
1. 概览
在当今竞争激烈的零售环境中,让客户能够快速直观地找到所需商品至关重要。传统的基于关键字的搜索往往存在不足,难以处理细致的查询和庞大的产品目录。此 Codelab 将揭示一个基于 AlloyDB 和 AlloyDB AI 构建的复杂零售搜索应用,该应用利用了先进的向量搜索、scaNN 索引、多面过滤器和智能自适应过滤、重新排名功能,以企业级规模提供动态混合搜索体验。
现在,我们已经对以下 3 个方面有了基础了解:
- 情境搜索对代理意味着什么,以及如何使用 Vector Search 实现情境搜索。
- 我们还深入探讨了如何在数据范围内(即在数据库本身内)实现向量搜索(如果您还不知道,所有 Google Cloud 数据库都支持这一点!)。
- 我们比世界其他国家/地区更进一步,告诉您如何利用由 ScaNN 索引提供支持的 AlloyDB Vector Search 功能,以高性能和高质量实现这种轻量级 Vector Search RAG 功能。
如果您尚未完成这些基本、中级和略微高级的 RAG 实验,建议您按所列顺序依次阅读此处、此处和此处的内容。
面临的挑战
超越过滤条件、关键字和上下文匹配:简单的关键字搜索可能会返回数千条结果,其中许多是不相关的。理想的解决方案需要了解查询背后的意图,将其与精确的过滤条件(例如品牌、材质或价格)相结合,并在几毫秒内呈现最相关的商品。这需要强大、灵活且可扩缩的搜索基础设施。当然,我们已经从关键字搜索发展到上下文匹配和相似性搜索。但假设客户在搜索“一款舒适、时尚、防水的春季徒步夹克”的同时应用了过滤条件,而您的应用不仅返回了高质量的回答,还具有高性能,并且所有这些的顺序都是由您的数据库动态选择的。
目标
为了通过集成
- 上下文搜索(Vector Search):理解查询和商品说明的语义
- 多面过滤:让用户能够使用特定属性优化结果
- 混合方法:将情境搜索与结构化过滤无缝融合
- 高级优化:利用专用索引编制、自适应过滤和重新排名来提高速度和相关性
- 由生成式 AI 驱动的质量控制:纳入 LLM 验证,以实现卓越的结果质量。
我们来详细了解一下架构和实现历程。
构建内容
Retail Search 应用
在此过程中,您将:
- 为电子商务数据集创建 AlloyDB 实例和表
- 设置嵌入和向量搜索
- 创建元数据索引和 ScaNN 索引
- 使用 ScaNN 的内嵌过滤方法在 AlloyDB 中实现高级向量搜索
- 在单个查询中设置分面过滤条件和混合搜索
- 通过重新排名和召回功能提高查询相关性(可选)
- 使用 Gemini 评估查询回答(可选)
- MCP Toolbox for Databases 和应用层
- 使用多面搜索的应用开发 (Java)
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用必需的 API:点击此链接并启用相应的 API。
或者,您也可以使用 gcloud 命令来完成此操作。如需了解 gcloud 命令和用法,请参阅文档。
3. 数据库设置
在本实验中,我们将使用 AlloyDB 作为电子商务数据的数据库。它使用集群来保存所有资源,例如数据库和日志。每个集群都有一个主实例,可提供对数据的接入点。表将包含实际数据。
我们来创建 AlloyDB 集群、实例和表,以便加载电子商务数据集。
创建集群和实例
- 在 Cloud 控制台中浏览 AlloyDB 页面。在 Cloud 控制台中查找大多数页面的简单方法是使用控制台的搜索栏进行搜索。
- 在该页面中选择创建集群:

- 您会看到如下所示的界面。使用以下值创建 集群和实例(如果您要从代码库克隆应用代码,请确保这些值匹配):
- 集群 ID:“
vector-cluster” - 密码:“
alloydb” - PostgreSQL 15 / 最新推荐版本
- 区域:“
us-central1” - 网络:“
default”
- 选择默认网络后,您会看到如下所示的界面。
选择设置连接。
- 然后,选择“使用自动分配的 IP 范围”,然后点击“继续”。查看信息后,选择“创建连接”。
- 设置好网络后,您可以继续创建集群。点击创建集群以完成集群设置,如下所示:
重要提示:
- 请务必将实例 ID(可在配置集群 / 实例时找到)更改为**
vector-instance**。如果您无法更改,请务必在所有后续参考中 **使用您的实例 ID**。 - 请注意,创建集群大约需要 10 分钟。成功后,您应该会看到一个屏幕,其中显示了您刚刚创建的集群的概览。
4. 数据注入
现在,我们来添加一个包含商店相关数据的表格。前往 AlloyDB,选择主集群,然后选择 AlloyDB Studio:
您可能需要等待实例完成创建。完成后,使用您在创建集群时创建的凭据登录 AlloyDB。使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”
成功通过身份验证进入 AlloyDB Studio 后,您可以在编辑器中输入 SQL 命令。您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。
您将在编辑器窗口中输入 AlloyDB 命令,并根据需要使用“运行”“格式化”和“清除”选项。
启用扩展程序
