
1. Introducción
Siempre me cautivó la intensidad de la sala del tribunal, y me imaginaba navegando con destreza por sus complejidades y presentando argumentos finales sólidos. Si bien mi trayectoria profesional me llevó por otro camino, me entusiasma compartir que, con la ayuda de la IA, es posible que todos estemos más cerca de cumplir ese sueño de estar en la sala del tribunal.

Hoy, analizaremos cómo usar las potentes herramientas de IA de Google, como Vertex AI, Firestore y Cloud Run Functions, para procesar y comprender datos legales, realizar búsquedas ultrarrápidas y, tal vez, ayudar a tu cliente imaginario (o a ti mismo) a salir de una situación difícil.
Es posible que no estés interrogando a un testigo, pero con nuestro sistema, podrás analizar grandes cantidades de información, generar resúmenes claros y presentar los datos más relevantes en segundos.
2. Arquitectura
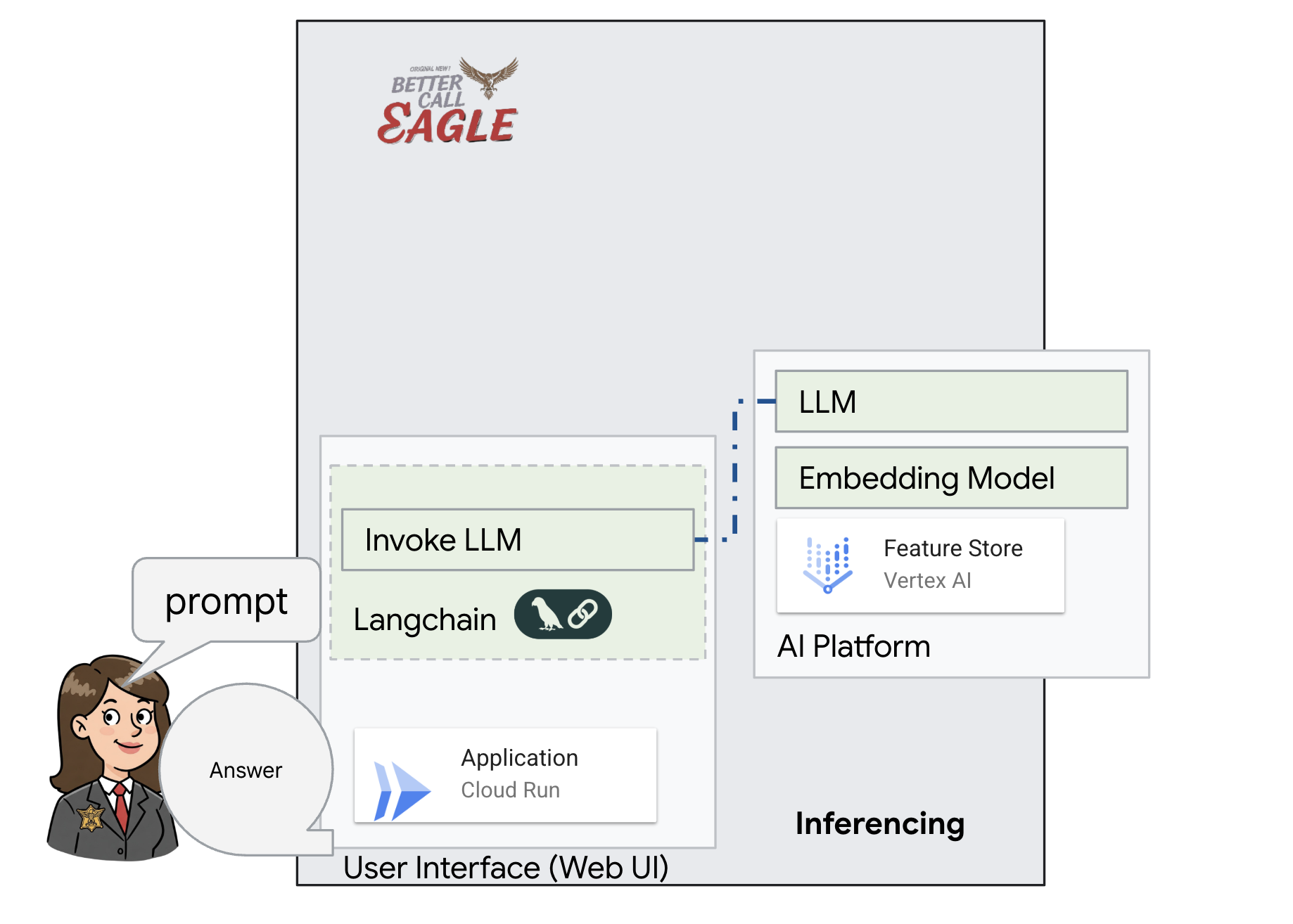
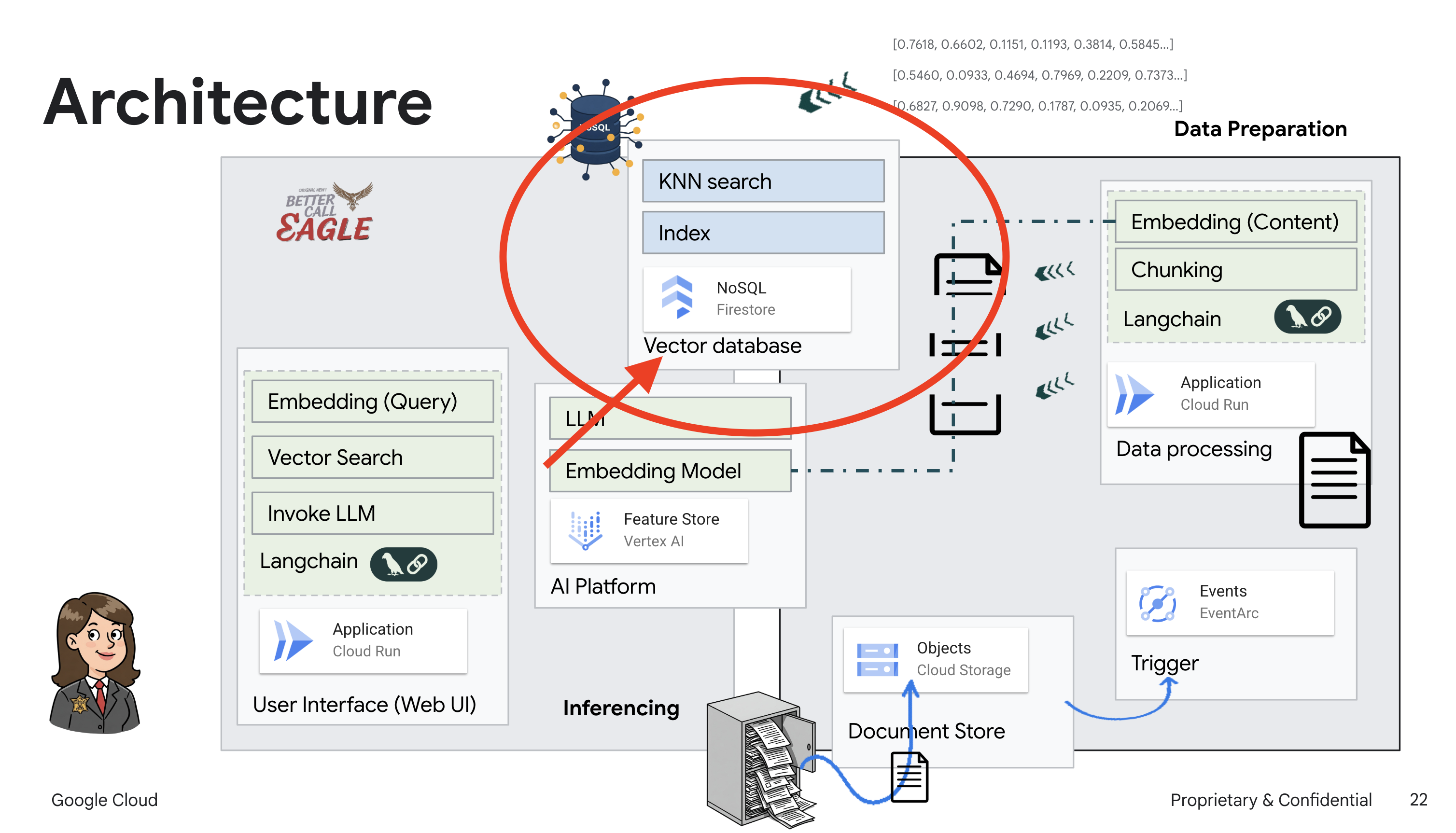
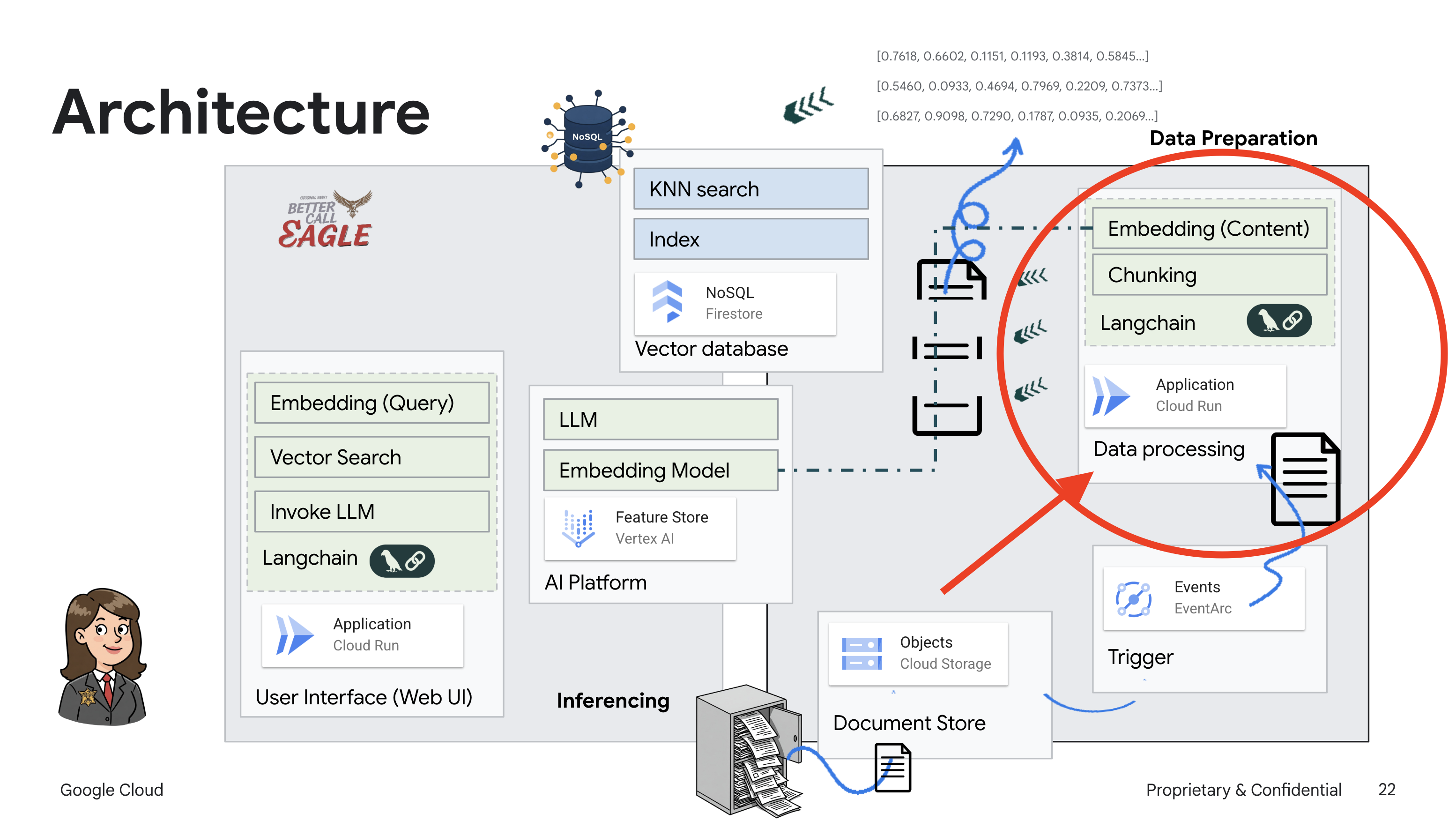
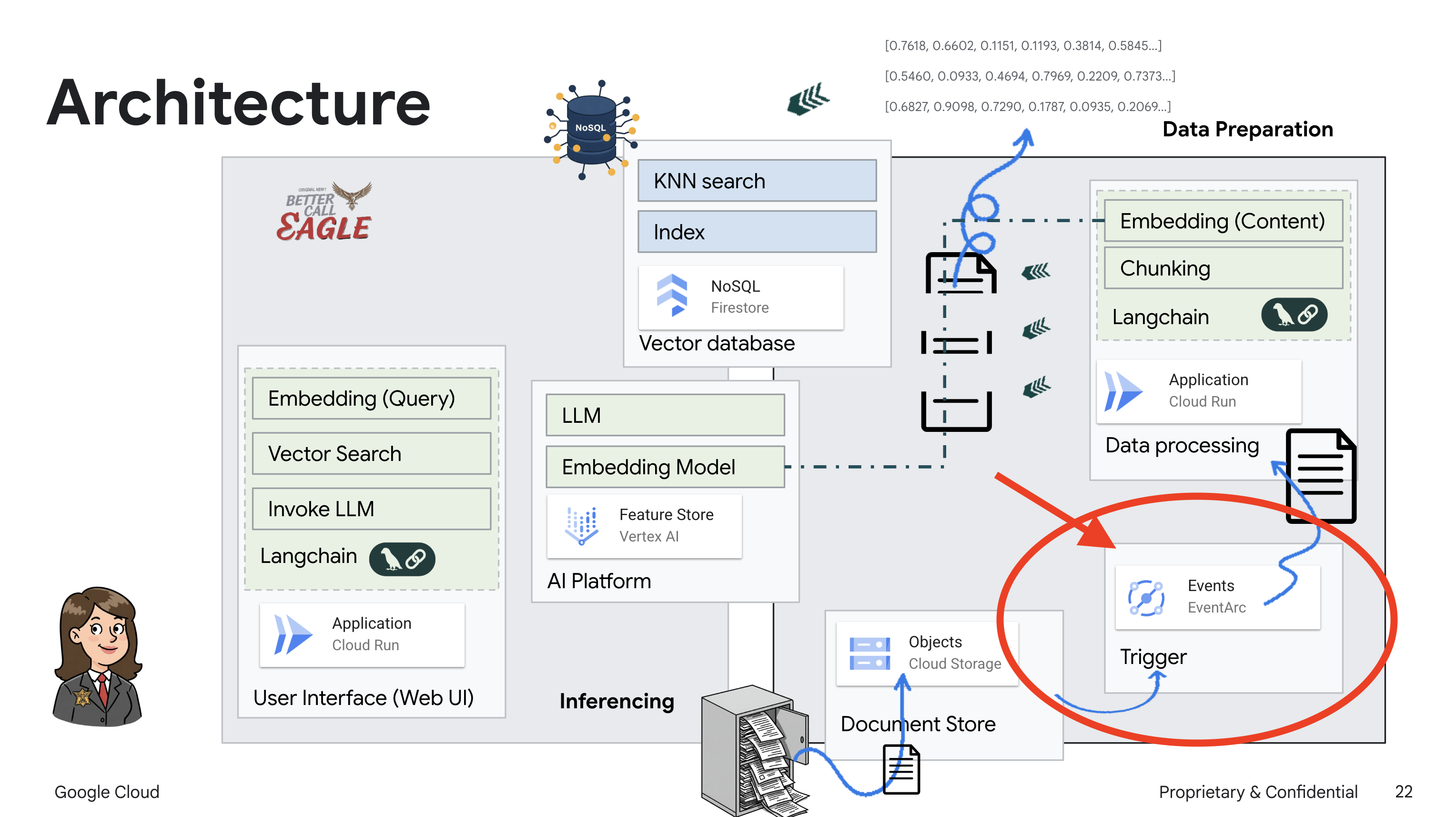
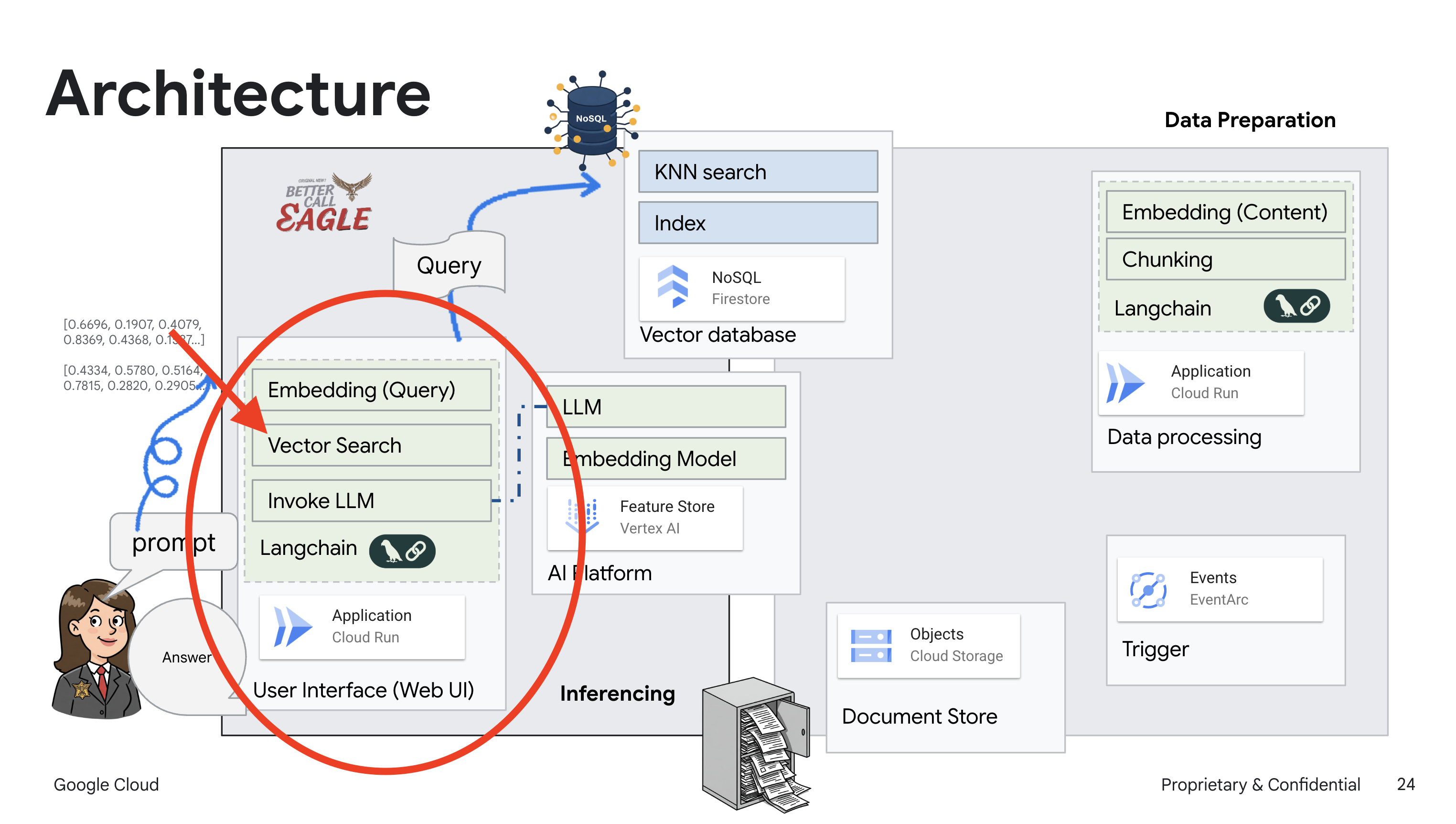
Este proyecto se enfoca en compilar un asistente legal con herramientas de IA de Google Cloud, y enfatiza cómo procesar, comprender y buscar datos legales. El sistema está diseñado para analizar grandes cantidades de información, generar resúmenes y presentar datos relevantes rápidamente. La arquitectura del asistente legal incluye varios componentes clave:
Compilación de una base de conocimiento a partir de datos no estructurados: Google Cloud Storage (GCS) se usa para almacenar documentos legales. Firestore, una base de datos NoSQL, funciona como un almacén de vectores que contiene fragmentos de documentos y sus respectivas incorporaciones. La búsqueda de vectores está habilitada en Firestore para permitir las búsquedas de similitud. Cuando se sube un documento legal nuevo a GCS, Eventarc activa una función de Cloud Run. Esta función procesa el documento dividiéndolo en fragmentos y generando embeddings para cada fragmento con el modelo de incorporación de texto de Vertex AI. Luego, estas incorporaciones se almacenan en Firestore junto con los fragmentos de texto. 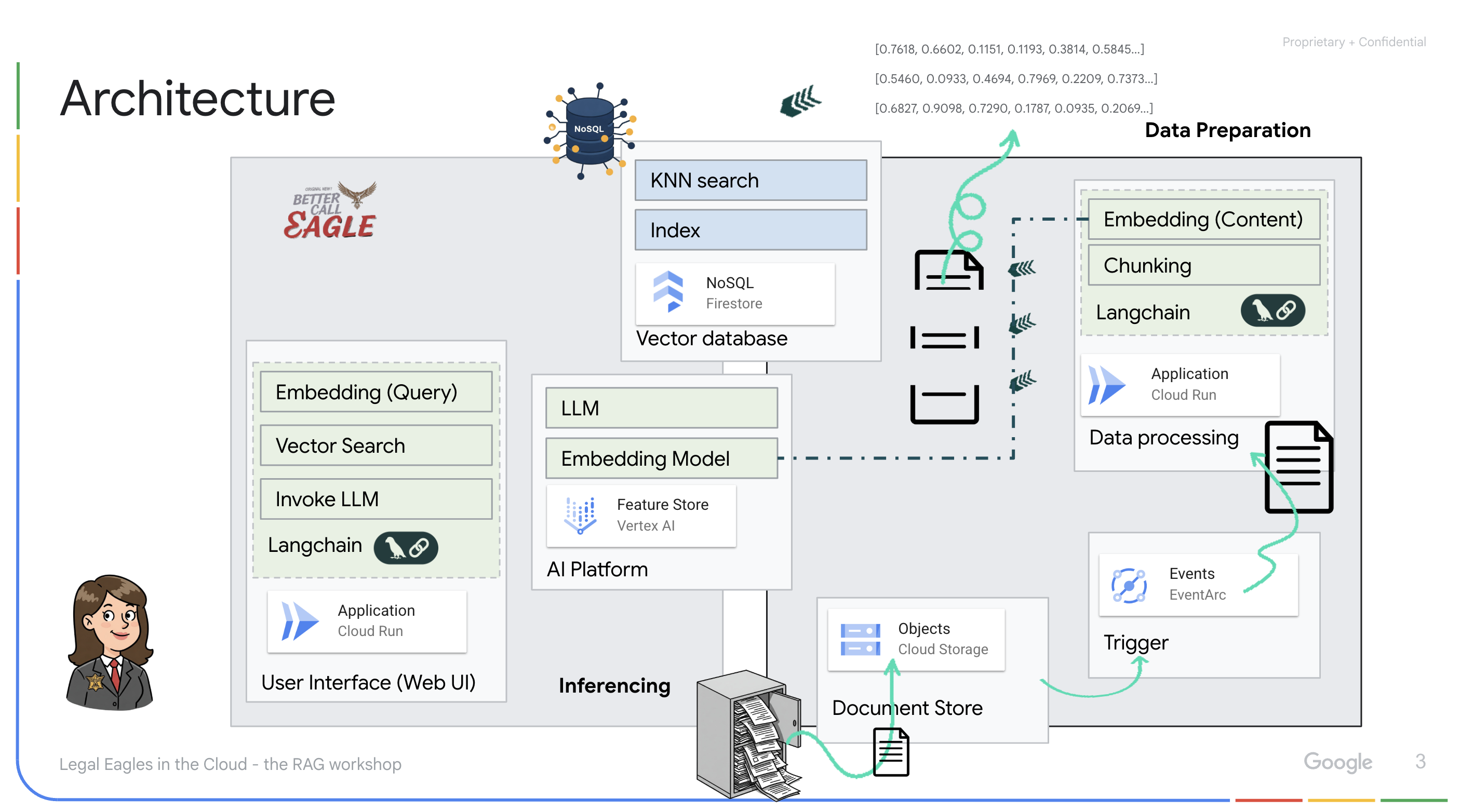
