
1. खास जानकारी
आज के प्रतिस्पर्धी खुदरा बाज़ार में, ग्राहकों को उनकी ज़रूरत के हिसाब से प्रॉडक्ट ढूंढने में मदद करना बहुत ज़रूरी है. साथ ही, यह भी ज़रूरी है कि वे आसानी से और जल्दी प्रॉडक्ट ढूंढ पाएं. कीवर्ड पर आधारित पारंपरिक खोज की सुविधा, अक्सर सटीक जवाब नहीं दे पाती. यह बारीकी से की गई क्वेरी और प्रॉडक्ट के बड़े कैटलॉग को समझने में मुश्किलों का सामना करती है. इस कोडलैब में, AlloyDB और AlloyDB AI पर बनाए गए एक बेहतर खुदरा खोज ऐप्लिकेशन के बारे में बताया गया है. यह ऐप्लिकेशन, वेक्टर सर्च, scaNN इंडेक्सिंग, फ़ैसेट फ़िल्टर, और इंटेलिजेंट अडैप्टिव फ़िल्टरिंग जैसी नई टेक्नोलॉजी का इस्तेमाल करता है. साथ ही, यह एंटरप्राइज़ लेवल पर डाइनैमिक और हाइब्रिड सर्च की सुविधा देने के लिए, नतीजों को फिर से रैंक करता है.
अब हमें तीन चीज़ों के बारे में बुनियादी जानकारी मिल चुकी है:
- कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा का आपके एजेंट पर क्या असर पड़ता है और Vector Search का इस्तेमाल करके, इस सुविधा को कैसे लागू किया जा सकता है.
- हमने आपके डेटा के दायरे में वेक्टर सर्च की सुविधा पाने के बारे में भी जानकारी दी. इसका मतलब है कि यह सुविधा आपके डेटाबेस में ही उपलब्ध है. अगर आपको नहीं पता, तो बता दें कि Google Cloud के सभी डेटाबेस में यह सुविधा काम करती है!
- हमने दुनिया के अन्य देशों के मुकाबले, आपको एक कदम आगे बढ़कर यह बताया है कि ScaNN इंडेक्स की मदद से, AlloyDB की वेक्टर सर्च सुविधा का इस्तेमाल करके, कम संसाधनों में वेक्टर सर्च वाली RAG सुविधा को बेहतर परफ़ॉर्मेंस और क्वालिटी के साथ कैसे लागू किया जा सकता है.
अगर आपने आरएजी के बुनियादी, सामान्य, और थोड़े ऐडवांस एक्सपेरिमेंट नहीं पढ़े हैं, तो हम आपको इन तीनों एक्सपेरिमेंट के बारे में पढ़ने का सुझाव देते हैं. इन्हें यहां, यहां, और यहां दिए गए क्रम में पढ़ें.
चुनौती
फ़िल्टर, कीवर्ड, और कॉन्टेक्स्ट के हिसाब से मैचिंग से आगे बढ़ना: सिर्फ़ कीवर्ड के हिसाब से खोज करने पर, आपको हज़ारों नतीजे मिल सकते हैं. इनमें से कई नतीजे काम के नहीं होते. सबसे सही जवाब देने के लिए, यह ज़रूरी है कि एआई क्वेरी के पीछे के मकसद को समझे. साथ ही, उसे फ़िल्टर करने के सटीक मानदंड (जैसे, ब्रैंड, मटीरियल या कीमत) के साथ जोड़े. इसके बाद, कुछ ही मिलीसेकंड में सबसे काम के आइटम दिखाए. इसके लिए, एक बेहतर, आसान, और ज़रूरत के हिसाब से बढ़ाया जा सकने वाला सर्च इन्फ़्रास्ट्रक्चर ज़रूरी है. ज़रूर, हमने कीवर्ड खोज से लेकर कॉन्टेक्स्ट के हिसाब से मैच करने और मिलते-जुलते खोज नतीजों तक का लंबा सफ़र तय किया है. हालांकि, कल्पना करें कि कोई ग्राहक "बसंत के मौसम में हाइकिंग के लिए आरामदायक, स्टाइलिश, और वॉटरप्रूफ़ जैकेट" खोज रहा है. साथ ही, वह फ़िल्टर भी लागू कर रहा है. ऐसे में, आपका ऐप्लिकेशन न सिर्फ़ क्वालिटी वाले जवाब दे रहा है, बल्कि बेहतर परफ़ॉर्म भी कर रहा है. साथ ही, इन सभी चीज़ों का क्रम आपके डेटाबेस से डाइनैमिक तरीके से चुना जा रहा है.
मकसद
इंटिग्रेट करके इस समस्या को हल करने के लिए
- संदर्भ के हिसाब से खोज (वेक्टर सर्च): क्वेरी और प्रॉडक्ट के ब्यौरे के सिमैंटिक मतलब को समझना
- फ़ैसेट फ़िल्टरिंग: उपयोगकर्ताओं को खास एट्रिब्यूट के हिसाब से नतीजों को बेहतर बनाने की सुविधा देना
- हाइब्रिड तरीका: इसमें कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा को स्ट्रक्चर्ड फ़िल्टरिंग के साथ आसानी से जोड़ा जाता है
- बेहतर ऑप्टिमाइज़ेशन: तेज़ी और काम के नतीजों के लिए, खास इंडेक्सिंग, अडैप्टिव फ़िल्टरिंग, और फिर से रैंकिंग करने की सुविधा का इस्तेमाल करना
- जनरेटिव एआई की मदद से क्वालिटी कंट्रोल: बेहतर नतीजे पाने के लिए, एलएलएम की मदद से पुष्टि करना.
आइए, आर्किटेक्चर और लागू करने की प्रोसेस के बारे में जानते हैं.
आपको क्या बनाना है
रीटेल सर्च ऐप्लिकेशन
इसके तहत, आपको ये काम करने होंगे:
- ई-कॉमर्स डेटासेट के लिए AlloyDB इंस्टेंस और टेबल बनाना
- Embeddings और Vector Search सेट अप करना
- मेटाडेटा इंडेक्स और ScaNN इंडेक्स बनाना
- ScaNN की इनलाइन फ़िल्टरिंग की सुविधा का इस्तेमाल करके, AlloyDB में ऐडवांस वेक्टर सर्च लागू करना
- एक ही क्वेरी में फ़ैसेट फ़िल्टर और हाइब्रिड सर्च सेट अप करना
- रीरैंकिंग और रीकॉल की मदद से, क्वेरी के नतीजों को ज़्यादा सटीक बनाना (वैकल्पिक)
- Gemini की मदद से क्वेरी के जवाब का आकलन करना (ज़रूरी नहीं)
- डेटाबेस और ऐप्लिकेशन लेयर के लिए एमसीपी टूलबॉक्स
- फ़ैसेट वाली खोज की सुविधा के साथ ऐप्लिकेशन डेवलपमेंट (Java)
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: लिंक पर जाएं और एपीआई चालू करें.
इसके अलावा, इसके लिए gcloud कमांड का इस्तेमाल किया जा सकता है. gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
3. डेटाबेस सेटअप करना
इस लैब में, हम ई-कॉमर्स डेटा के लिए AlloyDB को डेटाबेस के तौर पर इस्तेमाल करेंगे. यह सभी संसाधनों को सेव करने के लिए, क्लस्टर का इस्तेमाल करता है. जैसे, डेटाबेस और लॉग. हर क्लस्टर में एक प्राइमरी इंस्टेंस होता है, जो डेटा का ऐक्सेस पॉइंट उपलब्ध कराता है. टेबल में असल डेटा होगा.
आइए, एक AlloyDB क्लस्टर, इंस्टेंस, और टेबल बनाएं. इसमें ई-कॉमर्स डेटासेट लोड किया जाएगा.
क्लस्टर और इंस्टेंस बनाना
- Cloud Console में AlloyDB पेज पर जाएं. Cloud Console में ज़्यादातर पेजों को आसानी से ढूंढने के लिए, कंसोल के खोज बार का इस्तेमाल करके उन्हें खोजें.
- उस पेज पर जाकर, क्लस्टर बनाएं को चुनें:

- आपको नीचे दी गई स्क्रीन जैसी कोई स्क्रीन दिखेगी. नीचे दी गई वैल्यू का इस्तेमाल करके, क्लस्टर और इंस्टेंस बनाएं. अगर आपको रिपॉज़िटरी से ऐप्लिकेशन कोड क्लोन करना है, तो पक्का करें कि वैल्यू मैच होती हों:
- क्लस्टर आईडी: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / सुझाया गया नया वर्शन
- इलाका: "
us-central1" - नेटवर्किंग: "
default"
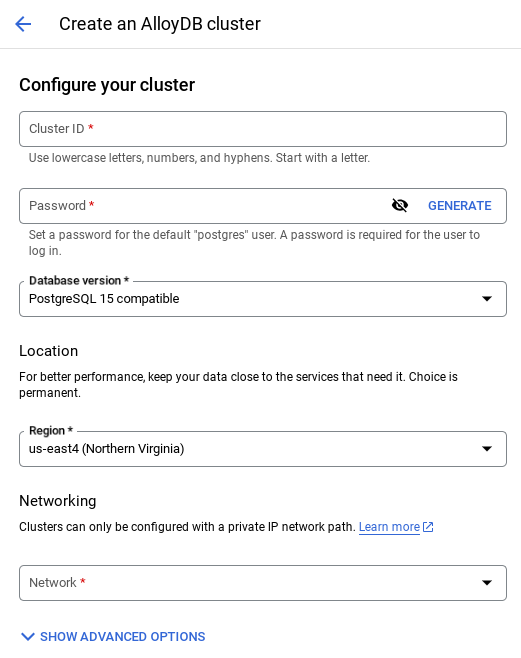
- डिफ़ॉल्ट नेटवर्क चुनने पर, आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी.
कनेक्शन सेट अप करें को चुनें.
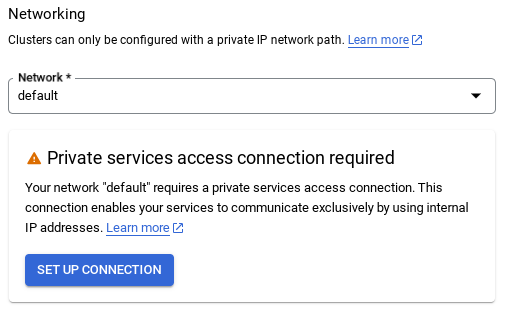
- इसके बाद, "अपने-आप असाइन की गई आईपी रेंज का इस्तेमाल करें" को चुनें और जारी रखें पर क्लिक करें. जानकारी देखने के बाद, कनेक्शन बनाएं को चुनें.
