
1. Einführung
Ich war schon immer von der Intensität des Gerichtssaals fasziniert und habe mir vorgestellt, wie ich die Komplexität des Gerichtssaals geschickt meistere und überzeugende Schlussplädoyers halte. Mein Karriereweg hat mich zwar woanders hingeführt, aber ich freue mich, dass wir mit der Hilfe von KI vielleicht alle näher an der Verwirklichung dieses Traums sind.

Heute sehen wir uns an, wie Sie die leistungsstarken KI-Tools von Google wie Vertex AI, Firestore und Cloud Run Functions verwenden können, um rechtliche Daten zu verarbeiten und zu analysieren, blitzschnelle Suchvorgänge durchzuführen und vielleicht sogar Ihrem imaginären Mandanten (oder sich selbst) aus einer schwierigen Situation zu helfen.
Sie befragen vielleicht keinen Zeugen, aber mit unserem System können Sie Berge von Informationen durchsuchen, übersichtliche Zusammenfassungen erstellen und die relevantesten Daten in Sekundenschnelle präsentieren.
2. Architektur
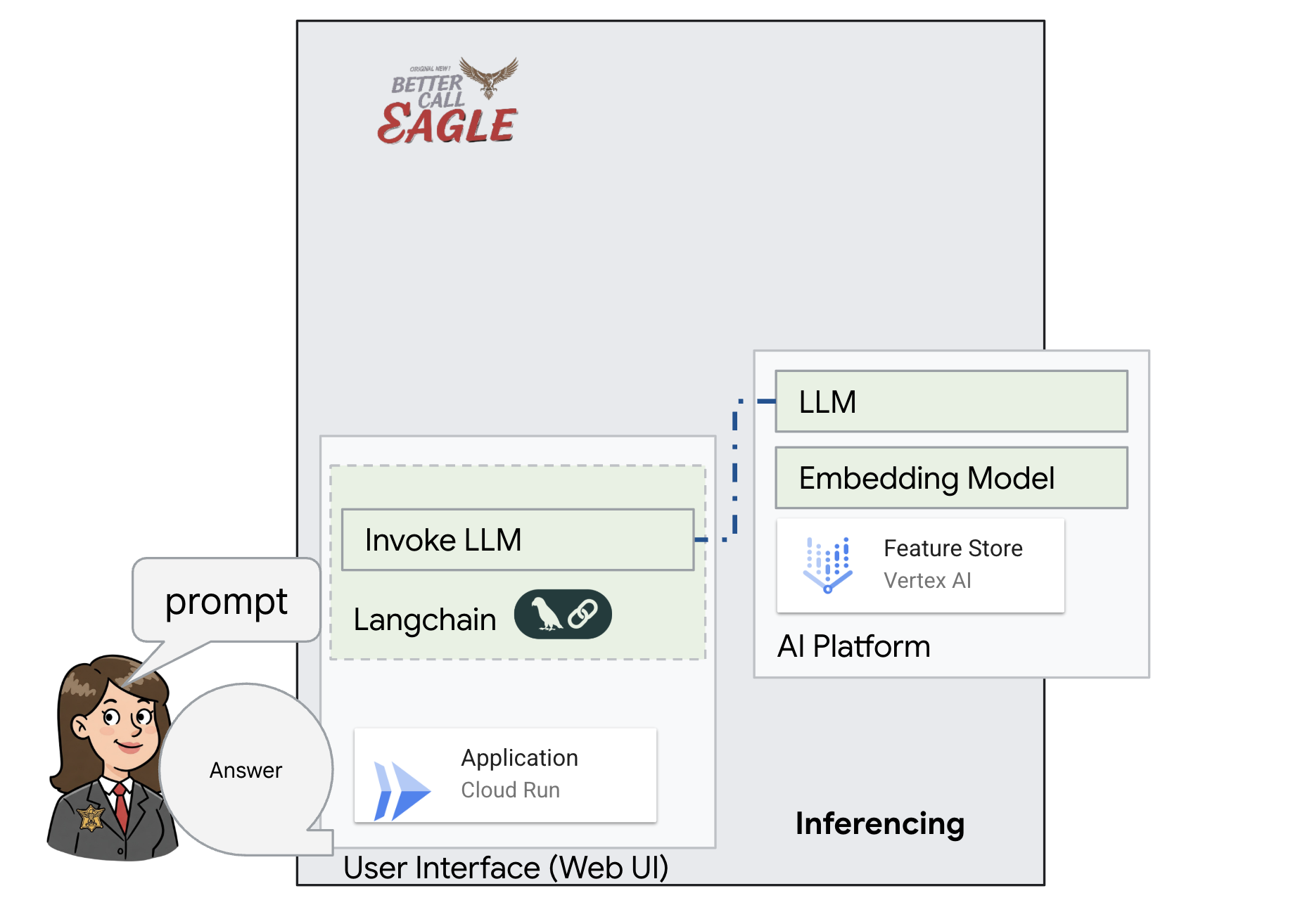
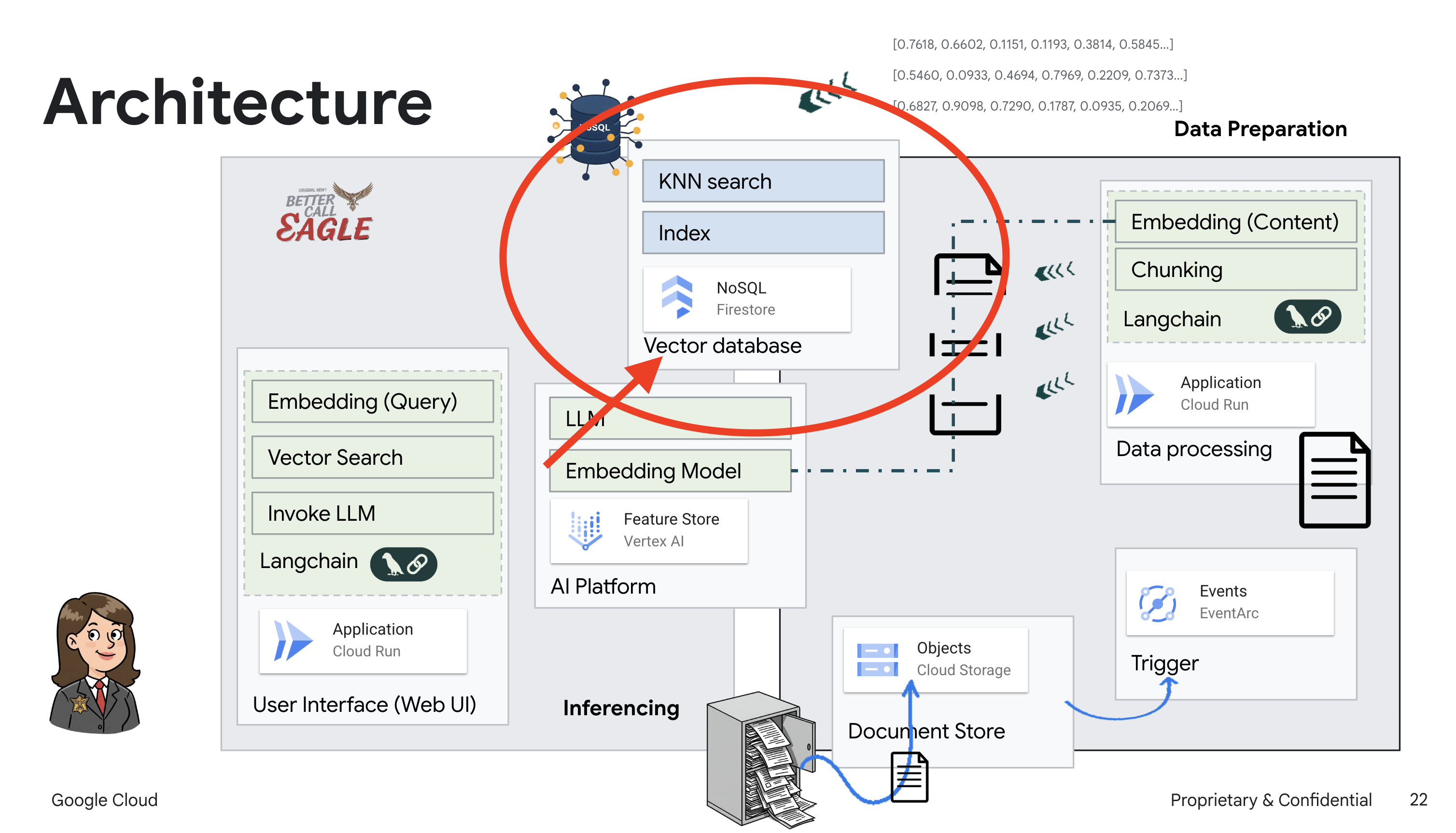
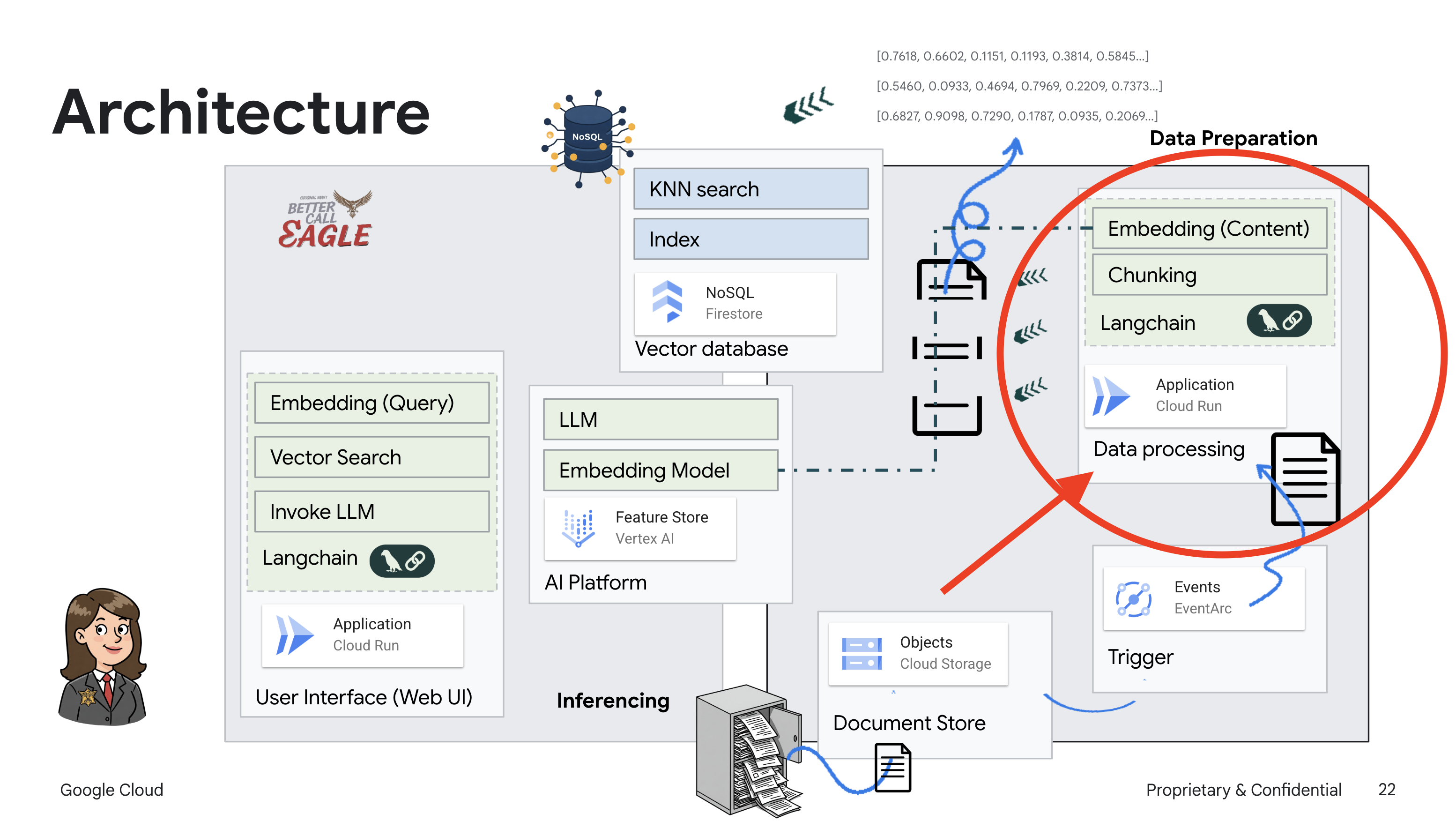
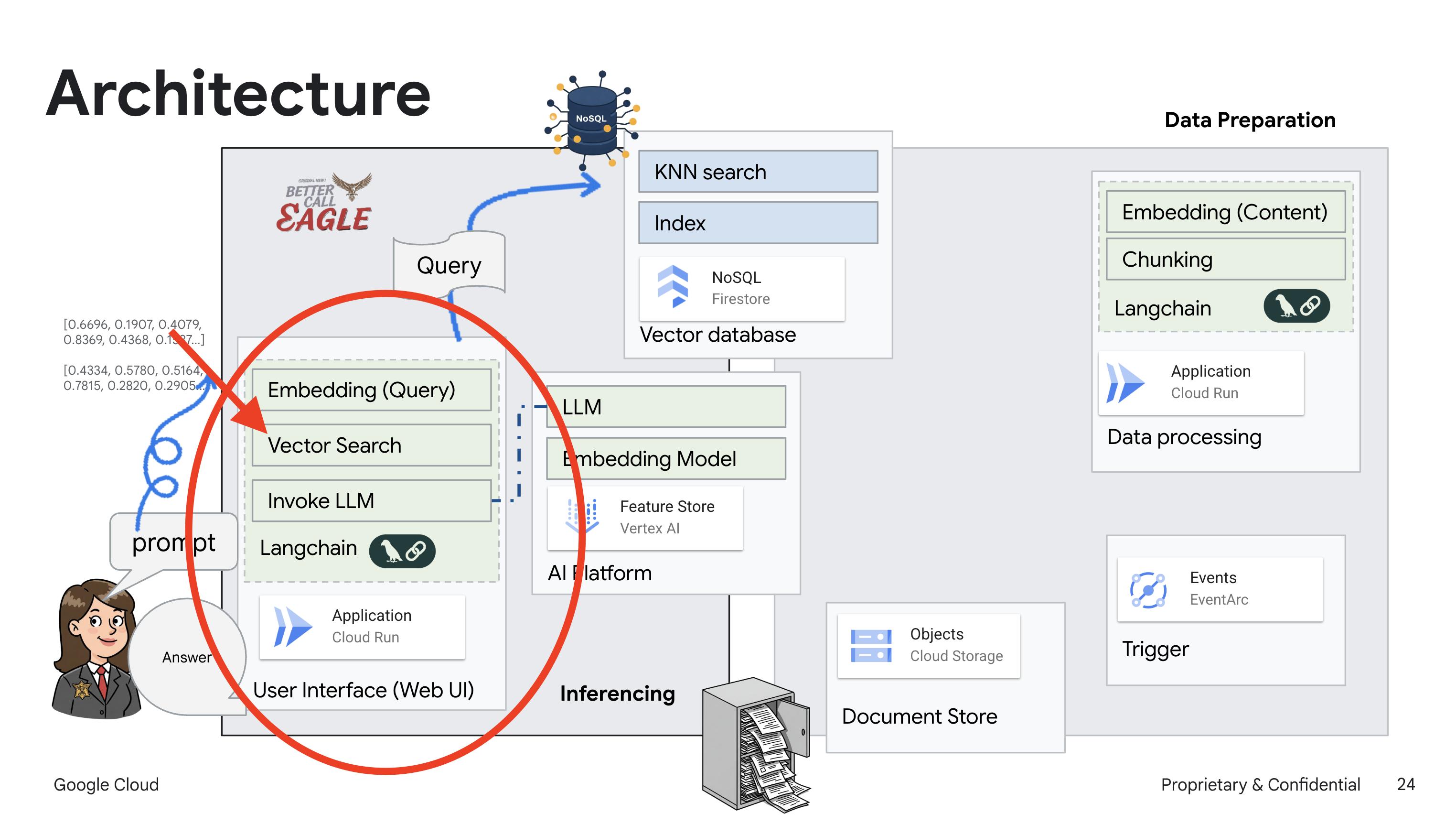
In diesem Projekt geht es darum, einen rechtlichen Assistenten mit Google Cloud AI-Tools zu erstellen. Dabei wird insbesondere darauf eingegangen, wie rechtliche Daten verarbeitet, analysiert und durchsucht werden. Das System ist darauf ausgelegt, große Mengen an Informationen zu durchsuchen, Zusammenfassungen zu erstellen und relevante Daten schnell zu präsentieren. Die Architektur des rechtlichen Assistenten umfasst mehrere wichtige Komponenten:
Wissensdatenbank aus unstrukturierten Daten erstellen: Google Cloud Storage (GCS) wird zum Speichern von Rechtsdokumenten verwendet. Firestore, eine NoSQL-Datenbank, fungiert als Vektorspeicher, in dem Dokumentchunks und die entsprechenden Einbettungen gespeichert werden. Die Vektorsuche ist in Firestore aktiviert, um Ähnlichkeitssuchen zu ermöglichen. Wenn ein neues rechtliches Dokument in GCS hochgeladen wird, löst Eventarc eine Cloud Run-Funktion aus. Mit dieser Funktion wird das Dokument verarbeitet, indem es in Chunks aufgeteilt und für jeden Chunk mit dem Texteinbettungsmodell von Vertex AI eine Einbettung generiert wird. Diese Einbettungen werden dann zusammen mit den Textblöcken in Firestore gespeichert. 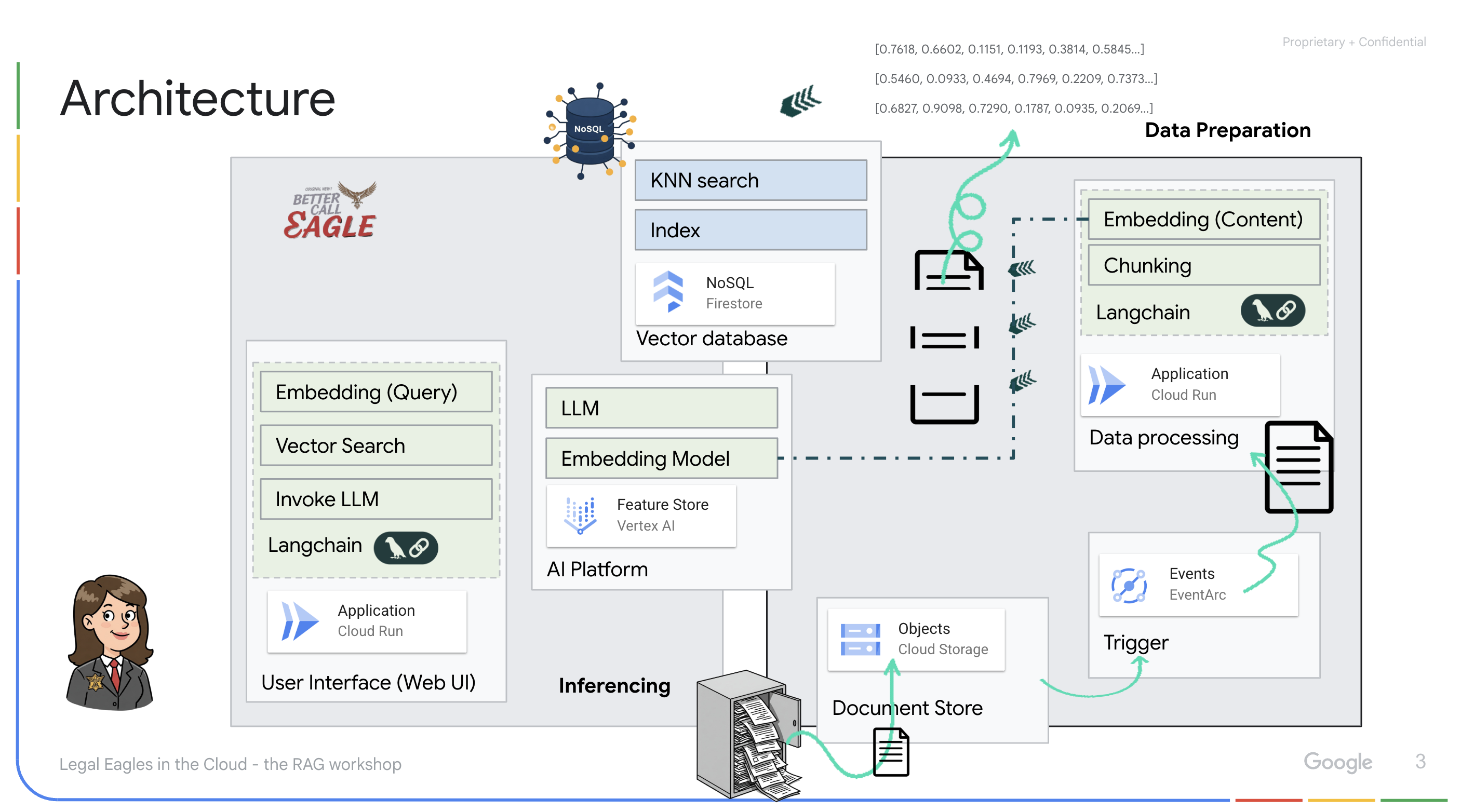
Anwendung mit LLM und RAG : Das Herzstück des Frage-Antwort-Systems ist die Funktion ask_llm, die die Langchain-Bibliothek verwendet, um mit einem Vertex AI Gemini Large Language Model zu interagieren. Es wird eine HumanMessage aus der Anfrage des Nutzers erstellt und eine SystemMessage eingefügt, in der das LLM angewiesen wird, als hilfreicher rechtlicher Assistent zu fungieren. Das System verwendet einen RAG-Ansatz (Retrieval-Augmented Generation). Bevor eine Anfrage beantwortet wird, ruft das System mit der Funktion search_resource relevanten Kontext aus dem Firestore-Vektorspeicher ab. Dieser Kontext wird dann in die SystemMessage aufgenommen, damit die Antwort des LLM auf den bereitgestellten rechtlichen Informationen basiert. 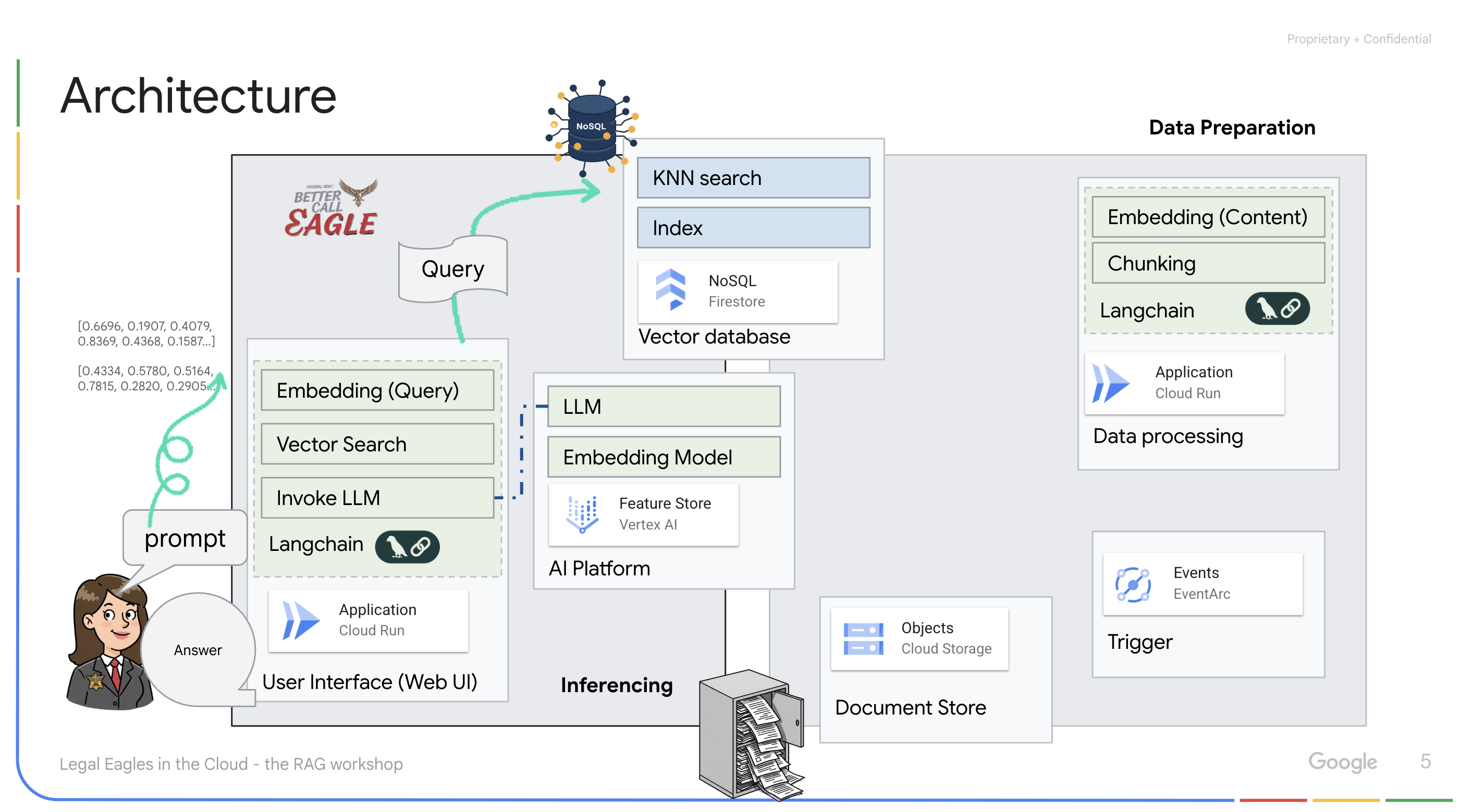
Das Projekt zielt darauf ab, die „kreativen Interpretationen“ von LLMs zu vermeiden, indem RAG verwendet wird. Dabei werden zuerst relevante Informationen aus einer vertrauenswürdigen Rechtsquelle abgerufen, bevor eine Antwort generiert wird. So können genauere, fundierte Antworten auf Grundlage tatsächlicher rechtlicher Informationen generiert werden. Das System basiert auf verschiedenen Google Cloud-Diensten wie Google Cloud Shell, Vertex AI, Firestore, Cloud Run und Eventarc.
