
1. ภาพรวม
ในโลกค้าปลีกที่มีการแข่งขันสูงในปัจจุบัน การช่วยให้ลูกค้าค้นหาสิ่งที่ต้องการได้อย่างรวดเร็วและง่ายดายเป็นสิ่งสำคัญอย่างยิ่ง การค้นหาแบบเดิมที่อิงตามคีย์เวิร์ดมักไม่เพียงพอ เนื่องจากรับมือกับคำค้นหาที่ซับซ้อนและแคตตาล็อกผลิตภัณฑ์จำนวนมากได้ยาก Codelab นี้จะเปิดตัวแอปพลิเคชันการค้นหาค้าปลีกที่ซับซ้อนซึ่งสร้างขึ้นบน AlloyDB, AlloyDB AI โดยใช้ประโยชน์จากการค้นหาเวกเตอร์ที่ล้ำสมัย การจัดทำดัชนี scaNN, ตัวกรองแบบ Facet และการกรองแบบอิงตามข้อมูลอัจฉริยะ การจัดอันดับใหม่เพื่อมอบประสบการณ์การค้นหาแบบไฮบริดแบบไดนามิกในระดับองค์กร
ตอนนี้เรามีความเข้าใจพื้นฐานเกี่ยวกับ 3 สิ่งต่อไปนี้แล้ว
- ความหมายของการค้นหาตามบริบทสำหรับเอเจนต์และวิธีดำเนินการโดยใช้การค้นหาเวกเตอร์
- นอกจากนี้ เรายังเจาะลึกถึงการใช้ Vector Search ภายในขอบเขตของข้อมูลของคุณ ซึ่งก็คือภายในฐานข้อมูลของคุณเอง (ฐานข้อมูลทั้งหมดของ Google Cloud รองรับฟีเจอร์นี้ หากคุณยังไม่ทราบ)
- เราก้าวไปอีกขั้นเหนือกว่าที่อื่นๆ ในโลกด้วยการบอกวิธีสร้างความสามารถ RAG ของ Vector Search ที่มีน้ำหนักเบาเช่นนี้ด้วยประสิทธิภาพและคุณภาพสูงด้วยความสามารถ Vector Search ของ AlloyDB ที่ขับเคลื่อนโดยดัชนี ScaNN
หากคุณยังไม่ได้ลองใช้การทดลอง RAG ขั้นพื้นฐาน ระดับกลาง และขั้นสูงเล็กน้อย โปรดอ่าน 3 บทความที่นี่ ที่นี่ และที่นี่ตามลำดับ
ความท้าทาย
การก้าวข้ามการกรอง คีย์เวิร์ด และการจับคู่ตามบริบท: การค้นหาคีย์เวิร์ดอย่างง่ายอาจแสดงผลลัพธ์หลายพันรายการ ซึ่งหลายรายการไม่เกี่ยวข้อง โซลูชันที่เหมาะสมควรทำความเข้าใจเจตนาเบื้องหลังคำค้นหา รวมเข้ากับเกณฑ์การกรองที่แม่นยำ (เช่น แบรนด์ วัสดุ หรือราคา) และแสดงรายการที่เกี่ยวข้องมากที่สุดในหน่วยมิลลิวินาที ซึ่งต้องใช้โครงสร้างพื้นฐานการค้นหาที่มีประสิทธิภาพ ยืดหยุ่น และปรับขนาดได้ แน่นอนว่าเราได้เดินทางมาไกลจากการค้นหาคีย์เวิร์ดไปสู่การจับคู่ตามบริบทและการค้นหาความคล้ายคลึง แต่ลองนึกถึงลูกค้าที่ค้นหา "เสื้อแจ็กเก็ตกันน้ำที่ใส่สบาย มีสไตล์ สำหรับเดินป่าในฤดูใบไม้ผลิ" ขณะเดียวกันก็ใช้ตัวกรองด้วย และแอปพลิเคชันของคุณไม่เพียงแสดงคำตอบที่มีคุณภาพ แต่ยังมีประสิทธิภาพสูง และลำดับของทั้งหมดนี้จะเลือกแบบไดนามิกโดยฐานข้อมูลของคุณ
วัตถุประสงค์
วิธีแก้ไขปัญหานี้โดยการผสานรวม
- การค้นหาตามบริบท (การค้นหาเวกเตอร์): ทำความเข้าใจความหมายเชิงความหมายของคำค้นหาและรายละเอียดสินค้า
- การกรองแบบเจียระไน: ช่วยให้ผู้ใช้ปรับแต่งผลลัพธ์ด้วยแอตทริบิวต์ที่เฉพาะเจาะจง
- แนวทางแบบผสมผสาน: ผสานการค้นหาตามบริบทกับการกรองที่มีโครงสร้างอย่างราบรื่น
- การเพิ่มประสิทธิภาพขั้นสูง: ใช้ประโยชน์จากการจัดทำดัชนีเฉพาะ การกรองแบบปรับได้ และการจัดอันดับใหม่เพื่อความเร็วและความเกี่ยวข้อง
- การควบคุมคุณภาพที่ขับเคลื่อนด้วย Generative AI: การผสานรวมการตรวจสอบ LLM เพื่อคุณภาพผลลัพธ์ที่เหนือกว่า
มาดูเส้นทางการออกแบบและการติดตั้งใช้งานกัน
สิ่งที่คุณจะสร้าง
แอปพลิเคชันการค้นหาค้าปลีก
โดยคุณจะต้องดำเนินการต่อไปนี้
- สร้างอินสแตนซ์และตาราง AlloyDB สำหรับชุดข้อมูลอีคอมเมิร์ซ
- ตั้งค่าการฝังและ Vector Search
- สร้างดัชนีข้อมูลเมตาและดัชนี ScaNN
- ใช้ Vector Search ขั้นสูงใน AlloyDB โดยใช้วิธีการกรองแบบอินไลน์ของ ScaNN
- ตั้งค่าตัวกรองแบบเจียระไนและการค้นหาแบบไฮบริดในการค้นหาเดียว
- ปรับความเกี่ยวข้องของคำค้นหาด้วยการจัดอันดับใหม่และการเรียกคืน (ไม่บังคับ)
- ประเมินคำตอบของคำค้นหาด้วย Gemini (ไม่บังคับ)
- MCP Toolbox สำหรับฐานข้อมูลและเลเยอร์แอปพลิเคชัน
- การพัฒนาแอปพลิเคชัน (Java) ด้วยการค้นหาตามประเภทที่จัดแบ่งไว้
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: ทำตามลิงก์และเปิดใช้ API
หรือจะใช้คำสั่ง gcloud สำหรับการดำเนินการนี้ก็ได้ โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลอีคอมเมิร์ซ โดยจะใช้คลัสเตอร์เพื่อเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลอีคอมเมิร์ซกัน
สร้างคลัสเตอร์และอินสแตนซ์
- ไปที่หน้า AlloyDB ใน Cloud Console วิธีง่ายๆ ในการค้นหาหน้าส่วนใหญ่ใน Cloud Console คือการค้นหาโดยใช้แถบค้นหาของคอนโซล
- เลือกสร้างคลัสเตอร์จากหน้านั้น

- คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง สร้างคลัสเตอร์และอินสแตนซ์ด้วยค่าต่อไปนี้ (ตรวจสอบว่าค่าตรงกันในกรณีที่คุณโคลนโค้ดของแอปพลิเคชันจากที่เก็บ)
- รหัสคลัสเตอร์: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / ล่าสุดที่แนะนำ
- ภูมิภาค: "
us-central1" - เครือข่าย: "
default"
- เมื่อเลือกเครือข่ายเริ่มต้น คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง
เลือกตั้งค่าการเชื่อมต่อ
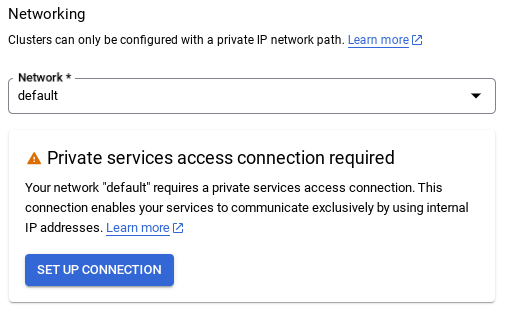
- จากนั้นเลือก "ใช้ช่วง IP ที่มีการจัดสรรโดยอัตโนมัติ" แล้วคลิก "ต่อไป" หลังจากตรวจสอบข้อมูลแล้ว ให้เลือกสร้างการเชื่อมต่อ
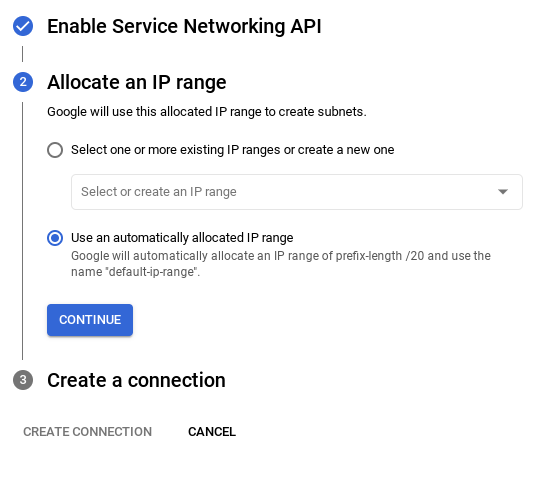
- เมื่อตั้งค่าเครือข่ายแล้ว คุณจะสร้างคลัสเตอร์ต่อไปได้ คลิกสร้างคลัสเตอร์เพื่อตั้งค่าคลัสเตอร์ให้เสร็จสมบูรณ์ตามที่แสดงด้านล่าง
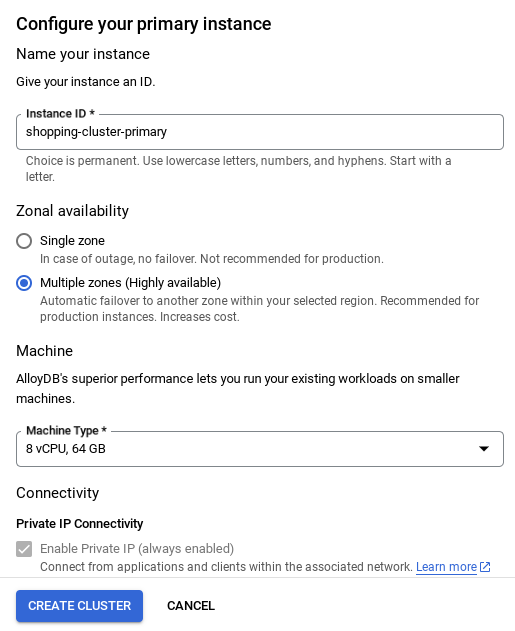
หมายเหตุสำคัญ:
- อย่าลืมเปลี่ยนรหัสอินสแตนซ์ (ซึ่งคุณดูได้ในขณะที่กำหนดค่าคลัสเตอร์ / อินสแตนซ์) เป็น**
vector-instance** หากเปลี่ยนไม่ได้ โปรดใช้รหัสอินสแตนซ์ในการอ้างอิงที่จะเกิดขึ้นทั้งหมด - โปรดทราบว่าการสร้างคลัสเตอร์จะใช้เวลาประมาณ 10 นาที เมื่อดำเนินการสำเร็จแล้ว คุณควรเห็นหน้าจอที่แสดงภาพรวมของคลัสเตอร์ที่เพิ่งสร้าง
4. การนำเข้าข้อมูล
ตอนนี้ก็ถึงเวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้าแล้ว ไปที่ AlloyDB เลือกคลัสเตอร์หลัก แล้วเลือก AlloyDB Studio โดยทำดังนี้
