
۱. مقدمه
من همیشه مجذوب شور و هیجان دادگاه بودهام، تصور اینکه چگونه ماهرانه از پیچیدگیهای آن عبور میکنم و استدلالهای نهایی قدرتمندی ارائه میدهم. در حالی که مسیر شغلی من به جای دیگری منتهی شده است، هیجانزدهام که این را به اشتراک بگذارم که با کمک هوش مصنوعی، ممکن است همه ما به تحقق رویای دادگاه نزدیکتر شویم.

امروز، ما به بررسی نحوه استفاده از ابزارهای قدرتمند هوش مصنوعی گوگل - مانند Vertex AI، Firestore و Cloud Run Functions - برای پردازش و درک دادههای حقوقی، انجام جستجوهای سریع و شاید، فقط شاید، کمک به مشتری خیالی شما (یا خودتان) برای خروج از یک وضعیت دشوار میپردازیم.
ممکن است شما از یک شاهد بازجویی متقابل نکنید، اما با سیستم ما، میتوانید انبوهی از اطلاعات را بررسی کنید، خلاصههای واضحی تهیه کنید و مرتبطترین دادهها را در عرض چند ثانیه ارائه دهید.
۲. معماری
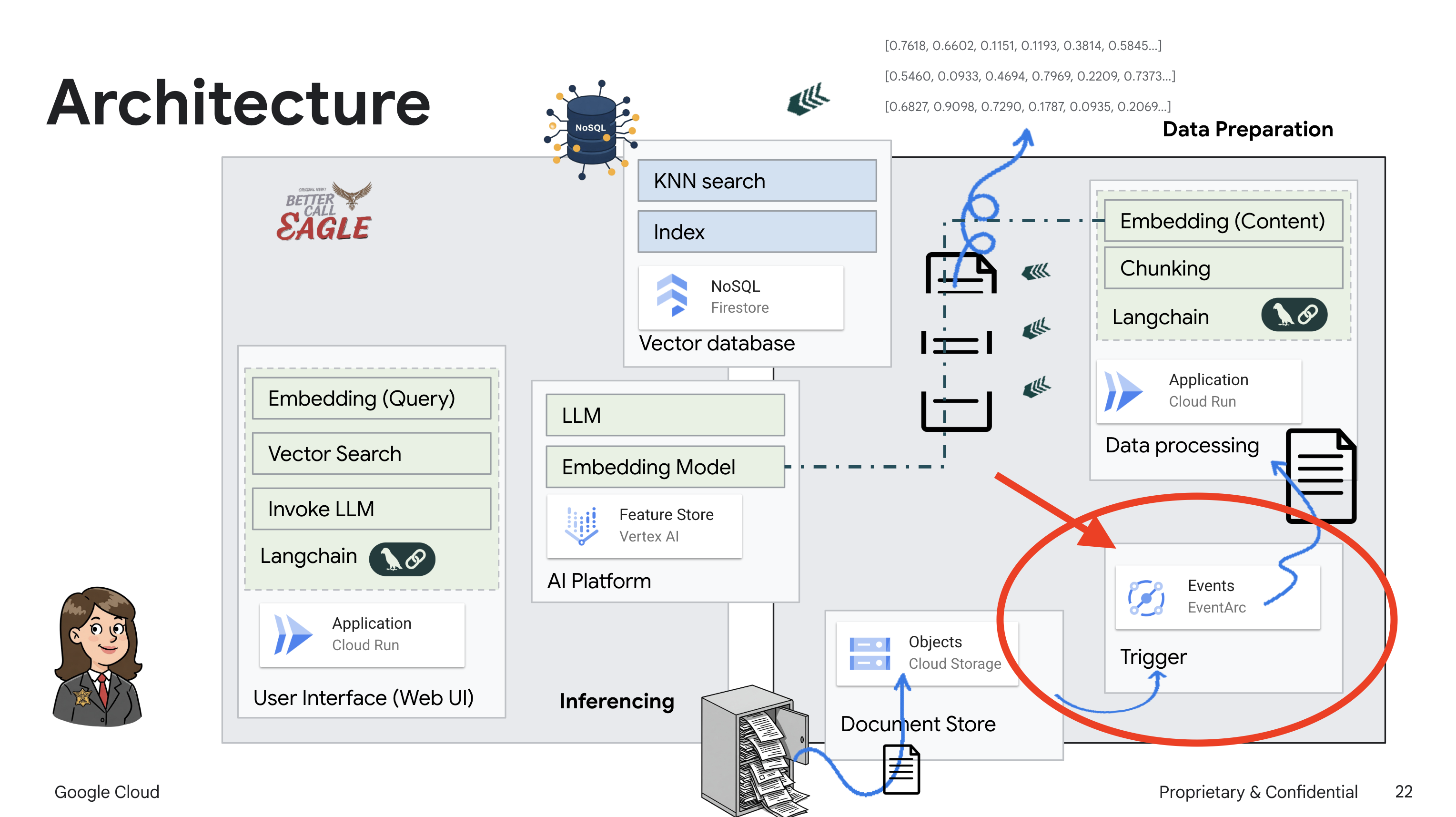
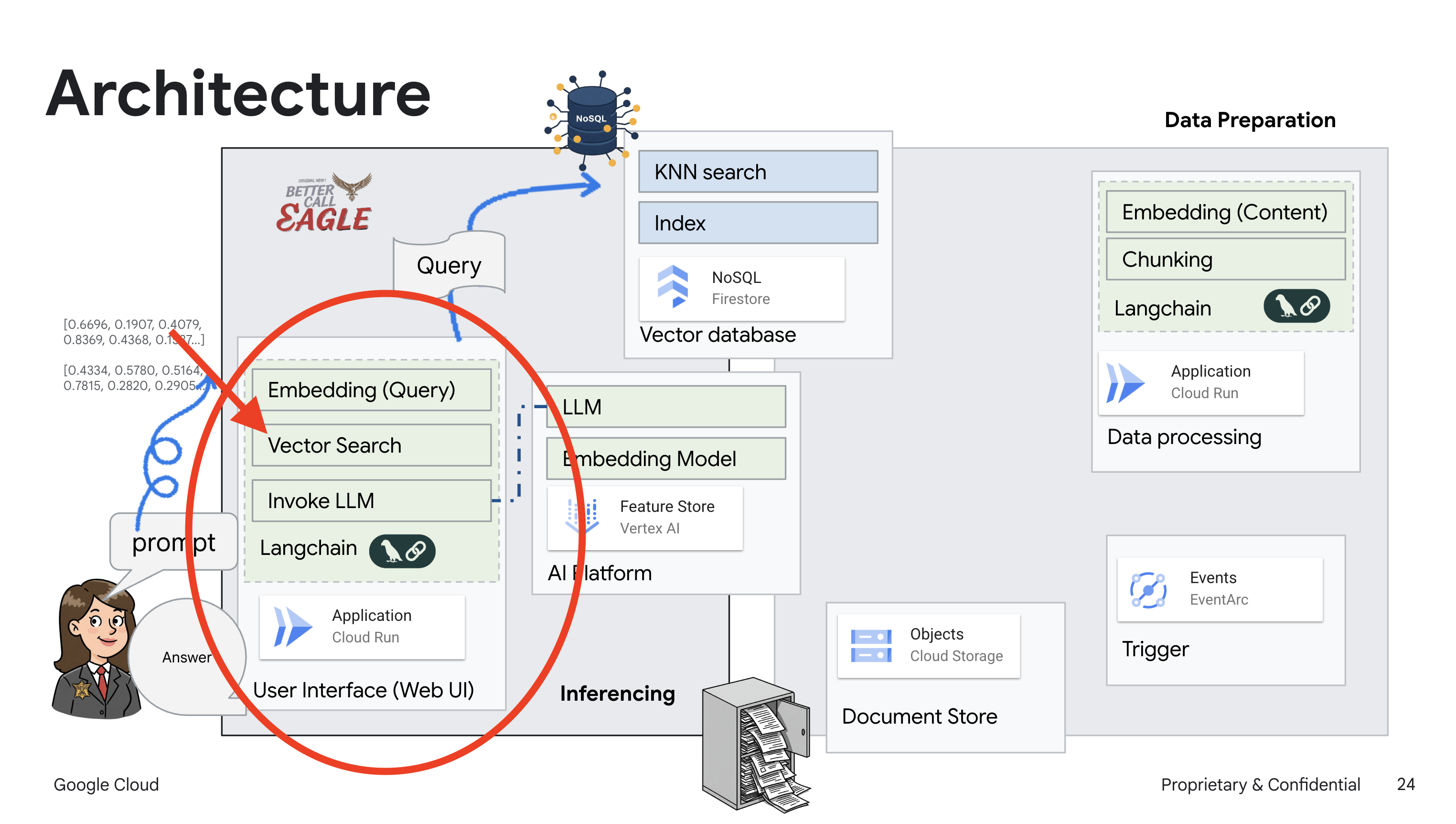
این پروژه بر ساخت یک دستیار حقوقی با استفاده از ابزارهای هوش مصنوعی گوگل کلود تمرکز دارد و بر نحوه پردازش، درک و جستجوی دادههای حقوقی تأکید دارد. این سیستم به گونهای طراحی شده است که حجم زیادی از اطلاعات را بررسی کند، خلاصههایی تولید کند و دادههای مرتبط را به سرعت ارائه دهد. معماری دستیار حقوقی شامل چندین مؤلفه کلیدی است:
ساخت پایگاه دانش از دادههای بدون ساختار : از فضای ذخیرهسازی ابری گوگل (GCS) برای ذخیره اسناد حقوقی استفاده میشود. فایراستور، یک پایگاه داده NoSQL، به عنوان یک مخزن برداری عمل میکند و تکههای سند و جاسازیهای مربوط به آنها را در خود نگه میدارد. جستجوی برداری در فایراستور فعال است تا امکان جستجوهای مشابه را فراهم کند. هنگامی که یک سند حقوقی جدید در GCS آپلود میشود، Eventarc یک تابع Cloud Run را فعال میکند. این تابع با تقسیم سند به تکهها و ایجاد جاسازیها برای هر تکه با استفاده از مدل جاسازی متن Vertex AI، سند را پردازش میکند. سپس این جاسازیها در کنار تکههای متن در فایراستور ذخیره میشوند. 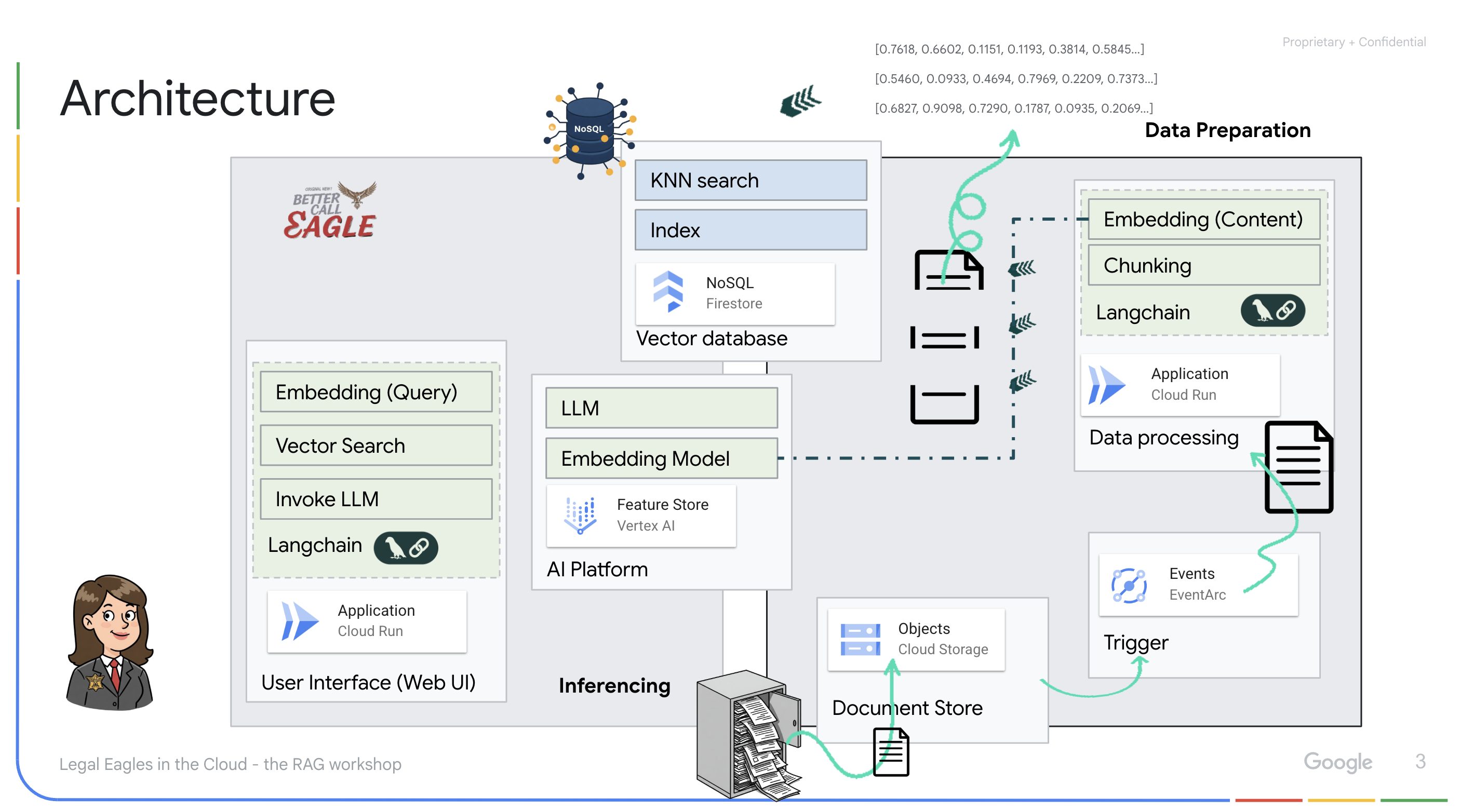
برنامهای که توسط LLM و RAG پشتیبانی میشود : هسته سیستم پرسش و پاسخ، تابع ask_llm است که از کتابخانه langchain برای تعامل با یک مدل زبان بزرگ Vertex AI Gemini استفاده میکند. این تابع یک HumanMessage از پرسوجوی کاربر ایجاد میکند و شامل یک SystemMessage است که به LLM دستور میدهد تا به عنوان یک دستیار حقوقی مفید عمل کند. این سیستم از رویکرد Retrieval-Augmented Generation (RAG) استفاده میکند، که در آن، قبل از پاسخ به یک پرسوجو، سیستم از تابع search_resource برای بازیابی متن مرتبط از مخزن بردار Firestore استفاده میکند. سپس این متن در SystemMessage گنجانده میشود تا پاسخ LLM را در اطلاعات حقوقی ارائه شده قرار دهد. 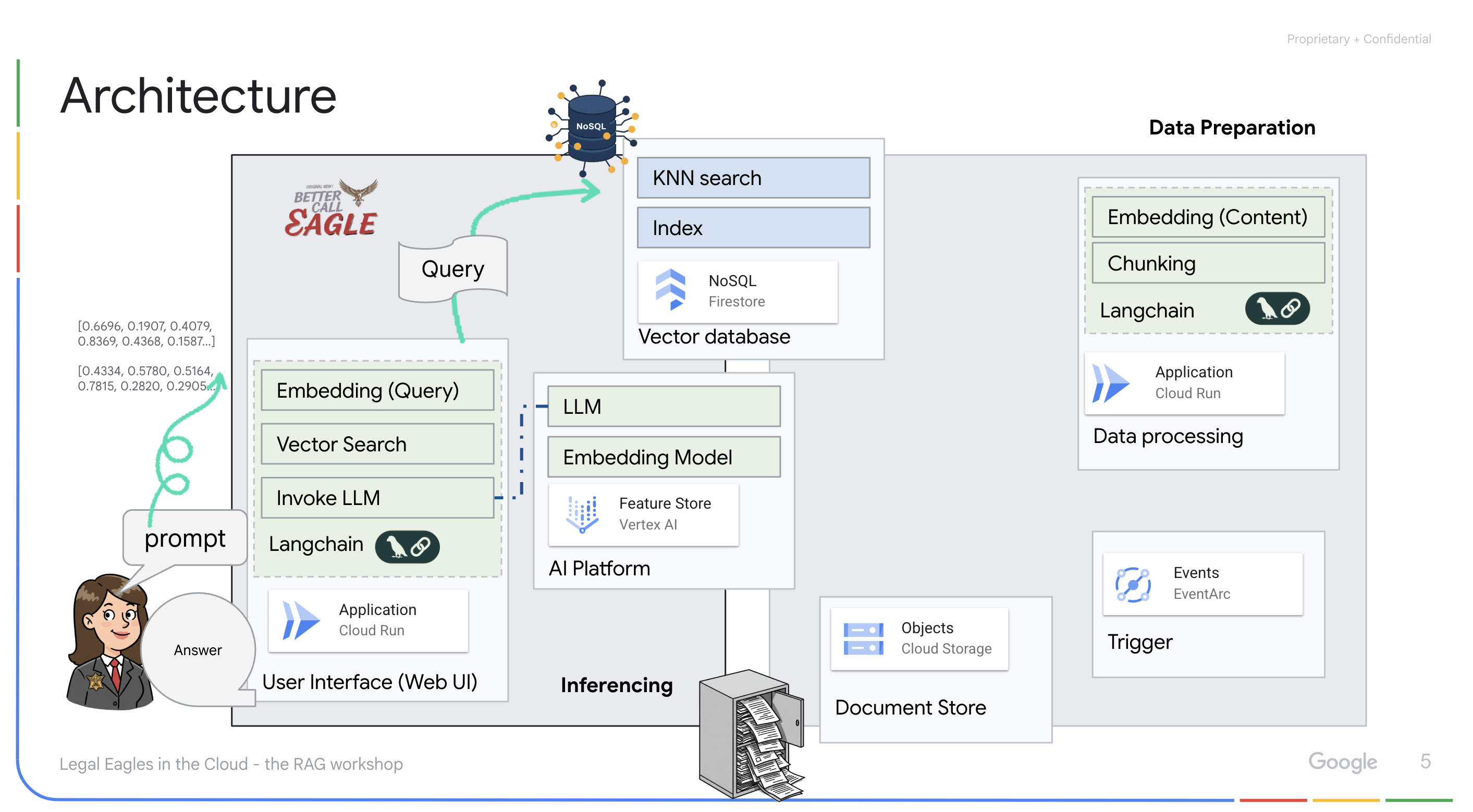
