
1. Panoramica
Nell'attuale panorama competitivo della vendita al dettaglio, è fondamentale consentire ai clienti di trovare esattamente ciò che cercano, in modo rapido e intuitivo. La tradizionale ricerca basata su parole chiave spesso non è sufficiente, in quanto ha difficoltà con query sfumate e cataloghi di prodotti vasti. Questo codelab presenta una sofisticata applicazione di ricerca per la vendita al dettaglio basata su AlloyDB e AlloyDB AI, che sfrutta la ricerca vettoriale all'avanguardia, l'indicizzazione scaNN, i filtri sfaccettati e il filtro adattivo intelligente, il ranking per offrire un'esperienza di ricerca ibrida e dinamica su scala aziendale.
Ora abbiamo già le nozioni di base su tre aspetti:
- Che cosa significa ricerca contestuale per il tuo agente e come realizzarla utilizzando Vector Search.
- Abbiamo anche approfondito l'argomento della ricerca vettoriale nell'ambito dei tuoi dati, ovvero all'interno del database stesso (tutti i database Google Cloud lo supportano, se non lo sapevi già).
- Abbiamo fatto un passo avanti rispetto al resto del mondo, spiegandoti come ottenere una funzionalità RAG di ricerca vettoriale leggera con prestazioni e qualità elevate con la funzionalità di ricerca vettoriale di AlloyDB basata sull'indice ScaNN.
Se non hai eseguito gli esperimenti RAG di base, intermedi e leggermente avanzati, ti consiglio di leggere questi tre articoli qui, qui e qui nell'ordine elencato.
La sfida
Oltre i filtri, le parole chiave e la corrispondenza contestuale: una semplice ricerca per parole chiave potrebbe restituire migliaia di risultati, molti dei quali non pertinenti. La soluzione ideale deve comprendere l'intento alla base della query, combinarlo con criteri di filtro precisi (come brand, materiale o prezzo) e presentare gli articoli più pertinenti in millisecondi. Ciò richiede un'infrastruttura di ricerca potente, flessibile e scalabile. Certo, abbiamo fatto molta strada dalla ricerca per parole chiave alle corrispondenze contestuali e alle ricerche per somiglianza. Immagina un cliente che cerca "una giacca comoda, elegante e impermeabile per le escursioni in primavera" mentre applica contemporaneamente i filtri e la tua applicazione non solo restituisce risposte di qualità, ma è anche ad alte prestazioni e la sequenza di tutto ciò viene scelta dinamicamente dal tuo database.
Obiettivo
Per risolvere questo problema integrando
- Ricerca contestuale (ricerca vettoriale): comprensione del significato semantico delle query e delle descrizioni dei prodotti
- Filtro sfaccettato: consente agli utenti di perfezionare i risultati con attributi specifici
- Approccio ibrido: combinare perfettamente la ricerca contestuale con il filtraggio strutturato
- Ottimizzazione avanzata: utilizzo di indicizzazione specializzata, filtri adattivi e riposizionamento per velocità e pertinenza
- Controllo qualità basato sull'AI generativa: incorporazione della convalida LLM per una qualità superiore dei risultati.
Analizziamo il percorso di architettura e implementazione.
Cosa creerai
Un'applicazione Retail Search
Nell'ambito di questo processo, potrai:
- Crea un'istanza e una tabella AlloyDB per il set di dati di e-commerce
- Configura gli embedding e la ricerca vettoriale
- Crea l'indice dei metadati e l'indice ScaNN
- Implementare la ricerca vettoriale avanzata in AlloyDB utilizzando il metodo di filtro incorporato di ScaNN
- Configurare filtri sfaccettati e ricerca ibrida in un'unica query
- Perfeziona la pertinenza delle query con il ranking e il richiamo (facoltativo)
- (Facoltativo) Valuta la risposta alla query con Gemini
- MCP Toolbox for Databases e livello applicazione
- Sviluppo di applicazioni (Java) con ricerca per sfaccettature
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati e-commerce. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati di e-commerce.
Crea un cluster e un'istanza
- Vai alla pagina AlloyDB nella console Cloud. Un modo semplice per trovare la maggior parte delle pagine in Cloud Console è cercarle utilizzando la barra di ricerca della console.
- Seleziona CREA CLUSTER da questa pagina:

- Verrà visualizzata una schermata come quella mostrata di seguito. Crea un cluster e un'istanza con i seguenti valori (assicurati che i valori corrispondano se cloni il codice dell'applicazione dal repository):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / ultima versione consigliata
- Regione: "
us-central1" - Networking: "
default"
- Quando selezioni la rete predefinita, viene visualizzata una schermata come quella mostrata di seguito.
Seleziona CONFIGURA CONNESSIONE.
- Da qui, seleziona "Utilizza un intervallo IP allocato automaticamente" e fai clic su Continua. Dopo aver esaminato le informazioni, seleziona CREA CONNESSIONE.
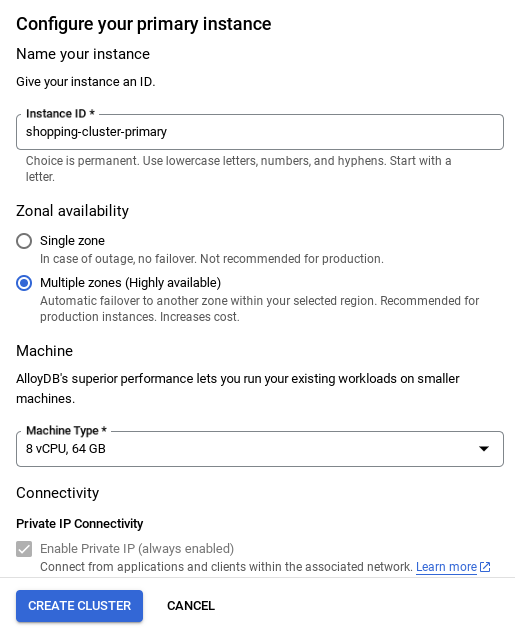
- Una volta configurata la rete, puoi continuare a creare il cluster. Fai clic su CREA CLUSTER per completare la configurazione del cluster come mostrato di seguito:
NOTA IMPORTANTE:
- Assicurati di modificare l'ID istanza (che puoi trovare al momento della configurazione del cluster / dell'istanza) in**
vector-instance**. Se non riesci a modificarlo, ricordati di utilizzare l'ID istanza in tutti i riferimenti futuri. - Tieni presente che la creazione del cluster richiederà circa 10 minuti. Una volta completata l'operazione, dovresti visualizzare una schermata che mostra la panoramica del cluster che hai appena creato.
4. Importazione dati
Ora è il momento di aggiungere una tabella con i dati del negozio. Vai ad AlloyDB, seleziona il cluster principale e poi AlloyDB Studio:
Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato quando hai creato il cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb"
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.
Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Attiva le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector consente di archiviare e cercare vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione di Vertex AI per ottenere previsioni in SQL. Abilita queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Se vuoi controllare le estensioni abilitate sul tuo database, esegui questo comando SQL:
select extname, extversion from pg_extension;
Creare una tabella
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La colonna degli incorporamenti consentirà l'archiviazione dei valori vettoriali del testo.
