
1. Genel Bakış
Günümüzün rekabetçi perakende ortamında, müşterilerin tam olarak aradıklarını hızlı ve sezgisel bir şekilde bulmalarını sağlamak çok önemlidir. Geleneksel anahtar kelime tabanlı arama, genellikle yetersiz kalır ve ayrıntılı sorgular ile geniş ürün kataloglarıyla ilgili sorunlar yaşar. Bu codelab'de, AlloyDB ve AlloyDB AI üzerinde oluşturulmuş gelişmiş bir perakende arama uygulaması tanıtılmaktadır. Bu uygulama, kurumsal ölçekte dinamik ve karma bir arama deneyimi sunmak için en yeni vektör arama, scaNN indeksleme, yönlü filtreler ve akıllı uyarlanabilir filtreleme ile yeniden sıralama özelliklerinden yararlanır.
Şu anda 3 temel konu hakkında bilgi sahibiyiz:
- Bağlamsal aramanın aracınız için ne anlama geldiği ve Vector Search'ü kullanarak bunu nasıl başaracağınız.
- Ayrıca, verileriniz kapsamında (yani veritabanınızın içinde) Vector Search'e ulaşma konusunu da ayrıntılı olarak ele aldık. (Zaten bilmiyorsanız tüm Google Cloud veritabanlarının bunu desteklediğini hatırlatırız.)
- ScaNN dizini tarafından desteklenen AlloyDB vektör arama özelliğiyle yüksek performans ve kaliteye sahip bu tür hafif bir vektör arama RAG özelliğini nasıl kullanacağınızı anlatarak dünyanın geri kalanından bir adım öteye gittik.
Temel, orta ve biraz daha ileri düzeydeki RAG denemelerini yapmadıysanız listelenen sırayla buradaki, buradaki ve buradaki 3 denemeyi okumanızı öneririz.
Hedef
Filtrelerin, anahtar kelimelerin ve bağlamsal eşlemenin ötesine geçme: Basit bir anahtar kelime araması, çoğu alakasız olmak üzere binlerce sonuç döndürebilir. İdeal çözüm, sorgunun arkasındaki amacı anlamalı, bunu hassas filtre ölçütleriyle (ör. marka, malzeme veya fiyat) birleştirmeli ve en alakalı öğeleri milisaniyeler içinde sunmalıdır. Bu durum, güçlü, esnek ve ölçeklenebilir bir arama altyapısı gerektirir. Anahtar kelime aramasından bağlamsal eşleşmelere ve benzerlik aramalarına kadar uzun bir yol katettik. Ancak bir müşterinin "ilkbaharda yürüyüş için rahat, şık ve su geçirmez bir ceket" aradığını ve aynı anda filtreler uyguladığını düşünün. Uygulamanız yalnızca kaliteli yanıtlar döndürmekle kalmıyor, aynı zamanda yüksek performans gösteriyor ve tüm bunların sırası veritabanınız tarafından dinamik olarak seçiliyor.
Hedef
Bu sorunu entegre ederek çözmek için
- Bağlamsal Arama (Vector Search): Sorguların ve ürün açıklamalarının semantik anlamını anlama
- Yönlü filtreleme: Kullanıcıların sonuçları belirli özelliklere göre daraltmasına olanak tanır.
- Karma Yaklaşım: Bağlamsal arama ile yapılandırılmış filtrelemeyi sorunsuz bir şekilde birleştirme
- Gelişmiş Optimizasyon: Hız ve alaka düzeyi için özel dizine ekleme, uyarlanabilir filtreleme ve yeniden sıralamadan yararlanma
- Üretken yapay zeka destekli kalite kontrolü: Üstün sonuç kalitesi için LLM doğrulaması.
Mimariyi ve uygulama sürecini inceleyelim.
Ne oluşturacaksınız?
Perakende Araması Uygulaması
Bu kapsamda:
- E-ticaret veri kümesi için AlloyDB örneği ve tablosu oluşturma
- Yerleştirilmiş öğeleri ve Vector Search'ü ayarlama
- Meta veri dizini ve ScaNN dizini oluşturma
- ScaNN'nin satır içi filtreleme yöntemini kullanarak AlloyDB'de gelişmiş vektör araması uygulama
- Tek sorguda Faceted Filters ve Hybrid Search'ü ayarlama
- Yeniden sıralama ve geri çağırma ile sorgu alaka düzeyini iyileştirme (isteğe bağlı)
- Gemini ile sorgu yanıtını değerlendirme (isteğe bağlı)
- Veritabanları ve uygulama katmanı için MCP Araç Kutusu
- Özelliklere Göre Arama ile Uygulama Geliştirme (Java)
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin .
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Bağlantıyı takip ederek API'leri etkinleştirin.
Alternatif olarak, bu işlem için gcloud komutunu kullanabilirsiniz. gcloud komutları ve kullanımı için belgelere bakın.
3. Veritabanı kurulumu
Bu laboratuvarda e-ticaret verileri için veritabanı olarak AlloyDB'yi kullanacağız. Veritabanları ve günlükler gibi tüm kaynakları tutmak için kümeler kullanılır. Her kümede, verilere erişim noktası sağlayan bir birincil örnek bulunur. Tablolar gerçek verileri içerir.
E-ticaret veri kümesinin yükleneceği bir AlloyDB kümesi, örneği ve tablosu oluşturalım.
Küme ve örnek oluşturma
- Cloud Console'da AlloyDB sayfasına gidin. Cloud Console'daki çoğu sayfayı bulmanın kolay bir yolu, konsolun arama çubuğunu kullanarak arama yapmaktır.
- Bu sayfada KÜME OLUŞTUR'u seçin:

- Aşağıdaki gibi bir ekran görürsünüz. Aşağıdaki değerlerle bir küme ve örnek oluşturun (Uygulama kodunu depodan klonluyorsanız değerlerin eşleştiğinden emin olun):
- küme kimliği: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / en son önerilen
- Region: "
us-central1" - Ağ: "
default"
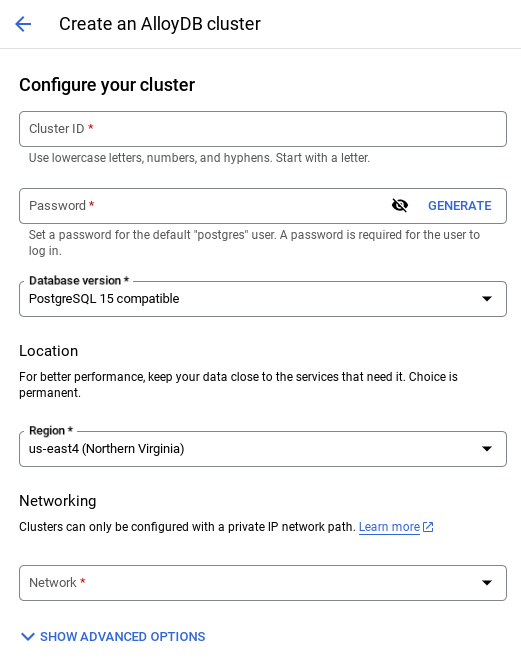
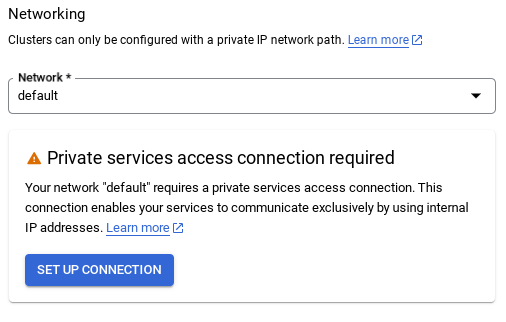
- Varsayılan ağı seçtiğinizde aşağıdaki gibi bir ekran görürsünüz.
BAĞLANTIYI OLUŞTUR'u seçin.
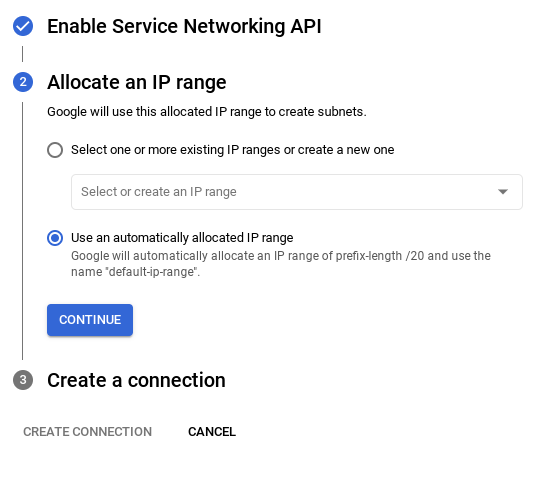
- Buradan "Otomatik olarak atanmış bir IP aralığı kullan"ı seçip Devam'ı tıklayın. Bilgileri inceledikten sonra BAĞLANTI OLUŞTUR'u seçin.
