
۱. مرور کلی
در چشمانداز رقابتی خردهفروشی امروز، توانمندسازی مشتریان برای یافتن دقیق آنچه به دنبالش هستند، به سرعت و به طور شهودی، بسیار مهم است. جستجوی سنتی مبتنی بر کلمات کلیدی اغلب با شکست مواجه میشود و با پرسوجوهای ظریف و کاتالوگهای گسترده محصولات دست و پنجه نرم میکند. این آزمایشگاه کد، یک برنامه جستجوی خردهفروشی پیشرفته ساخته شده بر روی AlloyDB، AlloyDB AI را رونمایی میکند که از جستجوی برداری پیشرفته، نمایهسازی scaNN، فیلترهای چندوجهی و فیلتر تطبیقی هوشمند بهره میبرد و برای ارائه یک تجربه جستجوی پویا و ترکیبی در مقیاس سازمانی، رتبهبندی مجدد میکند.
اکنون ما درک اساسی از ۳ چیز داریم:
- جستجوی زمینهای برای عامل شما به چه معناست و چگونه میتوان با استفاده از جستجوی برداری (Vector Search) آن را انجام داد.
- ما همچنین عمیقاً به دنبال دستیابی به جستجوی برداری در محدوده دادههای شما، یعنی درون خود پایگاه داده شما هستیم (اگر از قبل نمیدانستید، همه پایگاههای داده ابری گوگل از این قابلیت پشتیبانی میکنند!).
- ما با استفاده از قابلیت جستجوی برداری AlloyDB که توسط شاخص ScaNN پشتیبانی میشود، یک قدم فراتر از سایر نقاط جهان رفتیم و به شما گفتیم که چگونه میتوانید چنین قابلیت جستجوی برداری سبک RAG را با عملکرد و کیفیت بالا به دست آورید.
اگر آن آزمایشهای مقدماتی، متوسط و کمی پیشرفته RAG را انجام ندادهاید، توصیه میکنم آن ۳ مورد را به ترتیب اینجا ، اینجا و اینجا بخوانید.
چالش
فراتر رفتن از فیلترها، کلمات کلیدی و تطبیق متنی: یک جستجوی ساده کلمات کلیدی ممکن است هزاران نتیجه را برگرداند که بسیاری از آنها نامربوط هستند. راه حل ایده آل باید هدف پشت پرس و جو را درک کند، آن را با معیارهای دقیق فیلتر (مانند برند، جنس یا قیمت) ترکیب کند و مرتبط ترین موارد را در میلی ثانیه ارائه دهد. این امر مستلزم یک زیرساخت جستجوی قدرتمند، انعطاف پذیر و مقیاس پذیر است. مطمئناً ما از جستجوی کلمات کلیدی به تطابق های متنی و جستجوهای مشابه راه درازی را پیموده ایم. اما تصور کنید مشتری به دنبال "یک ژاکت راحت، شیک و ضد آب برای پیاده روی در بهار" است و همزمان فیلترها را اعمال می کند و برنامه شما نه تنها پاسخ های با کیفیت را برمی گرداند، بلکه عملکرد بالایی نیز دارد و توالی همه اینها به صورت پویا توسط پایگاه داده شما انتخاب می شود.
هدف
برای حل این مشکل با ادغام
- جستجوی متنی (جستجوی برداری): درک معنای معنایی پرسوجوها و توضیحات محصول
- فیلترینگ چندوجهی: کاربران را قادر میسازد تا نتایج را با ویژگیهای خاص اصلاح کنند.
- رویکرد ترکیبی: ترکیب یکپارچه جستجوی متنی با فیلترینگ ساختاریافته
- بهینهسازی پیشرفته: استفاده از نمایهسازی تخصصی، فیلتر تطبیقی و رتبهبندی مجدد برای سرعت و ارتباط
- کنترل کیفیت مولد مبتنی بر هوش مصنوعی: گنجاندن اعتبارسنجی LLM برای کیفیت برتر نتایج.
بیایید معماری و مسیر پیادهسازی را بررسی کنیم.
آنچه خواهید ساخت
یک برنامه جستجوی خرده فروشی
به عنوان بخشی از این، شما:
- ایجاد یک نمونه و جدول AlloyDB برای مجموعه دادههای تجارت الکترونیک
- تنظیم جاسازیها و جستجوی برداری
- ایجاد شاخص فراداده و شاخص ScaNN
- پیادهسازی جستجوی برداری پیشرفته در AlloyDB با استفاده از روش فیلترینگ درونخطی ScaNN
- فیلترهای چندوجهی و جستجوی ترکیبی را در یک پرسوجوی واحد راهاندازی کنید
- اصلاح ارتباط پرسوجو با رتبهبندی مجدد و فراخوانی (اختیاری)
- ارزیابی پاسخ پرسوجو با Gemini (اختیاری)
- جعبه ابزار MCP برای پایگاههای داده و لایه کاربرد
- توسعه اپلیکیشن (جاوا) با جستجوی چندوجهی
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: روی لینک کلیک کنید و API ها را فعال کنید.
به عنوان یک روش جایگزین، میتوانید از دستور gcloud برای این کار استفاده کنید. برای مشاهده دستورات و نحوه استفاده از gcloud به مستندات آن مراجعه کنید.
۳. راهاندازی پایگاه داده
در این آزمایش، ما از AlloyDB به عنوان پایگاه داده برای دادههای تجارت الکترونیک استفاده خواهیم کرد. این پایگاه داده از خوشهها برای نگهداری تمام منابع، مانند پایگاههای داده و گزارشها، استفاده میکند. هر خوشه یک نمونه اصلی دارد که یک نقطه دسترسی به دادهها را فراهم میکند. جداول، دادههای واقعی را نگهداری میکنند.
بیایید یک کلاستر، نمونه و جدول AlloyDB ایجاد کنیم که مجموعه دادههای تجارت الکترونیک در آن بارگذاری شود.
ایجاد یک کلاستر و نمونه
- در کنسول ابری، صفحه AlloyDB را پیمایش کنید. یک راه آسان برای یافتن اکثر صفحات در کنسول ابری، جستجوی آنها با استفاده از نوار جستجوی کنسول است.
- از آن صفحه، گزینه CREATE CLUSTER را انتخاب کنید:

- صفحهای مانند تصویر زیر خواهید دید. یک کلاستر و نمونه با مقادیر زیر ایجاد کنید (مطمئن شوید که مقادیر مطابقت دارند، در صورتی که کد برنامه را از مخزن کپی میکنید):
- شناسه خوشه : "
vector-cluster" - رمز عبور : "
alloydb" - PostgreSQL 15 / آخرین نسخه توصیه شده
- منطقه : "
us-central1" - شبکه : "
default"
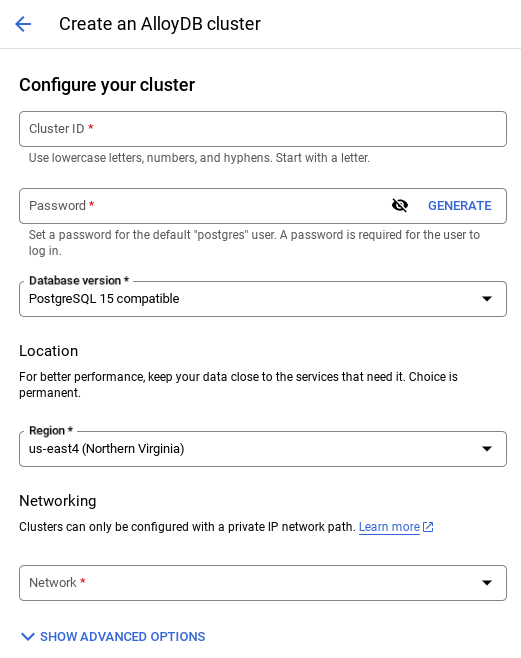
- وقتی شبکه پیشفرض را انتخاب میکنید، صفحهای مانند تصویر زیر مشاهده خواهید کرد.
تنظیم اتصال را انتخاب کنید.
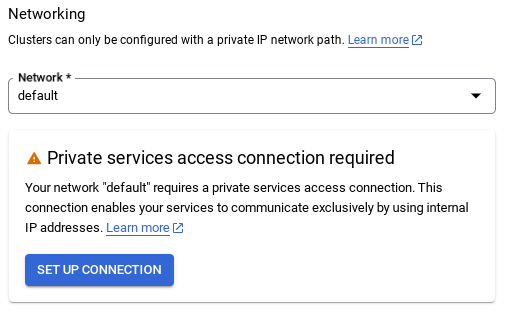
- از آنجا، « استفاده از یک محدوده IP اختصاص داده شده خودکار » را انتخاب کرده و ادامه دهید. پس از بررسی اطلاعات، «ایجاد اتصال» را انتخاب کنید.
