
1. Descripción general
En el competitivo panorama minorista actual, es fundamental permitir que los clientes encuentren exactamente lo que buscan de forma rápida e intuitiva. La búsqueda tradicional basada en palabras clave a menudo se queda corta, ya que tiene dificultades con las búsquedas matizadas y los catálogos de productos extensos. En este codelab, se presenta una sofisticada aplicación de búsqueda minorista creada en AlloyDB y AlloyDB AI, que aprovecha la búsqueda de vectores de vanguardia, la indexación de scaNN, los filtros facetados y el filtrado adaptativo inteligente, la clasificación de nuevo para ofrecer una experiencia de búsqueda híbrida y dinámica a escala empresarial.
Ahora ya tenemos una comprensión básica de 3 aspectos:
- Qué significa la búsqueda contextual para tu agente y cómo lograrlo con la Búsqueda de Vectores
- También analizamos en detalle cómo lograr la búsqueda de vectores dentro del alcance de tus datos, es decir, dentro de tu propia base de datos (todas las bases de datos de Google Cloud admiten esto, si aún no lo sabías).
- Fuimos un paso más allá que el resto del mundo para explicarte cómo lograr una capacidad de RAG de búsqueda de vectores tan liviana con alto rendimiento y calidad con la capacidad de búsqueda de vectores de AlloyDB potenciada por el índice ScaNN.
Si no has realizado esos experimentos básicos, intermedios y un poco avanzados de RAG, te recomiendo que leas estos 3 aquí, aquí y aquí en el orden indicado.
El desafío
Más allá de los filtros, las palabras clave y la concordancia contextual: Una simple búsqueda de palabras clave puede devolver miles de resultados, muchos de ellos irrelevantes. La solución ideal debe comprender la intención detrás de la búsqueda, combinarla con criterios de filtro precisos (como marca, material o precio) y presentar los elementos más relevantes en milisegundos. Esto exige una infraestructura de búsqueda potente, flexible y escalable. Sin duda, hemos recorrido un largo camino desde la búsqueda por palabras clave hasta las coincidencias contextuales y las búsquedas por similitud. Pero imagina a un cliente que busca "una chaqueta cómoda, elegante y resistente al agua para hacer senderismo en primavera" y, al mismo tiempo, aplica filtros. Tu aplicación no solo devuelve respuestas de calidad, sino que también tiene un alto rendimiento, y tu base de datos elige de forma dinámica la secuencia de todo esto.
Objetivo
Para abordar este problema, integra
- Búsqueda contextual (búsqueda de vectores): Comprende el significado semántico de las búsquedas y las descripciones de los productos.
- Filtrado por facetas: Permite a los usuarios definir mejor los resultados con atributos específicos
- Enfoque híbrido: Combinación perfecta de la búsqueda contextual con el filtrado estructurado
- Optimización avanzada: Aprovechamiento de la indexación especializada, el filtrado adaptable y la clasificación para la velocidad y la relevancia
- Control de calidad impulsado por IA generativa: Incorporación de la validación de LLM para una calidad superior de los resultados
Analicemos la arquitectura y el recorrido de implementación.
Qué compilarás
Una aplicación de Retail Search
Como parte de esto, harás lo siguiente:
- Crea una instancia y una tabla de AlloyDB para el conjunto de datos de comercio electrónico
- Configura los embeddings y la búsqueda de vectores
- Crea un índice de metadatos y un índice de ScaNN
- Implementa la búsqueda de vectores avanzada en AlloyDB con el método de filtrado en línea de ScaNN
- Configura filtros facetados y la búsqueda híbrida en una sola consulta
- Cómo mejorar la relevancia de la búsqueda con la clasificación y la recuperación (opcional)
- Evalúa la respuesta a la búsqueda con Gemini (opcional)
- MCP Toolbox para bases de datos y capa de aplicación
- Application Development (Java) with Faceted Search
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de comercio electrónico. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de comercio electrónico.
Crea un clúster y una instancia
- Navega por la página de AlloyDB en Cloud Console. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Selecciona CREATE CLUSTER en esa página:

- Verás una pantalla como la que se muestra a continuación. Crea un clúster y una instancia con los siguientes valores (asegúrate de que los valores coincidan si clonas el código de la aplicación desde el repositorio):
- ID del clúster: "
vector-cluster" - contraseña: "
alloydb" - PostgreSQL 15 o la versión recomendada más reciente
- Región: "
us-central1" - Networking: "
default"
- Cuando selecciones la red predeterminada, verás una pantalla como la que se muestra a continuación.
Selecciona CONFIGURAR CONEXIÓN.
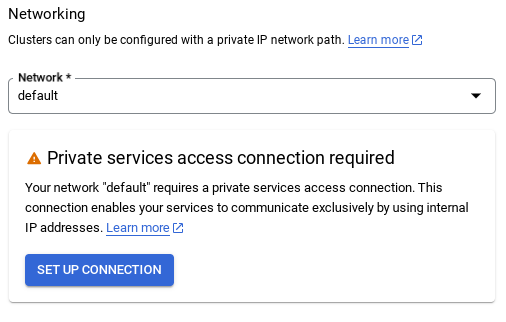
- Allí, selecciona "Usar un rango de IP asignado automáticamente" y haz clic en Continuar. Después de revisar la información, selecciona CREAR CONEXIÓN.
- Una vez que configures tu red, podrás continuar con la creación del clúster. Haz clic en CREATE CLUSTER para completar la configuración del clúster, como se muestra a continuación:
NOTA IMPORTANTE:
- Asegúrate de cambiar el ID de la instancia (que puedes encontrar en el momento de configurar el clúster o la instancia) a **
vector-instance**. Si no puedes cambiarlo, recuerda usar tu ID de instancia en todas las referencias futuras. - Ten en cuenta que la creación del clúster tardará alrededor de 10 minutos. Una vez que se complete correctamente, deberías ver una pantalla que muestre el resumen del clúster que acabas de crear.
4. Transferencia de datos
Ahora es el momento de agregar una tabla con los datos del almacén. Navega a AlloyDB, selecciona el clúster principal y, luego, AlloyDB Studio:
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo esté, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si quieres verificar las extensiones que se habilitaron en tu base de datos, ejecuta este comando de SQL:
select extname, extversion from pg_extension;
Crea una tabla
Puedes crear una tabla con la siguiente declaración DDL en AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La columna de incorporación permitirá el almacenamiento de los valores vectoriales del texto.
Otorgar permiso
Ejecuta la siguiente instrucción para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de Google Cloud IAM, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carga datos en la base de datos
- Copia las instrucciones de la consulta
insertde lainsert scripts sqlde la hoja al editor, como se mencionó anteriormente. Puedes copiar entre 10 y 50 instrucciones de inserción para una demostración rápida de este caso de uso. Aquí hay una lista seleccionada de inserciones en la pestaña "Selected Inserts 25-30 rows".
Puedes encontrar el vínculo a los datos en este archivo del repo de GitHub.
- Haz clic en Ejecutar. Los resultados de tu consulta aparecen en la tabla Resultados.