- Ağınız kurulduktan sonra kümenizi oluşturmaya devam edebilirsiniz. Aşağıda gösterildiği gibi küme kurulumunu tamamlamak için CREATE CLUSTER'ı (KÜME OLUŞTUR) tıklayın:
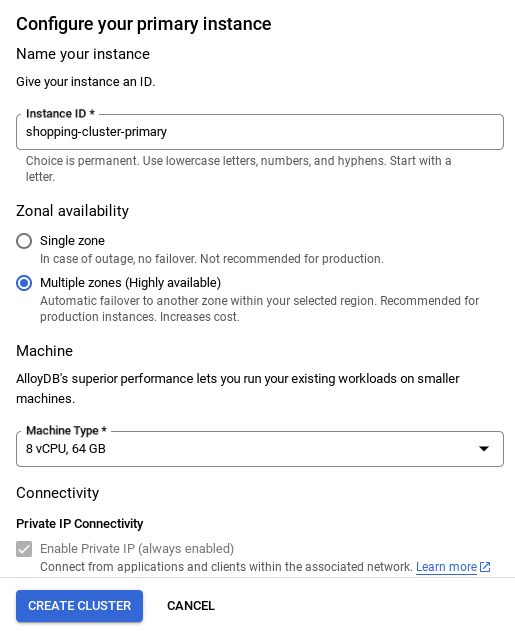
ÖNEMLİ NOT:
- Küme / örnek yapılandırılırken bulabileceğiniz örnek kimliğini **
vector-instance** olarak değiştirdiğinizden emin olun. Değiştiremiyorsanız gelecekteki tüm referanslarda örnek kimliğinizi kullanmayı unutmayın. - Küme oluşturma işleminin yaklaşık 10 dakika süreceğini unutmayın. İşlem başarılı olduğunda, yeni oluşturduğunuz kümenizin genel görünümünü gösteren bir ekran görürsünüz.
4. Veri kullanımı
Şimdi de mağazayla ilgili verilerin bulunduğu bir tablo ekleme zamanı. AlloyDB'ye gidin, birincil kümeyi ve ardından AlloyDB Studio'yu seçin:
Örneğinizin oluşturulmasının tamamlanmasını beklemeniz gerekebilir. Bu işlem tamamlandıktan sonra, kümeyi oluştururken oluşturduğunuz kimlik bilgilerini kullanarak AlloyDB'de oturum açın. PostgreSQL'de kimlik doğrulaması yapmak için aşağıdaki verileri kullanın:
- Kullanıcı adı : "
postgres" - Veritabanı : "
postgres" - Şifre : "
alloydb"
AlloyDB Studio'da kimliğinizi başarıyla doğruladıktan sonra SQL komutları Düzenleyici'ye girilir. Son pencerenin sağındaki artı işaretini kullanarak birden fazla düzenleyici penceresi ekleyebilirsiniz.
AlloyDB ile ilgili komutları, gerektiğinde Çalıştır, Biçimlendir ve Temizle seçeneklerini kullanarak düzenleyici pencerelerine gireceksiniz.
Uzantıları etkinleştirme
Bu uygulamayı oluşturmak için pgvector ve google_ml_integration uzantılarını kullanacağız. pgvector uzantısı, vektör yerleştirmelerini depolamanıza ve aramanıza olanak tanır. google_ml_integration uzantısı, SQL'de tahmin almak için Vertex AI tahmin uç noktalarına erişmek üzere kullandığınız işlevleri sağlar. Aşağıdaki DDL'leri çalıştırarak bu uzantıları etkinleştirin:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Veritabanınızda etkinleştirilen uzantıları kontrol etmek istiyorsanız şu SQL komutunu çalıştırın:
select extname, extversion from pg_extension;
Tablo oluşturma
AlloyDB Studio'da aşağıdaki DDL ifadesini kullanarak tablo oluşturabilirsiniz:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Yerleştirme sütunu, metnin vektör değerlerinin depolanmasına olanak tanır.
İzin Ver
"embedding" işlevinde yürütme izni vermek için aşağıdaki ifadeyi çalıştırın:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB hizmet hesabına Vertex AI Kullanıcısı ROLÜ'nü verme
Google Cloud IAM Console'dan AlloyDB hizmet hesabına (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com şeklinde görünür) "Vertex AI Kullanıcısı" rolüne erişim izni verin. PROJECT_NUMBER, proje numaranızı içerir.
Alternatif olarak, aşağıdaki komutu Cloud Shell terminalinden çalıştırabilirsiniz:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Verileri veritabanına yükleme
- E-tablodaki
insertsorgu ifadelerini kopyalayıp yukarıda belirtilen düzenleyiciye yapıştırın.insert scripts sqlBu kullanım alanının hızlı bir demosunu yapmak için 10-50 ekleme ifadesini kopyalayabilirsiniz. Bu "Seçilen Ekleme İşlemleri 25-30 satır" sekmesinde, seçilmiş bir ekleme listesi bulunur.
Verilere bağlantıyı bu GitHub depo dosyasında bulabilirsiniz.
- Çalıştır'ı tıklayın. Sorgunuzun sonuçları Sonuçlar tablosunda görünür.
ÖNEMLİ NOT:
Yalnızca 25-50 kaydı kopyalayıp yapıştırdığınızdan ve bunların kategori, alt_kategori, renk, cinsiyet türleri aralığından olduğundan emin olun.
5. Veriler için yerleştirilmiş öğeler oluşturma
Modern aramadaki gerçek yenilik, yalnızca anahtar kelimeleri değil, anlamı da anlamaktan geçer. Bu noktada yerleştirmeler ve vektör araması devreye girer.
Önceden eğitilmiş dil modellerini kullanarak ürün açıklamalarını ve kullanıcı sorgularını "gömme" adı verilen yüksek boyutlu sayısal gösterimlere dönüştürdük. Bu yerleştirmeler, semantik anlamı yakalayarak yalnızca eşleşen kelimeleri içeren ürünler yerine "anlam olarak benzer" ürünleri bulmamızı sağlar. Başlangıçta, bir temel oluşturmak için bu yerleştirmelerde doğrudan vektör benzerliği aramasıyla denemeler yaptık. Bu denemeler, performans optimizasyonlarından önce bile anlamsal anlayışın gücünü gösterdi.
Yerleştirme sütunu, ürün açıklaması metninin vektör değerlerinin depolanmasına olanak tanır. img_embeddings sütunu, resim yerleştirmelerinin (çok formatlı) depolanmasına olanak tanır. Bu şekilde, metin ile görüntü arasındaki mesafeye dayalı aramayı da kullanabilirsiniz. Ancak bu laboratuvarda yalnızca metin yerleştirmelerini kullanacağız.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Bu işlem, sorgudaki örnek metin için kayan nokta dizisi gibi görünen yerleştirme vektörünü döndürmelidir. Şöyle görünür:
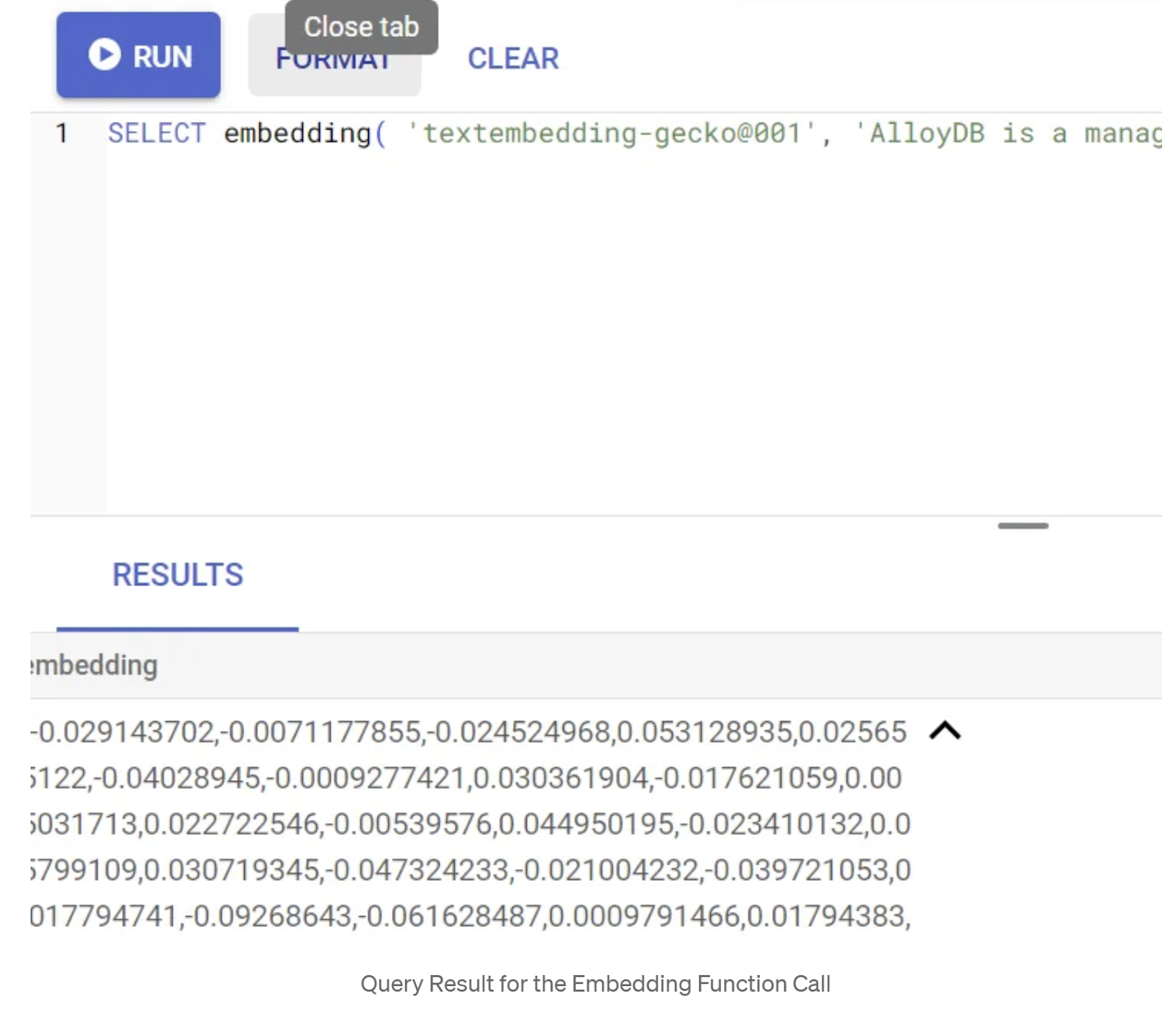
abstract_embeddings Vector alanını güncelleme
Tablodaki içerik açıklamasını ilgili yerleştirmelerle güncellemek için aşağıdaki DML'yi çalıştırın:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud için deneme kredisi faturalandırma hesabı kullanıyorsanız birkaç yerleştirme (ör. en fazla 20-25) oluşturmakta sorun yaşayabilirsiniz. Bu nedenle, ekleme komut dosyasındaki satır sayısını sınırlayın.
