
1. סקירה כללית
בסביבה הקמעונאית התחרותית של היום, חשוב מאוד לאפשר ללקוחות למצוא בדיוק את מה שהם מחפשים, במהירות ובאופן אינטואיטיבי. חיפוש מסורתי שמבוסס על מילות מפתח לרוב לא מספיק טוב, ומתקשה להתמודד עם שאילתות מורכבות ועם קטלוגים גדולים של מוצרים. ב-codelab הזה נציג אפליקציית חיפוש מוצרים קמעונאיים מתקדמת שמבוססת על AlloyDB ו-AlloyDB AI. האפליקציה משתמשת בחיפוש וקטורי מתקדם, באינדקס scaNN, במסננים עם היבטים שונים ובסינון אדפטיבי חכם, ומבצעת דירוג מחדש כדי לספק חוויית חיפוש דינמית והיברידית בקנה מידה ארגוני.
עכשיו יש לנו כבר ידע בסיסי לגבי 3 דברים:
- מהו חיפוש הקשרי לסוכן ואיך מבצעים אותו באמצעות חיפוש וקטורי.
- בנוסף, אנחנו מסבירים איך להשתמש בחיפוש וקטורי במסגרת הנתונים שלכם, כלומר בתוך מסד הנתונים עצמו (כל מסדי הנתונים של Google Cloud תומכים בזה, למקרה שלא ידעתם!).
- אנחנו עשינו צעד נוסף מעבר למה שנעשה בשאר העולם, והסברנו איך אפשר להשיג יכולת RAG קלה של חיפוש וקטורי עם ביצועים ואיכות גבוהים באמצעות יכולת החיפוש הווקטורי של AlloyDB שמבוססת על אינדקס ScaNN.
אם לא קראתם את המאמרים על ניסויי RAG ברמות הבסיסית, הבינונית והמתקדמת, מומלץ לקרוא אותם כאן, כאן וכאן, לפי הסדר שמופיע.
האתגר
מעבר לסינון, למילות מפתח ולהתאמה לפי הקשר: חיפוש פשוט של מילות מפתח עשוי להחזיר אלפי תוצאות, שרבות מהן לא רלוונטיות. הפתרון האידיאלי צריך להבין את הכוונה מאחורי השאילתה, לשלב אותה עם קריטריוני סינון מדויקים (כמו מותג, חומר או מחיר) ולהציג את הפריטים הרלוונטיים ביותר בתוך אלפיות השנייה. לכן נדרשת תשתית חיפוש חזקה, גמישה וניתנת להרחבה. נכון, עברנו דרך ארוכה מחיפוש מילות מפתח להתאמות הקשריות ולחיפושים של דמיון. אבל תארו לעצמכם לקוח שמחפש "מעיל נוח, אופנתי ועמיד למים לטיולים באביב", ובמקביל משתמש במסננים. האפליקציה שלכם לא רק מחזירה תשובות איכותיות, אלא גם פועלת בצורה יעילה, ורצף הפעולות נקבע באופן דינמי על ידי מסד הנתונים שלכם.
מטרה
כדי לפתור את הבעיה באמצעות שילוב
- חיפוש הקשרי (חיפוש וקטורי): הבנת המשמעות הסמנטית של שאילתות ותיאורי מוצרים
- סינון לפי מאפיינים: המשתמשים יכולים לצמצם את התוצאות לפי מאפיינים ספציפיים
- גישה היברידית: שילוב חלק בין חיפוש לפי הקשר לבין סינון מובנה
- אופטימיזציה מתקדמת: שימוש באינדקס מיוחד, בסינון אדפטיבי ובדירוג מחדש כדי לשפר את המהירות והרלוונטיות
- בקרת איכות מבוססת-AI גנרטיבי: שילוב אימות של מודלים של שפה גדולה (LLM) לאיכות תוצאות מעולה.
במאמר הזה נסביר על הארכיטקטורה ועל תהליך ההטמעה.
מה תפַתחו
אפליקציית חיפוש קמעונאית
כחלק מהתהליך הזה, תצטרכו:
- יצירת מכונה וטבלה של AlloyDB למערך נתונים של מסחר אלקטרוני
- הגדרת הטמעות וחיפוש וקטורי
- יצירת אינדקס של מטא-נתונים ואינדקס ScaNN
- הטמעה של חיפוש וקטורים מתקדם ב-AlloyDB באמצעות שיטת הסינון המובנית של ScaNN
- הגדרה של מסננים מדורגים וחיפוש היברידי בשאילתה אחת
- שיפור הרלוונטיות של השאילתה באמצעות דירוג מחדש ואחזור (אופציונלי)
- בדיקת התשובה לשאילתה באמצעות Gemini (אופציונלי)
- MCP Toolbox for Databases ושכבת האפליקציה
- פיתוח אפליקציות (Java) עם חיפוש עם היבטים
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: לוחצים על הקישור ומפעילים את ממשקי ה-API.
אפשר גם להשתמש בפקודת gcloud. אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
3. הגדרת מסד נתונים
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כמסד הנתונים של נתוני המסחר האלקטרוני. הוא משתמש באשכולות כדי להכיל את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. הטבלאות יכילו את הנתונים בפועל.
ניצור אשכול, מכונה וטבלה ב-AlloyDB שבהם ייטען מערך הנתונים של המסחר האלקטרוני.
יצירת אשכול ומופע
- עוברים לדף AlloyDB במסוף Cloud. דרך קלה למצוא את רוב הדפים ב-Cloud Console היא לחפש אותם באמצעות סרגל החיפוש של המסוף.
- בדף הזה, לוחצים על CREATE CLUSTER (יצירת אשכול):

- יוצג מסך כמו זה שבהמשך. יוצרים אשכול ומופע עם הערכים הבאים (חשוב לוודא שהערכים זהים אם משכפלים את קוד האפליקציה מהמאגר):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / הגרסה המומלצת האחרונה
- אזור: "
us-central1" - רשת: "
default"
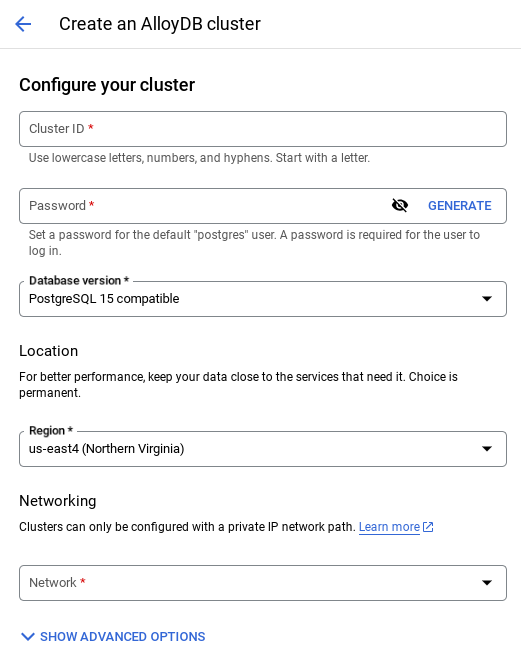
- כשבוחרים את רשת ברירת המחדל, מוצג מסך כמו זה שבהמשך.
לוחצים על הגדרת קישור.
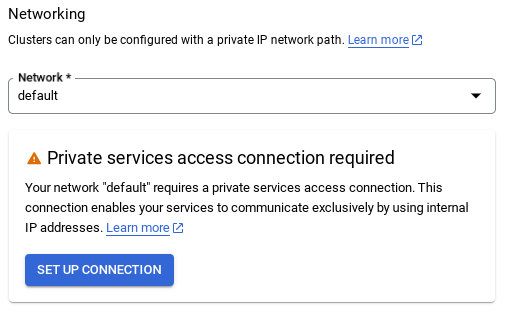
- משם, בוחרים באפשרות שימוש בטווח כתובות IP שהוקצה באופן אוטומטי ולוחצים על 'המשך'. אחרי שבודקים את המידע, לוחצים על CREATE CONNECTION (יצירת חיבור).