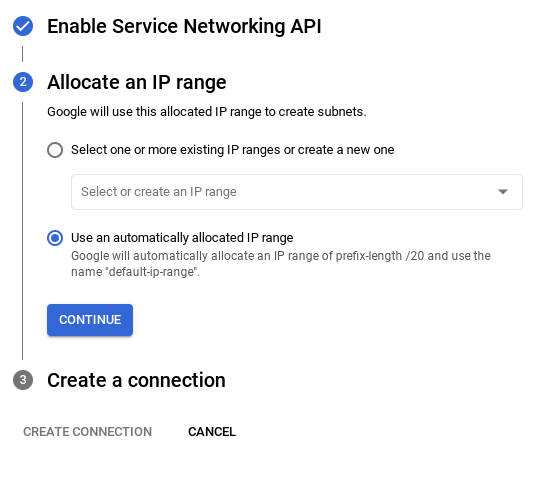
- پس از راهاندازی شبکه، میتوانید به ایجاد خوشه خود ادامه دهید. برای تکمیل راهاندازی خوشه، مطابق شکل زیر، روی CREATE CLUSTER کلیک کنید:
نکته مهم:
- مطمئن شوید که شناسه نمونه (که میتوانید در زمان پیکربندی کلاستر / نمونه پیدا کنید) را به
vector-instance** تغییر دهید. اگر نمیتوانید آن را تغییر دهید، به یاد داشته باشید که در تمام ارجاعات بعدی از شناسه نمونه خود استفاده کنید . - توجه داشته باشید که ایجاد خوشه حدود ۱۰ دقیقه طول خواهد کشید. پس از موفقیتآمیز بودن، باید صفحهای را مشاهده کنید که نمای کلی خوشه ایجاد شده شما را نشان میدهد.
۴. دریافت دادهها
حالا وقت آن رسیده که یک جدول با دادههای مربوط به فروشگاه اضافه کنیم. به AlloyDB بروید، خوشه اصلی و سپس AlloyDB Studio را انتخاب کنید:
ممکن است لازم باشد منتظر بمانید تا نمونه شما به طور کامل ایجاد شود. پس از اتمام این کار، با استفاده از اعتبارنامههایی که هنگام ایجاد خوشه ایجاد کردهاید، وارد AlloyDB شوید. از دادههای زیر برای تأیید اعتبار در PostgreSQL استفاده کنید:
- نام کاربری: "
postgres" - پایگاه داده: "
postgres" - رمز عبور: "
alloydb"
پس از اینکه با موفقیت در AlloyDB Studio احراز هویت شدید، دستورات SQL در ویرایشگر وارد میشوند. میتوانید با استفاده از علامت + در سمت راست آخرین پنجره، چندین پنجره ویرایشگر اضافه کنید.
شما میتوانید دستورات AlloyDB را در پنجرههای ویرایشگر وارد کنید و در صورت لزوم از گزینههای Run، Format و Clear استفاده کنید.
فعال کردن افزونهها
برای ساخت این برنامه، از افزونههای pgvector و google_ml_integration استفاده خواهیم کرد. افزونه pgvector به شما امکان ذخیره و جستجوی جاسازیهای برداری را میدهد. افزونه google_ml_integration توابعی را ارائه میدهد که برای دسترسی به نقاط پایانی پیشبینی هوش مصنوعی Vertex برای دریافت پیشبینیها در SQL استفاده میکنید. این افزونهها را با اجرای DDL های زیر فعال کنید :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
اگر میخواهید افزونههایی که در پایگاه داده شما فعال شدهاند را بررسی کنید، این دستور SQL را اجرا کنید:
select extname, extversion from pg_extension;
ایجاد یک جدول
شما میتوانید با استفاده از دستور DDL زیر در AlloyDB Studio یک جدول ایجاد کنید:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
ستون تعبیهشده امکان ذخیرهسازی مقادیر برداری متن را فراهم میکند.
اعطای مجوز
برای اعطای مجوز اجرا به تابع "embedding"، دستور زیر را اجرا کنید:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
اعطای نقش کاربری Vertex AI به حساب سرویس AlloyDB
از کنسول Google Cloud IAM ، به حساب سرویس AlloyDB (که به این شکل است: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) دسترسی به نقش "Vertex AI User" را بدهید. PROJECT_NUMBER شماره پروژه شما را خواهد داشت.
همچنین میتوانید دستور زیر را از ترمینال Cloud Shell اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
بارگذاری دادهها در پایگاه داده
- دستورات کوئری
insertرا ازinsert scripts sqlدر برگهای که در بالا ذکر شد، در ویرایشگر کپی کنید. میتوانید ۱۰ تا ۵۰ دستور درج را برای نمایش سریع این مورد استفاده کپی کنید. در اینجا، در تب "Selected Inserts 25-30 rows" فهرستی از درجها وجود دارد.
لینک دادهها را میتوانید در این فایل مخزن گیتهاب پیدا کنید .
- روی Run کلیک کنید. نتایج پرسوجوی شما در جدول نتایج ظاهر میشود.
نکته مهم:
مطمئن شوید که فقط ۲۵ تا ۵۰ رکورد را برای درج کپی میکنید و مطمئن شوید که از طیف وسیعی از انواع دستهبندی، زیررده، رنگ و جنسیت باشد.
۵. ایجاد جاسازیها برای دادهها
نوآوری واقعی در جستجوی مدرن در درک معنا نهفته است، نه فقط کلمات کلیدی. اینجاست که جاسازیها و جستجوی برداری وارد عمل میشوند.
ما توضیحات محصول و پرسوجوهای کاربر را با استفاده از مدلهای زبانی از پیش آموزشدیده به نمایشهای عددی با ابعاد بالا به نام «جاسازیها» تبدیل کردیم. این جاسازیها معنای معنایی را ثبت میکنند و به ما امکان میدهند محصولاتی را پیدا کنیم که «از نظر معنا مشابه» هستند، نه اینکه فقط حاوی کلمات منطبق باشند. در ابتدا، ما با جستجوی تشابه برداری مستقیم روی این جاسازیها آزمایش کردیم تا یک خط مبنا ایجاد کنیم و قدرت درک معنایی را حتی قبل از بهینهسازیهای عملکرد نشان دهیم.
ستون embedding امکان ذخیرهسازی مقادیر برداری متن توضیحات محصول را فراهم میکند. ستون img_embeddings امکان ذخیرهسازی جاسازیهای تصویر (چندوجهی) را فراهم میکند. به این ترتیب میتوانید از متن در مقابل جستجوی مبتنی بر فاصله تصویر نیز استفاده کنید. اما ما در این تمرین فقط از جاسازیهای متن استفاده خواهیم کرد.
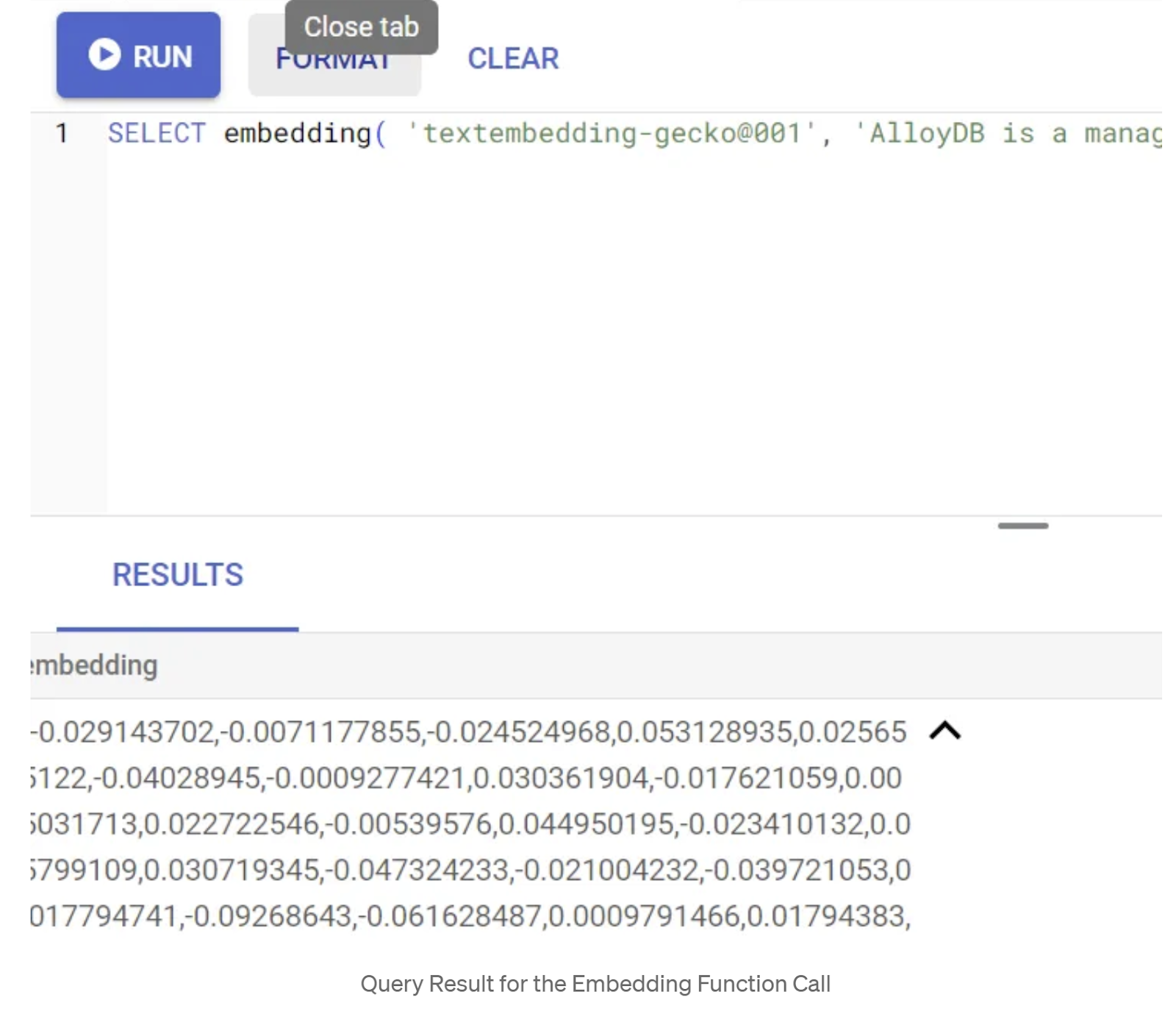
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
این باید بردار جاسازیها را که شبیه آرایهای از اعداد اعشاری است، برای متن نمونه در پرسوجو برگرداند. به این شکل است:
فیلد بردار abstract_embeddings را بهروزرسانی کنید
DML زیر را اجرا کنید تا توضیحات محتوا در جدول با جاسازیهای مربوطه بهروزرسانی شود:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
اگر از یک حساب پرداخت اعتباری آزمایشی برای Google Cloud استفاده میکنید، ممکن است در ایجاد بیش از چند جاسازی (مثلاً حداکثر ۲۰ تا ۲۵) مشکل داشته باشید. بنابراین تعداد ردیفها را در اسکریپت درج محدود کنید.
