
1. 總覽
在競爭激烈的零售環境中,讓顧客快速直覺地找到所需商品至關重要。傳統的關鍵字搜尋功能往往無法滿足需求,難以處理細微的查詢和龐大的產品目錄。本程式碼實驗室將揭曉以 AlloyDB 和 AlloyDB AI 為基礎建構的零售搜尋應用程式,運用最先進的向量搜尋、scaNN 索引、分層篩選器和智慧型自適應篩選器,以及重新排序功能,提供企業規模的動態混合搜尋體驗。
現在我們已初步瞭解以下 3 件事:
- 說明脈絡搜尋對代理程式的意義,以及如何使用向量搜尋達成這項功能。
- 我們也深入探討如何在資料範圍內 (也就是資料庫本身) 取得向量搜尋功能 (如果您還不知道,所有 Google Cloud 資料庫都支援這項功能!)。
- 我們更進一步,向您說明如何運用 ScaNN 索引支援的 AlloyDB 向量搜尋功能,以高效能和高品質達成這類輕量級的向量搜尋 RAG 功能。
如果您尚未完成這些基礎、中階和稍微進階的 RAG 實驗,建議您依列出的順序閱讀這 3 篇文章、文章和文章。
挑戰
超越篩選器、關鍵字和內容比對:簡單的關鍵字搜尋可能會傳回數千筆結果,其中許多不相關。理想的解決方案必須瞭解查詢背後的意圖,並結合精確的篩選條件 (例如品牌、材質或價格),在毫秒內呈現最相關的項目。因此需要強大、靈活且可擴充的搜尋基礎架構。當然,我們已從關鍵字搜尋發展到脈絡比對和相似性搜尋。但假設有位顧客搜尋「適合春季健行,舒適、時尚又防水的外套」,同時套用篩選條件,而您的應用程式不僅傳回符合條件的回覆,效能也很高,且所有這些內容的順序都是由資料庫動態選擇。
目標
如要解決這個問題,請整合
- 脈絡搜尋 (向量搜尋):瞭解查詢和產品說明的語意
- 多面向篩選:讓使用者透過特定屬性縮小搜尋結果範圍
- 混合式做法:將情境搜尋與結構化篩選功能完美結合
- 進階最佳化:運用專門的索引、自動調整篩選條件和重新排序功能,提升速度和相關性
- 生成式 AI 驅動的品質驗證 (QC):納入 LLM 驗證,確保結果品質優異。
我們將逐步說明架構和實作過程。
建構項目
零售搜尋應用程式
因此,您將:
- 為電子商務資料集建立 AlloyDB 執行個體和資料表
- 設定嵌入和向量搜尋
- 建立中繼資料索引和 ScaNN 索引
- 使用 ScaNN 的內嵌篩選方法,在 AlloyDB 中實作進階向量搜尋
- 在單一查詢中設定多面向篩選器和混合搜尋
- 使用重新排序和召回功能提升查詢關聯性 (選用)
- 使用 Gemini 評估查詢回覆 (選用)
- MCP Toolbox for Databases 和應用程式層
- 使用多面向搜尋功能開發 Java 應用程式
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API:按照連結啟用 API。
或者,您也可以使用 gcloud 指令。如要瞭解 gcloud 指令和用法,請參閱說明文件。
3. 資料庫設定
在本實驗室中,我們將使用 AlloyDB 做為電子商務資料的資料庫。並使用「叢集」保存所有資源,例如資料庫和記錄檔。每個叢集都有「主要執行個體」,可做為資料的存取點。資料表會保存實際資料。
我們來建立 AlloyDB 叢集、執行個體和資料表,以便載入電子商務資料集。
建立叢集和執行個體
- 在 Cloud 控制台中前往 AlloyDB 頁面。如要在 Cloud 控制台尋找大部分的頁面,只要使用控制台的搜尋列搜尋即可。
- 從該頁面選取「建立叢集」:

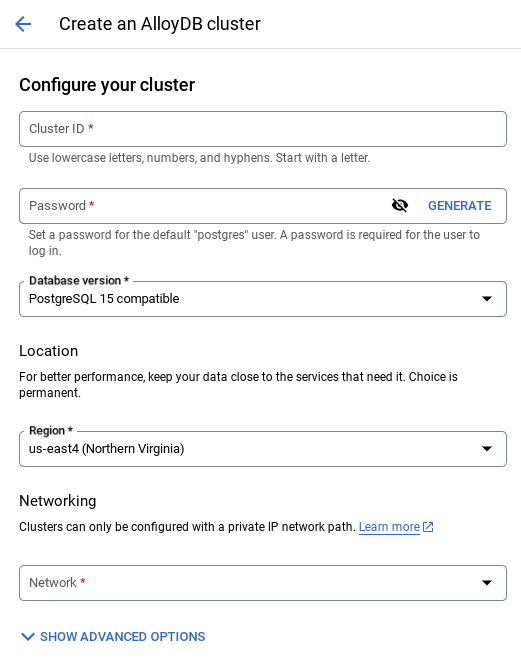
- 你會看到如下所示的畫面。使用下列值建立叢集和執行個體 (如果您要從存放區複製應用程式碼,請確保值相符):
- 叢集 ID:「
vector-cluster」 - password:「
alloydb」 - PostgreSQL 15 / 最新建議版本
- Region:「
us-central1」 - 網路:「
default」
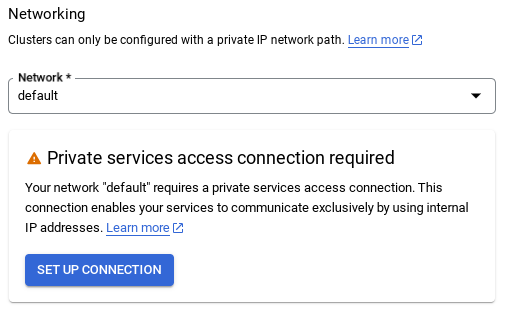
- 選取預設網路後,你會看到如下畫面。
選取「設定連線」。
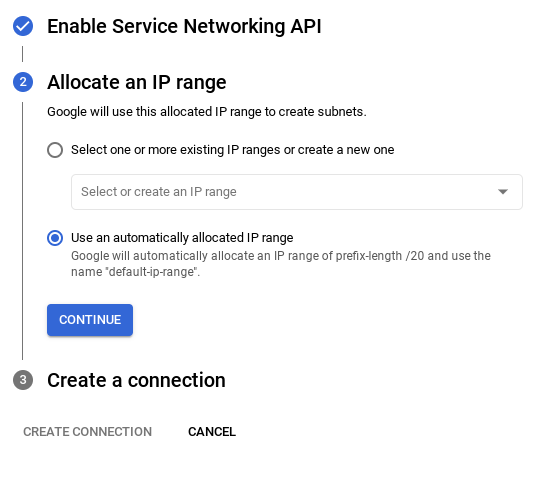
- 然後選取「使用系統自動分配的 IP 範圍」並繼續。確認資訊後,選取「建立連結」。
- 設定網路後,即可繼續建立叢集。按一下「CREATE CLUSTER」(建立叢集),完成叢集設定,如下所示:
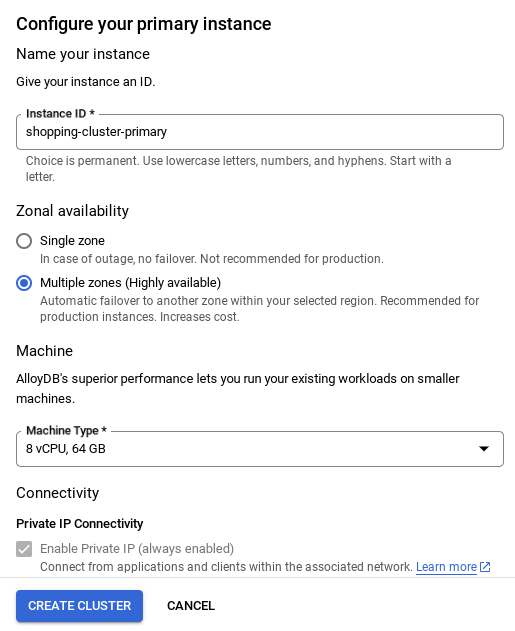
重要注意事項:
- 請務必將執行個體 ID (可在設定叢集 / 執行個體時找到) 變更為**
vector-instance**。如果無法變更,請記得在所有後續參照中使用執行個體 ID。 - 請注意,建立叢集約需 10 分鐘。成功後,畫面上會顯示您剛建立的叢集總覽。
4. 資料擷取
現在要新增包含商店資料的表格。前往 AlloyDB,選取主要叢集,然後選取 AlloyDB Studio:
您可能需要等待執行個體建立完成。完成後,請使用建立叢集時建立的憑證登入 AlloyDB。使用下列資料向 PostgreSQL 進行驗證:
- 使用者名稱:「
postgres」 - 資料庫:「
postgres」 - 密碼:「
alloydb」
