
1. 概要
競争の激しい今日の小売業界では、顧客が探しているものを迅速かつ直感的に見つけられるようにすることが最も重要です。従来のキーワード ベースの検索では、ニュアンスのあるクエリや膨大な商品カタログに対応できず、十分な結果が得られないことがよくあります。この Codelab では、AlloyDB と AlloyDB AI を基盤として構築された高度な小売検索アプリケーションを紹介します。このアプリケーションは、最先端のベクトル検索、scaNN インデックス、ファセット フィルタ、インテリジェントな適応型フィルタリング、再ランキングを活用して、エンタープライズ規模で動的なハイブリッド検索エクスペリエンスを実現します。
これで、次の 3 つの基本的な知識が身につきました。
- コンテキスト検索がエージェントに与える影響と、ベクトル検索を使用してコンテキスト検索を実現する方法。
- また、データ範囲内、つまりデータベース自体内でベクトル検索を実現する方法についても詳しく説明しました(ご存じないかもしれませんが、すべての Google Cloud データベースがこの機能をサポートしています)。
- Google は、ScaNN インデックスを搭載した AlloyDB ベクトル検索機能を使用して、高パフォーマンスと高品質の軽量ベクトル検索 RAG 機能を実現する方法を、世界に先駆けてご紹介しました。
RAG の基本的なテスト、中級のテスト、やや高度なテストをまだ実施していない場合は、こちら、こちら、こちらの順に 3 つのテストをお読みになることをおすすめします。
課題
フィルタ、キーワード、コンテキスト マッチングの枠を超える: 単純なキーワード検索では、数千件の結果が返されることがありますが、その多くは無関係です。理想的なソリューションでは、クエリの背後にある意図を理解し、それを正確なフィルタ条件(ブランド、素材、価格など)と組み合わせて、最も関連性の高いアイテムをミリ秒単位で提示する必要があります。そのためには、強力で柔軟かつスケーラブルな検索インフラストラクチャが必要です。キーワード検索からコンテキスト マッチや類似性検索へと、検索は大きく進化しました。お客様が「春のハイキングに最適な快適でスタイリッシュな防水ジャケット」を検索し、同時にフィルタを適用しているとします。アプリケーションは質の高い回答を返すだけでなく、パフォーマンスも高く、この一連の処理の順序はデータベースによって動的に選択されます。
目標
この問題を解決するには、
- コンテキスト検索(ベクトル検索): クエリと商品説明の意味を理解する
- ファセット フィルタリング: ユーザーが特定の属性で結果を絞り込めるようにする
- ハイブリッド アプローチ: コンテキスト検索と構造化フィルタリングをシームレスに統合
- 高度な最適化: 速度と関連性を高めるために、特殊なインデックス登録、適応型フィルタリング、再ランキングを活用する
- 生成 AI を活用した品質検証(QC): LLM 検証を組み込んで、結果の品質を向上させます。
アーキテクチャと実装の過程を詳しく見ていきましょう。
作成するアプリの概要
Retail Search アプリケーション
この一環として、次のことを行います。
- e コマース データセットの AlloyDB インスタンスとテーブルを作成する
- エンベディングとベクトル検索を設定する
- メタデータ インデックスと ScaNN インデックスを作成する
- ScaNN のインライン フィルタリング メソッドを使用して AlloyDB で高度なベクトル検索を実装する
- 単一のクエリでファセット フィルタとハイブリッド検索を設定する
- 再ランキングと再現率を使用してクエリの関連性を高める(省略可)
- Gemini でクエリ レスポンスを評価する(省略可)
- データベース向け MCP ツールボックスとアプリケーション レイヤ
- ファセット検索を使用したアプリケーション開発(Java)
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/hybrid-search-on-cloudrun/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: リンクにアクセスして、API を有効にします。
または、この操作に gcloud コマンドを使用することもできます。gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベースの設定
このラボでは、e コマースデータのデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
e コマース データセットが読み込まれる AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
クラスタとインスタンスを作成する
- Cloud コンソールで AlloyDB ページに移動します。Cloud コンソールでほとんどのページを簡単に見つけるには、コンソールの検索バーを使用して検索します。
- このページで [クラスタを作成] を選択します。

- 次のような画面が表示されます。次の値を使用して クラスタとインスタンスを作成します(リポジトリからアプリケーション コードを複製する場合は、値が一致していることを確認してください)。
- クラスタ ID: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / 最新の推奨バージョン
- Region: "
us-central1" - Networking: "
default"