NOTA IMPORTANTE:
Asegúrate de copiar solo entre 25 y 50 registros para insertar, y de que provengan de un rango de tipos de categoría, subcategoría, color y género.
5. Crea embeddings para los datos
La verdadera innovación en la búsqueda moderna radica en comprender el significado, no solo las palabras clave. Aquí es donde entran en juego los embeddings y la búsqueda de vectores.
Transformamos las descripciones de los productos y las búsquedas de los usuarios en representaciones numéricas de alta dimensión llamadas "embeddings" con modelos de lenguaje previamente entrenados. Estos embeddings capturan el significado semántico, lo que nos permite encontrar productos que son "similares en significado" en lugar de solo contener palabras coincidentes. Inicialmente, experimentamos con la búsqueda directa de similitud de vectores en estos embeddings para establecer un valor de referencia, lo que demostró el poder de la comprensión semántica incluso antes de las optimizaciones de rendimiento.
La columna de embedding permitirá almacenar los valores vectoriales del texto de la descripción del producto. La columna img_embeddings permitirá el almacenamiento de incorporaciones de imágenes (multimodales). De esta manera, también puedes usar la búsqueda basada en la distancia entre texto e imagen. Sin embargo, en este lab, solo usaremos las embeddings de texto.
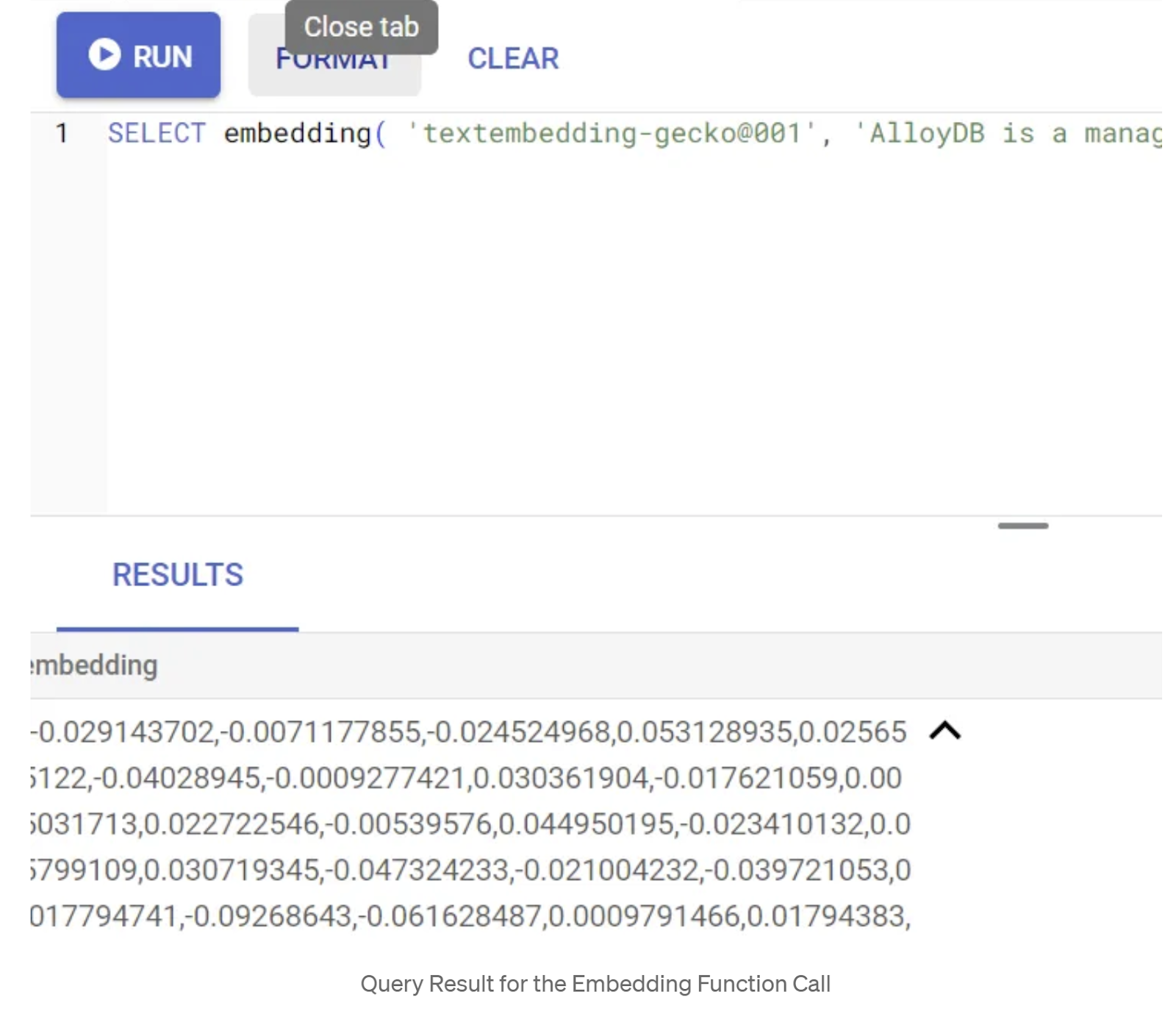
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Esto debería devolver el vector de embeddings, que se ve como un array de números de punto flotante, para el texto de muestra en la búsqueda. Se verá de la siguiente manera:
Actualiza el campo Vector de abstract_embeddings
Ejecuta la siguiente DML para actualizar la descripción del contenido en la tabla con los embeddings correspondientes:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Es posible que tengas problemas para generar más de unos pocos embeddings (por ejemplo, un máximo de 20 a 25) si usas una cuenta de facturación de crédito de prueba para Google Cloud. Por lo tanto, limita la cantidad de filas en la secuencia de comandos de inserción.
Si también deseas generar embeddings de imágenes (para realizar búsquedas contextuales multimodales), ejecuta la siguiente actualización:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Realiza RAG avanzado con las nuevas funciones de AlloyDB
Ahora que la tabla, los datos y los embeddings están listos, realicemos la búsqueda de vectores en tiempo real para el texto de búsqueda del usuario. Para probarlo, ejecuta la siguiente consulta:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
En esta consulta, comparamos la incorporación de texto de la búsqueda ingresada por el usuario "Camiseta de cuello redondo" con las incorporaciones de texto de todas las descripciones de productos en la tabla de prendas de vestir (almacenadas en la columna denominada "incorporación") con la función de distancia de similitud del coseno (representada por el símbolo "<=>"). Convertimos el resultado del método de incorporación al tipo de vector para que sea compatible con los vectores almacenados en la base de datos. LIMIT 10 representa que seleccionamos las 10 coincidencias más cercanas del texto de búsqueda.
AlloyDB lleva la RAG de búsqueda de vectores al siguiente nivel:
Para una solución a escala empresarial, la búsqueda de vectores sin procesar no es suficiente. El rendimiento es fundamental.