在构建此应用时,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供用于访问 Vertex AI 预测端点以在 SQL 中获取预测结果的函数。运行以下 DDL 以启用这些扩展程序:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如果您想查看数据库上已启用的扩展程序,请运行以下 SQL 命令:
select extname, extversion from pg_extension;
创建表
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
嵌入列将允许存储文本的向量值。
授予权限
运行以下语句,以授予对“embedding”函数的执行权限:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
为 AlloyDB 服务账号授予 Vertex AI User 角色
在 Google Cloud IAM 控制台中,向 AlloyDB 服务账号(格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)授予“Vertex AI 用户”角色访问权限。PROJECT_NUMBER 将包含您的项目编号。
或者,您也可以从 Cloud Shell 终端运行以下命令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
将数据加载到数据库中
- 将工作表中
insert scripts sql的insert查询语句复制到上述编辑器中。您可以复制 10-50 条 insert 语句,以便快速演示此使用情形。在此“所选插播广告 25-30 行”标签页中,有一个所选插播广告的列表。
您可以在此 github 代码库文件中找到指向数据的链接。
- 点击运行。查询结果会显示在结果表中。
重要提示:
请务必仅复制 25-50 条记录以进行插入,并确保这些记录来自一系列类别、子类别、颜色和适用性别类型。
5. 为数据创建嵌入
现代搜索的真正创新在于理解含义,而不仅仅是关键字。这时,嵌入和向量搜索就派上用场了。
我们使用预训练的语言模型将商品描述和用户查询转换为称为“嵌入”的高维数值表示形式。这些嵌入可捕获语义含义,使我们能够找到“含义相似”的产品,而不仅仅是包含匹配字词的产品。最初,我们尝试直接对这些嵌入进行向量相似度搜索,以建立基准,这表明即使在进行性能优化之前,语义理解也具有强大的功能。
嵌入列将允许存储商品说明文本的向量值。img_embeddings 列将用于存储图片嵌入(多模态)。这样,您还可以使用基于文本与图片距离的搜索。不过,在本实验中,我们只会使用文本嵌入。
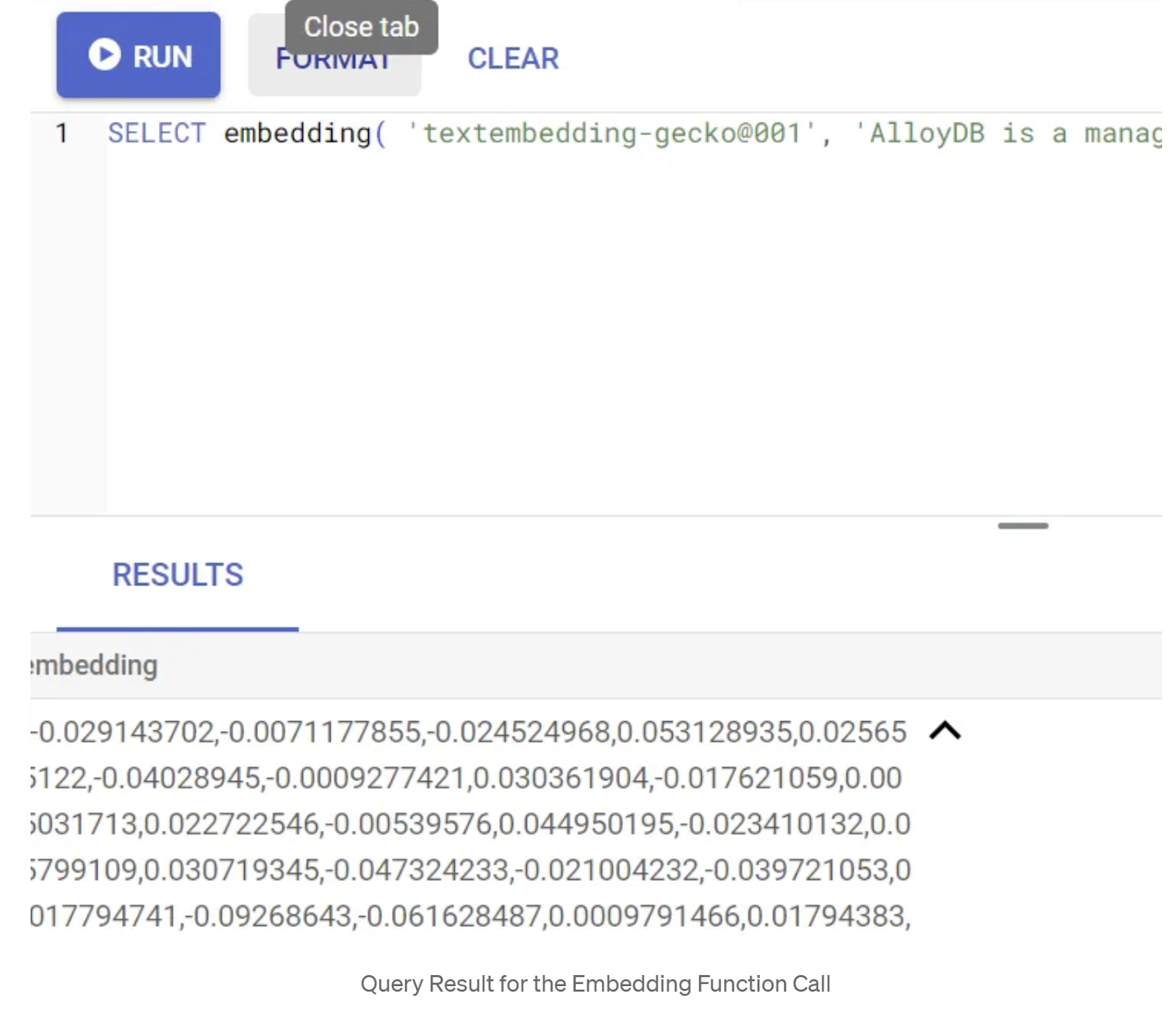
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
这应该会返回查询中示例文本的嵌入向量(看起来像一个浮点数数组)。如下所示:
更新 abstract_embeddings 向量字段
运行以下 DML 以使用相应的嵌入更新表中的内容说明:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
如果您使用的是 Google Cloud 的试用版信用额度结算账号,则可能难以生成超过少量(例如最多 20-25 个)的嵌入内容。因此,请限制插入脚本中的行数。
如果您想生成图片嵌入(用于执行多模态情境搜索),请同时运行以下更新:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. 利用 AlloyDB 的新功能执行高级 RAG
现在,表、数据和嵌入都已准备就绪,接下来我们来针对用户搜索文本执行实时向量搜索。您可以通过运行以下查询来测试这一点:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
在此查询中,我们使用余弦相似度距离函数(以符号“<=>”表示)将用户输入的搜索内容“圆领 T 恤”的文本嵌入与服装表中所有商品描述的文本嵌入(存储在名为“embedding”的列中)进行比较。我们将嵌入方法的结果转换为向量类型,使其与存储在数据库中的向量兼容。LIMIT 10 表示我们选择的是与搜索文本最接近的 10 个匹配项。
AlloyDB 将向量搜索 RAG 提升到了新的高度:
对于企业级解决方案,原始向量搜索是不够的。性能至关重要。
ScaNN(可扩容的最近邻)索引
为了实现超快的近似最近邻 (ANN) 搜索,我们在 AlloyDB 中启用了 scaNN 索引。ScaNN 是 Google 研究团队开发的一种先进的近似最近邻搜索算法,旨在实现高效的大规模向量相似度搜索。它通过高效剪枝搜索空间和使用量化技术,显著加快了查询速度,与其他的索引编制方法相比,向量查询速度最高可提高到 4 倍,同时内存占用量更小。如需了解详情,请点击此处和此处。
接下来,我们启用扩展程序并创建索引:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
为文本嵌入字段和图片嵌入字段创建索引(如果您想在搜索中使用图片嵌入):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
元数据索引
