
1. 개요
오늘날 경쟁이 치열한 소매 환경에서 고객이 원하는 것을 빠르고 직관적으로 찾을 수 있도록 지원하는 것이 무엇보다 중요합니다. 기존의 키워드 기반 검색은 미묘한 검색어와 방대한 제품 카탈로그로 인해 어려움을 겪는 경우가 많습니다. 이 Codelab에서는 AlloyDB, AlloyDB AI를 기반으로 구축된 정교한 소매 검색 애플리케이션을 소개합니다. 이 애플리케이션은 최첨단 벡터 검색, scaNN 색인, 패싯 필터, 지능형 적응형 필터링, 재순위 지정을 활용하여 엔터프라이즈 규모의 동적 하이브리드 검색 환경을 제공합니다.
이제 다음 3가지에 대한 기본적인 이해를 갖추었습니다.
- 컨텍스트 검색이 에이전트에 어떤 의미를 가지며 벡터 검색을 사용하여 이를 달성하는 방법
- 또한 데이터 범위 내, 즉 데이터베이스 자체 내에서 벡터 검색을 달성하는 방법을 자세히 살펴보았습니다. 아직 모르셨다면 모든 Google Cloud 데이터베이스가 이를 지원합니다.
- Google은 ScaNN 색인으로 구동되는 AlloyDB 벡터 검색 기능을 사용하여 고성능 및 고품질의 경량 벡터 검색 RAG 기능을 구현하는 방법을 전 세계에 알리는 데 한 걸음 더 나아갔습니다.
기본, 중급, 약간 고급 RAG 실험을 아직 진행하지 않았다면 나열된 순서대로 여기, 여기, 여기에서 3가지 실험을 읽어보시기 바랍니다.
과제
필터, 키워드, 컨텍스트 일치 이상의 기능: 간단한 키워드 검색은 수천 개의 결과를 반환할 수 있으며 그중 많은 수가 관련성이 없습니다. 이상적인 솔루션은 질문의 의도를 이해하고, 이를 정확한 필터 기준 (예: 브랜드, 소재, 가격)과 결합하여 가장 관련성 높은 항목을 밀리초 단위로 표시해야 합니다. 이를 위해서는 강력하고 유연하며 확장 가능한 검색 인프라가 필요합니다. 키워드 검색에서 컨텍스트 일치 및 유사성 검색으로 발전해 온 것은 사실입니다. 하지만 고객이 필터를 적용하면서 동시에 '봄에 하이킹하기에 편안하고 스타일리시한 방수 재킷'을 검색한다고 가정해 보겠습니다. 이때 애플리케이션은 고품질 응답을 반환할 뿐만 아니라 고성능이며 이 모든 순서는 데이터베이스에서 동적으로 선택됩니다.
목표
이 문제를 해결하기 위해
- 컨텍스트별 검색 (벡터 검색): 쿼리 및 제품 설명의 의미론적 의미 이해
- 패싯 필터링: 사용자가 특정 속성으로 결과를 상세검색할 수 있도록 지원
- 하이브리드 접근 방식: 컨텍스트 검색과 구조화된 필터링을 원활하게 혼합
- 고급 최적화: 속도와 관련성을 위해 전문 색인, 적응형 필터링, 재순위 지정 활용
- 생성형 AI 기반 품질 관리: 우수한 결과 품질을 위해 LLM 검사 통합
아키텍처와 구현 여정을 자세히 살펴보겠습니다.
빌드할 항목
Retail Search 애플리케이션
이 과정에서 다음 작업을 수행합니다.
- 전자상거래 데이터 세트용 AlloyDB 인스턴스 및 테이블 만들기
- 임베딩 및 벡터 검색 설정
- 메타데이터 색인 및 ScaNN 색인 만들기
- ScaNN의 인라인 필터링 방법을 사용하여 AlloyDB에서 고급 벡터 검색 구현
- 단일 쿼리에서 속성 필터 및 하이브리드 검색 설정
- 재순위 지정 및 재현율로 쿼리 관련성 개선 (선택사항)
- Gemini로 질문 응답 평가 (선택사항)
- 데이터베이스용 MCP 도구 상자 및 애플리케이션 레이어
- 패싯 검색을 사용한 애플리케이션 개발 (Java)
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 전자상거래 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
전자상거래 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
클러스터 및 인스턴스 만들기
- Cloud 콘솔에서 AlloyDB 페이지로 이동합니다. Cloud Console에서 대부분의 페이지를 쉽게 찾으려면 콘솔의 검색창을 사용하여 검색하면 됩니다.
- 해당 페이지에서 클러스터 만들기를 선택합니다.

- 아래와 같은 화면이 표시됩니다. 다음 값으로 클러스터 및 인스턴스를 만듭니다. 저장소에서 애플리케이션 코드를 클론하는 경우 값이 일치하는지 확인하세요.
- 클러스터 ID: '
vector-cluster' - password: "
alloydb" - PostgreSQL 15 / 최신 권장
- 리전: "
us-central1" - 네트워킹: "
default"
- 기본 네트워크를 선택하면 아래와 같은 화면이 표시됩니다.
연결 설정을 선택합니다.
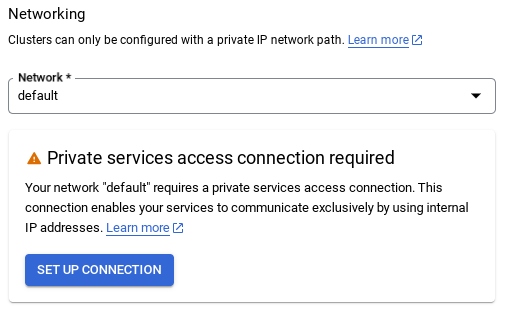
- 여기에서 '자동으로 할당된 IP 범위 사용'을 선택하고 계속을 클릭합니다. 정보를 검토한 후 연결 만들기를 선택합니다.
- 네트워크가 설정되면 클러스터를 계속 만들 수 있습니다. 클러스터 만들기를 클릭하여 아래와 같이 클러스터 설정을 완료합니다.
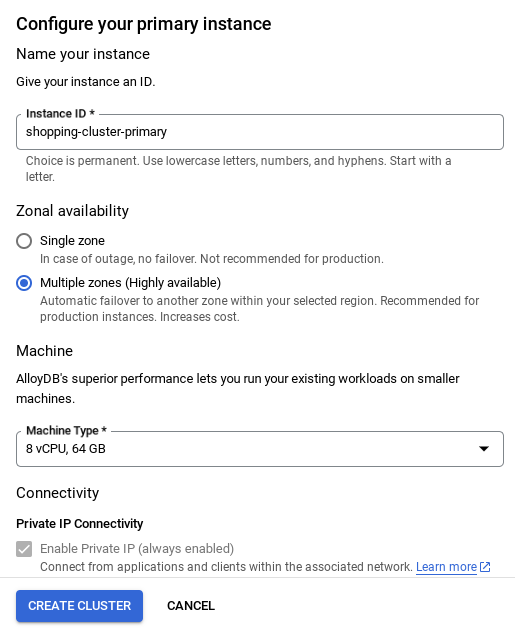
중요:
- 클러스터 / 인스턴스 구성 시 확인할 수 있는 인스턴스 ID를**
vector-instance**로 변경해야 합니다. 변경할 수 없는 경우 앞으로 나오는 모든 참조에서 인스턴스 ID를 사용해야 합니다. - 클러스터를 만드는 데 약 10분이 걸립니다. 성공하면 방금 만든 클러스터의 개요가 표시된 화면이 표시됩니다.
4. 데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. AlloyDB로 이동하여 기본 클러스터와 AlloyDB Studio를 선택합니다.