Görüntü yerleştirmeleri oluşturmak (çok formatlı bağlamsal arama yapmak için) istiyorsanız aşağıdaki güncellemeyi de çalıştırın:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. AlloyDB'nin yeni özellikleriyle gelişmiş RAG gerçekleştirme
Tablo, veriler ve yerleştirmeler hazır olduğuna göre artık kullanıcı arama metni için anlık Vector Search işlemini gerçekleştirebiliriz. Aşağıdaki sorguyu çalıştırarak bunu test edebilirsiniz:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
Bu sorguda, kullanıcının girdiği "yuvarlak yakalı tişört" aramasının metin yerleştirmesini, kosinüs benzerliği uzaklığı işlevini ("<=>" sembolüyle gösterilir) kullanarak giyim tablosundaki tüm ürün açıklamalarının metin yerleştirmeleriyle ("embedding" adlı sütunda depolanır) karşılaştırıyoruz. Yerleştirme yönteminin sonucunu, veritabanında depolanan vektörlerle uyumlu hale getirmek için vektör türüne dönüştürüyoruz. LIMIT 10, arama metninin en yakın 10 eşleşmesinin seçildiğini gösterir.
AlloyDB, vektör arama RAG'i bir üst seviyeye taşıyor:
Kurumsal ölçekli bir çözüm için ham vektör araması yeterli değildir. Performans çok önemlidir.
ScaNN (Ölçeklenebilir En Yakın Komşular) Dizini
Ultra hızlı yaklaşık en yakın komşu (ANN) araması yapmak için AlloyDB'de ScaNN dizinini etkinleştirdik. Google Research tarafından geliştirilen son teknoloji bir yaklaşık en yakın komşu arama algoritması olan ScaNN, ölçekli olarak etkili vektör benzerliği araması için tasarlanmıştır. Arama alanını etkili bir şekilde budayarak ve nicemleme tekniklerini kullanarak sorguları önemli ölçüde hızlandırır. Diğer indeksleme yöntemlerine kıyasla 4 kata kadar daha hızlı vektör sorguları ve daha küçük bir bellekte kaplanan yer sunar. Bu konu hakkında daha fazla bilgiye buradan ve buradan ulaşabilirsiniz.
Uzantıyı etkinleştirelim ve dizinleri oluşturalım:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Hem metin yerleştirme hem de resim yerleştirme alanları için dizin oluşturma (arama işleminizde resim yerleştirmelerini kullanmak istiyorsanız):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Meta Veri Dizinleri
ScaNN, vektör indekslemeyi yönetirken yapılandırılmış özelliklerde (ör. kategori, alt kategori, stil, renk vb.) geleneksel B-ağacı veya GIN indeksleri titizlikle ayarlanmıştır. Bu dizinler, yönlü filtrelemenin verimliliği açısından çok önemlidir. Meta veri dizinlerini ayarlamak için aşağıdaki ifadeleri çalıştırın:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
ÖNEMLİ NOT:
Yalnızca 25-50 kayıt eklemiş olabileceğiniz için dizinler (ScaNN veya bu konudaki herhangi bir dizin) etkili olmayacaktır.
Satır İçi Filtreleme
Vektör aramadaki yaygın zorluklardan biri, yapılandırılmış filtrelerle (ör. "kırmızı ayakkabılar") birleştirmektir. AlloyDB'nin satır içi filtreleme özelliği bu işlemi optimize eder. Satır içi filtreleme, geniş bir vektör aramasından elde edilen sonuçları filtreleme sonrası yerine filtre koşullarını vektör arama işlemi sırasında uygular. Bu sayede, filtrelenmiş vektör aramalarının performansı ve doğruluğu önemli ölçüde artar.
Satır içi filtrelemenin gerekliliği hakkında daha fazla bilgi edinmek için bu belgeye bakın. Ayrıca, vektör aramasının performansını optimize etmek için filtrelenmiş vektör araması hakkında buradan bilgi edinebilirsiniz. Uygulamanızda satır içi filtrelemeyi etkinleştirmek istiyorsanız düzenleyicinizden aşağıdaki ifadeyi çalıştırın:
SET scann.enable_inline_filtering = on;
Satır içi filtreleme, orta seçiciliğe sahip durumlar için en iyisidir. AlloyDB, vektör dizininde arama yaparken yalnızca meta veri filtreleme koşullarıyla eşleşen vektörlerin (genellikle WHERE ifadesinde işlenen bir sorgudaki işlevsel filtreleriniz) mesafelerini hesaplar. Bu, filtre sonrası veya filtre öncesi avantajlarını tamamlayarak bu sorguların performansını büyük ölçüde artırır.
Uyarlanabilir Filtreleme
Performansı daha da optimize etmek için AlloyDB'nin uyarlanabilir filtrelemesi, sorgu yürütme sırasında en verimli filtreleme stratejisini (satır içi veya ön filtreleme) dinamik olarak seçer. Sorgu kalıplarını ve veri dağıtımlarını analiz ederek manuel müdahale olmadan optimum performans sağlar. Özellikle vektör ve meta veri dizini kullanımı arasında otomatik olarak geçiş yaptığı filtrelenmiş vektör aramaları için faydalıdır. Uyarlanabilir filtrelemeyi etkinleştirmek için scann.enable_preview_features işaretini kullanın.
Uyarlanabilir filtreleme, yürütme sırasında satır içi filtrelemeden ön filtrelemeye geçişi tetiklediğinde sorgu planı dinamik olarak değişir.
SET scann.enable_preview_features = on;
ÖNEMLİ NOT: Yukarıdaki ifadeyi, örnek yeniden başlatılmadan çalıştıramayabilirsiniz. Bu durumda, örneğinizin veritabanı işaretleri bölümünden enable_preview_features işaretini etkinleştirmeniz önerilir.
Tüm dizinleri kullanan yönlü filtreler
Ayrıntılı arama, kullanıcıların belirli özelliklere veya "yönlere" (ör. marka, fiyat, boyut, müşteri puanı) göre birden fazla filtre uygulayarak sonuçları daraltmasına olanak tanır. Uygulamamız, bu yönleri vektör aramasıyla sorunsuz bir şekilde entegre eder. Tek bir sorgu artık doğal dili (bağlamsal arama) birden fazla yönlü seçimle birleştirebilir ve hem vektör hem de geleneksel dizinlerden dinamik olarak yararlanabilir. Bu sayede, kullanıcıların sonuçları tam olarak incelemesine olanak tanıyan, gerçekten dinamik bir karma arama özelliği sunulur.
Uygulamamızda tüm meta veri dizinlerini oluşturduğumuz için SQL sorgularını kullanarak doğrudan ele alarak web'de yönlü filtre kullanımına hazırız:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
Bu sorguda, hem
- WHERE koşulunda yönlü filtreleme ve
- ORDER BY ifadesinde kosinüs benzerliği yöntemi kullanılarak vektör araması.
