ Ihrer Datei „tools.yaml“ definieren. Normalerweise enthält eine Quellkonfiguration alle Informationen, die für die Verbindung mit und die Interaktion mit der Datenbank erforderlich sind.
Tools definieren Aktionen, die ein Agent ausführen kann, z. B. das Lesen und Schreiben in einer Quelle. Ein Tool stellt eine Aktion dar, die Ihr Agent ausführen kann, z. B. eine SQL-Anweisung. Sie können Tools als Map im Abschnitt „tools“ Ihrer Datei „tools.yaml“ definieren. Normalerweise ist für ein Tool eine Quelle erforderlich, auf die es sich beziehen kann.
Weitere Informationen zum Konfigurieren von „tools.yaml“ finden Sie in dieser Dokumentation.
- Führen Sie den folgenden Befehl aus dem Ordner „mcp-toolbox“ aus, um den Server zu starten:
./toolbox --tools-file "tools.yaml"
Wenn Sie den Server jetzt in einem Webvorschau-Modus in der Cloud öffnen, sollte der Toolbox-Server mit dem neuen Tool „get-order-data“ ausgeführt werden.
Der MCP Toolbox-Server wird standardmäßig auf Port 5000 ausgeführt. Wir verwenden Cloud Shell, um dies zu testen.
Klicken Sie in Cloud Shell auf „Webvorschau“, wie unten dargestellt:
Klicken Sie auf „Port ändern“, legen Sie den Port wie unten dargestellt auf 5000 fest und klicken Sie auf „Ändern und Vorschau“.
Dies sollte die folgende Ausgabe liefern:
- Stellen wir unsere Toolbox in Cloud Run bereit:
Zuerst können wir den MCP Toolbox-Server erstellen und in Cloud Run hosten. Dadurch erhalten wir einen öffentlichen Endpunkt, den wir in jede andere Anwendung und/oder die Agent-Anwendungen einbinden können. Eine Anleitung zum Hosten in Cloud Run finden Sie hier. Wir gehen nun die wichtigsten Schritte durch.
- Starten Sie ein neues Cloud Shell-Terminal oder verwenden Sie ein vorhandenes. Wechseln Sie zum Projektordner, in dem sich die Toolbox-Binärdatei und „tools.yaml“ befinden. In diesem Fall ist das „toolbox-tools“, falls Sie sich noch nicht darin befinden:
cd toolbox-tools
- Legen Sie die Variable PROJECT_ID auf Ihre Google Cloud-Projekt-ID fest.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Diese Google Cloud-Dienste aktivieren
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Erstellen wir ein separates Dienstkonto, das als Identität für den Toolbox-Dienst dient, den wir in Google Cloud Run bereitstellen.
gcloud iam service-accounts create toolbox-identity
- Wir sorgen auch dafür, dass dieses Dienstkonto die richtigen Rollen hat, d. h. Zugriff auf Secret Manager und die Möglichkeit, mit AlloyDB zu kommunizieren.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Wir laden die Datei „tools.yaml“ als Secret hoch:
gcloud secrets create tools --data-file=tools.yaml
Wenn Sie bereits ein Secret haben und die Secret-Version aktualisieren möchten, führen Sie Folgendes aus:
gcloud secrets versions add tools --data-file=tools.yaml
- Legen Sie eine Umgebungsvariable für das Container-Image fest, das Sie für Cloud Run verwenden möchten:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Der letzte Schritt im bekannten Bereitstellungsbefehl für Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Dadurch sollte der Prozess zum Bereitstellen des Toolbox-Servers mit unserer konfigurierten tools.yaml in Cloud Run gestartet werden. Bei erfolgreicher Bereitstellung wird eine Meldung ähnlich der folgenden angezeigt:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Sie können das neu bereitgestellte Tool jetzt in Ihrer Agent-Anwendung verwenden.
