
1. مقدمة
لطالما جذبتني أجواء قاعة المحكمة، وكنت أتخيّل نفسي أتعامل بمهارة مع تعقيداتها وأقدّم مرافعات ختامية مؤثرة. مع أنّ مسيرتي المهنية قادتني إلى مكان آخر، يسعدني أن أشاركك أنّنا قد نكون جميعًا أقرب إلى تحقيق حلم المحكمة هذا بمساعدة الذكاء الاصطناعي.

سنستكشف اليوم كيفية استخدام أدوات الذكاء الاصطناعي الفعّالة من Google، مثل Vertex AI وFirestore وCloud Run Functions، لمعالجة البيانات القانونية وفهمها، وإجراء عمليات بحث سريعة جدًا، وربما مساعدة عميلك الوهمي (أو نفسك) في الخروج من موقف صعب.
قد لا تكون بصدد استجواب شاهد، ولكن من خلال نظامنا، ستتمكّن من غربلة كميات هائلة من المعلومات، وإنشاء ملخّصات واضحة، وعرض البيانات الأكثر صلة في ثوانٍ.
2. الهندسة المعمارية
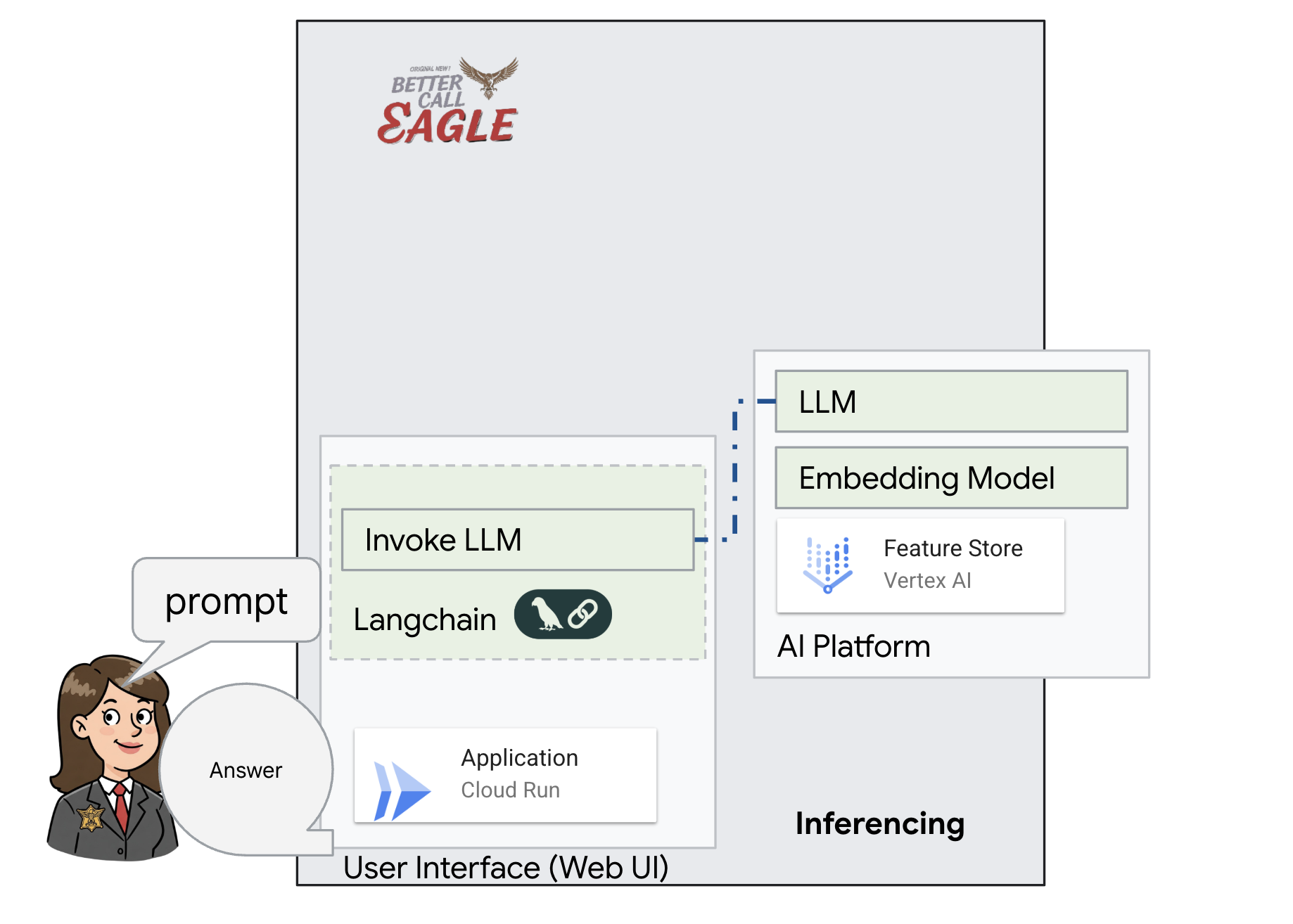
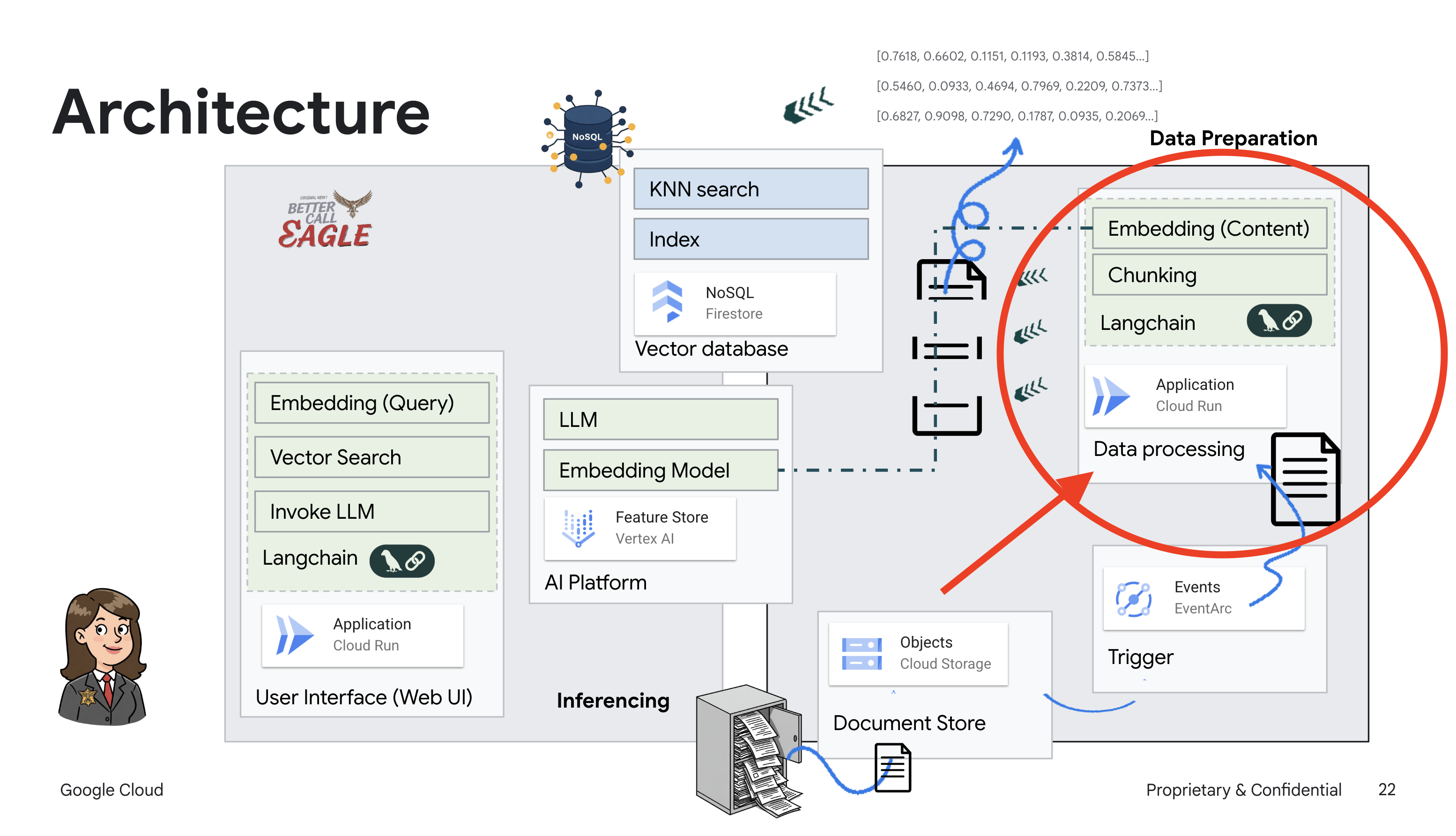
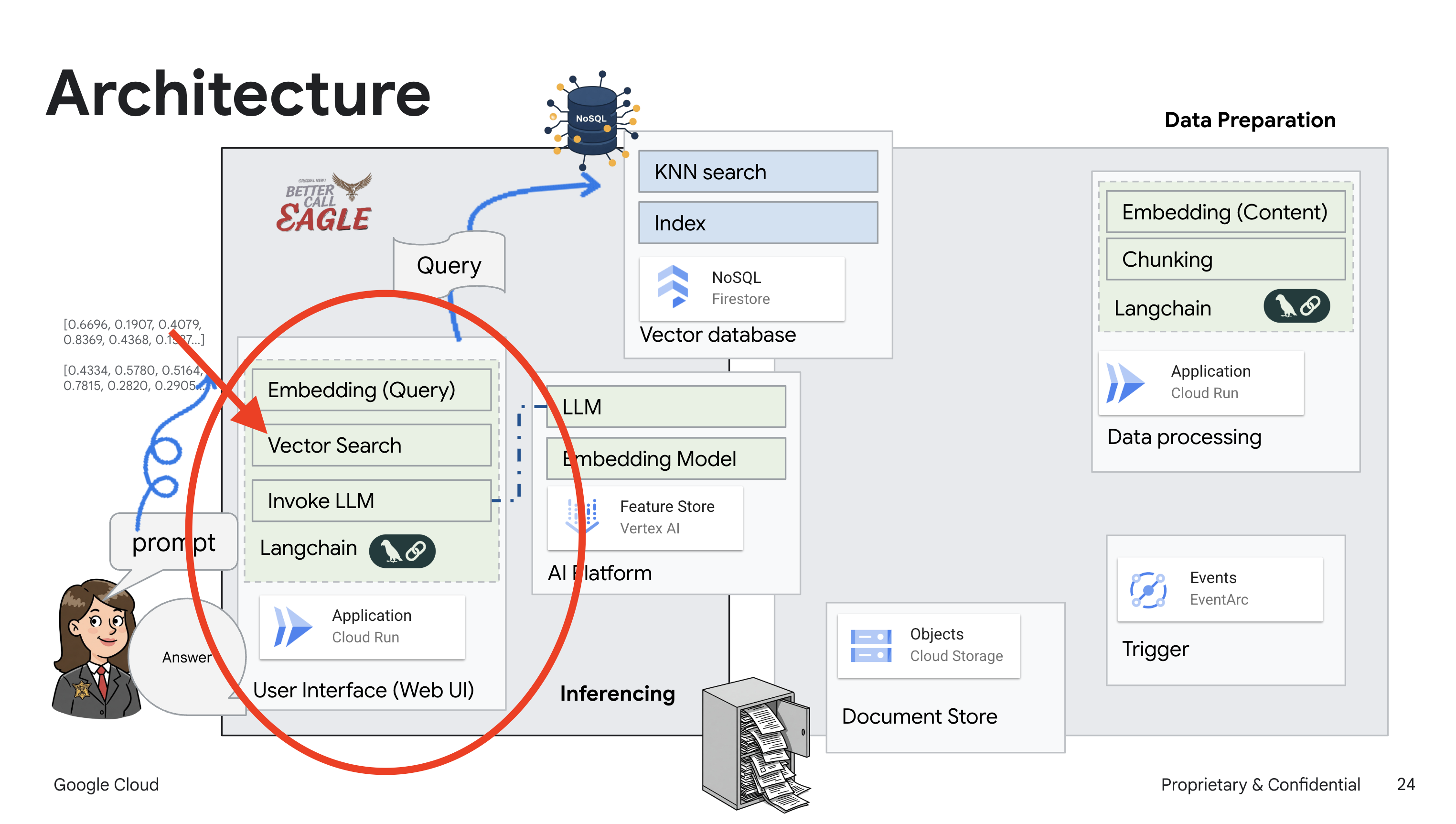
يركّز هذا المشروع على إنشاء مساعد قانوني باستخدام أدوات الذكاء الاصطناعي من Google Cloud، مع التركيز على كيفية معالجة البيانات القانونية وفهمها والبحث فيها. تم تصميم النظام لفحص كميات كبيرة من المعلومات وإنشاء ملخّصات وتقديم البيانات ذات الصلة بسرعة. يتضمّن تصميم المساعد القانوني عدة عناصر أساسية:
إنشاء قاعدة معارف من بيانات غير منظَّمة: يتم استخدام Google Cloud Storage (GCS) لتخزين المستندات القانونية. تعمل Firestore، وهي قاعدة بيانات NoSQL، كمخزن متّجهات، حيث تحتفظ بأجزاء المستندات وعمليات التضمين المقابلة لها. يتم تفعيل "البحث المتّجه" في Firestore للسماح بعمليات البحث عن التشابه. عند تحميل مستند قانوني جديد إلى GCS، يفعّل Eventarc دالة Cloud Run. تعالج هذه الدالة المستند من خلال تقسيمه إلى أجزاء وإنشاء تضمينات لكل جزء باستخدام نموذج تضمين النصوص في Vertex AI. يتم بعد ذلك تخزين هذه التضمينات في Firestore بجانب أجزاء النص. 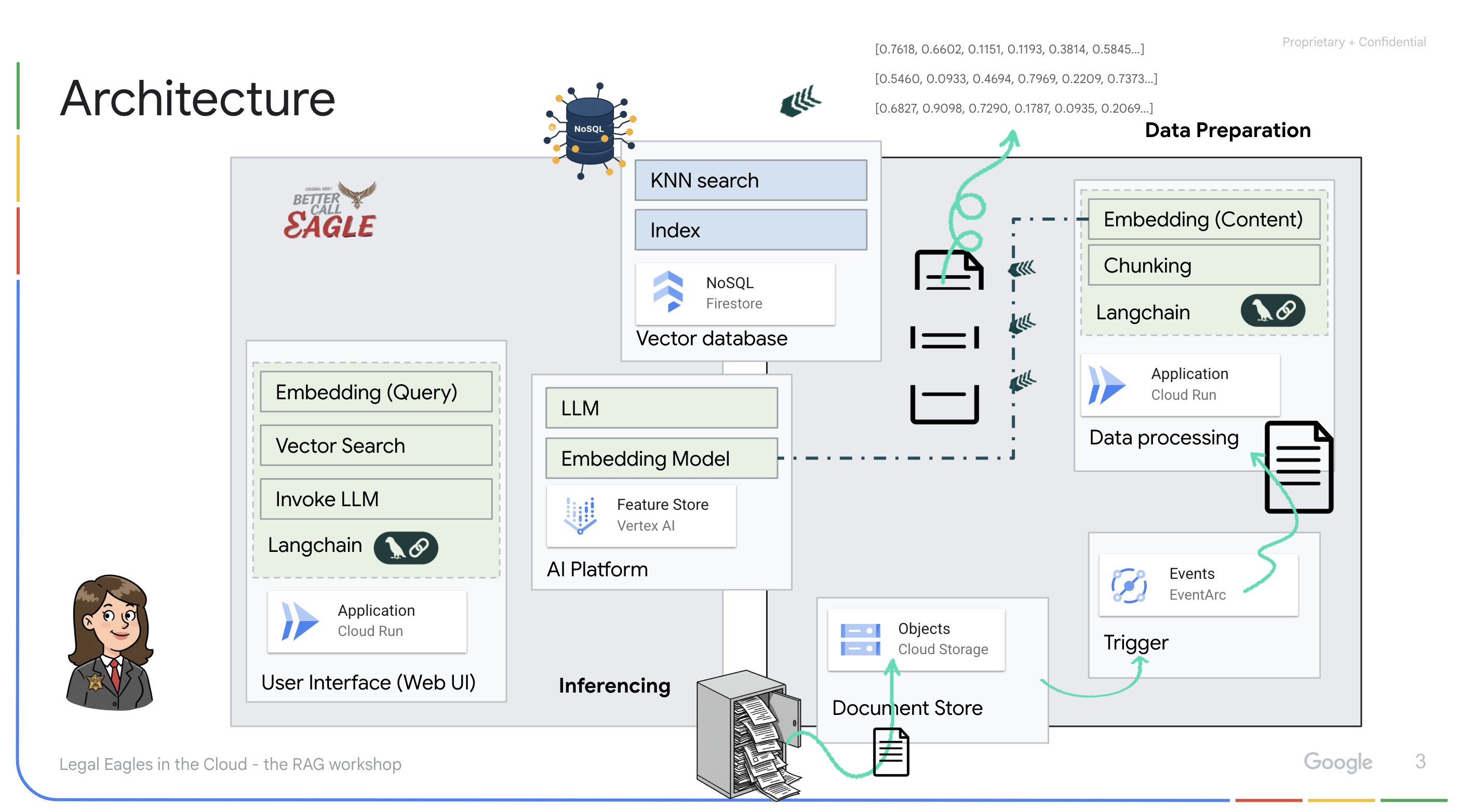