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 준비가 되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb'
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식 지정, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
확장 프로그램 사용 설정
이 앱을 빌드하기 위해 확장 프로그램 pgvector 및 google_ml_integration를 사용합니다. pgvector 확장 프로그램을 사용하면 벡터 임베딩을 저장하고 검색할 수 있습니다. google_ml_integration 확장 프로그램은 SQL에서 예측을 수행하기 위해 Vertex AI 예측 엔드포인트에 액세스하는 데 사용하는 함수를 제공합니다. 다음 DDL을 실행하여 이러한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
데이터베이스에서 사용 설정된 확장 프로그램을 확인하려면 다음 SQL 명령어를 실행하세요.
select extname, extversion from pg_extension;
테이블 만들기
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
임베딩 열을 사용하면 텍스트의 벡터 값을 저장할 수 있습니다.
권한 부여
아래 문을 실행하여 'embedding' 함수에 대한 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB 서비스 계정에 Vertex AI 사용자 역할 부여
Google Cloud IAM 콘솔에서 AlloyDB 서비스 계정 (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)에 'Vertex AI 사용자' 역할에 대한 액세스 권한을 부여합니다. PROJECT_NUMBER에는 프로젝트 번호가 표시됩니다.
또는 Cloud Shell 터미널에서 아래 명령어를 실행할 수 있습니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
데이터베이스에 데이터 로드
- 시트의
insert scripts sql에서insert쿼리 문을 위의 편집기에 복사합니다. 이 사용 사례를 빠르게 데모하려면 삽입 문을 10~50개 복사하면 됩니다. '선택한 인서트 25~30개 행' 탭에 선택된 인서트 목록이 있습니다.
데이터 링크는 이 GitHub 저장소 파일에서 확인할 수 있습니다.
- 실행을 클릭합니다. 쿼리 결과가 결과 테이블에 표시됩니다.
중요:
삽입할 레코드를 25~50개만 복사하고 카테고리, sub_category, color, gender 유형의 범위에 속하는지 확인합니다.
5. 데이터의 임베딩 만들기
최신 검색의 진정한 혁신은 키워드뿐만 아니라 의미를 이해하는 데 있습니다. 이때 임베딩과 벡터 검색이 사용됩니다.
사전 학습된 언어 모델을 사용하여 제품 설명과 사용자 쿼리를 '임베딩'이라는 고차원 수치 표현으로 변환했습니다. 이러한 임베딩은 시맨틱 의미를 포착하여 일치하는 단어가 포함된 제품뿐만 아니라 '의미가 유사한' 제품을 찾을 수 있도록 지원합니다. 처음에 Google은 이러한 임베딩에 대한 직접 벡터 유사성 검색을 실험하여 기준을 설정했으며, 이를 통해 성능 최적화 전에도 시맨틱 이해의 강력한 기능을 입증했습니다.
임베딩 열을 사용하면 제품 설명 텍스트의 벡터 값을 저장할 수 있습니다. img_embeddings 열을 사용하면 이미지 임베딩 (멀티모달)을 저장할 수 있습니다. 이렇게 하면 텍스트 대 이미지 거리 기반 검색도 사용할 수 있습니다. 하지만 이 실습에서는 텍스트 임베딩만 사용합니다.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
그러면 쿼리의 샘플 텍스트에 대한 임베딩 벡터가 반환됩니다. 이 벡터는 부동 소수점 배열과 유사합니다. 다음과 같이 표시됩니다.
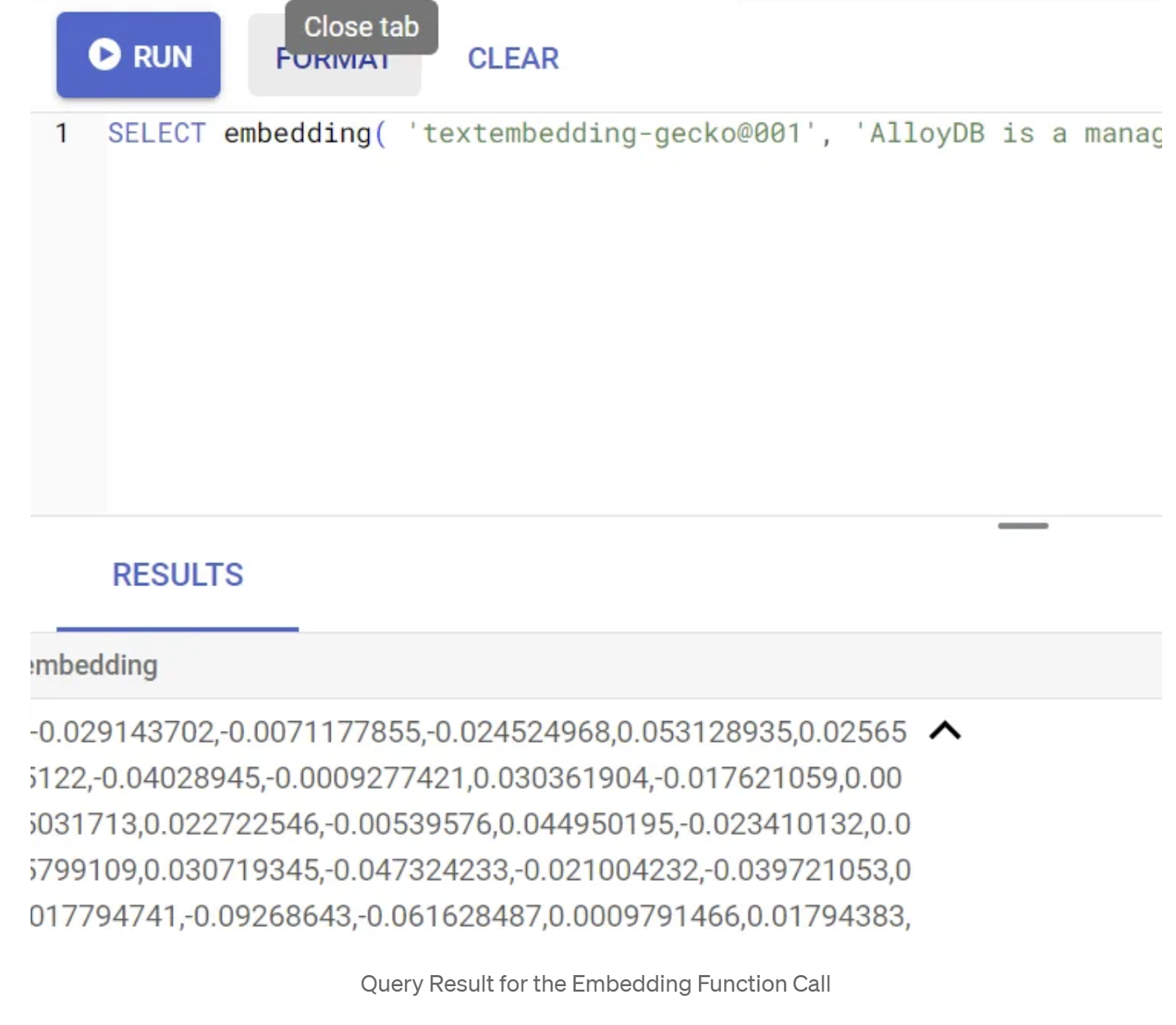
abstract_embeddings 벡터 필드 업데이트
아래 DML을 실행하여 테이블의 콘텐츠 설명을 해당 임베딩으로 업데이트합니다.
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud의 무료 체험판 크레딧 결제 계정을 사용하는 경우 20~25개 이상의 임베딩을 생성하는 데 문제가 있을 수 있습니다. 따라서 삽입 스크립트의 행 수를 제한하세요.
이미지 임베딩 (멀티모달 컨텍스트 검색 실행)을 생성하려면 아래 업데이트도 실행하세요.
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. AlloyDB의 새로운 기능으로 고급 RAG 실행
이제 테이블, 데이터, 임베딩이 모두 준비되었으므로 사용자 검색 텍스트에 대해 실시간 벡터 검색을 실행해 보겠습니다. 아래 쿼리를 실행하여 이를 테스트할 수 있습니다.