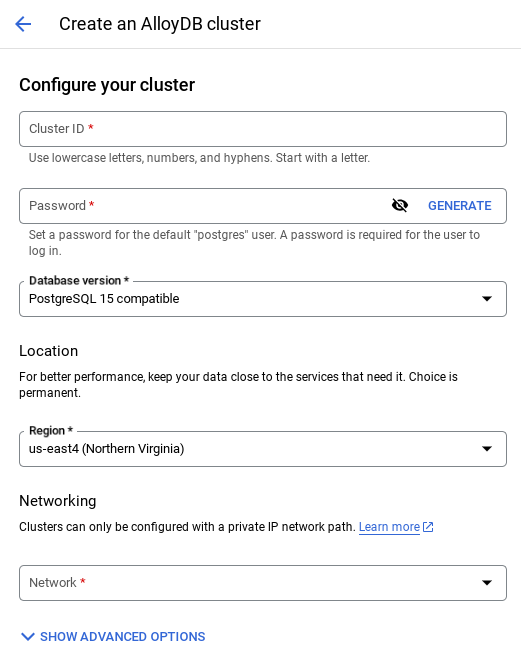
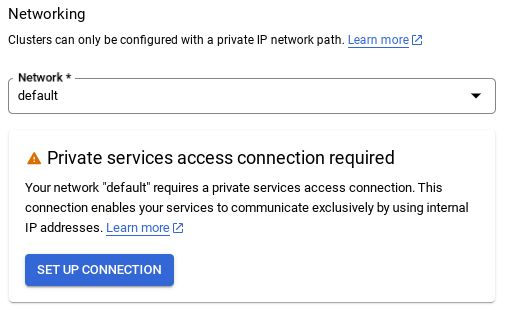
- デフォルトのネットワークを選択すると、次のような画面が表示されます。
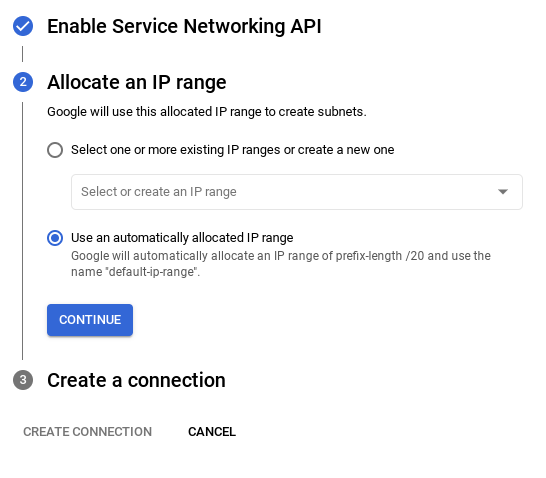
[接続の設定] を選択します。
- [自動的に割り当てられた IP 範囲を使用する] を選択して、[続行] をクリックします。情報を確認したら、[接続を作成] を選択します。
- ネットワークを設定したら、クラスタの作成を続行できます。[CREATE CLUSTER] をクリックして、次のようにクラスタの設定を完了します。
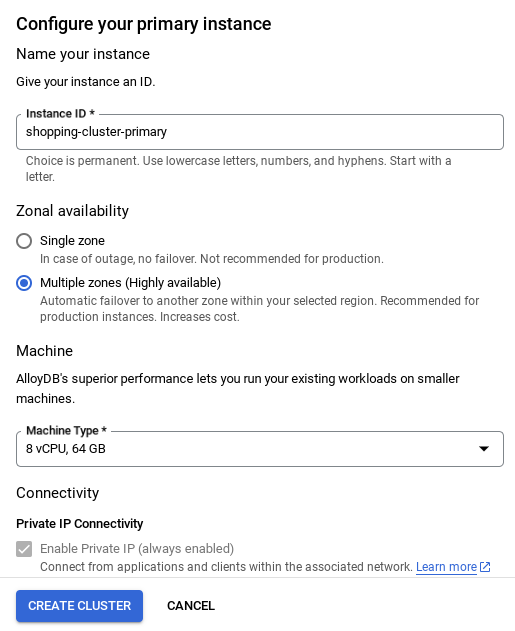
重要な注意事項:
- インスタンス ID を必ず変更してください(クラスタ / インスタンスの構成時に確認できます)。**
vector-instance** に変更できない場合は、以降のすべての参照でインスタンス ID を使用してください。 - クラスタの作成には 10 分ほどかかります。成功すると、作成したクラスタの概要を示す画面が表示されます。
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタと AlloyDB Studio を選択します。
インスタンスの作成が完了するまで待つ必要がある場合があります。準備ができたら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。
必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
データベースで有効になっている拡張機能を確認するには、次の SQL コマンドを実行します。
select extname, extversion from pg_extension;
テーブルを作成する
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
エンベディング列を使用すると、テキストのベクトル値を保存できます。
権限を付与
次のステートメントを実行して、「embedding」関数に対する実行権限を付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Google Cloud IAM コンソールで、AlloyDB サービス アカウント(service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com のような形式)に「Vertex AI ユーザー」ロールへのアクセス権を付与します。PROJECT_NUMBER にはプロジェクト番号が設定されます。
または、Cloud Shell ターミナルから次のコマンドを実行することもできます。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
データベースにデータを読み込む
- シートの
insert scripts sqlから上記のinsertクエリ ステートメントをエディタにコピーします。このユースケースのクイックデモ用に、10 ~ 50 個の挿入ステートメントをコピーできます。この「Selected Inserts 25-30 rows」タブに、選択した挿入のリストが表示されます。
データへのリンクは、こちらの GitHub リポジトリ ファイルで確認できます。
- [実行] をクリックします。クエリの結果が [結果] テーブルに表示されます。
重要な注意事項:
挿入するレコードは 25 ~ 50 件のみをコピーし、カテゴリ、サブカテゴリ、色、性別の範囲からコピーするようにしてください。
5. データのエンベディングを作成する
現代の検索の真の革新は、キーワードだけでなく意味を理解することにあります。ここでエンベディングとベクトル検索が役立ちます。
事前トレーニング済みの言語モデルを使用して、商品紹介文とユーザーのクエリを高次元の数値表現(エンベディング)に変換しました。これらのエンベディングはセマンティックな意味を捉えるため、一致する単語を含むだけでなく、「意味が類似している」商品を見つけることができます。まず、これらのエンベディングで直接ベクトル類似性検索を試してベースラインを確立し、パフォーマンスの最適化を行う前からセマンティック理解の威力を実証しました。
エンベディング列を使用すると、商品説明テキストのベクトル値を保存できます。img_embeddings 列を使用すると、画像エンベディング(マルチモーダル)を保存できます。これにより、テキストと画像の距離に基づく検索も使用できます。ただし、このラボではテキスト エンベディングのみを使用します。
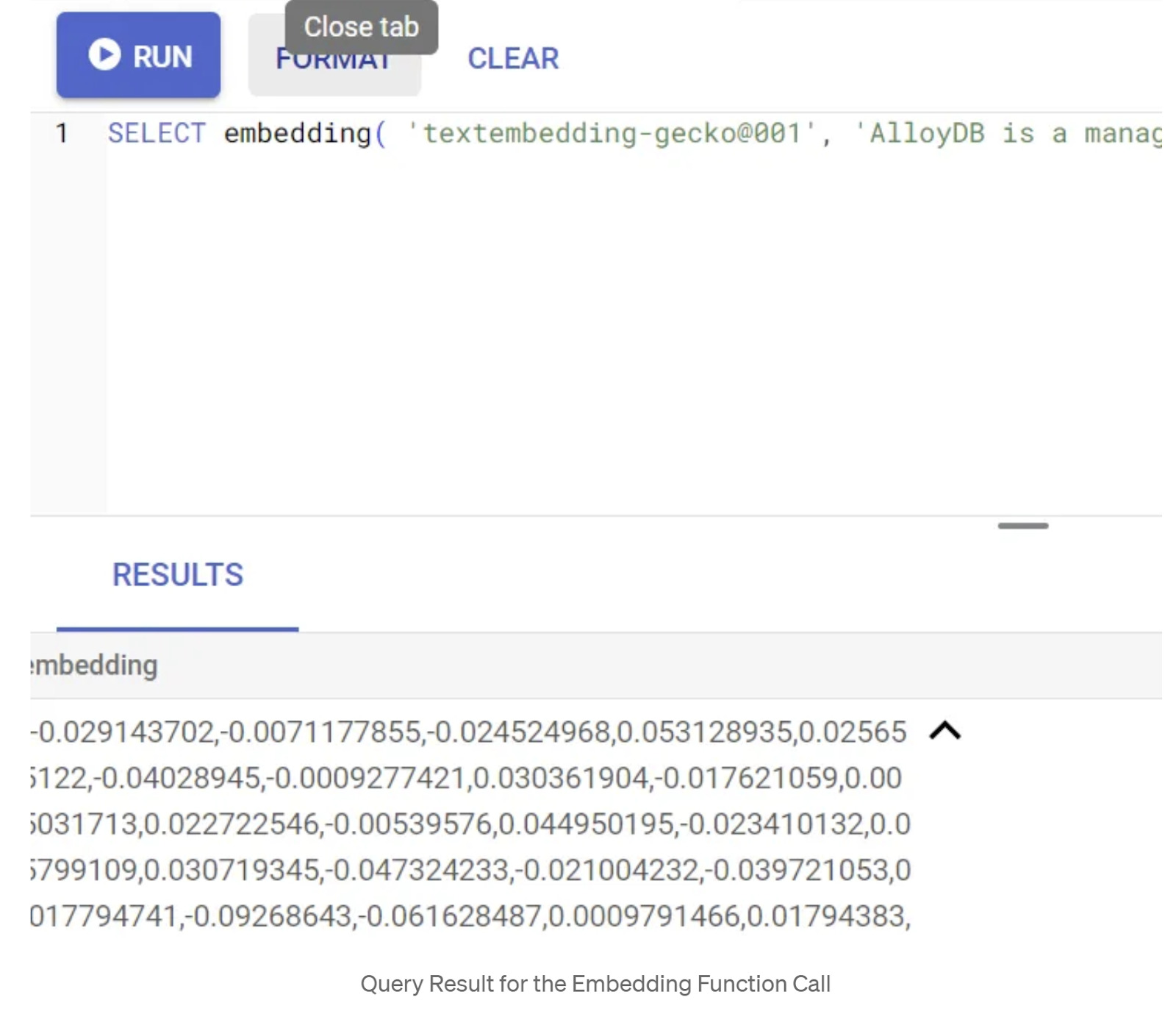
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
これにより、クエリ内のサンプル テキストのエンベディング ベクトル(浮動小数点数の配列のようなもの)が返されます。次のように表示されます。
abstract_embeddings ベクトル フィールドを更新する
次の DML を実行して、テーブル内のコンテンツの説明を対応するエンベディングで更新します。
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud のトライアル クレジットの請求先アカウントを使用している場合、少数のエンベディング(最大 20 ~ 25 個程度)を超えるエンベディングを生成できないことがあります。そのため、挿入スクリプトの行数を制限します。
