
1. Ringkasan
Dalam lanskap retail yang kompetitif saat ini, memberdayakan pelanggan untuk menemukan dengan cepat dan intuitif apa yang mereka cari adalah hal yang sangat penting. Penelusuran tradisional berbasis kata kunci sering kali tidak memadai, kesulitan menangani kueri bernuansa dan katalog produk yang luas. Codelab ini mengungkap aplikasi penelusuran retail canggih yang dibangun di AlloyDB, AlloyDB AI, dengan memanfaatkan Penelusuran Vektor mutakhir, pengindeksan scaNN, filter berfaset, dan pemfilteran Adaptif cerdas, serta pengurutan ulang untuk menghadirkan pengalaman penelusuran hibrida yang dinamis dalam skala perusahaan.
Sekarang kita sudah memiliki pemahaman dasar tentang 3 hal:
- Arti penelusuran kontekstual bagi agen Anda dan cara melakukannya menggunakan Vector Search.
- Kami juga mempelajari secara mendalam cara mendapatkan Penelusuran Vektor dalam cakupan data Anda, yaitu dalam database Anda sendiri (semua Database Google Cloud mendukungnya, jika Anda belum mengetahuinya).
- Kami selangkah lebih maju dari seluruh dunia dalam memberi tahu Anda cara mencapai kemampuan RAG Penelusuran Vektor yang ringan dengan performa dan kualitas tinggi menggunakan kemampuan Penelusuran Vektor AlloyDB yang didukung oleh indeks ScaNN.
Jika Anda belum mempelajari eksperimen RAG dasar, menengah, dan sedikit lanjutan tersebut, sebaiknya baca ketiga artikel tersebut di sini, di sini, dan di sini dalam urutan yang tercantum.
Tantangan
Melampaui Filter, Kata Kunci, dan Pencocokan Kontekstual: Penelusuran kata kunci sederhana dapat menampilkan ribuan hasil, yang sebagian besar tidak relevan. Solusi yang ideal harus memahami maksud di balik kueri, menggabungkannya dengan kriteria filter yang tepat (seperti merek, bahan, atau harga), dan menampilkan item yang paling relevan dalam milidetik. Hal ini memerlukan infrastruktur penelusuran yang andal, fleksibel, dan skalabel. Tentu saja, kita telah menempuh perjalanan panjang dari penelusuran kata kunci ke kecocokan kontekstual dan penelusuran kesamaan. Namun, bayangkan seorang pelanggan menelusuri "jaket yang nyaman, bergaya, dan tahan air untuk mendaki di musim semi" sambil menerapkan filter. Aplikasi Anda tidak hanya menampilkan respons berkualitas, tetapi juga berperforma tinggi dan urutan semua ini dipilih secara dinamis oleh database Anda.
Tujuan
Untuk mengatasi hal ini dengan mengintegrasikan
- Penelusuran Kontekstual (Penelusuran Vektor): Memahami makna semantik kueri dan deskripsi produk
- Pemfilteran Berfacet: Memungkinkan pengguna menyempurnakan hasil dengan atribut tertentu
- Pendekatan Hybrid: Memadukan penelusuran kontekstual dengan pemfilteran terstruktur secara lancar
- Pengoptimalan Lanjutan: Memanfaatkan pengindeksan khusus, pemfilteran adaptif, dan pengurutan ulang untuk kecepatan dan relevansi
- Kendali Mutu yang Didukung AI Generatif: Menggabungkan validasi LLM untuk kualitas hasil yang lebih unggul.
Mari kita uraikan arsitektur dan perjalanan implementasinya.
Yang akan Anda build
Aplikasi Penelusuran Retail
Sebagai bagian dari proses ini, Anda akan:
- Membuat instance dan tabel AlloyDB untuk set data e-commerce
- Menyiapkan embedding dan Penelusuran Vektor
- Membuat indeks metadata dan indeks ScaNN
- Menerapkan Penelusuran Vektor lanjutan di AlloyDB menggunakan metode pemfilteran inline ScaNN
- Menyiapkan Filter Berfacet dan Penelusuran Hybrid dalam satu kueri
- Meningkatkan kualitas relevansi kueri dengan pengurutan ulang dan perolehan (opsional)
- Mengevaluasi respons kueri dengan Gemini (opsional)
- MCP Toolbox for Databases dan Lapisan Aplikasi
- Pengembangan Aplikasi (Java) dengan Penelusuran Berfacet
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project .
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Ikuti link dan aktifkan API.
Atau, Anda dapat menggunakan perintah gcloud untuk melakukannya. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
3. Penyiapan database
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data e-commerce. Cloud SQL menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data e-commerce akan dimuat.
Membuat cluster dan instance
- Buka halaman AlloyDB di Konsol Cloud. Cara mudah untuk menemukan sebagian besar halaman di Konsol Cloud adalah dengan menelusurinya menggunakan kotak penelusuran konsol.
- Pilih CREATE CLUSTER dari halaman tersebut:

- Anda akan melihat layar seperti di bawah. Buat cluster dan instance dengan nilai berikut (Pastikan nilai cocok jika Anda meng-clone kode aplikasi dari repo):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / versi terbaru yang direkomendasikan
- Region: "
us-central1" - Jaringan: "
default"
- Saat Anda memilih jaringan default, Anda akan melihat layar seperti di bawah.
Pilih SIAPKAN KONEKSI.
- Dari sana, pilih "Use an automatically allocated IP range" dan Lanjutkan. Setelah meninjau informasi, pilih BUAT KONEKSI.
- Setelah jaringan disiapkan, Anda dapat melanjutkan pembuatan cluster. Klik CREATE CLUSTER untuk menyelesaikan penyiapan cluster seperti yang ditunjukkan di bawah:
CATATAN PENTING:
- Pastikan untuk mengubah ID instance (yang dapat Anda temukan pada saat konfigurasi cluster / instance) menjadi **
vector-instance**. Jika Anda tidak dapat mengubahnya, ingatlah untuk menggunakan ID instance Anda dalam semua referensi mendatang. - Perhatikan bahwa pembuatan Cluster akan memerlukan waktu sekitar 10 menit. Setelah berhasil, Anda akan melihat layar yang menampilkan ringkasan cluster yang baru saja Anda buat.
4. Penyerapan data
Sekarang saatnya menambahkan tabel dengan data tentang toko. Buka AlloyDB, pilih cluster utama, lalu AlloyDB Studio:
Anda mungkin perlu menunggu hingga instance selesai dibuat. Setelah selesai, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk melakukan autentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb"
Setelah Anda berhasil diautentikasi ke AlloyDB Studio, perintah SQL dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.
Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Jalankan, Format, dan Hapus sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk membangun aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jika Anda ingin memeriksa ekstensi yang telah diaktifkan di database Anda, jalankan perintah SQL ini:
select extname, extversion from pg_extension;
Membuat tabel
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Kolom embedding akan memungkinkan penyimpanan untuk nilai vektor teks.
Berikan Izin
Jalankan pernyataan di bawah untuk memberikan izin eksekusi pada fungsi "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Vertex AI User ke akun layanan AlloyDB
Dari konsol IAM Google Cloud, berikan akses akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) ke peran "Pengguna Vertex AI". PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Memuat data ke dalam database
- Salin pernyataan kueri
insertdariinsert scripts sqldi sheet ke editor seperti yang disebutkan di atas. Anda dapat menyalin 10-50 pernyataan penyisipan untuk demo cepat kasus penggunaan ini. Ada daftar sisipan yang dipilih di sini di tab "Selected Inserts 25-30 rows".
Link ke data dapat ditemukan di file repositori github ini.
- Klik Run. Hasil kueri Anda akan muncul di tabel Results.