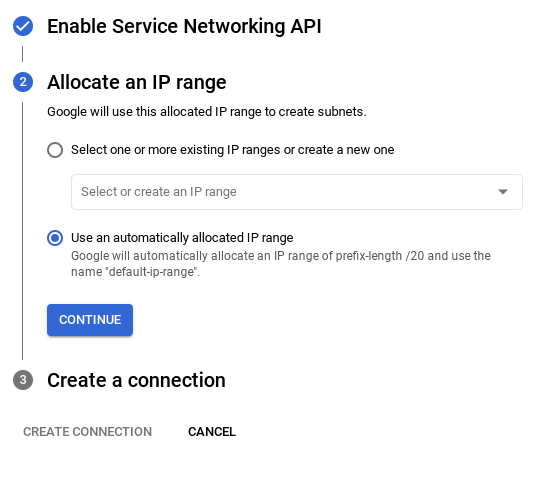
- नेटवर्क सेट अप हो जाने के बाद, क्लस्टर बनाना जारी रखा जा सकता है. नीचे दिए गए तरीके से क्लस्टर सेट अप करने के लिए, क्लस्टर बनाएं पर क्लिक करें:
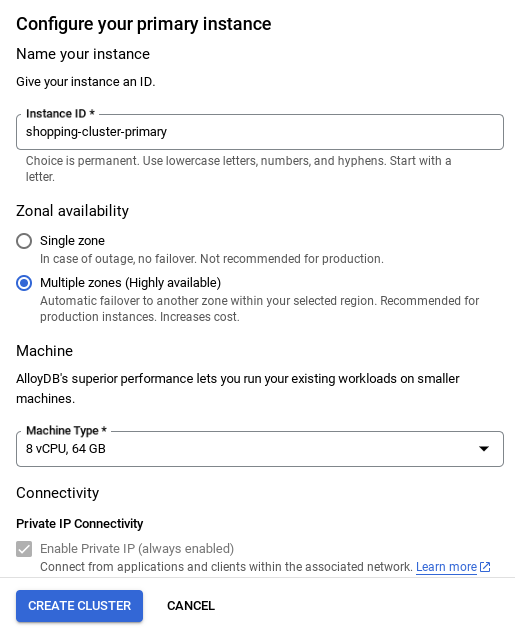
अहम जानकारी:
- इंस्टेंस आईडी को (यह आपको क्लस्टर / इंस्टेंस को कॉन्फ़िगर करते समय मिलेगा) बदलकर **
vector-instance** करना न भूलें. अगर इसे बदला नहीं जा सकता, तो आने वाले सभी रेफ़रंस में अपने इंस्टेंस आईडी का इस्तेमाल करना न भूलें. - ध्यान दें कि क्लस्टर बनने में करीब 10 मिनट लगेंगे. प्रोसेस पूरी होने के बाद, आपको एक स्क्रीन दिखेगी. इसमें, आपके बनाए गए क्लस्टर की खास जानकारी दिखेगी.
4. डेटा डालना
अब स्टोर के बारे में जानकारी देने वाली टेबल जोड़ें. AlloyDB पर जाएं. इसके बाद, प्राइमरी क्लस्टर और फिर AlloyDB Studio चुनें:
आपको इंस्टेंस बनने तक इंतज़ार करना पड़ सकता है. इसके बाद, क्लस्टर बनाते समय बनाए गए क्रेडेंशियल का इस्तेमाल करके, AlloyDB में साइन इन करें. PostgreSQL में पुष्टि करने के लिए, इस डेटा का इस्तेमाल करें:
- उपयोगकर्ता नाम : "
postgres" - डेटाबेस : "
postgres" - पासवर्ड : "
alloydb"
AlloyDB Studio में पुष्टि हो जाने के बाद, SQL कमांड को एडिटर में डाला जाता है. आखिरी विंडो के दाईं ओर मौजूद प्लस आइकॉन का इस्तेमाल करके, एक से ज़्यादा Editor विंडो जोड़ी जा सकती हैं.
AlloyDB के लिए एडिटर विंडो में कमांड डालें. इसके लिए, ज़रूरत के हिसाब से Run, Format, और Clear विकल्पों का इस्तेमाल करें.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव और खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जा सकता है. इससे एसक्यूएल में अनुमान मिलते हैं. इन एक्सटेंशन को चालू करें. इसके लिए, ये DDL चलाएं:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
अगर आपको अपने डेटाबेस पर चालू किए गए एक्सटेंशन देखने हैं, तो यह एसक्यूएल कमांड चलाएं:
select extname, extversion from pg_extension;
एक टेबल बनाओ
AlloyDB Studio में, नीचे दिए गए डीडीएल स्टेटमेंट का इस्तेमाल करके टेबल बनाई जा सकती है:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
एम्बेडिंग कॉलम में, टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी.
अनुमति दें
"embedding" फ़ंक्शन पर 'execute' की अनुमति देने के लिए, नीचे दिया गया स्टेटमेंट चलाएं:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB सेवा खाते को Vertex AI उपयोगकर्ता की भूमिका असाइन करना
Google Cloud IAM Console में जाकर, AlloyDB सेवा खाते को "Vertex AI User" की भूमिका का ऐक्सेस दें. यह सेवा खाता इस तरह दिखता है: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com. PROJECT_NUMBER में आपका प्रोजेक्ट नंबर होगा.
इसके अलावा, Cloud Shell टर्मिनल से यह कमांड भी चलाई जा सकती है:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
डेटाबेस में डेटा लोड करना
- शीट में मौजूद
insert scripts sqlसेinsertक्वेरी स्टेटमेंट को कॉपी करके, ऊपर बताए गए एडिटर में चिपकाएं. इस इस्तेमाल के उदाहरण का तुरंत डेमो देने के लिए, 10 से 50 इंसर्ट स्टेटमेंट कॉपी किए जा सकते हैं. यहां "चुने गए इंसर्ट 25 से 30 लाइनें" टैब में, चुने गए इंसर्ट की सूची दी गई है.
डेटा का लिंक, इस GitHub रिपॉज़िटरी फ़ाइल में मिल सकता है.
- चलाएं पर क्लिक करें. आपकी क्वेरी के नतीजे, नतीजे टेबल में दिखते हैं.
अहम जानकारी:
सिर्फ़ 25 से 50 रिकॉर्ड कॉपी करके डालें. साथ ही, पक्का करें कि ये रिकॉर्ड कैटगरी, उप_कैटगरी, रंग, और लिंग के हिसाब से अलग-अलग टाइप के हों.
5. डेटा के लिए एम्बेडिंग बनाना
मॉडर्न सर्च में, सिर्फ़ कीवर्ड ही नहीं, बल्कि खोज के मतलब को समझना भी ज़रूरी है. ऐसे में, एम्बेडिंग और वेक्टर सर्च की सुविधा काम आती है.
हमने पहले से ट्रेन किए गए भाषा मॉडल का इस्तेमाल करके, प्रॉडक्ट के ब्यौरे और उपयोगकर्ता की क्वेरी को "एम्बेडिंग" कहे जाने वाले हाई-डाइमेंशनल संख्यात्मक प्रज़ेंटेशन में बदल दिया है. ये एम्बेडिंग, शब्दों के मतलब को कैप्चर करती हैं. इससे हमें ऐसे प्रॉडक्ट ढूंढने में मदद मिलती है जो "मतलब के हिसाब से मिलते-जुलते" हों. ऐसा नहीं है कि सिर्फ़ मिलते-जुलते शब्दों वाले प्रॉडक्ट दिखाए जाते हैं. शुरुआत में, हमने इन एम्बेडिंग पर सीधे तौर पर वेक्टर सिमिलैरिटी सर्च का इस्तेमाल किया, ताकि एक बेसलाइन तैयार की जा सके. इससे यह पता चला कि परफ़ॉर्मेंस ऑप्टिमाइज़ेशन से पहले भी, सिमेंटिक अंडरस्टैंडिंग कितनी अहम होती है.
एम्बेडिंग कॉलम में, प्रॉडक्ट के ब्यौरे के टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी. img_embeddings कॉलम में, इमेज एम्बेडिंग (मल्टीमॉडल) को सेव किया जा सकेगा. इस तरह, इमेज के आस-पास मौजूद टेक्स्ट के आधार पर भी खोज की जा सकती है. हालांकि, इस लैब में हम सिर्फ़ टेक्स्ट एम्बेडिंग का इस्तेमाल करेंगे.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
इससे क्वेरी में मौजूद सैंपल टेक्स्ट के लिए, एम्बेडिंग वेक्टर मिलना चाहिए. यह फ़्लोट की एक ऐरे की तरह दिखता है. यह इस तरह दिखता है:
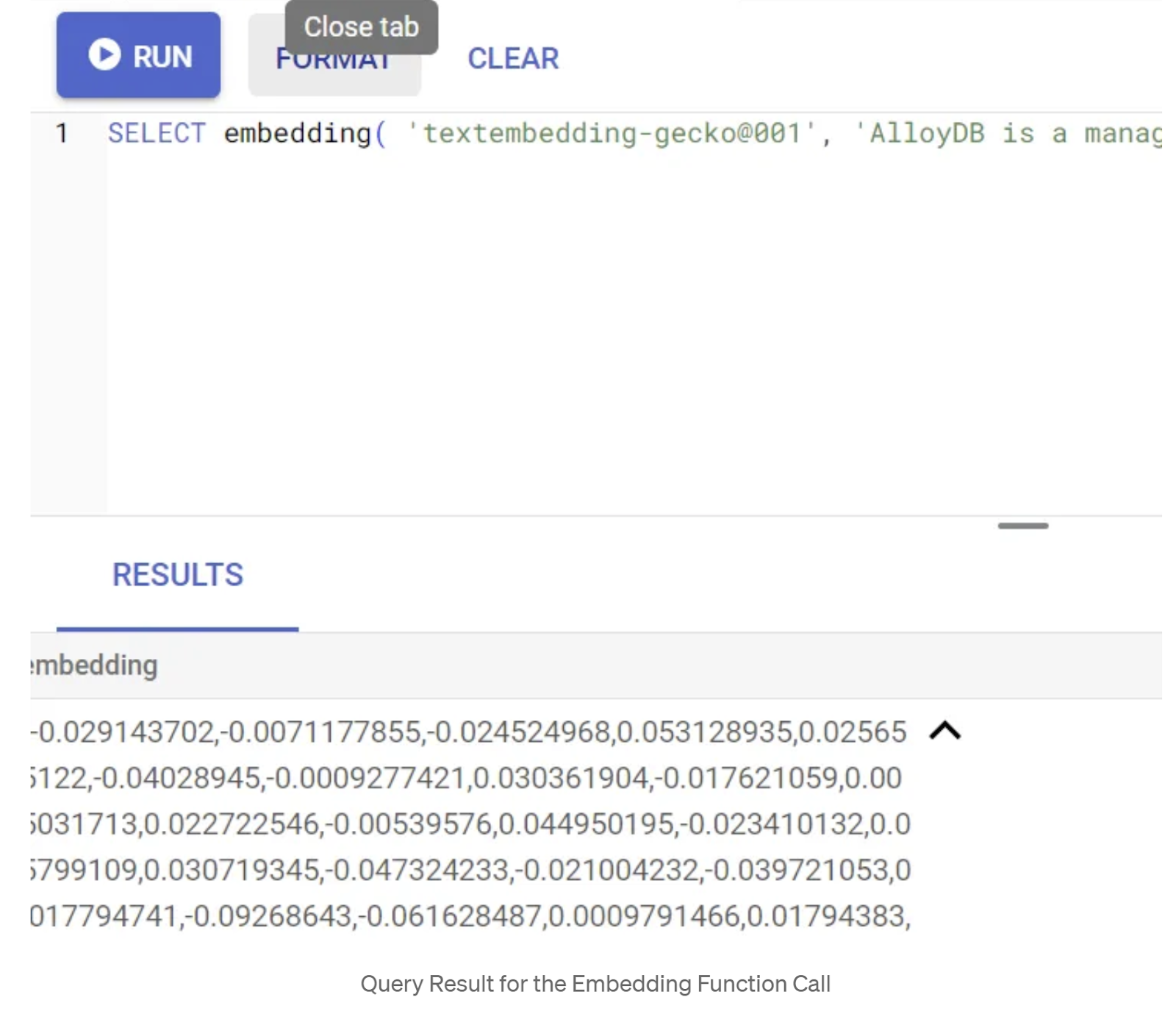
abstract_embeddings वेक्टर फ़ील्ड को अपडेट करना
टेबल में कॉन्टेंट के ब्यौरे को उससे जुड़ी एम्बेडिंग के साथ अपडेट करने के लिए, नीचे दिए गए डीएमएल को चलाएं:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
अगर Google Cloud के लिए, बिना किसी शुल्क के आज़माने की सुविधा वाले क्रेडिट बिलिंग खाते का इस्तेमाल किया जा रहा है, तो आपको कुछ से ज़्यादा एम्बेडिंग (जैसे कि ज़्यादा से ज़्यादा 20-25) जनरेट करने में समस्या आ सकती है. इसलिए, इंसर्ट स्क्रिप्ट में पंक्तियों की संख्या सीमित करें.
