
1. Przegląd
W dzisiejszym konkurencyjnym środowisku handlu detalicznego najważniejsze jest umożliwienie klientom szybkiego i intuicyjnego znajdowania dokładnie tego, czego szukają. Tradycyjne wyszukiwanie oparte na słowach kluczowych często nie sprawdza się w przypadku zapytań o niuansach i obszernych katalogów produktów. To ćwiczenie pokazuje zaawansowaną aplikację do wyszukiwania w handlu detalicznym opartą na AlloyDB i AlloyDB AI, która wykorzystuje najnowocześniejsze wyszukiwanie wektorowe, indeksowanie scaNN, filtry fasetowe i inteligentne filtrowanie adaptacyjne oraz ponowne rankingowanie, aby zapewnić dynamiczne, hybrydowe wyszukiwanie na skalę przedsiębiorstwa.
Znasz już podstawowe informacje o 3 rzeczach:
- Co oznacza wyszukiwanie kontekstowe dla Twojego agenta i jak to osiągnąć za pomocą wyszukiwania wektorowego.
- Przyjrzeliśmy się też szczegółowo uzyskiwaniu wyszukiwania wektorowego w zakresie Twoich danych, czyli w samej bazie danych (wszystkie bazy danych Google Cloud to obsługują, jeśli jeszcze o tym nie wiesz).
- Poszliśmy o krok dalej niż reszta świata i wyjaśniliśmy, jak osiągnąć taką lekką funkcję RAG wyszukiwania wektorowego o wysokiej wydajności i jakości dzięki funkcji wyszukiwania wektorowego AlloyDB opartej na indeksie ScaNN.
Jeśli nie masz za sobą tych podstawowych, średnio zaawansowanych i nieco bardziej zaawansowanych eksperymentów z RAG, zachęcam Cię do przeczytania tych 3 artykułów w podanej kolejności: tutaj, tutaj i tutaj.
Wyzwanie
Wykraczanie poza filtry, słowa kluczowe i dopasowanie kontekstowe: proste wyszukiwanie słów kluczowych może zwrócić tysiące wyników, z których wiele będzie nieistotnych. Idealne rozwiązanie musi rozumieć intencje użytkownika, łączyć je z precyzyjnymi kryteriami filtrowania (takimi jak marka, materiał czy cena) i w milisekundach wyświetlać najbardziej odpowiednie produkty. Wymaga to wydajnej, elastycznej i skalowalnej infrastruktury wyszukiwania. Oczywiście przeszliśmy długą drogę od wyszukiwania słów kluczowych do dopasowań kontekstowych i wyszukiwań podobieństw. Wyobraź sobie jednak klienta, który szuka „wygodnej, stylowej, wodoszczelnej kurtki na wiosenne piesze wędrówki”, a jednocześnie stosuje filtry. Twoja aplikacja nie tylko zwraca wysokiej jakości odpowiedzi, ale też działa wydajnie, a sekwencja tych działań jest dynamicznie wybierana przez bazę danych.
Cel
Aby rozwiązać ten problem, zintegruj
- Wyszukiwanie kontekstowe (wyszukiwanie wektorowe): zrozumienie semantycznego znaczenia zapytań i opisów produktów.
- Filtrowanie fasetowe: umożliwia użytkownikom zawężanie wyników za pomocą określonych atrybutów.
- Podejście hybrydowe: płynne łączenie wyszukiwania kontekstowego z filtrowaniem strukturalnym
- Optymalizacja zaawansowana: wykorzystywanie specjalistycznego indeksowania, adaptacyjnego filtrowania i ponownego rankingu w celu zwiększenia szybkości i trafności.
- Kontrola jakości oparta na generatywnej AI: włączenie weryfikacji LLM w celu uzyskania lepszej jakości wyników.
Przyjrzyjmy się architekturze i procesowi wdrażania.
Co utworzysz
Aplikacja do wyszukiwania w handlu detalicznym
W ramach tego procesu:
- Tworzenie instancji i tabeli AlloyDB na potrzeby zbioru danych e-commerce
- Konfigurowanie wektorów dystrybucyjnych i wyszukiwania wektorowego
- Tworzenie indeksu metadanych i indeksu ScaNN
- Wdrażanie zaawansowanego wyszukiwania wektorowego w AlloyDB za pomocą metody filtrowania wbudowanego ScaNN
- Konfigurowanie filtrów fasetowych i wyszukiwania hybrydowego w jednym zapytaniu
- Ulepszanie trafności zapytania za pomocą ponownego rankingu i przywoływania (opcjonalnie)
- Ocena odpowiedzi na zapytanie za pomocą Gemini (opcjonalnie)
- MCP Toolbox for Databases i warstwa aplikacji
- Tworzenie aplikacji (Java) z wyszukiwaniem wieloaspektowym
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć do tego polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych dla danych e-commerce. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie wczytany zbiór danych e-commerce.
Tworzenie klastra i instancji
- Otwórz stronę AlloyDB w konsoli Cloud. Najprostszym sposobem na znalezienie większości stron w Cloud Console jest wyszukanie ich za pomocą paska wyszukiwania w konsoli.
- Na tej stronie kliknij UTWÓRZ KLASTER:

- Wyświetli się ekran podobny do tego poniżej. Utwórz klaster i instancję z tymi wartościami (upewnij się, że wartości są zgodne, jeśli klonujesz kod aplikacji z repozytorium):
- id klastra: „
vector-cluster” - password: "
alloydb" - PostgreSQL 15 / najnowsza zalecana
- Region: "
us-central1" - Sieć: „
default”
- Po wybraniu sieci domyślnej zobaczysz ekran podobny do tego poniżej.
Wybierz SKONFIGURUJ POŁĄCZENIE.
- Następnie wybierz „Użyj automatycznie przydzielonego zakresu adresów IP” i kliknij Dalej. Po sprawdzeniu informacji kliknij UTWÓRZ POŁĄCZENIE.
- Po skonfigurowaniu sieci możesz utworzyć klaster. Kliknij UTWÓRZ KLASTER, aby dokończyć konfigurowanie klastra w sposób pokazany poniżej:
WAŻNA UWAGA:
- Pamiętaj, aby zmienić identyfikator instancji (który możesz znaleźć podczas konfigurowania klastra lub instancji) na**
vector-instance**. Jeśli nie możesz go zmienić, pamiętaj, aby używać identyfikatora instancji we wszystkich kolejnych odwołaniach. - Pamiętaj, że utworzenie klastra zajmie około 10 minut. Po zakończeniu procesu powinien wyświetlić się ekran z omówieniem utworzonego klastra.
4. Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz AlloyDB, wybierz klaster główny, a następnie AlloyDB Studio:
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb”
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, używając w razie potrzeby opcji Uruchom, Formatuj i Wyczyść.
Włączanie rozszerzeń
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jeśli chcesz sprawdzić, które rozszerzenia są włączone w bazie danych, uruchom to polecenie SQL:
select extname, extversion from pg_extension;
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą poniższej instrukcji DDL w AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Kolumna wektorów dystrybucyjnych będzie umożliwiać przechowywanie wartości wektorowych tekstu.
Przyznaj uprawnienia
Aby przyznać uprawnienia do wykonywania funkcji „embedding”, uruchom to polecenie:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Wczytywanie danych do bazy danych
- Skopiuj instrukcje zapytania
insertzinsert scripts sqlw arkuszu do edytora. Możesz skopiować 10–50 instrukcji wstawiania, aby szybko zademonstrować ten przypadek użycia. Wybrana lista wstawek znajduje się na karcie „Wybrane wstawki 25–30 wierszy”.