Concedi autorizzazione
Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi al service account AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carica i dati nel database
- Copia le istruzioni della query
insertdainsert scripts sqlnel foglio all'editor, come indicato sopra. Puoi copiare da 10 a 50 istruzioni di inserimento per una rapida demo di questo caso d'uso. In questa scheda "Inserti selezionati 25-30 righe" è presente un elenco selezionato di inserti.
Il link ai dati è disponibile in questo file del repository GitHub.
- Fai clic su Esegui. I risultati della query vengono visualizzati nella tabella Risultati.
NOTA IMPORTANTE:
Assicurati di copiare solo 25-50 record da inserire e che provengano da un intervallo di tipi di categoria, sottocategoria, colore e genere.
5. Crea incorporamenti per i dati
La vera innovazione nella ricerca moderna consiste nel comprendere il significato, non solo le parole chiave. È qui che entrano in gioco gli embedding e la ricerca vettoriale.
Abbiamo trasformato le descrizioni dei prodotti e le query degli utenti in rappresentazioni numeriche ad alta dimensionalità chiamate "incorporamenti" utilizzando modelli linguistici pre-addestrati. Questi embedding acquisiscono il significato semantico, consentendoci di trovare prodotti "simili per significato" anziché contenenti solo parole corrispondenti. Inizialmente, abbiamo sperimentato la ricerca di similarità vettoriale diretta su questi incorporamenti per stabilire una base di riferimento, dimostrando la potenza della comprensione semantica anche prima delle ottimizzazioni del rendimento.
La colonna degli incorporamenti consentirà di memorizzare i valori vettoriali del testo della descrizione del prodotto. La colonna img_embeddings consentirà l'archiviazione degli incorporamenti di immagini (multimodali). In questo modo puoi utilizzare anche la ricerca basata sulla distanza tra testo e immagine. In questo lab, però, utilizzeremo solo gli incorporamenti di testo.
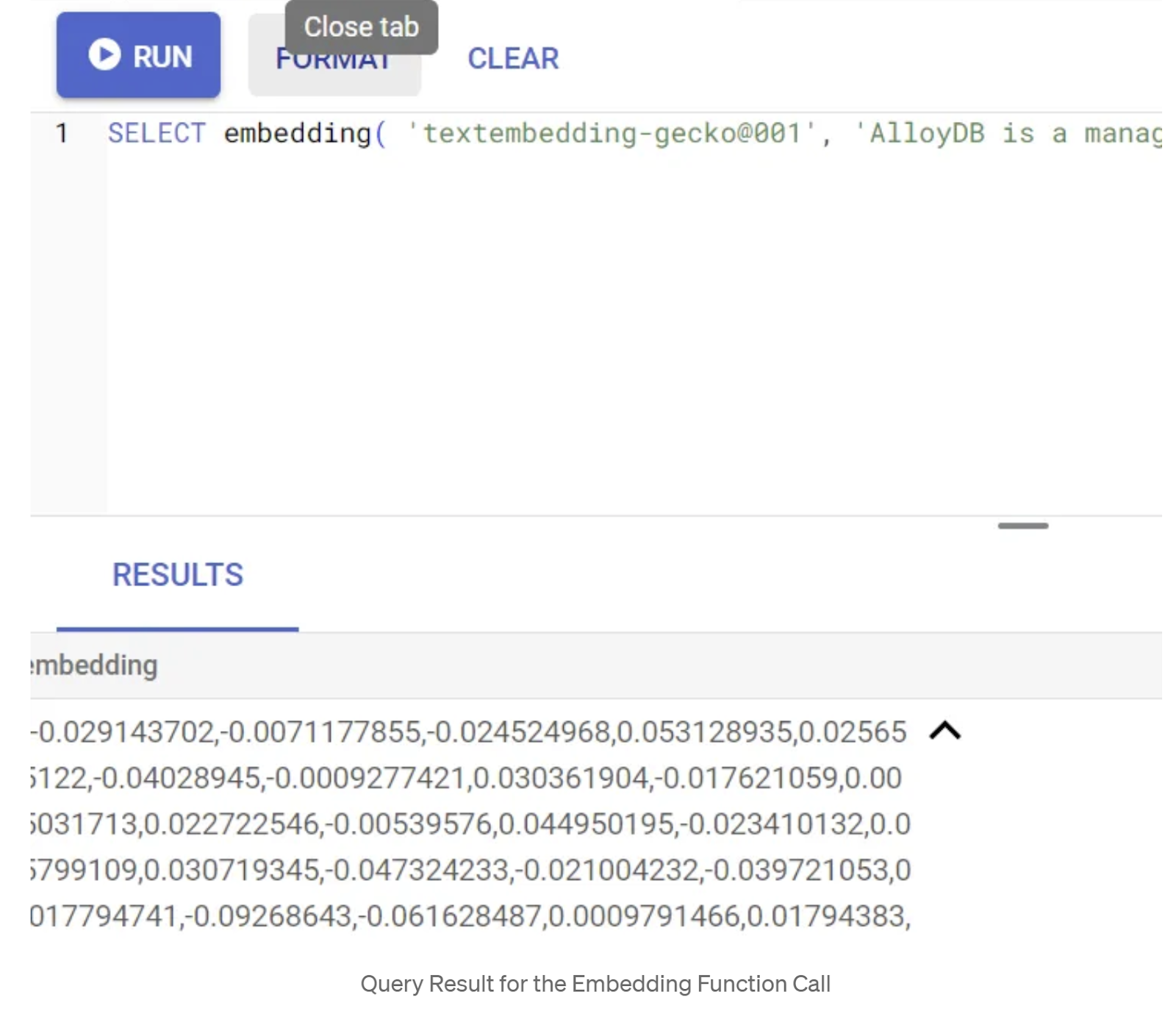
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dovrebbe restituire il vettore di incorporamento, che ha l'aspetto di un array di numeri in virgola mobile, per il testo di esempio nella query. Ecco come appare:
Aggiorna il campo vettoriale abstract_embeddings
Esegui il seguente DML per aggiornare la descrizione dei contenuti nella tabella con gli embedding corrispondenti:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Se utilizzi un account di fatturazione con crediti di prova per Google Cloud, potresti avere difficoltà a generare più di pochi incorporamenti (ad esempio 20-25 al massimo). Pertanto, limita il numero di righe nello script di inserimento.
Se vuoi generare incorporamenti di immagini (per eseguire la ricerca contestuale multimodale), esegui anche l'aggiornamento riportato di seguito:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Eseguire RAG avanzato con le nuove funzionalità di AlloyDB
Ora che la tabella, i dati e gli incorporamenti sono pronti, eseguiamo la ricerca vettoriale in tempo reale per il testo di ricerca dell'utente. Puoi testarlo eseguendo la query riportata di seguito:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
In questa query, confrontiamo il text embedding della ricerca inserita dall'utente"T-shirt con scollo rotondo " con i text embedding di tutte le descrizioni dei prodotti nella tabella degli indumenti (memorizzati nella colonna denominata"embedding ") utilizzando la funzione di distanza di similarità del coseno (rappresentata dal simbolo "<=>". Convertiamo il risultato del metodo di embedding in tipo di vettore per renderlo compatibile con i vettori memorizzati nel database. LIMIT 10 indica che stiamo selezionando le 10 corrispondenze più vicine al testo di ricerca.