3. Hinweis
Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines. Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Gemini Code Assist in der Cloud Shell-IDE aktivieren
👉 Rufen Sie in der Google Cloud Console die Gemini Code Assist-Tools auf und aktivieren Sie Gemini Code Assist kostenlos, indem Sie den Nutzungsbedingungen zustimmen.
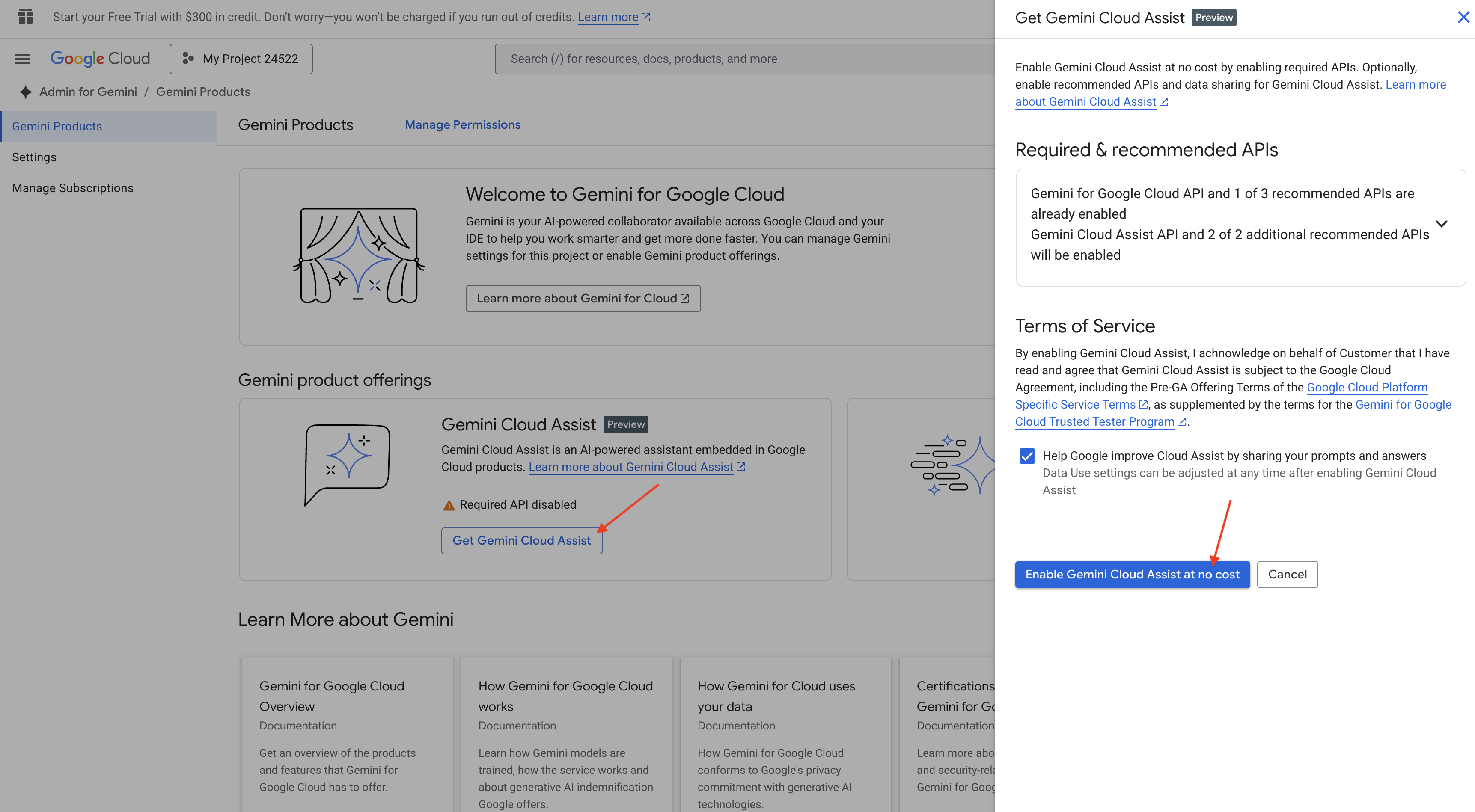
Ignorieren Sie die Einrichtung der Berechtigungen und verlassen Sie diese Seite.
Mit dem Cloud Shell-Editor arbeiten
👉 Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“ (das Symbol für das Terminal oben im Cloud Shell-Bereich).
👉 Klicken Sie auf die Schaltfläche „Editor öffnen“ (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Editor im Fenster geöffnet. Auf der linken Seite sehen Sie einen Datei-Explorer.

👉 Klicken Sie in der unteren Statusleiste auf den Button Cloud Code – Anmelden, wie dargestellt. Autorisieren Sie das Plug-in wie beschrieben. Wenn in der Statusleiste Cloud Code – kein Projekt angezeigt wird, wählen Sie diese Option im Drop-down-Menü „Google Cloud-Projekt auswählen“ aus und wählen Sie dann das Google Cloud-Projekt aus der Liste der Projekte aus, mit denen Sie arbeiten möchten.
👉 Öffnen Sie das Terminal in der Cloud-IDE  .
.
👉 Prüfen Sie im neuen Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
👉 Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
gcloud config set project <YOUR_PROJECT_ID>
👉 Führen Sie den folgenden Befehl aus, um die erforderlichen Google Cloud APIs zu aktivieren:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Klicken Sie in der Cloud Shell-Symbolleiste (oben im Cloud Shell-Bereich) auf die Schaltfläche „Editor öffnen“ (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite sehen Sie einen Datei-Explorer.
👉 Laden Sie das Bootstrap-Basisprojekt im Terminal herunter:
git clone https://github.com/weimeilin79/legal-eagle.git
OPTIONAL: SPANISH VERSION
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Nachdem Sie diesen Befehl im Cloud Shell-Terminal ausgeführt haben, wird in Ihrer Cloud Shell-Umgebung ein neuer Ordner mit dem Repository-Namen legal-eagle erstellt.
4. Inferenzanwendung mit Gemini Code Assist schreiben
In diesem Abschnitt konzentrieren wir uns auf die Entwicklung des Kerns unseres juristischen Assistenten – der Webanwendung, die Nutzerfragen empfängt und mit dem KI-Modell interagiert, um Antworten zu generieren. Wir nutzen Gemini Code Assist, um den Python-Code für diesen Inferenzteil zu schreiben.
Zuerst erstellen wir eine Flask-Anwendung, die die LangChain-Bibliothek verwendet, um direkt mit dem Vertex AI Gemini-Modell zu kommunizieren. Diese erste Version wird als hilfreicher rechtlicher Assistent auf dem allgemeinen Wissen des Modells basieren, aber noch keinen Zugriff auf unsere spezifischen Gerichtsakten haben. So können wir die Baseline-Leistung des LLM sehen, bevor wir es später mit RAG verbessern.
Im Bereich „Explorer“ des Cloud Code-Editors (normalerweise auf der linken Seite) sollte jetzt der Ordner angezeigt werden, der beim Klonen des Git-Repositorys erstellt wurde. Öffnen Sie den Stammordner Ihres Projekts im Explorer.legal-eagle Darin finden Sie den Unterordner webapp. Öffnen Sie auch diesen. 
👉 Wenn Sie die Datei legal.py im Cloud Code-Editor bearbeiten, können Sie Gemini Code Assist auf verschiedene Arten auffordern.
👉 Kopieren Sie den folgenden Prompt an das Ende von legal.py, in dem Sie genau beschreiben, was Gemini Code Assist generieren soll, klicken Sie auf das Glühbirnensymbol 💡 und wählen Sie Gemini: Code erstellen aus. Das genaue Menüelement kann je nach Cloud Code-Version leicht variieren.
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Generierten Code sorgfältig prüfen
- Entspricht es in etwa den Schritten, die du im Kommentar beschrieben hast?
- Wird ein
ChatPromptTemplate-Objekt mitSystemMessageundHumanMessageerstellt? - Ist eine grundlegende Fehlerbehandlung (
try...except) enthalten?
Wenn der generierte Code gut und größtenteils korrekt ist, können Sie ihn übernehmen. Drücken Sie dazu die Tabulatortaste oder die Eingabetaste für Inline-Vorschläge oder klicken Sie bei größeren Codeblöcken auf „Akzeptieren“.
Wenn der generierte Code nicht genau Ihren Vorstellungen entspricht oder Fehler enthält, ist das kein Problem. Gemini Code Assist ist ein Tool, das Sie unterstützt, aber nicht dazu gedacht ist, beim ersten Versuch perfekten Code zu schreiben.
Bearbeiten und ändern Sie den generierten Code, um ihn zu optimieren, Fehler zu beheben und ihn besser an Ihre Anforderungen anzupassen. Sie können Gemini Code Assist weitere Prompts geben, indem Sie im Code Assist-Chatfeld weitere Kommentare hinzufügen oder spezifische Fragen stellen.
Wenn Sie das SDK noch nicht kennen, finden Sie hier ein funktionierendes Beispiel.
👉 Kopieren Sie den folgenden Code und fügen Sie ihn in Ihre legal.py ein. ERSETZEN Sie dabei den vorhandenen Code:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPTIONAL: SPANISH VERSION
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
Erstellen Sie als Nächstes eine Funktion, die eine Route verarbeitet, die auf Nutzerfragen antwortet.
