
1. قبل البدء
من أبرز الإنجازات في مجال تعلُّم الآلة مؤخرًا النماذج اللغوية الكبيرة (LLM). ويمكن استخدامها لإنشاء نص وترجمة اللغات والإجابة عن الأسئلة بطريقة شاملة وغنية بالمعلومات. يتم تدريب النماذج اللغوية الكبيرة، مثل LaMDA وPaLM من Google، على كميات هائلة من البيانات النصية، ما يتيح لها تعلُّم الأنماط الإحصائية والعلاقات بين الكلمات والعبارات. ويتيح ذلك إنشاء نصوص مشابهة للنصوص التي يكتبها البشر، وترجمة اللغات بدقة عالية.
تتطلّب النماذج اللغوية الكبيرة مساحة تخزين كبيرة جدًا، وتستهلك عادةً الكثير من طاقة الحوسبة لتشغيلها، ما يعني أنّه يتم نشرها عادةً على السحابة الإلكترونية، ويصعب استخدامها في "تعلُّم الآلة على الجهاز" بسبب محدودية طاقة الحوسبة على الأجهزة الجوّالة. ومع ذلك، يمكن تشغيل نماذج لغوية كبيرة أصغر حجمًا (مثل GPT-2) على جهاز Android حديث وتحقيق نتائج رائعة.
إليك عرضًا توضيحيًا لتشغيل إصدار من نموذج Google PaLM يتضمّن 1.5 مليار مَعلمة على هاتف Google Pixel 7 Pro بدون تسريع سرعة التشغيل.

في هذا الدرس التطبيقي حول الترميز، ستتعرّف على التقنيات والأدوات اللازمة لإنشاء تطبيق يستند إلى نموذج لغوي كبير (باستخدام GPT-2 كمثال على النموذج) من خلال:
- KerasNLP لتحميل نموذج لغوي كبير مدرَّب مسبقًا
- استخدام KerasNLP لضبط نموذج لغوي كبير
- TensorFlow Lite لتحويل النموذج اللغوي الكبير وتحسينه ونشره على Android
المتطلبات الأساسية
- معرفة متوسطة المستوى بإطارَي Keras وTensorFlow Lite
- معرفة أساسية بتطوير تطبيقات Android
أهداف الدورة التعليمية
- كيفية استخدام KerasNLP لتحميل نموذج لغة كبير مُدرَّب مسبقًا وضبطه بدقة
- كيفية تحديد كمية نموذج لغة كبير (LLM) وتحويله إلى TensorFlow Lite
- كيفية تنفيذ الاستدلال على نموذج TensorFlow Lite المحوَّل
المتطلبات
- إذن الوصول إلى Colab
- أحدث إصدار من استوديو Android
- جهاز Android حديث مزوّد بذاكرة وصول عشوائي (RAM) بسعة تزيد عن 4 غيغابايت
2. طريقة الإعداد
لتنزيل الرمز البرمجي لهذا الدرس التطبيقي حول الترميز، اتّبِع الخطوات التالية:
- انتقِل إلى مستودع GitHub الخاص بهذا الدرس العملي.
- انقر على الرمز > تنزيل ملف zip لتنزيل كل الرمز البرمجي لهذا الدرس التطبيقي حول الترميز.