تطبيق يستند إلى نموذج لغوي كبير (LLM) والتوليد المعزّز بالاسترجاع (RAG) : إنّ جوهر نظام الأسئلة والأجوبة هو الدالة ask_llm التي تستخدم مكتبة Langchain للتفاعل مع نموذج لغوي كبير من Gemini على Vertex AI. تنشئ هذه الدالة HumanMessage من طلب المستخدم، وتتضمّن SystemMessage توجّه النموذج اللغوي الكبير إلى العمل كمساعد قانوني مفيد. يستخدم النظام أسلوب التوليد المعزّز بالاسترجاع، حيث يستخدم النظام وظيفة search_resource قبل الإجابة عن طلب بحث لاسترجاع السياق ذي الصلة من مستودع متجهات Firestore. يتم بعد ذلك تضمين هذا السياق في SystemMessage ليكون ردّ النموذج اللغوي الكبير مستندًا إلى المعلومات القانونية المقدَّمة. 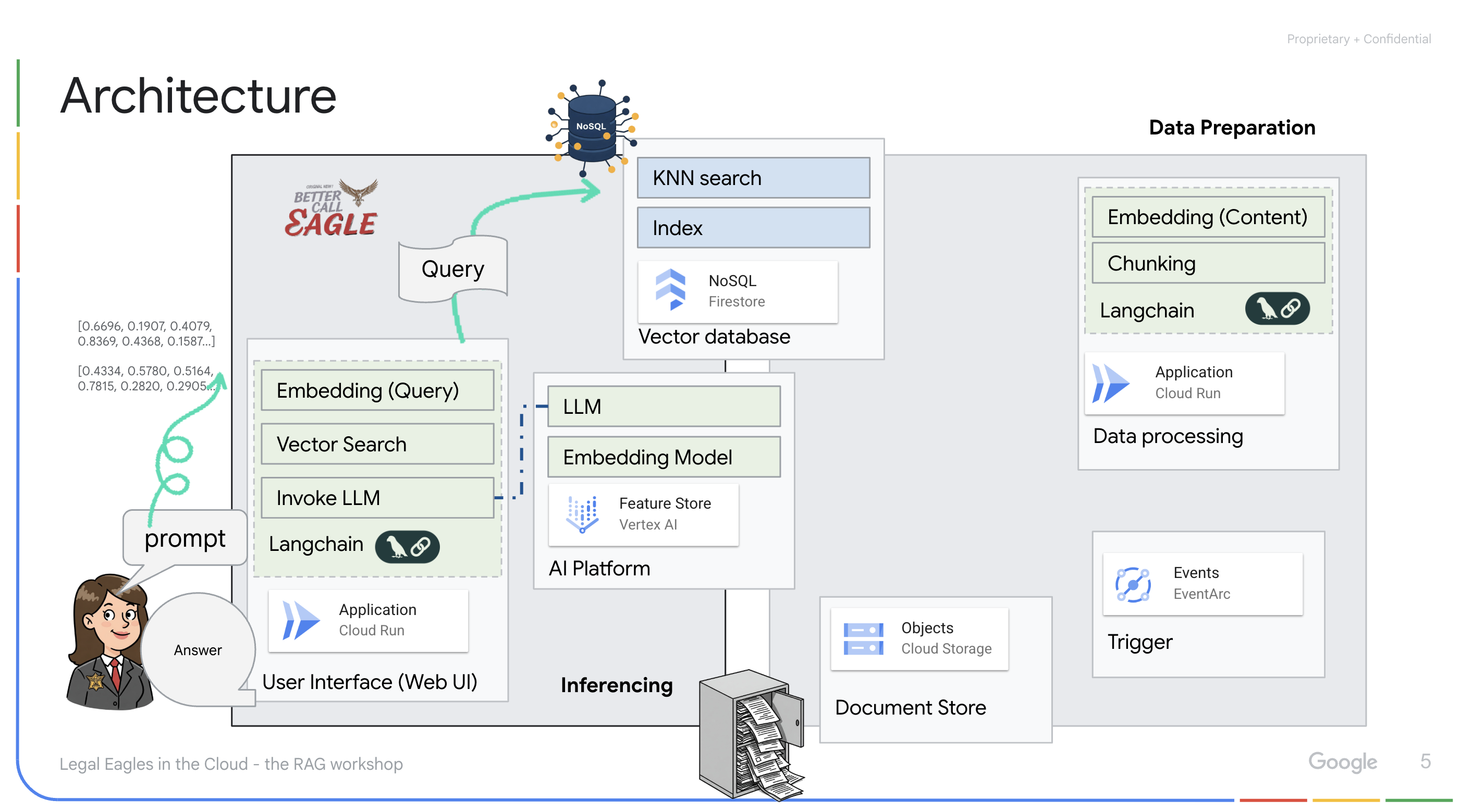
يهدف المشروع إلى التخلّص من "التفسيرات الإبداعية" التي تقدّمها النماذج اللغوية الكبيرة من خلال استخدام التوليد المعزّز بالاسترجاع، الذي يسترجع أولاً المعلومات ذات الصلة من مصدر قانوني موثوق به قبل إنشاء إجابة. ويؤدي ذلك إلى الحصول على ردود أكثر دقةً واستنارةً استنادًا إلى معلومات قانونية فعلية. تم إنشاء النظام باستخدام خدمات مختلفة من Google Cloud، مثل Google Cloud Shell وVertex AI وFirestore وCloud Run وEventarc.
3- قبل البدء
في Google Cloud Console، في صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud. تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
تفعيل Gemini Code Assist في بيئة تطوير متكاملة (IDE) في Cloud Shell
👉 في Google Cloud Console، انتقِل إلى أدوات Gemini Code Assist، وفعِّل Gemini Code Assist بدون أي تكلفة من خلال الموافقة على البنود والشروط.
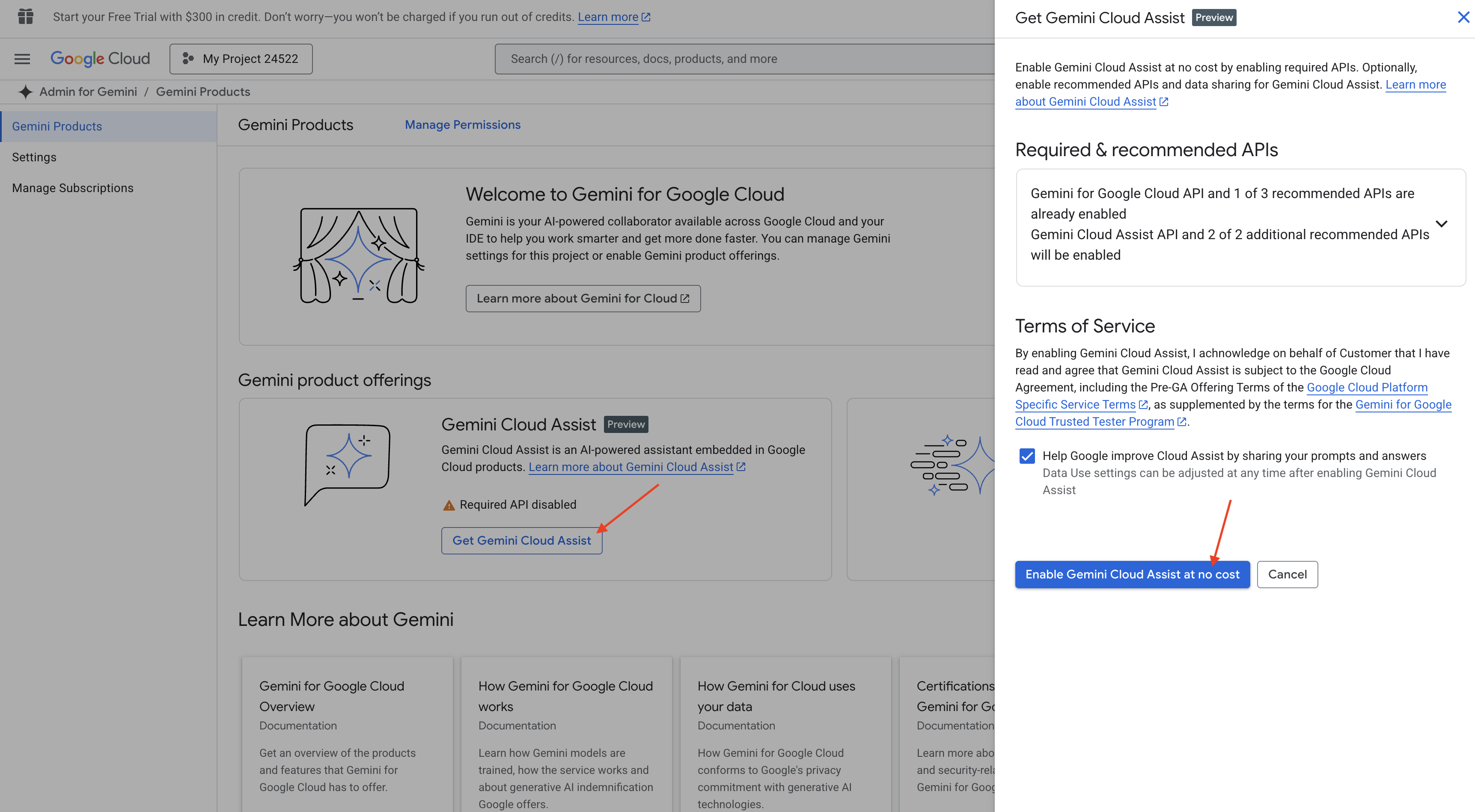
تجاهل إعداد الأذونات، وغادِر هذه الصفحة.
