
1. Visão geral
No cenário competitivo do varejo atual, é fundamental permitir que os clientes encontrem exatamente o que procuram, de forma rápida e intuitiva. A pesquisa tradicional baseada em palavras-chave geralmente não funciona bem, tendo dificuldades com consultas complexas e catálogos de produtos grandes. Este codelab revela um sofisticado aplicativo de pesquisa de varejo criado no AlloyDB e no AlloyDB AI, aproveitando a pesquisa vetorial de ponta, a indexação scaNN, os filtros facetados e a filtragem adaptativa inteligente, a reclassificação para oferecer uma experiência de pesquisa híbrida e dinâmica em escala empresarial.
Agora já temos o entendimento básico de três coisas:
- O que a pesquisa contextual significa para seu agente e como fazer isso usando a Pesquisa Vetorial.
- Também analisamos a fundo como fazer uma pesquisa vetorial no escopo dos seus dados, ou seja, no próprio banco de dados. Todos os bancos de dados do Google Cloud oferecem suporte a isso, caso você não saiba.
- Fomos um passo além do resto do mundo ao mostrar como realizar uma pesquisa vetorial RAG leve com alta performance e qualidade usando o recurso de pesquisa vetorial do AlloyDB com tecnologia do índice ScaNN.
Se você ainda não fez esses experimentos básicos, intermediários e um pouco avançados de RAG, leia os três aqui, aqui e aqui na ordem listada.
O desafio
Além de filtros, palavras-chave e correspondência contextual: uma pesquisa simples por palavra-chave pode retornar milhares de resultados, muitos deles irrelevantes. A solução ideal precisa entender a intenção por trás da consulta, combiná-la com critérios de filtro precisos (como marca, material ou preço) e apresentar os itens mais relevantes em milissegundos. Isso exige uma infraestrutura de pesquisa avançada, flexível e escalonável. Claro que evoluímos muito desde a pesquisa de palavras-chave até as correspondências contextuais e as pesquisas de similaridade. Mas imagine um cliente pesquisando "uma jaqueta confortável, elegante e à prova d'água para caminhadas na primavera" e aplicando filtros simultaneamente. Seu aplicativo não apenas retorna respostas de qualidade, mas também tem alto desempenho, e a sequência de tudo isso é escolhida dinamicamente pelo seu banco de dados.
Objetivo
Para resolver isso, integre
- Pesquisa contextual (Pesquisa vetorial): entender o significado semântico das consultas e descrições de produtos
- Filtragem por facetas: permite que os usuários refinem os resultados com atributos específicos.
- Abordagem híbrida: combinação perfeita da pesquisa contextual com a filtragem estruturada
- Otimização avançada: uso de indexação especializada, filtragem adaptativa e reclassificação para velocidade e relevância
- Controle de qualidade com tecnologia de IA generativa: incorporação da validação de LLM para uma qualidade superior dos resultados.
Vamos analisar a arquitetura e a jornada de implementação.
O que você vai criar
Um aplicativo de pesquisa de varejo
Como parte disso, você vai:
- Criar uma instância e uma tabela do AlloyDB para o conjunto de dados de e-commerce
- Configurar embeddings e pesquisa vetorial
- Criar índice de metadados e índice ScaNN
- Implementar a pesquisa vetorial avançada no AlloyDB usando o método de filtragem em linha do ScaNN
- Configurar filtros facetados e pesquisa híbrida em uma única consulta
- Aprimorar a relevância da consulta com reclassificação e recall (opcional)
- Avaliar a resposta da consulta com o Gemini (opcional)
- MCP Toolbox for Databases e camada de aplicativo
- Desenvolvimento de aplicativos (Java) com pesquisa facetada
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
3. Configuração do banco de dados
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de e-commerce. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de e-commerce será carregado.
criar um cluster e uma instância
- Navegue até a página do AlloyDB no console do Cloud. Uma maneira fácil de encontrar a maioria das páginas no console do Cloud é pesquisar usando a barra de pesquisa do console.
- Selecione CRIAR CLUSTER nessa página:

- Você vai acessar uma tela como esta. Crie um cluster e uma instância com os seguintes valores. Verifique se os valores correspondem caso você esteja clonando o código do aplicativo do repositório:
- ID do cluster: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mais recente recomendado
- Região: "
us-central1" - Rede: "
default"
- Ao selecionar a rede padrão, você vai ver uma tela como a abaixo.
Selecione CONFIGURAR CONEXÃO.
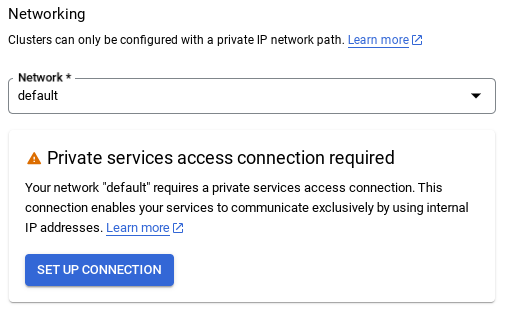
- Em seguida, selecione Usar um intervalo de IP alocado automaticamente e clique em "Continuar". Depois de revisar as informações, selecione "CRIAR CONEXÃO".
- Depois que a rede for configurada, você poderá continuar criando o cluster. Clique em CRIAR CLUSTER para concluir a configuração do cluster, conforme mostrado abaixo:
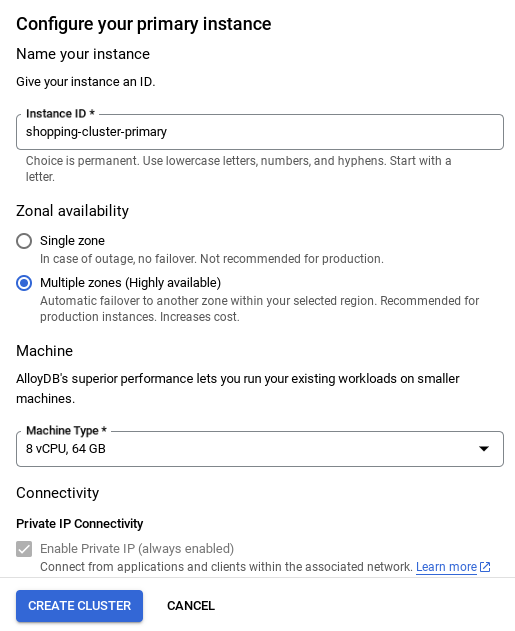
OBSERVAÇÃO IMPORTANTE:
- Mude o ID da instância (que pode ser encontrado no momento da configuração do cluster / instância) para**
vector-instance**. Se não for possível mudar, use o ID da instância em todas as referências futuras. - A criação do cluster leva cerca de 10 minutos. Quando a operação for concluída, uma tela vai mostrar a visão geral do cluster que você acabou de criar.
