
1. Обзор
В условиях современной конкурентной розничной торговли крайне важно дать клиентам возможность быстро и интуитивно находить именно то, что им нужно. Традиционный поиск по ключевым словам часто оказывается неэффективным, с трудом справляясь со сложными запросами и обширными каталогами товаров. В этом практическом занятии будет представлено сложное приложение для поиска в розничной торговле, построенное на базе AlloyDB и AlloyDB AI, использующее передовые технологии векторного поиска, индексирование scaNN, фасетные фильтры и интеллектуальную адаптивную фильтрацию, которая переранжирует результаты поиска, обеспечивая динамичный гибридный поиск в масштабах предприятия.
Теперь у нас уже есть базовое понимание трех вещей:
- Что означает контекстный поиск для вашего агента и как его реализовать с помощью векторного поиска.
- Мы также подробно рассмотрели возможность реализации векторного поиска в рамках ваших данных, то есть в самой базе данных (все облачные базы данных Google поддерживают эту функцию, если вы еще не знали!).
- Мы пошли на шаг дальше, чем остальной мир, рассказав вам, как реализовать столь легковесный векторный поиск RAG с высокой производительностью и качеством, используя возможности векторного поиска AlloyDB на основе индекса ScaNN.
Если вы еще не ознакомились с базовыми, промежуточными и немного более сложными экспериментами RAG, я бы посоветовал вам прочитать их здесь , здесь и здесь в указанном порядке.
Вызов
Выходя за рамки фильтров, ключевых слов и контекстного сопоставления: простой поиск по ключевым словам может выдать тысячи результатов, многие из которых нерелевантны. Идеальное решение должно понимать намерение, стоящее за запросом, сочетать его с точными критериями фильтрации (например, бренд, материал или цена) и представлять наиболее релевантные элементы за миллисекунды. Это требует мощной, гибкой и масштабируемой поисковой инфраструктуры. Конечно, мы прошли долгий путь от поиска по ключевым словам до контекстного сопоставления и поиска по сходству. Но представьте себе клиента, ищущего «удобную, стильную, водонепроницаемую куртку для походов весной», одновременно применяя фильтры, и ваше приложение не только возвращает качественные ответы, но и работает с высокой производительностью, а последовательность всего этого динамически выбирается вашей базой данных.
Цель
Для решения этой проблемы путем интеграции
- Контекстный поиск (векторный поиск): понимание семантического значения запросов и описаний товаров.
- Фасетная фильтрация: позволяет пользователям уточнять результаты поиска по определенным атрибутам.
- Гибридный подход: органичное сочетание контекстного поиска и структурированной фильтрации.
- Расширенная оптимизация: использование специализированного индексирования, адаптивной фильтрации и переранжирования для повышения скорости и релевантности.
- Генеративный контроль качества на основе ИИ: использование валидации LLM для достижения превосходного качества результатов.
Давайте разберем архитектуру и процесс внедрения.
Что вы построите
Приложение для поиска в розничной торговле
В рамках этого процесса вы будете:
- Создайте экземпляр AlloyDB и таблицу для набора данных по электронной коммерции.
- Настройте векторные представления и векторный поиск.
- Создайте индекс метаданных и индекс ScaNN.
- Реализуйте расширенный векторный поиск в AlloyDB, используя метод встроенной фильтрации ScaNN.
- Настройте фасетные фильтры и гибридный поиск в одном запросе.
- Уточните релевантность запроса с помощью переранжирования и полноты (необязательно).
- Оценить ответ на запрос с помощью Gemini (необязательно)
- MCP Toolbox для баз данных и прикладного уровня
- Разработка приложений (Java) с использованием фасетного поиска.
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его настройки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для данных электронной коммерции. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут хранить сами данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будут загружены данные об электронной коммерции.
Создайте кластер и экземпляр.
- Перейдите на страницу AlloyDB в Cloud Console. Большинство страниц в Cloud Console легко найти, используя строку поиска консоли.
- На этой странице выберите пункт «СОЗДАТЬ КЛАСТЕР» :

- Вы увидите экран, похожий на тот, что показан ниже. Создайте кластер и экземпляр со следующими значениями (убедитесь, что значения совпадают, если вы клонируете код приложения из репозитория):
- идентификатор кластера : "
vector-cluster" - пароль : "
alloydb" - Рекомендуемая последняя версия PostgreSQL: 15.
- Регион : "
us-central1" - Сетевые настройки : "
default"
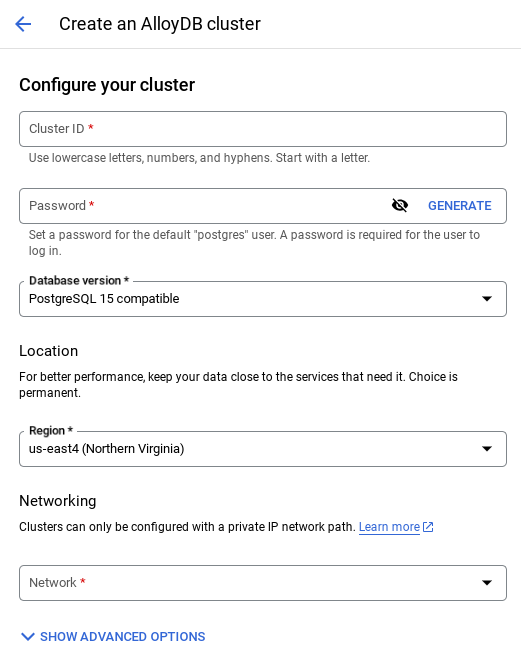
- При выборе сети по умолчанию вы увидите экран, похожий на тот, что показан ниже.
Выберите «НАСТРОЙКА СОЕДИНЕНИЯ» .
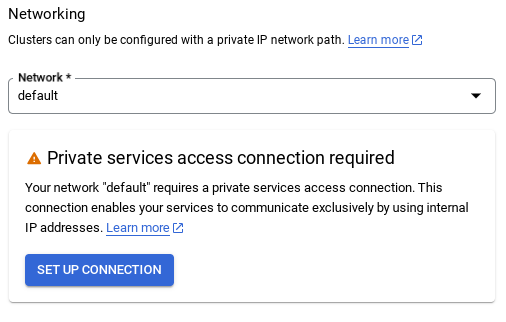
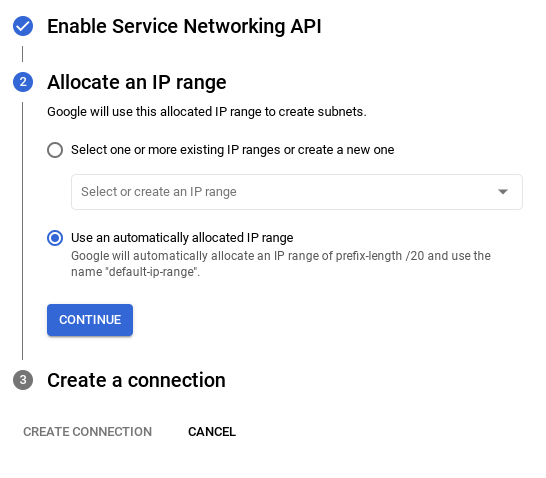
- Затем выберите « Использовать автоматически выделенный диапазон IP-адресов » и продолжите. После проверки информации выберите «СОЗДАТЬ СОЕДИНЕНИЕ».