1, 2, 3 ve 4 ABD doları, bir dizideki yönlü filtre değerlerini, 5 ABD doları ise kullanıcı arama metnini temsil eder. 1-4 ABD doları arasındaki değerleri, aşağıda gösterildiği gibi istediğiniz yönlü filtre değerleriyle değiştirin:
category = ANY([‘Apparel', ‘Footwear'])
5 ABD doları yerine istediğiniz bir arama metnini (ör. "Polo Tişörtler") girin.
ÖNEMLİ NOT: Eklediğiniz kayıtların sınırlı olması nedeniyle dizinleriniz yoksa performans etkisi görmezsiniz. Ancak tam bir üretim veri kümesinde, aynı vektör araması için yürütme süresinin önemli ölçüde kısaldığını gözlemlersiniz. Vektör aramasında satır içi filtreleme ile desteklenen ScaNN dizini kullanılarak bu mümkün hale gelmiştir.
Şimdi de ScaNN'nin etkinleştirildiği bu vektör aramasının hatırlama oranını değerlendirelim.
Yeniden sıralama
Gelişmiş arama ile bile ilk sonuçların son bir düzenlemeye ihtiyacı olabilir. Bu, alaka düzeyini artırmak için ilk arama sonuçlarını yeniden sıralayan kritik bir adımdır. İlk karma arama, bir grup aday ürün sağladıktan sonra daha gelişmiş (ve genellikle hesaplama açısından daha ağır) bir model, daha ayrıntılı bir alaka düzeyi puanı uygular. Bu sayede, kullanıcıya sunulan en iyi sonuçlar en alakalı olanlar olur ve arama kalitesi önemli ölçüde artar. Sistemin belirli bir sorguyla ilgili tüm öğeleri ne kadar iyi aldığını ölçmek için sürekli olarak geri çağırmayı değerlendiririz. Modellerimizi, müşterinin ihtiyacı olanı bulma olasılığını en üst düzeye çıkaracak şekilde iyileştiririz.
Bu özelliği uygulamanızda kullanmadan önce tüm ön koşulları karşıladığınızdan emin olun:
- google_ml_integration uzantısının yüklü olduğunu doğrulayın.
- google_ml_integration.enable_model_support işaretinin açık olarak ayarlandığını doğrulayın.
- Vertex AI ile entegre edin.
- Discovery Engine API'yi etkinleştirin.
- Sıralama modellerini kullanmak için gerekli rolleri edinin.
Ardından, karma arama yapılan sonuç kümesini yeniden sıralamak için uygulamamızda aşağıdaki sorguyu kullanabilirsiniz:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
Bu sorguda, ORDER BY ifadesinde belirtilen bağlamsal aramanın ürün sonuç kümesini kosinüs benzerliği yöntemiyle yeniden sıralıyoruz. "Pembe üst", kullanıcının aradığı metindir.
ÖNEMLİ NOT: Bazı kullanıcılar henüz yeniden sıralama özelliğine erişemeyebilir. Bu nedenle, yeniden sıralama özelliğini uygulama koduna dahil etmedim. Ancak bu özelliği eklemek isterseniz yukarıda ele aldığımız örneği takip edebilirsiniz.
Geri Çağırma Değerlendiricisi
Benzerlik aramasında geri çağırma, bir aramadan alınan alakalı örneklerin yüzdesidir. Diğer bir deyişle, doğru pozitiflerin sayısıdır. Bu metrik, arama kalitesini ölçmek için en sık kullanılan metriktir. Geri çağırma kaybının bir nedeni, yaklaşık en yakın komşu araması (aNN) ile k (tam) en yakın komşu araması (kNN) arasındaki farktır. AlloyDB'nin ScaNN'si gibi vektör dizinleri aNN algoritmalarını uygular. Bu sayede, hatırlama konusunda küçük bir ödün vererek büyük veri kümelerinde vektör aramasını hızlandırabilirsiniz. AlloyDB artık bu dengeyi doğrudan veritabanında tek tek sorgular için ölçmenize ve zaman içinde istikrarlı olmasını sağlamanıza olanak tanır. Daha iyi sonuçlar ve performans elde etmek için bu bilgilere yanıt olarak sorgu ve dizin parametrelerini güncelleyebilirsiniz.
Arama sonuçlarının geri çağrılmasının mantığı nedir?
Vektör arama bağlamında hatırlama, dizinin döndürdüğü ve gerçek en yakın komşular olan vektörlerin yüzdesini ifade eder. Örneğin, en yakın 20 komşuya yönelik bir en yakın komşu sorgusu, gerçek en yakın komşulardan 19'unu döndürürse hatırlama oranı 19/20x100 = %95 olur. Arama kalitesi için kullanılan metrik geri çağırma'dır ve sorgu vektörlerine en yakın olan döndürülen sonuçların yüzdesi olarak tanımlanır.
Belirli bir yapılandırma için vektör dizinindeki vektör sorgusunun geri çağırma değerini evaluate_query_recall işlevini kullanarak bulabilirsiniz. Bu işlev, istediğiniz vektör sorgusu hatırlama sonuçlarını elde etmek için parametrelerinizi ayarlamanıza olanak tanır.
ÖNEMLİ NOT:
Aşağıdaki adımlarda HNSW dizininde "izin reddedildi" hatasıyla karşılaşırsanız bu hatırlama değerlendirmesi bölümünün tamamını şimdilik atlayın. Bu codelab belgelendirildiği sırada yeni yayınlandığı için bu durum, erişim kısıtlamalarıyla ilgili olabilir.
- ScaNN dizininde ve HNSW dizininde dizin taramayı etkinleştirme işaretini ayarlayın:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio'da aşağıdaki sorguyu çalıştırın:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall işlevi, sorguyu parametre olarak alır ve geri çağırmasını döndürür. İşlev giriş sorgusu olarak performansı kontrol etmek için kullandığım sorguyu kullanıyorum. Dizin yöntemi olarak SCaNN'yi ekledim. Daha fazla parametre seçeneği için belgelere bakın.
Bu Vector Search sorgusu için kullandığımız geri çağırma:
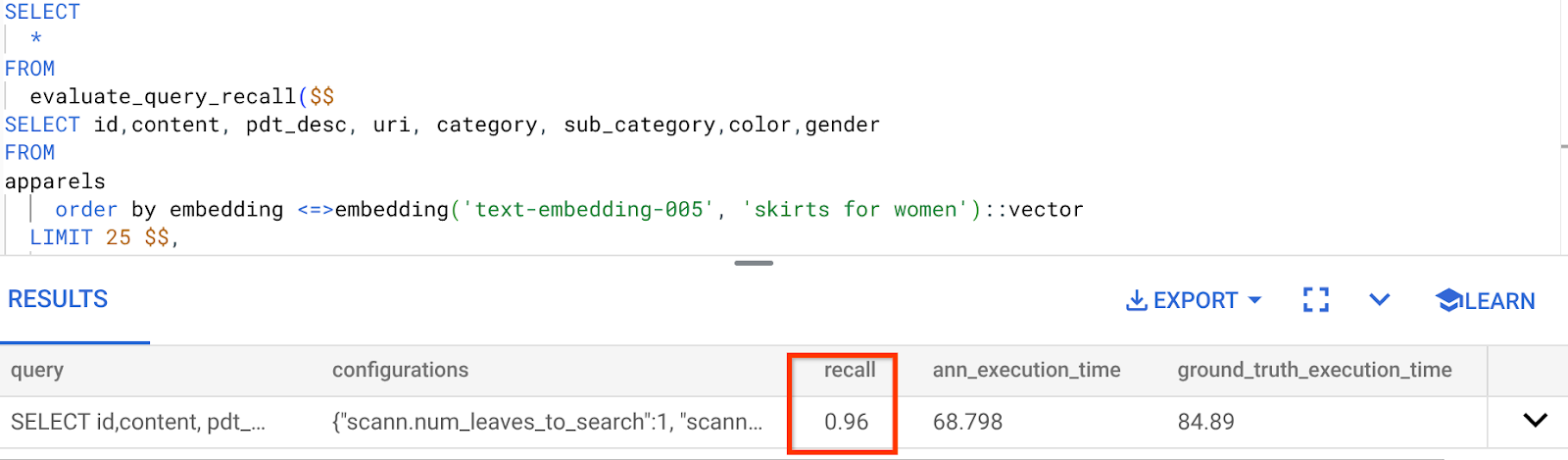
RECALL değerinin %96 olduğunu görüyorum. Bu durumda geri çağırma gerçekten iyi. Ancak bu değer kabul edilemez bir değerse dizin parametrelerini, yöntemlerini ve sorgu parametrelerini değiştirmek için bu bilgileri kullanabilir ve bu Vector Search için hatırlama oranımı artırabilirsin.
Değiştirilmiş sorgu ve dizin parametreleriyle test etme
Şimdi, alınan geri çağırma işlemine göre sorgu parametrelerini değiştirerek sorguyu test edelim.
- Dizin parametrelerini değiştirme:
Bu test için "Kosinüs" benzerlik uzaklığı işlevi yerine "L2 Uzaklığı" işlevini kullanacağım.
Çok Önemli Not: "Bu sorgunun COSINE benzerliğini kullandığını nereden biliyoruz?" diye sorabilirsiniz. Kosinüs uzaklığını temsil etmek için "<=>" kullanılarak uzaklık işlevi tanımlanabilir.