Link do danych znajdziesz w tym pliku w repozytorium GitHub.
- Kliknij Wykonaj. Wyniki zapytania pojawią się w tabeli Wyniki.
WAŻNA UWAGA:
Skopiuj tylko 25–50 rekordów do wstawienia i upewnij się, że pochodzą one z zakresu kategorii, podkategorii, kolorów i typów płci.
5. Tworzenie wektorów dystrybucyjnych na podstawie danych
Prawdziwa innowacja w nowoczesnym wyszukiwaniu polega na rozumieniu znaczenia, a nie tylko słów kluczowych. W takich sytuacjach przydają się wektory dystrybucyjne i wyszukiwanie wektorowe.
Opisy produktów i zapytania użytkowników przekształciliśmy w wielowymiarowe reprezentacje numeryczne zwane „wektorami osadzania”, korzystając z wytrenowanych modeli językowych. Te wektory dystrybucyjne odzwierciedlają znaczenie semantyczne, dzięki czemu możemy znajdować produkty, które są „podobne pod względem znaczenia”, a nie tylko zawierają pasujące słowa. Początkowo przeprowadziliśmy eksperymenty z bezpośrednim wyszukiwaniem podobieństwa wektorowego w przypadku tych osadzeń, aby ustalić wartość bazową. Pokazało to możliwości rozumienia semantycznego jeszcze przed optymalizacją skuteczności.
Kolumna wektorów dystrybucyjnych będzie umożliwiać przechowywanie wartości wektorowych tekstu opisu produktu. Kolumna img_embeddings umożliwi przechowywanie wektorów dystrybucyjnych obrazów (wielomodalnych). W ten sposób możesz też używać wyszukiwania na podstawie odległości tekstu od obrazu. W tym module użyjemy jednak tylko osadzania tekstu.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Powinien on zwrócić wektor dystrybucyjny, który wygląda jak tablica liczb zmiennoprzecinkowych, dla przykładowego tekstu w zapytaniu. Wygląda to tak:
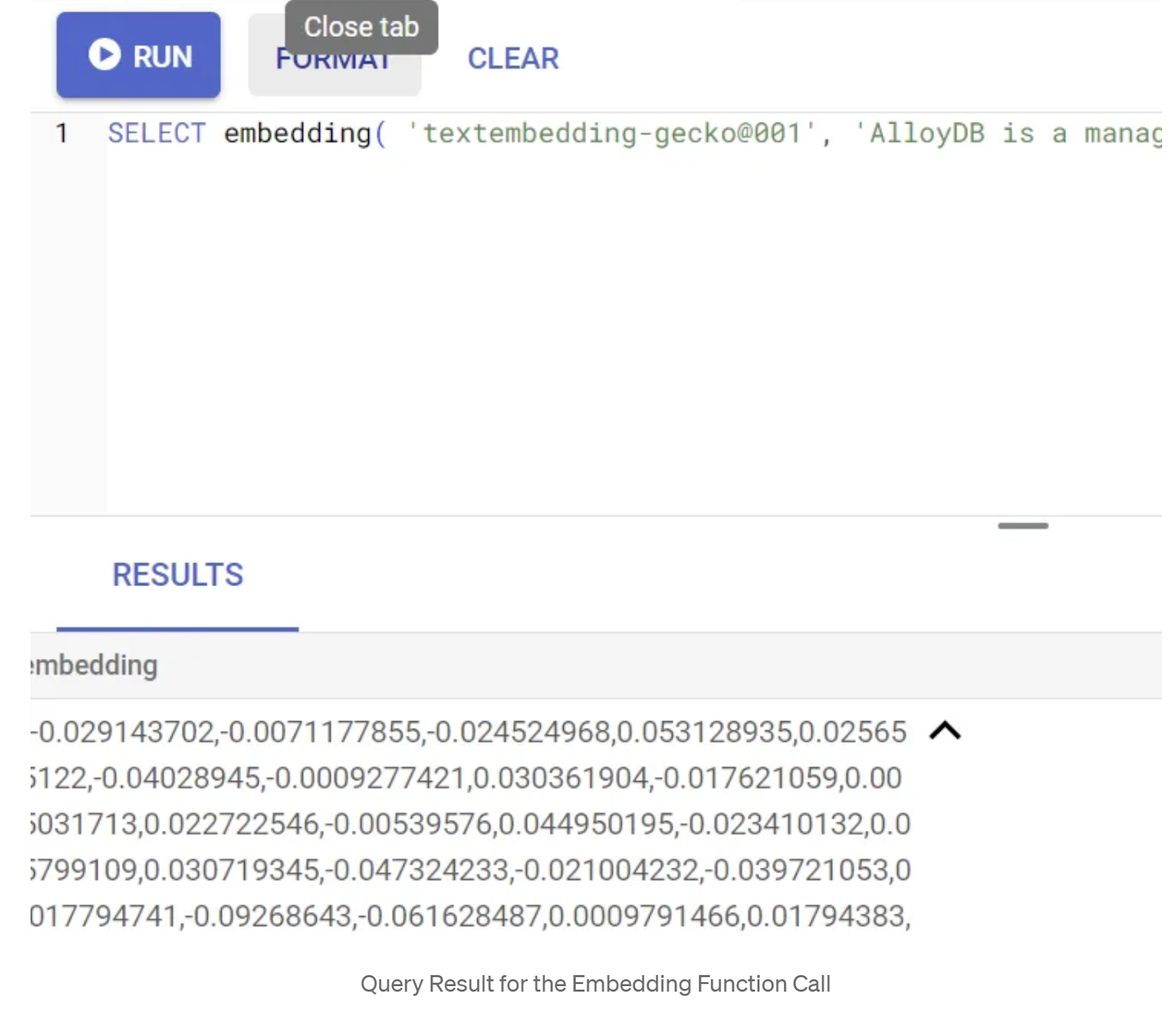
Zaktualizuj pole wektora abstract_embeddings.
Uruchom poniższy język DML, aby zaktualizować opis treści w tabeli za pomocą odpowiednich wektorów dystrybucyjnych:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Jeśli używasz konta rozliczeniowego z kredytem próbnym w Google Cloud, możesz mieć problem z wygenerowaniem więcej niż kilku osadzeń (maksymalnie 20–25). Dlatego ogranicz liczbę wierszy w skrypcie wstawiania.
Jeśli chcesz wygenerować osadzanie obrazów (aby przeprowadzić multimodalne wyszukiwanie kontekstowe), uruchom też poniższą aktualizację:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Zaawansowane RAG z użyciem nowych funkcji AlloyDB
Tabela, dane i osadzenia są już gotowe, więc możemy przeprowadzić wyszukiwanie wektorowe w czasie rzeczywistym na podstawie tekstu wyszukiwanego przez użytkownika. Możesz to sprawdzić, uruchamiając to zapytanie:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
W tym zapytaniu porównujemy wektor dystrybucyjny tekstu wpisanego przez użytkownika zapytania „T-shirt z okrągłym dekoltem” z wektorami dystrybucyjnymi tekstu wszystkich opisów produktów w tabeli odzieży (przechowywanych w kolumnie o nazwie „embedding”) za pomocą funkcji odległości podobieństwa cosinusowego (reprezentowanej przez symbol „<=>”). Konwertujemy wynik metody osadzania na typ wektorowy, aby był zgodny z wektorami przechowywanymi w bazie danych. LIMIT 10 oznacza, że wybieramy 10 najbliższych dopasowań tekstu wyszukiwania.
AlloyDB przenosi RAG z wyszukiwaniem wektorowym na wyższy poziom:
W przypadku rozwiązania na skalę przedsiębiorstwa samo wyszukiwanie wektorowe nie wystarczy. Wydajność ma kluczowe znaczenie.