अगर आपको इमेज एम्बेडिंग जनरेट करनी हैं, ताकि मल्टीमोडल कॉन्टेक्स्ट के हिसाब से खोज की जा सके, तो नीचे दिए गए अपडेट को भी चलाएं:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. AlloyDB की नई सुविधाओं के साथ, बेहतर RAG सुविधा का इस्तेमाल करना
टेबल, डेटा, और एम्बेडिंग तैयार हो जाने के बाद, अब उपयोगकर्ता के खोज टेक्स्ट के लिए रीयल टाइम वेक्टर सर्च करते हैं. नीचे दी गई क्वेरी चलाकर, इसकी जांच की जा सकती है:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
इस क्वेरी में, हम उपयोगकर्ता की ओर से खोजे गए शब्द "गोल गले वाली टी-शर्ट" की टेक्स्ट एम्बेडिंग की तुलना, कपड़ों की टेबल में मौजूद सभी प्रॉडक्ट के ब्यौरों की टेक्स्ट एम्बेडिंग से कर रहे हैं. इसके लिए, कोसाइन सिमिलैरिटी डिस्टेंस फ़ंक्शन का इस्तेमाल किया जा रहा है. यह फ़ंक्शन, "embedding" नाम के कॉलम में सेव है और इसे "<=>" सिंबल से दिखाया गया है. हम एम्बेडिंग के तरीके से मिले नतीजे को वेक्टर टाइप में बदल रहे हैं, ताकि यह डेटाबेस में सेव किए गए वेक्टर के साथ काम कर सके. LIMIT 10 का मतलब है कि हम खोजे गए टेक्स्ट से सबसे ज़्यादा मिलते-जुलते 10 नतीजे चुन रहे हैं.
AlloyDB, वेक्टर सर्च RAG को बेहतर बनाता है:
बड़े कारोबारों के लिए, रॉ वेक्टर सर्च काफ़ी नहीं है. परफ़ॉर्मेंस अहम है.
ScaNN (स्केलेबल नियरेस्ट नेबर) इंडेक्स
ज़्यादा तेज़ गति से अनुमानित नियरेस्ट नेबर (एएनएन) खोजने के लिए, हमने AlloyDB में scaNN इंडेक्स चालू किया. ScaNN, Google की रिसर्च टीम ने बनाया है. यह सबसे आधुनिक एप्रोक्सिमेट नियरेस्ट नेबर सर्च एल्गोरिदम है. इसे बड़े पैमाने पर, वेक्टर सिमिलैरिटी सर्च को बेहतर बनाने के लिए डिज़ाइन किया गया है. यह खोज के दायरे को कम करके और क्वांटाइज़ेशन तकनीकों का इस्तेमाल करके, क्वेरी को काफ़ी तेज़ी से प्रोसेस करता है. यह इंडेक्सिंग के अन्य तरीकों की तुलना में, वेक्टर क्वेरी को चार गुना तेज़ी से प्रोसेस करता है और कम मेमोरी का इस्तेमाल करता है. इसके बारे में ज़्यादा जानने के लिए, यहां और यहां क्लिक करें.
चलिए, एक्सटेंशन चालू करते हैं और इंडेक्स बनाते हैं:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
टेक्स्ट एम्बेडिंग और इमेज एम्बेडिंग, दोनों फ़ील्ड के लिए इंडेक्स बनाना. ऐसा तब करें, जब आपको खोज में इमेज एम्बेडिंग का इस्तेमाल करना हो:
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
मेटाडेटा इंडेक्स
scaNN, वेक्टर इंडेक्सिंग को मैनेज करता है. वहीं, स्ट्रक्चर्ड एट्रिब्यूट (जैसे कि कैटगरी, सब कैटगरी, स्टाइल, रंग वगैरह) पर, पारंपरिक B-ट्री या GIN इंडेक्स को सावधानीपूर्वक सेट अप किया गया था. ये इंडेक्स, फ़ैसेट फ़िल्टरिंग को बेहतर बनाने के लिए ज़रूरी हैं. मेटाडेटा इंडेक्स सेट अप करने के लिए, यहां दिए गए स्टेटमेंट चलाएं:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
अहम जानकारी:
आपने सिर्फ़ 25 से 50 रिकॉर्ड डाले हैं. इसलिए, इंडेक्स (ScaNN या कोई भी इंडेक्स) असरदार नहीं होंगे.
इनलाइन फ़िल्टरिंग
वेक्टर सर्च में, स्ट्रक्चर्ड फ़िल्टर (जैसे, "लाल रंग के जूते") के साथ इसे कंबाइन करना एक आम समस्या है. AlloyDB की इनलाइन फ़िल्टरिंग, इसे ऑप्टिमाइज़ करती है. ब्रॉड वेक्टर सर्च के नतीजों को फ़िल्टर करने के बजाय, इनलाइन फ़िल्टरिंग, वेक्टर सर्च की प्रोसेस के दौरान ही फ़िल्टर की शर्तें लागू करती है. इससे, फ़िल्टर किए गए वेक्टर सर्च की परफ़ॉर्मेंस और सटीक नतीजे मिलने की संभावना काफ़ी बढ़ जाती है.
इनलाइन फ़िल्टरिंग की ज़रूरत के बारे में ज़्यादा जानने के लिए, यह दस्तावेज़ पढ़ें. वेक्टर सर्च की परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, फ़िल्टर की गई वेक्टर सर्च के बारे में भी यहां जानें. अगर आपको अपने ऐप्लिकेशन के लिए इनलाइन फ़िल्टर करने की सुविधा चालू करनी है, तो अपने एडिटर से यह स्टेटमेंट चलाएं:
SET scann.enable_inline_filtering = on;
इनलाइन फ़िल्टरिंग, ऐसे मामलों के लिए सबसे सही होती है जिनमें मीडियम सिलेक्टिविटी होती है. AlloyDB, वेक्टर इंडेक्स में खोज करता है. इसलिए, यह सिर्फ़ उन वेक्टर के बीच की दूरी का हिसाब लगाता है जो मेटाडेटा फ़िल्टर करने की शर्तों से मेल खाते हैं. ये शर्तें, क्वेरी में इस्तेमाल किए गए फ़ंक्शनल फ़िल्टर से मेल खाती हैं. आम तौर पर, इन्हें WHERE क्लॉज़ में हैंडल किया जाता है. इससे इन क्वेरी की परफ़ॉर्मेंस काफ़ी बेहतर हो जाती है. साथ ही, पोस्ट-फ़िल्टर या प्री-फ़िल्टर के फ़ायदे भी मिलते हैं.
अडैप्टिव फ़िल्टरिंग
परफ़ॉर्मेंस को और बेहतर बनाने के लिए, AlloyDB की अडैप्टिव फ़िल्टरिंग की सुविधा, क्वेरी को एक्ज़ीक्यूट करने के दौरान सबसे असरदार फ़िल्टरिंग की रणनीति (इनलाइन या प्री-फ़िल्टरिंग) को डाइनैमिक तरीके से चुनती है. यह क्वेरी पैटर्न और डेटा डिस्ट्रिब्यूशन का विश्लेषण करता है, ताकि मैन्युअल तरीके से किए जाने वाले काम के बिना बेहतर परफ़ॉर्मेंस मिल सके. यह फ़िल्टर की गई वेक्टर खोजों के लिए खास तौर पर फ़ायदेमंद है, क्योंकि यह वेक्टर और मेटाडेटा इंडेक्स के इस्तेमाल के बीच अपने-आप स्विच करता है. अडैप्टिव फ़िल्टरिंग की सुविधा चालू करने के लिए, scann.enable_preview_features फ़्लैग का इस्तेमाल करें.
जब अडैप्टिव फ़िल्टरिंग, क्वेरी को प्रोसेस करने के दौरान इनलाइन फ़िल्टरिंग से प्री-फ़िल्टरिंग पर स्विच करती है, तो क्वेरी प्लान डाइनैमिक तौर पर बदल जाता है.
SET scann.enable_preview_features = on;
अहम जानकारी: अगर आपको गड़बड़ी मिलती है, तो हो सकता है कि इंस्टेंस को रीस्टार्ट किए बिना ऊपर दिए गए स्टेटमेंट को न चलाया जा सके. इसलिए, अपने इंस्टेंस के डेटाबेस फ़्लैग सेक्शन में जाकर, enable_preview_features फ़्लैग को चालू करें.
