
1. Tổng quan
Trong bối cảnh bán lẻ cạnh tranh hiện nay, việc giúp khách hàng tìm thấy chính xác những gì họ đang tìm kiếm một cách nhanh chóng và trực quan là điều tối quan trọng. Tìm kiếm truyền thống dựa trên từ khoá thường không hiệu quả, gặp khó khăn với các cụm từ tìm kiếm phức tạp và danh mục sản phẩm rộng lớn. Lớp học lập trình này giới thiệu một ứng dụng tìm kiếm bán lẻ tinh vi được xây dựng trên AlloyDB, AlloyDB AI, tận dụng công nghệ Tìm kiếm vectơ, lập chỉ mục scaNN, bộ lọc theo khía cạnh và tính năng Lọc thích ứng thông minh, sắp xếp lại kết quả để mang đến trải nghiệm tìm kiếm kết hợp, linh hoạt ở quy mô doanh nghiệp.
Giờ đây, chúng ta đã có kiến thức cơ bản về 3 điều:
- Ý nghĩa của tính năng tìm kiếm theo ngữ cảnh đối với tác nhân của bạn và cách thực hiện việc đó bằng tính năng Tìm kiếm vectơ.
- Chúng tôi cũng đi sâu vào việc đạt được tính năng Tìm kiếm vectơ trong phạm vi dữ liệu của bạn, tức là trong chính cơ sở dữ liệu của bạn (tất cả Cơ sở dữ liệu trên Google Cloud đều hỗ trợ tính năng đó, nếu bạn chưa biết!).
- Chúng tôi đã tiến thêm một bước so với phần còn lại của thế giới trong việc cho bạn biết cách đạt được khả năng RAG Tìm kiếm vectơ có trọng lượng nhẹ như vậy với hiệu suất và chất lượng cao bằng khả năng Tìm kiếm vectơ của AlloyDB dựa trên chỉ mục ScaNN.
Nếu chưa thực hiện những thử nghiệm cơ bản, trung cấp và hơi nâng cao về RAG, bạn nên đọc 3 thử nghiệm đó tại đây, tại đây và tại đây theo thứ tự được liệt kê.
Thách thức
Vượt ra ngoài bộ lọc, từ khoá và tính năng so khớp theo ngữ cảnh: Một cụm từ tìm kiếm đơn giản có thể trả về hàng nghìn kết quả, trong đó có nhiều kết quả không liên quan. Giải pháp lý tưởng cần hiểu được ý định đằng sau cụm từ tìm kiếm, kết hợp ý định đó với tiêu chí lọc chính xác (chẳng hạn như thương hiệu, chất liệu hoặc giá) và trình bày các mặt hàng phù hợp nhất trong vài mili giây. Điều này đòi hỏi cơ sở hạ tầng tìm kiếm mạnh mẽ, linh hoạt và có khả năng mở rộng. Chắc chắn chúng ta đã đi một chặng đường dài từ tìm kiếm bằng từ khoá đến so khớp theo ngữ cảnh và tìm kiếm theo mức độ tương tự. Nhưng hãy tưởng tượng một khách hàng đang tìm kiếm "một chiếc áo khoác thoải mái, phong cách và chống thấm nước để đi bộ đường dài vào mùa xuân" trong khi đồng thời áp dụng các bộ lọc và ứng dụng của bạn không chỉ trả về các câu trả lời chất lượng mà còn có hiệu suất cao và chuỗi của tất cả những điều này được cơ sở dữ liệu của bạn chọn một cách linh hoạt.
Mục tiêu
Để giải quyết vấn đề này bằng cách tích hợp
- Tìm kiếm theo bối cảnh (Tìm kiếm vectơ): Hiểu ý nghĩa ngữ nghĩa của cụm từ tìm kiếm và nội dung mô tả sản phẩm
- Lọc theo khía cạnh: Cho phép người dùng tinh chỉnh kết quả bằng các thuộc tính cụ thể
- Phương pháp kết hợp: Kết hợp mượt mà giữa tìm kiếm theo ngữ cảnh và lọc có cấu trúc
- Tối ưu hoá nâng cao: Tận dụng tính năng lập chỉ mục chuyên biệt, lọc thích ứng và xếp hạng lại để tăng tốc độ và mức độ liên quan
- Quản lý chất lượng dựa trên AI tạo sinh: Kết hợp quy trình xác thực bằng LLM (mô hình ngôn ngữ lớn) để đảm bảo kết quả có chất lượng cao hơn.
Hãy cùng tìm hiểu về cấu trúc và hành trình triển khai.
Sản phẩm bạn sẽ tạo ra
Ứng dụng tìm kiếm bán lẻ
Trong quá trình này, bạn sẽ:
- Tạo một thực thể và bảng AlloyDB cho tập dữ liệu thương mại điện tử
- Thiết lập tính năng nhúng và Tìm kiếm vectơ
- Tạo chỉ mục siêu dữ liệu và chỉ mục ScaNN
- Triển khai tính năng Tìm kiếm vectơ nâng cao trong AlloyDB bằng phương thức lọc nội tuyến của ScaNN
- Thiết lập Bộ lọc theo khía cạnh và Tìm kiếm kết hợp trong một cụm từ tìm kiếm duy nhất
- Tinh chỉnh mức độ liên quan của truy vấn bằng cách sắp xếp lại và thu hồi (không bắt buộc)
- Đánh giá câu trả lời cho truy vấn bằng Gemini (không bắt buộc)
- Bộ công cụ MCP cho cơ sở dữ liệu và Lớp ứng dụng
- Phát triển ứng dụng (Java) bằng tính năng Tìm kiếm theo khía cạnh
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không .
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu Cloud Console.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt dự án:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Truy cập vào đường liên kết rồi bật các API.
Ngoài ra, bạn có thể dùng lệnh gcloud cho việc này. Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
3. Thiết lập cơ sở dữ liệu
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng AlloyDB làm cơ sở dữ liệu cho dữ liệu thương mại điện tử. Nó sử dụng cụm để lưu giữ tất cả các tài nguyên, chẳng hạn như cơ sở dữ liệu và nhật ký. Mỗi cụm có một phiên bản chính cung cấp điểm truy cập vào dữ liệu. Các bảng sẽ chứa dữ liệu thực tế.
Hãy tạo một cụm, thực thể và bảng AlloyDB nơi tập dữ liệu thương mại điện tử sẽ được tải.
Tạo một cụm và phiên bản
- Chuyển đến trang AlloyDB trong Cloud Console. Một cách dễ dàng để tìm hầu hết các trang trong Cloud Console là tìm kiếm các trang đó bằng thanh tìm kiếm của bảng điều khiển.
- Chọn TẠO CỤM trên trang đó:

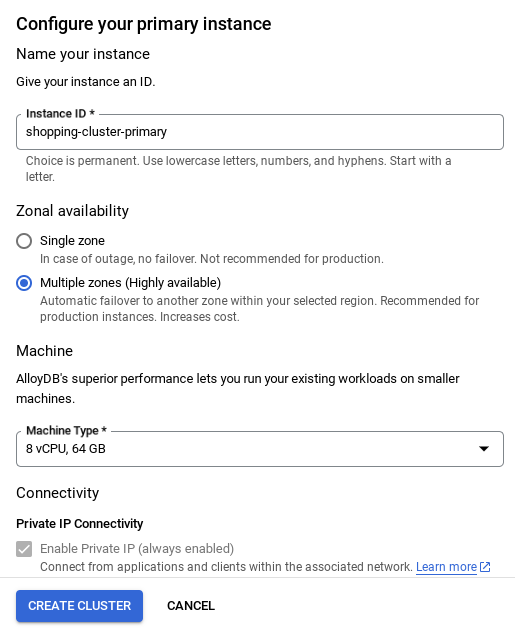
- Bạn sẽ thấy một màn hình như màn hình bên dưới. Tạo một cụm và thực thể bằng các giá trị sau (Đảm bảo các giá trị khớp nhau trong trường hợp bạn đang sao chép mã xử lý ứng dụng từ kho lưu trữ):
- mã nhận dạng cụm: "
vector-cluster" - mật khẩu: "
alloydb" - PostgreSQL 15 / mới nhất (nên dùng)
- Vùng: "
us-central1" - Mạng: "
default"
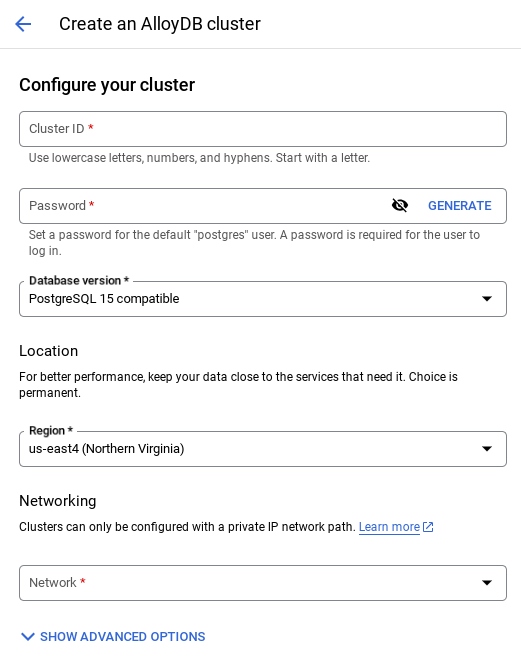
- Khi chọn mạng mặc định, bạn sẽ thấy một màn hình như màn hình bên dưới.
Chọn THIẾT LẬP KẾT NỐI.