4. Ingestão de dados
Agora é hora de adicionar uma tabela com os dados da loja. Navegue até o AlloyDB, selecione o cluster primário e o AlloyDB Studio:
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb"
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetores. A extensão google_ml_integration oferece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Ative essas extensões executando os seguintes DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Se você quiser verificar as extensões ativadas no seu banco de dados, execute este comando SQL:
select extname, extversion from pg_extension;
Criar uma tabela
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
A coluna de embedding permite armazenar os valores vetoriais do texto.
Conceder permissão
Execute a instrução abaixo para conceder a execução na função "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Conceder o papel de usuário da Vertex AI à conta de serviço do AlloyDB
No console do Google Cloud IAM, conceda à conta de serviço do AlloyDB (que tem esta aparência: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acesso à função "Usuário da Vertex AI". PROJECT_NUMBER vai ter o número do seu projeto.
Como alternativa, execute o comando abaixo no terminal do Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carregar dados no banco de dados
- Copie as instruções de consulta
insertdainsert scripts sqlna planilha para o editor, conforme mencionado acima. Você pode copiar de 10 a 50 instruções de inserção para uma demonstração rápida desse caso de uso. Há uma lista selecionada de encartes na guia "Linhas de encartes selecionadas de 25 a 30".
O link para os dados pode ser encontrado neste arquivo do repositório do GitHub.
- Clique em Executar. Os resultados da consulta aparecem na tabela Resultados.
OBSERVAÇÃO IMPORTANTE:
Copie apenas 25 a 50 registros para inserir e verifique se eles são de um intervalo de categoria, subcategoria, cor e tipos de gênero.
5. Criar embeddings para os dados
A verdadeira inovação na pesquisa moderna está em entender o significado, não apenas as palavras-chave. É aí que entram os embeddings e a pesquisa vetorial.
Transformamos descrições de produtos e consultas de usuários em representações numéricas de alta dimensão chamadas "embeddings" usando modelos de linguagem pré-treinados. Esses embeddings capturam o significado semântico, permitindo encontrar produtos que são "semelhantes em significado", em vez de apenas conter palavras correspondentes. Inicialmente, testamos a pesquisa direta por similaridade vetorial nesses embeddings para estabelecer um valor de referência, demonstrando o poder da compreensão semântica mesmo antes das otimizações de performance.
A coluna de embedding permite o armazenamento dos valores de vetor do texto de descrição do produto. A coluna "img_embeddings" permite armazenar embeddings de imagens (multimodais). Assim, você também pode usar a pesquisa baseada na distância entre texto e imagem. Mas vamos usar apenas embeddings de texto neste laboratório.
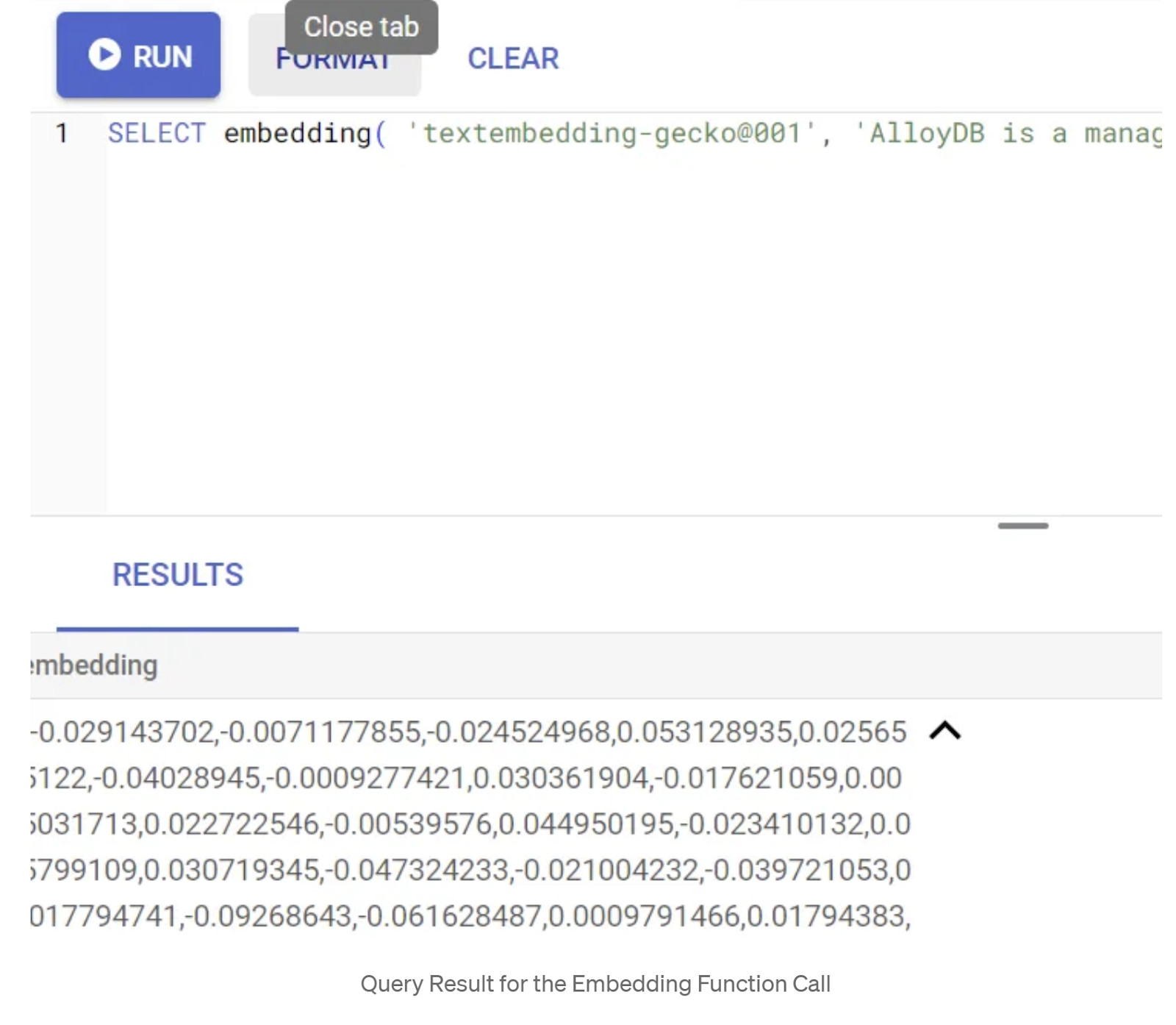
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Isso vai retornar o vetor de embeddings, que parece uma matriz de números de ponto flutuante, para o texto de exemplo na consulta. Ela é assim:
Atualizar o campo de vetor abstract_embeddings
Execute a DML abaixo para atualizar a descrição do conteúdo na tabela com os embeddings correspondentes:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Você pode ter problemas para gerar mais do que alguns embeddings (digamos, no máximo 20 a 25) se estiver usando uma conta de faturamento de crédito de teste do Google Cloud. Portanto, limite o número de linhas no script de inserção.