सभी इंडेक्स का इस्तेमाल करने वाले फ़ेसटेड फ़िल्टर
फ़ैसेटेड सर्च की मदद से, उपयोगकर्ता किसी खास एट्रिब्यूट या "फ़ैसेट" (जैसे, ब्रैंड, कीमत, साइज़, ग्राहक रेटिंग) के आधार पर कई फ़िल्टर लगाकर, नतीजों को बेहतर बना सकते हैं. हमारा ऐप्लिकेशन, इन पहलुओं को वेक्टर सर्च के साथ आसानी से इंटिग्रेट करता है. अब एक ही क्वेरी में, नैचुरल लैंग्वेज (संदर्भ के हिसाब से खोज) के साथ-साथ कई फ़ैसेट वाले विकल्पों को जोड़ा जा सकता है. साथ ही, वेक्टर और पारंपरिक इंडेक्स, दोनों का डाइनैमिक तरीके से इस्तेमाल किया जा सकता है. इससे हाइब्रिड सर्च की डाइनैमिक सुविधा मिलती है. इससे उपयोगकर्ता, नतीजों को अपनी ज़रूरत के हिसाब से फ़िल्टर कर सकते हैं.
हमारे ऐप्लिकेशन में, हमने पहले ही सभी मेटाडेटा इंडेक्स बना लिए हैं. इसलिए, हम वेब पर फ़ैसेट वाले फ़िल्टर का इस्तेमाल करने के लिए तैयार हैं. इसके लिए, हम सीधे तौर पर एसक्यूएल क्वेरी का इस्तेमाल करते हैं:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
इस क्वेरी में, हम हाइब्रिड सर्च कर रहे हैं. इसमें ये दोनों शामिल हैं
- WHERE क्लॉज़ में फ़ेसटेड फ़िल्टरिंग और
- कोसाइन सिमिलैरिटी (दो वेक्टर के बीच के कोण का कोसाइन) के तरीके का इस्तेमाल करके, ORDER BY क्लॉज़ में वेक्टर सर्च की सुविधा.
$1, $2, $3, और $4, फ़ेसटेड फ़िल्टर की वैल्यू को एक ऐरे में दिखाते हैं. वहीं, $5, उपयोगकर्ता के खोजे गए टेक्स्ट को दिखाता है. $1 से $4 को, फ़ैसेट वाले फ़िल्टर की अपनी पसंद की वैल्यू से बदलें. जैसे:
category = ANY([‘Apparel', ‘Footwear'])
500 रुपये को अपनी पसंद के सर्च टेक्स्ट से बदलें. जैसे, "पोलो टी-शर्ट".
अहम जानकारी: अगर आपने कम रिकॉर्ड डाले हैं, तो आपको इंडेक्स नहीं मिलेंगे. इसलिए, आपको परफ़ॉर्मेंस पर पड़ने वाला असर नहीं दिखेगा. हालांकि, पूरे प्रोडक्शन डेटासेट में आपको दिखेगा कि ScaNN इंडेक्स में इनलाइन फ़िल्टरिंग का इस्तेमाल करने से, वेक्टर सर्च के लिए एक्ज़ीक्यूशन का समय काफ़ी कम हो गया है!!!
इसके बाद, ScaNN की सुविधा के साथ काम करने वाली वेक्टर सर्च के लिए, रीकॉल का आकलन करते हैं.
फिर से रैंक करना
बेहतर खोज की सुविधा का इस्तेमाल करने पर भी, शुरुआती नतीजों को बेहतर बनाने की ज़रूरत पड़ सकती है. यह एक अहम चरण है. इसमें खोज के शुरुआती नतीजों को फिर से क्रम में लगाया जाता है, ताकि वे ज़्यादा काम के हों. हाइब्रिड सर्च के शुरुआती नतीजे के तौर पर, प्रॉडक्ट का एक सेट मिलता है. इसके बाद, ज़्यादा बेहतर (और अक्सर कंप्यूटेशनल तौर पर ज़्यादा मुश्किल) मॉडल, ज़्यादा सटीक तरीके से काम का स्कोर लागू करता है. इससे यह पक्का होता है कि उपयोगकर्ता को दिखाए गए सबसे ऊपर के नतीजे, खोज क्वेरी से सबसे ज़्यादा मिलते-जुलते हों. इससे खोज के नतीजों की क्वालिटी बेहतर होती है. हम लगातार रीकॉल का आकलन करते हैं, ताकि यह पता लगाया जा सके कि सिस्टम किसी क्वेरी के लिए सभी काम के आइटम कितनी अच्छी तरह से ढूंढता है. साथ ही, हम अपने मॉडल को बेहतर बनाते हैं, ताकि खरीदार को उसकी ज़रूरत का सामान मिलने की संभावना बढ़ाई जा सके.
अपने ऐप्लिकेशन में इसका इस्तेमाल करने से पहले, पक्का करें कि आपने सभी ज़रूरी शर्तें पूरी कर ली हों:
- पुष्टि करें कि google_ml_integration एक्सटेंशन इंस्टॉल किया गया हो.
- पुष्टि करें कि google_ml_integration.enable_model_support फ़्लैग चालू पर सेट हो.
- Vertex AI के साथ इंटिग्रेट करें.
- Discovery Engine API चालू करें.
- रैंकिंग मॉडल इस्तेमाल करने के लिए, ज़रूरी भूमिकाएं पाएं.
इसके बाद, हाइब्रिड सर्च के नतीजों के सेट को फिर से रैंक करने के लिए, हमारे ऐप्लिकेशन में इस क्वेरी का इस्तेमाल किया जा सकता है:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
इस क्वेरी में, हम कॉन्टेक्स्ट के हिसाब से खोज के नतीजों के सेट को फिर से रैंक कर रहे हैं. इसके लिए, ORDER BY क्लॉज़ में दिए गए कॉसाइन सिमिलैरिटी मेथड का इस्तेमाल किया जा रहा है. ‘गुलाबी टॉप' वह टेक्स्ट है जिसे उपयोगकर्ता खोज रहा है.
अहम जानकारी: ऐसा हो सकता है कि आप में से कुछ लोगों के पास, फ़िलहाल रीरैंकिंग की सुविधा का ऐक्सेस न हो. इसलिए, मैंने इसे ऐप्लिकेशन कोड से हटा दिया है. हालांकि, अगर आपको इसे शामिल करना है, तो ऊपर दिए गए सैंपल का इस्तेमाल किया जा सकता है.
रीकॉल का आकलन करने वाला
मिलती-जुलती इमेज खोजने की सुविधा में रिकॉल, खोज से वापस पाए गए काम के इंस्टेंस का प्रतिशत होता है. इसका मतलब है कि यह ट्रू पॉज़िटिव की संख्या होती है. सर्च क्वालिटी को मेज़र करने के लिए, इस मेट्रिक का सबसे ज़्यादा इस्तेमाल किया जाता है. मिलते-जुलते आइटम न मिलने की एक वजह, सबसे मिलते-जुलते पड़ोसी आइटम की अनुमानित खोज (एएनएन) और सबसे मिलते-जुलते पड़ोसी आइटम की सटीक खोज (केएनएन) के बीच का अंतर है. वेक्टर इंडेक्स, AlloyDB के ScaNN में aNN एल्गोरिदम लागू करते हैं. इससे बड़े डेटासेट पर वेक्टर सर्च को तेज़ किया जा सकता है. हालांकि, इसके लिए रिकॉल में थोड़ा समझौता करना पड़ता है. अब AlloyDB, आपको अलग-अलग क्वेरी के लिए डेटाबेस में सीधे तौर पर इस ट्रेडऑफ़ को मेज़र करने की सुविधा देता है. साथ ही, यह पक्का करता है कि यह समय के साथ स्थिर रहे. बेहतर नतीजे और परफ़ॉर्मेंस पाने के लिए, इस जानकारी के आधार पर क्वेरी और इंडेक्स पैरामीटर अपडेट किए जा सकते हैं.
खोज के नतीजों को वापस लाने के पीछे क्या लॉजिक है?
वेक्टर सर्च के संदर्भ में, रीकॉल का मतलब उन वेक्टर के प्रतिशत से है जिन्हें इंडेक्स दिखाता है और जो सबसे नज़दीकी वेक्टर होते हैं. उदाहरण के लिए, अगर सबसे नज़दीकी 20 पॉइंट के लिए की गई क्वेरी में, सबसे नज़दीकी 19 पॉइंट की ग्राउंड ट्रुथ जानकारी मिलती है, तो रिकॉल 19/20x100 = 95% होगा. रिकॉल का इस्तेमाल, खोज के नतीजों की क्वालिटी को मेज़र करने के लिए किया जाता है. इसे ऐसे नतीजों के प्रतिशत के तौर पर तय किया जाता है जो क्वेरी वेक्टर के सबसे करीब होते हैं.
evaluate_query_recall फ़ंक्शन का इस्तेमाल करके, किसी कॉन्फ़िगरेशन के लिए वेक्टर इंडेक्स पर वेक्टर क्वेरी का रीकॉल पता लगाया जा सकता है. इस फ़ंक्शन की मदद से, अपने पैरामीटर को इस तरह से ट्यून किया जा सकता है कि आपको वेक्टर क्वेरी रिकॉल के मनमुताबिक नतीजे मिलें.
अहम जानकारी:
अगर आपको यहां दिए गए चरणों में, HNSW इंडेक्स पर अनुमति नहीं होने की गड़बड़ी का सामना करना पड़ रहा है, तो फ़िलहाल, रिकॉल के आकलन वाले इस पूरे सेक्शन को छोड़ दें. ऐसा हो सकता है कि इस समय ऐक्सेस से जुड़ी पाबंदियां लागू हों, क्योंकि यह कोडलैब दस्तावेज़ बनाते समय ही रिलीज़ किया गया है.
- ScaNN इंडेक्स और HNSW इंडेक्स पर, Enable Index Scan फ़्लैग सेट करें:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio में यह क्वेरी चलाएं:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall फ़ंक्शन, क्वेरी को पैरामीटर के तौर पर लेता है और उसके रीकॉल को दिखाता है. मैंने फ़ंक्शन के इनपुट क्वेरी के तौर पर, उसी क्वेरी का इस्तेमाल किया है जिसका इस्तेमाल मैंने परफ़ॉर्मेंस की जांच करने के लिए किया था. मैंने SCaNN को इंडेक्स के तरीके के तौर पर जोड़ा है. पैरामीटर के ज़्यादा विकल्पों के लिए, दस्तावेज़ देखें.