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb"
เมื่อตรวจสอบสิทธิ์ใน AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงอุปกรณ์ปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
หากต้องการตรวจสอบส่วนขยายที่เปิดใช้ในฐานข้อมูล ให้เรียกใช้คำสั่ง SQL นี้
select extname, extversion from pg_extension;
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
คอลัมน์การฝังจะช่วยให้จัดเก็บค่าเวกเตอร์ของข้อความได้
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "embedding"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือจะเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
โหลดข้อมูลลงในฐานข้อมูล
- คัดลอก
insertคำสั่งการค้นหาจากinsert scripts sqlในชีตไปยังตัวแก้ไขตามที่กล่าวถึงข้างต้น คุณสามารถคัดลอกคำสั่ง INSERT 10-50 รายการเพื่อสาธิตกรณีการใช้งานนี้อย่างรวดเร็ว คุณจะเห็นรายการแทรกที่เลือกได้ที่นี่ในแท็บ "แทรกที่เลือก 25-30 แถว"
คุณดูลิงก์ไปยังข้อมูลได้ในไฟล์ที่เก็บ GitHub
- คลิกเรียกใช้ ผลลัพธ์ของคำค้นหาจะปรากฏในตารางผลลัพธ์
หมายเหตุสำคัญ:
โปรดคัดลอกเฉพาะระเบียน 25-50 รายการเพื่อแทรก และตรวจสอบว่ามาจากช่วงของหมวดหมู่ หมวดหมู่ย่อย สี และประเภทเพศ
5. สร้างการฝังสำหรับข้อมูล
นวัตกรรมที่แท้จริงในการค้นหาในปัจจุบันอยู่ที่การทำความเข้าใจความหมาย ไม่ใช่แค่คีย์เวิร์ด ซึ่งเป็นจุดที่การฝังและการค้นหาเวกเตอร์เข้ามามีบทบาท
เราแปลงคำอธิบายผลิตภัณฑ์และคำค้นหาของผู้ใช้ให้เป็นการแสดงตัวเลขแบบหลายมิติที่เรียกว่า "การฝัง" โดยใช้โมเดลภาษาที่ฝึกไว้ล่วงหน้า การฝังเหล่านี้จะบันทึกความหมายเชิงความหมาย ซึ่งช่วยให้เราค้นหาผลิตภัณฑ์ที่ "มีความหมายคล้ายกัน" แทนที่จะมีเพียงคำที่ตรงกัน ในตอนแรก เราได้ทดลองใช้การค้นหาความคล้ายคลึงของเวกเตอร์โดยตรงในการฝังเหล่านี้เพื่อสร้างพื้นฐาน ซึ่งแสดงให้เห็นถึงพลังของการทำความเข้าใจเชิงความหมายแม้ก่อนการเพิ่มประสิทธิภาพ
คอลัมน์การฝังจะช่วยให้จัดเก็บค่าเวกเตอร์ของข้อความคำอธิบายผลิตภัณฑ์ได้ คอลัมน์ img_embeddings จะช่วยให้จัดเก็บการฝังรูปภาพ (มัลติโมดัล) ได้ วิธีนี้จะช่วยให้คุณใช้การค้นหาตามระยะห่างของข้อความกับรูปภาพได้ด้วย แต่เราจะใช้เฉพาะการฝังข้อความใน Lab นี้
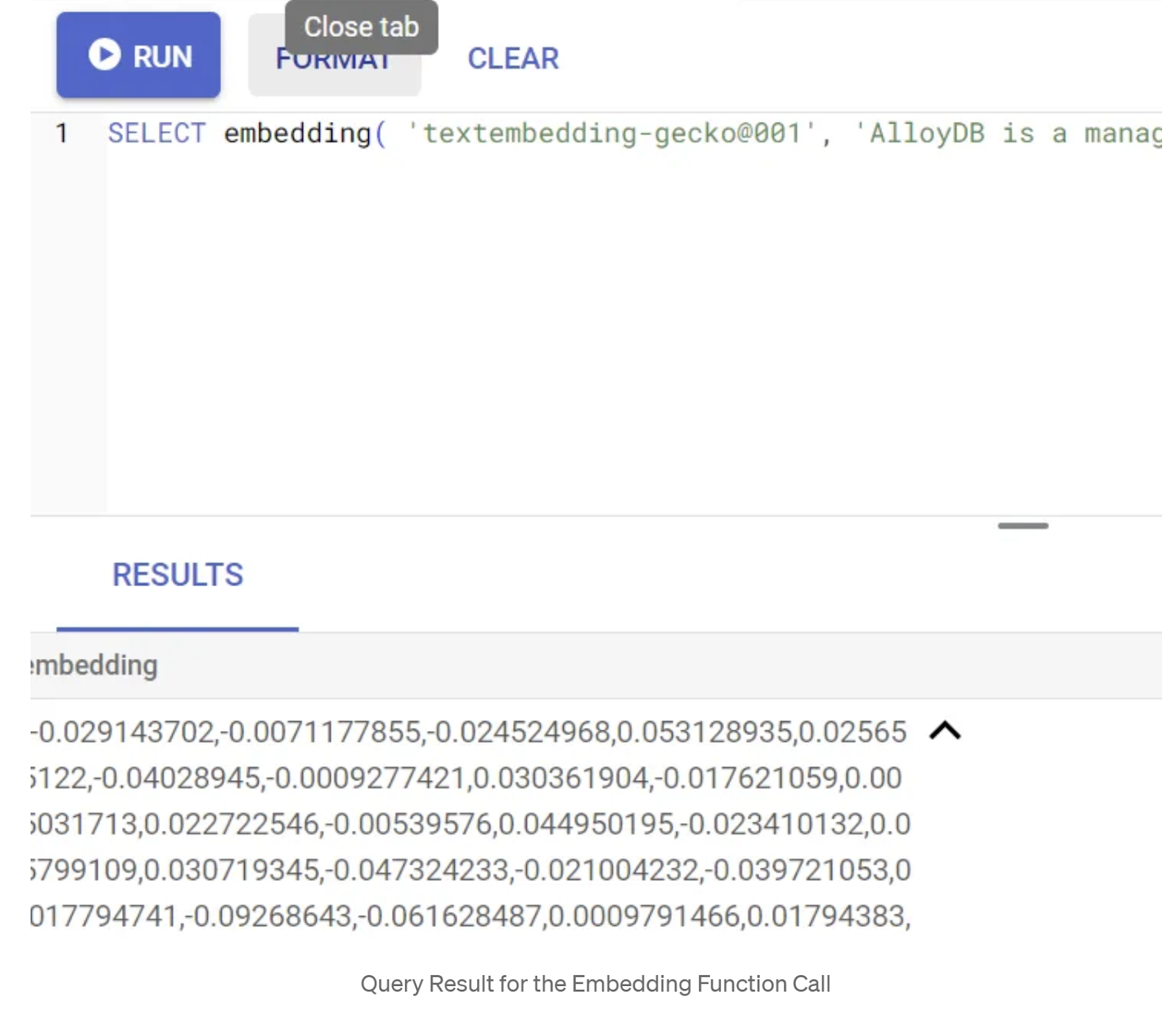
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งควรแสดงผลเวกเตอร์การฝังที่มีลักษณะคล้ายอาร์เรย์ของจำนวนทศนิยมสำหรับข้อความตัวอย่างในการค้นหา ซึ่งจะมีลักษณะดังนี้
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
เรียกใช้ DML ด้านล่างเพื่ออัปเดตคำอธิบายเนื้อหาในตารางด้วยการฝังที่เกี่ยวข้อง
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
คุณอาจพบปัญหาในการสร้าง Embedding มากกว่า 2-3 รายการ (เช่น สูงสุด 20-25 รายการ) หากใช้บัญชีสำหรับการเรียกเก็บเงินเครดิตทดลองใช้สำหรับ Google Cloud ดังนั้นให้จำกัดจำนวนแถวในสคริปต์การแทรก
หากต้องการสร้างการฝังรูปภาพ (เพื่อทำการค้นหาตามบริบทแบบมัลติโมดัล) ให้เรียกใช้การอัปเดตด้านล่างด้วย
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. ใช้ RAG ขั้นสูงด้วยฟีเจอร์ใหม่ของ AlloyDB
ตอนนี้ตาราง ข้อมูล และการฝังพร้อมใช้งานแล้ว เรามาทำการค้นหาเวกเตอร์แบบเรียลไทม์สำหรับข้อความค้นหาของผู้ใช้กัน คุณทดสอบได้โดยเรียกใช้คำค้นหาด้านล่าง
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
ในคำค้นหานี้ เราจะเปรียบเทียบการฝังข้อความของคำค้นหาที่ผู้ใช้ป้อน "เสื้อยืดคอกลม" กับการฝังข้อความของคำอธิบายผลิตภัณฑ์ทั้งหมดในตารางเครื่องแต่งกาย (จัดเก็บไว้ในคอลัมน์ชื่อ "การฝัง") โดยใช้ฟังก์ชันระยะทางความคล้ายโคไซน์ (แสดงด้วยสัญลักษณ์ "<=>") เราจะแปลงผลลัพธ์ของวิธีการฝังเป็นประเภทเวกเตอร์เพื่อให้เข้ากันได้กับเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูล LIMIT 10 หมายความว่าเราจะเลือกผลการค้นหาที่ตรงกับข้อความค้นหามากที่สุด 10 รายการ
AlloyDB ยกระดับ RAG ของ Vector Search ไปอีกขั้น
สำหรับโซลูชันระดับองค์กร การค้นหาเวกเตอร์แบบดิบนั้นไม่เพียงพอ ประสิทธิภาพเป็นสิ่งสำคัญ
ดัชนี ScaNN (Scalable Nearest Neighbors)
เราได้เปิดใช้ดัชนี scaNN ใน AlloyDB เพื่อให้การค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ (ANN) รวดเร็วเป็นพิเศษ ScaNN ซึ่งเป็นอัลกอริทึมการค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณที่ทันสมัยที่สุดซึ่งพัฒนาโดยทีมวิจัยของ Google ออกแบบมาเพื่อการค้นหาความคล้ายคลึงของเวกเตอร์อย่างมีประสิทธิภาพในวงกว้าง ซึ่งจะช่วยเพิ่มความเร็วในการค้นหาได้อย่างมากด้วยการตัดพื้นที่การค้นหาอย่างมีประสิทธิภาพและการใช้เทคนิคการหาปริมาณ ทำให้การค้นหาเวกเตอร์เร็วกว่าวิธีการจัดทำดัชนีอื่นๆ ถึง 4 เท่า และใช้หน่วยความจำน้อยลง อ่านเพิ่มเติมได้ที่นี่และที่นี่
มาเปิดใช้ส่วนขยายและสร้างดัชนีกัน
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
การสร้างดัชนีสำหรับทั้งฟิลด์การฝังข้อความและการฝังรูปภาพ (ในกรณีที่คุณต้องการใช้การฝังรูปภาพในการค้นหา)
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
ดัชนีข้อมูลเมตา
ในขณะที่ scaNN จัดการการจัดทำดัชนีเวกเตอร์ เราได้ตั้งค่าดัชนี B-tree หรือ GIN แบบดั้งเดิมอย่างพิถีพิถันในแอตทริบิวต์ที่มีโครงสร้าง (เช่น หมวดหมู่ หมวดหมู่ย่อย สไตล์ สี ฯลฯ) ดัชนีเหล่านี้มีความสําคัญต่อประสิทธิภาพของการกรองแบบเจียระไน เรียกใช้คำสั่งด้านล่างเพื่อตั้งค่าดัชนีข้อมูลเมตา
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
หมายเหตุสำคัญ:
เนื่องจากคุณอาจแทรกเฉพาะ 25-50 ระเบียน ดัชนี (ScaNN หรือดัชนีใดๆ ก็ตาม) จะไม่มีผล
