
1. Présentation
Bienvenue au "Jour 2". Si la création d'une application et le fait de cliquer sur "Publier" sont magiques, le trafic réel entraîne des échecs réels. Au lieu de passer vos journées à lutter avec YAML ou à parcourir les journaux, vous pouvez créer un essaim d'agents spécialisés pour gérer l'infrastructure opérationnelle à votre place. Cet atelier de programmation vous montre comment la pile unifiée de Google Cloud (Eventarc, Cloud Run, Firestore, Cloud Build, BigQuery) permet aux agents d'extraire des secrets, de diffuser des journaux et de résoudre des problèmes de manière sécurisée et prête à l'emploi.

Dans cet atelier de programmation, vous allez créer DinoQuest, un jeu d'aventure avec des dinosaures optimisé par Gemini, de A à Z, et le connecter à un pipeline CI/CD entièrement agentique. À la fin de ce cours, vous aurez :
- Une application Web DinoQuest fonctionnelle s'exécutant sur Cloud Run (nom du service :
dinoquest) - Un pipeline d'analyse de journaux qui diffuse les journaux Cloud Run dans BigQuery et génère un tableau de bord interactif sur les insights de jeu
- Agent de correction (
remediation-agent) : agent de correction ADK qui surveille les erreurs Cloud Run et les corrige automatiquement. Il est déployé en tant que service Cloud Run distinct déclenché par Eventarc. - Un agent CI (
ci-agent) qui lit le diff de votre demande d'extraction, définit intelligemment le champ d'application des tests, crée une image Docker via Cloud Build et publie un état de commit sur GitHub - Un agent CD qui évalue le risque de déploiement, répartit le trafic, surveille les métriques et promeut ou restaure automatiquement
Points abordés
- Déployer une application Vite + FastAPI full stack sur Cloud Run en tant que conteneur unique
- Configurer Firebase Auth et Firestore pour une application React
- Comment créer et déployer un agent ADK qui réagit aux événements Pub/Sub via Eventarc
- Acheminer les journaux Cloud Run vers BigQuery et interroger les données analytiques sur les jeux
- Écrire des compétences agentiques pour la CI et le déploiement canary
Prérequis
- Un projet Google Cloud avec facturation activée
- Un projet Firebase (qui peut être le même projet GCP)
- Un compte GitHub et une copie du dépôt DinoQuest
- Accès à Antigravity avec Gemini (l'outil d'exécution d'agents de Google)
- La gcloud CLI est installée et authentifiée. Consultez les instructions d'installation ci-dessous.
gcloud node≥ 18 etnpmpython3≥ 3.11gitetgh(GitHub CLI)
Installer gcloud CLI
macOS
brew install --cask google-cloud-sdk
Vous pouvez également télécharger le programme d'installation depuis cloud.google.com/sdk/docs/install.
Windows
winget install Google.CloudSDK
Vous pouvez également télécharger le programme d'installation Windows (.exe) depuis cloud.google.com/sdk/docs/install et l'exécuter.
Après l'installation, initialisez et authentifiez :
gcloud init
gcloud auth login
gcloud auth application-default login
2. Configurer Firebase
Chaque agent a besoin de données pour raisonner. DinoQuest utilise Firestore et Firebase Auth pour fournir une couche de données prête pour la production que nos agents découvriront, exploreront et mettront à jour ultérieurement en langage naturel.
Comme cette application a été générée via AI Studio, elle est fortement intégrée à Firebase. L'utilisation de Firebase offre plusieurs avantages, dont une architecture pré-sécurisée et un accès aux données géré prêt à l'emploi, ce qui garantit la protection de l'état de votre jeu dès le premier jour.
A. Créer un projet Firebase
- Accédez à console.firebase.google.com.
- Cliquez sur Ajouter un projet (cette option est masquée dans l'option "Créer un projet") → sélectionnez votre projet GCP existant (ou créez-en un).
- Désactivez Google Analytics si vous y êtes invité → Créer un projet (ou conservez le paramètre par défaut).
B. Activation de l'authentification Google
- Dans la console Firebase, accédez à Sécurité → Authentification (Premiers pas) → Méthode de connexion.
- Cliquez sur Google → activez Activer → enregistrez votre adresse e-mail d'assistance → Enregistrer.
C. Ajouter localhost en tant que domaine autorisé
- Toujours dans Authentification, cliquez sur l'onglet Paramètres.
- Sous Domaines autorisés, vérifiez que
localhostest listé (il devrait l'être par défaut).
D. Créer une base de données Firestore
- Accédez à Base de données et stockage → Base de données Firestore → Créer une base de données.
- Sélectionnez Édition Standard → Suivant.
- Sélectionnez une région
us-central1(ou celle de votre région Cloud Run). - Sélectionnez Démarrer en mode production → Créer.
Une fois la base de données créée, notez son ID. Il ressemblera à (default), sauf si vous lui avez donné un nom.
E. Définir des règles de sécurité Firebase
Dans Firestore Database → Rules (Base de données Firestore → Règles), remplacez les règles par défaut par les suivantes :
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
// ===============================================================
// Helper Functions
// ===============================================================
function isAuthenticated() {
return request.auth != null;
}
function isOwner(userId) {
return isAuthenticated() && request.auth.uid == userId;
}
function isValidUser(data) {
return data.keys().hasAll(['uid', 'email']) &&
data.uid is string && data.uid.size() > 0 &&
(data.email == null || (data.email is string && data.email.matches("^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$")));
}
function isValidDinosaur(data) {
return data.keys().hasAll(['userId', 'name', 'type']) &&
data.userId == request.auth.uid &&
data.name is string && data.name.size() > 0 && data.name.size() < 50 &&
data.type in ['Speedy', 'Tank', 'Balanced', 'Agile'];
}
function isValidGame(data) {
return data.keys().hasAll(['userId', 'score']) &&
data.userId == request.auth.uid &&
data.score is number && data.score >= 0;
}
match /users/{userId} {
allow read: if isOwner(userId);
allow create: if isOwner(userId) && isValidUser(request.resource.data);
allow update: if isOwner(userId) && isValidUser(request.resource.data);
match /dinosaurs/{dinoId} {
allow read: if isOwner(userId);
allow create: if isOwner(userId) && isValidDinosaur(request.resource.data);
allow update: if isOwner(userId) && isValidDinosaur(request.resource.data);
}
match /games/{gameId} {
allow read: if isOwner(userId);
allow create: if isOwner(userId) && isValidGame(request.resource.data);
}
match /seenAnnouncements/{announcementId} {
allow read, create: if isOwner(userId);
}
}
match /announcements/{announcementId} {
allow read: if isAuthenticated();
}
// Default deny
match /{document=**} {
allow read, write: if false;
}
match /scores/{scoreId} {
allow read: if true;
allow create: if isAuthenticated();
allow update: if false;
}
}
}
Cliquez sur Publier.
F. Ajouter une application Web et obtenir la configuration
- Accédez à Paramètres du projet (icône en forme de roue dentée) → onglet Général.
- Faites défiler la page jusqu'à Vos applications → cliquez sur Ajouter une application → choisissez l'icône Web (
). - Nommez-le
dinoquest→ Enregistrer l'application - Copiez l'objet
firebaseConfigaffiché, vous en aurez besoin dans un instant.
3. Exécuter le jeu
Rôle de l'agent : l'environnement Avant de pouvoir faire travailler nos agents, nous avons besoin d'un monde à gérer. Dans cette étape, nous allons déployer la version "Day One" de DinoQuest. Cette opération crée le service en direct, les journaux et l'état que notre essaim découvrira et gérera ultérieurement.
Choisissez l'une des deux options ci-dessous. Dans les deux cas, vous obtenez un GEMINI_API_KEY que vous utilisez de manière identique à chaque étape ultérieure. Aucune autre modification n'est nécessaire.
A. Configurer la clé API Gemini
Option A : Clé API Vertex AI Gemini (recommandée si vous disposez d'un projet GCP)
Vertex AI vous permet de créer une clé API Gemini directement associée à votre projet GCP et facturée à celui-ci, à l'aide du compte de service par défaut du projet. Vous n'avez pas besoin d'un compte AI Studio distinct.