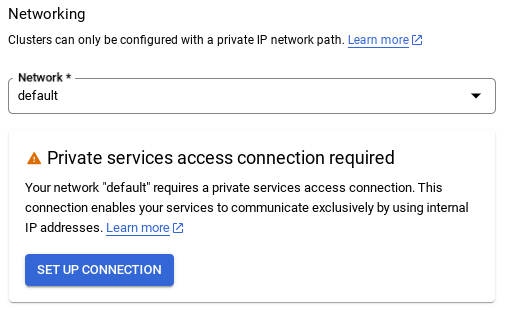
- Tại đó, hãy chọn "Sử dụng dải IP được phân bổ tự động" rồi chọn Tiếp tục. Sau khi xem xét thông tin, hãy chọn TẠO KẾT NỐI.
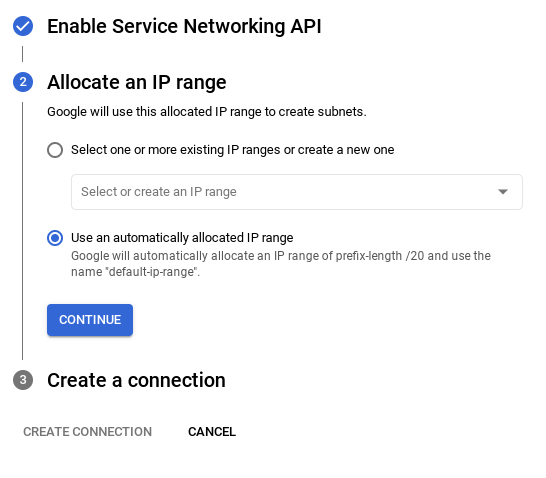
- Sau khi thiết lập mạng, bạn có thể tiếp tục tạo cụm. Nhấp vào TẠO CỤM để hoàn tất việc thiết lập cụm như minh hoạ bên dưới:
LƯU Ý QUAN TRỌNG:
- Nhớ thay đổi mã nhận dạng phiên bản (bạn có thể tìm thấy mã này tại thời điểm định cấu hình cụm / phiên bản) thành **
vector-instance**. Nếu không thay đổi được, hãy nhớ sử dụng mã nhận dạng phiên bản trong tất cả các thông tin tham chiếu sắp tới. - Xin lưu ý rằng quá trình tạo Cụm sẽ mất khoảng 10 phút. Sau khi tạo thành công, bạn sẽ thấy một màn hình cho biết thông tin tổng quan về cụm mà bạn vừa tạo.
4. Nhập dữ liệu
Bây giờ, bạn cần thêm một bảng có dữ liệu về cửa hàng. Chuyển đến AlloyDB, chọn cụm chính rồi chọn AlloyDB Studio:
Bạn có thể phải đợi phiên bản của mình được tạo xong. Sau khi tạo xong, hãy đăng nhập vào AlloyDB bằng thông tin đăng nhập mà bạn đã tạo khi tạo cụm. Sử dụng dữ liệu sau để xác thực với PostgreSQL:
- Tên người dùng : "
postgres" - Cơ sở dữ liệu : "
postgres" - Mật khẩu : "
alloydb"
Sau khi bạn xác thực thành công vào AlloyDB Studio, các lệnh SQL sẽ được nhập vào Trình chỉnh sửa. Bạn có thể thêm nhiều cửa sổ Trình chỉnh sửa bằng cách nhấp vào dấu cộng ở bên phải cửa sổ cuối cùng.
Bạn sẽ nhập các lệnh cho AlloyDB trong cửa sổ trình chỉnh sửa, sử dụng các lựa chọn Chạy, Định dạng và Xoá khi cần.
Bật tiện ích
Để tạo ứng dụng này, chúng ta sẽ sử dụng các tiện ích pgvector và google_ml_integration. Tiện ích pgvector cho phép bạn lưu trữ và tìm kiếm các vectơ nhúng. Tiện ích google_ml_integration cung cấp các hàm mà bạn dùng để truy cập vào các điểm cuối dự đoán của Vertex AI nhằm nhận thông tin dự đoán bằng SQL. Bật các tiện ích này bằng cách chạy các DDL sau:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Nếu bạn muốn kiểm tra các tiện ích đã được bật trên cơ sở dữ liệu của mình, hãy chạy lệnh SQL sau:
select extname, extversion from pg_extension;
Tạo bảng
Bạn có thể tạo một bảng bằng câu lệnh DDL bên dưới trong AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Cột nhúng sẽ cho phép lưu trữ các giá trị vectơ của văn bản.
Cấp quyền
Chạy câu lệnh bên dưới để cấp quyền thực thi cho hàm "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Cấp VAI TRÒ Người dùng Vertex AI cho tài khoản dịch vụ AlloyDB
Trên bảng điều khiển IAM của Google Cloud, hãy cấp cho tài khoản dịch vụ AlloyDB (có dạng như sau: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) quyền truy cập vào vai trò "Người dùng Vertex AI". PROJECT_NUMBER sẽ có số dự án của bạn.
Ngoài ra, bạn có thể chạy lệnh bên dưới trong Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tải dữ liệu vào cơ sở dữ liệu
- Sao chép câu lệnh truy vấn
inserttừinsert scripts sqltrong trang tính vào trình chỉnh sửa như đã đề cập ở trên. Bạn có thể sao chép 10 đến 50 câu lệnh chèn để xem nhanh bản minh hoạ về trường hợp sử dụng này. Có một danh sách các đoạn chèn được chọn ở đây trong thẻ "Các đoạn chèn được chọn từ 25 đến 30 hàng".
Bạn có thể tìm thấy đường liên kết đến dữ liệu trong tệp kho lưu trữ github này.
- Nhấp vào Chạy. Kết quả của truy vấn sẽ xuất hiện trong bảng Results (Kết quả).
LƯU Ý QUAN TRỌNG:
Hãy nhớ chỉ sao chép từ 25 đến 50 bản ghi để chèn và đảm bảo rằng bản ghi đó thuộc một dải ô gồm các loại danh mục, danh mục phụ, màu sắc, giới tính.
5. Tạo các vectơ nhúng cho dữ liệu
Sự đổi mới thực sự trong hoạt động tìm kiếm hiện đại nằm ở việc hiểu được ý nghĩa, chứ không chỉ là từ khoá. Đây là lúc các tính năng nhúng và tìm kiếm vectơ phát huy tác dụng.
Chúng tôi đã chuyển đổi nội dung mô tả sản phẩm và cụm từ tìm kiếm của người dùng thành các biểu diễn số có nhiều chiều (gọi là "embedding") bằng cách sử dụng các mô hình ngôn ngữ được huấn luyện trước. Các vectơ nhúng này nắm bắt ý nghĩa ngữ nghĩa, cho phép chúng tôi tìm thấy những sản phẩm "tương tự về ý nghĩa" thay vì chỉ chứa các từ khớp. Ban đầu, chúng tôi đã thử nghiệm tính năng tìm kiếm mức độ tương đồng của vectơ trực tiếp trên các mục nhúng này để thiết lập đường cơ sở, cho thấy sức mạnh của khả năng hiểu ngữ nghĩa ngay cả trước khi tối ưu hoá hiệu suất.