Índice de ScaNN (vecinos más cercanos escalables)
Para lograr una búsqueda de vecino más cercano aproximado (ANN) ultrarrápida, habilitamos el índice de ScaNN en AlloyDB. ScaNN, un algoritmo de búsqueda de vecinos más cercanos aproximado de última generación desarrollado por Google Research, está diseñado para la búsqueda eficiente de similitud de vectores a gran escala. Acelera significativamente las consultas, ya que reduce de manera eficiente el espacio de búsqueda y usa técnicas de cuantización, lo que ofrece consultas vectoriales hasta 4 veces más rápidas que otros métodos de indexación y un menor espacio en memoria. Obtén más información aquí y aquí.
Habilitemos la extensión y creemos los índices:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Crea índices para los campos de incorporación de texto y de imagen (en caso de que quieras usar incorporaciones de imagen en tu búsqueda):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Índices de metadatos
Si bien scaNN controla la indexación de vectores, los índices tradicionales de B-tree o GIN se configuraron meticulosamente en atributos estructurados (como categoría, subcategoría, diseño, color, etcétera). Estos índices son fundamentales para la eficiencia del filtrado facetado. Ejecuta las siguientes sentencias para configurar los índices de metadatos:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
NOTA IMPORTANTE:
Dado que es posible que solo hayas insertado entre 25 y 50 registros, los índices (ScaNN o cualquier otro índice) no serán eficaces.
Filtrado intercalado
Un desafío común en la búsqueda de vectores es combinarla con filtros estructurados (p.ej., "zapatos rojos"). El filtrado intercalado de AlloyDB optimiza este proceso. En lugar de filtrar los resultados después de una búsqueda de vectores amplia, el filtrado intercalado aplica condiciones de filtro durante el proceso de búsqueda de vectores, lo que mejora drásticamente el rendimiento y la precisión de las búsquedas de vectores filtradas.
Consulta esta documentación para obtener más información sobre la necesidad del filtrado intercalado. También puedes obtener información sobre la búsqueda de vectores filtrada para optimizar el rendimiento de la búsqueda de vectores aquí. Ahora, si deseas habilitar el filtrado intercalado para tu aplicación, ejecuta la siguiente instrucción desde tu editor:
SET scann.enable_inline_filtering = on;
El filtrado intercalado es mejor para los casos con selectividad media. A medida que AlloyDB busca en el índice de vectores, solo calcula las distancias para los vectores que coinciden con las condiciones de filtrado de metadatos (tus filtros funcionales en una consulta que suelen controlarse en la cláusula WHERE). Esto mejora enormemente el rendimiento de estas consultas y complementa las ventajas del filtrado posterior o previo.
Filtro adaptable
Para optimizar aún más el rendimiento, el filtrado adaptable de AlloyDB elige de forma dinámica la estrategia de filtrado más eficiente (filtrado intercalado o previo) durante la ejecución de la consulta. Analiza los patrones de búsqueda y las distribuciones de datos para garantizar un rendimiento óptimo sin intervención manual, lo que resulta especialmente beneficioso para las búsquedas de vectores filtrados, en las que cambia automáticamente entre el uso del índice de vectores y el de metadatos. Para habilitar el filtrado adaptable, usa la marca scann.enable_preview_features.
Cuando el filtrado adaptable activa un cambio del filtrado intercalado al filtrado previo durante la ejecución, el plan de consultas cambia de forma dinámica.
SET scann.enable_preview_features = on;
NOTA IMPORTANTE: Es posible que no puedas ejecutar la instrucción anterior sin reiniciar la instancia. Si encuentras un error, es mejor que habilites la marca enable_preview_features en la sección de marcas de la base de datos de tu instancia.
Filtros facetados que usan todos los índices
La búsqueda por facetas permite a los usuarios definir mejor los resultados aplicando varios filtros basados en atributos o "facetas" específicos (p.ej., marca, precio, tamaño, calificación del cliente). Nuestra aplicación integra estas facetas sin problemas con la búsqueda de vectores. Ahora, una sola búsqueda puede combinar el lenguaje natural (búsqueda contextual) con varias selecciones facetadas, lo que aprovecha de forma dinámica los índices vectoriales y los tradicionales. Esto proporciona una capacidad de búsqueda híbrida verdaderamente dinámica, lo que permite a los usuarios explorar los resultados con precisión.
En nuestra aplicación, como ya creamos todos los índices de metadatos, ya estamos listos para usar el filtro facetado en la Web. Para ello, abordamos el tema directamente con consultas en SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
En esta búsqueda, realizamos una búsqueda híbrida, que incorpora tanto
- Filtrado por facetas en la cláusula WHERE
- Vector Search en la cláusula ORDER BY con el método de similitud de coseno.
$1, $2, $3 y $4 representan los valores del filtro facetado en un array, y $5 representa el texto de la búsqueda del usuario. Reemplaza los valores de $1 a $4 por los valores de filtro facetado que elijas, como se muestra a continuación:
category = ANY([‘Apparel', ‘Footwear'])
Reemplaza USD 5 por el texto de búsqueda que prefieras, por ejemplo, "Polos".
NOTA IMPORTANTE: Si no tienes los índices debido al conjunto limitado de registros que insertaste, no verás el impacto en el rendimiento. Sin embargo, en un conjunto de datos de producción completo, observarás que el tiempo de ejecución se reduce significativamente para la misma búsqueda vectorial con el índice de ScaNN con filtrado intercalado en la búsqueda vectorial, lo que hizo posible esta mejora.
A continuación, evaluemos la recuperación de esta búsqueda de vectores habilitada para ScaNN.
Reclasificación
Incluso con la búsqueda avanzada, es posible que los resultados iniciales necesiten un pulido final. Es un paso fundamental que reordena los resultados de la búsqueda inicial para mejorar la relevancia. Después de que la búsqueda híbrida inicial proporciona un conjunto de productos candidatos, un modelo más sofisticado (y, a menudo, más pesado desde el punto de vista computacional) aplica una puntuación de relevancia más detallada. Esto garantiza que los resultados principales que se le presentan al usuario sean los más pertinentes, lo que mejora significativamente la calidad de la búsqueda. Evaluamos continuamente la recuperación para medir qué tan bien el sistema recupera todos los elementos pertinentes para una búsqueda determinada, y perfeccionamos nuestros modelos para maximizar la probabilidad de que un cliente encuentre lo que necesita.
Antes de usar esta función en tu aplicación, asegúrate de cumplir con todos los requisitos previos:
- Verifica que la extensión google_ml_integration esté instalada.
- Verifica que la marca de verificación google_ml_integration.enable_model_support esté activada.
- Se integra en Vertex AI.
- Habilita la API de Discovery Engine.
- Obtén los roles necesarios para usar los modelos de clasificación.
Luego, puedes usar la siguiente consulta en nuestra aplicación para volver a clasificar el conjunto de resultados de la búsqueda híbrida:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
En esta consulta, se RECLASIFICAN los resultados de productos de la búsqueda contextual que se abordan en la cláusula ORDER BY con el método de similitud del coseno. "Camisa rosa" es el texto que busca el usuario.