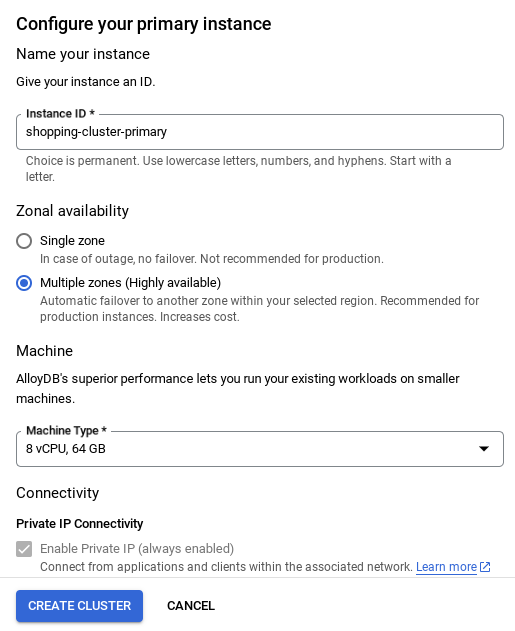
- После настройки сети вы можете продолжить создание кластера. Нажмите кнопку «СОЗДАТЬ КЛАСТЕР» , чтобы завершить настройку кластера, как показано ниже:
ВАЖНОЕ ЗАМЕЧАНИЕ:
- Обязательно измените идентификатор экземпляра (который можно найти во время настройки кластера/экземпляра) на **
vector-instance**. Если вы не можете его изменить, не забудьте использовать свой идентификатор экземпляра во всех последующих ссылках. - Обратите внимание, что создание кластера займет около 10 минут. После успешного завершения процесса вы увидите экран с обзором только что созданного кластера.
4. Ввод данных
Теперь пришло время добавить таблицу с данными о магазине. Перейдите в AlloyDB, выберите основной кластер, а затем AlloyDB Studio:
Возможно, вам потребуется дождаться завершения создания экземпляра. После этого войдите в AlloyDB, используя учетные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb"
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, используя значок плюса справа от последнего окна.
Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI и получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Чтобы проверить, какие расширения включены в вашей базе данных, выполните следующую SQL-команду:
select extname, extversion from pg_extension;
Создайте таблицу
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Столбец "Встраивание" позволит хранить векторные значения текста.
Предоставить разрешение
Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду в терминале Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Загрузите данные в базу данных.
- Скопируйте операторы запроса
insertизinsert scripts sqlв указанном выше листе в редактор. Для быстрой демонстрации этого варианта использования можно скопировать от 10 до 50 операторов вставки. На вкладке «Выбранные вставки (25-30 строк)» представлен список выбранных вставок.
Ссылка на данные находится в этом файле репозитория GitHub .
- Нажмите кнопку «Выполнить» . Результаты вашего запроса отобразятся в таблице «Результаты» .
ВАЖНОЕ ЗАМЕЧАНИЕ:
Убедитесь, что для вставки копируется только 25-50 записей, и что они относятся к диапазону категорий, подкатегорий, цветов и типов пола.
5. Создайте векторные представления данных.
Истинное новшество в современном поиске заключается в понимании смысла, а не только ключевых слов. Именно здесь вступают в игру векторные представления и векторный поиск.
Мы преобразовали описания товаров и пользовательские запросы в многомерные числовые представления, называемые «эмбеддингами», используя предварительно обученные языковые модели. Эти эмбеддинги отражают семантическое значение, позволяя нам находить товары, «похожие по смыслу», а не просто содержащие совпадающие слова. Первоначально мы экспериментировали с прямым векторным поиском сходства на этих эмбеддингах, чтобы установить базовый уровень, продемонстрировав возможности семантического понимания даже до оптимизации производительности.
Столбец embedding позволит хранить векторные значения текста описания товара. Столбец img_embeddings позволит хранить векторные представления изображений (мультимодальные). Таким образом, вы также сможете использовать поиск по расстоянию между текстом и изображением. Но в этой лабораторной работе мы будем использовать только векторные представления текста.
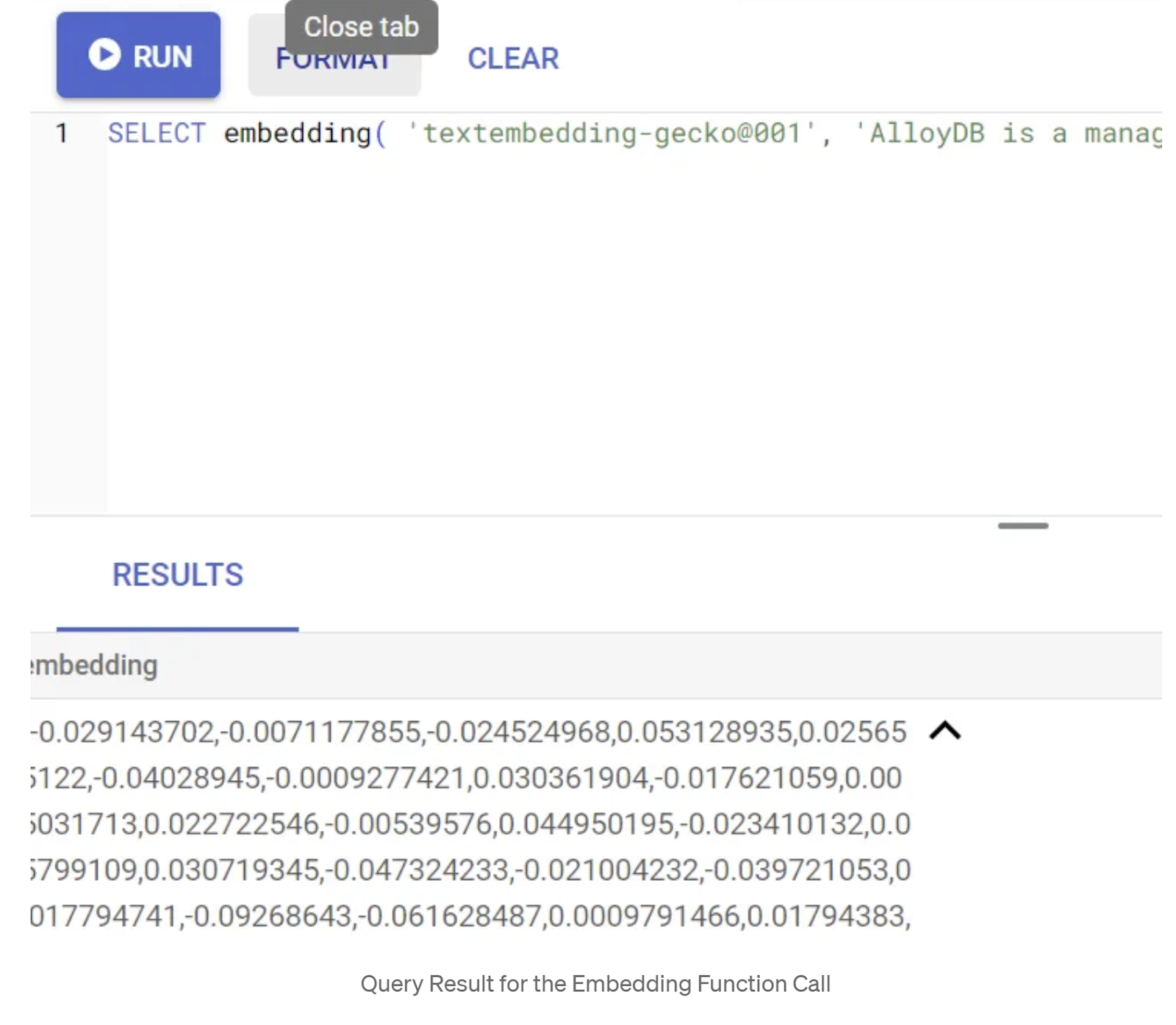
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Эта функция должна вернуть вектор эмбеддингов, который выглядит как массив чисел с плавающей запятой, для примера текста в запросе. Выглядит это так:
Обновите поле Abstract_Embeddings Vector.