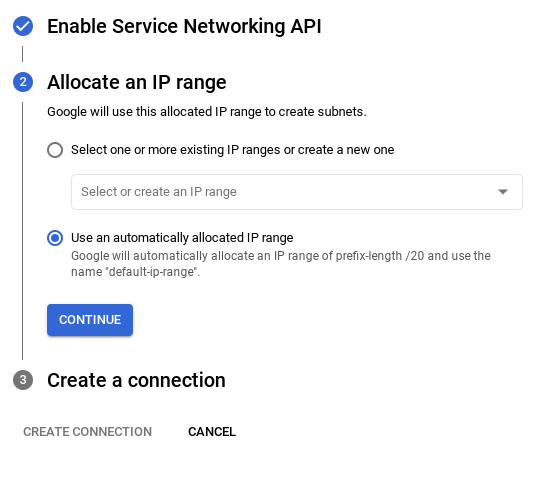
- אחרי שמגדירים את הרשת, אפשר להמשיך ליצור את האשכול. לוחצים על CREATE CLUSTER (יצירת אשכול) כדי להשלים את הגדרת האשכול, כמו שמוצג בהמשך:
הערה חשובה:
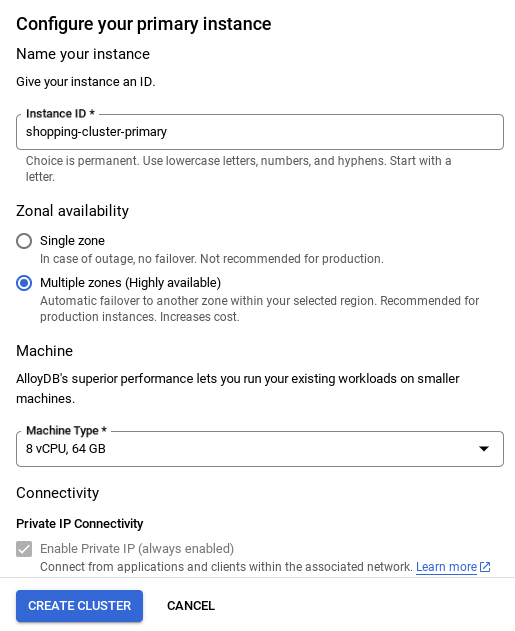
- חשוב לשנות את מזהה המופע (שאפשר למצוא בזמן ההגדרה של האשכול או המופע) ל **
vector-instance**. אם אי אפשר לשנות אותו, חשוב להשתמש במזהה המופע בכל ההפניות הבאות. - שימו לב: תהליך יצירת האשכול יימשך כ-10 דקות. אחרי שהפעולה תסתיים בהצלחה, יוצג מסך עם סקירה כללית של האשכול שיצרתם.
4. הטמעת נתונים
עכשיו צריך להוסיף טבלה עם הנתונים על החנות. עוברים אל AlloyDB, בוחרים את האשכול הראשי ואז בוחרים באפשרות AlloyDB Studio:
יכול להיות שתצטרכו לחכות עד שהמופע שלכם יסיים את תהליך היצירה. אחרי שיוצרים את האשכול, נכנסים ל-AlloyDB באמצעות פרטי הכניסה שיצרתם. משתמשים בנתונים הבאים כדי לבצע אימות ב-PostgreSQL:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה : "
alloydb"
אחרי שתעברו בהצלחה את תהליך האימות ב-AlloyDB Studio, תוכלו להזין פקודות SQL בכלי העריכה. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמשמאל לחלון האחרון.
מזינים פקודות ל-AlloyDB בחלונות של כלי העריכה, ומשתמשים באפשרויות Run (הפעלה), Format (עיצוב) ו-Clear (ניקוי) לפי הצורך.
הפעלת תוספים
כדי לבנות את האפליקציה הזו, נשתמש בתוספים pgvector ו-google_ml_integration. התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות של וקטורים. התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה (endpoints) של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL. מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
כדי לבדוק אילו תוספים הופעלו במסד הנתונים, מריצים את פקודת ה-SQL הבאה:
select extname, extversion from pg_extension;
צור טבלה
אתם יכולים ליצור טבלה באמצעות הצהרת ה-DDL שבהמשך ב-AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
בעמודת ההטמעה יאוחסנו ערכי הווקטור של הטקסט.
מתן הרשאה
מריצים את ההצהרה הבאה כדי להעניק הרשאת הפעלה לפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
הענקת התפקיד Vertex AI User לחשבון השירות של AlloyDB
במסוף IAM של Google Cloud, מעניקים לחשבון השירות של AlloyDB (שנראה כך: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) גישה לתפקיד Vertex AI User. PROJECT_NUMBER יכיל את מספר הפרויקט.
לחלופין, אפשר להריץ את הפקודה הבאה מ-Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
טעינת נתונים למסד הנתונים
- מעתיקים את הצהרות השאילתה
insertמ-insert scripts sqlבגיליון אל העורך שצוין למעלה. אפשר להעתיק 10-50 הצהרות של insert כדי ליצור הדגמה מהירה של תרחיש השימוש הזה. בכרטיסייה Selected Inserts 25-30 rows מופיעה רשימה של תוספים שנבחרו.
הקישור לנתונים נמצא בקובץ במאגר GitHub.
- לוחצים על Run. התוצאות של השאילתה יופיעו בטבלה Results.
הערה חשובה:
חשוב להקפיד להעתיק רק 25 עד 50 רשומות להוספה, ולוודא שהן מטווח של סוגי קטגוריות, קטגוריות משנה, צבעים ומגדרים.
5. יצירת הטמעות לנתונים
החידוש האמיתי בחיפוש המודרני הוא ההבנה של המשמעות, ולא רק של מילות המפתח. כאן נכנסים לתמונה הטמעות וחיפוש וקטורי.
המרנו תיאורי מוצרים ושאילתות של משתמשים לייצוגים מספריים רב-ממדיים שנקראים 'הטמעות', באמצעות מודלים של שפה שאומנו מראש. ההטמעות האלה מתעדות את המשמעות הסמנטית, ומאפשרות לנו למצוא מוצרים ש "דומים במשמעות" ולא רק מכילים מילים תואמות. בתחילה, ערכנו ניסויים בחיפוש ישיר של דמיון וקטורי בהטמעות האלה כדי ליצור בסיס להשוואה. כך הוכחנו את היכולת של הבנה סמנטית עוד לפני ביצוע אופטימיזציות של הביצועים.
בעמודת ההטמעה אפשר לאחסן את ערכי הווקטור של הטקסט בתיאור המוצר. בעמודה img_embeddings אפשר לאחסן הטמעות של תמונות (מולטימודאליות). כך תוכלו גם להשתמש בחיפוש לפי טקסט על בסיס מרחק מהתמונה. אבל בשיעור ה-Lab הזה נשתמש רק בהטמעות טקסט.
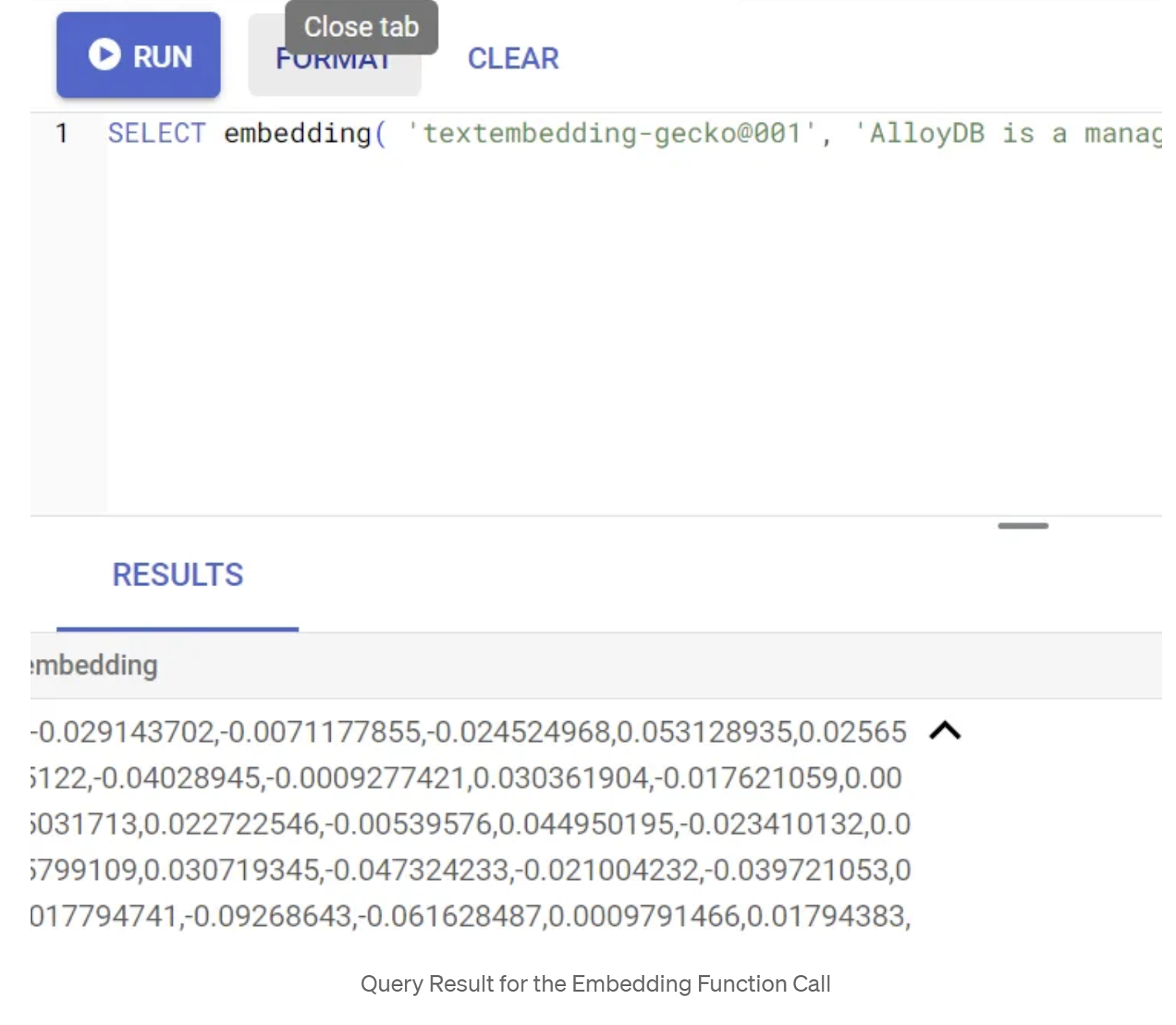
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
הפונקציה אמורה להחזיר את וקטור ההטמעה, שנראה כמו מערך של מספרים ממשיים, עבור טקסט הדוגמה בשאילתה. כך זה נראה:
עדכון שדה הווקטור abstract_embeddings
מריצים את פקודת ה-DML הבאה כדי לעדכן את תיאור התוכן בטבלה עם ההטמעות המתאימות:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
אם אתם משתמשים בחשבון לחיוב עם קרדיט לתקופת ניסיון ב-Google Cloud, יכול להיות שתתקשו ליצור יותר מכמה הטמעות (נניח 20-25 לכל היותר). לכן, כדאי להגביל את מספר השורות בסקריפט ההוספה.