CATATAN PENTING:
Pastikan untuk menyalin hanya 25-50 data yang akan disisipkan dan pastikan data tersebut berasal dari berbagai jenis kategori, sub_kategori, warna, dan jenis kelamin.
5. Buat Embedding untuk data
Inovasi sebenarnya dalam penelusuran modern terletak pada pemahaman makna, bukan hanya kata kunci. Di sinilah embedding dan penelusuran vektor berperan.
Kami mengubah deskripsi produk dan kueri pengguna menjadi representasi numerik berdimensi tinggi yang disebut "embedding" menggunakan model bahasa terlatih. Embedding ini menangkap makna semantik, sehingga memungkinkan kita menemukan produk yang "mirip maknanya", bukan hanya berisi kata-kata yang cocok. Awalnya, kami bereksperimen dengan penelusuran kesamaan vektor langsung pada embedding ini untuk menetapkan dasar pengukuran, yang menunjukkan keunggulan pemahaman semantik bahkan sebelum pengoptimalan performa.
Kolom embedding akan memungkinkan penyimpanan nilai vektor teks deskripsi produk. Kolom img_embeddings akan memungkinkan penyimpanan embedding gambar (multimodal). Dengan cara ini, Anda juga dapat menggunakan penelusuran berbasis jarak teks terhadap gambar. Namun, kita hanya akan menggunakan embedding teks di lab ini.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Ini akan menampilkan vektor embedding, yang terlihat seperti array float, untuk teks contoh dalam kueri. Tampilannya seperti ini:
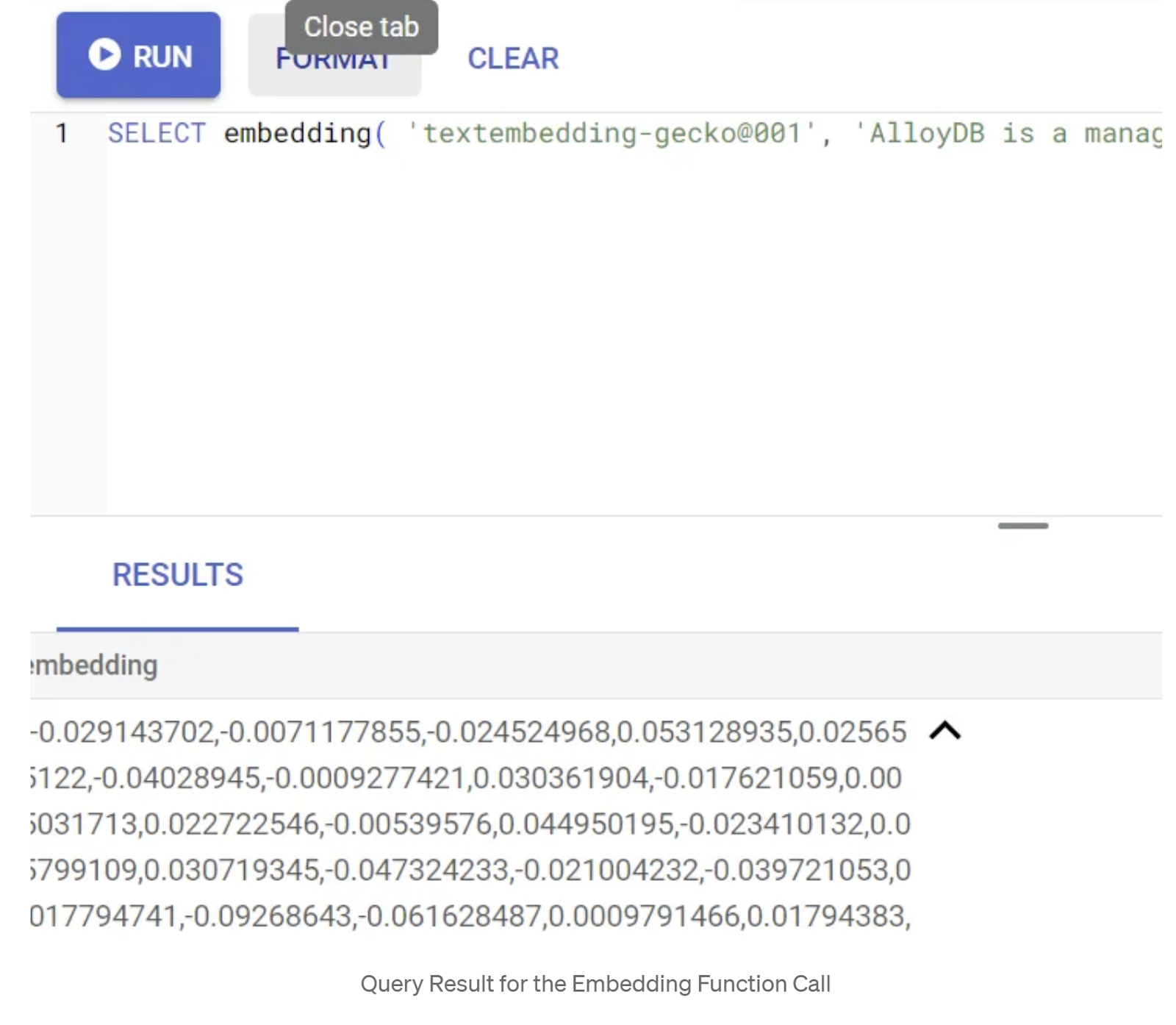
Perbarui kolom Vektor abstract_embeddings
Jalankan DML di bawah untuk memperbarui deskripsi konten dalam tabel dengan embedding yang sesuai:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Anda mungkin mengalami masalah saat membuat lebih dari beberapa sematan (maksimal 20-25) jika menggunakan akun penagihan kredit uji coba untuk Google Cloud. Jadi, batasi jumlah baris dalam skrip penyisipan.
Jika Anda ingin membuat embedding gambar (untuk melakukan penelusuran kontekstual multimodal), jalankan update di bawah ini juga:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Melakukan RAG Lanjutan dengan Fitur baru AlloyDB
Setelah tabel, data, dan embedding siap, mari lakukan Penelusuran Vektor real-time untuk teks penelusuran pengguna. Anda dapat mengujinya dengan menjalankan kueri di bawah:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
Dalam kueri ini, kita membandingkan embedding teks dari penelusuran yang dimasukkan pengguna "T-shirt berleher bulat" dengan embedding teks dari semua deskripsi produk dalam tabel pakaian (disimpan dalam kolom bernama "embedding") menggunakan fungsi jarak kemiripan kosinus (diwakili oleh simbol "<=>"). Kita mengonversi hasil metode embedding ke jenis vektor agar kompatibel dengan vektor yang disimpan dalam database. LIMIT 10 menunjukkan bahwa kita memilih 10 kecocokan terdekat dari teks penelusuran.
AlloyDB meningkatkan kualitas RAG Penelusuran Vektor:
Untuk solusi skala perusahaan, penelusuran vektor mentah saja tidak cukup. Performa sangat penting.
Indeks ScaNN (Scalable Nearest Neighbors)
Untuk mencapai penelusuran perkiraan tetangga terdekat (ANN) yang sangat cepat, kami mengaktifkan indeks scaNN di AlloyDB. ScaNN, algoritma penelusuran perkiraan tetangga terdekat yang canggih yang dikembangkan oleh Google Riset, dirancang untuk penelusuran kemiripan vektor yang efisien dalam skala besar. ScaNN secara signifikan mempercepat kueri dengan memangkas ruang penelusuran secara efisien dan menggunakan teknik kuantisasi, sehingga menawarkan kueri vektor hingga 4x lebih cepat daripada metode pengindeksan lainnya dan footprint memori yang lebih kecil. Baca selengkapnya di sini dan di sini.