العمل على "محرّر Cloud Shell"
👉 انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud" (رمز شكل الوحدة الطرفية في أعلى لوحة Cloud Shell)
👉 انقر على الزر "فتح المحرّر" (يبدو كملف مفتوح مع قلم رصاص). سيؤدي ذلك إلى فتح "محرِّر Cloud Shell" في النافذة. سيظهر لك مستكشف الملفات على الجانب الأيمن.

👉 انقر على الزر تسجيل الدخول باستخدام رمز السحابة الإلكترونية في شريط الحالة أسفل الصفحة كما هو موضّح. امنح المصادقة للمكوّن الإضافي حسب التعليمات. إذا ظهرت لك الرسالة Cloud Code - no project في شريط الحالة، اختَرها ثم اختَر "اختيار مشروع Google Cloud" (Select a Google Cloud Project) من القائمة المنسدلة، ثم اختَر مشروع Google Cloud المحدّد من قائمة المشاريع التي تخطّط للعمل عليها.
👉 افتح نافذة المحطة الطرفية في بيئة التطوير المتكاملة المستندة إلى السحابة الإلكترونية، 
👉 في الوحدة الطرفية الجديدة، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
👉 انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
gcloud config set project <YOUR_PROJECT_ID>
👉 نفِّذ الأمر التالي لتفعيل Cloud APIs اللازمة في Google Cloud:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
في شريط أدوات Cloud Shell (في أعلى لوحة Cloud Shell)، انقر على الزر "فتح المحرّر" (يشبه مجلدًا مفتوحًا مع قلم رصاص). سيؤدي ذلك إلى فتح "محرِّر Cloud Shell للرموز" في النافذة. سيظهر لك مستكشف الملفات على الجانب الأيمن.
👉 في نافذة الأوامر، نزِّل مشروع Bootstrap Skeleton:
git clone https://github.com/weimeilin79/legal-eagle.git
اختياري: النسخة الإسبانية
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
بعد تنفيذ هذا الأمر في وحدة Cloud Shell الطرفية، سيتم إنشاء مجلد جديد باسم المستودع legal-eagle في بيئة Cloud Shell.
4. كتابة تطبيق الاستدلال باستخدام Gemini Code Assist
في هذا القسم، سنركّز على إنشاء الجزء الأساسي من مساعدنا القانوني، وهو تطبيق الويب الذي يتلقّى أسئلة المستخدمين ويتفاعل مع نموذج الذكاء الاصطناعي لإنشاء الإجابات. سنستفيد من Gemini Code Assist لمساعدتنا في كتابة رمز Python البرمجي الخاص بجزء الاستنتاج هذا.
في البداية، سننشئ تطبيق Flask يستخدم مكتبة LangChain للتواصل مباشرةً مع نموذج Gemini من Vertex AI. سيعمل هذا الإصدار الأول كمساعد قانوني مفيد استنادًا إلى المعرفة العامة للنموذج، ولكن لن يتمكّن بعد من الوصول إلى مستندات قضايا المحاكم المحدّدة. سيسمح لنا ذلك بالاطّلاع على الأداء الأساسي للنموذج اللغوي الكبير قبل تحسينه باستخدام تقنية الاسترجاع والإنشاء لاحقًا.
في جزء "المستكشف" في "محرّر Cloud Code" (عادةً على الجانب الأيمن)، من المفترض أن يظهر الآن المجلد الذي تم إنشاؤه عند استنساخ مستودع Git legal-eagle. افتح المجلد الجذر لمشروعك في "المستكشف". ستجد مجلدًا فرعيًا باسم webapp داخله، افتحه أيضًا. 
👉 لتعديل ملف legal.py في "أداة تعديل الرموز البرمجية في Cloud"، يمكنك استخدام طرق مختلفة لطلب المساعدة من Gemini Code Assist.
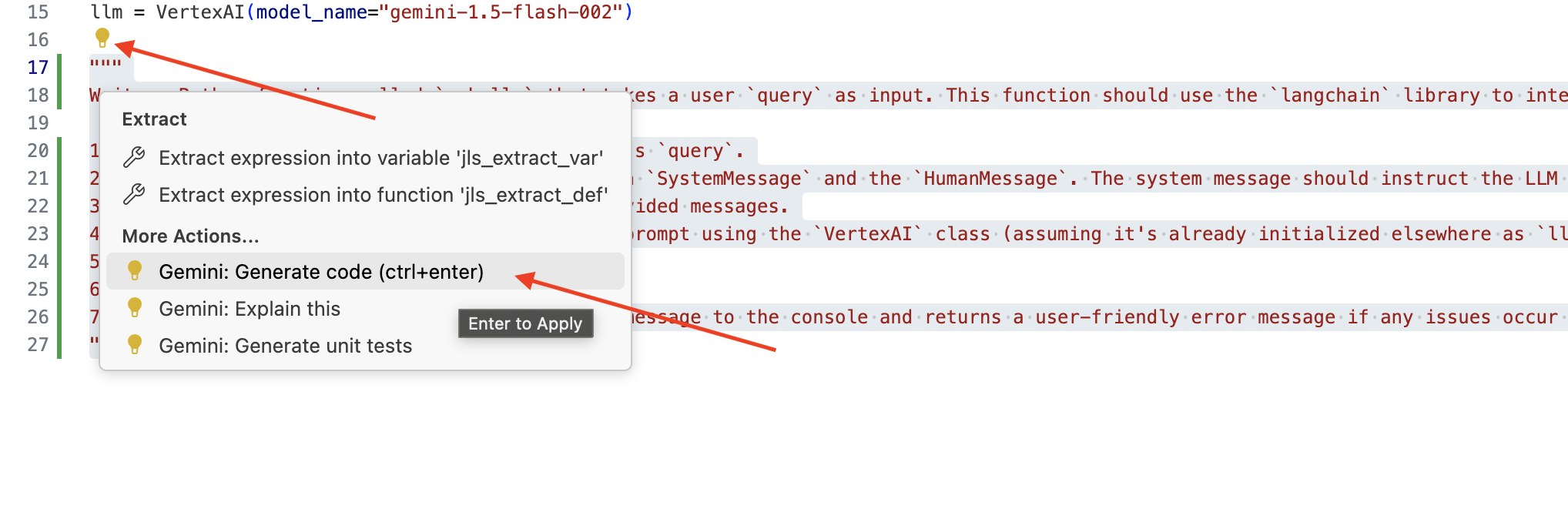
👉 انسخ الطلب التالي إلى أسفل legal.py الذي يصف بوضوح ما تريد أن ينشئه Gemini Code Assist، وانقر على رمز المصباح 💡 الذي يظهر، ثم اختَر Gemini: إنشاء الرمز (قد يختلف عنصر القائمة الدقيق قليلاً حسب إصدار Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
مراجعة الرمز البرمجي الذي تم إنشاؤه بعناية
- هل تتّبع هذه الخطوات بشكل عام الخطوات التي أشرت إليها في التعليق؟
- هل يتم إنشاء
ChatPromptTemplateمعSystemMessageوHumanMessage؟ - هل يتضمّن معالجة الأخطاء الأساسية (
try...except)؟
إذا كان الرمز البرمجي الذي تم إنشاؤه جيدًا وصحيحًا في الغالب، يمكنك قبوله (اضغط على Tab أو Enter للحصول على اقتراحات مضمّنة، أو انقر على "قبول" لكتل الرموز البرمجية الأكبر).
إذا لم يكن الرمز الذي تم إنشاؤه هو ما تريده بالضبط، أو إذا كان يتضمّن أخطاء، لا تقلق. Gemini Code Assist هي أداة لمساعدتك، وليس لكتابة رموز برمجية مثالية من المحاولة الأولى.
عدِّل الرمز الذي تم إنشاؤه لتنقيحه وتصحيح الأخطاء فيه ومطابقته مع متطلباتك بشكل أفضل. يمكنك توجيه المزيد من الطلبات إلى Gemini Code Assist من خلال إضافة المزيد من التعليقات أو طرح أسئلة محدّدة في لوحة محادثة Code Assist.
إذا كنت لا تزال جديدًا على حزمة تطوير البرامج (SDK)، إليك مثال عملي.
👉 انسخ الرمز التالي والصِقه وlegal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 اختياري: النسخة الإسبانية
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
بعد ذلك، أنشئ دالة للتعامل مع مسار سيستجيب لأسئلة المستخدم.
افتح main.py في "محرِّر Cloud Shell". على غرار طريقة إنشاء ask_llm في legal.py، استخدِم Gemini Code Assist لإنشاء مسار Flask والدالة ask_question. اكتب PROMPT التالي كتعليق في main.py: (تأكَّد من إضافته قبل بدء تطبيق Flask في if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
يجب قبول الرمز الذي تم إنشاؤه فقط إذا كان جيدًا وصحيحًا في الغالب. إذا لم تكن على دراية بلغة Python، إليك مثال عملي، يمكنك نسخ هذا الرمز ولصقه في main.py ضمن الرمز المتوفّر حاليًا.
👉 تأكَّد من لصق ما يلي قبل بدء تطبيق الويب (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
باتّباع هذه الخطوات، من المفترض أن تتمكّن من تفعيل Gemini Code Assist وإعداد مشروعك واستخدامه لإنشاء الدالة ask في ملف main.py.
5- الاختبار المحلي في "محرّر السحابة الإلكترونية"
👉 في نافذة المحرر الطرفية، ثبِّت المكتبات التابعة وابدأ تشغيل واجهة مستخدم الويب محليًا.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
ابحث عن رسائل بدء التشغيل في ناتج وحدة طرفية Cloud Shell. عادةً ما تطبع Flask رسائل تشير إلى أنّها تعمل وإلى المنفذ الذي تعمل عليه.
- Running on http://127.0.0.1:8080
يجب أن يظل التطبيق قيد التشغيل لتلبية الطلبات.
👉 من قائمة "معاينة الويب"، اختَر المعاينة على المنفذ 8080. سيفتح Cloud Shell علامة تبويب متصفّح أو نافذة جديدة تتضمّن معاينة الويب لتطبيقك. 
👉 في واجهة التطبيق، اكتب بعض الأسئلة المتعلقة تحديدًا بمراجع القضايا القانونية واطّلِع على طريقة استجابة النموذج اللغوي الكبير. على سبيل المثال، يمكنك تجربة ما يلي:
- كم عدد سنوات السجن التي حُكم بها على مايكل براون؟
- ما هو المبلغ الذي تم تحصيله من الرسوم غير المصرَّح بها نتيجةً لإجراءات "سميرة فؤاد"؟
- ما هو الدور الذي لعبته شهادات الجيران في التحقيق في قضية إميلي وايت؟
👉 اختياري: النسخة الإسبانية
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
إذا دقّقت في الإجابات، من المحتمل أن تلاحظ أنّ النموذج قد يقدّم إجابات غير صحيحة أو مبهمة أو عامة، وقد يسيء أحيانًا فهم أسئلتك، خاصةً أنّه لا يمكنه بعد الوصول إلى مستندات قانونية محدّدة.
👉 يمكنك إيقاف النص البرمجي بالضغط على Ctrl+C.
👉 للخروج من البيئة الافتراضية، شغِّل الأمر التالي في الوحدة الطرفية:
deactivate
6. إعداد "متجر المتجهات"
حان الوقت لوضع حدّ لهذه "التفسيرات الإبداعية" التي تقدّمها النماذج اللغوية الكبيرة للقانون، وهنا يأتي دور التوليد المعزّز بالاسترجاع (RAG). يمكنك التفكير في الأمر على أنّه منح نموذجنا اللغوي الكبير إذن الوصول إلى مكتبة قانونية فائقة القوة قبل أن يجيب عن أسئلتك. بدلاً من الاعتماد فقط على معرفته العامة (التي يمكن أن تكون غير واضحة أو قديمة حسب النموذج)، يسترجع "التوليد المعزّز بالاسترجاع" أولاً المعلومات ذات الصلة من مصدر موثوق، مثل المستندات القانونية في حالتنا، ثم يستخدم هذا السياق لإنشاء إجابة أكثر استنارة ودقة. هذا يشبه قيام النموذج اللغوي الكبير بواجباته قبل الدخول إلى قاعة المحكمة.