Indeks ScaNN (Scalable Nearest Neighbors)
Aby uzyskać ultraszybkie przybliżone wyszukiwanie najbliższych sąsiadów (ANN), włączyliśmy w AlloyDB indeks scaNN. ScaNN to najnowocześniejszy algorytm przybliżonego wyszukiwania najbliższych sąsiadów opracowany przez zespół ds. badań Google. Został on zaprojektowany z myślą o wydajnym wyszukiwaniu podobieństw wektorów na dużą skalę. Znacznie przyspiesza zapytania dzięki efektywnemu ograniczaniu przestrzeni wyszukiwania i stosowaniu technik kwantyzacji. Oferuje do 4 razy szybsze zapytania wektorowe niż inne metody indeksowania i zajmuje mniej pamięci. Więcej informacji znajdziesz tutaj i tutaj.
Włączmy rozszerzenie i utwórzmy indeksy:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Utwórz indeksy dla pól wektorów dystrybucyjnych tekstu i obrazu (jeśli chcesz używać wektorów dystrybucyjnych obrazu w wyszukiwaniu):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Indeksy metadanych
ScaNN obsługuje indeksowanie wektorów, a tradycyjne indeksy B-drzewa lub GIN zostały starannie skonfigurowane dla atrybutów strukturalnych (takich jak kategoria, podkategoria, styl, kolor itp.). Indeksy te mają kluczowe znaczenie dla skuteczności filtrowania fasetowego. Aby skonfigurować indeksy metadanych, uruchom te instrukcje:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
WAŻNA UWAGA:
Ponieważ mogłeś(-aś) wstawić tylko 25–50 rekordów, indeksy (ScaNN lub dowolny inny indeks) nie będą skuteczne.
Filtrowanie w tekście
Częstym problemem w wyszukiwaniu wektorowym jest łączenie go z filtrami strukturalnymi (np. „czerwone buty”). Wbudowane filtrowanie w AlloyDB optymalizuje ten proces. Zamiast filtrować wyniki po szerokim wyszukiwaniu wektorowym, filtrowanie wbudowane stosuje warunki filtrowania podczas samego procesu wyszukiwania wektorowego, co znacznie poprawia wydajność i dokładność filtrowanych wyszukiwań wektorowych.
Więcej informacji o konieczności stosowania filtrowania wbudowanego znajdziesz w tej dokumentacji. Więcej informacji o filtrowanym wyszukiwaniu wektorowym, które pozwala optymalizować skuteczność wyszukiwania wektorowego, znajdziesz tutaj. Jeśli chcesz włączyć filtrowanie wbudowane w swojej aplikacji, uruchom w edytorze to polecenie:
SET scann.enable_inline_filtering = on;
Filtrowanie wbudowane najlepiej sprawdza się w przypadku średniej selektywności. Podczas przeszukiwania indeksu wektorowego AlloyDB oblicza odległości tylko w przypadku wektorów, które spełniają warunki filtrowania metadanych (filtry funkcjonalne w zapytaniu zwykle obsługiwane w klauzuli WHERE). Znacznie zwiększa to wydajność tych zapytań, uzupełniając zalety filtrowania po lub przed.
Filtrowanie adaptacyjne
Aby jeszcze bardziej zoptymalizować wydajność, adaptacyjne filtrowanie AlloyDB dynamicznie wybiera najbardziej wydajną strategię filtrowania (wbudowaną lub filtrowanie wstępne) podczas wykonywania zapytań. Analizuje wzorce zapytań i rozkłady danych, aby zapewnić optymalną wydajność bez interwencji ręcznej. Jest to szczególnie przydatne w przypadku filtrowanych wyszukiwań wektorowych, w których automatycznie przełącza się między użyciem indeksu wektorowego a indeksu metadanych. Aby włączyć filtrowanie adaptacyjne, użyj flagi scann.enable_preview_features.
Gdy filtrowanie adaptacyjne spowoduje przełączenie z filtrowania wbudowanego na filtrowanie wstępne podczas wykonywania, plan zapytania zmieni się dynamicznie.
SET scann.enable_preview_features = on;
WAŻNA UWAGA: jeśli po uruchomieniu powyższego polecenia bez ponownego uruchomienia instancji pojawi się błąd, włącz flagę enable_preview_features w sekcji flag bazy danych instancji.
Filtry z aspektami korzystające ze wszystkich indeksów
Wyszukiwanie fasetowe umożliwia użytkownikom zawężanie wyników przez stosowanie wielu filtrów na podstawie określonych atrybutów lub „aspektów” (np. marka, cena, rozmiar, ocena klienta). Nasza aplikacja bezproblemowo integruje te aspekty z wyszukiwaniem wektorowym. Pojedyncze zapytanie może teraz łączyć język naturalny (wyszukiwanie kontekstowe) z wieloma wyborami z różnych kategorii, dynamicznie wykorzystując zarówno indeksy wektorowe, jak i tradycyjne. Zapewnia to prawdziwie dynamiczną funkcję wyszukiwania hybrydowego, która umożliwia użytkownikom precyzyjne zagłębianie się w wyniki.
W naszej aplikacji, ponieważ utworzyliśmy już wszystkie indeksy metadanych, możemy używać w internecie filtrów fasetowych, bezpośrednio odwołując się do nich za pomocą zapytań SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
W tym zapytaniu przeprowadzamy wyszukiwanie hybrydowe, które obejmuje zarówno
- filtrowanie fasetowe w klauzuli WHERE,
- Wyszukiwanie wektorowe w klauzuli ORDER BY za pomocą metody podobieństwa cosinusowego.
$1, $2, $3 i $4 reprezentują wartości filtra fasetowego w tablicy, a $5 reprezentuje tekst wyszukiwania użytkownika. Zastąp $1–$4 wybranymi wartościami filtra fasetowego, jak poniżej:
category = ANY([‘Odzież’, ‘Obuwie’])
Zastąp wartość 5 zł wybranym tekstem wyszukiwania, np. „koszulki polo”.
WAŻNA UWAGA: jeśli nie masz indeksów z powodu ograniczonego zestawu wstawionych rekordów, nie zobaczysz wpływu na wydajność. Jednak w pełnym zbiorze danych produkcyjnych zauważysz, że czas wykonania jest znacznie krótszy w przypadku tego samego wyszukiwania wektorowego z użyciem indeksu ScaNN z wbudowanym filtrowaniem w wyszukiwaniu wektorowym.
Teraz sprawdźmy skuteczność wyszukiwania wektorowego z włączoną funkcją ScaNN.
Ponowne pozycjonowanie
Nawet w przypadku wyszukiwania zaawansowanego wstępne wyniki mogą wymagać ostatecznego dopracowania. Jest to kluczowy krok, który polega na ponownym uporządkowaniu początkowych wyników wyszukiwania w celu zwiększenia ich trafności. Po tym, jak początkowe wyszukiwanie hybrydowe dostarczy zestaw produktów kandydatów, bardziej zaawansowany (i często bardziej wymagający obliczeniowo) model zastosuje dokładniejszy wynik trafności. Dzięki temu użytkownikom wyświetlane są najbardziej trafne wyniki, co znacznie poprawia jakość wyszukiwania. Stale oceniamy skuteczność, aby sprawdzić, jak dobrze system wyszukuje wszystkie odpowiednie elementy dla danego zapytania. Ulepszamy nasze modele, aby zmaksymalizować prawdopodobieństwo znalezienia przez klienta tego, czego potrzebuje.
Zanim użyjesz tego w aplikacji, upewnij się, że spełniasz wszystkie wymagania wstępne:
- Sprawdź, czy rozszerzenie google_ml_integration jest zainstalowane.