Se você quiser gerar embeddings de imagem (para realizar uma pesquisa contextual multimodal), execute a atualização abaixo também:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Realizar RAG avançado com os novos recursos do AlloyDB
Agora que a tabela, os dados e os embeddings estão prontos, vamos realizar a pesquisa vetorial em tempo real para o texto de pesquisa do usuário. Para testar, execute a consulta abaixo:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
Nesta consulta, comparamos o embedding de texto da pesquisa inserida pelo usuário "camiseta com gola redonda" com os embeddings de texto de todas as descrições de produtos na tabela de roupas (armazenadas na coluna "embedding") usando a função de distância de similaridade de cosseno (representada pelo símbolo "<=>"). Convertemos o resultado do método de embedding para o tipo de vetor para torná-lo compatível com os vetores armazenados no banco de dados. LIMIT 10 representa que estamos selecionando as 10 correspondências mais próximas do texto de pesquisa.
O AlloyDB leva o RAG de pesquisa vetorial a outro nível:
Para uma solução em escala empresarial, a pesquisa de vetores bruta não é suficiente. O desempenho é essencial.
Índice do ScaNN (vizinhos mais próximos escalonáveis)
Para realizar uma pesquisa de vizinho mais próximo aproximada (ANN) ultrarrápida, ativamos o índice scaNN no AlloyDB. O ScaNN, um algoritmo de pesquisa de vizinho mais próximo aproximado de última geração desenvolvido pela Google Research, foi projetado para uma pesquisa de similaridade vetorial eficiente em grande escala. Ele acelera significativamente as consultas ao reduzir o espaço de pesquisa e usar técnicas de quantização, oferecendo consultas vetoriais até 4 vezes mais rápidas do que outros métodos de indexação e um consumo de memória menor. Saiba mais aqui e aqui.
Vamos ativar a extensão e criar os índices:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Criar índices para os campos de embedding de texto e de imagem (caso você queira usar embeddings de imagem na pesquisa):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Índices de metadados
Enquanto o scaNN processa a indexação de vetores, os índices tradicionais de árvore B ou GIN foram meticulosamente configurados em atributos estruturados (como categoria, subcategoria, estilo, cor etc.). Esses índices são cruciais para a eficiência da filtragem facetada. Execute as instruções abaixo para configurar índices de metadados:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
OBSERVAÇÃO IMPORTANTE:
Como você pode ter inserido apenas 25 a 50 registros, os índices (ScaNN ou qualquer outro) não serão eficazes.
Filtragem inline
Um desafio comum na pesquisa vetorial é combiná-la com filtros estruturados (por exemplo, "sapatos vermelhos"). A filtragem inline do AlloyDB otimiza isso. Em vez de pós-filtragem de resultados de uma pesquisa vetorial ampla, a filtragem inline aplica condições de filtro durante o processo de pesquisa vetorial, melhorando drasticamente o desempenho e a acurácia para pesquisas vetoriais filtradas.
Consulte esta documentação para saber mais sobre a necessidade de filtragem inline. Saiba mais sobre a pesquisa de vetor filtrada para otimizar o desempenho da pesquisa de vetor aqui. Agora, se você quiser ativar a filtragem in-line para seu aplicativo, execute a seguinte instrução no editor:
SET scann.enable_inline_filtering = on;
A filtragem inline é ideal para casos com seletividade média. À medida que o AlloyDB pesquisa no índice vetorial, ele só calcula distâncias para vetores que correspondem às condições de filtragem de metadados (seus filtros funcionais em uma consulta geralmente processada na cláusula WHERE). Isso melhora muito o desempenho dessas consultas, complementando as vantagens do pós-filtro ou pré-filtro.
Filtragem adaptativa
Para otimizar ainda mais o desempenho, a filtragem adaptativa do AlloyDB escolhe dinamicamente a estratégia de filtragem mais eficiente (inline ou pré-filtragem) durante a execução da consulta. Ele analisa padrões de consulta e distribuições de dados para garantir o desempenho ideal sem intervenção manual, o que é especialmente útil para pesquisas vetoriais filtradas, em que ele alterna automaticamente entre o uso de vetores e índices de metadados. Para ativar a filtragem adaptativa, use a flag scann.enable_preview_features.
Quando a filtragem adaptativa aciona uma alteração da filtragem inline para a pré-filtragem durante a execução, o plano de consulta é alterado dinamicamente.
SET scann.enable_preview_features = on;
OBSERVAÇÃO IMPORTANTE: talvez não seja possível executar a instrução acima sem reiniciar a instância. Se ocorrer um erro, ative a flag "enable_preview_features" na seção de flags do banco de dados da instância.
Filtros facetados usando todos os índices
Com a pesquisa facetada, os usuários podem refinar os resultados aplicando vários filtros com base em atributos específicos ou "atributos" (por exemplo, marca, preço, tamanho, classificação do cliente). Nosso aplicativo integra essas facetas perfeitamente à pesquisa de vetor. Uma única consulta agora pode combinar linguagem natural (pesquisa contextual) com várias seleções facetadas, aproveitando dinamicamente os índices vetoriais e tradicionais. Isso oferece uma capacidade de pesquisa híbrida verdadeiramente dinâmica, permitindo que os usuários detalhem os resultados com precisão.
No nosso aplicativo, como já criamos todos os índices de metadados, estamos prontos para o uso do filtro facetado na Web. Para isso, basta usar consultas SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
Nesta consulta, estamos realizando uma pesquisa híbrida, incorporando
- Filtragem facetada na cláusula WHERE e
- Pesquisa vetorial na cláusula ORDER BY usando o método de semelhança de cosseno.
$1, $2, $3 e $4 representam os valores do filtro facetado em uma matriz, e $5 representa o texto de pesquisa do usuário. Substitua $1 a $4 por valores de filtro facetado de sua escolha, como abaixo:
category = ANY([‘Apparel', ‘Footwear'])
Substitua $5 por um texto de pesquisa de sua escolha, por exemplo, "Camisetas polo".
OBSERVAÇÃO IMPORTANTE: se você não tiver os índices devido ao conjunto limitado de registros inseridos, não vai notar o impacto na performance. Mas em um conjunto de dados de produção completo, você vai observar que o tempo de execução é reduzido significativamente para a mesma Pesquisa vetorial usando o índice ScaNN com filtragem inline. Isso foi possível graças à Pesquisa vetorial.
Em seguida, vamos avaliar o recall para essa pesquisa vetorial ativada pelo ScaNN.
Reclassificação
Mesmo com a pesquisa avançada, os resultados iniciais podem precisar de um toque final. Essa é uma etapa crítica que reordena os resultados da pesquisa inicial para melhorar a relevância. Depois que a pesquisa híbrida inicial fornece um conjunto de produtos candidatos, um modelo mais sofisticado (e geralmente mais pesado computacionalmente) aplica uma pontuação de relevância mais refinada. Isso garante que os principais resultados apresentados ao usuário sejam os mais pertinentes, melhorando significativamente a qualidade da pesquisa. Avaliamos continuamente o recall para medir a eficiência do sistema em recuperar todos os itens relevantes para uma determinada consulta, refinando nossos modelos para maximizar a probabilidade de um cliente encontrar o que precisa.