Aplicación potenciada por LLM y RAG : El núcleo del sistema de respuesta a preguntas es la función ask_llm, que usa la biblioteca de LangChain para interactuar con un modelo de lenguaje grande de Gemini de Vertex AI. Crea un HumanMessage a partir de la búsqueda del usuario y también incluye un SystemMessage que le indica al LLM que actúe como un asistente legal útil. El sistema usa un enfoque de generación mejorada por recuperación (RAG), en el que, antes de responder una búsqueda, el sistema usa la función search_resource para recuperar contexto relevante del almacén de vectores de Firestore. Luego, este contexto se incluye en el SystemMessage para fundamentar la respuesta del LLM en la información legal proporcionada. 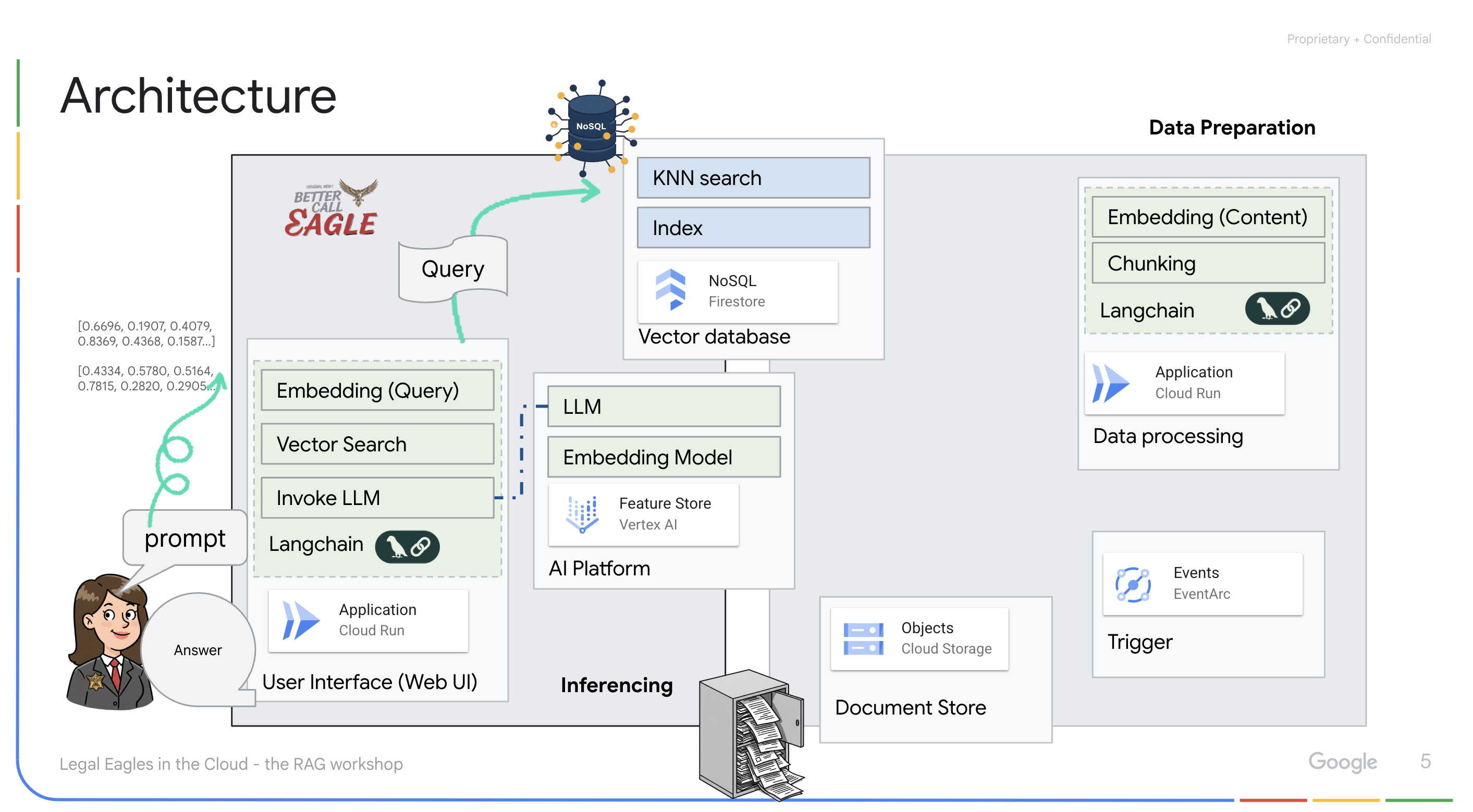
El objetivo del proyecto es alejarse de las "interpretaciones creativas" de los LLMs usando la RAG, que primero recupera información pertinente de una fuente legal confiable antes de generar una respuesta. Esto genera respuestas más precisas y fundamentadas basadas en información legal real. El sistema se creó con varios servicios de Google Cloud, como Google Cloud Shell, Vertex AI, Firestore, Cloud Run y Eventarc.
3. Antes de comenzar
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud. Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Habilita Gemini Code Assist en el IDE de Cloud Shell
👉 En la consola de Google Cloud, ve a Herramientas de Gemini Code Assist, habilita Gemini Code Assist sin costo aceptando las condiciones.
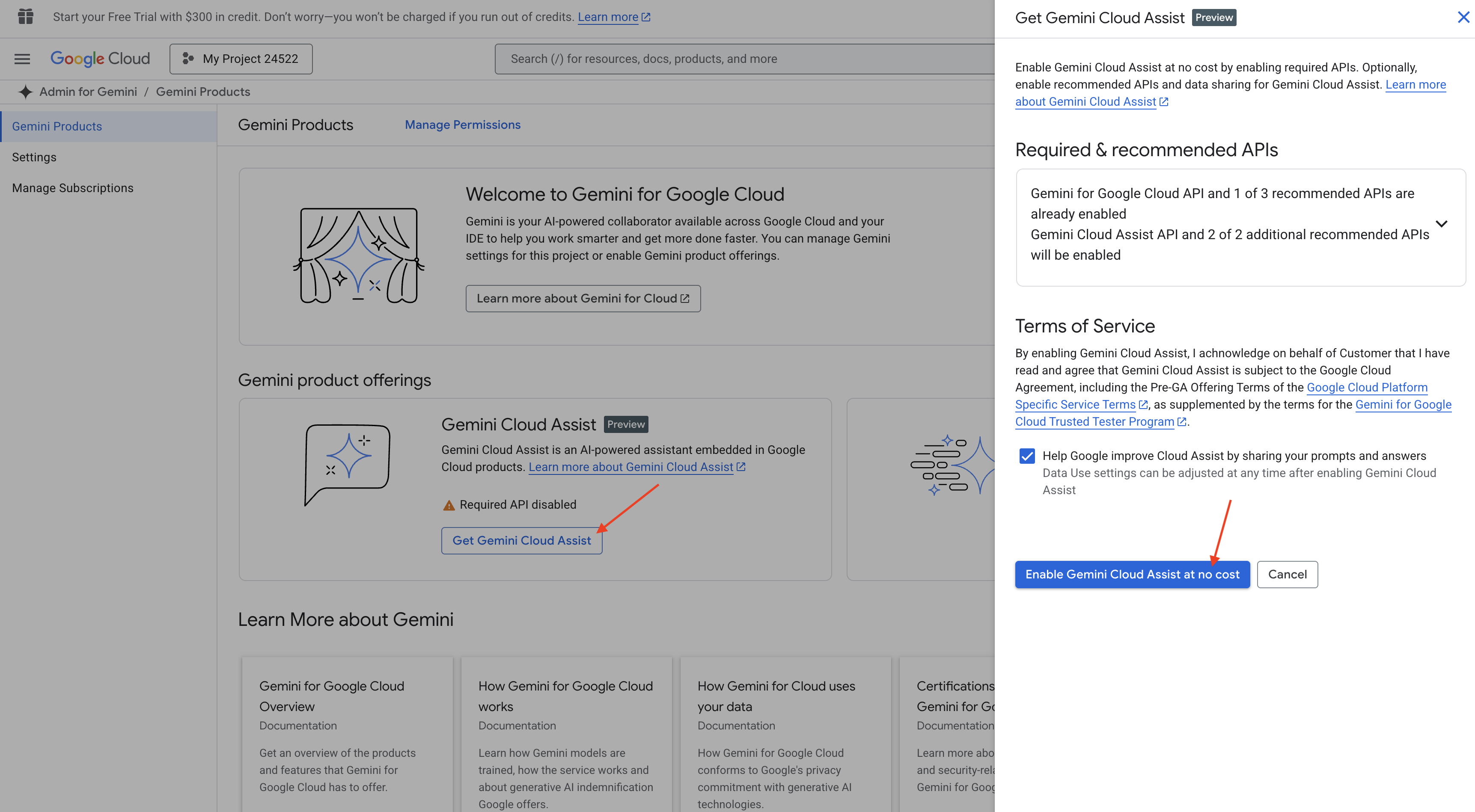
Ignora la configuración de permisos y sal de esta página.
Trabaja en el editor de Cloud Shell
👉 Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud (es el ícono con forma de terminal en la parte superior del panel de Cloud Shell).
👉 Haz clic en el botón "Abrir editor" (parece una carpeta abierta con un lápiz). Se abrirá el Editor de Cloud Shell en la ventana. Verás un explorador de archivos en el lado izquierdo.

👉 Haz clic en el botón Cloud Code Sign-in en la barra de estado de la parte inferior, como se muestra. Autoriza el complemento según las instrucciones. Si ves Cloud Code - Sin proyecto en la barra de estado, selecciónalo y, luego, en el menú desplegable "Seleccionar un proyecto de Google Cloud", elige el proyecto específico de Google Cloud de la lista de proyectos con los que planeas trabajar.
👉 Abre la terminal en el IDE de Cloud, 
👉 En la nueva terminal, verifica que ya te autenticaste y que el proyecto está configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list
👉 Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Ejecuta el siguiente comando para habilitar las APIs de Google Cloud necesarias:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