NOTA IMPORTANTE: Es posible que algunos de ustedes aún no tengan acceso a la función de reranking, por lo que la excluí del código de la aplicación. Sin embargo, si desean incluirla, pueden seguir el ejemplo que vimos anteriormente.
Evaluador de recuperación
La recuperación en la búsqueda por similitud es el porcentaje de instancias relevantes que se recuperaron de una búsqueda, es decir, la cantidad de verdaderos positivos. Esta es la métrica más común que se usa para medir la calidad de la búsqueda. Una fuente de pérdida de recuperación proviene de la diferencia entre la búsqueda aproximada de vecino más cercano (aNN) y la búsqueda de k vecinos más cercanos (kNN). Los índices de vectores, como la implementación de ScaNN de AlloyDB de algoritmos de aNN, te permiten acelerar la búsqueda de vectores en conjuntos de datos grandes a cambio de una pequeña compensación en la recuperación. Ahora, AlloyDB te permite medir esta compensación directamente en la base de datos para consultas individuales y garantizar que sea estable con el tiempo. Puedes actualizar los parámetros de índice y consulta en respuesta a esta información para obtener mejores resultados y rendimiento.
¿Cuál es la lógica detrás de la recuperación de los resultados de la búsqueda?
En el contexto de la búsqueda vectorial, la recuperación se refiere al porcentaje de vectores que devuelve el índice y que son vecinos más cercanos verdaderos. Por ejemplo, si una consulta de vecino más cercano para los 20 vecinos más cercanos muestra 19 de los vecinos más cercanos de verdad fundamental, la recuperación será 19/20*100 = 95%. La recuperación es la métrica que se usa para medir la calidad de la búsqueda y se define como el porcentaje de los resultados devueltos que son objetivamente los más cercanos a los vectores de la búsqueda.
Puedes encontrar la recuperación de una búsqueda vectorial en un índice de vectores para una configuración determinada con la función evaluate_query_recall. Esta función te permite ajustar tus parámetros para lograr los resultados de recuperación de la consulta vectorial que deseas.
NOTA IMPORTANTE:
Si tienes problemas de permisos denegados en el índice de HNSW en los siguientes pasos, omite toda esta sección de evaluación de recuperación por el momento. Es posible que se deba a restricciones de acceso en este punto, ya que se acaba de lanzar en el momento en que se documenta este codelab.
- Establece la marca Enable Index Scan en el índice de ScaNN y el índice de HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Ejecuta la siguiente consulta en AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La función evaluate_query_recall toma la búsqueda como parámetro y devuelve su recuperación. Uso la misma búsqueda que usé para verificar el rendimiento como la búsqueda de entrada de la función. Agregué SCaNN como método de indexación. Para obtener más opciones de parámetros, consulta la documentación.
La recuperación para esta búsqueda de vectores que hemos estado usando es la siguiente:
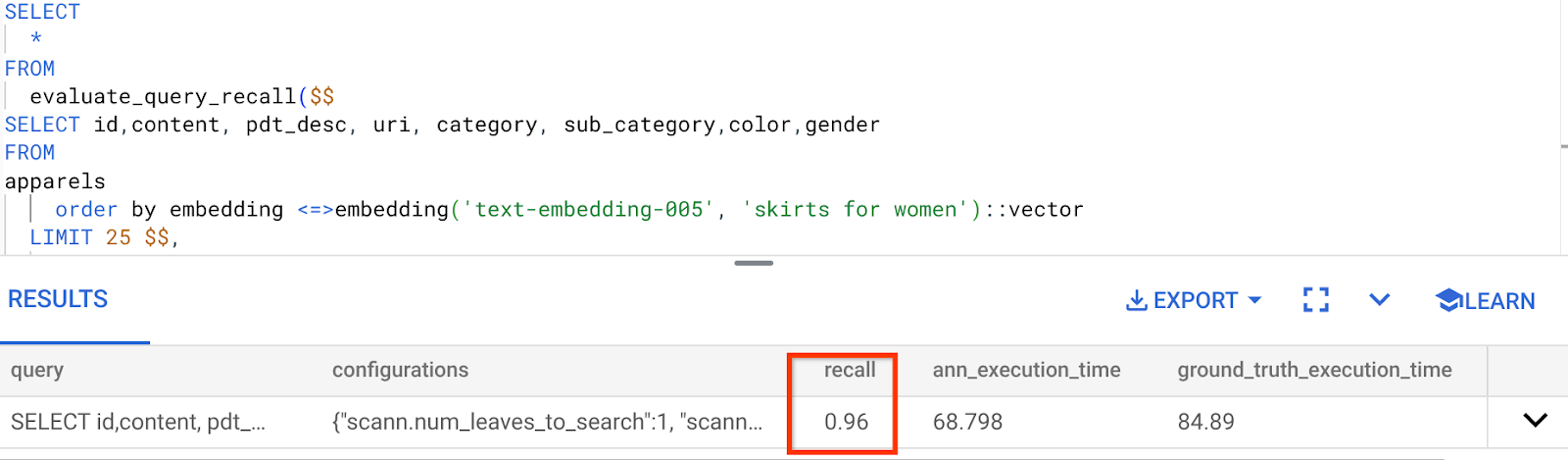
Veo que el RECALL es del 96%. En este caso, la recuperación es muy buena. Sin embargo, si se trataba de un valor inaceptable, puedes usar esta información para cambiar los parámetros del índice, los métodos y los parámetros de consulta, y mejorar mi recuperación para esta búsqueda vectorial.
Probar con parámetros de índice y búsqueda modificados
Ahora, probemos la consulta modificando los parámetros de consulta según la recuperación recibida.
- Para modificar los parámetros del índice, haz lo siguiente:
Para esta prueba, usaré la "distancia L2" en lugar de la función de distancia de similitud "coseno".
Nota muy importante: "¿Cómo sabemos que esta búsqueda usa la similitud de COSENO?", te preguntarás. Puedes identificar la función de distancia por el uso de "<=>" para representar la distancia del coseno.
Vínculo a la documentación para las funciones de distancia de la Búsqueda de vectores.
La consulta anterior usa la función de distancia de similitud del coseno, mientras que ahora probaremos la distancia L2. Sin embargo, para ello, también debemos asegurarnos de que el índice de ScaNN subyacente también use la función de distancia L2. Ahora, creemos un índice con una consulta de función de distancia diferente: Distancia L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
La instrucción para descartar el índice solo sirve para garantizar que no haya índices innecesarios en la tabla.
Ahora puedo ejecutar la siguiente consulta para evaluar la RECALL después de cambiar la función de distancia de mi funcionalidad de Vector Search.
[AFTER] Consulta que usa la función L2 Distance:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Puedes ver la diferencia o transformación en el valor de recuperación del índice actualizado.
Hay otros parámetros que puedes cambiar en el índice, como num_leaves, etc., según el valor de recuperación deseado y el conjunto de datos que usa tu aplicación.