Cột nhúng sẽ cho phép lưu trữ các giá trị vectơ của văn bản nội dung mô tả sản phẩm. Cột img_embeddings sẽ cho phép lưu trữ các mục nhúng hình ảnh (đa phương thức). Bằng cách này, bạn cũng có thể sử dụng tính năng tìm kiếm dựa trên khoảng cách giữa văn bản và hình ảnh. Tuy nhiên, chúng ta sẽ chỉ sử dụng các vectơ nhúng văn bản trong phòng thí nghiệm này.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Thao tác này sẽ trả về vectơ nhúng (có dạng một mảng số thực) cho văn bản mẫu trong truy vấn. Có dạng như sau:
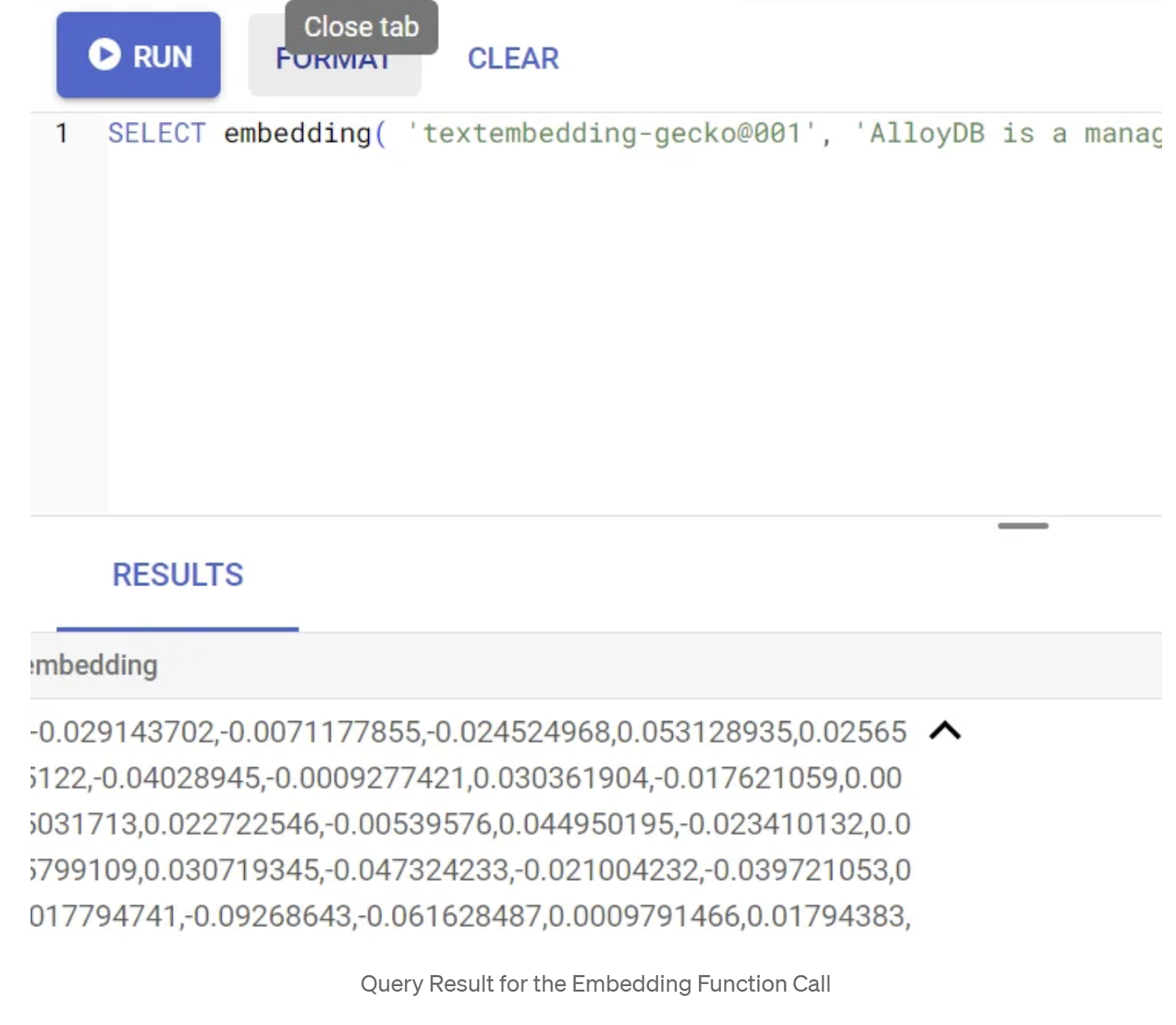
Cập nhật trường Vector abstract_embeddings
Chạy DML bên dưới để cập nhật nội dung mô tả trong bảng bằng các mục nhúng tương ứng:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Bạn có thể gặp vấn đề khi tạo nhiều hơn một vài vectơ nhúng (chẳng hạn như tối đa 20-25) nếu đang sử dụng tài khoản thanh toán có tín dụng dùng thử cho Google Cloud. Vì vậy, hãy giới hạn số lượng hàng trong tập lệnh chèn.
Nếu bạn muốn tạo các vectơ nhúng hình ảnh (để thực hiện tìm kiếm theo ngữ cảnh đa phương thức), hãy chạy bản cập nhật bên dưới:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Thực hiện RAG nâng cao bằng các tính năng mới của AlloyDB
Giờ đây, khi bảng, dữ liệu và các thành phần nhúng đều đã sẵn sàng, hãy thực hiện tính năng Tìm kiếm vectơ theo thời gian thực cho văn bản tìm kiếm của người dùng. Bạn có thể kiểm thử điều này bằng cách chạy truy vấn bên dưới:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
Trong truy vấn này, chúng ta đang so sánh vectơ nhúng văn bản của cụm từ tìm kiếm do người dùng nhập "Áo thun cổ tròn" với vectơ nhúng văn bản của tất cả nội dung mô tả sản phẩm trong bảng quần áo (được lưu trữ trong cột có tên là "embedding") bằng cách sử dụng hàm khoảng cách tương đồng cosine (được biểu thị bằng ký hiệu "<=>"). Chúng ta đang chuyển đổi kết quả của phương thức nhúng thành loại vectơ để tương thích với các vectơ được lưu trữ trong cơ sở dữ liệu. LIMIT 10 cho biết chúng ta đang chọn 10 kết quả phù hợp nhất với văn bản tìm kiếm.
AlloyDB nâng RAG Tìm kiếm vectơ lên một tầm cao mới:
Đối với một giải pháp ở quy mô doanh nghiệp, chỉ tìm kiếm vectơ thô là chưa đủ. Hiệu suất là yếu tố quan trọng.
Chỉ mục ScaNN (Lân cận có thể mở rộng)
Để đạt được tốc độ tìm kiếm siêu nhanh cho láng giềng gần nhất (ANN) gần đúng, chúng tôi đã bật chỉ mục scaNN trong AlloyDB. ScaNN, một thuật toán tìm kiếm lân cận gần đúng tiên tiến do Google Research phát triển, được thiết kế để tìm kiếm mức độ tương đồng của vectơ một cách hiệu quả ở quy mô lớn. Thao tác này giúp tăng tốc đáng kể các truy vấn bằng cách cắt tỉa hiệu quả không gian tìm kiếm và sử dụng kỹ thuật lượng tử hoá, cung cấp các truy vấn vectơ nhanh hơn gấp 4 lần so với các phương pháp lập chỉ mục khác và mức sử dụng bộ nhớ nhỏ hơn. Đọc thêm về vấn đề này tại đây và tại đây.
Hãy bật tiện ích và tạo chỉ mục:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Tạo chỉ mục cho cả trường văn bản và trường nhúng hình ảnh (trong trường hợp bạn muốn sử dụng tính năng nhúng hình ảnh trong tìm kiếm):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
Chỉ mục siêu dữ liệu
Trong khi scaNN xử lý việc lập chỉ mục vectơ, chỉ mục B-tree hoặc GIN truyền thống được thiết lập tỉ mỉ trên các thuộc tính có cấu trúc (như danh mục, danh mục phụ, kiểu dáng, màu sắc, v.v.). Các chỉ mục này đóng vai trò quan trọng đối với hiệu quả của tính năng lọc theo khía cạnh. Chạy các câu lệnh bên dưới để thiết lập chỉ mục siêu dữ liệu:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
LƯU Ý QUAN TRỌNG:
Vì bạn có thể chỉ chèn 25 đến 50 bản ghi, nên các chỉ mục (ScaNN hoặc bất kỳ chỉ mục nào) sẽ không hiệu quả.
Lọc cùng dòng
Một thách thức thường gặp trong tìm kiếm vectơ là kết hợp tìm kiếm vectơ với các bộ lọc có cấu trúc (ví dụ: "giày màu đỏ"). Tính năng lọc nội tuyến của AlloyDB sẽ tối ưu hoá việc này. Thay vì lọc kết quả sau khi tìm kiếm vectơ trên diện rộng, tính năng lọc nội tuyến sẽ áp dụng các điều kiện lọc trong chính quy trình tìm kiếm vectơ, giúp cải thiện đáng kể hiệu suất và độ chính xác cho các lượt tìm kiếm vectơ được lọc.
Hãy tham khảo tài liệu này để tìm hiểu thêm về nhu cầu Lọc nội tuyến. Bạn cũng có thể tìm hiểu về tính năng tìm kiếm vectơ được lọc để tối ưu hoá hiệu suất của tính năng tìm kiếm vectơ tại đây. Giờ đây, nếu bạn muốn bật tính năng lọc trực tiếp cho ứng dụng của mình, hãy chạy câu lệnh sau trong trình chỉnh sửa:
SET scann.enable_inline_filtering = on;
Lọc nội tuyến phù hợp nhất cho các trường hợp có tính chọn lọc trung bình. Khi tìm kiếm trong chỉ mục vectơ, AlloyDB chỉ tính toán khoảng cách cho những vectơ khớp với các điều kiện lọc siêu dữ liệu (các bộ lọc chức năng của bạn trong một truy vấn thường được xử lý trong mệnh đề WHERE). Điều này giúp cải thiện đáng kể hiệu suất cho các truy vấn này, bổ sung cho những lợi thế của bộ lọc sau hoặc bộ lọc trước.
Lọc thích ứng
Để tối ưu hoá hiệu suất hơn nữa, tính năng lọc thích ứng của AlloyDB sẽ tự động chọn chiến lược lọc hiệu quả nhất (lọc nội tuyến hoặc lọc trước) trong quá trình thực thi truy vấn. Tính năng này phân tích các mẫu truy vấn và phân phối dữ liệu để đảm bảo hiệu suất tối ưu mà không cần can thiệp thủ công, đặc biệt hữu ích cho các tìm kiếm vectơ được lọc, trong đó tính năng này tự động chuyển đổi giữa việc sử dụng chỉ mục vectơ và chỉ mục siêu dữ liệu. Để bật tính năng lọc thích ứng, hãy sử dụng cờ scann.enable_preview_features.
Khi tính năng lọc thích ứng kích hoạt quá trình chuyển đổi từ lọc nội tuyến sang lọc trước trong quá trình thực thi, kế hoạch truy vấn sẽ thay đổi linh hoạt.
SET scann.enable_preview_features = on;
LƯU Ý QUAN TRỌNG: Bạn có thể không chạy được câu lệnh trên mà không cần khởi động lại phiên bản. Nếu gặp lỗi, bạn nên bật cờ enable_preview_features trong phần cờ cơ sở dữ liệu của phiên bản.
