
1. Présentation
Dans le paysage commercial concurrentiel actuel, il est essentiel de permettre aux clients de trouver exactement ce qu'ils recherchent, rapidement et de manière intuitive. La recherche traditionnelle basée sur les mots clés est souvent insuffisante, car elle a du mal à gérer les requêtes nuancées et les vastes catalogues de produits. Cet atelier de programmation présente une application de recherche pour le commerce sophistiquée, conçue sur AlloyDB et AlloyDB AI. Il exploite la recherche vectorielle de pointe, l'indexation scaNN, les filtres à facettes et le filtrage adaptatif intelligent, ainsi que le reclassement pour offrir une expérience de recherche hybride et dynamique à l'échelle de l'entreprise.
Nous avons déjà les bases de trois éléments :
- Ce que signifie la recherche contextuelle pour votre agent et comment l'effectuer à l'aide de Vector Search.
- Nous avons également étudié en détail la recherche vectorielle dans le champ de vos données, c'est-à-dire dans votre base de données elle-même (toutes les bases de données Google Cloud sont compatibles avec cette fonctionnalité, si vous ne le saviez pas déjà).
- Nous sommes allés plus loin que le reste du monde en vous expliquant comment obtenir une fonctionnalité RAG de recherche vectorielle légère, performante et de haute qualité grâce à la fonctionnalité de recherche vectorielle AlloyDB basée sur l'index ScaNN.
Si vous n'avez pas encore effectué ces tests RAG de base, intermédiaires et légèrement avancés, je vous encourage à les lire dans l'ordre indiqué : ici, ici et ici.
Le défi
Aller au-delà des filtres, des mots clés et de la correspondance contextuelle : une simple recherche par mots clés peut renvoyer des milliers de résultats, dont beaucoup ne sont pas pertinents. La solution idéale doit comprendre l'intention derrière la requête, la combiner avec des critères de filtrage précis (comme la marque, la matière ou le prix) et présenter les articles les plus pertinents en quelques millisecondes. Cela nécessite une infrastructure de recherche puissante, flexible et évolutive. Bien sûr, nous avons parcouru un long chemin depuis la recherche par mots clés jusqu'aux correspondances contextuelles et aux recherches par similarité. Imaginez un client qui recherche "une veste confortable, élégante et imperméable pour la randonnée au printemps" tout en appliquant des filtres. Votre application ne se contente pas de renvoyer des réponses de qualité, mais elle est également très performante et la séquence de tout cela est choisie de manière dynamique par votre base de données.
Objectif
Pour résoudre ce problème en intégrant
- Recherche contextuelle (Vector Search) : comprendre la signification sémantique des requêtes et des descriptions de produits
- Filtrage par facettes : permettre aux utilisateurs d'affiner les résultats avec des attributs spécifiques
- Approche hybride : combiner de manière fluide la recherche contextuelle et le filtrage structuré
- Optimisation avancée : utilisation de l'indexation spécialisée, du filtrage adaptatif et du reclassement pour la rapidité et la pertinence
- Contrôle qualité basé sur l'IA générative : intégration de la validation LLM pour une qualité de résultat supérieure.
Analysons l'architecture et le parcours d'implémentation.
Ce que vous allez faire
Application Retail Search
Dans ce cadre, vous allez :
- Créer une instance et une table AlloyDB pour l'ensemble de données e-commerce
- Configurer les embeddings et la recherche vectorielle
- Créer un index de métadonnées et un index ScaNN
- Implémenter la recherche vectorielle avancée dans AlloyDB à l'aide de la méthode de filtrage intégré de ScaNN
- Configurer des filtres à facettes et la recherche hybride dans une même requête
- Améliorer la pertinence des requêtes avec le reranking et le rappel (facultatif)
- Évaluer la réponse à la requête avec Gemini (facultatif)
- MCP Toolbox for Databases et couche Application
- Développement d'applications (Java) avec recherche à facettes
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Configuration de la base de données
Dans cet atelier, nous allons utiliser AlloyDB comme base de données pour les données d'e-commerce. Il utilise des clusters pour contenir toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données sur l'e-commerce sera chargé.
Créer un cluster et une instance
- Accédez à la page AlloyDB de la console Cloud. Pour trouver facilement la plupart des pages de la console Cloud, vous pouvez les rechercher à l'aide de la barre de recherche de la console.
- Sur cette page, sélectionnez CRÉER UN CLUSTER :

- Un écran semblable à celui ci-dessous s'affiche. Créez un cluster et une instance avec les valeurs suivantes (assurez-vous que les valeurs correspondent si vous clonez le code de l'application à partir du dépôt) :
- ID du cluster : "
vector-cluster" - password : "
alloydb" - PostgreSQL 15 / dernière version recommandée
- Région : "
us-central1" - Networking : "
default"
- Lorsque vous sélectionnez le réseau par défaut, un écran semblable à celui ci-dessous s'affiche.
Sélectionnez CONFIGURER LA CONNEXION.
- Sélectionnez ensuite Utiliser une plage d'adresses IP automatiquement allouée, puis cliquez sur "Continuer". Après avoir vérifié les informations, sélectionnez CRÉER UNE CONNEXION.
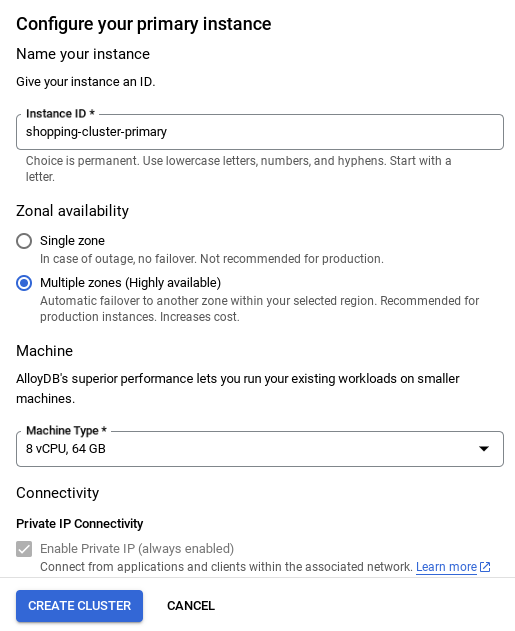
- Une fois votre réseau configuré, vous pouvez continuer à créer votre cluster. Cliquez sur CRÉER UN CLUSTER pour terminer la configuration du cluster, comme indiqué ci-dessous :
REMARQUE IMPORTANTE :
- Veillez à remplacer l'ID d'instance (que vous trouverez lors de la configuration du cluster / de l'instance) par **
vector-instance**. Si vous ne pouvez pas le modifier, n'oubliez pas d'utiliser votre ID d'instance dans toutes les références à venir. - Notez que la création du cluster prendra environ 10 minutes. Une fois l'opération réussie, un écran affichant l'aperçu du cluster que vous venez de créer devrait s'afficher.
4. Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à AlloyDB, sélectionnez le cluster principal, puis AlloyDB Studio :
Vous devrez peut-être patienter jusqu'à ce que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb"
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez des commandes pour AlloyDB dans des fenêtres d'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si vous souhaitez vérifier les extensions qui ont été activées dans votre base de données, exécutez la commande SQL suivante :
select extname, extversion from pg_extension;
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La colonne d'embedding permettra de stocker les valeurs vectorielles du texte.