虽然 scaNN 可以处理向量索引,但我们仍会在结构化属性(例如类别、子类别、款式、颜色等)上精心设置传统的 B 树或 GIN 索引。这些索引对于分面过滤的效率至关重要。运行以下语句以设置元数据索引:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
重要提示:
由于您可能只插入了 25-50 条记录,因此索引(ScaNN 或任何其他索引)不会有效。
内嵌过滤
向量搜索中的一个常见挑战是将其与结构化过滤条件(例如“红鞋”)相结合。AlloyDB 的内嵌过滤功能可优化此流程。内嵌过滤会在向量搜索过程中应用过滤条件,而不是在广泛的向量搜索后过滤结果,从而大幅提高过滤向量搜索的性能和准确性。
如需详细了解内嵌过滤的必要性,请参阅此文档。您还可以点击此处了解过滤式向量搜索,以便优化向量搜索的性能。现在,如果您想为应用启用内嵌过滤,请在编辑器中运行以下语句:
SET scann.enable_inline_filtering = on;
内嵌过滤最适合中等选择性的情况。当 AlloyDB 搜索向量索引时,只会计算符合元数据过滤条件(查询中通常在 WHERE 子句中处理的功能性过滤条件)的向量的距离。这可大幅提升这些查询的性能,从而弥补后过滤或预过滤的优势。
自适应过滤
为了进一步优化性能,AlloyDB 的自适应过滤功能会在查询执行期间动态选择最有效的过滤策略(内嵌过滤或预过滤)。它会分析查询模式和数据分布,以确保在无需人工干预的情况下实现最佳性能,尤其适用于过滤式向量搜索,因为它可以自动在向量索引和元数据索引用法之间切换。如需启用自适应过滤,请使用 scann.enable_preview_features 标志。
当自适应过滤在执行期间触发从内嵌过滤到预过滤的切换时,查询计划会动态更改。
SET scann.enable_preview_features = on;
重要提示:如果您遇到错误,可能需要在不重启实例的情况下运行上述语句,最好从实例的数据库标志部分启用 enable_preview_features 标志。
使用所有索引的分面过滤条件
借助分面搜索,用户可以根据特定属性或“分面”(例如品牌、价格、尺码、客户评分)应用多个过滤条件来优化结果。我们的应用可将这些方面与向量搜索无缝集成。现在,单个查询可以将自然语言(情境搜索)与多个多面选择相结合,动态利用向量索引和传统索引。这提供了真正动态的混合搜索功能,让用户能够精准地深入了解搜索结果。
在我们的应用中,由于我们已创建所有元数据索引,因此可以直接使用 SQL 查询来解决问题,从而在 Web 中使用多面过滤条件:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
在此查询中,我们执行的是混合搜索,其中同时包含
- WHERE 子句中的多面过滤和
- 在 ORDER BY 子句中使用余弦相似度方法的 Vector Search。
$1、$2、$3 和 $4 表示数组中的分面过滤条件值,$5 表示用户搜索文本。将 $1 至 $4 替换为您选择的分面过滤条件值,如下所示:
category = ANY([‘Apparel', ‘Footwear'])
将 $5 替换为您选择的搜索文本,例如“Polo T-Shirts”。
重要提示:如果您因插入的记录集有限而没有索引,则不会看到性能影响。但在完整的生产数据集中,您会发现,使用注入了内嵌过滤功能的 ScaNN 索引的 Vector Search 可显著缩短执行时间!
接下来,我们来评估启用 ScaNN 的向量搜索的召回率。
重排序
即使使用高级搜索,初始结果也可能需要进行最终润饰。这是一个关键步骤,可对初始搜索结果重新排序,以提高相关性。初始混合搜索提供一组候选商品后,更精细(且通常计算量更大)的模型会应用更精细的相关性得分。这样可确保向用户展示的顶部结果是最相关的,从而显著提升搜索质量。我们会不断评估召回率,以衡量系统在多大程度上能够检索给定查询的所有相关项,并优化模型,以最大限度地提高客户找到所需内容的可能性。
在应用中使用此功能之前,请确保您已满足所有前提条件:
- 验证 google_ml_integration 扩展程序是否已安装。
- 验证 google_ml_integration.enable_model_support 标志是否已设置为开启。
- 与 Vertex AI 集成。
- 启用 Discovery Engine API。
- 获得使用排名模型所需的角色。
然后,您可以在应用中使用以下查询对混合搜索结果集进行重新排名:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
在此查询中,我们使用余弦相似度方法对 ORDER BY 子句中提及的上下文搜索的产品结果集执行重新排名。“粉色上衣”是用户搜索的文本。
重要提示:部分用户可能还无法使用重新排名功能,因此我已将其从应用代码中排除,但如果您希望包含此功能,可以参考我们上面介绍的示例。
召回率评估器
相似度搜索中的召回率是指从搜索中检索到的相关实例的百分比,即真正例数。这是衡量搜索质量最常用的指标。召回率损失的一个来源是近似最近邻搜索 (aNN) 与 k(精确)近邻搜索 (kNN) 之间的差异。AlloyDB 的 ScaNN 等向量索引实现了 aNN 算法,让您能够加快对大型数据集的向量搜索速度,但召回率会略有下降。现在,AlloyDB 可让您直接在数据库中衡量这种权衡,以确保其随时间推移保持稳定。您可以根据这些信息更新查询和索引参数,以获得更好的结果和性能。
搜索结果召回背后的逻辑是什么?