Aktifkan ekstensi dan buat indeks:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Membuat indeks untuk kolom embedding teks dan embedding gambar (jika Anda ingin menggunakan embedding gambar dalam penelusuran):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Indeks Metadata
Meskipun scaNN menangani pengindeksan vektor, indeks B-tree atau GIN tradisional disiapkan dengan cermat pada atribut terstruktur (seperti kategori, subkategori, gaya, warna, dll.). Indeks ini sangat penting untuk efisiensi pemfilteran berfaset. Jalankan pernyataan di bawah untuk menyiapkan indeks metadata:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
CATATAN PENTING:
Karena Anda mungkin hanya memasukkan 25-50 data, indeks (ScaNN atau indeks apa pun) tidak akan efektif.
Pemfilteran Inline
Tantangan umum dalam penelusuran vektor adalah menggabungkannya dengan filter terstruktur (misalnya, "sepatu merah"). Pemfilteran inline AlloyDB mengoptimalkan hal ini. Alih-alih memfilter hasil setelah penelusuran vektor yang luas, pemfilteran inline menerapkan kondisi filter selama proses penelusuran vektor itu sendiri, sehingga meningkatkan performa dan akurasi penelusuran vektor yang difilter secara drastis.
Lihat dokumentasi ini untuk mempelajari lebih lanjut kebutuhan Pemfilteran Inline. Pelajari juga penelusuran vektor yang difilter untuk pengoptimalan performa penelusuran vektor di sini. Sekarang, jika Anda ingin mengaktifkan pemfilteran inline untuk aplikasi, jalankan pernyataan berikut dari editor:
SET scann.enable_inline_filtering = on;
Pemfilteran inline paling cocok untuk kasus dengan selektivitas sedang. Saat menelusuri indeks vektor, AlloyDB hanya menghitung jarak untuk vektor yang cocok dengan kondisi pemfilteran metadata (filter fungsional Anda dalam kueri yang biasanya ditangani dalam klausa WHERE). Hal ini akan sangat meningkatkan performa untuk kueri ini, sekaligus melengkapi keunggulan pasca-filter atau pra-filter.
Pemfilteran Adaptif
Untuk mengoptimalkan performa lebih lanjut, pemfilteran adaptif AlloyDB secara dinamis memilih strategi pemfilteran yang paling efisien (inline atau pra-pemfilteran) selama eksekusi kueri. Fitur ini menganalisis pola kueri dan distribusi data untuk memastikan performa optimal tanpa intervensi manual, terutama bermanfaat untuk penelusuran vektor yang difilter, yang secara otomatis beralih antara penggunaan indeks vektor dan metadata. Untuk mengaktifkan pemfilteran adaptif, gunakan tanda scann.enable_preview_features.
Saat pemfilteran adaptif memicu peralihan dari pemfilteran inline ke pra-pemfilteran selama eksekusi, rencana kueri akan berubah secara dinamis.
SET scann.enable_preview_features = on;
CATATAN PENTING: Anda mungkin tidak dapat menjalankan pernyataan di atas tanpa memulai ulang instance, jika Anda mengalami error — sebaiknya aktifkan tanda enable_preview_features dari bagian tanda database instance Anda.
Filter Berfacet menggunakan semua Indeks
Penelusuran berfacet memungkinkan pengguna mempersempit hasil dengan menerapkan beberapa filter berdasarkan atribut atau "facet" tertentu (misalnya, merek, harga, ukuran, rating pelanggan). Aplikasi kami mengintegrasikan aspek ini dengan lancar dengan penelusuran vektor. Satu kueri kini dapat menggabungkan bahasa alami (penelusuran kontekstual) dengan beberapa pilihan berfacet, yang secara dinamis memanfaatkan indeks vektor dan tradisional. Hal ini memberikan kemampuan penelusuran hibrida yang benar-benar dinamis, sehingga pengguna dapat melihat perincian hasil dengan tepat.
Dalam aplikasi kita, karena kita telah membuat semua indeks metadata, kita siap menggunakan filter berfaset di web dengan menanganinya secara langsung menggunakan kueri SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
Dalam kueri ini, kita melakukan penelusuran campuran — menggabungkan
- Pemfilteran berfaset dalam klausa WHERE dan
- Penelusuran Vektor dalam klausa ORDER BY menggunakan metode kesamaan kosinus.
$1, $2, $3, dan $4 mewakili nilai filter berfaset dalam array dan $5 mewakili teks penelusuran pengguna. Ganti $1 hingga $4 dengan nilai filter berfaset pilihan Anda seperti di bawah:
category = ANY([‘Apparel', ‘Footwear'])
Ganti $5 dengan teks penelusuran pilihan Anda, misalnya, "Kaos Polo".
CATATAN PENTING: Jika Anda tidak memiliki indeks karena kumpulan data yang Anda masukkan terbatas, Anda tidak akan melihat dampak performa. Namun, dalam set data produksi lengkap, Anda akan melihat bahwa waktu eksekusi berkurang secara signifikan untuk Penelusuran Vektor yang sama menggunakan indeks ScaNN dengan Pemfilteran Inline di Penelusuran Vektor. Hal ini memungkinkan terjadi karena indeks ScaNN dengan Pemfilteran Inline di Penelusuran Vektor.
Selanjutnya, mari kita evaluasi perolehan untuk Vector Search yang diaktifkan ScaNN ini.
Peringkat ulang
Meskipun dengan penelusuran lanjutan, hasil awal mungkin perlu disempurnakan. Langkah ini merupakan langkah penting yang mengurutkan ulang hasil penelusuran awal untuk meningkatkan relevansi. Setelah penelusuran hibrida awal memberikan serangkaian produk kandidat, model yang lebih canggih (dan sering kali lebih berat secara komputasi) menerapkan skor relevansi yang lebih terperinci. Hal ini memastikan bahwa hasil teratas yang ditampilkan kepada pengguna adalah yang paling relevan, sehingga meningkatkan kualitas penelusuran secara signifikan. Kami terus mengevaluasi perolehan untuk mengukur seberapa baik sistem mengambil semua item yang relevan untuk kueri tertentu, menyempurnakan model kami untuk memaksimalkan kemungkinan pelanggan menemukan apa yang mereka butuhkan.
Sebelum menggunakannya di aplikasi, pastikan Anda telah memenuhi semua prasyarat:
- Pastikan ekstensi google_ml_integration telah diinstal.
- Pastikan tanda google_ml_integration.enable_model_support disetel ke aktif.
- Berintegrasi dengan Vertex AI.
- Aktifkan Discovery Engine API.
- Dapatkan peran yang diperlukan untuk menggunakan model peringkat.
Kemudian, Anda dapat menggunakan kueri berikut di aplikasi kami untuk mengurutkan ulang kumpulan hasil penelusuran hibrida:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
Dalam kueri ini, kita melakukan RERANKING pada kumpulan hasil produk penelusuran kontekstual yang ditangani dalam klausa ORDER BY menggunakan metode kemiripan kosinus. 'Atasan pink' adalah teks yang ditelusuri pengguna.
CATATAN PENTING: Beberapa dari Anda mungkin belum memiliki akses ke Reranking, jadi saya telah mengecualikannya dari kode aplikasi, tetapi jika Anda ingin menyertakannya, Anda dapat mengikuti contoh yang telah kita bahas di atas.