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Charger des données dans la base de données
- Copiez les instructions de requête
insertde la feuilleinsert scripts sqlvers l'éditeur mentionné ci-dessus. Vous pouvez copier entre 10 et 50 instructions d'insertion pour une démonstration rapide de ce cas d'utilisation. Une liste d'encarts sélectionnés est disponible dans l'onglet "Selected Inserts 25-30 rows" (Encarts sélectionnés, 25 à 30 lignes).
Le lien vers les données se trouve dans ce fichier du dépôt GitHub.
- Cliquez sur Exécuter. Les résultats de votre requête s'affichent dans la table Résultats.
REMARQUE IMPORTANTE :
Veillez à ne copier que 25 à 50 enregistrements à insérer et assurez-vous qu'ils proviennent d'une plage de types de catégories, de sous-catégories, de couleurs et de genres.
5. Créer des embeddings pour les données
La véritable innovation dans la recherche moderne réside dans la compréhension du sens, et pas seulement des mots clés. C'est là que les embeddings et la recherche vectorielle entrent en jeu.
Nous avons transformé les descriptions de produits et les requêtes utilisateur en représentations numériques de grande dimensionnalité appelées "embeddings" à l'aide de modèles de langage pré-entraînés. Ces embeddings capturent la signification sémantique, ce qui nous permet de trouver des produits dont la signification est similaire, et pas seulement ceux qui contiennent des mots correspondants. Au départ, nous avons testé la recherche directe de similarité vectorielle sur ces embeddings pour établir une référence, démontrant ainsi la puissance de la compréhension sémantique avant même les optimisations des performances.
La colonne d'embedding permettra de stocker les valeurs vectorielles du texte de la description du produit. La colonne "img_embeddings" permettra de stocker les embeddings d'images (multimodaux). Vous pouvez également utiliser la recherche basée sur la distance entre le texte et l'image. Toutefois, nous n'utiliserons que des embeddings de texte dans cet atelier.
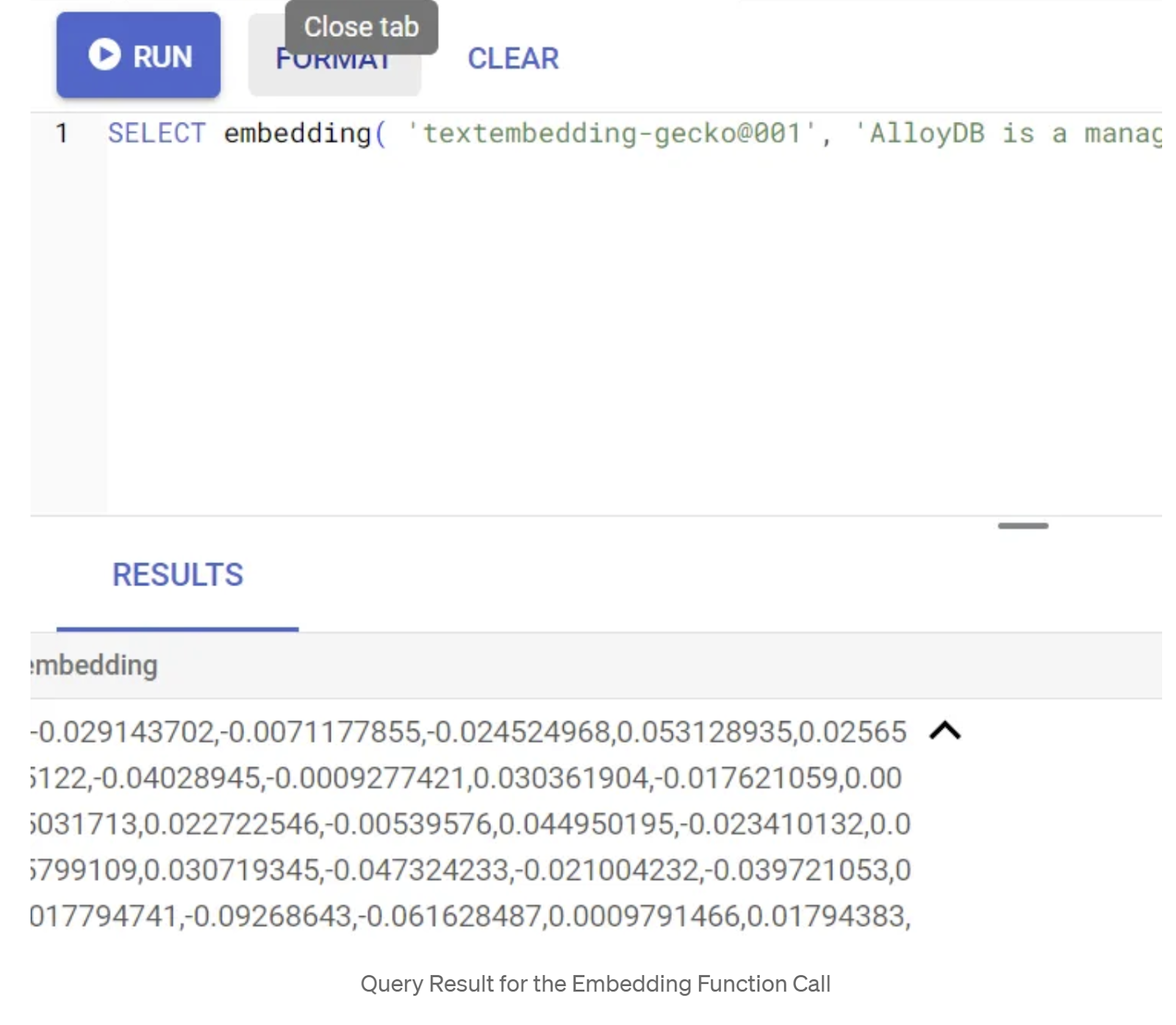
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Le vecteur d'embedding, qui ressemble à un tableau de valeurs flottantes, devrait être renvoyé pour l'exemple de texte dans la requête. Voici à quoi il ressemble :
Mettre à jour le champ vectoriel "abstract_embeddings"
Exécutez le LMD ci-dessous pour mettre à jour la description du contenu dans le tableau avec les embeddings correspondants :
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Si vous utilisez un compte de facturation avec crédit d'essai pour Google Cloud, vous risquez de rencontrer des difficultés pour générer plus d'une vingtaine d'embeddings. Limitez donc le nombre de lignes dans le script d'insertion.
Si vous souhaitez générer des embeddings d'images (pour effectuer une recherche contextuelle multimodale), exécutez également la mise à jour ci-dessous :
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Effectuer un RAG avancé avec les nouvelles fonctionnalités d'AlloyDB
Maintenant que la table, les données et les embeddings sont prêts, effectuons la recherche vectorielle en temps réel pour le texte de recherche de l'utilisateur. Pour tester cela, exécutez la requête ci-dessous :
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
Dans cette requête, nous comparons l'embedding de texte de la recherche saisie par l'utilisateur "T-shirt à col rond" aux embeddings de texte de toutes les descriptions de produits de la table "apparels" (stockées dans la colonne "embedding") à l'aide de la fonction de distance de similarité cosinus (représentée par le symbole "<=>"). Nous convertissons le résultat de la méthode d'embedding en type vectoriel pour le rendre compatible avec les vecteurs stockés dans la base de données. LIMIT 10 signifie que nous sélectionnons les 10 correspondances les plus proches du texte de recherche.
AlloyDB booste le RAG de recherche vectorielle :
Pour une solution à l'échelle de l'entreprise, la recherche vectorielle brute ne suffit pas. Les performances sont essentielles.