हम इस Vector Search क्वेरी के लिए इस रिकॉल का इस्तेमाल कर रहे हैं:
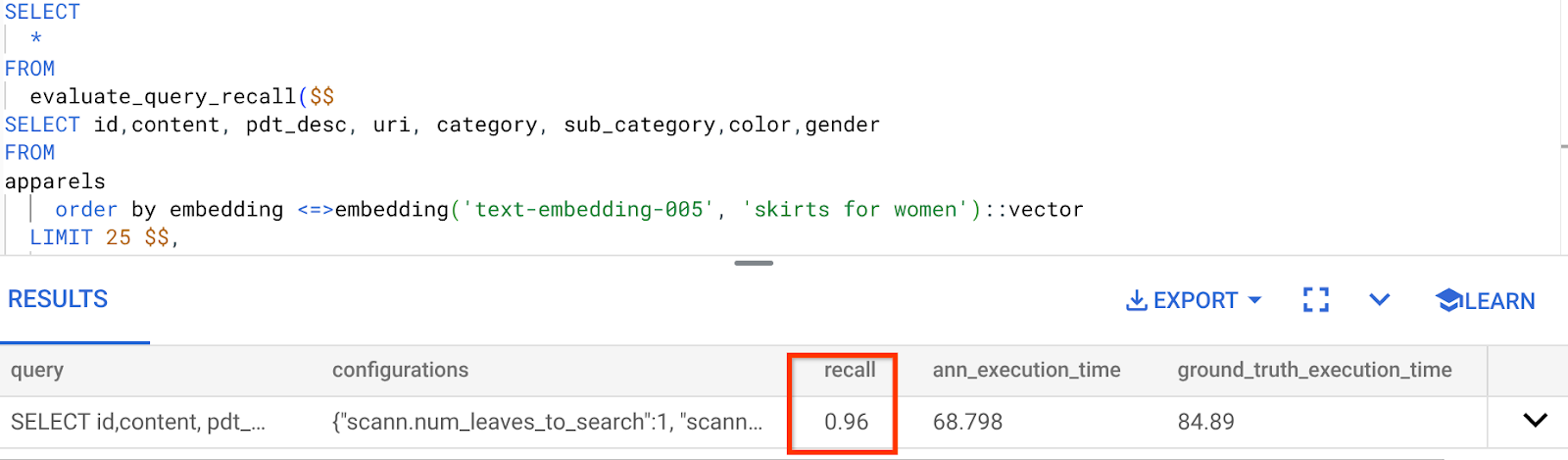
मुझे दिख रहा है कि RECALL 96% है. इस मामले में, जानकारी को काफ़ी हद तक याद रखा गया है. हालांकि, अगर यह वैल्यू स्वीकार नहीं की गई है, तो इस जानकारी का इस्तेमाल करके इंडेक्स पैरामीटर, तरीके, और क्वेरी पैरामीटर बदले जा सकते हैं. साथ ही, इस वेक्टर सर्च के लिए, मेरी रीकॉल क्षमता को बेहतर बनाया जा सकता है!
बदले गए क्वेरी और इंडेक्स पैरामीटर के साथ इसकी जांच करें
अब मिले हुए रीकॉल के आधार पर, क्वेरी पैरामीटर में बदलाव करके क्वेरी की जांच करते हैं.
- इंडेक्स पैरामीटर में बदलाव करना:
इस टेस्ट के लिए, मैं समानता के लिए दूरी का पता लगाने वाले "कोसाइन" फ़ंक्शन के बजाय, "L2 दूरी" का इस्तेमाल करूंगा.
बहुत ज़रूरी जानकारी: "हमें कैसे पता चलेगा कि इस क्वेरी में कोसाइन सिमिलैरिटी का इस्तेमाल किया गया है?" कोसाइन दूरी को दिखाने के लिए, "<=>" का इस्तेमाल करके, दूरी के फ़ंक्शन की पहचान की जा सकती है.
वेक्टर सर्च के डिस्टेंस फ़ंक्शन के लिए, Docs का लिंक.
पिछली क्वेरी में कोसाइन सिमिलैरिटी डिस्टेंस फ़ंक्शन का इस्तेमाल किया गया था. हालांकि, अब हम L2 डिस्टेंस का इस्तेमाल करेंगे. हालांकि, इसके लिए हमें यह भी पक्का करना होगा कि ScaNN इंडेक्स भी L2 डिस्टेंस फ़ंक्शन का इस्तेमाल करता हो. अब, दूरी के फ़ंक्शन वाली एक अलग क्वेरी के साथ इंडेक्स बनाते हैं: L2 दूरी: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
ड्रॉप इंडेक्स स्टेटमेंट का इस्तेमाल सिर्फ़ यह पक्का करने के लिए किया जाता है कि टेबल पर कोई गैर-ज़रूरी इंडेक्स न हो.
अब, मैं इस क्वेरी को चलाकर, वेक्टर सर्च की सुविधा के डिस्टेंस फ़ंक्शन में बदलाव करने के बाद RECALL का आकलन कर सकता हूं.
[AFTER] L2 Distance फ़ंक्शन का इस्तेमाल करने वाली क्वेरी:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
अपडेट किए गए इंडेक्स के लिए, आपको रीकॉल वैल्यू में अंतर / बदलाव दिखेगा.
इंडेक्स में कई अन्य पैरामीटर बदले जा सकते हैं. जैसे, num_leaves वगैरह. ये पैरामीटर, आपकी ज़रूरत के हिसाब से रीकॉल वैल्यू और आपके ऐप्लिकेशन के इस्तेमाल किए गए डेटासेट के आधार पर बदले जा सकते हैं.
वेक्टर सर्च के नतीजों की एलएलएम से पुष्टि करना
बेहतरीन क्वालिटी की कंट्रोल की गई खोज के लिए, हमने एलएलएम की पुष्टि करने वाली एक वैकल्पिक लेयर शामिल की है. लार्ज लैंग्वेज मॉडल का इस्तेमाल, खोज नतीजों की अहमियत और सुसंगतता का आकलन करने के लिए किया जा सकता है. खास तौर पर, जटिल या अस्पष्ट क्वेरी के लिए. इसमें ये शामिल हो सकते हैं:
सिमेंटिक पुष्टि:
एलएलएम, क्वेरी के मकसद के हिसाब से नतीजों की तुलना कर रहा है.
लॉजिकल फ़िल्टरिंग:
जटिल कारोबारी नियम या ऐसे नियमों को लागू करने के लिए एलएलएम का इस्तेमाल करना जिन्हें पारंपरिक फ़िल्टर में कोड करना मुश्किल होता है. साथ ही, बारीकी से तय किए गए मानदंड के आधार पर प्रॉडक्ट लिस्ट को और बेहतर बनाना.
क्वालिटी अश्योरेंस:
मैन्युअल तरीके से समीक्षा करने या मॉडल को बेहतर बनाने के लिए, कम काम के नतीजों का अपने-आप पता लगाना और उन्हें फ़्लैग करना.
AlloyDB AI की सुविधाओं में, हमने इस तरह से यह काम किया है:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
इसमें इस्तेमाल की गई क्वेरी वही है जो हमने फ़ैसेट वाली खोज, हाइब्रिड खोज, और फिर से रैंक करने वाले सेक्शन में देखी है. अब इस क्वेरी में, हमने ml_predict_row कंस्ट्रक्ट से दिखाए गए, फिर से रैंक किए गए नतीजों के सेट का GEMINI से आकलन करने की लेयर शामिल की है. मैंने फ़ैसेट वाले फ़िल्टर को हटा दिया है. हालांकि, आपके पास प्लेसहोल्डर $1 से $4 के लिए, अपनी पसंद के आइटम को ऐरे में शामिल करने का विकल्प है. $5 की जगह वह टेक्स्ट डालें जिसे आपको खोजना है. जैसे, "गुलाबी टॉप, फ़्लोरल पैटर्न नहीं".
7. डेटाबेस और ऐप्लिकेशन लेयर के लिए एमसीपी टूलबॉक्स
पर्दे के पीछे, मज़बूत टूल और अच्छी तरह से बनाया गया ऐप्लिकेशन, यह पक्का करता है कि यह सुविधा बिना किसी रुकावट के काम करे.
डेटाबेस के लिए एमसीपी (मॉडल कॉन्टेक्स्ट प्रोटोकॉल) टूलबॉक्स, AlloyDB के साथ जनरेटिव एआई और एजेंटिक टूल को इंटिग्रेट करने की प्रोसेस को आसान बनाता है. यह एक ओपन-सोर्स सर्वर के तौर पर काम करता है. इससे कनेक्शन पूलिंग, पुष्टि करने की प्रोसेस, और डेटाबेस की सुविधाओं को एआई एजेंट या अन्य ऐप्लिकेशन के साथ सुरक्षित तरीके से शेयर करने की प्रोसेस को आसान बनाया जा सकता है.
हमने अपने ऐप्लिकेशन में, डेटाबेस के लिए एमसीपी टूलबॉक्स का इस्तेमाल किया है. यह हमारी सभी इंटेलिजेंट हाइब्रिड सर्च क्वेरी के लिए ऐब्स्ट्रैक्शन लेयर के तौर पर काम करता है.
हमारे इस्तेमाल के उदाहरण के लिए, Toolbox को सेट अप और डिप्लॉय करने के लिए, यहां दिया गया तरीका अपनाएं:
आपको दिख रहा होगा कि डेटाबेस के लिए एमसीपी टूलबॉक्स के साथ काम करने वाले डेटाबेस में से एक AlloyDB है. हमने पिछले सेक्शन में इसे पहले ही प्रोविज़न कर दिया है. इसलिए, अब हम टूलबॉक्स को सेट अप करते हैं.
- Cloud Shell टर्मिनल पर जाएं. पक्का करें कि आपका प्रोजेक्ट चुना गया हो और टर्मिनल के प्रॉम्प्ट में दिख रहा हो. अपने प्रोजेक्ट की डायरेक्ट्री में जाने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं:
mkdir toolbox-tools
cd toolbox-tools
- अपने नए फ़ोल्डर में टूलबॉक्स को डाउनलोड और इंस्टॉल करने के लिए, यहां दिया गया कमांड चलाएं:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- कोड में बदलाव करने के मोड के लिए, Cloud Shell Editor पर जाएं. इसके बाद, प्रोजेक्ट के रूट फ़ोल्डर में "tools.yaml" नाम की फ़ाइल जोड़ें.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
पक्का करें कि आपने Tools.yaml स्क्रिप्ट को इस repo फ़ाइल के कोड से बदल दिया हो.
आइए, tools.yaml को समझते हैं:
सोर्स, आपके अलग-अलग डेटा सोर्स होते हैं. टूल इनके साथ इंटरैक्ट कर सकता है. सोर्स, ऐसे डेटा सोर्स को कहते हैं जिससे कोई टूल इंटरैक्ट कर सकता है. अपने tools.yaml फ़ाइल के sources सेक्शन में, सोर्स को मैप के तौर पर तय किया जा सकता है. आम तौर पर, सोर्स कॉन्फ़िगरेशन में डेटाबेस से कनेक्ट करने और उससे इंटरैक्ट करने के लिए ज़रूरी जानकारी होती है.