画像エンベディング(マルチモーダル コンテキスト検索を実行するため)を生成する場合は、次の更新も実行します。
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. AlloyDB の新機能を使用して高度な RAG を実行する
テーブル、データ、エンベディングの準備が整ったので、ユーザーの検索テキストに対してリアルタイムのベクトル検索を実行しましょう。これをテストするには、次のクエリを実行します。
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
このクエリでは、ユーザーが入力した検索語句「丸首の T シャツ」のテキスト エンベディングと、アパレル テーブル内のすべての商品説明のテキスト エンベディング(「embedding」という名前の列に保存)をコサイン類似度距離関数(「<=>」という記号で表される)を使用して比較しています。エンベディング メソッドの結果をベクトル型に変換して、データベースに保存されているベクトルと互換性を持たせています。LIMIT 10 は、検索テキストの最も近い 10 個の一致を選択することを表します。
AlloyDB は、ベクトル検索 RAG を次のレベルに引き上げます。
エンタープライズ規模のソリューションでは、生のベクトル検索だけでは不十分です。パフォーマンスが重要です。
ScaNN(スケーラブルな最近傍探索)インデックス
超高速の近似最近傍(ANN)検索を実現するために、AlloyDB で scaNN インデックスを有効にしました。Google Research が開発した最先端の近似最近傍検索アルゴリズムである ScaNN は、大規模な効率的なベクトル類似検索用に設計されています。検索空間を効率的に枝刈りし、量子化手法を使用することで、クエリを大幅に高速化します。他のインデックス作成方法と比較して、ベクトルクエリの速度が最大 4 倍になり、メモリ使用量が削減されます。詳しくは、こちらとこちらをご覧ください。
拡張機能を有効にして、インデックスを作成しましょう。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
テキスト エンベディング フィールドと画像エンベディング フィールドの両方のインデックスを作成する(検索で画像エンベディングを使用する場合):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
メタデータ インデックス
scaNN はベクトル インデックスを処理しますが、従来の B-tree インデックスまたは GIN インデックスは、構造化された属性(カテゴリ、サブカテゴリ、スタイル、色など)に慎重に設定されていました。これらのインデックスは、ファセット フィルタリングの効率を高めるうえで非常に重要です。次のステートメントを実行して、メタデータ インデックスを設定します。
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
重要な注意事項:
25 ~ 50 件のレコードのみを挿入した可能性があるため、インデックス(ScaNN やその他のインデックス)は有効になりません。
インライン フィルタリング
ベクトル検索の一般的な課題は、構造化フィルタ(「赤い靴」など)と組み合わせることです。AlloyDB のインライン フィルタリングは、これを最適化します。インライン フィルタリングでは、広範なベクトル検索の結果を事後フィルタリングするのではなく、ベクトル検索プロセス自体でフィルタ条件を適用するため、フィルタ付きベクトル検索のパフォーマンスと精度が大幅に向上します。
インライン フィルタリングの必要性について詳しくは、こちらのドキュメントをご覧ください。ベクトル検索のパフォーマンス最適化のためのフィルタ付きベクトル検索については、こちらをご覧ください。アプリケーションでインライン フィルタリングを有効にするには、エディタから次のステートメントを実行します。
SET scann.enable_inline_filtering = on;
インライン フィルタリングは、選択性が中程度の場合に最適です。AlloyDB はベクトル インデックスを検索する際に、メタデータのフィルタ条件(通常は WHERE 句で処理されるクエリの関数フィルタ)に一致するベクトルの距離のみを計算します。これにより、ポストフィルタまたはプレフィルタの利点を補完し、クエリのパフォーマンスを大幅に向上させます。
適応型フィルタリング
パフォーマンスをさらに最適化するために、AlloyDB の適応型フィルタリングは、クエリ実行中に最も効率的なフィルタリング戦略(インライン フィルタリングまたは事前フィルタリング)を動的に選択します。クエリパターンとデータ分布を分析して、手動操作なしで最適なパフォーマンスを確保します。これは、特にフィルタ付きベクトル検索に役立ちます。フィルタ付きベクトル検索では、ベクトル インデックスとメタデータ インデックスの使用が自動的に切り替わります。適応型フィルタリングを有効にするには、scann.enable_preview_features フラグを使用します。
適応型フィルタリングにより、実行中にインライン フィルタリングから事前フィルタリングへの切り替えがトリガーされると、クエリプランが動的に変更されます。
SET scann.enable_preview_features = on;