成功驗證 AlloyDB Studio 後,即可在編輯器中輸入 SQL 指令。如要新增多個編輯器視窗,請按一下最後一個視窗右側的加號。
您會在編輯器視窗中輸入 AlloyDB 指令,並視需要使用「執行」、「格式化」和「清除」選項。
啟用擴充功能
我們會使用 pgvector 和 google_ml_integration 擴充功能建構這個應用程式。pgvector 擴充功能可讓您儲存及搜尋向量嵌入。google_ml_integration 擴充功能提供多種函式,可供您存取 Vertex AI 預測端點,並在 SQL 中取得預測結果。執行下列 DDL,啟用這些擴充功能:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如要查看資料庫已啟用的擴充功能,請執行下列 SQL 指令:
select extname, extversion from pg_extension;
建立資料表
您可以在 AlloyDB Studio 中使用下列 DDL 陳述式建立資料表:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
嵌入資料欄可儲存文字的向量值。
授予權限
執行下列陳述式,授予「embedding」函式的執行權:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
為 AlloyDB 服務帳戶授予 Vertex AI 使用者角色
在 Google Cloud IAM 控制台,授予 AlloyDB 服務帳戶 (格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)「Vertex AI 使用者」角色存取權。PROJECT_NUMBER 會顯示您的專案編號。
或者,您也可以從 Cloud Shell 終端機執行下列指令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
將資料載入資料庫
- 從工作表複製
insert查詢陳述式,並貼到上述編輯器。insert scripts sql您可以複製 10 到 50 個插入陳述式,快速展示這個用途。「Selected Inserts 25-30 rows」(所選插入內容 25 至 30 列) 分頁中,會顯示所選插入內容的清單。
資料連結位於這個 github 存放區檔案。
- 按一下「執行」。查詢結果會顯示在「結果」表格中。
重要注意事項:
請務必只複製 25 到 50 筆記錄來插入,並確保記錄來自類別、子類別、顏色和性別類型範圍。
5. 為資料建立嵌入
現代搜尋的真正創新之處在於理解意義,而不只是關鍵字。這時嵌入和向量搜尋技術就能派上用場。
我們使用預先訓練的語言模型,將產品說明和使用者查詢轉換為高維度數值表示法,也就是「嵌入」。這些嵌入會擷取語意,讓我們找出「語意相似」的產品,而不只是包含相符的字詞。一開始,我們對這些嵌入內容進行直接向量相似度搜尋實驗,建立基準,展現語意理解的強大功能,即使在成效最佳化之前也是如此。
嵌入資料欄可儲存產品說明文字的向量值。img_embeddings 欄可儲存圖片嵌入 (多模態)。這樣一來,您也可以使用以文字與圖片距離為依據的搜尋功能。但本實驗室只會使用文字嵌入。
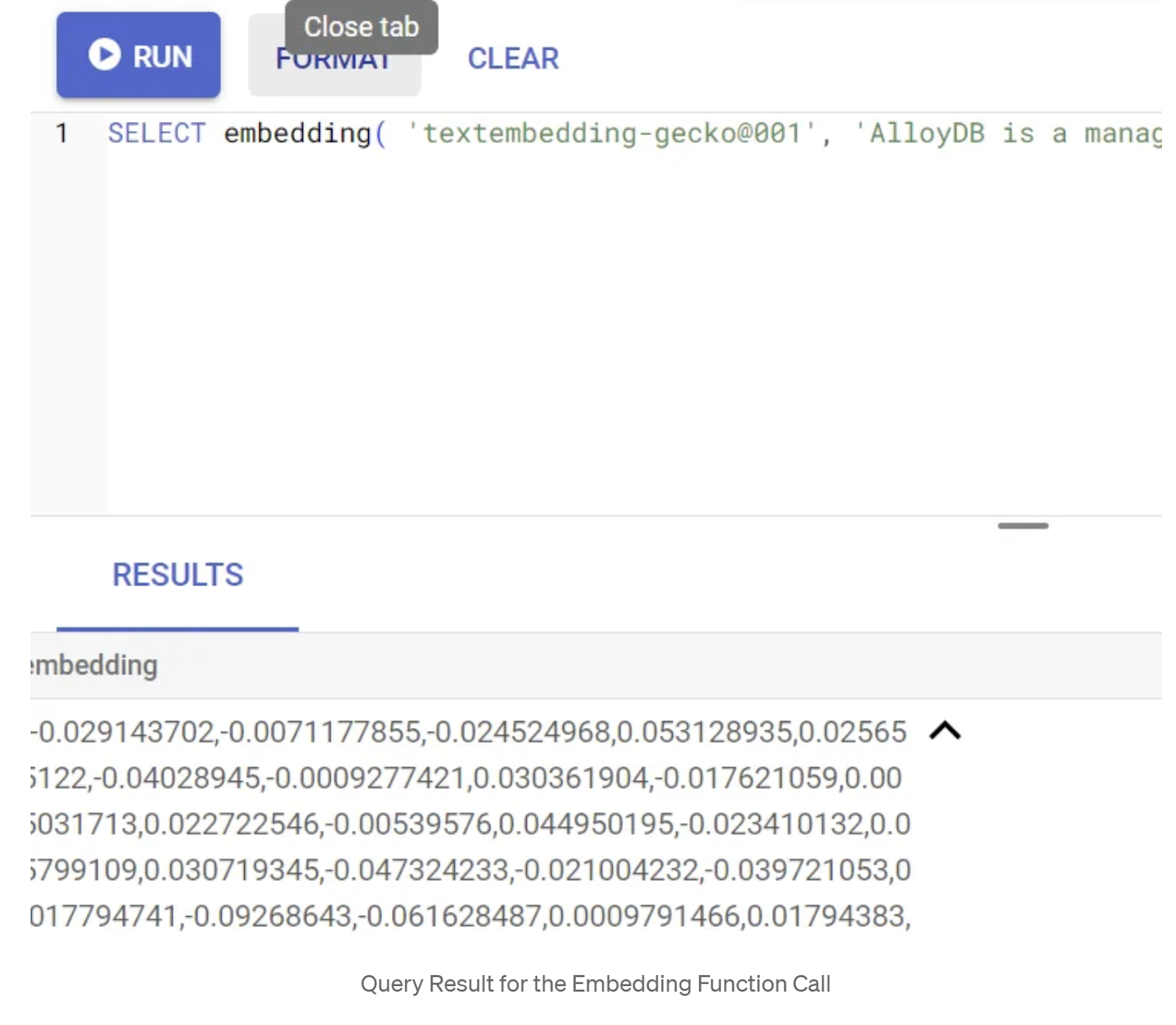
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
這應該會傳回嵌入向量,看起來像是查詢中範例文字的浮點數陣列。如下所示:
更新 abstract_embeddings 向量欄位
執行下列 DML,使用對應的嵌入更新資料表中的內容說明:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
如果您使用 Google Cloud 的試用額度帳單帳戶,可能無法產生超過幾個 (最多 20 到 25 個) 嵌入內容。因此請限制插入指令碼中的資料列數。
如要生成圖片嵌入 (用於執行多模態情境搜尋),請一併執行下列更新:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. 運用 AlloyDB 的新功能執行進階 RAG
現在資料表、資料和嵌入都已準備就緒,讓我們對使用者搜尋文字執行即時向量搜尋。您可以執行下列查詢來測試這項功能:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
ORDER BY embedding <=> embedding('text-embedding-005','T-shirt with round neck')::vector limit 10 ;
在這項查詢中,我們會使用餘弦相似度距離函式 (以「<=>」符號表示),比較使用者輸入的搜尋內容「圓領 T 恤」的文字嵌入,與服飾表格中所有產品說明的文字嵌入 (儲存在名為「embedding」的資料欄中)。我們會將嵌入方法的結果轉換為向量類型,使其與資料庫中儲存的向量相容。LIMIT 10 代表我們選取與搜尋文字最接近的 10 個相符項目。
AlloyDB 可將向量搜尋 RAG 提升至全新境界:
對於企業級解決方案而言,原始向量搜尋功能並不夠用。效能至關重要。
ScaNN (可擴充的最近鄰) 索引