Öffnen Sie main.py im Cloud Shell-Editor. Ähnlich wie beim Generieren von „ask_llm“ in legal.py können Sie Gemini Code Assist verwenden, um die Flask-Route und die Funktion ask_question zu generieren. Geben Sie den folgenden PROMPT als Kommentar in main.py ein. Achten Sie darauf, dass er vor dem Starten der Flask-App unter if __name__ == "__main__": hinzugefügt wird:
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Akzeptiere NUR, wenn der generierte Code gut und größtenteils korrekt ist. Wenn Sie sich mit Python nicht auskennen, können Sie das folgende funktionierende Beispiel kopieren und in Ihre main.py einfügen, und zwar unter den bereits vorhandenen Code.
👉 Achten Sie darauf, dass Sie Folgendes VOR dem Start der Webanwendung einfügen (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Wenn Sie diese Schritte ausführen, sollten Sie Gemini Code Assist erfolgreich aktivieren, Ihr Projekt einrichten und damit die Funktion ask in Ihrer Datei main.py generieren können.
5. Lokale Tests im Cloud Editor
👉 Installieren Sie im Terminal des Editors abhängige Bibliotheken und starten Sie die Web-UI lokal.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Suchen Sie in der Cloud Shell-Terminalausgabe nach Startmeldungen. Flask gibt normalerweise Meldungen aus, die angeben, dass es ausgeführt wird und auf welchem Port.
- Running on http://127.0.0.1:8080
Die Anwendung muss weiter ausgeführt werden, um Anfragen zu bearbeiten.
👉 Wählen Sie im Menü „Webvorschau“ die Option Vorschau auf Port 8080 aus. In Cloud Shell wird ein neuer Browsertab oder ein neues Browserfenster mit der Webvorschau Ihrer Anwendung geöffnet. 
👉 Geben Sie in der Anwendungsoberfläche einige Fragen ein, die sich speziell auf Verweise auf Gerichtsverfahren beziehen, und sehen Sie sich an, wie das LLM reagiert. Sie können beispielsweise Folgendes ausprobieren:
- Zu wie vielen Jahren Gefängnis wurde Michael Brown verurteilt?
- Wie viel Geld wurde durch unautorisierte Gebühren aufgrund der Aktionen von Jane Smith generiert?
- Welche Rolle spielten die Aussagen der Nachbarn bei der Untersuchung des Falls um Emily White?
👉 OPTIONAL: SPANISH VERSION
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Wenn Sie sich die Antworten genau ansehen, werden Sie wahrscheinlich feststellen, dass das Modell Halluzinationen haben, vage oder allgemein gehalten sein und Ihre Fragen manchmal falsch interpretieren kann, insbesondere da es noch keinen Zugriff auf bestimmte Rechtsdokumente hat.
👉 Beenden Sie das Skript, indem Sie Strg+C drücken.
👉 Beenden Sie die virtuelle Umgebung, indem Sie im Terminal Folgendes ausführen:
deactivate
6. Vektorspeicher einrichten
Es ist an der Zeit, diesen „kreativen Interpretationen“ des Gesetzes durch LLMs ein Ende zu setzen. Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel. Stellen Sie sich vor, dass unser LLM Zugriff auf eine leistungsstarke juristische Bibliothek erhält, bevor es Ihre Fragen beantwortet. Anstatt sich nur auf das allgemeine Wissen zu verlassen (das je nach Modell ungenau oder veraltet sein kann), ruft RAG zuerst relevante Informationen aus einer vertrauenswürdigen Quelle ab – in unserem Fall aus rechtlichen Dokumenten – und verwendet diesen Kontext dann, um eine fundiertere und genauere Antwort zu generieren. Es ist, als würde das LLM seine Hausaufgaben machen, bevor es in den Gerichtssaal geht.
Um unser RAG-System zu entwickeln, benötigen wir einen Ort, an dem wir alle diese rechtlichen Dokumente speichern und vor allem nach Bedeutung durchsuchen können. Hier kommt Firestore ins Spiel. Firestore ist die flexible, skalierbare NoSQL-Dokumentendatenbank von Google Cloud.
Wir verwenden Firestore als Vektorspeicher. Wir speichern Blöcke unserer rechtlichen Dokumente in Firestore und für jeden Block auch seine Einbettung – die numerische Darstellung seiner Bedeutung.
Wenn Sie dann unserem Legal Eagle eine Frage stellen, verwenden wir die Vektorsuche von Firestore, um die Textblöcke mit Rechtstext zu finden, die für Ihre Anfrage am relevantesten sind. Dieser abgerufene Kontext wird von RAG verwendet, um Ihnen Antworten zu geben, die auf tatsächlichen rechtlichen Informationen beruhen und nicht nur auf der Fantasie des LLM.
👉 Rufen Sie in einem neuen Tab/Fenster Firestore in der Google Cloud Console auf.
👉 Klicken Sie auf Datenbank erstellen.
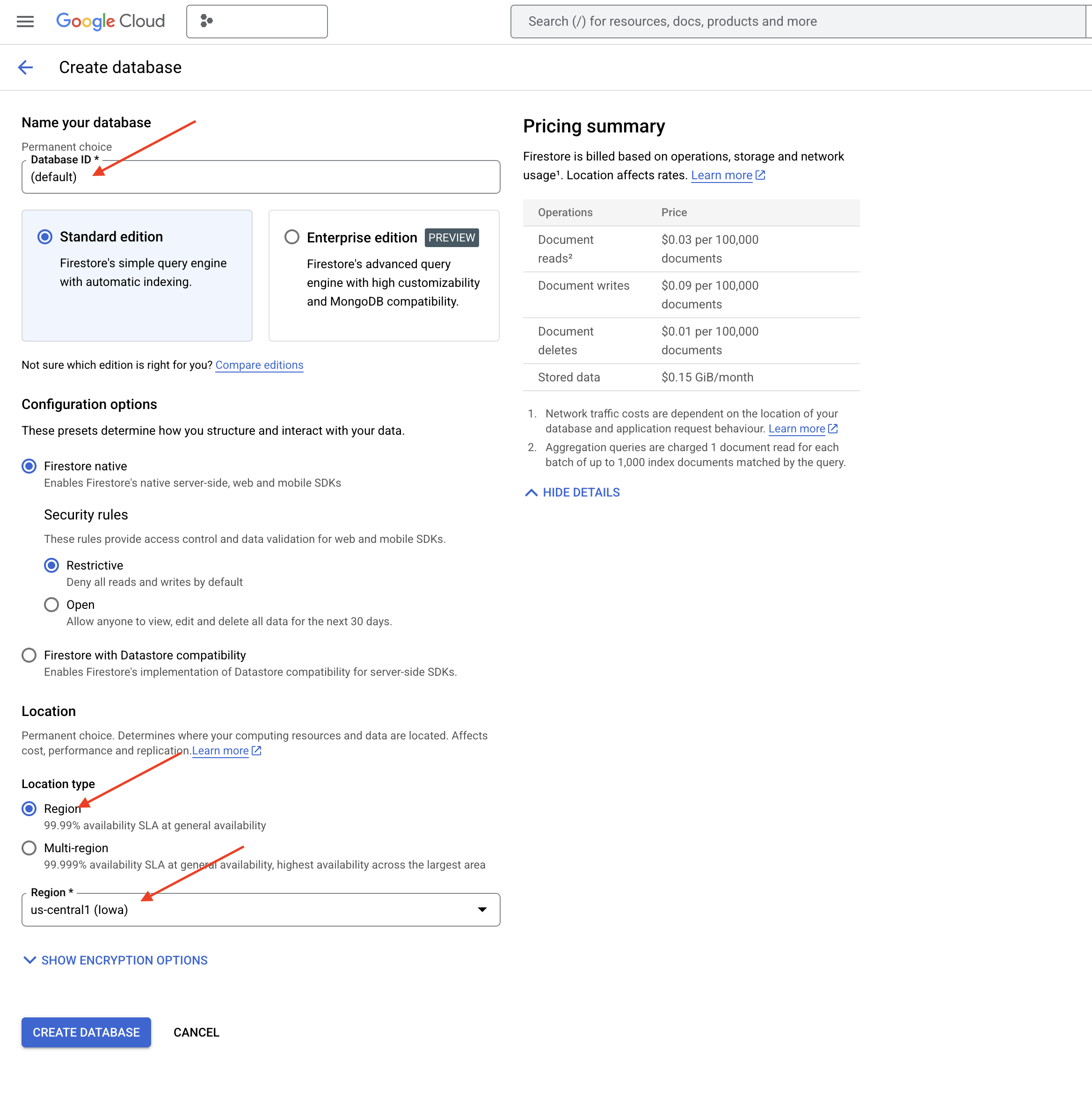
👉 Wählen Sie Native mode und den Datenbanknamen (default) aus.
👉 Wählen Sie eine einzelne region aus: us-central1 und klicken Sie auf Datenbank erstellen. Ihre Datenbank wird in Firestore bereitgestellt. Das kann einige Momente dauern.
👉 Erstellen Sie im Terminal der Cloud IDE einen Vektorindex für das Feld „embedding_vector“, um die Vektorsuche in der Sammlung „legal_documents“ zu aktivieren.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore beginnt mit der Erstellung des Vektorindex. Die Indexerstellung kann einige Zeit in Anspruch nehmen, insbesondere bei größeren Datasets. Der Index hat den Status „Wird erstellt“ und ändert sich in „Bereit“, wenn er erstellt wurde. 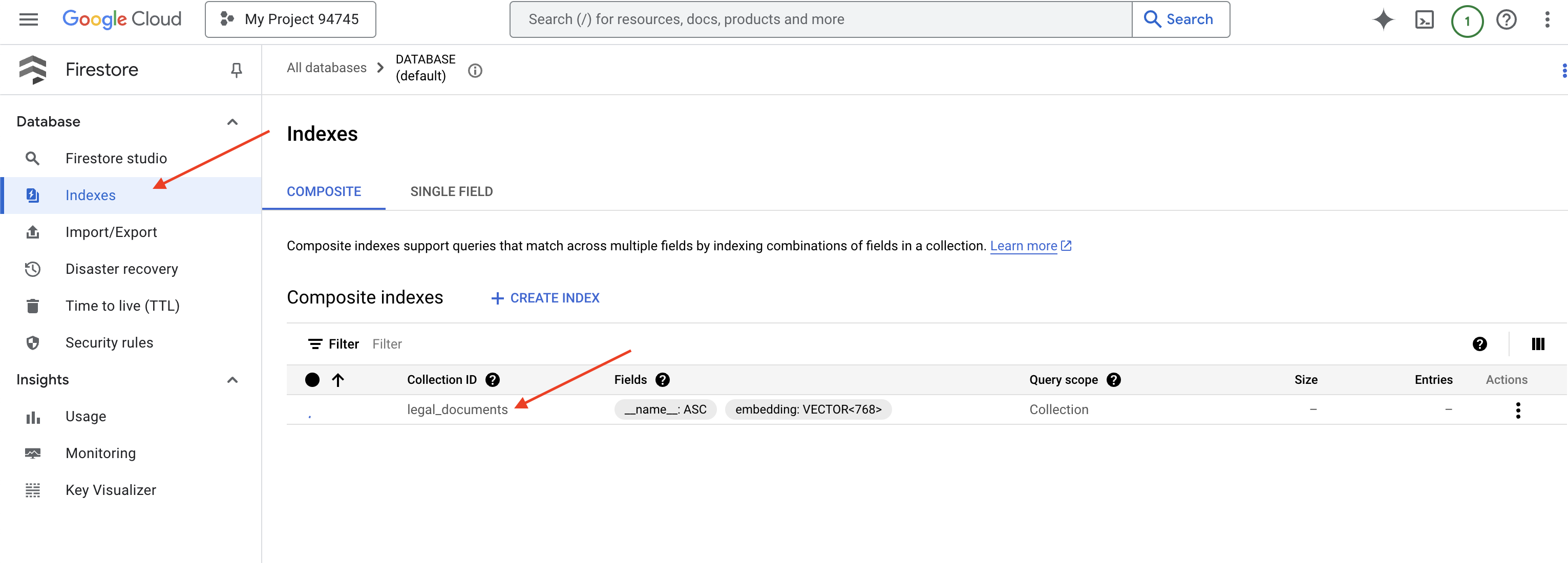
7. Daten in den Vektorspeicher laden
Nachdem wir RAG und unseren Vektorspeicher kennengelernt haben, ist es an der Zeit, die Engine zu erstellen, mit der unsere Rechtsbibliothek gefüllt wird. Wie können wir also Rechtsdokumente „nach Bedeutung durchsuchbar“ machen? Der Zauber liegt in den Einbettungen. Einbettungen wandeln Wörter, Sätze oder sogar ganze Dokumente in numerische Vektoren um – Listen mit Zahlen, die ihre semantische Bedeutung erfassen. Ähnliche Konzepte erhalten Vektoren, die im Vektorraum „nahe“ beieinander liegen. Für diese Konvertierung verwenden wir leistungsstarke Modelle wie die von Vertex AI.