Index ScaNN (Scalable Nearest Neighbors)
Pour effectuer des recherches de plus proche voisin approximatif (ANN) ultra-rapides, nous avons activé l'index scaNN dans AlloyDB. ScaNN est un algorithme de recherche approximative des voisins les plus proches de pointe développé par Google Research. Il est conçu pour une recherche efficace de similarité vectorielle à grande échelle. Il accélère considérablement les requêtes en élaguant efficacement l'espace de recherche et en utilisant des techniques de quantification. Il offre des requêtes vectorielles jusqu'à quatre fois plus rapides que les autres méthodes d'indexation et un espace mémoire utilisé plus petit. Pour en savoir plus, cliquez ici et ici.
Activons l'extension et créons les index :
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Créez des index pour les champs d'embedding textuel et d'embedding d'image (si vous souhaitez utiliser des embeddings d'image dans votre recherche) :
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Index de métadonnées
Alors que scaNN gère l'indexation vectorielle, des index B-tree ou GIN traditionnels ont été méticuleusement configurés sur les attributs structurés (comme la catégorie, la sous-catégorie, le style, la couleur, etc.). Ces index sont essentiels à l'efficacité du filtrage par facettes. Exécutez les instructions ci-dessous pour configurer les index de métadonnées :
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
REMARQUE IMPORTANTE :
Étant donné que vous n'avez peut-être inséré que 25 à 50 enregistrements, les index (ScaNN ou tout autre index) ne seront pas efficaces.
Filtrage intégré
Un défi courant dans la recherche vectorielle consiste à la combiner avec des filtres structurés (par exemple, "chaussures rouges"). Le filtrage intégré d'AlloyDB optimise ce processus. Au lieu de post-filtrer les résultats d'une recherche vectorielle étendue, le filtrage intégré applique des conditions de filtre pendant le processus de recherche vectorielle lui-même, ce qui améliore considérablement les performances et la justesse des recherches vectorielles filtrées.
Pour en savoir plus sur la nécessité du filtrage intégré, consultez cette documentation. Pour en savoir plus sur la recherche vectorielle filtrée et l'optimisation des performances de la recherche vectorielle, cliquez ici. Si vous souhaitez activer le filtrage intégré pour votre application, exécutez l'instruction suivante à partir de votre éditeur :
SET scann.enable_inline_filtering = on;
Le filtrage intégré est idéal pour les cas de sélectivité moyenne. Lorsqu'AlloyDB effectue une recherche dans l'index vectoriel, il ne calcule les distances que pour les vecteurs qui correspondent aux conditions de filtrage des métadonnées (vos filtres fonctionnels dans une requête généralement gérée dans la clause WHERE). Cela améliore considérablement les performances de ces requêtes, en complément des avantages du filtrage après ou avant.
Filtrage adaptatif
Pour optimiser davantage les performances, le filtrage adaptatif d'AlloyDB choisit de manière dynamique la stratégie de filtrage la plus efficace (filtrage intégré ou préfiltrage) lors de l'exécution des requêtes. Il analyse les modèles de requêtes et les distributions de données pour garantir des performances optimales sans intervention manuelle. Cela est particulièrement utile pour les recherches vectorielles filtrées, où il bascule automatiquement entre l'utilisation de l'index vectoriel et de l'index de métadonnées. Pour activer le filtrage adaptatif, utilisez l'option scann.enable_preview_features.
Lorsque le filtrage adaptatif déclenche un passage du filtrage intégré au préfiltrage lors de l'exécution, le plan de requête change de manière dynamique.
SET scann.enable_preview_features = on;
IMPORTANT : Si vous rencontrez une erreur et que vous ne parvenez pas à exécuter l'instruction ci-dessus sans redémarrer l'instance, il est préférable d'activer l'indicateur enable_preview_features dans la section des indicateurs de base de données de votre instance.
Filtres à facettes utilisant tous les index
La recherche par attribut permet aux utilisateurs d'affiner les résultats en appliquant plusieurs filtres basés sur des attributs spécifiques (par exemple, la marque, le prix, la taille ou la note des clients). Notre application intègre ces facettes de manière fluide à la recherche vectorielle. Une même requête peut désormais combiner le langage naturel (recherche contextuelle) avec plusieurs sélections à facettes, en exploitant de manière dynamique les index vectoriels et traditionnels. Cela offre une véritable capacité de recherche hybride dynamique, permettant aux utilisateurs d'examiner précisément les résultats.
Dans notre application, comme nous avons déjà créé tous les index de métadonnées, nous sommes prêts à utiliser le filtre à facettes sur le Web en nous adressant directement à celui-ci à l'aide de requêtes SQL :
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
Dans cette requête, nous effectuons une recherche hybride en intégrant à la fois
- Filtrage à facettes dans la clause WHERE
- Vector Search dans la clause ORDER BY à l'aide de la méthode de similarité cosinus.
$1, $2, $3 et $4 représentent les valeurs de filtre à facettes dans un tableau, et $5 représente le texte de recherche de l'utilisateur. Remplacez $1 à $4 par les valeurs de filtre à facettes de votre choix, comme ci-dessous :
category = ANY([‘Apparel', ‘Footwear'])
Remplacez "5 $" par le texte de recherche de votre choix, par exemple "Polos".
IMPORTANT : Si vous n'avez pas les index en raison du nombre limité d'enregistrements que vous avez insérés, vous ne verrez pas l'impact sur les performances. Toutefois, dans un ensemble de données de production complet, vous constaterez que le temps d'exécution est considérablement réduit pour la même recherche vectorielle. Cela est possible grâce à l'index ScaNN avec filtrage intégré sur la recherche vectorielle.
Évaluons maintenant le rappel pour cette recherche vectorielle compatible avec ScaNN.
Reclassement
Même avec la recherche avancée, les résultats initiaux peuvent nécessiter une dernière retouche. Il s'agit d'une étape essentielle qui permet de réorganiser les résultats de recherche initiaux pour améliorer leur pertinence. Une fois que la recherche hybride initiale a fourni un ensemble de produits candidats, un modèle plus sophistiqué (et souvent plus lourd en termes de calcul) applique un score de pertinence plus précis. Cela garantit que les premiers résultats présentés à l'utilisateur sont les plus pertinents, ce qui améliore considérablement la qualité de la recherche. Nous évaluons continuellement le rappel pour mesurer la capacité du système à récupérer tous les éléments pertinents pour une requête donnée. Nous affinons nos modèles pour maximiser la probabilité qu'un client trouve ce dont il a besoin.
Avant d'utiliser cette fonctionnalité dans votre application, assurez-vous de remplir toutes les conditions préalables :
- Vérifiez que l'extension google_ml_integration est installée.
- Vérifiez que le flag google_ml_integration.enable_model_support est activé.
- Intégrez-le à Vertex AI.
- Activez l'API Discovery Engine.
- Obtenez les rôles requis pour utiliser les modèles de classement.
Vous pouvez ensuite utiliser la requête suivante dans notre application pour reclasser l'ensemble de résultats de la recherche hybride :
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
Dans cette requête, nous effectuons un RECLASSEMENT de l'ensemble des résultats de produits de la recherche contextuelle, qui est traité dans la clause ORDER BY à l'aide de la méthode de similarité cosinus. "Haut rose" est le texte recherché par l'utilisateur.
REMARQUE IMPORTANTE : Il est possible que certains d'entre vous n'aient pas encore accès au reranking. Je l'ai donc exclu du code de l'application. Toutefois, si vous souhaitez l'inclure, vous pouvez suivre l'exemple que nous avons vu ci-dessus.