- Exportez votre ID de projet GCP :
export PROJECT_ID=<YOUR_PROJECT_ID> - Activez les API requises et accordez les autorisations nécessaires au compte de service Compute Engine par défaut :
gcloud auth application-default set-quota-project $PROJECT_ID gcloud config set project $PROJECT_ID # Enable Vertex AI, Compute Engine, and Generative Language APIs gcloud services enable aiplatform.googleapis.com \ compute.googleapis.com \ generativelanguage.googleapis.com # Grant Vertex AI User role to the default compute service account PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:${PROJECT_NUMBER}-compute@developer.gserviceaccount.com" \ --role="roles/aiplatform.user" \ --condition=None - Ouvrez la page Clés API Vertex AI dans la console Cloud.
- Cliquez sur Créer des identifiants → sélectionnez Clé API.
- Dans la boîte de dialogue de création :
- Nommez la clé
Dino_Key. - Cochez la case Authentifier les appels d'API avec un compte de service.
- Sous "Compte de service", sélectionnez le compte de service Compute par défaut (
PROJECT_NUMBER-compute@developer.gserviceaccount.com). - De retour dans Sélectionner des restrictions d'API, cochez GEMINI API.
- Cliquez sur Créer.
- Nommez la clé
- Copiez la clé générée.
Option B : AI Studio (la plus rapide pour le développement en local)
- Ouvrez aistudio.google.com.
- Cliquez sur Obtenir une clé API dans la barre latérale de gauche.
- Cliquez sur Créer une clé API → choisissez votre projet GCP → copiez la clé.
Dans les étapes suivantes, l'une ou l'autre des clés est définie sur GEMINI_API_KEY. Le backend les traite de la même manière.
Cloner le dépôt
Le dépôt du cours se trouve dans https://github.com/gca-americas/dinoquest. Veuillez d'abord le dupliquer sur votre propre compte GitHub. L'agent travaillera plutôt sur votre dépôt.
Après avoir créé un fork, clonez la branche main de votre dépôt DinoQuest et accédez au répertoire du projet :
git clone https://github.com/YOUR_GITHUB_USERNAME/dinoquest.git
cd dinoquest
B. Configurer des variables d'environnement
Dans chaque nouveau terminal Bash que vous ouvrez au cours de cet atelier de programmation, assurez-vous de définir ces variables d'environnement essentielles. Remplacez les valeurs d'espace réservé par les informations réelles de votre projet :
Commencez par exporter l'URL de votre dépôt GitHub :
export GITHUB_REPO_URL=https://github.com/YOUR_GITHUB_USERNAME/dinoquest
Exportez ensuite les variables d'environnement restantes :
export PROJECT_ID=your-project-id
export GOOGLE_CLOUD_PROJECT=$PROJECT_ID
export CLOUD_RUN_REGION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
export HARNESS_EVENTS_TOPIC=projects/$PROJECT_ID/topics/harness-events
export CLOUD_BUILD_REPO=<YOUR_GITHUB_USERNAME>-dinoquest
Vérifiez que la structure est correcte :
dinoquest/
├── backend/ # FastAPI backend (serves frontend + Gemini API calls)
├── frontend/ # React/Vite frontend
├── skills/ # Agentic CI/CD skill files
├── Dockerfile # Multi-stage build (React → Python)
├── start.sh # Local dev launcher
└── README.md
B. Créer le fichier d'environnement backend
Commencez par exporter votre clé API Gemini :
export GEMINI_API_KEY=YOUR_GEMINI_API_KEY_FROM_STEP_2
Créez ensuite le fichier .env :
cat > backend/.env <<EOF
GEMINI_API_KEY=$GEMINI_API_KEY
GOOGLE_GENAI_USE_VERTEXAI=False
GOOGLE_CLOUD_PROJECT=$PROJECT_ID
EOF
C. Activer Firebase App Check / le compte de service (pour Cloud Run)
Lors de l'exécution sur Cloud Run, le backend utilise les identifiants par défaut de l'application pour communiquer avec Firebase. Aucun fichier de clé de compte de service n'est nécessaire. L'appel firebase_admin.initialize_app() dans backend/main.py le récupère automatiquement.
Pour le développement local, authentifiez-vous une seule fois :
gcloud auth application-default login
D. Créer le fichier de configuration de l'application Firebase
Dans le répertoire frontend/, créez firebase-applet-config.json avec votre configuration de l'étape précédente :
{
"apiKey": "YOUR_API_KEY",
"authDomain": "YOUR_PROJECT_ID.firebaseapp.com",
"projectId": "YOUR_PROJECT_ID",
"storageBucket": "YOUR_PROJECT_ID.appspot.com",
"messagingSenderId": "YOUR_SENDER_ID",
"appId": "YOUR_APP_ID",
"firestoreDatabaseId": "(default)"
}
Remarque : firestoreDatabaseId doit correspondre à l'ID de base de données que vous avez créé à l'étape précédente. Si vous avez utilisé la valeur par défaut, laissez-la telle quelle ("(default)").
Effectuez un commit des modifications dans votre dépôt :
git add frontend/firebase-applet-config.json
git commit -m "chore: add firebase config"
git push origin main
C. Exécuter DinoQuest en local
1. Activer les API requises
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
secretmanager.googleapis.com \
firestore.googleapis.com \
logging.googleapis.com \
pubsub.googleapis.com \
eventarc.googleapis.com \
aiplatform.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com
2. Démarrer DinoQuest
Le script start.sh crée l'interface React et transmet le terminal au backend FastAPI, qui diffuse les fichiers statiques compilés :
cd backend
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt -q
cd ..
# Force-remove the Vertex AI flag from the current terminal session to avoid conflicts
unset GOOGLE_GENAI_USE_VERTEXAI
./start.sh
Ouvrez http://localhost:8000 dans votre navigateur. L'écran de titre de Dino Quest devrait s'afficher. Connectez-vous avec Google, générez votre premier dinosaure et vérifiez qu'il est bien enregistré dans Firestore.
Dépannage : Si une page blanche s'affiche ou si des erreurs d'authentification Firebase se produisent, vérifiez que frontend/firebase-applet-config.json contient les valeurs correctes et que localhost figure dans la liste des domaines autorisés.
E. Déployer DinoQuest sur Cloud Run
1. Définir votre projet
export PROJECT_ID=$(gcloud config get-value project)
3. Créer un dépôt Artifact Registry
gcloud artifacts repositories create dinoquest \
--repository-format=docker \
--location=$CLOUD_RUN_REGION \
--description="DinoQuest container images"
4. Stocker la clé API Gemini dans Secret Manager
echo -n $GEMINI_API_KEY | \
gcloud secrets create gemini-api-key --data-file=-
# Grant the default compute service account access to the secret
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
gcloud secrets add-iam-policy-binding gemini-api-key \
--member="serviceAccount:${PROJECT_NUMBER}-compute@developer.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Créer l'image de conteneur avec Cloud Build
gcloud builds submit \
--tag $CLOUD_RUN_REGION-docker.pkg.dev/$PROJECT_ID/dinoquest/app:latest .
Cela exécute le fichier Dockerfile à plusieurs étapes : il crée d'abord l'application React, puis empaquette la sortie dans l'image FastAPI. Cela prend environ trois à cinq minutes.
6. Déployer dans Cloud Run
Commencez par exporter votre adresse e-mail d'administrateur :
export ADMIN_EMAIL=<YOUR_TEST_ACCOUNT_EMAIL>
Déployez ensuite le service :
gcloud run deploy dinoquest \
--image=$CLOUD_RUN_REGION-docker.pkg.dev/$PROJECT_ID/dinoquest/app:latest \
--region=$CLOUD_RUN_REGION \
--platform=managed \
--allow-unauthenticated \
--memory=128Mi \
--set-secrets="GEMINI_API_KEY=gemini-api-key:latest" \
--set-env-vars="ADMIN_EMAILS=$ADMIN_EMAIL" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=False" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=$PROJECT_ID"
Une fois la commande exécutée, Cloud Run affiche une URL du service. Copiez cette URL, car vous en aurez besoin pour autoriser le domaine dans Firebase.
7. Autoriser le domaine Cloud Run dans Firebase
Pour permettre aux utilisateurs de se connecter depuis votre application déployée, vous devez ajouter l'URL Cloud Run aux domaines autorisés de Firebase :
- Revenez à la console Firebase → Authentification → Paramètres → Domaines autorisés.
- Cliquez sur Ajouter un domaine.
- Collez l'URL de votre service Cloud Run (par exemple,
dinoquest-xxxxx.us-central1.run.app) : supprimez le préfixehttps://. - Cliquez sur Enregistrer.
8. Insérer les données du classement
Pour donner un peu de "vie" à votre jeu et vous assurer que vos agents disposent de données, vous pouvez alimenter le classement avec des scores de départ.