Auf die Tools im Toolbox-Server zugreifen
Nachdem die Toolbox bereitgestellt wurde, erstellen wir einen Python Cloud Run Functions-Shim für die Interaktion mit dem bereitgestellten Toolbox-Server. Das liegt daran, dass Toolbox derzeit kein Java SDK hat. Daher haben wir einen Python-Shim erstellt, um mit dem Server zu interagieren. Hier ist der Quellcode für diese Cloud Run-Funktion.
Sie müssen diese Cloud Run-Funktion erstellen und bereitstellen, um auf die Toolbox-Tools zugreifen zu können, die wir in den vorherigen Schritten erstellt und bereitgestellt haben:
- Wechseln Sie in der Google Cloud Console zur Cloud Run-Seite.
- Klicken Sie auf „Funktion schreiben“.
- Geben Sie im Feld „Dienstname“ einen Namen ein, um Ihre Funktion zu beschreiben. Dienstnamen müssen mit einem Buchstaben beginnen und dürfen maximal 49 Zeichen enthalten, darunter Buchstaben, Zahlen oder Bindestriche. Dienstnamen dürfen nicht auf Bindestriche enden und müssen pro Region und Projekt eindeutig sein. Ein Dienstname kann später nicht mehr geändert werden und ist öffentlich sichtbar. (Enter retail-product-search-quality)
- Verwenden Sie in der Liste „Region“ den Standardwert oder wählen Sie die Region aus, in der Sie Ihre Funktion bereitstellen möchten. (Wählen Sie „us-central1“ aus.)
- Verwenden Sie in der Liste „Laufzeit“ den Standardwert oder wählen Sie eine Laufzeitversion aus. (Python 3.11 auswählen)
- Wählen Sie im Bereich „Authentifizierung“ die Option „Öffentlichen Zugriff zulassen“ aus.
- Klicken Sie auf die Schaltfläche „Erstellen“.
- Die Funktion wird erstellt und mit einer Vorlage für „main.py“ und „requirements.txt“ geladen.
- Ersetzen Sie die Datei durch die Dateien main.py und requirements.txt aus dem Repository dieses Projekts.
- Stellen Sie die Funktion bereit. Sie sollten einen Endpunkt für Ihre Cloud Run-Funktion erhalten.
Ihr Endpunkt sollte so oder ähnlich aussehen:
Cloud Run Functions-Endpunkt für den Zugriff auf die Toolbox: „https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app“
Damit Sie das Projekt im Zeitrahmen der praxisorientierten, von Kursleitern geführten Sitzungen problemlos abschließen können, wird die Projektnummer für den Endpunkt während der praxisorientierten Sitzung mit Ihnen geteilt.
WICHTIGER HINWEIS:
Alternativ können Sie den Datenbankteil auch direkt als Teil Ihres Anwendungscodes oder der Cloud Run-Funktion implementieren.
8. Application Development (Java) with Faceted Search
Schließlich werden all diese leistungsstarken Backend-Komponenten durch die Anwendungsschicht zum Leben erweckt. Die in Java entwickelte Anwendung bietet die Benutzeroberfläche für die Interaktion mit dem Suchsystem. Es orchestriert die Abfragen an AlloyDB, verarbeitet die Anzeige von Facettenfiltern, verwaltet Nutzerauswahlen und präsentiert die neu gerankten, validierten Suchergebnisse auf nahtlose und intuitive Weise.
- Rufen Sie zuerst Ihr Cloud Shell-Terminal auf und klonen Sie das Repository:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Rufen Sie den Cloud Shell-Editor auf. Dort sehen Sie den neu erstellten Ordner „faceted_searching_retail“.
- Löschen Sie die folgenden Schritte, da sie bereits in den vorherigen Abschnitten ausgeführt wurden:
- Löschen Sie den Ordner „Cloud_Run_Function“.
- Löschen Sie die Datei „db_script.sql“.
- Löschen Sie die Datei „tools.yaml“.
- Navigieren Sie zum Projektordner „retail-faceted-search“. Dort sollte die Projektstruktur angezeigt werden:
- In der Datei ProductRepository.java müssen Sie die Variable TOOLBOX_ENDPOINT mit dem Endpunkt Ihrer (bereitgestellten) Cloud Run-Funktion ändern oder den Endpunkt vom Referenten übernehmen.