Bộ lọc theo khía cạnh sử dụng tất cả các chỉ mục
Tính năng tìm kiếm theo khía cạnh cho phép người dùng tinh chỉnh kết quả bằng cách áp dụng nhiều bộ lọc dựa trên các thuộc tính hoặc "khía cạnh" cụ thể (ví dụ: thương hiệu, giá, kích thước, điểm xếp hạng của khách hàng). Ứng dụng của chúng tôi tích hợp liền mạch các khía cạnh này với tính năng tìm kiếm vectơ. Giờ đây, một truy vấn có thể kết hợp ngôn ngữ tự nhiên (tìm kiếm theo ngữ cảnh) với nhiều lựa chọn theo khía cạnh, tận dụng linh hoạt cả chỉ mục vectơ và chỉ mục truyền thống. Điều này mang đến khả năng tìm kiếm kết hợp thực sự linh hoạt, cho phép người dùng tìm hiểu kỹ kết quả một cách chính xác.
Trong ứng dụng của mình, vì đã tạo tất cả các chỉ mục siêu dữ liệu, nên chúng ta đã sẵn sàng sử dụng bộ lọc theo khía cạnh trên web bằng cách giải quyết vấn đề đó trực tiếp bằng các truy vấn SQL:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
Trong truy vấn này, chúng ta đang thực hiện tìm kiếm kết hợp – kết hợp cả hai
- Lọc theo khía cạnh trong mệnh đề WHERE và
- Tìm kiếm vectơ trong mệnh đề ORDER BY bằng phương thức tương đồng cosine.
$1, $2, $3 và $4 đại diện cho các giá trị bộ lọc theo khía cạnh trong một mảng và $5 đại diện cho văn bản tìm kiếm của người dùng. Thay thế $1 đến $4 bằng các giá trị bộ lọc theo khía cạnh mà bạn chọn như bên dưới:
category = ANY(["Quần áo", "Giày dép"])
Thay thế $5 bằng một văn bản tìm kiếm mà bạn chọn, chẳng hạn như "Áo polo".
LƯU Ý QUAN TRỌNG: Nếu không có chỉ mục do số lượng bản ghi bạn đã chèn bị hạn chế, thì bạn sẽ không thấy ảnh hưởng đến hiệu suất. Nhưng trong một tập dữ liệu sản xuất đầy đủ, bạn sẽ nhận thấy rằng thời gian thực thi giảm đáng kể đối với cùng một tính năng Tìm kiếm vectơ bằng cách sử dụng chỉ mục ScaNN được truyền tính năng Lọc nội tuyến trên tính năng Tìm kiếm vectơ đã giúp điều này trở nên khả thi!!!
Tiếp theo, hãy đánh giá khả năng thu hồi cho tính năng Tìm kiếm vectơ được bật ScaNN này.
Sắp xếp lại
Ngay cả khi sử dụng tính năng tìm kiếm nâng cao, kết quả ban đầu vẫn có thể cần được tinh chỉnh lần cuối. Đây là một bước quan trọng giúp sắp xếp lại kết quả tìm kiếm ban đầu để cải thiện mức độ liên quan. Sau khi tìm kiếm kết hợp ban đầu cung cấp một nhóm sản phẩm đề xuất, một mô hình phức tạp hơn (và thường tốn nhiều tài nguyên tính toán hơn) sẽ áp dụng điểm số mức độ liên quan chi tiết hơn. Điều này đảm bảo rằng những kết quả hàng đầu mà người dùng nhìn thấy là phù hợp nhất, giúp nâng cao đáng kể chất lượng tìm kiếm. Chúng tôi liên tục đánh giá khả năng thu hồi để đo lường mức độ hiệu quả của hệ thống trong việc truy xuất tất cả các mục có liên quan cho một cụm từ tìm kiếm nhất định, tinh chỉnh các mô hình của chúng tôi để tối đa hoá khả năng khách hàng tìm thấy những gì họ cần.
Trước khi sử dụng tính năng này trong ứng dụng, hãy đảm bảo bạn đáp ứng tất cả các điều kiện tiên quyết:
- Xác minh rằng bạn đã cài đặt tiện ích google_ml_integration.
- Xác minh rằng cờ google_ml_integration.enable_model_support được đặt thành on.
- Tích hợp với Vertex AI.
- Bật Discovery Engine API.
- Có được các vai trò cần thiết để sử dụng mô hình xếp hạng.
Sau đó, bạn có thể sử dụng truy vấn sau trong ứng dụng của chúng tôi để sắp xếp lại thứ hạng cho tập kết quả tìm kiếm kết hợp:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
Trong truy vấn này, chúng ta đang thực hiện việc SẮP XẾP LẠI tập kết quả sản phẩm của tìm kiếm theo ngữ cảnh được đề cập trong mệnh đề ORDER BY bằng phương thức tính độ tương tự theo hàm cô-sin. "Áo màu hồng" là văn bản mà người dùng đang tìm kiếm.
LƯU Ý QUAN TRỌNG: Một số bạn có thể chưa có quyền truy cập vào tính năng Sắp xếp lại, vì vậy, tôi đã loại trừ tính năng này khỏi mã xử lý ứng dụng. Tuy nhiên, nếu muốn thêm tính năng này, bạn có thể làm theo mẫu mà chúng ta đã đề cập ở trên.
Người đánh giá mức độ liên quan
Độ thu hồi trong tìm kiếm tương tự là tỷ lệ phần trăm số trường hợp có liên quan được truy xuất từ một lượt tìm kiếm, tức là số lượng dương tính thật. Đây là chỉ số phổ biến nhất được dùng để đo lường chất lượng tìm kiếm. Một nguồn gây ra tình trạng giảm khả năng thu hồi là sự khác biệt giữa tìm kiếm lân cận gần đúng (aNN) và tìm kiếm k lân cận (chính xác) (kNN). Các chỉ mục vectơ như ScaNN của AlloyDB triển khai các thuật toán aNN, cho phép bạn tăng tốc tìm kiếm vectơ trên các tập dữ liệu lớn để đổi lấy một điểm đánh đổi nhỏ về khả năng thu hồi. Giờ đây, AlloyDB cho phép bạn đo lường sự đánh đổi này ngay trong cơ sở dữ liệu cho từng truy vấn và đảm bảo rằng sự đánh đổi này ổn định theo thời gian. Bạn có thể cập nhật các tham số truy vấn và chỉ mục dựa trên thông tin này để đạt được kết quả và hiệu suất tốt hơn.
Logic đằng sau việc thu hồi kết quả tìm kiếm là gì?
Trong bối cảnh tìm kiếm vectơ, độ thu hồi đề cập đến tỷ lệ phần trăm vectơ mà chỉ mục trả về là những vectơ láng giềng gần nhất thực sự. Ví dụ: nếu một truy vấn về điểm dữ liệu láng giềng gần nhất cho 20 điểm dữ liệu láng giềng gần nhất trả về 19 điểm dữ liệu láng giềng gần nhất trong thực tế, thì độ thu hồi là 19/20 x 100 = 95%. Mức độ phù hợp là chỉ số được dùng để đánh giá chất lượng tìm kiếm, được xác định là tỷ lệ phần trăm kết quả được trả về gần nhất với các vectơ truy vấn một cách khách quan.
Bạn có thể tìm thấy độ thu hồi cho một truy vấn vectơ trên chỉ mục vectơ cho một cấu hình nhất định bằng cách sử dụng hàm evaluate_query_recall. Hàm này cho phép bạn điều chỉnh các tham số để đạt được kết quả truy vấn vectơ mà bạn muốn.
LƯU Ý QUAN TRỌNG:
Nếu bạn gặp lỗi từ chối quyền trên chỉ mục HNSW trong các bước sau, hãy bỏ qua toàn bộ phần đánh giá khả năng thu hồi này. Nguyên nhân có thể là do các hạn chế về quyền truy cập tại thời điểm này vì tính năng này chỉ được phát hành tại thời điểm lớp học lập trình này được ghi lại.
- Đặt cờ Bật tính năng quét chỉ mục trên chỉ mục ScaNN và chỉ mục HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Chạy truy vấn sau trong AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Hàm evaluate_query_recall nhận truy vấn làm tham số và trả về độ thu hồi của truy vấn đó. Tôi đang sử dụng cùng một truy vấn mà tôi đã dùng để kiểm tra hiệu suất làm truy vấn đầu vào của hàm. Tôi đã thêm SCaNN làm phương thức lập chỉ mục. Để biết thêm các lựa chọn về tham số, hãy tham khảo tài liệu.