Antes de usar isso no seu aplicativo, verifique se você atende a todos os pré-requisitos:
- Verifique se a extensão google_ml_integration está instalada.
- Verifique se a flag google_ml_integration.enable_model_support está ativada.
- Integrar com a Vertex AI.
- Ative a API Discovery Engine.
- Ter os papéis necessários para usar modelos de classificação.
Depois, use a consulta a seguir no aplicativo para reclassificar o conjunto de resultados da pesquisa híbrida:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
Nesta consulta, estamos RECLASSIFICANDO o conjunto de resultados de produtos da pesquisa contextual abordada na cláusula ORDER BY usando o método de similaridade de cosseno. "Blusa rosa" é o texto que o usuário está pesquisando.
OBSERVAÇÃO IMPORTANTE: alguns de vocês ainda não têm acesso à reclassificação. Por isso, excluí esse recurso do código do aplicativo. No entanto, se quiser incluir, siga o exemplo que abordamos acima.
Avaliador de recall
O recall na pesquisa de similaridade é a porcentagem de instâncias relevantes que foram recuperadas de uma pesquisa, ou seja, o número de verdadeiros positivos. Essa é a métrica mais comum usada para medir a qualidade da pesquisa. Uma fonte de perda de recall vem da diferença entre a pesquisa de vizinho mais próximo aproximado (aNN) e a pesquisa de vizinho k (exato) mais próximo (kNN). Os índices vetoriais, como o ScaNN do AlloyDB, implementam algoritmos aNN, permitindo acelerar a pesquisa vetorial em grandes conjuntos de dados em troca de uma pequena compensação na recuperação. Agora, o AlloyDB permite medir essa troca diretamente no banco de dados para consultas individuais e garantir que ela seja estável ao longo do tempo. É possível atualizar os parâmetros de consulta e índice em resposta a essas informações para alcançar melhores resultados e desempenho.
Qual é a lógica por trás da recuperação de resultados da pesquisa?
No contexto da pesquisa de vetores, o recall se refere à porcentagem de vetores retornados pelo índice que são vizinhos mais próximos verdadeiros. Por exemplo, se uma consulta de vizinho mais próxima de 20 vizinhos mais próximos retornar 19 dos vizinhos mais próximos, o recall será de 19/20x100 = 95%. O recall é a métrica usada para a qualidade da pesquisa e é definida como a porcentagem dos resultados retornados que estão objetivamente mais próximos dos vetores de consulta.
É possível encontrar o recall de uma consulta vetorial em um índice vetorial para uma determinada configuração usando a função evaluate_query_recall. Com essa função, é possível ajustar os parâmetros para alcançar os resultados de recall da consulta vetorial desejados.
OBSERVAÇÃO IMPORTANTE:
Se você estiver enfrentando um erro de permissão negada no índice HNSW nas etapas a seguir, pule toda esta seção de avaliação de recall por enquanto. Isso pode estar relacionado a restrições de acesso, já que ele foi lançado recentemente quando este codelab foi documentado.
- Defina a flag "Ativar verificação de índice" no índice ScaNN e HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Execute a seguinte consulta no AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
A função "evaluate_query_recall" usa a consulta como um parâmetro e retorna a acurácia dela. Estou usando a mesma consulta que usei para verificar a performance como consulta de entrada da função. Adicionei o SCaNN como método de indexação. Para mais opções de parâmetros, consulte a documentação.
O recall para esta consulta de pesquisa vetorial que estamos usando:
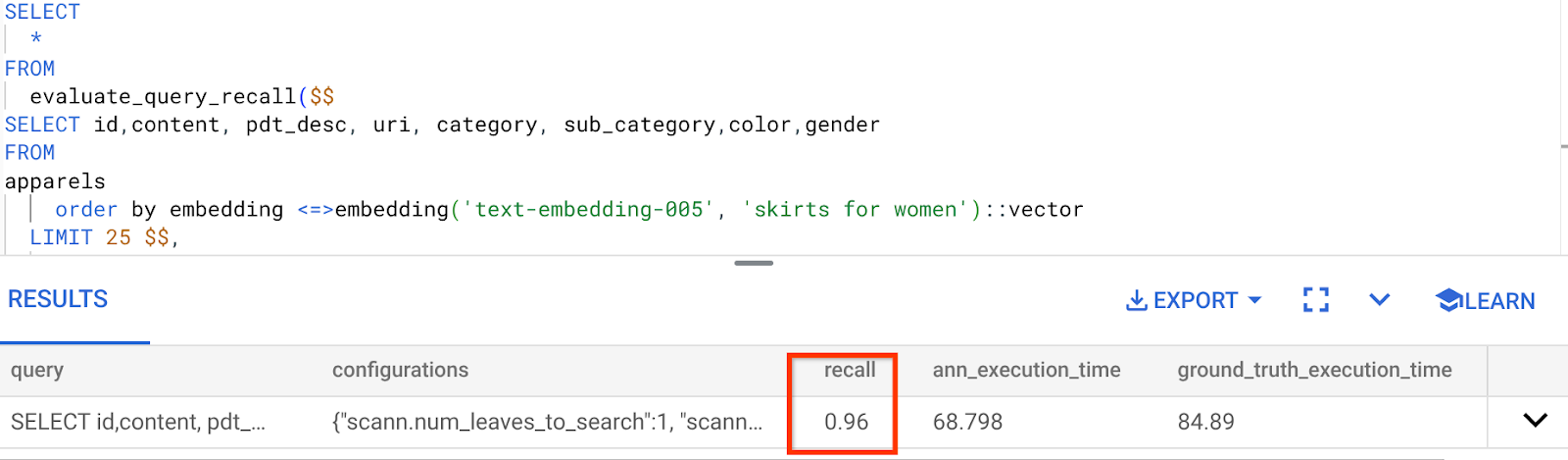
Vejo que o RECALL é de 96%. Nesse caso, o recall é muito bom. Mas se for um valor inaceitável, você poderá usar essas informações para mudar os parâmetros de índice, métodos e parâmetros de consulta e melhorar minha capacidade de recall para essa pesquisa vetorial.
Teste com parâmetros de consulta e índice modificados
Agora vamos testar a consulta modificando os parâmetros de consulta com base no recall recebido.
- Para modificar os parâmetros do índice:
Para este teste, vou usar a distância L2 em vez da função de distância de similaridade cosseno.
Observação muito importante: "Como sabemos que essa consulta usa a similaridade de cosseno?", você pergunta. É possível identificar a função de distância pelo uso de "<=>" para representar a distância de cosseno.
Link da documentação para funções de distância da pesquisa vetorial.
A consulta anterior usa a função de distância de similaridade de cosseno, mas agora vamos tentar a distância L2. Mas, para isso, também precisamos garantir que o índice ScaNN subjacente use a função de distância L2. Agora vamos criar um índice com uma consulta de função de distância diferente: Distância L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
A instrução "drop index" serve apenas para garantir que não haja um índice desnecessário na tabela.
Agora, posso executar a seguinte consulta para avaliar o RECALL depois de mudar a função de distância da minha funcionalidade de pesquisa de vetor.