اگر میخواهید جاسازی تصویر ایجاد کنید (برای انجام جستجوی متنی چندوجهی)، بهروزرسانی زیر را نیز اجرا کنید:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
۶. انجام RAG پیشرفته با ویژگیهای جدید AlloyDB
حالا که جدول، دادهها و جاسازیها آماده هستند، بیایید جستجوی برداری بلادرنگ (real-time Vector Search) را برای متن جستجوی کاربر انجام دهیم. میتوانید این را با اجرای کوئری زیر آزمایش کنید:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
در این پرسوجو، ما جاسازی متن عبارت جستجوی کاربر با عنوان "تیشرت یقه گرد" را با جاسازی متن تمام توضیحات محصول در جدول پوشاک (که در ستونی به نام "جاسازی" ذخیره شده است) با استفاده از تابع فاصله شباهت کسینوسی (که با نماد "<=>" نشان داده میشود) مقایسه میکنیم. ما نتیجه روش جاسازی را به نوع بردار تبدیل میکنیم تا با بردارهای ذخیره شده در پایگاه داده سازگار باشد. محدودیت 10 نشان میدهد که ما 10 مورد از نزدیکترین تطابقها با متن جستجو را انتخاب میکنیم.
AlloyDB، جستجوی برداری RAG را به سطح بالاتری میبرد:
برای یک راهکار در مقیاس سازمانی، جستجوی بردار خام کافی نیست. عملکرد بسیار مهم است.
شاخص ScaNN (نزدیکترین همسایههای مقیاسپذیر)
برای دستیابی به جستجوی فوقالعاده سریع نزدیکترین همسایه تقریبی (ANN)، شاخص scaNN را در AlloyDB فعال کردیم. ScaNN، یک الگوریتم جستجوی نزدیکترین همسایه تقریبی پیشرفته که توسط Google Research توسعه داده شده است، برای جستجوی کارآمد شباهت برداری در مقیاس بزرگ طراحی شده است. این الگوریتم با هرس کردن کارآمد فضای جستجو و استفاده از تکنیکهای کوانتیزاسیون، سرعت پرسوجوها را به طور قابل توجهی افزایش میدهد و پرسوجوهای برداری تا ۴ برابر سریعتر از سایر روشهای شاخصگذاری و فضای حافظه کمتری را ارائه میدهد. برای اطلاعات بیشتر در مورد آن اینجا و اینجا را بخوانید.
بیایید افزونه را فعال کنیم و ایندکسها را ایجاد کنیم:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
ایجاد فهرست برای هر دو فیلد جاسازی متن و جاسازی تصویر (در صورتی که میخواهید از جاسازی تصویر در جستجوی خود استفاده کنید):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
شاخصهای فراداده
در حالی که scaNN نمایهسازی برداری را مدیریت میکند، نمایههای سنتی B-tree یا GIN با دقت بر روی ویژگیهای ساختاریافته (مانند دستهبندی، زیر دستهبندی، استایل، رنگ و غیره) تنظیم میشدند. این نمایهها برای کارایی فیلتر وجهی بسیار مهم هستند. برای تنظیم نمایههای فراداده، دستورات زیر را اجرا کنید:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
نکته مهم:
از آنجایی که ممکن است فقط ۲۵ تا ۵۰ رکورد وارد کرده باشید، اندیسها (ScaNN یا هر اندیس دیگری) مؤثر نخواهند بود.
فیلتر درون خطی
یک چالش رایج در جستجوی برداری، ترکیب آن با فیلترهای ساختاریافته (مثلاً "کفشهای قرمز") است. فیلترینگ درونخطی AlloyDB این مشکل را بهینه میکند. به جای فیلتر کردن نتایج پس از جستجوی برداری گسترده، فیلترینگ درونخطی شرایط فیلتر را در طول فرآیند جستجوی برداری اعمال میکند و عملکرد و دقت جستجوهای برداری فیلترشده را به طرز چشمگیری بهبود میبخشد.
برای کسب اطلاعات بیشتر در مورد نیاز به فیلتر درون خطی به این مستندات مراجعه کنید. همچنین در اینجا در مورد جستجوی برداری فیلتر شده برای بهینه سازی عملکرد جستجوی برداری اطلاعات کسب کنید. حال اگر میخواهید فیلتر درون خطی را برای برنامه خود فعال کنید، عبارت زیر را از ویرایشگر خود اجرا کنید:
SET scann.enable_inline_filtering = on;
فیلترینگ درونخطی برای مواردی با گزینشپذیری متوسط بهترین گزینه است. از آنجایی که AlloyDB در شاخص بردار جستجو میکند، فقط فواصل بردارهایی را محاسبه میکند که با شرایط فیلترینگ فراداده مطابقت دارند (فیلترهای عملکردی شما در یک پرسوجو که معمولاً در بند WHERE مدیریت میشوند). این امر عملکرد این پرسوجوها را به طور چشمگیری بهبود میبخشد و مزایای پس از فیلتر یا پیش از فیلتر را تکمیل میکند.
فیلتر تطبیقی
برای بهینهسازی بیشتر عملکرد، فیلتر تطبیقی AlloyDB به صورت پویا کارآمدترین استراتژی فیلترینگ (درونخطی یا پیشفیلترینگ) را در حین اجرای پرسوجو انتخاب میکند. این فیلتر، الگوهای پرسوجو و توزیع دادهها را تجزیه و تحلیل میکند تا عملکرد بهینه را بدون دخالت دستی تضمین کند، به خصوص برای جستجوهای برداری فیلتر شده که در آن به طور خودکار بین استفاده از شاخص برداری و فراداده جابجا میشود، مفید است. برای فعال کردن فیلتر تطبیقی، از پرچم scann.enable_preview_features استفاده کنید.
وقتی فیلترینگ تطبیقی در حین اجرا، باعث تغییر از فیلترینگ درونخطی به پیشفیلترینگ میشود، طرح پرسوجو به صورت پویا تغییر میکند.
SET scann.enable_preview_features = on;
نکته مهم: اگر با خطا مواجه شدید، ممکن است نتوانید دستور فوق را بدون راهاندازی مجدد نمونه اجرا کنید - بهتر است پرچم enable_preview_features را از بخش پرچمهای پایگاه داده نمونه خود فعال کنید.
فیلترهای چندوجهی با استفاده از تمام شاخصها
جستجوی چندوجهی به کاربران این امکان را میدهد که با اعمال فیلترهای متعدد بر اساس ویژگیها یا «وجهههای» خاص (مثلاً برند، قیمت، اندازه، رتبهبندی مشتری)، نتایج را اصلاح کنند. برنامه ما این جنبهها را به طور یکپارچه با جستجوی برداری ادغام میکند. اکنون یک پرسوجوی واحد میتواند زبان طبیعی (جستجوی متنی) را با انتخابهای چندوجهی ترکیب کند و به صورت پویا از هر دو شاخص برداری و سنتی بهره ببرد. این قابلیت، یک جستجوی ترکیبی واقعاً پویا را فراهم میکند و به کاربران امکان میدهد تا به طور دقیق به نتایج دسترسی پیدا کنند.
در برنامه ما، از آنجایی که قبلاً تمام شاخصهای فراداده را ایجاد کردهایم، با استفاده از کوئریهای SQL، برای استفاده از فیلتر وجهی در وب آماده هستیم:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
در این پرس و جو، ما در حال انجام جستجوی ترکیبی هستیم - که هر دو را در بر میگیرد
- فیلترینگ چندوجهی در بند WHERE و
- جستجوی برداری در دستور ORDER BY با استفاده از روش تشابه کسینوسی.