אם רוצים ליצור הטמעות של תמונות (כדי לבצע חיפוש הקשרי מולטי-מודאלי), מריצים גם את העדכון הבא:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. ביצוע RAG מתקדם באמצעות התכונות החדשות של AlloyDB
עכשיו, אחרי שהטבלה, הנתונים וההטמעות מוכנים, אפשר לבצע חיפוש וקטורי בזמן אמת של טקסט החיפוש של המשתמש. כדי לבדוק את זה, מריצים את השאילתה הבאה:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
בשילתא הזו, אנחנו משווים את הטמעת הטקסט של החיפוש שהמשתמש הזין 'חולצת טי עם צווארון עגול' להטמעות הטקסט של כל תיאורי המוצרים בטבלת הבגדים (שמאוחסנים בעמודה בשם 'הטמעה') באמצעות פונקציית המרחק של דמיון הקוסינוס (שמיוצגת על ידי הסמל "<=>"). אנחנו ממירים את התוצאה של שיטת ההטמעה לסוג וקטור כדי שתהיה תואמת לווקטורים שמאוחסנים במסד הנתונים. LIMIT 10 מייצג את העובדה שאנחנו בוחרים את 10 ההתאמות הכי קרובות לטקסט החיפוש.
AlloyDB מעלה את RAG של Vector Search לרמה הבאה:
כדי לקבל פתרון שמתאים לארגונים גדולים, חיפוש וקטורי גולמי לא מספיק. הביצועים הם קריטיים.
אינדקס ScaNN (שכנים קרובים ניתנים להרחבה)
כדי להשיג חיפוש מהיר במיוחד של שכן קרוב משוער (ANN), הפעלנו את אינדקס scaNN ב-AlloyDB. ScaNN הוא אלגוריתם מתקדם לחיפוש של השכן הקרוב המשוער, שפותח על ידי צוות המחקר של Google. הוא מיועד לחיפוש יעיל של דמיון וקטורי בקנה מידה גדול. היא מאיצה משמעותית את השאילתות על ידי גיזום יעיל של מרחב החיפוש ושימוש בטכניקות קוונטיזציה, ומציעה שאילתות וקטוריות מהירות פי 4 בהשוואה לשיטות אחרות של יצירת אינדקסים, ושימוש קטן יותר בזיכרון שבשימוש. מידע נוסף זמין כאן וכאן.
נפעיל את התוסף וניצור את האינדקסים:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
יצירת אינדקסים לשדות של הטמעת טקסט והטמעת תמונות (אם רוצים להשתמש בהטמעת תמונות בחיפוש):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
מדדי מטא-נתונים
בעוד ש-scaNN מטפל באינדוקס וקטורי, אינדקסים מסורתיים של B-tree או GIN הוגדרו בקפידה במאפיינים מובנים (כמו קטגוריה, קטגוריית משנה, סגנון, צבע וכו'). האינדקסים האלה חיוניים ליעילות של סינון לפי מאפיינים. מריצים את ההצהרות הבאות כדי להגדיר אינדקסים של מטא-נתונים:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
הערה חשובה:
יכול להיות שהוספתם רק 25-50 רשומות, ולכן האינדקסים (ScaNN או כל אינדקס אחר) לא יהיו יעילים.
סינון בתוך השורה
אתגר נפוץ בחיפוש וקטורי הוא שילוב שלו עם מסננים מובנים (למשל, 'נעליים אדומות'). סינון מוטבע ב-AlloyDB מבצע אופטימיזציה של התהליך הזה. במקום לסנן את התוצאות אחרי חיפוש וקטורי רחב, סינון מוטבע מחיל תנאי סינון במהלך תהליך החיפוש הווקטורי עצמו, וכך משפר באופן משמעותי את הביצועים ואת הדיוק של חיפושים וקטוריים מסוננים.
מידע נוסף על הצורך בסינון מוטבע זמין במאמרי העזרה האלה. כאן אפשר לקרוא גם על חיפוש וקטורי עם סינון לאופטימיזציה של הביצועים של חיפוש וקטורי. אם רוצים להפעיל סינון מוטבע באפליקציה, מריצים את ההצהרה הבאה מהכלי לעריכה:
SET scann.enable_inline_filtering = on;
סינון מוטבע מתאים במיוחד למקרים עם סלקטיביות בינונית. במהלך החיפוש במדד הווקטורים, מערכת AlloyDB מחשבת מרחקים רק לווקטורים שתואמים לתנאי הסינון של המטא-נתונים (המסננים הפונקציונליים בשאילתה, שמטופלים בדרך כלל במשפט WHERE). השיפור הזה משפר משמעותית את הביצועים של השאילתות האלה, ומשלים את היתרונות של סינון אחרי או לפני.
סינון דינמי
כדי לשפר עוד יותר את הביצועים, סינון אדפטיבי ב-AlloyDB בוחר באופן דינמי את אסטרטגיית הסינון היעילה ביותר (סינון מוטבע או סינון מראש) במהלך ביצוע השאילתה. הוא מנתח דפוסי שאילתות והתפלגויות נתונים כדי להבטיח ביצועים אופטימליים ללא התערבות ידנית. זה מועיל במיוחד לחיפושים וקטוריים מסוננים, שבהם הוא עובר אוטומטית בין שימוש בווקטור לבין שימוש באינדקס מטא-נתונים. כדי להפעיל סינון אדפטיבי, משתמשים בדגל scann.enable_preview_features.
כשהסינון הדינמי מפעיל מעבר מסינון מוטבע לסינון מקדים במהלך ההרצה, תוכנית לביצוע שאילתה משתנה באופן דינמי.
SET scann.enable_preview_features = on;
הערה חשובה: יכול להיות שלא תוכלו להריץ את ההצהרה שלמעלה בלי להפעיל מחדש את המופע, אם תיתקלו בשגיאה. במקרה כזה, עדיף להפעיל את הדגל enable_preview_features בקטע database flags של המופע.
מסננים מורכבים שמשתמשים בכל האינדקסים
חיפוש עם היבטים מאפשר למשתמשים לצמצם את התוצאות על ידי החלת כמה מסננים על סמך מאפיינים ספציפיים או "היבטים" (למשל, מותג, מחיר, גודל, דירוג לקוחות). האפליקציה שלנו משלבת את ההיבטים האלה בצורה חלקה עם חיפוש וקטורי. עכשיו אפשר לשלב בשאילתה אחת שפה טבעית (חיפוש לפי הקשר) עם כמה בחירות של היבטים, תוך שימוש דינמי באינדקסים וקטוריים וגם באינדקסים מסורתיים. כך מתקבלת יכולת חיפוש היברידית דינמית באמת, שמאפשרת למשתמשים להתעמק בתוצאות בצורה מדויקת.
באפליקציה שלנו, מכיוון שכבר יצרנו את כל אינדקסי המטא-נתונים, אנחנו מוכנים לשימוש במסנן הפנים באינטרנט על ידי פנייה ישירה אליו באמצעות שאילתות SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
בשאילתה הזו, אנחנו מבצעים חיפוש היברידי – משלבים בין
- סינון לפי מאפיינים בתנאי WHERE
- חיפוש וקטורי בסעיף ORDER BY באמצעות שיטת הדמיון הקוסינוסי.