Vector Search uzaklık işlevleri için Dokümanlar bağlantısı.
Önceki sorguda kosinüs benzerliği uzaklık işlevi kullanılıyordu. Şimdi ise L2 uzaklığını deneyeceğiz. Ancak bunun için temel ScaNN dizininin de L2 mesafe işlevini kullandığından emin olmamız gerekir. Şimdi farklı bir mesafe işlevi sorgusuyla dizin oluşturalım: L2 mesafesi: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
DROP INDEX ifadesi, tabloda gereksiz bir dizin olmamasını sağlamak için kullanılır.
Artık Vector Search işlevimin mesafe işlevini değiştirdikten sonra RECALL'u değerlendirmek için aşağıdaki sorguyu yürütebilirim.
[SONRA] L2 mesafesi işlevini kullanan sorgu:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Güncellenen dizinin hatırlama değerindeki farkı / dönüşümü görebilirsiniz.
İstenen geri çağırma değerine ve uygulamanızın kullandığı veri kümesine bağlı olarak dizinde değiştirebileceğiniz başka parametreler de vardır (ör. num_leaves).
Vektör Arama Sonuçlarının LLM Doğrulaması
En yüksek kaliteli kontrollü aramayı elde etmek için isteğe bağlı bir LLM doğrulama katmanı ekledik. Büyük dil modelleri, özellikle karmaşık veya belirsiz sorgular için arama sonuçlarının alaka düzeyini ve tutarlılığını değerlendirmek amacıyla kullanılabilir. Bu işlem şunları içerebilir:
Anlamsal Doğrulama:
Sorgu amacına göre sonuçlara çapraz referans veren bir LLM.
Mantıksal Filtreleme:
Geleneksel filtrelerde kodlanması zor olan karmaşık işletme mantığını veya kurallarını uygulamak için LLM kullanma, ürün listesini ayrıntılı ölçütlere göre daha da hassaslaştırma.
Kalite Güvencesi:
Daha az alakalı sonuçları otomatik olarak tanımlayıp uzman incelemesi veya model iyileştirme için işaretleme.
AlloyDB AI özelliklerinde bunu şu şekilde gerçekleştirdik:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
Temel sorgu, daraltılmış arama, karma arama ve yeniden sıralama bölümlerinde gördüğümüz sorguyla aynıdır. Bu sorguya, ml_predict_row yapısıyla temsil edilen yeniden sıralanmış sonuç kümesinin GEMINI değerlendirmesi katmanı ekledik. Faset filtrelerini yorum satırı yaptım ancak $1 ile $4 arasındaki yer tutucular için istediğiniz öğeleri bir diziye ekleyebilirsiniz. 5 ABD doları yerine arama yapmak istediğiniz metni (ör. "Çiçek deseni olmayan pembe üst") girin.
7. Veritabanları ve uygulama katmanı için MCP Araç Kutusu
Arka planda, sağlam araçlar ve iyi yapılandırılmış bir uygulama sorunsuz çalışmayı sağlar.
Veritabanları için MCP (Model Bağlam Protokolü) Toolbox, üretken yapay zeka ve ajan tabanlı araçların AlloyDB ile entegrasyonunu basitleştirir. Bağlantı havuzunu, kimlik doğrulamayı ve veritabanı işlevlerinin yapay zeka aracılarına veya diğer uygulamalara güvenli bir şekilde sunulmasını kolaylaştıran açık kaynaklı bir sunucu görevi görür.
Uygulamamızda, tüm akıllı karma arama sorgularımız için bir soyutlama katmanı olarak MCP Toolbox for Databases'i kullandık.
Kullanım alanımız için Toolbox'ı ayarlamak ve dağıtmak üzere aşağıdaki adımları uygulayın:
MCP Toolbox for Databases tarafından desteklenen veritabanlarından birinin AlloyDB olduğunu görebilirsiniz. Önceki bölümde bu veritabanını zaten sağladığımız için Toolbox'ı kurmaya devam edelim.
- Cloud Shell terminalinize gidin ve projenizin seçilip terminal isteminde gösterildiğinden emin olun. Proje dizininize gitmek için Cloud Shell terminalinizde aşağıdaki komutu çalıştırın:
mkdir toolbox-tools
cd toolbox-tools
- Araç kutusunu yeni klasörünüze indirip yüklemek için aşağıdaki komutu çalıştırın:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Cloud Shell Düzenleyici'ye (kod düzenleme modu için) gidin ve proje kök klasörüne "tools.yaml" adlı bir dosya ekleyin.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Tools.yaml komut dosyasını bu repo dosyasındaki kodla değiştirdiğinizden emin olun.
tools.yaml dosyasını inceleyelim:
Kaynaklar, bir aracın etkileşimde bulunabileceği farklı veri kaynaklarınızı temsil eder. Kaynak, bir aracın etkileşimde bulunabileceği bir veri kaynağını temsil eder. Kaynakları, tools.yaml dosyanızın kaynaklar bölümünde harita olarak tanımlayabilirsiniz. Genellikle bir kaynak yapılandırması, veritabanına bağlanmak ve veritabanıyla etkileşim kurmak için gereken tüm bilgileri içerir.
Araçlar, bir aracının gerçekleştirebileceği işlemleri (ör. bir kaynağı okuma ve kaynağa yazma) tanımlar. Araç, temsilcinizin gerçekleştirebileceği bir işlemi (ör. SQL ifadesi çalıştırma) temsil eder. Araçlar'ı tools.yaml dosyanızın araçlar bölümünde harita olarak tanımlayabilirsiniz. Genellikle bir aracın işlem yapması için kaynak gerekir.
tools.yaml dosyanızı yapılandırma hakkında daha fazla bilgi için bu belgeye bakın.
- Sunucuyu başlatmak için aşağıdaki komutu (mcp-toolbox klasöründen) çalıştırın:
./toolbox --tools-file "tools.yaml"
Artık sunucuyu bulutta web önizleme modunda açarsanız get-order-data adlı yeni aracınızla birlikte Toolbox sunucusunun çalıştığını görebilirsiniz.
MCP Toolbox sunucusu varsayılan olarak 5000 bağlantı noktasında çalışır. Bunu test etmek için Cloud Shell'i kullanalım.
Aşağıda gösterildiği gibi Cloud Shell'de Web Önizlemesi'ni tıklayın:
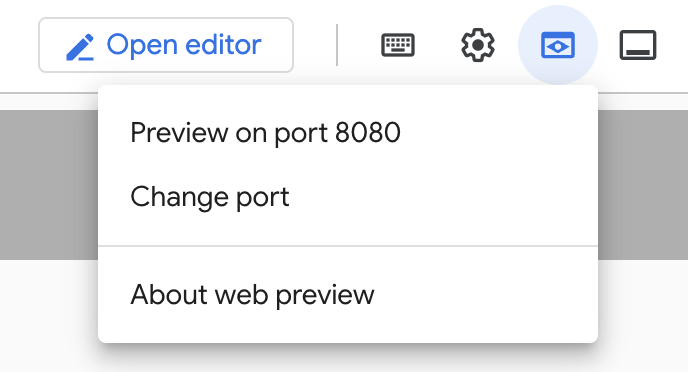
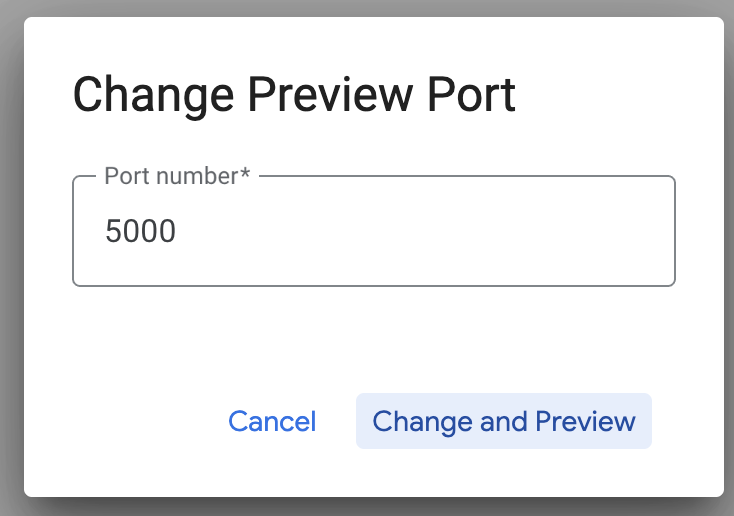
Bağlantı noktasını değiştir'i tıklayın ve bağlantı noktasını aşağıda gösterildiği gibi 5000 olarak ayarlayıp Değiştir ve Önizle'yi tıklayın.
Bu işlem sonucunda şu çıkış elde edilir:
- Araç kutumuzu Cloud Run'a dağıtalım:
İlk olarak MCP Toolbox sunucusuyla başlayıp Cloud Run'da barındırabiliriz. Bu sayede, diğer uygulamalar ve/veya aracı uygulamalarıyla entegre edebileceğimiz herkese açık bir uç nokta elde ederiz. Bunu Cloud Run'da barındırma talimatları burada verilmiştir. Şimdi temel adımları inceleyelim.