- Sprawdź, czy flaga google_ml_integration.enable_model_support jest włączona.
- Integracja z Vertex AI
- Włącz interfejs Discovery Engine API.
- Uzyskaj wymagane role, aby korzystać z modeli rankingowych.
Następnie możesz użyć w naszej aplikacji tego zapytania, aby ponownie uszeregować wyniki wyszukiwania hybrydowego:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
W tym zapytaniu ponownie oceniamy zestaw wyników wyszukiwania kontekstowego produktów, do którego odnosi się klauzula ORDER BY, za pomocą metody podobieństwa cosinusowego. „Różowy top” to tekst, którego szuka użytkownik.
WAŻNA UWAGA: niektórzy z Was mogą jeszcze nie mieć dostępu do ponownego rankingu, dlatego wykluczyłem go z kodu aplikacji. Jeśli jednak chcesz go uwzględnić, możesz skorzystać z przykładowego kodu, który omówiliśmy powyżej.
Ocena czułości
Wyszukiwanie podobieństw to odsetek trafnych wyników wyszukiwania, czyli liczba wyników prawdziwie pozytywnych. To najczęstszy wskaźnik używany do pomiaru jakości wyszukiwania. Jednym ze źródeł utraty precyzji jest różnica między przybliżonym wyszukiwaniem najbliższych sąsiadów (aNN) a wyszukiwaniem k najbliższych sąsiadów (kNN). Indeksy wektorowe, takie jak ScaNN w AlloyDB, implementują algorytmy aNN, co pozwala przyspieszyć wyszukiwanie wektorowe w dużych zbiorach danych w zamian za niewielkie obniżenie czułości. AlloyDB umożliwia teraz bezpośrednie mierzenie tego kompromisu w bazie danych w przypadku poszczególnych zapytań i zapewnienie jego stabilności w czasie. Na podstawie tych informacji możesz aktualizować parametry zapytań i indeksów, aby osiągać lepsze wyniki i wydajność.
Jaka jest logika przywoływania wyników wyszukiwania?
W kontekście wyszukiwania wektorowego precyzja odnosi się do odsetka wektorów zwracanych przez indeks, które są prawdziwymi najbliższymi sąsiadami. Jeśli na przykład zapytanie o 20 najbliższych sąsiadów zwróci 19 najbliższych sąsiadów z prawdziwych danych, to precyzja wynosi 19/20 x 100 = 95%. Recall to miara używana do określania jakości wyszukiwania. Jest ona definiowana jako odsetek zwróconych wyników, które są obiektywnie najbliższe wektorom zapytania.
Wartość przypomnienia dla zapytania wektorowego w indeksie wektorowym w przypadku danej konfiguracji możesz znaleźć za pomocą funkcji evaluate_query_recall. Ta funkcja umożliwia dostosowanie parametrów w celu uzyskania oczekiwanych wyników zapytania wektorowego.
WAŻNA UWAGA:
Jeśli podczas wykonywania poniższych kroków dotyczących indeksu HNSW wystąpi błąd odmowy uprawnień, na razie pomiń całą sekcję oceny przywoływania. Może to mieć związek z ograniczeniami dostępu, ponieważ w momencie dokumentowania tego laboratorium kodowego usługa została dopiero udostępniona.
- Ustaw flagę Włącz skanowanie indeksu w indeksie ScaNN i indeksie HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Uruchom to zapytanie w AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Funkcja evaluate_query_recall przyjmuje zapytanie jako parametr i zwraca jego przypomnienie. Używam tego samego zapytania, którego użyłem do sprawdzenia wydajności, jako zapytania wejściowego funkcji. Jako metodę indeksowania dodano SCaNN. Więcej opcji parametrów znajdziesz w dokumentacji.
Wartość przypomnienia dla używanego przez nas zapytania do wyszukiwarki wektorowej:
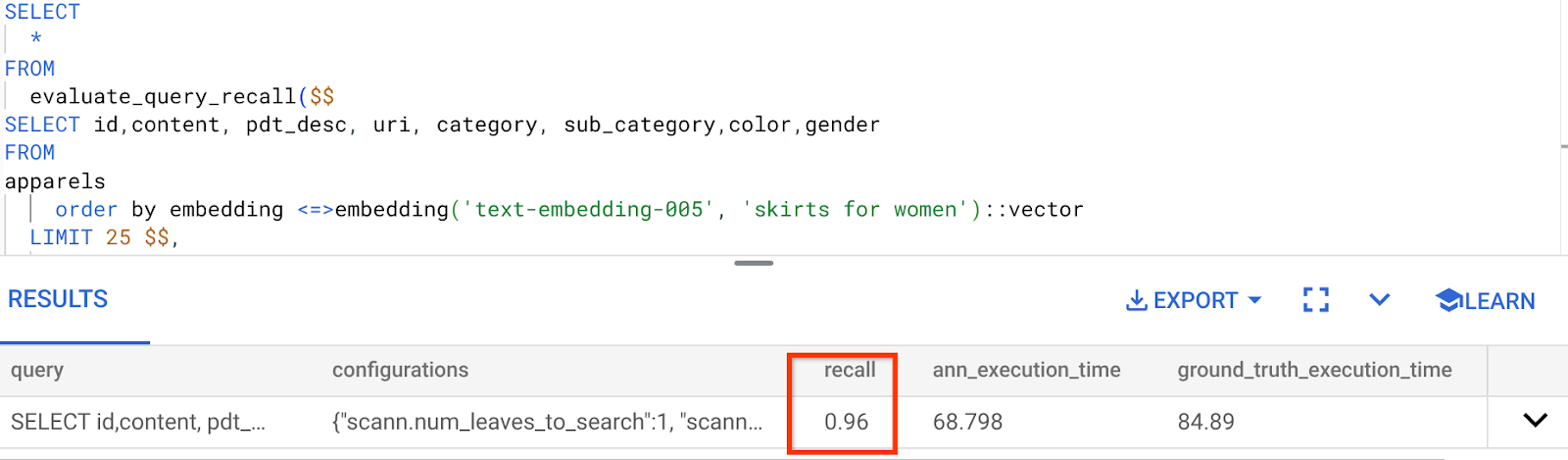
Widzę, że wartość RECALL wynosi 96%. W tym przypadku przypomnienie jest bardzo dobre. Jeśli jednak była to niedopuszczalna wartość, możesz użyć tych informacji, aby zmienić parametry indeksu, metody i parametry zapytania oraz poprawić skuteczność wyszukiwania wektorowego.
Przetestuj go ze zmodyfikowanymi parametrami zapytania i indeksu
Teraz przetestuj zapytanie, modyfikując parametry zapytania na podstawie otrzymanego wycofania.
- Modyfikowanie parametrów indeksu:
W tym teście użyję funkcji podobieństwa „Odległość L2” zamiast funkcji „Cosinus”.
Bardzo ważna uwaga: „Skąd wiemy, że to zapytanie używa podobieństwa COSINE?” – zapytasz. Funkcję odległości możesz rozpoznać po użyciu symbolu „<=>”, który oznacza odległość kosinusową.
Link do dokumentów z informacjami o funkcjach odległości w Wyszukiwaniu wektorowym.
W poprzednim zapytaniu użyto funkcji odległości podobieństwa cosinusowego, a teraz wypróbujemy odległość L2. W tym celu musimy jednak zadbać o to, aby podstawowy indeks ScaNN też używał funkcji odległości L2. Teraz utwórzmy indeks z innym zapytaniem dotyczącym funkcji odległości: odległość L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
Instrukcja drop index służy tylko do zapewnienia, że w tabeli nie ma niepotrzebnego indeksu.