1$, 2$, 3$ ו-4 $מייצגים את ערכי המסננים המדורגים במערך, ו-5 $מייצג את טקסט החיפוש של המשתמש. מחליפים את $1 עד $4 בערכים של מסננים עם היבטים שתבחרו, כמו בדוגמה הבאה:
category = ANY([‘Apparel', ‘Footwear'])
מחליפים את $5 בטקסט חיפוש לבחירתכם, למשל Polo T-Shirts.
הערה חשובה: אם אין לכם את האינדקסים בגלל קבוצת הרשומות המוגבלת שהוספתם, לא תראו את ההשפעה על הביצועים. אבל במערך נתונים מלא של ייצור, תראו שזמן הביצוע מצטמצם באופן משמעותי עבור אותו חיפוש וקטורי באמצעות אינדקס ScaNN עם סינון מוטמע בחיפוש הווקטורי.
בשלב הבא, נבדוק את ההחזרה של חיפוש וקטורי עם ScaNN.
דירוג מחדש
גם כשמשתמשים בחיפוש מתקדם, יכול להיות שיהיה צורך לערוך את התוצאות הראשוניות. זהו שלב קריטי שבו המערכת מסדרת מחדש את תוצאות החיפוש הראשוניות כדי לשפר את הרלוונטיות שלהן. אחרי שהחיפוש ההיברידי הראשוני מספק קבוצה של מוצרים פוטנציאליים, מודל מתוחכם יותר (ולעתים קרובות כבד יותר מבחינת חישובים) מחיל ציון רלוונטיות מדויק יותר. כך מוודאים שהתוצאות הראשונות שמוצגות למשתמש הן הרלוונטיות ביותר, ומשפרים משמעותית את איכות החיפוש. אנחנו מעריכים באופן רציף את יכולת השליפה כדי למדוד את היעילות של המערכת באחזור כל הפריטים הרלוונטיים לשאילתה נתונה, ומשפרים את המודלים שלנו כדי למקסם את הסיכוי של הלקוח למצוא את מה שהוא צריך.
לפני שמשתמשים בשיטה הזו באפליקציה, חשוב לוודא שמתקיימות כל הדרישות המוקדמות:
- מוודאים שהתוסף google_ml_integration מותקן.
- מוודאים שהדגל google_ml_integration.enable_model_support מוגדר למצב on.
- שילוב עם Vertex AI.
- מפעילים את Discovery Engine API.
- קבלת התפקידים הנדרשים לשימוש במודלים של דירוג
לאחר מכן תוכלו להשתמש בשאילתה הבאה באפליקציה שלנו כדי לדרג מחדש את קבוצת התוצאות של החיפוש ההיברידי:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
בשאילתה הזו, אנחנו מבצעים דירוג מחדש של קבוצת תוצאות המוצרים של חיפוש הקשרי שמצוין בתנאי ORDER BY באמצעות שיטת הדמיון הקוסינוסי. 'חולצה ורודה' הוא הטקסט שהמשתמש מחפש.
הערה חשובה: יכול להיות שלחלקכם עדיין אין גישה לדירוג מחדש, ולכן לא כללתי אותו בקוד האפליקציה. אם אתם רוצים לכלול אותו, אתם יכולים לפעול לפי הדוגמה שציינתי למעלה.
כלי להערכת זכירת המודעה
ההחזרה בחיפוש דמיון היא אחוז המקרים הרלוונטיים שאותרו בחיפוש, כלומר מספר התוצאות החיוביות האמיתיות. זהו המדד הנפוץ ביותר למדידת איכות החיפוש. אחד הגורמים לאובדן של recall הוא ההבדל בין חיפוש של השכן הקרוב המשוער (aNN) לבין חיפוש של השכן הקרוב k (מדויק) (kNN). אינדקסים וקטוריים כמו ScaNN של AlloyDB מיישמים אלגוריתמים של חיפוש שכנים קרובים (aNN), ומאפשרים לכם להאיץ את החיפוש הווקטורי במערכי נתונים גדולים, בתמורה לפשרה קטנה בזיכרון. מעכשיו, ב-AlloyDB יש לכם אפשרות למדוד את האיזון הזה ישירות במסד הנתונים עבור שאילתות ספציפיות, ולוודא שהוא נשאר יציב לאורך זמן. אפשר לעדכן את הפרמטרים של השאילתה והאינדקס בתגובה למידע הזה כדי לשפר את התוצאות והביצועים.
מהי הלוגיקה שמאחורי שליפת תוצאות חיפוש?
בהקשר של חיפוש וקטורי, recall (החזרה) מתייחס לאחוז הווקטורים שהאינדקס מחזיר שהם השכנים הקרובים האמיתיים. לדוגמה, אם שאילתת שכנים קרובים ל-20 השכנים הקרובים ביותר מחזירה 19 מהשכנים הקרובים ביותר של נתוני האמת, אז ה-recall הוא 19/20x100 = 95%. החזרה היא המדד שמשמש לאיכות החיפוש, והיא מוגדרת כאחוז התוצאות שהוחזרו שהן הכי קרובות באופן אובייקטיבי לווקטורים של השאילתה.
אפשר למצוא את הזיכרון של שאילתת וקטור באינדקס וקטור עבור הגדרה נתונה באמצעות הפונקציה evaluate_query_recall. הפונקציה הזו מאפשרת לכם לשנות את הפרמטרים כדי להשיג את תוצאות ההחזרה של שאילתת הווקטור שאתם רוצים.
הערה חשובה:
אם נתקלתם בשגיאה 'ההרשאה נדחתה' באינדקס HNSW בשלבים הבאים, דלגו כרגע על כל הקטע הזה של הערכת ההחזרה. יכול להיות שזה קשור להגבלות גישה בשלב הזה, כי הוא רק הושק בזמן שבו נכתב ה-codelab הזה.
- מגדירים את הדגל Enable Index Scan באינדקס ScaNN ובאינדקס HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- מריצים את השאילתה הבאה ב-AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
הפונקציה evaluate_query_recall מקבלת את השאילתה כפרמטר ומחזירה את הזיכרון שלה. אני משתמש באותה שאילתה שבה השתמשתי כדי לבדוק את הביצועים כשאילתת הקלט של הפונקציה. הוספתי את SCaNN כשיטת האינדקס. אפשרויות נוספות לפרמטרים מפורטות במאמרי העזרה.
ההחזרה (recall) של שאילתת החיפוש הווקטורי שבה השתמשנו:
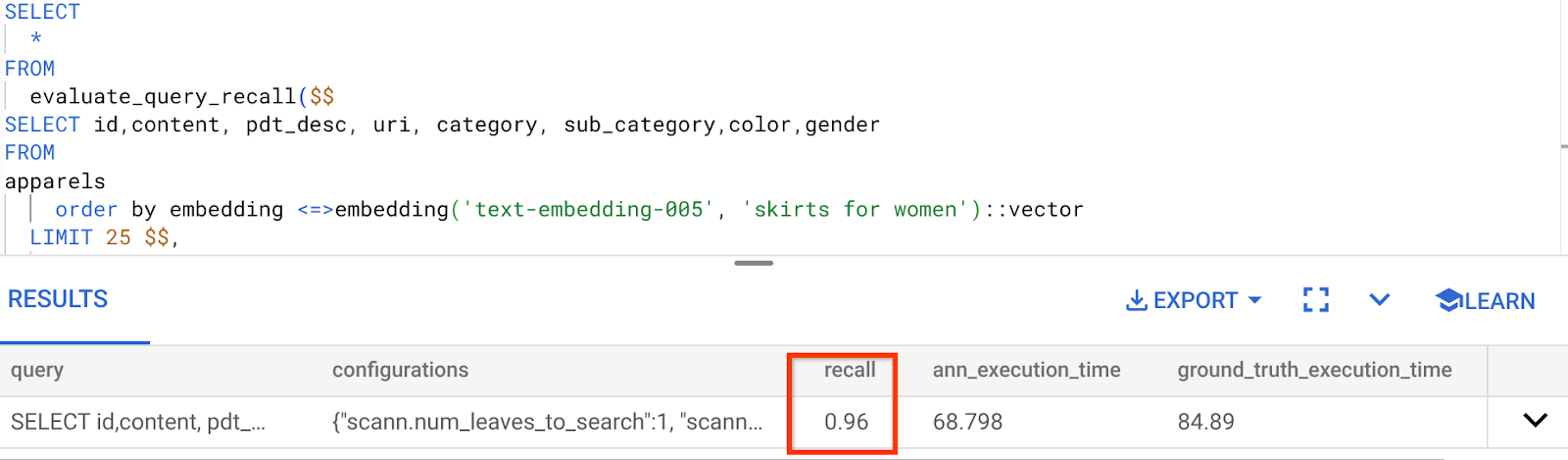
אני רואה שה-RECALL הוא 96%. במקרה הזה, ההיזכרות טובה מאוד. אבל אם זה היה ערך לא מקובל, תוכל להשתמש במידע הזה כדי לשנות את פרמטרים, שיטות ופרמטרים של שאילתות של האינדקס ולשפר את ההחזרה של התוצאות בחיפוש הווקטורי הזה.