為實現超快速的近似最鄰近 (ANN) 搜尋,我們在 AlloyDB 中啟用 scaNN 索引。ScaNN 是 Google 研究開發的先進近似最鄰近搜尋演算法,專為大規模執行高效率的向量相似度搜尋而設計。這項技術可有效剪除搜尋空間並使用量化技術,大幅加快查詢速度,向量查詢速度比其他索引方法快 4 倍,且記憶體用量較小。詳情請參閱這篇文章和這篇文章。
啟用擴充功能並建立索引:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
為文字嵌入和圖片嵌入欄位建立索引 (如要在搜尋中使用圖片嵌入):
CREATE INDEX apparels_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=32);
CREATE INDEX apparels_img_index ON apparels
USING scann (img_embeddings cosine)
WITH (num_leaves=32);
中繼資料索引
scaNN 負責處理向量索引,而傳統 B 樹狀結構或 GIN 索引則是在結構化屬性 (例如類別、子類別、樣式、顏色等) 上精心設定。這些索引對於多面向篩選的效率至關重要。執行下列陳述式,設定中繼資料索引:
CREATE INDEX idx_category ON apparels (category);
CREATE INDEX idx_sub_category ON apparels (sub_category);
CREATE INDEX idx_color ON apparels (color);
CREATE INDEX idx_gender ON apparels (gender);
重要注意事項:
由於您可能只插入 25 到 50 筆記錄,因此索引 (ScaNN 或任何索引) 不會生效。
內嵌篩選
向量搜尋的常見挑戰是結合結構化篩選器 (例如「紅鞋」)。AlloyDB 的內嵌篩選功能可最佳化這項作業。內嵌篩選功能會在向量搜尋程序中套用篩選條件,而非在廣泛的向量搜尋後篩選結果,因此能大幅提升篩選向量搜尋的效能和準確度。
如要進一步瞭解內嵌篩選的必要性,請參閱這份說明文件。此外,您也可以參閱這篇文章,瞭解如何透過篩選向量搜尋結果來提升向量搜尋的效能。如要為應用程式啟用內嵌篩選功能,請從編輯器執行下列陳述式:
SET scann.enable_inline_filtering = on;
內嵌篩選最適合中等選擇性的情況。AlloyDB 搜尋向量索引時,只會計算符合中繼資料篩選條件的向量距離 (查詢中的功能篩選條件通常會在 WHERE 子句中處理)。這類查詢的效能大幅提升,可補足篩選後或篩選前的優勢。
自動調整篩選
為進一步提升效能,AlloyDB 的自適應篩選功能會在查詢執行期間,動態選擇最有效率的篩選策略 (內嵌或預先篩選)。這項功能會分析查詢模式和資料分布情形,確保效能達到最佳狀態,不需要手動介入,特別適合用於已篩選的向量搜尋,因為系統會自動在向量和中繼資料索引之間切換。如要啟用自動調整篩選功能,請使用 scann.enable_preview_features 標記。
當適應性篩選在執行期間觸發從內嵌篩選切換至預先篩選時,查詢計畫會動態變更。
SET scann.enable_preview_features = on;
重要注意事項:如果遇到錯誤,您可能需要重新啟動執行個體,才能執行上述陳述式。建議您從執行個體的資料庫旗標部分啟用 enable_preview_features 旗標。
使用所有索引的切面篩選器
分層搜尋功能可讓使用者根據特定屬性或「商情項目」(例如品牌、價格、尺寸、消費者評分) 套用多個篩選條件,縮小搜尋結果範圍。我們的應用程式會將這些層面與向量搜尋功能無縫整合。現在單一查詢可結合自然語言 (情境搜尋) 和多個切面選取項目,動態運用向量和傳統索引。這項功能提供真正動態的混合搜尋功能,讓使用者能精確地深入瞭解結果。
在我們的應用程式中,由於我們已建立所有中繼資料索引,因此可以直接使用 SQL 查詢解決問題,在網頁中使用多面向篩選器:
SELECT id, content, uri, category, sub_category,color,gender
FROM apparels
WHERE category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
ORDER BY embedding <=> embedding('text-embedding-005',$5)::vector limit 10 ;
在這項查詢中,我們執行的是混合搜尋,同時納入
- WHERE 子句中的分層篩選和
- 使用餘弦相似度方法,在 ORDER BY 子句中進行向量搜尋。
$1、$2、$3 和 $4 代表陣列中的切面篩選器值,$5 則代表使用者搜尋文字。將 $1 至 $4 替換為您選擇的切面篩選器值,如下所示:
category = ANY([‘Apparel', ‘Footwear'])
將 $5 替換為您選擇的搜尋文字,例如「Polo T-Shirts」。
重要注意事項:如果插入的記錄集有限,導致您沒有索引,就不會看到效能影響。但在完整的生產資料集中,您會發現使用內嵌篩選注入 ScaNN 索引的相同向量搜尋,執行時間大幅縮短!