- Yeni bir Cloud Shell terminali başlatın veya mevcut bir Cloud Shell terminalini kullanın. Araç kutusu ikili programının ve tools.yaml dosyasının bulunduğu proje klasörüne gidin (bu örnekte toolbox-tools). Henüz klasörün içinde değilseniz aşağıdaki komutu kullanın:
cd toolbox-tools
- PROJECT_ID değişkenini Google Cloud proje kimliğinizi gösterecek şekilde ayarlayın.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Bu Google Cloud hizmetlerini etkinleştirin
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Google Cloud Run'da dağıtacağımız Toolbox hizmetinin kimliği olarak hareket edecek ayrı bir hizmet hesabı oluşturalım.
gcloud iam service-accounts create toolbox-identity
- Ayrıca, bu hizmet hesabının doğru rollere (ör.Secret Manager'a erişme ve AlloyDB ile iletişim kurma) sahip olmasını sağlıyoruz.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- tools.yaml dosyasını gizli olarak yükleyeceğiz:
gcloud secrets create tools --data-file=tools.yaml
Zaten bir gizli anahtarınız varsa ve gizli anahtar sürümünü güncellemek istiyorsanız aşağıdakileri yürütün:
gcloud secrets versions add tools --data-file=tools.yaml
- Cloud Run için kullanmak istediğiniz container görüntüsüne bir ortam değişkeni ayarlayın:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Cloud Run'a dağıtım için kullanılan komutun son adımı:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Bu işlem, yapılandırılmış tools.yaml dosyamızla birlikte Toolbox sunucusunu Cloud Run'a dağıtma sürecini başlatır. Dağıtım başarılı olduğunda aşağıdakine benzer bir mesaj görürsünüz:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Yeni dağıtılan aracınızı agentic uygulamanızda kullanmaya hazırsınız.
Toolbox sunucusundaki araçlara erişme
Araç kutusu dağıtıldıktan sonra, dağıtılan araç kutusu sunucusuyla etkileşim kurmak için bir Python Cloud Run Functions ara katmanı oluştururuz. Bunun nedeni, şu anda Toolbox'ın Java SDK'sının olmamasıdır. Bu nedenle, sunucuyla etkileşim kurmak için Python ara katmanı oluşturduk. İlgili Cloud Run işlevinin kaynak kodunu burada bulabilirsiniz.
Az önce oluşturduğumuz ve önceki adımlarda dağıttığımız araç kutusu araçlarına erişebilmek için bu Cloud Run işlevini oluşturup dağıtmanız gerekir:
- Google Cloud Console'da Cloud Run sayfasına gidin.
- İşlev yaz'ı tıklayın.
- Hizmet adı alanına işlevinizi açıklayan bir ad girin. Hizmet adları yalnızca harfle başlamalı ve harf, sayı ya da kısa çizgi dahil en fazla 49 karakter içermelidir. Hizmet adları tireyle bitemez ve bölge ile proje başına benzersiz olmalıdır. Hizmet adı daha sonra değiştirilemez ve herkese görünür durumdadır. (Enter retail-product-search-quality)
- Bölge listesinde varsayılan değeri kullanın veya işlevinizi dağıtmak istediğiniz bölgeyi seçin. (us-central1'i seçin)
- Çalışma zamanı listesinde varsayılan değeri kullanın veya bir çalışma zamanı sürümü seçin. (Python 3.11'i seçin)
- Kimlik doğrulama bölümünde "Herkese açık erişime izin ver"i seçin.
- "Oluştur" düğmesini tıklayın.
- İşlev oluşturulur ve main.py ile requirements.txt şablonuyla yüklenir.
- Bu dosyayı, projenin deposundaki main.py ve requirements.txt dosyalarıyla değiştirin.
- İşlevi dağıtın. Cloud Run işleviniz için bir uç nokta alırsınız.
Uç noktanız aşağıdaki gibi (veya benzer şekilde) görünmelidir:
Araç kutusuna erişmek için Cloud Run Function Endpoint: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Zaman çizelgesi içinde tamamlamayı kolaylaştırmak için (uygulamalı eğitmen liderliğindeki oturumlar için) bitiş noktasının proje numarası, uygulamalı oturum sırasında paylaşılacaktır.
ÖNEMLİ NOT:
Alternatif olarak, veritabanı bölümünü doğrudan uygulama kodunuzun veya Cloud Run işlevinizin bir parçası olarak da uygulayabilirsiniz.
8. Özelliklere Göre Arama ile Uygulama Geliştirme (Java)
Son olarak, tüm bu güçlü arka uç bileşenleri uygulama katmanı aracılığıyla hayata geçirilir. Java ile geliştirilen uygulama, arama sistemiyle etkileşim kurmak için kullanıcı arayüzü sağlar. AlloyDB'ye yönelik sorguları düzenler, yönlendirilen filtrelerin gösterilmesini sağlar, kullanıcı seçimlerini yönetir ve yeniden sıralanmış, doğrulanmış arama sonuçlarını sorunsuz ve sezgisel bir şekilde sunar.
- Cloud Shell Terminal'inize gidip depoyu klonlayarak başlayabilirsiniz:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Yeni oluşturulan faceted_searching_retail klasörünü görebileceğiniz Cloud Shell Düzenleyici'ye gidin.
- Aşağıdaki adımları silin. Bu adımlar önceki bölümlerde zaten tamamlanmıştır:
- Cloud_Run_Function klasörünü silin.
- db_script.sql dosyasını silin.
- file_tools.yaml dosyasını silin.
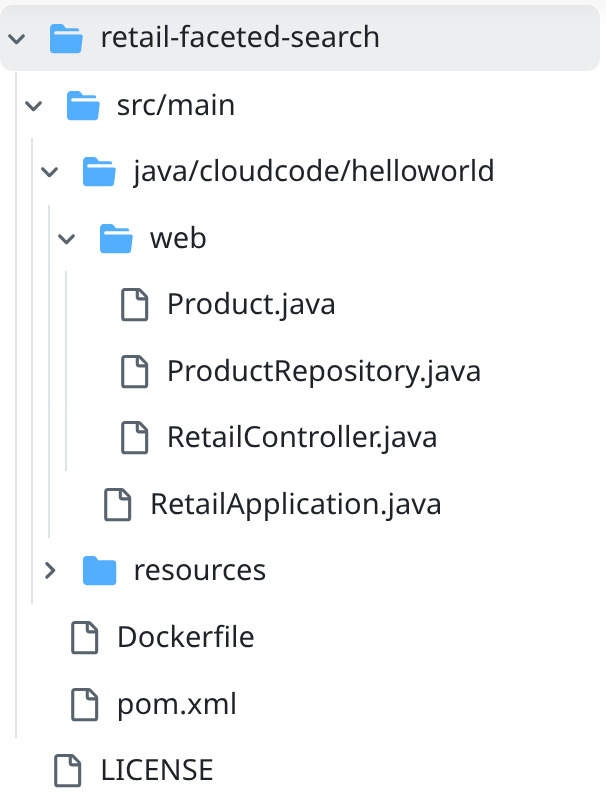
- retail-faceted-search proje klasörüne gidin. Proje yapısını görmeniz gerekir:
- ProductRepository.java dosyasında TOOLBOX_ENDPOINT değişkenini Cloud Run işlevinizdeki (dağıtılmış) uç nokta ile değiştirmeniz veya uç noktayı uygulamalı oturumdaki konuşmacıdan almanız gerekir.
Aşağıdaki kod satırını arayın ve uç noktanızla değiştirin:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Dockerfile ve pom.xml dosyalarının proje yapılandırmanıza uygun olduğundan emin olun (herhangi bir sürümü veya yapılandırmayı açıkça değiştirmediyseniz değişiklik yapmanız gerekmez).