בדיקה עם שאילתה ופרמטרים של אינדקס שעברו שינוי
עכשיו נבדוק את השאילתה על ידי שינוי פרמטרים של שאילתה על סמך התשובה שקיבלנו.
- שינוי פרמטרים של האינדקס:
בבדיקה הזו, אשתמש ב"מרחק L2" במקום בפונקציית מרחק הדמיון "קוסינוס".
הערה חשובה מאוד: "איך אנחנו יודעים שהשאילתה הזו משתמשת בדמיון קוסינוס?" אתם שואלים. אפשר לזהות את פונקציית המרחק לפי השימוש בסימן "<=>" שמייצג מרחק קוסינוס.
קישור ל-Docs לפונקציות של מרחק ב-Vector Search.
בשילתא הקודמת השתמשנו בפונקציית המרחק של דמיון קוסינוס, ועכשיו ננסה את המרחק L2. אבל כדי לעשות את זה, צריך לוודא שגם באינדקס הבסיסי של ScaNN נעשה שימוש בפונקציית המרחק L2. עכשיו ניצור אינדקס עם שאילתה שמשתמשת בפונקציית מרחק אחרת: מרחק L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
ההצהרה drop index נועדה לוודא שאין אינדקס מיותר בטבלה.
עכשיו אפשר להריץ את השאילתה הבאה כדי להעריך את ה-RECALL אחרי שינוי פונקציית המרחק של הפונקציונליות של חיפוש וקטורים.
[אחרי] שאילתה שמשתמשת בפונקציה L2 Distance:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
אפשר לראות את ההבדל או השינוי בערך ההחזרה של האינדקס המעודכן.
יש פרמטרים נוספים שאפשר לשנות באינדקס, כמו num_leaves וכו', על סמך ערך ההחזרה הרצוי ומערך הנתונים שבו האפליקציה משתמשת.
אימות תוצאות חיפוש וקטור על ידי מודל שפה גדול (LLM)
כדי להשיג את האיכות הכי גבוהה של חיפוש מבוקר, שילבנו שכבת אימות אופציונלית של מודל שפה גדול (LLM). אפשר להשתמש במודלים גדולים של שפה כדי להעריך את הרלוונטיות והקוהרנטיות של תוצאות החיפוש, במיוחד בשאילתות מורכבות או דו-משמעיות. הפעולות האלה יכולות לכלול:
אימות סמנטי:
מודל LLM שמצליב את התוצאות עם כוונת השאילתה.
סינון לוגי:
שימוש ב-LLM כדי להחיל כללים או לוגיקה עסקית מורכבת שקשה לקודד במסננים רגילים, וכך לשפר עוד יותר את רשימת המוצרים על סמך קריטריונים מדויקים.
הבטחת איכות:
זיהוי אוטומטי של תוצאות פחות רלוונטיות וסימון שלהן לצורך בדיקה אנושית או שיפור המודל.
כך עשינו את זה בתכונות של AlloyDB AI:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
שאילתת הבסיס היא אותה שאילתה שראינו בקטעים של חיפוש עם היבטים, חיפוש היברידי ודירוג מחדש. עכשיו בשאילתה הזו שילבנו שכבת הערכה של GEMINI של קבוצת התוצאות שדורגו מחדש, שמיוצגת על ידי מבנה ml_predict_row. הוספתי הערות למסננים המורכבים, אבל אפשר לכלול פריטים לבחירתך במערך של משתני placeholder $1 עד $4. מחליפים את $5 בכל טקסט שרוצים לחפש, למשל, 'חולצה ורודה, ללא דוגמה פרחונית'.
7. MCP Toolbox for Databases ושכבת האפליקציה
מאחורי הקלעים, כלי פיתוח חזקים ואפליקציה בנויה היטב מבטיחים פעולה חלקה.
MCP (Model Context Protocol) Toolbox for Databases מפשט את השילוב של כלי AI גנרטיבי וכלי סוכנים עם AlloyDB. הוא פועל כשרת קוד פתוח שמייעל את איגום החיבורים, האימות והחשיפה המאובטחת של פונקציות מסד הנתונים לסוכני AI או לאפליקציות אחרות.
באפליקציה שלנו השתמשנו ב-MCP Toolbox for Databases כשכבת הפשטה לכל השאילתות החכמות של החיפוש ההיברידי.
כדי להגדיר ולפרוס את Toolbox לתרחיש השימוש שלנו:
אפשר לראות שאחד ממסדי הנתונים שנתמכים על ידי MCP Toolbox for Databases הוא AlloyDB, ומכיוון שכבר הקצנו אותו בקטע הקודם, נמשיך להגדיר את Toolbox.
- עוברים למסוף Cloud Shell ומוודאים שהפרויקט נבחר ומוצג בהנחיה של המסוף. מריצים את הפקודה הבאה מ-Cloud Shell Terminal כדי להיכנס לספריית הפרויקט:
mkdir toolbox-tools
cd toolbox-tools
- מריצים את הפקודה הבאה כדי להוריד ולהתקין את ארגז הכלים בתיקייה החדשה:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- עוברים אל Cloud Shell Editor (למצב עריכת קוד) ובתיקיית השורש של הפרויקט מוסיפים קובץ בשם tools.yaml.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
חשוב להקפיד להחליף את הסקריפט Tools.yaml בקוד מקובץ המאגר הזה.
הסבר על הקובץ tools.yaml:
מקורות מייצגים את מקורות הנתונים השונים שהכלי יכול ליצור איתם אינטראקציה. מקור מייצג מקור נתונים שכלי יכול ליצור איתו אינטראקציה. אפשר להגדיר את המקורות כמפה בקטע sources בקובץ tools.yaml. בדרך כלל, הגדרת מקור תכיל את כל המידע שנדרש כדי להתחבר למסד הנתונים ולקיים איתו אינטראקציה.
כלים מגדירים את הפעולות שהסוכן יכול לבצע – כמו קריאה וכתיבה במקור. כלי מייצג פעולה שהסוכן יכול לבצע, כמו הפעלת הצהרת SQL. אפשר להגדיר כלי כמפה בקטע Tools בקובץ tools.yaml. בדרך כלל, כדי להשתמש בכלי צריך להגדיר מקור.
פרטים נוספים על הגדרת הקובץ tools.yaml מופיעים במאמר הזה.
- מריצים את הפקודה הבאה (מהתיקייה mcp-toolbox) כדי להפעיל את השרת:
./toolbox --tools-file "tools.yaml"
עכשיו, אם תפתחו את השרת במצב תצוגה מקדימה באינטרנט בענן, תוכלו לראות שהשרת של ערכת הכלים פועל עם הכלי החדש שלכם שנקרא get-order-data.
שרת ה-MCP Toolbox פועל כברירת מחדל ביציאה 5000. נשתמש ב-Cloud Shell כדי לבדוק את זה.
לוחצים על Web Preview (תצוגה מקדימה של אתר) ב-Cloud Shell כמו שמוצג למטה:
לוחצים על 'שינוי יציאה' ומגדירים את היציאה ל-5000 כמו שמוצג למטה. לוחצים על 'שינוי ותצוגה מקדימה'.
הפלט הבא אמור להתקבל:
- נפרוס את ערכת הכלים שלנו ב-Cloud Run:
קודם כול, אפשר להתחיל עם שרת ה-MCP Toolbox ולארח אותו ב-Cloud Run. כך נקבל נקודת קצה ציבורית שנוכל לשלב עם כל אפליקציה אחרת ו/או עם אפליקציות של סוכנים. הוראות לאירוח ב-Cloud Run זמינות כאן. עכשיו נסביר את השלבים העיקריים.