AlloyDB porta la RAG di ricerca vettoriale a un livello superiore:
Per una soluzione su scala aziendale, la ricerca vettoriale non è sufficiente. Le prestazioni sono fondamentali.
Indice ScaNN (Scalable Nearest Neighbors)
Per ottenere una ricerca approssimativa del vicino più prossimo (ANN) ultraveloce, abbiamo attivato l'indice scaNN in AlloyDB. ScaNN, un algoritmo di ricerca del vicino più prossimo approssimato allo stato dell'arte sviluppato da Google Research, è progettato per una ricerca di similarità vettoriale efficiente su larga scala. Accelera notevolmente le query riducendo in modo efficiente lo spazio di ricerca e utilizzando tecniche di quantizzazione, offrendo query vettoriali fino a 4 volte più veloci rispetto ad altri metodi di indicizzazione e un footprint della memoria più piccolo. Scopri di più qui e qui.
Attiviamo l'estensione e creiamo gli indici:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Creazione di indici per i campi di incorporamento di testo e di incorporamento di immagini (nel caso in cui tu voglia utilizzare gli incorporamenti di immagini nella ricerca):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Indici dei metadati
Mentre scaNN gestisce l'indicizzazione dei vettori, gli indici B-tree o GIN tradizionali sono stati configurati meticolosamente su attributi strutturati (come categoria, sottocategoria, stile, colore e così via). Questi indici sono fondamentali per l'efficienza del filtro sfaccettato. Esegui le seguenti istruzioni per configurare gli indici dei metadati:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
NOTA IMPORTANTE:
Poiché potresti aver inserito solo 25-50 record, gli indici (ScaNN o qualsiasi altro indice) non saranno efficaci.
Filtro in linea
Una sfida comune nella ricerca vettoriale è la combinazione con filtri strutturati (ad es. "scarpe rosse"). Il filtro incorporato di AlloyDB ottimizza questa operazione. Anziché eseguire il post-filtraggio dei risultati di una ricerca vettoriale generica, il filtro in linea applica le condizioni di filtro durante il processo di ricerca vettoriale stesso, migliorando drasticamente il rendimento e l'accuratezza delle ricerche vettoriali filtrate.
Consulta questa documentazione per scoprire di più sulla necessità del filtro in linea. Scopri di più sulla ricerca vettoriale filtrata per l'ottimizzazione del rendimento della ricerca vettoriale qui. Ora, se vuoi attivare il filtro incorporato per la tua applicazione, esegui la seguente istruzione dall'editor:
SET scann.enable_inline_filtering = on;
Il filtro in linea è ideale per i casi con selettività media. Man mano che AlloyDB esegue ricerche nell'indice vettoriale, calcola le distanze solo per i vettori che corrispondono alle condizioni di filtro dei metadati (i filtri funzionali in una query gestiti di solito nella clausola WHERE). In questo modo, le prestazioni di queste query migliorano notevolmente, integrando i vantaggi del pre-filtraggio o del post-filtraggio.
Filtro adattivo
Per ottimizzare ulteriormente le prestazioni, il filtro adattivo di AlloyDB sceglie dinamicamente la strategia di filtraggio più efficiente (in linea o pre-filtraggio) durante l'esecuzione della query. Analizza i pattern di query e le distribuzioni dei dati per garantire prestazioni ottimali senza intervento manuale, il che è particolarmente utile per le ricerche vettoriali filtrate, in cui passa automaticamente dall'utilizzo dell'indice vettoriale a quello dei metadati. Per attivare il filtro adattivo, utilizza il flag scann.enable_preview_features.
Quando il filtro adattivo attiva il passaggio dal filtro in linea al pre-filtraggio durante l'esecuzione, il piano di query cambia in modo dinamico.
SET scann.enable_preview_features = on;
NOTA IMPORTANTE: potresti non essere in grado di eseguire l'istruzione precedente senza riavviare l'istanza. Se si verifica un errore, è meglio abilitare il flag enable_preview_features dalla sezione dei flag di database dell'istanza.
Filtri sfaccettati che utilizzano tutti gli indici
La ricerca per facet consente agli utenti di perfezionare i risultati applicando più filtri in base ad attributi o "facet" specifici (ad es. brand, prezzo, taglia, valutazione dei clienti). La nostra applicazione integra queste sfaccettature in modo fluido con la ricerca vettoriale. Una singola query ora può combinare il linguaggio naturale (ricerca contestuale) con più selezioni sfaccettate, sfruttando dinamicamente sia gli indici vettoriali che quelli tradizionali. In questo modo si ottiene una funzionalità di ricerca ibrida veramente dinamica, che consente agli utenti di esaminare in dettaglio i risultati con precisione.
Nella nostra applicazione, poiché abbiamo già creato tutti gli indici dei metadati, siamo pronti per l'utilizzo del filtro sfaccettato nel web indirizzandolo direttamente tramite query SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
In questa query, eseguiamo una ricerca ibrida, incorporando sia
- Filtro sfaccettato nella clausola WHERE
- Ricerca vettoriale nella clausola ORDER BY utilizzando il metodo di similarità del coseno.
$1, $2, $3 e $4 rappresentano i valori del filtro sfaccettato in un array e $5 rappresenta il testo di ricerca dell'utente. Sostituisci da $1 a $4 con i valori del filtro sfaccettato che preferisci, come di seguito:
category = ANY([‘Apparel', ‘Footwear'])
Sostituisci 5 $con un testo di ricerca a tua scelta, ad esempio "Polo".
NOTA IMPORTANTE: se non disponi degli indici a causa del numero limitato di record che hai inserito, non noterai l'impatto sul rendimento. Tuttavia, in un set di dati di produzione completo noterai che il tempo di esecuzione si riduce in modo significativo per la stessa ricerca vettoriale. Questo è possibile grazie all'indice ScaNN con filtro incorporato nella ricerca vettoriale.
Successivamente, valutiamo il richiamo per questa ricerca vettoriale abilitata a ScaNN.
Re-ranking
Anche con la ricerca avanzata, i risultati iniziali potrebbero aver bisogno di un'ultima revisione. Si tratta di un passaggio fondamentale che riordina i risultati di ricerca iniziali per migliorare la pertinenza. Dopo che la ricerca ibrida iniziale fornisce un insieme di prodotti candidati, un modello più sofisticato (e spesso più pesante dal punto di vista computazionale) applica un punteggio di pertinenza più granulare. In questo modo, i primi risultati presentati all'utente sono i più pertinenti, migliorando significativamente la qualità della ricerca. Valutiamo continuamente il richiamo per misurare l'efficacia del sistema nel recuperare tutti gli elementi pertinenti per una determinata query, perfezionando i nostri modelli per massimizzare la probabilità che un cliente trovi ciò di cui ha bisogno.
Prima di utilizzarlo nella tua applicazione, assicurati di soddisfare tutti i prerequisiti:
- Verifica che l'estensione google_ml_integration sia installata.
- Verifica che il flag google_ml_integration.enable_model_support sia impostato su on.
- Esegui l'integrazione con Vertex AI.
- Attiva l'API Discovery Engine.
- Ottenere i ruoli richiesti per utilizzare i modelli di ranking.