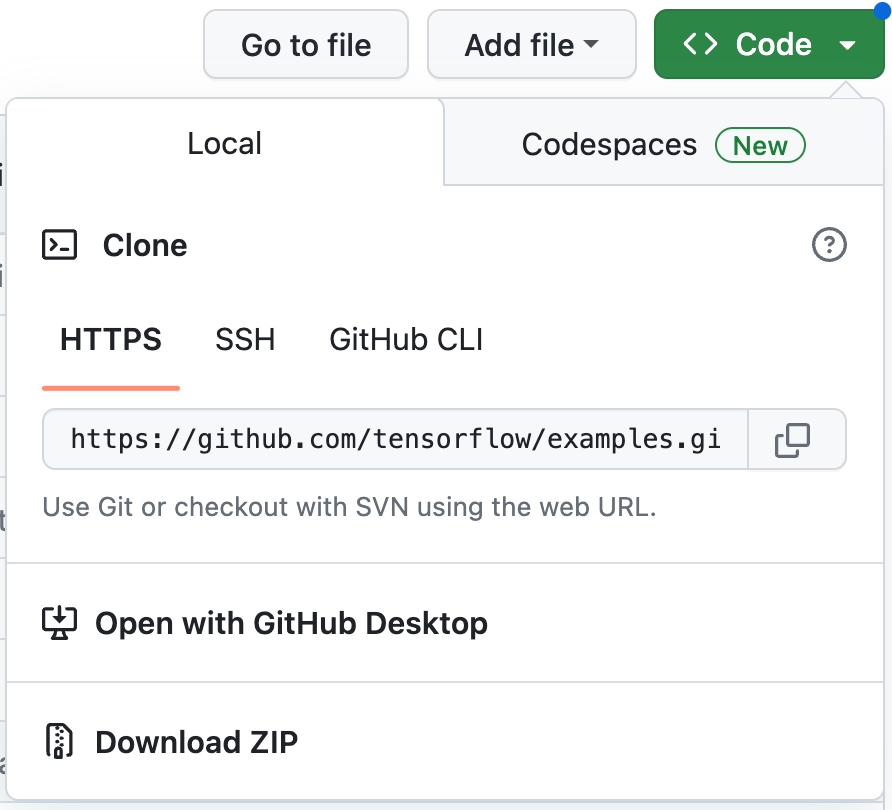
- فك ضغط ملف zip الذي تم تنزيله لفتح مجلد جذر
examplesيحتوي على جميع الموارد التي تحتاج إليها.
3- تشغيل التطبيق النموذجي
- استورِد مجلد
examples/lite/examples/generative_ai/androidإلى "استوديو Android". - ابدأ تشغيل "محاكي Android"، ثم انقر على
 تشغيل في قائمة التنقّل.
تشغيل في قائمة التنقّل.
تشغيل التطبيق واستكشافه
من المفترض أن يتم تشغيل التطبيق على جهاز Android. اسم التطبيق هو "الإكمال التلقائي". واجهة المستخدم بسيطة جدًا: يمكنك كتابة بعض الكلمات الأساسية في مربّع النص والنقر على إنشاء، ثم ينفّذ التطبيق استنتاجًا على نموذج لغوي كبير وينشئ نصًا إضافيًا استنادًا إلى ما أدخلته.
في الوقت الحالي، إذا نقرت على إنشاء بعد كتابة بعض الكلمات، لن يحدث شيء. ويرجع ذلك إلى أنّه لا يتم تشغيل نموذج لغوي كبير حتى الآن.
4. تحضير النموذج اللغوي الكبير للنشر على الجهاز