این پروژه با استفاده از RAG، که ابتدا اطلاعات مربوطه را از یک منبع حقوقی معتبر قبل از تولید پاسخ بازیابی میکند، قصد دارد از «تفسیرهای خلاقانه» LLMها فاصله بگیرد. این امر منجر به پاسخهای دقیقتر و آگاهانهتر بر اساس اطلاعات حقوقی واقعی میشود. این سیستم با استفاده از سرویسهای مختلف Google Cloud مانند Google Cloud Shell، Vertex AI، Firestore، Cloud Run و Eventarc ساخته شده است.
۳. قبل از شروع
در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید. مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
فعال کردن دستیار کد Gemini در Cloud Shell IDE
👉 در کنسول گوگل کلود، به ابزارهای کمکی کد جمینی بروید، با موافقت با شرایط و ضوابط، دستیار کد جمینی را بدون هیچ هزینهای فعال کنید.
تنظیمات مجوز را نادیده بگیرید، از این صفحه خارج شوید.
کار روی ویرایشگر Cloud Shell
👉 روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید (این آیکون به شکل ترمینال در بالای پنل Cloud Shell قرار دارد)
👉 روی دکمهی «باز کردن ویرایشگر» کلیک کنید (شبیه یک پوشهی باز شده با مداد است). با این کار ویرایشگر Cloud Shell در پنجره باز میشود. یک فایل اکسپلورر در سمت چپ خواهید دید.

👉 مطابق شکل، روی دکمه ورود به سیستم Cloud Code در نوار وضعیت پایین کلیک کنید. افزونه را طبق دستورالعمل تأیید کنید. اگر عبارت Cloud Code - no project را در نوار وضعیت مشاهده کردید، آن را انتخاب کنید، سپس در منوی کشویی «Select a Google Cloud Project» آن را انتخاب کنید و سپس پروژه Google Cloud خاص را از فهرست پروژههایی که قصد دارید با آنها کار کنید، انتخاب کنید.