接著,我們來評估啟用 ScaNN 的向量搜尋的召回率。
重新排序
即使使用進階搜尋,初始結果可能仍需潤飾。這項重要步驟會重新排序初始搜尋結果,以提升關聯性。初始混合搜尋提供一組候選產品後,更精密的模型 (通常需要較多運算資源) 會套用更精細的關聯性分數。確保使用者看到最相關的結果,大幅提升搜尋品質。我們會持續評估召回率,衡量系統為特定查詢擷取所有相關項目的成效,並調整模型,盡可能讓顧客找到所需內容。
在應用程式中使用這項功能前,請先確認您符合所有先決條件:
- 確認已安裝 google_ml_integration 擴充功能。
- 確認 google_ml_integration.enable_model_support 旗標已設為開啟。
- 與 Vertex AI 整合。
- 啟用 Discovery Engine API。
- 取得使用排名模型所需的角色。
然後,您可以在應用程式中使用下列查詢,重新排序混合搜尋結果集:
WITH initial_ranking AS (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender,
ROW_NUMBER() OVER () AS ref_number
FROM apparels
order by embedding <=>embedding('text-embedding-005', 'Pink top')::vector),
reranked_results AS (
SELECT index, score from
ai.rank(
model_id => 'semantic-ranker-default-003',
search_string => 'Pink top',
documents => (SELECT ARRAY_AGG(pdt_desc ORDER BY ref_number) FROM initial_ranking)
)
)
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender, score
FROM initial_ranking, reranked_results
WHERE initial_ranking.ref_number = reranked_results.index
ORDER BY reranked_results.score DESC
limit 25;
在這項查詢中,我們使用餘弦相似度方法,對 ORDER BY 子句中提及的內容搜尋產品結果集執行重新排序。「粉紅色上衣」是使用者搜尋的文字。
重要注意事項:部分使用者可能還無法存取重新排序功能,因此我已將這項功能從應用程式程式碼中排除,但如果您想加入這項功能,可以參考上述範例。
召回評估人員
相似性搜尋的召回率是指從搜尋中擷取的相關例項百分比,也就是真陽性數。這是最常用的搜尋品質評估指標。召回率損失的其中一個來源,是近似最鄰近搜尋 (aNN) 與 k (精確) 最鄰近搜尋 (kNN) 之間的差異。AlloyDB 的 ScaNN 等向量索引會實作 aNN 演算法,讓您加快大型資料集的向量搜尋速度,但召回率會略有下降。現在,AlloyDB 可讓您直接在資料庫中,針對個別查詢評估這項取捨,並確保長期穩定。您可以根據這項資訊更新查詢和索引參數,以獲得更出色的結果和效能。
搜尋結果的召回邏輯為何?
在向量搜尋的脈絡中,召回率是指索引傳回的向量中,屬於真正最鄰近向量的百分比。舉例來說,如果 20 個最近鄰的最近鄰查詢傳回 19 個基本事實最近鄰,則召回率為 19/20x100 = 95%。召回率是搜尋品質的指標,定義為客觀上最接近查詢向量的傳回結果所占百分比。
您可以使用 evaluate_query_recall 函式,找出特定設定的向量索引向量查詢召回率。您可以使用這個函式調整參數,以取得所需的向量查詢召回結果。
重要注意事項:
如果在下列步驟中,HNSW 索引發生權限遭拒錯誤,請暫時略過整個召回評估部分。這可能是因為本程式碼研究室撰寫時,該功能才剛發布,因此存取權受到限制。
- 在 ScaNN 索引和 HNSW 索引上設定「啟用索引掃描」旗標:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- 在 AlloyDB Studio 中執行下列查詢:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <=> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 函式會將查詢做為參數,並傳回查詢的召回率。我使用與檢查效能時相同的查詢做為函式輸入查詢。我已新增 SCaNN 做為索引方法。如需更多參數選項,請參閱說明文件。
我們使用的這項向量搜尋查詢的召回率:
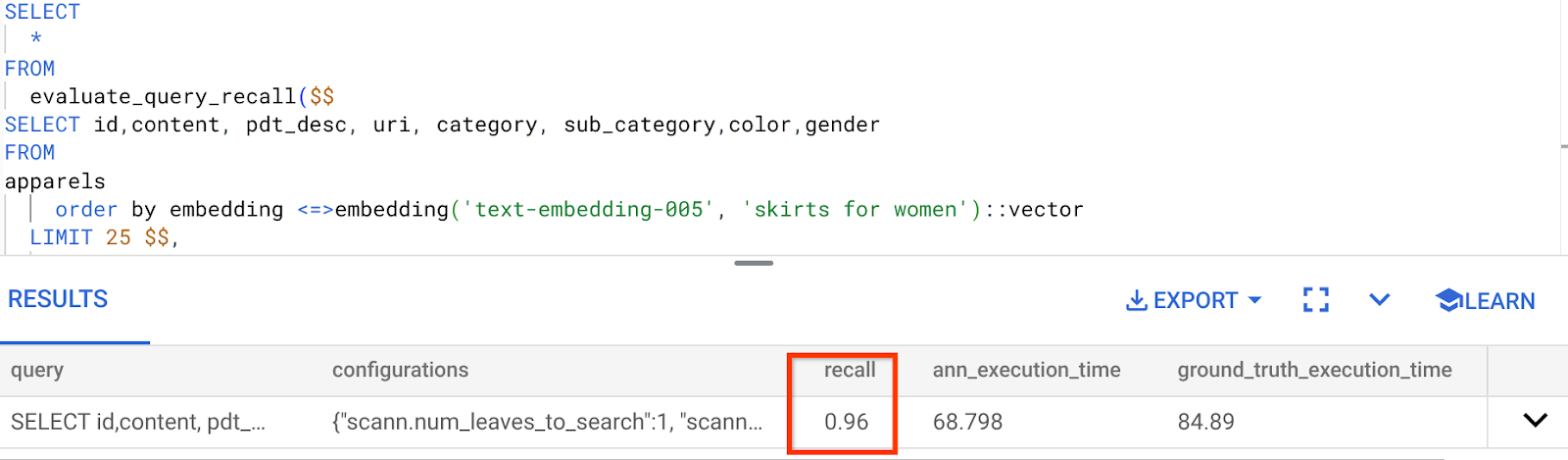
我看到 RECALL 是 96%。在本例中,喚回度非常高。但如果是不接受的值,您可以使用這項資訊變更索引參數、方法和查詢參數,並改善這項向量搜尋的召回率!