Evaluator Perolehan
Perolehan dalam penelusuran kesamaan adalah persentase instance relevan yang diambil dari penelusuran, yaitu jumlah positif benar. Ini adalah metrik paling umum yang digunakan untuk mengukur kualitas penelusuran. Salah satu sumber kehilangan ingatan berasal dari perbedaan antara penelusuran perkiraan tetangga terdekat, atau aNN, dan penelusuran k (exact) tetangga terdekat, atau kNN. Indeks vektor seperti implementasi ScaNN di AlloyDB menerapkan algoritma aNN, sehingga Anda dapat mempercepat penelusuran vektor pada set data besar dengan sedikit mengorbankan perolehan. Sekarang, AlloyDB memberi Anda kemampuan untuk mengukur kompromi ini secara langsung di database untuk setiap kueri dan memastikan bahwa kompromi tersebut stabil dari waktu ke waktu. Anda dapat memperbarui parameter kueri dan indeks sebagai respons terhadap informasi ini untuk mendapatkan hasil dan performa yang lebih baik.
Apa logika di balik penarikan hasil penelusuran?
Dalam konteks penelusuran vektor, perolehan mengacu pada persentase vektor yang ditampilkan indeks yang merupakan tetangga terdekat sebenarnya. Misalnya, jika kueri tetangga terdekat untuk 20 tetangga terdekat menampilkan 19 tetangga terdekat dari kebenaran nyata, maka perolehannya adalah 19/20x100 = 95%. Perolehan adalah metrik yang digunakan untuk kualitas penelusuran, dan didefinisikan sebagai persentase hasil yang ditampilkan yang secara objektif paling dekat dengan vektor kueri.
Anda dapat menemukan recall untuk kueri vektor pada indeks vektor untuk konfigurasi tertentu menggunakan fungsi evaluate_query_recall. Fungsi ini memungkinkan Anda menyesuaikan parameter untuk mendapatkan hasil perolehan kueri vektor yang diinginkan.
CATATAN PENTING:
Jika Anda mengalami error izin ditolak pada indeks HNSW dalam langkah-langkah berikut, lewati seluruh bagian evaluasi recall ini untuk saat ini. Hal ini mungkin terkait dengan batasan akses pada saat ini karena baru dirilis pada saat codelab ini didokumentasikan.
- Tetapkan tanda Aktifkan Pemindaian Indeks pada indeks ScaNN & indeks HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Jalankan kueri berikut di AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Fungsi evaluate_query_recall menggunakan kueri sebagai parameter dan menampilkan perolehan kueri tersebut. Saya menggunakan kueri yang sama dengan yang saya gunakan untuk memeriksa performa sebagai kueri input fungsi. Saya telah menambahkan SCaNN sebagai metode indeks. Untuk mengetahui opsi parameter lainnya, lihat dokumentasi.
Recall untuk kueri Penelusuran Vektor yang telah kita gunakan:
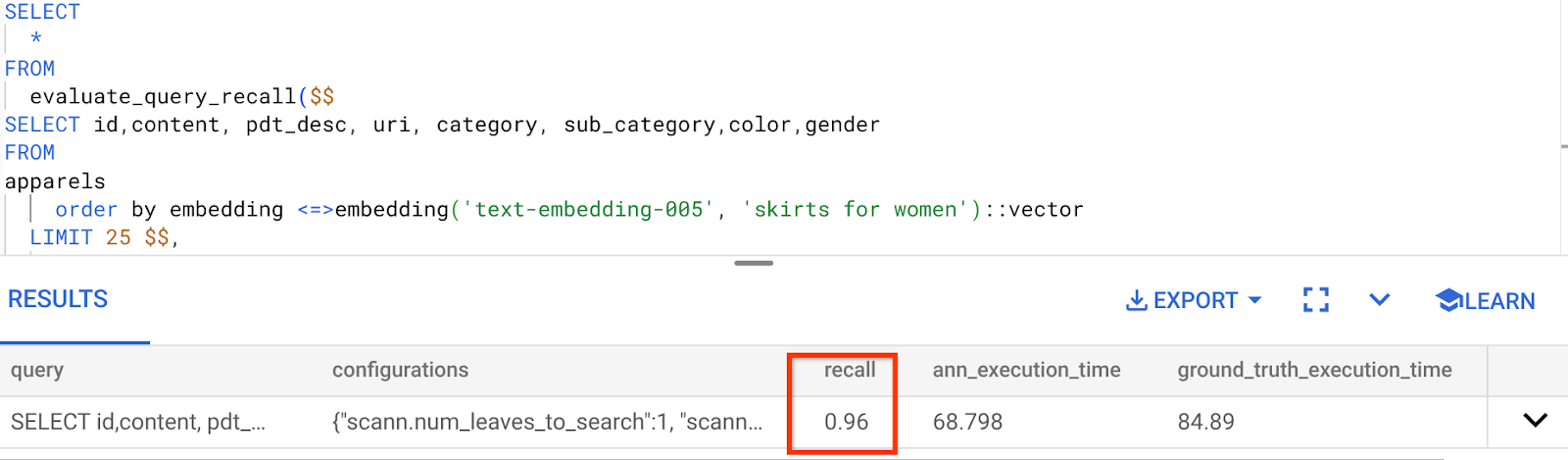
Saya melihat bahwa RECALL adalah 96%. Dalam hal ini, perolehannya sangat baik. Namun, jika nilainya tidak dapat diterima, Anda dapat menggunakan informasi ini untuk mengubah parameter indeks, metode, dan parameter kueri serta meningkatkan kemampuan mengingat saya untuk Penelusuran Vektor ini.
Uji dengan parameter kueri & indeks yang diubah
Sekarang, mari kita uji kueri dengan mengubah parameter kueri berdasarkan pemberitahuan penarikan yang diterima.
- Mengubah parameter indeks:
Untuk pengujian ini, saya akan menggunakan fungsi jarak kesamaan "L2 Distance", bukan "Cosine".
Catatan Sangat Penting: "Bagaimana kita tahu kueri ini menggunakan kesamaan COSINE?" tanya Anda. Anda dapat mengidentifikasi fungsi jarak dengan penggunaan "<=>" untuk merepresentasikan jarak Kosinus.
Link Dokumen untuk fungsi jarak Vector Search.
Kueri sebelumnya menggunakan fungsi jarak Cosine Similarity, sedangkan sekarang kita akan mencoba Jarak L2. Namun, untuk itu, kita juga harus memastikan bahwa indeks ScaNN yang mendasarinya juga menggunakan Fungsi Jarak L2. Sekarang, buat indeks dengan kueri fungsi jarak yang berbeda: Jarak L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
Pernyataan drop index hanya untuk memastikan tidak ada indeks yang tidak perlu pada tabel.
Sekarang, saya dapat menjalankan kueri berikut untuk mengevaluasi RECALL setelah mengubah fungsi jarak dari fungsi Penelusuran Vektor saya.
[SETELAH] Kueri yang menggunakan Fungsi L2 Distance:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Anda dapat melihat perbedaan / transformasi dalam nilai recall untuk indeks yang diperbarui.
Ada parameter lain yang dapat Anda ubah dalam indeks, seperti num_leaves, dll. berdasarkan nilai perolehan yang diinginkan dan set data yang digunakan aplikasi Anda.
Validasi LLM untuk Hasil Penelusuran Vektor
Untuk mencapai penelusuran terkontrol dengan kualitas tertinggi, kami menyertakan lapisan validasi LLM opsional. Model Bahasa Besar dapat digunakan untuk menilai relevansi dan koherensi hasil penelusuran, terutama untuk kueri yang kompleks atau ambigu. Hal ini dapat mencakup:
Verifikasi Semantik:
LLM yang melakukan referensi silang hasil terhadap maksud kueri.
Pemfilteran Logis:
Menggunakan LLM untuk menerapkan logika atau aturan bisnis yang kompleks yang sulit dienkode dalam filter tradisional, sehingga lebih menyempurnakan daftar produk berdasarkan kriteria yang mendalam.