Độ chính xác của truy vấn Tìm kiếm vectơ mà chúng tôi đang sử dụng:
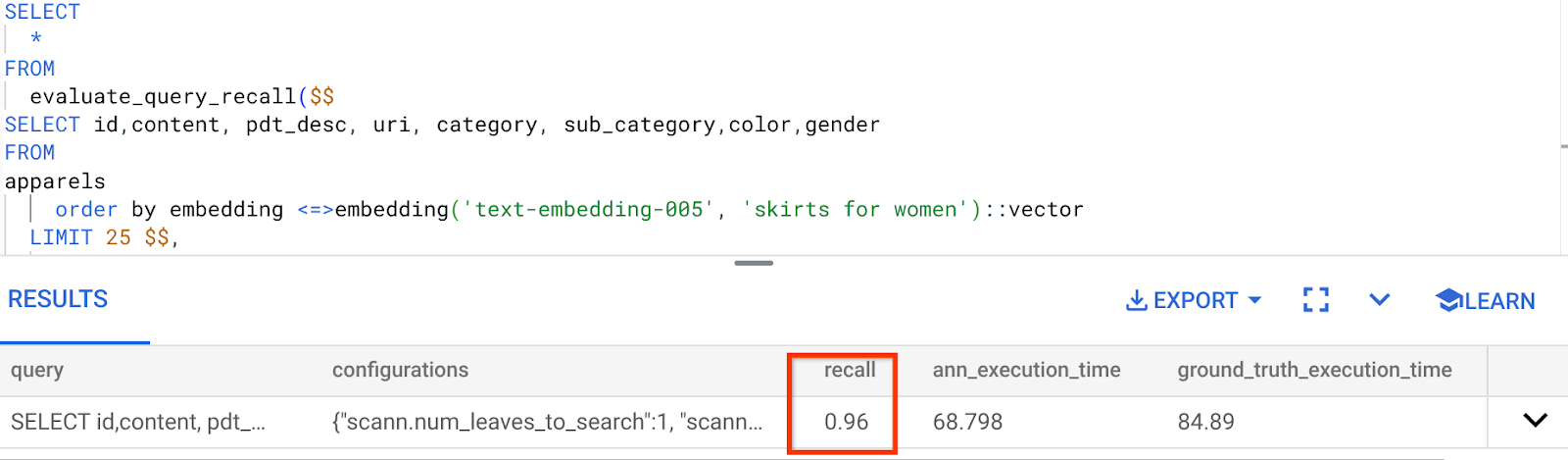
Tôi nhận thấy RECALL là 96%. Trong trường hợp này, độ thu hồi thực sự tốt. Nhưng nếu đó là một giá trị không chấp nhận được, thì bạn có thể sử dụng thông tin này để thay đổi các tham số chỉ mục, phương thức và tham số truy vấn, đồng thời cải thiện khả năng thu hồi của tôi cho tính năng Tìm kiếm vectơ này!
Thử nghiệm với truy vấn và tham số chỉ mục đã sửa đổi
Bây giờ, hãy kiểm thử truy vấn bằng cách sửa đổi các tham số truy vấn dựa trên thông tin thu hồi nhận được.
- Sửa đổi các tham số chỉ mục:
Đối với kiểm thử này, tôi sẽ sử dụng "L2 Distance" thay vì hàm khoảng cách tương tự "Cosine".
Lưu ý rất quan trọng: "Làm sao chúng ta biết truy vấn này sử dụng độ tương đồng COSINE?" bạn hỏi. Bạn có thể xác định hàm khoảng cách bằng cách sử dụng "<=>" để biểu thị khoảng cách Cosine.
Đường liên kết đến tài liệu cho các hàm khoảng cách của tính năng Tìm kiếm vectơ.
Truy vấn trước đó sử dụng hàm khoảng cách Tương đồng Cosine, trong khi giờ đây chúng ta sẽ thử Khoảng cách L2. Nhưng để làm được điều đó, chúng ta cũng phải đảm bảo rằng chỉ mục ScaNN cơ bản cũng sử dụng Hàm khoảng cách L2. Bây giờ, hãy tạo một chỉ mục bằng truy vấn hàm khoảng cách khác: Khoảng cách L2: <->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
Câu lệnh xoá chỉ mục chỉ nhằm đảm bảo không có chỉ mục không cần thiết trên bảng.
Giờ đây, tôi có thể thực thi truy vấn sau để đánh giá RECALL sau khi thay đổi hàm khoảng cách của chức năng Tìm kiếm vectơ.
[SAU] Truy vấn sử dụng hàm Khoảng cách L2:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Bạn có thể thấy sự khác biệt / biến đổi về giá trị nhớ lại cho chỉ mục được cập nhật.
Bạn có thể thay đổi các tham số khác trong chỉ mục, chẳng hạn như num_leaves, v.v. dựa trên giá trị recall mong muốn và tập dữ liệu mà ứng dụng của bạn sử dụng.
Xác thực LLM đối với kết quả Tìm kiếm vectơ
Để đạt được chất lượng tìm kiếm có kiểm soát cao nhất, chúng tôi đã kết hợp một lớp xác thực LLM không bắt buộc. Bạn có thể sử dụng Mô hình ngôn ngữ lớn để đánh giá mức độ liên quan và tính nhất quán của kết quả tìm kiếm, đặc biệt là đối với những cụm từ tìm kiếm phức tạp hoặc mơ hồ. Việc này có thể bao gồm:
Xác minh ngữ nghĩa:
Mô hình ngôn ngữ lớn (LLM) tham chiếu chéo kết quả với ý định tìm kiếm.
Lọc logic:
Sử dụng LLM để áp dụng logic hoặc quy tắc kinh doanh phức tạp mà khó mã hoá trong các bộ lọc truyền thống, từ đó tinh chỉnh danh sách sản phẩm dựa trên các tiêu chí tinh tế.
Đảm bảo chất lượng:
Tự động xác định và gắn cờ những kết quả ít liên quan để nhân viên đánh giá hoặc tinh chỉnh mô hình.
Đây là cách chúng tôi đã thực hiện điều đó trong các tính năng AI của AlloyDB:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
Cụm từ tìm kiếm cơ bản là cụm từ tìm kiếm mà chúng ta đã thấy trong các phần tìm kiếm theo khía cạnh, tìm kiếm kết hợp và xếp hạng lại. Giờ đây, trong truy vấn này, chúng ta đã kết hợp một lớp đánh giá GEMINI của tập kết quả được sắp xếp lại, được biểu thị bằng cấu trúc ml_predict_row. Tôi đã nhận xét về các bộ lọc theo khía cạnh, nhưng bạn có thể thoải mái thêm các mục bạn chọn vào một mảng cho các phần giữ chỗ từ $1 đến $4. Thay thế $5 bằng văn bản bạn muốn tìm kiếm, chẳng hạn như "Áo màu hồng, không có hoạ tiết hoa".
7. Bộ công cụ MCP cho cơ sở dữ liệu và Lớp ứng dụng
Đằng sau đó, công cụ mạnh mẽ và ứng dụng có cấu trúc hợp lý sẽ đảm bảo hoạt động trơn tru.
Bộ công cụ MCP (Giao thức ngữ cảnh mô hình) cho Cơ sở dữ liệu giúp đơn giản hoá việc tích hợp AI tạo sinh và các công cụ dựa trên tác nhân với AlloyDB. Đây là một máy chủ nguồn mở giúp đơn giản hoá việc gộp kết nối, xác thực và việc cung cấp các chức năng cơ sở dữ liệu một cách an toàn cho các tác nhân AI hoặc các ứng dụng khác.
Trong ứng dụng của mình, chúng tôi đã sử dụng MCP Toolbox for Databases làm lớp trừu tượng cho tất cả các truy vấn tìm kiếm kết hợp thông minh.
Làm theo các bước bên dưới để thiết lập và triển khai Toolbox cho trường hợp sử dụng của chúng tôi:
Bạn có thể thấy rằng một trong những cơ sở dữ liệu được Bộ công cụ MCP cho cơ sở dữ liệu hỗ trợ là AlloyDB. Vì chúng ta đã cung cấp cơ sở dữ liệu đó trong phần trước, nên hãy tiếp tục thiết lập Bộ công cụ.
- Chuyển đến Cloud Shell Terminal và đảm bảo dự án của bạn được chọn và xuất hiện trong lời nhắc của thiết bị đầu cuối. Chạy lệnh bên dưới qua Cloud Shell Terminal để chuyển đến thư mục dự án:
mkdir toolbox-tools
cd toolbox-tools
- Chạy lệnh bên dưới để tải xuống và cài đặt hộp công cụ trong thư mục mới:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Chuyển đến Cloud Shell Editor (để chỉnh sửa mã) rồi thêm một tệp có tên là "tools.yaml" vào thư mục gốc của dự án.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
Hãy nhớ thay thế tập lệnh Tools.yaml bằng mã trong tệp repo này.
Hãy tìm hiểu về tools.yaml:
Nguồn đại diện cho các nguồn dữ liệu khác nhau mà một công cụ có thể tương tác. Nguồn đại diện cho một nguồn dữ liệu mà công cụ có thể tương tác. Bạn có thể xác định Nguồn dưới dạng bản đồ trong phần nguồn của tệp tools.yaml. Thông thường, cấu hình nguồn sẽ chứa mọi thông tin cần thiết để kết nối và tương tác với cơ sở dữ liệu.
Công cụ xác định những hành động mà một tác nhân có thể thực hiện, chẳng hạn như đọc và ghi vào một nguồn. Công cụ đại diện cho một hành động mà tác nhân của bạn có thể thực hiện, chẳng hạn như chạy một câu lệnh SQL. Bạn có thể xác định Công cụ dưới dạng bản đồ trong phần công cụ của tệp tools.yaml. Thông thường, một công cụ sẽ cần một nguồn để hoạt động.
Để biết thêm thông tin chi tiết về cách định cấu hình tools.yaml, hãy tham khảo tài liệu này.
- Chạy lệnh sau (từ thư mục mcp-toolbox) để khởi động máy chủ:
./toolbox --tools-file "tools.yaml"
Giờ đây, nếu mở máy chủ ở chế độ xem trước trên web trên đám mây, bạn sẽ thấy máy chủ Toolbox đang chạy với công cụ mới có tên get-order-data.
Theo mặc định, MCP Toolbox Server chạy trên cổng 5000. Hãy dùng Cloud Shell để kiểm thử.
Nhấp vào Web Preview (Xem trước trên web) trong Cloud Shell như minh hoạ dưới đây:
Nhấp vào Change port (Thay đổi cổng) rồi đặt cổng thành 5000 như minh hoạ bên dưới, sau đó nhấp vào Change and Preview (Thay đổi và xem trước).