En la barra de herramientas de Cloud Shell (en la parte superior del panel de Cloud Shell), haz clic en el botón "Abrir editor" (parece una carpeta abierta con un lápiz). Se abrirá el editor de código de Cloud Shell en la ventana. Verás un explorador de archivos en el lado izquierdo.
👉 En la terminal, descarga el proyecto Bootstrap Skeleton:
git clone https://github.com/weimeilin79/legal-eagle.git
OPCIONAL: VERSIÓN EN ESPAÑOL
👉 Existe una versión alternativa en español. Por favor, utiliza la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Después de ejecutar este comando en la terminal de Cloud Shell, se creará una carpeta nueva con el nombre del repositorio legal-eagle en tu entorno de Cloud Shell.
4. Cómo escribir la aplicación de inferencia con Gemini Code Assist
En esta sección, nos enfocaremos en crear el núcleo de nuestro asistente legal: la aplicación web que recibe preguntas de los usuarios y que interactúa con el modelo de IA para generar respuestas. Aprovecharemos Gemini Code Assist para escribir el código de Python para esta parte de la inferencia.
Inicialmente, crearemos una aplicación de Flask que use la biblioteca de LangChain para comunicarse directamente con el modelo Gemini de Vertex AI. Esta primera versión actuará como un asistente legal útil basado en el conocimiento general del modelo, pero aún no tendrá acceso a los documentos específicos de nuestros casos judiciales. Esto nos permitirá ver el rendimiento de referencia del LLM antes de mejorarlo con la RAG más adelante.
En el panel Explorador del editor de Cloud Code (por lo general, en el lado izquierdo), ahora deberías ver la carpeta que se creó cuando clonaste el repositorio de Git legal-eagle. Abre la carpeta raíz de tu proyecto en el Explorador. Dentro de ella, encontrarás una subcarpeta webapp. Ábrela también. 
👉 Edita el archivo legal.py en el editor de Cloud Code. Puedes usar diferentes métodos para solicitar Gemini Code Assist.
👉 Copia la siguiente instrucción en la parte inferior de legal.py, que describe claramente lo que quieres que genere Gemini Code Assist, haz clic en el ícono de bombilla 💡 que apareció y selecciona Gemini: Genera código (el elemento de menú exacto puede variar ligeramente según la versión de Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Revisa cuidadosamente el código generado
- ¿Sigue aproximadamente los pasos que describiste en el comentario?
- ¿Crea un
ChatPromptTemplateconSystemMessageyHumanMessage? - ¿Incluye el manejo de errores básicos (
try...except)?