Évaluateur de rappel
Dans la recherche par similarité, le rappel correspond au pourcentage d'instances pertinentes récupérées à partir d'une recherche, c'est-à-dire au nombre de vrais positifs. Il s'agit de la métrique la plus courante pour mesurer la qualité de la recherche. Une source de perte de rappel provient de la différence entre la recherche approximative des voisins les plus proches (aNN) et la recherche des k (exacts) plus proches voisins (kNN). Les index vectoriels tels que ScaNN d'AlloyDB implémentent des algorithmes aNN, ce qui vous permet d'accélérer la recherche vectorielle sur de grands ensembles de données en échange d'un léger compromis en termes de rappel. AlloyDB vous permet désormais de mesurer ce compromis directement dans la base de données pour les requêtes individuelles et de vous assurer qu'il reste stable au fil du temps. Vous pouvez mettre à jour les paramètres de requête et d'index en fonction de ces informations pour obtenir de meilleurs résultats et performances.
Quelle est la logique derrière le rappel des résultats de recherche ?
Dans le contexte de la recherche vectorielle, le rappel fait référence au pourcentage de vecteurs renvoyés par l'index qui sont de vrais voisins les plus proches. Par exemple, si une requête de 20 voisins les plus proches renvoie un résultat de 19 voisins les plus proches de "vérité terrain", le rappel est de 19/20 x 100 = 95%. Le rappel est la métrique utilisée pour la qualité de la recherche. Il est défini comme le pourcentage de résultats renvoyés qui sont objectivement les plus proches des vecteurs de requête.
Vous pouvez trouver le rappel d'une requête vectorielle sur un index vectoriel pour une configuration donnée à l'aide de la fonction evaluate_query_recall. Cette fonction vous permet d'ajuster vos paramètres pour obtenir les résultats de rappel de requête vectorielle souhaités.
REMARQUE IMPORTANTE :
Si vous rencontrez une erreur d'autorisation refusée sur l'index HNSW lors des étapes suivantes, ignorez pour le moment toute cette section sur l'évaluation du rappel. Il peut s'agir de restrictions d'accès, car il vient d'être publié au moment où cet atelier de programmation est documenté.
- Définissez l'indicateur "Enable Index Scan" (Activer l'analyse de l'index) sur l'index ScaNN et l'index HNSW :
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Exécutez la requête suivante dans AlloyDB Studio :
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La fonction evaluate_query_recall prend la requête comme paramètre et renvoie son rappel. J'utilise la même requête que celle que j'ai utilisée pour vérifier les performances comme requête d'entrée de la fonction. J'ai ajouté ScaNN comme méthode d'index. Pour obtenir d'autres options de paramètres, consultez la documentation.
Voici le rappel pour cette requête de recherche vectorielle que nous avons utilisée :
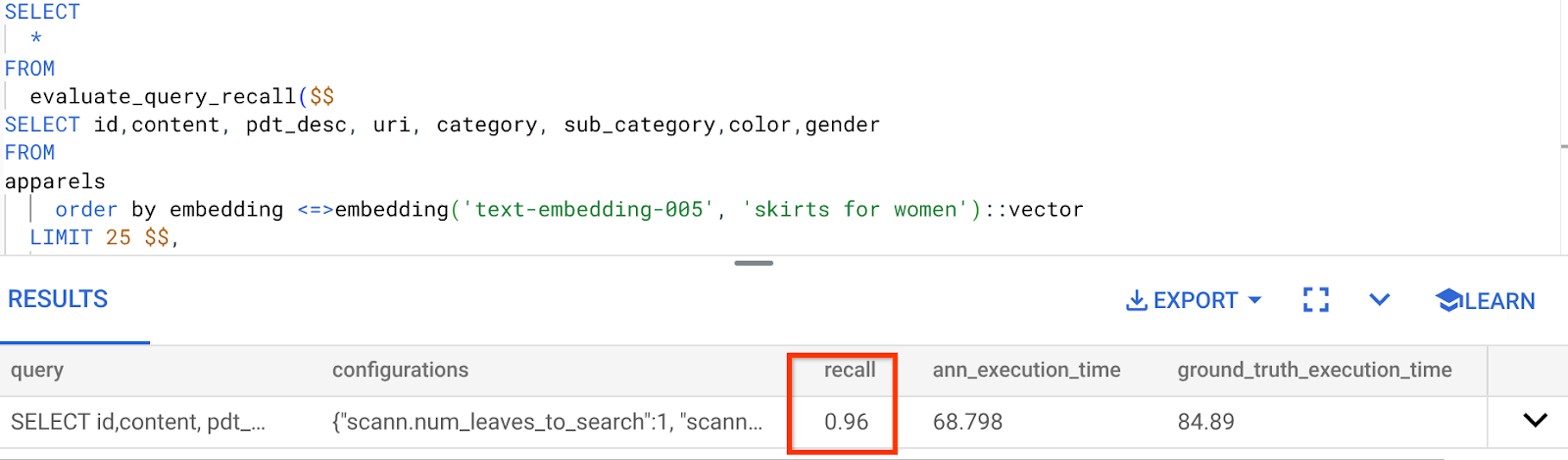
Je vois que le RECALL est de 96%. Dans ce cas, le rappel est très bon. Mais si la valeur était inacceptable, vous pouvez utiliser ces informations pour modifier les paramètres d'index, les méthodes et les paramètres de requête, et améliorer mon rappel pour cette recherche vectorielle.
Testez-le avec des paramètres de requête et d'index modifiés.
Testons maintenant la requête en modifiant les paramètres de requête en fonction du rappel reçu.
- Modifier les paramètres d'index :
Pour ce test, je vais utiliser la distance L2 au lieu de la fonction de distance de similarité cosinus.
Remarque très importante : Vous vous demandez peut-être comment nous savons que cette requête utilise la similarité COSINE. Vous pouvez identifier la fonction de distance en utilisant "<=>" pour représenter la distance cosinus.
Lien vers la documentation pour les fonctions de distance Vector Search.
La requête précédente utilise la fonction de distance de similarité cosinus, alors que nous allons maintenant essayer la distance L2. Mais pour cela, nous devons également nous assurer que l'index ScaNN sous-jacent utilise également la fonction de distance L2. Créons maintenant un index avec une autre requête de fonction de distance : Distance L2 : <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
L'instruction de suppression d'index sert uniquement à s'assurer qu'il n'y a pas d'index inutile sur la table.
Je peux maintenant exécuter la requête suivante pour évaluer le RECALL après avoir modifié la fonction de distance de ma fonctionnalité Vector Search.
Requête [APRÈS] utilisant la fonction Distance L2 :
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Vous pouvez constater la différence / transformation dans la valeur de rappel pour l'index mis à jour.
Vous pouvez modifier d'autres paramètres dans l'index, comme num_leaves, en fonction de la valeur de rappel souhaitée et de l'ensemble de données utilisé par votre application.
Validation des résultats de la recherche vectorielle par le LLM
Pour obtenir une recherche contrôlée de la meilleure qualité possible, nous avons intégré une couche facultative de validation par LLM. Les grands modèles de langage peuvent être utilisés pour évaluer la pertinence et la cohérence des résultats de recherche, en particulier pour les requêtes complexes ou ambiguës. Cela peut inclure :
Validation sémantique :
Un LLM effectuant des références croisées entre les résultats et l'intention de la requête.