$1، $2، $3 و $4 مقادیر فیلتر چندوجهی را در یک آرایه نشان میدهند و $5 متن جستجوی کاربر را نشان میدهد. $1 تا $4 را با مقادیر فیلتر چندوجهی دلخواه خود مانند زیر جایگزین کنید:
دسته = هر (['پوشاک'، 'کفش'])
به جای $5، عبارت مورد نظر خود را برای جستجو وارد کنید، مثلاً «تیشرتهای پولو».
نکته مهم: اگر به دلیل محدودیت مجموعه رکوردهایی که وارد کردهاید، ایندکسها را نداشته باشید، تأثیر عملکرد را نخواهید دید. اما در یک مجموعه داده کامل، مشاهده خواهید کرد که زمان اجرا برای همان جستجوی برداری با استفاده از فیلتر درونخطی، که با استفاده از اندیس ScaNN تزریقشده روی جستجوی برداری انجام شده است، به طور قابل توجهی کاهش مییابد!!!
در مرحله بعد، بیایید میزان فراخوانی این جستجوی برداری فعالشده با ScaNN را ارزیابی کنیم.
رتبهبندی مجدد
حتی با جستجوی پیشرفته، نتایج اولیه ممکن است نیاز به اصلاح نهایی داشته باشند. این یک گام حیاتی است که نتایج جستجوی اولیه را برای بهبود ارتباط، مرتب میکند. پس از اینکه جستجوی ترکیبی اولیه مجموعهای از محصولات کاندید را ارائه میدهد، یک مدل پیچیدهتر (و اغلب از نظر محاسباتی سنگینتر) امتیاز ارتباط دقیقتری را اعمال میکند. این تضمین میکند که بهترین نتایج ارائه شده به کاربر، مرتبطترین نتایج هستند و کیفیت جستجو را به طور قابل توجهی افزایش میدهند. ما به طور مداوم میزان بازیابی را ارزیابی میکنیم تا میزان موفقیت سیستم در بازیابی تمام موارد مرتبط برای یک عبارت جستجو شده را اندازهگیری کنیم و مدلهای خود را اصلاح کنیم تا احتمال یافتن آنچه مشتری نیاز دارد را به حداکثر برسانیم.
قبل از استفاده از این در برنامه خود، مطمئن شوید که تمام پیشنیازها را رعایت کردهاید:
- تأیید کنید که افزونه google_ml_integration نصب شده است.
- تأیید کنید که پرچم google_ml_integration.enable_model_support روی روشن تنظیم شده باشد.
- با Vertex AI ادغام شوید.
- فعال کردن API موتور اکتشاف (Discovery Engine API).
- نقشهای مورد نیاز برای استفاده از مدلهای رتبهبندی را دریافت کنید.
و سپس میتوانید از کوئری زیر در برنامه ما برای رتبهبندی مجدد مجموعه نتایج جستجو شده ترکیبی استفاده کنید:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
در این پرسوجو، ما در حال انجام رتبهبندی مجدد مجموعه نتایج محصول از جستجوی متنی هستیم که در بند ORDER BY با استفاده از روش شباهت کسینوسی به آن پرداخته شده است. 'Pink top' متنی است که کاربر در حال جستجو برای آن است.
نکته مهم: ممکن است برخی از شما هنوز به Reranking دسترسی نداشته باشید، بنابراین من آن را از کد درخواست حذف کردهام، اما اگر میخواهید آن را اضافه کنید، میتوانید نمونهای را که در بالا پوشش دادیم، دنبال کنید.
ارزیاب یادآوری
فراخوانی در جستجوی شباهت، درصد نمونههای مرتبطی است که از یک جستجو بازیابی شدهاند، یعنی تعداد موارد مثبت واقعی. این رایجترین معیار مورد استفاده برای اندازهگیری کیفیت جستجو است. یکی از منابع از دست دادن فراخوانی، تفاوت بین جستجوی تقریبی نزدیکترین همسایه یا aNN و جستجوی k (دقیق) نزدیکترین همسایه یا kNN است. شاخصهای برداری مانند ScaNN از AlloyDB، الگوریتمهای aNN را پیادهسازی میکنند و به شما این امکان را میدهند که در ازای یک بدهبستان کوچک در فراخوانی، جستجوی برداری را در مجموعه دادههای بزرگ سرعت بخشید. اکنون، AlloyDB این امکان را برای شما فراهم میکند که این بدهبستان را مستقیماً در پایگاه داده برای پرسوجوهای فردی اندازهگیری کنید و از پایداری آن در طول زمان اطمینان حاصل کنید. میتوانید پارامترهای پرسوجو و شاخص را در پاسخ به این اطلاعات بهروزرسانی کنید تا به نتایج و عملکرد بهتری دست یابید.
منطق پشت یادآوری نتایج جستجو چیست؟
در زمینه جستجوی برداری، فراخوانی به درصد بردارهایی اشاره دارد که شاخص، نزدیکترین همسایههای واقعی را برمیگرداند. برای مثال، اگر یک جستجوی نزدیکترین همسایه برای 20 نزدیکترین همسایه، 19 نزدیکترین همسایه واقعی را برگرداند، آنگاه فراخوانی برابر با 19/20x100 = 95% است. فراخوانی معیاری است که برای کیفیت جستجو استفاده میشود و به عنوان درصد نتایج برگشتی که به طور عینی به بردارهای جستجو نزدیک هستند، تعریف میشود.
شما میتوانید با استفاده از تابع evaluate_query_recall، فراخوانی یک پرسوجوی برداری را روی یک اندیس برداری برای یک پیکربندی مشخص پیدا کنید. این تابع به شما امکان میدهد پارامترهای خود را تنظیم کنید تا به نتایج فراخوانی پرسوجوی برداری مورد نظر خود برسید.
نکته مهم:
اگر در مراحل بعدی با خطای عدم اجازه دسترسی در شاخص HNSW مواجه شدید، فعلاً از کل این بخش ارزیابی فراخوان صرف نظر کنید. ممکن است در حال حاضر مربوط به محدودیتهای دسترسی باشد، زیرا این خطا در زمان انتشار این کد منتشر شده است.
- پرچم Enable Index Scan را روی شاخص ScaNN و شاخص HNSW تنظیم کنید:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- کوئری زیر را در AlloyDB Studio اجرا کنید:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
تابع evaluate_query_recall پرسوجو را به عنوان پارامتر دریافت میکند و فراخوانی آن را برمیگرداند. من از همان پرسوجویی که برای بررسی عملکرد به عنوان پرسوجوی ورودی تابع استفاده کردم، استفاده میکنم. من SCaNN را به عنوان متد شاخص اضافه کردهام. برای گزینههای پارامتر بیشتر به مستندات مراجعه کنید.
فراخوانی برای این کوئری جستجوی برداری که ما استفاده کردهایم:
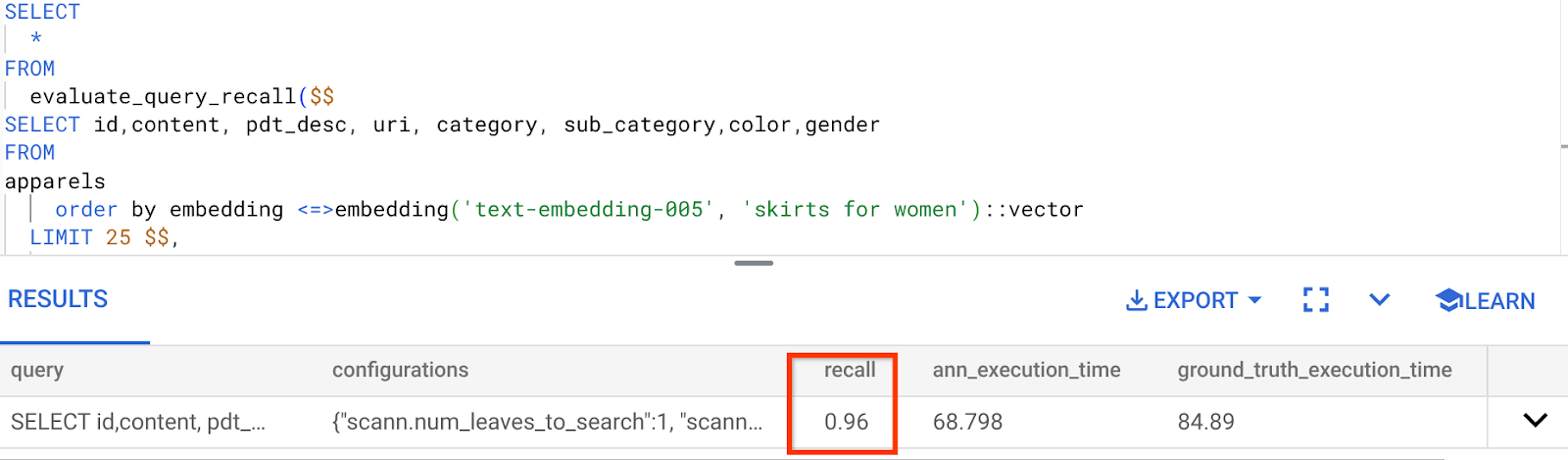
میبینم که میزان بازیابی ۹۶٪ است. در این مورد، بازیابی واقعاً خوب است. اما اگر مقدار غیرقابل قبولی بود، میتوانید از این اطلاعات برای تغییر پارامترهای شاخص، روشها و پارامترهای پرسوجو استفاده کنید و میزان بازیابی من را برای این جستجوی برداری بهبود بخشید!