Thao tác này sẽ cho ra kết quả sau:
- Hãy triển khai Hộp công cụ của chúng ta lên Cloud Run:
Trước tiên, chúng ta có thể bắt đầu với máy chủ MCP Toolbox và lưu trữ máy chủ này trên Cloud Run. Sau đó, việc này sẽ cung cấp cho chúng ta một điểm cuối công khai mà chúng ta có thể tích hợp với bất kỳ ứng dụng nào khác và/hoặc cả ứng dụng Agent. Hướng dẫn về cách lưu trữ ứng dụng này trên Cloud Run có tại đây. Giờ chúng ta sẽ xem xét các bước chính.
- Khởi chạy một Cửa sổ dòng lệnh Cloud Shell mới hoặc sử dụng Cửa sổ dòng lệnh Cloud Shell hiện có. Chuyển đến thư mục dự án có tệp nhị phân toolbox và tools.yaml, trong trường hợp này là toolbox-tools, nếu bạn chưa ở trong thư mục đó:
cd toolbox-tools
- Đặt biến PROJECT_ID để trỏ đến mã dự án Google Cloud của bạn.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Bật các dịch vụ Google Cloud này
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Hãy tạo một tài khoản dịch vụ riêng biệt đóng vai trò là danh tính cho dịch vụ Toolbox mà chúng ta sẽ triển khai trên Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Chúng tôi cũng đảm bảo rằng tài khoản dịch vụ này có đúng vai trò, tức là có khả năng truy cập vào Secret Manager và tương tác với AlloyDB
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Chúng ta sẽ tải tệp tools.yaml lên dưới dạng một mã bí mật:
gcloud secrets create tools --data-file=tools.yaml
Nếu bạn đã có một khoá bí mật và muốn cập nhật phiên bản khoá bí mật, hãy thực thi lệnh sau:
gcloud secrets versions add tools --data-file=tools.yaml
- Đặt một biến môi trường cho hình ảnh vùng chứa mà bạn muốn dùng cho Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Bước cuối cùng trong lệnh triển khai quen thuộc đối với Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
Thao tác này sẽ bắt đầu quy trình triển khai Toolbox Server bằng tools.yaml đã định cấu hình của chúng tôi lên Cloud Run. Khi triển khai thành công, bạn sẽ thấy một thông báo tương tự như sau:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Bạn đã sẵn sàng sử dụng công cụ mới triển khai trong ứng dụng dựa trên tác nhân của mình!!!
Truy cập vào các công cụ trong Toolbox Server
Sau khi triển khai Toolbox, chúng ta sẽ tạo một shim Cloud Run Functions bằng Python để tương tác với máy chủ Toolbox đã triển khai. Lý do là vì hiện tại Toolbox không có Java SDK, nên chúng tôi đã tạo một shim Python để tương tác với máy chủ. Đây là mã nguồn của Cloud Run Function đó.
Bạn phải tạo và triển khai Cloud Run Function này để có thể truy cập vào các công cụ trong hộp công cụ mà bạn vừa tạo và triển khai ở các bước trước:
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Cloud Run
- Nhấp vào Viết hàm.
- Trong trường Tên dịch vụ, hãy nhập tên để mô tả hàm của bạn. Tên dịch vụ chỉ được bắt đầu bằng một chữ cái và có tối đa 49 ký tự, bao gồm cả chữ cái, chữ số hoặc dấu gạch ngang. Tên dịch vụ không được kết thúc bằng dấu gạch ngang và phải là tên duy nhất cho mỗi khu vực và dự án. Sau này, bạn không thể thay đổi tên dịch vụ và tên này sẽ hiển thị công khai. (Nhập retail-product-search-quality)
- Trong danh sách Khu vực, hãy sử dụng giá trị mặc định hoặc chọn khu vực mà bạn muốn triển khai hàm. (Chọn us-central1)
- Trong danh sách Thời gian chạy, hãy sử dụng giá trị mặc định hoặc chọn một phiên bản thời gian chạy. (Chọn Python 3.11)
- Trong phần Xác thực, hãy chọn "Cho phép truy cập công khai"
- Nhấp vào nút "Tạo"
- Hàm này được tạo và tải bằng một mẫu main.py và requirements.txt
- Thay thế bằng các tệp: main.py và requirements.txt trong kho lưu trữ của dự án này
- Triển khai hàm và bạn sẽ nhận được một điểm cuối cho Hàm Cloud Run
Điểm cuối của bạn sẽ có dạng như sau (hoặc tương tự):
Điểm cuối của hàm Cloud Run để truy cập vào hộp công cụ: "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app"
Để dễ dàng hoàn thành trong thời gian quy định (đối với các phiên thực hành có người hướng dẫn), số dự án cho điểm cuối sẽ được chia sẻ tại thời điểm diễn ra phiên thực hành.
LƯU Ý QUAN TRỌNG:
Ngoài ra, bạn cũng có thể triển khai trực tiếp phần cơ sở dữ liệu trong mã xử lý ứng dụng hoặc Hàm Cloud Run.
8. Phát triển ứng dụng (Java) bằng tính năng Tìm kiếm theo khía cạnh
Cuối cùng, tất cả các thành phần phụ trợ mạnh mẽ này đều được đưa vào hoạt động thông qua lớp ứng dụng. Được phát triển bằng Java, ứng dụng này cung cấp giao diện người dùng để tương tác với hệ thống tìm kiếm. Ứng dụng này điều phối các truy vấn đến AlloyDB, xử lý việc hiển thị các bộ lọc theo khía cạnh, quản lý lựa chọn của người dùng và trình bày kết quả tìm kiếm đã được xác thực và sắp xếp lại một cách liền mạch và trực quan.
- Bạn có thể bắt đầu bằng cách chuyển đến Cloud Shell Terminal và sao chép kho lưu trữ:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- Chuyển đến Cloud Shell Editor. Tại đây, bạn có thể thấy thư mục mới tạo faceted_searching_retail
- Xoá những bước sau vì bạn đã hoàn tất các bước đó trong những phần trước:
- Xoá thư mục Cloud_Run_Function
- Xoá tệp db_script.sql
- Xoá tệp tools.yaml
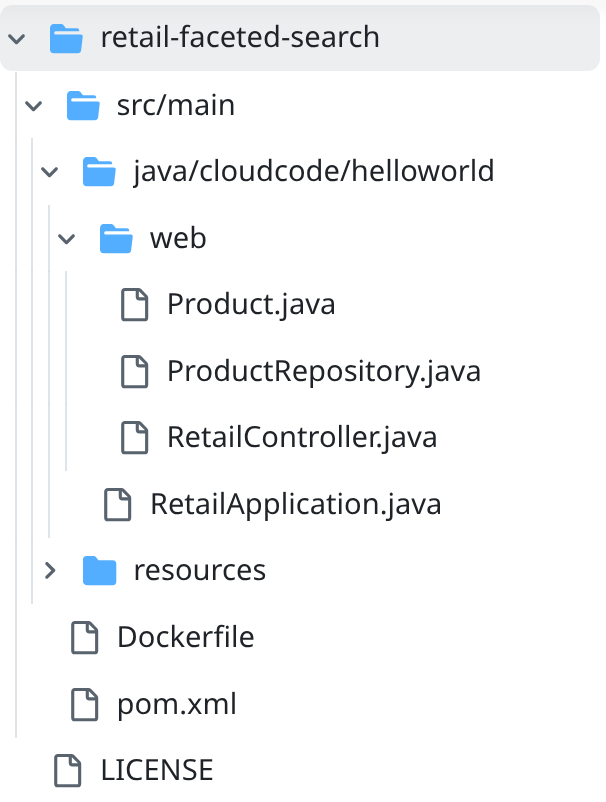
- Chuyển đến thư mục dự án retail-faceted-search, bạn sẽ thấy cấu trúc dự án như sau:
- Trong tệp ProductRepository.java, bạn phải sửa đổi biến TOOLBOX_ENDPOINT bằng điểm cuối từ Hàm Cloud Run (đã triển khai) hoặc lấy điểm cuối từ người hướng dẫn thực hành.
Tìm dòng mã sau rồi thay thế bằng điểm cuối của bạn:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- Đảm bảo Dockerfile và pom.xml phù hợp với cấu hình dự án của bạn (không cần thay đổi trừ phi bạn đã thay đổi rõ ràng bất kỳ phiên bản hoặc cấu hình nào.