Poi puoi utilizzare la seguente query nella nostra applicazione per riordinare il set di risultati della ricerca ibrida:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
In questa query, eseguiamo il RERANKING del set di risultati dei prodotti della ricerca contestuale indirizzata nella clausola ORDER BY utilizzando il metodo della similarità del coseno. "Maglietta rosa" è il testo che l'utente sta cercando.
NOTA IMPORTANTE: alcuni di voi potrebbero non avere ancora accesso al Riassegnazione del ranking, quindi l'ho escluso dal codice dell'applicazione, ma se volete includerlo, potete seguire l'esempio che abbiamo trattato in precedenza.
Richiamo del valutatore
Il richiamo nella ricerca per similarità è la percentuale di istanze pertinenti recuperate da una ricerca, ovvero il numero di veri positivi. Si tratta della metrica più comune utilizzata per misurare la qualità della ricerca. Una fonte di perdita di richiamo deriva dalla differenza tra la ricerca approssimativa del vicino più prossimo (ANN) e la ricerca esatta del vicino più prossimo (KNN). Gli indici vettoriali come ScaNN di AlloyDB implementano algoritmi ANN, consentendoti di velocizzare la ricerca vettoriale su set di dati di grandi dimensioni in cambio di un piccolo compromesso nel richiamo. Ora AlloyDB ti offre la possibilità di misurare questo compromesso direttamente nel database per le singole query e di assicurarti che sia stabile nel tempo. Puoi aggiornare i parametri di query e indice in risposta a queste informazioni per ottenere risultati e prestazioni migliori.
Qual è la logica alla base del richiamo dei risultati di ricerca?
Nel contesto della ricerca vettoriale, il richiamo si riferisce alla percentuale di vettori restituiti dall'indice che sono i vicini più prossimi effettivi. Ad esempio, se una query per i 20 vicini più prossimi restituisce 19 dei vicini più prossimi della verità di base, il richiamo è 19/20 x 100 = 95%. Il richiamo è la metrica utilizzata per la qualità della ricerca ed è definita come la percentuale dei risultati restituiti che sono oggettivamente più vicini ai vettori di query.
Puoi trovare il richiamo per una query vettoriale su un indice vettoriale per una determinata configurazione utilizzando la funzione evaluate_query_recall. Questa funzione ti consente di ottimizzare i parametri per ottenere i risultati di richiamo della query vettoriale che desideri.
NOTA IMPORTANTE:
Se nei passaggi successivi si verifica l'errore di autorizzazione negata nell'indice HNSW, per il momento salta l'intera sezione di valutazione del richiamo. A questo punto, potrebbe trattarsi di restrizioni di accesso, in quanto è appena stato rilasciato al momento della documentazione di questo codelab.
- Imposta il flag Enable Index Scan (Attiva scansione indice) sull'indice ScaNN e sull'indice HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Esegui la seguente query in AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La funzione evaluate_query_recall accetta la query come parametro e restituisce il relativo richiamo. Utilizzo la stessa query che ho utilizzato per controllare il rendimento come query di input della funzione. Ho aggiunto SCaNN come metodo di indice. Per ulteriori opzioni di parametri, consulta la documentazione.
Il richiamo per questa query di Vector Search che abbiamo utilizzato:
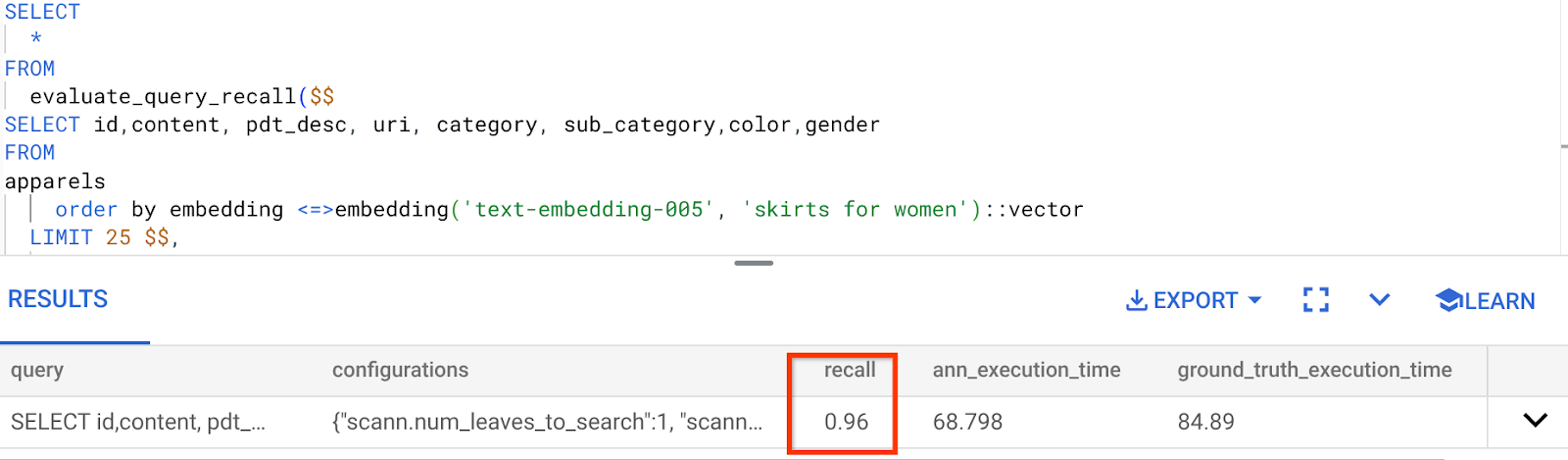
Vedo che il RECALL è del 96%. In questo caso, il richiamo è molto buono. Tuttavia, se il valore non era accettabile, puoi utilizzare queste informazioni per modificare i parametri di indice, i metodi e i parametri di query e migliorare il recupero per questa ricerca vettoriale.
Testalo con parametri di query e indice modificati
Ora testiamo la query modificando i parametri di query in base al richiamo ricevuto.
- Modifica dei parametri dell'indice:
Per questo test, utilizzerò la "Distanza L2" anziché la funzione di distanza di similarità "Coseno".
Nota molto importante: "Come facciamo a sapere che questa query utilizza la similarità COSINE?" ti starai chiedendo. Puoi identificare la funzione di distanza dall'uso di "<=>" per rappresentare la distanza del coseno.
Link a Documenti per le funzioni di distanza di Vector Search.
La query precedente utilizza la funzione di distanza di similarità del coseno, mentre ora proveremo la distanza L2. Ma per questo dobbiamo anche assicurarci che l'indice ScaNN sottostante utilizzi anche la funzione di distanza L2. Ora creiamo un indice con una query di funzione di distanza diversa: Distanza L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
L'istruzione di eliminazione dell'indice serve solo a garantire che non ci siano indici non necessari nella tabella.
Ora posso eseguire la seguente query per valutare il RECALL dopo aver modificato la funzione di distanza della funzionalità di ricerca vettoriale.
[AFTER] Query che utilizza la funzione Distanza L2:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Puoi vedere la differenza / trasformazione nel valore di richiamo per l'indice aggiornato.