👉 ترمینال را در محیط توسعه ابری (cloud IDE) باز کنید، 
👉 در ترمینال جدید، با استفاده از دستور زیر تأیید کنید که از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است:
gcloud auth list
👉 روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
gcloud config set project <YOUR_PROJECT_ID>
👉 دستور زیر را برای فعال کردن APIهای لازم Google Cloud اجرا کنید:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
در نوار ابزار Cloud Shell (در بالای پنل Cloud Shell)، روی دکمهی «Open Editor» کلیک کنید (شبیه یک پوشهی باز شده با مداد است). با این کار، ویرایشگر کد Cloud Shell در پنجره باز میشود. در سمت چپ، یک فایل اکسپلورر مشاهده خواهید کرد.
👉 در ترمینال، پروژه اسکلت بوتاسترپ را دانلود کنید:
git clone https://github.com/weimeilin79/legal-eagle.git
اختیاری: نسخه اسپانیایی
👉 یک نسخه جایگزین در اسپانیا وجود دارد. بهخوبی، دستورالعملهای مربوط به نسخههای اصلاحی کلونار را مورد استفاده قرار دهید.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
پس از اجرای این دستور در ترمینال Cloud Shell، یک پوشه جدید با نام مخزن legal-eagle در محیط Cloud Shell شما ایجاد خواهد شد.