Выполните приведенный ниже DML-запрос, чтобы обновить описание содержимого в таблице, добавив соответствующие векторные представления:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
При использовании пробного аккаунта Google Cloud у вас могут возникнуть проблемы с генерацией более чем нескольких встраиваний (например, максимум 20-25). Поэтому ограничьте количество строк в скрипте вставки.
Если вы хотите сгенерировать векторные представления изображений (для выполнения контекстного поиска в мультимодальной среде), выполните также следующее обновление:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Выполняйте расширенные операции RAG с помощью новых функций AlloyDB.
Теперь, когда таблица, данные и векторные представления готовы, давайте выполним векторный поиск в реальном времени для поискового запроса пользователя. Вы можете проверить это, выполнив запрос ниже:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
В этом запросе мы сравниваем текстовое представление поискового запроса пользователя "Футболка с круглым вырезом" с текстовыми представлениями всех описаний товаров в таблице одежды (хранящихся в столбце с именем "embedding"), используя функцию косинусного расстояния (обозначаемую символом "<=>". Мы преобразуем результат метода встраивания в векторный тип, чтобы сделать его совместимым с векторами, хранящимися в базе данных. LIMIT 10 означает, что мы выбираем 10 наиболее близких совпадений с поисковым текстом.
AlloyDB выводит векторный поиск RAG на новый уровень:
Для решения корпоративного масштаба простого векторного поиска недостаточно. Производительность имеет решающее значение.
Индекс ScaNN (Scalable Nearest Neighbors)
Для достижения сверхбыстрого приблизительного поиска ближайшего соседа (ANN) мы включили индекс scaNN в AlloyDB. ScaNN, современный алгоритм приблизительного поиска ближайшего соседа, разработанный Google Research, предназначен для эффективного поиска векторного сходства в больших масштабах. Он значительно ускоряет запросы за счет эффективного сокращения пространства поиска и использования методов квантования, обеспечивая до 4 раз более быстрые векторные запросы по сравнению с другими методами индексирования и меньший объем используемой памяти. Подробнее об этом можно прочитать здесь и здесь .
Давайте включим расширение и создадим индексы:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Создание индексов для полей, содержащих текстовые вставки и изображения (если вы хотите использовать изображения в поиске):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Индексы метаданных
В то время как scaNN обрабатывает векторное индексирование, традиционные B-деревья или GIN-индексы тщательно настраиваются на основе структурированных атрибутов (таких как категория, подкатегория, стиль, цвет и т. д.). Эти индексы имеют решающее значение для эффективности фасетной фильтрации. Выполните следующие команды для настройки индексов метаданных:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
ВАЖНОЕ ЗАМЕЧАНИЕ:
Поскольку вы, возможно, добавили всего 25-50 записей, индексы (ScaNN или любой другой индекс) будут неэффективны.
Встроенная фильтрация
Распространенная проблема в векторном поиске — это его сочетание со структурированными фильтрами (например, «красные туфли»). Встроенная фильтрация AlloyDB оптимизирует этот процесс. Вместо постобработки результатов широкого векторного поиска, встроенная фильтрация применяет условия фильтрации непосредственно в процессе векторного поиска, что значительно повышает производительность и точность при поиске векторных данных с фильтрами.
Для получения дополнительной информации о необходимости использования встроенной фильтрации обратитесь к этой документации . Также здесь вы можете узнать о фильтрованном векторном поиске для оптимизации производительности векторного поиска. Теперь, если вы хотите включить встроенную фильтрацию для своего приложения, выполните следующую команду в редакторе:
SET scann.enable_inline_filtering = on;
Встроенная фильтрация лучше всего подходит для случаев со средней избирательностью. При поиске по векторному индексу AlloyDB вычисляет расстояния только для тех векторов, которые соответствуют условиям фильтрации метаданных (ваши функциональные фильтры в запросе, обычно обрабатываемые в предложении WHERE). Это значительно повышает производительность таких запросов, дополняя преимущества пост-фильтрации или пре-фильтрации .
Адаптивная фильтрация
Для дальнейшей оптимизации производительности адаптивная фильтрация AlloyDB динамически выбирает наиболее эффективную стратегию фильтрации (встроенная или предварительная фильтрация) во время выполнения запроса. Она анализирует шаблоны запросов и распределение данных, чтобы обеспечить оптимальную производительность без ручного вмешательства, что особенно полезно для поиска по отфильтрованным векторам, где она автоматически переключается между использованием векторного и метаданных индексов. Чтобы включить адаптивную фильтрацию, используйте флаг scann.enable_preview_features.
Когда адаптивная фильтрация инициирует переключение с встроенной фильтрации на предварительную фильтрацию во время выполнения, план запроса динамически изменяется.
SET scann.enable_preview_features = on;
ВАЖНОЕ ПРИМЕЧАНИЕ: Возможно, вам не удастся выполнить указанное выше выражение без перезапуска экземпляра, если возникнет ошибка — лучше включить флаг enable_preview_features в разделе флагов базы данных вашего экземпляра.
Фасетные фильтры с использованием всех индексов
Фасетный поиск позволяет пользователям уточнять результаты, применяя несколько фильтров на основе определенных атрибутов или «фасетов» (например, бренд, цена, размер, рейтинг клиентов). Наше приложение органично интегрирует эти фасеты с векторным поиском. Теперь один запрос может сочетать поиск на естественном языке (контекстный поиск) с несколькими фасетными выборками, динамически используя как векторные, так и традиционные индексы. Это обеспечивает по-настоящему динамичные возможности гибридного поиска, позволяя пользователям точно детализировать результаты.
В нашем приложении, поскольку мы уже создали все индексы метаданных, мы полностью готовы к использованию фасетных фильтров в веб-среде, обращаясь к ним напрямую с помощью SQL-запросов:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
В этом запросе мы выполняем гибридный поиск, объединяющий оба подхода.
- Фасетная фильтрация в предложении WHERE и
- Векторный поиск в предложении ORDER BY с использованием метода косинусного сходства.
$1, $2, $3 и $4 представляют собой значения фасетного фильтра в массиве, а $5 — текст поиска пользователя. Замените $1–$4 на значения фасетного фильтра по вашему выбору, как показано ниже:
category = ANY(['Одежда', 'Обувь'])
Замените $5 на любой поисковый запрос, например, "Футболки поло".
ВАЖНОЕ ЗАМЕЧАНИЕ: Если у вас нет индексов из-за ограниченного количества вставленных записей, вы не заметите снижения производительности. Но на полном рабочем наборе данных вы увидите, что время выполнения значительно сокращается для того же векторного поиска с использованием встроенной фильтрации и индекса ScaNN, применяемого к векторному поиску!!!