Uji Mutu:
Mengidentifikasi dan menandai hasil yang kurang relevan secara otomatis untuk peninjauan manual atau penyempurnaan model.
Berikut cara kami melakukannya di fitur AI AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
Kueri yang mendasarinya adalah kueri yang sama dengan yang telah kita lihat di bagian penelusuran berfaset, penelusuran campuran, dan pengurutan ulang. Sekarang dalam kueri ini, kita telah menggabungkan lapisan evaluasi GEMINI dari set hasil yang Diurutkan Ulang yang diwakili oleh konstruksi ml_predict_row. Saya telah mengomentari filter berfacet, tetapi Anda dapat menyertakan item pilihan Anda dalam array untuk placeholder $1 hingga $4. Ganti $5 dengan teks apa pun yang ingin Anda telusuri, misalnya, "Atasan pink, tanpa motif bunga".
7. MCP Toolbox for Databases dan Lapisan Aplikasi
Di balik layar, alat yang tangguh dan aplikasi yang terstruktur dengan baik memastikan pengoperasian yang lancar.
Toolbox MCP (Model Context Protocol) for Databases menyederhanakan integrasi alat AI Generatif dan Agentic dengan AlloyDB. Server ini berfungsi sebagai server open source yang menyederhanakan penggabungan koneksi, autentikasi, dan eksposur fungsi database yang aman ke agen AI atau aplikasi lain.
Dalam aplikasi kita, kita telah menggunakan MCP Toolbox for Databases sebagai lapisan abstraksi untuk semua kueri penelusuran hibrida cerdas kita.
Ikuti langkah-langkah di bawah untuk menyiapkan dan men-deploy Toolbox untuk kasus penggunaan kita:
Anda dapat melihat bahwa salah satu database yang didukung oleh MCP Toolbox for Databases adalah AlloyDB dan karena kita telah menyediakannya di bagian sebelumnya, mari kita lanjutkan dan siapkan Toolbox.
- Buka Terminal Cloud Shell Anda dan pastikan project Anda dipilih dan ditampilkan di perintah terminal. Jalankan perintah di bawah dari Terminal Cloud Shell untuk membuka direktori project Anda:
mkdir toolbox-tools
cd toolbox-tools
- Jalankan perintah di bawah untuk mendownload dan menginstal toolbox di folder baru Anda:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Buka Cloud Shell Editor (untuk mode pengeditan kode) dan di folder root project, tambahkan file bernama "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Pastikan Anda mengganti skrip Tools.yaml dengan kode dari file repo ini.
Mari kita pahami tools.yaml:
Sumber mewakili berbagai sumber data yang dapat berinteraksi dengan alat. Sumber mewakili sumber data yang dapat berinteraksi dengan alat. Anda dapat menentukan Sumber sebagai peta di bagian sumber file tools.yaml. Biasanya, konfigurasi sumber akan berisi informasi apa pun yang diperlukan untuk terhubung dan berinteraksi dengan database.
Alat menentukan tindakan yang dapat dilakukan agen – seperti membaca dan menulis ke sumber. Alat merepresentasikan tindakan yang dapat dilakukan agen Anda, seperti menjalankan pernyataan SQL. Anda dapat menentukan Alat sebagai peta di bagian alat pada file tools.yaml. Biasanya, alat akan memerlukan sumber untuk ditindaklanjuti.
Untuk mengetahui detail selengkapnya tentang cara mengonfigurasi tools.yaml, lihat dokumentasi ini.
- Jalankan perintah berikut (dari folder mcp-toolbox) untuk memulai server:
./toolbox --tools-file "tools.yaml"
Sekarang, jika Anda membuka server dalam mode pratinjau web di cloud, Anda akan dapat melihat server Toolbox berjalan dengan alat baru Anda yang bernama get-order-data.
Server MCP Toolbox berjalan secara default di port 5000. Mari kita gunakan Cloud Shell untuk mengujinya.
Klik Pratinjau Web di Cloud Shell seperti yang ditunjukkan di bawah:
Klik Change port dan tetapkan port ke 5000 seperti yang ditunjukkan di bawah, lalu klik Change and Preview.
Tindakan ini akan menghasilkan output:
- Mari kita deploy Toolbox ke Cloud Run:
Pertama, kita dapat memulai dengan server MCP Toolbox dan menghostingnya di Cloud Run. Kemudian, kita akan mendapatkan endpoint publik yang dapat diintegrasikan dengan aplikasi lain dan/atau aplikasi Agen. Petunjuk untuk menghostingnya di Cloud Run diberikan di sini. Sekarang kita akan membahas langkah-langkah utamanya.
- Luncurkan Terminal Cloud Shell baru atau gunakan Terminal Cloud Shell yang sudah ada. Buka folder project tempat biner toolbox dan tools.yaml berada, dalam hal ini toolbox-tools, jika Anda belum membukanya:
cd toolbox-tools
- Tetapkan variabel PROJECT_ID untuk mengarah ke Project ID Google Cloud Anda.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Aktifkan layanan Google Cloud ini
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Buat akun layanan terpisah yang akan bertindak sebagai identitas untuk layanan Toolbox yang akan kita deploy di Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Kami juga memastikan bahwa akun layanan ini memiliki peran yang benar, yaitu kemampuan untuk mengakses Secret Manager dan berkomunikasi dengan AlloyDB
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Kita akan mengupload file tools.yaml sebagai secret:
gcloud secrets create tools --data-file=tools.yaml
Jika Anda sudah memiliki secret dan ingin memperbarui versi secret, jalankan perintah berikut:
gcloud secrets versions add tools --data-file=tools.yaml
- Tetapkan variabel lingkungan ke image container yang ingin Anda gunakan untuk Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Langkah terakhir dalam perintah deployment yang sudah dikenal ke Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Perintah ini akan memulai proses men-deploy Server Toolbox dengan tools.yaml yang telah dikonfigurasi ke Cloud Run. Setelah deployment berhasil, Anda akan melihat pesan yang mirip dengan berikut ini:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Anda sudah siap menggunakan alat yang baru di-deploy di aplikasi agentik Anda.
Mengakses Alat di Server Toolbox
Setelah Toolbox di-deploy, kita akan membuat shim Cloud Run Functions Python untuk berinteraksi dengan server Toolbox yang di-deploy. Hal ini karena saat ini Toolbox tidak memiliki Java SDK, jadi kami membuat shim Python untuk berinteraksi dengan server. Berikut adalah kode sumber untuk Cloud Run Function tersebut.
Anda harus membuat dan men-deploy Cloud Run Function ini agar dapat mengakses alat toolbox yang baru saja kita buat dan deploy pada langkah-langkah sebelumnya:
- Di konsol Google Cloud, buka halaman Cloud Run.
- Klik Write a function.
- Di kolom Nama layanan, masukkan nama untuk mendeskripsikan fungsi Anda. Nama layanan hanya boleh diawali dengan huruf, dan berisi hingga 49 karakter atau kurang, termasuk huruf, angka, atau tanda hubung. Nama layanan tidak boleh diakhiri dengan tanda hubung, dan harus unik per region dan project. Nama layanan tidak dapat diubah nanti dan akan terlihat secara publik. (Masukkan kualitas penelusuran produk retail)
- Dalam daftar Region, gunakan nilai default, atau pilih region tempat Anda ingin men-deploy fungsi. (Pilih us-central1)
- Dalam daftar Runtime, gunakan nilai default, atau pilih versi runtime. (Pilih Python 3.11)
- Di bagian Authentication, pilih "Allow public access"
- Klik tombol "Buat"
- Fungsi dibuat dan dimuat dengan template main.py dan requirements.txt
- Ganti dengan file: main.py dan requirements.txt dari repo project ini
- Deploy fungsi dan Anda akan mendapatkan endpoint untuk Cloud Run Function Anda
Endpoint Anda akan terlihat seperti ini (atau yang serupa):
Endpoint Cloud Run Function untuk mengakses toolbox: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Untuk mempermudah penyelesaian dalam linimasa (untuk sesi praktik yang dipandu instruktur), nomor project untuk endpoint akan dibagikan pada saat sesi praktik.