टूल से यह तय होता है कि एजेंट कौनसी कार्रवाइयां कर सकता है. जैसे, किसी सोर्स से जानकारी पढ़ना और उसमें जानकारी लिखना. टूल, एक ऐसी कार्रवाई को दिखाता है जिसे आपका एजेंट कर सकता है. जैसे, SQL स्टेटमेंट चलाना. tools.yaml फ़ाइल के टूल सेक्शन में, टूल को मैप के तौर पर तय किया जा सकता है. आम तौर पर, किसी टूल को कार्रवाई करने के लिए सोर्स की ज़रूरत होती है.
tools.yaml को कॉन्फ़िगर करने के बारे में ज़्यादा जानने के लिए, यह दस्तावेज़ पढ़ें.
- सर्वर शुरू करने के लिए, mcp-toolbox फ़ोल्डर से यह कमांड चलाएं:
./toolbox --tools-file "tools.yaml"
अब अगर क्लाउड पर वेब प्रीव्यू मोड में सर्वर खोला जाता है, तो आपको get-order-data नाम के नए टूल के साथ, Toolbox सर्वर चालू और काम करता हुआ दिखेगा.
MCP Toolbox सर्वर, डिफ़ॉल्ट रूप से पोर्ट 5000 पर चलता है. आइए, Cloud Shell का इस्तेमाल करके इसकी जांच करें.
नीचे दिए गए तरीके से, Cloud Shell में वेब की झलक देखें पर क्लिक करें:
पोर्ट बदलें पर क्लिक करें. इसके बाद, नीचे दिखाए गए तरीके से पोर्ट को 5000 पर सेट करें. इसके बाद, बदलें और झलक देखें पर क्लिक करें.
इससे यह आउटपुट मिलेगा:
- चलिए, अपने टूलबॉक्स को Cloud Run पर डिप्लॉय करते हैं:
सबसे पहले, MCP Toolbox सर्वर को Cloud Run पर होस्ट किया जा सकता है. इसके बाद, हमें एक सार्वजनिक एंडपॉइंट मिलेगा. इसे किसी अन्य ऐप्लिकेशन और/या एजेंट ऐप्लिकेशन के साथ इंटिग्रेट किया जा सकता है. इसे Cloud Run पर होस्ट करने के निर्देश यहां दिए गए हैं. अब हम मुख्य चरणों के बारे में जानेंगे.
- नया Cloud Shell टर्मिनल लॉन्च करें या किसी मौजूदा Cloud Shell टर्मिनल का इस्तेमाल करें. उस प्रोजेक्ट फ़ोल्डर पर जाएं जहां toolbox बाइनरी और tools.yaml मौजूद हैं. इस मामले में, toolbox-tools. अगर आप पहले से इसमें नहीं हैं, तो:
cd toolbox-tools
- PROJECT_ID वैरिएबल को अपने Google Cloud प्रोजेक्ट आईडी पर सेट करें.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Google Cloud की इन सेवाओं को चालू करें
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- आइए, एक अलग सेवा खाता बनाते हैं. यह खाता, Toolbox सेवा के लिए पहचान के तौर पर काम करेगा. इस सेवा को Google Cloud Run पर डिप्लॉय किया जाएगा.
gcloud iam service-accounts create toolbox-identity
- हम यह भी पक्का कर रहे हैं कि इस सेवा खाते के पास सही भूमिकाएं हों. जैसे, Secret Manager को ऐक्सेस करने और AlloyDB से कम्यूनिकेट करने की क्षमता
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- हम tools.yaml फ़ाइल को सीक्रेट के तौर पर अपलोड करेंगे:
gcloud secrets create tools --data-file=tools.yaml
अगर आपके पास पहले से कोई सीक्रेट है और आपको सीक्रेट का वर्शन अपडेट करना है, तो यह कमांड चलाएं:
gcloud secrets versions add tools --data-file=tools.yaml
- उस कंटेनर इमेज के लिए एनवायरमेंट वैरिएबल सेट करें जिसका इस्तेमाल Cloud Run के लिए करना है:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Cloud Run पर डिप्लॉय करने के लिए, जानी-पहचानी डिप्लॉयमेंट कमांड का आखिरी चरण:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
इससे, कॉन्फ़िगर किए गए tools.yaml की मदद से, Cloud Run पर Toolbox Server को डिप्लॉय करने की प्रोसेस शुरू हो जाएगी. डेटा सोर्स को सही तरीके से डिप्लॉय करने के बाद, आपको इस तरह का मैसेज दिखेगा:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
अब आपके पास, अपने एजेंटिक ऐप्लिकेशन में नए टूल का इस्तेमाल करने का विकल्प उपलब्ध है!!!
टूलबॉक्स सर्वर में मौजूद टूल ऐक्सेस करना
Toolbox डिप्लॉय होने के बाद, हम डिप्लॉय किए गए Toolbox सर्वर के साथ इंटरैक्ट करने के लिए, Python Cloud Run Functions शिम बनाएंगे. ऐसा इसलिए है, क्योंकि फ़िलहाल Toolbox में Java SDK टूल नहीं है. इसलिए, हमने सर्वर के साथ इंटरैक्ट करने के लिए Python शिम बनाया है. उस Cloud Run फ़ंक्शन का सोर्स कोड यहां दिया गया है.
आपको इस Cloud Run फ़ंक्शन को बनाना और डिप्लॉय करना होगा, ताकि पिछले चरणों में बनाए गए और डिप्लॉय किए गए टूलबॉक्स टूल को ऐक्सेस किया जा सके:
- Google Cloud Console में, Cloud Run पेज पर जाएं
- 'कोई फ़ंक्शन लिखें' पर क्लिक करें.
- 'सेवा का नाम' फ़ील्ड में, अपने फ़ंक्शन के बारे में बताने के लिए कोई नाम डालें. सेवा के नाम की शुरुआत सिर्फ़ किसी अक्षर से होनी चाहिए. इसमें अक्षर, संख्याएं या हाइफ़न मिलाकर 49 या इससे कम वर्ण होने चाहिए. सेवा के नाम, हाइफ़न से खत्म नहीं होने चाहिए. साथ ही, हर क्षेत्र और प्रोजेक्ट के लिए अलग होने चाहिए. सेवा का नाम बाद में नहीं बदला जा सकता. यह नाम सार्वजनिक तौर पर दिखता है. (Enter retail-product-search-quality)
- रीजन की सूची में, डिफ़ॉल्ट वैल्यू का इस्तेमाल करें या वह रीजन चुनें जहां आपको फ़ंक्शन डिप्लॉय करना है. (us-central1 चुनें)
- रनटाइम की सूची में, डिफ़ॉल्ट वैल्यू का इस्तेमाल करें या कोई रनटाइम वर्शन चुनें. (Python 3.11 चुनें)
- Authentication सेक्शन में जाकर, "Allow public access" चुनें
- "बनाएं" बटन पर क्लिक करें
- फ़ंक्शन बनाया जाता है और main.py और requirements.txt टेंप्लेट के साथ लोड होता है
- इस प्रोजेक्ट के रेपो से, इन फ़ाइलों को बदलें: main.py और requirements.txt
- फ़ंक्शन को डिप्लॉय करें. इसके बाद, आपको Cloud Run फ़ंक्शन के लिए एक एंड पॉइंट मिलेगा
आपका एंडपॉइंट ऐसा दिखना चाहिए (या इससे मिलता-जुलता):
टूलबॉक्स को ऐक्सेस करने के लिए Cloud Run फ़ंक्शन एंडपॉइंट: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
समयसीमा के अंदर आसानी से पूरा करने के लिए (इंस्ट्रक्टर की निगरानी में होने वाले हैंड्स-ऑन सेशन के लिए), एंडपॉइंट का प्रोजेक्ट नंबर, हैंड्स-ऑन सेशन के दौरान शेयर किया जाएगा.
अहम जानकारी:
इसके अलावा, डेटाबेस के हिस्से को सीधे तौर पर अपने ऐप्लिकेशन कोड या Cloud Run फ़ंक्शन के हिस्से के तौर पर भी लागू किया जा सकता है.
8. फ़ैसेट वाली खोज की सुविधा के साथ ऐप्लिकेशन डेवलपमेंट (Java)
आखिर में, इन सभी पावरफ़ुल बैकएंड कॉम्पोनेंट को ऐप्लिकेशन लेयर के ज़रिए इस्तेमाल किया जाता है. Java में डेवलप किया गया यह ऐप्लिकेशन, खोज सिस्टम के साथ इंटरैक्ट करने के लिए यूज़र इंटरफ़ेस उपलब्ध कराता है. यह AlloyDB को क्वेरी भेजता है, फ़ेसटेड फ़िल्टर दिखाता है, उपयोगकर्ता के चुने गए विकल्पों को मैनेज करता है, और खोज के नतीजों को फिर से रैंक करके, उन्हें आसानी से समझने वाले तरीके से दिखाता है.
- इसके लिए, Cloud Shell टर्मिनल पर जाएं और रिपॉज़िटरी को क्लोन करें:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Cloud Shell Editor पर जाएं. यहां आपको नया फ़ोल्डर faceted_searching_retail दिखेगा
- नीचे दिए गए चरणों को मिटाएं, क्योंकि ये चरण पिछले सेक्शन में पहले ही पूरे किए जा चुके हैं:
- Cloud_Run_Function फ़ोल्डर मिटाएँ
- db_script.sql फ़ाइल मिटाएं
- tools.yaml फ़ाइल मिटाएं
- retail-faceted-search प्रोजेक्ट फ़ोल्डर पर जाएं. आपको प्रोजेक्ट का स्ट्रक्चर दिखेगा:
- आपको फ़ाइल ProductRepository.java में, TOOLBOX_ENDPOINT वैरिएबल को अपने Cloud Run फ़ंक्शन (डिप्लॉय किया गया) के एंडपॉइंट से बदलना होगा. इसके अलावा, आपके पास हैंड्स-ऑन स्पीकर से एंडपॉइंट लेने का विकल्प भी है.
कोड की इस लाइन को खोजें और इसे अपने एंडपॉइंट से बदलें:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- पक्का करें कि Dockerfile और pom.xml, आपके प्रोजेक्ट कॉन्फ़िगरेशन के हिसाब से हों. अगर आपने किसी वर्शन या कॉन्फ़िगरेशन में साफ़ तौर पर बदलाव नहीं किया है, तो आपको कोई बदलाव करने की ज़रूरत नहीं है.