Далее оценим показатель полноты (recall) для этого векторного поиска с использованием ScaNN.
Переранжирование
Даже при использовании расширенного поиска первоначальные результаты могут нуждаться в окончательной доработке. Это критически важный шаг, который переупорядочивает первоначальные результаты поиска для повышения релевантности. После того, как первоначальный гибридный поиск предоставляет набор потенциальных товаров, более сложная (и часто более ресурсоемкая) модель применяет более точную оценку релевантности. Это гарантирует, что лучшие результаты, представленные пользователю, будут наиболее релевантными, что значительно повышает качество поиска. Мы постоянно оцениваем полноту поиска, чтобы измерить, насколько хорошо система извлекает все релевантные элементы для данного запроса, совершенствуя наши модели для максимизации вероятности того, что клиент найдет то, что ему нужно.
Прежде чем использовать это в своем приложении, убедитесь, что выполнены все необходимые предварительные условия :
- Убедитесь, что расширение google_ml_integration установлено.
- Убедитесь, что флаг google_ml_integration.enable_model_support установлен в значение on.
- Интеграция с Vertex AI.
- Включите API механизма обнаружения.
- Для использования моделей ранжирования необходимо указать требуемые роли.
Затем вы можете использовать следующий запрос в нашем приложении для переранжирования набора результатов гибридного поиска:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
В этом запросе мы выполняем ПЕРЕРАНЖИРОВАНИЕ набора результатов контекстного поиска, указанного в предложении ORDER BY, используя метод косинусного сходства. «Pink top» — это текст, который ищет пользователь.
ВАЖНОЕ ЗАМЕЧАНИЕ: У некоторых из вас может еще не быть доступа к функции переранжирования, поэтому я исключил ее из кода приложения, но если вы хотите ее добавить, вы можете следовать примеру, который мы рассмотрели выше.
Оценщик отзыва
Показатель полноты (recall) в поиске по сходству — это процент релевантных результатов, полученных в ходе поиска, то есть количество истинных положительных результатов. Это наиболее распространенная метрика, используемая для измерения качества поиска. Одна из причин потери полноты связана с разницей между приблизительным поиском ближайшего соседа (aNN) и поиском k (точных) ближайших соседей (kNN). Векторные индексы, такие как ScaNN в AlloyDB, реализуют алгоритмы aNN , что позволяет ускорить векторный поиск на больших наборах данных за счет небольшого снижения полноты. Теперь AlloyDB предоставляет возможность измерять этот компромисс непосредственно в базе данных для отдельных запросов и гарантировать его стабильность во времени. Вы можете обновлять параметры запроса и индекса в ответ на эту информацию для достижения лучших результатов и производительности.
Какова логика запоминания результатов поиска?
В контексте векторного поиска показатель полноты (recall) относится к проценту векторов, возвращаемых индексом, которые являются истинными ближайшими соседями. Например, если запрос на поиск ближайших соседей для 20 ближайших соседей возвращает 19 из истинных ближайших соседей, то показатель полноты составляет 19/20x100 = 95%. Полнота — это метрика, используемая для оценки качества поиска, и определяется как процент возвращаемых результатов, которые объективно наиболее близки к векторам запроса.
Для расчета полноты запроса к векторному индексу для заданной конфигурации можно использовать функцию evaluate_query_recall . Эта функция позволяет настраивать параметры для достижения желаемых результатов полноты запроса к векторному индексу.
ВАЖНОЕ ЗАМЕЧАНИЕ:
Если на следующих шагах вы сталкиваетесь с ошибкой "Доступ запрещен" при работе с индексом HNSW, пропустите пока весь раздел оценки восстановления. Возможно, это связано с ограничениями доступа, поскольку на момент написания этого руководства это было только что выпущено.
- Установите флаг Enable Index Scan для индексов ScaNN и HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Выполните следующий запрос в AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Функция evaluate_query_recall принимает запрос в качестве параметра и возвращает его значение recall. В качестве входного запроса для функции я использую тот же запрос, что и для проверки производительности. В качестве метода индексации я добавил SCaNN. Дополнительные параметры см. в документации .
Для данного запроса векторного поиска мы использовали показатель полноты:
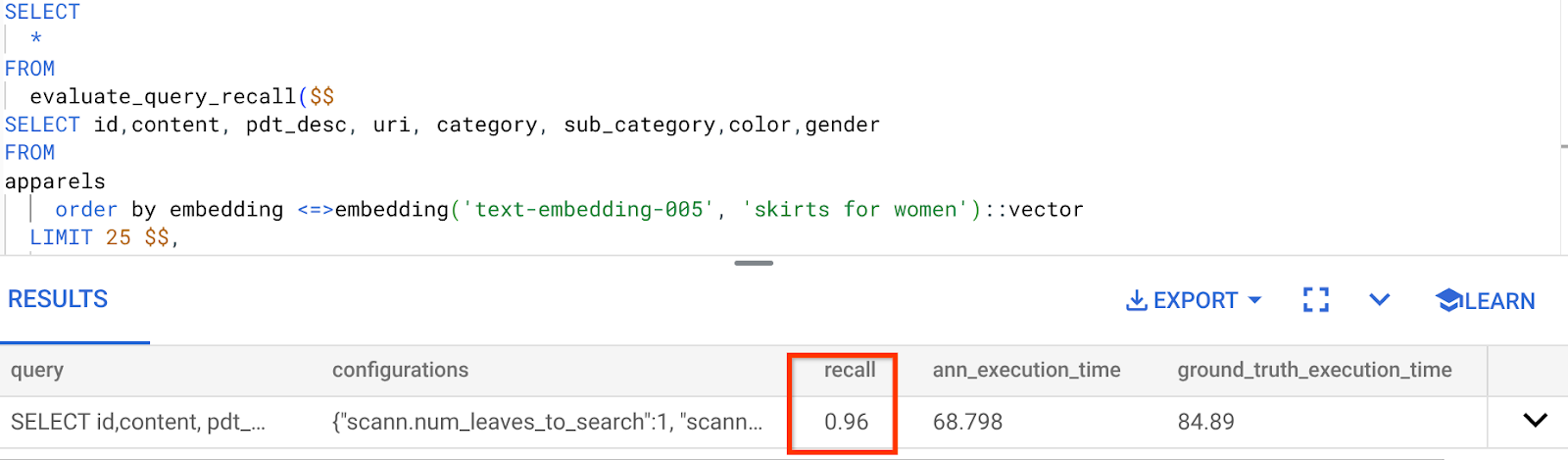
Я вижу, что показатель полноты (RECALL) составляет 96%. В данном случае полнота действительно хорошая. Но если бы это было неприемлемое значение, вы могли бы использовать эту информацию для изменения параметров индекса, методов и параметров запроса, чтобы улучшить полноту моего векторного поиска!
Протестируйте с измененными параметрами запроса и индекса.
Теперь давайте протестируем запрос, изменив параметры запроса на основе полученного значения отзыва.
- Изменение параметров индекса:
Для этого теста я буду использовать "L2-расстояние" вместо функции расстояния сходства "Косинус" .
Очень важное замечание: «Как узнать, что в этом запросе используется косинусное сходство?» — спросите вы. Функцию расстояния можно определить по использованию символа «<=>», обозначающего косинусное расстояние.
Ссылка на документацию по функциям поиска векторного расстояния.