آن را با پارامترهای پرس و جو و شاخص اصلاح شده آزمایش کنید
حالا بیایید با تغییر پارامترهای پرسوجو بر اساس فراخوانی دریافتی، پرسوجو را آزمایش کنیم.
- اصلاح پارامترهای شاخص:
برای این آزمون، به جای تابع فاصله تشابه «کسینوسی»، از «فاصله L2» استفاده خواهم کرد.
نکته بسیار مهم: شما میپرسید: «از کجا بفهمیم که این پرسوجو از شباهت کسینوسی استفاده میکند؟» میتوانید تابع فاصله را با استفاده از «<=>» برای نمایش فاصله کسینوسی شناسایی کنید.
لینک اسناد برای توابع فاصله جستجوی برداری.
پرسوجوی قبلی از تابع فاصله شباهت کسینوسی استفاده میکرد، در حالی که اکنون میخواهیم فاصله L2 را امتحان کنیم. اما برای این کار باید مطمئن شویم که شاخص ScaNN زیرین نیز از تابع فاصله L2 استفاده میکند. اکنون بیایید یک شاخص با پرسوجوی تابع فاصله متفاوت ایجاد کنیم: فاصله L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
دستور drop index فقط برای اطمینان از عدم وجود ایندکس غیرضروری در جدول است.
اکنون، میتوانم کوئری زیر را برای ارزیابی RECALL پس از تغییر تابع فاصلهی قابلیت جستجوی برداری خود اجرا کنم.
[بعد از] پرس و جویی که از تابع فاصله L2 استفاده میکند:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
میتوانید تفاوت/تبدیل را در مقدار فراخوانی برای اندیس بهروزرسانیشده مشاهده کنید.
پارامترهای دیگری نیز وجود دارند که میتوانید در اندیس تغییر دهید، مانند num_leaves و غیره. این پارامترها را میتوانید بر اساس مقدار فراخوانی مورد نظر و مجموعه دادهای که برنامه شما استفاده میکند، تنظیم کنید.
اعتبارسنجی LLM نتایج جستجوی برداری
برای دستیابی به بالاترین کیفیت جستجوی کنترلشده، ما یک لایه اختیاری از اعتبارسنجی LLM را در نظر گرفتیم. مدلهای زبان بزرگ میتوانند برای ارزیابی ارتباط و انسجام نتایج جستجو، بهویژه برای پرسوجوهای پیچیده یا مبهم، مورد استفاده قرار گیرند. این میتواند شامل موارد زیر باشد:
تأیید معنایی:
نتایج ارجاع متقابل LLM برخلاف هدف پرسوجو است.
فیلترینگ منطقی:
استفاده از یک LLM برای اعمال منطق پیچیده کسب و کار یا قوانینی که کدگذاری آنها در فیلترهای سنتی دشوار است، و همچنین اصلاح بیشتر لیست محصولات بر اساس معیارهای ظریف.
تضمین کیفیت:
شناسایی و علامتگذاری خودکار نتایج کماهمیتتر برای بررسی انسانی یا اصلاح مدل.
اینگونه است که ما در ویژگیهای هوش مصنوعی AlloyDB به این هدف دست یافتهایم:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
عبارت جستجو شده در این پرس و جو، همان عبارتی است که در بخشهای جستجوی چندوجهی، جستجوی ترکیبی و رتبهبندی مجدد دیدهایم. اکنون در این پرس و جو، لایهای از ارزیابی GEMINI از مجموعه نتایج رتبهبندی مجدد شده که توسط ساختار ml_predict_row نمایش داده میشود را گنجاندهایم. من فیلترهای چندوجهی را کامنت کردهام، اما میتوانید موارد دلخواه خود را در یک آرایه برای متغیرهای $1 تا $4 قرار دهید. $5 را با هر متنی که میخواهید جستجو کنید، مثلاً "تاپ صورتی، بدون طرح گلدار" جایگزین کنید.
۷. جعبه ابزار MCP برای پایگاههای داده و لایه برنامه
در پشت صحنه، ابزارهای قوی و یک برنامهی کاربردیِ ساختارمند، عملکرد روان را تضمین میکنند.
جعبه ابزار MCP (پروتکل زمینه مدل) برای پایگاههای داده، ادغام ابزارهای هوش مصنوعی مولد و عاملدار را با AlloyDB ساده میکند. این جعبه ابزار به عنوان یک سرور متنباز عمل میکند که جمعآوری اتصال، احراز هویت و ارائه ایمن قابلیتهای پایگاه داده به عاملهای هوش مصنوعی یا سایر برنامهها را ساده میکند.
در برنامه خود، از جعبه ابزار MCP برای پایگاههای داده به عنوان یک لایه انتزاعی برای همه پرسوجوهای جستجوی ترکیبی هوشمند خود استفاده کردهایم.
برای راهاندازی و استقرار Toolbox برای مورد استفاده ما، مراحل زیر را دنبال کنید:
میتوانید ببینید که یکی از پایگاههای دادهای که توسط MCP Toolbox for Databases پشتیبانی میشود، AlloyDB است و از آنجایی که قبلاً آن را در بخش قبلی فراهم کردهایم، بیایید Toolbox را راهاندازی کنیم.
- به ترمینال Cloud Shell خود بروید و مطمئن شوید که پروژه شما انتخاب شده و در اعلان ترمینال نمایش داده میشود. دستور زیر را از ترمینال Cloud Shell خود اجرا کنید تا به دایرکتوری پروژه خود بروید:
mkdir toolbox-tools
cd toolbox-tools
- دستور زیر را برای دانلود و نصب toolbox در پوشه جدید خود اجرا کنید:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- به ویرایشگر Cloud Shell (برای حالت ویرایش کد) بروید و در پوشه ریشه پروژه، فایلی به نام "tools.yaml" اضافه کنید.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
مطمئن شوید که اسکریپت Tools.yaml را با کد موجود در این فایل repo جایگزین کنید .
بیایید tools.yaml را درک کنیم:
منابع (Sources) منابع داده مختلف شما را که یک ابزار میتواند با آنها تعامل داشته باشد، نشان میدهند. یک منبع (source) نشان دهنده منبع دادهای است که یک ابزار میتواند با آن تعامل داشته باشد. میتوانید منابع (Sources) را به عنوان یک نقشه (map) در بخش منابع (sources) فایل tools.yaml خود تعریف کنید. به طور معمول، پیکربندی منبع (source configuration) شامل هرگونه اطلاعات مورد نیاز برای اتصال و تعامل با پایگاه داده خواهد بود.
ابزارها اقداماتی را که یک عامل میتواند انجام دهد تعریف میکنند - مانند خواندن و نوشتن در یک منبع. یک ابزار نشان دهنده عملی است که عامل شما میتواند انجام دهد، مانند اجرای یک دستور SQL. میتوانید ابزارها را به عنوان یک نقشه در بخش ابزارهای فایل tools.yaml خود تعریف کنید. معمولاً، یک ابزار برای اقدام به یک منبع نیاز دارد.
برای جزئیات بیشتر در مورد پیکربندی tools.yaml خود، به این مستندات مراجعه کنید.
- برای شروع سرور، دستور زیر را (از پوشه mcp-toolbox) اجرا کنید:
./toolbox --tools-file "tools.yaml"
حالا اگر سرور را در حالت پیشنمایش وب روی فضای ابری باز کنید، باید بتوانید سرور Toolbox را در حال اجرا با ابزار جدیدتان به نام get-order-data ببینید.
سرور جعبه ابزار MCP به طور پیشفرض روی پورت ۵۰۰۰ اجرا میشود. بیایید از Cloud Shell برای آزمایش این مورد استفاده کنیم.
مطابق شکل زیر، روی پیشنمایش وب در Cloud Shell کلیک کنید:
روی Change port کلیک کنید و پورت را مانند تصویر زیر روی ۵۰۰۰ تنظیم کنید و روی Change and Preview کلیک کنید.
این باید خروجی را به همراه داشته باشد:
- بیایید جعبه ابزار خود را در Cloud Run مستقر کنیم:
اول از همه، میتوانیم با سرور MCP Toolbox شروع کنیم و آن را روی Cloud Run میزبانی کنیم. این کار به ما یک نقطه پایانی عمومی میدهد که میتوانیم آن را با هر برنامه دیگری و/یا برنامههای Agent نیز ادغام کنیم. دستورالعملهای میزبانی این مورد روی Cloud Run در اینجا آورده شده است. اکنون مراحل کلیدی را بررسی خواهیم کرد.