- Cloud Shell terminalinde ana klasörünüzün ve proje klasörünün (faceted_searching_retail / retail-faceted-search) içinde olduğunuzdan emin olun. Terminalde doğru klasörde değilseniz aşağıdaki komutları kullanarak doğru klasöre gidin:
cd faceted_searching_retail
cd retail-faceted-search
- Uygulamanızı paketleme, derleme ve yerel olarak test etme:
mvn package
mvn spring-boot:run
Aşağıda gösterildiği gibi, Cloud Shell terminalinde "8080 numaralı bağlantı noktasında önizle"yi tıklayarak uygulamanızı görüntüleyebilirsiniz:
9. Cloud Run'a dağıtma: ***ÖNEMLİ ADIM
Cloud Shell terminalinde ana klasörünüzün ve proje klasörünün içinde olduğunuzdan emin olun (faceted_searching_retail / retail-faceted-search). Terminalde doğru klasörde değilseniz aşağıdaki komutları kullanarak doğru klasöre gidin:
cd faceted_searching_retail
cd retail-faceted-search
Proje klasöründe olduğunuzdan emin olduktan sonra aşağıdaki komutu çalıştırın:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Dağıtım tamamlandıktan sonra aşağıdaki gibi bir dağıtılmış Cloud Run uç noktası alırsınız:
https://retail-search-**********-uc.a.run.app/
10. Demo
Tüm bu özellikleri uygulamalı olarak görelim:
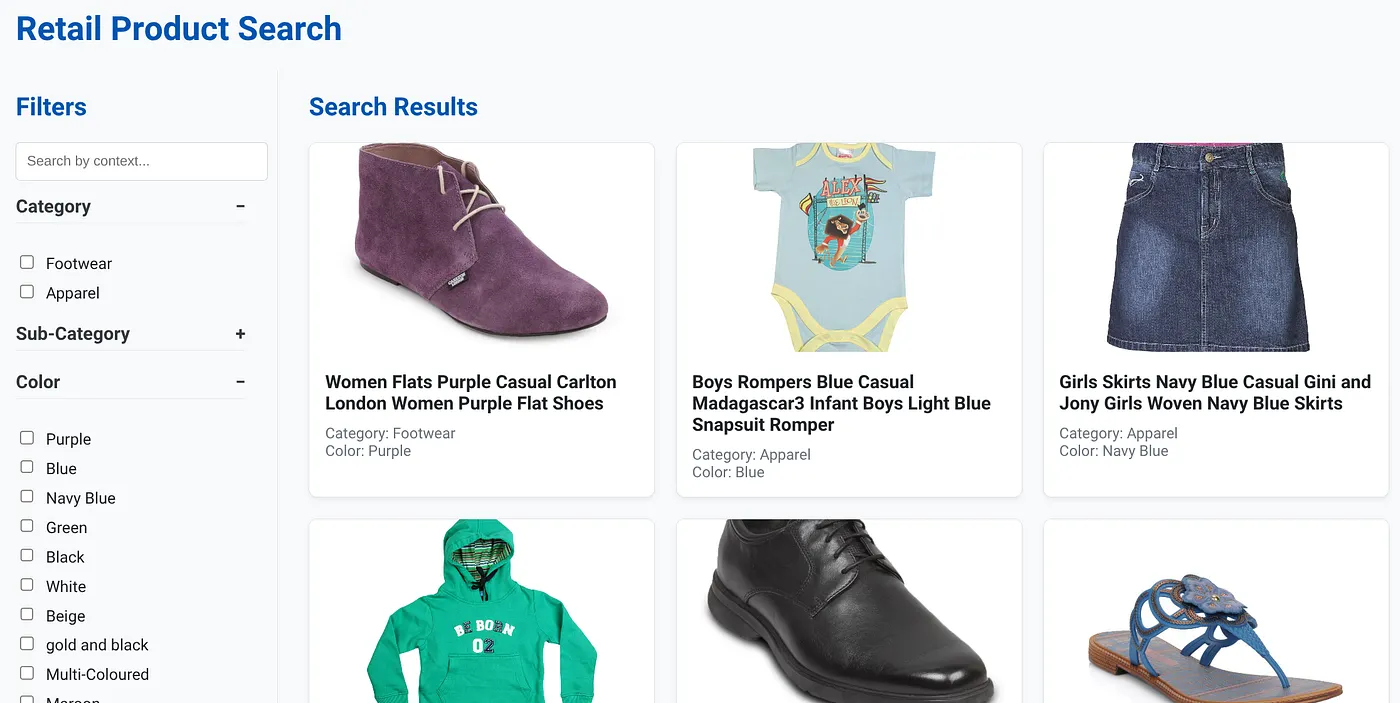
Yukarıdaki resimde, dinamik karma arama uygulamasının açılış sayfası gösterilmektedir.
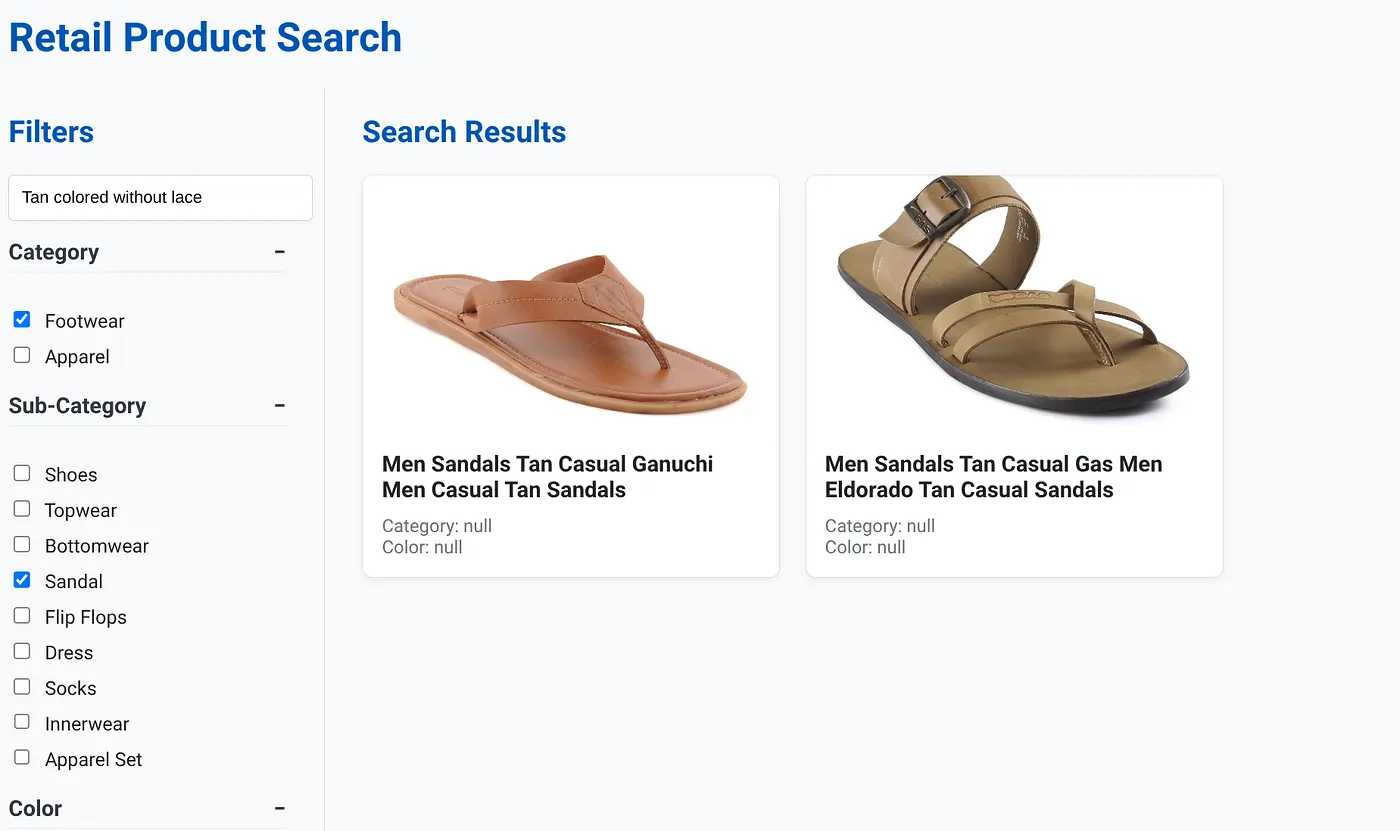
Yukarıdaki resimde "Bağcıksız ten rengi" aramasının sonuçları gösterilmektedir. Seçilen yönlü filtreler: Ayakkabı, Sandalet.