Filtrage logique :
Utiliser un LLM pour appliquer une logique métier ou des règles complexes difficiles à encoder dans des filtres traditionnels, afin d'affiner davantage la liste de produits en fonction de critères nuancés.
Assurance qualité :
Identifier et signaler automatiquement les résultats moins pertinents pour un examen manuel ou un affinement du modèle
Voici comment nous avons procédé dans les fonctionnalités AlloyDB/AI :
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
La requête sous-jacente est la même que celle que nous avons vue dans les sections sur la recherche à facettes, la recherche hybride et le reclassement. Dans cette requête, nous avons intégré une couche d'évaluation GEMINI de l'ensemble de résultats réorganisés représenté par le constructeur ml_predict_row. J'ai mis en commentaire les filtres à facettes, mais n'hésitez pas à inclure les éléments de votre choix dans un tableau pour les espaces réservés $1 à $4. Remplacez "5 $" par le texte sur lequel vous souhaitez effectuer une recherche, par exemple "Haut rose sans motif floral".
7. MCP Toolbox for Databases et couche Application
En coulisses, des outils robustes et une application bien structurée assurent un fonctionnement fluide.
La Toolbox MCP (Model Context Protocol) for Databases simplifie l'intégration des outils d'IA générative et agentiques à AlloyDB. Il s'agit d'un serveur Open Source qui simplifie le regroupement de connexions, l'authentification et l'exposition sécurisée des fonctionnalités de base de données aux agents d'IA ou à d'autres applications.
Dans notre application, nous avons utilisé MCP Toolbox for Databases comme couche d'abstraction pour toutes nos requêtes de recherche hybrides intelligentes.
Suivez les étapes ci-dessous pour configurer et déployer Toolbox pour notre cas d'utilisation :
Vous pouvez voir qu'AlloyDB est l'une des bases de données compatibles avec MCP Toolbox for Databases. Comme nous l'avons déjà provisionnée dans la section précédente, nous allons configurer Toolbox.
- Accédez à votre terminal Cloud Shell et assurez-vous que votre projet est sélectionné et affiché dans l'invite du terminal. Exécutez la commande ci-dessous depuis votre terminal Cloud Shell pour accéder au répertoire de votre projet :
mkdir toolbox-tools
cd toolbox-tools
- Exécutez la commande ci-dessous pour télécharger et installer la boîte à outils dans votre nouveau dossier :
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Accédez à l'éditeur Cloud Shell (pour le mode d'édition de code) et, dans le dossier racine du projet, ajoutez un fichier nommé "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Veillez à remplacer le script Tools.yaml par le code de ce fichier de dépôt.
Examinons le fichier tools.yaml :
Les sources représentent les différentes sources de données avec lesquelles un outil peut interagir. Une source représente une source de données avec laquelle un outil peut interagir. Vous pouvez définir des sources sous forme de mappage dans la section "sources" de votre fichier tools.yaml. En règle générale, une configuration de source contient toutes les informations nécessaires pour se connecter à la base de données et interagir avec elle.
Les outils définissent les actions qu'un agent peut effectuer, comme lire et écrire dans une source. Un outil représente une action que votre agent peut effectuer, comme exécuter une instruction SQL. Vous pouvez définir des outils sous forme de mappage dans la section "tools" de votre fichier tools.yaml. En règle générale, un outil a besoin d'une source sur laquelle agir.
Pour en savoir plus sur la configuration de votre fichier tools.yaml, consultez cette documentation.
- Exécutez la commande suivante (à partir du dossier mcp-toolbox) pour démarrer le serveur :
./toolbox --tools-file "tools.yaml"
Si vous ouvrez le serveur en mode Aperçu sur le Web dans le cloud, vous devriez voir le serveur Toolbox en cours d'exécution avec votre nouvel outil nommé get-order-data.
Par défaut, le serveur MCP Toolbox s'exécute sur le port 5000. Utilisons Cloud Shell pour tester cela.
Cliquez sur "Aperçu sur le Web" dans Cloud Shell, comme indiqué ci-dessous :
Cliquez sur "Change port" (Modifier le port), définissez le port sur 5000 comme indiqué ci-dessous, puis cliquez sur "Change and Preview" (Modifier et prévisualiser).
Vous devriez obtenir le résultat suivant :
- Déployons notre boîte à outils sur Cloud Run :
Pour commencer, nous pouvons démarrer avec le serveur MCP Toolbox et l'héberger sur Cloud Run. Nous obtiendrons ainsi un point de terminaison public que nous pourrons intégrer à n'importe quelle autre application et/ou aux applications Agent. Les instructions pour héberger ce service sur Cloud Run sont disponibles ici. Nous allons maintenant passer en revue les étapes clés.
- Lancez un terminal Cloud Shell ou utilisez-en un existant. Accédez au dossier du projet où se trouvent le fichier binaire de la boîte à outils et tools.yaml (toolbox-tools dans le cas présent), si vous n'y êtes pas déjà :
cd toolbox-tools
- Définissez la variable PROJECT_ID pour qu'elle pointe vers l'ID de votre projet Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Activez ces services Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Créons un compte de service distinct qui servira d'identité au service Toolbox que nous allons déployer sur Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Nous nous assurons également que ce compte de service dispose des rôles appropriés, c'est-à-dire qu'il peut accéder à Secret Manager et communiquer avec AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Nous allons importer le fichier tools.yaml en tant que secret :
gcloud secrets create tools --data-file=tools.yaml
Si vous avez déjà un secret et que vous souhaitez mettre à jour sa version, exécutez la commande suivante :
gcloud secrets versions add tools --data-file=tools.yaml
- Définissez une variable d'environnement sur l'image de conteneur que vous souhaitez utiliser pour Cloud Run :
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- La dernière étape de la commande de déploiement habituelle vers Cloud Run :
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Cela devrait lancer le processus de déploiement du serveur Toolbox avec notre fichier tools.yaml configuré sur Cloud Run. Si le déploiement réussit, un message semblable à celui-ci s'affiche :
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Vous pouvez maintenant utiliser votre nouvel outil déployé dans votre application agentique !!!
Accéder aux outils dans le serveur de la boîte à outils
Une fois la boîte à outils déployée, nous allons créer un shim de fonctions Cloud Run Python pour interagir avec le serveur de boîte à outils déployé. En effet, Toolbox ne dispose actuellement pas de SDK Java. Nous avons donc créé un shim Python pour interagir avec le serveur. Voici le code source de cette fonction Cloud Run.
Vous devez créer et déployer cette fonction Cloud Run pour pouvoir accéder aux outils de la boîte à outils que vous venez de créer et de déployer lors des étapes précédentes :
- Dans la console Google Cloud, accédez à la page Cloud Run.
- Cliquez sur "Écrire une fonction".
- Dans le champ "Nom du service", saisissez un nom pour décrire votre fonction. Les noms de service doivent commencer par une lettre et comporter 49 caractères au maximum (lettres, chiffres ou traits d'union). Les noms de service ne peuvent pas se terminer par un tiret et doivent être uniques par région et par projet. Un nom de service ne peut pas être modifié ultérieurement et il est visible publiquement. (Enter retail-product-search-quality)
- Dans la liste "Région", utilisez la valeur par défaut ou sélectionnez la région dans laquelle vous souhaitez déployer votre fonction. (Choisissez us-central1)
- Dans la liste "Runtime", utilisez la valeur par défaut ou sélectionnez une version du runtime. (Choisissez Python 3.11)
- Dans la section "Authentification", sélectionnez "Autoriser l'accès public".
- Cliquez sur le bouton "Créer".