В предыдущем запросе использовалась функция расстояния косинусного сходства, тогда как сейчас мы попробуем расстояние L2. Но для этого необходимо убедиться, что базовый индекс ScaNN также использует функцию расстояния L2. Теперь давайте создадим индекс с другим запросом на использование функции расстояния: Расстояние L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
Оператор drop index используется лишь для того, чтобы исключить наличие ненужных индексов в таблице.
Теперь я могу выполнить следующий запрос для оценки полноты (RECALL) после изменения функции расстояния в моей функции векторного поиска.
[ПОСЛЕ] Запрос, использующий функцию расстояния L2 :
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Вы можете увидеть разницу/преобразование в значении показателя полноты для обновленного индекса.
В индексе можно изменять и другие параметры, например, num_leaves и т.д., в зависимости от желаемого значения полноты и набора данных, используемого вашим приложением.
Проверка результатов векторного поиска с помощью LLM
Для достижения максимально высокого качества контролируемого поиска мы включили дополнительный уровень проверки с помощью больших языковых моделей (LLM). Большие языковые модели могут использоваться для оценки релевантности и согласованности результатов поиска, особенно для сложных или неоднозначных запросов. Это может включать в себя:
Семантическая верификация:
LLM-система сопоставляет результаты с намерением пользователя.
Логическая фильтрация:
Использование LLM для применения сложной бизнес-логики или правил, которые трудно закодировать в традиционных фильтрах, позволяет дополнительно уточнить список товаров на основе тонких критериев.
Гарантия качества:
Автоматическое выявление и пометка менее релевантных результатов для проверки человеком или уточнения модели.
Вот как мы этого добились с помощью функций искусственного интеллекта в AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
В основе запроса лежит тот же запрос, который мы рассматривали в разделах, посвященных фасетному поиску, гибридному поиску и переранжированию. Теперь в этот запрос мы добавили слой оценки GEMINI для набора результатов переранжирования, представленного конструкцией ml_predict_row. Я закомментировал фасетные фильтры, но вы можете добавить элементы по своему выбору в массив для заполнителей от $1 до $4. Замените $5 любым текстом, по которому вы хотите выполнить поиск, например, «Розовый топ, без цветочного узора».
7. MCP Toolbox для баз данных и прикладного уровня
За кулисами надёжный инструментарий и хорошо структурированное приложение обеспечивают бесперебойную работу.
Инструментарий MCP (Model Context Protocol) для баз данных упрощает интеграцию инструментов генеративного ИИ и агентных систем с AlloyDB. Он выступает в качестве сервера с открытым исходным кодом, который оптимизирует объединение соединений, аутентификацию и безопасное предоставление доступа к функциям базы данных агентам ИИ или другим приложениям.
В нашем приложении мы использовали MCP Toolbox for Databases в качестве уровня абстракции для всех наших интеллектуальных гибридных поисковых запросов.
Для настройки и развертывания Toolbox в соответствии с нашим сценарием выполните следующие действия:
Как видите, одной из баз данных, поддерживаемых MCP Toolbox for Databases, является AlloyDB, и поскольку мы уже настроили её в предыдущем разделе, давайте перейдём к настройке Toolbox.
- Откройте терминал Cloud Shell и убедитесь, что ваш проект выбран и отображается в командной строке. Выполните следующую команду в терминале Cloud Shell, чтобы перейти в каталог вашего проекта:
mkdir toolbox-tools
cd toolbox-tools
- Выполните следующую команду, чтобы загрузить и установить Toolbox в новую папку:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Перейдите в редактор Cloud Shell (для режима редактирования кода) и в корневой папке проекта добавьте файл с именем "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Обязательно замените скрипт Tools.yaml кодом из этого файла репозитория .
Давайте разберемся с файлом tools.yaml:
Источники представляют собой различные источники данных, с которыми может взаимодействовать инструмент. Источник — это источник данных, с которым может взаимодействовать инструмент. Вы можете определить источники в виде карты в разделе sources файла tools.yaml. Как правило, конфигурация источников содержит всю информацию, необходимую для подключения к базе данных и взаимодействия с ней.
Инструменты определяют действия, которые может выполнять агент, например, чтение и запись в источник. Инструмент представляет собой действие, которое может выполнить ваш агент, например, выполнение SQL-запроса. Вы можете определить инструменты в виде карты в разделе tools вашего файла tools.yaml. Как правило, для работы с инструментом требуется источник.
Для получения более подробной информации о настройке файла tools.yaml обратитесь к этой документации .
- Для запуска сервера выполните следующую команду (из папки mcp-toolbox):
./toolbox --tools-file "tools.yaml"
Теперь, если вы откроете сервер в режиме веб-просмотра в облаке, вы сможете увидеть, что сервер Toolbox запущен и работает с вашим новым инструментом под названием get-order-data.
Сервер MCP Toolbox по умолчанию работает на порту 5000. Давайте протестируем это с помощью Cloud Shell.
В Cloud Shell нажмите на кнопку «Предварительный просмотр веб-страницы», как показано ниже:
Нажмите «Изменить порт» и установите порт на 5000, как показано ниже, затем нажмите «Изменить и просмотреть».
В результате должно получиться следующее:
- Давайте развернем наш Toolbox в Cloud Run:
Для начала мы можем разместить сервер MCP Toolbox на платформе Cloud Run. Это даст нам общедоступную конечную точку, которую мы сможем интегрировать с любыми другими приложениями и/или приложениями агентов. Инструкции по размещению на Cloud Run приведены здесь . Теперь рассмотрим основные шаги.
- Запустите новый терминал Cloud Shell или используйте существующий. Перейдите в папку проекта, где находятся исполняемый файл toolbox и файл tools.yaml, в данном случае toolbox-tools, если вы еще не находитесь в ней:
cd toolbox-tools
- Установите переменную PROJECT_ID так, чтобы она указывала на идентификатор вашего проекта в Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Включите эти сервисы Google Cloud.
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Давайте создадим отдельную учетную запись службы, которая будет выступать в качестве идентификатора для службы Toolbox, которую мы будем развертывать в Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Мы также обеспечиваем наличие у этой учетной записи службы необходимых ролей, то есть возможности доступа к Secret Manager и взаимодействия с AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Мы загрузим файл tools.yaml в качестве секретного файла:
gcloud secrets create tools --data-file=tools.yaml
Если у вас уже есть секретный ключ и вы хотите обновить его версию, выполните следующие действия:
gcloud secrets versions add tools --data-file=tools.yaml
- Установите переменную среды, указывающую на образ контейнера, который вы хотите использовать для Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Последний шаг в знакомой команде развертывания в Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Это запустит процесс развертывания сервера Toolbox с настроенным файлом tools.yaml в Cloud Run. После успешного развертывания вы должны увидеть сообщение, похожее на следующее:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Теперь вы полностью готовы использовать свой недавно развернутый инструмент в своем агентском приложении!!!
Доступ к инструментам на сервере Toolbox
После развертывания Toolbox мы создадим вспомогательную функцию Cloud Run Functions на Python для взаимодействия с развернутым сервером Toolbox. Это связано с тем, что в настоящее время Toolbox не имеет Java SDK , поэтому мы создали вспомогательную функцию на Python для взаимодействия с сервером. Вот исходный код этой функции Cloud Run Function.
Для доступа к инструментам из набора инструментов, которые мы создали и развернули на предыдущих шагах, необходимо создать и развернуть эту функцию Cloud Run.