- Assurez-vous d'être dans le répertoire racine
dinoquest:cd ~/dinoquest - Créez et activez un environnement virtuel :
python3 -m venv venv source venv/bin/activate - Installez la dépendance Firestore requise :
pip install google-cloud-firestore - Exécutez le script d'amorçage :
python3 prep/seed_scores.py - Désactivez l'environnement virtuel :
deactivate
Vous pouvez maintenant ouvrir l'URL du service dans votre navigateur. DinoQuest est entièrement en ligne.
4. Configurer Dino Theater
Rôle d'agent : Visualiseur. Comment surveiller une équipe d'agents autonomes ? Dino Theater offre une fenêtre en temps réel sur l'esprit de votre essaim d'agents. Au lieu de fixer les journaux du terminal, vous pouvez regarder vos agents raisonner, s'appeler et exécuter des tâches dans le cloud dans un tableau de bord visuel en direct.
A. Déployer Dino Theater sur Cloud Run
Commencez par revenir à votre répertoire d'accueil et clonez le code Dino Theater :
cd ~
git clone https://github.com/gca-americas/dinoquest-theater.git
cd dinoquest-theater
- Créez et transférez le conteneur :
gcloud builds submit --tag $CLOUD_RUN_REGION-docker.pkg.dev/$PROJECT_ID/dinoquest/dino-theater:latest . - Configurer le compte de service et les autorisations :
# Create the service account gcloud iam service-accounts create dino-theater # Create the Pub/Sub topic (if you haven't yet) gcloud pubsub topics create harness-events # Create the subscription gcloud pubsub subscriptions create harness-events-theater \ --topic=harness-events # Grant subscriber role gcloud pubsub subscriptions add-iam-policy-binding harness-events-theater \ --member="serviceAccount:dino-theater@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber" - Déployez l'application :
gcloud run deploy dino-theater \ --image $CLOUD_RUN_REGION-docker.pkg.dev/$PROJECT_ID/dinoquest/dino-theater:latest \ --region=$CLOUD_RUN_REGION \ --service-account=dino-theater@${PROJECT_ID}.iam.gserviceaccount.com \ --set-env-vars="GOOGLE_CLOUD_PROJECT=$PROJECT_ID" \ --allow-unauthenticated \ --min-instances=1--min-instances=1est recommandé pour maintenir la connexion SSE active entre les événements. - Vérifiez que cela fonctionne : ouvrez l'URL du service déployé dans votre navigateur (par exemple,
https://dino-theater-xxx-uc.a.run.app/demo).
5. DevOps agentique dans l'IDE
Rôle de l'agent : Antigravity natif. Pour combler le fossé entre votre IDE et le cloud, nous connectons Antigravity aux serveurs MCP gérés de Google Cloud. Cela donne à votre agent natif des "yeux" sur votre projet, ce qui lui permet d'analyser les journaux, de vérifier les métriques et de raisonner sur l'infrastructure sans que vous ayez à jongler avec les clés API ni à passer à la console.
Avant d'exécuter des compétences, vous devez configurer l'accès d'Antigravity à Google Cloud et charger les playbooks de compétences DinoQuest.
A. Installer le service MCP géré de Google
Le service MCP géré de Google permet d'accéder à toutes les API Cloud de Google via un seul point de terminaison hébergé.
Authentifiez-vous à l'aide des identifiants par défaut de l'application :
gcloud auth application-default login
B. Configurer mcp_config.json
Créez ou mettez à jour mcp_config.json dans votre répertoire de configuration Antigravity (généralement ~/.gemini/antigravity/mcp_config.json) ou depuis la console. Cela permet à Antigravity d'accéder aux outils Google Cloud et GitHub dont les compétences ont besoin :
{
"mcpServers": {
"google-developer-knowledge": {
"serverUrl": "https://developerknowledge.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-bigquery": {
"serverUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-cloud-logging": {
"serverUrl": "https://logging.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-cloud-monitoring": {
"serverUrl": "https://monitoring.googleapis.com/mcp",
"authProviderType": "google_credentials",
"disabledTools": [
"get_dashboard",
"list_dashboards"
]
},
"google-cloud-run": {
"serverUrl": "https://run.googleapis.com/mcp",
"authProviderType": "google_credentials",
"disabledTools": [
"deploy_service_from_image",
"deploy_service_from_archive",
"deploy_service_from_file_contents"
]
},
"google-cloud-sql": {
"serverUrl": "https://sqladmin.googleapis.com/mcp",
"authProviderType": "google_credentials",
"disabled": true
},
"google-cloud-trace": {
"serverUrl": "https://cloudtrace.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-error-reporting": {
"serverUrl": "https://clouderrorreporting.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-firestore": {
"serverUrl": "https://firestore.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"google-resource-manager": {
"serverUrl": "https://cloudresourcemanager.googleapis.com/mcp",
"authProviderType": "google_credentials"
},
"gemini-cloud-assist": {
"serverUrl": "https://geminicloudassist.googleapis.com/mcp",
"authProviderType": "google_credentials"
}
}
}
C. Charger des compétences dans Antigravity (facultatif)
Antigravity découvre les compétences dans des répertoires standards spécifiques. Copiez les compétences DinoQuest de votre dépôt cloné dans le dossier global des compétences Antigravity :
# Create the standard skills directory if it doesn't exist
mkdir -p ~/.gemini/antigravity/skills
# Copy all DinoQuest skills into the global skills folder
cp -r skills/* ~/.gemini/antigravity/skills/
D. Redémarrer Antigravity(facultatif)
Pour appliquer les modifications apportées à mcp_config.json et charger les compétences nouvellement copiées, redémarrez l'application Antigravity.
Une fois le redémarrage effectué :
- Vérifiez que les serveurs MCP google et github affichent l'état "Connecté" en vert dans Paramètres.
- Vérifiez que les skills DinoQuest apparaissent dans votre liste de skills.
Remarque : Chaque compétence dispose d'un tableau ## Configuration en haut de sa SKILL.md. Après la copie, vous devez mettre à jour les valeurs dans ~/.gemini/antigravity/skills/ pour qu'elles correspondent à votre projet.
E. Corriger un service cloud dans un IDE local
- Déclenchez l'erreur : ouvrez l'URL DinoQuest déployée (à partir de la dernière étape) dans votre navigateur.
- Accéder au classement : cliquez sur le bouton Classement. L'implémentation actuelle du classement est intentionnellement inefficace. Elle tente de charger une énorme quantité de données en mémoire, ce qui déclenche une erreur de mémoire insuffisante (OOM).
- Dans Antigravity Agent Manager (Agent HUB), demandez-lui de vous aider à résoudre l'erreur et éventuellement à corriger la cause première.
- prompt 1: Find out what's wrong with dinoquest.
- Requête 2 : Peux-tu examiner le code du jeu Dinoquest et corriger ce qui a provoqué l'erreur de mémoire insuffisante ?