使用修改後的查詢和索引參數進行測試
現在,請根據收到的召回通知修改查詢參數,測試查詢。
- 修改索引參數:
在這項測試中,我將使用「L2 距離」,而非「餘弦」相似度距離函式。
非常重要的注意事項:您可能會問「我們怎麼知道這個查詢使用餘弦相似度?」您可以使用「<=>」代表餘弦距離,藉此識別距離函式。
文件連結,適用於 Vector Search 距離函式。
先前的查詢使用餘弦相似度距離函式,現在我們要嘗試 L2 距離。但為此,我們也應確保基礎 ScaNN 索引使用 L2 距離函式。現在,我們來建立使用不同距離函式查詢的索引:L2 距離:<->
drop index apparels_index;
CREATE INDEX apparels_index ON apparels
USING scann (embedding L2)
WITH (num_leaves=32);
刪除索引陳述式只是為了確保資料表上沒有不必要的索引。
現在,我可以執行下列查詢,評估變更向量搜尋功能距離函式後的 RECALL。
[AFTER] 使用 L2 距離函式的查詢:
SELECT
*
FROM
evaluate_query_recall($$
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM
apparels
order by embedding <-> embedding('text-embedding-005', 'skirts for women')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
您可以查看更新後索引的召回值差異 / 轉換。
您可以在索引中變更其他參數,例如 num_leaves 等,具體取決於所需的召回值和應用程式使用的資料集。
大型語言模型驗證向量搜尋結果
為確保受控搜尋的最高品質,我們納入了選用的大型語言模型驗證層。大型語言模型可用於評估搜尋結果的關聯性和一致性,特別是複雜或模糊的查詢。這可能包括:
語意驗證:
LLM 會根據查詢意圖交叉參照結果。
邏輯篩選:
使用 LLM 套用複雜的商業邏輯或規則,這些邏輯或規則難以在傳統篩選器中編碼,並根據細微的條件進一步調整產品清單。
品質保證:
自動識別並標記較不相關的結果,供人工審查或模型改良。
以下說明我們如何在 AlloyDB AI 功能中達成這項目標:
WITH
apparels_temp as (
SELECT id,content, pdt_desc, uri, category, sub_category,color,gender
FROM apparels
-- where category = ANY($1) and sub_category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005', $5)::vector
limit 25
),
prompt AS (
SELECT 'You are a friendly advisor helping to filter whether a product match' || pdt_desc || 'is reasonably (not necessarily 100% but contextually in agreement) related to the customer''s request: ' || $5 || '. Respond only in YES or NO. Do not add any other text.'
AS prompt_text, *
from apparels_temp
)
,
response AS (
SELECT id,content,pdt_desc,uri,
json_array_elements(ml_predict_row('projects/abis-345004/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text', prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT id, content,uri,replace(replace(resp::text,'\n',''),'"','') as result
FROM
response where replace(replace(resp::text,'\n',''),'"','') in ('YES', 'NO')
limit 10;
基礎查詢與我們在多面向搜尋、混合型搜尋和重新排序部分看到的查詢相同。現在,我們在這項查詢中納入了以 ml_predict_row 建構函式表示的重新排序結果集,並透過 GEMINI 進行評估。我已註解多面向篩選器,但您可以在 $1 到 $4 的預留位置陣列中加入所選項目。將 $5 替換為要搜尋的文字,例如「粉紅色上衣,沒有花卉圖案」。
7. MCP Toolbox for Databases 和應用程式層
在幕後,完善的工具和結構良好的應用程式可確保運作順暢。
MCP (Model Context Protocol) Toolbox for Databases 可簡化生成式 AI 和具備代理功能的工具與 AlloyDB 的整合程序。這項開放原始碼伺服器可簡化連線集區、驗證程序,並安全地向 AI 代理或其他應用程式公開資料庫功能。
在應用程式中,我們使用 MCP Toolbox for Databases 做為所有智慧型混合搜尋查詢的抽象層。
請按照下列步驟,為我們的用途設定及部署 Toolbox:
您會發現 MCP Toolbox for Databases 支援的資料庫之一是 AlloyDB,而我們已在上一節中佈建該資料庫,因此請繼續設定 Toolbox。
- 前往 Cloud Shell 終端機,確認已選取專案,且專案顯示在終端機提示中。在 Cloud Shell 終端機執行下列指令,前往專案目錄:
mkdir toolbox-tools
cd toolbox-tools
- 執行下列指令,在新資料夾中下載及安裝工具箱:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- 前往 Cloud Shell 編輯器 (程式碼編輯模式),在專案根資料夾中新增名為「tools.yaml」的檔案。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
<<tools go here... Refer to the github repo file>>
請務必將 Tools.yaml 指令碼換成這個存放區檔案中的程式碼。
讓我們瞭解 tools.yaml:
來源代表工具可互動的不同資料來源。來源代表工具可互動的資料來源。您可以在 tools.yaml 檔案的來源部分中,將來源定義為對應。一般來說,來源設定會包含連線至資料庫及與資料庫互動所需的任何資訊。
工具會定義代理可執行的動作,例如讀取及寫入來源。工具代表代理程式可執行的動作,例如執行 SQL 陳述式。您可以在 tools.yaml 檔案的工具區段中,將工具定義為對應。通常工具需要來源才能執行動作。
如要進一步瞭解如何設定 tools.yaml,請參閱這份說明文件。
- 從 mcp-toolbox 資料夾執行下列指令,啟動伺服器:
./toolbox --tools-file "tools.yaml"
現在,如果您在雲端以網頁預覽模式開啟伺服器,應該就能看到 Toolbox 伺服器已啟動並執行,且其中包含名為 get-order-data 的新工具。
MCP Toolbox 伺服器預設會在通訊埠 5000 上執行。我們將使用 Cloud Shell 測試這項功能。
在 Cloud Shell 中點選「網頁預覽」,如下所示:
按一下「變更通訊埠」,將通訊埠設為 5000 (如下所示),然後按一下「變更並預覽」。
這應該會產生以下輸出內容:
- 將 Toolbox 部署至 Cloud Run:
首先,我們可以從 MCP Toolbox 伺服器開始,並將其託管在 Cloud Run 上。這樣一來,我們就能取得公用端點,並與任何其他應用程式和/或代理程式應用程式整合。如需在 Cloud Run 上託管這項服務的操作說明,請參閱這篇文章。我們現在來看看重要步驟。
- 啟動新的 Cloud Shell 終端機,或使用現有的 Cloud Shell 終端機。前往工具箱二進位檔和 tools.yaml 所在的專案資料夾 (在本例中為 toolbox-tools),如果尚未進入該資料夾:
cd toolbox-tools
- 將 PROJECT_ID 變數設為指向您的 Google Cloud 專案 ID。
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- 啟用下列 Google Cloud 服務
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- 我們將建立個別服務帳戶,做為要在 Google Cloud Run 部署的 Toolbox 服務身分。
gcloud iam service-accounts create toolbox-identity
- 我們也會確保這個服務帳戶具備正確角色,也就是有權存取 Secret Manager 並與 AlloyDB 通訊
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- 我們會將 tools.yaml 檔案上傳為密鑰:
gcloud secrets create tools --data-file=tools.yaml
如果您已有密鑰,並想更新密鑰版本,請執行下列指令:
gcloud secrets versions add tools --data-file=tools.yaml
- 將環境變數設為要用於 Cloud Run 的容器映像檔:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- 最後一個步驟是使用熟悉的部署指令將應用程式部署至 Cloud Run:
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-search-toolbox
這會開始將 Toolbox 伺服器連同設定的 tools.yaml 部署至 Cloud Run。部署成功後,您應該會看到類似以下的訊息:
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
您已設定妥當,現在可以在代理程式應用程式中使用新部署的工具了!