在向量搜索的上下文中,召回率是指索引返回的、真正最近邻向量的百分比。例如,如果对 20 个最近邻进行的最近邻查询返回 19 个接地最近邻,则召回率为 19/20x100 = 95%。召回率是一种用于搜索质量的指标,定义为返回结果中与查询向量客观上最接近的结果所占的百分比。
您可以使用 evaluate_query_recall 函数获得采用给定配置时,对向量索引进行的向量查询的召回率。借助此函数,您可以对参数进行调优以实现所需的向量查询召回率结果。
重要提示:
如果您在以下步骤中遇到 HNSW 索引的权限被拒错误,请暂时跳过整个召回率评估部分。这可能与当前阶段的访问权限限制有关,因为此功能是在编写此 Codelab 文档时刚刚发布。
- 在 ScaNN 索引和 HNSW 索引上设置“启用索引扫描”标志:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- 在 AlloyDB Studio 中运行以下查询:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 函数会将查询作为参数并返回其召回率。我将用于检查性能的查询用作函数输入查询。我已添加 SCaNN 作为索引方法。如需了解更多参数选项,请参阅文档。
我们一直在使用的 Vector Search 查询的召回率:
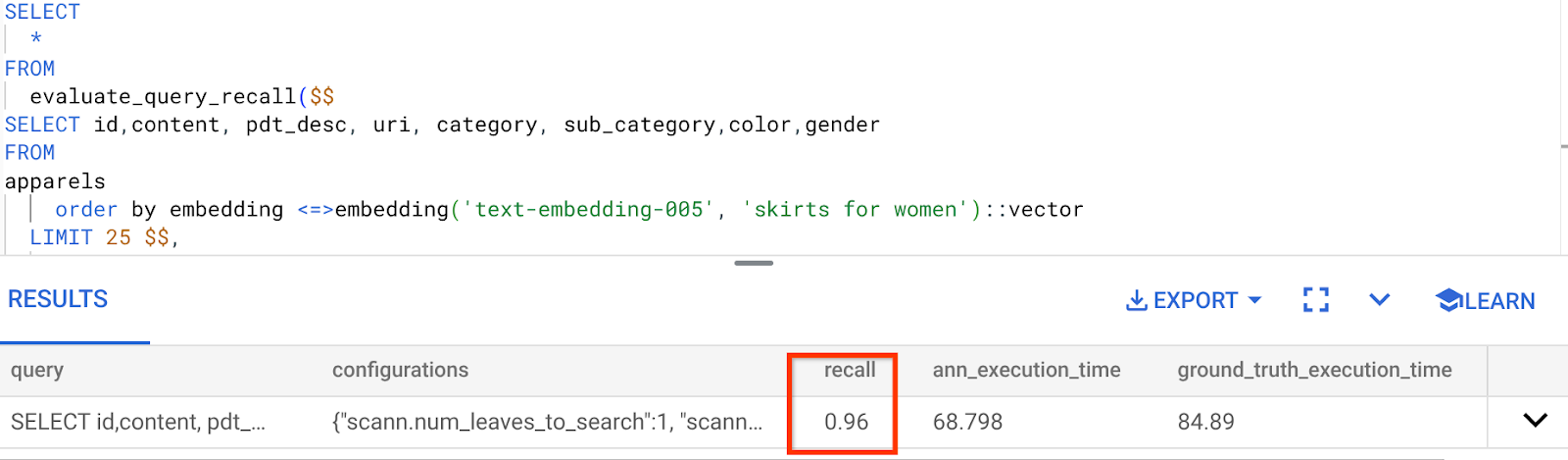
我看到召回率为 96%。现在,在这种情况下,召回率非常高。但如果是不接受的值,您可以使用此信息来更改索引参数、方法和查询参数,并提高此向量搜索的召回率!
使用修改后的查询和索引参数进行测试
现在,我们来测试查询,方法是根据收到的召回信息修改查询参数。
- 修改索引参数:
在此测试中,我将使用 L2 距离,而不是余弦相似度距离函数。
非常重要的注意事项:您可能会问:“我们怎么知道此查询使用的是余弦相似度?”您可以通过使用“<=>”来表示余弦距离,从而识别距离函数。
文档链接,其中介绍了 Vector Search 距离函数。
之前的查询使用的是余弦相似度距离函数,而现在我们将尝试使用 L2 距离。但为此,我们还应确保底层 ScaNN 索引也使用 L2 距离函数。现在,我们来创建一个具有不同距离函数查询的索引:L2 距离:<->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
drop index 语句只是为了确保表上没有不必要的索引。
现在,我可以执行以下查询,以评估更改向量搜索功能的距离函数后的召回率。
[之后] 使用 L2 距离函数的查询:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
您可以查看更新后的索引的召回价值差异 / 转换。
您还可以根据所需的召回率值和应用所用的数据集,更改索引中的其他参数,例如 num_leaves 等。
LLM 对向量搜索结果的验证
为了实现最高质量的受控搜索,我们纳入了可选的 LLM 验证层。大语言模型可用于评估搜索结果的相关性和连贯性,尤其是在查询复杂或模棱两可的情况下。这可能涉及:
语义验证:
LLM 根据查询意图对结果进行交叉引用。
逻辑过滤:
使用 LLM 应用难以在传统过滤条件中编码的复杂业务逻辑或规则,根据细致的条件进一步优化商品列表。
质量保证:
自动识别并标记相关性较低的结果,以供人工审核或模型优化。
以下是我们如何在 AlloyDB AI 功能中实现这一点的:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