۴. نوشتن برنامه استنتاج با Gemini Code Assist
در این بخش، ما بر ساخت هسته دستیار حقوقی خود تمرکز خواهیم کرد - برنامه تحت وب که سوالات کاربران را دریافت میکند و با مدل هوش مصنوعی برای تولید پاسخها تعامل دارد. ما از Gemini Code Assist برای کمک به نوشتن کد پایتون برای این بخش استنتاج استفاده خواهیم کرد.
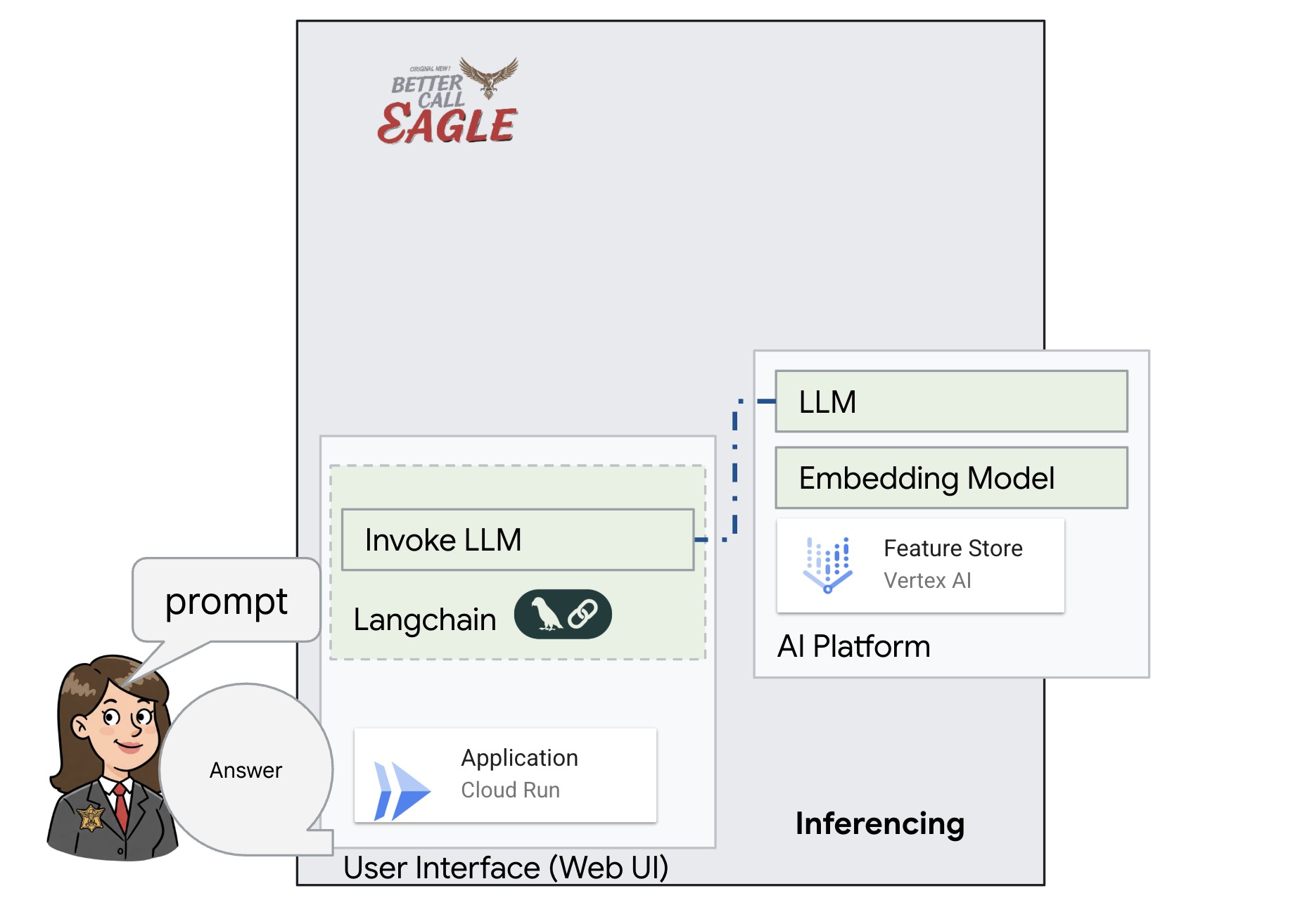
در ابتدا، ما یک برنامه Flask ایجاد خواهیم کرد که از کتابخانه LangChain برای ارتباط مستقیم با مدل Vertex AI Gemini استفاده میکند. این نسخه اولیه بر اساس دانش عمومی مدل، به عنوان یک دستیار حقوقی مفید عمل خواهد کرد، اما هنوز به اسناد خاص پروندههای دادگاهی ما دسترسی نخواهد داشت. این به ما امکان میدهد تا عملکرد پایه LLM را قبل از اینکه بعداً آن را با RAG بهبود بخشیم، ببینیم.
در پنجره اکسپلورر ویرایشگر کد ابری (معمولاً در سمت چپ)، اکنون باید پوشهای را که هنگام کلون کردن مخزن گیت legal-eagle ایجاد شده است، ببینید. پوشه ریشه پروژه خود را در اکسپلورر باز کنید. یک زیرپوشه webapp درون آن خواهید یافت، آن را نیز باز کنید. 