Si el código generado es bueno y casi correcto, puedes aceptarlo (presiona Tab o Intro para las sugerencias intercaladas, o haz clic en "Aceptar" para los bloques de código más grandes).
Si el código generado no es exactamente lo que quieres o tiene errores, no te preocupes. Gemini Code Assist es una herramienta para ayudarte, no para escribir código perfecto en el primer intento.
Edita y modifica el código generado para perfeccionarlo, corregir errores y adaptarlo mejor a tus requisitos. Puedes darle más instrucciones a Gemini Code Assist agregando más comentarios o haciendo preguntas específicas en el panel de chat de Code Assist.
Y si aún no conoces el SDK, aquí tienes un ejemplo práctico.
👉 Copia y pega el siguiente código y REEMPLÁZALO en tu legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCIONAL: VERSIÓN EN ESPAÑOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, a You are a helpful assistant that speaks Spanish,
A continuación, crea una función para controlar una ruta que responderá a las preguntas del usuario.
Abre main.py en el editor de Cloud Shell. De manera similar a como generaste ask_llm en legal.py, usa Gemini Code Assist para generar la ruta de Flask y la función ask_question. Escribe la siguiente INSTRUCCIÓN como comentario en main.py: (asegúrate de agregarla antes de iniciar la app de Flask en if __name__ == "__main__":).
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Solo acepta si el código generado es bueno y mayormente correcto. Si no conoces Python, aquí tienes un ejemplo funcional.Copia y pega esto en tu main.py debajo del código que ya está allí.
👉 Asegúrate de pegar lo siguiente ANTES del inicio de la aplicación web (si name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Si sigues estos pasos, deberías poder habilitar Gemini Code Assist, configurar tu proyecto y usarlo para generar la función ask en tu archivo main.py.
5. Pruebas locales en Cloud Editor
👉 En la terminal del editor, instala las bibliotecas dependientes y, luego, inicia la IU web de forma local.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Busca mensajes de inicio en el resultado de la terminal de Cloud Shell. Por lo general, Flask imprime mensajes que indican que se está ejecutando y en qué puerto.
- Running on http://127.0.0.1:8080
La aplicación debe seguir ejecutándose para atender las solicitudes.
👉 En el menú "Vista previa en la Web", elige Vista previa en el puerto 8080. Cloud Shell abrirá una nueva pestaña o ventana del navegador con la vista previa web de tu aplicación. 
👉 En la interfaz de la aplicación, escribe algunas preguntas relacionadas específicamente con referencias de casos legales y observa cómo responde el LLM. Por ejemplo, podrías probar lo siguiente:
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel desempeñaron los testimonios de los vecinos en la investigación del caso de Emily White?
👉 OPCIONAL: VERSIÓN EN ESPAÑOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Si observas las respuestas con atención, es probable que notes que el modelo puede alucinar, ser vago o genérico, y, a veces, malinterpretar tus preguntas, especialmente porque aún no tiene acceso a documentos legales específicos.
👉 Presiona Ctrl + C para detener la secuencia de comandos.
👉 Para salir del entorno virtual, ejecuta lo siguiente en la terminal:
deactivate
6. Cómo configurar el almacén de vectores
Es hora de poner fin a estas "interpretaciones creativas" de la ley por parte de los LLM. Ahí es donde la generación mejorada por recuperación (RAG) viene al rescate. Es como darle a nuestro LLM acceso a una biblioteca jurídica superpotente justo antes de que responda tus preguntas. En lugar de depender únicamente de su conocimiento general (que puede ser impreciso o estar desactualizado según el modelo), la RAG primero recupera información pertinente de una fuente confiable (en nuestro caso, documentos legales) y, luego, usa ese contexto para generar una respuesta mucho más fundamentada y precisa. Es como si el LLM hiciera su tarea antes de entrar a la sala del tribunal.
Para crear nuestro sistema RAG, necesitamos un lugar donde almacenar todos esos documentos legales y, lo que es más importante, hacer que se puedan buscar por significado. Aquí es donde entra en juego Firestore. Firestore es la base de datos de documentos NoSQL flexible y escalable de Google Cloud.
Usaremos Firestore como nuestro almacén de vectores. Almacenaremos fragmentos de nuestros documentos legales en Firestore y, para cada fragmento, también almacenaremos su embedding, es decir, la representación numérica de su significado.
Luego, cuando le hagas una pregunta a nuestro Legal Eagle, usaremos la búsqueda de vectores de Firestore para encontrar los fragmentos de texto legal más relevantes para tu consulta. Este contexto recuperado es lo que usa la RAG para brindarte respuestas basadas en información legal real, no solo en la imaginación del LLM.
👉 En una pestaña o ventana nueva, ve a Firestore en la consola de Google Cloud.
👉 Haz clic en Crear base de datos.
👉 Elige Native mode y el nombre de la base de datos como (default).
👉 Selecciona un solo region: us-central1 y haz clic en Crear base de datos. Firestore aprovisionará tu base de datos, lo que podría tardar unos minutos.
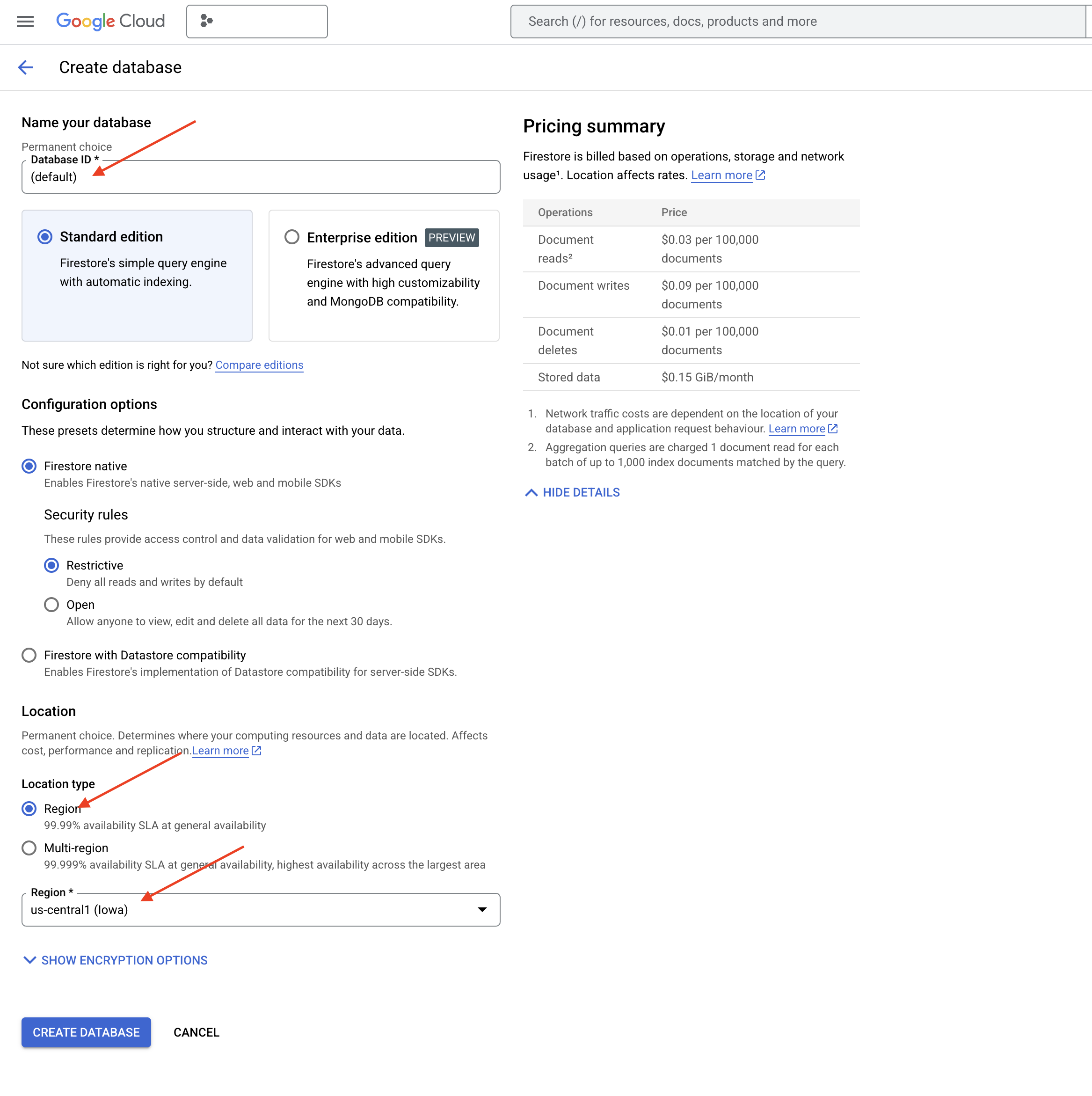
👉 De vuelta en la terminal del IDE de Cloud, crea un índice vectorial en el campo embedding_vector para habilitar la búsqueda vectorial en tu colección legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore comenzará a crear el índice vectorial. La creación del índice puede tardar un tiempo, especialmente para los conjuntos de datos más grandes. Verás el índice en estado “Creando”, y pasará a “Listo” cuando se compile. 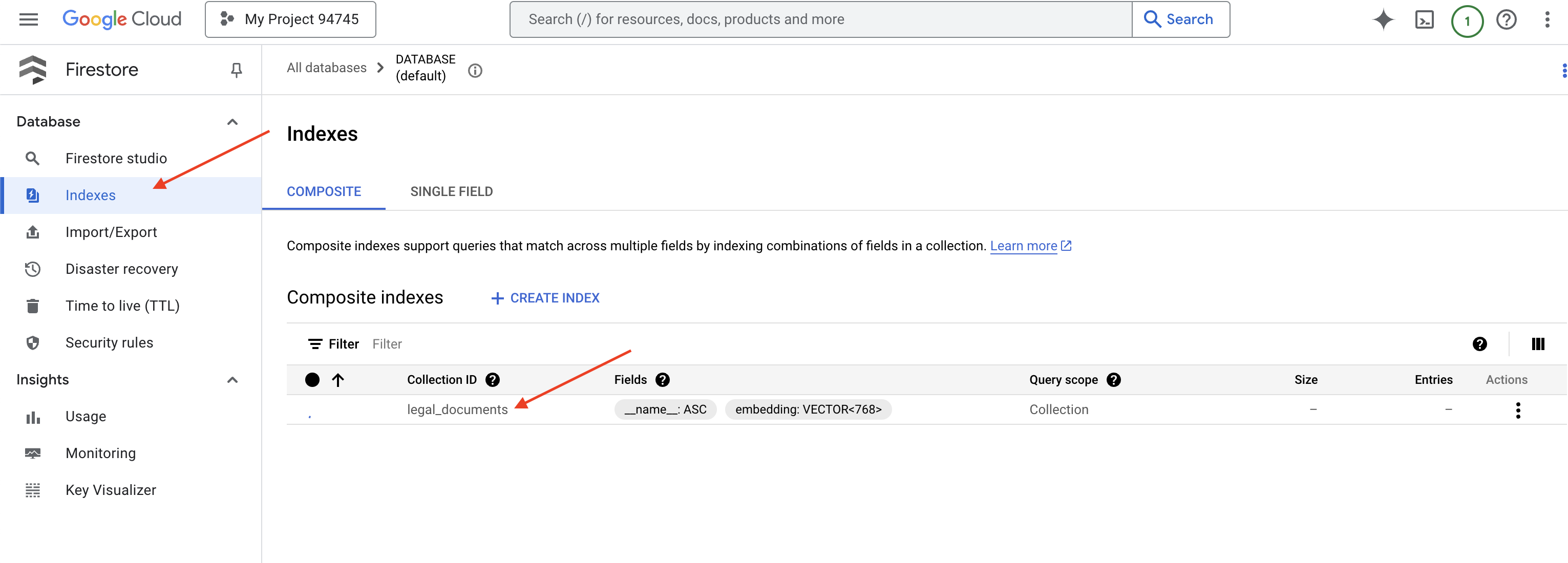
7. Carga de datos en el almacén de vectores
Ahora que comprendemos el RAG y nuestro almacén de vectores, es hora de compilar el motor que propagará nuestra biblioteca jurídica. Entonces, ¿cómo hacemos que los documentos legales se puedan buscar por significado? La magia está en las incorporaciones. Piensa en los embeddings como la conversión de palabras, oraciones o incluso documentos completos en vectores numéricos, es decir, listas de números que capturan su significado semántico. Los conceptos similares obtienen vectores que están "cerca" entre sí en el espacio vectorial. Usamos modelos potentes (como los de Vertex AI) para realizar esta conversión.