底层查询与我们在分面搜索、混合搜索和重新排名部分中看到的查询相同。在此查询中,我们纳入了一层对由 ml_predict_row 结构表示的重新排名结果集的 GEMINI 评估。我已将多面过滤条件注释掉,但您可以随意在占位符 $1 到 $4 的数组中添加您选择的项。将 $5 替换为您要搜索的任何文本,例如“粉色上衣,无花卉图案”。
7. MCP Toolbox for Databases 和应用层
在幕后,强大的工具和结构合理的应用可确保顺畅运行。
借助适用于数据库的 MCP(模型上下文协议)工具箱,您可以更轻松地将生成式 AI 和智能体工具与 AlloyDB 集成。它充当开源服务器,可简化连接池、身份验证以及向 AI 智能体或其他应用安全公开数据库功能的过程。
在我们的应用中,我们使用 MCP Toolbox for Databases 作为所有智能混合搜索查询的抽象层。
按照以下步骤设置并部署适用于我们使用情形的 Toolbox:
您可以看到,MCP Toolbox for Databases 支持的数据库之一是 AlloyDB,由于我们在上一部分中已预配该数据库,因此接下来设置 Toolbox。
- 前往 Cloud Shell 终端,确保您的项目处于选中状态,并且显示在终端的提示中。在 Cloud Shell 终端中运行以下命令,以进入您的项目目录:
mkdir toolbox-tools
cd toolbox-tools
- 运行以下命令,在新文件夹中下载并安装工具箱:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- 前往 Cloud Shell Editor(用于代码修改模式),然后在项目根文件夹中添加一个名为“tools.yaml”的文件。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
请务必将 Tools.yaml 脚本替换为此代码库文件中的代码。
我们来了解一下 tools.yaml:
来源表示工具可以与之互动的数据源。来源表示工具可以与之互动的数据源。您可以在 tools.yaml 文件的 sources 部分中将来源定义为映射。通常,来源配置将包含连接数据库并与之互动所需的任何信息。
工具定义了智能体可以采取的操作,例如读取和写入来源。工具表示代理可以执行的操作,例如运行 SQL 语句。您可以在 tools.yaml 文件的 tools 部分中将工具定义为映射。通常,工具需要一个要处理的来源。
如需详细了解如何配置 tools.yaml,请参阅此文档。
- 运行以下命令(从 mcp-toolbox 文件夹中)启动服务器:
./toolbox --tools-file "tools.yaml"
现在,如果您在云端以网页预览模式打开服务器,应该能够看到工具箱服务器正在运行,其中包含名为 get-order-data 的新工具。
MCP Toolbox 服务器默认在端口 5000 上运行。我们来使用 Cloud Shell 测试一下。
点击 Cloud Shell 中的“网页预览”,如下所示:
点击“更改端口”,然后将端口设置为 5000(如下所示),再点击“更改并预览”。
这应该会带来以下输出:
- 接下来,我们将 Toolbox 部署到 Cloud Run:
首先,我们可以从 MCP Toolbox 服务器入手,将其托管在 Cloud Run 上。这样一来,我们便会获得一个公共端点,可以将其与任何其他应用和/或代理应用集成。有关如何在 Cloud Run 上托管此应用的说明,请参阅此处。我们现在来了解一下关键步骤。
- 启动新的 Cloud Shell 终端或使用现有的 Cloud Shell 终端。前往包含工具箱二进制文件和 tools.yaml 的项目文件夹(在本例中为 toolbox-tools),如果您尚未进入该文件夹,请执行以下操作:
cd toolbox-tools
- 将 PROJECT_ID 变量设置为指向您的 Google Cloud 项目 ID。