[AFTER] Consulta que usa a função Distância L2:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
É possível ver a diferença / transformação no valor de recall do índice atualizado.
Há outros parâmetros que podem ser mudados no índice, como "num_leaves" etc., com base no valor de recall desejado e no conjunto de dados usado pelo aplicativo.
Validação de LLM dos resultados da pesquisa vetorial
Para alcançar a mais alta qualidade de pesquisa controlada, incorporamos uma camada opcional de validação de LLM. Os modelos de linguagem grandes podem ser usados para avaliar a relevância e a coerência dos resultados da pesquisa, especialmente para consultas complexas ou ambíguas. Isso pode envolver os seguintes aspectos:
Verificação semântica:
Um LLM que faz referências cruzadas entre os resultados e a intenção da consulta.
Filtragem lógica:
Usar um LLM para aplicar regras ou lógica de negócios complexas que são difíceis de codificar em filtros tradicionais, refinando ainda mais a lista de produtos com base em critérios sutis.
Controle de qualidade:
Identificar e sinalizar automaticamente resultados menos relevantes para revisão humana ou refinamento do modelo.
É assim que fizemos isso nos recursos da IA do AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
A consulta subjacente é a mesma que vimos nas seções de pesquisa facetada, híbrida e de reclassificação. Agora, nessa consulta, incorporamos uma camada de avaliação do GEMINI do conjunto de resultados reclassificados representado pela construção ml_predict_row. Comentei os filtros facetados, mas você pode incluir os itens que quiser em uma matriz para os marcadores de posição $1 a $4. Substitua $5 pelo texto que você quer pesquisar, por exemplo, "Blusa rosa sem estampa floral".
7. MCP Toolbox for Databases e camada de aplicativo
Nos bastidores, ferramentas robustas e um aplicativo bem estruturado garantem uma operação tranquila.
A caixa de ferramentas do MCP (Protocolo de Contexto de Modelo) para bancos de dados simplifica a integração da IA generativa e das ferramentas agênticas com o AlloyDB. Ele funciona como um servidor de código aberto que simplifica o pool de conexões, a autenticação e a exposição segura de funcionalidades de banco de dados para agentes de IA ou outros aplicativos.
No nosso aplicativo, usamos o MCP Toolbox for Databases como uma camada de abstração para todas as nossas consultas de pesquisa híbrida inteligente.
Siga as etapas abaixo para configurar e implantar a caixa de ferramentas no nosso caso de uso:
Um dos bancos de dados compatíveis com o MCP Toolbox for Databases é o AlloyDB. Como já provisionamos isso na seção anterior, vamos configurar a caixa de ferramentas.
- Acesse o terminal do Cloud Shell e verifique se o projeto está selecionado e aparece no prompt do terminal. Execute o comando abaixo no terminal do Cloud Shell para acessar o diretório do projeto:
mkdir toolbox-tools
cd toolbox-tools
- Execute o comando abaixo para fazer o download e instalar a caixa de ferramentas na nova pasta:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Acesse o editor do Cloud Shell (para o modo de edição de código) e, na pasta raiz do projeto, adicione um arquivo chamado "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Substitua o script Tools.yaml pelo código deste arquivo do repositório.
Vamos entender o arquivo tools.yaml:
As fontes representam as diferentes origens de dados com que uma ferramenta pode interagir. Uma origem representa uma fonte de dados com que uma ferramenta pode interagir. É possível definir fontes como um mapa na seção "sources" do arquivo tools.yaml. Normalmente, uma configuração de origem contém todas as informações necessárias para se conectar e interagir com o banco de dados.
As ferramentas definem as ações que um agente pode realizar, como ler e gravar em uma fonte. Uma ferramenta representa uma ação que o agente pode realizar, como executar uma instrução SQL. É possível definir ferramentas como um mapa na seção "tools" do arquivo tools.yaml. Normalmente, uma ferramenta precisa de uma fonte para agir.
Para mais detalhes sobre como configurar o arquivo tools.yaml, consulte esta documentação.
- Execute o seguinte comando (na pasta mcp-toolbox) para iniciar o servidor:
./toolbox --tools-file "tools.yaml"
Agora, se você abrir o servidor no modo de visualização na Web na nuvem, poderá ver o servidor da caixa de ferramentas em execução com sua nova ferramenta chamada "get-order-data".
O servidor do MCP Toolbox é executado por padrão na porta 5000. Vamos usar o Cloud Shell para testar isso.
Clique em "Visualização da Web" no Cloud Shell, conforme mostrado abaixo:
Clique em "Alterar porta", defina a porta como 5000, conforme mostrado abaixo, e clique em "Alterar e visualizar".
Isso vai gerar a saída:
- Vamos implantar nossa caixa de ferramentas no Cloud Run:
Primeiro, podemos começar com o servidor do MCP Toolbox e hospedá-lo no Cloud Run. Isso nos daria um endpoint público que pode ser integrado a qualquer outro aplicativo e/ou aos aplicativos do agente também. As instruções para hospedar isso no Cloud Run estão aqui. Vamos conferir as etapas principais agora.
- Inicie um novo terminal do Cloud Shell ou use um terminal existente. Acesse a pasta do projeto em que o binário da caixa de ferramentas e o arquivo tools.yaml estão presentes. Nesse caso, é "toolbox-tools".
cd toolbox-tools
- Defina a variável PROJECT_ID para apontar para o ID do projeto do Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Ative estes serviços do Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Vamos criar uma conta de serviço separada que vai atuar como a identidade do serviço da caixa de ferramentas que vamos implantar no Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Também estamos garantindo que essa conta de serviço tenha os papéis corretos, ou seja, a capacidade de acessar o Secret Manager e se comunicar com o AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Vamos fazer upload do arquivo tools.yaml como um secret:
gcloud secrets create tools --data-file=tools.yaml
Se você já tiver um secret e quiser atualizar a versão dele, execute o seguinte:
gcloud secrets versions add tools --data-file=tools.yaml
- Defina uma variável de ambiente para a imagem do contêiner que você quer usar no Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- A última etapa do comando de implantação familiar no Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Isso vai iniciar o processo de implantação do servidor da caixa de ferramentas com nosso arquivo tools.yaml configurado no Cloud Run. Se a implantação for bem-sucedida, você vai receber uma mensagem semelhante a esta:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Você já pode usar a ferramenta recém-implantada no seu aplicativo de agente.
Acessar as ferramentas no servidor da caixa de ferramentas
Depois que o Toolbox for implantado, vamos criar um shim de funções do Cloud Run em Python para interagir com o servidor do Toolbox implantado. Isso acontece porque, no momento, a Toolbox não tem um SDK Java. Por isso, criamos um shim do Python para interagir com o servidor. Este é o código-fonte dessa função do Cloud Run.
Você precisa criar e implantar essa função do Cloud Run para acessar as ferramentas da caixa de ferramentas que acabamos de criar e implantar nas etapas anteriores:
- No console do Google Cloud, acesse a página do Cloud Run.
- Clique em "Escrever uma função".