Para automatizar la carga de documentos, usaremos Cloud Run Functions y Eventarc. Cloud Run Functions es un contenedor ligero y sin servidores que ejecuta tu código solo cuando es necesario. Empaquetaremos nuestra secuencia de comandos de Python para el procesamiento de documentos en un contenedor y la implementaremos como una Cloud Run Function.
👉 En una pestaña o ventana nueva, ve a Cloud Storage.
👉 Haz clic en "Buckets" en el menú de la izquierda.
👉 Haz clic en el botón “+ CREAR” que se encuentra en la parte superior.
👉 Configura tu bucket (parámetros de configuración importantes):
- Nombre del bucket: “yourprojectID”-doc-bucket (DEBES incluir el sufijo -doc-bucket al final)
- región: Selecciona la región
us-central1. - Clase de almacenamiento: "Estándar". Standard Storage es adecuado para los datos a los que se accede con frecuencia.
- Control de acceso: Deja seleccionada la opción predeterminada "Control de acceso uniforme". Esto proporciona un control de acceso coherente a nivel del bucket.
- Opciones avanzadas: Para este instructivo, la configuración predeterminada suele ser suficiente.
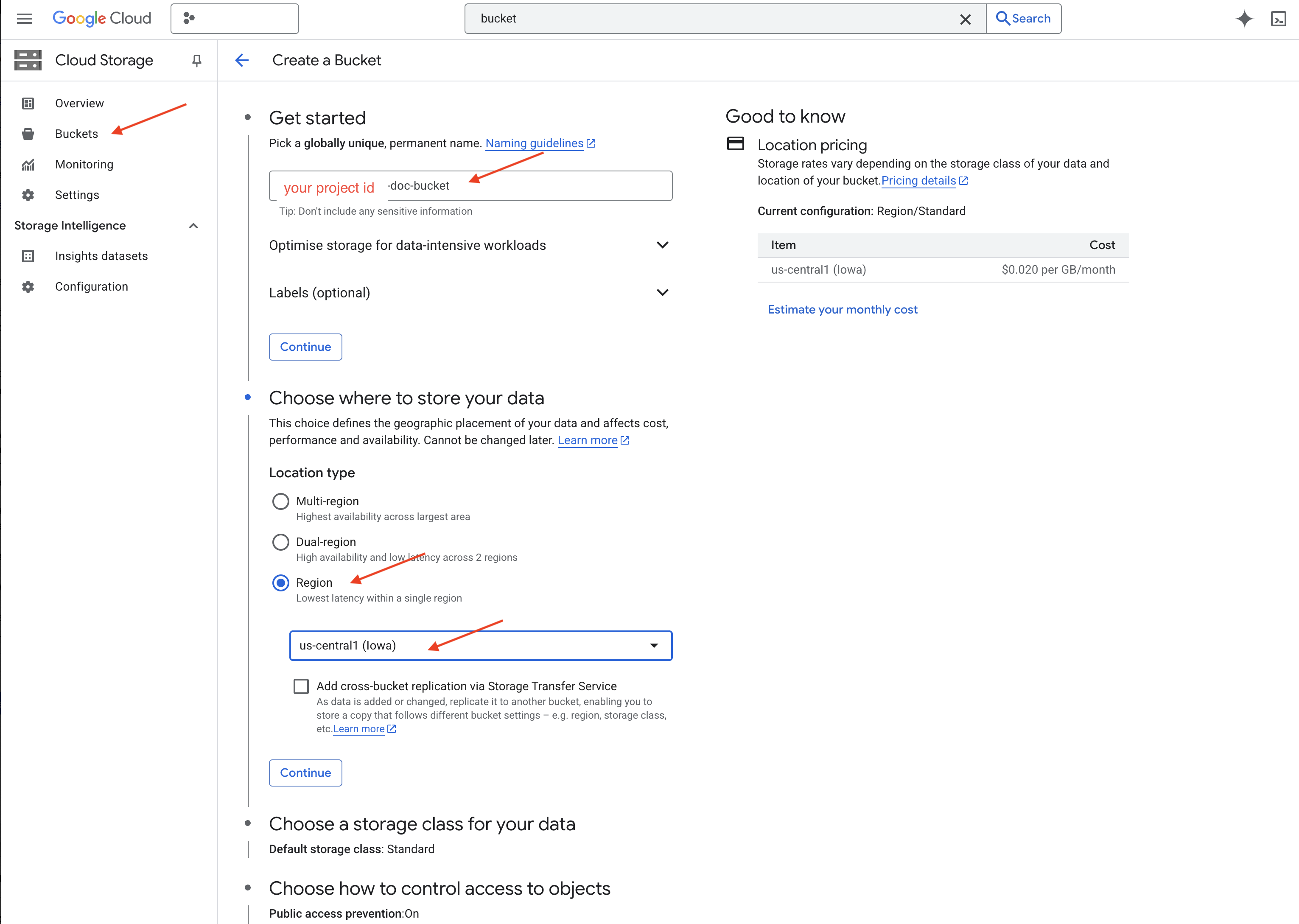
👉 Haz clic en el botón CREAR para crear tu bucket.
👉 Es posible que veas una ventana emergente sobre la prevención del acceso público. Deja marcada la casilla y haz clic en “Confirmar”.
Ahora verás el bucket que acabas de crear en la lista Buckets. Recuerda el nombre del bucket, ya que lo necesitarás más adelante.
8. Configura una Cloud Run Function
👉 En el editor de código de Cloud Shell, navega al directorio de trabajo legal-eagle: Usa el comando cd en la terminal del editor de Cloud para crear la carpeta.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Crea archivos main.py,requirements.txt y Dockerfile. En la terminal de Cloud Shell, usa el comando touch para crear los archivos:
touch main.py requirements.txt Dockerfile
Verás la carpeta recién creada llamada *loader y los tres archivos.
👉 Edita main.py en la carpeta loader. En el explorador de archivos de la izquierda, navega al directorio en el que creaste los archivos y haz doble clic en main.py para abrirlo en el editor.
Pega el siguiente código de Python en main.py:
Esta aplicación procesa los archivos nuevos que se suben al bucket de GCS, divide el texto en fragmentos, genera incorporaciones para cada fragmento y almacena los fragmentos y sus incorporaciones en Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Edita requirements.txt.Pega las siguientes líneas en el archivo:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Prueba y compila la Cloud Run Function
👉 Ejecutaremos esto en un entorno virtual y, luego, instalaremos las bibliotecas de Python necesarias para la función de Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Inicia un emulador local para la función de Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Mantén la última terminal en ejecución, abre una terminal nueva y ejecuta el comando para subir un archivo al bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Mientras se ejecuta el emulador, puedes enviarle CloudEvents de prueba. Para ello, necesitarás una terminal independiente en el IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Debería mostrar OK.
👉 Verificarás los datos en Firestore. Para ello, ve a la consola de Google Cloud, navega a "Bases de datos" y, luego, a "Firestore". Selecciona la pestaña "Datos" y, luego, la colección legal_documents. Verás que se crearon documentos nuevos en tu colección, cada uno de los cuales representa una parte del texto del archivo subido. 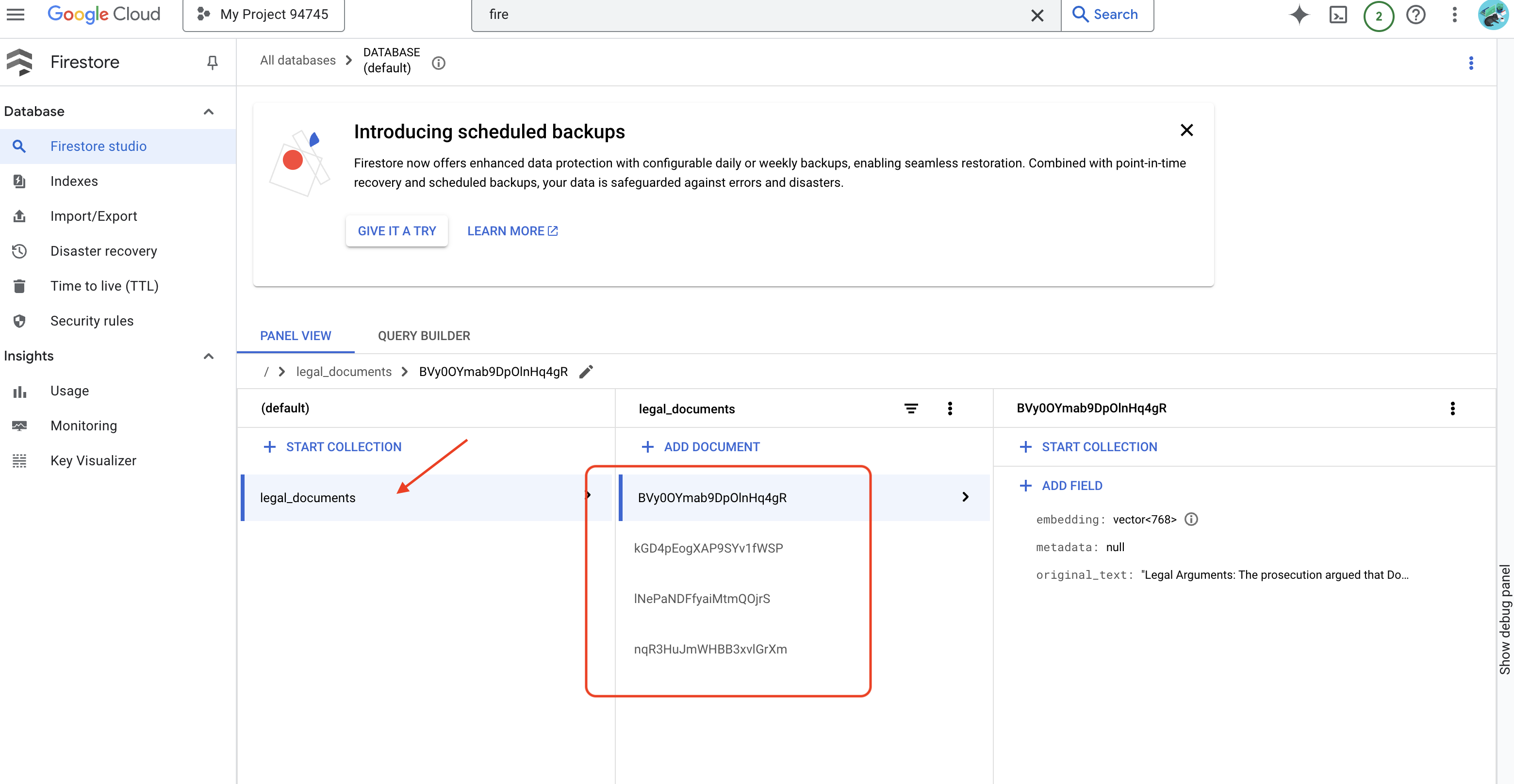
👉 En la terminal que ejecuta el emulador, escribe Ctrl+C para salir. Cierra la segunda terminal.