لإنشاء نظام RAG، نحتاج إلى مكان لتخزين جميع المستندات القانونية، والأهم من ذلك، إتاحة البحث فيها حسب المعنى. وهنا يأتي دور Firestore. Firestore هي قاعدة بيانات مستنِدة إلى تنسيق NoSQL مرنة وقابلة للتوسّع من Google Cloud.
سنستخدم Firestore كـ مخزن متجهات. سنخزّن أجزاءً من مستنداتنا القانونية في Firestore، وسنخزّن أيضًا التمثيل الرقمي لمعنى كل جزء.
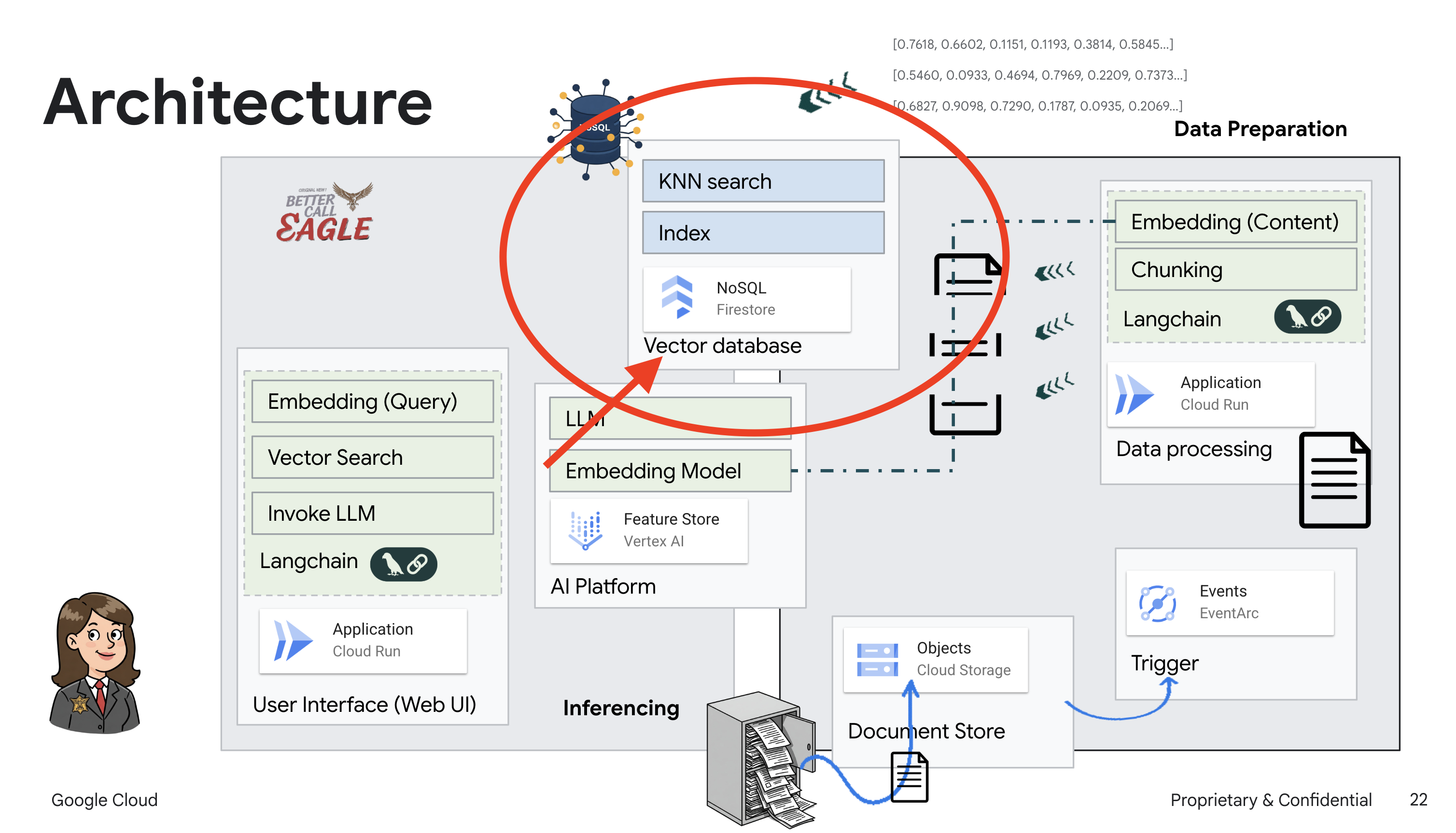
بعد ذلك، عندما تطرح سؤالاً على Legal Eagle، سنستخدم ميزة "البحث المتّجه" في Firestore للعثور على أجزاء النص القانوني الأكثر صلةً بطلبك. هذا السياق المسترجَع هو ما يستخدمه التوليد المعزّز بالاسترجاع لتقديم إجابات تستند إلى معلومات قانونية فعلية، وليس إلى مجرد تخيّلات النموذج اللغوي الكبير.
👉 في علامة تبويب أو نافذة جديدة، انتقِل إلى Firestore في وحدة تحكّم Google Cloud.
👉 انقر على إنشاء قاعدة بيانات
👉 اختَر Native mode واسم قاعدة البيانات (default).
👉 اختَر region: us-central1، ثم انقر على إنشاء قاعدة بيانات. ستوفّر Firestore قاعدة البيانات، وقد يستغرق ذلك بضع لحظات.
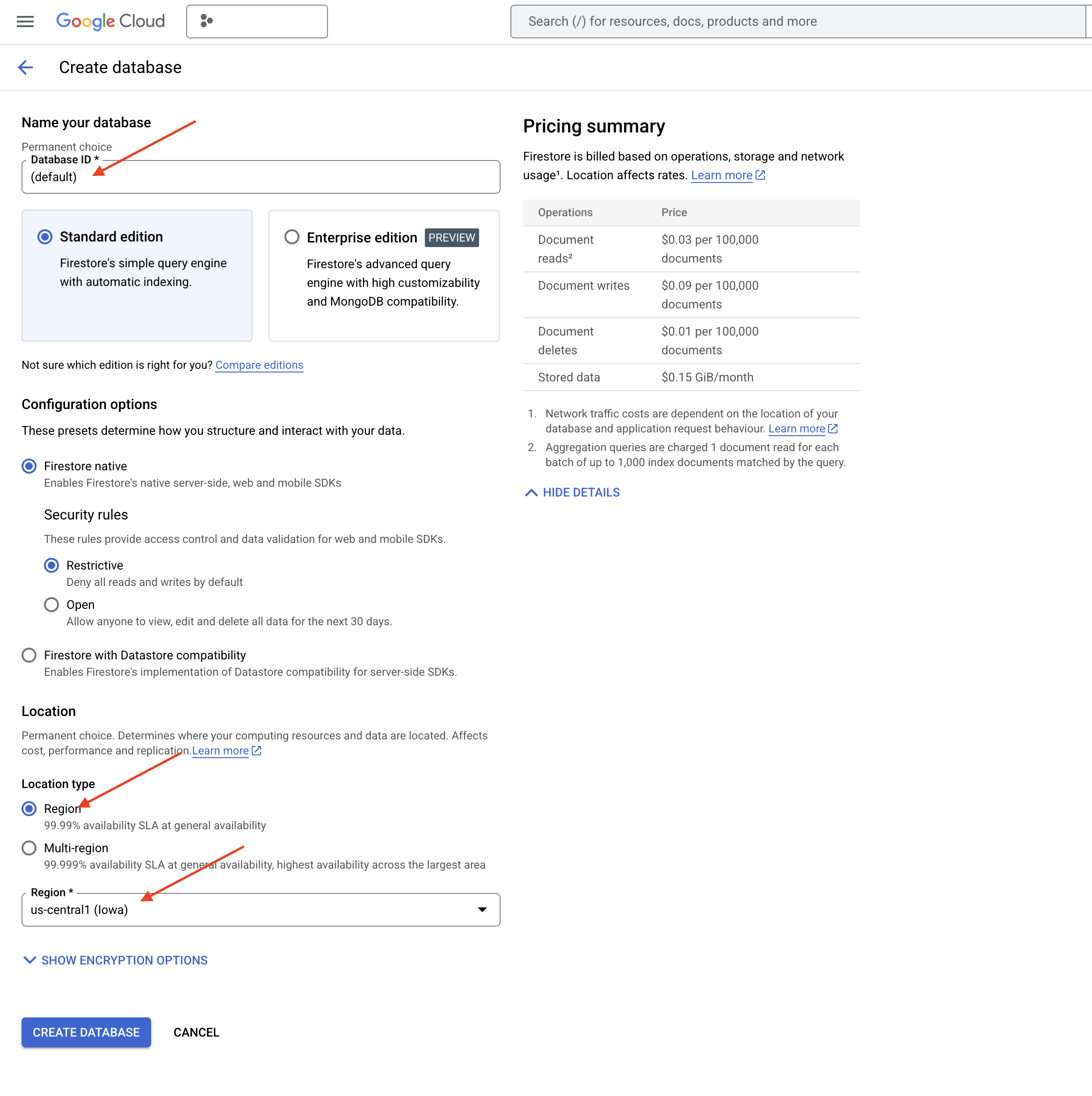
👉 في نافذة Cloud IDE، أنشئ فهرسًا متّجهًا في حقل embedding_vector لتفعيل البحث المتّجه في مجموعة legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
ستبدأ خدمة Firestore في إنشاء فهرس المتجهات. قد يستغرق إنشاء الفهرس بعض الوقت، خاصةً لمجموعات البيانات الأكبر حجمًا. سيظهر الفهرس في الحالة "قيد الإنشاء"، وسيتم الانتقال إلى الحالة "جاهز" عند اكتمال إنشائه. 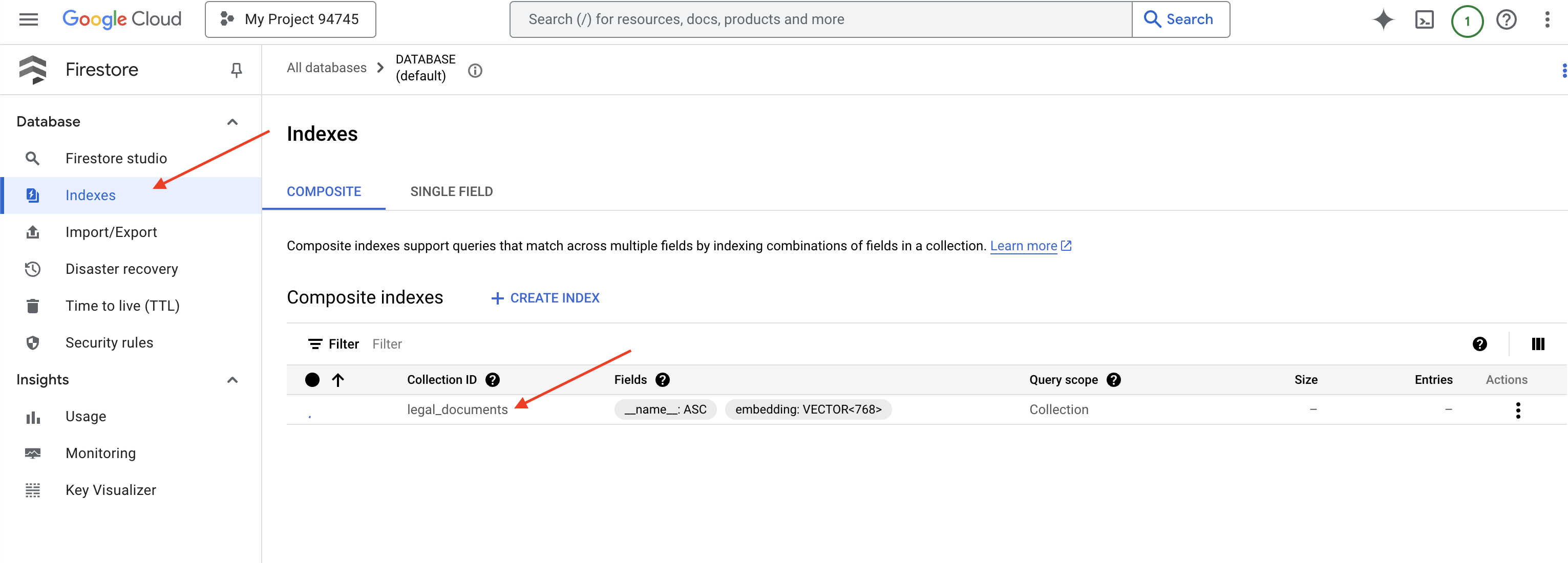
7. تحميل البيانات إلى مستودع المتجهات
بعد أن فهمنا عملية الاسترجاع المستند إلى إنشاء الردود (RAG) ومتجر المتجهات، حان الوقت لإنشاء المحرّك الذي يملأ مكتبتنا القانونية. إذًا، كيف يمكننا جعل المستندات القانونية "قابلة للبحث حسب المعنى"؟ يكمن السحر في التضمينات! يمكنك اعتبار التضمينات بمثابة تحويل للكلمات أو الجُمل أو حتى المستندات الكاملة إلى متجهات رقمية، أي قوائم من الأرقام التي تعكس معناها الدلالي. تحصل المفاهيم المتشابهة على متجهات "قريبة" من بعضها البعض في مساحة المتجهات. نستخدم نماذج فعّالة (مثل تلك المتوفّرة في Vertex AI) لإجراء عملية التحويل هذه.