การกรองแบบอินไลน์
ความท้าทายที่พบบ่อยในการค้นหาเวกเตอร์คือการรวมเข้ากับตัวกรองที่มีโครงสร้าง (เช่น "รองเท้าสีแดง") การกรองแบบอินไลน์ของ AlloyDB จะเพิ่มประสิทธิภาพในส่วนนี้ การกรองแบบอินไลน์จะใช้เงื่อนไขตัวกรองในระหว่างกระบวนการค้นหาเวกเตอร์เอง ซึ่งจะช่วยปรับปรุงประสิทธิภาพและความแม่นยําของการค้นหาเวกเตอร์ที่กรองแล้วได้อย่างมาก แทนที่จะกรองผลลัพธ์ภายหลังจากการค้นหาเวกเตอร์แบบกว้าง
ดูข้อมูลเพิ่มเติมเกี่ยวกับความจำเป็นในการกรองแบบอินไลน์ได้ในเอกสารประกอบนี้ นอกจากนี้ คุณยังดูข้อมูลเกี่ยวกับการค้นหาเวกเตอร์ที่กรองแล้วเพื่อเพิ่มประสิทธิภาพการค้นหาเวกเตอร์ได้ที่นี่ ตอนนี้หากต้องการเปิดใช้การกรองในบรรทัดสำหรับแอปพลิเคชัน ให้เรียกใช้คำสั่งต่อไปนี้จากเอดิเตอร์
SET scann.enable_inline_filtering = on;
การกรองในบรรทัดเหมาะที่สุดสำหรับกรณีที่มีการเลือกปานกลาง ขณะที่ AlloyDB ค้นหาผ่านดัชนีเวกเตอร์ ระบบจะคำนวณระยะทางสำหรับเวกเตอร์ที่ตรงกับเงื่อนไขการกรองข้อมูลเมตาเท่านั้น (โดยปกติแล้วตัวกรองฟังก์ชันในคำค้นหาจะได้รับการจัดการในอนุประโยค WHERE) ซึ่งจะช่วยปรับปรุงประสิทธิภาพของการค้นหาเหล่านี้ได้อย่างมาก โดยจะช่วยเสริมข้อดีของการกรองหลังการรวมหรือการกรองก่อนการรวม
การกรองแบบปรับอัตโนมัติ
การกรองแบบปรับได้ของ AlloyDB จะเลือกกลยุทธ์การกรองที่มีประสิทธิภาพสูงสุด (การกรองในบรรทัดหรือการกรองล่วงหน้า) แบบไดนามิกระหว่างการดำเนินการค้นหาเพื่อเพิ่มประสิทธิภาพให้ดียิ่งขึ้น โดยจะวิเคราะห์รูปแบบการค้นหาและการกระจายข้อมูลเพื่อให้มั่นใจถึงประสิทธิภาพสูงสุดโดยไม่ต้องมีการแทรกแซงด้วยตนเอง ซึ่งจะเป็นประโยชน์อย่างยิ่งสำหรับการค้นหาเวกเตอร์ที่กรองแล้ว ซึ่งจะสลับระหว่างการใช้ดัชนีเวกเตอร์และข้อมูลเมตาโดยอัตโนมัติ หากต้องการเปิดใช้การกรองแบบปรับได้ ให้ใช้การตั้งค่าสถานะ scann.enable_preview_features
เมื่อการกรองแบบปรับอัตโนมัติทริกเกอร์การเปลี่ยนจากการกรองในบรรทัดเป็นการกรองล่วงหน้าระหว่างการดำเนินการ แผนการค้นหาจะเปลี่ยนไปแบบไดนามิก
SET scann.enable_preview_features = on;
หมายเหตุสำคัญ: คุณอาจเรียกใช้คำสั่งข้างต้นไม่ได้โดยไม่ต้องรีสตาร์ทอินสแตนซ์ หากพบข้อผิดพลาด ให้เปิดใช้แฟล็ก enable_preview_features จากส่วนแฟล็กฐานข้อมูลของอินสแตนซ์
ตัวกรองแบบเจียระไนที่ใช้ดัชนีทั้งหมด
การค้นหาแบบเจียระไนช่วยให้ผู้ใช้ปรับแต่งผลการค้นหาได้โดยใช้ตัวกรองหลายรายการตามแอตทริบิวต์หรือ "แง่มุม" ที่เฉพาะเจาะจง (เช่น แบรนด์ ราคา ขนาด การให้คะแนนของลูกค้า) แอปพลิเคชันของเราผสานรวมแง่มุมเหล่านี้เข้ากับการค้นหาเวกเตอร์ได้อย่างราบรื่น ตอนนี้คำค้นหาเดียวสามารถรวมภาษาที่เป็นธรรมชาติ (การค้นหาตามบริบท) กับการเลือกแบบหลายแง่มุมได้ โดยใช้ประโยชน์จากทั้งดัชนีเวกเตอร์และดัชนีแบบเดิมแบบไดนามิก ซึ่งจะช่วยให้ผู้ใช้สามารถค้นหาแบบไฮบริดแบบไดนามิกได้อย่างแท้จริง และเจาะลึกผลการค้นหาได้อย่างแม่นยำ
ในแอปพลิเคชันของเรา เนื่องจากเราได้สร้างดัชนีข้อมูลเมตาทั้งหมดแล้ว เราจึงพร้อมสำหรับการใช้ตัวกรองแบบเจียระไนในเว็บโดยการจัดการโดยตรงโดยใช้คำค้นหา SQL ดังนี้
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
ในคำค้นหานี้ เราจะทำการค้นหาแบบไฮบริด ซึ่งรวมทั้ง
- การกรองแบบเจียระไนในคําสั่ง WHERE และ
- การค้นหาเวกเตอร์ในอนุประโยค ORDER BY โดยใช้วิธีความคล้ายกันของโคไซน์
$1, $2, $3 และ $4 แสดงค่าตัวกรองแบบเจียระไนในอาร์เรย์ และ $5 แสดงข้อความค้นหาของผู้ใช้ แทนที่ $1 ถึง $4 ด้วยค่าตัวกรองแบบเจียระไนที่คุณเลือก ดังนี้
category = ANY([‘Apparel', ‘Footwear'])
แทนที่ $5 ด้วยข้อความค้นหาที่คุณต้องการ เช่น "เสื้อโปโล"
หมายเหตุสำคัญ: หากไม่มีดัชนีเนื่องจากชุดระเบียนที่จำกัดซึ่งคุณแทรกไว้ คุณจะไม่เห็นผลกระทบต่อประสิทธิภาพ แต่ในชุดข้อมูลการใช้งานจริงแบบเต็ม คุณจะเห็นว่าเวลาในการดำเนินการลดลงอย่างมากสำหรับการค้นหาเวกเตอร์เดียวกันโดยใช้ดัชนี ScaNN ที่ผสานรวมการกรองแบบอินไลน์ในการค้นหาเวกเตอร์
ต่อไป มาประเมินการเรียกคืนสำหรับการค้นหาเวกเตอร์ที่เปิดใช้ ScaNN นี้กัน
การจัดอันดับใหม่
แม้จะใช้การค้นหาขั้นสูงแล้ว แต่ผลลัพธ์เริ่มต้นก็อาจต้องมีการปรับแต่งขั้นสุดท้าย ซึ่งเป็นขั้นตอนสำคัญที่จัดลำดับผลการค้นหาเบื้องต้นใหม่เพื่อปรับปรุงความเกี่ยวข้อง หลังจากที่การค้นหาแบบไฮบริดครั้งแรกแสดงชุดผลิตภัณฑ์ที่เป็นไปได้แล้ว โมเดลที่ซับซ้อนมากขึ้น (และมักจะใช้การคำนวณหนักกว่า) จะใช้คะแนนความเกี่ยวข้องที่ละเอียดยิ่งขึ้น ซึ่งจะช่วยให้มั่นใจได้ว่าผลการค้นหาอันดับต้นๆ ที่แสดงต่อผู้ใช้มีความเกี่ยวข้องมากที่สุด ซึ่งจะช่วยเพิ่มคุณภาพการค้นหาได้อย่างมาก เราประเมินการเรียกคืนอย่างต่อเนื่องเพื่อวัดประสิทธิภาพของระบบในการดึงข้อมูลรายการที่เกี่ยวข้องทั้งหมดสำหรับคำค้นหาที่กำหนด และปรับแต่งโมเดลเพื่อเพิ่มโอกาสที่ลูกค้าจะพบสิ่งที่ต้องการ
ก่อนใช้ในแอปพลิเคชัน โปรดตรวจสอบว่าคุณมีคุณสมบัติตรงตามข้อกำหนดเบื้องต้นทั้งหมด
- ตรวจสอบว่าได้ติดตั้งส่วนขยาย google_ml_integration แล้ว
- ตรวจสอบว่าได้ตั้งค่าฟีเจอร์ google_ml_integration.enable_model_support เป็นเปิดแล้ว
- ผสานรวมกับ Vertex AI
- เปิดใช้ Discovery Engine API
- รับบทบาทที่จำเป็นเพื่อใช้โมเดลการจัดอันดับ
จากนั้นคุณสามารถใช้คำค้นหาต่อไปนี้ในแอปพลิเคชันของเราเพื่อจัดอันดับชุดผลลัพธ์ที่ค้นหาแบบไฮบริดใหม่ได้
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
ในคำค้นหานี้ เราจะทำการจัดอันดับใหม่ของชุดผลลัพธ์ผลิตภัณฑ์ของการค้นหาตามบริบทที่ระบุไว้ในคําสั่ง ORDER BY โดยใช้วิธีความคล้ายกันของโคไซน์ "เสื้อสีชมพู" คือข้อความที่ผู้ใช้ค้นหา