Validación de los resultados de la búsqueda vectorial por parte del LLM
Para lograr la búsqueda controlada de mayor calidad, incorporamos una capa opcional de validación del LLM. Los modelos de lenguaje grandes se pueden usar para evaluar la relevancia y la coherencia de los resultados de la búsqueda, en especial para las búsquedas complejas o ambiguas. Esto puede incluir lo siguiente:
Verificación semántica:
Un LLM que compara los resultados con la intención de la búsqueda.
Filtrado lógico:
Usar un LLM para aplicar lógica empresarial o reglas complejas que son difíciles de codificar en filtros tradicionales, lo que permite refinar aún más la lista de productos según criterios matizados
Control de calidad:
Identificar y marcar automáticamente los resultados menos relevantes para la revisión humana o el perfeccionamiento del modelo
Así es como lo logramos en las funciones de AlloyDB AI:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
La consulta subyacente es la misma que vimos en las secciones de búsqueda por facetas, búsqueda híbrida y reordenamiento. Ahora, en esta consulta, incorporamos una capa de evaluación de GEMINI del conjunto de resultados reordenados que representa la construcción ml_predict_row. Comenté los filtros facetados, pero puedes incluir los elementos que desees en un array para los marcadores de posición del $1 al $4. Reemplaza $5 por el texto que quieras buscar, por ejemplo, "Top rosa sin estampado floral".
7. MCP Toolbox para bases de datos y capa de aplicación
Tras bambalinas, las herramientas sólidas y una aplicación bien estructurada garantizan un funcionamiento sin problemas.
La caja de herramientas MCP (Protocolo de contexto del modelo) para bases de datos simplifica la integración de herramientas de IA generativa y de agentes con AlloyDB. Actúa como un servidor de código abierto que optimiza la agrupación de conexiones, la autenticación y la exposición segura de las funciones de la base de datos a los agentes de IA o a otras aplicaciones.
En nuestra aplicación, usamos MCP Toolbox para bases de datos como una capa de abstracción para todas nuestras consultas de búsqueda híbrida inteligente.
Sigue los pasos que se indican a continuación para configurar e implementar Toolbox en nuestro caso de uso:
Puedes ver que una de las bases de datos compatibles con MCP Toolbox para bases de datos es AlloyDB y, como ya la aprovisionamos en la sección anterior, configuremos Toolbox.
- Navega a la terminal de Cloud Shell y asegúrate de que tu proyecto esté seleccionado y se muestre en el mensaje de la terminal. Ejecuta el siguiente comando desde tu terminal de Cloud Shell para navegar al directorio de tu proyecto:
mkdir toolbox-tools
cd toolbox-tools
- Ejecuta el siguiente comando para descargar e instalar la caja de herramientas en tu carpeta nueva:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Navega al editor de Cloud Shell (para el modo de edición de código) y, en la carpeta raíz del proyecto, agrega un archivo llamado "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Asegúrate de reemplazar la secuencia de comandos de Tools.yaml por el código de este archivo de repo.
Analicemos tools.yaml:
Las fuentes representan las diferentes fuentes de datos con las que una herramienta puede interactuar. Una fuente representa una fuente de datos con la que puede interactuar una herramienta. Puedes definir fuentes como un mapa en la sección sources de tu archivo tools.yaml. Por lo general, una configuración de origen contendrá toda la información necesaria para conectarse con la base de datos y para interactuar con ella.
Las herramientas definen las acciones que puede realizar un agente, como leer y escribir en una fuente. Una herramienta representa una acción que puede realizar tu agente, como ejecutar una sentencia de SQL. Puedes definir herramientas como un mapa en la sección de herramientas de tu archivo tools.yaml. Por lo general, una herramienta requerirá una fuente para actuar.
Para obtener más detalles sobre cómo configurar tu archivo tools.yaml, consulta esta documentación.
- Ejecuta el siguiente comando (desde la carpeta mcp-toolbox) para iniciar el servidor:
./toolbox --tools-file "tools.yaml"
Ahora, si abres el servidor en modo de vista previa web en la nube, deberías poder ver el servidor de Toolbox en funcionamiento con tu nueva herramienta llamada get-order-data.
El servidor de MCP Toolbox se ejecuta de forma predeterminada en el puerto 5000. Usemos Cloud Shell para probarlo.
Haz clic en Vista previa en la Web en Cloud Shell, como se muestra a continuación:
Haz clic en Cambiar puerto y establece el puerto en 5000, como se muestra a continuación, y haz clic en Cambiar y obtener vista previa.
Esto debería generar el siguiente resultado:
- Implementemos nuestra Toolbox en Cloud Run:
Primero, podemos comenzar con el servidor de MCP Toolbox y alojarlo en Cloud Run. Esto nos proporcionaría un extremo público que podríamos integrar con cualquier otra aplicación o con las aplicaciones del agente. Las instrucciones para alojar esto en Cloud Run se proporcionan aquí. Ahora veremos los pasos clave.
- Inicia una nueva terminal de Cloud Shell o usa una existente. Ve a la carpeta del proyecto en la que se encuentran el objeto binario de la caja de herramientas y el archivo tools.yaml (en este caso, toolbox-tools) si aún no estás en ella:
cd toolbox-tools
- Configura la variable PROJECT_ID para que apunte a tu ID del proyecto de Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Habilita estos servicios de Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Creemos una cuenta de servicio independiente que actuará como la identidad del servicio de Toolbox que implementaremos en Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- También nos aseguramos de que esta cuenta de servicio tenga los roles correctos, es decir, la capacidad de acceder a Secret Manager y comunicarse con AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Subiremos el archivo tools.yaml como un secreto:
gcloud secrets create tools --data-file=tools.yaml
Si ya tienes un secreto y quieres actualizar su versión, ejecuta el siguiente comando:
gcloud secrets versions add tools --data-file=tools.yaml
- Establece una variable de entorno en la imagen de contenedor que deseas usar para Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- El último paso en el comando de implementación conocido en Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Esto debería iniciar el proceso de implementación del servidor de Toolbox con nuestro archivo tools.yaml configurado en Cloud Run. Si la implementación se realiza correctamente, deberías ver un mensaje similar al siguiente:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Ya está todo listo para usar la herramienta que acabas de implementar en tu aplicación basada en agentes.
Cómo acceder a las herramientas en el servidor de la caja de herramientas
Una vez que se implemente Toolbox, crearemos un shim de Python Cloud Run Functions para interactuar con el servidor de Toolbox implementado. Esto se debe a que, actualmente, Toolbox no tiene un SDK de Java, por lo que creamos un shim de Python para interactuar con el servidor. Este es el código fuente de esa Cloud Run Function.
Debes crear e implementar esta función de Cloud Run para poder acceder a las herramientas de la caja de herramientas que acabamos de crear e implementar en los pasos anteriores:
- En la consola de Google Cloud, ve a la página de Cloud Run.
- Haz clic en Escribir una función.