- מפעילים טרמינל חדש של Cloud Shell או משתמשים בטרמינל קיים של Cloud Shell. אם אתם לא נמצאים בתיקיית הפרויקט, עוברים אליה. במקרה הזה, התיקייה היא toolbox-tools, שבה נמצאים הקובץ הבינארי של ארגז הכלים והקובץ tools.yaml:
cd toolbox-tools
- מגדירים את המשתנה PROJECT_ID כך שיצביע על מזהה הפרויקט ב-Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- הפעלת שירותי Google Cloud הבאים
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- ניצור חשבון שירות נפרד שישמש כזהות של שירות ארגז הכלים שנפרוס ב-Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- אנחנו גם מוודאים שלחשבון השירות הזה יש את התפקידים הנכונים, כלומר אפשרות לגשת ל-Secret Manager ולתקשר עם AlloyDB
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- נעלה את הקובץ tools.yaml כסוד:
gcloud secrets create tools --data-file=tools.yaml
אם כבר יש לכם סוד ואתם רוצים לעדכן את גרסת הסוד, מריצים את הפקודה הבאה:
gcloud secrets versions add tools --data-file=tools.yaml
- מגדירים משתנה סביבה לקובץ אימג' של קונטיינר שרוצים להשתמש בו ב-Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- השלב האחרון בפקודת הפריסה המוכרת ל-Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
הפעולה הזו אמורה להתחיל את תהליך הפריסה של השרת Toolbox עם הקובץ tools.yaml שהגדרנו ב-Cloud Run. אם הפריסה בוצעה בהצלחה, תוצג הודעה שדומה לזו:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
הכלי החדש שהטמעת מוכן לשימוש באפליקציה שלך שמבוססת על סוכנים דיגיטליים!!!
גישה לכלים בשרת של Toolbox
אחרי פריסת ערכת הכלים, ניצור shim של פונקציות Python Cloud Run כדי ליצור אינטראקציה עם שרת ערכת הכלים שנפרס. הסיבה לכך היא שכרגע ל-Toolbox אין Java SDK, ולכן יצרנו Python shim כדי ליצור אינטראקציה עם השרת. הנה קוד המקור של פונקציית Cloud Run.
כדי לגשת לכלים של ארגז הכלים שיצרנו ופרסנו בשלבים הקודמים, צריך ליצור ולפרוס את הפונקציה הזו ב-Cloud Run:
- במסוף Google Cloud, נכנסים אל הדף Cloud Run.
- לוחצים על 'כתיבת פונקציה'.
- בשדה 'שם השירות', מזינים שם שמתאר את הפונקציה. שמות השירותים חייבים להתחיל באות, ויכולים להכיל עד 49 תווים, כולל אותיות, מספרים או מקפים. שמות השירותים לא יכולים להסתיים במקפים, והם צריכים להיות ייחודיים לכל אזור ולכל פרויקט. אי אפשר לשנות את שם השירות אחר כך, והוא גלוי לכולם. (Enter retail-product-search-quality)
- ברשימת האזורים, משתמשים בערך ברירת המחדל או בוחרים את האזור שבו רוצים לפרוס את הפונקציה. (בוחרים us-central1)
- ברשימה Runtime, משתמשים בערך ברירת המחדל או בוחרים גרסת זמן ריצה. (בוחרים באפשרות Python 3.11)
- בקטע 'אימות', בוחרים באפשרות 'מתן גישה ציבורית'.
- לוחצים על הלחצן 'יצירה'.
- הפונקציה נוצרת ונטענת עם תבנית main.py ו-requirements.txt
- מחליפים את הקובץ הזה בקבצים: main.py ו- requirements.txt ממאגר הפרויקט הזה
- פורסים את הפונקציה וצריכה להתקבל נקודת קצה לפונקציית Cloud Run
נקודת הקצה שלכם אמורה להיראות כך (או משהו דומה):
נקודת הקצה של פונקציית Cloud Run לגישה לערכת הכלים: https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app
כדי שיהיה קל יותר להשלים את הפרויקט במסגרת הזמן (בסשנים המעשיים בהנחיית מדריך), מספר הפרויקט של נקודת הקצה ישותף בזמן הסשן המעשי.
הערה חשובה:
לחלופין, אפשר להטמיע את החלק של מסד הנתונים ישירות כחלק מקוד האפליקציה או מפונקציית Cloud Run.
8. פיתוח אפליקציות (Java) עם חיפוש עם היבטים
לבסוף, כל רכיבי ה-Backend העוצמתיים האלה מופעלים באמצעות שכבת האפליקציה. האפליקציה, שפותחה ב-Java, מספקת את ממשק המשתמש לאינטראקציה עם מערכת החיפוש. הוא מתזמן את השאילתות ל-AlloyDB, מטפל בהצגה של מסננים עם מאפיינים, מנהל את הבחירות של המשתמשים ומציג את תוצאות החיפוש שסודרו מחדש ואומתו בצורה חלקה ואינטואיטיבית.
- כדי להתחיל, מנווטים אל Cloud Shell Terminal ומשכפלים את המאגר:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- עוברים אל Cloud Shell Editor, שבו אפשר לראות את התיקייה החדשה שנוצרה faceted_searching_retail
- מוחקים את השלבים הבאים כי הם כבר הושלמו בקטעים הקודמים:
- מחיקת התיקייה Cloud_Run_Function
- מוחקים את הקובץ db_script.sql.
- מחיקת הקובץ tools.yaml
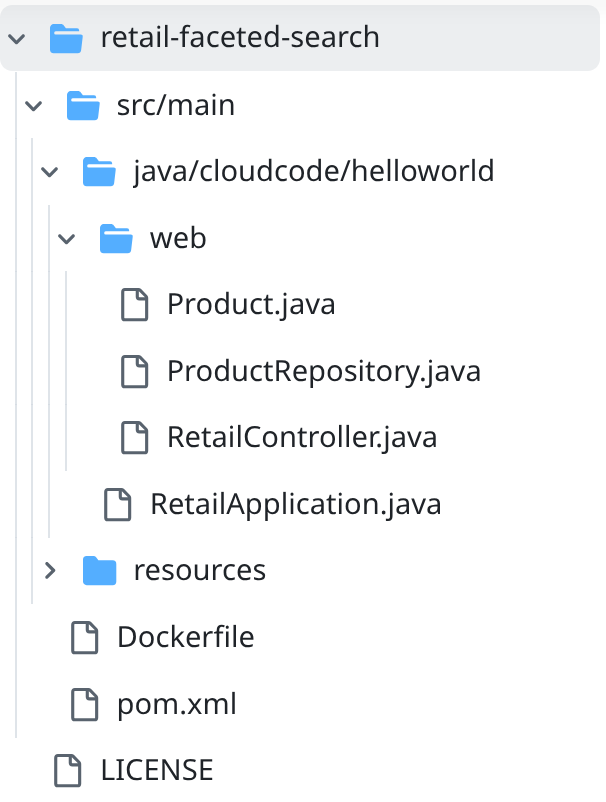
- עוברים לתיקיית הפרויקט retail-faceted-search ורואים את מבנה הפרויקט:
- בקובץ ProductRepository.java צריך לשנות את המשתנה TOOLBOX_ENDPOINT לנקודת הקצה מפונקציית Cloud Run (שנפרסה) או לקחת את נקודת הקצה מהרמקול המעשי.
מחפשים את שורת הקוד הבאה ומחליפים אותה בנקודת הקצה שלכם:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- מוודאים שקובצי Dockerfile ו-pom.xml תואמים להגדרת הפרויקט (אין צורך בשינוי אלא אם שיניתם באופן מפורש גרסה או הגדרה כלשהי).