หมายเหตุสำคัญ: บางท่านอาจยังไม่มีสิทธิ์เข้าถึงการจัดอันดับใหม่ ดังนั้นฉันจึงไม่รวมการจัดอันดับใหม่ไว้ในโค้ดของแอปพลิเคชัน แต่หากต้องการรวมไว้ด้วย คุณสามารถทำตามตัวอย่างที่เรากล่าวถึงข้างต้นได้
ผู้ประเมินฟีเจอร์ความทรงจำ
การเรียกคืนในการค้นหาที่คล้ายกันคือเปอร์เซ็นต์ของอินสแตนซ์ที่เกี่ยวข้องซึ่งดึงมาจากการค้นหา นั่นคือจำนวนผลบวกจริง นี่คือเมตริกที่ใช้กันโดยทั่วไปในการวัดคุณภาพการค้นหา แหล่งที่มาหนึ่งของการสูญเสียการเรียกคืนเกิดจากความแตกต่างระหว่างการค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ หรือ aNN กับการค้นหาเพื่อนบ้านที่ใกล้ที่สุด (ที่แน่นอน) หรือ kNN ดัชนีเวกเตอร์ เช่น ScaNN ของ AlloyDB จะใช้อัลกอริทึม aNN ซึ่งช่วยให้คุณเร่งการค้นหาเวกเตอร์ในชุดข้อมูลขนาดใหญ่ได้โดยแลกกับการลดความสามารถในการเรียกคืนลงเล็กน้อย ตอนนี้ AlloyDB ช่วยให้คุณวัดการแลกเปลี่ยนนี้ได้โดยตรงในฐานข้อมูลสำหรับคำค้นหาแต่ละรายการ และมั่นใจได้ว่าการแลกเปลี่ยนนี้จะคงที่ตลอดเวลา คุณสามารถอัปเดตพารามิเตอร์การค้นหาและดัชนีเพื่อตอบสนองต่อข้อมูลนี้เพื่อให้ได้ผลลัพธ์และประสิทธิภาพที่ดีขึ้น
ตรรกะเบื้องหลังการเรียกคืนผลการค้นหาคืออะไร
ในบริบทของการค้นหาเวกเตอร์ การเรียกคืนหมายถึงเปอร์เซ็นต์ของเวกเตอร์ที่ดัชนีแสดงผลซึ่งเป็นจุดข้อมูลข้างเคียงที่แท้จริง ตัวอย่างเช่น หากการค้นหาเพื่อนบ้านที่ใกล้ที่สุดสำหรับเพื่อนบ้านที่ใกล้ที่สุด 20 รายแรกแสดงผลเพื่อนบ้านที่ใกล้ที่สุด 19 รายแรกของความจริงพื้นฐาน แสดงว่าการเรียกคืนคือ 19/20x100 = 95% การเรียกคืนคือเมตริกที่ใช้สำหรับคุณภาพการค้นหา และกำหนดเป็นเปอร์เซ็นต์ของผลลัพธ์ที่แสดงซึ่งใกล้เคียงกับเวกเตอร์คำค้นหามากที่สุดตามวัตถุประสงค์
คุณดูการเรียกคืนสำหรับการค้นหาเวกเตอร์ในดัชนีเวกเตอร์สำหรับการกำหนดค่าที่ระบุได้โดยใช้ฟังก์ชัน evaluate_query_recall ฟังก์ชันนี้ช่วยให้คุณปรับแต่งพารามิเตอร์เพื่อให้ได้ผลลัพธ์การเรียกคืนการค้นหาเวกเตอร์ที่ต้องการ
หมายเหตุสำคัญ:
หากคุณพบข้อผิดพลาด "ปฏิเสธการเข้าถึง" ในดัชนี HNSW ในขั้นตอนต่อไปนี้ ให้ข้ามส่วนการประเมินการเรียกคืนทั้งหมดนี้ไปก่อน ซึ่งอาจเกี่ยวข้องกับข้อจำกัดในการเข้าถึงในตอนนี้ เนื่องจากเพิ่งเปิดตัวในขณะที่บันทึก Codelab นี้
- ตั้งค่าสถานะเปิดใช้การสแกนดัชนีในดัชนี ScaNN และดัชนี HNSW
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- เรียกใช้การค้นหาต่อไปนี้ใน AlloyDB Studio
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ฟังก์ชัน evaluate_query_recall จะรับการค้นหาเป็นพารามิเตอร์และแสดงผลการเรียกคืนของการค้นหานั้น ฉันใช้การค้นหาเดียวกันกับที่ใช้ตรวจสอบประสิทธิภาพเป็นการค้นหาอินพุตของฟังก์ชัน ฉันได้เพิ่ม SCaNN เป็นวิธีการจัดทำดัชนีแล้ว ดูตัวเลือกพารามิเตอร์เพิ่มเติมได้ในเอกสารประกอบ
การเรียกคืนสำหรับคำค้นหา Vector Search ที่เราใช้มีดังนี้
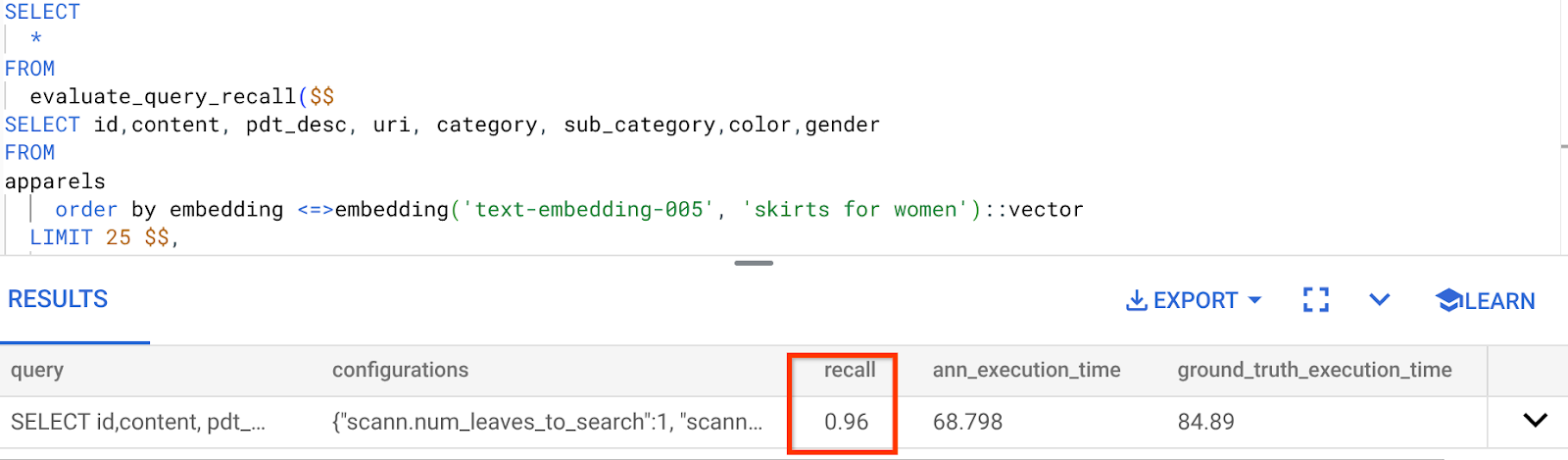
เราพบว่า RECALL คือ 96% ในกรณีนี้ การเรียกคืนจึงดีมาก แต่หากเป็นค่าที่ยอมรับไม่ได้ คุณสามารถใช้ข้อมูลนี้เพื่อเปลี่ยนพารามิเตอร์ดัชนี วิธีการ และพารามิเตอร์การค้นหา และปรับปรุงการเรียกคืนสำหรับการค้นหาเวกเตอร์นี้ได้
ทดสอบด้วยพารามิเตอร์การค้นหาและดัชนีที่แก้ไขแล้ว
ตอนนี้มาทดสอบการค้นหาโดยการแก้ไขพารามิเตอร์การค้นหาตามการเรียกคืนที่ได้รับ
- การแก้ไขพารามิเตอร์ดัชนี
สำหรับการทดสอบนี้ ฉันจะใช้ฟังก์ชันระยะทางความคล้ายคลึงกันของ "L2 Distance" แทนฟังก์ชัน "Cosine"
หมายเหตุสำคัญ: "เราจะรู้ได้อย่างไรว่าคำค้นหานี้ใช้ความคล้ายคลึงแบบโคไซน์" คุณอาจสงสัย คุณระบุฟังก์ชันระยะทางได้โดยใช้ "<=>" เพื่อแสดงระยะทางโคไซน์
ลิงก์เอกสาร สำหรับฟังก์ชันระยะทางของ Vector Search
การค้นหาก่อนหน้านี้ใช้ฟังก์ชันระยะทาง Cosine Similarity แต่ตอนนี้เราจะลองใช้ระยะทาง L2 แต่ในกรณีนี้ เราควรตรวจสอบว่าดัชนี ScaNN พื้นฐานใช้ฟังก์ชันระยะทาง L2 ด้วย ตอนนี้มาสร้างดัชนีด้วยการค้นหาฟังก์ชันระยะทางอื่นกัน ระยะทาง L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
คำสั่ง DROP INDEX มีไว้เพื่อให้แน่ใจว่าไม่มีดัชนีที่ไม่จำเป็นในตาราง
ตอนนี้ฉันสามารถเรียกใช้การค้นหาต่อไปนี้เพื่อประเมินการเรียกคืนหลังจากเปลี่ยนฟังก์ชันระยะทางของฟังก์ชันการค้นหาเวกเตอร์
[AFTER] คำค้นหาที่ใช้ฟังก์ชันระยะทาง L2
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
คุณจะเห็นความแตกต่าง / การเปลี่ยนแปลงในค่าการเรียกคืนสำหรับดัชนีที่อัปเดต
นอกจากนี้ ยังมีพารามิเตอร์อื่นๆ ที่คุณเปลี่ยนได้ในดัชนี เช่น num_leaves เป็นต้น โดยอิงตามค่าการเรียกคืนที่ต้องการและชุดข้อมูลที่แอปพลิเคชันของคุณใช้
การตรวจสอบความถูกต้องของผลการค้นหาเวกเตอร์โดย LLM
เราได้รวมเลเยอร์การตรวจสอบ LLM ที่ไม่บังคับไว้ด้วยเพื่อให้ได้การค้นหาที่ควบคุมคุณภาพสูงสุด คุณสามารถใช้โมเดลภาษาขนาดใหญ่เพื่อประเมินความเกี่ยวข้องและความสอดคล้องของผลการค้นหา โดยเฉพาะอย่างยิ่งสำหรับการค้นหาที่ซับซ้อนหรือคลุมเครือ ซึ่งอาจรวมถึง
การยืนยันเชิงความหมาย:
LLM อ้างอิงผลลัพธ์เทียบกับเจตนาของคำค้นหา
การกรองเชิงตรรกะ:
การใช้ LLM เพื่อใช้ตรรกะทางธุรกิจหรือกฎที่ซับซ้อนซึ่งยากต่อการเข้ารหัสในตัวกรองแบบดั้งเดิม ซึ่งจะช่วยปรับแต่งรายการผลิตภัณฑ์เพิ่มเติมตามเกณฑ์ที่ละเอียด
การประกันคุณภาพ:
ระบุและแจ้งผลการค้นหาที่เกี่ยวข้องน้อยกว่าโดยอัตโนมัติเพื่อให้เจ้าหน้าที่ตรวจสอบหรือปรับแต่งโมเดล
เราได้ดำเนินการดังกล่าวในฟีเจอร์ AI ของ AlloyDB ดังนี้
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