Teraz mogę wykonać to zapytanie, aby ocenić RECALL po zmianie funkcji odległości w funkcji wyszukiwania wektorowego.
[PO] Zapytanie, które korzysta z funkcji odległości L2:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
W przypadku zaktualizowanego indeksu możesz zobaczyć różnicę lub przekształcenie w wartości przywołania.
W indeksie możesz zmienić inne parametry, np. num_leaves, w zależności od pożądanej wartości przypomnienia i zbioru danych używanego przez aplikację.
Weryfikacja wyników wyszukiwania wektorowego przez LLM
Aby zapewnić najwyższą jakość kontrolowanego wyszukiwania, wprowadziliśmy opcjonalną warstwę weryfikacji LLM. Duże modele językowe mogą służyć do oceny trafności i spójności wyników wyszukiwania, zwłaszcza w przypadku złożonych lub niejednoznacznych zapytań. Może to obejmować:
Weryfikacja semantyczna:
Duży model językowy porównuje wyniki z intencją zapytania.
Filtrowanie logiczne:
Używanie LLM do stosowania złożonej logiki biznesowej lub reguł, które trudno zakodować w tradycyjnych filtrach, co pozwala jeszcze bardziej zawęzić listę produktów na podstawie niuansowych kryteriów.
Zapewnienie jakości:
automatyczne identyfikowanie i oznaczanie mniej trafnych wyników do sprawdzenia przez weryfikatorów lub udoskonalenia modelu;
Oto jak to zrobiliśmy w przypadku funkcji AI w AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
Podstawowe zapytanie jest takie samo jak w sekcjach dotyczących wyszukiwania z filtrowaniem, wyszukiwania hybrydowego i ponownego rankingu. W tym zapytaniu uwzględniliśmy warstwę oceny GEMINI zbioru wyników po ponownym rankingu, która jest reprezentowana przez konstrukcję ml_predict_row. Filtry fasetowe zostały przeze mnie wykomentowane, ale możesz dodać wybrane przez siebie elementy do tablicy dla zmiennych zastępczych od $1 do $4. Zastąp 5 zł dowolnym tekstem, którego chcesz użyć do wyszukiwania, np. „Różowy top bez wzoru w kwiaty”.
7. MCP Toolbox for Databases i warstwa aplikacji
Za kulisami działają zaawansowane narzędzia i dobrze skonstruowana aplikacja, które zapewniają płynne działanie.
Zestaw narzędzi MCP (Model Context Protocol) dla baz danych upraszcza integrację generatywnej AI i narzędzi opartych na agentach z AlloyDB. Jest to serwer open source, który usprawnia pulę połączeń, uwierzytelnianie i bezpieczne udostępnianie funkcji bazy danych agentom AI lub innym aplikacjom.
W naszej aplikacji użyliśmy zestawu narzędzi MCP dla baz danych jako warstwy abstrakcji dla wszystkich naszych inteligentnych zapytań dotyczących wyszukiwania hybrydowego.
Aby skonfigurować i wdrożyć Toolbox w naszym przypadku użycia, wykonaj te czynności:
Jak widać, jedną z baz danych obsługiwanych przez MCP Toolbox for Databases jest AlloyDB. Skonfigurowaliśmy ją już w poprzedniej sekcji, więc teraz skonfigurujmy Toolbox.
- Otwórz terminal Cloud Shell i sprawdź, czy projekt jest wybrany i wyświetlany w prompcie terminala. Aby przejść do katalogu projektu, uruchom w terminalu Cloud Shell to polecenie:
mkdir toolbox-tools
cd toolbox-tools
- Aby pobrać i zainstalować pakiet narzędzi w nowym folderze, uruchom to polecenie:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Otwórz edytor Cloud Shell (w trybie edycji kodu) i w głównym folderze projektu dodaj plik o nazwie „tools.yaml”.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Zastąp skrypt Tools.yaml kodem z tego pliku repozytorium.
Omówmy plik tools.yaml:
Źródła to różne źródła danych, z którymi narzędzie może wchodzić w interakcje. Źródło to źródło danych, z którym narzędzie może wchodzić w interakcje. Źródła możesz zdefiniować jako mapę w sekcji źródeł pliku tools.yaml. Zwykle konfiguracja źródła zawiera wszystkie informacje potrzebne do połączenia z bazą danych i interakcji z nią.
Narzędzia określają działania, które może wykonywać agent, np. odczytywanie i zapisywanie danych w źródle. Narzędzie reprezentuje działanie, które może wykonać agent, np. uruchomienie instrukcji SQL. Narzędzia możesz zdefiniować jako mapę w sekcji narzędzi w pliku tools.yaml. Zwykle narzędzie wymaga źródła, na którym ma działać.
Więcej informacji o konfigurowaniu pliku tools.yaml znajdziesz w tej dokumentacji.
- Aby uruchomić serwer, wykonaj to polecenie (w folderze mcp-toolbox):
./toolbox --tools-file "tools.yaml"
Jeśli teraz otworzysz serwer w trybie podglądu w chmurze, powinien być widoczny serwer Toolbox działający z nowym narzędziem o nazwie get-order-data.
Serwer MCP Toolbox działa domyślnie na porcie 5000. Aby to przetestować, użyjemy Cloud Shell.
W Cloud Shell kliknij Podgląd w przeglądarce, jak pokazano poniżej:
Kliknij Zmień port i ustaw port na 5000, jak pokazano poniżej, a następnie kliknij Zmień i wyświetl podgląd.
Powinny się pojawić te wyniki:
- Wdróżmy Toolbox w Cloud Run:
Na początek możemy uruchomić serwer MCP Toolbox w Cloud Run. Dzięki temu uzyskamy publiczny punkt końcowy, który możemy zintegrować z dowolną inną aplikacją lub aplikacjami agenta. Instrukcje dotyczące hostowania tego w Cloud Run znajdziesz tutaj. Omówimy teraz najważniejsze kroki.
- Uruchom nowy terminal Cloud Shell lub użyj istniejącego. Otwórz folder projektu, w którym znajdują się pliki binarne zestawu narzędzi i tools.yaml. W tym przypadku jest to folder toolbox-tools. Jeśli nie jesteś jeszcze w tym folderze:
cd toolbox-tools
- Ustaw zmienną PROJECT_ID tak, aby wskazywała identyfikator projektu Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Włącz te usługi Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Utwórzmy osobne konto usługi, które będzie tożsamością usługi Toolbox, którą wdrożymy w Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Dbamy też o to, aby to konto usługi miało odpowiednie role, czyli możliwość dostępu do Secret Manager i komunikowania się z AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Prześlemy plik tools.yaml jako tajny token:
gcloud secrets create tools --data-file=tools.yaml
Jeśli masz już obiekt tajny i chcesz zaktualizować jego wersję, wykonaj te czynności:
gcloud secrets versions add tools --data-file=tools.yaml
- Ustaw zmienną środowiskową na obraz kontenera, którego chcesz używać w Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Ostatni krok w znanym poleceniu wdrażania w Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Powinno to rozpocząć proces wdrażania serwera Toolbox z naszym skonfigurowanym plikiem tools.yaml w Cloud Run. Po pomyślnym wdrożeniu powinien wyświetlić się komunikat podobny do tego:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Możesz już używać nowo wdrożonego narzędzia w aplikacji opartej na agentach.
Uzyskiwanie dostępu do narzędzi na serwerze Toolbox
Po wdrożeniu zestawu narzędzi utworzymy w Cloud Run Functions w Pythonie warstwę pośrednią do interakcji z wdrożonym serwerem zestawu narzędzi. Dzieje się tak, ponieważ Toolbox nie ma obecnie pakietu SDK Javy, więc utworzyliśmy nakładkę w Pythonie, która umożliwia interakcję z serwerem. Oto kod źródłowy tej funkcji Cloud Run.