重要な注意事項: エラーが発生した場合は、インスタンスを再起動せずに上記のステートメントを実行できないことがあります。インスタンスのデータベース フラグ セクションで enable_preview_features フラグを有効にすることをおすすめします。
すべてのインデックスを使用するファセット フィルタ
ファセット検索では、特定の属性または「ファセット」(ブランド、価格、サイズ、顧客評価など)に基づいて複数のフィルタを適用することで、検索結果を絞り込むことができます。アプリケーションは、これらのファセットをベクトル検索とシームレスに統合します。1 つのクエリで自然言語(コンテキスト検索)と複数のファセット選択を組み合わせ、ベクトル インデックスと従来のインデックスの両方を動的に活用できるようになりました。これにより、真に動的なハイブリッド検索機能が提供され、ユーザーは検索結果を正確に絞り込むことができます。
このアプリケーションでは、すべてのメタデータ インデックスがすでに作成されているため、SQL クエリを使用して直接アドレス指定することで、ウェブでのファセット フィルタの使用の準備が整っています。
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
このクエリでは、ハイブリッド検索を実行しています。つまり、
- WHERE 句と
- コサイン類似度メソッドを使用する ORDER BY 句のベクトル検索。
$1、$2、$3、$4 は配列内のファセット フィルタ値を表し、$5 はユーザーの検索テキストを表します。$1 から $4 を、次のように任意のファセット フィルタ値に置き換えます。
category = ANY([‘Apparel', ‘Footwear'])
$5 は、任意の検索テキスト(「ポロシャツ」など)に置き換えます。
重要な注意事項: 挿入したレコードのセットが限られているためにインデックスがない場合、パフォーマンスへの影響は確認できません。ただし、完全な本番環境データセットでは、インライン フィルタリングが組み込まれた ScaNN インデックスを使用する同じベクトル検索で実行時間が大幅に短縮されることがわかります。
次に、この ScaNN 対応のベクトル検索の再現率を評価します。
再ランキング
検索オプションを使用しても、最初の結果には最終的な調整が必要になることがあります。これは、関連性を高めるために最初の検索結果を並べ替える重要なステップです。最初のハイブリッド検索で候補商品のセットが提供された後、より高度な(多くの場合、計算負荷の高い)モデルがより細かい粒度の関連性スコアを適用します。これにより、ユーザーに表示される上位の結果が最も関連性の高いものとなり、検索の品質が大幅に向上します。Google は、特定のクエリに関連するすべてのアイテムをシステムがどれだけ効果的に取得したかを測定するために、再現率を継続的に評価しています。また、お客様が必要なものを見つけられる可能性を最大限に高めるために、モデルを改良しています。
アプリケーションでこれを使用する前に、すべての前提条件が満たされていることを確認してください。
- google_ml_integration 拡張機能がインストールされていることを確認します。
- google_ml_integration.enable_model_support フラグがオンに設定されていることを確認します。
- Vertex AI と統合します。
- Discovery Engine API を有効にします。
- ランキング モデルを使用するために必要なロールを取得します。
アプリケーションで次のクエリを使用して、ハイブリッド検索の結果セットを再ランキングできます。
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
このクエリでは、コサイン類似度法を使用して、ORDER BY 句で指定されたコンテキスト検索の商品結果セットの再ランキングを行っています。「ピンクのトップス」はユーザーが検索しているテキストです。
重要な注意事項: 一部のユーザーはまだ Reranking にアクセスできない可能性があるため、アプリケーション コードから除外しましたが、含めたい場合は、上記のサンプルに沿って対応してください。
再現率エバリュエータ
類似検索における再現率とは、検索から取得された該当インスタンスの割合、つまり真陽性の数です。これは、検索品質の測定に使用される最も一般的な指標です。再現率低下の一因は、近似最近傍検索(aNN)と K 最近傍検索(kNN)の違いにあります。AlloyDB の ScaNN のようなベクトル インデックスは aNN アルゴリズムを実装しており、再現率のわずかなトレードオフと引き換えに、大規模データセットでのベクトル検索を高速化できます。AlloyDB では、個々のクエリのトレードオフをデータベース内で直接測定し、経時的な安定性を確認できるようになりました。この情報に応じてクエリやインデックスのパラメータを更新すれば、より良い検索結果とパフォーマンスを実現できます。
検索結果の再現率の背後にあるロジックは何ですか?
ベクトル検索のコンテキストにおける再現率とは、インデックスから返されたベクトルのうち、真の最近傍であるものの割合を指します。たとえば、20 個の最近傍に対する最近傍のクエリで、グラウンド トゥルースの最近傍が 19 個返された場合、再現率は 19÷20×100 = 95% となります。再現率は検索品質に使用される指標で、クエリベクトルに客観的に最も近い結果が返された割合として定義されます。