Nell'indice puoi modificare altri parametri, ad esempio num_leaves, in base al valore di richiamo desiderato e al set di dati utilizzato dall'applicazione.
Convalida LLM dei risultati della ricerca vettoriale
Per ottenere una ricerca controllata di massima qualità, abbiamo incorporato un livello facoltativo di convalida LLM. I modelli linguistici di grandi dimensioni possono essere utilizzati per valutare la pertinenza e la coerenza dei risultati di ricerca, soprattutto per query complesse o ambigue. Ciò può comportare:
Verifica semantica:
Un LLM che esegue il controllo incrociato dei risultati rispetto all'intent della query.
Filtro logico:
Utilizzando un LLM per applicare regole o logiche di business complesse difficili da codificare nei filtri tradizionali, perfezionando ulteriormente l'elenco dei prodotti in base a criteri sfumati.
Garanzia di qualità:
Identificazione e segnalazione automatica dei risultati meno pertinenti per la revisione umana o il perfezionamento del modello.
Ecco come abbiamo ottenuto questo risultato nelle funzionalità di AI di AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
La query sottostante è la stessa che abbiamo visto nelle sezioni di ricerca per sfaccettature, ricerca ibrida e riposizionamento. Ora in questa query abbiamo incorporato un livello di valutazione di GEMINI del set di risultati riordinato rappresentato dal costrutto ml_predict_row. Ho commentato i filtri sfaccettati, ma puoi includere gli elementi che preferisci in un array per i segnaposto da $1 a $4. Sostituisci 5 $con il testo che vuoi cercare, ad esempio "Top rosa, senza motivi floreali".
7. MCP Toolbox for Databases e livello applicazione
Dietro le quinte, strumenti solidi e un'applicazione ben strutturata garantiscono un funzionamento ottimale.
La toolbox MCP (Model Context Protocol) per i database semplifica l'integrazione di strumenti di AI generativa e agentici con AlloyDB. Funge da server open source che semplifica il raggruppamento delle connessioni, l'autenticazione e l'esposizione sicura delle funzionalità del database agli agenti AI o ad altre applicazioni.
Nella nostra applicazione abbiamo utilizzato MCP Toolbox for Databases come livello di astrazione per tutte le nostre query di ricerca ibrida intelligente.
Segui i passaggi riportati di seguito per configurare e implementare Toolbox per il nostro caso d'uso:
Puoi notare che uno dei database supportati da MCP Toolbox for Databases è AlloyDB e, poiché l'abbiamo già eseguito il provisioning nella sezione precedente, procediamo con la configurazione di Toolbox.
- Vai al terminale Cloud Shell e assicurati che il progetto sia selezionato e visualizzato nel prompt del terminale. Esegui il comando riportato di seguito dal terminale Cloud Shell per passare alla directory del progetto:
mkdir toolbox-tools
cd toolbox-tools
- Esegui il comando riportato di seguito per scaricare e installare toolbox nella nuova cartella:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Vai all'editor di Cloud Shell (per la modalità di modifica del codice) e, nella cartella radice del progetto, aggiungi un file denominato "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Assicurati di sostituire lo script Tools.yaml con il codice di questo file del repository.
Vediamo il file tools.yaml:
Le origini rappresentano le diverse origini dati con cui uno strumento può interagire. Un'origine rappresenta un'origine dati con cui uno strumento può interagire. Puoi definire le origini come una mappa nella sezione sources del file tools.yaml. In genere, una configurazione dell'origine contiene tutte le informazioni necessarie per connettersi al database e interagire con esso.
Gli strumenti definiscono le azioni che un agente può intraprendere, ad esempio leggere e scrivere in una sorgente. Uno strumento rappresenta un'azione che l'agente può intraprendere, ad esempio l'esecuzione di un'istruzione SQL. Puoi definire gli strumenti come una mappa nella sezione degli strumenti del file tools.yaml. In genere, uno strumento richiede un'origine su cui agire.
Per ulteriori dettagli sulla configurazione di tools.yaml, consulta questa documentazione.
- Esegui questo comando (dalla cartella mcp-toolbox) per avviare il server:
./toolbox --tools-file "tools.yaml"
Ora, se apri il server in modalità di anteprima web sul cloud, dovresti essere in grado di vedere il server Toolbox in esecuzione con il nuovo strumento denominato get-order-data.
Per impostazione predefinita, il server MCP Toolbox viene eseguito sulla porta 5000. Utilizziamo Cloud Shell per testare questa funzionalità.
Fai clic su Anteprima web in Cloud Shell come mostrato di seguito:
Fai clic su Cambia porta e imposta la porta su 5000 come mostrato di seguito, poi fai clic su Cambia e visualizza anteprima.
Dovrebbe essere visualizzato l'output:
- Eseguiamo il deployment di Toolbox in Cloud Run:
Per prima cosa, possiamo iniziare con il server MCP Toolbox e ospitarlo su Cloud Run. In questo modo, avremo un endpoint pubblico che potremo integrare con qualsiasi altra applicazione e/o con le applicazioni dell'agente. Le istruzioni per l'hosting su Cloud Run sono disponibili qui. Ora esamineremo i passaggi chiave.
- Avvia un nuovo terminale Cloud Shell o utilizzane uno esistente. Vai alla cartella del progetto in cui sono presenti il file binario toolbox e tools.yaml, in questo caso toolbox-tools, se non l'hai già fatto:
cd toolbox-tools
- Imposta la variabile PROJECT_ID in modo che punti al tuo ID progetto Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Attiva questi servizi Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Creiamo un service account separato che fungerà da identità per il servizio Toolbox che verrà sottoposto a deployment su Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Ci stiamo anche assicurando che questo service account disponga dei ruoli corretti, ovvero la possibilità di accedere a Secret Manager e comunicare con AlloyDB
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Caricheremo il file tools.yaml come secret:
gcloud secrets create tools --data-file=tools.yaml
Se hai già un secret e vuoi aggiornare la versione del secret, esegui il comando riportato di seguito:
gcloud secrets versions add tools --data-file=tools.yaml
- Imposta una variabile di ambiente sull'immagine container che vuoi utilizzare per Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- L'ultimo passaggio del comando di deployment familiare in Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
In questo modo dovrebbe iniziare il processo di deployment di Toolbox Server con il file tools.yaml configurato in Cloud Run. Se il deployment è andato a buon fine, dovresti visualizzare un messaggio simile al seguente:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Ora puoi utilizzare lo strumento appena implementato nella tua applicazione con agenti.
Accedere agli strumenti nel server Toolbox
Una volta eseguito il deployment di Toolbox, creeremo uno shim di Python Cloud Run Functions per interagire con il server Toolbox di cui è stato eseguito il deployment. Questo perché al momento Toolbox non dispone di un SDK Java, quindi abbiamo creato uno shim Python per interagire con il server. Ecco il codice sorgente per questa funzione Cloud Run.
Devi creare ed eseguire il deployment di questa funzione Cloud Run per poter accedere agli strumenti della casella degli attrezzi che abbiamo appena creato e di cui abbiamo eseguito il deployment nei passaggi precedenti:
- Nella console Google Cloud, vai alla pagina Cloud Run.
- Fai clic su Scrivi una funzione.