- Cloud Shell टर्मिनल में, पक्का करें कि आप अपने मुख्य फ़ोल्डर और प्रोजेक्ट फ़ोल्डर (faceted_searching_retail / retail-faceted-search) में हों. यह पक्का करने के लिए कि आप टर्मिनल में सही फ़ोल्डर में हैं, इन कमांड का इस्तेमाल करें:
cd faceted_searching_retail
cd retail-faceted-search
- अपने ऐप्लिकेशन को स्थानीय तौर पर पैकेज करें, बनाएं, और टेस्ट करें:
mvn package
mvn spring-boot:run
आपको Cloud Shell टर्मिनल में "पोर्ट 8080 पर झलक देखें" पर क्लिक करके, अपना ऐप्लिकेशन दिखना चाहिए. यह नीचे दिखाया गया है:
9. Cloud Run पर डिप्लॉय करें: ***अहम चरण
Cloud Shell टर्मिनल में, पक्का करें कि आप अपने मुख्य फ़ोल्डर और प्रोजेक्ट फ़ोल्डर में हों (faceted_searching_retail / retail-faceted-search). यह पक्का करने के लिए कि टर्मिनल में सही फ़ोल्डर में न होने पर, इन कमांड का इस्तेमाल करें:
cd faceted_searching_retail
cd retail-faceted-search
जब आपको पक्का हो जाए कि आप प्रोजेक्ट फ़ोल्डर में हैं, तब यह कमांड चलाएं:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
डप्लॉय होने के बाद, आपको डप्लॉय किया गया Cloud Run Endpoint मिलेगा. यह कुछ ऐसा दिखेगा:
https://retail-search-**********-uc.a.run.app/
10. डेमो
आइए, देखते हैं कि ये सभी सुविधाएं कैसे काम करती हैं:
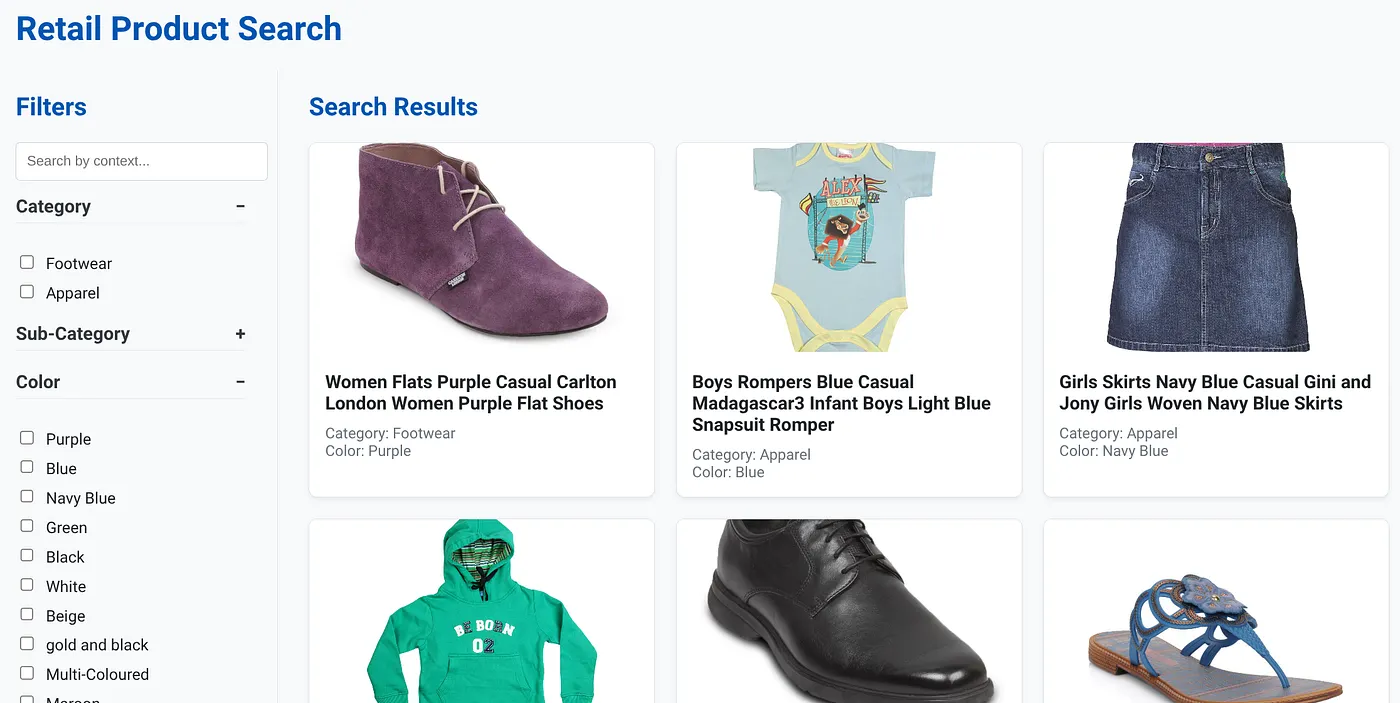
ऊपर दी गई इमेज में, डाइनैमिक हाइब्रिड सर्च ऐप्लिकेशन का लैंडिंग पेज दिखाया गया है.
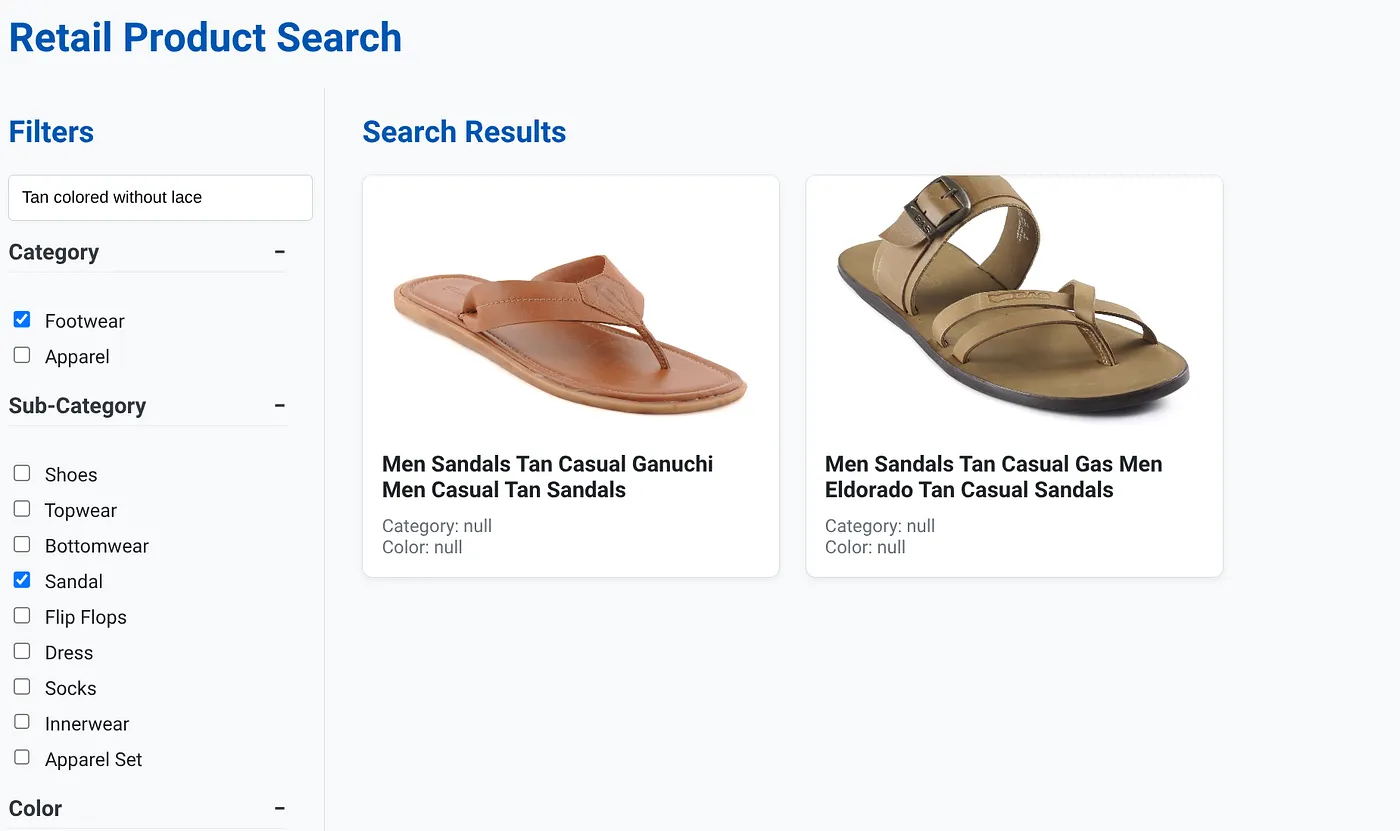
ऊपर दी गई इमेज में, "बिना लेस वाले टैन कलर के जूते" के लिए खोज के नतीजे दिखाए गए हैं. चुने गए फ़ैसेट फ़िल्टर ये हैं: जूते, सैंडल.