特定の構成のベクトル インデックスに対するベクトルクエリの再現率は、evaluate_query_recall 関数で確認できます。この関数を使用すると、目的のベクトルクエリの再現率を達成するようにパラメータをチューニングできます。
重要な注意事項:
次の手順で HNSW インデックスに対する権限拒否エラーが発生した場合は、この再現率評価セクション全体をスキップしてください。この Codelab のドキュメント作成時点ではリリースされたばかりであるため、この時点でアクセス制限が適用されている可能性があります。
- ScaNN インデックスと HNSW インデックスで Enable Index Scan フラグを設定します。
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio で次のクエリを実行します。
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 関数はクエリをパラメータとして受け取り、再現率を返します。パフォーマンスの確認に使用したクエリと同じクエリを、関数入力クエリとして使用しています。インデックス メソッドとして SCaNN を追加しました。その他のパラメータ オプションについては、ドキュメントをご覧ください。
これまで使用してきたこのベクトル検索クエリの再現率は次のとおりです。
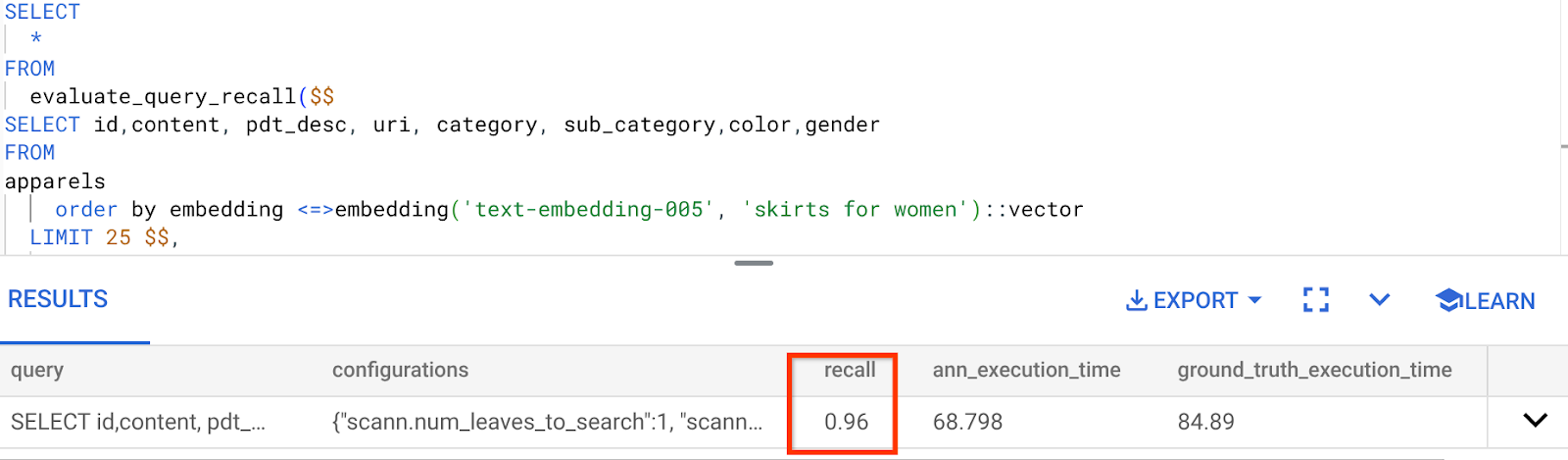
再現率が 96% であることがわかります。この場合、再現率は非常に高くなります。ただし、許容できない値だった場合は、この情報を使用して、インデックス パラメータ、メソッド、クエリ パラメータを変更し、このベクトル検索の再現率を向上させることができます。
変更したクエリとインデックスのパラメータでテストする
それでは、リコールに基づいてクエリ パラメータを変更して、クエリをテストしてみましょう。
- インデックス パラメータの変更:
このテストでは、「コサイン」類似度距離関数の代わりに 「L2 距離」を使用します。
非常に重要な注意: 「このクエリでコサイン類似度を使用していることはどうすればわかるのですか?」という質問が寄せられる可能性があります。コサイン距離を表す "<=>" を使用して、距離関数を識別できます。
前のクエリではコサイン類似度距離関数を使用しましたが、ここでは L2 距離を試します。ただし、その場合は、基盤となる ScaNN インデックスも L2 距離関数を使用していることを確認する必要があります。次に、異なる距離関数クエリを使用してインデックスを作成します。L2 距離: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
インデックスの削除ステートメントは、テーブルに不要なインデックスがないことを確認するためのものです。
次のクエリを実行して、ベクトル検索機能の距離関数を変更した後の再現率を評価できます。
[変更後] L2 距離関数を使用するクエリ:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
更新されたインデックスの再現率の値で、差分 / 変換を確認できます。
インデックスでは、num_leaves など、他のパラメータも変更できます。これらのパラメータは、必要な再現率の値とアプリケーションで使用するデータセットに基づいて変更します。
ベクトル検索結果の LLM 検証
制御された検索の品質を最大限に高めるため、LLM 検証のオプション レイヤを組み込みました。大規模言語モデルは、検索結果の関連性と一貫性を評価するために使用できます。特に、複雑なクエリや曖昧なクエリで有効です。これには以下が含まれます。
セマンティック検証:
クエリの意図と照らし合わせて結果を相互参照する LLM。
論理フィルタリング:
LLM を使用して、従来のフィルタではエンコードが難しい複雑なビジネス ロジックやルールを適用し、ニュアンスのある条件に基づいて商品リストをさらに絞り込みます。
品質保証:
関連性の低い結果を自動的に特定してフラグを設定し、人間によるレビューやモデルの改善に役立てる。
AlloyDB AI 機能でこれを実現する方法は次のとおりです。
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
基盤となるクエリは、ファセット検索、ハイブリッド検索、再ランキングのセクションで説明したクエリと同じです。このクエリでは、ml_predict_row 構造で表される再ランキングされた結果セットの GEMINI 評価レイヤが組み込まれています。ファセット フィルタはコメントアウトしましたが、プレースホルダ $1 ~ $4 の配列に任意の項目を含めることができます。$5 は、検索するテキスト(「ピンクのトップス、花柄なし」など)に置き換えます。
7. データベース向け MCP ツールボックスとアプリケーション レイヤ
バックエンドでは、堅牢なツールと適切に構造化されたアプリケーションにより、スムーズな運用が実現されています。
データベース向け MCP(Model Context Protocol)ツールボックスを使用すると、生成 AI ツールとエージェント ツールを AlloyDB と簡単に統合できます。これは、接続プーリング、認証、データベース機能の AI エージェントや他のアプリケーションへの安全な公開を効率化するオープンソース サーバーとして機能します。
アプリケーションでは、すべてのインテリジェント ハイブリッド検索クエリの抽象化レイヤとして MCP Toolbox for Databases を使用しています。
以下の手順に沿って、ユースケースに合わせて Toolbox を設定してデプロイします。