- Nel campo Nome servizio, inserisci un nome per descrivere la funzione. I nomi dei servizi devono iniziare solo con una lettera e contenere un massimo di 49 caratteri, tra cui lettere, numeri o trattini. I nomi dei servizi non possono terminare con trattini e devono essere univoci per regione e progetto. Il nome del servizio non può essere modificato in seguito ed è visibile pubblicamente. (Enter retail-product-search-quality)
- Nell'elenco Regione, utilizza il valore predefinito o seleziona la regione in cui vuoi eseguire il deployment della funzione. (Scegli us-central1)
- Nell'elenco Runtime, utilizza il valore predefinito o seleziona una versione del runtime. (Scegli Python 3.11)
- Nella sezione Autenticazione, scegli "Consenti accesso pubblico".
- Fai clic sul pulsante "Crea".
- La funzione viene creata e caricata con un modello main.py e requirements.txt
- Sostituisci il file con i file main.py e requirements.txt dal repository di questo progetto.
- Esegui il deployment della funzione e dovresti ottenere un endpoint per la tua funzione Cloud Run
L'endpoint dovrebbe avere il seguente aspetto (o uno simile):
Endpoint della funzione Cloud Run per accedere alla casella degli strumenti: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Per facilitare il completamento entro la tempistica (per le sessioni pratiche guidate dall'istruttore), il numero di progetto per l'endpoint verrà condiviso al momento della sessione pratica.
NOTA IMPORTANTE:
In alternativa, puoi implementare la parte del database direttamente come parte del codice dell'applicazione o della funzione Cloud Run.
8. Sviluppo di applicazioni (Java) con ricerca per sfaccettature
Infine, tutti questi potenti componenti di backend prendono vita attraverso il livello applicazione. Sviluppata in Java, l'applicazione fornisce l'interfaccia utente per interagire con il sistema di ricerca. Coordina le query ad AlloyDB, gestisce la visualizzazione dei filtri sfaccettati, gestisce le selezioni degli utenti e presenta i risultati di ricerca riordinati e convalidati in modo semplice e intuitivo.
- Puoi iniziare andando al terminale Cloud Shell e clonando il repository:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Vai all'editor di Cloud Shell, dove puoi vedere la cartella appena creata faceted_searching_retail.
- Elimina quanto segue, poiché questi passaggi sono già stati completati nelle sezioni precedenti:
- Elimina la cartella Cloud_Run_Function
- Elimina il file db_script.sql
- Elimina il file tools.yaml
- Vai alla cartella del progetto retail-faceted-search e dovresti visualizzare la struttura del progetto:
- Nel file ProductRepository.java devi modificare la variabile TOOLBOX_ENDPOINT con l'endpoint della tua funzione Cloud Run (di cui è stato eseguito il deployment) o prendere l'endpoint dal relatore dell'esercizio pratico.
Cerca la seguente riga di codice e sostituiscila con il tuo endpoint:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Assicurati che Dockerfile e pom.xml siano aggiornati alla configurazione del progetto (non sono necessarie modifiche, a meno che tu non abbia modificato esplicitamente una versione o una configurazione).
- Nel terminale Cloud Shell, assicurati di trovarti nella cartella principale e all'interno della cartella del progetto (faceted_searching_retail / retail-faceted-search). Utilizza i seguenti comandi per assicurarti di trovarti nella cartella giusta nel terminale:
cd faceted_searching_retail
cd retail-faceted-search
- Crea pacchetti, build e testa la tua applicazione localmente:
mvn package
mvn spring-boot:run
Dovresti essere in grado di visualizzare l'applicazione facendo clic su "Anteprima sulla porta 8080" nel terminale Cloud Shell, come mostrato di seguito:
9. Esegui il deployment in Cloud Run: ***PASSAGGIO IMPORTANTE
Nel terminale Cloud Shell assicurati di trovarti all'interno della cartella principale e della cartella del progetto (faceted_searching_retail / retail-faceted-search). Utilizza i seguenti comandi per assicurarti di trovarti nella cartella giusta nel terminale:
cd faceted_searching_retail
cd retail-faceted-search
Una volta che ti trovi nella cartella del progetto, esegui questo comando:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Una volta eseguito il deployment, dovresti ricevere un endpoint Cloud Run di cui è stato eseguito il deployment simile al seguente:
https://retail-search-**********-uc.a.run.app/
10. Demo
Vediamo come tutto questo si traduce nella pratica:
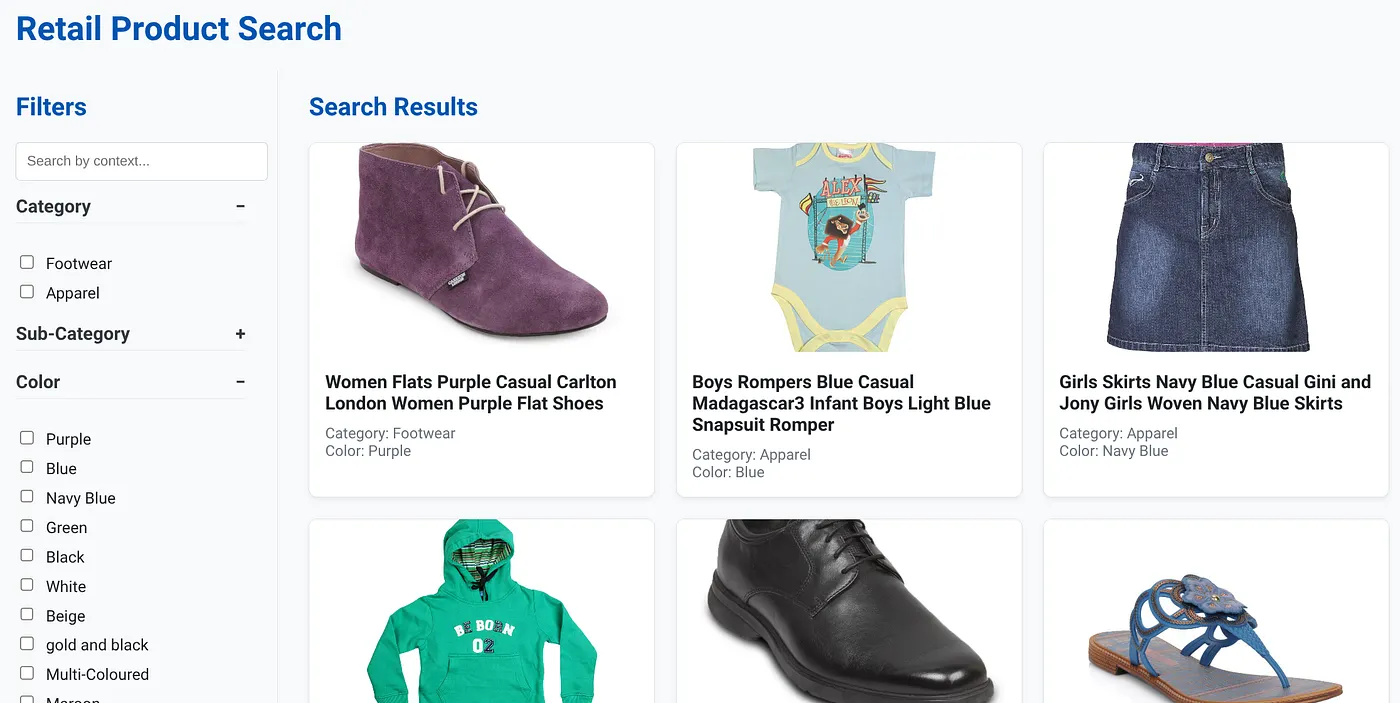
L'immagine sopra mostra la pagina di destinazione dell'app di ricerca ibrida dinamica.