6. Transférer des journaux vers BigQuery et générer des données analytiques
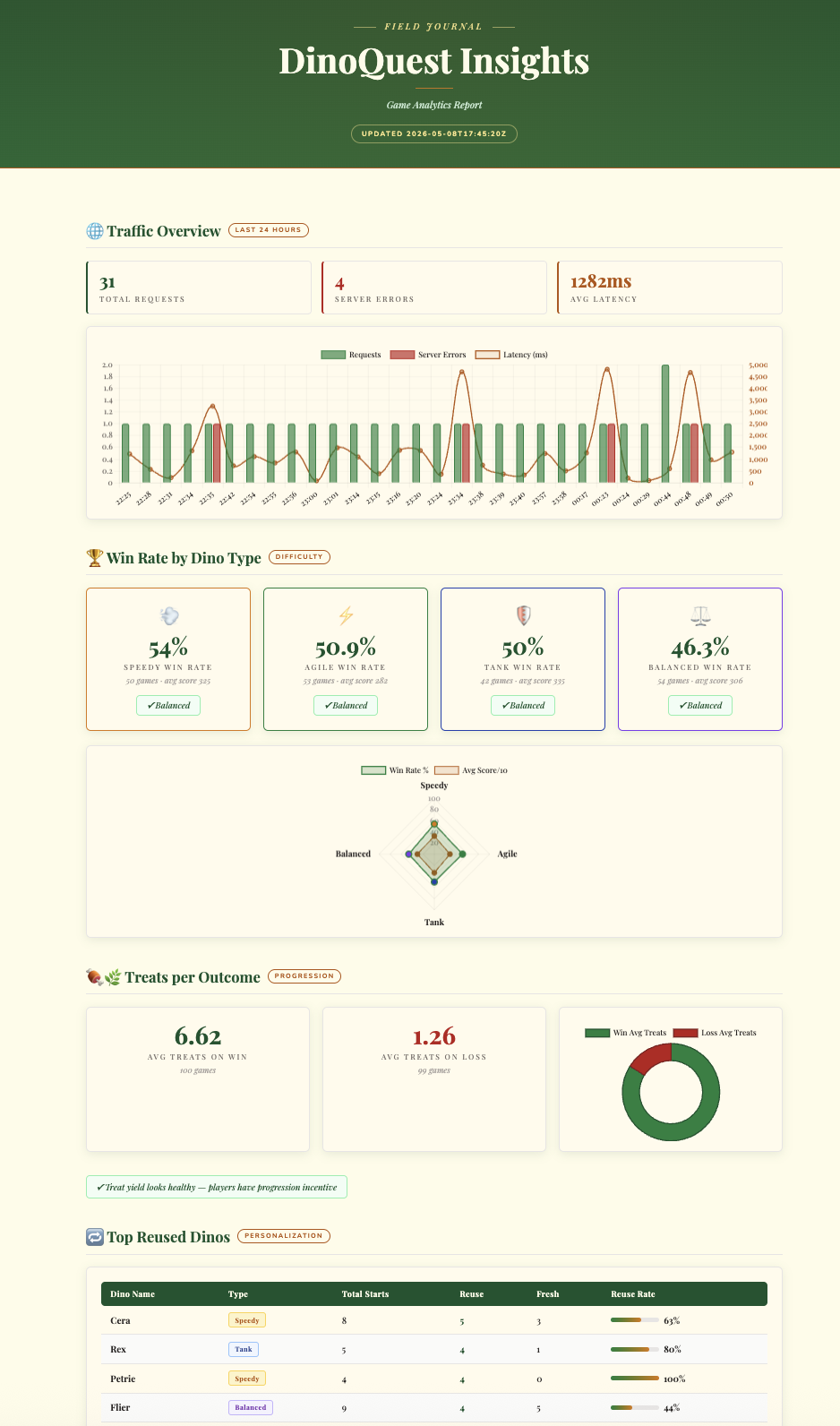
Rôle de l'agent : agent de données. Transformer des journaux bruts en stratégie produit exploitable ne devrait pas prendre des heures de traitement manuel des données. À l'aide du kit d'agent de données et de BigQuery MCP, nous créons un pipeline "Zero ETL" qui diffuse les journaux directement dans BigQuery, ce qui permet à l'agent de générer un tableau de bord d'analyse premium en moins de deux minutes.
La compétence log-router-bq-report configure un récepteur Cloud Logging qui diffuse en continu les journaux Cloud Run de DinoQuest dans BigQuery, puis interroge les données pour générer des rapports sur le trafic et des insights sur l'analyse des jeux.
A. Configurer les variables de compétence
Ouvrez skills/log-router-bq-report/SKILL.md dans votre dépôt DinoQuest et mettez à jour la section Configuration en haut :
| Variable | Your Value |
|---------------|--------------------|
| SERVICE_NAME | dinoquest |
| BQ_DATASET | dinoquest_logs |
| LOG_SINK_NAME | dinoquest-bq-sink |
B. Exécuter la compétence dans Antigravity
Ouvrez Antigravity avec le dépôt DinoQuest comme contexte et dites à Gemini :
Run the log-router-bq-report skill
La compétence :
- Résoudre automatiquement les problèmes liés à votre projet GCP
- Vérifiez si le récepteur BigQuery existe déjà. Si ce n'est pas le cas, l'ensemble de données et le récepteur seront créés.
- Accorder des autorisations IAM : accorde le rôle Éditeur de données BigQuery à
writerIdentitydu récepteur sur l'ensemble de données.
Remarque : Tout comme pour le récepteur Eventarc, vous pouvez voir un avertissement de gcloud pendant ce processus : "N'oubliez pas d'attribuer le rôle Éditeur de données BigQuery à serviceAccount:service-... sur l'ensemble de données." La skill gère cela automatiquement.
C. Utiliser Antigravity pour générer le rapport
Il vous suffit de demander à Antigravity de configurer le collecteur de journaux BigQuery et de générer le rapport d'analyse. L'agent :
- Configurer l'infrastructure : créez l'ensemble de données BigQuery et le récepteur Cloud Logging.
- Gérer les autorisations : accorde automatiquement les rôles IAM nécessaires à l'identité du rédacteur du récepteur.
- Générer des insights : analysez les journaux et générez un tableau de bord HTML interactif premium avec des données télémétriques sur le jeu et une analyse du taux de victoire.
7. Agent de correction autoréparateur
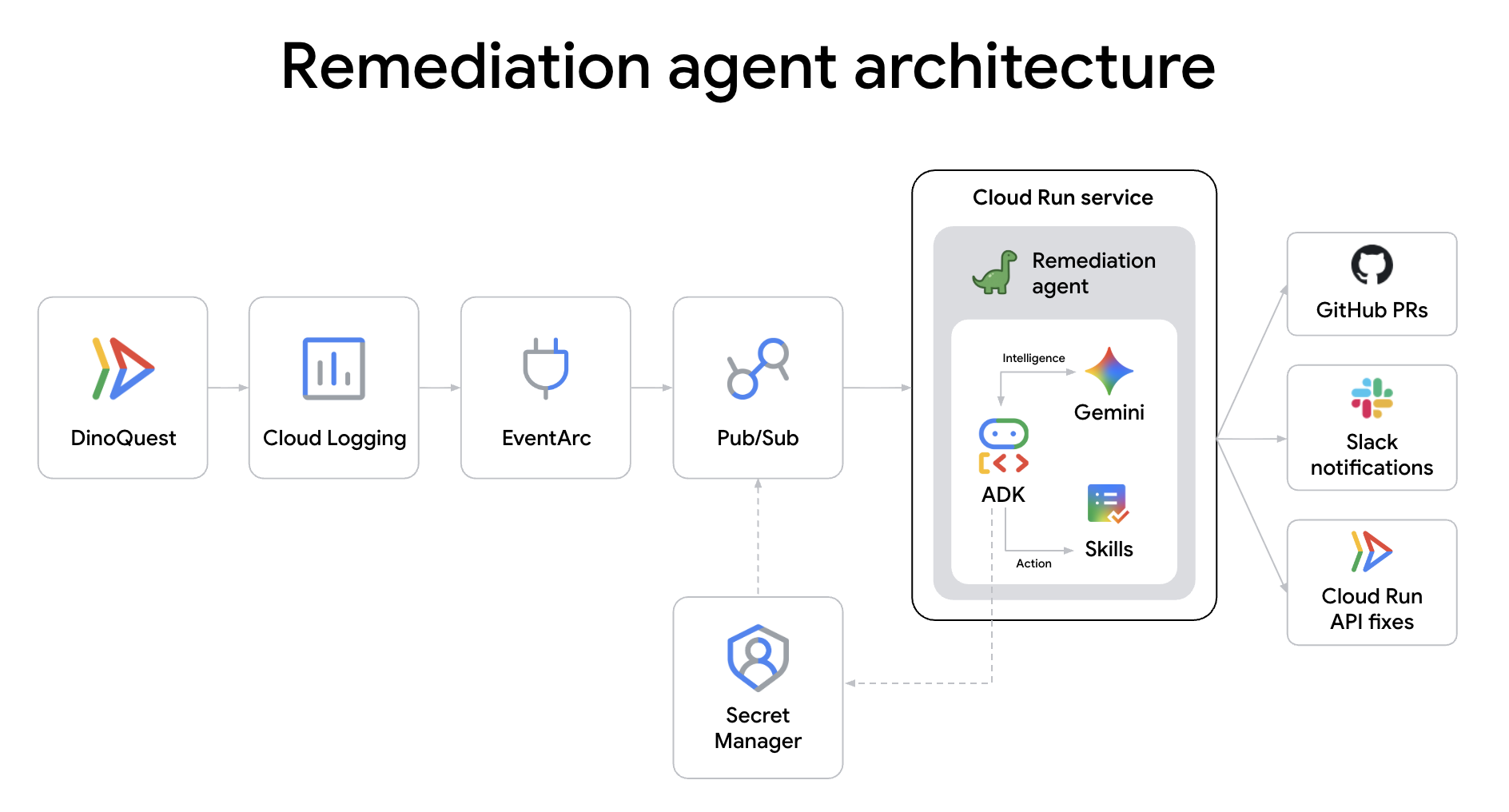
Rôle de l'agent : agent SRE. Lorsqu'un service de production échoue à 2 h du matin, vous ne devriez pas avoir à vous réveiller. Cet agent est votre premier interlocuteur. Déclenché par les journaux d'erreurs Cloud Run via Eventarc, il analyse automatiquement le plantage, propose une solution et lance un pipeline de correction, le tout avant même que vous ne vous connectiez à la console.