CATATAN PENTING:
Atau, Anda juga dapat menerapkan bagian database secara langsung sebagai bagian dari kode aplikasi atau Cloud Run Function.
8. Pengembangan Aplikasi (Java) dengan Penelusuran Berfacet
Terakhir, semua komponen backend yang canggih ini diwujudkan melalui lapisan aplikasi. Dikembangkan di Java, aplikasi ini menyediakan antarmuka pengguna untuk berinteraksi dengan sistem penelusuran. Aplikasi ini mengatur kueri ke AlloyDB, menangani tampilan filter berfacet, mengelola pilihan pengguna, dan menyajikan hasil penelusuran yang divalidasi dan diberi peringkat ulang dengan cara yang lancar dan intuitif.
- Anda dapat memulai dengan membuka Terminal Cloud Shell dan meng-clone repositori:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Buka Cloud Shell Editor, tempat Anda dapat melihat folder faceted_searching_retail yang baru dibuat
- Hapus langkah-langkah berikut karena telah diselesaikan di bagian sebelumnya:
- Hapus folder Cloud_Run_Function
- Hapus file db_script.sql
- Hapus file tools.yaml
- Buka folder project retail-faceted-search dan Anda akan melihat struktur project:
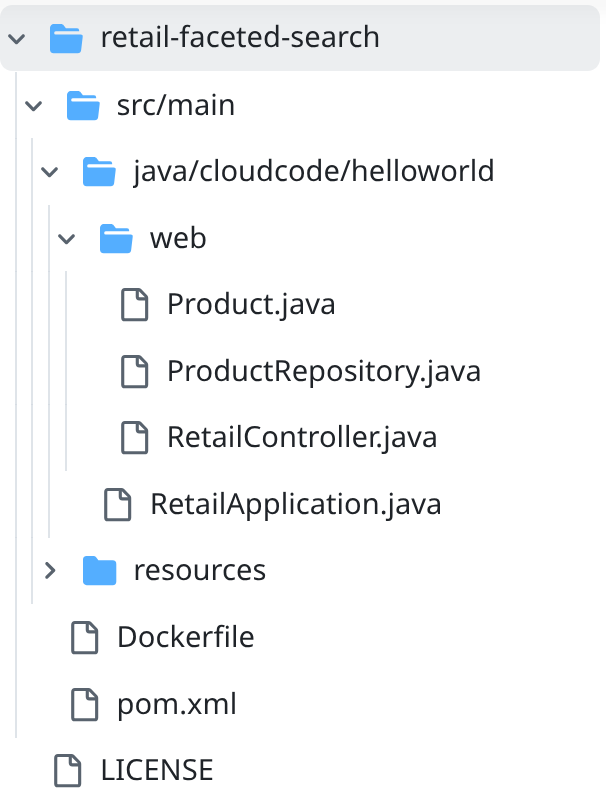
- Dalam file ProductRepository.java, Anda harus mengubah variabel TOOLBOX_ENDPOINT dengan endpoint dari Fungsi Cloud Run (yang di-deploy) atau mengambil endpoint dari pembicara yang memberikan pelatihan langsung.
Telusuri baris kode berikut dan ganti dengan endpoint Anda:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Pastikan Dockerfile dan pom.xml sesuai dengan konfigurasi project Anda (tidak perlu ada perubahan kecuali jika Anda telah mengubah versi atau konfigurasi secara eksplisit.
- Di Cloud Shell Terminal, pastikan Anda berada di dalam folder utama dan di dalam folder project (faceted_searching_retail / retail-faceted-search). Gunakan perintah berikut untuk memastikan bahwa Anda berada di folder yang tepat di terminal, kecuali jika Anda sudah berada di folder yang tepat:
cd faceted_searching_retail
cd retail-faceted-search
- Paketkan, bangun, dan uji aplikasi Anda secara lokal:
mvn package
mvn spring-boot:run
Anda akan dapat melihat aplikasi dengan mengklik "Preview on port 8080" di Terminal Cloud Shell seperti yang ditunjukkan di bawah:
9. Deploy ke Cloud Run: ***LANGKAH PENTING
Di Cloud Shell Terminal, pastikan Anda berada di dalam folder utama dan di dalam folder project (faceted_searching_retail / retail-faceted-search). Gunakan perintah berikut untuk memastikan bahwa Anda berada di folder yang tepat di terminal, kecuali jika Anda sudah berada di folder yang tepat:
cd faceted_searching_retail
cd retail-faceted-search
Setelah Anda yakin berada di folder project, jalankan perintah berikut:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Setelah di-deploy, Anda akan menerima Endpoint Cloud Run yang di-deploy dan terlihat seperti ini:
https://retail-search-**********-uc.a.run.app/
10. Demo
Mari kita lihat penerapannya:
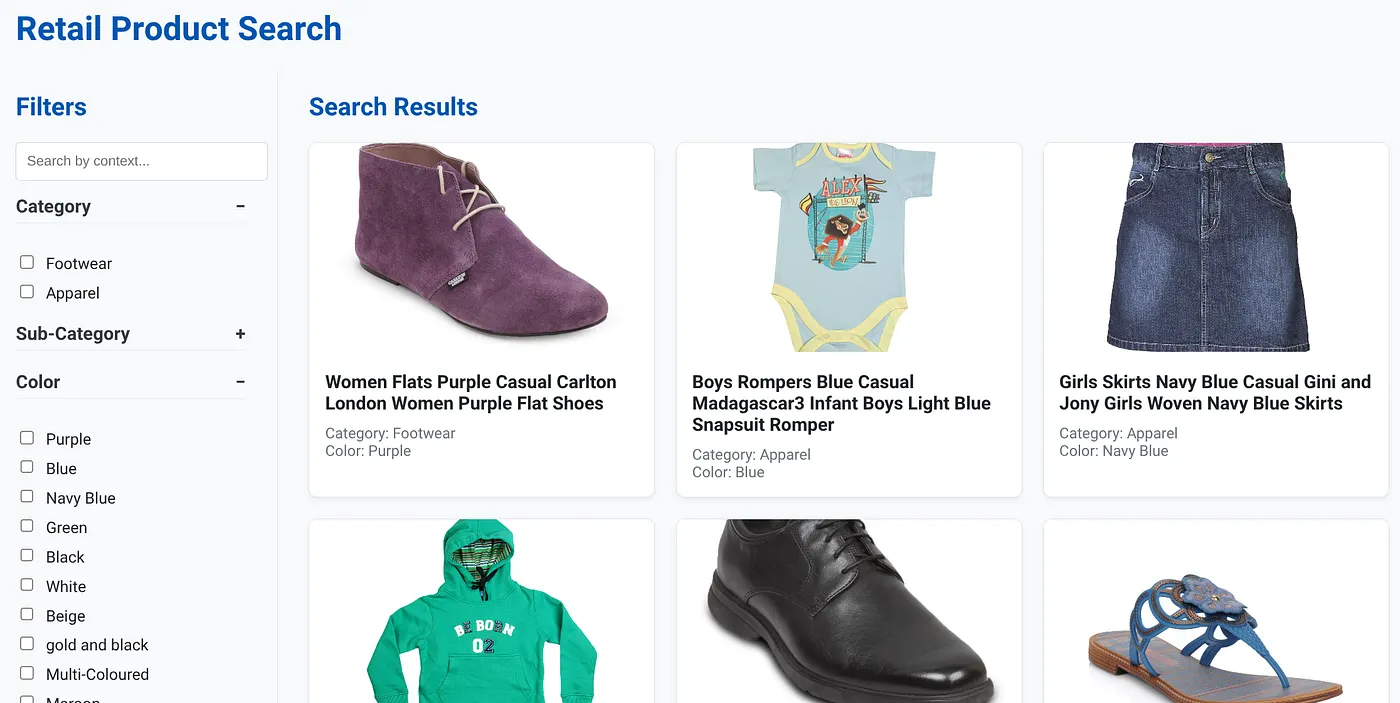
Gambar di atas menampilkan halaman landing untuk aplikasi penelusuran hibrida dinamis.