Aby mieć dostęp do narzędzi przybornika, które zostały utworzone i wdrożone w poprzednich krokach, musisz utworzyć i wdrożyć tę funkcję Cloud Run:
- W konsoli Google Cloud otwórz stronę Cloud Run.
- Kliknij Napisz funkcję.
- W polu Nazwa usługi wpisz nazwę opisującą funkcję. Nazwy usług muszą zaczynać się od litery i zawierać maksymalnie 49 znaków, w tym litery, cyfry i łączniki. Nazwy usług nie mogą kończyć się myślnikami i muszą być unikalne w obrębie regionu i projektu. Nazwy usługi nie można później zmienić i jest ona widoczna publicznie. (Enter retail-product-search-quality)
- Na liście Region (Region) użyj wartości domyślnej lub wybierz region, w którym chcesz wdrożyć funkcję. (Wybierz us-central1)
- Na liście Środowisko wykonawcze pozostaw wartość domyślną lub wybierz wersję środowiska wykonawczego. (Wybierz Python 3.11)
- W sekcji Uwierzytelnianie kliknij „Zezwól na dostęp publiczny”.
- Kliknij przycisk „Utwórz”.
- Funkcja zostanie utworzona i wczytana z plikami szablonu main.py i requirements.txt.
- Zastąp je plikami main.py i requirements.txt z repozytorium tego projektu.
- Wdróż funkcję, a powinien pojawić się punkt końcowy funkcji Cloud Run.
Punkt końcowy powinien wyglądać tak (lub podobnie):
Punkt końcowy funkcji Cloud Run umożliwiający dostęp do zestawu narzędzi: „https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app”
Aby ułatwić wykonanie zadań w określonym czasie (w przypadku sesji praktycznych prowadzonych przez instruktora), numer projektu punktu końcowego zostanie udostępniony podczas sesji praktycznej.
WAŻNA UWAGA:
Możesz też zaimplementować część bazy danych bezpośrednio w kodzie aplikacji lub funkcji Cloud Run.
8. Tworzenie aplikacji (Java) z wyszukiwaniem wieloaspektowym
Wszystkie te zaawansowane komponenty backendu są ożywiane przez warstwę aplikacji. Aplikacja została opracowana w języku Java i zapewnia interfejs użytkownika do interakcji z systemem wyszukiwania. Orkiestruje zapytania do AlloyDB, obsługuje wyświetlanie filtrów fasetowych, zarządza wyborami użytkowników i prezentuje ponownie uszeregowane, zweryfikowane wyniki wyszukiwania w sposób płynny i intuicyjny.
- Zacznij od przejścia do terminala Cloud Shell i sklonowania repozytorium:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Otwórz edytor Cloud Shell, w którym zobaczysz nowo utworzony folder faceted_searching_retail.
- Usuń te elementy, ponieważ te czynności zostały już wykonane w poprzednich sekcjach:
- Usuń folder Cloud_Run_Function.
- Usuń plik db_script.sql
- Usuń plik tools.yaml
- Przejdź do folderu projektu retail-faceted-search. Powinna się w nim wyświetlić struktura projektu:
- W pliku ProductRepository.java musisz zmodyfikować zmienną TOOLBOX_ENDPOINT, podając punkt końcowy funkcji Cloud Run (wdrożonej) lub punkt końcowy podany przez prowadzącego.
Wyszukaj ten wiersz kodu i zastąp go swoim punktem końcowym:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Upewnij się, że pliki Dockerfile i pom.xml są zgodne z konfiguracją projektu (nie musisz niczego zmieniać, chyba że wersja lub konfiguracja zostały przez Ciebie zmienione).
- W terminalu Cloud Shell sprawdź, czy jesteś w folderze głównym i w folderze projektu (faceted_searching_retail / retail-faceted-search). Użyj tych poleceń, aby upewnić się, że jesteś w odpowiednim folderze w terminalu:
cd faceted_searching_retail
cd retail-faceted-search
- Spakuj, skompiluj i przetestuj aplikację lokalnie:
mvn package
mvn spring-boot:run
Aby wyświetlić aplikację, kliknij „Podgląd na porcie 8080” w terminalu Cloud Shell, jak pokazano poniżej:
9. Wdróż w Cloud Run: ***WAŻNY KROK
W terminalu Cloud Shell sprawdź, czy jesteś w folderze głównym i w folderze projektu (faceted_searching_retail / retail-faceted-search). Użyj tych poleceń, aby upewnić się, że jesteś w odpowiednim folderze w terminalu:
cd faceted_searching_retail
cd retail-faceted-search
Gdy będziesz mieć pewność, że znajdujesz się w folderze projektu, uruchom to polecenie:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Po wdrożeniu powinien pojawić się wdrożony punkt końcowy Cloud Run, który wygląda tak:
https://retail-search-**********-uc.a.run.app/
10. Prezentacja
Zobaczmy, jak to wszystko działa w praktyce:
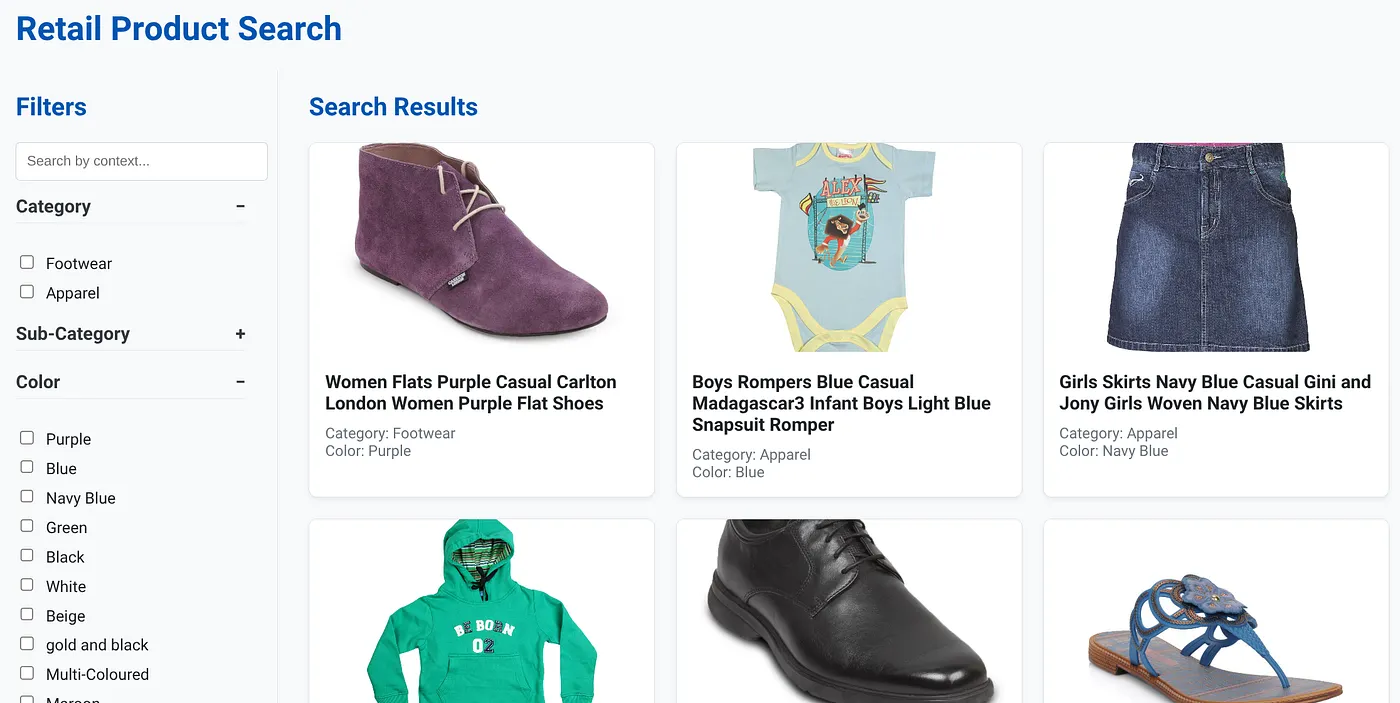
Obraz powyżej przedstawia stronę docelową aplikacji do dynamicznego wyszukiwania hybrydowego.