- En el campo Nombre del servicio, ingresa un nombre para describir tu función. Los nombres de servicios solo deben comenzar con una letra y contener hasta 49 caracteres o menos, incluidas letras, números o guiones. Los nombres de los servicios no pueden terminar con guiones y deben ser únicos por región y proyecto. Un nombre de servicio no se puede cambiar más adelante y es visible de forma pública. (Ingresa retail-product-search-quality)
- En la lista Región, usa el valor predeterminado o selecciona la región en la que quieres implementar la función. (Elige us-central1)
- En la lista Runtime, usa el valor predeterminado o selecciona una versión de entorno de ejecución. (Elige Python 3.11)
- En la sección Autenticación, elige "Permitir acceso público".
- Haz clic en el botón "Crear".
- Se crea la función y se carga con una plantilla de main.py y requirements.txt
- Reemplaza ese contenido por los archivos main.py y requirements.txt del repo de este proyecto.
- Implementa la función y deberías obtener un extremo para tu Cloud Run Function
Tu extremo debería verse así (o de forma similar):
Extremo de Cloud Run Function para acceder a la caja de herramientas: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Para facilitar la finalización dentro del cronograma (en el caso de las sesiones prácticas dirigidas por el instructor), el número de proyecto del endpoint se compartirá en el momento de la sesión práctica.
NOTA IMPORTANTE:
Como alternativa, también puedes implementar la parte de la base de datos directamente como parte del código de tu aplicación o de la función de Cloud Run.
8. Application Development (Java) with Faceted Search
Por último, todos estos potentes componentes de backend se hacen realidad a través de la capa de aplicación. Desarrollada en Java, la aplicación proporciona la interfaz de usuario para interactuar con el sistema de búsqueda. Coordina las consultas a AlloyDB, controla la visualización de los filtros facetados, administra las selecciones del usuario y presenta los resultados de la búsqueda validados y reclasificados de una manera intuitiva y fluida.
- Para comenzar, navega a la terminal de Cloud Shell y clona el repositorio:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Navega al editor de Cloud Shell, donde puedes ver la carpeta recién creada faceted_searching_retail.
- Borra lo siguiente, ya que esos pasos ya se completaron en las secciones anteriores:
- Borra la carpeta Cloud_Run_Function
- Borra el archivo db_script.sql
- Borra el archivo tools.yaml
- Navega a la carpeta del proyecto retail-faceted-search y deberías ver la estructura del proyecto:
- En el archivo ProductRepository.java, debes modificar la variable TOOLBOX_ENDPOINT con el extremo de tu función de Cloud Run (implementada) o tomar el extremo del orador de la sesión práctica.
Busca la siguiente línea de código y reemplázala por tu extremo:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Asegúrate de que los archivos Dockerfile y pom.xml coincidan con la configuración de tu proyecto (no es necesario realizar cambios, a menos que hayas cambiado explícitamente alguna versión o configuración).
- En la terminal de Cloud Shell, asegúrate de estar dentro de tu carpeta principal y dentro de la carpeta del proyecto (faceted_searching_retail / retail-faceted-search). Usa los siguientes comandos para asegurarte de que, a menos que ya estés en la carpeta correcta en la terminal,
cd faceted_searching_retail
cd retail-faceted-search
- Empaqueta, compila y prueba tu aplicación de forma local:
mvn package
mvn spring-boot:run
Para ver tu aplicación, haz clic en "Vista previa en el puerto 8080" en la terminal de Cloud Shell, como se muestra a continuación:
9. Implementa en Cloud Run: ***PASO IMPORTANTE
En la terminal de Cloud Shell, asegúrate de estar dentro de tu carpeta principal y de la carpeta del proyecto (faceted_searching_retail / retail-faceted-search). Usa los siguientes comandos para asegurarte de que, a menos que ya estés en la carpeta correcta en la terminal,
cd faceted_searching_retail
cd retail-faceted-search
Cuando te asegures de que estás en la carpeta del proyecto, ejecuta el siguiente comando:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Una vez que se implemente, deberías recibir un extremo de Cloud Run implementado similar al siguiente:
https://retail-search-**********-uc.a.run.app/
10. Demostración
Veamos cómo todo se integra en acción:
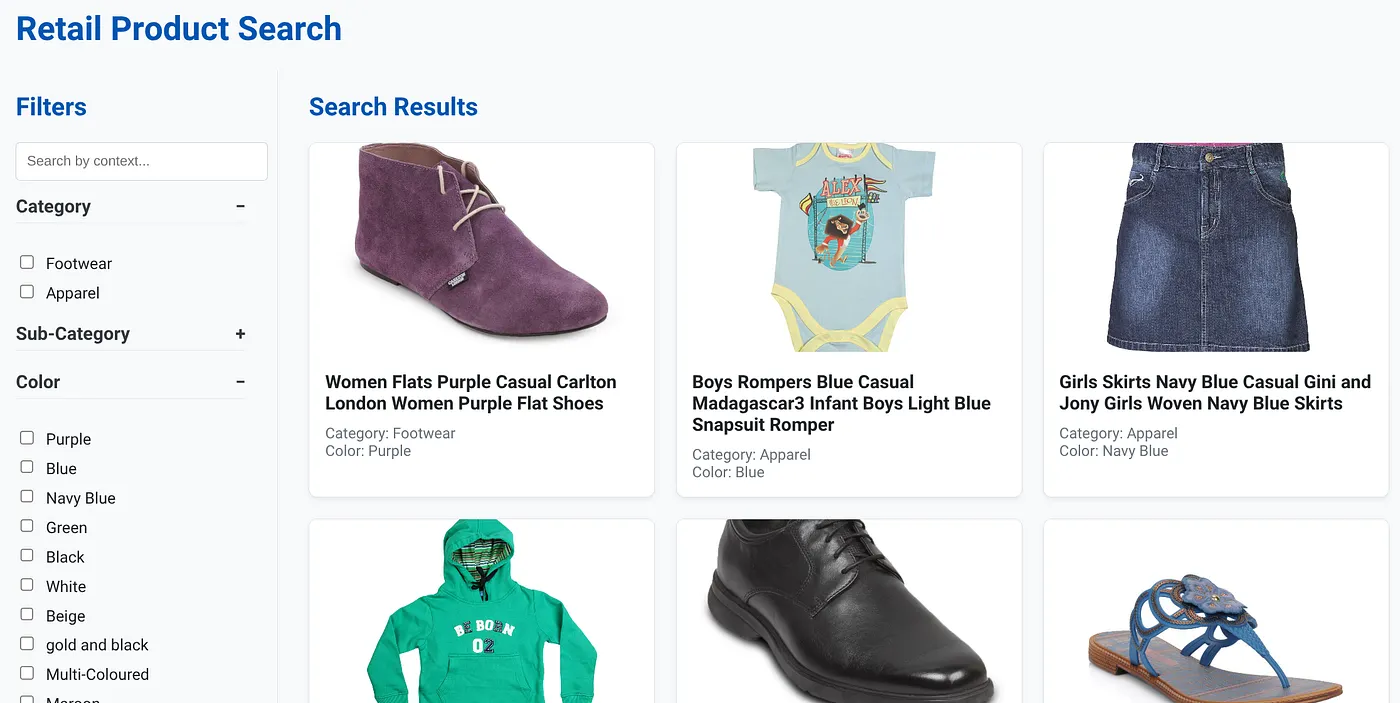
La imagen anterior muestra la página de destino de la app de búsqueda híbrida dinámica.