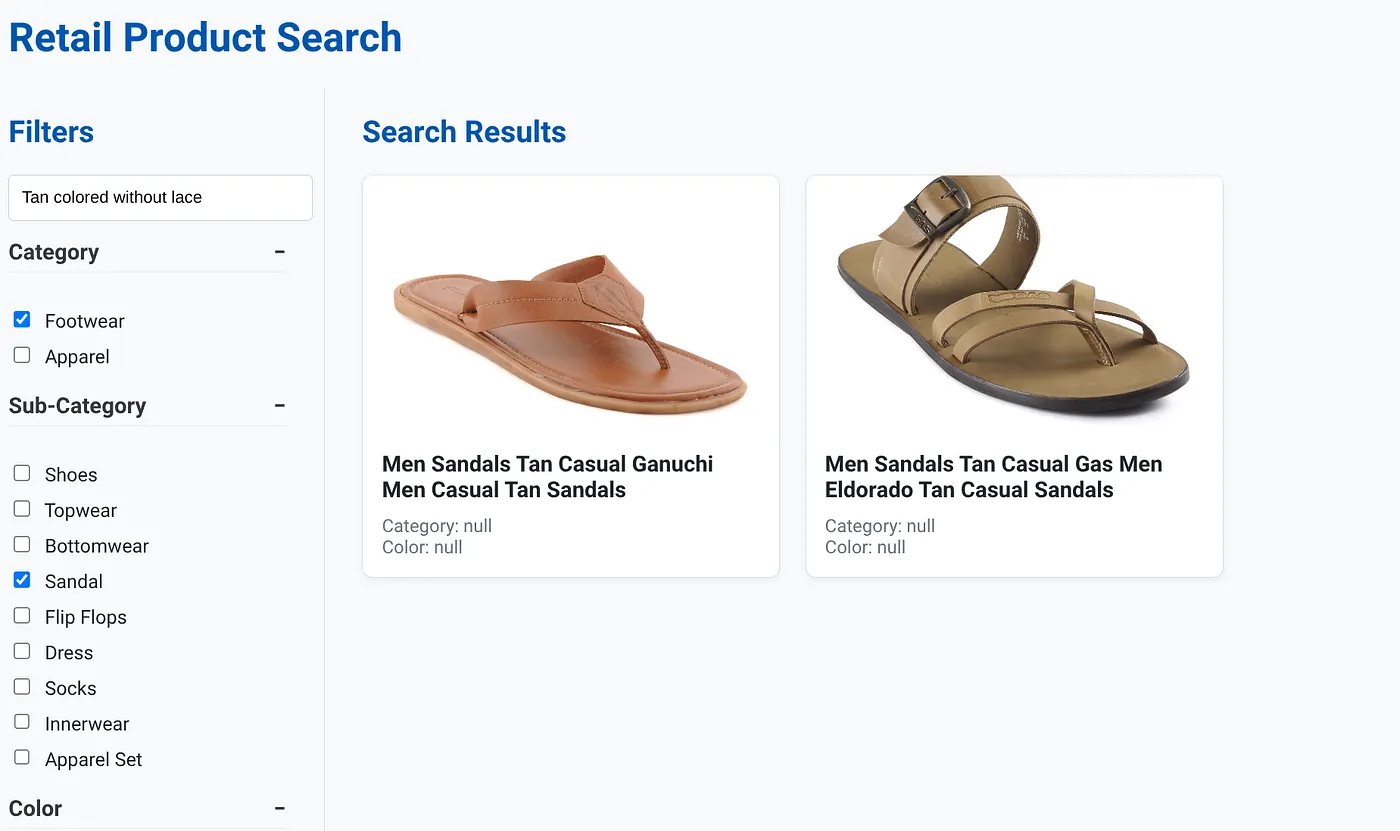
L'immagine sopra mostra i risultati di ricerca per "Color cuoio senza lacci" . I filtri sfaccettati selezionati sono: calzature, sandali.
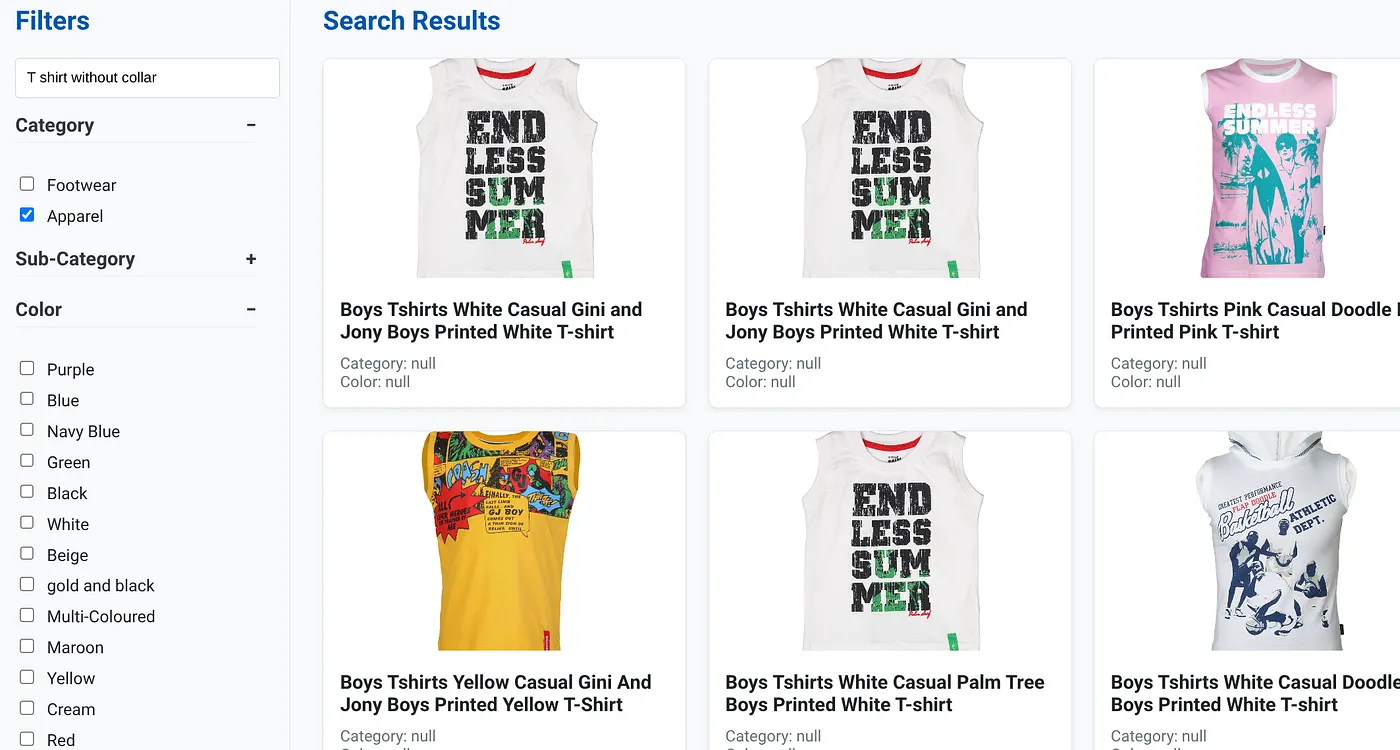
L'immagine sopra mostra i risultati di ricerca per "T-shirt senza colletto" . Filtri sfaccettati: abbigliamento
Ora puoi incorporare più funzionalità generative e di agenti per rendere questa applicazione utilizzabile.