- В консоли Google Cloud перейдите на страницу Cloud Run .
- Нажмите «Написать функцию».
- В поле «Название услуги» введите название, описывающее вашу функцию. Названия услуг должны начинаться только с буквы и содержать не более 49 символов, включая буквы, цифры или дефисы. Названия услуг не могут заканчиваться дефисами и должны быть уникальными для каждого региона и проекта. Название услуги нельзя изменить позже, оно является общедоступным. (Введите retail-product-search-quality)
- В списке регионов используйте значение по умолчанию или выберите регион, в котором вы хотите развернуть свою функцию. (Выберите us-central1)
- В списке «Среда выполнения» используйте значение по умолчанию или выберите версию среды выполнения. (Выберите Python 3.11)
- В разделе «Аутентификация» выберите «Разрешить публичный доступ».
- Нажмите кнопку «Создать».
- Функция создается и загружается с помощью шаблона main.py и requirements.txt.
- Замените это файлами main.py и requirements.txt из репозитория этого проекта.
- Разверните функцию, и вы получите конечную точку для вашей функции Cloud Run.
Ваш адрес электронной почты должен выглядеть примерно так (или аналогично):
Конечная точка функции Cloud Run для доступа к инструментарию: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Для удобства выполнения в установленные сроки (для практических занятий под руководством инструктора) номер проекта для конечной точки будет сообщен во время практического занятия.
ВАЖНОЕ ЗАМЕЧАНИЕ:
В качестве альтернативы вы также можете реализовать часть, отвечающую за базу данных, непосредственно в коде вашего приложения или в функции Cloud Run.
8. Разработка приложений (Java) с использованием фасетного поиска.
Наконец, все эти мощные компоненты бэкэнда воплощаются в жизнь на уровне приложения. Разработанное на Java, приложение предоставляет пользовательский интерфейс для взаимодействия с системой поиска. Оно координирует запросы к AlloyDB, обрабатывает отображение фасетных фильтров, управляет выбором пользователя и представляет переранжированные и проверенные результаты поиска в удобном и интуитивно понятном виде.
- Для начала перейдите в терминал Cloud Shell и клонируйте репозиторий:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Перейдите в редактор Cloud Shell, где вы увидите недавно созданную папку faceted_searching_retail.
- Удалите следующие строки, так как эти шаги уже были выполнены в предыдущих разделах:
- Удалите папку Cloud_Run_Function
- Удалите файл db_script.sql
- Удалите файл tools.yaml
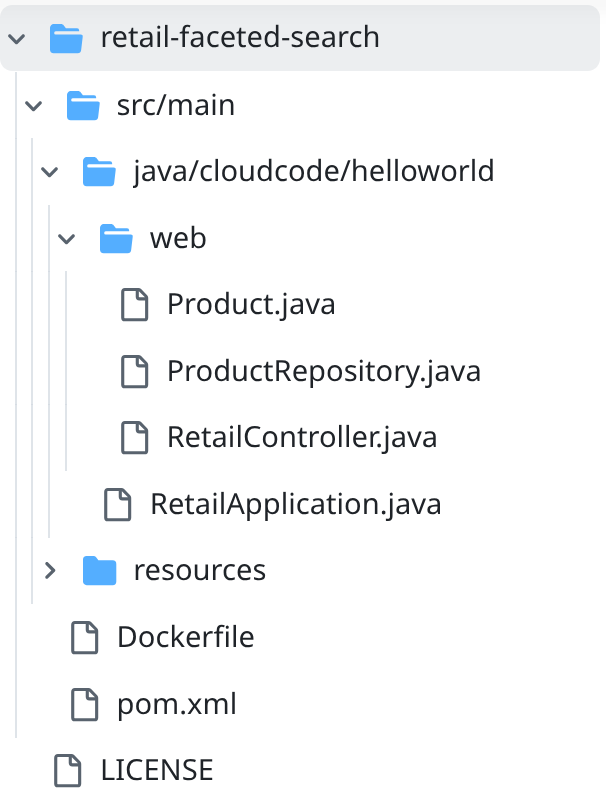
- Перейдите в папку проекта retail-faceted-search, и вы увидите структуру проекта:
- В файле ProductRepository.java необходимо изменить переменную TOOLBOX_ENDPOINT, указав в ней конечную точку из вашей облачной функции запуска (развернутой) или конечную точку, предоставленную докладчиком на практическом занятии.
Найдите следующую строку кода и замените её на адрес вашей конечной точки:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Убедитесь, что файлы Dockerfile и pom.xml соответствуют конфигурации вашего проекта (изменения не требуются, если вы явно не меняли версию или конфигурацию).
- В терминале Cloud Shell убедитесь, что вы находитесь в основной папке и в папке проекта (faceted_searching_retail / retail-faceted-search). Используйте следующие команды, чтобы убедиться, что вы находитесь в нужной папке в терминале:
cd faceted_searching_retail
cd retail-faceted-search
- Упакуйте, соберите и протестируйте ваше приложение локально:
mvn package
mvn spring-boot:run
Вы сможете просмотреть свое приложение, нажав на кнопку «Предварительный просмотр на порту 8080» в терминале Cloud Shell, как показано ниже:
9. Развертывание в Cloud Run: ***ВАЖНЫЙ ШАГ
В терминале Cloud Shell убедитесь, что вы находитесь в основной папке и в папке проекта (faceted_searching_retail / retail-faceted-search). Используйте следующие команды, чтобы убедиться, что вы находитесь в нужной папке в терминале:
cd faceted_searching_retail
cd retail-faceted-search
Убедившись, что вы находитесь в папке проекта, выполните следующую команду:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
После развертывания вы должны получить развернутую конечную точку Cloud Run, которая будет выглядеть следующим образом:
https://retail-search-**********-uc.a.run.app/
10. Демонстрация
Давайте посмотрим, как всё это работает на практике:
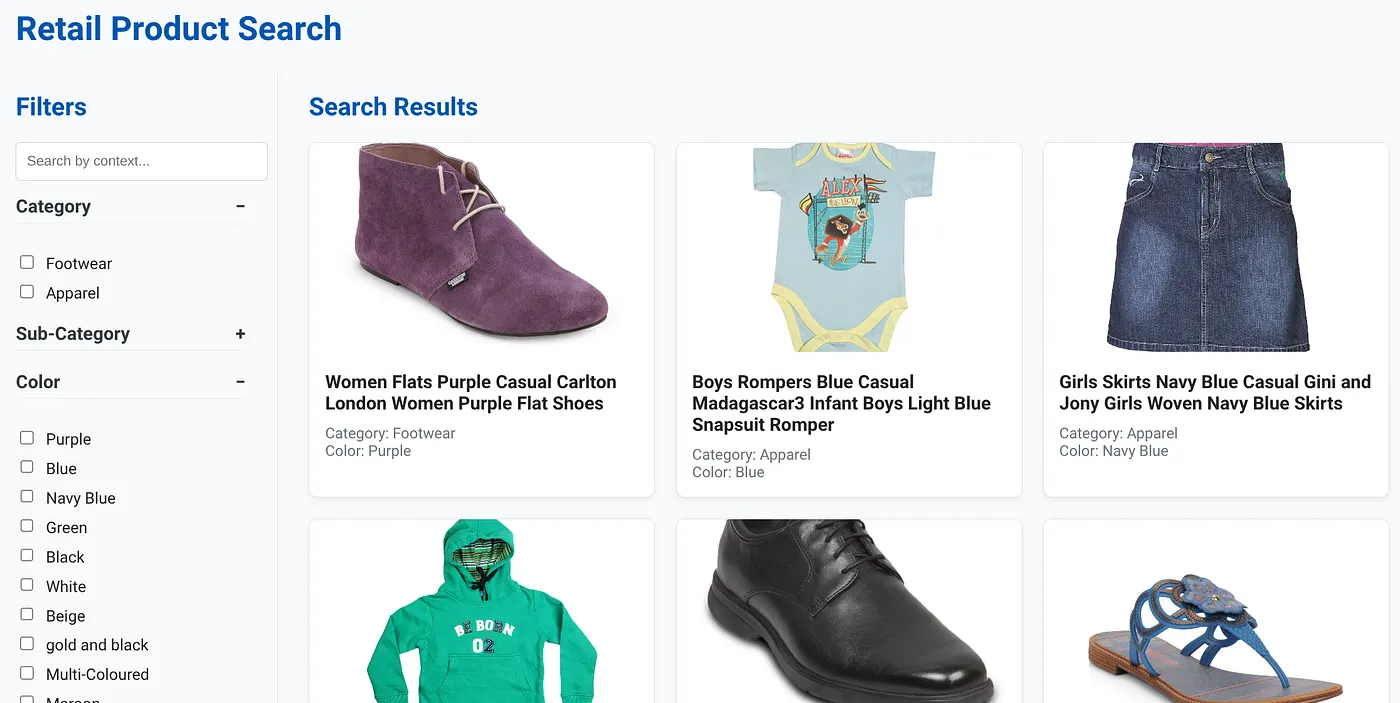
The above image shows the landing page for the dynamic hybrid search app.