DinoAgent est un agent ADK qui écoute les journaux d'erreurs Cloud Run via Eventarc, diagnostique la cause première et corrige automatiquement le problème en augmentant la mémoire, en rétablissant le trafic ou en déposant une demande d'extraction de correction de code sur GitHub.
A. Cloner le dépôt de l'agent de correction
cd ~
git clone https://github.com/gca-americas/dinoquest-reme-agent.git
cd dinoquest-reme-agent
Structure du projet :
dinoquest-reme-agent/
├── main.py # Service entrypoint — receives Eventarc HTTP POST, runs agent
├── runner.py # ADK Runner + session service
├── agent.py # LlmAgent definition, loads skill from file
├── tools.py # Cloud Run v2 API tools (list/get/rollback/update)
├── skills/
│ └── remediation/
│ ├── SKILL.md # Agent playbook — edit this to change behavior
│ └── scripts/ # Shell scripts for the code-fix track
│ ├── clone_repo.sh
│ ├── read_file.sh
│ ├── apply_fix.sh
│ ├── commit_branch.sh
│ ├── open_pr.sh
│ └── rollback_fix.sh
├── requirements.txt
└── Dockerfile
B. Configurer l'accès à GitHub (piste de correction du code)
Le suivi de correction de code clone votre dépôt DinoQuest, lit les fichiers sources, applique les correctifs et ouvre les demandes d'extraction. Il a besoin d'un jeton d'accès personnel GitHub avec le champ d'application repo.
- Accédez à github.com/settings/tokens → Generate new token (classic) (Générer un jeton (classique)).
- Donnez-lui un nom, sélectionnez le champ d'application
repo→ Générer un jeton → copiez-le.
Stocker le jeton dans Secret Manager :
Commencez par exporter votre jeton GitHub :
export GH_TOKEN=ghp_YOUR_TOKEN_HERE
Créez ensuite le secret :
echo -n $GH_TOKEN | \
gcloud secrets create github-token --data-file=-
C. Configurer les notifications Slack (facultatif)
Lorsqu'une correction est terminée, DinoAgent publie un récapitulatif dans un canal Slack.
- Accédez à api.slack.com/apps → Create New App → From scratch (Créer une application → À partir de zéro).
- Nommez-la
DinoAgent, sélectionnez votre espace de travail → Créer une application - Sous Fonctionnalités → Webhooks entrants → activez l'option.
- Cliquez sur Add New Webhook to Workspace (Ajouter un nouveau webhook à l'espace de travail) → choisissez un canal → Allow (Autoriser).
- Copiez l'URL du webhook (
https://hooks.slack.com/services/...).
Stocker le jeton dans Secret Manager :
export SLACK_TOKEN=YOUR_SLACK_WEBHOOK
echo -n "https://hooks.slack.com/services/$SLACK_TOKEN" | \
gcloud secrets create slack-webhook --data-file=-
D. Créer le compte de service DinoAgent
gcloud iam service-accounts create remediation-agent \
--display-name="Cloud Run Remediation Agent"
export SA="remediation-agent@${PROJECT_ID}.iam.gserviceaccount.com"
for ROLE in \
roles/run.admin \
roles/iam.serviceAccountUser \
roles/eventarc.eventReceiver \
roles/aiplatform.user \
roles/artifactregistry.reader \
roles/secretmanager.secretAccessor \
roles/pubsub.publisher \
roles/logging.viewer; do
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA}" --role="$ROLE" \
--condition=None
done
Accordez-lui l'accès aux secrets :
for SECRET in github-token slack-webhook; do
gcloud secrets add-iam-policy-binding $SECRET \
--member="serviceAccount:${SA}" \
--role="roles/secretmanager.secretAccessor"
done
E. Créer et déployer DinoAgent sur Cloud Run
# Get Project Number for the CIAgent URL
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export CIAGENT_URL=https://ci-agent-${PROJECT_NUMBER}.${CLOUD_RUN_REGION}.run.app
export SA="remediation-agent@${PROJECT_ID}.iam.gserviceaccount.com"
export GITHUB_REPO_URL=https://github.com/YOUR_REPO
HARNESS_EVENTS_TOPIC=projects/$PROJECT_ID/topics/harness-events
AGENT_IMAGE="$CLOUD_RUN_REGION-docker.pkg.dev/${PROJECT_ID}/dinoquest/remediation-agent:latest"
gcloud builds submit --tag $AGENT_IMAGE .
gcloud run deploy remediation-agent \
--image=$AGENT_IMAGE \
--region=$CLOUD_RUN_REGION \
--service-account=$SA \
--memory=2Gi \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID},GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="GITHUB_REPO_URL=${GITHUB_REPO_URL}" \
--set-secrets="SLACK_WEBHOOK_URL=slack-webhook:latest" \
--set-env-vars="HARNESS_EVENTS_TOPIC=${HARNESS_EVENTS_TOPIC}" \
--set-env-vars="CIAGENT_URL=${CIAGENT_URL}" \
--set-secrets="GITHUB_TOKEN=github-token:latest" \
--no-allow-unauthenticated \
--min-instances=1 \
--no-cpu-throttling \
--timeout=300
F. Connecter le déclencheur Eventarc
Créez un sujet Pub/Sub pour recevoir les journaux d'erreur Cloud Run :
gcloud pubsub topics create cloud-run-errors
Créez un récepteur Cloud Logging qui filtre les journaux d'erreur de votre service dinoquest et les achemine vers le sujet :
export SERVICE_NAME=dinoquest
FILTER="resource.type=\"cloud_run_revision\" resource.labels.service_name=\"$SERVICE_NAME\" severity=ERROR NOT logName=~\"cloudaudit\" NOT httpRequest.requestUrl=~\"/_ah/health\""
gcloud logging sinks create cloud-run-errors-sink \
pubsub.googleapis.com/projects/${PROJECT_ID}/topics/cloud-run-errors \
--log-filter="$FILTER"
Remarque : Lorsque vous exécutez la commande ci-dessus, gcloud affiche un message Info indiquant : "N'oubliez pas d'attribuer le rôle d'éditeur Pub/Sub au compte de service serviceAccount:service-... sur le sujet." C'est exactement ce que fait l'étape suivante.
Accordez l'autorisation de publier à l'identité du rédacteur du récepteur (le compte de service mentionné dans l'avertissement) :
SINK_SA=$(gcloud logging sinks describe cloud-run-errors-sink \
--format='value(writerIdentity)')
gcloud pubsub topics add-iam-policy-binding cloud-run-errors \
--member="${SINK_SA}" --role="roles/pubsub.publisher"
Vérifiez qu'il est actif :
gcloud eventarc triggers describe remediation-trigger --location=$CLOUD_RUN_REGION
Accordez à Eventarc l'autorisation d'appeler l'agent de correction :
gcloud run services add-iam-policy-binding remediation-agent \
--region=$CLOUD_RUN_REGION \
--member="serviceAccount:${SA}" \
--role="roles/run.invoker"
Créez le déclencheur Eventarc :
gcloud eventarc triggers create remediation-trigger \
--location=$CLOUD_RUN_REGION \
--destination-run-service=remediation-agent \
--destination-run-region=$CLOUD_RUN_REGION \
--event-filters="type=google.cloud.pubsub.topic.v1.messagePublished" \
--transport-topic=projects/${PROJECT_ID}/topics/cloud-run-errors \
--service-account=${SA}
La correction est désormais entièrement automatisée. Au-delà de la simple mise à l'échelle de l'infrastructure, DinoAgent effectue une analyse approfondie des causes premières du code de l'application, applique un correctif sémantique et utilise la communication Agent-to-Agent (A2A) pour transmettre le correctif à l'agent CI afin qu'il le vérifie et le déploie. Vous pouvez explorer les détails de l'implémentation dans le codebase de l'agent reme.