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
이 쿼리에서는 코사인 유사도 거리 함수('<=>' 기호로 표시)를 사용하여 사용자가 입력한 검색어 '라운드넥 티셔츠'의 텍스트 임베딩을 apparels 테이블의 모든 제품 설명의 텍스트 임베딩('embedding'이라는 열에 저장됨)과 비교합니다. 임베딩 메서드의 결과를 벡터 유형으로 변환하여 데이터베이스에 저장된 벡터와 호환되도록 합니다. LIMIT 10은 검색 텍스트와 가장 일치하는 10개를 선택한다는 것을 나타냅니다.
AlloyDB는 벡터 검색 RAG를 한 단계 업그레이드합니다.
엔터프라이즈 규모 솔루션의 경우 원시 벡터 검색만으로는 충분하지 않습니다. 성능이 중요합니다.
ScaNN (확장 가능한 최근접 이웃) 색인
초고속 근사 최근접 이웃 (ANN) 검색을 위해 AlloyDB에서 scaNN 색인을 사용 설정했습니다. Google 연구팀에서 개발한 최첨단 근사 최근접 이웃 검색 알고리즘인 ScaNN은 대규모의 효율적인 벡터 유사성 검색을 위해 설계되었습니다. 검색 공간을 효율적으로 가지치고 양자화 기법을 사용하여 쿼리 속도를 크게 높여 다른 색인 생성 방법보다 최대 4배 빠른 벡터 쿼리와 더 작은 메모리 사용량을 제공합니다. 자세한 내용은 여기와 여기를 참고하세요.
확장 프로그램을 사용 설정하고 색인을 만들어 보겠습니다.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
검색에서 이미지 임베딩을 사용하려는 경우 텍스트 임베딩 필드와 이미지 임베딩 필드 모두에 대한 색인을 만듭니다.
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
메타데이터 색인
scaNN은 벡터 색인을 처리하는 반면, 기존 B-트리 또는 GIN 색인은 구조화된 속성 (예: 카테고리, 하위 카테고리, 스타일, 색상 등)에 세심하게 설정되었습니다. 이러한 색인은 패싯 필터링의 효율성에 매우 중요합니다. 아래 문을 실행하여 메타데이터 색인을 설정합니다.
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
중요:
레코드를 25~50개만 삽입했을 수 있으므로 색인 (ScaNN 또는 기타 색인)이 효과적이지 않습니다.
인라인 필터링
벡터 검색의 일반적인 과제는 구조화된 필터 (예: '빨간색 신발')와 결합하는 것입니다. AlloyDB의 인라인 필터링은 이를 최적화합니다. 광범위한 벡터 검색에서 결과를 사후 필터링하는 대신 인라인 필터링은 벡터 검색 프로세스 자체에서 필터 조건을 적용하여 필터링된 벡터 검색의 성능과 정확도를 크게 개선합니다.
인라인 필터링의 필요성에 대해 자세히 알아보려면 이 문서를 참고하세요. 여기에서 벡터 검색의 성능 최적화를 위한 필터링된 벡터 검색에 대해서도 알아보세요. 이제 애플리케이션에 인라인 필터링을 사용 설정하려면 편집기에서 다음 문을 실행합니다.
SET scann.enable_inline_filtering = on;
인라인 필터링은 선택도가 중간인 경우에 가장 적합합니다. AlloyDB는 벡터 색인을 검색할 때 메타데이터 필터링 조건 (일반적으로 WHERE 절에서 처리되는 쿼리의 기능 필터)과 일치하는 벡터의 거리만 계산합니다. 이렇게 하면 후반 필터 또는 사전 필터의 장점을 보완하여 이러한 쿼리의 성능이 크게 향상됩니다.
적응형 필터링
성능을 더욱 최적화하기 위해 AlloyDB의 적응형 필터링은 쿼리 실행 중에 가장 효율적인 필터링 전략 (인라인 또는 사전 필터링)을 동적으로 선택합니다. 쿼리 패턴과 데이터 분포를 분석하여 수동 개입 없이 최적의 성능을 보장합니다. 특히 벡터와 메타데이터 색인 사용 간에 자동으로 전환되는 필터링된 벡터 검색에 유용합니다. 적응형 필터링을 사용 설정하려면 scann.enable_preview_features 플래그를 사용합니다.
실행 중에 적응형 필터링으로 인해 인라인 필터링에서 사전 필터링으로 전환되면 쿼리 계획이 동적으로 변경됩니다.
SET scann.enable_preview_features = on;
중요: 오류가 발생하면 인스턴스를 다시 시작하지 않고 위의 문을 실행하지 못할 수 있습니다. 인스턴스의 데이터베이스 플래그 섹션에서 enable_preview_features 플래그를 사용 설정하는 것이 좋습니다.
모든 색인을 사용하는 패싯 필터
상품 속성 검색을 사용하면 사용자가 특정 속성 또는 '상품 속성' (예: 브랜드, 가격, 크기, 고객 평가)을 기반으로 여러 필터를 적용하여 결과를 세분화할 수 있습니다. 애플리케이션은 이러한 패싯을 벡터 검색과 원활하게 통합합니다. 이제 단일 쿼리에서 자연어 (맥락 검색)와 다면적 선택을 결합하여 벡터와 기존 색인을 모두 동적으로 활용할 수 있습니다. 이를 통해 사용자가 결과를 정확하게 드릴다운할 수 있는 진정한 동적 하이브리드 검색 기능이 제공됩니다.
애플리케이션에서 모든 메타데이터 색인을 이미 만들었으므로 SQL 쿼리를 사용하여 직접 해결하여 웹에서 패싯 필터를 사용할 준비가 되었습니다.
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
이 쿼리에서는 밀집 임베딩과 희소 임베딩을 모두
- WHERE 절의 패싯 필터링
- 코사인 유사성 메서드를 사용하여 ORDER BY 절에서 벡터 검색
$1, $2, $3, $4는 배열의 패싯 필터 값을 나타내고 $5는 사용자 검색 텍스트를 나타냅니다. $1~ $4를 아래와 같이 패싯 필터 값으로 바꿉니다.
category = ANY([‘Apparel', ‘Footwear'])
$5를 원하는 검색 텍스트(예: '폴로 티셔츠')로 바꿉니다.
중요: 삽입한 레코드 집합이 제한되어 인덱스가 없는 경우 성능 영향이 표시되지 않습니다. 하지만 전체 프로덕션 데이터 세트에서는 벡터 검색에서 인라인 필터링이 적용된 ScaNN 색인을 사용하면 동일한 벡터 검색의 실행 시간이 크게 단축되는 것을 확인할 수 있습니다.
다음으로 ScaNN 지원 벡터 검색의 재현율을 평가해 보겠습니다.
순위 재지정
고급 검색을 사용하더라도 초기 결과에 최종 수정이 필요할 수 있습니다. 이 단계는 관련성을 개선하기 위해 초기 검색 결과를 재정렬하는 중요한 단계입니다. 초기 하이브리드 검색에서 후보 제품 세트를 제공한 후 더 정교한 (그리고 종종 계산량이 더 많은) 모델이 더 세부적인 관련성 점수를 적용합니다. 이를 통해 사용자에게 표시되는 상위 결과가 가장 관련성이 높아 검색 품질이 크게 향상됩니다. Google은 재현율을 지속적으로 평가하여 시스템이 지정된 쿼리와 관련된 모든 항목을 얼마나 잘 검색하는지 측정하고, 고객이 필요한 항목을 찾을 가능성을 극대화하기 위해 모델을 개선합니다.
애플리케이션에서 이를 사용하기 전에 모든 기본 요건을 충족하는지 확인하세요.
- google_ml_integration 확장 프로그램이 설치되어 있는지 확인합니다.
- google_ml_integration.enable_model_support 플래그가 사용 설정되어 있는지 확인합니다.