👉 Ejecuta deactivate para salir del entorno virtual.
deactivate
10. Compila la imagen del contenedor y envíala a los repositorios de Artifacts
👉 Es hora de implementar esto en la nube. En el explorador de archivos, haz doble clic en Dockerfile. Pídele a Gemini que genere el archivo Dockerfile por ti, abre Gemini Code Assist y usa la siguiente instrucción para generar el archivo.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Como práctica recomendada, se recomienda hacer clic en Diff with Open File(dos flechas en direcciones opuestas y aceptar los cambios). 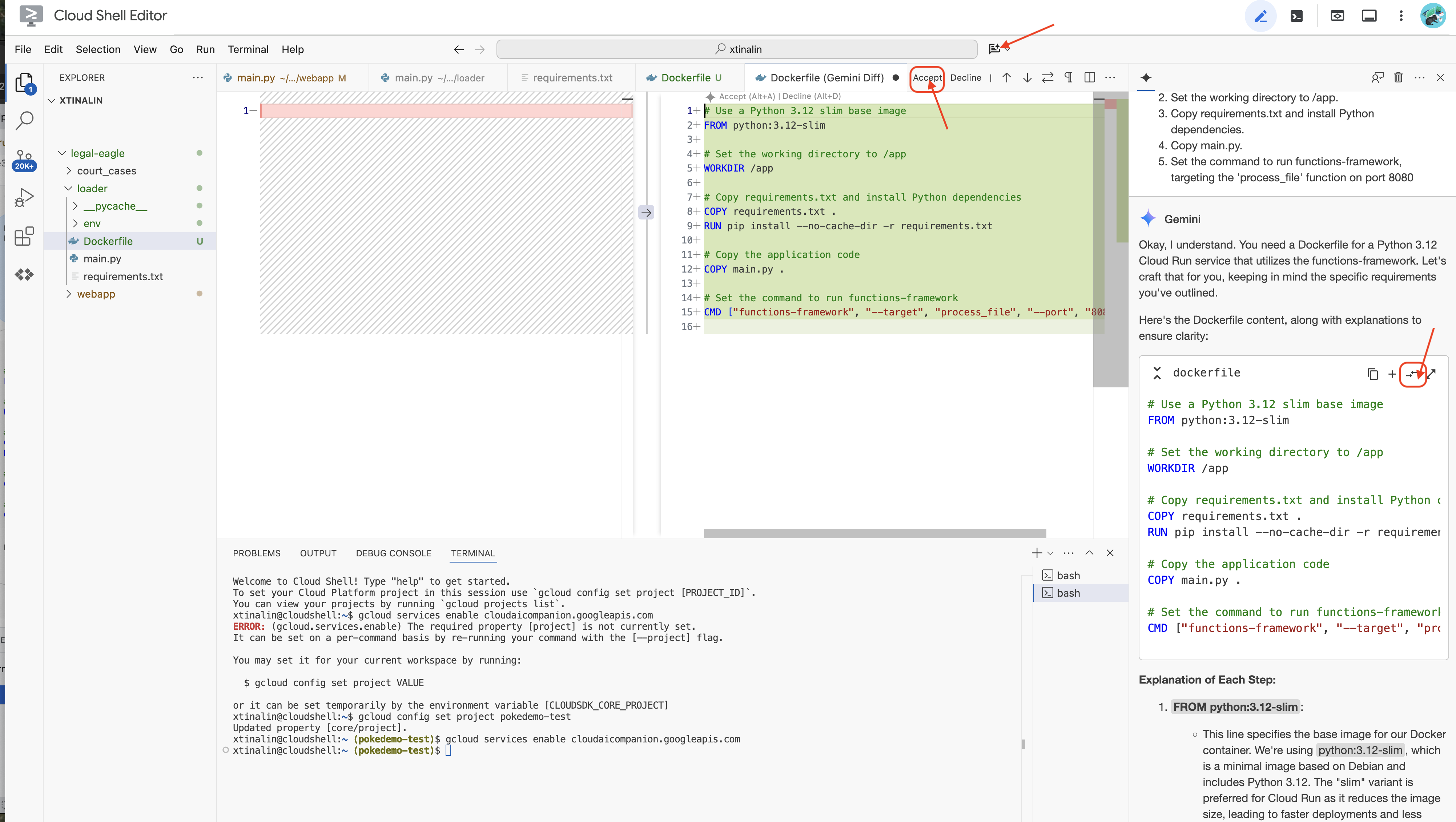
👉 Si es la primera vez que usas contenedores, aquí tienes un ejemplo práctico:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 En la terminal, crea un repositorio de artefactos para almacenar la imagen de Docker que compilaremos.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Deberías ver el mensaje Created repository [my-repository].
👉 Ejecuta el siguiente comando para compilar la imagen de Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Ahora enviarás eso al registro
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
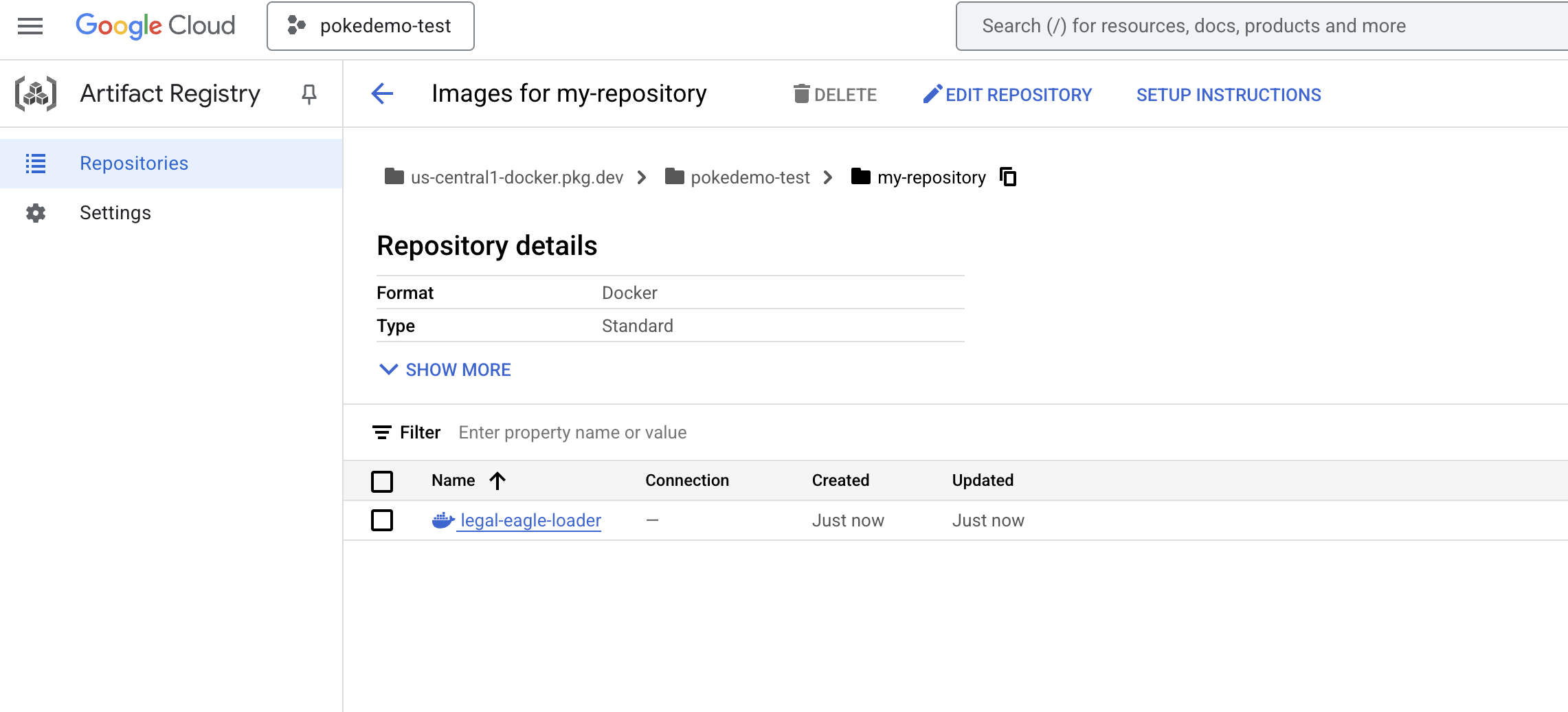
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
La imagen de Docker ahora está disponible en el repositorio de artefactos my-repository .
11. Crea la función de Cloud Run y configura el activador de Eventarc
Antes de profundizar en los detalles de la implementación de nuestro cargador de documentos legales, comprendamos brevemente los componentes involucrados: Cloud Run es una plataforma sin servidores completamente administrada que te permite implementar aplicaciones alojadas en contenedores de forma rápida y sencilla. Abstrae la administración de la infraestructura, lo que te permite enfocarte en escribir e implementar tu código.
Implementaremos nuestro cargador de documentos como un servicio de Cloud Run. Ahora, continuemos con la configuración de nuestra función de Cloud Run:
👉 En la consola de Google Cloud, navega a Cloud Run.
👉 Ve a Implementar contenedor y, en el menú desplegable, haz clic en SERVICIO.
👉 Configura tu servicio de Cloud Run:
- Imagen del contenedor: Haz clic en "Seleccionar" en el campo de URL. Busca la URL de la imagen que enviaste a Artifact Registry (p.ej., us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Nombre del servicio:
legal-eagle-loader - Región: Selecciona la región
us-central1. - Autenticación: Para los fines de este taller, puedes permitir "Permitir invocaciones no autenticadas". Para la producción, es probable que desees restringir el acceso.
- Contenedores, herramientas de redes y seguridad : Es la opción predeterminada.
👉 Haz clic en CREAR. Cloud Run implementará tu servicio. 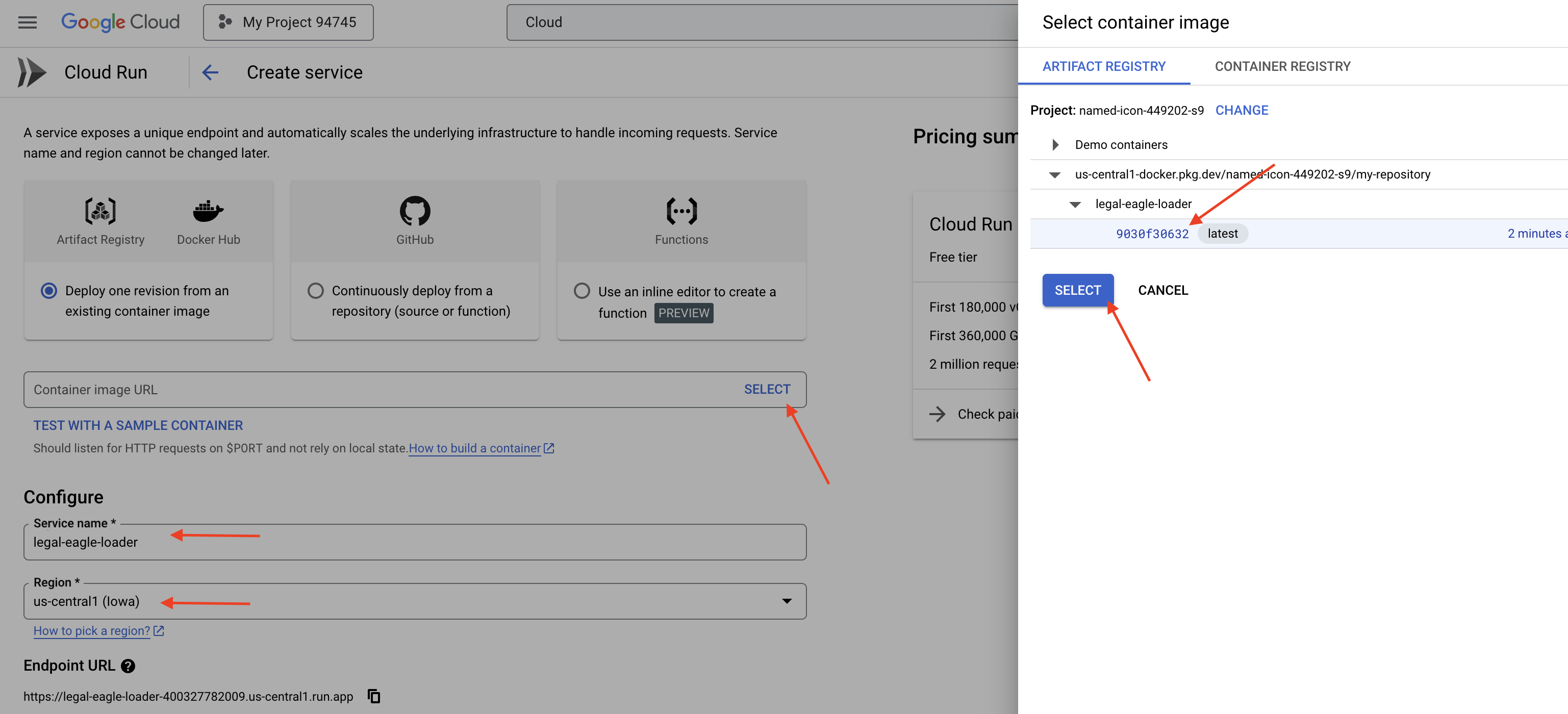
Para activar este servicio automáticamente cuando se agreguen archivos nuevos a nuestro bucket de almacenamiento, usaremos Eventarc. Eventarc te permite crear arquitecturas basadas en eventos enrutando eventos de varias fuentes a tus servicios.
Si configuramos Eventarc, nuestro servicio de Cloud Run cargará automáticamente los documentos recién agregados en Firestore en cuanto se suban, lo que permitirá actualizaciones de datos en tiempo real para nuestra aplicación de RAG.