- בטרמינל של Cloud Shell, מוודאים שאתם נמצאים בתיקייה הראשית ובתיקיית הפרויקט (faceted_searching_retail / retail-faceted-search). כדי לוודא שאתם נמצאים בתיקייה הנכונה בטרמינל, אלא אם אתם כבר נמצאים בה, משתמשים בפקודות הבאות:
cd faceted_searching_retail
cd retail-faceted-search
- אריזה, פיתוח גרסת build ובדיקה של האפליקציה באופן מקומי:
mvn package
mvn spring-boot:run
אפשר לראות את האפליקציה בלחיצה על 'תצוגה מקדימה ביציאה 8080' במסוף Cloud Shell, כמו שמוצג בהמשך:
9. פריסה ב-Cloud Run: ***שלב חשוב
בטרמינל של Cloud Shell מוודאים שאתם נמצאים בתיקייה הראשית ובתיקיית הפרויקט (faceted_searching_retail / retail-faceted-search). כדי לוודא שאתם נמצאים בתיקייה הנכונה בטרמינל, אלא אם אתם כבר נמצאים בה, משתמשים בפקודות הבאות:
cd faceted_searching_retail
cd retail-faceted-search
אחרי שמוודאים שנמצאים בתיקיית הפרויקט, מריצים את הפקודה הבאה:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
אחרי הפריסה, תקבלו נקודת קצה (endpoint) של Cloud Run שנפרסה, שצריכה להיראות כך:
https://retail-search-**********-uc.a.run.app/
10. הדגמה (דמו)
בואו נראה איך הכל משתלב בפועל:
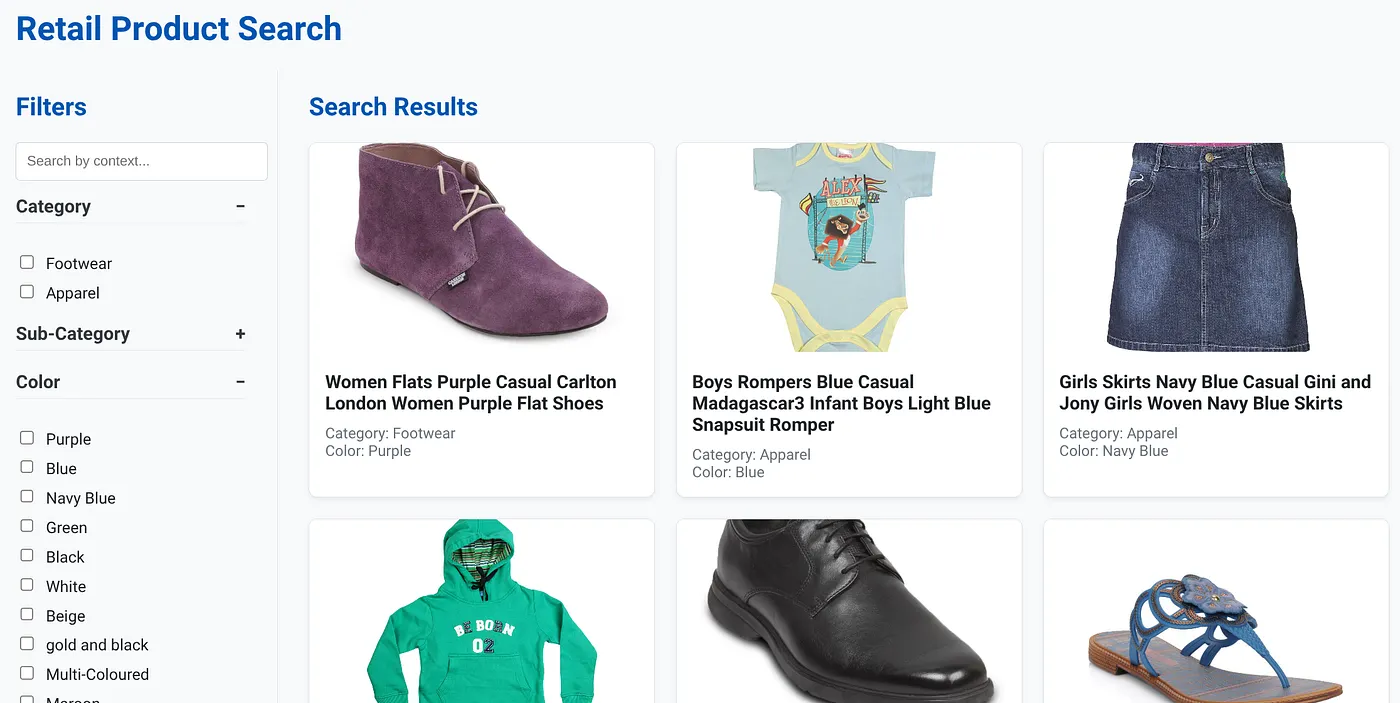
בתמונה שלמעלה מוצג דף הנחיתה של אפליקציית החיפוש הדינמי ההיברידי.
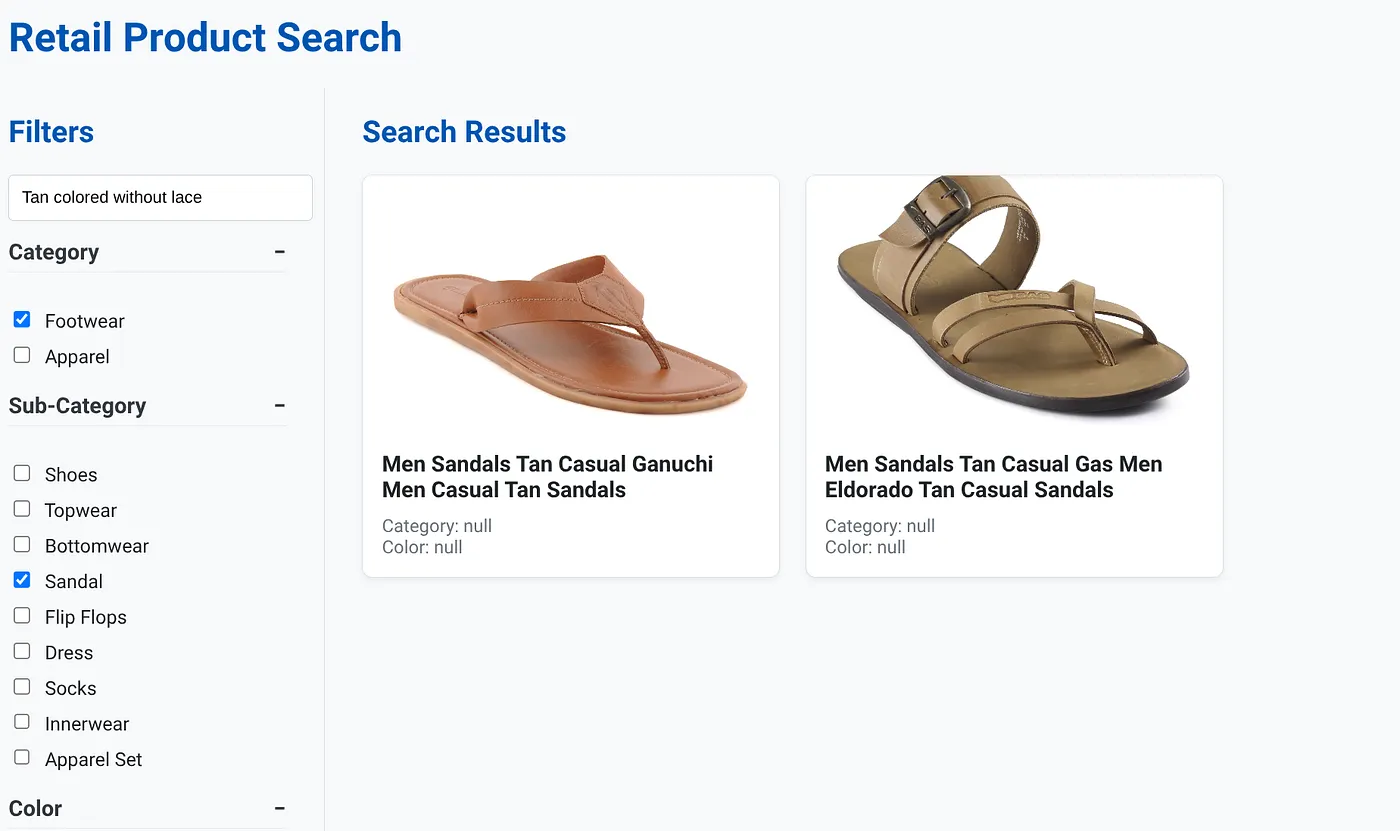
בתמונה שלמעלה מוצגות תוצאות החיפוש של 'נעליים בצבע חום בהיר ללא שרוכים' . המסננים שנבחרו הם: הנעלה, סנדל.
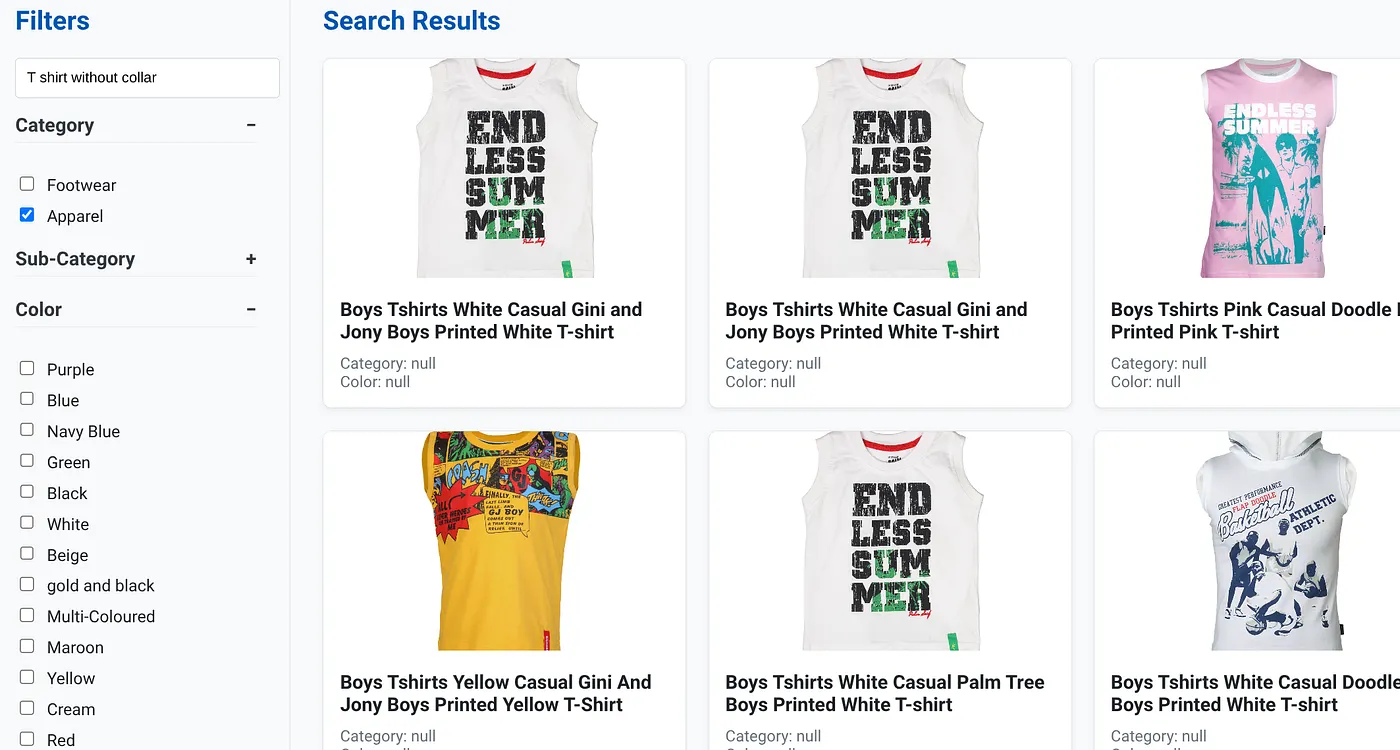
בתמונה שלמעלה מוצגות תוצאות החיפוש של 'חולצת טי בלי צווארון' . מסננים עם היבטים: ביגוד
עכשיו אפשר לשלב עוד תכונות גנרטיביות ותכונות של סוכנים כדי להפוך את האפליקציה הזו לשימושית.