- Vertex AI와 통합
- Discovery Engine API를 사용 설정합니다.
- 순위 모델을 사용하는 데 필요한 역할을 얻습니다.
그런 다음 애플리케이션에서 다음 쿼리를 사용하여 하이브리드 검색 결과 집합의 순위를 다시 지정할 수 있습니다.
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
이 쿼리에서는 코사인 유사도 방법을 사용하여 ORDER BY 절에 지정된 컨텍스트 검색의 제품 결과 집합을 재정렬합니다. '핑크색 상의'는 사용자가 검색하는 텍스트입니다.
중요: 아직 리랭킹에 액세스할 수 없는 사용자가 있을 수 있으므로 애플리케이션 코드에서 제외했습니다. 하지만 리랭킹을 포함하려면 위에 설명된 샘플을 따르세요.
재현율 평가자
유사성 검색의 재현율은 검색에서 검색된 관련 인스턴스의 비율, 즉 참양성 수입니다. 검색 품질을 측정하는 데 가장 일반적으로 사용되는 측정항목입니다. 재현율 손실의 한 가지 원인은 근사 최근접 이웃 검색(aNN)과 k(정확한) 최근접 이웃 검색(kNN) 간의 차이입니다. AlloyDB의 ScaNN이 aNN 알고리즘을 구현하는 것과 같은 벡터 색인을 사용하면 재현율에서 약간의 절충을 하는 대신 대규모 데이터 세트에서 벡터 검색 속도를 높일 수 있습니다. 이제 AlloyDB를 사용하면 개별 쿼리에 대해 데이터베이스에서 직접 이 트레이드오프를 측정하고 시간이 지나도 안정적인지 확인할 수 있습니다. 이 정보를 바탕으로 쿼리 및 색인 매개변수를 업데이트하여 더 나은 결과와 성능을 얻을 수 있습니다.
검색 결과의 리콜 뒤에 숨겨진 논리는 무엇인가요?
벡터 검색에서 재현율은 색인이 반환하는 벡터 중 실제 최근접 이웃인 벡터의 비율을 의미합니다. 예를 들어 최근접 이웃 20개를 찾는 최근접 이웃 쿼리에서 실제 최근접 이웃 19개를 반환했다면 재현율은 19/20x100 = 95%가 됩니다. 재현율은 검색 품질에 사용되는 측정항목으로, 쿼리 벡터와 객관적으로 가장 가까운 결과 중 반환된 결과의 비율로 정의됩니다.
evaluate_query_recall 함수를 사용하면 특정 구성에 대해 벡터 색인의 벡터 쿼리에 대한 재현율을 확인할 수 있습니다. 이 함수는 원하는 벡터 쿼리 리콜 결과를 달성할 수 있도록 파라미터를 조정하는 데 유용합니다.
중요:
다음 단계에서 HNSW 색인에 대한 권한 거부 오류가 발생하면 지금은 이 전체 리콜 평가 섹션을 건너뛰세요. 이 Codelab이 문서화될 때 막 출시되었으므로 액세스 제한과 관련이 있을 수 있습니다.
- ScaNN 색인 및 HNSW 색인에서 색인 스캔 사용 설정 플래그를 설정합니다.
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio에서 다음 쿼리를 실행합니다.
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 함수는 쿼리를 매개변수로 받아 재현율을 반환합니다. 성능을 확인하는 데 사용한 쿼리를 함수 입력 쿼리로 사용하고 있습니다. SCaNN을 색인 방법으로 추가했습니다. 매개변수 옵션에 대한 자세한 내용은 문서를 참고하세요.
지금까지 사용한 이 벡터 검색 쿼리의 재현율은 다음과 같습니다.
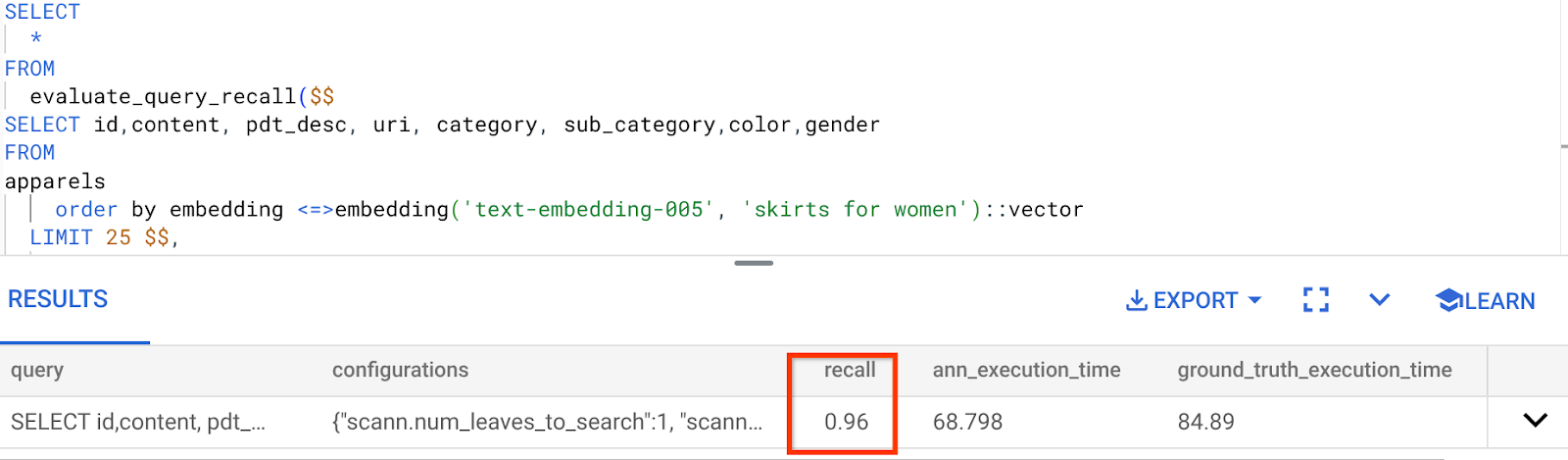
리콜이 96%인 것으로 확인됩니다. 이 경우 재현율은 매우 좋습니다. 하지만 허용되지 않는 값인 경우 이 정보를 사용하여 색인 매개변수, 메서드, 쿼리 매개변수를 변경하고 이 벡터 검색의 리콜을 개선할 수 있습니다.
수정된 쿼리 및 색인 매개변수로 테스트
이제 수신된 리콜에 따라 쿼리 매개변수를 수정하여 쿼리를 테스트해 보겠습니다.
- 색인 매개변수 수정:
이 테스트에서는 '코사인' 유사성 거리 함수 대신 'L2 거리'를 사용합니다.
매우 중요한 참고사항: '이 쿼리가 코사인 유사도를 사용하는지 어떻게 알 수 있나요?'라고 질문할 수 있습니다. 코사인 거리를 나타내는 '<=>'를 사용하여 거리 함수를 식별할 수 있습니다.
벡터 검색 거리 함수 에 대한 문서 링크
이전 쿼리에서는 코사인 유사도 거리 함수를 사용했지만 이제 L2 거리를 사용해 보겠습니다. 하지만 이를 위해서는 기본 ScaNN 색인도 L2 거리 함수를 사용해야 합니다. 이제 다른 거리 함수 쿼리(L2 거리: <->)로 색인을 만들어 보겠습니다.
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
drop index 문은 테이블에 불필요한 색인이 없도록 하기 위한 것입니다.
이제 벡터 검색 기능의 거리 함수를 변경한 후 다음 쿼리를 실행하여 재현율을 평가할 수 있습니다.
[AFTER] L2 거리 함수를 사용하는 쿼리:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
업데이트된 색인의 재현 값에서 차이점 / 변환을 확인할 수 있습니다.
원하는 재현율 값과 애플리케이션에서 사용하는 데이터 세트에 따라 num_leaves 등 색인에서 변경할 수 있는 다른 매개변수가 있습니다.