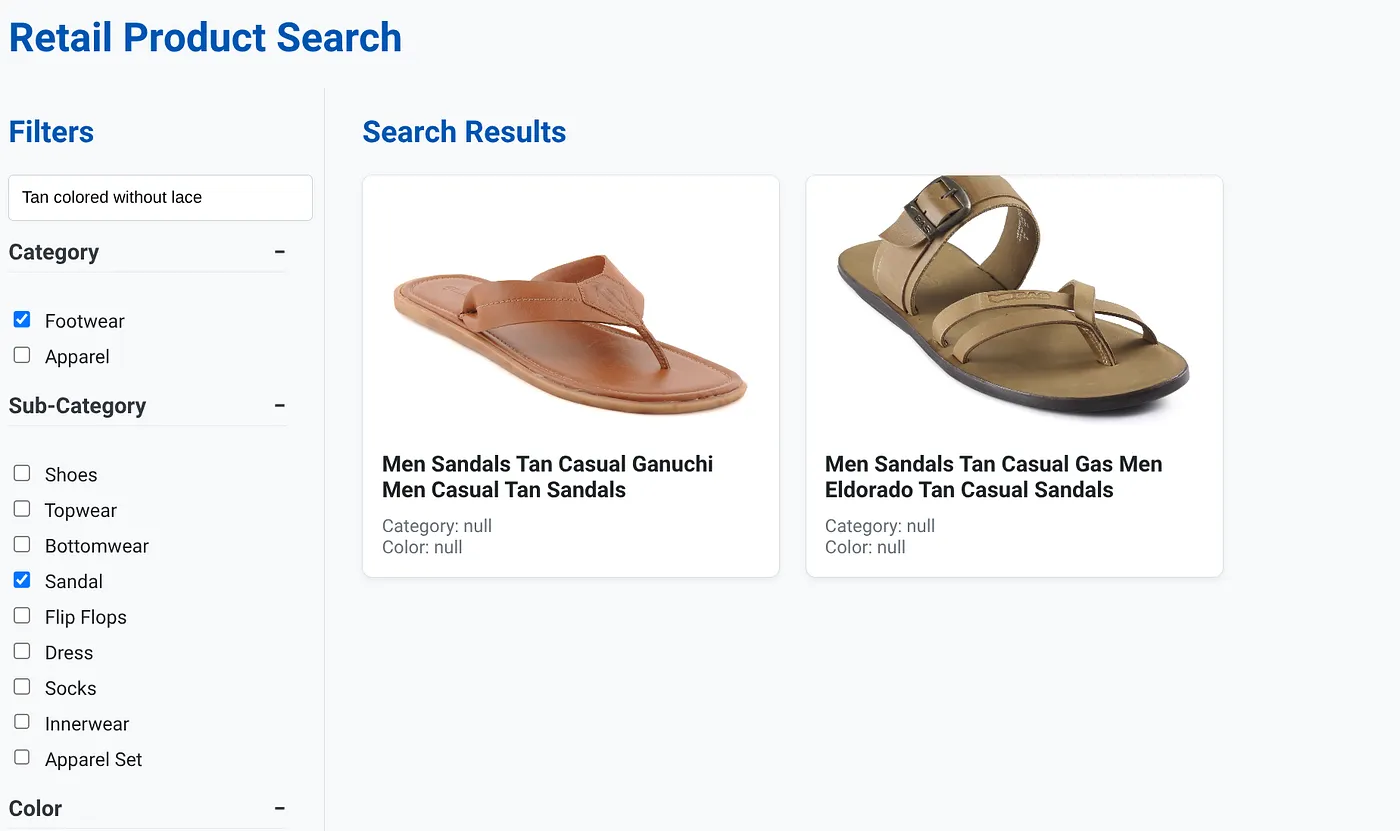
The above image has the search results for "Tan colored without lace" . The Faceted filters selected are: Footwear, Sandal.