8. Configurer l'agent CI
Rôle de l'agent : pipeline CI. Arrêtez de vous battre avec des fichiers YAML complexes et des scripts de compilation manuels. Cet agent gère les aspects opérationnels de vos demandes d'extraction. Il lit les modifications apportées à votre code, comprend le contexte, définit la portée des tests nécessaires et crée vos images Docker via Cloud Build. Il s'assure ainsi que chaque commit est "approuvé par l'agent" avant d'atteindre la branche principale.
ci-agent est un agent de pipeline CI autonome déployé en tant que service Cloud Run. Il envoie les compilations Docker à Cloud Build, interroge l'état d'achèvement, vérifie l'image dans Artifact Registry et envoie un rapport à GitHub.
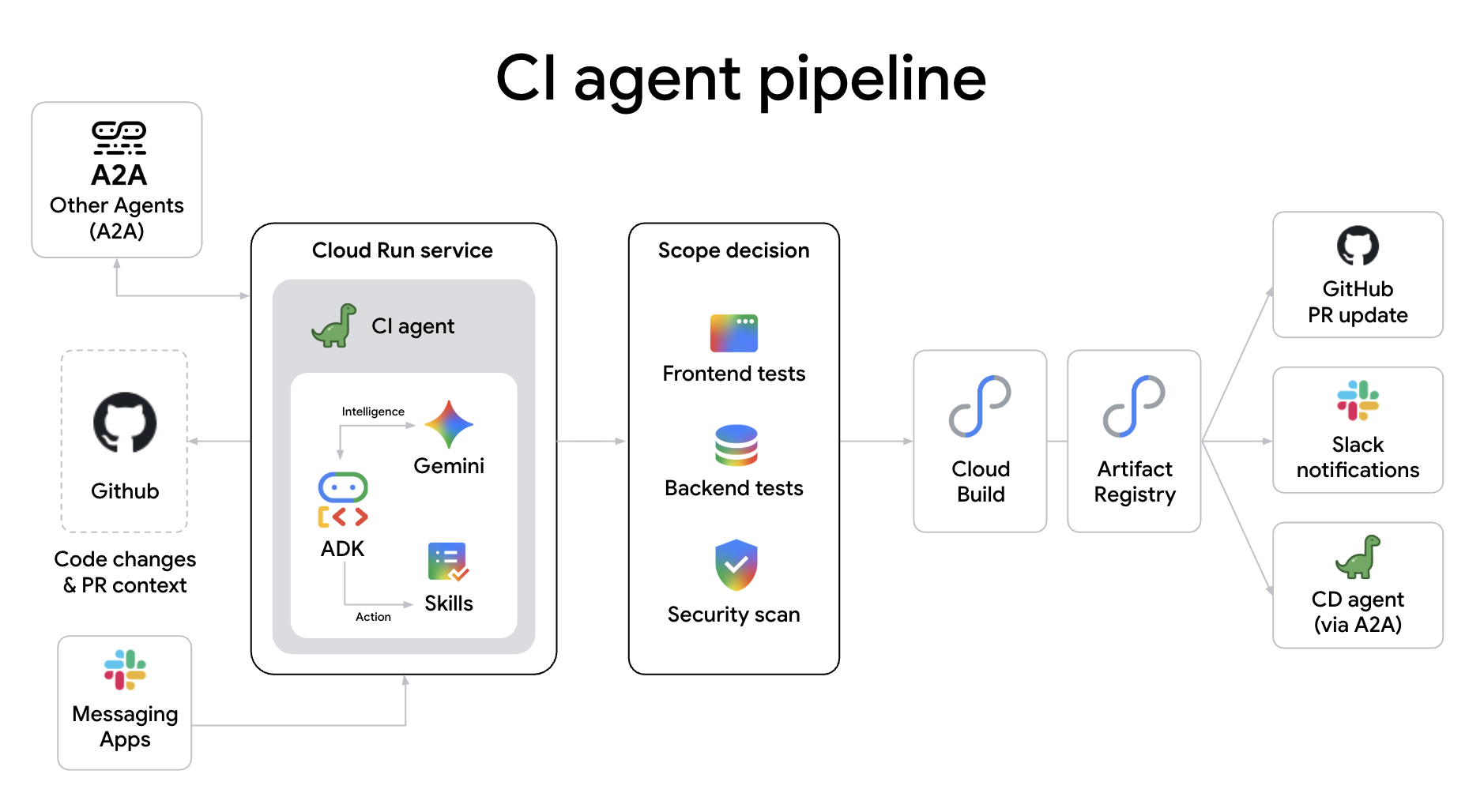
Pourquoi utiliser un agent pour votre pipeline d'intégration continue ? Contrairement aux scripts statiques traditionnels, un pipeline CI agentique offre les avantages suivants :
- Classification de la portée cognitive : elle détermine intelligemment la profondeur de test requise (en basculant entre les vérifications de type, les tests unitaires ou les suites d'intégration complètes) en fonction de l'impact sémantique des modifications apportées à votre code.
- Gestion autonome des demandes d'extraction : l'agent peut créer automatiquement des demandes d'extraction, publier des résumés détaillés des modifications et même gérer l'analyse des secrets et les audits de sécurité sans intervention humaine.
- Diagnostic des échecs en temps réel : lorsqu'une compilation échoue, l'agent ne se contente pas d'afficher les journaux. Il analyse la trace de la pile, identifie la cause probable et publie un diagnostic lisible par l'humain directement dans la demande d'extraction.
A. Cloner le dépôt CIAgent
cd ~
git clone https://github.com/gca-americas/dinoquest-ci-agent.git
cd dinoquest-ci-agent
B. Créer le compte de service CIAgent
gcloud iam service-accounts create ci-agent \
--display-name="CIAgent CI Pipeline"
export SA="ci-agent@${PROJECT_ID}.iam.gserviceaccount.com"
# Grant necessary roles to the service account
for ROLE in \
roles/cloudbuild.builds.editor \
roles/cloudbuild.builds.builder \
roles/artifactregistry.reader \
roles/artifactregistry.writer \
roles/aiplatform.user \
roles/secretmanager.secretAccessor \
roles/pubsub.publisher \
roles/developerconnect.admin; do
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA}" --role="$ROLE" \
--condition=None
done
# ci-agent needs to act as itself when running build steps
gcloud iam service-accounts add-iam-policy-binding $SA \
--member="serviceAccount:${SA}" \
--role="roles/iam.serviceAccountUser"
C. Connecter un dépôt GitHub à Cloud Build
CIAgent envoie les compilations via repoSource, ce qui nécessite que le dépôt GitHub soit connecté à Cloud Build Developer Connect.
- Accédez à Console GCP → Cloud Build → Dépôts.
- Cliquez sur Connecter un dépôt.
- Sélectionnez GitHub (application GitHub Cloud Build).
- Autorisez et sélectionnez votre dépôt
YOUR_GITHUB_USERNAME/dinoquest. - Cliquez sur Connecter, puis sur Ignorer lorsque vous êtes invité à créer un déclencheur.
- Notez le nom de votre connexion (par défaut, il s'agit généralement de votre nom d'utilisateur GitHub ou d'un nom similaire).
D. Accorder l'accès aux secrets à CIAgent
Nous allons réutiliser les secrets créés précédemment pour DinoAgent :
gcloud secrets add-iam-policy-binding github-token \
--member="serviceAccount:${SA}" \
--role="roles/secretmanager.secretAccessor"
gcloud secrets add-iam-policy-binding slack-webhook-ci \
--member="serviceAccount:${SA}" \
--role="roles/secretmanager.secretAccessor"
E. Créer et déployer CIAgent sur Cloud Run
# Set up required variables for orchestration
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export CDAGENT_URL=https://cd-agent-${PROJECT_NUMBER}.${CLOUD_RUN_REGION}.run.app
export CI_AGENT_URL=ci-agent-${PROJECT_NUMBER}.${CLOUD_RUN_REGION}.run.app
export GITHUB_OWNER="YOUR_GITHUB_USERNAME"
export CLOUD_BUILD_CONNECTION="YOUR_CONNECTION_NAME" # Update this if your connection name is different
export CLOUD_BUILD_REPO="YOUR_GITHUB_USERNAME-dinoquest" # Update this if your connection name is different
export SLACK_TOKEN=YOUR_SLACK_WEBHOOK
echo -n "https://hooks.slack.com/services/$SLACK_TOKEN" | \
gcloud secrets create slack-webhook-ci --data-file=-
export SA="ci-agent@${PROJECT_ID}.iam.gserviceaccount.com"
AGENT_IMAGE="$CLOUD_RUN_REGION-docker.pkg.dev/${PROJECT_ID}/dinoquest/ci-agent:latest"
gcloud builds submit --tag $AGENT_IMAGE .