คําค้นหาพื้นฐานคือคําค้นหาเดียวกันกับที่เราเห็นในส่วนการค้นหาแบบเจียระไน การค้นหาแบบไฮบริด และการจัดอันดับใหม่ ตอนนี้ในคำค้นหานี้ เราได้รวมเลเยอร์การประเมิน GEMINI ของชุดผลลัพธ์ที่จัดอันดับใหม่ซึ่งแสดงโดยโครงสร้าง ml_predict_row เราได้แสดงความคิดเห็นเกี่ยวกับตัวกรองแบบเจียระไนแล้ว แต่คุณสามารถใส่รายการที่ต้องการในอาร์เรย์สำหรับตัวยึดตำแหน่ง $1 ถึง $4 ได้ แทนที่ $5 ด้วยข้อความที่ต้องการค้นหา เช่น "เสื้อสีชมพู ไม่มีลายดอกไม้"
7. MCP Toolbox สำหรับฐานข้อมูลและเลเยอร์แอปพลิเคชัน
เบื้องหลัง เครื่องมือที่แข็งแกร่งและแอปพลิเคชันที่มีโครงสร้างดีจะช่วยให้การทำงานเป็นไปอย่างราบรื่น
Toolbox สำหรับฐานข้อมูลของ MCP (Model Context Protocol) ช่วยให้การผสานรวมเครื่องมือ Generative AI และเครื่องมือแบบเป็น Agent กับ AlloyDB เป็นเรื่องง่าย โดยจะทำหน้าที่เป็นเซิร์ฟเวอร์โอเพนซอร์สที่เพิ่มประสิทธิภาพการจัดกลุ่มการเชื่อมต่อ การตรวจสอบสิทธิ์ และการเปิดเผยฟังก์ชันฐานข้อมูลอย่างปลอดภัยต่อ Agent AI หรือแอปพลิเคชันอื่นๆ
ในแอปพลิเคชันของเรา เราใช้ MCP Toolbox สำหรับฐานข้อมูลเป็นเลเยอร์การแยกข้อมูลสำหรับการค้นหาแบบไฮบริดอัจฉริยะทั้งหมด
ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าและติดตั้งใช้งานกล่องเครื่องมือสำหรับกรณีการใช้งานของเรา
คุณจะเห็นว่าฐานข้อมูลหนึ่งที่ MCP Toolbox สำหรับฐานข้อมูลรองรับคือ AlloyDB และเนื่องจากเราได้จัดสรรฐานข้อมูลดังกล่าวในส่วนก่อนหน้าแล้ว เราจึงมาตั้งค่า Toolbox กันเลย
- ไปที่เทอร์มินัล Cloud Shell และตรวจสอบว่าได้เลือกโปรเจ็กต์และแสดงในพรอมต์ของเทอร์มินัลแล้ว เรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell เพื่อไปยังไดเรกทอรีโปรเจ็กต์
mkdir toolbox-tools
cd toolbox-tools
- เรียกใช้คำสั่งด้านล่างเพื่อดาวน์โหลดและติดตั้งกล่องเครื่องมือในโฟลเดอร์ใหม่
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- ไปที่ Cloud Shell Editor (สำหรับโหมดแก้ไขโค้ด) แล้วเพิ่มไฟล์ชื่อ "tools.yaml" ในโฟลเดอร์รูทของโปรเจ็กต์
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
อย่าลืมแทนที่สคริปต์ Tools.yaml ด้วยโค้ดจากไฟล์ repo
มาทำความเข้าใจ tools.yaml กัน
แหล่งข้อมูลแสดงถึงแหล่งข้อมูลต่างๆ ที่เครื่องมือโต้ตอบด้วยได้ แหล่งที่มาแสดงถึงแหล่งข้อมูลที่เครื่องมือโต้ตอบด้วยได้ คุณกำหนดแหล่งข้อมูลเป็นแผนที่ได้ในส่วนแหล่งข้อมูลของไฟล์ tools.yaml โดยปกติแล้ว การกำหนดค่าแหล่งที่มาจะมีข้อมูลที่จำเป็นต่อการเชื่อมต่อและโต้ตอบกับฐานข้อมูล
เครื่องมือกำหนดการดำเนินการที่ Agent สามารถทำได้ เช่น การอ่านและเขียนไปยังแหล่งที่มา เครื่องมือแสดงถึงการดำเนินการที่เอเจนต์ทำได้ เช่น การเรียกใช้คำสั่ง SQL คุณกำหนดเครื่องมือเป็นแผนที่ได้ในส่วนเครื่องมือของไฟล์ tools.yaml โดยปกติแล้ว เครื่องมือจะต้องมีแหล่งที่มาเพื่อดำเนินการ
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการกำหนดค่า tools.yaml ได้ในเอกสารประกอบนี้
- เรียกใช้คำสั่งต่อไปนี้ (จากโฟลเดอร์ mcp-toolbox) เพื่อเริ่มเซิร์ฟเวอร์
./toolbox --tools-file "tools.yaml"
ตอนนี้หากคุณเปิดเซิร์ฟเวอร์ในโหมดแสดงตัวอย่างเว็บในระบบคลาวด์ คุณควรจะเห็นเซิร์ฟเวอร์ Toolbox ทำงานพร้อมเครื่องมือใหม่ชื่อ get-order-data
เซิร์ฟเวอร์ MCP Toolbox จะทำงานในพอร์ต 5000 โดยค่าเริ่มต้น มาใช้ Cloud Shell เพื่อทดสอบกัน
คลิกตัวอย่างเว็บใน Cloud Shell ดังที่แสดงด้านล่าง
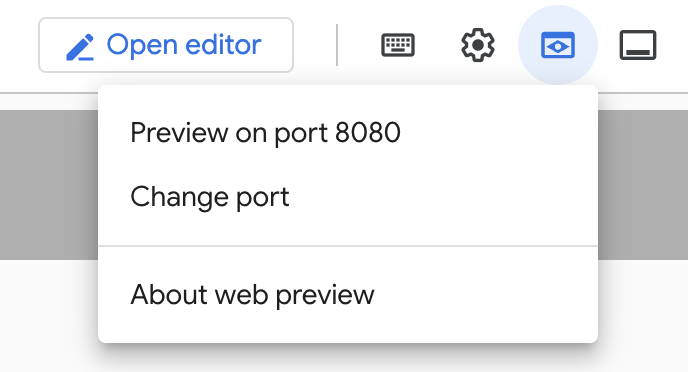
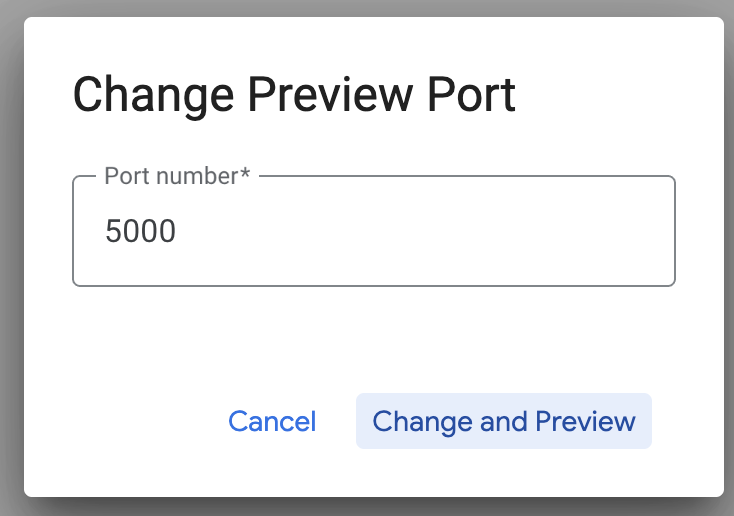
คลิกเปลี่ยนพอร์ตและตั้งค่าพอร์ตเป็น 5000 ตามที่แสดงด้านล่าง แล้วคลิกเปลี่ยนและแสดงตัวอย่าง
ซึ่งควรให้ผลลัพธ์ดังนี้
- มาทำให้กล่องเครื่องมือใช้งานได้ใน Cloud Run กัน
ก่อนอื่น เราจะเริ่มต้นด้วยเซิร์ฟเวอร์ MCP Toolbox และโฮสต์ใน Cloud Run จากนั้นเราจะมีปลายทางสาธารณะที่สามารถผสานรวมกับแอปพลิเคชันอื่นๆ และ/หรือแอปพลิเคชันตัวแทนได้ด้วย ดูวิธีการโฮสต์ใน Cloud Run ได้ที่นี่ เราจะไปดูขั้นตอนสำคัญกันเลย
- เปิดใช้เทอร์มินัล Cloud Shell ใหม่หรือใช้เทอร์มินัล Cloud Shell ที่มีอยู่ ไปที่โฟลเดอร์โปรเจ็กต์ที่มีไบนารีของกล่องเครื่องมือและ tools.yaml ในกรณีนี้คือ toolbox-tools ในกรณีที่คุณยังไม่ได้อยู่ในโฟลเดอร์ดังกล่าว
cd toolbox-tools
- ตั้งค่าตัวแปร PROJECT_ID ให้ชี้ไปยังรหัสโปรเจ็กต์ Google Cloud
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- เปิดใช้บริการ Google Cloud เหล่านี้
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- มาสร้างบัญชีบริการแยกต่างหากที่จะทำหน้าที่เป็นข้อมูลประจำตัวสำหรับบริการกล่องเครื่องมือที่เราจะทำให้ใช้งานได้ใน Google Cloud Run กัน
gcloud iam service-accounts create toolbox-identity
- นอกจากนี้ เรายังตรวจสอบว่าบัญชีบริการนี้มีบทบาทที่ถูกต้อง เช่น ความสามารถในการเข้าถึง Secret Manager และสื่อสารกับ AlloyDB
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- เราจะอัปโหลดไฟล์ tools.yaml เป็นข้อมูลลับ
gcloud secrets create tools --data-file=tools.yaml
หากมีข้อมูลลับอยู่แล้วและต้องการอัปเดตเวอร์ชันของข้อมูลลับ ให้ดำเนินการดังนี้
gcloud secrets versions add tools --data-file=tools.yaml
- ตั้งค่าตัวแปรสภาพแวดล้อมเป็นอิมเมจคอนเทนเนอร์ที่ต้องการใช้สำหรับ Cloud Run โดยทำดังนี้
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- ขั้นตอนสุดท้ายในคำสั่งการติดตั้งใช้งานที่คุ้นเคยไปยัง Cloud Run
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
ซึ่งจะเริ่มกระบวนการติดตั้งใช้งานเซิร์ฟเวอร์กล่องเครื่องมือด้วยไฟล์ tools.yaml ที่กำหนดค่าไว้ใน Cloud Run เมื่อติดตั้งใช้งานสำเร็จ คุณควรเห็นข้อความที่คล้ายกับข้อความต่อไปนี้
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
คุณพร้อมแล้วที่จะใช้เครื่องมือที่เพิ่งติดตั้งใช้งานในแอปพลิเคชันเอเจนต์!!!