- Trong Cloud Shell Terminal, hãy đảm bảo rằng bạn đang ở trong thư mục chính và trong thư mục dự án (faceted_searching_retail / retail-faceted-search). Hãy dùng các lệnh sau để đảm bảo rằng bạn đang ở đúng thư mục trong thiết bị đầu cuối:
cd faceted_searching_retail
cd retail-faceted-search
- Đóng gói, tạo và kiểm thử ứng dụng của bạn trên thiết bị:
mvn package
mvn spring-boot:run
Bạn có thể xem ứng dụng của mình bằng cách nhấp vào "Preview on port 8080" (Xem trước trên cổng 8080) trong Cloud Shell Terminal như minh hoạ dưới đây:
9. Triển khai lên Cloud Run: ***BƯỚC QUAN TRỌNG
Trong Cloud Shell Terminal, hãy đảm bảo rằng bạn đang ở trong thư mục chính và trong thư mục dự án (faceted_searching_retail / retail-faceted-search). Hãy dùng các lệnh sau để đảm bảo rằng bạn đang ở đúng thư mục trong thiết bị đầu cuối:
cd faceted_searching_retail
cd retail-faceted-search
Sau khi bạn chắc chắn mình đang ở trong thư mục dự án, hãy chạy lệnh sau:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
Sau khi triển khai, bạn sẽ nhận được một Điểm cuối Cloud Run đã triển khai có dạng như sau:
https://retail-search-**********-uc.a.run.app/
10. Bản minh hoạ
Hãy xem tất cả những điều này được kết hợp với nhau trong thực tế:
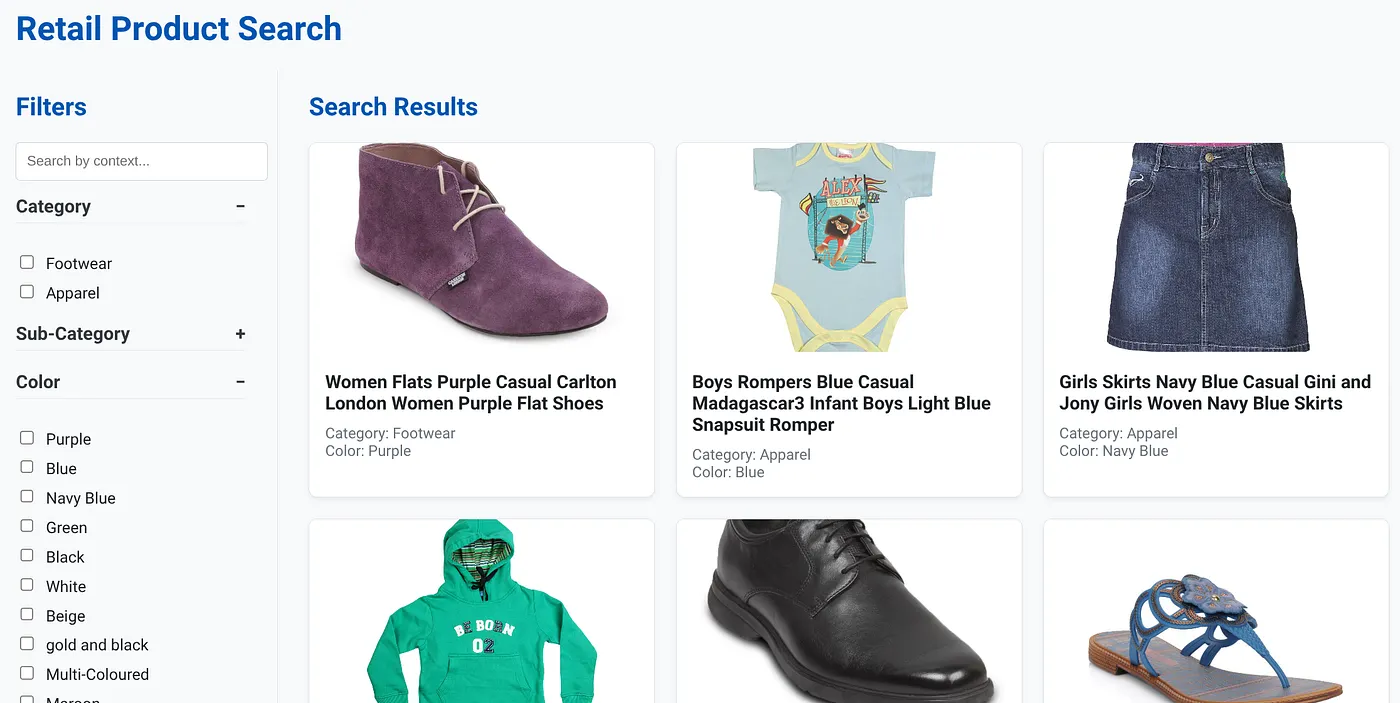
Hình ảnh trên cho thấy trang đích của ứng dụng tìm kiếm kết hợp linh hoạt.
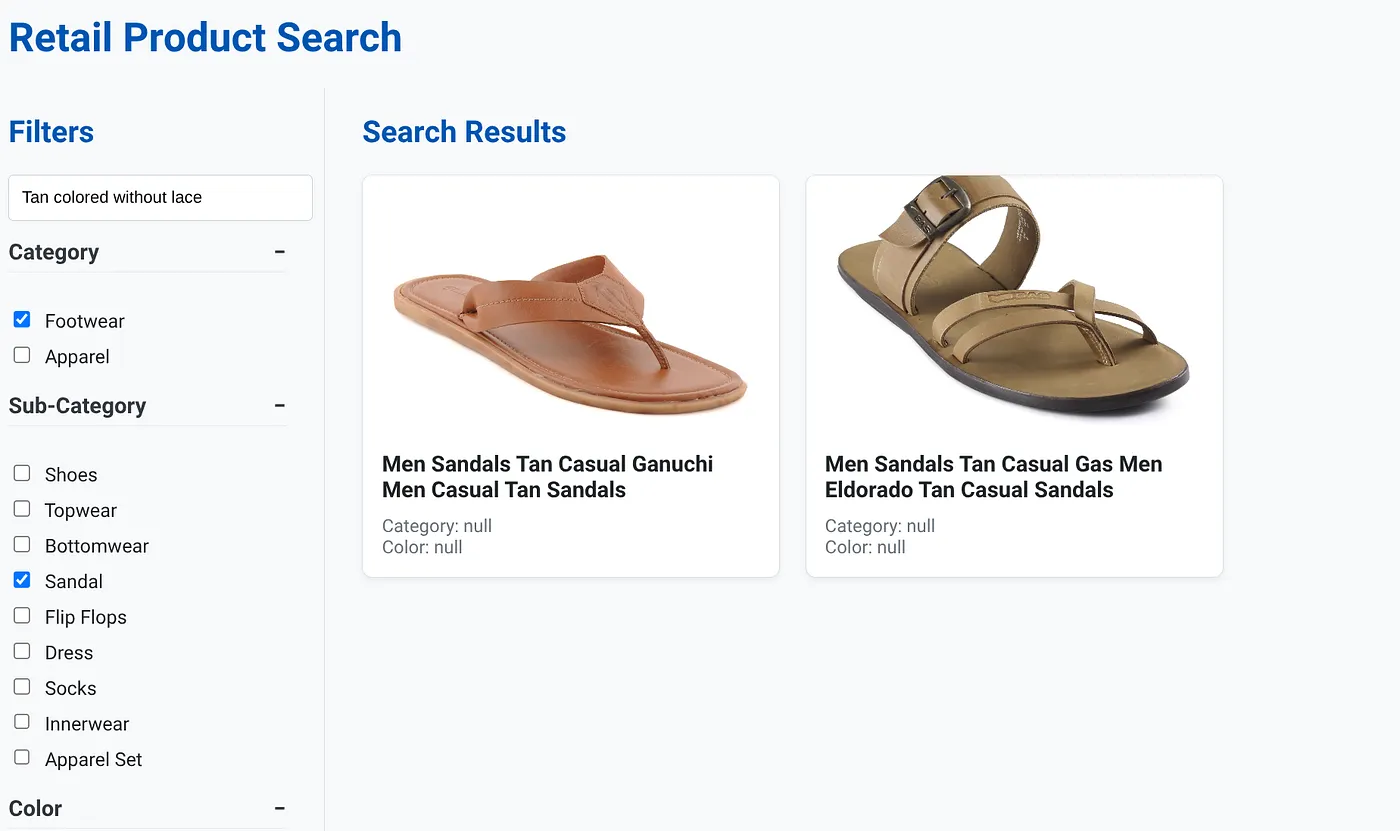
Hình ảnh trên cho thấy kết quả tìm kiếm cho cụm từ "Màu nâu nhạt không có dây buộc" . Các bộ lọc theo khía cạnh được chọn là: Giày dép, Dép.
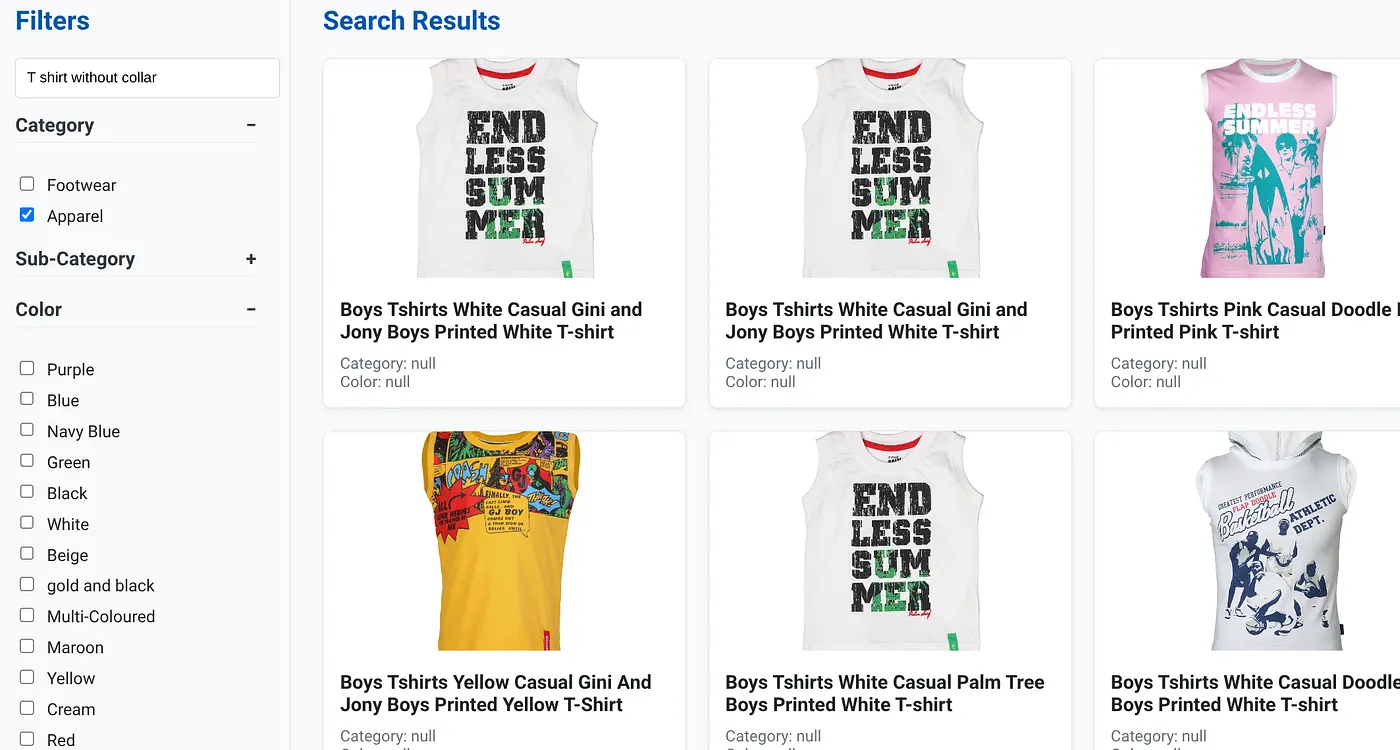
Hình ảnh trên cho thấy kết quả tìm kiếm cho "Áo thun không cổ" . Bộ lọc theo khía cạnh: Quần áo
Giờ đây, bạn có thể kết hợp nhiều tính năng tạo sinh và tính năng dựa trên tác nhân hơn để giúp ứng dụng này có thể thực hiện được.