Um das Laden von Dokumenten zu automatisieren, verwenden wir Cloud Run-Funktionen und Eventarc. Cloud Run Functions ist ein einfacher, serverloser Container, der Ihren Code nur bei Bedarf ausführt. Wir verpacken unser Python-Skript für die Dokumentenverarbeitung in einen Container und stellen es als Cloud Run-Funktion bereit.
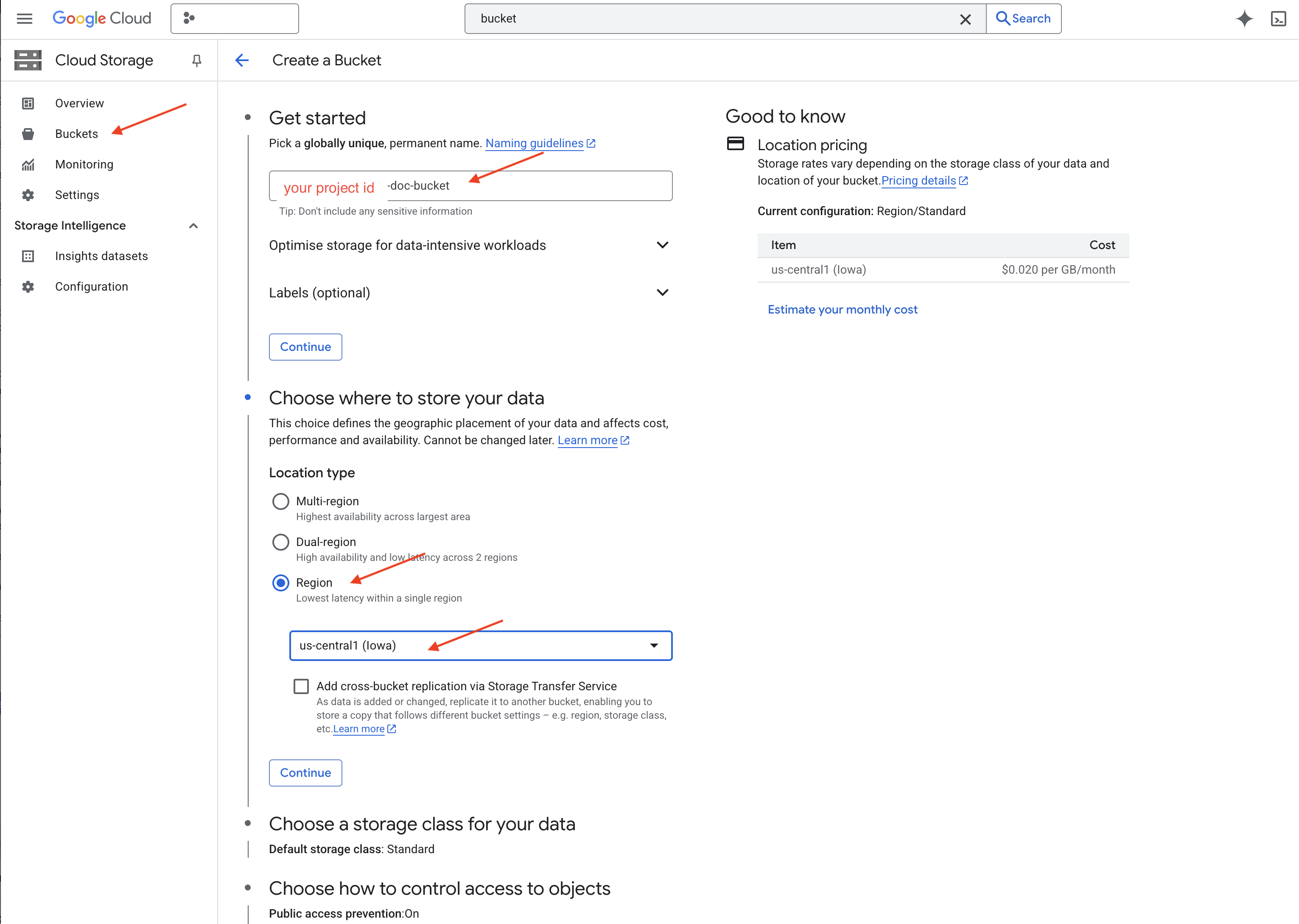
👉 Rufen Sie in einem neuen Tab/Fenster Cloud Storage auf.
👉 Klicken Sie im Menü auf der linken Seite auf „Buckets“.
👉 Klicke oben auf die Schaltfläche „+ ERSTELLEN“.
👉 Bucket konfigurieren (wichtige Einstellungen):
- Bucket-Name: yourprojectID-doc-bucket (Sie MÜSSEN das Suffix -doc-bucket am Ende verwenden)
- Region: Wählen Sie die Region
us-central1aus. - Speicherklasse: „Standard“ Standard eignet sich für Daten, auf die häufig zugegriffen wird.
- Zugriffssteuerung: Lassen Sie die Standardeinstellung „Einheitliche Zugriffssteuerung“ ausgewählt. Dies ermöglicht eine einheitliche Zugriffssteuerung auf Bucket-Ebene.
- Erweiterte Optionen: Für diese Anleitung sind die Standardeinstellungen in der Regel ausreichend.
👉 Klicken Sie auf die Schaltfläche ERSTELLEN, um den Bucket zu erstellen.
👉 Möglicherweise wird ein Pop-up-Fenster zur Verhinderung des öffentlichen Zugriffs angezeigt. Lassen Sie das Kästchen angeklickt und klicken Sie auf „Bestätigen“.
Der neu erstellte Bucket wird jetzt in der Liste „Buckets“ angezeigt. Merken Sie sich den Namen des Buckets, da Sie ihn später benötigen.
8. Cloud Run-Funktion einrichten
👉 Rufen Sie im Cloud Shell-Codeeditor das Arbeitsverzeichnis legal-eagle auf: Verwenden Sie den Befehl „cd“ im Cloud Editor-Terminal, um den Ordner zu erstellen.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Erstellen Sie die Dateien main.py, requirements.txt und Dockerfile. Erstellen Sie die Dateien mit dem Befehl „touch“ im Cloud Shell-Terminal:
touch main.py requirements.txt Dockerfile
Sie sehen den neu erstellten Ordner mit dem Namen *loader und die drei Dateien.
👉 Bearbeiten Sie main.py im Ordner loader. Rufen Sie im Dateiexplorer auf der linken Seite das Verzeichnis auf, in dem Sie die Dateien erstellt haben, und doppelklicken Sie auf main.py, um die Datei im Editor zu öffnen.
Fügen Sie den folgenden Python-Code in main.py ein:
Diese Anwendung verarbeitet neue Dateien, die in den GCS-Bucket hochgeladen werden, teilt den Text in Chunks auf, generiert Einbettungen für jeden Chunk und speichert die Chunks und ihre Einbettungen in Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Bearbeiten Sie requirements.txt.Fügen Sie die folgenden Zeilen in die Datei ein:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Cloud Run-Funktion testen und erstellen
👉 Wir führen diesen Befehl in einer virtuellen Umgebung aus und installieren die erforderlichen Python-Bibliotheken für die Cloud Run-Funktion.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Lokalen Emulator für die Cloud Run-Funktion starten
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Lassen Sie das letzte Terminal geöffnet, öffnen Sie ein neues Terminal und führen Sie den Befehl zum Hochladen einer Datei in den Bucket aus.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Während der Emulator ausgeführt wird, können Sie Test-CloudEvents an ihn senden. Dazu benötigen Sie ein separates Terminal in der IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Es sollte „OK“ zurückgegeben werden.
👉 Sie überprüfen die Daten in Firestore. Rufen Sie dazu die Google Cloud Console auf, gehen Sie zu „Datenbanken“ und dann zu „Firestore“, wählen Sie den Tab „Daten“ und dann die Sammlung legal_documents aus. In Ihrer Sammlung wurden neue Dokumente erstellt, die jeweils einen Teil des Texts aus der hochgeladenen Datei enthalten. 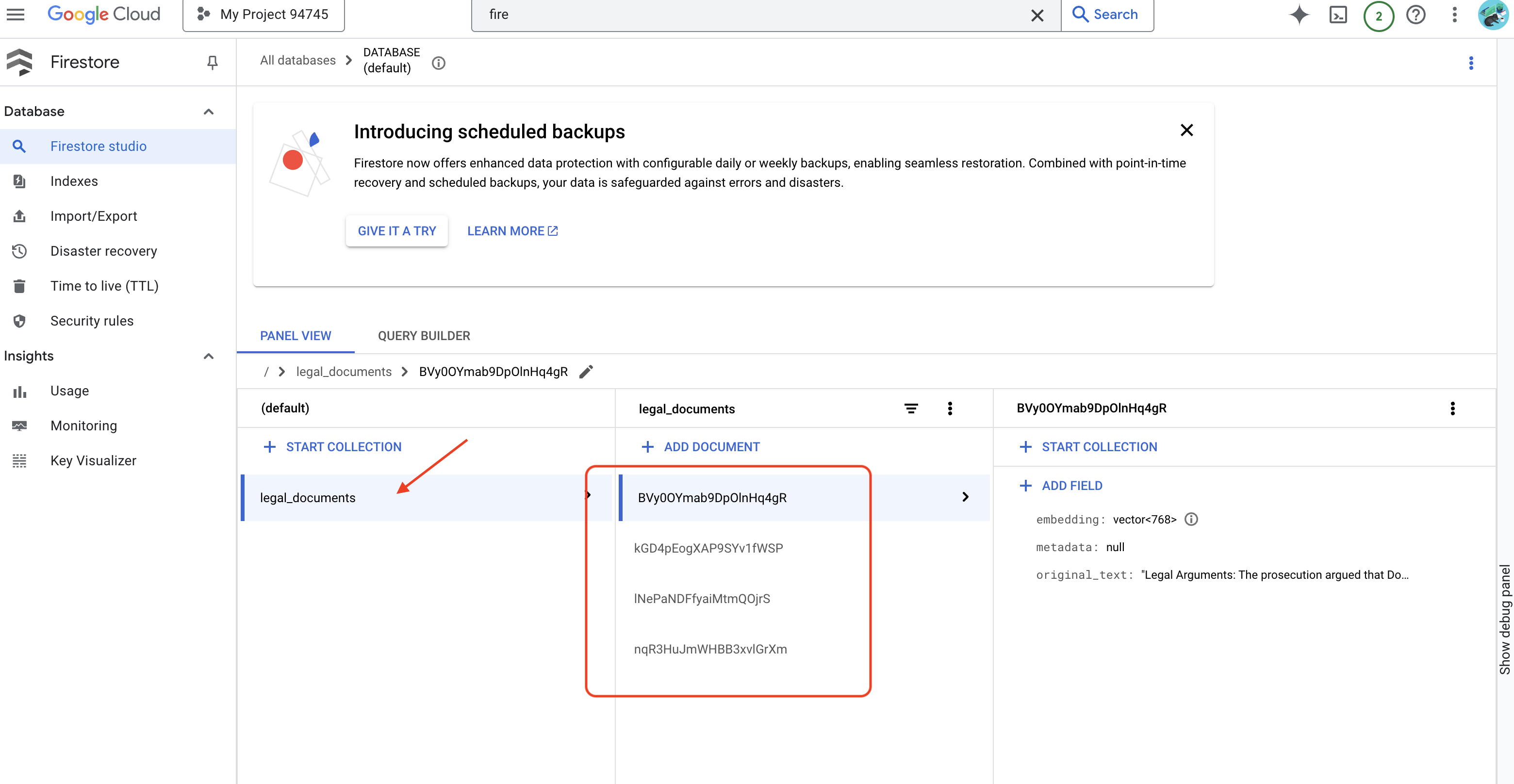
👉 Geben Sie im Terminal, in dem der Emulator ausgeführt wird, Ctrl+C ein, um ihn zu beenden. Schließen Sie das zweite Terminal.