การเข้าถึงเครื่องมือในเซิร์ฟเวอร์กล่องเครื่องมือ
เมื่อติดตั้งใช้งานกล่องเครื่องมือแล้ว เราจะสร้างโปรแกรมจำลองฟังก์ชัน Python Cloud Run เพื่อโต้ตอบกับเซิร์ฟเวอร์กล่องเครื่องมือที่ติดตั้งใช้งาน เนื่องจากปัจจุบัน Toolbox ไม่มี Java SDK เราจึงสร้าง Python Shim เพื่อโต้ตอบกับเซิร์ฟเวอร์ นี่คือซอร์สโค้ดสำหรับฟังก์ชัน Cloud Run ดังกล่าว
คุณต้องสร้างและทำให้ฟังก์ชัน Cloud Run นี้ใช้งานได้เพื่อให้เข้าถึงเครื่องมือในกล่องเครื่องมือที่เราเพิ่งสร้างและทำให้ใช้งานได้ในขั้นตอนก่อนหน้านี้
- ในคอนโซล Google Cloud ให้ไปที่หน้า Cloud Run
- คลิกเขียนฟังก์ชัน
- ในช่องชื่อบริการ ให้ป้อนชื่อเพื่ออธิบายฟังก์ชัน ชื่อบริการต้องขึ้นต้นด้วยตัวอักษรเท่านั้น และมีความยาวไม่เกิน 49 อักขระ ซึ่งรวมถึงตัวอักษร ตัวเลข หรือขีดกลาง ชื่อบริการต้องไม่ลงท้ายด้วยขีดกลาง และต้องไม่ซ้ำกันในแต่ละภูมิภาคและโปรเจ็กต์ ชื่อบริการจะเปลี่ยนในภายหลังไม่ได้และจะแสดงต่อสาธารณะ (Enter retail-product-search-quality)
- ในรายการภูมิภาค ให้ใช้ค่าเริ่มต้น หรือเลือกภูมิภาคที่คุณต้องการติดตั้งใช้งานฟังก์ชัน (เลือก us-central1)
- ในรายการรันไทม์ ให้ใช้ค่าเริ่มต้นหรือเลือกรุ่นรันไทม์ (เลือก Python 3.11)
- ในส่วนการตรวจสอบสิทธิ์ ให้เลือก "อนุญาตการเข้าถึงแบบสาธารณะ"
- คลิกปุ่ม "สร้าง"
- ระบบจะสร้างฟังก์ชันและโหลดด้วยเทมเพลต main.py และ requirements.txt
- แทนที่ด้วยไฟล์ main.py และ requirements.txt จากที่เก็บของโปรเจ็กต์นี้
- ทำให้ฟังก์ชันใช้งานได้ แล้วคุณควรได้รับจุดสิ้นสุดสำหรับฟังก์ชัน Cloud Run
ปลายทางควรมีลักษณะดังนี้ (หรือคล้ายกัน)
ปลายทางฟังก์ชัน Cloud Run สำหรับเข้าถึงกล่องเครื่องมือ: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
เพื่อความสะดวกในการดำเนินการให้เสร็จสิ้นภายในไทม์ไลน์ (สำหรับเซสชันเชิงปฏิบัติที่นำโดยผู้สอน) ระบบจะแชร์หมายเลขโปรเจ็กต์สำหรับปลายทางในเวลาที่เซสชันเชิงปฏิบัติ
หมายเหตุสำคัญ:
หรือคุณจะใช้ส่วนฐานข้อมูลโดยตรงเป็นส่วนหนึ่งของโค้ดของแอปพลิเคชันหรือฟังก์ชัน Cloud Run ก็ได้
8. การพัฒนาแอปพลิเคชัน (Java) ด้วยการค้นหาตามประเภทที่จัดแบ่งไว้
สุดท้ายนี้ คอมโพเนนต์แบ็กเอนด์ที่มีประสิทธิภาพทั้งหมดนี้จะทำงานผ่านเลเยอร์แอปพลิเคชัน แอปพลิเคชันนี้พัฒนาด้วยภาษา Java และมีอินเทอร์เฟซผู้ใช้สำหรับการโต้ตอบกับระบบค้นหา โดยจะจัดระเบียบคำค้นหาไปยัง AlloyDB จัดการการแสดงตัวกรองแบบเจียระไน จัดการการเลือกของผู้ใช้ และนำเสนอผลการค้นหาที่จัดอันดับใหม่และผ่านการตรวจสอบแล้วในลักษณะที่ราบรื่นและใช้งานง่าย
- คุณเริ่มต้นได้โดยไปที่เทอร์มินัล Cloud Shell และโคลนที่เก็บ
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- ไปที่ Cloud Shell Editor ซึ่งคุณจะเห็นโฟลเดอร์ faceted_searching_retail ที่สร้างขึ้นใหม่