- یک ترمینال Cloud Shell جدید راهاندازی کنید یا از یک ترمینال Cloud Shell موجود استفاده کنید. به پوشه پروژه که فایل باینری toolbox و tools.yaml در آن قرار دارند، بروید، در این مورد toolbox-tools، در صورتی که هنوز وارد آن نشدهاید:
cd toolbox-tools
- متغیر PROJECT_ID را طوری تنظیم کنید که به شناسه پروژه گوگل کلود شما اشاره کند.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- فعال کردن این سرویسهای ابری گوگل
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- بیایید یک حساب سرویس جداگانه ایجاد کنیم که به عنوان هویت سرویس Toolbox که در Google Cloud Run مستقر خواهیم کرد، عمل خواهد کرد.
gcloud iam service-accounts create toolbox-identity
- ما همچنین اطمینان حاصل میکنیم که این حساب کاربری سرویس، نقشهای صحیحی مانند توانایی دسترسی به Secret Manager و ارتباط با AlloyDB را دارد.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- ما فایل tools.yaml را به عنوان یک فایل مخفی آپلود خواهیم کرد:
gcloud secrets create tools --data-file=tools.yaml
اگر از قبل یک نسخه مخفی دارید و میخواهید نسخه مخفی را بهروزرسانی کنید، دستور زیر را اجرا کنید:
gcloud secrets versions add tools --data-file=tools.yaml
- یک متغیر محیطی را روی تصویر کانتینری که میخواهید برای Cloud Run استفاده کنید، تنظیم کنید:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- آخرین مرحله در دستور استقرار آشنا برای Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
این باید فرآیند استقرار Toolbox Server را با tools.yaml پیکربندی شده ما در Cloud Run آغاز کند. در صورت استقرار موفقیتآمیز، باید پیامی مشابه پیام زیر مشاهده کنید:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
شما آمادهاید تا از ابزار تازه مستقر شده خود در برنامه عامل خود استفاده کنید!!!
دسترسی به ابزارها در جعبه ابزار سرور
پس از استقرار Toolbox، یک شیم Python Cloud Run Functions برای تعامل با سرور Toolbox مستقر شده ایجاد خواهیم کرد. دلیل این امر آن است که Toolbox در حال حاضر SDK جاوا ندارد ، بنابراین ما یک شیم Python برای تعامل با سرور ایجاد کردیم. در اینجا کد منبع آن Cloud Run Function آمده است.
برای دسترسی به ابزارهای جعبه ابزاری که در مراحل قبلی ایجاد و مستقر کردهایم، باید این تابع Cloud Run را ایجاد و مستقر کنید:
- در کنسول گوگل کلود، به صفحه Cloud Run بروید
- روی نوشتن یک تابع کلیک کنید.
- در فیلد نام سرویس، نامی را برای توصیف عملکرد خود وارد کنید. نام سرویسها فقط باید با یک حرف شروع شوند و حداکثر شامل ۴۹ کاراکتر یا کمتر، شامل حروف، اعداد یا خط فاصله باشند. نام سرویسها نمیتوانند با خط فاصله تمام شوند و باید برای هر منطقه و پروژه منحصر به فرد باشند. نام سرویس بعداً قابل تغییر نیست و به صورت عمومی قابل مشاهده است. (retail-product-search-quality را وارد کنید)
- در لیست منطقه، از مقدار پیشفرض استفاده کنید، یا منطقهای را که میخواهید عملکرد خود را در آن مستقر کنید، انتخاب کنید. (us-central1 را انتخاب کنید)
- در لیست Runtime، از مقدار پیشفرض استفاده کنید یا یک نسخه runtime انتخاب کنید. (پایتون ۳.۱۱ را انتخاب کنید)
- در بخش احراز هویت، گزینه «اجازه دسترسی عمومی» را انتخاب کنید.
- روی دکمه "ایجاد" کلیک کنید
- تابع ایجاد شده و با قالب main.py و requirements.txt بارگذاری میشود.
- آن را با فایلهای main.py و requirements.txt از مخزن این پروژه جایگزین کنید.
- تابع را مستقر کنید و باید یک نقطه پایان برای تابع Cloud Run خود دریافت کنید
نقطه پایانی شما باید به این شکل (یا چیزی شبیه به آن) باشد:
نقطه پایانی تابع Cloud Run برای دسترسی به جعبه ابزار: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
برای سهولت تکمیل در جدول زمانی (برای جلسات عملی با هدایت مربی)، شماره پروژه برای نقطه پایانی در زمان جلسه عملی به اشتراک گذاشته خواهد شد.
نکته مهم:
از طرف دیگر، میتوانید بخش پایگاه داده را مستقیماً به عنوان بخشی از کد برنامه خود یا تابع Cloud Run پیادهسازی کنید.
۸. توسعه اپلیکیشن (جاوا) با جستجوی چندوجهی
در نهایت، تمام این اجزای قدرتمند backend از طریق لایه برنامه به اجرا در میآیند. این برنامه که با جاوا توسعه داده شده است، رابط کاربری را برای تعامل با سیستم جستجو فراهم میکند. این برنامه، پرسوجوها را برای AlloyDB هماهنگ میکند، نمایش فیلترهای چندوجهی را مدیریت میکند، انتخابهای کاربر را مدیریت میکند و نتایج جستجوی رتبهبندی مجدد و اعتبارسنجی شده را به روشی یکپارچه و شهودی ارائه میدهد.
- میتوانید با رفتن به ترمینال Cloud Shell خود و کلون کردن مخزن شروع کنید:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- به ویرایشگر Cloud Shell بروید ، جایی که میتوانید پوشه تازه ایجاد شده faceted_searching_retail را مشاهده کنید.
- موارد زیر را حذف کنید زیرا این مراحل قبلاً در بخشهای قبلی انجام شدهاند:
- پوشه Cloud_Run_Function را حذف کنید
- فایل db_script.sql را حذف کنید.
- فایل tools.yaml را حذف کنید.
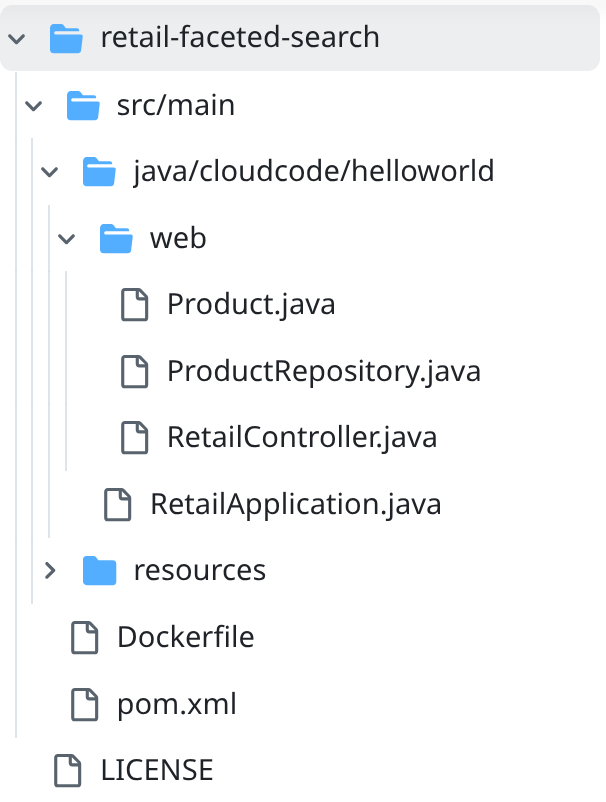
- به پوشه پروژه retail-faceted-search بروید ، در آنجا باید ساختار پروژه را ببینید:
- در فایل ProductRepository.java باید متغیر TOOLBOX_ENDPOINT را با نقطه پایانی از تابع Cloud Run (استقرار یافته) خود تغییر دهید یا نقطه پایانی را از بلندگوی عملی بگیرید.
خط کد زیر را جستجو کنید و آن را با نقطه پایانی خود جایگزین کنید:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- مطمئن شوید که Dockerfile و pom.xml با پیکربندی پروژه شما مطابقت دارند (نیازی به تغییر نیست، مگر اینکه صریحاً نسخه یا پیکربندی را تغییر داده باشید).