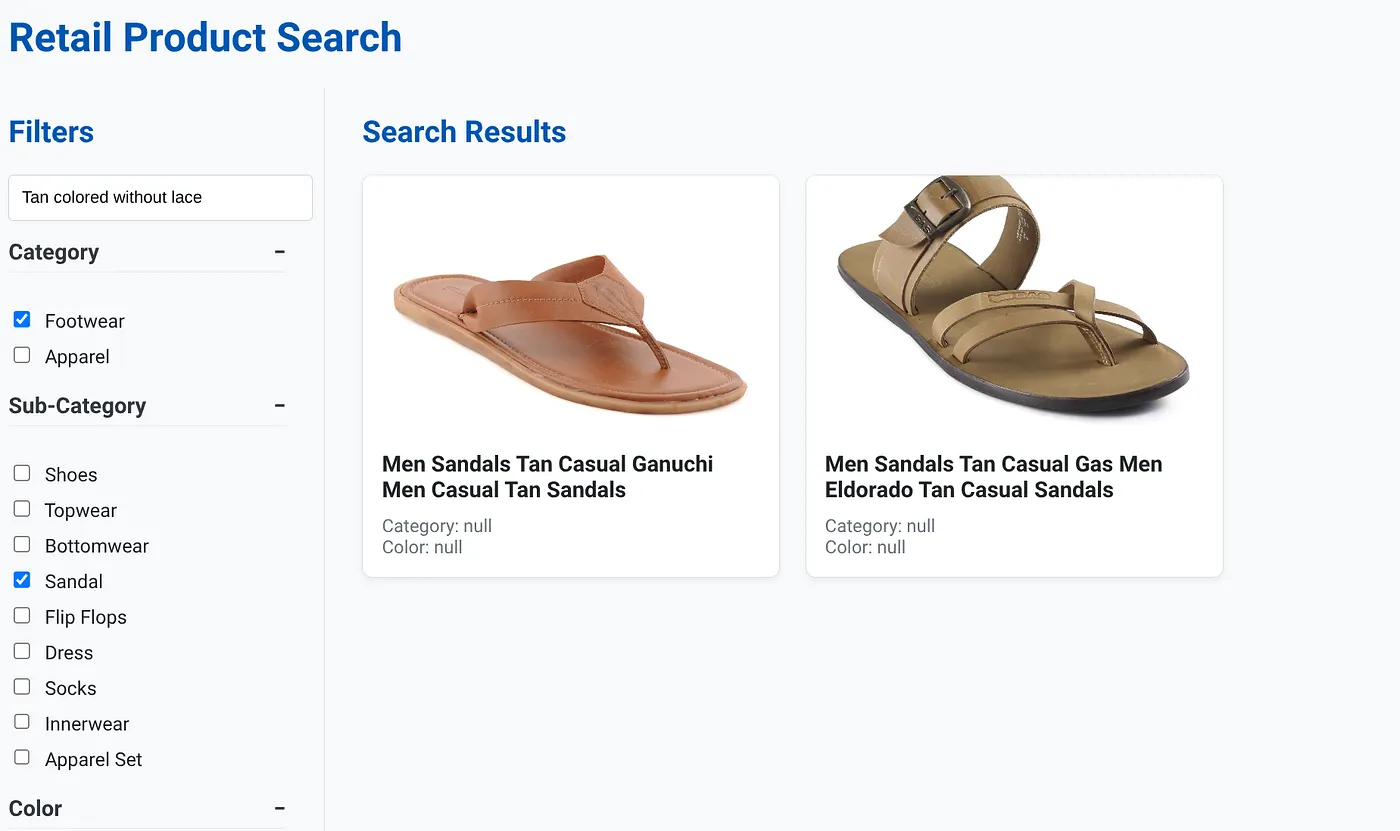
Na powyższym obrazie widać wyniki wyszukiwania hasła „Tan colored without lace” (Brązowe bez sznurowadeł). Wybrane filtry to: Obuwie, Sandały.
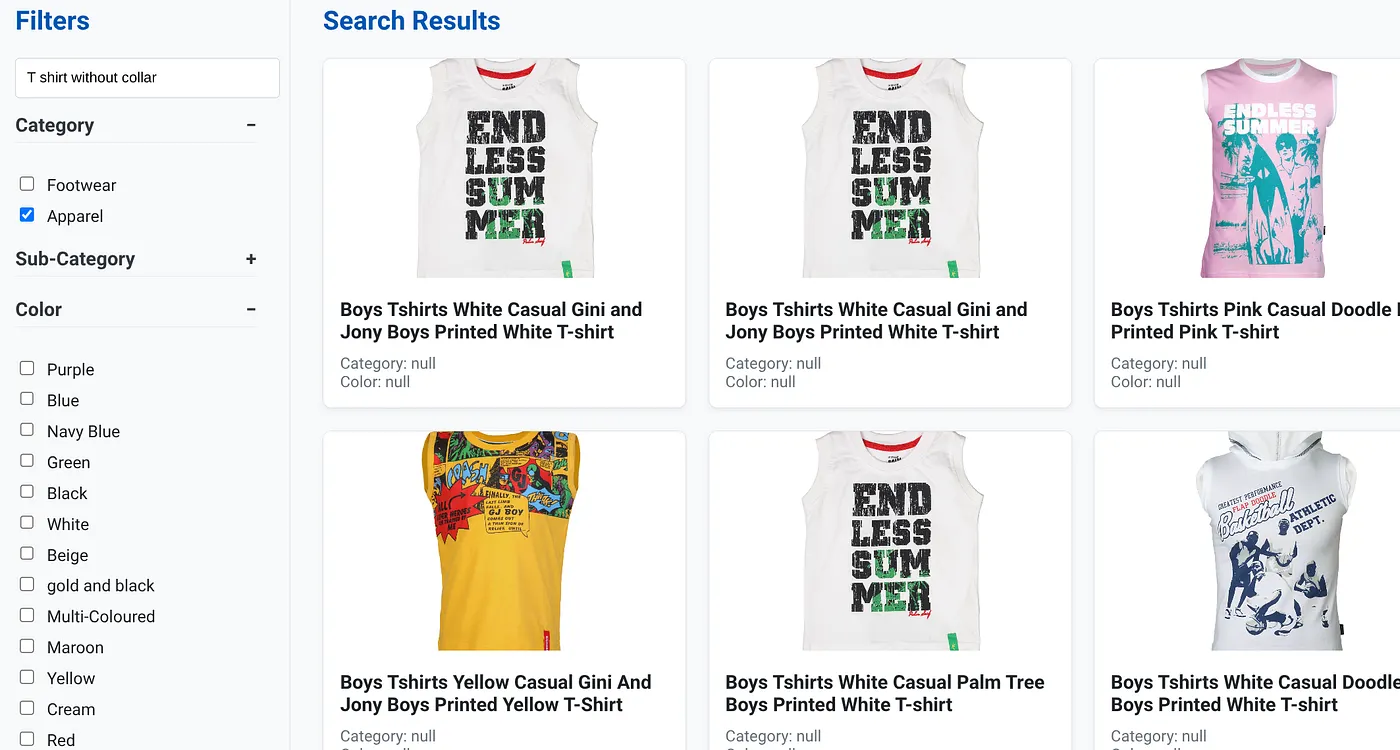
Obraz powyżej przedstawia wyniki wyszukiwania zapytania „T-shirt bez kołnierzyka”. Filtry fasetowe: odzież
Możesz teraz dodać więcej funkcji generatywnych i opartych na agentach, aby ta aplikacja była bardziej przydatna.