👉 فایل legal.py را در ویرایشگر کد ابری ویرایش کنید، میتوانید از روشهای مختلفی برای فعال کردن دستیار کد Gemini استفاده کنید.
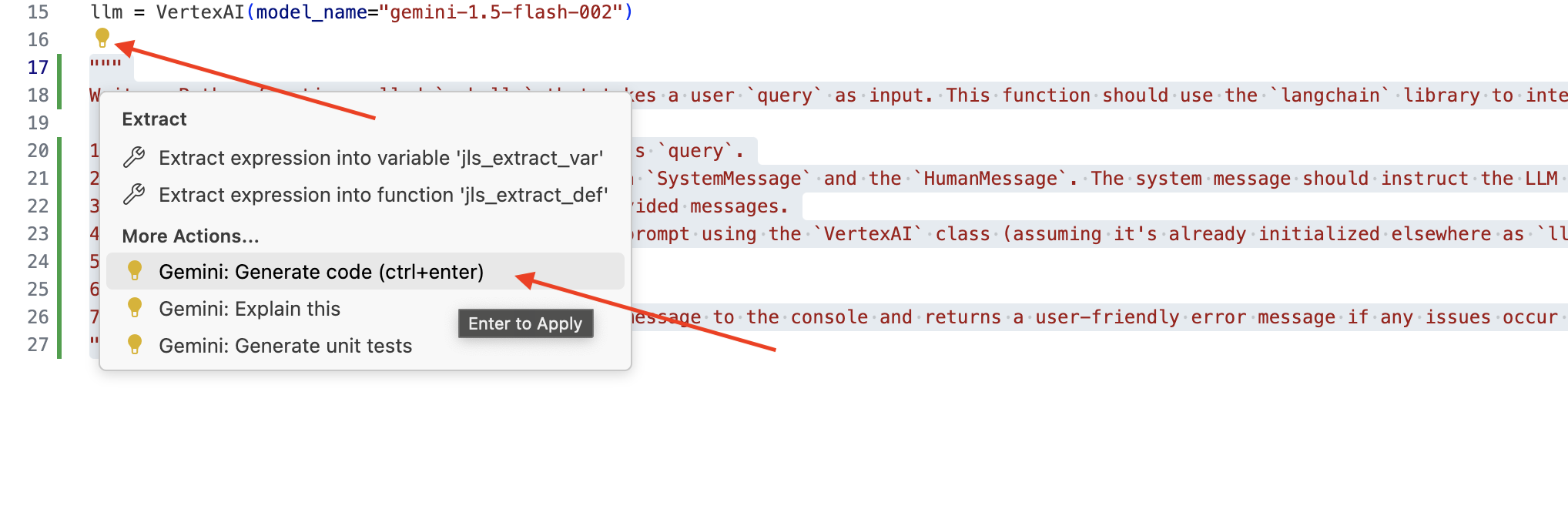
👉 دستور زیر را در انتهای legal.py کپی کنید که به وضوح آنچه را که میخواهید Gemini Code Assist تولید کند، شرح میدهد، روی نماد لامپ 💡 که ظاهر میشود کلیک کنید و Gemini: Generate Code را انتخاب کنید (گزینه دقیق منو ممکن است بسته به نسخه Cloud Code کمی متفاوت باشد).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
کد تولید شده را با دقت بررسی کنید
- آیا تقریباً مراحلی را که در کامنت ذکر کردید دنبال میکند؟
- آیا با
SystemMessageوHumanMessageیکChatPromptTemplateایجاد میکند؟ - آیا شامل مدیریت خطاهای اولیه (
try...except) میشود؟
اگر کد تولید شده خوب و تقریباً صحیح است، میتوانید آن را بپذیرید (برای پیشنهادات درونخطی، Tab یا Enter را فشار دهید، یا برای بلوکهای کد بزرگتر، روی «پذیرش» کلیک کنید).
اگر کد تولید شده دقیقاً همان چیزی نیست که شما میخواهید یا دارای خطا است، نگران نباشید! Gemini Code Assist ابزاری برای کمک به شماست، نه برای نوشتن کد بینقص در اولین تلاش.
کد تولید شده را ویرایش و اصلاح کنید تا اصلاح شود، خطاها را اصلاح کنید و با نیازهای شما بهتر مطابقت داشته باشد. میتوانید با اضافه کردن نظرات بیشتر یا پرسیدن سوالات خاص در پنل چت Code Assist ، Gemini Code Assist را بیشتر فعال کنید.
و اگر هنوز با SDK آشنا نیستید، در اینجا یک مثال کاربردی ارائه شده است.
👉 کد زیر را کپی، جایگذاری و در legal.py خود جایگزین کنید:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 اختیاری: نسخه اسپانیایی
Sustituye el siguiente texto como se indica: You are a helpful assistant, به You are a helpful assistant that speaks Spanish,
در مرحله بعد، یک تابع برای مدیریت مسیری که به سوالات کاربر پاسخ میدهد، ایجاد کنید.
main.py در ویرایشگر Cloud Shell باز کنید. مشابه نحوه تولید ask_llm در legal.py ، از Gemini Code Assist برای تولید Flask Route و تابع ask_question استفاده کنید. عبارت PROMPT زیر را به عنوان کامنت در main.py تایپ کنید: ( قبل از شروع برنامه Flask در if __name__ == "__main__": مطمئن شوید که اضافه شده است.)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
فقط در صورتی که کد تولید شده خوب و تقریباً صحیح باشد، آن را بپذیرید. اگر با پایتون آشنا نیستید. در اینجا یک مثال کاربردی وجود دارد، آن را کپی کرده و در main.py خود، زیر کدی که از قبل وجود دارد، قرار دهید.