存取 Toolbox 伺服器中的工具
部署工具箱後,我們會建立 Python Cloud Run Functions 墊片,與部署的工具箱伺服器互動。這是因為目前 Toolbox 沒有 Java SDK,因此我們建立了 Python 墊片來與伺服器互動。這是該 Cloud Run 函式的原始碼。
您必須建立並部署這項 Cloud Run 函式,才能存取我們在先前步驟中建立及部署的工具箱工具:
- 前往 Google Cloud 控制台的 Cloud Run 頁面。
- 按一下「編寫函式」。
- 在「服務名稱」欄位中,輸入函式的描述名稱。服務名稱開頭須為英文字母,且最多只能包含 49 個字元,包括英文字母、數字或連字號。服務名稱不得以連字號結尾,且每個區域和專案的服務名稱不得重複。服務名稱一經設定即無法變更,而且會公開顯示。(Enter retail-product-search-quality)
- 在「Region」(區域) 清單中,使用預設值,或選取要部署函式的區域。(選擇 us-central1)
- 在「執行階段」清單中,使用預設值或選取執行階段版本。(選擇 Python 3.11)
- 在「驗證」部分中,選擇「允許公開存取」
- 按一下「建立」按鈕
- 系統會建立函式,並載入範本 main.py 和 requirements.txt
- 將這些檔案替換為這個專案存放區中的 main.py 和 requirements.txt
- 部署函式後,您應該會取得 Cloud Run 函式的端點
端點應如下所示 (或類似的內容):
用來存取工具箱的 Cloud Run 函式端點:「https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app」
為方便在時限內完成 (實作導覽課程),端點的專案編號會在實作課程中提供。
重要注意事項:
或者,您也可以直接在應用程式程式碼或 Cloud Run 函式中實作資料庫部分。
8. 應用程式開發 (Java) - 具備分層搜尋功能
最後,應用程式層會將所有這些強大的後端元件付諸實現。這款應用程式以 Java 開發,提供與搜尋系統互動的使用者介面。這項服務會協調對 AlloyDB 的查詢、處理多面向篩選器的顯示方式、管理使用者選取項目,並以流暢直覺的方式呈現重新排名和驗證過的搜尋結果。
- 首先,請前往 Cloud Shell 終端機並複製存放區:
git clone https://github.com/AbiramiSukumaran/faceted_searching_retail
- 前往 Cloud Shell 編輯器,您會看到新建立的資料夾 faceted_searching_retail
- 刪除下列項目,因為這些步驟已在前幾節中完成:
- 刪除 Cloud_Run_Function 資料夾
- 刪除 db_script.sql 檔案
- 刪除 tools.yaml 檔案
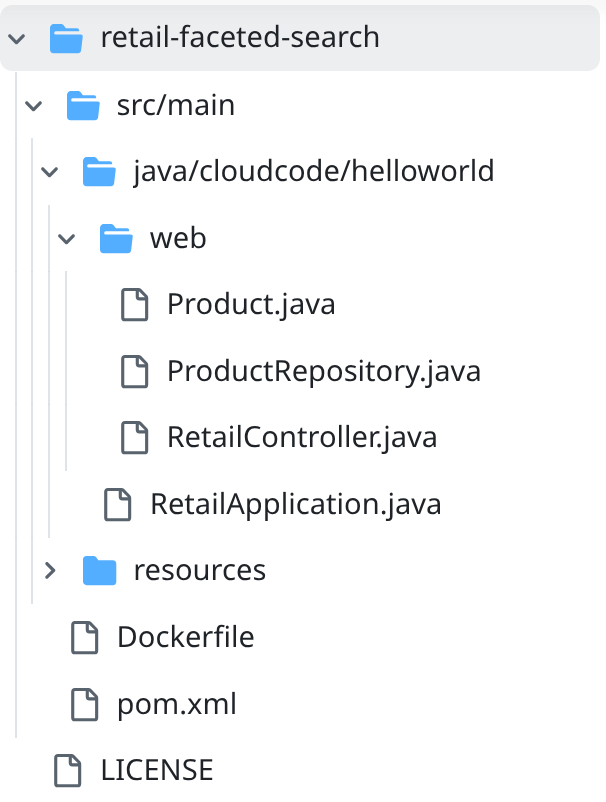