Provalo per trovare l'ispirazione e creare i tuoi contenuti.
11. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Resource Manager.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi eliminare il cluster AlloyDB (modifica la posizione in questo collegamento ipertestuale se non hai scelto us-central1 per il cluster al momento della configurazione) che abbiamo appena creato per questo progetto facendo clic sul pulsante ELIMINA CLUSTER.
12. Complimenti
Complimenti! Hai creato ed eseguito correttamente il deployment di un'APP DI RICERCA IBRIDA con ALLOYDB su CLOUD RUN.
Perché è importante per le attività:
Questa applicazione di ricerca ibrida dinamica, basata su AlloyDB AI, offre vantaggi significativi per le attività di vendita al dettaglio e altre attività:
Pertinenza superiore:combinando la ricerca contestuale (vettoriale) con un filtro sfaccettato preciso e un ranking intelligente, i clienti ricevono risultati altamente pertinenti, con conseguente aumento della soddisfazione e delle conversioni.
Scalabilità: l'architettura e l'indicizzazione ScaNN di AlloyDB sono progettate per gestire cataloghi di prodotti di grandi dimensioni e volumi di query elevati, elementi fondamentali per la crescita delle attività di e-commerce.
Rendimento:risposte alle query più rapide, anche per le ricerche ibride complesse, garantiscono un'esperienza utente fluida e riducono al minimo i tassi di abbandono.
Preparazione per il futuro:l'integrazione delle funzionalità di AI (incorporamenti, convalida LLM) posiziona l'applicazione per i futuri progressi in termini di suggerimenti personalizzati, commercio conversazionale e scoperta intelligente dei prodotti.
Architettura semplificata:l'integrazione della ricerca vettoriale direttamente in AlloyDB elimina la necessità di database vettoriali separati o di una sincronizzazione complessa, semplificando lo sviluppo e la manutenzione.
Supponiamo che un utente abbia digitato una query in linguaggio naturale come "scarpe da corsa ecologiche per donna con supporto per arco plantare alto".
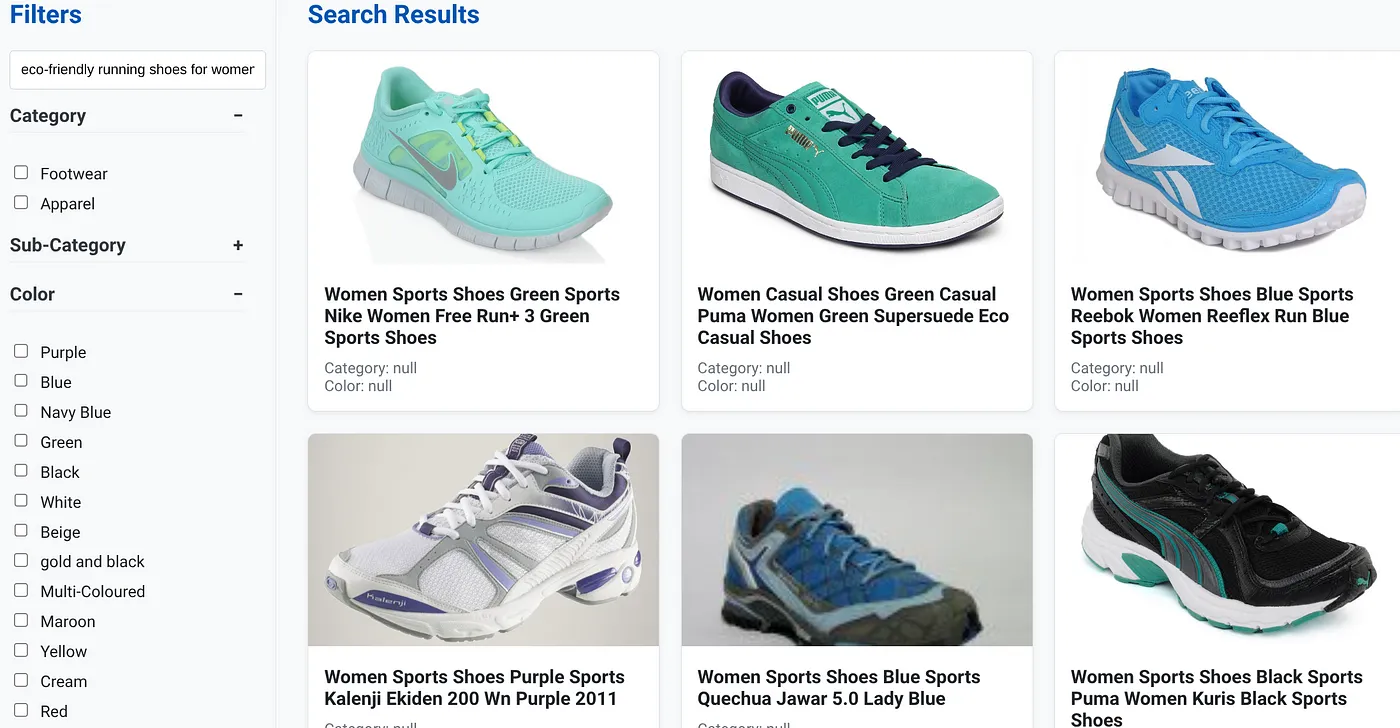
mentre l'utente applica contemporaneamente i filtri sfaccettati per "Categoria: <<>>", "Colore: <<>>" e dice "Prezzo: 100-150 $":
- Il sistema restituisce immediatamente un elenco raffinato di prodotti, allineati semanticamente al linguaggio naturale e corrispondenti con precisione ai filtri scelti.
- Dietro le quinte, l'indice scaNN accelera la ricerca vettoriale, il filtraggio in linea e adattivo garantisce il rendimento con criteri combinati e il ranking presenta i risultati ottimali in primo piano.
- La velocità e l'accuratezza dei risultati illustrano chiaramente la potenza della combinazione di queste tecnologie per un'esperienza di ricerca per la vendita al dettaglio davvero intelligente.
La creazione di un'applicazione di ricerca per la vendita al dettaglio di nuova generazione richiede di andare oltre i metodi convenzionali. Utilizzando la potenza di AlloyDB, Vertex AI, Vector Search con l'indicizzazione scaNN, il filtro sfaccettato dinamico, il riposizionamento e la convalida LLM, possiamo offrire un'esperienza cliente senza precedenti che aumenta il coinvolgimento e le vendite. Questa soluzione solida, scalabile e intelligente dimostra come le moderne funzionalità di database, integrate con l'AI, stiano rimodellando il futuro del retail.