ولأتمتة عملية تحميل المستندات، سنستخدم دوال Cloud Run وEventarc. دوال Cloud Run هي حاوية خفيفة الوزن وبدون خادم تشغّل الرمز البرمجي عند الحاجة إليه فقط. سنجمّع نص Python البرمجي الخاص بمعالجة المستندات في حاوية وننشره كدالة Cloud Run.
👉 في علامة تبويب أو نافذة جديدة، انتقِل إلى مساحة التخزين السحابية.
👉 انقر على "الحِزم" في القائمة اليمنى.
👉 انقر على الزر "+ إنشاء" في أعلى الصفحة.
👉 ضبط الحزمة (إعدادات مهمة):
- اسم الحزمة: yourprojectID'-doc-bucket (يجب تضمين اللاحقة -doc-bucket في النهاية)
- المنطقة: اختَر المنطقة
us-central1. - فئة التخزين: "عادية" يُعدّ Standard مناسبًا للبيانات التي يتم الوصول إليها بشكل متكرر.
- التحكّم في الوصول: اترُك الخيار التلقائي "التحكّم الموحّد في الوصول" محدّدًا. يوفّر ذلك إمكانية التحكّم في الوصول بشكل متّسق على مستوى الحزمة.
- الخيارات المتقدّمة: في هذا البرنامج التعليمي، تكون الإعدادات التلقائية كافية عادةً.
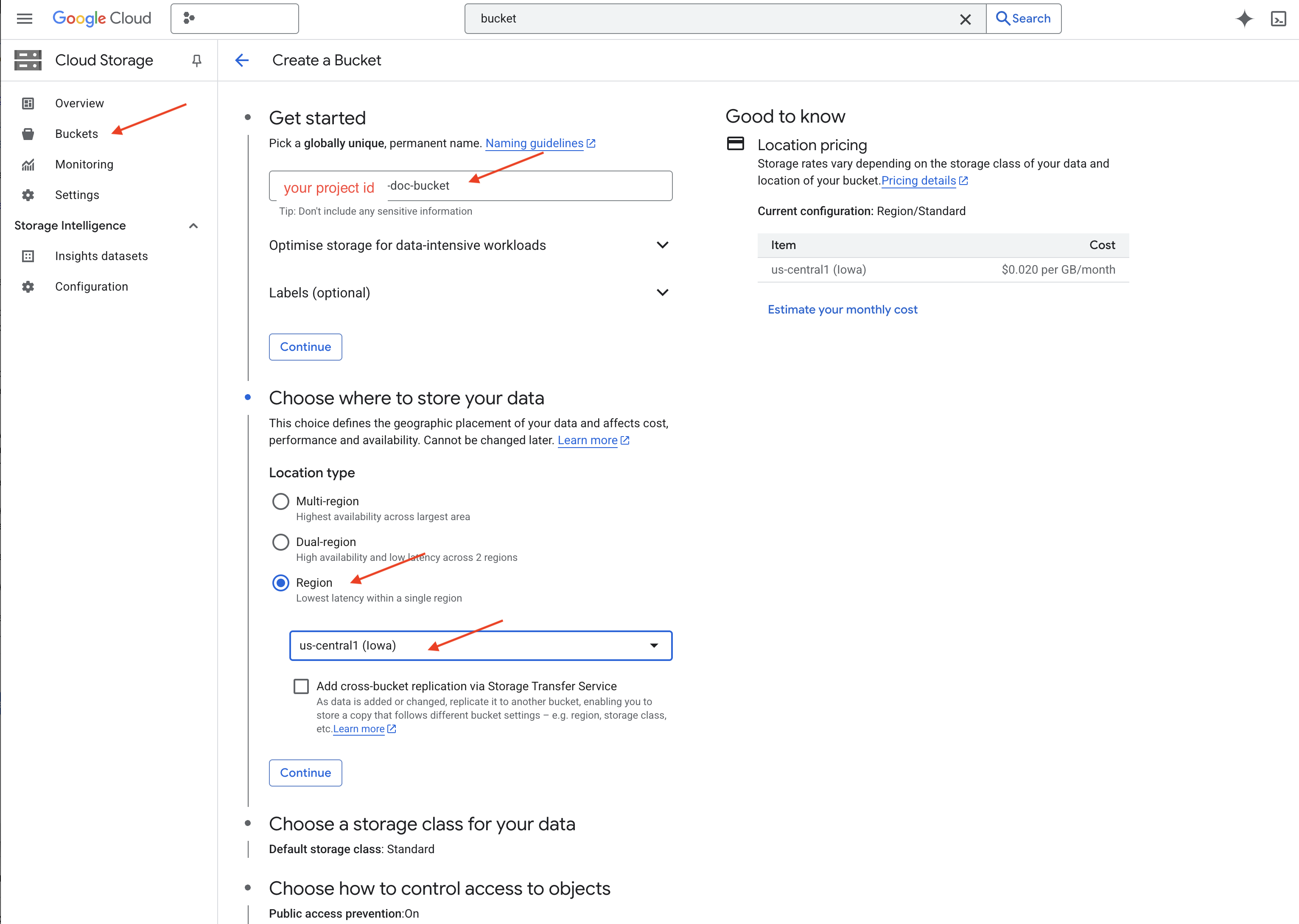
👉 انقر على الزر إنشاء لإنشاء حزمتك.
👈 قد يظهر لك إشعار منبثق بشأن منع الوصول للجميع. اترك المربّع محدّدًا وانقر على "تأكيد".
سيظهر لك الآن الحزمة التي أنشأتها حديثًا في قائمة "الحِزم". تذكَّر اسم الحزمة، ستحتاج إليه لاحقًا.
8. إعداد دالة Cloud Run
في "محرِّر الرموز" في Cloud Shell، انتقِل إلى دليل العمل legal-eagle: استخدِم الأمر cd في وحدة Cloud Editor الطرفية لإنشاء المجلد.
cd ~/legal-eagle
mkdir loader
cd loader
👉 إنشاء ملفات main.py وrequirements.txt وDockerfile في نافذة Cloud Shell الطرفية، استخدِم الأمر touch لإنشاء الملفات:
touch main.py requirements.txt Dockerfile
سيظهر لك المجلد الذي تم إنشاؤه حديثًا باسم *loader والملفات الثلاثة.
👉 تعديل main.py ضمن المجلد loader في مستكشف الملفات على يمين الشاشة، انتقِل إلى الدليل الذي أنشأت فيه الملفات وانقر مرّتين على main.py لفتحه في المحرّر.
ألصِق رمز Python التالي في main.py:
يعالج هذا التطبيق الملفات الجديدة التي يتم تحميلها إلى حزمة GCS، ويقسّم النص إلى أجزاء، وينشئ عمليات تضمين لكل جزء، ويخزّن الأجزاء وعمليات التضمين الخاصة بها في Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
عدِّل ملف requirements.txt.الصِق الأسطر التالية في الملف:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9- اختبار وظيفة Cloud Run وإنشاؤها
👉 سننفّذ هذا الإجراء في بيئة افتراضية ونثبّت مكتبات Python اللازمة لدالة Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 بدء محاكي محلي لوظيفة Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 أبقِ الوحدة الطرفية الأخيرة قيد التشغيل، ثم افتح وحدة طرفية جديدة، ونفِّذ الأمر لتحميل ملف إلى الحزمة.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 أثناء تشغيل المحاكي، يمكنك إرسال أحداث CloudEvents تجريبية إليه. ستحتاج إلى نافذة طرفية منفصلة في بيئة التطوير المتكاملة لتنفيذ هذا الإجراء.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
يجب أن تعرض الحالة OK.
👉 يمكنك إثبات صحة البيانات في Firestore، والانتقال إلى Google Cloud Console ثم إلى "قواعد البيانات" ثم "Firestore" واختيار علامة التبويب "البيانات" ثم مجموعة legal_documents. ستلاحظ أنّه تم إنشاء مستندات جديدة في مجموعتك، يمثّل كل منها جزءًا من النص من الملف الذي تم تحميله. 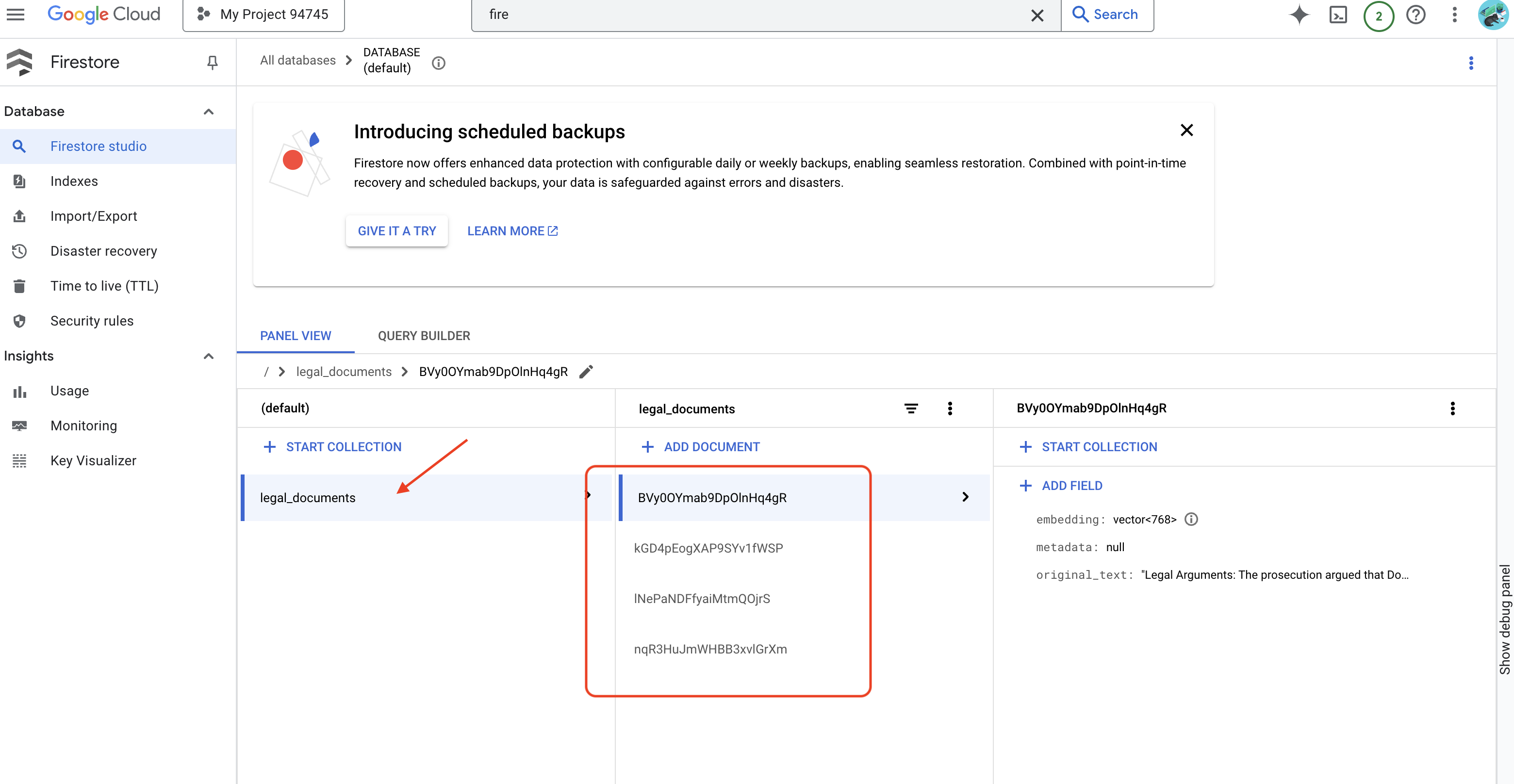
في الوحدة الطرفية التي يتم تشغيل المحاكي فيها، اكتب Ctrl+C للخروج. وأغلِق المحطة الطرفية الثانية.