Suchen Sie nach der folgenden Codezeile und ersetzen Sie sie durch Ihren Endpunkt:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Achten Sie darauf, dass das Dockerfile und die pom.xml-Datei Ihrer Projektkonfiguration entsprechen. Eine Änderung ist nur erforderlich, wenn Sie eine Version oder Konfiguration explizit geändert haben.
- Prüfen Sie im Cloud Shell-Terminal, ob Sie sich in Ihrem Hauptordner und im Projektordner (faceted_searching_retail / retail-faceted-search) befinden. Verwenden Sie die folgenden Befehle, um sicherzustellen, dass Sie sich im Terminal im richtigen Ordner befinden:
cd faceted_searching_retail
cd retail-faceted-search
- Verpacken, erstellen und testen Sie Ihre Anwendung lokal:
mvn package
mvn spring-boot:run
Sie sollten Ihre Anwendung aufrufen können, indem Sie im Cloud Shell-Terminal auf „Vorschau auf Port 8080“ klicken (siehe unten):
9. In Cloud Run bereitstellen: ***WICHTIGER SCHRITT
Prüfen Sie im Cloud Shell-Terminal, ob Sie sich in Ihrem Hauptordner und im Projektordner befinden (faceted_searching_retail / retail-faceted-search). Verwenden Sie die folgenden Befehle, um sicherzustellen, dass Sie sich im Terminal im richtigen Ordner befinden:
cd faceted_searching_retail
cd retail-faceted-search
Wenn Sie sich sicher sind, dass Sie sich im Projektordner befinden, führen Sie den folgenden Befehl aus:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Nach der Bereitstellung sollten Sie einen bereitgestellten Cloud Run-Endpunkt erhalten, der so aussieht:
https://retail-search-**********-uc.a.run.app/
10. Demo
Sehen wir uns an, wie das alles in der Praxis aussieht:
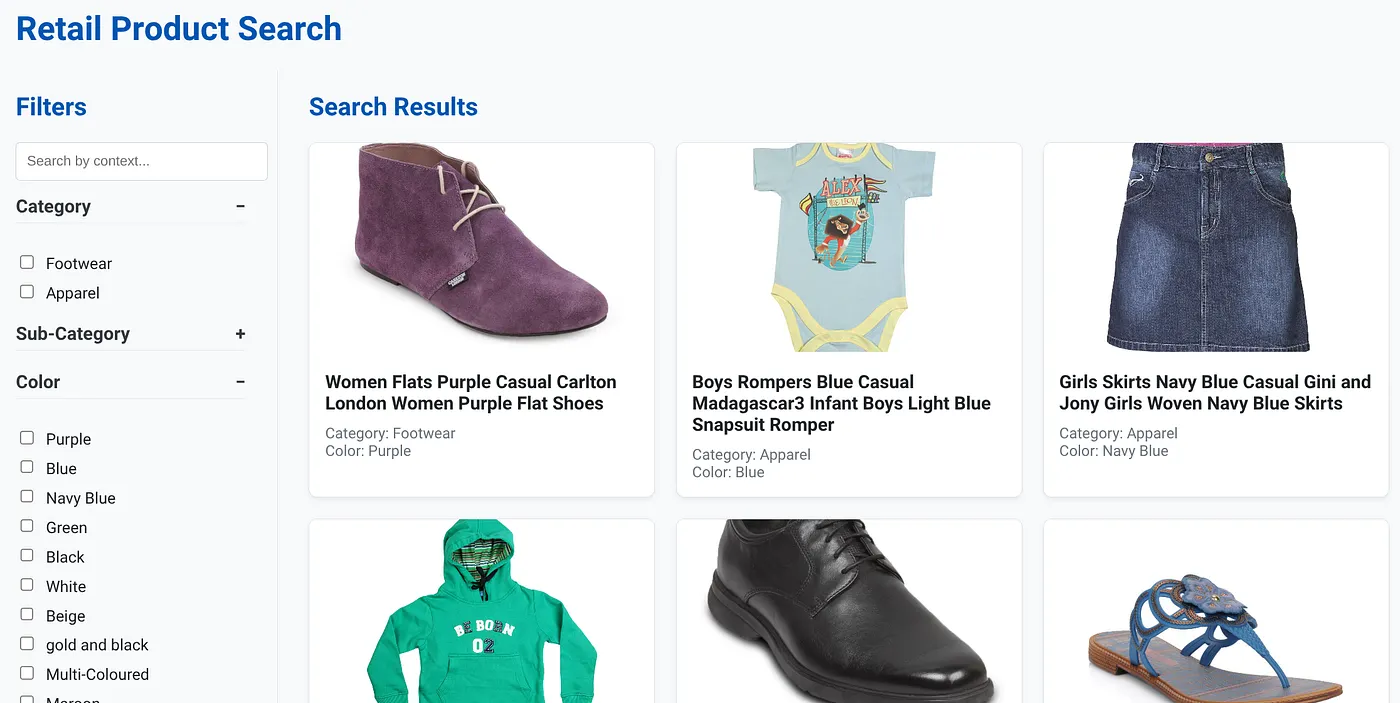
Das Bild oben zeigt die Landingpage für die dynamische Hybrid-Such-App.
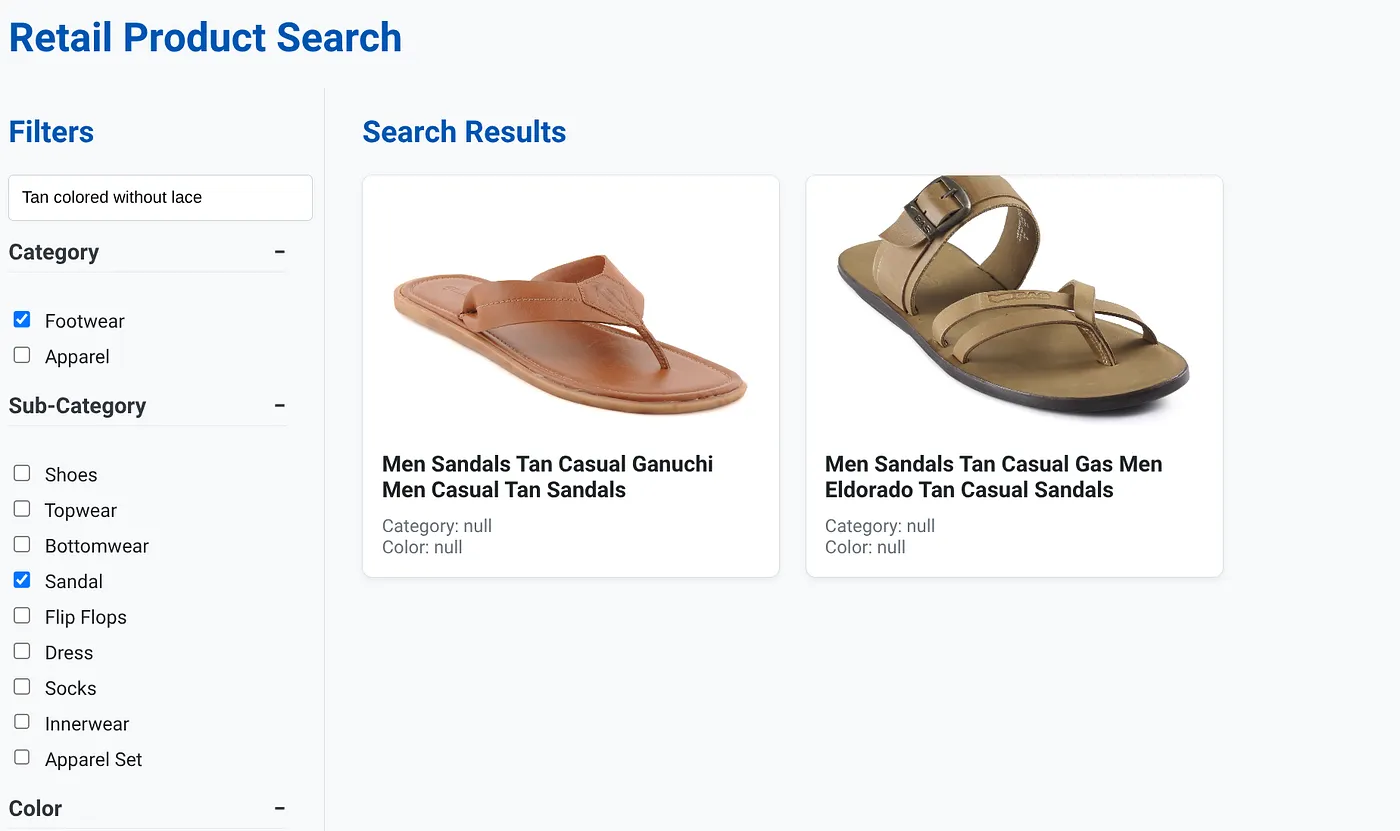
Das Bild oben zeigt die Suchergebnisse für „Tan colored without lace“ (Hellbraun ohne Schnürsenkel). Die ausgewählten Facettenfilter sind: Schuhe, Sandale.
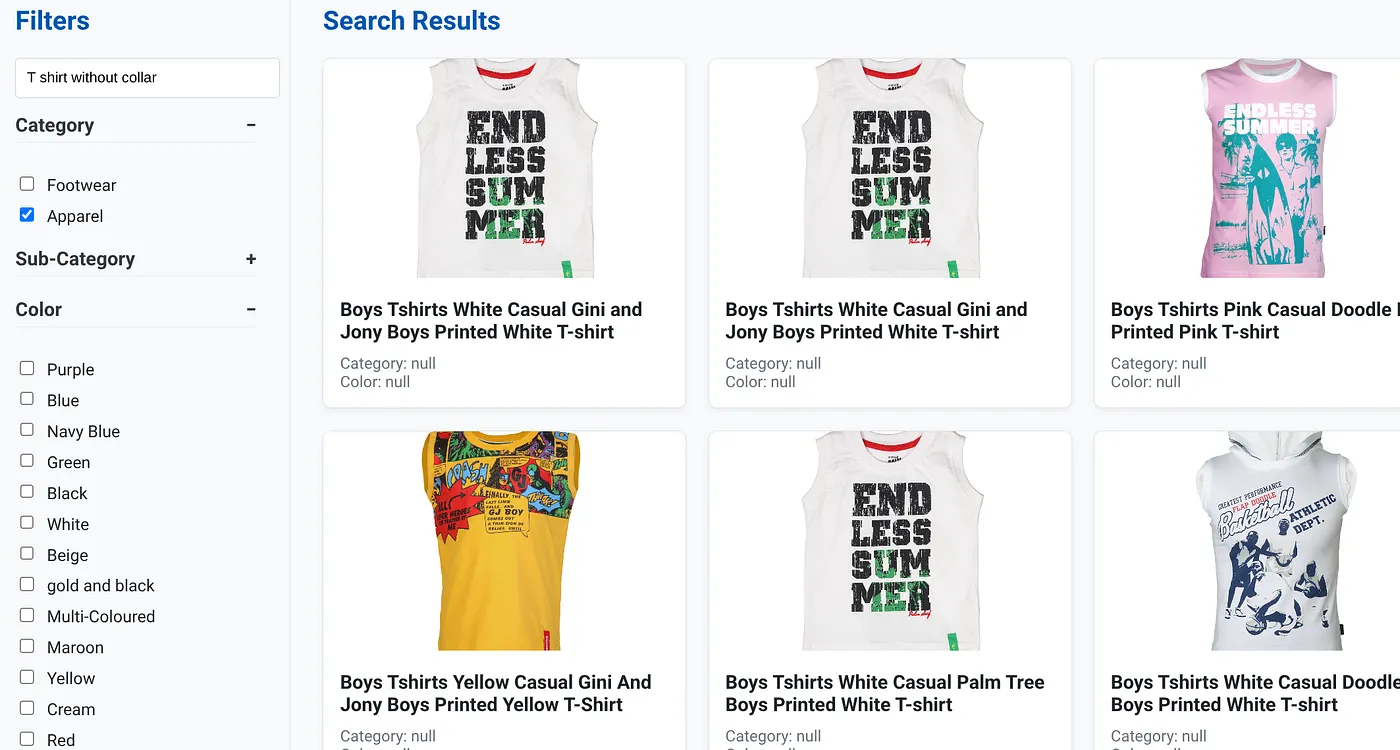
Das Bild oben zeigt die Suchergebnisse für „T-Shirt ohne Kragen“. Faceted Filters: Apparel
Sie können jetzt mehr generative und agentenbasierte Funktionen einbinden, um diese Anwendung nutzbar zu machen.