👉 Führen Sie „deactivate“ aus, um die virtuelle Umgebung zu beenden.
deactivate
10. Container-Image erstellen und per Push in Artifacts-Repositories übertragen
👉 Zeit, das in der Cloud bereitzustellen. Doppelklicken Sie im Datei-Explorer auf „Dockerfile“. Bitten Sie Gemini, das Dockerfile für Sie zu generieren. Öffnen Sie dazu Gemini Code Assist und verwenden Sie den folgenden Prompt:
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Als Best Practice wird empfohlen, auf Vergleich mit geöffneter Datei(zwei Pfeile in entgegengesetzter Richtung) zu klicken und die Änderungen zu übernehmen. 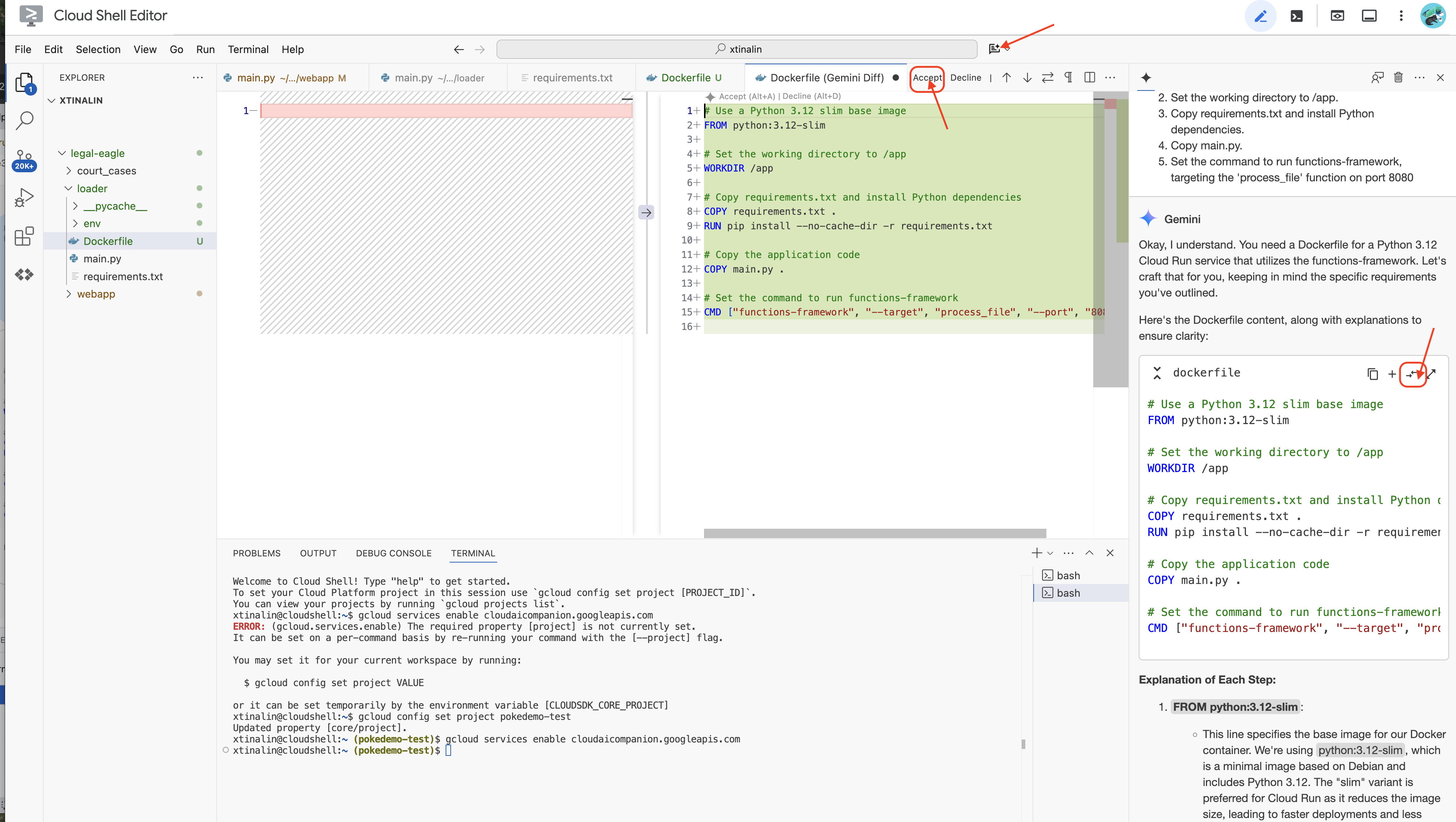
👉 Wenn Sie noch nicht mit Containern vertraut sind, finden Sie hier ein funktionierendes Beispiel:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 Erstellen Sie im Terminal ein Artefakt-Repository zum Speichern des Docker-Images, das wir erstellen werden.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Sie sollten die Meldung Repository [my-repository] wurde erstellt. sehen.
👉 Führen Sie den folgenden Befehl aus, um das Docker-Image zu erstellen.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Sie pushen das jetzt in die Registry.
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
Das Docker-Image ist jetzt im Artifacts Repository my-repository verfügbar.
11. Cloud Run-Funktion erstellen und Eventarc-Trigger einrichten
Bevor wir uns die Details der Bereitstellung unseres Loaders für rechtliche Dokumente ansehen, wollen wir uns kurz die beteiligten Komponenten ansehen: Cloud Run ist eine vollständig verwaltete serverlose Plattform, mit der Sie containerisierte Anwendungen schnell und einfach bereitstellen können. Die Infrastrukturverwaltung wird abstrahiert, sodass Sie sich auf das Schreiben und Bereitstellen von Code konzentrieren können.
Wir stellen unseren Dokument-Loader als Cloud Run-Dienst bereit. Fahren wir nun mit der Einrichtung unserer Cloud Run-Funktion fort:
👉 Rufen Sie in der Google Cloud Console Cloud Run auf.
👉 Klicken Sie auf Container bereitstellen und wählen Sie im Drop-down-Menü DIENST aus.
👉 Cloud Run-Dienst konfigurieren:
- Container-Image: Klicken Sie im URL-Feld auf „Auswählen“. Suchen Sie die Image-URL, die Sie in Artifact Registry hochgeladen haben, z.B. „us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage“.
- Service name:
legal-eagle-loader - Region: Wählen Sie die Region
us-central1aus. - Authentifizierung: Für diesen Workshop können Sie „Nicht authentifizierte Aufrufe zulassen“ aktivieren. In der Produktion sollten Sie den Zugriff wahrscheinlich einschränken.
- Container, Netzwerk, Sicherheit : Standard.
👉 Klicke auf ERSTELLEN. Cloud Run stellt Ihren Dienst bereit. 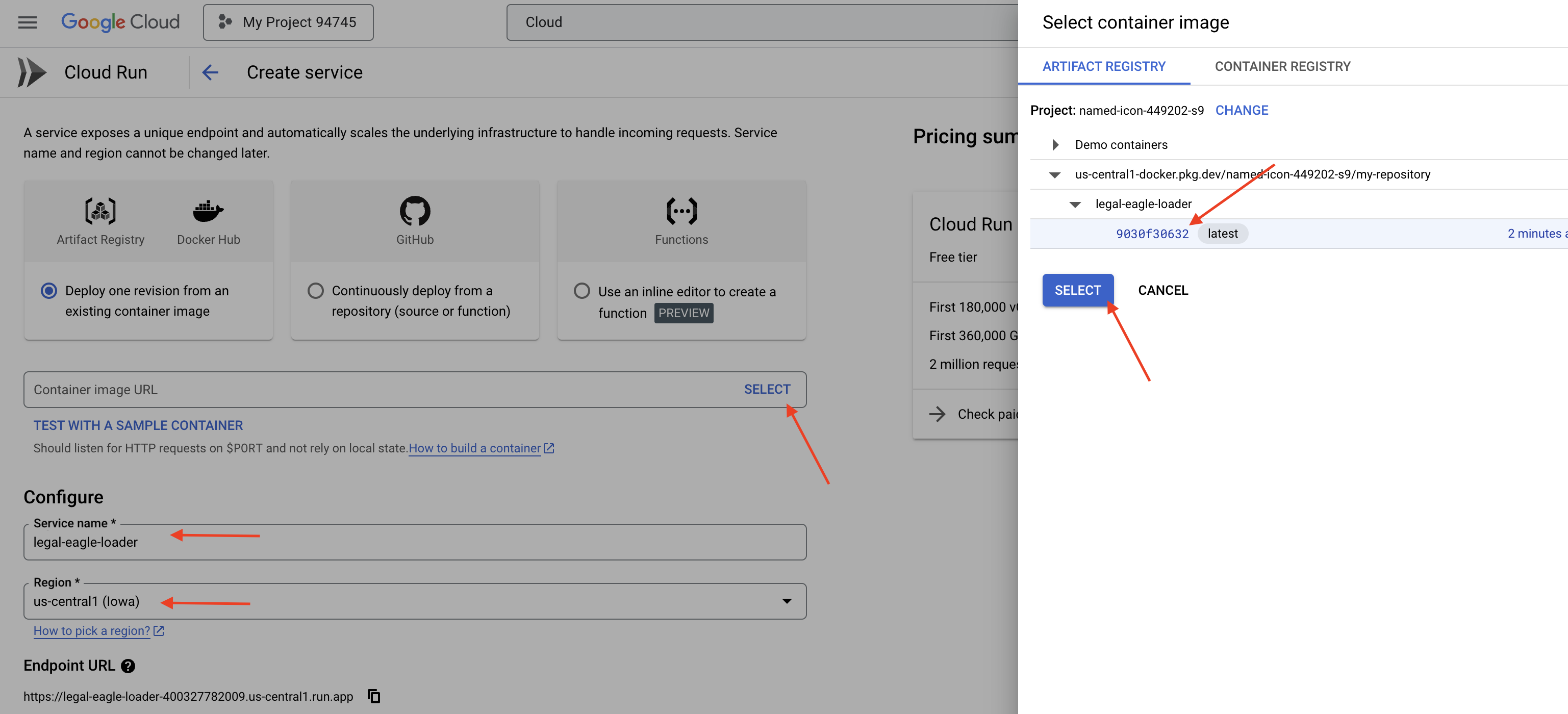
Damit dieser Dienst automatisch ausgelöst wird, wenn neue Dateien in unserem Speicher-Bucket hinzugefügt werden, verwenden wir Eventarc. Mit Eventarc können Sie ereignisgesteuerte Architekturen erstellen, indem Sie Ereignisse aus verschiedenen Quellen an Ihre Dienste weiterleiten.