- La fonction est créée et chargée avec un fichier main.py et requirements.txt de modèle.
- Remplacez-le par les fichiers main.py et requirements.txt du dépôt de ce projet.
- Déployez la fonction. Vous devriez obtenir un point de terminaison pour votre fonction Cloud Run.
Votre point de terminaison doit se présenter comme suit (ou de manière similaire) :
Point de terminaison Cloud Run Functions pour accéder à la boîte à outils : "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Pour faciliter la réalisation dans les délais (pour les sessions pratiques dirigées par un instructeur), le numéro de projet du point de terminaison sera communiqué au moment de la session pratique.
REMARQUE IMPORTANTE :
Vous pouvez également implémenter la partie base de données directement dans le code de votre application ou dans la fonction Cloud Run.
8. Développement d'applications (Java) avec recherche à facettes
Enfin, tous ces puissants composants de backend prennent vie grâce à la couche Application. Développée en Java, l'application fournit l'interface utilisateur permettant d'interagir avec le système de recherche. Il orchestre les requêtes vers AlloyDB, gère l'affichage des filtres à facettes, gère les sélections des utilisateurs et présente les résultats de recherche reclassés et validés de manière fluide et intuitive.
- Vous pouvez commencer par accéder à votre terminal Cloud Shell et cloner le dépôt :
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Accédez à l'éditeur Cloud Shell, où vous pouvez voir le dossier faceted_searching_retail que vous venez de créer.
- Supprimez les éléments suivants, car ces étapes ont déjà été effectuées dans les sections précédentes :
- Supprimez le dossier Cloud_Run_Function.
- Supprimez le fichier db_script.sql.
- Supprimer le fichier tools.yaml
- Accédez au dossier du projet retail-faceted-search. La structure du projet devrait s'afficher :
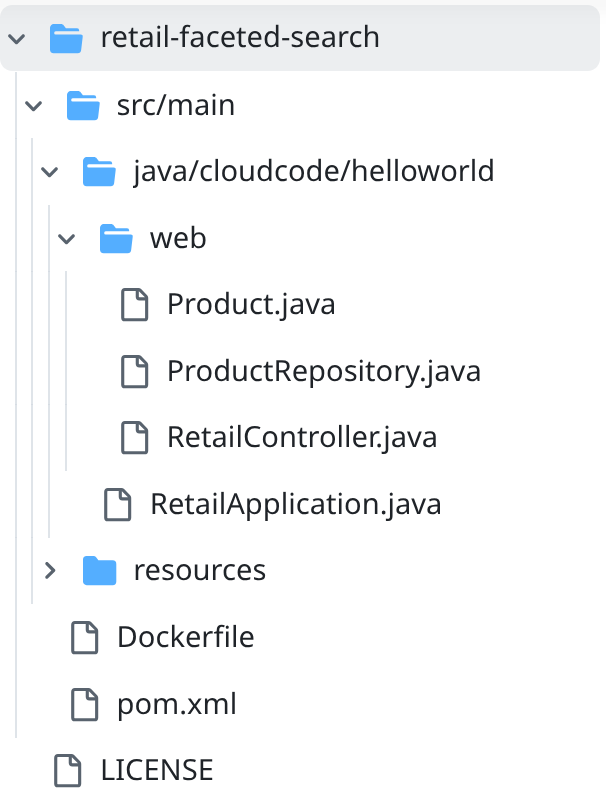
- Dans le fichier ProductRepository.java, vous devez modifier la variable TOOLBOX_ENDPOINT avec le point de terminaison de votre fonction Cloud Run (déployée) ou récupérer le point de terminaison auprès de l'animateur de l'atelier pratique.
Recherchez la ligne de code suivante et remplacez-la par votre point de terminaison :
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Assurez-vous que les fichiers Dockerfile et pom.xml sont adaptés à la configuration de votre projet (aucune modification n'est nécessaire, sauf si vous avez explicitement modifié une version ou une configuration).
- Dans le terminal Cloud Shell, assurez-vous d'être dans votre dossier principal et dans le dossier du projet (faceted_searching_retail / retail-faceted-search). Utilisez les commandes suivantes pour vous assurer d'être dans le bon dossier du terminal :
cd faceted_searching_retail
cd retail-faceted-search
- Empaquetez, créez et testez votre application localement :
mvn package
mvn spring-boot:run
Vous devriez pouvoir afficher votre application en cliquant sur "Prévisualiser sur le port 8080" dans le terminal Cloud Shell, comme indiqué ci-dessous :
9. Déployer sur Cloud Run : ***ÉTAPE IMPORTANTE
Dans le terminal Cloud Shell, assurez-vous d'être dans votre dossier principal et dans le dossier du projet (faceted_searching_retail / retail-faceted-search). Utilisez les commandes suivantes pour vous assurer d'être dans le bon dossier du terminal :
cd faceted_searching_retail
cd retail-faceted-search
Une fois que vous êtes sûr d'être dans le dossier du projet, exécutez la commande suivante :
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Une fois le déploiement effectué, vous devriez recevoir un point de terminaison Cloud Run déployé qui ressemble à ceci :
https://retail-search-**********-uc.a.run.app/
10. Démo
Voyons tout cela en action :
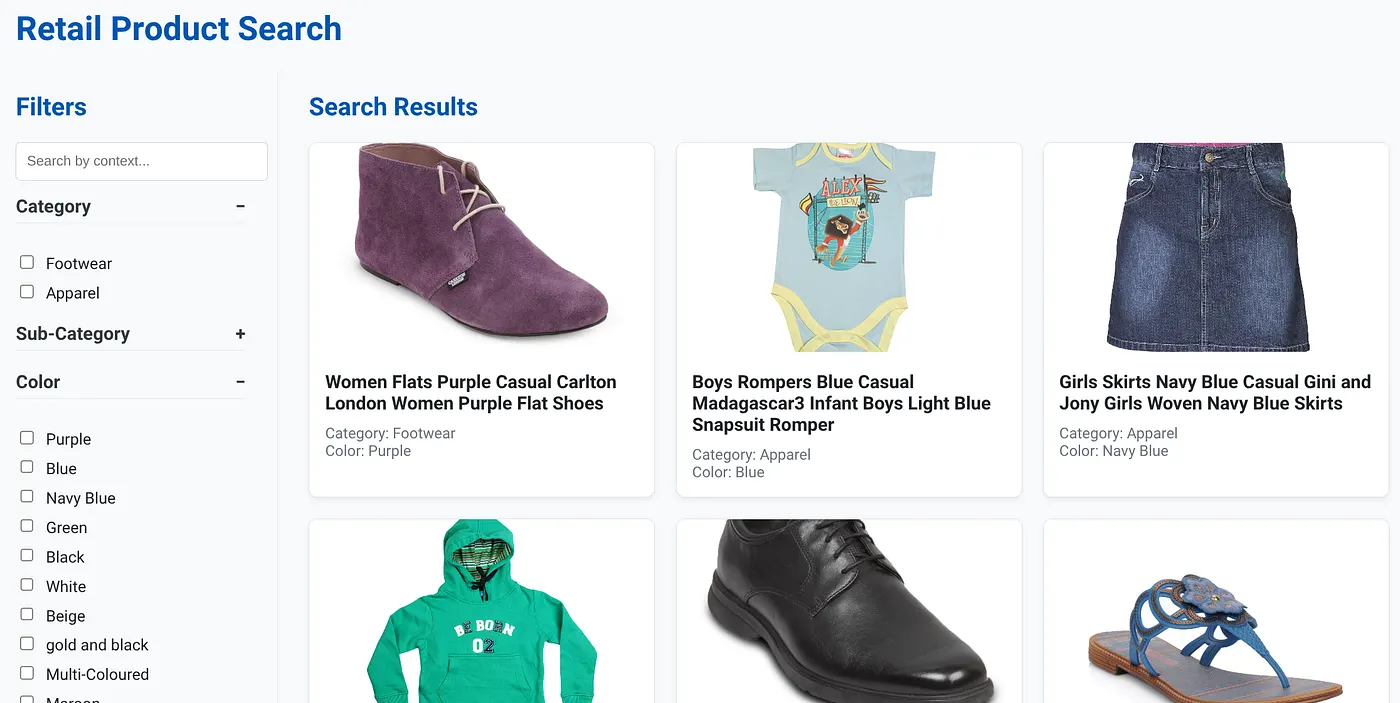
L'image ci-dessus montre la page de destination de l'application de recherche hybride dynamique.