Probier es aus und lass dich inspirieren, selbst etwas zu entwickeln.
11. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcenmanager.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Herunterfahren, um das Projekt zu löschen.
- Alternativ können Sie einfach den AlloyDB-Cluster löschen, den wir gerade für dieses Projekt erstellt haben. Klicken Sie dazu auf die Schaltfläche „CLUSTER LÖSCHEN“. Wenn Sie bei der Konfiguration nicht „us-central1“ für den Cluster ausgewählt haben, ändern Sie den Speicherort in diesem Hyperlink.
12. Glückwunsch
Das wars! Sie haben das Lab erfolgreich abgeschlossen. Sie haben erfolgreich eine HYBRID SEARCH APP mit ALLOYDB in CLOUD RUN erstellt und bereitgestellt.
Warum das für Unternehmen wichtig ist:
Diese dynamische hybride Suchanwendung, die auf AlloyDB AI basiert, bietet erhebliche Vorteile für den Einzelhandel und andere Unternehmen:
Höhere Relevanz:Durch die Kombination von kontextbezogener (Vektor-)Suche mit präziser facettierter Filterung und intelligentem Neusortieren erhalten Kunden hochrelevante Ergebnisse, was zu einer höheren Zufriedenheit und mehr Conversions führt.
Skalierbarkeit:Die Architektur von AlloyDB und die scaNN-Indexierung sind für die Verarbeitung großer Produktkataloge und hoher Anfragevolumen konzipiert, was für wachsende E-Commerce-Unternehmen entscheidend ist.
Leistung:Schnellere Antworten auf Anfragen, auch bei komplexen hybriden Suchanfragen, sorgen für eine reibungslose Nutzererfahrung und minimieren die Abbruchraten.
Zukunftssicherheit:Durch die Integration von KI-Funktionen (Einbettungen, LLM-Validierung) ist die Anwendung für zukünftige Fortschritte bei personalisierten Empfehlungen, interaktivem Handel und intelligenter Produktsuche gerüstet.
Vereinfachte Architektur:Durch die Integration der Vektorsuche direkt in AlloyDB sind keine separaten Vektordatenbanken oder eine komplexe Synchronisierung mehr erforderlich, was die Entwicklung und Wartung vereinfacht.
Angenommen, ein Nutzer hat eine Anfrage in natürlicher Sprache eingegeben, z. B. „Umweltfreundliche Laufschuhe für Frauen mit hoher Unterstützung des Fußgewölbes“.