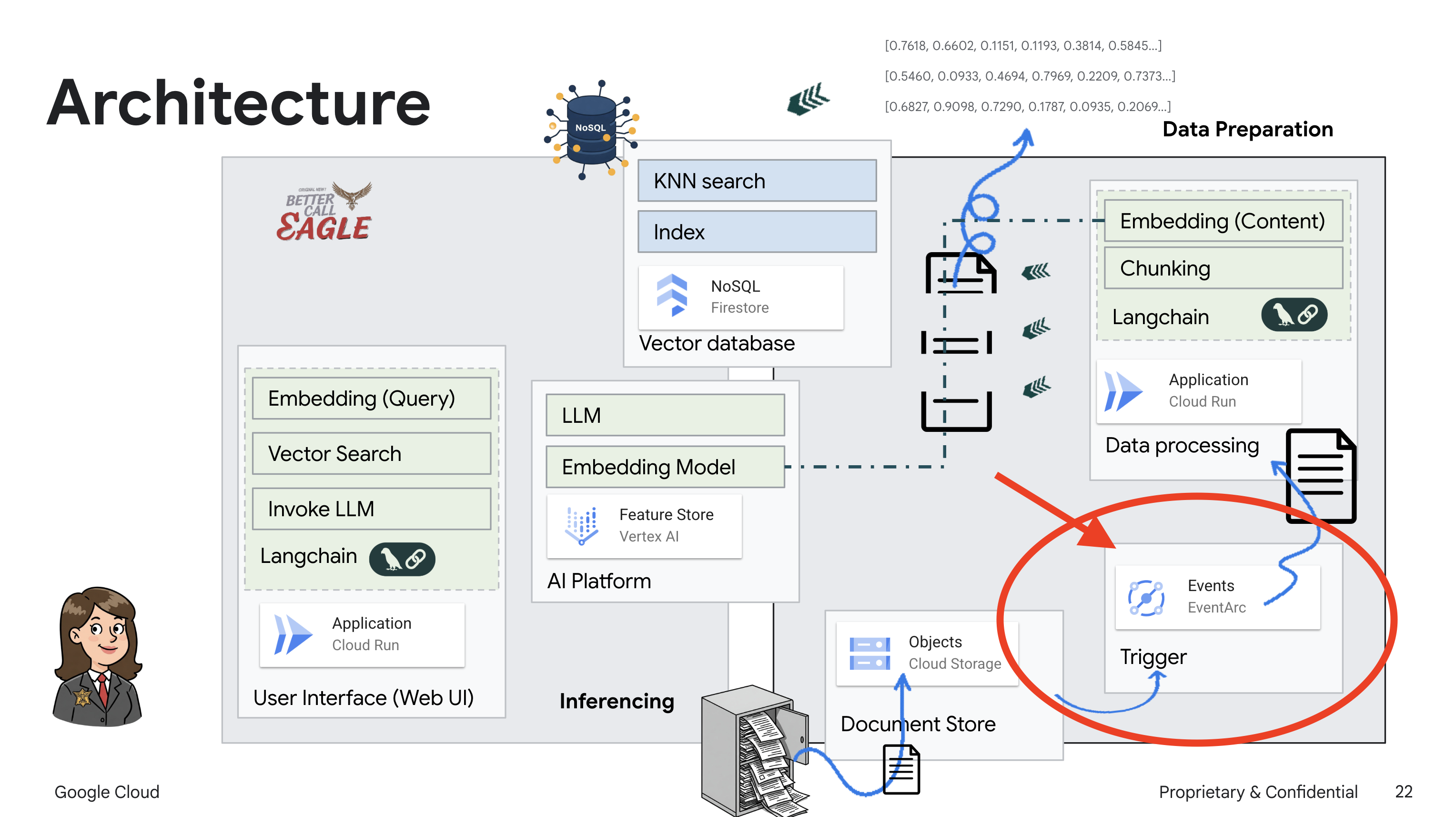
Durch die Einrichtung von Eventarc werden die neu hinzugefügten Dokumente automatisch in Firestore geladen, sobald sie hochgeladen werden. So können wir Daten in Echtzeit für unsere RAG-Anwendung aktualisieren.
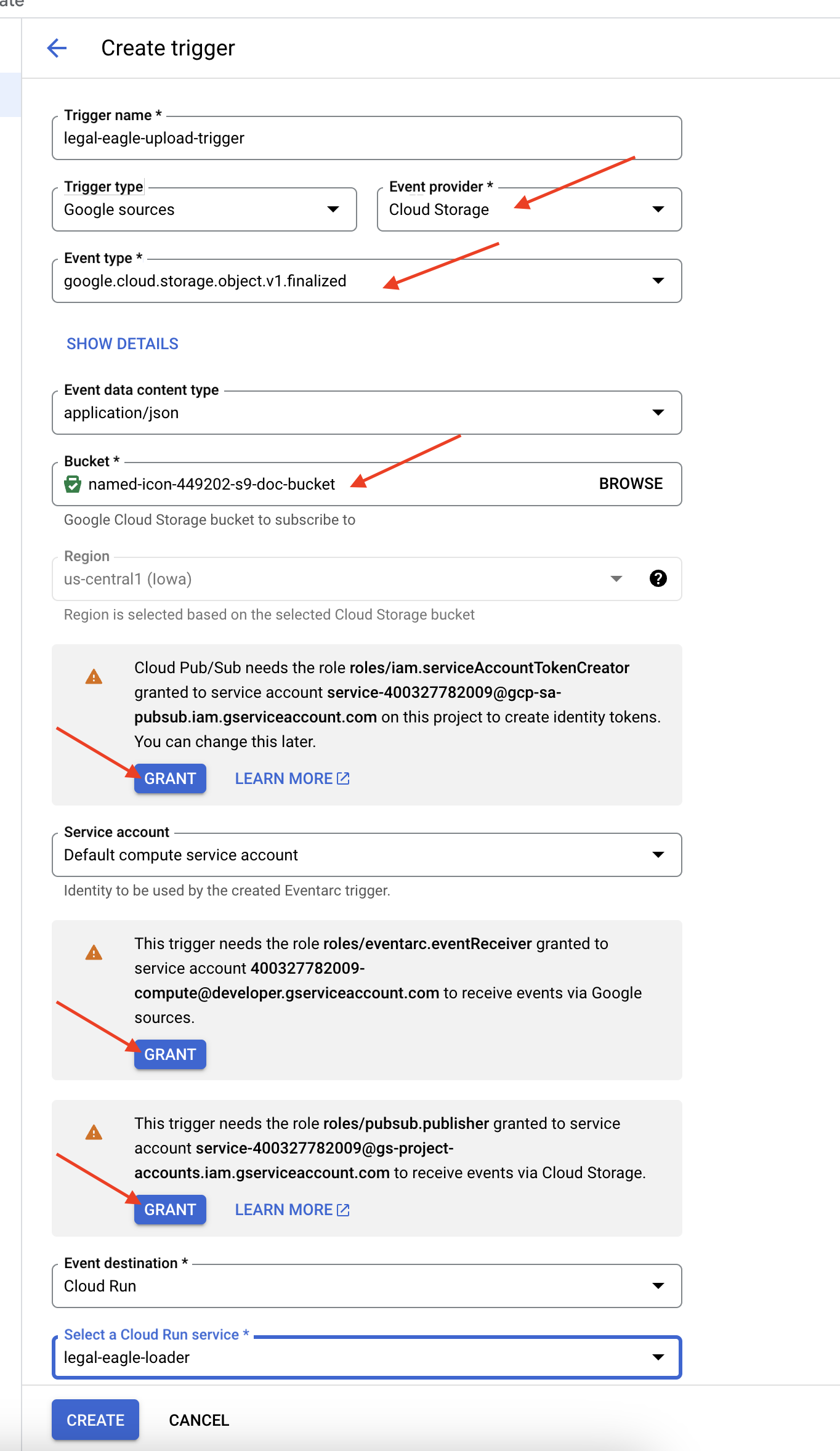
👉 Rufen Sie in der Google Cloud Console unter Eventarc Trigger auf. Klicken Sie auf „+ TRIGGER ERSTELLEN“. 👉 Eventarc-Trigger konfigurieren:
- Trigger name:
legal-eagle-upload-trigger. - TriggerType: Google-Quellen
- Ereignisanbieter: Wählen Sie Cloud Storage aus.
- Ereignistyp: Wählen Sie
google.cloud.storage.object.v1.finalizedaus. - Cloud Storage-Bucket: Wählen Sie Ihren GCS-Bucket aus dem Drop-down-Menü aus.
- Zieltyp: „Cloud Run-Dienst“
- Dienst: Wählen Sie
legal-eagle-loaderaus. - Region:
us-central1 - Pfad: Lassen Sie dieses Feld vorerst leer .
- Gewähren Sie alle Berechtigungen, die auf der Seite angefordert werden.
👉 Klicke auf ERSTELLEN. Eventarc richtet den Trigger jetzt ein.
Der Cloud Run-Dienst benötigt die Berechtigung, Dateien aus verschiedenen Komponenten zu lesen. Wir müssen dem Dienstkonto des Dienstes die erforderliche Berechtigung erteilen.
12. Rechtsdokumente in den GCS-Bucket hochladen
👉 Laden Sie die Gerichtsakte in Ihren GCS-Bucket hoch. Denken Sie daran, Ihren Bucket-Namen zu ersetzen.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Rufen Sie die Cloud Run-Dienstlogs unter Cloud Run -> Ihr Dienst legal-eagle-loader -> „Logs“ auf. Suchen Sie in den Logs nach Meldungen zur erfolgreichen Verarbeitung, z. B.:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
Je nachdem, wie schnell das Logging eingerichtet wurde, sehen Sie hier auch detailliertere Logs.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Suchen Sie in den Logs nach Fehlermeldungen und beheben Sie die Fehler bei Bedarf. 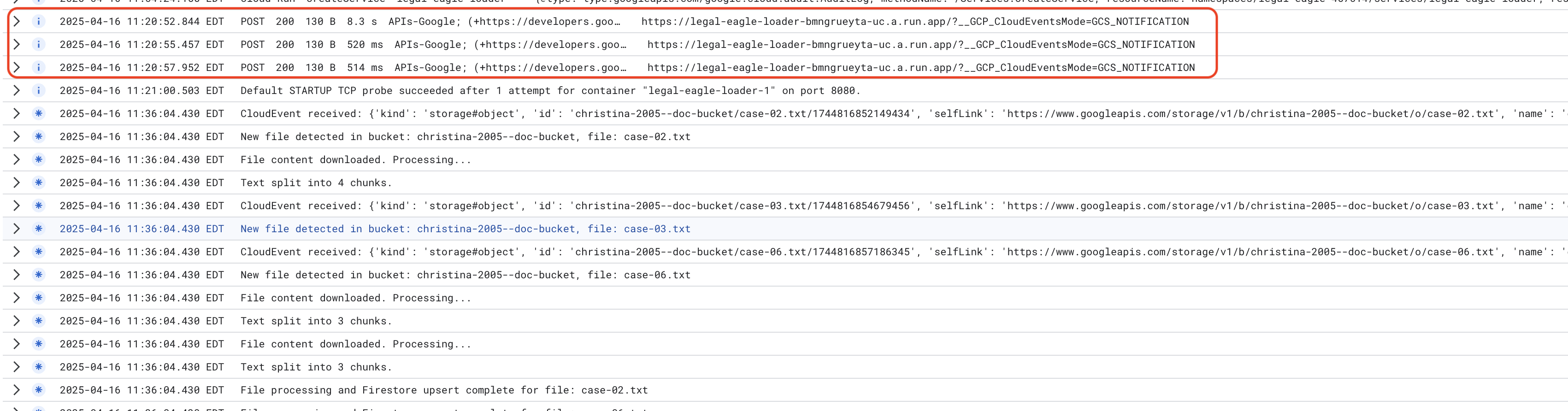
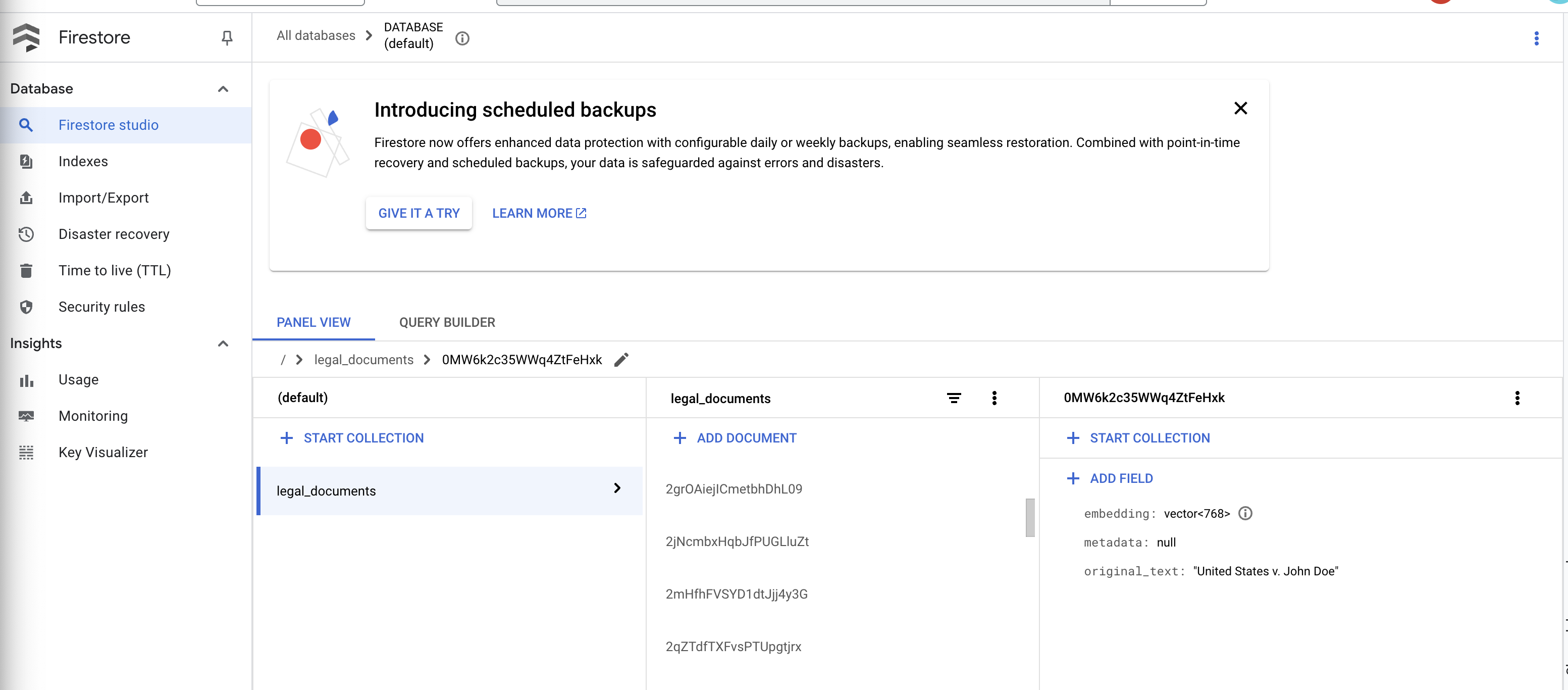
👉 Daten in Firestore überprüfen Öffnen Sie die Sammlung legal_documents.