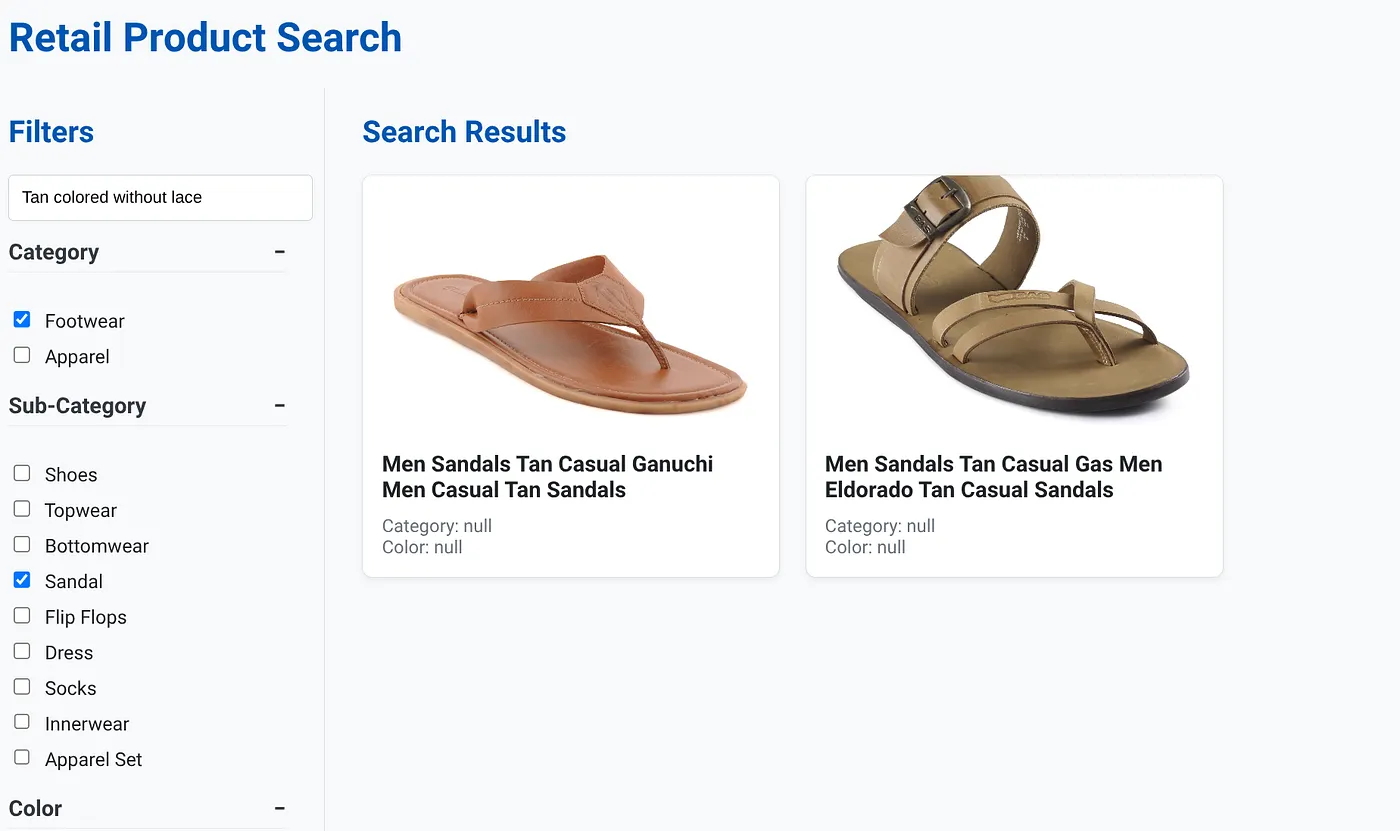
La imagen anterior muestra los resultados de la búsqueda "Color tostado sin cordones" . Los filtros facetados seleccionados son: Calzado, Sandalias.
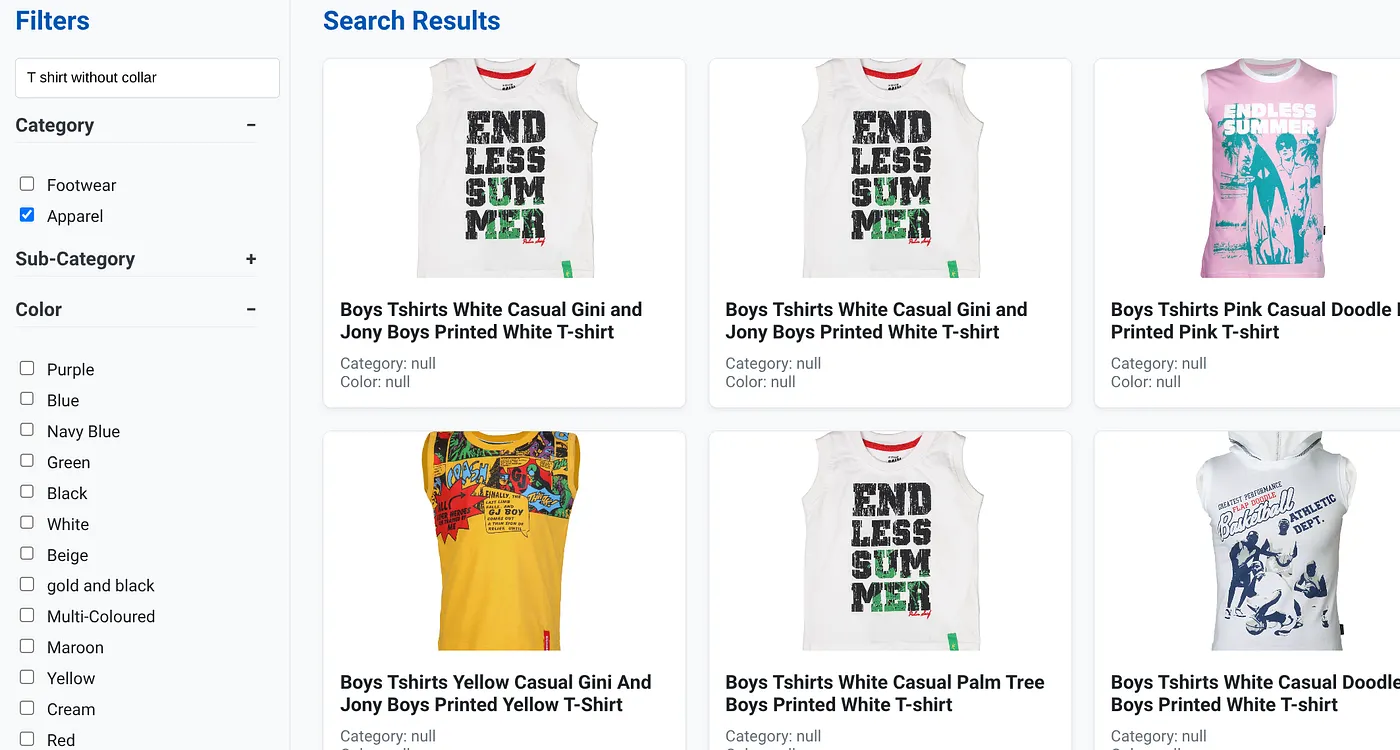
En la imagen anterior, se muestran los resultados de la búsqueda de "camiseta sin cuello" . Filtros facetados: Indumentaria
Ahora puedes incorporar más funciones generativas y de agente para que esta aplicación sea práctica.