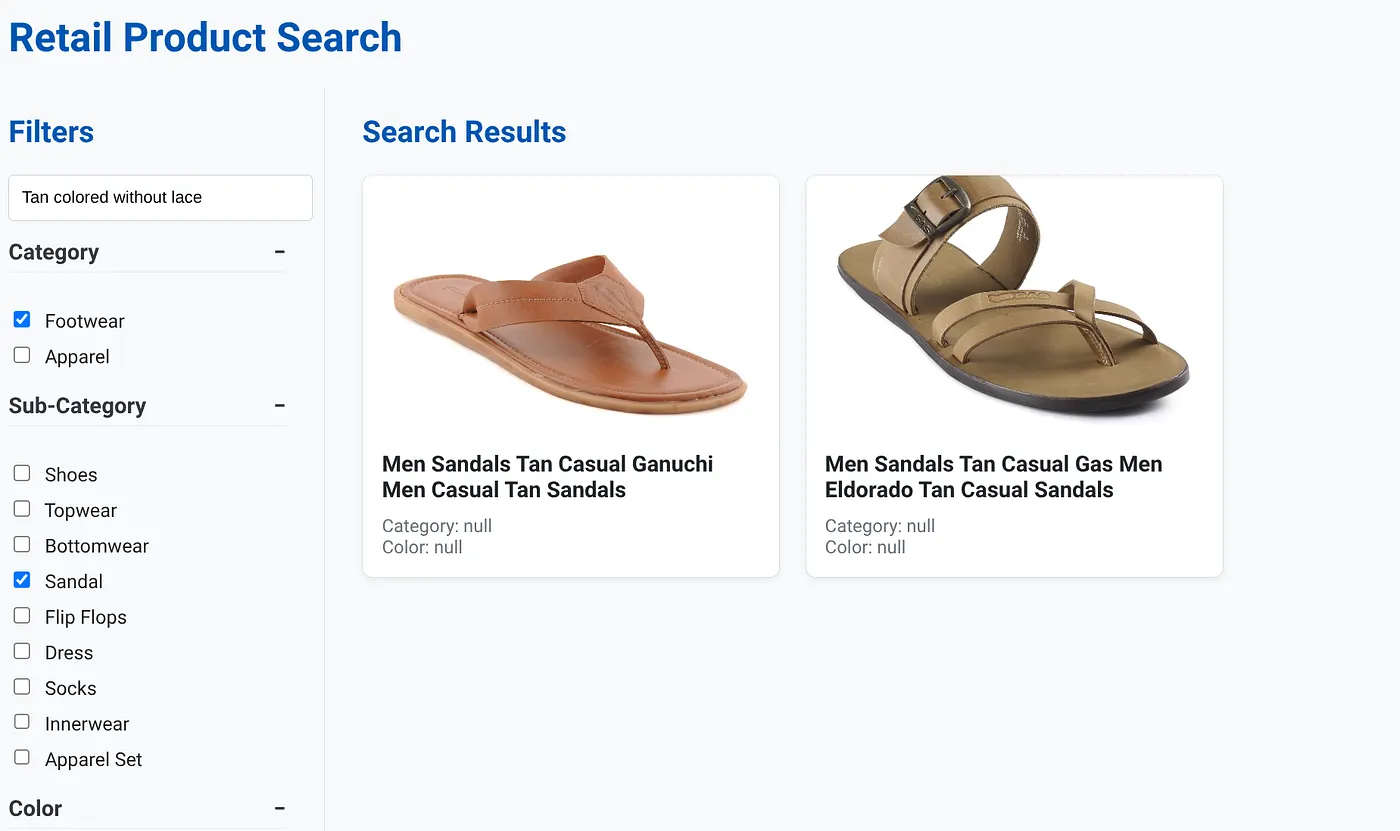
L'image ci-dessus montre les résultats de recherche pour "couleur marron clair sans lacets" . Les filtres à facettes sélectionnés sont : Chaussures, Sandales.
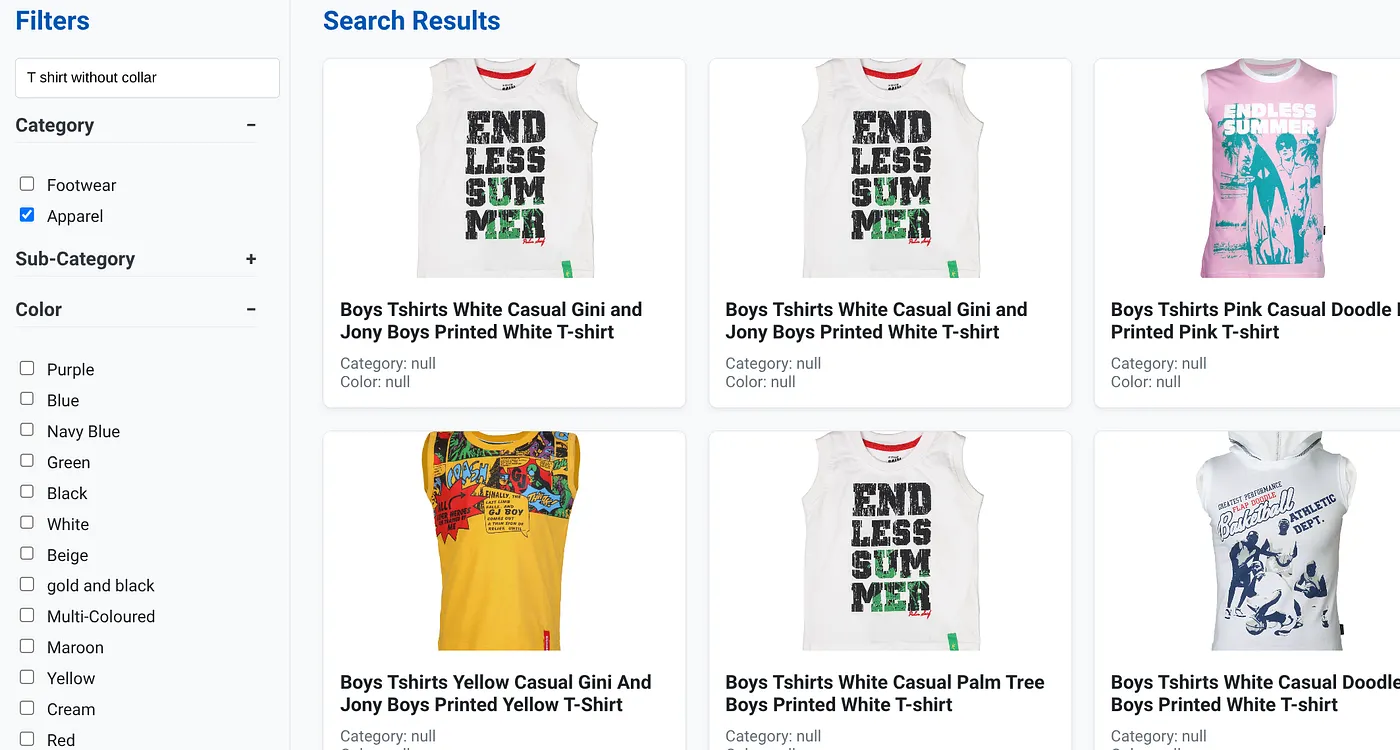
L'image ci-dessus montre les résultats de recherche pour "T-shirt sans col" . Filtres à facettes : vêtements
Vous pouvez désormais intégrer davantage de fonctionnalités génératives et agentiques pour rendre cette application exploitable.