データベース向け MCP ツールボックスでサポートされているデータベースの 1 つが AlloyDB であることがわかります。前のセクションで AlloyDB をすでにプロビジョニングしているので、ツールボックスの設定に進みましょう。
- Cloud Shell ターミナルに移動し、プロジェクトが選択され、ターミナルのプロンプトに表示されていることを確認します。Cloud Shell ターミナルから次のコマンドを実行して、プロジェクト ディレクトリに移動します。
mkdir toolbox-tools
cd toolbox-tools
- 次のコマンドを実行して、新しいフォルダにツールボックスをダウンロードしてインストールします。
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Cloud Shell エディタ(コード編集モード)に移動し、プロジェクトのルートフォルダに「tools.yaml」というファイルを追加します。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Tools.yaml スクリプトをこのリポジトリ ファイルのコードに置き換えてください。
tools.yaml について説明します。
ソースは、ツールが操作できるさまざまなデータソースを表します。ソースは、ツールが操作できるデータソースを表します。ツールファイルの sources セクションで、ソースをマップとして定義できます。通常、移行元構成には、データベースに接続して操作するために必要な情報が含まれます。
ツールは、エージェントが実行できるアクション(ソースの読み取りや書き込みなど)を定義します。ツールは、エージェントが実行できるアクション(SQL ステートメントの実行など)を表します。tools.yaml ファイルの tools セクションで、ツールをマップとして定義できます。通常、ツールは処理対象のソースを必要とします。
tools.yaml の構成の詳細については、こちらのドキュメントをご覧ください。
- 次のコマンド(mcp-toolbox フォルダから)を実行して、サーバーを起動します。
./toolbox --tools-file "tools.yaml"
クラウドでウェブ プレビュー モードでサーバーを開くと、get-order-data という名前の新しいツールを使用して Toolbox サーバーが起動し、実行されていることを確認できます。
MCP Toolbox サーバーはデフォルトでポート 5000 で実行されます。Cloud Shell を使用してテストしてみましょう。
Cloud Shell で [ウェブでプレビュー] をクリックします。
[ポートの変更] をクリックし、下図のようにポートを 5000 に設定して、[変更してプレビュー] をクリックします。
次のような出力が表示されます。
- ツールボックスを Cloud Run にデプロイしましょう。
まず、MCP ツールボックス サーバーから始めて、Cloud Run でホストできます。これにより、他のアプリケーションやエージェント アプリケーションと統合できるパブリック エンドポイントが提供されます。Cloud Run でホストする手順については、こちらをご覧ください。それでは、主な手順を見ていきましょう。
- 新しい Cloud Shell ターミナルを起動するか、既存の Cloud Shell ターミナルを使用します。ツールボックス バイナリと tools.yaml が存在するプロジェクト フォルダ(この場合は toolbox-tools)に移動します。
cd toolbox-tools
- PROJECT_ID 変数を Google Cloud プロジェクト ID を指すように設定します。
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- これらの Google Cloud サービスを有効にする
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Google Cloud Run にデプロイする Toolbox サービスの ID として機能する別のサービス アカウントを作成しましょう。
gcloud iam service-accounts create toolbox-identity
- また、このサービス アカウントに適切なロール(Secret Manager にアクセスして AlloyDB と通信する権限など)があることも確認しています。
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- tools.yaml ファイルをシークレットとしてアップロードします。
gcloud secrets create tools --data-file=tools.yaml
Secret がすでに存在し、Secret バージョンを更新する場合は、次のコマンドを実行します。
gcloud secrets versions add tools --data-file=tools.yaml
- Cloud Run で使用するコンテナ イメージの環境変数を設定します。
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Cloud Run へのデプロイ コマンドの最後のステップ:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