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- 启用以下 Google Cloud 服务
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- 我们来创建一个单独的服务账号,该账号将作为我们要在 Google Cloud Run 上部署的 Toolbox 服务的身份。
gcloud iam service-accounts create toolbox-identity
- 我们还确保此服务账号具有正确的角色,即能够访问 Secret Manager 并与 AlloyDB 通信
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- 我们将上传 tools.yaml 文件作为密钥:
gcloud secrets create tools --data-file=tools.yaml
如果您已有密文,并想更新密文版本,请执行以下操作:
gcloud secrets versions add tools --data-file=tools.yaml
- 为要用于 Cloud Run 的容器映像设置环境变量:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- 熟悉的 Cloud Run 部署命令中的最后一步:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
这应该会开始将配置了 tools.yaml 的 Toolbox 服务器部署到 Cloud Run 的过程。成功部署后,您应该会看到类似于以下内容的消息:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
您已一切就绪,可以在代理应用中使用新部署的工具了!
访问 Toolbox 服务器中的工具
部署 Toolbox 后,我们将创建一个 Python Cloud Run Functions shim 来与已部署的 Toolbox 服务器交互。这是因为目前工具箱没有 Java SDK,因此我们创建了一个 Python shim 来与服务器交互。以下是相应 Cloud Run 函数的源代码。
您必须创建并部署此 Cloud Run 函数,才能访问我们在上一步中刚刚创建并部署的工具箱工具:
- 在 Google Cloud 控制台中,前往 Cloud Run 页面
- 点击“编写函数”。
- 在“服务名称”字段中,输入一个名称以描述您的函数。服务名称只能以字母开头,最多可以包含 49 个字符(包括字母、数字或连字符)。服务名称不能以连字符结尾,并且在每个区域和项目中必须唯一。服务名称一旦指定便无法更改,并且公开显示。(输入零售产品搜索质量)
- 在“区域”列表中,使用默认值,或选择要在其中部署函数的区域。(选择 us-central1)
- 在“运行时”列表中,使用默认值,或选择一个运行时版本。(选择 Python 3.11)
- 在“身份验证”部分中,选择“允许公开访问”
- 点击“创建”按钮
- 系统会创建该函数,并加载模板 main.py 和 requirements.txt
- 将这些文件替换为相应项目代码库中的 main.py 和 requirements.txt
- 部署函数,您应该会获得 Cloud Run 函数的终点
您的端点应如下所示(或类似):
用于访问工具箱的 Cloud Run 函数端点:“https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app”
为了便于在规定时间内完成实操(对于实操讲师主导的课程),我们会在实操课程开始时分享端点的项目编号。
重要提示:
或者,您也可以直接在应用代码或 Cloud Run 函数中实现数据库部分。
8. 使用多面搜索的应用开发 (Java)
最后,所有这些强大的后端组件都通过应用层得以实现。该应用采用 Java 开发,可提供与搜索系统互动的界面。它可协调对 AlloyDB 的查询,处理分面过滤器的显示,管理用户选择,并以无缝且直观的方式呈现重新排名和验证的搜索结果。
- 您可以先前往 Cloud Shell 终端并克隆代码库:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- 前往 Cloud Shell 编辑器,您可以在其中看到新创建的文件夹 faceted_searching_retail
- 删除以下内容,因为这些步骤已在前面的部分中完成:
- 删除 Cloud_Run_Function 文件夹
- 删除文件 db_script.sql
- 删除文件 tools.yaml
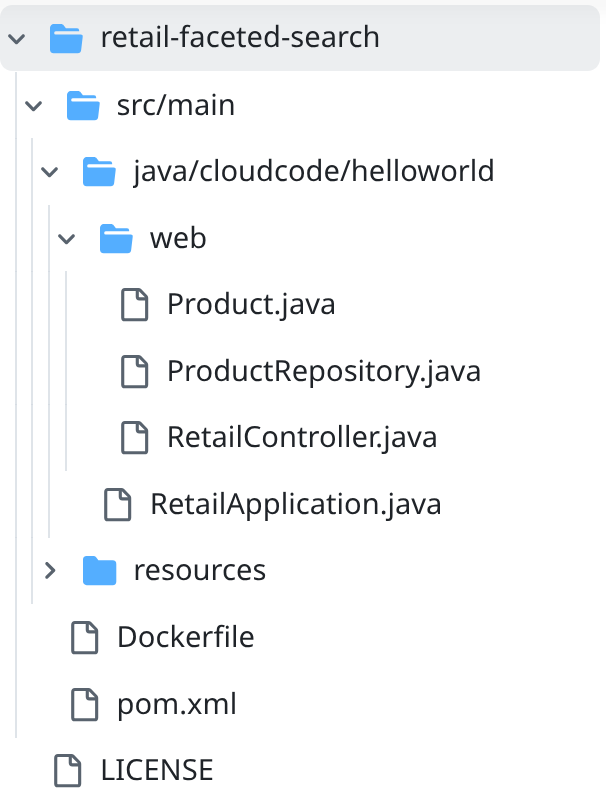
- 导航到项目文件夹 retail-faceted-search,您应该会看到以下项目结构:
- 在 ProductRepository.java 文件中,您必须使用 Cloud Run 函数(已部署)中的端点修改 TOOLBOX_ENDPOINT 变量,或者从实践讲师处获取端点。
搜索以下代码行,并将其替换为您的端点:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- 确保 Dockerfile 和 pom.xml 符合您的项目配置(除非您明确更改了任何版本或配置,否则无需进行任何更改)。
- 在 Cloud Shell 终端中,确保您位于主文件夹和项目文件夹(faceted_searching_retail / retail-faceted-search)中。使用以下命令确保您位于终端中的正确文件夹中(除非您已位于该文件夹中):
cd faceted_searching_retail
cd retail-faceted-search
- 在本地封装、构建和测试应用:
mvn package
mvn spring-boot:run
您应该能够在 Cloud Shell 终端中点击“在端口 8080 上预览”来查看应用,如下所示:
9. 部署到 Cloud Run:***重要步骤
在 Cloud Shell 终端中,确保您位于主文件夹和项目文件夹 (faceted_searching_retail / retail-faceted-search) 中。使用以下命令确保您位于终端中的正确文件夹中(除非您已位于该文件夹中):
cd faceted_searching_retail
cd retail-faceted-search
确认您位于项目文件夹中后,运行以下命令:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
部署完成后,您应该会收到如下所示的已部署 Cloud Run 端点:
https://retail-search-**********-uc.a.run.app/
10. 演示
让我们来看看实际用例:
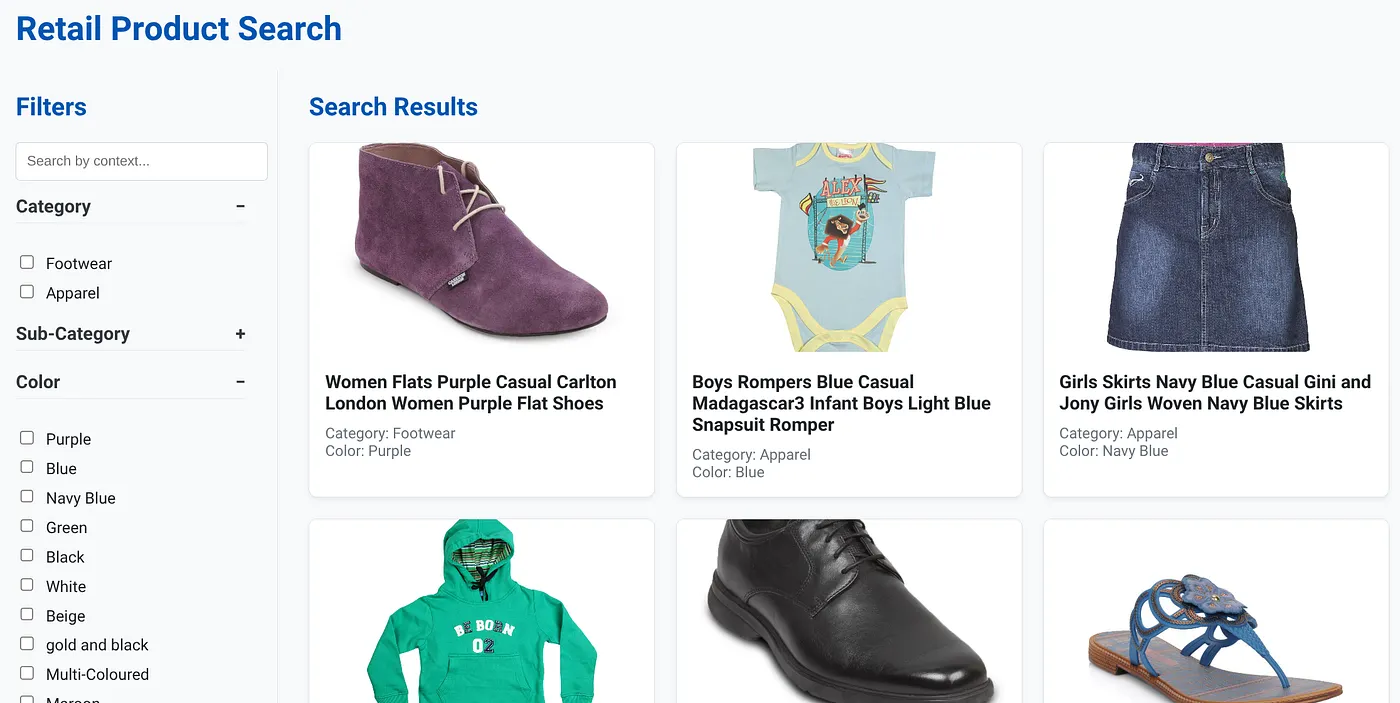
上图显示了动态混合搜索应用的着陆页。
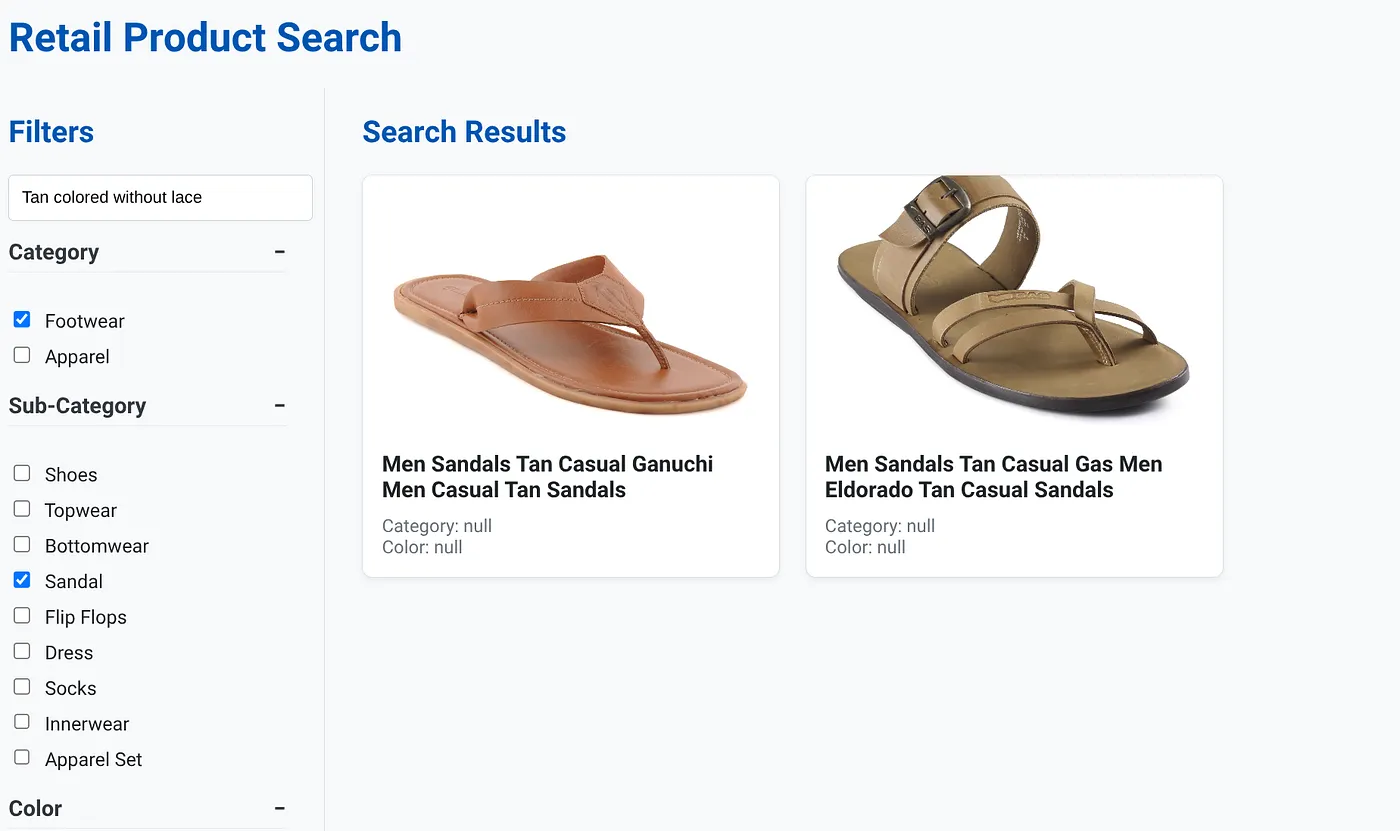
上图显示了“棕色无系带”的搜索结果。所选的多面过滤条件为:鞋类、凉鞋。
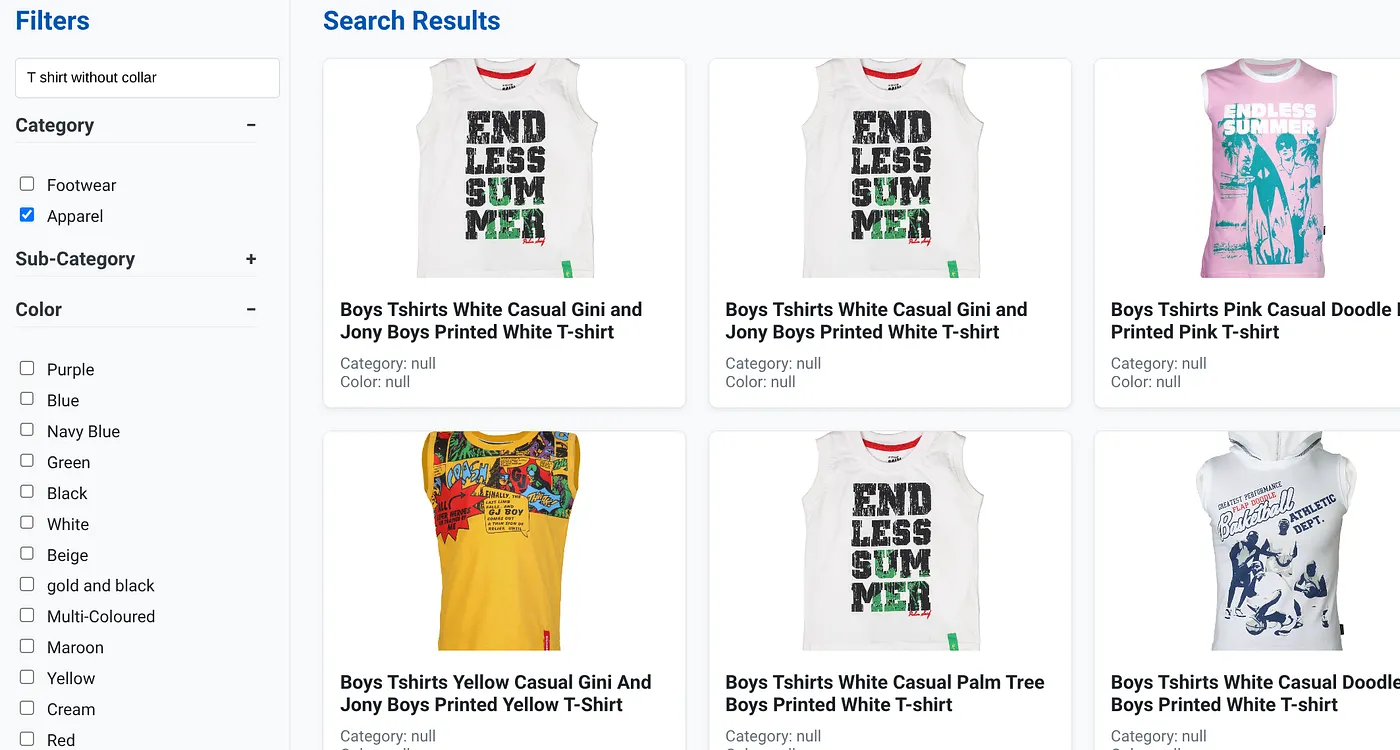
上图显示了“无领 T 恤”的搜索结果。多面过滤条件:服装
现在,您可以添加更多生成式功能和智能体功能,使此应用能够执行操作。
快来试试吧,激发您自行构建应用的灵感!