- در ترمینال Cloud Shell مطمئن شوید که داخل پوشه اصلی خود و داخل پوشه پروژه (faceted_searching_retail / retail-faceted-search) هستید. از دستورات زیر برای اطمینان از این موضوع استفاده کنید، مگر اینکه از قبل در پوشه صحیح در ترمینال باشید:
cd faceted_searching_retail
cd retail-faceted-search
- برنامه خود را به صورت محلی بستهبندی، ساخته و آزمایش کنید:
mvn package
mvn spring-boot:run
شما باید بتوانید برنامه خود را با کلیک روی «پیشنمایش روی پورت ۸۰۸۰» در ترمینال Cloud Shell، مطابق شکل زیر مشاهده کنید:
۹. استقرار در Cloud Run: ***مرحله مهم
در ترمینال Cloud Shell مطمئن شوید که داخل پوشه اصلی خود و داخل پوشه پروژه (faceted_searching_retail / retail-faceted-search) هستید . از دستورات زیر برای اطمینان از این موضوع استفاده کنید، مگر اینکه از قبل در پوشه صحیح در ترمینال باشید:
cd faceted_searching_retail
cd retail-faceted-search
وقتی مطمئن شدید که در پوشه پروژه هستید، دستور زیر را اجرا کنید:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
پس از استقرار، باید یک Cloud Run Endpoint مستقر شده دریافت کنید که به شکل زیر است:
https://retail-search-**********-uc.a.run.app/
۱۰. نسخه آزمایشی
بیایید ببینیم همه اینها در عمل چگونه به کار میآیند:
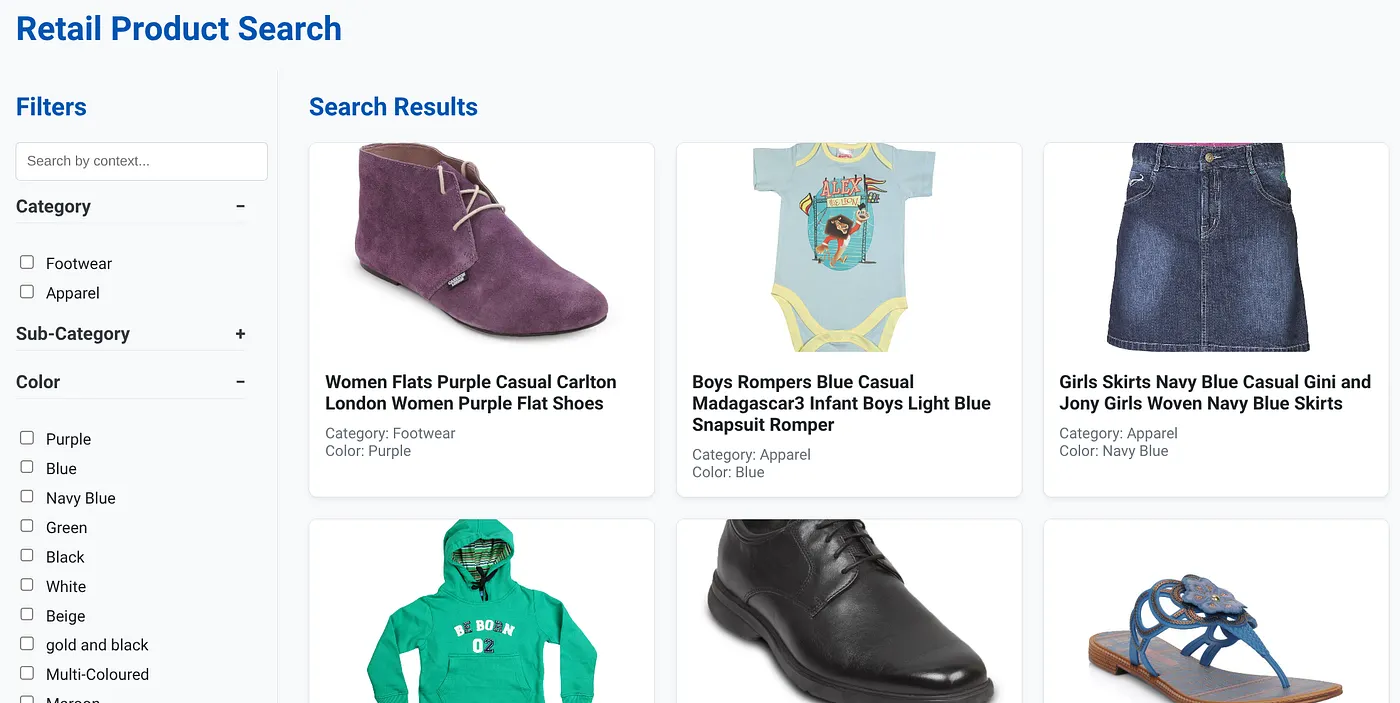
تصویر بالا صفحه فرود (لندینگ پیج) اپلیکیشن جستجوی ترکیبی پویا را نشان میدهد.
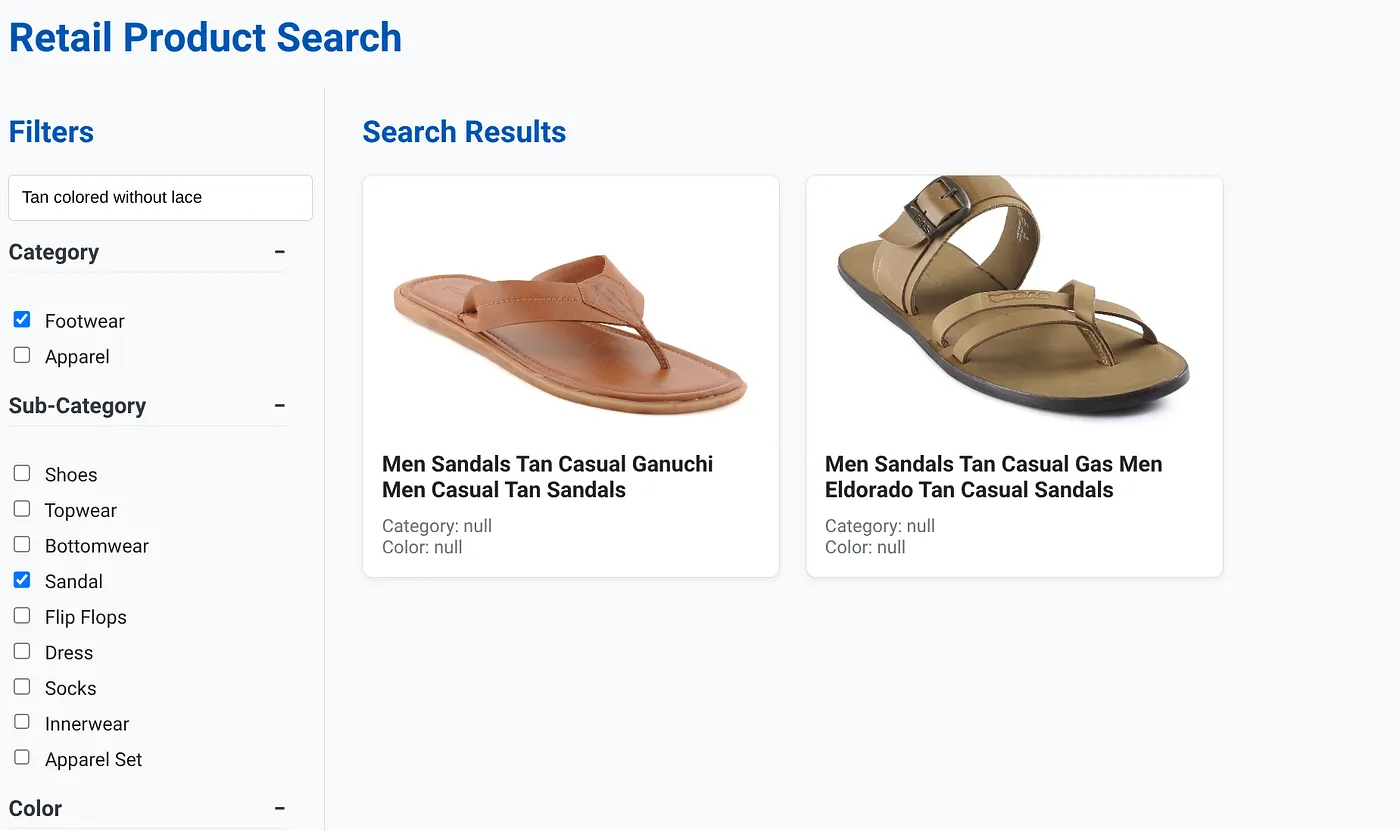
تصویر بالا نتایج جستجو برای "قهوهای روشن بدون بند" را نشان میدهد. فیلترهای چندوجهی انتخاب شده عبارتند از: کفش، صندل.