👉 شغِّل الأمر deactivate للخروج من البيئة الافتراضية.
deactivate
10. إنشاء صورة حاوية ونشرها في مستودعات Artifacts
👉 حان الوقت لنشر هذا التطبيق على السحابة الإلكترونية. في مستكشف الملفات، انقر مرّتين على Dockerfile. اسأل Gemini لإنشاء ملف dockerfile لك، وافتح Gemini Code Assist واستخدِم الطلب التالي لإنشاء الملف.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
للحصول على أفضل الممارسات، ننصحك بالنقر على Diff with Open File(سهمان في اتجاهين متعاكسين، وقبول التغييرات). 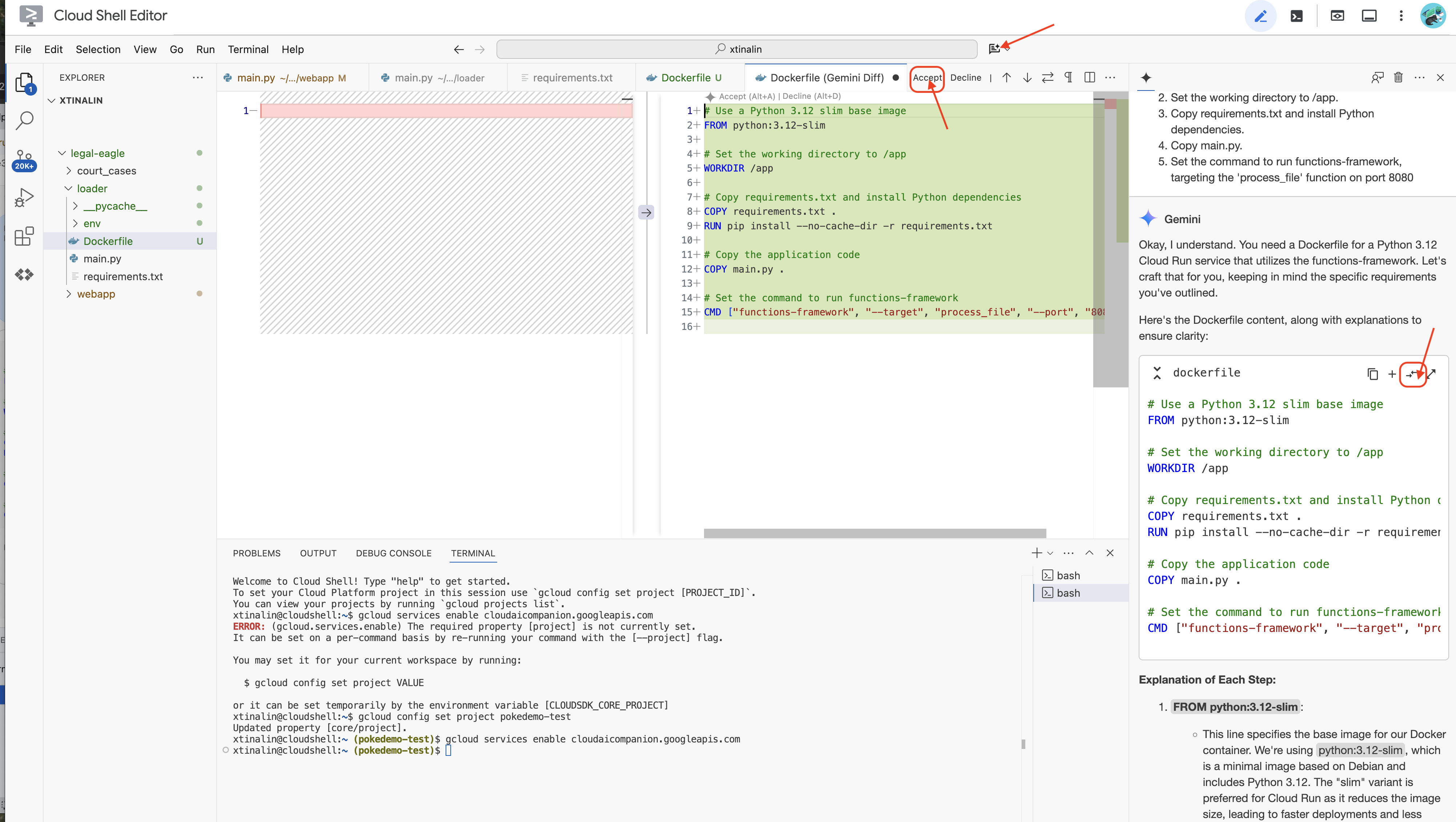
👉 إذا كنت جديدًا على الحاويات، إليك مثال عملي:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 في الوحدة الطرفية، أنشئ مستودعًا للعناصر لتخزين صورة Docker التي سننشئها.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
من المفترض أن تظهر لك الرسالة تم إنشاء المستودع [my-repository].
👉 شغِّل الأمر التالي لإنشاء صورة Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 عليك إرسال هذا التغيير إلى السجلّ الآن
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
تتوفّر الآن صورة Docker في my-repository مستودع Artifacts.
11. إنشاء دالة Cloud Run وإعداد مشغّل Eventarc
قبل التعرّف على تفاصيل نشر أداة تحميل المستندات القانونية، دعونا نتعرّف باختصار على المكوّنات المعنية: Cloud Run هو نظام أساسي مُدار بالكامل بدون خادم يتيح لك نشر التطبيقات ضمن الحاويات بسرعة وسهولة. وتجرّد إدارة البنية الأساسية، ما يتيح لك التركيز على كتابة الرموز البرمجية ونشرها.
سننفّذ أداة تحميل المستندات كخدمة Cloud Run. لننتقل الآن إلى إعداد وظيفة Cloud Run:
👉 في Google Cloud Console، انتقِل إلى Cloud Run.
👉 انتقِل إلى نشر الحاوية وفي القائمة المنسدلة، انقر على الخدمة.
👉 اضبط خدمة Cloud Run على النحو التالي:
- صورة الحاوية: انقر على "اختيار" في حقل عنوان URL. ابحث عن عنوان URL للصورة التي أرسلتها إلى Artifact Registry (مثلاً، us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- اسم الخدمة:
legal-eagle-loader - المنطقة: اختَر المنطقة
us-central1. - المصادقة: لأغراض ورشة العمل هذه، يمكنك السماح بـ "السماح باستدعاءات غير مصادَق عليها". بالنسبة إلى الإصدار العلني، من الأفضل حظر الوصول.
- الحاوية والشبكات والأمان : تلقائي
👉 انقر على إنشاء. ستنشر Cloud Run خدمتك. 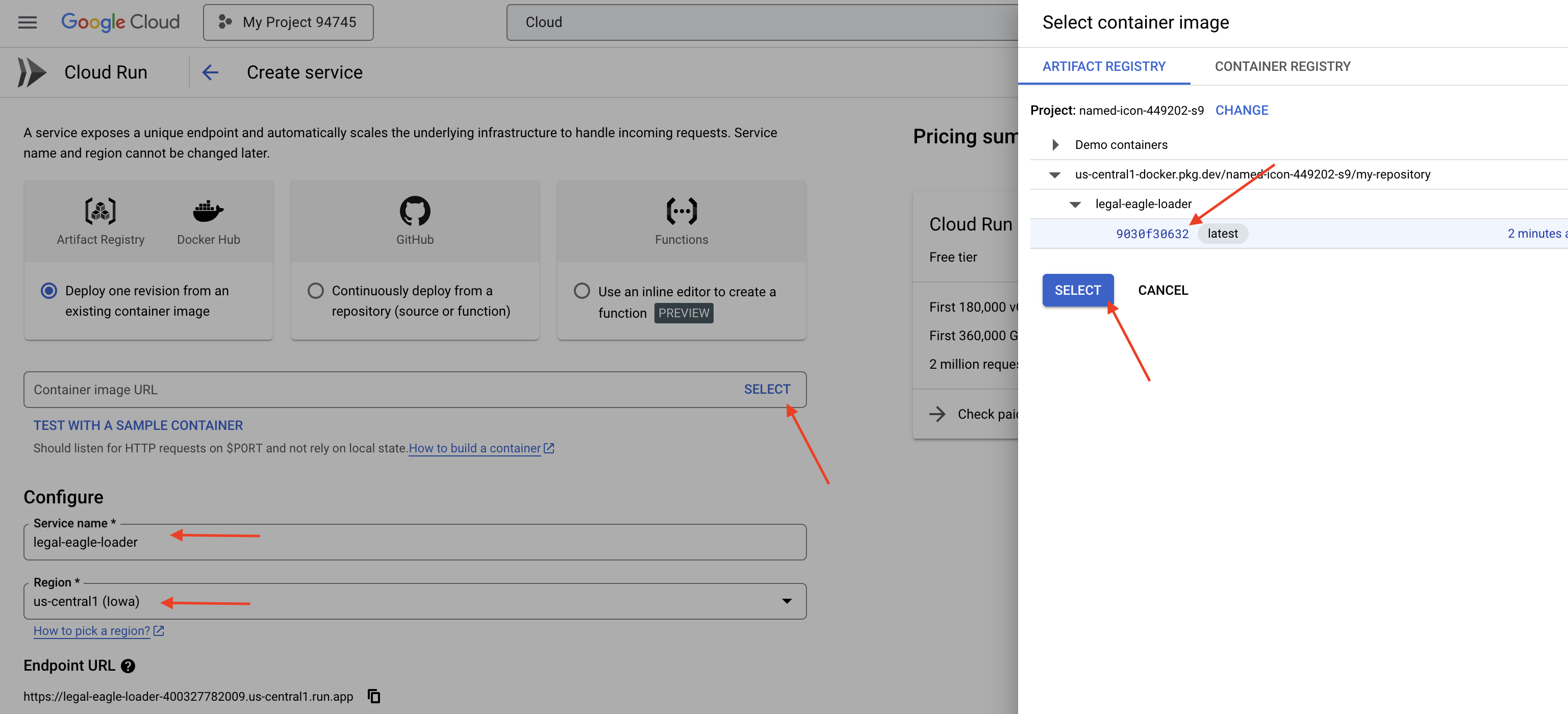
لتفعيل هذه الخدمة تلقائيًا عند إضافة ملفات جديدة إلى حزمة التخزين، سنستخدم Eventarc. تتيح لك خدمة Eventarc إنشاء بنى تعتمد على الأحداث من خلال توجيه الأحداث من مصادر مختلفة إلى خدماتك.
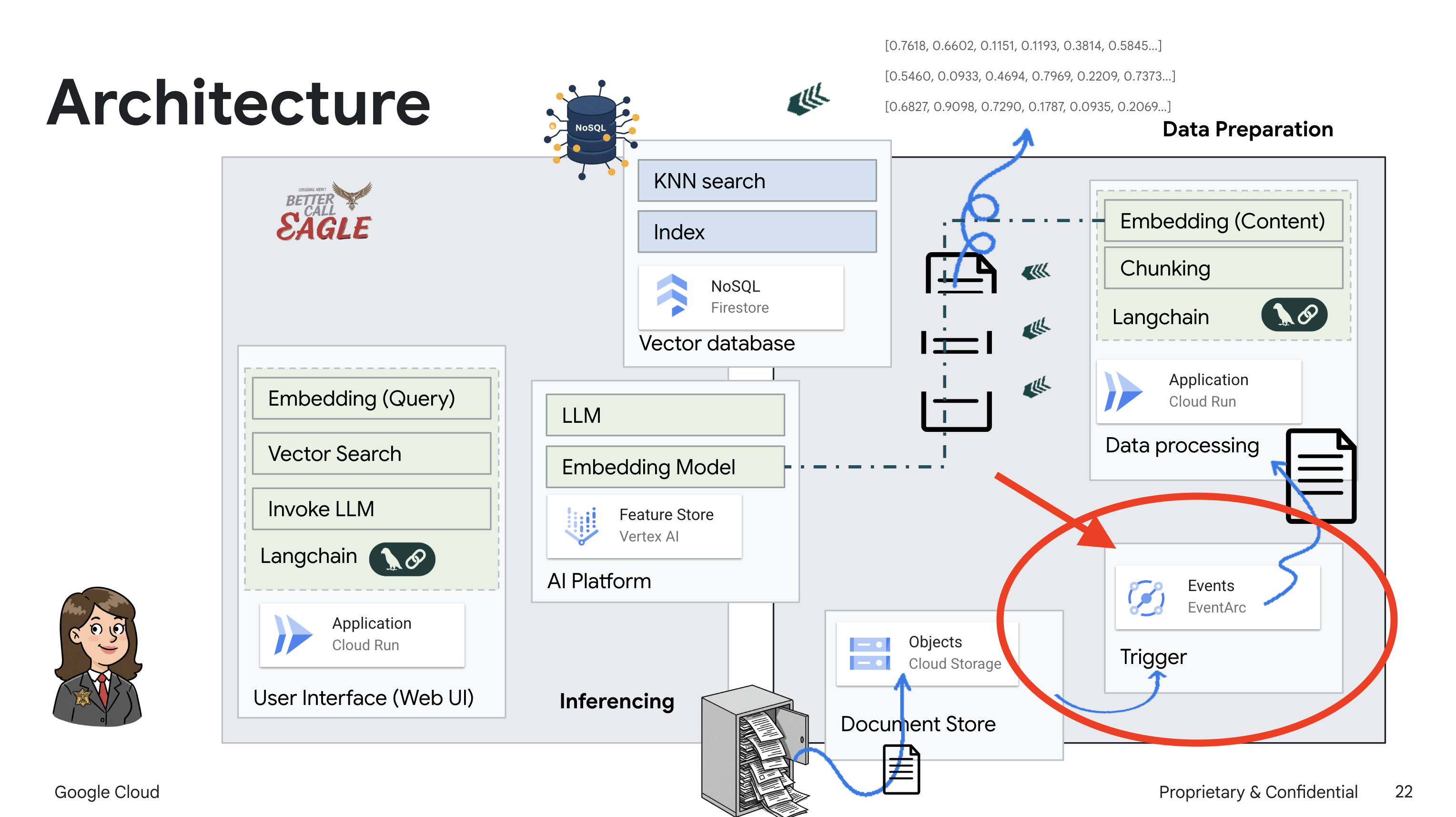
من خلال إعداد Eventarc، ستحمّل خدمة Cloud Run تلقائيًا المستندات المضافة حديثًا إلى Firestore فور تحميلها، ما يتيح تحديث البيانات في الوقت الفعلي لتطبيق RAG.