- 前往 retail-faceted-search 專案資料夾,您應該會看到專案結構:
- 在 ProductRepository.java 檔案中,您必須使用 Cloud Run 函式 (已部署) 的端點修改 TOOLBOX_ENDPOINT 變數,或是從實作練習講師取得端點。
搜尋下列程式碼行,並將其替換為端點:
public static final String TOOLBOX_ENDPOINT = "https://retail-product-search-quality-<<YOUR_PROJECT_NUMBER>>.us-central1.run.app";
- 確認 Dockerfile 和 pom.xml 符合專案設定 (除非您明確變更任何版本或設定,否則不需要變更)。
- 在 Cloud Shell 終端機中,確認您位於主要資料夾和專案資料夾 (faceted_searching_retail / retail-faceted-search) 內。使用下列指令,確保終端機位於正確的資料夾中:
cd faceted_searching_retail
cd retail-faceted-search
- 在本機封裝、建構及測試應用程式:
mvn package
mvn spring-boot:run
按一下 Cloud Shell 終端機中的「透過以下通訊埠預覽:8080」,即可查看應用程式,如下所示:
9. 部署至 Cloud Run:***重要步驟
在 Cloud Shell 終端機中,確認您位於主要資料夾和專案資料夾 (faceted_searching_retail / retail-faceted-search) 內。使用下列指令,確保終端機位於正確的資料夾中:
cd faceted_searching_retail
cd retail-faceted-search
確認位於專案資料夾後,請執行下列指令:
gcloud run deploy retail-search --source . \
--region us-central1 \
--allow-unauthenticated \
--labels dev-tutorial=codelab-alloydb-hybrid-search
部署完成後,您會收到類似下方的 Cloud Run 端點:
https://retail-search-**********-uc.a.run.app/
10. 試用版
我們來看看實際的運作情形:
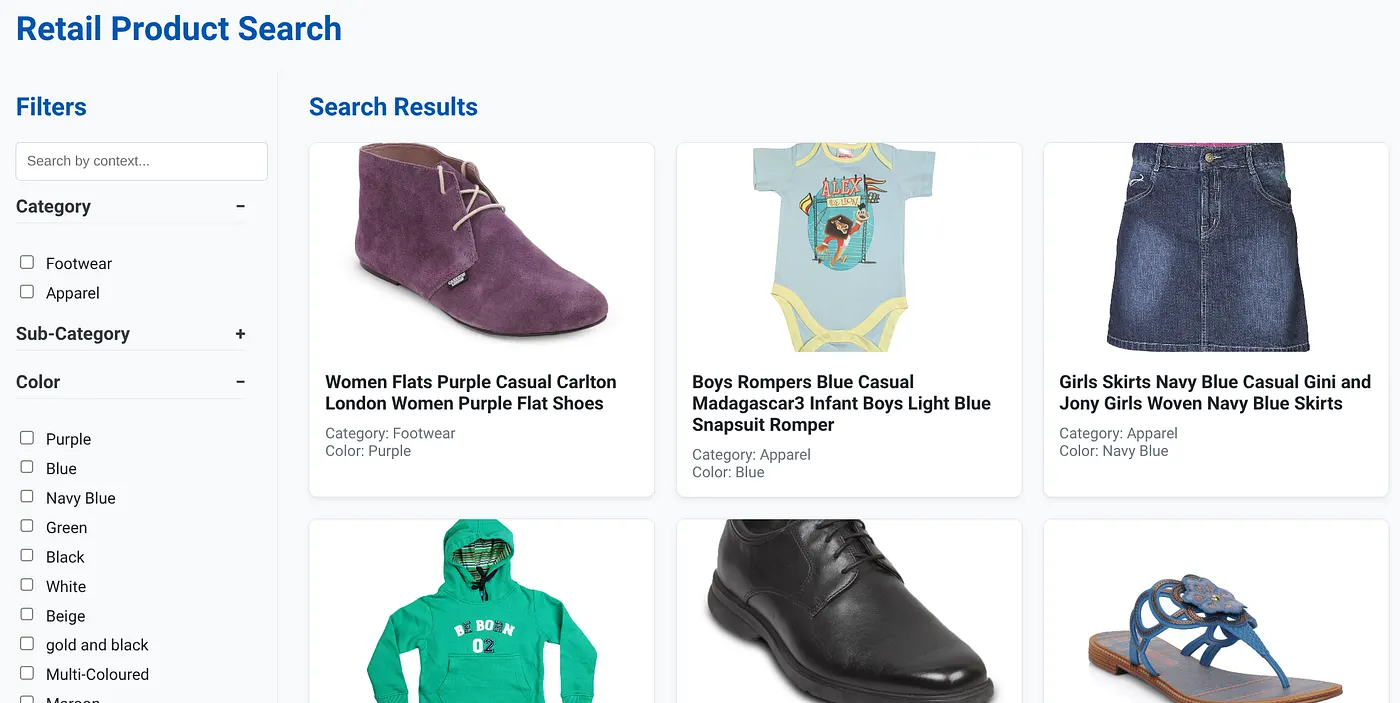
上圖顯示動態混合型搜尋應用程式的到達網頁。
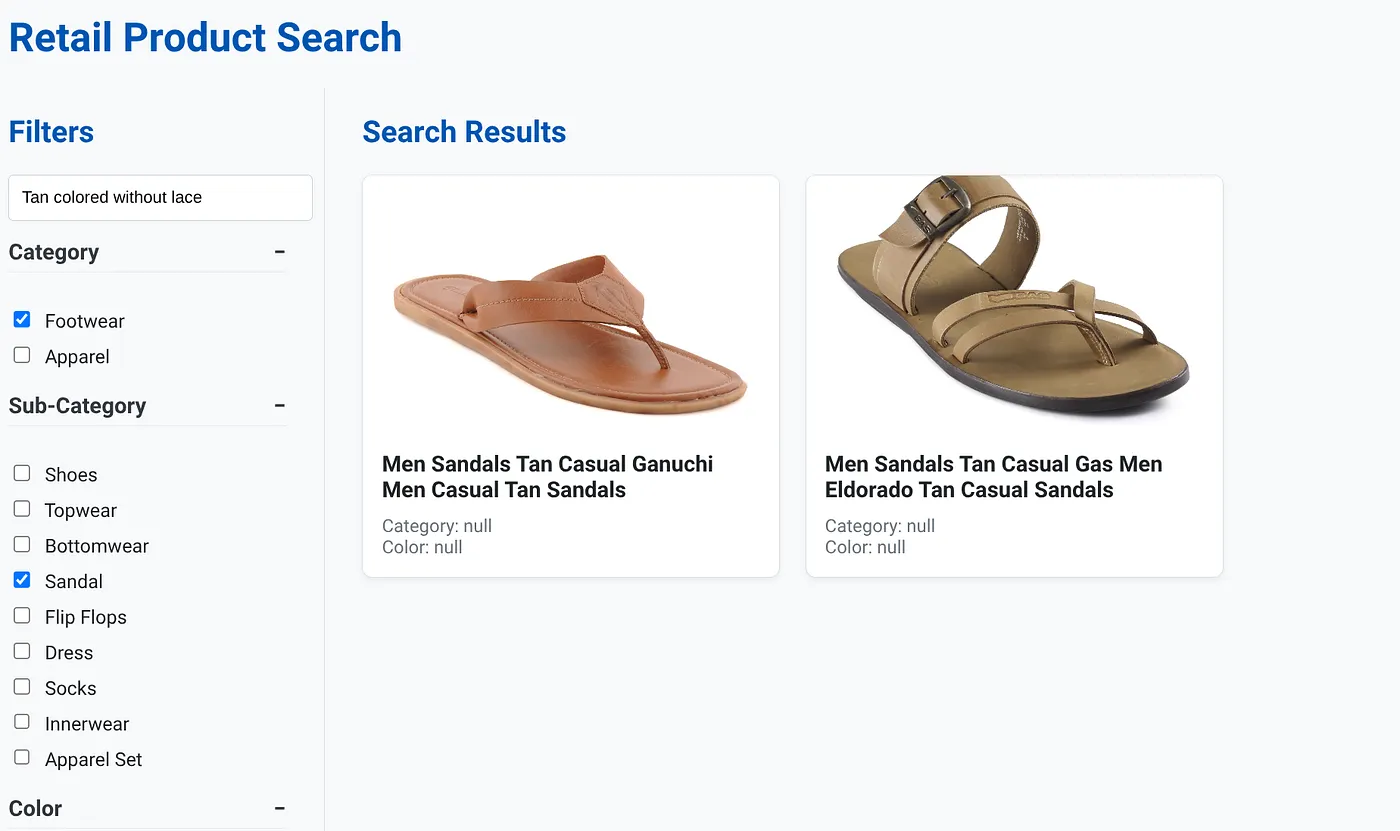
上圖顯示「無鞋帶棕色」的搜尋結果。選取的切面篩選器為:鞋類、涼鞋。
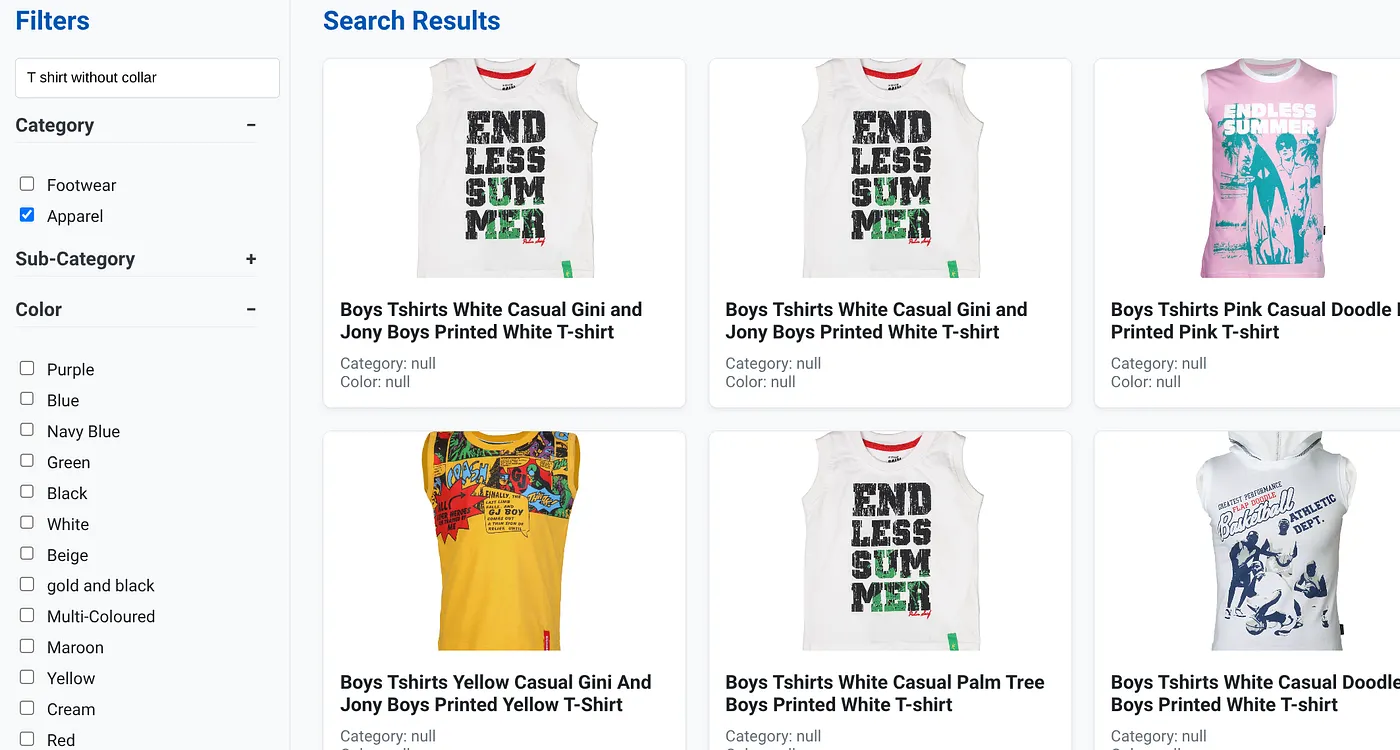
上圖顯示「無領 T 恤」的搜尋結果。分層篩選器:服飾
您現在可以加入更多生成式和代理程式功能,讓這個應用程式發揮實際作用。
立即試用,激發你的靈感,打造專屬的應用程式!