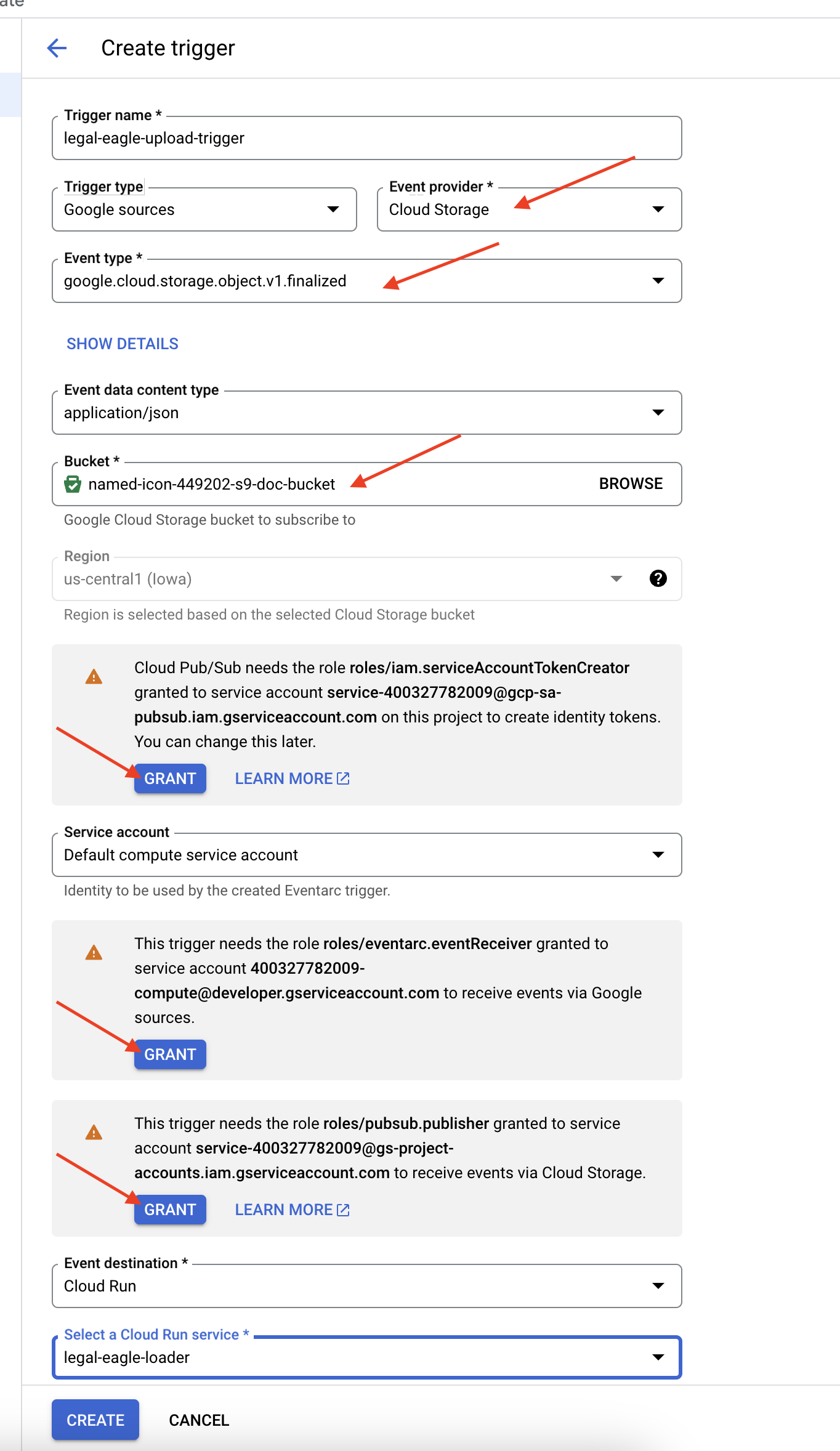
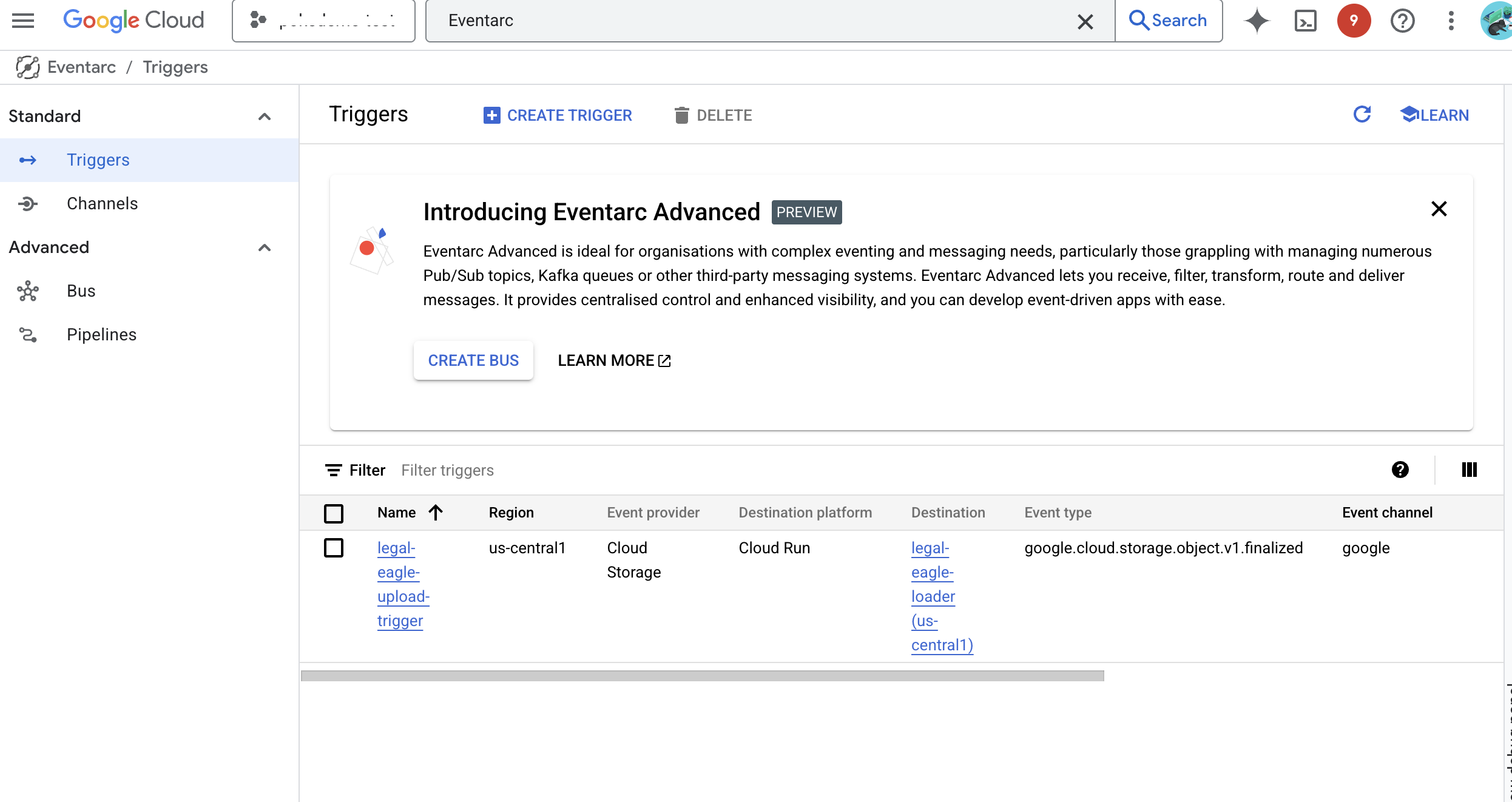
👉 En la consola de Google Cloud, navega a Activadores en Eventarc. Haz clic en "+ CREAR ACTIVADOR". 👉 Configura el activador de Eventarc:
- Nombre del activador:
legal-eagle-upload-trigger. - TriggerType: Fuentes de Google
- Proveedor de eventos: Selecciona Cloud Storage.
- Tipo de evento: Elige
google.cloud.storage.object.v1.finalized - Bucket de Cloud Storage: Selecciona tu bucket de GCS en el menú desplegable.
- Tipo de destino: "Servicio de Cloud Run".
- Servicio: Selecciona
legal-eagle-loader. - Región:
us-central1 - Ruta de acceso: Por ahora, deja este campo en blanco .
- Otorga todos los permisos que se solicitaron en la página.
👉 Haz clic en CREAR. Eventarc ahora configurará el activador.
El servicio de Cloud Run necesita permiso para leer archivos de varios componentes. Debemos otorgar a la cuenta de servicio del servicio el permiso que necesita.
12. Sube documentos legales al bucket de GCS
👉 Sube el archivo del caso judicial a tu bucket de GCS. Recuerda reemplazar el nombre de tu bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Supervisa los registros del servicio de Cloud Run. Para ello, ve a Cloud Run -> tu servicio legal-eagle-loader -> "Registros". Verifica los registros para ver los mensajes de procesamiento exitoso, incluidos los siguientes:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
Y, según la rapidez con la que se configuró el registro, también verás registros más detallados aquí.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Busca mensajes de error en los registros y soluciona los problemas si es necesario. 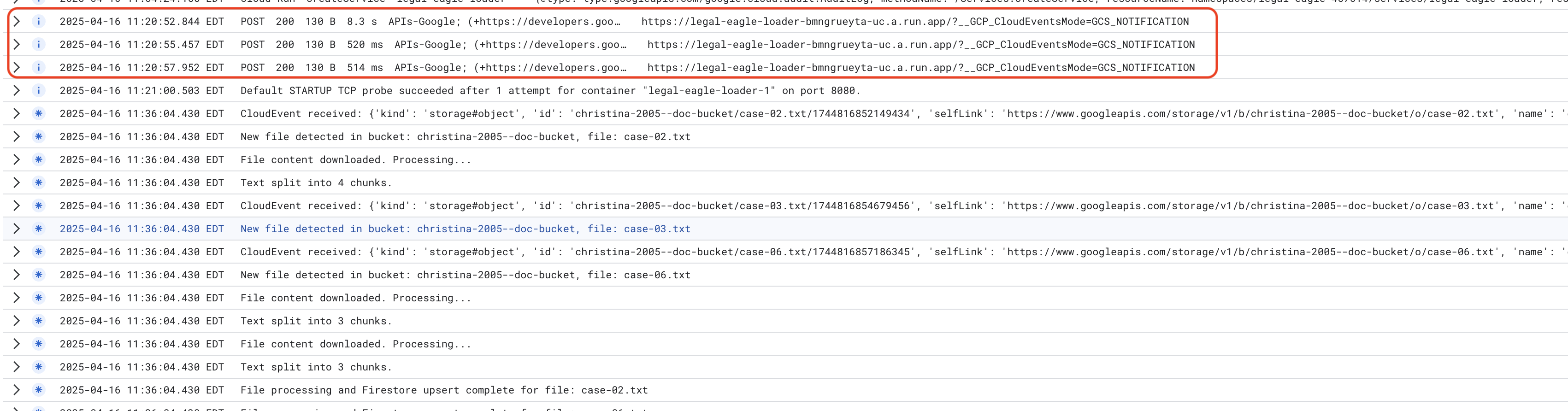
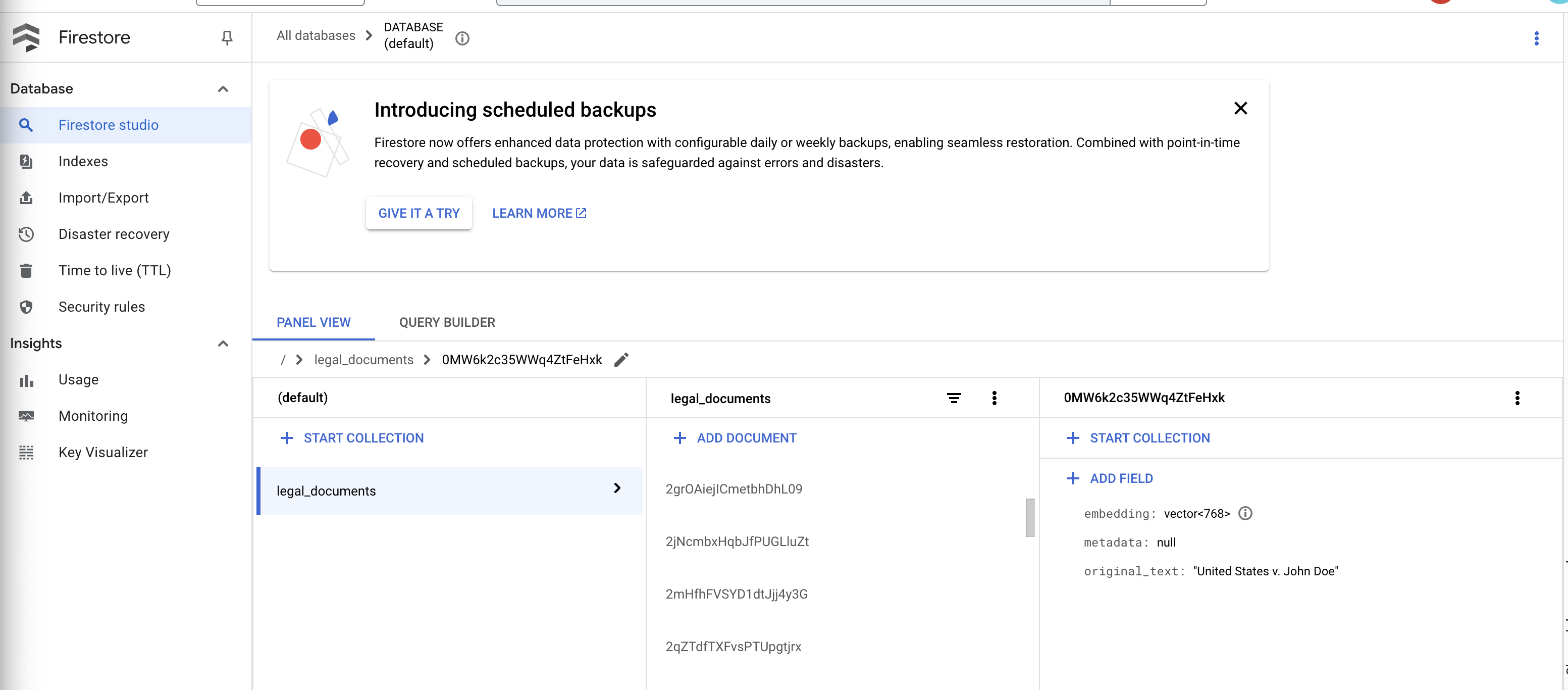
👉 Verifica los datos en Firestore. Abre tu colección legal_documents.