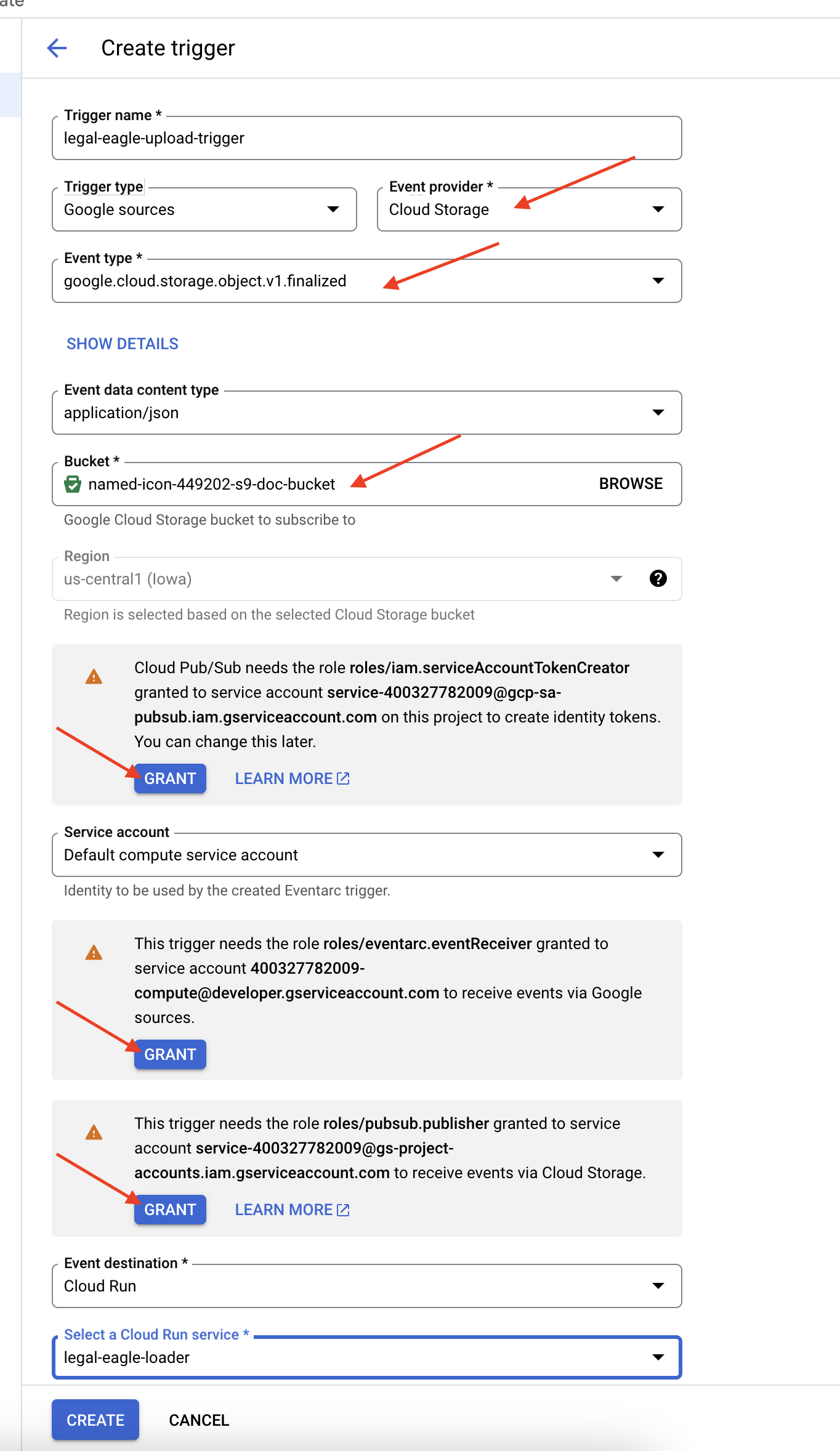
👉 في Google Cloud Console، انتقِل إلى المشغّلات ضمن EventArc. انقر على "+ إنشاء مشغّل". 👉 ضبط مشغّل Eventarc:
- اسم المشغّل:
legal-eagle-upload-trigger. - TriggerType: Google Sources
- مقدّم الحدث: اختَر Cloud Storage.
- نوع الحدث: اختَر
google.cloud.storage.object.v1.finalized - حزمة Cloud Storage: اختَر حزمة GCS من القائمة المنسدلة.
- نوع الوجهة: "خدمة Cloud Run"
- الخدمة: انقر على
legal-eagle-loader. - المنطقة:
us-central1 - المسار: اترك هذا الحقل فارغًا في الوقت الحالي .
- منح جميع الأذونات التي طلبها على الصفحة
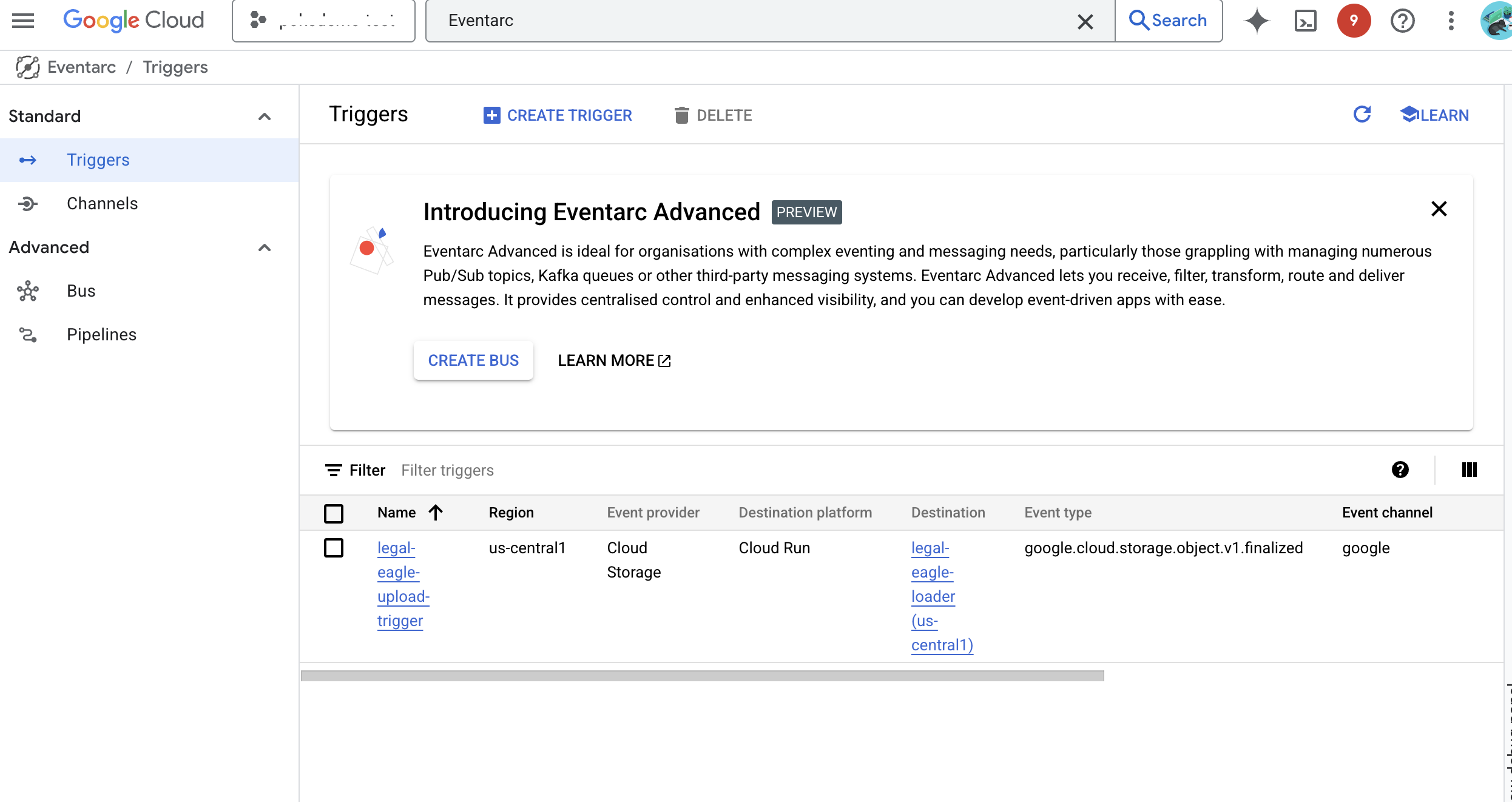
👉 انقر على إنشاء. ستعمل خدمة Eventarc الآن على إعداد المشغّل.
تحتاج خدمة Cloud Run إلى إذن لقراءة الملفات من مكوّنات مختلفة. علينا منح حساب خدمة الخدمة الإذن الذي يحتاج إليه.