- افتح Colab واطّلِع على دفتر الملاحظات (المستضاف في مستودع GitHub الخاص بـ TensorFlow Codelabs).
5- إكمال تطبيق Android
بعد تحويل نموذج GPT-2 إلى TensorFlow Lite، يمكنك أخيرًا نشره في التطبيق.
تشغيل التطبيق
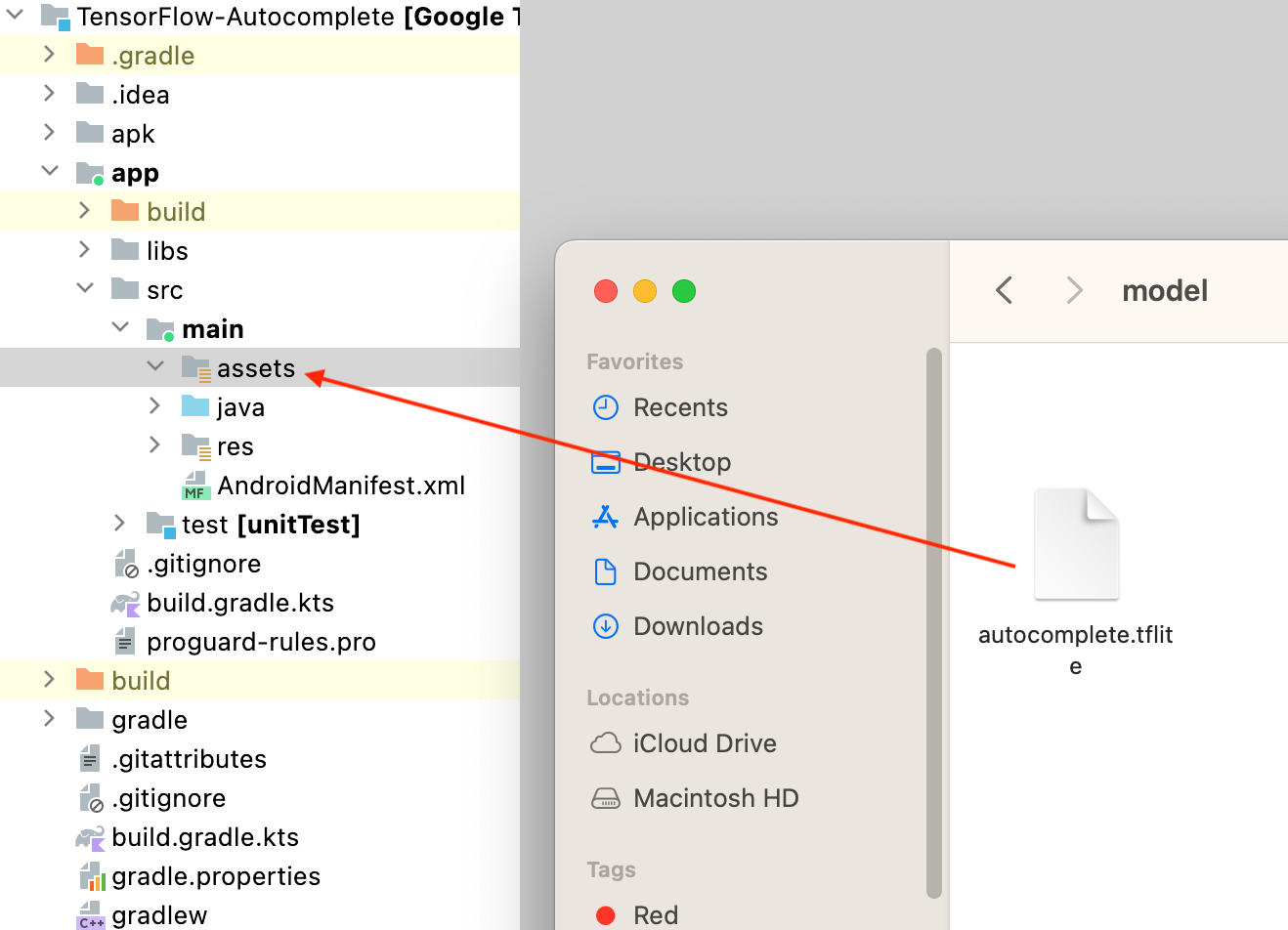
- اسحب ملف نموذج
autocomplete.tfliteالذي تم تنزيله من الخطوة الأخيرة إلى المجلدapp/src/main/assets/في "استوديو Android".
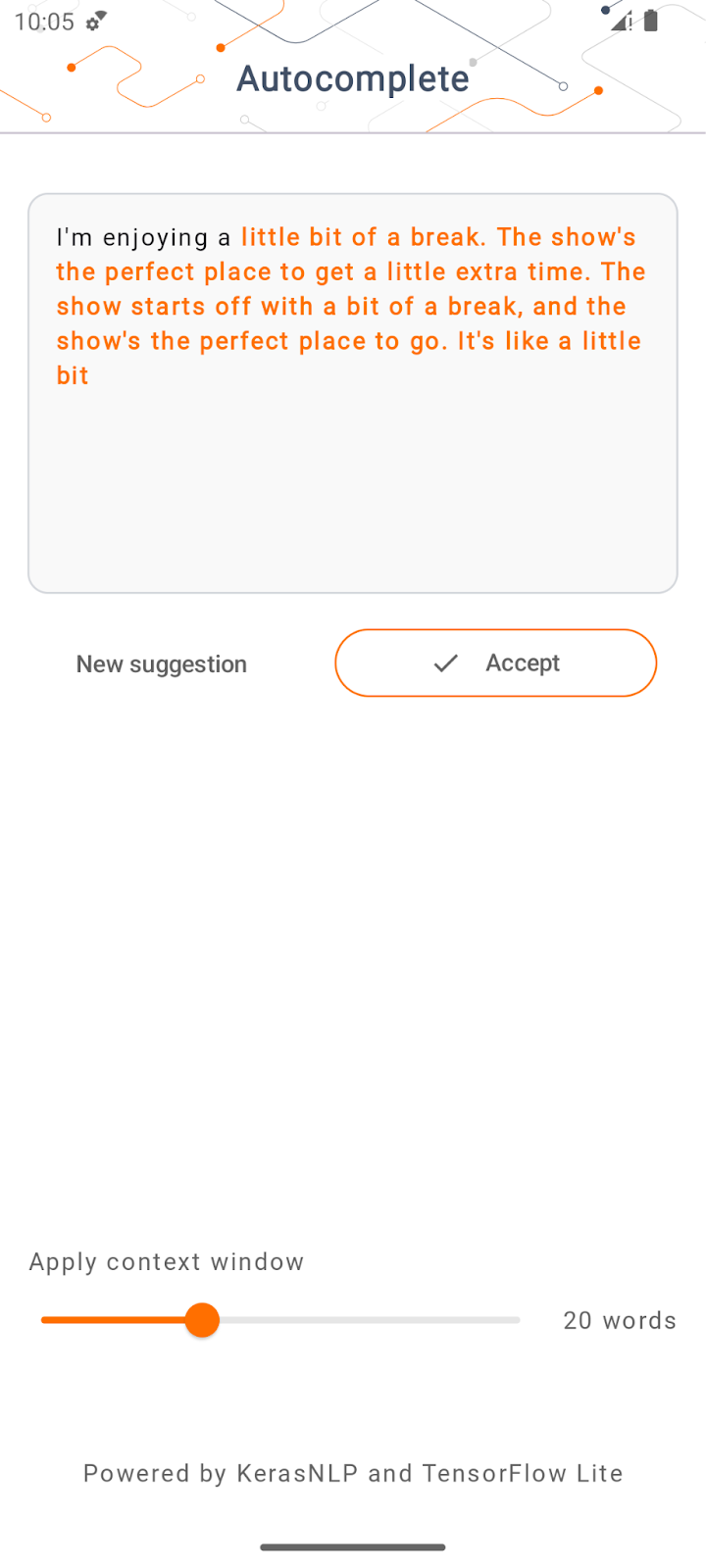
- انقر على تشغيل في قائمة التنقّل، ثمّ انتظِر إلى أن يتم تحميل التطبيق.
- اكتب بعض الكلمات الأساسية في حقل النص، ثم انقر على إنشاء.
6. ملاحظات حول الذكاء الاصطناعي المسؤول
كما هو موضّح في إعلان OpenAI GPT-2 الأصلي، هناك تحذيرات وقيود جديرة بالذكر بشأن نموذج GPT-2. في الواقع، تواجه النماذج اللغوية الكبيرة اليوم بشكل عام بعض التحديات المعروفة، مثل الهلوسة والنتائج المسيئة والإنصاف والتحيز، وذلك لأنّ هذه النماذج يتم تدريبها على بيانات من العالم الحقيقي، ما يجعلها تعكس مشاكل العالم الحقيقي.
تم إنشاء هذا الدرس التطبيقي حول الترميز فقط لتوضيح كيفية إنشاء تطبيق يستند إلى نماذج اللغات الكبيرة باستخدام أدوات TensorFlow. النموذج الذي تم إنشاؤه في هذا الدرس التطبيقي حول الترميز مخصّص لأغراض تعليمية فقط وليس للاستخدام الإنتاجي.
يتطلّب استخدام النماذج اللغوية الكبيرة في مرحلة الإنتاج اختيارًا مدروسًا لمجموعات بيانات التدريب وتدابير شاملة للحدّ من المخاطر. لمعرفة المزيد عن الذكاء الاصطناعي المسؤول في سياق النماذج اللغوية الكبيرة، احرص على مشاهدة الجلسة الفنية التطوير الآمن والمسؤول باستخدام النماذج اللغوية التوليدية في مؤتمر Google I/O 2023 والاطّلاع على مجموعة أدوات الذكاء الاصطناعي المسؤول.
7. الخاتمة
تهانينا! لقد أنشأت تطبيقًا لإنشاء نص متماسك استنادًا إلى إدخال المستخدم من خلال تشغيل نموذج لغوي كبير مُدرَّب مسبقًا على الجهاز فقط.