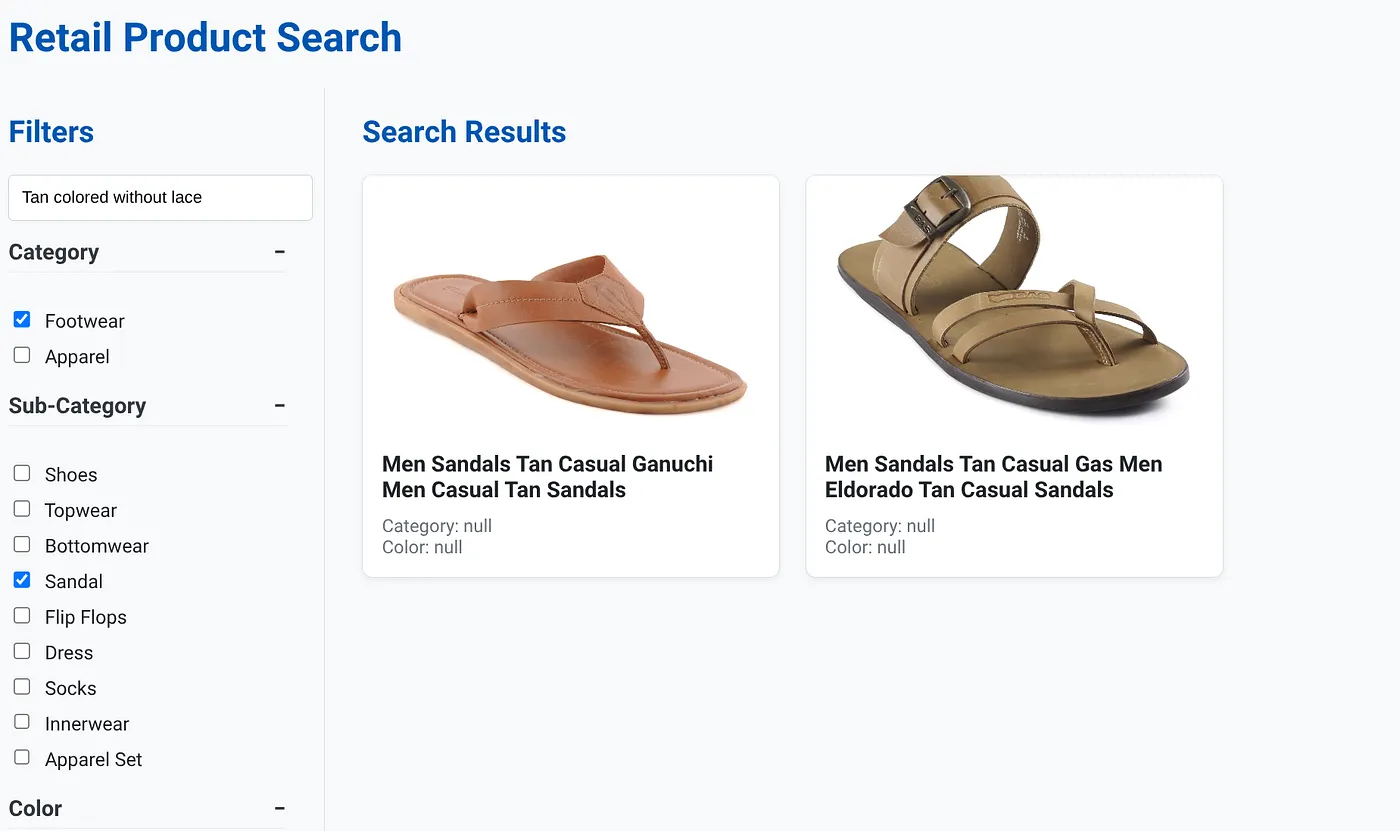
Gambar di atas menampilkan hasil penelusuran untuk "Tanpa tali berwarna cokelat" . Filter Berfacet yang dipilih adalah: Alas Kaki, Sandal.
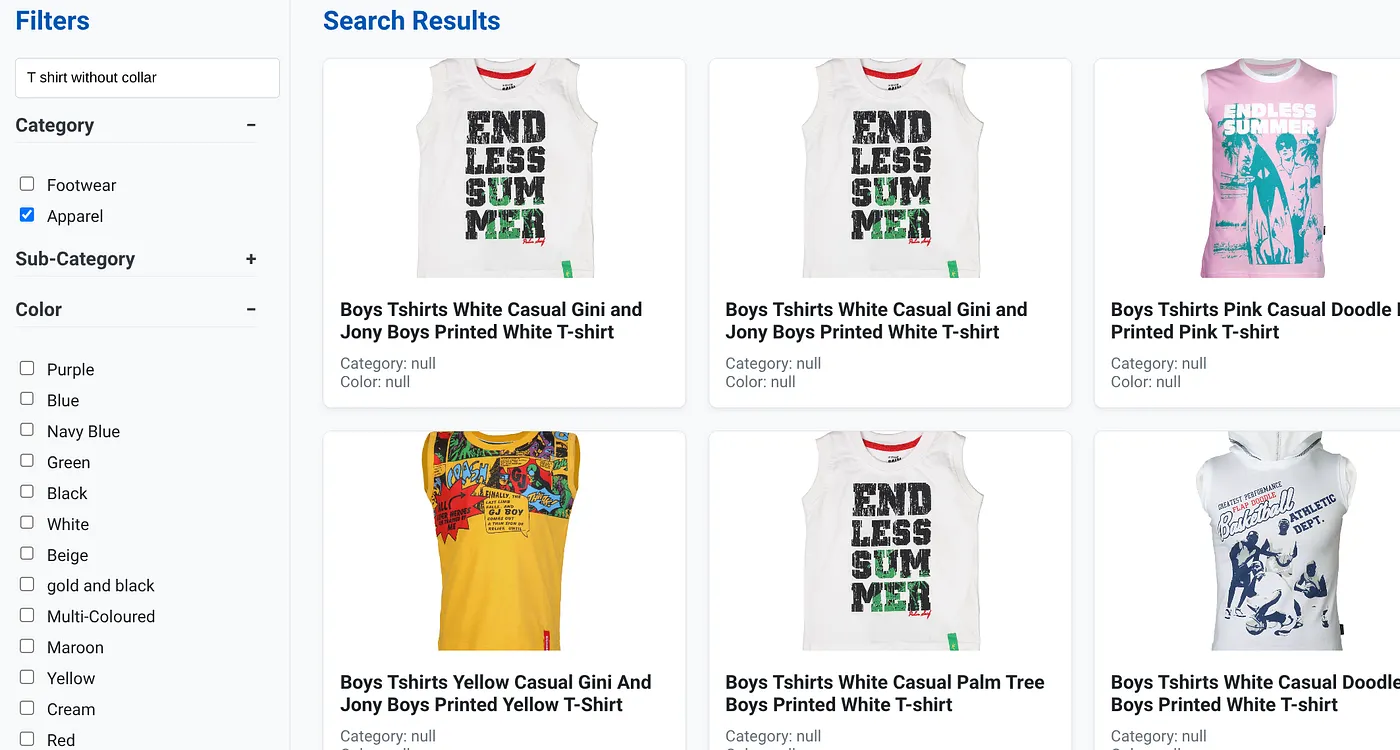
Gambar di atas menampilkan hasil penelusuran untuk "Kaos tanpa kerah" . Filter berfacet: Pakaian
Anda kini dapat menyertakan lebih banyak fitur generatif dan agentik untuk membuat aplikasi ini dapat ditindaklanjuti.