- No campo "Nome do serviço", insira um nome para descrever a função. Os nomes de serviços precisam começar com uma letra e conter até 49 caracteres, incluindo letras, números ou hífens. Os nomes de serviço não podem terminar com hífens e precisam ser exclusivos por região e projeto. Não é possível alterar o nome de um serviço depois e ele fica visível publicamente. (Enter retail-product-search-quality)
- Na lista "Região", use o valor padrão ou selecione a região em que você quer implantar a função. Escolha us-central1
- Na lista "Ambiente de execução", use o valor padrão ou selecione uma versão. Escolha Python 3.11
- Na seção "Autenticação", escolha "Permitir acesso público".
- Clique no botão "Criar".
- A função é criada e carregada com um main.py e um requirements.txt de modelo.
- Substitua por estes arquivos: main.py e requirements.txt do repositório deste projeto.
- Implante a função para receber um destino para sua função do Cloud Run.
O endpoint vai ficar assim (ou algo parecido):
Endpoint da função do Cloud Run para acessar a caixa de ferramentas: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Para facilitar a conclusão dentro do cronograma (para as sessões práticas com instrutor), o número do projeto do endpoint será compartilhado no momento da sessão prática.
OBSERVAÇÃO IMPORTANTE:
Como alternativa, é possível implementar a parte do banco de dados diretamente como parte do código do aplicativo ou da função do Cloud Run.
8. Desenvolvimento de aplicativos (Java) com pesquisa facetada
Por fim, todos esses componentes de back-end eficientes são implementados na camada de aplicativo. Desenvolvido em Java, o aplicativo fornece a interface do usuário para interagir com o sistema de pesquisa. Ele organiza as consultas ao AlloyDB, processa a exibição de filtros facetados, gerencia as seleções do usuário e apresenta os resultados da pesquisa reclassificados e validados de maneira integrada e intuitiva.
- Para começar, navegue até o terminal do Cloud Shell e clone o repositório:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Navegue até o editor do Cloud Shell, onde você pode ver a pasta recém-criada faceted_searching_retail.
- Exclua o seguinte, já que essas etapas já foram concluídas nas seções anteriores:
- Exclua a pasta Cloud_Run_Function
- Exclua o arquivo db_script.sql
- Exclua o arquivo tools.yaml
- Navegue até a pasta do projeto retail-faceted-search. A estrutura do projeto vai aparecer:
- No arquivo ProductRepository.java, modifique a variável TOOLBOX_ENDPOINT com o endpoint da sua função do Cloud Run (implantada) ou pegue o endpoint com o palestrante prático.
Procure a seguinte linha de código e substitua pelo seu endpoint:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Verifique se o Dockerfile e o pom.xml estão de acordo com a configuração do projeto. Não é necessário fazer mudanças, a menos que você tenha alterado explicitamente alguma versão ou configuração.
- No terminal do Cloud Shell, verifique se você está na pasta principal e na pasta do projeto (faceted_searching_retail / retail-faceted-search). Use os seguintes comandos para garantir que, a menos que você já esteja na pasta certa no terminal:
cd faceted_searching_retail
cd retail-faceted-search
- Empacote, crie e teste o aplicativo localmente:
mvn package
mvn spring-boot:run
Para acessar o aplicativo, clique em "Visualizar na porta 8080" no terminal do Cloud Shell, conforme mostrado abaixo:
9. Implante no Cloud Run: ***ETAPA IMPORTANTE
No terminal do Cloud Shell, confirme se você está na pasta principal e na pasta do projeto (faceted_searching_retail / retail-faceted-search). Use os seguintes comandos para garantir que, a menos que você já esteja na pasta certa no terminal:
cd faceted_searching_retail
cd retail-faceted-search
Depois de confirmar que você está na pasta do projeto, execute o seguinte comando:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Depois da implantação, você vai receber um endpoint do Cloud Run implantado semelhante a este:
https://retail-search-**********-uc.a.run.app/
10. Demonstração
Vamos conferir como isso funciona na prática:
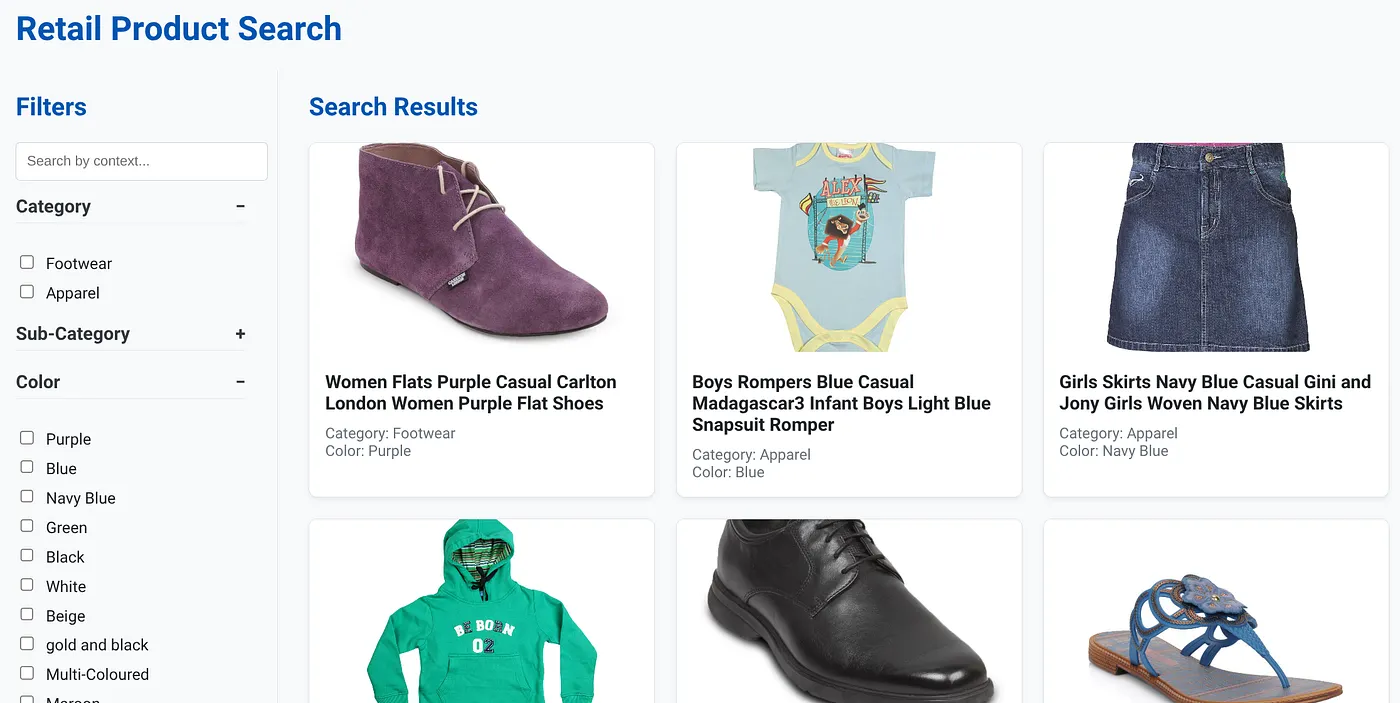
A imagem acima mostra a página de destino do app de pesquisa híbrida dinâmica.