これにより、構成済みの tools.yaml を使用して Toolbox サーバーを Cloud Run にデプロイするプロセスが開始されます。デプロイが成功すると、次のようなメッセージが表示されます。
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
これで、エージェント アプリケーションで新しくデプロイしたツールを使用する準備が整いました。
ツールボックス サーバーのツールへのアクセス
ツールボックスがデプロイされたら、デプロイされたツールボックス サーバーとやり取りするための Python Cloud Run Functions シムを作成します。これは、現在 Toolbox に Java SDK がないため、サーバーとやり取りするための Python シムを作成したためです。この Cloud Run 関数のソースコードは次のとおりです。
前の手順で作成してデプロイしたツールボックス ツールにアクセスできるようにするには、この Cloud Run 関数を作成してデプロイする必要があります。
- Google Cloud コンソールで、Cloud Run ページに移動します。
- [関数を作成] をクリックします。
- [サービス名] フィールドに、関数を表す名前を入力します。サービス名は、先頭を英字にして、49 文字以下の英字、数字、ハイフンで構成します。サービス名はハイフンで終わることはできません。また、リージョンとプロジェクトごとに一意にする必要があります。サービス名は後から変更することはできません。この名前は一般公開されます。(retail-product-search-quality と入力)
- [リージョン] リストで、デフォルト値を使用するか、関数をデプロイするリージョンを選択します。(us-central1 を選択)
- [ランタイム] リストで、デフォルト値を使用するか、ランタイム バージョンを選択します。(Python 3.11 を選択)
- [認証] セクションで、[一般公開アクセスを許可] を選択します。
- [作成] ボタンをクリックします。
- 関数が作成され、テンプレートの main.py と requirements.txt が読み込まれます。
- このプロジェクトのリポジトリにある main.py ファイルと requirements.txt ファイルに置き換えます。
- 関数をデプロイすると、Cloud Run functions のエンドポイントが取得されます。
エンドポイントは次のようになります。
ツールボックスにアクセスするための Cloud Run 関数のエンドポイント: 「https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app」
タイムライン内で簡単に完了できるように(ハンズオンのインストラクター主導のセッションの場合)、エンドポイントのプロジェクト番号はハンズオン セッションのときに共有されます。
重要な注意事項:
または、データベース部分をアプリケーション コードまたは Cloud Run 関数の一部として直接実装することもできます。
8. ファセット検索を使用したアプリケーション開発(Java)
最後に、これらの強力なバックエンド コンポーネントはすべて、アプリケーション レイヤを通じて実現されます。Java で開発されたこのアプリケーションは、検索システムとやり取りするためのユーザー インターフェースを提供します。AlloyDB へのクエリをオーケストレートし、ファセット フィルタの表示を処理し、ユーザーの選択を管理し、再ランキングされた検証済みの検索結果をシームレスかつ直感的な方法で提示します。
- まず、Cloud Shell ターミナルに移動して、リポジトリのクローンを作成します。
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Cloud Shell エディタに移動します。ここで、新しく作成されたフォルダ faceted_searching_retail を確認できます。
- 次の手順は前のセクションで完了しているため、削除します。
- フォルダ Cloud_Run_Function を削除する
- ファイル db_script.sql を削除する
- tools.yaml ファイルを削除する
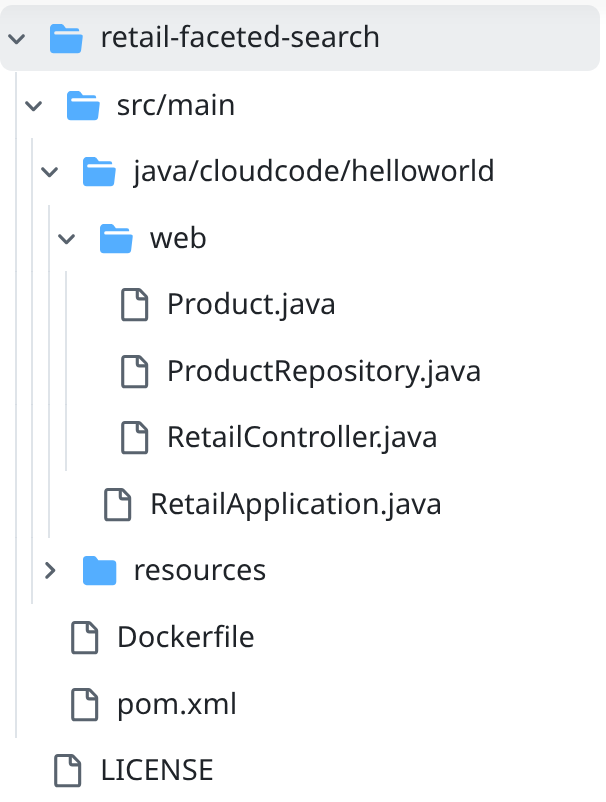
- プロジェクト フォルダ retail-faceted-search に移動すると、次のようなプロジェクト構造が表示されます。
- ProductRepository.java ファイルで、TOOLBOX_ENDPOINT 変数を Cloud Run 関数(デプロイ済み)のエンドポイントで変更するか、ハンズオンの講師からエンドポイントを取得する必要があります。
次のコード行を検索し、エンドポイントに置き換えます。
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Dockerfile と pom.xml がプロジェクト構成に沿っていることを確認します(バージョンや構成を明示的に変更していない限り、変更は不要です)。
- Cloud Shell ターミナルで、メイン フォルダとプロジェクト フォルダ(faceted_searching_retail / retail-faceted-search)内にいることを確認します。ターミナルで正しいフォルダに移動していない場合は、次のコマンドを使用します。
cd faceted_searching_retail
cd retail-faceted-search
- アプリケーションをパッケージ化、ビルド、テストします。