Coba fitur ini agar Anda terinspirasi untuk membangunnya sendiri.
11. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman resource manager.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Matikan untuk menghapus project.
- Atau, Anda dapat menghapus cluster AlloyDB (ubah lokasi di hyperlink ini jika Anda tidak memilih us-central1 untuk cluster pada saat konfigurasi) yang baru saja kita buat untuk project ini dengan mengklik tombol DELETE CLUSTER.
12. Selamat
Selamat! Anda telah berhasil membangun dan men-deploy APLIKASI PENELUSURAN HYBRID dengan ALLOYDB di CLOUD RUN!!!
Mengapa Hal Ini Penting bagi bisnis:
Aplikasi penelusuran hybrid dinamis ini, yang didukung oleh AlloyDB AI, menawarkan keuntungan signifikan bagi retail perusahaan dan bisnis lainnya:
Relevansi yang Lebih Baik: Dengan menggabungkan penelusuran kontekstual (vektor) dengan pemfilteran berfaset yang presisi dan pengurutan ulang cerdas, pelanggan akan menerima hasil yang sangat relevan, sehingga meningkatkan kepuasan dan konversi.
Skalabilitas: Arsitektur AlloyDB dan pengindeksan scaNN dirancang untuk menangani katalog produk yang sangat besar dan volume kueri yang tinggi, yang sangat penting untuk mengembangkan bisnis e-commerce.
Performa: Respons kueri yang lebih cepat, bahkan untuk penelusuran hybrid yang kompleks, memastikan pengalaman pengguna yang lancar dan meminimalkan rasio pengabaian.
Siap Menghadapi Masa Depan: Integrasi kemampuan AI (embeddings, validasi LLM) memosisikan aplikasi untuk kemajuan di masa mendatang dalam Rekomendasi yang Dipersonalisasi, conversational commerce, dan penemuan produk yang cerdas.
Arsitektur yang Disederhanakan: Mengintegrasikan penelusuran vektor langsung dalam AlloyDB menghilangkan kebutuhan akan database vektor terpisah atau sinkronisasi yang kompleks, sehingga menyederhanakan pengembangan dan pemeliharaan.
Misalkan pengguna mengetik kueri bahasa alami seperti "sepatu lari ramah lingkungan untuk wanita dengan dukungan lengkungan tinggi".
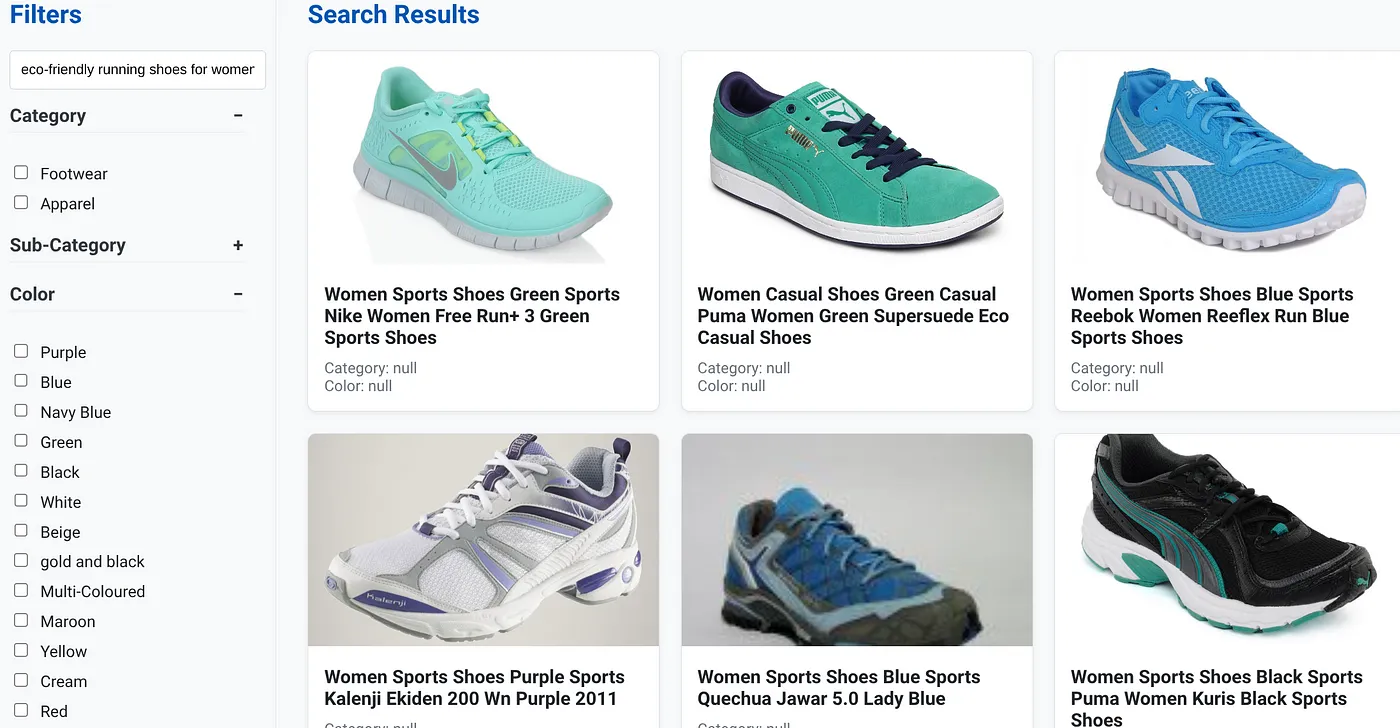
sementara secara bersamaan, pengguna menerapkan filter berfaset untuk "Kategori: <<>>", "Warna: <<>>", dan mengucapkan "Harga: Rp1.000.000-Rp1.500.000":
- Sistem langsung menampilkan daftar produk yang lebih baik, yang secara semantik selaras dengan bahasa alami dan cocok dengan filter yang dipilih.
- Di balik layar, indeks scaNN mempercepat penelusuran vektor, pemfilteran inline dan adaptif memastikan performa dengan kriteria gabungan, dan pengurutan ulang menampilkan hasil optimal di bagian atas.
- Kecepatan dan akurasi hasilnya dengan jelas menggambarkan keefektifan penggabungan teknologi ini untuk pengalaman penelusuran retail yang benar-benar cerdas.
Membangun aplikasi penelusuran retail generasi berikutnya memerlukan lebih dari sekadar metode konvensional. Dengan menggunakan kecanggihan AlloyDB, Vertex AI, Vector Search dengan pengindeksan scaNN, pemfilteran berfacet dinamis, peringkat ulang, dan validasi LLM, kita dapat memberikan pengalaman pelanggan yang tak tertandingi yang mendorong engagement dan meningkatkan penjualan. Solusi yang tangguh, skalabel, dan cerdas ini menunjukkan bagaimana kemampuan database modern, yang didukung AI, membentuk kembali masa depan retail.