Hãy thử để có cảm hứng xây dựng dự án của riêng bạn!!!
11. Dọn dẹp
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong bài đăng này, hãy làm theo các bước sau:
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang trình quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
- Ngoài ra, bạn có thể xoá cụm AlloyDB (thay đổi vị trí trong siêu liên kết này nếu bạn không chọn us-central1 cho cụm tại thời điểm định cấu hình) mà chúng ta vừa tạo cho dự án này bằng cách nhấp vào nút XOÁ CỤM.
12. Xin chúc mừng
Xin chúc mừng! Bạn đã xây dựng và triển khai thành công một ỨNG DỤNG TÌM KIẾM KẾT HỢP bằng ALLOYDB trên CLOUD RUN!!!
Lý do điều này quan trọng đối với doanh nghiệp:
Ứng dụng tìm kiếm kết hợp linh hoạt này, hoạt động dựa trên AI của AlloyDB, mang lại những lợi ích đáng kể cho hoạt động bán lẻ của doanh nghiệp và các doanh nghiệp khác:
Mức độ liên quan vượt trội: Bằng cách kết hợp tìm kiếm theo ngữ cảnh (dạng vectơ) với tính năng lọc chính xác theo khía cạnh và sắp xếp lại thông minh, khách hàng sẽ nhận được kết quả có mức độ liên quan cao, từ đó tăng mức độ hài lòng và số lượt chuyển đổi.
Khả năng mở rộng: Cấu trúc của AlloyDB và tính năng lập chỉ mục scaNN được thiết kế để xử lý danh mục sản phẩm khổng lồ và số lượng truy vấn lớn, điều này rất quan trọng đối với các doanh nghiệp thương mại điện tử đang phát triển.
Hiệu suất: Phản hồi nhanh hơn cho các truy vấn, ngay cả đối với những cụm từ tìm kiếm kết hợp phức tạp, giúp đảm bảo trải nghiệm mượt mà cho người dùng và giảm thiểu tỷ lệ bỏ qua.
Đảm bảo cho tương lai: Việc tích hợp các chức năng AI (nhúng, xác thực LLM) giúp ứng dụng sẵn sàng cho những tiến bộ trong tương lai về đề xuất được cá nhân hoá, thương mại đàm thoại và khám phá sản phẩm thông minh.
Kiến trúc đơn giản: Việc tích hợp tính năng tìm kiếm vectơ ngay trong AlloyDB giúp bạn không cần phải sử dụng cơ sở dữ liệu vectơ riêng biệt hoặc quy trình đồng bộ hoá phức tạp, từ đó đơn giản hoá quá trình phát triển và bảo trì.
Giả sử người dùng nhập một cụm từ tìm kiếm bằng ngôn ngữ tự nhiên như "giày chạy bộ thân thiện với môi trường cho nữ có phần hỗ trợ vòm bàn chân cao".
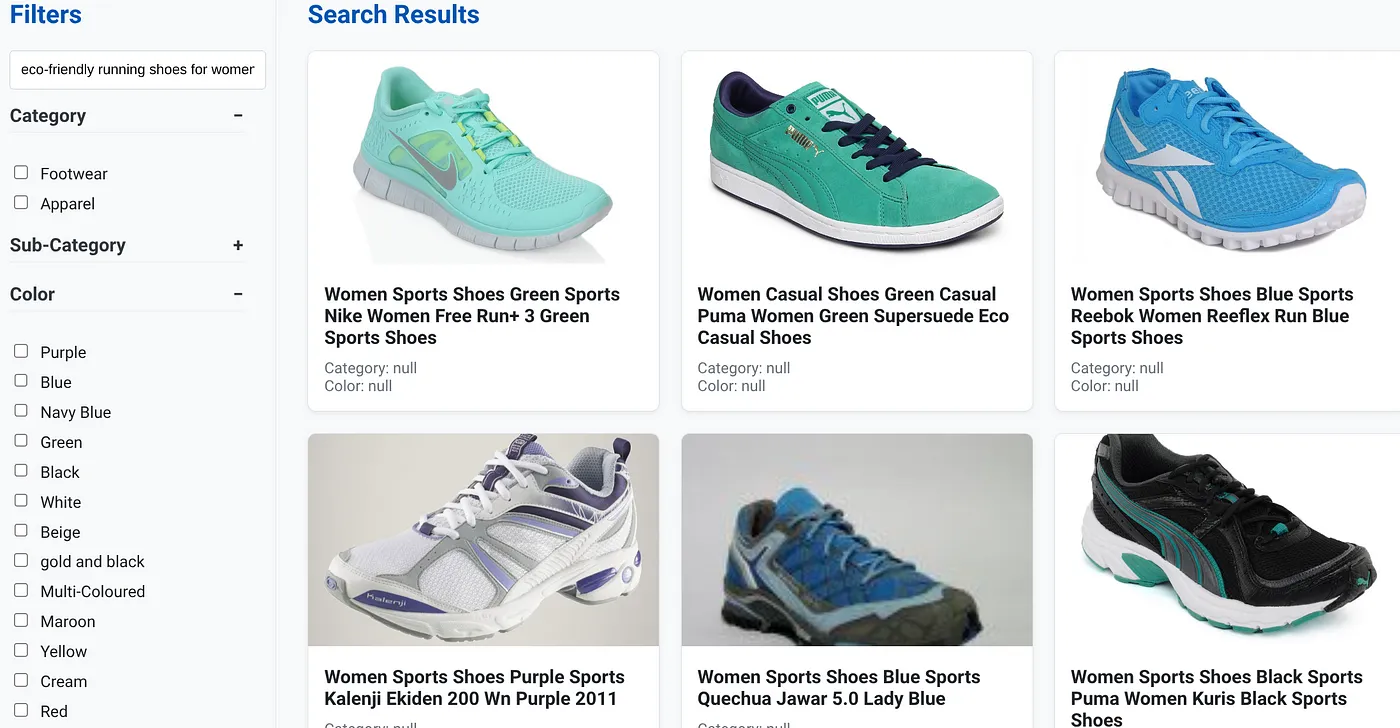
trong khi đó, người dùng áp dụng bộ lọc theo khía cạnh cho "Danh mục: <<>>","Màu sắc: <<>>" và giả sử "Giá: 1.000.000 – 1.500.000 VND":
- Hệ thống sẽ ngay lập tức trả về một danh sách sản phẩm tinh chỉnh, được điều chỉnh về mặt ngữ nghĩa cho phù hợp với ngôn ngữ tự nhiên và hoàn toàn khớp với các bộ lọc đã chọn.
- Ở phía sau, chỉ mục scaNN giúp tăng tốc quá trình tìm kiếm vectơ, tính năng lọc thích ứng và nội tuyến đảm bảo hiệu suất với các tiêu chí kết hợp, đồng thời tính năng xếp hạng lại sẽ trình bày kết quả tối ưu ở trên cùng.
- Tốc độ và độ chính xác của kết quả cho thấy rõ sức mạnh của việc kết hợp các công nghệ này để mang lại trải nghiệm tìm kiếm thông minh thực sự trong ngành bán lẻ.
Để xây dựng một ứng dụng tìm kiếm bán lẻ thế hệ tiếp theo, chúng ta cần vượt ra ngoài các phương pháp thông thường. Bằng cách sử dụng sức mạnh của AlloyDB, Vertex AI, Vector Search với tính năng lập chỉ mục scaNN, tính năng lọc theo khía cạnh linh hoạt, tính năng tái xếp hạng và tính năng xác thực LLM (mô hình ngôn ngữ lớn), chúng ta có thể mang đến trải nghiệm khách hàng chưa từng có, giúp tăng mức độ gắn bó và doanh số bán hàng. Giải pháp mạnh mẽ, có thể mở rộng quy mô và thông minh này minh hoạ cách các chức năng cơ sở dữ liệu hiện đại, được tích hợp AI, đang định hình lại tương lai của ngành bán lẻ!!!