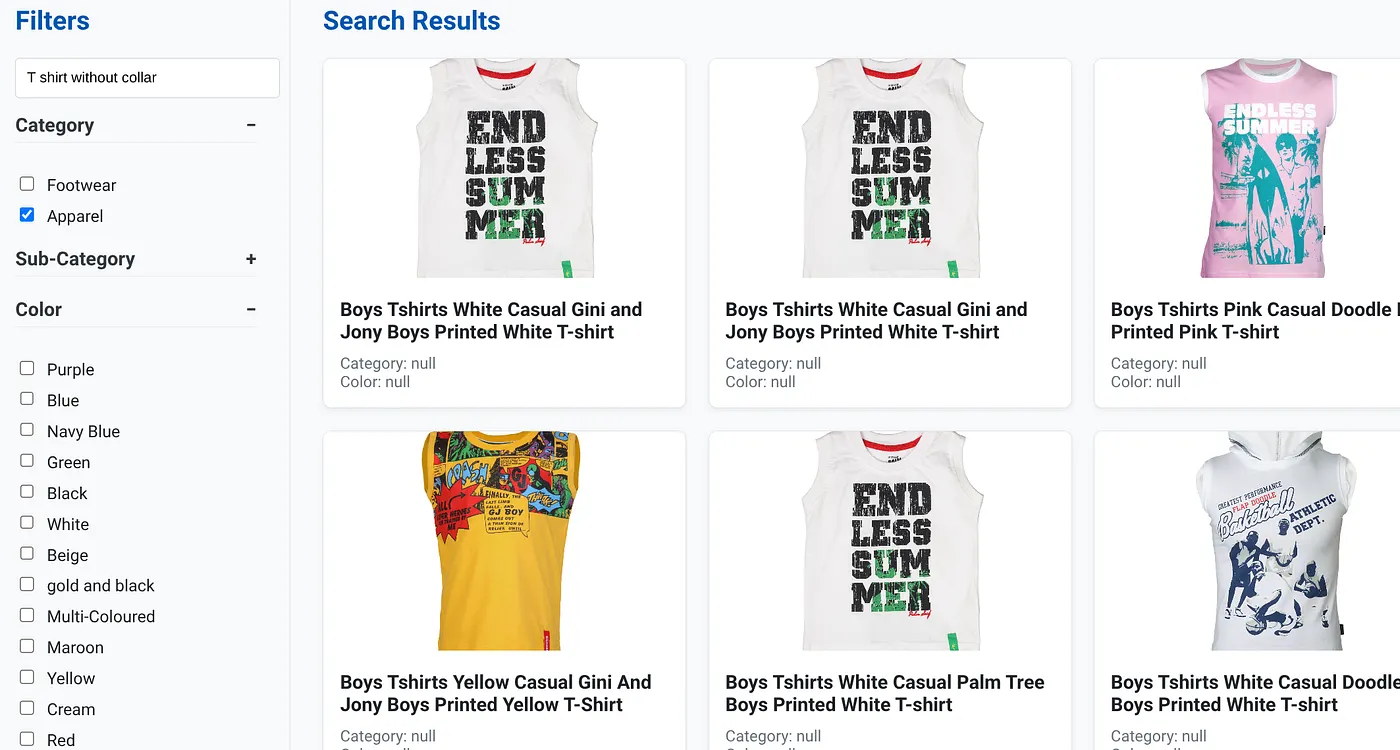
ऊपर दी गई इमेज में, "बिना कॉलर वाली टी-शर्ट" के खोज नतीजे दिखाए गए हैं. फ़ैसेट वाले फ़िल्टर: कपड़े
अब इस ऐप्लिकेशन को ज़्यादा काम का बनाने के लिए, जनरेटिव और एजेंटिक सुविधाओं को शामिल किया जा सकता है.
इसे आज़माएं, ताकि आपको खुद का कॉन्टेंट बनाने के लिए प्रेरणा मिल सके!!!
11. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेजर पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए शट डाउन करें पर क्लिक करें.
- इसके अलावा, DELETE CLUSTER बटन पर क्लिक करके, इस प्रोजेक्ट के लिए अभी-अभी बनाए गए AlloyDB क्लस्टर को मिटाया जा सकता है. अगर आपने कॉन्फ़िगरेशन के समय क्लस्टर के लिए us-central1 नहीं चुना था, तो इस हाइपरलिंक में जगह की जानकारी बदलें.
12. बधाई हो
बधाई हो! आपने CLOUD RUN पर ALLOYDB की मदद से, HYBRID SEARCH APP को बना लिया है और उसे डिप्लॉय कर दिया है!!!
कारोबारों के लिए यह ज़रूरी क्यों है:
AlloyDB AI की मदद से काम करने वाला यह डाइनैमिक हाइब्रिड सर्च ऐप्लिकेशन, एंटरप्राइज़ रीटेल और अन्य कारोबारों के लिए कई फ़ायदे देता है:
ज़्यादा काम के नतीजे: कॉन्टेक्स्ट के हिसाब से (वेक्टर) खोज करने की सुविधा को सटीक फ़ैसेट फ़िल्टरिंग और स्मार्ट रीरैंकिंग के साथ मिलाकर, खरीदारों को ज़्यादा काम के नतीजे मिलते हैं. इससे उनकी संतुष्टि बढ़ती है और कन्वर्ज़न में बढ़ोतरी होती है.
स्केलेबिलिटी: AlloyDB के आर्किटेक्चर और scaNN इंडेक्सिंग को बड़े प्रॉडक्ट कैटलॉग और क्वेरी की ज़्यादा संख्या को हैंडल करने के लिए डिज़ाइन किया गया है. यह ई-कॉमर्स कारोबारों को बढ़ाने के लिए ज़रूरी है.
परफ़ॉर्मेंस: क्वेरी के जवाब तेज़ी से मिलते हैं. इससे उपयोगकर्ता अनुभव बेहतर होता है और खरीदारी बीच में छोड़ने की दर कम होती है. ऐसा हाइब्रिड सर्च के लिए भी होता है.
आने वाले समय के लिए तैयार रहना: एआई की सुविधाओं (एम्बेडिंग, एलएलएम की पुष्टि) को इंटिग्रेट करने से, ऐप्लिकेशन को आने वाले समय में बेहतर बनाने में मदद मिलती है. जैसे, लोगों की दिलचस्पी के हिसाब से सुझाव देना, बातचीत करके खरीदारी करना, और स्मार्ट तरीके से प्रॉडक्ट ढूंढना.
आसान आर्किटेक्चर: वेक्टर सर्च को सीधे तौर पर AlloyDB में इंटिग्रेट करने से, अलग वेक्टर डेटाबेस या जटिल सिंक्रनाइज़ेशन की ज़रूरत नहीं पड़ती. इससे डेवलपमेंट और रखरखाव आसान हो जाता है.
मान लें कि किसी व्यक्ति ने नैचुरल लैंग्वेज क्वेरी टाइप की है. जैसे, "महिलाओं के लिए, ज़्यादा आर्च सपोर्ट वाले पर्यावरण के अनुकूल रनिंग शूज़."
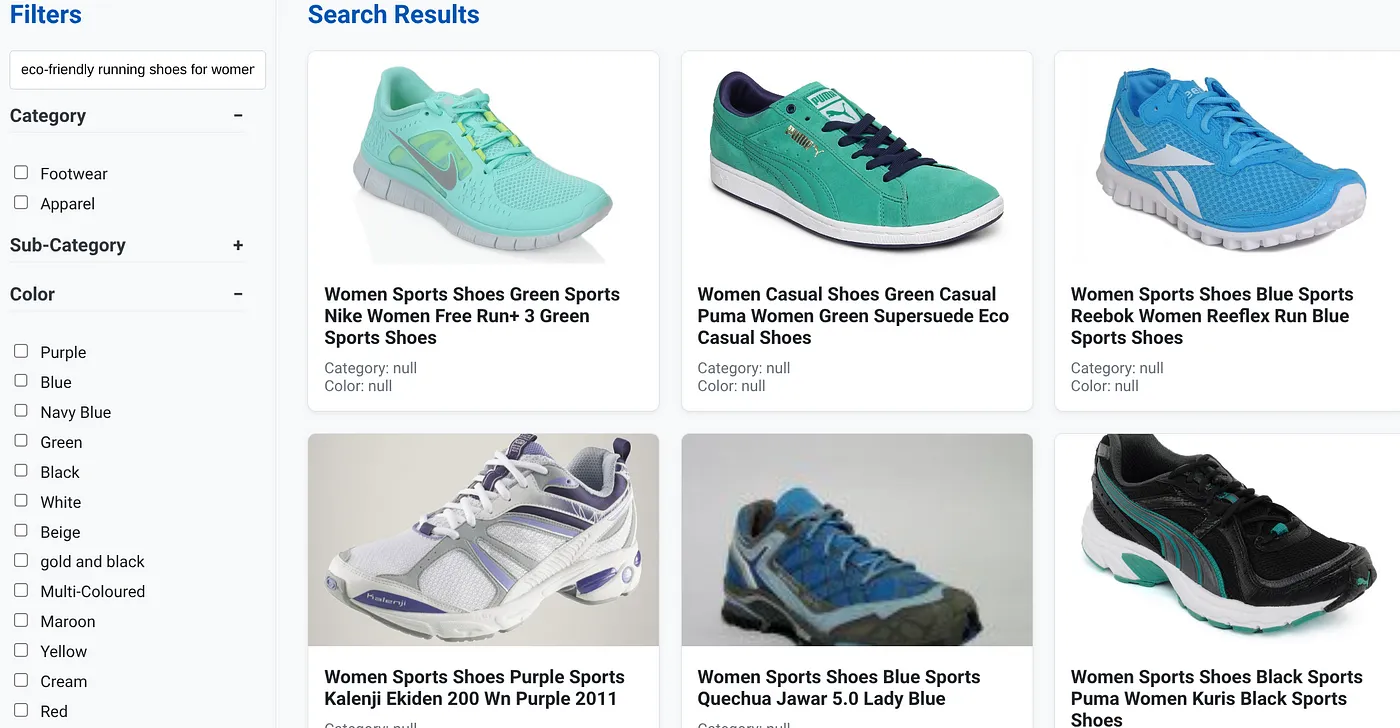
इसके साथ ही, उपयोगकर्ता "कैटगरी: <<>>" "रंग: <<>>" के लिए फ़ैसेट फ़िल्टर लागू करता है और कहता है "कीमत: 100 से 150 डॉलर":
- सिस्टम तुरंत प्रॉडक्ट की बेहतर सूची दिखाता है. यह सूची, नैचुरल लैंग्वेज के हिसाब से होती है. साथ ही, इसमें चुने गए फ़िल्टर से सटीक तौर पर मेल खाने वाले प्रॉडक्ट शामिल होते हैं.
- इसकी प्रोसेस में, scaNN इंडेक्स वेक्टर सर्च को तेज़ करता है. साथ ही, इनलाइन और अडैप्टिव फ़िल्टरिंग, एक साथ कई शर्तों के हिसाब से परफ़ॉर्मेंस को बेहतर बनाती है. इसके अलावा, रीरैंकिंग की सुविधा, सबसे सही नतीजे सबसे ऊपर दिखाती है.
- नतीजों की तेज़ी और सटीक जानकारी से पता चलता है कि खुदरा खोज के बेहतर अनुभव के लिए, इन टेक्नोलॉजी को एक साथ इस्तेमाल करना कितना फ़ायदेमंद है.
अगली जनरेशन का खुदरा खोज ऐप्लिकेशन बनाने के लिए, हमें पारंपरिक तरीकों से आगे बढ़ना होगा. AlloyDB, Vertex AI, scaNN इंडेक्सिंग के साथ Vector Search, डाइनैमिक फ़ैसेट फ़िल्टरिंग, रीरैंकिंग, और LLM की पुष्टि करने की सुविधाओं का इस्तेमाल करके, हम खरीदारों को बेहतरीन अनुभव दे सकते हैं. इससे खरीदारों की दिलचस्पी बढ़ेगी और बिक्री में बढ़ोतरी होगी. यह मज़बूत, बड़े पैमाने पर इस्तेमाल किया जा सकने वाला, और स्मार्ट समाधान दिखाता है कि एआई से जुड़ी आधुनिक डेटाबेस की सुविधाएं, खुदरा कारोबार के भविष्य को कैसे बदल रही हैं!!!