벡터 검색 결과의 LLM 검증
최고 품질의 관리 검색을 구현하기 위해 선택적 LLM 검증 레이어를 통합했습니다. 대규모 언어 모델을 사용하면 특히 복잡하거나 모호한 검색어의 경우 검색 결과의 관련성과 일관성을 평가할 수 있습니다. 여기에는 다음이 포함될 수 있습니다.
의미론적 검증:
LLM이 쿼리 의도에 대해 결과를 상호 참조합니다.
논리적 필터링:
LLM을 사용하여 기존 필터로 인코딩하기 어려운 복잡한 비즈니스 로직이나 규칙을 적용하여 미묘한 기준에 따라 제품 목록을 추가로 세부 조정합니다.
품질 보증:
사람의 검토 또는 모델 개선을 위해 관련성이 낮은 결과를 자동으로 식별하고 신고합니다.
AlloyDB AI 기능에서 이를 달성한 방법은 다음과 같습니다.
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
기본 쿼리는 패싯 검색, 하이브리드 검색, 재순위 지정 섹션에서 살펴본 쿼리와 동일합니다. 이제 이 쿼리에는 ml_predict_row 구조로 표현된 재순위 지정된 결과 집합에 대한 Gemini 평가 레이어가 통합되었습니다. 패싯 필터는 주석 처리했지만, $1~ $4 자리표시자 배열에 원하는 항목을 포함해도 됩니다. $5를 검색하려는 텍스트(예: '꽃무늬가 없는 분홍색 상의')로 바꿉니다.
7. 데이터베이스용 MCP 도구 상자 및 애플리케이션 레이어
백엔드에서는 강력한 도구와 잘 구성된 애플리케이션이 원활한 작동을 보장합니다.
데이터베이스용 MCP (모델 컨텍스트 프로토콜) 도구 상자를 사용하면 생성형 AI 및 에이전트 도구를 AlloyDB와 간편하게 통합할 수 있습니다. 연결 풀링, 인증, 데이터베이스 기능의 AI 에이전트 또는 기타 애플리케이션에 대한 보안 노출을 간소화하는 오픈소스 서버 역할을 합니다.
애플리케이션에서 데이터베이스용 MCP 도구 상자를 모든 지능형 하이브리드 검색 쿼리의 추상화 레이어로 사용했습니다.
아래 단계에 따라 사용 사례에 맞게 Toolbox를 설정하고 배포하세요.
데이터베이스용 MCP 도구 상자에서 지원하는 데이터베이스 중 하나가 AlloyDB이며 이전 섹션에서 이미 프로비저닝했으므로 도구 상자를 설정해 보겠습니다.
- Cloud Shell 터미널로 이동하여 프로젝트가 선택되어 있고 터미널 프롬프트에 표시되는지 확인합니다. Cloud Shell 터미널에서 아래 명령어를 실행하여 프로젝트 디렉터리로 이동합니다.
mkdir toolbox-tools
cd toolbox-tools
- 아래 명령어를 실행하여 새 폴더에 툴박스를 다운로드하고 설치합니다.
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Cloud Shell 편집기 (코드 편집 모드)로 이동하여 프로젝트 루트 폴더에 'tools.yaml'이라는 파일을 추가합니다.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Tools.yaml 스크립트를 이 저장소 파일의 코드로 바꿔야 합니다.
tools.yaml을 이해해 보겠습니다.
소스는 도구가 상호작용할 수 있는 다양한 데이터 소스를 나타냅니다. 소스는 도구가 상호작용할 수 있는 데이터 소스를 나타냅니다. tools.yaml 파일의 소스 섹션에서 소스를 맵으로 정의할 수 있습니다. 일반적으로 소스 구성에는 데이터베이스와 연결하고 상호작용하는 데 필요한 모든 정보가 포함됩니다.
도구는 에이전트가 취할 수 있는 작업(예: 소스 읽기 및 쓰기)을 정의합니다. 도구는 상담사가 SQL 문을 실행하는 등 취할 수 있는 작업을 나타냅니다. tools.yaml 파일의 도구 섹션에서 도구를 맵으로 정의할 수 있습니다. 일반적으로 도구는 조치를 취할 소스가 필요합니다.
tools.yaml 구성에 대한 자세한 내용은 이 문서를 참고하세요.
- (mcp-toolbox 폴더에서) 다음 명령어를 실행하여 서버를 시작합니다.
./toolbox --tools-file "tools.yaml"
이제 클라우드에서 웹 미리보기 모드로 서버를 열면 get-order-data라는 새 도구가 실행되는 Toolbox 서버를 확인할 수 있습니다.
MCP 도구 상자 서버는 기본적으로 포트 5000에서 실행됩니다. Cloud Shell을 사용하여 이를 테스트해 보겠습니다.
아래와 같이 Cloud Shell에서 웹 미리보기를 클릭합니다.
포트 변경을 클릭하고 아래와 같이 포트를 5000으로 설정한 후 변경 및 미리보기를 클릭합니다.
다음과 같은 출력이 표시됩니다.
- Cloud Run에 도구 상자를 배포해 보겠습니다.
먼저 MCP 도구 상자 서버를 시작하고 Cloud Run에서 호스팅할 수 있습니다. 그러면 다른 애플리케이션 및/또는 에이전트 애플리케이션과 통합할 수 있는 공개 엔드포인트가 제공됩니다. Cloud Run에서 호스팅하는 방법은 여기를 참고하세요. 이제 주요 단계를 살펴보겠습니다.
- 새 Cloud Shell 터미널을 실행하거나 기존 Cloud Shell 터미널을 사용합니다. 아직 프로젝트 폴더에 있지 않다면 툴박스 바이너리와 tools.yaml이 있는 프로젝트 폴더(이 경우 toolbox-tools)로 이동합니다.
cd toolbox-tools
- Google Cloud 프로젝트 ID를 가리키도록 PROJECT_ID 변수를 설정합니다.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- 다음 Google Cloud 서비스를 사용 설정합니다.
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Google Cloud Run에 배포할 도구 상자 서비스의 ID 역할을 할 별도의 서비스 계정을 만들어 보겠습니다.
gcloud iam service-accounts create toolbox-identity
- 또한 이 서비스 계정에 Secret Manager에 액세스하고 AlloyDB와 통신할 수 있는 올바른 역할이 있는지 확인합니다.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- tools.yaml 파일을 보안 비밀로 업로드합니다.
gcloud secrets create tools --data-file=tools.yaml
이미 보안 비밀이 있고 보안 비밀 버전을 업데이트하려면 다음을 실행하세요.
gcloud secrets versions add tools --data-file=tools.yaml
- Cloud Run에 사용할 컨테이너 이미지의 환경 변수를 설정합니다.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Cloud Run에 배포하는 데 익숙한 명령의 마지막 단계는 다음과 같습니다.
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
이렇게 하면 구성된 tools.yaml을 사용하여 도구 상자 서버를 Cloud Run에 배포하는 프로세스가 시작됩니다. 배포가 성공하면 다음과 유사한 메시지가 표시됩니다.
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
에이전트 애플리케이션에서 새로 배포된 도구를 사용할 준비가 되었습니다.
도구 상자 서버의 도구에 액세스
도구 상자가 배포되면 배포된 도구 상자 서버와 상호작용하는 Python Cloud Run Functions shim을 만듭니다. 현재 Toolbox에 Java SDK가 없기 때문에 서버와 상호작용하기 위해 Python shim을 만들었습니다. 다음은 해당 Cloud Run 함수의 소스 코드입니다.
이전 단계에서 만들고 배포한 툴박스 도구에 액세스하려면 이 Cloud Run 함수를 만들고 배포해야 합니다.
- Google Cloud 콘솔에서 Cloud Run 페이지로 이동합니다.
- 함수 작성을 클릭합니다.