Wypróbuj to, aby zainspirować się do tworzenia własnych projektów.
11. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Menedżer zasobów.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też po prostu usunąć klaster AlloyDB (jeśli podczas konfiguracji nie wybrano lokalizacji us-central1, zmień lokalizację w tym hiperlinku), który został utworzony dla tego projektu, klikając przycisk USUN KLASER.
12. Gratulacje
Gratulacje! Udało Ci się utworzyć i wdrożyć APLIKACJĘ WYSZUKIWANIA HYBRYDOWEGO z ALLOYDB w CLOUD RUN!!!
Dlaczego to jest ważne dla firm:
Ta dynamiczna hybrydowa aplikacja do wyszukiwania oparta na AlloyDB AI zapewnia znaczące korzyści dla przedsiębiorstw z branży handlu detalicznego i innych firm:
Wyższa trafność: dzięki połączeniu wyszukiwania kontekstowego (wektorowego) z precyzyjnym filtrowaniem fasetowym i inteligentnym ponownym rankingiem klienci otrzymują bardzo trafne wyniki, co zwiększa ich zadowolenie i liczbę konwersji.
Skalowalność: architektura AlloyDB i indeksowanie scaNN zostały zaprojektowane z myślą o obsłudze ogromnych katalogów produktów i dużych ilości zapytań, co jest kluczowe dla rozwijających się firm e-commerce.
Wydajność: szybsze odpowiedzi na zapytania, nawet w przypadku złożonych wyszukiwań hybrydowych, zapewniają płynne działanie i minimalizują współczynnik porzuceń.
Przyszłościowe rozwiązanie: integracja funkcji AI (osadzanie, weryfikacja LLM) przygotowuje aplikację na przyszłe postępy w zakresie spersonalizowanych rekomendacji, handlu konwersacyjnego i inteligentnego odkrywania produktów.
Uproszczona architektura: integracja wyszukiwania wektorowego bezpośrednio w AlloyDB eliminuje potrzebę korzystania z oddzielnych baz danych wektorowych lub złożonej synchronizacji, co upraszcza programowanie i konserwację.
Załóżmy, że użytkownik wpisał zapytanie w języku naturalnym, np. „ekologiczne buty do biegania dla kobiet z wysokim podbiciem”.
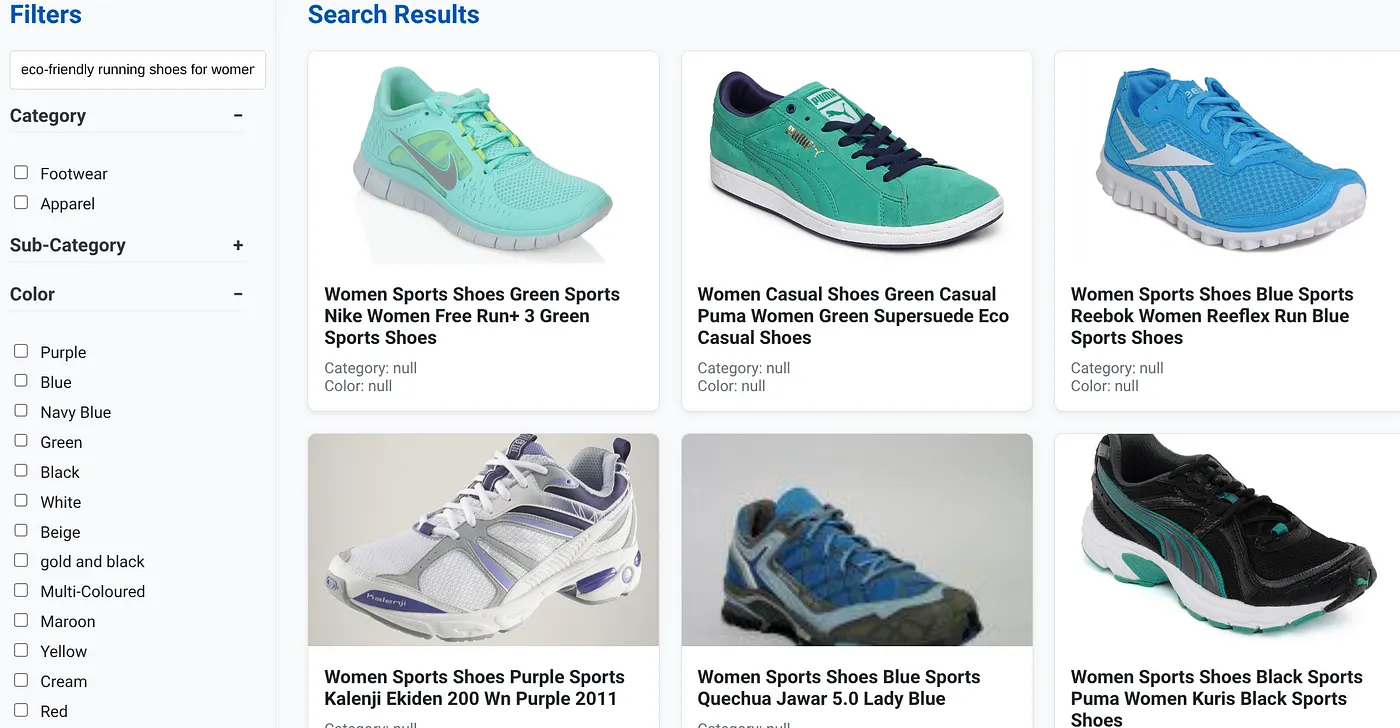
użytkownik jednocześnie stosuje filtry fasetowe „Kategoria: <<>>”, „Kolor: <<>>” i mówi „Cena: 100–150 zł”:
- System natychmiast zwraca przefiltrowaną listę produktów, które są semantycznie zgodne z językiem naturalnym i dokładnie pasują do wybranych filtrów.
- Za kulisami indeks scaNN przyspiesza wyszukiwanie wektorowe, a filtrowanie wbudowane i adaptacyjne zapewnia wydajność przy połączonych kryteriach. Ponowne rankingowanie wyświetla optymalne wyniki na górze.
- Szybkość i dokładność wyników wyraźnie pokazują, jak potężne jest połączenie tych technologii, które zapewnia prawdziwie inteligentne wyszukiwanie w sklepie.
Stworzenie aplikacji do wyszukiwania w branży handlowej nowej generacji wymaga wyjścia poza konwencjonalne metody. Wykorzystując możliwości AlloyDB, Vertex AI, wyszukiwania wektorowego z indeksowaniem scaNN, dynamicznego filtrowania fasetowego, ponownego rankingu i weryfikacji LLM, możemy zapewnić niezrównane wrażenia klienta, które zwiększają zaangażowanie i sprzedaż. To solidne, skalowalne i inteligentne rozwiązanie pokazuje, jak nowoczesne możliwości baz danych wzbogacone o AI zmieniają przyszłość handlu detalicznego.