- ลบรายการต่อไปนี้เนื่องจากขั้นตอนเหล่านั้นเสร็จสมบูรณ์แล้วในส่วนก่อนหน้า
- ลบโฟลเดอร์ Cloud_Run_Function
- ลบไฟล์ db_script.sql
- ลบไฟล์ tools.yaml
- ไปที่โฟลเดอร์โปรเจ็กต์ retail-faceted-search แล้วคุณจะเห็นโครงสร้างโปรเจ็กต์ดังนี้
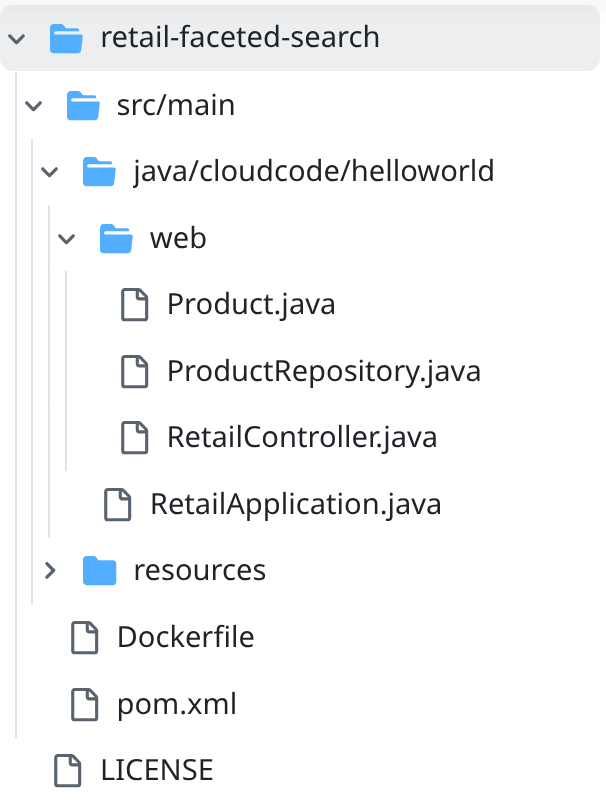
- ในไฟล์ ProductRepository.java คุณต้องแก้ไขตัวแปร TOOLBOX_ENDPOINT ด้วยปลายทางจากฟังก์ชัน Cloud Run (ที่กําหนด) หรือใช้ปลายทางจากผู้บรรยายที่สอนภาคปฏิบัติ
ค้นหาบรรทัดโค้ดต่อไปนี้ แล้วแทนที่ด้วยปลายทางของคุณ
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- ตรวจสอบว่า Dockerfile และ pom.xml เป็นไปตามการกำหนดค่าโปรเจ็กต์ (ไม่จำเป็นต้องเปลี่ยนแปลงเว้นแต่คุณจะเปลี่ยนเวอร์ชันหรือการกำหนดค่าอย่างชัดเจน)
- ในเทอร์มินัล Cloud Shell ให้ตรวจสอบว่าคุณอยู่ในโฟลเดอร์หลักและภายในโฟลเดอร์โปรเจ็กต์ (faceted_searching_retail / retail-faceted-search) ใช้คำสั่งต่อไปนี้เพื่อให้แน่ใจว่าคุณอยู่ในโฟลเดอร์ที่ถูกต้องในเทอร์มินัล
cd faceted_searching_retail
cd retail-faceted-search
- แพ็กเกจ สร้าง และทดสอบแอปพลิเคชันในเครื่อง
mvn package
mvn spring-boot:run
คุณควรจะดูแอปพลิเคชันได้โดยคลิก "ดูตัวอย่างบนพอร์ต 8080" ในเทอร์มินัล Cloud Shell ดังที่แสดงด้านล่าง
9. ทำให้ใช้งานได้กับ Cloud Run: ***ขั้นตอนสำคัญ
ในเทอร์มินัล Cloud Shell ตรวจสอบว่าคุณอยู่ในโฟลเดอร์หลักและภายในโฟลเดอร์โปรเจ็กต์ (faceted_searching_retail / retail-faceted-search) ใช้คำสั่งต่อไปนี้เพื่อให้แน่ใจว่าคุณอยู่ในโฟลเดอร์ที่ถูกต้องในเทอร์มินัล
cd faceted_searching_retail
cd retail-faceted-search
เมื่อแน่ใจว่าคุณอยู่ในโฟลเดอร์โปรเจ็กต์แล้ว ให้เรียกใช้คำสั่งต่อไปนี้
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
เมื่อติดตั้งใช้งานแล้ว คุณควรได้รับปลายทาง Cloud Run ที่ติดตั้งใช้งานแล้วซึ่งมีลักษณะดังนี้
https://retail-search-**********-uc.a.run.app/
10. สาธิต
มาดูการทำงานจริงกันเลย
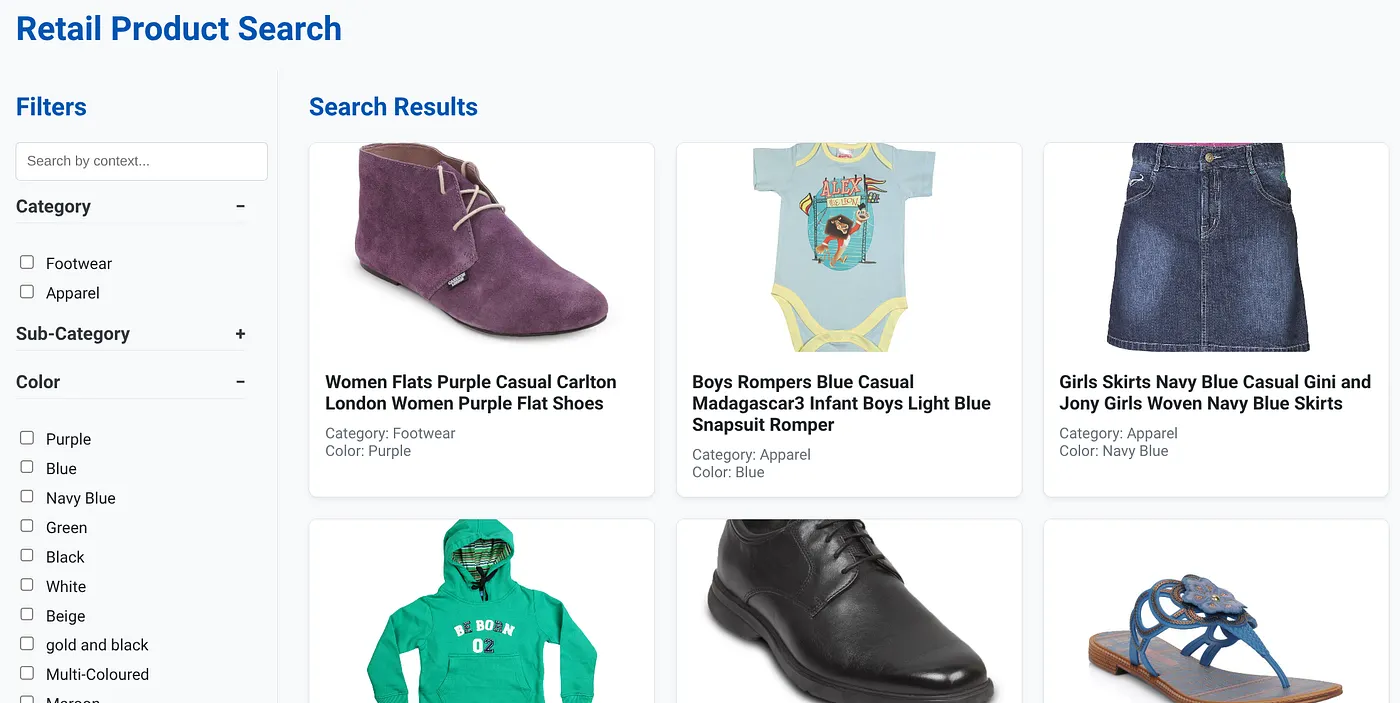
รูปภาพด้านบนแสดงหน้า Landing Page ของแอปการค้นหาแบบไฮบริดแบบไดนามิก
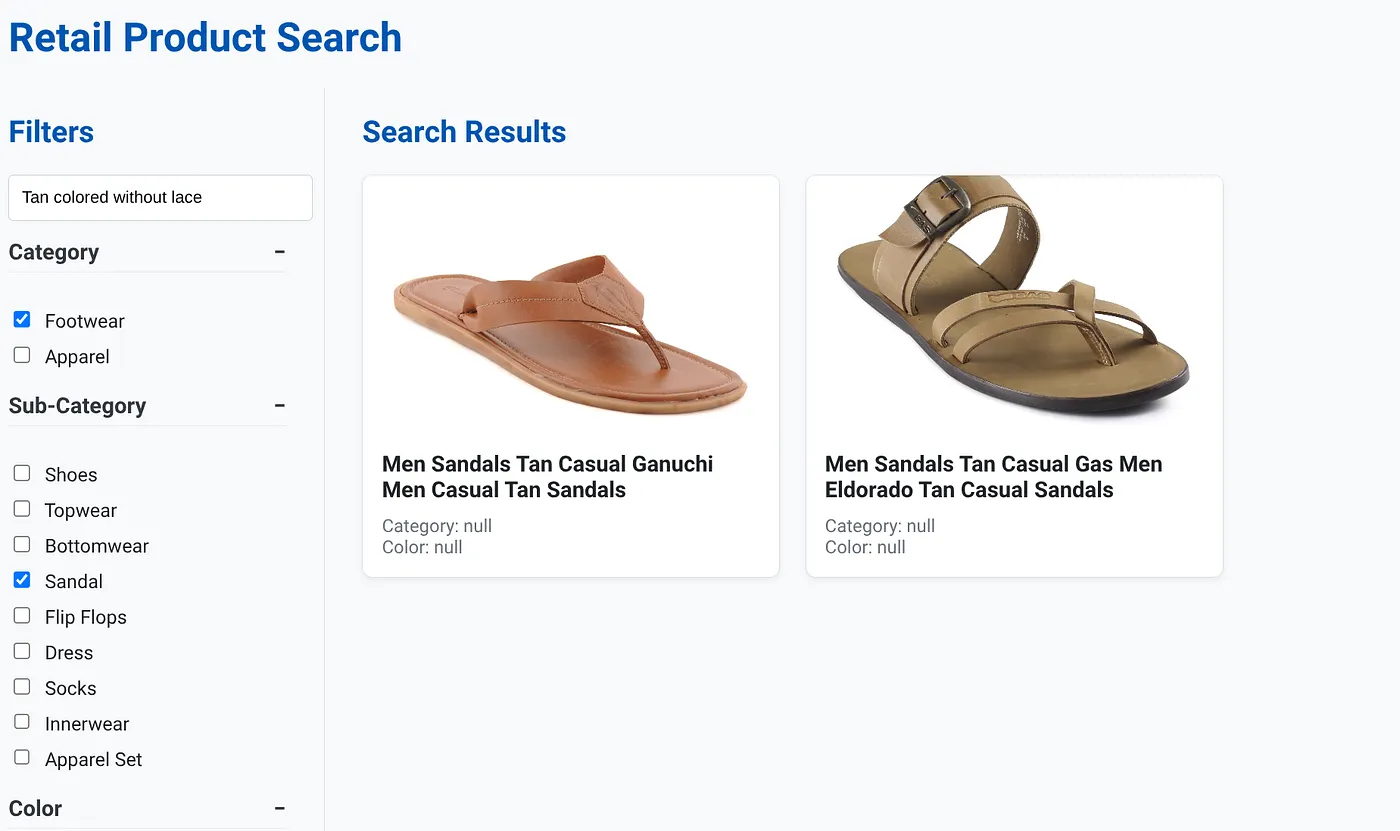
รูปภาพด้านบนแสดงผลการค้นหาสำหรับ "สีแทนแบบไม่มีเชือก" ตัวกรองแบบเจียระไนที่เลือกคือ รองเท้าและรองเท้าแตะ
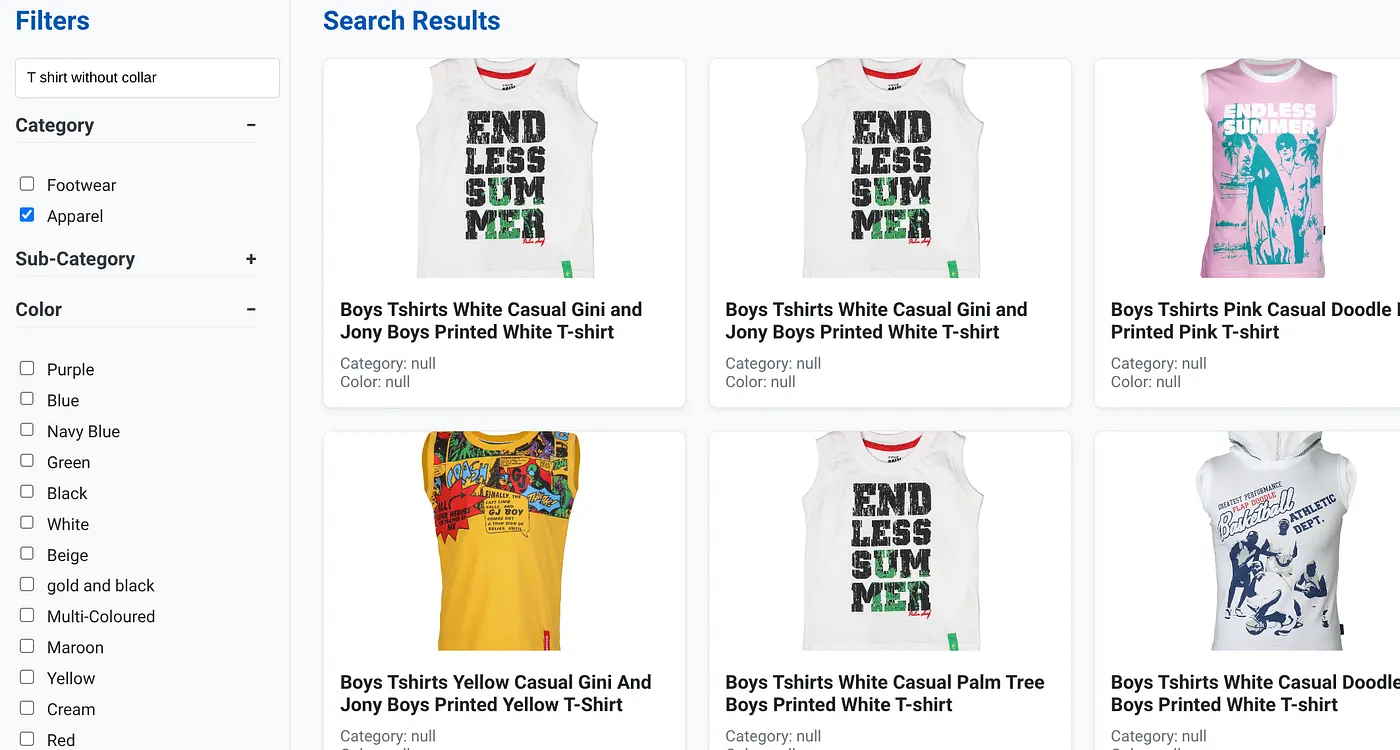
รูปภาพด้านบนแสดงผลการค้นหาสำหรับ "เสื้อยืดไม่มีปก" ตัวกรองแบบเจียระไน: เครื่องแต่งกาย
ตอนนี้คุณสามารถรวมฟีเจอร์แบบ Generative และ Agentic เพิ่มเติมเพื่อทำให้แอปพลิเคชันนี้ใช้งานได้จริง
ลองใช้เพื่อเป็นแรงบันดาลใจในการสร้างสรรค์ผลงานของคุณเอง!!!
11. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าResource Manager
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
- หรือคุณจะลบคลัสเตอร์ AlloyDB ที่เราเพิ่งสร้างขึ้นสำหรับโปรเจ็กต์นี้ก็ได้ (เปลี่ยนตำแหน่งในไฮเปอร์ลิงก์นี้หากคุณไม่ได้เลือก us-central1 สำหรับคลัสเตอร์ในขณะที่กำหนดค่า) โดยคลิกปุ่มลบคลัสเตอร์
12. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างและติดตั้งใช้งานแอป HYBRID SEARCH ด้วย ALLOYDB ใน CLOUD RUN เรียบร้อยแล้ว!!!
เหตุผลที่การเปลี่ยนแปลงนี้สำคัญต่อธุรกิจ
แอปพลิเคชันการค้นหาแบบไฮบริดแบบไดนามิกนี้ขับเคลื่อนโดย AlloyDB AI และมีข้อดีที่สำคัญสำหรับธุรกิจค้าปลีกระดับองค์กรและธุรกิจอื่นๆ ดังนี้
ความเกี่ยวข้องที่เหนือกว่า: การรวมการค้นหาตามบริบท (เวกเตอร์) เข้ากับการกรองแบบ Faceted ที่แม่นยำและการจัดอันดับใหม่อัจฉริยะจะช่วยให้ลูกค้าได้รับผลการค้นหาที่มีความเกี่ยวข้องสูง ซึ่งจะนำไปสู่ความพึงพอใจและ Conversion ที่เพิ่มขึ้น
ความสามารถในการปรับขนาด: สถาปัตยกรรมของ AlloyDB และการจัดทำดัชนี scaNN ออกแบบมาเพื่อรองรับแคตตาล็อกผลิตภัณฑ์จำนวนมากและปริมาณการค้นหาที่สูง ซึ่งมีความสำคัญต่อการขยายธุรกิจอีคอมเมิร์ซ
ประสิทธิภาพ: การตอบกลับคำค้นหาที่เร็วขึ้นแม้สำหรับการค้นหาแบบไฮบริดที่ซับซ้อนจะช่วยให้ผู้ใช้ได้รับประสบการณ์ที่ราบรื่นและลดอัตราการละทิ้ง
เตรียมพร้อมสำหรับอนาคต: การผสานรวมความสามารถของ AI (การฝัง การตรวจสอบ LLM) จะช่วยให้แอปพลิเคชันพร้อมรับความก้าวหน้าในอนาคตในด้านคำแนะนำที่ปรับเปลี่ยนในแบบของคุณ การค้าขายผ่านการสนทนา และการค้นพบผลิตภัณฑ์อัจฉริยะ
สถาปัตยกรรมที่เรียบง่าย: การผสานรวมการค้นหาเวกเตอร์โดยตรงภายใน AlloyDB ช่วยลดความจำเป็นในการใช้ฐานข้อมูลเวกเตอร์แยกต่างหากหรือการซิงค์ที่ซับซ้อน ซึ่งทำให้การพัฒนาและการบำรุงรักษาง่ายขึ้น
สมมติว่าผู้ใช้พิมพ์คำค้นหาที่เป็นภาษาธรรมชาติ เช่น "รองเท้าวิ่งที่เป็นมิตรต่อสิ่งแวดล้อมสำหรับผู้หญิงที่มีส่วนรองรับอุ้งเท้าสูง"
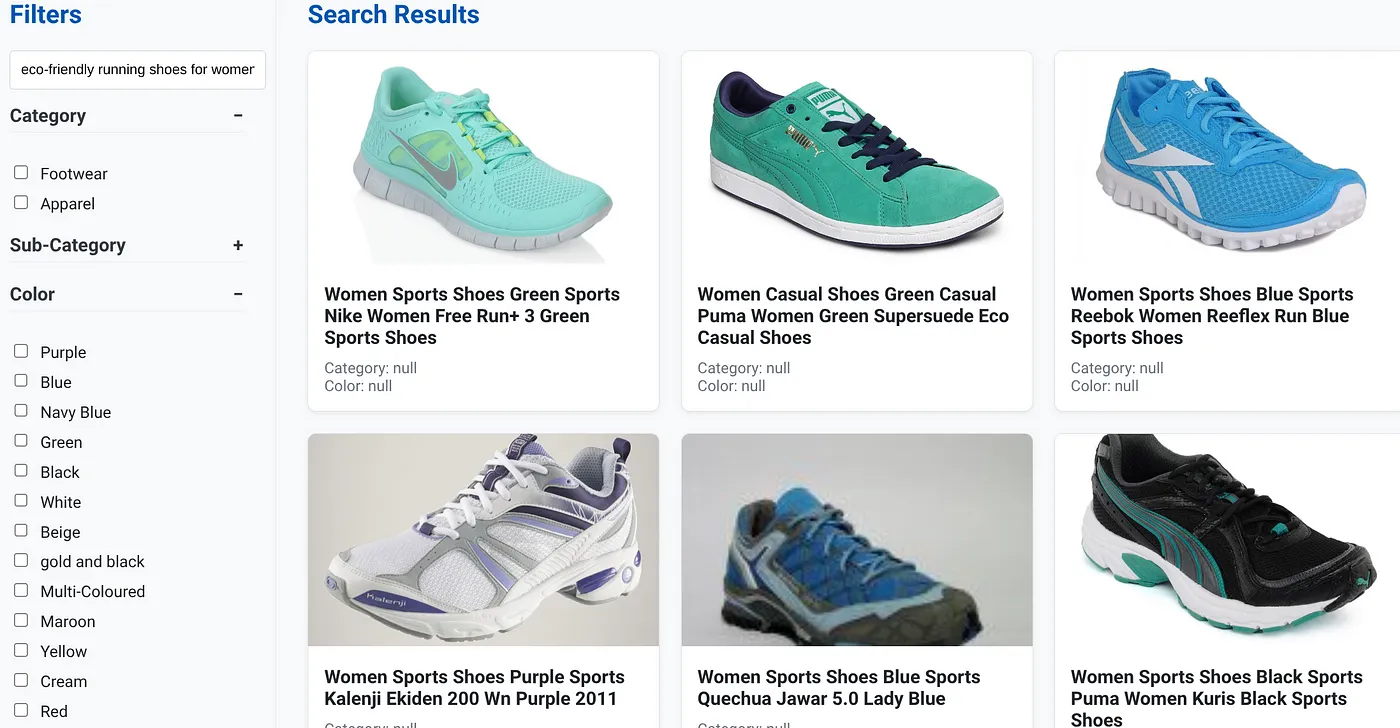
ขณะเดียวกัน ผู้ใช้ก็ใช้ตัวกรองแบบเจียระไนสำหรับ "หมวดหมู่: <<>>" "สี: <<>>" และพูดว่า "ราคา: $100-$150"
- ระบบจะแสดงรายการผลิตภัณฑ์ที่ปรับแต่งแล้วทันที ซึ่งสอดคล้องกับภาษาธรรมชาติในเชิงความหมายและตรงกับตัวกรองที่เลือกอย่างแม่นยำ
- เบื้องหลังการทำงาน ดัชนี scaNN จะเร่งการค้นหาเวกเตอร์ การกรองแบบอินไลน์และการกรองแบบปรับได้จะช่วยให้มั่นใจได้ถึงประสิทธิภาพตามเกณฑ์ที่รวมกัน และการจัดอันดับใหม่จะแสดงผลลัพธ์ที่เหมาะสมที่สุดที่ด้านบน
- ความเร็วและความแม่นยำของผลลัพธ์แสดงให้เห็นอย่างชัดเจนถึงประสิทธิภาพของการรวมเทคโนโลยีเหล่านี้เข้าด้วยกันเพื่อประสบการณ์การค้นหาในร้านค้าปลีกที่ชาญฉลาดอย่างแท้จริง
การสร้างแอปพลิเคชันการค้นหาค้าปลีกรุ่นถัดไปต้องก้าวข้ามวิธีการเดิมๆ และการใช้ประโยชน์จาก AlloyDB, Vertex AI, การค้นหาเวกเตอร์ที่มีการจัดทำดัชนี scaNN, การกรองแบบเจียระไนแบบไดนามิก, การจัดอันดับใหม่ และการตรวจสอบ LLM ช่วยให้เรามอบประสบการณ์ของลูกค้าที่ยอดเยี่ยม ซึ่งจะช่วยกระตุ้นความผูกพันและเพิ่มยอดขาย โซลูชันที่มีประสิทธิภาพ ปรับขนาดได้ และอัจฉริยะนี้แสดงให้เห็นว่าความสามารถของฐานข้อมูลสมัยใหม่ที่ผสานรวมกับ AI กำลังปรับโฉมอนาคตของธุรกิจค้าปลีกอย่างไร!!!