11. 清理
如要避免系統向您的 Google Cloud 帳戶收取本文所用資源的費用,請按照下列步驟操作:
- 前往 Google Cloud 控制台的資源管理員頁面。
- 在專案清單中選取要刪除的專案,然後點按「刪除」。
- 在對話方塊中輸入專案 ID,然後按一下「Shut down」(關機) 即可刪除專案。
- 或者,您也可以點選「DELETE CLUSTER」按鈕,刪除我們剛為這個專案建立的 AlloyDB 叢集 (如果您在設定叢集時未選擇 us-central1,請變更這個超連結中的位置)。
12. 恭喜
恭喜!您已成功在 CLOUD RUN 上建構及部署 HYBRID SEARCH APP (混合搜尋應用程式) (使用 ALLOYDB)!
這項異動對商家的影響:
這款由 AlloyDB AI 支援的動態混合型搜尋應用程式,可為企業零售和其他商家帶來顯著優勢:
更貼切的搜尋結果:結合情境 (向量) 搜尋、精確的切面篩選和智慧重新排序功能,為顧客提供高度相關的結果,進而提高滿意度和轉換次數。
擴充性:AlloyDB 的架構和 scaNN 索引設計可處理大量產品目錄和高查詢量,這對成長中的電子商務商家至關重要。
效能:即使是複雜的混合搜尋,也能快速回應查詢,確保使用者體驗流暢,並盡量減少放棄率。
為未來做好準備:整合 AI 功能 (嵌入、LLM 驗證) 後,應用程式就能因應未來趨勢,提供個人化推薦、對話式商務和智慧型產品探索功能。
簡化架構:直接在 AlloyDB 中整合向量搜尋功能,不必使用獨立的向量資料庫或複雜的同步程序,簡化開發和維護作業。
假設使用者輸入自然語言查詢,例如「適合高足弓女性的環保跑步鞋」。
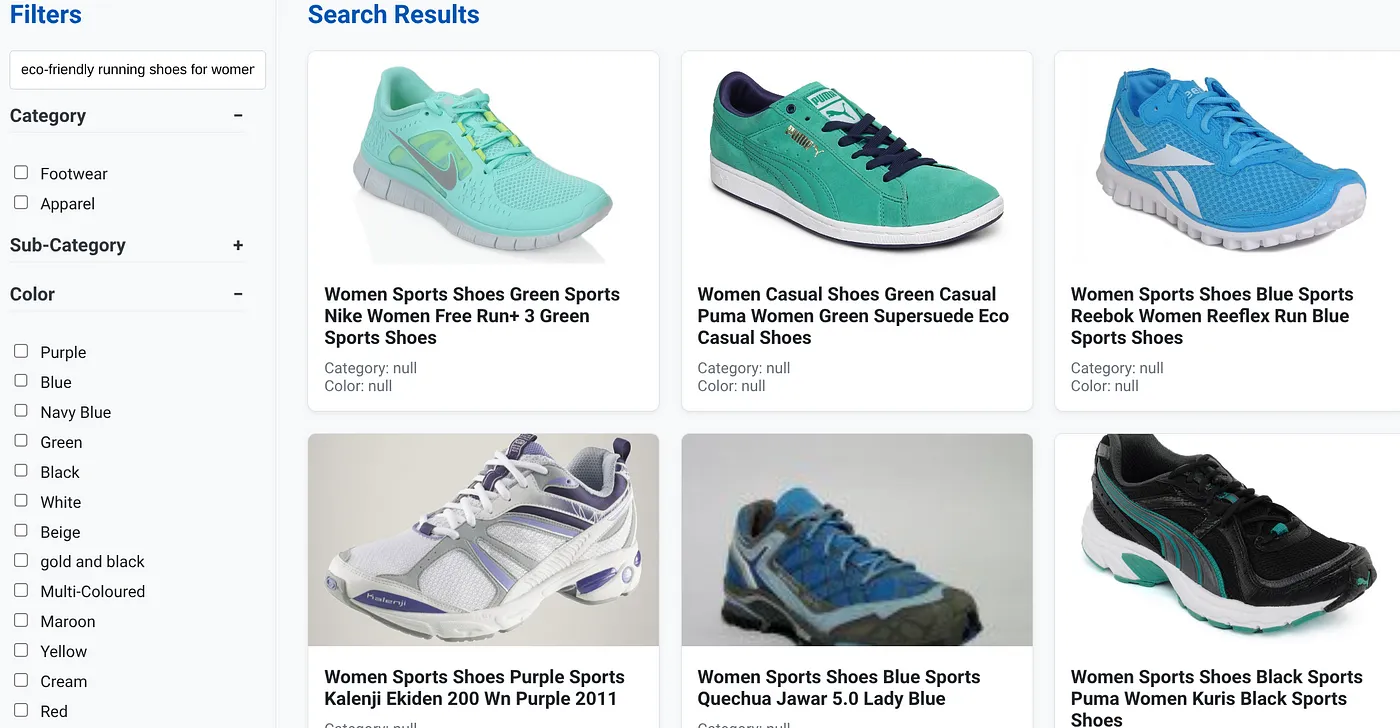
同時,使用者套用「類別:<<>>」、「顏色:<<>>」和「價格:$100-$150」的切面篩選器:
- 系統會立即傳回經過篩選的產品清單,這些產品在語意上與自然語言相符,且完全符合所選篩選條件。
- 在幕後,scaNN 索引會加快向量搜尋速度,內嵌和自動調適篩選功能則可確保符合合併條件的結果能發揮最佳效能,重新排序功能則會將最佳結果顯示在最上方。
- 結果的速度和準確度清楚說明瞭結合這些技術的力量,可打造真正智慧的零售搜尋體驗。
建構新一代零售搜尋應用程式時,我們需要超越傳統方法,運用 AlloyDB、Vertex AI、Vector Search (搭配 scaNN 索引)、動態切面篩選、重新排序和 LLM 驗證的強大功能,提供無與倫比的顧客體驗,進而提高參與度和銷售量。這項強大、可擴充的智慧解決方案,展示了融入 AI 的現代資料庫功能如何重塑零售業的未來!