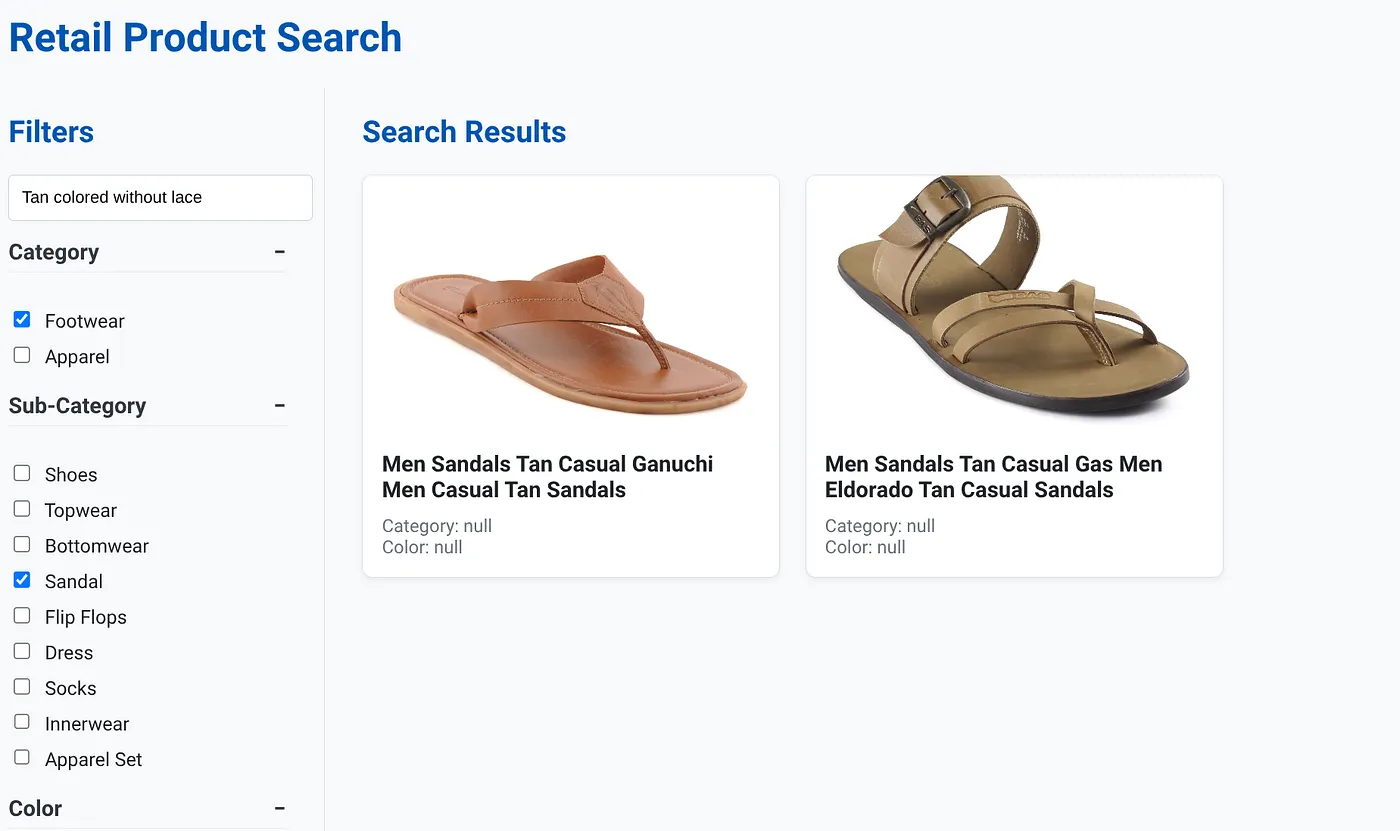
A imagem acima mostra os resultados da pesquisa "Cor bronzeado sem cadarço" . Os filtros facetados selecionados são: calçados, sandálias.
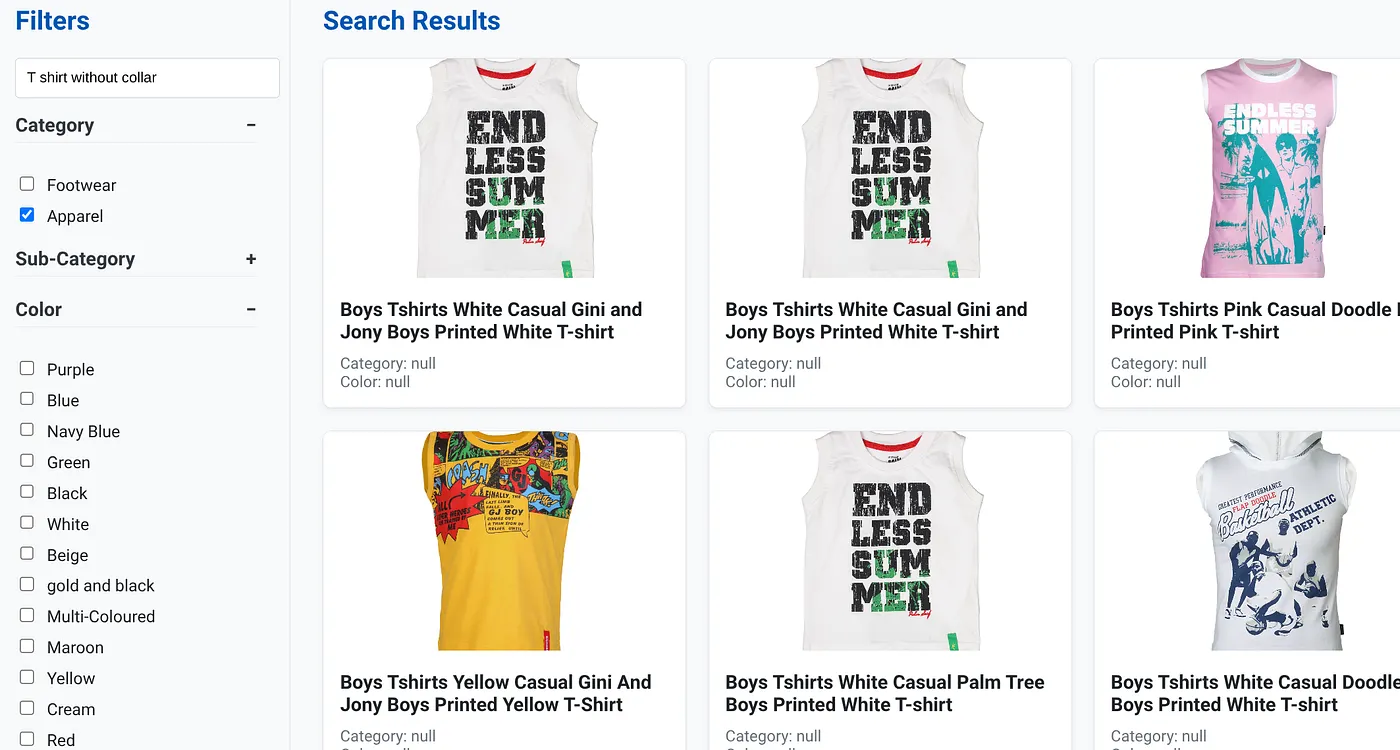
A imagem acima mostra os resultados da pesquisa por "camiseta sem gola" . Filtros facetados: vestuário
Agora você pode incorporar mais recursos generativos e de agente para tornar esse aplicativo útil.