👉 Deberías ver documentos nuevos creados en tu colección. Cada documento representará una parte del texto del archivo que subiste y contendrá lo siguiente:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Implementa RAG
LangChain es un potente framework diseñado para optimizar el desarrollo de aplicaciones potenciadas por modelos de lenguaje grandes (LLM). En lugar de lidiar directamente con las complejidades de las APIs de LLM, la ingeniería de instrucciones y el manejo de datos, LangChain proporciona una capa de abstracción de alto nivel. Ofrece componentes y herramientas prediseñados para tareas como la conexión a varios LLM (como los de OpenAI, Google o de otros proveedores), la creación de cadenas complejas de operaciones (p.ej., recuperación de datos seguida de un resumen) y la administración de la memoria conversacional.
En el caso de la RAG específicamente, los almacenes de vectores en LangChain son esenciales para habilitar el aspecto de recuperación de la RAG. Son bases de datos especializadas diseñadas para almacenar y consultar de manera eficiente incorporaciones de vectores, en las que los fragmentos de texto semánticamente similares se asignan a puntos cercanos en el espacio vectorial. LangChain se encarga de los detalles de bajo nivel, lo que permite a los desarrolladores enfocarse en la lógica y la funcionalidad principales de su aplicación de RAG. Esto reduce significativamente el tiempo y la complejidad del desarrollo, lo que te permite crear prototipos e implementar rápidamente aplicaciones basadas en RAG, a la vez que aprovechas la solidez y la escalabilidad de la infraestructura de Google Cloud.
Ahora que ya sabes qué es LangChain, deberás actualizar tu archivo legal.py en la carpeta webapp para la implementación de RAG. Esto permitirá que el LLM busque documentos relevantes en Firestore antes de proporcionar una respuesta.
👉 Importa FirestoreVectorStore y otros módulos obligatorios de langchain y vertexai. Agrega lo siguiente al legal.py actual
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Inicializa Vertex AI y el modelo de incorporación.Usarás text-embedding-004. Agrega el siguiente código justo después de importar los módulos.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Crea un FirestoreVectorStore que apunte a la colección legal_documents, usando el modelo de incorporación inicializado y especificando los campos de contenido y de incorporación. Agrega este código inmediatamente después del código del modelo de incorporación anterior.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Define una función llamada search_resource que tome una búsqueda, realice una búsqueda de similitud con vector_store.similarity_search y muestre los resultados combinados.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 REEMPLAZA la función ask_llm y usa la función search_resource para recuperar el contexto pertinente según la búsqueda del usuario.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCIONAL: VERSIÓN EN ESPAÑOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, a You are a helpful assistant that speaks Spanish,
👉 Después de implementar RAG en legal.py, debes probarlo de forma local antes de la implementación. Para ello, ejecuta la aplicación con el siguiente comando:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Usa webpreview para acceder a la aplicación, hablar con la asistencia y escribir ctrl+c para salir del proceso que se ejecuta de forma local. Luego, ejecuta deactivate para salir del entorno virtual.
deactivate
👉 Para implementar la aplicación web en Cloud Run, será similar a la función de carga. Compilarás, etiquetarás y enviarás la imagen de Docker a Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Es hora de implementar la aplicación web en Google Cloud. En la terminal, ejecuta los siguientes comandos:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Para verificar la implementación, ve a Cloud Run en la consola de Google Cloud.Deberías ver un servicio nuevo llamado legal-eagle-webapp en la lista.
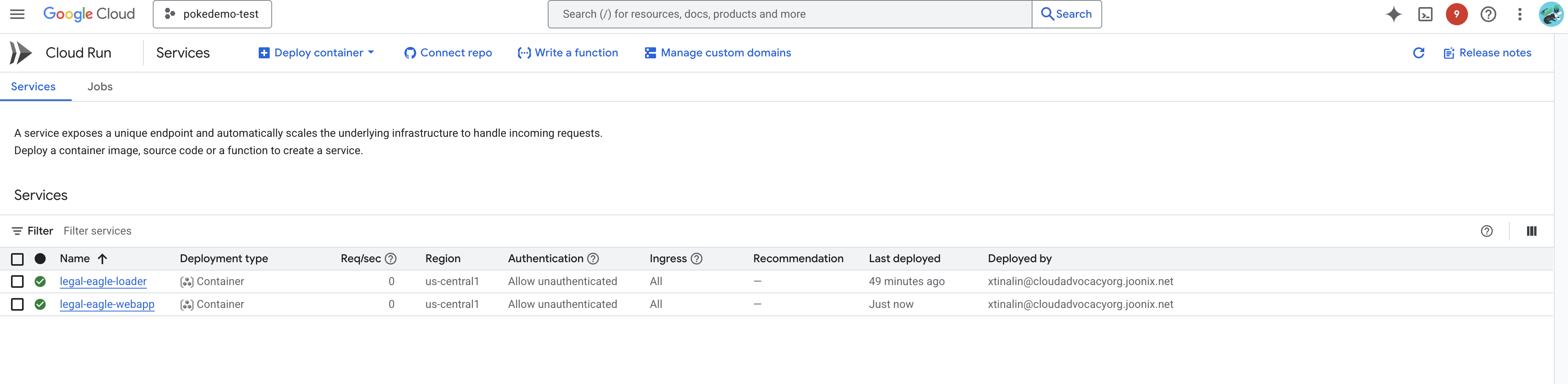
Haz clic en el servicio para ir a su página de detalles. En la parte superior, encontrarás la URL implementada. 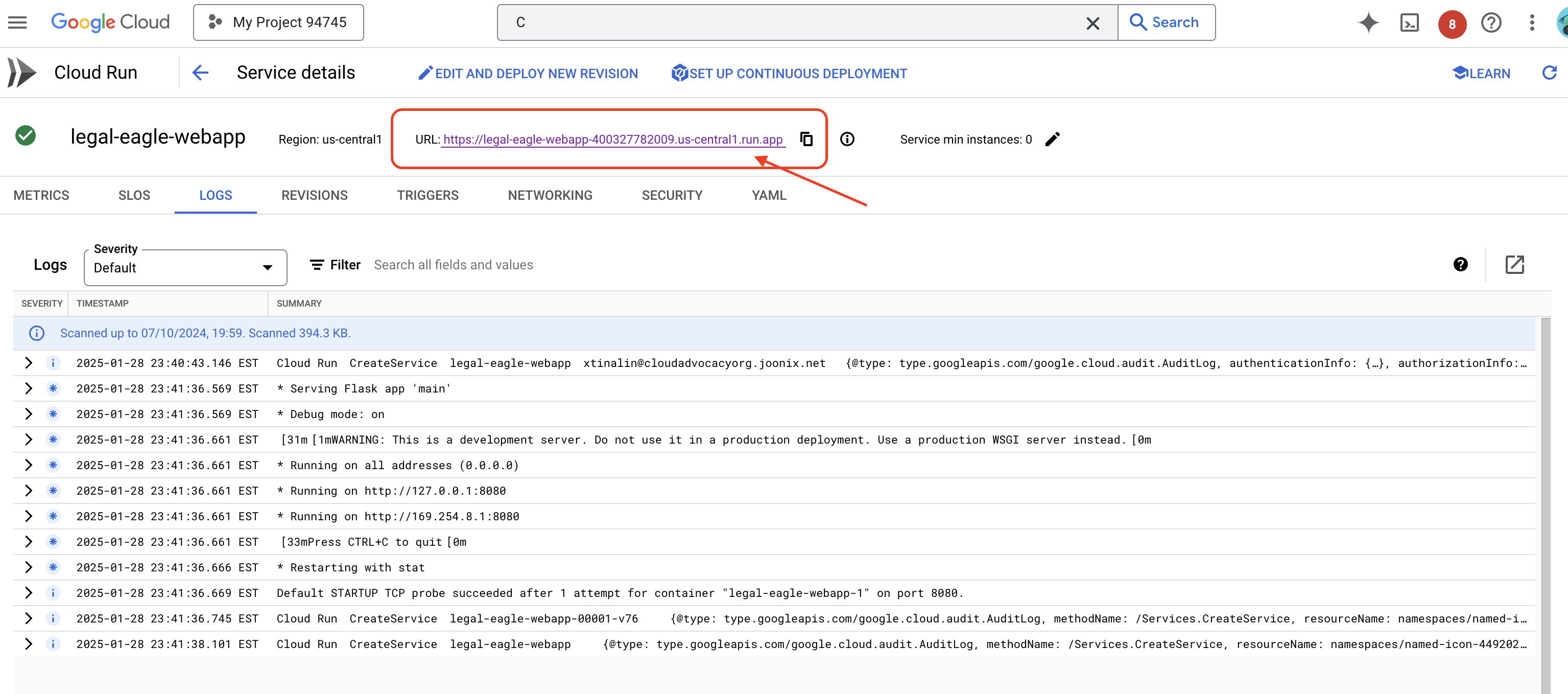
👉 Ahora, abre la URL implementada en una nueva pestaña del navegador. Puedes interactuar con el asistente legal y hacer preguntas relacionadas con los casos judiciales que cargaste(en la carpeta court_cases):
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel desempeñaron los testimonios de los vecinos en la investigación del caso de Emily White?
👉 OPCIONAL: VERSIÓN EN ESPAÑOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Deberías notar que las respuestas ahora son más precisas y se basan en el contenido de los documentos legales que subiste, lo que demuestra el poder de la RAG.
¡Felicitaciones por completar el taller! Compilaste e implementaste correctamente una aplicación de análisis de documentos legales con LLM, LangChain y Google Cloud. Aprendiste a transferir y procesar documentos legales, aumentar las respuestas de los LLM con información pertinente a través de RAG y, luego, implementar tu aplicación como un servicio sin servidores. Este conocimiento y la aplicación creada te ayudarán a explorar aún más el poder de los LLM para las tareas legales. ¡Bien hecho!".
14. Desafío
Diversidad de tipos de medios::
Cómo ingerir y procesar diversos tipos de medios, como videos judiciales y grabaciones de audio, y extraer texto relevante
Recursos en línea:
Cómo procesar en vivo recursos en línea, como páginas web