- '서비스 이름' 필드에 함수를 설명하는 이름을 입력합니다. 서비스 이름은 문자로만 시작해야 하고 문자, 숫자, 하이픈을 포함하여 최대 49자까지 포함할 수 있습니다. 서비스 이름은 하이픈으로 끝날 수 없고 리전 및 프로젝트별로 고유해야 합니다. 서비스 이름은 나중에 변경할 수 없으며 공개적으로 표시됩니다. (Enter retail-product-search-quality)
- '리전' 목록에서 기본값을 사용하거나 함수를 배포하려는 리전을 선택합니다. (us-central1 선택)
- 런타임 목록에서 기본값을 사용하거나 런타임 버전을 선택합니다. (Python 3.11 선택)
- 인증 섹션에서 '공개 액세스 허용'을 선택합니다.
- '만들기' 버튼을 클릭합니다.
- 함수가 생성되고 템플릿 main.py 및 requirements.txt와 함께 로드됩니다.
- 이 프로젝트의 저장소에 있는 main.py 및 requirements.txt 파일로 바꿉니다.
- 함수를 배포하면 Cloud Run 함수의 엔드포인트가 표시됩니다.
엔드포인트는 다음과 같거나 이와 유사해야 합니다.
도구 상자에 액세스하기 위한 Cloud Run 함수 엔드포인트: 'https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app'
타임라인 내에서 쉽게 완료할 수 있도록 (실습 강사 주도 세션의 경우) 엔드포인트의 프로젝트 번호는 실습 세션 시점에 공유됩니다.
중요:
또는 애플리케이션 코드나 Cloud Run Functions의 일부로 데이터베이스 부분을 직접 구현할 수도 있습니다.
8. 패싯 검색을 사용한 애플리케이션 개발 (Java)
마지막으로 이러한 강력한 백엔드 구성요소는 애플리케이션 레이어를 통해 구현됩니다. Java로 개발된 이 애플리케이션은 검색 시스템과 상호작용할 수 있는 사용자 인터페이스를 제공합니다. AlloyDB에 대한 쿼리를 오케스트레이션하고, 패싯 필터 표시를 처리하고, 사용자 선택을 관리하고, 재정렬되고 검증된 검색 결과를 원활하고 직관적인 방식으로 표시합니다.
- 먼저 Cloud Shell 터미널로 이동하여 저장소를 클론합니다.
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Cloud Shell 편집기로 이동하면 새로 만든 폴더 faceted_searching_retail이 표시됩니다.
- 이전 섹션에서 이미 완료된 단계이므로 다음을 삭제합니다.
- Cloud_Run_Function 폴더 삭제
- db_script.sql 파일을 삭제합니다.
- tools.yaml 파일 삭제
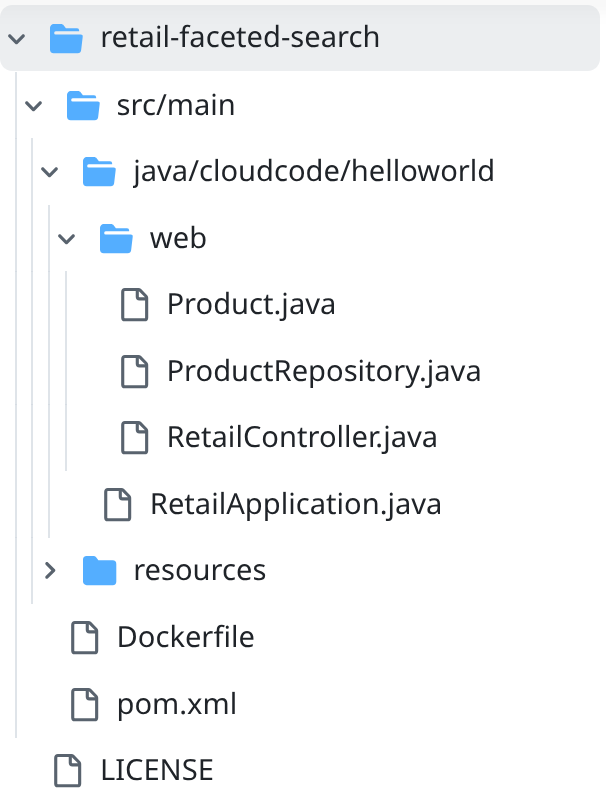
- retail-faceted-search 프로젝트 폴더로 이동하면 프로젝트 구조가 표시됩니다.
- ProductRepository.java 파일에서 TOOLBOX_ENDPOINT 변수를 배포된 Cloud Run 함수의 엔드포인트로 수정하거나 실습 강사의 엔드포인트를 사용해야 합니다.
다음 코드 줄을 검색하여 엔드포인트로 바꿉니다.
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Dockerfile과 pom.xml이 프로젝트 구성에 맞는지 확인합니다 (버전이나 구성을 명시적으로 변경하지 않은 경우 변경할 필요가 없음).
- Cloud Shell 터미널에서 기본 폴더와 프로젝트 폴더 (faceted_searching_retail / retail-faceted-search) 내에 있는지 확인합니다. 터미널에서 올바른 폴더에 있지 않은 경우 다음 명령어를 사용하여 올바른 폴더로 이동합니다.
cd faceted_searching_retail
cd retail-faceted-search
- 애플리케이션을 패키징, 빌드, 테스트합니다.
mvn package
mvn spring-boot:run
아래와 같이 Cloud Shell 터미널에서 '포트 8080에서 미리보기'를 클릭하면 애플리케이션을 볼 수 있습니다.
9. Cloud Run에 배포: ***중요한 단계
Cloud Shell 터미널에서 기본 폴더와 프로젝트 폴더 내에 있는지 확인합니다 (faceted_searching_retail / retail-faceted-search). 터미널에서 올바른 폴더에 있지 않은 경우 다음 명령어를 사용하여 올바른 폴더로 이동합니다.
cd faceted_searching_retail
cd retail-faceted-search
프로젝트 폴더에 있는지 확인한 후 다음 명령어를 실행합니다.
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
배포가 완료되면 다음과 같은 배포된 Cloud Run 엔드포인트가 표시됩니다.
https://retail-search-**********-uc.a.run.app/
10. 데모
실제 사례를 통해 함께 살펴보겠습니다.
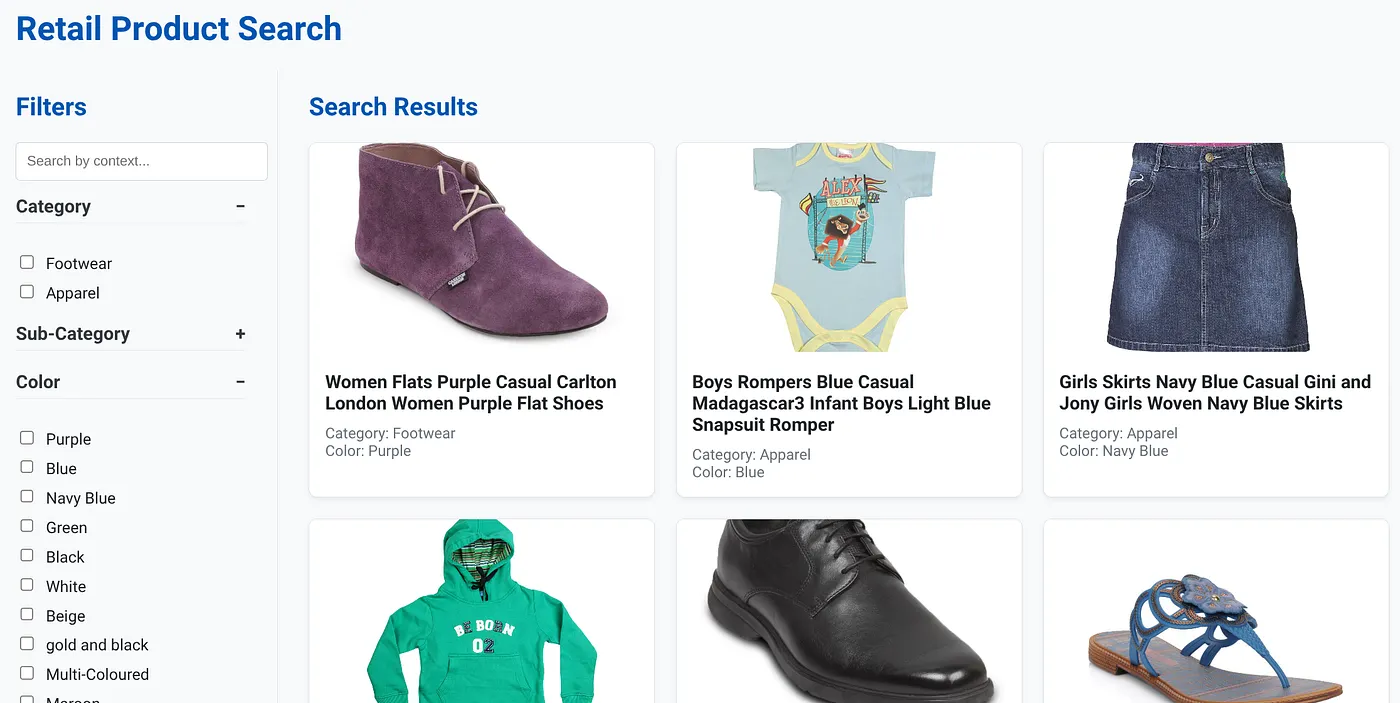
위 이미지는 동적 하이브리드 검색 앱의 방문 페이지를 보여줍니다.