כדאי לנסות כדי לקבל השראה ליצירת תמונות משלכם.
11. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים לדף resource manager.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
- לחלופין, אפשר פשוט למחוק את אשכול AlloyDB (אם לא בחרתם במיקום us-central1 לאשכול בזמן ההגדרה, צריך לשנות את המיקום בהיפר-קישור הזה) שיצרנו זה עתה עבור הפרויקט הזה, על ידי לחיצה על הלחצן DELETE CLUSTER (מחיקת האשכול).
12. מזל טוב
מעולה! הצלחתם ליצור ולפרוס אפליקציית חיפוש היברידית עם AlloyDB ב-Cloud Run!!!
למה זה חשוב לעסקים:
אפליקציית החיפוש הדינמית וההיברידית הזו, שמבוססת על AlloyDB AI, מציעה יתרונות משמעותיים לעסקים קמעונאיים ולעסקים אחרים:
רלוונטיות גבוהה יותר: שילוב של חיפוש הקשרי (וקטורי) עם סינון מדויק לפי מאפיינים ודירוג מחדש חכם מאפשר ללקוחות לקבל תוצאות רלוונטיות מאוד, מה שמוביל לשביעות רצון גבוהה יותר ולהמרות.
יכולת הרחבה: הארכיטקטורה של AlloyDB והוספת האינדקסים של scaNN נועדו לטפל בקטלוגים עצומים של מוצרים ובנפחים גדולים של שאילתות, וזה חיוני לעסקי מסחר אלקטרוני בצמיחה.
ביצועים: תגובות מהירות יותר לשאילתות, גם בחיפושים היברידיים מורכבים, מבטיחות חוויית משתמש חלקה ומצמצמות את שיעורי הנטישה.
הכנה לעתיד: השילוב של יכולות AI (הטמעה, אימות של מודל שפה גדול) מכין את האפליקציה להתקדמות עתידית בהמלצות מותאמות אישית, במסחר בממשק שיחה ובגילוי מוצרים חכם.
ארכיטקטורה פשוטה יותר: שילוב של חיפוש וקטורי ישירות ב-AlloyDB מבטל את הצורך במסדי נתונים וקטוריים נפרדים או בסנכרון מורכב, ומפשט את תהליך הפיתוח והתחזוקה.
נניח שמשתמש הקליד שאילתה בשפה טבעית כמו "נעלי ריצה ידידותיות לסביבה לנשים עם תמיכה גבוהה בקשת כף הרגל".
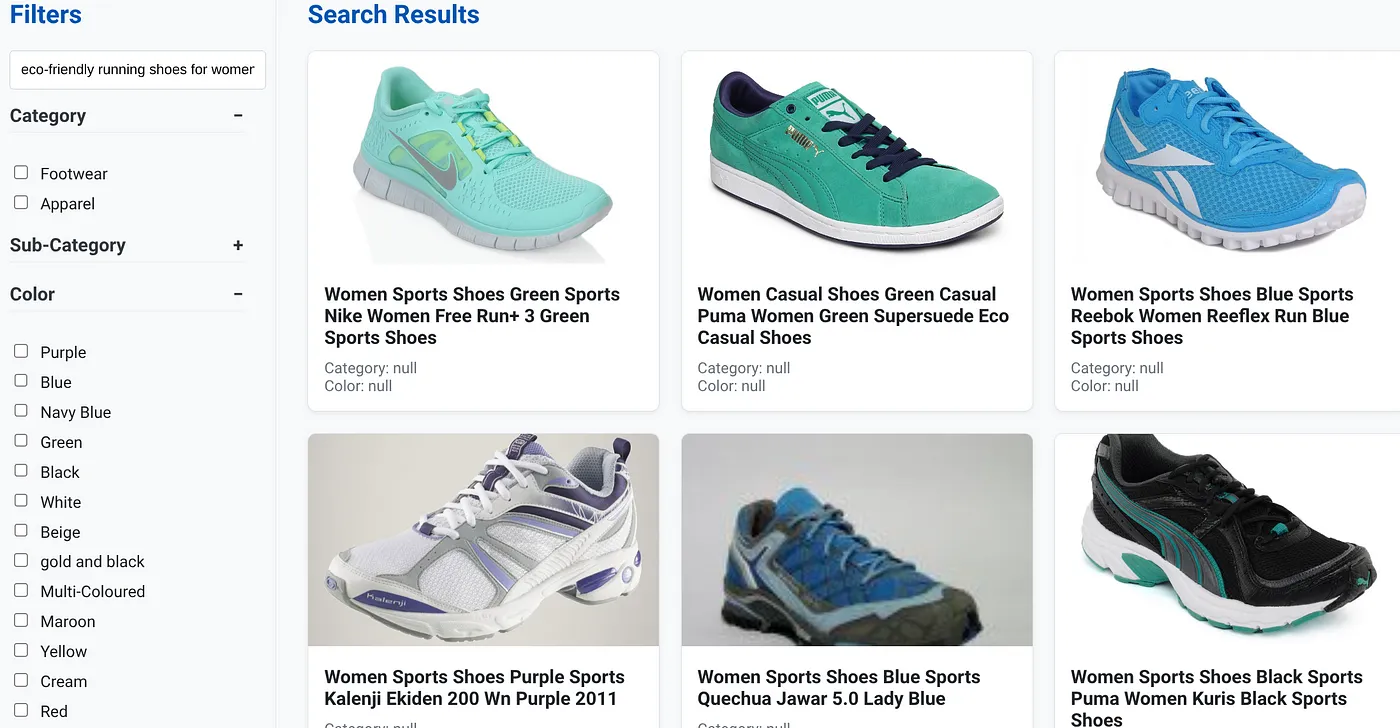
במקביל, המשתמש מחיל מסננים מפורטים לפי 'קטגוריה: <<>>','צבע: <<>>' ואומר 'מחיר: 100$-150$':
- המערכת מחזירה באופן מיידי רשימה מעודנת של מוצרים, שתואמת מבחינה סמנטית לשפה הטבעית ומתאימה בדיוק למסננים שנבחרו.
- מאחורי הקלעים, אינדקס scaNN מאיץ את חיפוש הווקטורים, סינון מוטבע וסינון מותאם מבטיחים ביצועים עם קריטריונים משולבים, ודירוג מחדש מציג את התוצאות האופטימליות בראש.
- המהירות והדיוק של התוצאות ממחישים בבירור את היכולות של שילוב הטכנולוגיות האלה כדי ליצור חוויית חיפוש חכמה באמת בקמעונאות.
כדי ליצור אפליקציית חיפוש קמעונאית מהדור הבא, צריך לצאת מהשיטות המקובלות ולהשתמש ביכולות של AlloyDB, Vertex AI, Vector Search עם אינדוקס scaNN, סינון דינמי לפי היבטים, דירוג מחדש ואימות LLM. כך אפשר לספק חוויית לקוח שאין שנייה לה, שמגבירה את המעורבות ומעודדת מכירות. הפתרון החזק, החכם והניתן להרחבה הזה מדגים איך יכולות מודרניות של מסדי נתונים, שמשולב בהן AI, מעצבות מחדש את העתיד של הקמעונאות!!!