gcloud run deploy ci-agent \
--image=$AGENT_IMAGE \
--region=$CLOUD_RUN_REGION \
--service-account=$SA \
--memory=1Gi \
--timeout=600 \
--allow-unauthenticated \
--min-instances=1 \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID},GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="HARNESS_EVENTS_TOPIC=${HARNESS_EVENTS_TOPIC}" \
--set-env-vars="HOST=${CI_AGENT_URL},PROTOCOL=https" \
--set-secrets="SLACK_WEBHOOK_URL=slack-webhook-ci:latest" \
--set-env-vars="GITHUB_OWNER=${GITHUB_OWNER},GITHUB_REPO=dinoquest" \
--set-env-vars="CLOUD_BUILD_CONNECTION=${CLOUD_BUILD_CONNECTION},CLOUD_BUILD_REPO=${CLOUD_BUILD_REPO},CLOUD_BUILD_REGION=${CLOUD_RUN_REGION}" \
--set-env-vars="CDAGENT_URL=${CDAGENT_URL}" \
--set-secrets="GITHUB_TOKEN=github-token:latest" \
--min-instances=1
F. Configurer les commandes à barre oblique Slack
- Accédez à api.slack.com/apps → Create New App (Créer une application) → From scratch (À partir de zéro).
- Nommez-la
CIAgent, sélectionnez votre espace de travail → Créer une application - Sous Fonctionnalités → Commandes à barre oblique → Créer une commande
- Commande :
/runci - URL de la requête : URL Cloud Run de votre CIAgent ci-dessus avec
/slackajouté (par exemple,https://ci-agent-xxx-.us-central1.run.app/slack) - Brève description :
Trigger CI - Enregistrer
- Sous Paramètres → Installer l'application, cliquez sur Installer dans Workspace, puis sur "Autoriser".
L'agent CI agit comme un "cerveau" au-dessus de services Google Cloud robustes tels que Cloud Build et Artifact Registry. Une fois la build vérifiée, elle déclenche la phase de déploiement final en appelant l'agent CD via A2A, ce qui assure une transition fluide entre les cycles de compilation et de publication.
9. Configurer le déploiement
Rôle de l'agent : agent CD Le déploiement ne doit pas être une question de chance. Cet agent gère les risques pour vous. Il évalue la sécurité du déploiement, gère les répartitions du trafic canary et surveille les métriques en temps réel pour décider de promouvoir une version ou de la rétablir. Il s'agit du dernier rempart de votre essaim d'agents autonomes.
cd-agent est un agent de déploiement canary autonome déployé en tant que service Cloud Run. Il reçoit les demandes de déploiement A2A de ci-agent, calcule un score de risque, définit un pourcentage Canary calibré en fonction du risque, surveille les métriques et promeut ou restaure automatiquement. Elle apprend également des déploiements passés à l'aide de Firestore.
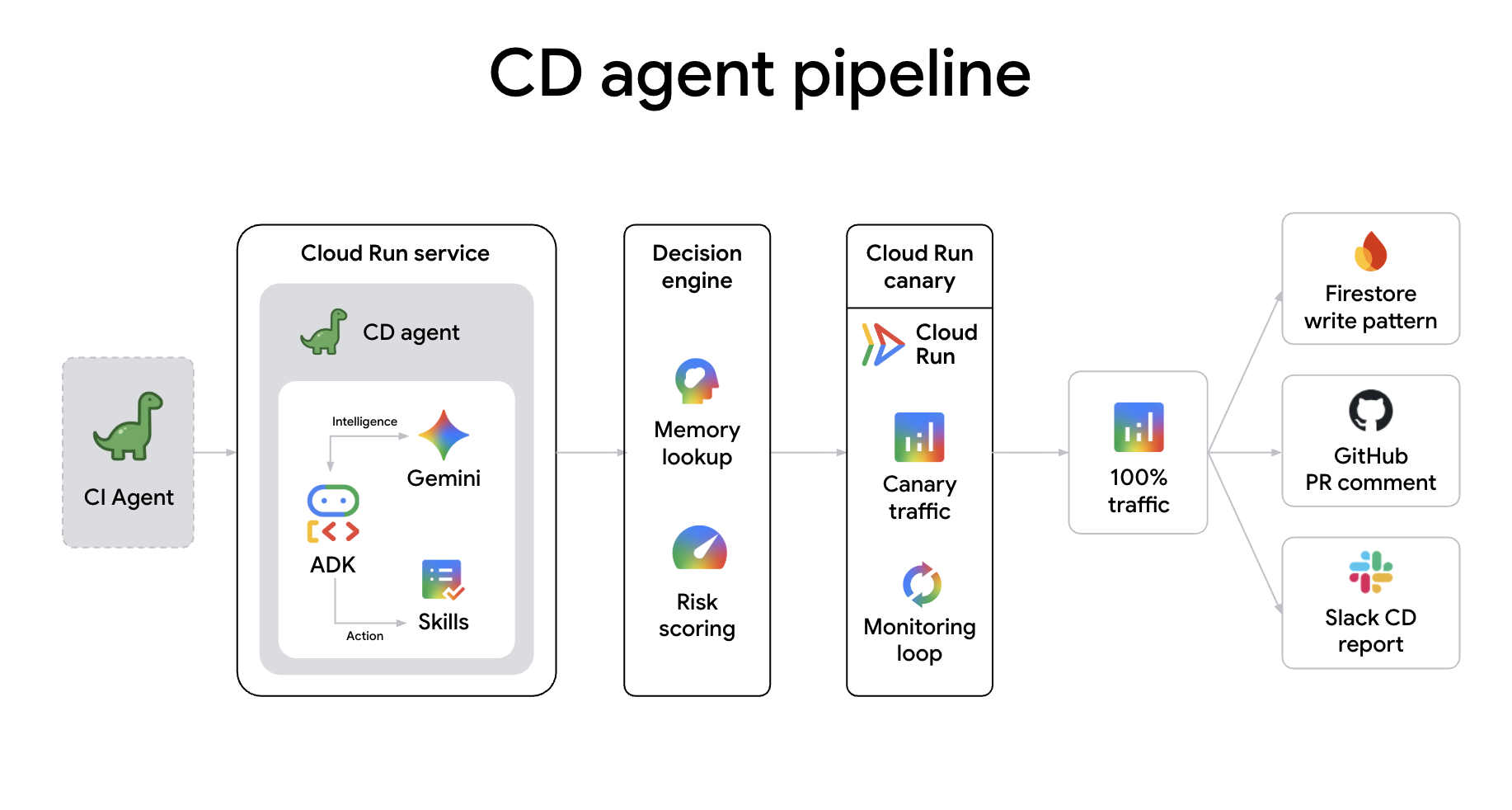
La connexion directe des agents crée un "pipeline cognitif" où chaque transfert est un transfert riche d'intention et de contexte. Contrairement aux webhooks traditionnels, la communication A2A permet :
- Partage intelligent du contexte : les agents transmettent l'intégralité des mémoires de session, des différences de demandes de pull et des scores de risque, ce qui permet à l'agent suivant de comprendre pleinement le contexte avant de commencer à travailler.
- Poignées de main cognitives : les agents peuvent négocier des portes. Par exemple, l'agent CD peut demander des tests de fumée spécifiques à l'agent CI lors d'un déploiement canary pour vérifier un correctif en temps réel.
- Correction collaborative : en cas d'échec d'un déploiement, l'agent CD peut avertir de manière proactive l'agent de correction des métriques en échec, ce qui lance une analyse autonome des causes premières avant même qu'un humain ne soit contacté.
- Négociation des ressources : les agents peuvent négocier les besoins en infrastructure. Par exemple, l'agent CI peut demander à l'agent de correction de provisionner davantage de capacité de compilation s'il détecte une refactorisation à grande échelle, ou l'agent CD peut suggérer de mettre à l'échelle le cluster de production avant une version majeure.
- Consensus multi-agents : pour les modifications à haut risque, plusieurs agents (par exemple, l'agent de sécurité et l'agent CD) peuvent effectuer une "approbation conjointe" via A2A, ce qui garantit que le code est non seulement compilé et déployé, mais qu'il respecte également les règles de sécurité avant d'être mis en production.