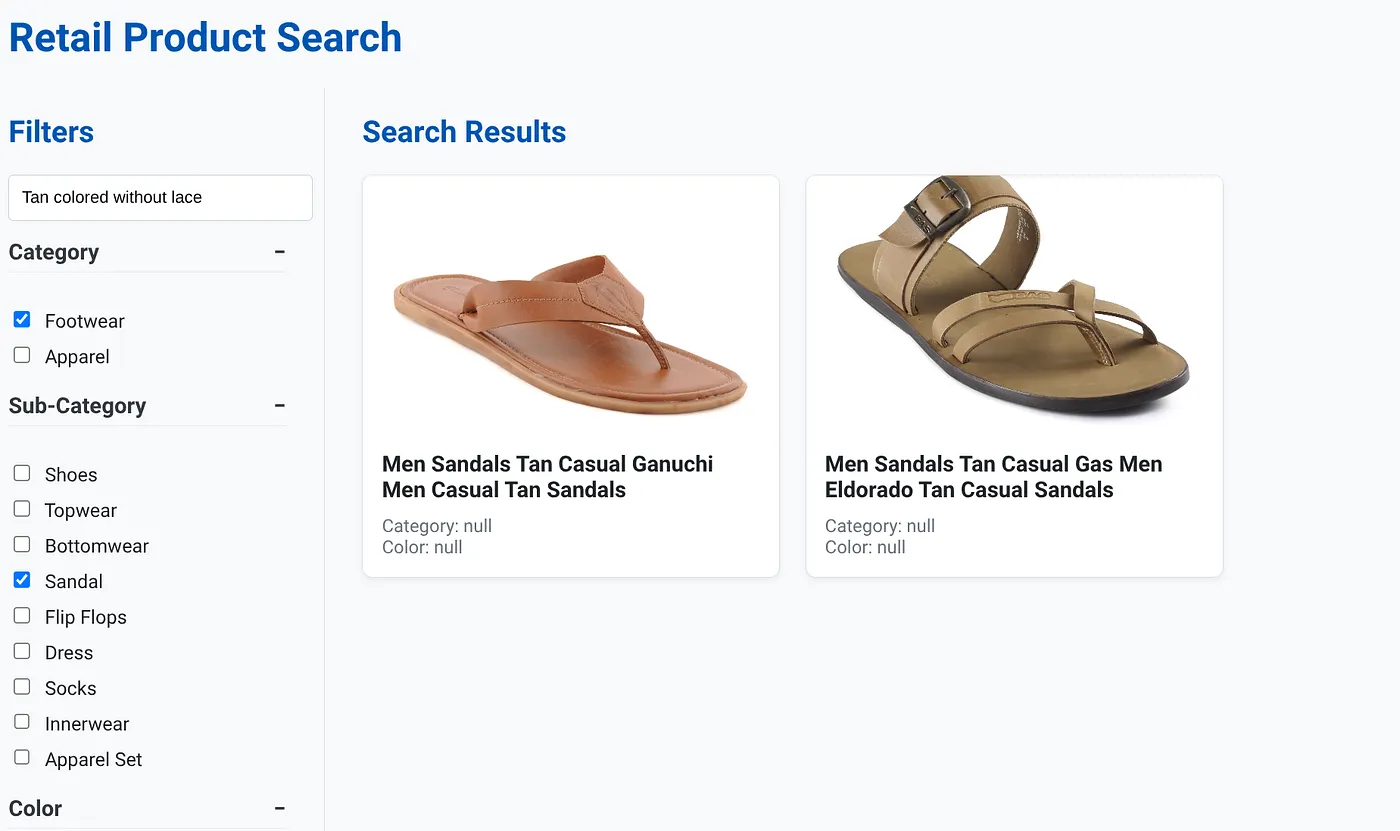
위 이미지는 '끈이 없는 황갈색'의 검색 결과를 보여줍니다. 선택한 패싯 필터는 신발, 샌들입니다.
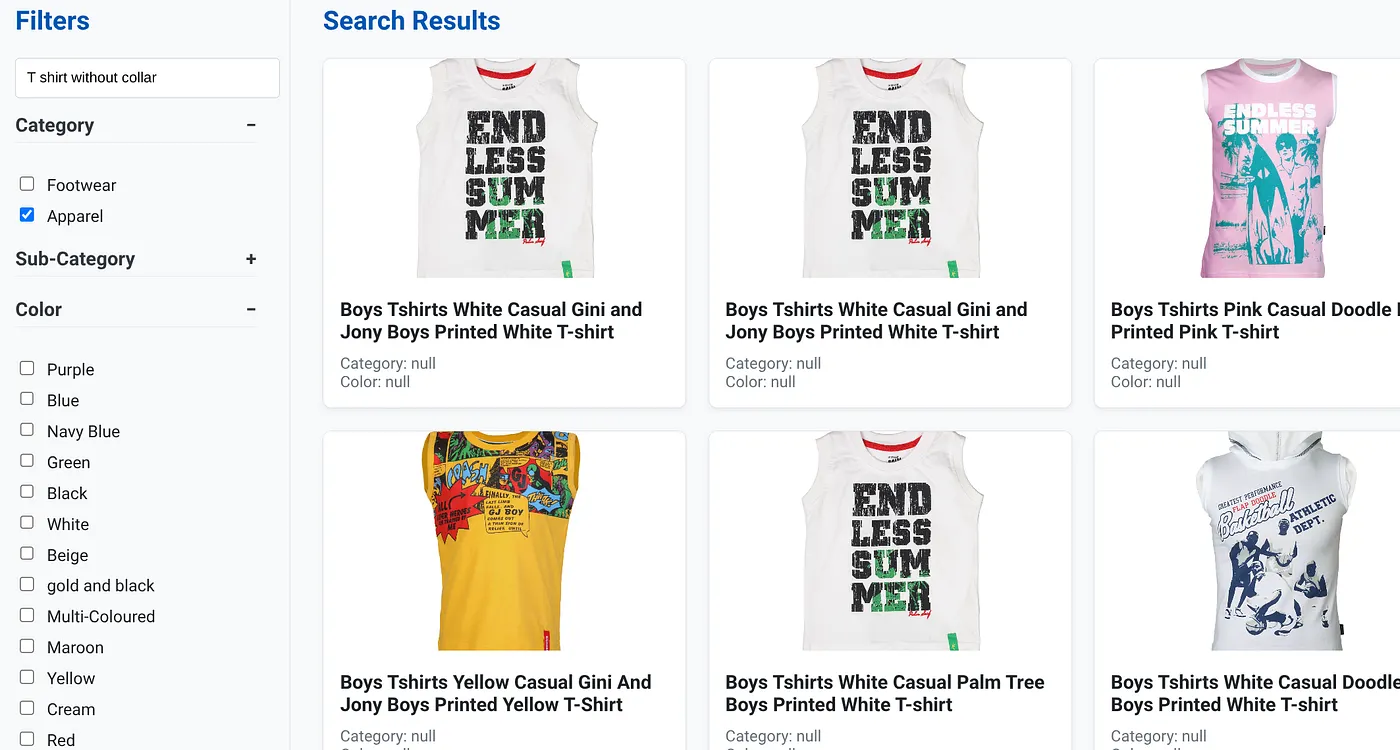
위 이미지는 '칼라 없는 티셔츠'의 검색 결과를 보여줍니다. 패싯 필터: 의류
이제 생성형 기능과 에이전트 기능을 더 많이 통합하여 이 애플리케이션을 실행 가능하게 만들 수 있습니다.