👉 مطمئن شوید که قبل از شروع برنامه وب، کد زیر را وارد کردهاید (اگر نام == "main" باشد:)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
با دنبال کردن این مراحل، باید بتوانید با موفقیت Gemini Code Assist را فعال کنید، پروژه خود را راهاندازی کنید و از آن برای تولید تابع ask در فایل main.py خود استفاده کنید.
۵. تست محلی در ویرایشگر ابری
👉 در ترمینال ویرایشگر، کتابخانههای وابسته را نصب کنید و رابط کاربری وب را به صورت محلی اجرا کنید.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
به دنبال پیامهای راهاندازی در خروجی ترمینال Cloud Shell باشید. Flask معمولاً پیامهایی را چاپ میکند که نشان میدهد در حال اجرا است و روی چه پورتی.
- در حال اجرا روی http://127.0.0.1:8080
برنامه برای ارائه درخواستها باید به اجرا ادامه دهد.
👉 از منوی «پیشنمایش وب»، پیشنمایش را روی پورت ۸۰۸۰ انتخاب کنید. Cloud Shell یک تب یا پنجره مرورگر جدید با پیشنمایش وب برنامه شما باز خواهد کرد. 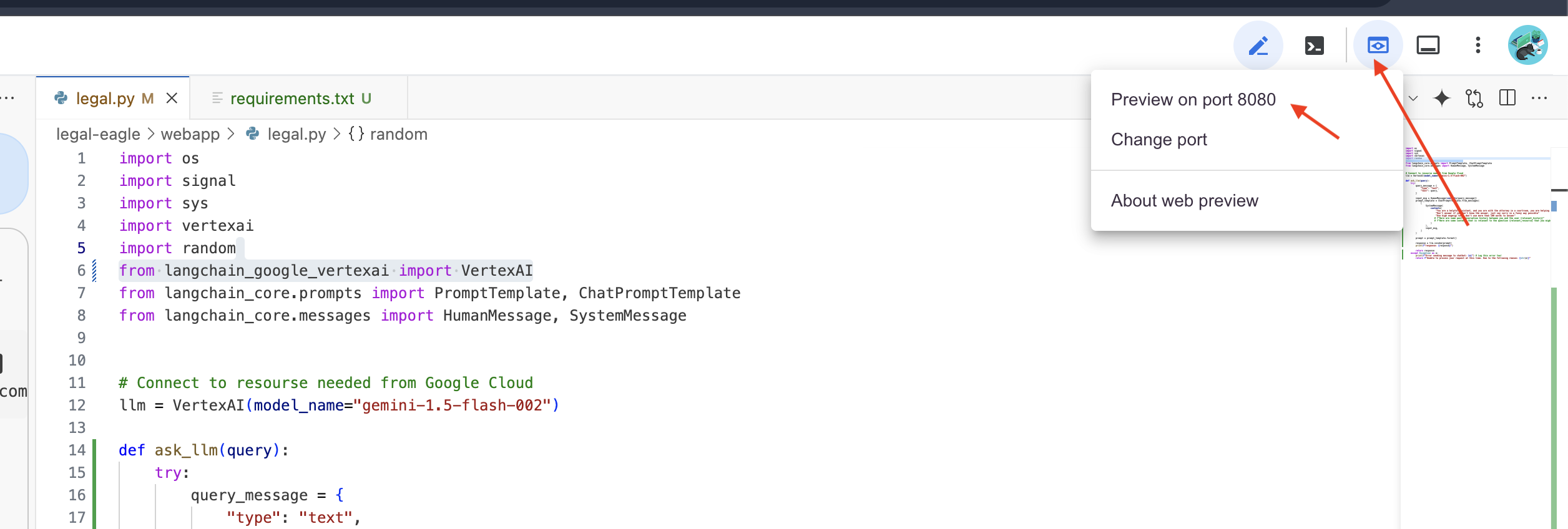
👉 در رابط کاربری برنامه، چند سوال که بهطور خاص مربوط به ارجاعات پروندههای حقوقی هستند را تایپ کنید و ببینید که LLM چگونه پاسخ میدهد. برای مثال، میتوانید موارد زیر را امتحان کنید:
- مایکل براون به چند سال زندان محکوم شد؟
- در نتیجه اقدامات جین اسمیت، چه مقدار پول از طریق برداشتهای غیرمجاز به دست آمد؟
- شهادت همسایهها چه نقشی در تحقیقات پرونده امیلی وایت داشت؟
👉 اختیاری: نسخه اسپانیایی
- ¿A cuántos años de prisión fue sentenciado Michael Brown؟
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith؟
- ¿Qué papel jugaron los testimonios de los vecinos en la investigation del caso de Emily White؟
اگر با دقت به پاسخها نگاه کنید، احتمالاً متوجه خواهید شد که این مدل ممکن است دچار توهم شود، مبهم یا کلی باشد و گاهی اوقات سوالات شما را اشتباه تفسیر کند، به خصوص که هنوز به اسناد قانونی خاصی دسترسی ندارد.
👉 ادامه دهید و با فشردن Ctrl+C اسکریپت را متوقف کنید.