11. 清理
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,前往资源管理器页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
- 或者,您也可以点击“DELETE CLUSTER”按钮,删除我们刚刚为此项目创建的 AlloyDB 集群(如果您在配置时未选择 us-central1 作为集群的位置,请更改此超链接中的位置)。
12. 恭喜
恭喜!您已成功在 Cloud Run 上构建并部署了一个使用 AlloyDB 的混合搜索应用!
这对商家有何影响:
这款由 AlloyDB AI 提供支持的动态混合搜索应用可为企业零售和其他企业带来显著优势:
相关性更高:通过将情境(向量)搜索与精确的分面过滤和智能重新排名相结合,客户可以获得高度相关的结果,从而提高满意度和转化率。
可伸缩性:AlloyDB 的架构和 ScaNN 索引旨在处理海量产品目录和高查询量,这对于不断发展的电子商务企业至关重要。
性能:即使是复杂的混合搜索,也能更快地响应查询,确保流畅的用户体验并最大限度地降低放弃率。
面向未来:通过集成 AI 功能(嵌入、LLM 验证),该应用可为个性化推荐、对话式商务和智能商品发现等未来的发展做好准备。
简化架构:直接在 AlloyDB 中集成向量搜索功能,无需单独的向量数据库或复杂的同步,从而简化开发和维护。
假设用户输入了自然语言查询,例如“适合女性的高足弓环保跑鞋”。
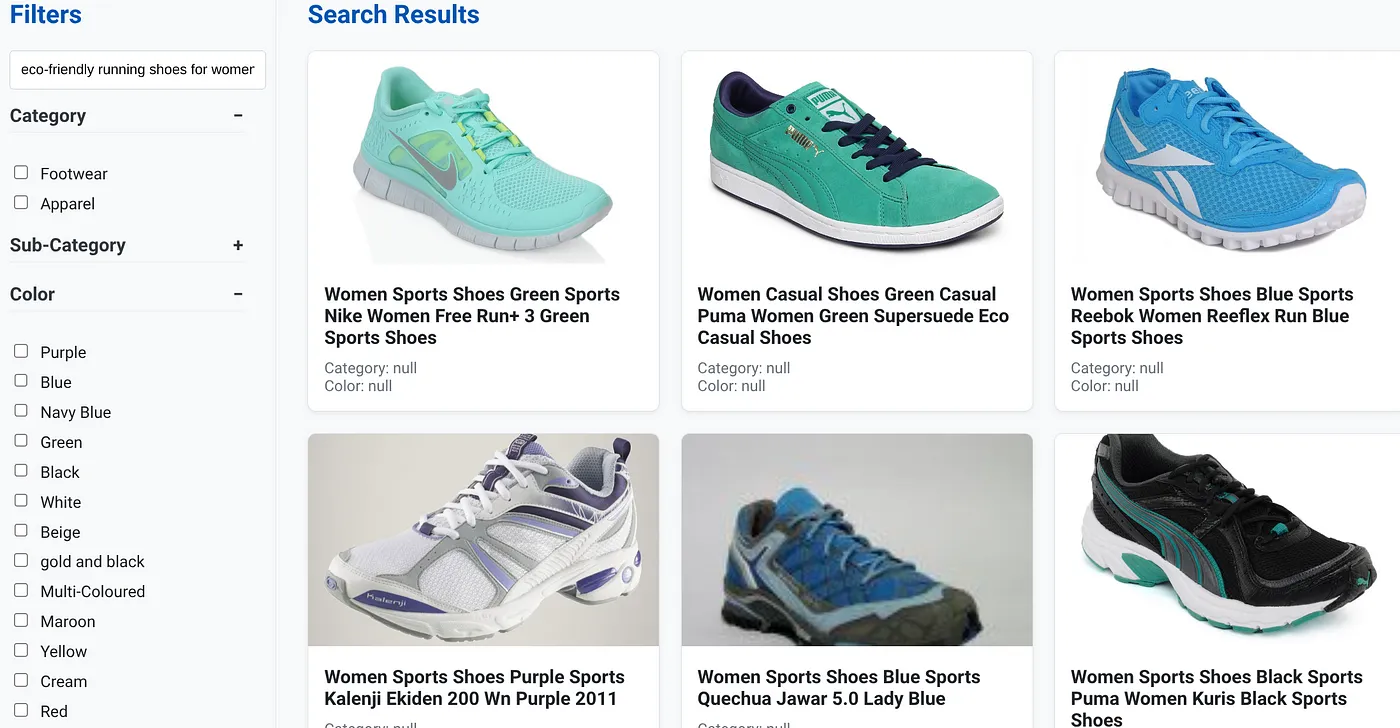
同时,用户应用了“类别:<<>>”“颜色:<<>>”的分面过滤条件,并说出“价格:100 美元到 150 美元”:
- 系统会立即返回经过优化的商品列表,该列表在语义上与自然语言保持一致,并与所选过滤条件完全匹配。
- 在幕后,ScaNN 索引可加快向量搜索速度,内嵌过滤和自适应过滤可确保在组合条件下的性能,而重新排名则可将最佳结果显示在顶部。
- 结果的速度和准确性清楚地表明,将这些技术相结合可打造真正智能的零售搜索体验。
构建新一代零售搜索应用需要超越传统方法。借助 AlloyDB、Vertex AI、使用 scaNN 索引的 Vector Search、动态多面过滤、重新排名和 LLM 验证的强大功能,我们可以提供无与伦比的客户体验,从而提高互动度和销售额。这款强大、可伸缩且智能的解决方案展示了融入 AI 的现代数据库功能如何重塑零售业的未来!
立即开始!