A. Cloner le dépôt CDAgent
cd ~
git clone https://github.com/gca-americas/dinoquest-cd-agent.git
cd dinoquest-cd-agent
B. Créer la base de données Firestore
CDAgent stocke ses modèles de mémoire de déploiement dans Firestore :
gcloud firestore databases create \
--region=$CLOUD_RUN_REGION \
--project=$PROJECT_ID
(Si vous avez déjà créé une base de données dans ce projet, vous pouvez ignorer cette étape.)
C. Créer le compte de service CDAgent
gcloud iam service-accounts create cd-agent \
--display-name="CDAgent Canary Deployer"
export SA="cd-agent@${PROJECT_ID}.iam.gserviceaccount.com"
# Grant necessary roles
for ROLE in \
roles/run.developer \
roles/iam.serviceAccountUser \
roles/artifactregistry.reader \
roles/artifactregistry.writer \
roles/monitoring.viewer \
roles/datastore.user \
roles/aiplatform.user \
roles/run.admin \
roles/pubsub.publisher; do
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA}" --role="$ROLE" \
--condition=None
done
D. Accorder l'accès aux secrets à CDAgent
Nous allons réutiliser le jeton GitHub et le webhook Slack précédents, et accorder au compte de service de calcul Cloud Run l'accès à la clé API Gemini afin que l'application déployée puisse l'utiliser :
gcloud secrets add-iam-policy-binding github-token \
--member="serviceAccount:${SA}" \
--role="roles/secretmanager.secretAccessor"
gcloud secrets add-iam-policy-binding slack-webhook-cd \
--member="serviceAccount:${SA}" \
--role="roles/secretmanager.secretAccessor"
# Grant the compute service account access to Gemini API key
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
gcloud secrets add-iam-policy-binding gemini-api-key \
--project=$PROJECT_ID \
--member="serviceAccount:${PROJECT_NUMBER}-compute@developer.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
E. Créer et déployer CDAgent sur Cloud Run
export GITHUB_OWNER="YOUR_GITHUB_USERNAME"
export CD_AGENT_URL=cd-agent-${PROJECT_NUMBER}.${CLOUD_RUN_REGION}.run.app
export SLACK_TOKEN=YOUR_SLACK_WEBHOOK
echo -n "https://hooks.slack.com/services/$SLACK_TOKEN" | \
gcloud secrets create slack-webhook-cd --data-file=-
AGENT_IMAGE="$CLOUD_RUN_REGION-docker.pkg.dev/${PROJECT_ID}/dinoquest/cd-agent:latest"
gcloud builds submit --tag $AGENT_IMAGE .
export SA="cd-agent@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud run deploy cd-agent \
--image=$AGENT_IMAGE \
--region=$CLOUD_RUN_REGION \
--service-account=$SA \
--memory=1Gi \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="HOST=${CD_AGENT_URL},PROTOCOL=https" \
--set-env-vars="CD_TARGET_SERVICE=dinoquest" \
--set-env-vars="HARNESS_EVENTS_TOPIC=${HARNESS_EVENTS_TOPIC}" \
--set-env-vars="GITHUB_OWNER=${GITHUB_OWNER}" \
--set-env-vars="GITHUB_REPO=dinoquest" \
--set-env-vars="DEMO_MODE=true" \
--set-env-vars="LEADERBOARD_ENABLED=true" \
--set-secrets="SLACK_WEBHOOK_URL=slack-webhook-cd:latest" \
--set-secrets="GITHUB_TOKEN=github-token:latest" \
--allow-unauthenticated \
--min-instances=1 \
--no-cpu-throttling \
--timeout=300
Remarque : --min-instances=1 --no-cpu-throttling maintient l'instance active pour qu'elle puisse répondre rapidement aux commandes Slack et A2A.
L'agent CD est le dernier rempart de votre environnement de production. Il évalue le risque de chaque déploiement, exécute un canari calibré en fonction du risque et surveille les métriques en temps réel. Si des anomalies sont détectées, un rollback automatique est lancé.
10. Passer à la vitesse supérieure : débloquer le niveau 2 avec l'essaim d'agents
A. Tester l'essaim complet
- Déclenchez l'erreur : ouvrez l'URL DinoQuest déployée (à partir de la dernière étape) dans votre navigateur.
- Accéder au classement : cliquez sur le bouton Classement. L'implémentation actuelle du classement est intentionnellement inefficace. Elle tente de charger une énorme quantité de données en mémoire, ce qui déclenche une erreur de mémoire insuffisante (OOM).
- Attendez l'agent : dans environ 60 secondes,
remediation-agentrecevra l'événement d'erreur via Eventarc et commencera son diagnostic. - Vérifiez Slack : une notification semblable à celle-ci devrait s'afficher dans votre canal Slack : Récapitulatif de la correction DinoAgent
- Service : dinoquest
- Version ayant échoué : dinoquest-xxxx-xxxx
- Preuve : "Limite de mémoire de 128 Mio dépassée (13x Mio utilisés)."
- Pourquoi cette révision était mauvaise : le point de terminaison
/api/leaderboarda été xxxxx de manière inefficace, ce qui a entraîné une erreur OOM. - Action effectuée : la mémoire du service
dinoquestest passée de x Mi à y Gi. Une révision a été créée. - PR de la cause racine : https://github.com/YOUR_USERNAME/DinoQuest/pull/x
- Vérifiez les corrections :
- GitHub : vérifiez si une nouvelle branche et une demande d'extraction ont été créées dans votre dépôt. L'agent a corrigé le code de l'application pour résoudre la fuite de mémoire sous-jacente.
- Cloud Run : dans la console GCP, vous verrez une nouvelle révision du service
dinoquestavec l'allocation de mémoire mise à jour. - Classement : réessayez d'accéder au classement. Il devrait maintenant se charger correctement grâce à l'augmentation de la mémoire et à la correction du code.
B. Évolution : implémenter la logique du jeu de niveau 2
Vous allez ajouter une nouvelle fonctionnalité importante : Niveau 2 (Destructeur d'astéroïdes). Les dinosaures ayant obtenu un score élevé peuvent ainsi accéder à un nouveau mode de jeu.
- Revenez à votre dépôt dinoquest :
cd ~/dinoquest - Créer une branche et passer à une autre :
git checkout -b level_2 - Appliquez le correctif de niveau 2 : exécutez le script fourni pour corriger votre codebase local avec les éléments, les composants et la logique de jeu de niveau 2 :
bash level_2_backup/levelup.sh - Validez et transférez les modifications :
git add . git commit -m "feat: add Level 2" git push origin level_2
Au lieu d'utiliser curl pour déclencher manuellement l'agent, nous allons utiliser la commande slash Slack que vous avez configurée précédemment. Voici comment interagir avec votre pipeline d'intégration continue autonome dans un scénario réel.
- Ouvrez Slack et accédez à un canal sur lequel l'application
CIAgentest installée. - Déclenchez la compilation CI en saisissant la commande suivante :
/runci run ci on branch level_2 - Suivez la progression :
- Slack : l'agent accusera réception de votre commande et publiera des informations à mesure que la compilation progresse.
- Dino Theater : regardez les "bulles de pensée" lorsque l'agent classe la modification, envoie le job Cloud Build et communique avec l'agent CD.
- GitHub : vérifiez votre demande d'extraction
level_2. Vous verrez l'agent publier des états de validation et un commentaire complet sur le rapport CI.
- Regardez le processus :
- Consultez Dino Theater pour voir l'agent CI réfléchir, classer la modification et exécuter le pipeline.
- Consultez votre demande d'extraction GitHub pour voir l'agent CI publier l'état du commit et le rapport final.
11. Conclusion
Vous avez créé une pile DevOps agentive complète sur Google Cloud :
Composant | Description |
DinoQuest (Cloud Run | Jeu optimisé par Gemini : frontend React + backend FastAPI |
Firebase Auth + Firestore | Authentification des utilisateurs et stockage des profils de dinosaures |
Agent de correction (Cloud Run + Eventarc) | Agent SRE qui corrige automatiquement les erreurs OOM et les bugs de code |
log-router-bq-report | Agent de données qui diffuse les journaux dans BigQuery et génère des insights |
CIAgent (Cloud Run) | Agent CI qui définit le champ d'application des tests, crée des images et appelle CD via A2A |
CDAgent (Cloud Run) | Agent CD qui exécute des déploiements Canary avec évaluation des risques et rollback automatique |
Tous les comportements de l'agent se trouvent dans le répertoire skills/ sous forme de playbooks Markdown. Pour modifier le comportement, modifiez la compétence, et non le code. Les compétences s'exécutent sur Antigravity avec Gemini et sont invoquées en indiquant à l'agent la compétence à exécuter.