12. تحميل المستندات القانونية إلى حزمة GCS
👉 حمِّل ملف قضية المحكمة إلى حزمة GCS. تذكَّر استبدال اسم الحزمة.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
لمراقبة سجلّات خدمة Cloud Run، انتقِل إلى Cloud Run -> خدمتك legal-eagle-loader -> "السجلّات". تحقَّق من السجلّات بحثًا عن رسائل المعالجة الناجحة، بما في ذلك:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
واعتمادًا على سرعة إعداد التسجيل، ستظهر لك أيضًا سجلات أكثر تفصيلاً هنا
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
ابحث عن أي رسائل خطأ في السجلّات وحدِّد المشاكل وحلّها إذا لزم الأمر. 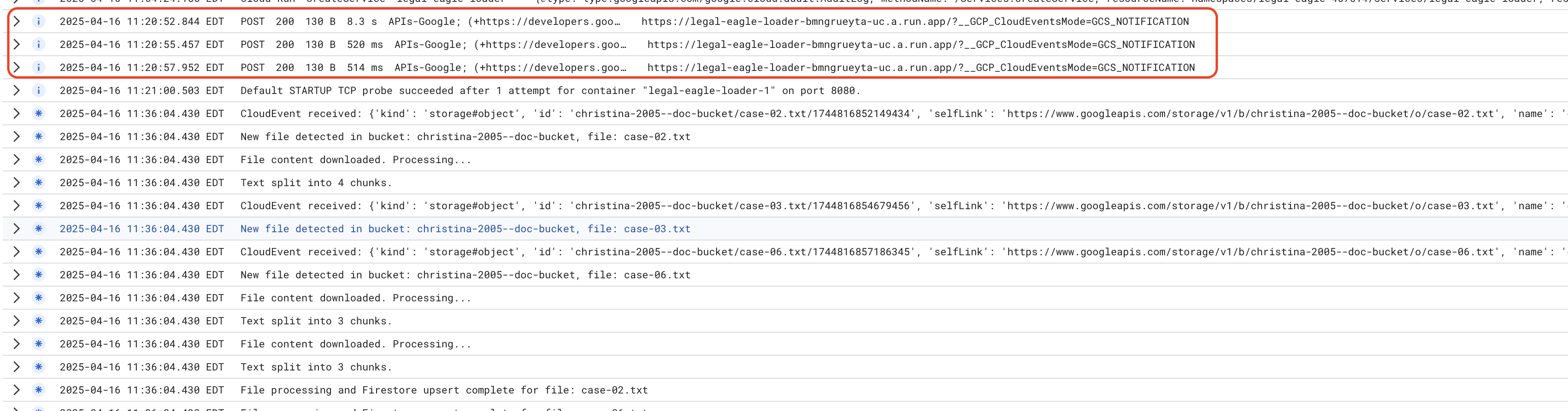
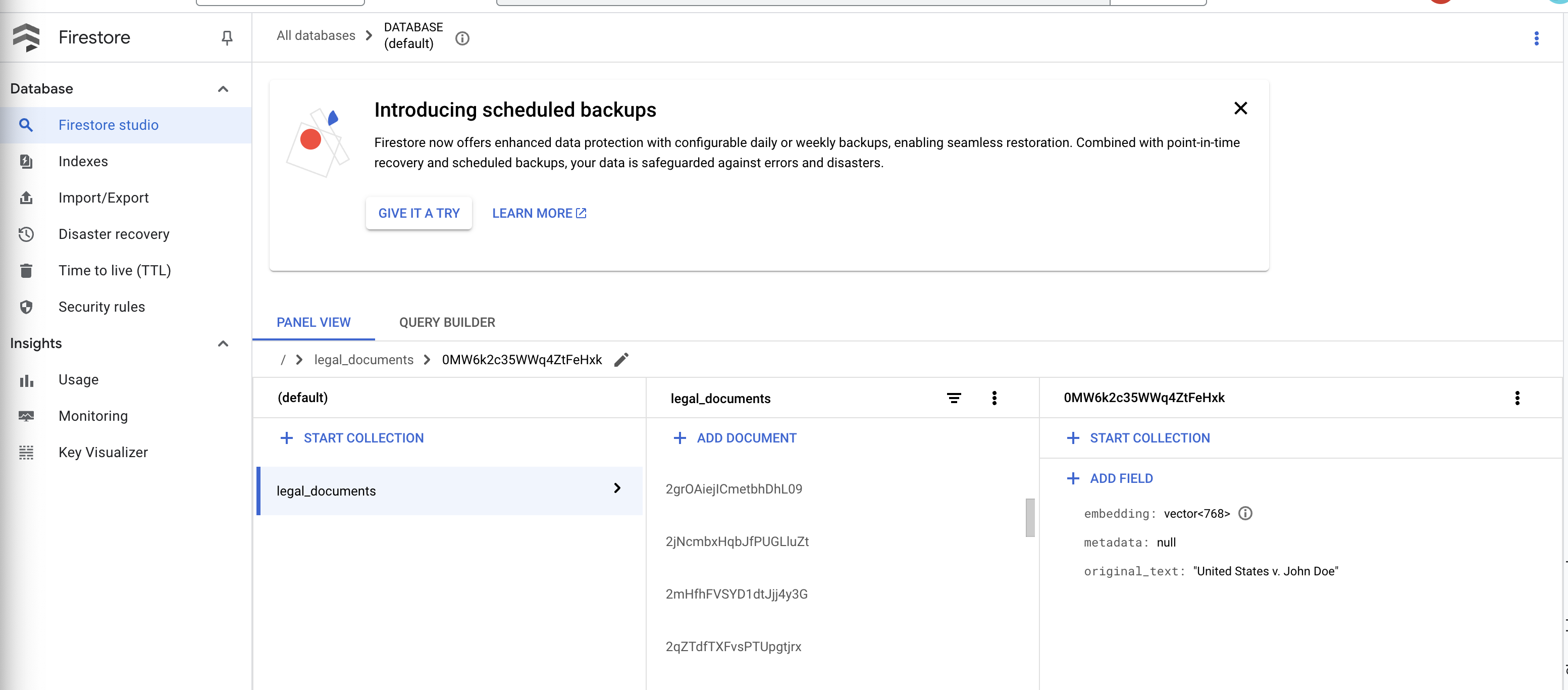
👉 التحقّق من البيانات في Firestore وافتح مجموعة legal_documents.
👉 من المفترض أن تظهر لك مستندات جديدة تم إنشاؤها في مجموعتك. سيمثّل كل مستند جزءًا من النص من الملف الذي حمّلته وسيتضمّن ما يلي:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. تنفيذ RAG
LangChain هو إطار عمل قوي مصمَّم لتبسيط عملية تطوير التطبيقات المستندة إلى النماذج اللغوية الكبيرة (LLM). بدلاً من التعامل مباشرةً مع تعقيدات واجهات برمجة التطبيقات الخاصة بالنماذج اللغوية الكبيرة وهندسة الطلبات ومعالجة البيانات، توفّر LangChain طبقة تجريد عالية المستوى. وتوفّر هذه المكتبة مكوّنات وأدوات مُعدّة مسبقًا لتنفيذ مهام مثل الربط بنماذج لغوية كبيرة مختلفة (مثل تلك المقدَّمة من OpenAI أو Google أو غيرهما)، وإنشاء سلاسل معقّدة من العمليات (مثل استرجاع البيانات ثم تلخيصها)، وإدارة الذاكرة الحوارية.
بالنسبة إلى RAG تحديدًا، تُعدّ مخازن المتجهات في LangChain ضرورية لتفعيل جانب الاسترجاع في RAG. وهي قواعد بيانات متخصّصة مصمَّمة لتخزين تضمينات المتّجهات والاستعلام عنها بكفاءة، حيث يتم ربط أجزاء النص المتشابهة دلاليًا بنقاط قريبة من بعضها في مساحة المتّجهات. تتولّى LangChain المهام الأساسية، ما يتيح للمطوّرين التركيز على المنطق والوظائف الأساسية لتطبيق RAG. يقلّل ذلك بشكل كبير من وقت التطوير وتعقيده، ما يتيح لك إنشاء نماذج أولية للتطبيقات المستندة إلى RAG ونشرها بسرعة مع الاستفادة من قوة بنية Google Cloud الأساسية وقابليتها للتوسّع.
بعد أن تعرّفت على LangChain، عليك الآن تعديل ملف legal.py ضمن المجلد webapp لتنفيذ RAG. سيتيح ذلك للنموذج اللغوي الكبير البحث في مستندات ذات صلة في Firestore قبل تقديم إجابة.
👉 استيراد FirestoreVectorStore والوحدات المطلوبة الأخرى من langchain وvertexai إضافة ما يلي إلى legal.py الحالي
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 ابدأ Vertex AI ونموذج التضمين.ستستخدم text-embedding-004. أضِف الرمز التالي بعد استيراد الوحدات مباشرةً.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 أنشئ FirestoreVectorStore يشير إلى مجموعة legal_documents، باستخدام نموذج التضمين الذي تمّت تهيئته وتحديد حقلَي المحتوى والتضمين. أضِف هذا الرمز بعد رمز نموذج التضمين السابق مباشرةً.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 عرِّف دالة باسم search_resource تأخذ طلب بحث وتجري بحثًا عن التشابه باستخدام vector_store.similarity_search وتعرض النتائج المدمجة.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 استبدِل الدالة ask_llm واستخدِم الدالة search_resource لاسترداد السياق ذي الصلة استنادًا إلى طلب المستخدم.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 اختياري: النسخة الإسبانية
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 بعد تنفيذ RAG في legal.py، يجب اختباره محليًا قبل النشر، وتشغيل التطبيق باستخدام الأمر:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 استخدِم webpreview للوصول إلى التطبيق والتحدث إلى المساعد واكتب ctrl+c للخروج من العملية التي يتم تشغيلها محليًا، وشغِّل deactivate للخروج من البيئة الافتراضية.
deactivate
لنشر تطبيق الويب على Cloud Run، سيكون الأمر مشابهًا لوظيفة أداة التحميل. ستنشئ صورة Docker وتضع علامة عليها وتنشرها في Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 حان الوقت لنشر تطبيق الويب على Google Cloud. في الوحدة الطرفية، شغِّل الأوامر التالية:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
تحقَّق من عملية النشر من خلال الانتقال إلى Cloud Run في Google Cloud Console.من المفترض أن تظهر لك خدمة جديدة باسم legal-eagle-webapp.
انقر على الخدمة للانتقال إلى صفحة التفاصيل الخاصة بها، ويمكنك العثور على عنوان URL الذي تم نشره في أعلى الصفحة. 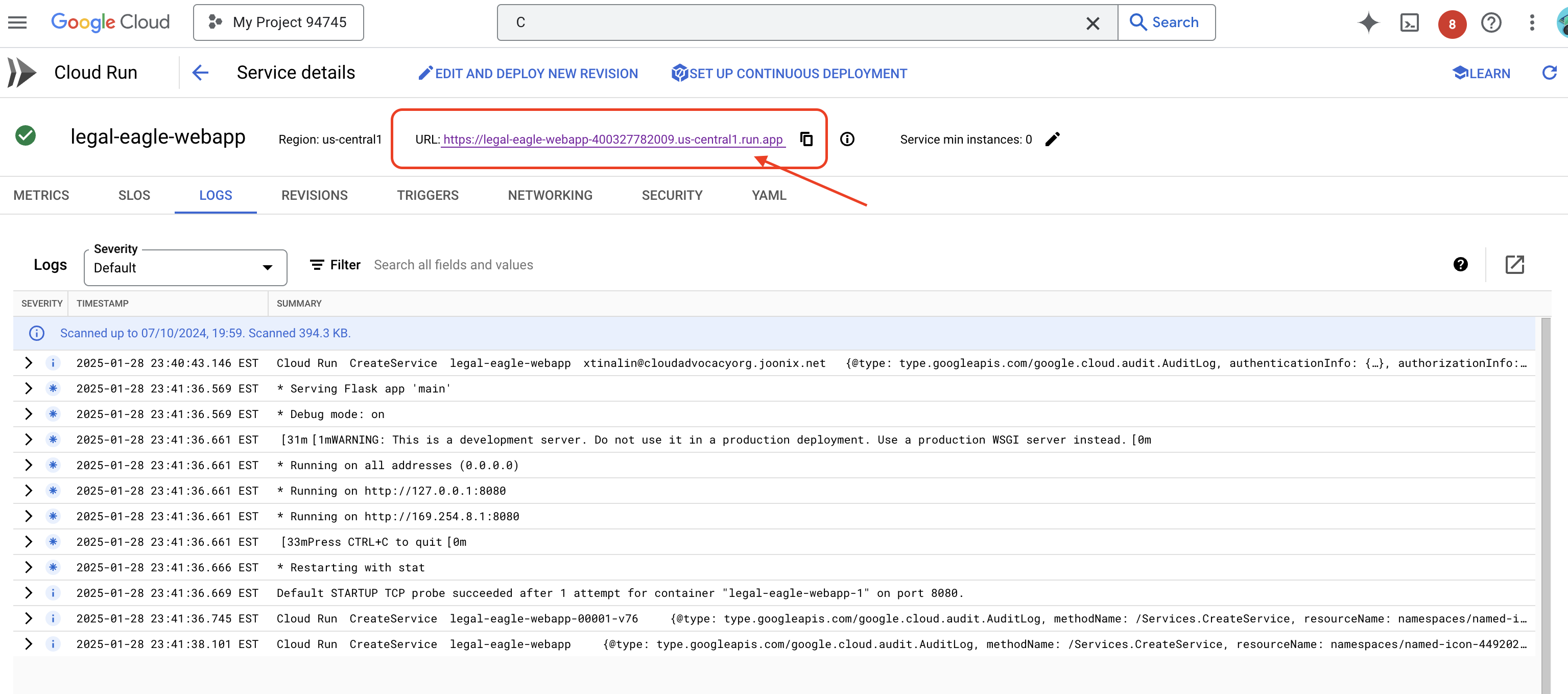
الآن، افتح عنوان URL الذي تم نشره في علامة تبويب جديدة في المتصفّح. يمكنك التفاعل مع المساعد القانوني وطرح أسئلة متعلقة بقضايا المحكمة التي حمّلتها(ضمن مجلد court_cases):
- كم عدد سنوات السجن التي حُكم بها على مايكل براون؟
- ما هو المبلغ الذي تم تحصيله من الرسوم غير المصرَّح بها نتيجةً لإجراءات "سميرة فؤاد"؟
- ما هو الدور الذي لعبته شهادات الجيران في التحقيق في قضية إميلي وايت؟
👉 اختياري: النسخة الإسبانية
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
ستلاحظ أنّ الردود أصبحت الآن أكثر دقة وتستند إلى محتوى المستندات القانونية التي حمّلتها، ما يوضّح فعالية عملية الاسترجاع والإنشاء.
تهانينا على إكمال ورشة العمل!! لقد تمكّنت من إنشاء تطبيق لتحليل المستندات القانونية ونشره باستخدام النماذج اللغوية الكبيرة وLangChain وGoogle Cloud. لقد تعلّمت كيفية استيعاب المستندات القانونية ومعالجتها، وتحسين ردود النماذج اللغوية الكبيرة باستخدام المعلومات ذات الصلة من خلال التوليد المعزّز بالاسترجاع، ونشر تطبيقك كخدمة بلا خادم. ستساعدك هذه المعرفة والتطبيق الذي تم إنشاؤه في استكشاف المزيد من إمكانات النماذج اللغوية الكبيرة للمهام القانونية. أحسنت".
14. التحدي
أنواع الوسائط المتنوعة::
كيفية استيعاب ومعالجة أنواع مختلفة من الوسائط، مثل فيديوهات المحكمة والتسجيلات الصوتية، واستخراج النصوص ذات الصلة
مواد العرض على الإنترنت:
كيفية معالجة مواد العرض على الإنترنت، مثل صفحات الويب، مباشرةً