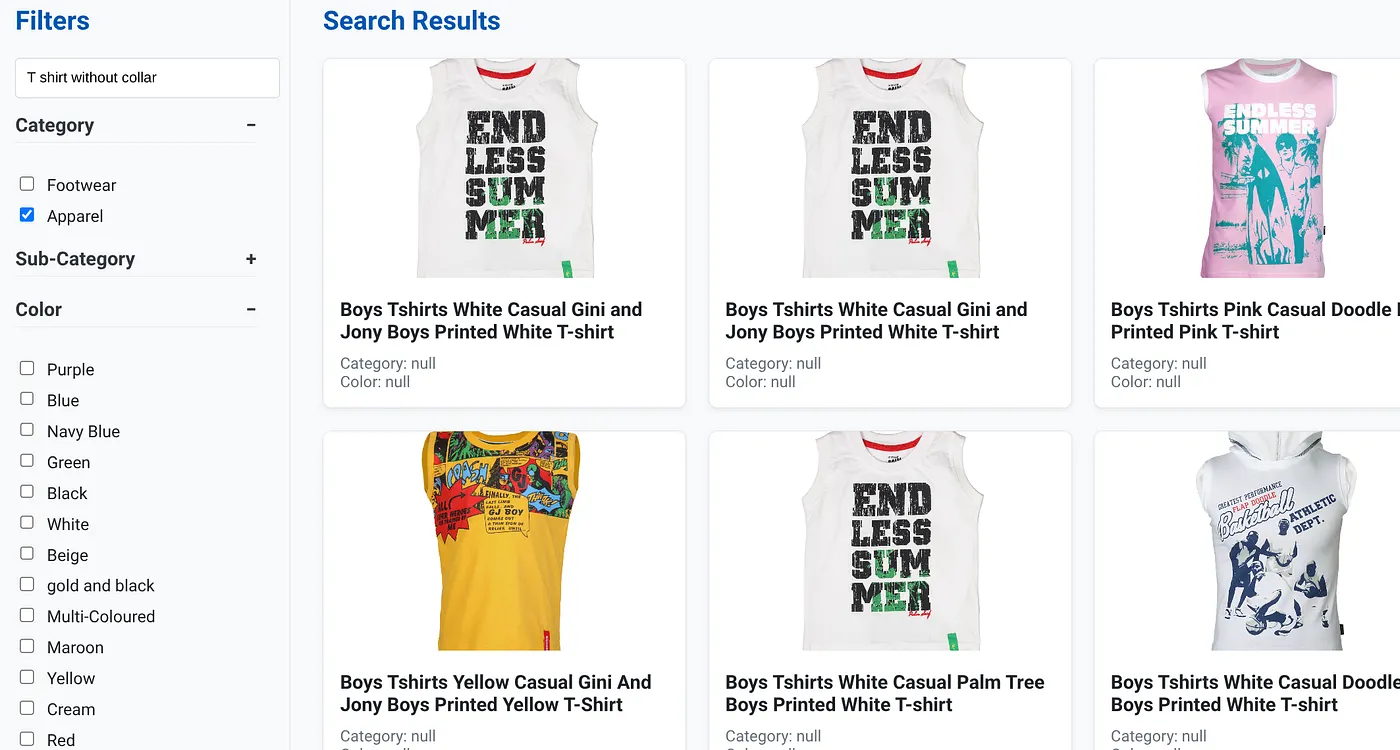
تصویر بالا نتایج جستجو برای "تیشرت بدون یقه" را نشان میدهد. فیلترهای چندوجهی: پوشاک
اکنون میتوانید ویژگیهای مولد و عامل بیشتری را برای کاربردیتر کردن این برنامه در نظر بگیرید.
امتحانش کن تا الهام بگیری خودت یه چیزی بسازی!!!
۱۱. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
- از طرف دیگر، میتوانید کلاستر AlloyDB را که برای این پروژه ایجاد کردهایم، با کلیک روی دکمهی DELETE CLUSTER حذف کنید (اگر در زمان پیکربندی، us-central1 را برای کلاستر انتخاب نکردهاید، مکان آن را در این هایپرلینک تغییر دهید).
۱۲. تبریک
تبریک! شما با موفقیت یک برنامه جستجوی ترکیبی (HYBRID SEARCH APP) را با ALLOYDB روی CLOUD RUN ساختید و مستقر کردید!!!
چرا این موضوع برای کسب و کارها اهمیت دارد:
این برنامه جستجوی ترکیبی پویا، که توسط AlloyDB AI پشتیبانی میشود، مزایای قابل توجهی را برای خردهفروشیهای سازمانی و سایر مشاغل ارائه میدهد:
ارتباط برتر: با ترکیب جستجوی متنی (برداری) با فیلترینگ دقیق وجهی و رتبهبندی هوشمند، مشتریان نتایج بسیار مرتبطی دریافت میکنند که منجر به افزایش رضایت و نرخ تبدیل میشود.
مقیاسپذیری: معماری AlloyDB و شاخصگذاری scaNN به گونهای طراحی شدهاند که بتوانند کاتالوگهای عظیم محصولات و حجم بالای پرسوجو را مدیریت کنند، که برای رشد کسبوکارهای تجارت الکترونیک بسیار مهم است.
عملکرد: پاسخهای سریعتر به پرسوجوها، حتی برای جستجوهای ترکیبی پیچیده، تجربه کاربری روان را تضمین کرده و نرخ رها کردن را به حداقل میرساند.
آیندهنگر: ادغام قابلیتهای هوش مصنوعی (جاسازیها، اعتبارسنجی LLM) این برنامه را در موقعیت پیشرفتهای آینده در توصیههای شخصیسازیشده، تجارت محاورهای و کشف هوشمند محصول قرار میدهد.
معماری سادهشده: ادغام جستجوی برداری مستقیماً در AlloyDB نیاز به پایگاههای داده برداری جداگانه یا هماهنگسازی پیچیده را از بین میبرد و توسعه و نگهداری را ساده میکند.
فرض کنید کاربری یک عبارت جستجو به زبان طبیعی مانند «کفشهای دویدن سازگار با محیط زیست برای خانمها با پشتیبانی قوس زیاد پا» را تایپ کرده است.
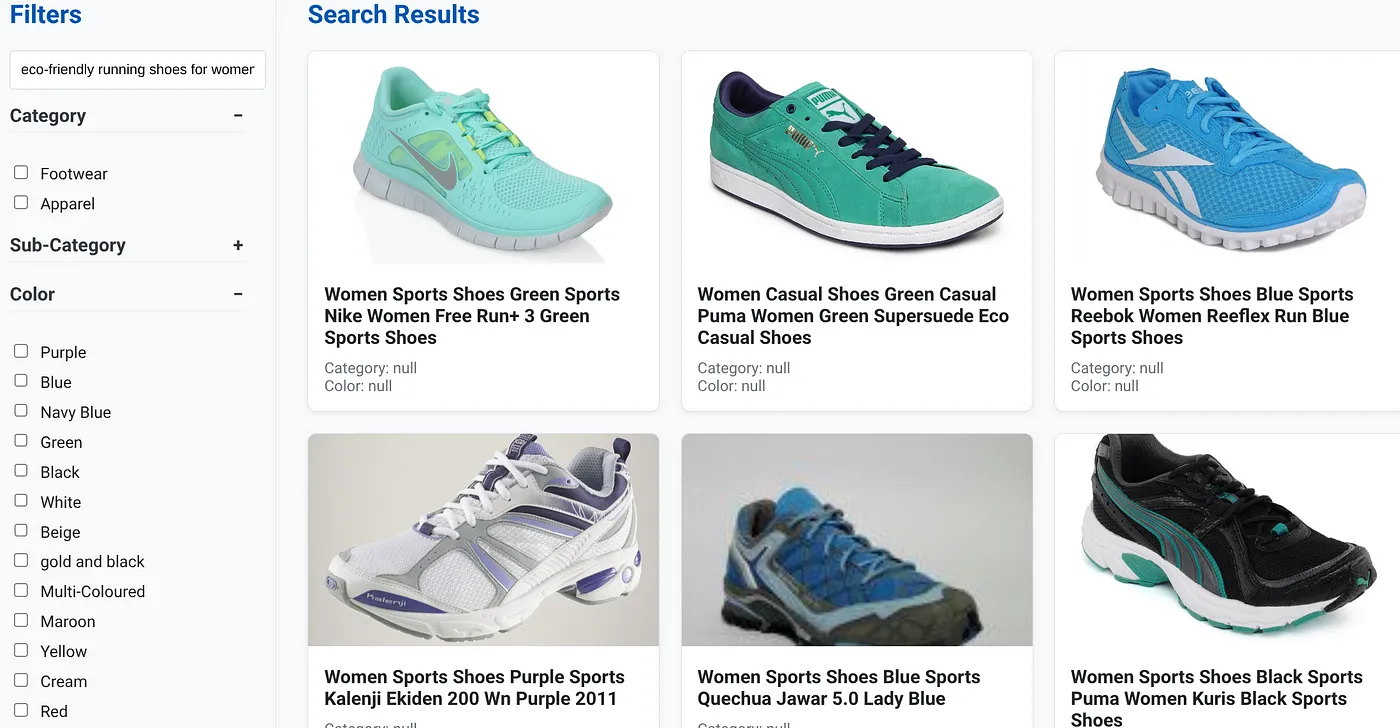
در حالی که همزمان، کاربر فیلترهای چندوجهی را برای "رده: <<>>" "رنگ: <<>>" اعمال میکند و میگوید "قیمت: ۱۰۰ تا ۱۵۰ دلار":
- سیستم فوراً فهرستی اصلاحشده از محصولات را برمیگرداند که از نظر معنایی با زبان طبیعی همسو بوده و دقیقاً با فیلترهای انتخابشده مطابقت دارد.
- در پشت صحنه، شاخص scaNN جستجوی برداری را تسریع میکند، فیلترینگ درونخطی و تطبیقی عملکرد را با معیارهای ترکیبی تضمین میکند و رتبهبندی مجدد، نتایج بهینه را در صدر ارائه میدهد.
- سرعت و دقت نتایج به وضوح قدرت ترکیب این فناوریها را برای یک تجربه جستجوی واقعاً هوشمند در خردهفروشی نشان میدهد.
ساخت یک اپلیکیشن جستجوی خردهفروشی نسل بعدی نیازمند فراتر رفتن از روشهای مرسوم است و با استفاده از قدرت AlloyDB، Vertex AI، Vector Search با نمایهسازی scaNN، فیلترینگ وجهی پویا، رتبهبندی مجدد و اعتبارسنجی LLM، میتوانیم یک تجربه مشتری بینظیر ارائه دهیم که باعث افزایش تعامل و افزایش فروش میشود. این راهکار قوی، مقیاسپذیر و هوشمند نشان میدهد که چگونه قابلیتهای مدرن پایگاه داده، همراه با هوش مصنوعی، آینده خردهفروشی را تغییر میدهند!!!