직접 사용해 보세요. 나만의 스타일을 구축하는 데 도움이 될 것입니다.
11. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리자 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
- 또는 클러스터 삭제 버튼을 클릭하여 이 프로젝트를 위해 방금 만든 AlloyDB 클러스터 (구성 시 클러스터에 us-central1을 선택하지 않은 경우 이 하이퍼링크의 위치를 변경)를 삭제하면 됩니다.
12. 축하합니다
수고하셨습니다 Cloud Run에서 AlloyDB를 사용하여 하이브리드 검색 앱을 빌드하고 배포했습니다.
비즈니스에 중요한 이유:
AlloyDB AI로 구동되는 이 동적 하이브리드 검색 애플리케이션은 엔터프라이즈 소매업체 및 기타 비즈니스에 다음과 같은 중요한 이점을 제공합니다.
뛰어난 관련성: 문맥 (벡터) 검색과 정확한 패싯 필터링 및 지능형 재순위 지정을 결합하여 고객에게 관련성이 높은 결과를 제공하므로 만족도와 전환이 증가합니다.
확장성: AlloyDB의 아키텍처와 scaNN 색인은 이커머스 비즈니스 성장에 중요한 대규모 제품 카탈로그와 높은 쿼리 볼륨을 처리하도록 설계되었습니다.
성능: 복잡한 하이브리드 검색에서도 쿼리 응답이 더 빨라져 원활한 사용자 환경을 보장하고 포기율을 최소화합니다.
미래 대비: AI 기능 (임베딩, LLM 검증)을 통합하면 맞춤 추천, 대화형 커머스, 지능형 제품 검색의 미래 발전에 대비할 수 있습니다.
간소화된 아키텍처: AlloyDB 내에 벡터 검색을 직접 통합하면 별도의 벡터 데이터베이스나 복잡한 동기화가 필요하지 않아 개발 및 유지보수가 간소화됩니다.
사용자가 '아치가 높은 여성을 위한 친환경 러닝화'와 같은 자연어 질문을 입력했다고 가정해 보겠습니다.
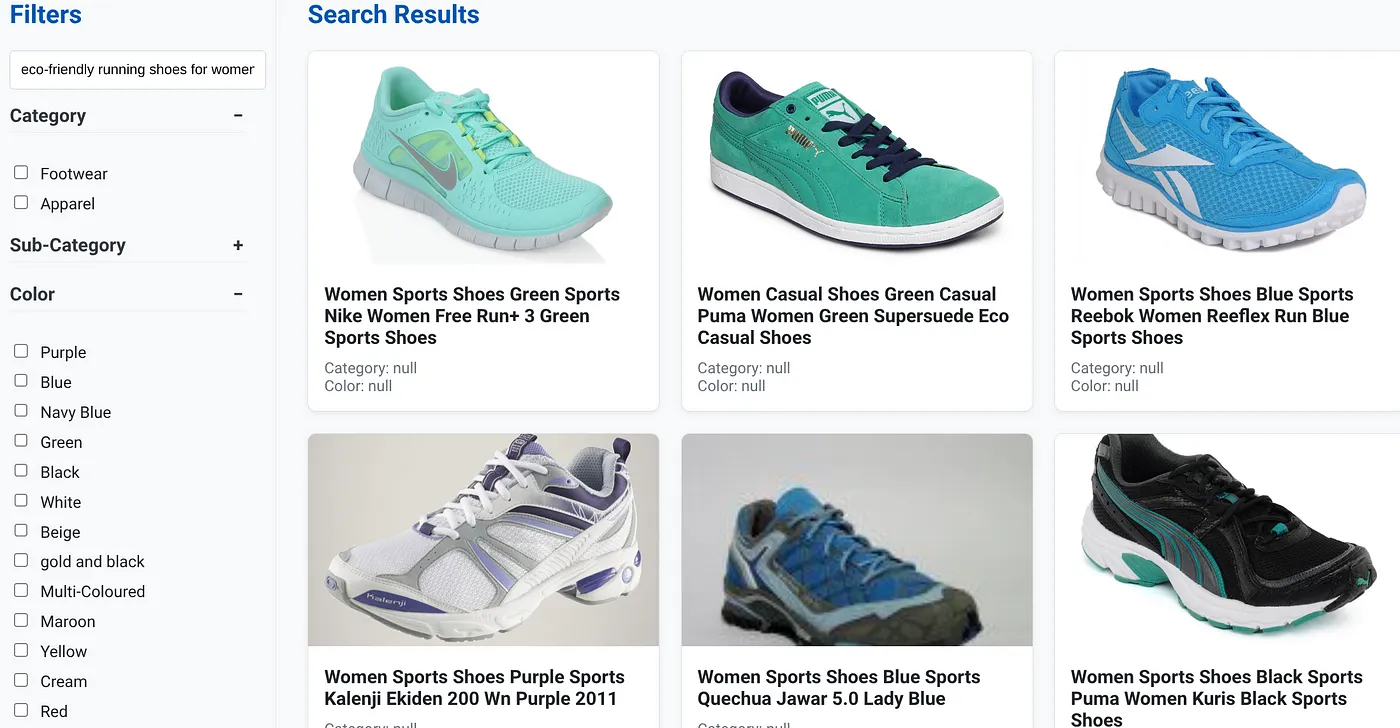
사용자가 동시에 '카테고리: <<>>', '색상: <<>>'에 패싯 필터를 적용하고 '가격: $100~$150'이라고 말합니다.
- 시스템은 자연어와 의미적으로 일치하고 선택한 필터와 정확히 일치하는 세련된 제품 목록을 즉시 반환합니다.
- 백그라운드에서 ScaNN 색인은 벡터 검색을 가속화하고, 인라인 및 적응형 필터링은 결합된 기준에 따라 성능을 보장하며, 재순위 지정은 최적의 결과를 상단에 표시합니다.
- 결과의 속도와 정확성은 진정한 지능형 소매 검색 환경을 위해 이러한 기술을 결합하는 것이 얼마나 강력한지 명확하게 보여줍니다.
차세대 소매 검색 애플리케이션을 빌드하려면 기존 방식을 넘어 AlloyDB, Vertex AI, ScaNN 색인 생성 기능이 있는 벡터 검색, 동적 패싯 필터링, 재순위 지정, LLM 검증의 기능을 사용해야 합니다. 이를 통해 참여를 유도하고 매출을 늘리는 최고의 고객 경험을 제공할 수 있습니다. 이 강력하고 확장 가능하며 지능적인 솔루션은 AI가 주입된 최신 데이터베이스 기능이 소매업의 미래를 어떻게 재편하고 있는지 보여줍니다.