Teste para se inspirar e criar seu próprio conteúdo.
11. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página do Gerenciador de recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Como alternativa, você pode excluir o cluster do AlloyDB (mude o local neste hiperlink se não tiver escolhido us-central1 para o cluster no momento da configuração) que acabamos de criar para este projeto clicando no botão EXCLUIR CLUSTER.
12. Parabéns
Parabéns! Você criou e implantou um APP DE PESQUISA HÍBRIDA com ALLOYDB no CLOUD RUN!!!
Por que isso é importante para as empresas:
Esse aplicativo dinâmico de pesquisa híbrida, com tecnologia da IA do AlloyDB, oferece vantagens significativas para o varejo empresarial e outras empresas:
Relevância superior:ao combinar a pesquisa contextual (vetorial) com a filtragem facetada precisa e a reclassificação inteligente, os clientes recebem resultados altamente relevantes, o que aumenta a satisfação e as conversões.
Escalabilidade:a arquitetura e a indexação scaNN do AlloyDB foram projetadas para processar catálogos de produtos enormes e grandes volumes de consultas, o que é crucial para empresas de e-commerce em crescimento.
Performance:respostas mais rápidas às consultas, mesmo em pesquisas híbridas complexas, garantem uma experiência do usuário tranquila e minimizam as taxas de desistência.
Preparação para o futuro:a integração de recursos de IA (incorporações, validação de LLM) posiciona o aplicativo para avanços futuros em recomendações personalizadas, comércio conversacional e descoberta inteligente de produtos.
Arquitetura simplificada:a integração da pesquisa vetorial diretamente no AlloyDB elimina a necessidade de bancos de dados vetoriais separados ou sincronização complexa, simplificando o desenvolvimento e a manutenção.
Digamos que um usuário tenha digitado uma consulta em linguagem natural como "tênis de corrida ecológicos para mulheres com suporte de arco alto".
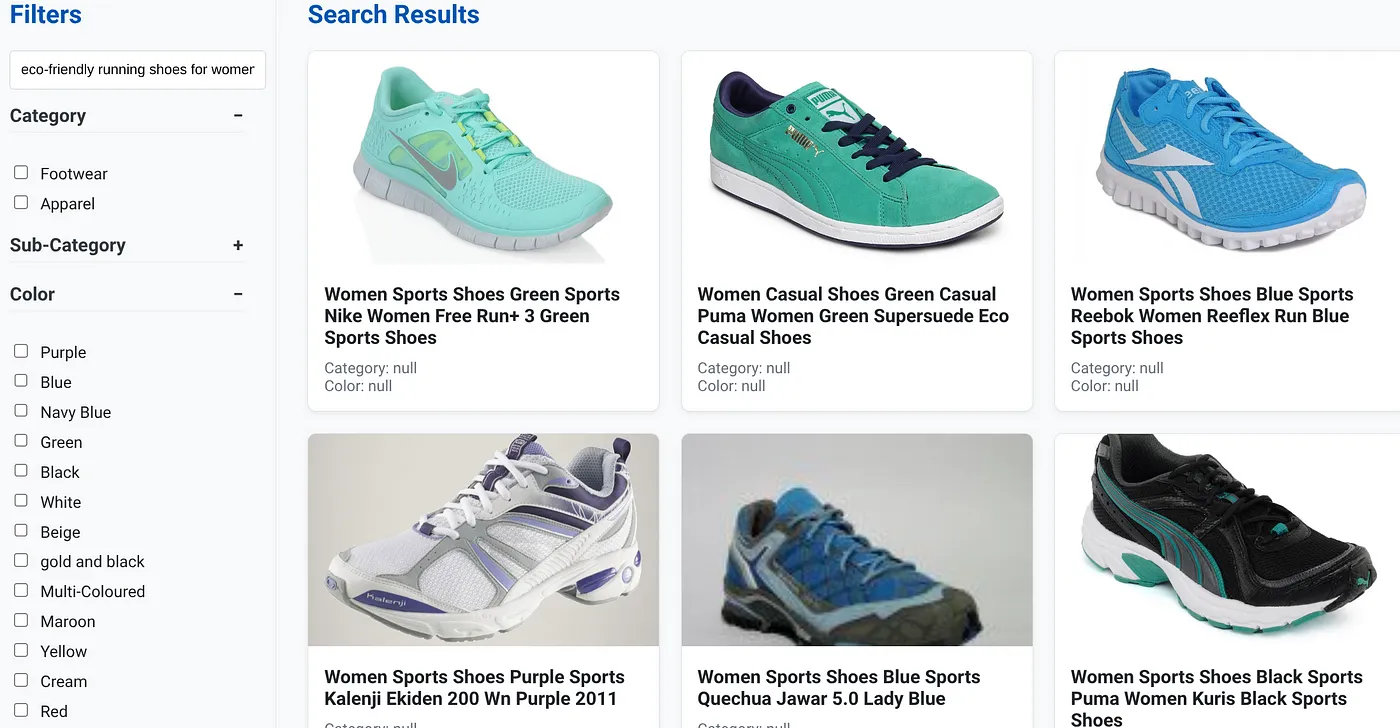
enquanto o usuário aplica filtros facetados para "Categoria: <<>>", "Cor: <<>>" e diz "Preço: R$ 100 a R$ 150":
- O sistema retorna instantaneamente uma lista refinada de produtos, alinhada semanticamente com a linguagem natural e correspondente aos filtros escolhidos.
- Nos bastidores, o índice scaNN acelera a pesquisa vetorial, a filtragem adaptativa e em linha garante o desempenho com critérios combinados, e a reclassificação apresenta os resultados ideais na parte superior.
- A velocidade e a acurácia dos resultados ilustram claramente o poder de combinar essas tecnologias para uma experiência de pesquisa de varejo verdadeiramente inteligente.
Para criar um aplicativo de pesquisa de varejo de última geração, é necessário ir além dos métodos convencionais. Ao usar o poder do AlloyDB, da Vertex AI, da pesquisa vetorial com indexação scaNN, da filtragem dinâmica por facetas, da reclassificação e da validação de LLM, podemos oferecer uma experiência do cliente incomparável que impulsiona o engajamento e aumenta as vendas. Essa solução robusta, escalonável e inteligente demonstra como os recursos modernos de banco de dados, com IA, estão transformando o futuro do varejo.