
1. 什么是双向流式传输?
双向流式传输(双向流式传输)可在应用与 AI 模型之间实现同步双向通信。与您发送完整消息并等待完整回复的传统请求-响应模式不同,双向流式传输允许:
- 连续输入:在捕获音频、视频或文本时进行流式传输
- 实时输出:在生成 AI 回答时接收回答
- 自然中断:用户可以在 AI 回答到一半时中断其回答,就像在人类对话中一样
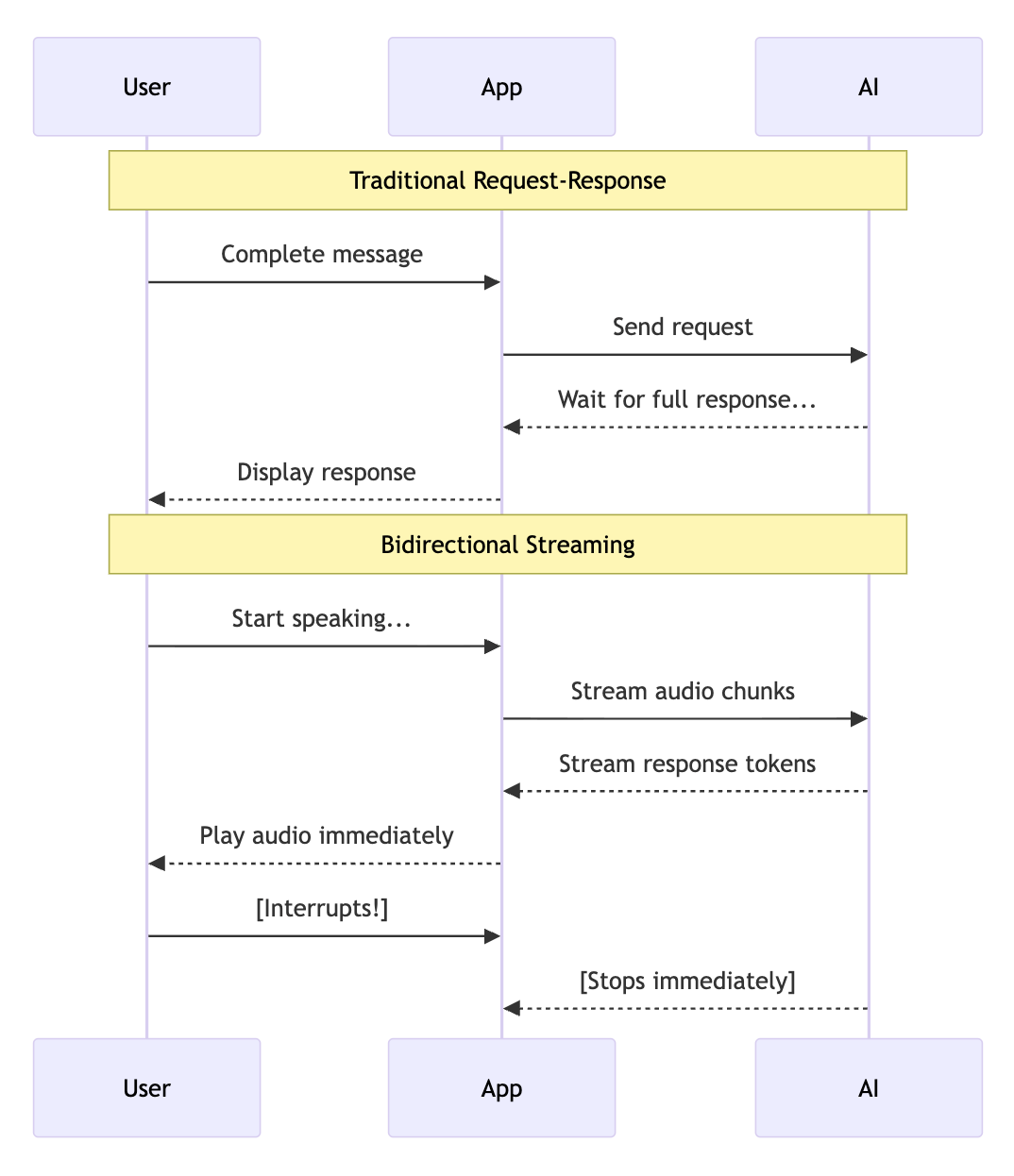
重要性:双向流式传输让 AI 对话更自然。AI 可以在您仍在提供上下文时做出回答,并且您可以在听到足够的信息后打断它,就像与人交谈一样。
什么是 ADK Gemini Live API 工具包?
智能体开发套件 (ADK) 可针对 Gemini Live API 提供高级别抽象,处理实时流式传输的复杂管道,以便您专注于构建应用。

ADK Gemini Live API 工具包可管理:
- 连接生命周期:建立、维护和恢复 WebSocket 连接
- 消息路由:将音频、文本和图片定向到正确的处理程序
- 会话状态:在重新连接时保留对话历史记录
- 工具执行:自动调用和从函数调用中恢复
为什么选择 ADK 而不是原始 Live API?
您可以直接基于 Gemini Live API 进行构建,但 ADK 会处理复杂的基础设施,因此您可以专注于应用:

功能 | Raw Live API | ADK Gemini Live API 工具包 |
代理框架 | 从头开始构建 | 具有工具、评估和安全性的单代理/多代理 |
工具执行 | 手动处理 | 自动并行执行 |
连接管理 | 手动重新连接 | 透明会话恢复 |
活动模型 | 自定义结构 | 统一的类型化 Event 对象 |
异步框架 | 人工协调 | LiveRequestQueue + run_live() 生成器 |
会话持久性 | 手动实现 | 内置 SQL、Vertex AI 或内存中 |
总结:ADK 可将数月的基础设施开发时间缩短为数天的应用开发时间。您只需专注于智能体的功能,无需了解流式传输的运作方式。
实际应用场景
- 客户服务:客户通过手机摄像头展示有缺陷的咖啡机,同时说明问题。AI 会识别模型和故障点,客户可以在对话过程中打断 AI,以更正详细信息。
- 电子商务:一位买家对着网络摄像头举起一件衣服,询问“帮我找一双能搭配这条裤子的鞋子”。智能体分析风格,并进行流畅的来回对话:“展示一些更休闲的款式”→“这款运动鞋怎么样?”→“添加 10 号蓝色款。”
- 现场服务:一位佩戴智能眼镜的技术人员在提问时,串流自己的视野:“我听到这个压缩机发出奇怪的声音,你能识别出来吗?”代理会提供分步指导,无需动手操作。
- 医疗保健:患者分享皮肤状况的实时视频。AI 会执行初步分析、提出澄清问题,并指导后续步骤。
- 金融服务:客户查看自己的投资组合,而代理则显示图表并模拟交易影响。客户可以共享屏幕,以便讨论具体的新闻报道。
Shopper's Concierge 2 演示:使用 ADK Gemini Live API 工具包和 Vertex AI Vector Search、Embeddings、Feature Store 和 Ranking API 构建的电子商务实时智能体 RAG 演示:

了解详情:开发者指南
如需深入了解,请参阅 ADK Gemini Live API 工具包开发者指南,该指南共分为 5 部分,涵盖从架构到生产部署的各个方面:
部分 | 焦点 | 学习内容 |
基础 | 架构、Live API 平台、4 阶段生命周期 | |
上行 | 通过 LiveRequestQueue 发送文本、音频、视频 | |
下行 | 事件处理、工具执行、多智能体工作流 | |
配置 | 会话管理、配额、生产控制 | |
多模态 | 音频规格、模型架构、高级功能 |
2. 研讨会概览
构建内容
在这场实操研讨会中,您将从头开始构建一个完整的双向流式 AI 应用。完成本教程后,您将获得一个可正常运行的语音 AI,该 AI 可以:
- 接受文本、音频和图片输入
- 以流式文本或自然语音回答
- 自然地处理中断
- 使用 Google 搜索等工具
与阅读文档不同,您将逐步检查每个组件,并在逐步构建的过程中了解各个部分如何组合在一起。
学习方法
我们采用增量 build 方法:
- 第 1 步:最小 WebSocket 服务器 →“Hello World”响应
- 第 2 步:添加智能体 → 定义 AI 行为和工具
- 第 3 步:应用初始化 → Runner 和会话服务
- 第 4 步:会话初始化 → RunConfig 和 LiveRequestQueue
- 步骤 5:上游任务 → 客户端到队列通信
- 第 6 步:下游任务 → 向客户端流式传输事件
- 第 7 步:添加音频 → 语音输入和输出
- 第 8 步:添加图片输入 → 多模态 AI
每个步骤都基于上一个步骤。您将在每个步骤后进行测试,以查看自己的进度。
前提条件
- 启用了结算功能的 Google Cloud 账号
- Python 和异步编程 (async/await) 基础知识
- 可访问麦克风和网络摄像头的网络浏览器(建议使用 Chrome)
时间估算
- 完整版研讨会:约 90 分钟
- 快速版(仅包含第 1-4 步):约 45 分钟
3. 研讨会
按照此处的说明开始工作坊:
https://github.com/kazunori279/adk-streaming-guide/blob/main/workshops/workshop.md
4. 总结与要点
您构建的内容
您从头开始构建了一个完整的双向流式 AI 应用。该应用可处理文字、语音和图片输入,并提供实时流式响应,是构建可用于生产用途的对话式 AI 的基础。
组件 | 功能 | Step |
代理 | 定义 AI 个性、指令和可用工具(例如 Google 搜索) | 第 2 步 |
SessionService | 在重新连接后保留对话记录 | 第 3 步 |
运行程序 | 编排直播生命周期,将代理连接到 Live API | 第 3 步 |
RunConfig | 配置响应模态(文本/音频)、转写、会话恢复 | 第 4 步 |
LiveRequestQueue | 统一的界面,用于向模型发送文本、音频和图片 | 第 5 步 |
run_live() | 异步生成器,用于生成来自模型的流式传输事件 | 第 6 步 |
send_realtime() | 发送音频/图片 blob 以实现连续流式输入 | 第 7-8 步 |
资源
请参阅以下官方资源,继续学习。ADK Gemini Live API 工具包指南更深入地介绍了本研讨会中的所有内容。
资源 | 网址 |
ADK 文档 | |
ADK Gemini Live API 工具包指南 | |
Gemini Live API | |
Vertex AI Live API | https://cloud.google.com/vertex-ai/generative-ai/docs/live-api |
ADK 示例代码库 |