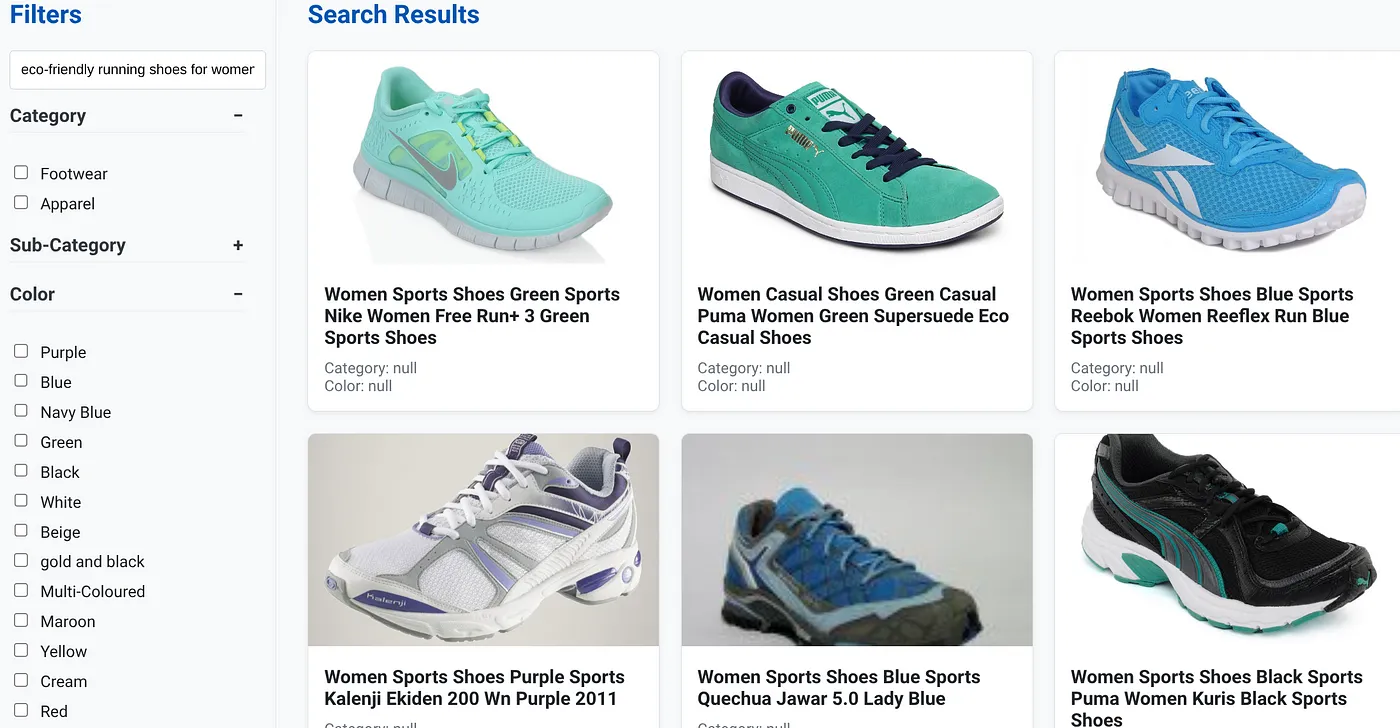
Gleichzeitig wendet der Nutzer Facettenfilter für „Kategorie: <<>>“, „Farbe: <<>>“ und „Preis: 100–150 $“ an:
- Das System gibt sofort eine optimierte Liste von Produkten zurück, die semantisch auf die natürliche Sprache abgestimmt sind und genau den ausgewählten Filtern entsprechen.
- Hinter den Kulissen beschleunigt der scaNN-Index die Vektorsuche, Inline- und adaptive Filterung sorgen für Leistung bei kombinierten Kriterien und durch Reranking werden die optimalen Ergebnisse oben angezeigt.
- Die Geschwindigkeit und Genauigkeit der Ergebnisse zeigen deutlich, wie leistungsstark die Kombination dieser Technologien für eine wirklich intelligente Einzelhandelssuche ist.
Für die Entwicklung einer Einzelhandelssuchanwendung der nächsten Generation sind innovative Methoden erforderlich. Mit AlloyDB, Vertex AI, Vector Search mit scaNN-Indexierung, dynamischer facettierter Filterung, Reranking und LLM-Validierung können wir eine beispiellose Kundenerfahrung bieten, die das Engagement steigert und den Umsatz ankurbelt. Diese robuste, skalierbare und intelligente Lösung zeigt, wie moderne Datenbankfunktionen, die mit KI angereichert sind, die Zukunft des Einzelhandels verändern.