mvn package
mvn spring-boot:run
Cloud Shell ターミナルで [ポート 8080 でプレビュー] をクリックすると、次のようにアプリケーションを表示できます。
9. Cloud Run にデプロイする: ***重要なステップ
Cloud Shell ターミナルで、メインフォルダとプロジェクト フォルダ(faceted_searching_retail / retail-faceted-search)内にいることを確認します。ターミナルで正しいフォルダに移動していない場合は、次のコマンドを使用します。
cd faceted_searching_retail
cd retail-faceted-search
プロジェクト フォルダに移動したら、次のコマンドを実行します。
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
デプロイが完了すると、次のような Cloud Run エンドポイントがデプロイされます。
https://retail-search-**********-uc.a.run.app/
10. デモ
実際に動作する様子を見てみましょう。
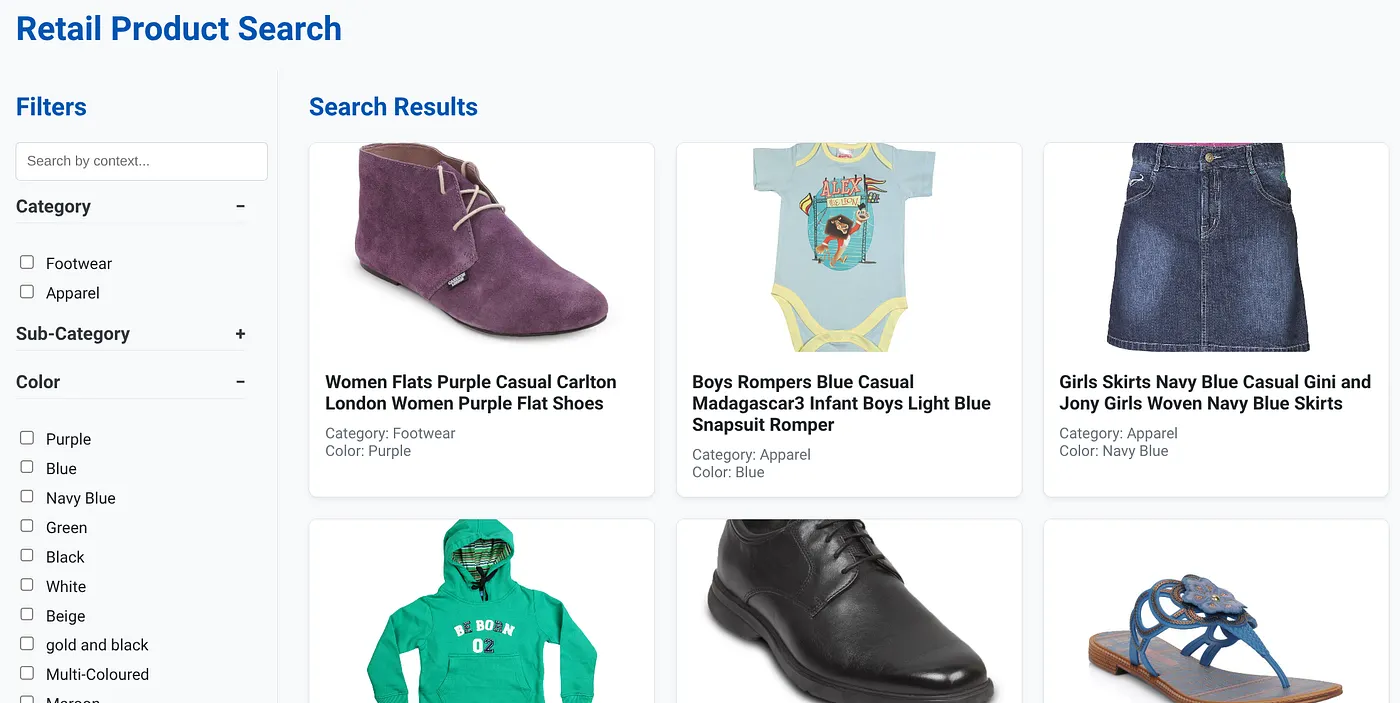
上の画像は、動的ハイブリッド検索アプリのランディング ページを示しています。
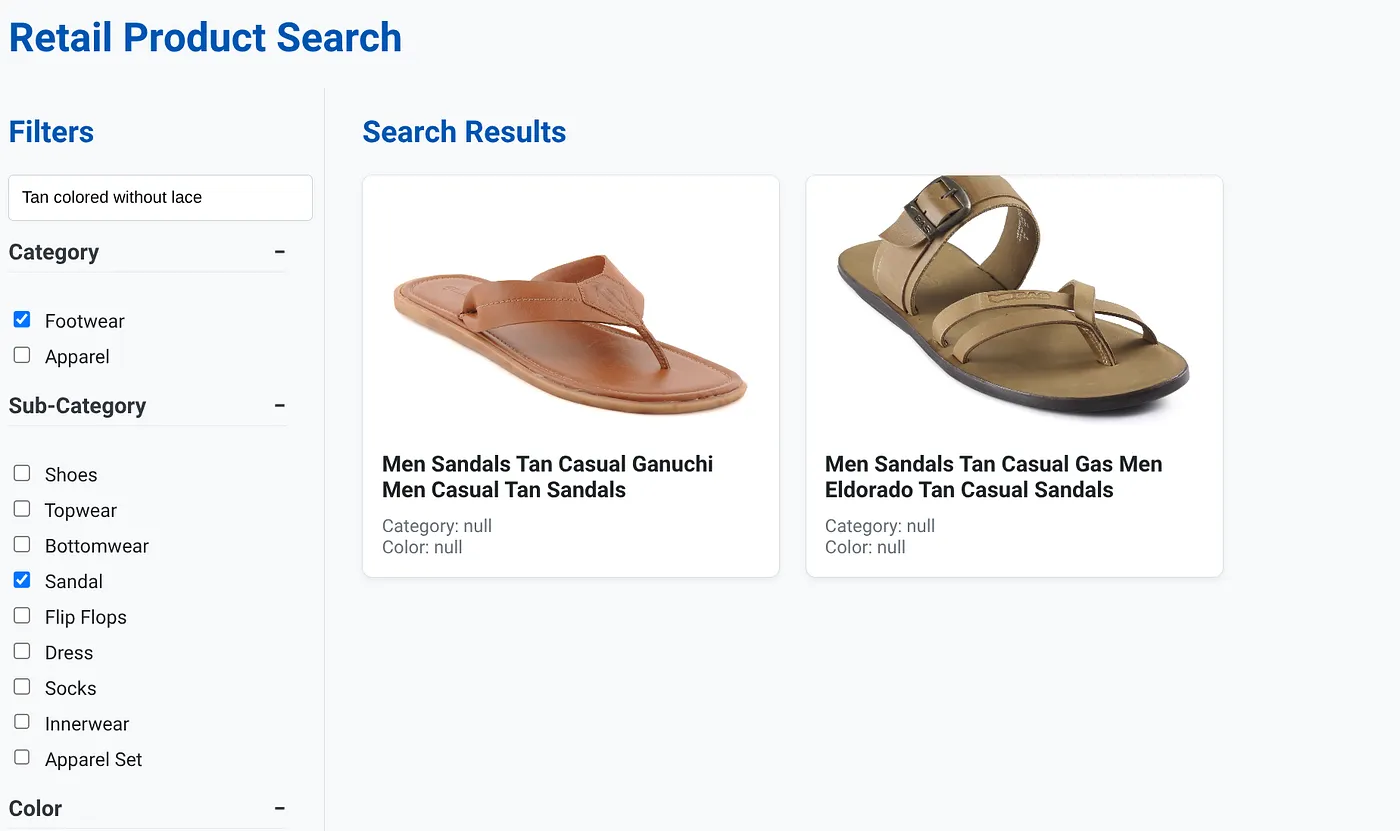
上の画像は、「Tan colored without lace」の検索結果です。選択したファセット フィルタは、[Footwear](フットウェア)、[Sandal](サンダル)です。
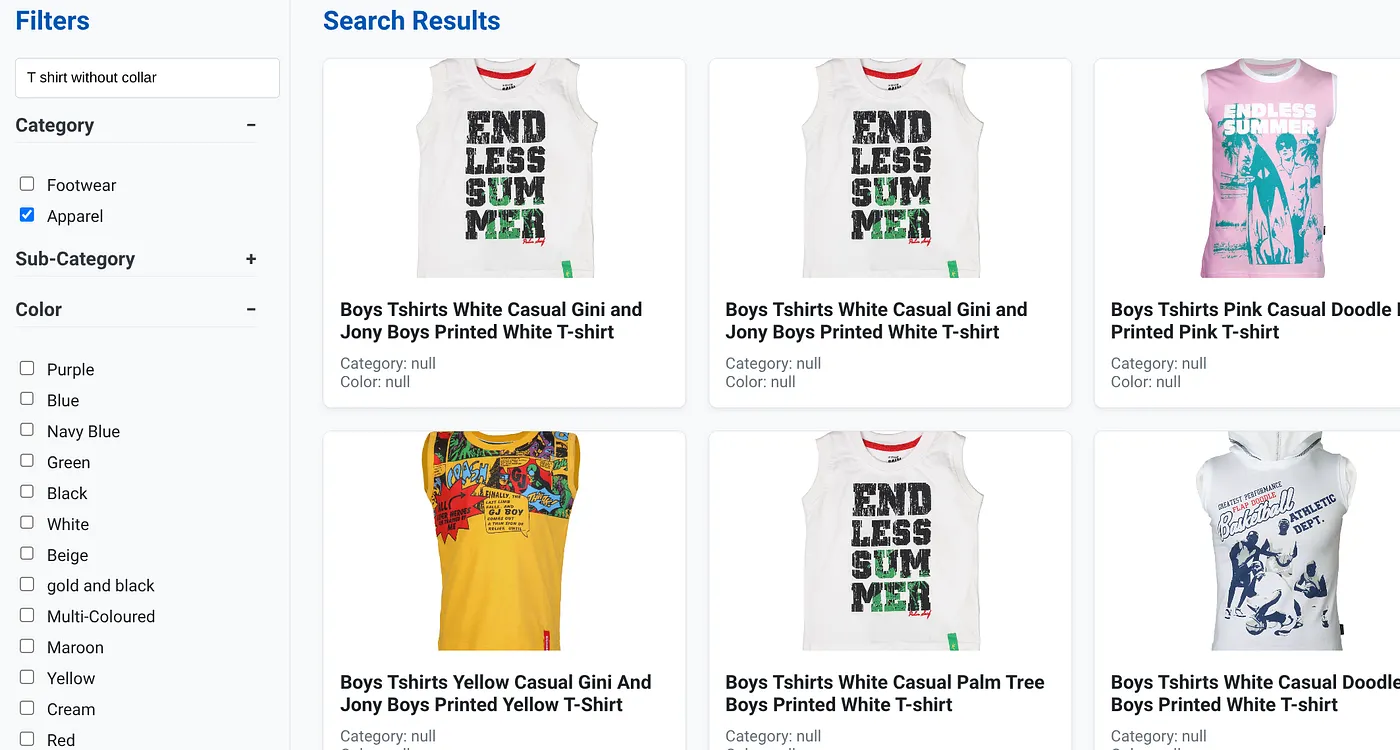
上の画像は、「襟なし T シャツ」の検索結果を示しています。ファセット フィルタ: アパレル
生成機能とエージェント機能をさらに組み込んで、このアプリケーションを実用的なものにすることができます。
ぜひお試しください。きっと、ご自身のアイデアを形にしたくなるはずです。
11. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
- Google Cloud コンソールで、[リソース マネージャー] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
- または、[クラスタを削除] ボタンをクリックして、このプロジェクト用に作成した AlloyDB クラスタを削除することもできます(構成時にクラスタに us-central1 を選択しなかった場合は、このハイパーリンクのロケーションを変更してください)。
12. 完了
おめでとうございます!CLOUD RUN で ALLOYDB を使用してハイブリッド検索アプリを構築してデプロイしました。
ビジネスにとってのメリット:
AlloyDB AI を活用したこの動的なハイブリッド検索アプリケーションは、エンタープライズ リテールなどのビジネスに大きなメリットをもたらします。
関連性の向上: コンテキスト(ベクトル)検索と正確なファセット フィルタリング、インテリジェントな再ランキングを組み合わせることで、関連性の高い検索結果が顧客に表示され、満足度とコンバージョン率が向上します。
スケーラビリティ: AlloyDB のアーキテクチャと scaNN インデックスは、急成長中の e コマース ビジネスに不可欠な、大規模な商品カタログと大量のクエリを処理するように設計されています。
パフォーマンス: 複雑なハイブリッド検索でもクエリの応答が速いため、ユーザー エクスペリエンスがスムーズになり、離脱率を最小限に抑えることができます。
将来を見据えた設計: AI 機能(エンベディング、LLM 検証)の統合により、パーソナライズされたレコメンデーション、会話型コマース、インテリジェントな商品検索の将来の進歩に対応できます。
アーキテクチャの簡素化: ベクトル検索を AlloyDB に直接統合することで、個別のベクトル データベースや複雑な同期が不要になり、開発とメンテナンスが簡素化されます。
たとえば、ユーザーが「アーチサポートの高い女性用エコフレンドリー ランニング シューズ」などの自然言語クエリを入力したとします。
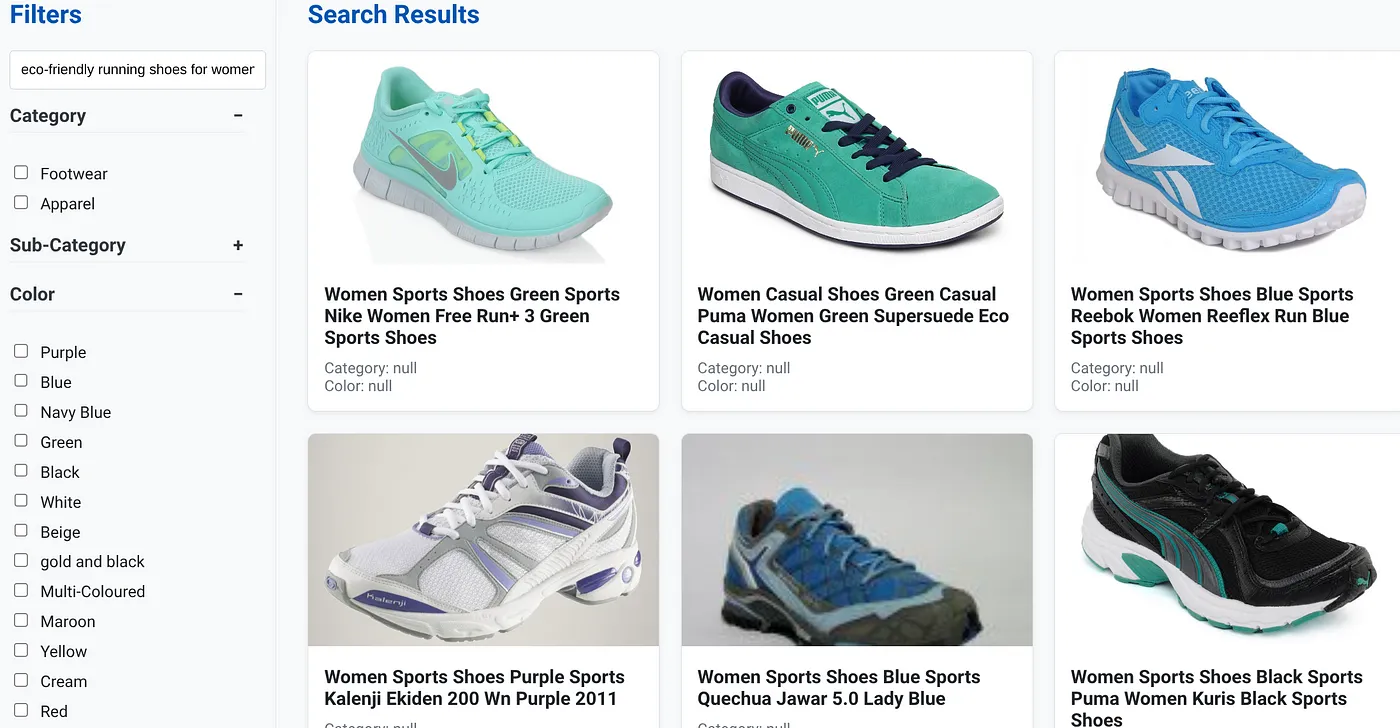
同時に、ユーザーが「カテゴリ: <<>>」、「色: <<>>」のファセット フィルタを適用し、「価格: $100 ~$150」と発言した場合:
- システムは、自然言語と意味的に一致し、選択したフィルタに正確に一致する商品の絞り込みリストを即座に返します。
- 舞台裏では、scaNN インデックスがベクトル検索を高速化し、インライン フィルタリングと適応型フィルタリングが結合条件でパフォーマンスを確保し、再ランキングが最適な結果を上位に表示します。
- 結果のスピードと精度は、これらのテクノロジーを組み合わせることで、真にインテリジェントな小売検索エクスペリエンスを実現できることを明確に示しています。
次世代の小売検索アプリケーションを構築するには、従来のメソッドを超えて、AlloyDB、Vertex AI、scaNN インデックス登録によるベクトル検索、動的ファセット フィルタリング、再ランキング、LLM 検証の機能を活用する必要があります。これにより、エンゲージメントを高め、売上を伸ばす比類のない顧客体験を提供できます。この堅牢でスケーラブルなインテリジェント ソリューションは、AI を活用した最新のデータベース機能が小売業の未来をどのように変革するかを示しています。