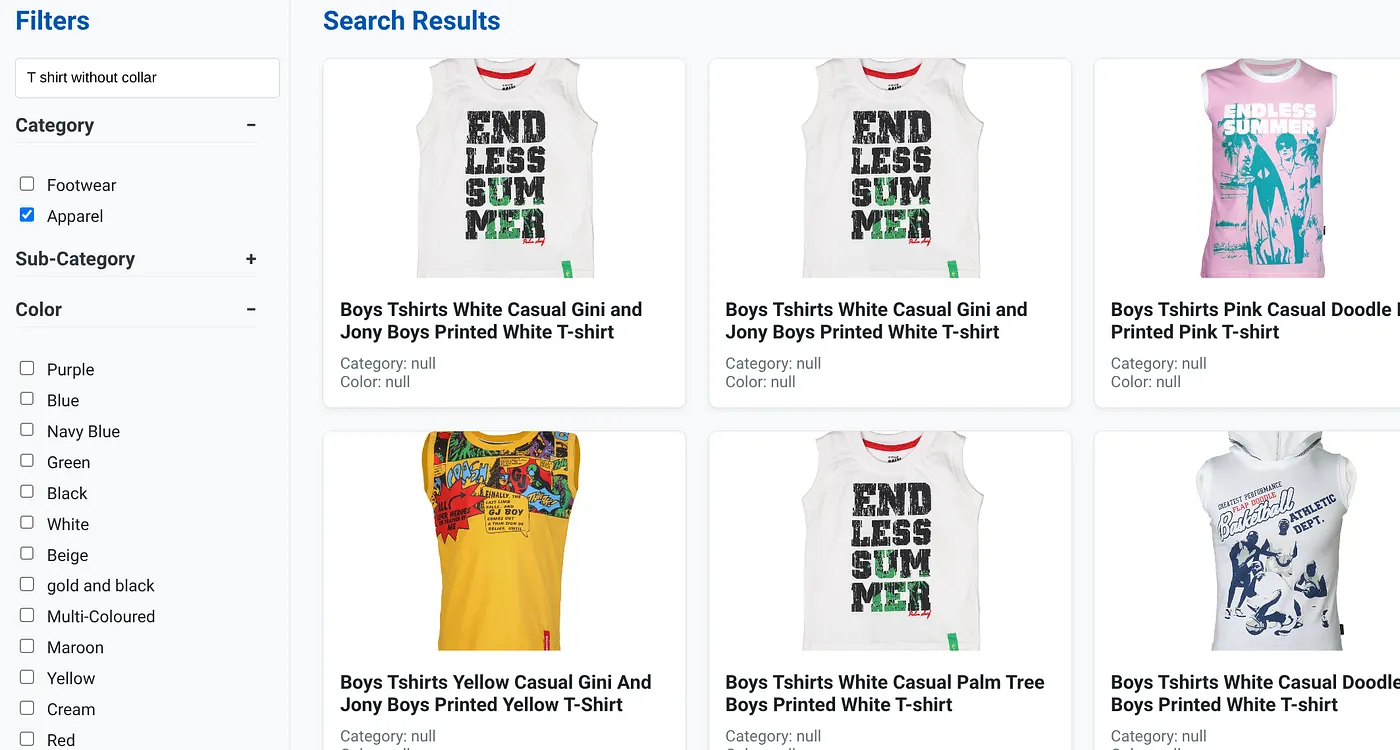
Yukarıdaki resimde, "yakasız tişört" ile ilgili arama sonuçları gösterilmektedir. Fasetli filtreler: Giyim
Artık bu uygulamayı uygulanabilir hale getirmek için daha fazla üretken ve temsilci özelliklerini kullanabilirsiniz.
Deneyin ve kendi projelerinizi oluşturmak için ilham alın.
11. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynak Yöneticisi sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
- Alternatif olarak, KÜMEYİ SİL düğmesini tıklayarak bu proje için yeni oluşturduğumuz AlloyDB kümesini silebilirsiniz (yapılandırma sırasında küme için us-central1'i seçmediyseniz bu köprüdeki konumu değiştirin).
12. Tebrikler
Tebrikler! CLOUD RUN'da ALLOYDB ile başarıyla HİBRİT ARAMA UYGULAMASI oluşturup dağıttınız.
Bu neden işletmeler için önemli?
AlloyDB AI tarafından desteklenen bu dinamik karma arama uygulaması, kurumsal perakende ve diğer işletmeler için önemli avantajlar sunar:
Üstün Alaka Düzeyi: Bağlamsal (vektör) arama, hassas yönlü filtreleme ve akıllı yeniden sıralama birleştirilerek müşterilere son derece alakalı sonuçlar sunulur. Bu da memnuniyetin ve dönüşümlerin artmasını sağlar.
Ölçeklenebilirlik: AlloyDB'nin mimarisi ve scaNN dizine ekleme özelliği, e-ticaret işletmelerinin büyümesi için çok önemli olan büyük ürün kataloglarını ve yüksek sorgu hacimlerini işlemek üzere tasarlanmıştır.
Performans: Karmaşık karma aramalarda bile daha hızlı sorgu yanıtları, sorunsuz bir kullanıcı deneyimi sağlar ve terk etme oranlarını en aza indirir.
Geleceğe Hazırlık: Yapay zeka özelliklerinin (yerleştirme, LLM doğrulama) entegrasyonu, uygulamayı Kişiselleştirilmiş Öneriler, sohbet tabanlı ticaret ve akıllı ürün keşfi alanlarındaki gelecekteki gelişmeler için hazırlar.
Basitleştirilmiş mimari: Vektör aramanın doğrudan AlloyDB'ye entegre edilmesi, ayrı vektör veritabanlarına veya karmaşık senkronizasyona gerek kalmadan geliştirme ve bakımı basitleştirir.
Bir kullanıcının "Yüksek ayak kemeri desteği sunan, çevre dostu kadın koşu ayakkabıları" gibi doğal dilde bir sorgu yazdığını varsayalım.
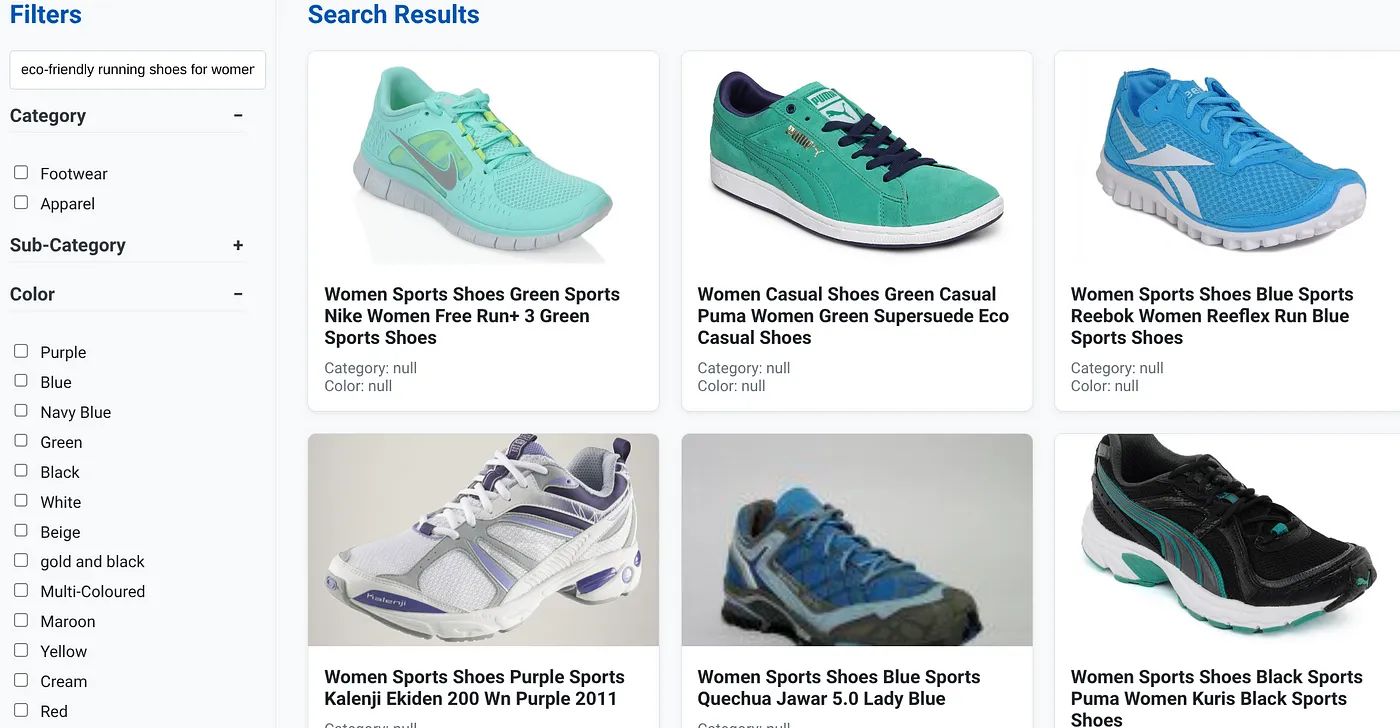
Aynı anda kullanıcı "Kategori: <<>>", "Renk: <<>>" için ayrıntılı filtreler uyguluyor ve "Fiyat: 100-150 TL" diyor:
- Sistem, doğal dil ile anlamsal olarak uyumlu ve seçilen filtrelerle tam olarak eşleşen, iyileştirilmiş bir ürün listesini anında döndürür.
- Arka planda, ScaNN dizini vektör aramasını hızlandırır, satır içi ve uyarlanabilir filtreleme birleştirilmiş ölçütlerle performansı sağlar ve yeniden sıralama en iyi sonuçları en üstte gösterir.
- Sonuçların hızı ve doğruluğu, bu teknolojileri birleştirmenin gerçekten akıllı bir perakende arama deneyimi için ne kadar etkili olduğunu açıkça gösteriyor.
Yeni nesil bir perakende arama uygulaması oluşturmak için geleneksel yöntemlerin ötesine geçmek gerekir. AlloyDB, Vertex AI, scaNN dizinli Vector Search, dinamik yönlü filtreleme, yeniden sıralama ve LLM doğrulama özelliklerinin gücünden yararlanarak etkileşimi artıran ve satışları yükselten benzersiz bir müşteri deneyimi sunabiliriz. Bu sağlam, ölçeklenebilir ve akıllı çözüm, yapay zeka ile desteklenen modern veritabanı özelliklerinin perakendeciliğin geleceğini nasıl yeniden şekillendirdiğini gösteriyor.