👉 In Ihrer Sammlung sollten neue Dokumente angezeigt werden. Jedes Dokument stellt einen Teil des Texts aus der hochgeladenen Datei dar und enthält Folgendes:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. RAG implementieren
LangChain ist ein leistungsstarkes Framework, das die Entwicklung von Anwendungen auf Basis von Large Language Models (LLMs) vereinfachen soll. Anstatt sich direkt mit den Feinheiten von LLM-APIs, Prompt Engineering und Datenverarbeitung auseinanderzusetzen, bietet LangChain eine Abstraktionsebene auf hoher Ebene. Sie bietet vorgefertigte Komponenten und Tools für Aufgaben wie das Herstellen einer Verbindung zu verschiedenen LLMs (z. B. von OpenAI, Google oder anderen), das Erstellen komplexer Operationsketten (z. B. Datenabruf gefolgt von einer Zusammenfassung) und das Verwalten des Konversationsspeichers.
Speziell für RAG sind Vektorspeicher in LangChain unerlässlich, um den Abrufaspekt von RAG zu ermöglichen. Sie sind spezialisierte Datenbanken, die zum effizienten Speichern und Abfragen von Vektoreinbettungen entwickelt wurden. Dabei werden semantisch ähnliche Textelemente auf Punkte abgebildet, die im Vektorraum nahe beieinander liegen. LangChain kümmert sich um die Low-Level-Details, sodass sich Entwickler auf die Kernlogik und ‑funktionen ihrer RAG-Anwendung konzentrieren können. Dadurch werden Entwicklungszeit und Komplexität erheblich reduziert. Sie können schnell Prototypen erstellen und RAG-basierte Anwendungen bereitstellen und dabei die Robustheit und Skalierbarkeit der Google Cloud-Infrastruktur nutzen.
Nachdem Sie sich mit LangChain vertraut gemacht haben, müssen Sie nun Ihre legal.py-Datei im Ordner webapp für die RAG-Implementierung aktualisieren. So kann das LLM vor der Antwortgenerierung relevante Dokumente in Firestore durchsuchen.
👉 Importieren Sie FirestoreVectorStore und andere erforderliche Module aus langchain und vertexai. Füge Folgendes zur aktuellen legal.py hinzu:
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Initialisieren Sie Vertex AI und das Einbettungsmodell.Sie verwenden text-embedding-004. Fügen Sie den folgenden Code direkt nach dem Importieren der Module hinzu.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Erstellen Sie einen FirestoreVectorStore, der auf die Sammlung „legal_documents“ verweist. Verwenden Sie dazu das initialisierte Einbettungsmodell und geben Sie die Felder „content“ und „embedding“ an. Fügen Sie diesen Code direkt nach dem vorherigen Code für das Einbettungsmodell ein.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Definieren Sie eine Funktion namens search_resource, die eine Anfrage entgegennimmt, eine Ähnlichkeitssuche mit vector_store.similarity_search durchführt und die kombinierten Ergebnisse zurückgibt.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 REPLACE ask_llm-Funktion und verwenden Sie die search_resource-Funktion, um relevanten Kontext basierend auf der Nutzeranfrage abzurufen.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPTIONAL: SPANISH VERSION
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 Nachdem Sie RAG in legal.py implementiert haben, sollten Sie es lokal testen, bevor Sie es bereitstellen. Führen Sie die Anwendung mit dem folgenden Befehl aus:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Verwenden Sie „webpreview“, um auf die Anwendung zuzugreifen, mit dem Assistenten zu sprechen und ctrl+c einzugeben, um den lokal ausgeführten Prozess zu beenden. Führen Sie „deactivate“ aus, um die virtuelle Umgebung zu beenden.
deactivate
👉 Die Bereitstellung der Webanwendung in Cloud Run ähnelt der Loader-Funktion. Sie erstellen, taggen und übertragen das Docker-Image per Push an Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Jetzt ist es an der Zeit, die Webanwendung in Google Cloud bereitzustellen. Führen Sie im Terminal die folgenden Befehle aus:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Prüfen Sie die Bereitstellung, indem Sie in der Google Cloud Console zu Cloud Run wechseln.Dort sollte ein neuer Dienst mit dem Namen legal-eagle-webapp aufgeführt sein.
Klicken Sie auf den Dienst, um die zugehörige Detailseite aufzurufen. Die bereitgestellte URL wird oben angezeigt. 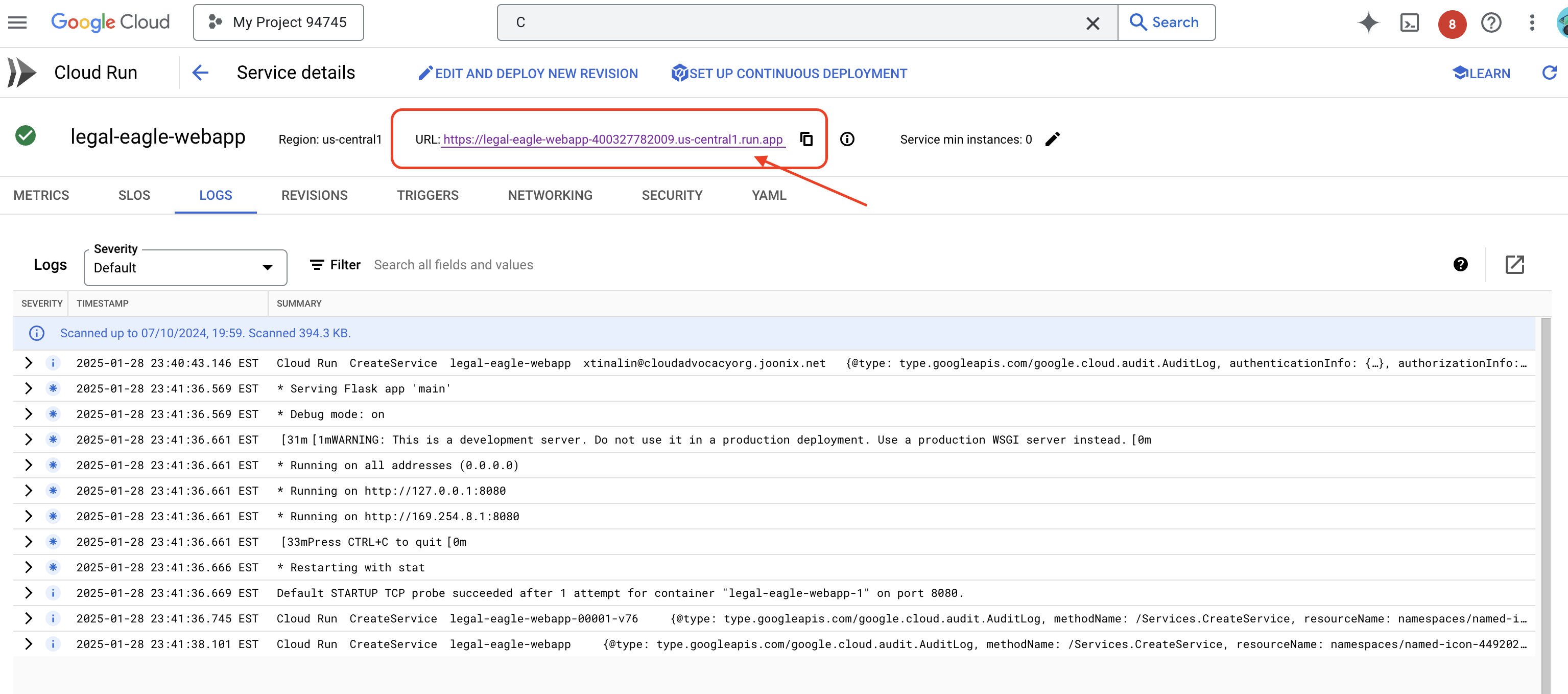
👉 Öffnen Sie die bereitgestellte URL in einem neuen Browsertab. Sie können mit dem Rechtsassistenten interagieren und Fragen zu den von Ihnen geladenen Gerichtsverfahren stellen(im Ordner „court_cases“):
- Zu wie vielen Jahren Haft wurde Michael Brown verurteilt?
- Wie viel Geld wurde durch unautorisierte Gebühren aufgrund der Aktionen von Jane Smith generiert?
- Welche Rolle spielten die Aussagen der Nachbarn bei der Untersuchung des Falls um Emily White?
👉 OPTIONAL: SPANISH VERSION
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Die Antworten sind jetzt genauer und basieren auf den Inhalten der von Ihnen hochgeladenen rechtlichen Dokumente. Das zeigt, wie leistungsstark RAG ist.
Herzlichen Glückwunsch zum Abschluss des Workshops! Sie haben mit LLMs, LangChain und Google Cloud erfolgreich eine Anwendung zur Analyse von Rechtsdokumenten entwickelt und bereitgestellt. Sie haben gelernt, wie Sie juristische Dokumente aufnehmen und verarbeiten, LLM-Antworten mit relevanten Informationen mithilfe von RAG erweitern und Ihre Anwendung als serverlosen Dienst bereitstellen. Mit diesem Wissen und der erstellten Anwendung können Sie die Leistungsfähigkeit von LLMs für rechtliche Aufgaben weiter erkunden. Gut gemacht!“
14. Herausforderung
Verschiedene Medientypen:
Wie verschiedene Medientypen wie Gerichts-Videos und Audioaufnahmen aufgenommen und verarbeitet werden und wie relevanter Text extrahiert wird.
Online-Assets:
So verarbeiten Sie Online-Assets wie Webseiten live.