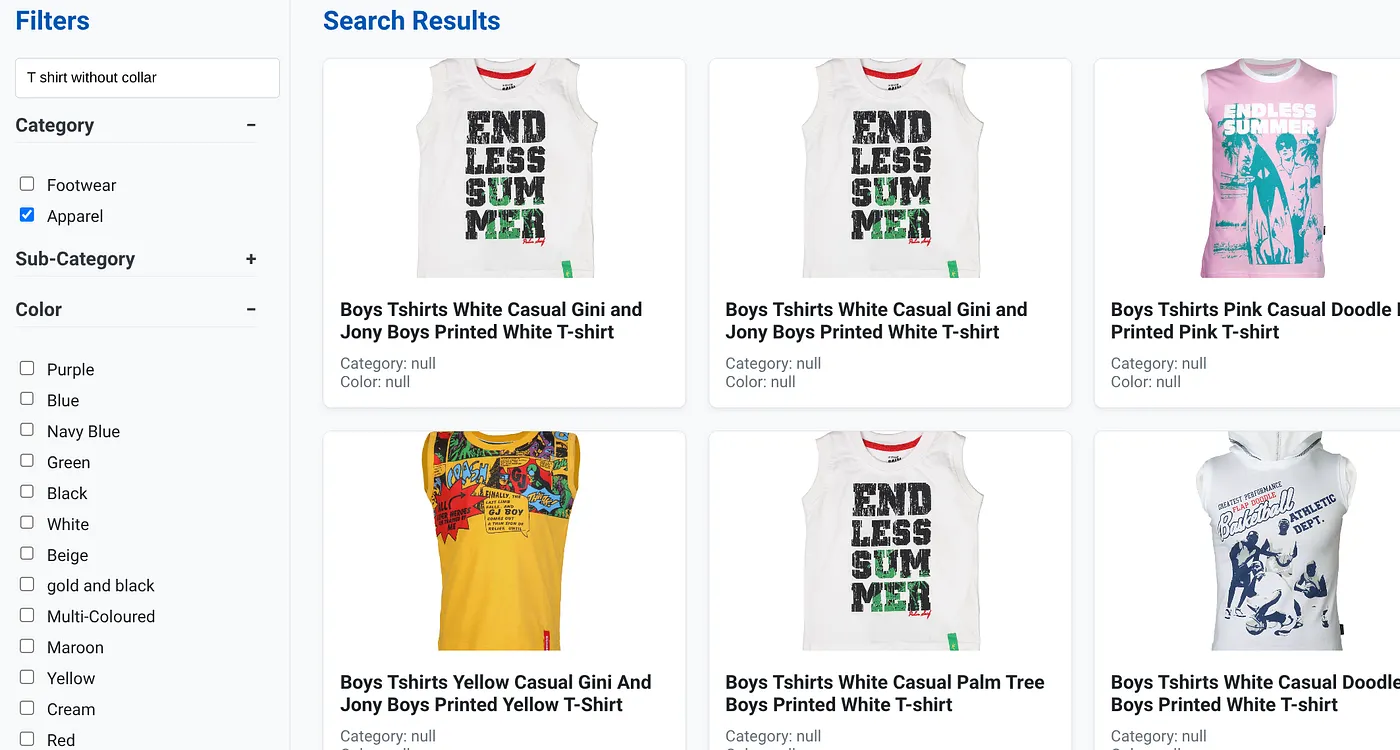
The above image shows the search results for "T shirt without collar" . Faceted filters: Apparel
You can now incorporate more generative and agentic features to make this application actionable.
Try it out so you're inspired to build on your own!!!
11. Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this post, follow these steps:
- In the Google Cloud console, go to the resource manager page.
- In the project list, select the project that you want to delete, and then click Delete .
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Alternatively, you can just delete the AlloyDB cluster (change the location in this hyperlink if you didn't choose us-central1 for the cluster at the time of configuration) that we just created for this project by clicking the DELETE CLUSTER button.
12. Congratulations
Congratulations! You have successfully built and deployed a HYBRID SEARCH APP with ALLOYDB on CLOUD RUN!!!
Why This Matters for businesses:
This dynamic hybrid search application, powered by AlloyDB AI, offers significant advantages for enterprise retail and other businesses:
Superior Relevance: By combining contextual (vector) search with precise faceted filtering and intelligent reranking, customers receive highly relevant results, leading to increased satisfaction and conversions.
Scalability: AlloyDB's architecture and scaNN indexing are designed to handle massive product catalogs and high query volumes, crucial for growing e-commerce businesses.
Performance: Faster query responses, even for complex hybrid searches, ensure a smooth user experience and minimize abandonment rates.
Future-Proofing: The integration of AI capabilities (embeddings, LLM validation) positions the application for future advancements in personalized recommendations, conversational commerce, and intelligent product discovery.
Simplified Architecture: Integrating vector search directly within AlloyDB eliminates the need for separate vector databases or complex synchronization, simplifying development and maintenance.
Let's say a user typed in a natural language query like "eco-friendly running shoes for women with high arch support."
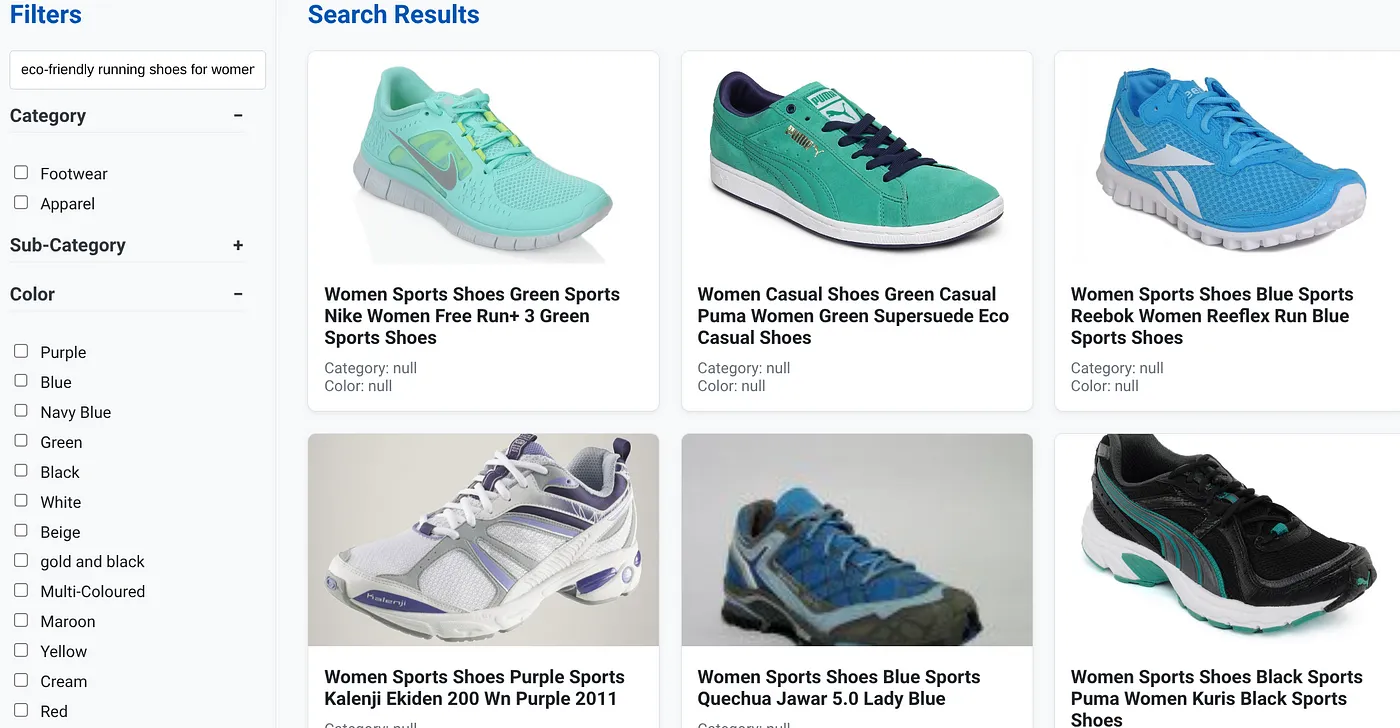
while simultaneously, the user applies faceted filters for "Category: <<>>" "Color: <<>>," and say "Price: $100-$150":
- The system instantly returns a refined list of products, semantically aligned with the natural language and precisely matching the chosen filters.
- Behind the scenes, the scaNN index accelerates the vector search, inline and adaptive filtering ensure performance with combined criteria, and reranking presents the optimal results at the top.
- The speed and accuracy of the results clearly illustrate the power of combining these technologies for a truly intelligent retail search experience.
Building a next-generation retail search application requires moving beyond conventional methods and by using the power of AlloyDB, Vertex AI, Vector Search with scaNN indexing, dynamic faceted filtering, reranking, and LLM validation, we can deliver an unparalleled customer experience that drives engagement and boosts sales. This robust, scalable, and intelligent solution demonstrates how modern database capabilities, infused with AI, are reshaping the future of retail!!!