Essayez-le pour trouver l'inspiration et créer votre propre version !
11. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gestionnaire de ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également supprimer le cluster AlloyDB que nous venons de créer pour ce projet en cliquant sur le bouton "SUPPRIMER LE CLUSTER". (Si vous n'avez pas choisi us-central1 pour le cluster lors de la configuration, modifiez l'emplacement dans cet hyperlien.)
12. Félicitations
Félicitations ! Vous avez créé et déployé une APPLICATION DE RECHERCHE HYBRIDE avec ALLOYDB sur CLOUD RUN.
Pourquoi cela est important pour les entreprises :
Cette application de recherche hybride dynamique, optimisée par AlloyDB AI, offre des avantages considérables aux entreprises de vente au détail et à d'autres entreprises :
Pertinence supérieure : en combinant la recherche contextuelle (vectorielle) avec un filtrage précis par facettes et un reclassement intelligent, les clients obtiennent des résultats très pertinents, ce qui augmente leur satisfaction et les conversions.
Évolutivité : l'architecture et l'indexation scaNN d'AlloyDB sont conçues pour gérer des catalogues de produits volumineux et des volumes de requêtes élevés, ce qui est essentiel pour les entreprises d'e-commerce en pleine croissance.
Performances : des réponses plus rapides aux requêtes, même pour les recherches hybrides complexes, garantissent une expérience utilisateur fluide et minimisent les taux d'abandon.
Préparation pour l'avenir : l'intégration des fonctionnalités d'IA (validation des embeddings et des LLM) prépare l'application aux futures avancées en matière de recommandations personnalisées, de commerce conversationnel et de découverte intelligente de produits.
Architecture simplifiée : l'intégration de la recherche vectorielle directement dans AlloyDB élimine le besoin de bases de données vectorielles distinctes ou de synchronisation complexe, ce qui simplifie le développement et la maintenance.
Imaginons qu'un utilisateur saisisse une requête en langage naturel comme "chaussures de course écologiques pour femmes avec un bon soutien de la voûte plantaire".
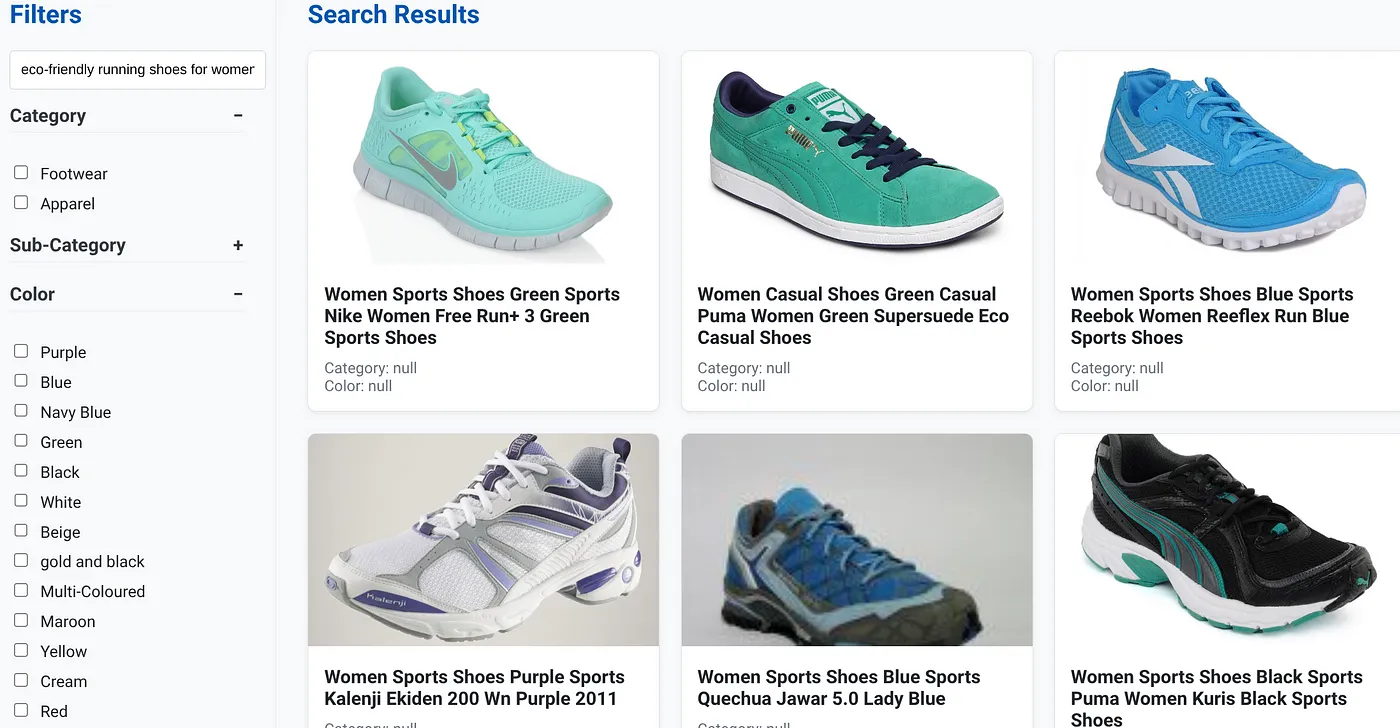
En même temps, l'utilisateur applique des filtres à facettes pour "Catégorie : <<>>","Couleur : <<>>" et dit "Prix : 100 € à 150 €" :
- Le système renvoie instantanément une liste affinée de produits, alignés sémantiquement sur le langage naturel et correspondant précisément aux filtres choisis.
- En coulisses, l'index scaNN accélère la recherche vectorielle, tandis que le filtrage intégré et adaptatif assure les performances avec des critères combinés, et le reclassement présente les résultats optimaux en haut de la liste.
- La rapidité et la précision des résultats illustrent clairement la puissance de la combinaison de ces technologies pour une expérience de recherche vraiment intelligente dans le secteur du commerce.
Pour créer une application de recherche pour le commerce de nouvelle génération, il faut aller au-delà des méthodes conventionnelles. En exploitant la puissance d'AlloyDB, de Vertex AI, de la recherche vectorielle avec l'indexation scaNN, du filtrage dynamique à facettes, du reclassement et de la validation LLM, nous pouvons offrir une expérience client inégalée qui stimule l'engagement et augmente les ventes. Cette solution robuste, évolutive et intelligente montre comment les fonctionnalités modernes de base de données, enrichies par l'IA, remodèlent l'avenir du commerce !