Pruébalo para que te inspires a crear tu propio contenido.
11. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página del administrador de recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes hacer clic en el botón BORRAR CLÚSTER para borrar el clúster de AlloyDB (cambia la ubicación en este hipervínculo si no elegiste us-central1 para el clúster en el momento de la configuración) que acabamos de crear para este proyecto.
12. ¡Felicitaciones!
¡Felicitaciones! Creaste e implementaste correctamente una APP DE BÚSQUEDA HÍBRIDA con ALLOYDB en CLOUD RUN.
Por qué es importante para las empresas:
Esta aplicación de búsqueda híbrida dinámica, potenciada por AlloyDB AI, ofrece ventajas significativas para el comercio minorista empresarial y otras empresas:
Relevancia superior: Cuando se combina la búsqueda contextual (vectorial) con el filtrado preciso por facetas y la clasificación inteligente, los clientes reciben resultados muy relevantes, lo que genera mayor satisfacción y más conversiones.
Escalabilidad: La arquitectura de AlloyDB y la indexación de ScaNN están diseñadas para controlar catálogos de productos masivos y grandes volúmenes de consultas, lo que es fundamental para el crecimiento de los negocios de comercio electrónico.
Rendimiento: Las respuestas más rápidas a las búsquedas, incluso para las búsquedas híbridas complejas, garantizan una experiencia del usuario fluida y minimizan las tasas de abandono.
Preparación para el futuro: La integración de capacidades de IA (incorporaciones, validación de LLM) posiciona la aplicación para futuros avances en recomendaciones personalizadas, comercio conversacional y descubrimiento inteligente de productos.
Arquitectura simplificada: La integración de la búsqueda de vectores directamente en AlloyDB elimina la necesidad de bases de datos de vectores separadas o de una sincronización compleja, lo que simplifica el desarrollo y el mantenimiento.
Supongamos que un usuario escribió una búsqueda en lenguaje natural, como "zapatillas para correr ecológicas para mujeres con soporte de arco alto".
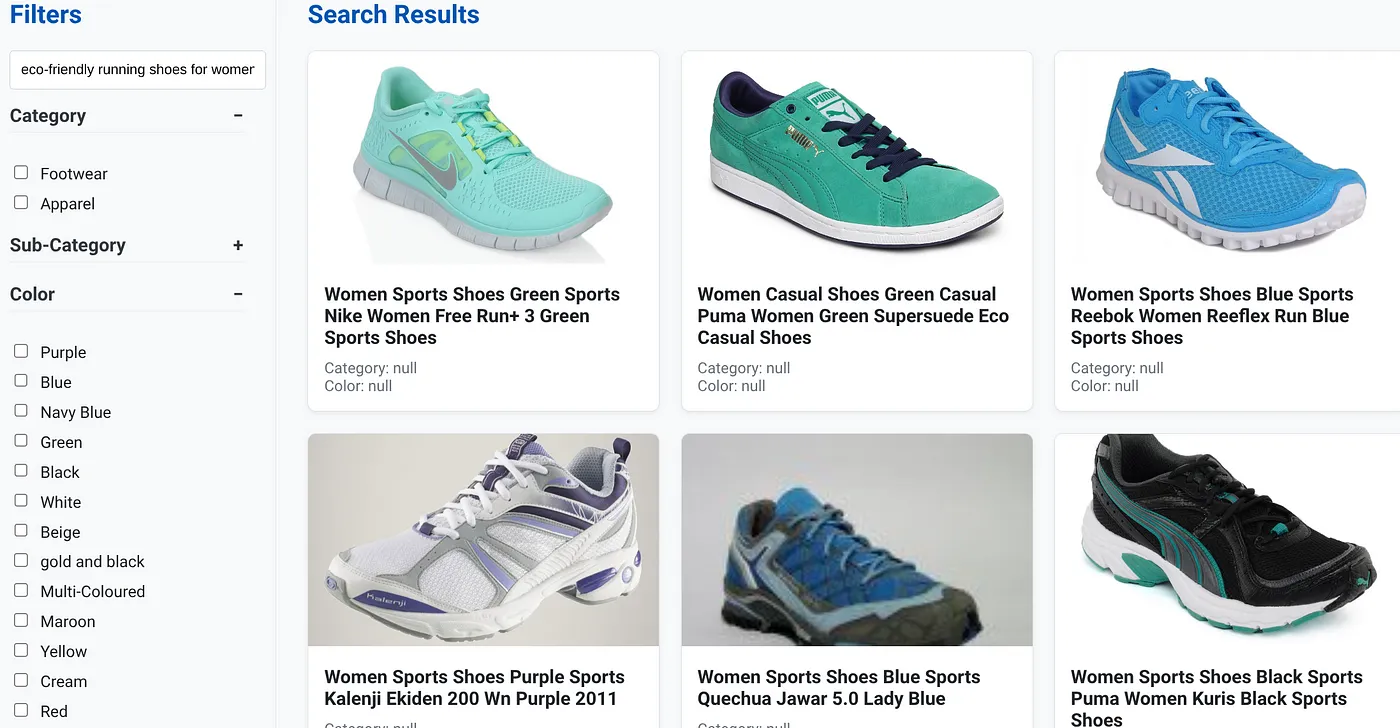
Mientras que, de forma simultánea, el usuario aplica filtros facetados para "Categoría: <<>>", "Color: <<>>" y dice "Precio: USD 100 a USD 150":
- El sistema devuelve al instante una lista refinada de productos, alineada semánticamente con el lenguaje natural y que coincide con precisión con los filtros elegidos.
- Tras bambalinas, el índice de ScaNN acelera la búsqueda de vectores, el filtrado adaptable y en línea garantiza el rendimiento con criterios combinados, y la clasificación vuelve a ordenar los resultados para presentar los óptimos en la parte superior.
- La velocidad y la precisión de los resultados ilustran claramente el poder de combinar estas tecnologías para brindar una experiencia de búsqueda minorista verdaderamente inteligente.
Para crear una aplicación de búsqueda minorista de próxima generación, es necesario ir más allá de los métodos convencionales. Con el poder de AlloyDB, Vertex AI, la búsqueda de vectores con indexación de scaNN, el filtrado dinámico por facetas, la clasificación de nuevo y la validación de LLM, podemos ofrecer una experiencia del cliente sin igual que impulse la participación y aumente las ventas. Esta solución sólida, inteligente y escalable demuestra cómo las capacidades modernas de las bases de datos, potenciadas por la IA, están transformando el futuro del comercio minorista.