👉 از محیط مجازی خارج شوید، در ترمینال دستور زیر را اجرا کنید:
deactivate
۶. راهاندازی فروشگاه وکتور
وقت آن رسیده که به این «تفسیرهای خلاقانه» LLM از قانون پایان دهیم. اینجاست که نسل بازیابی-تقویتشده (RAG) به کمک میآید! تصور کنید که درست قبل از اینکه LLM به سوالات شما پاسخ دهد، به یک کتابخانه حقوقی فوقالعاده قدرتمند دسترسی میدهد. RAG به جای تکیه صرف بر دانش عمومی خود (که بسته به مدل میتواند مبهم یا قدیمی باشد)، ابتدا اطلاعات مرتبط را از یک منبع معتبر - در مورد ما، اسناد حقوقی - دریافت میکند و سپس از آن زمینه برای تولید پاسخی بسیار آگاهانهتر و دقیقتر استفاده میکند. مثل این است که LLM قبل از ورود به دادگاه، تکالیف خود را انجام دهد!
برای ساخت سیستم RAG خود، به مکانی نیاز داریم تا تمام آن اسناد حقوقی را ذخیره کنیم و از همه مهمتر، آنها را بر اساس معنی قابل جستجو کنیم. اینجاست که Firestore وارد عمل میشود! Firestore پایگاه داده اسناد NoSQL انعطافپذیر و مقیاسپذیر Google Cloud است.
ما قصد داریم از Firestore به عنوان مخزن بردار خود استفاده کنیم. ما بخشهایی از اسناد حقوقی خود را در Firestore ذخیره خواهیم کرد و برای هر بخش، جاسازی آن - آن نمایش عددی از معنای آن - را نیز ذخیره خواهیم کرد.
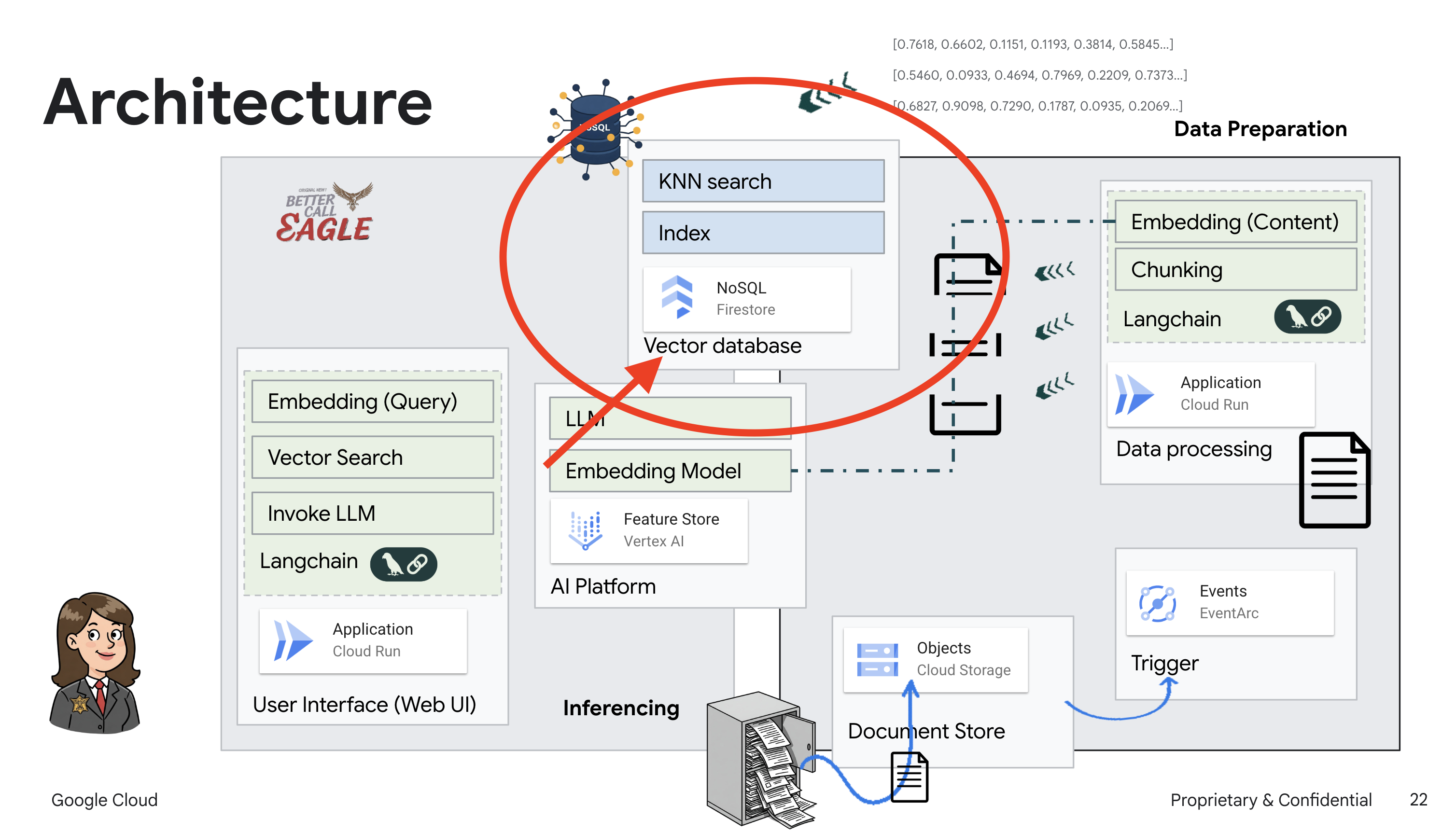
سپس، وقتی از عقاب حقوقی ما سوالی میپرسید، ما از جستجوی برداری Firestore برای یافتن بخشهایی از متن حقوقی که بیشترین ارتباط را با پرسش شما دارند، استفاده خواهیم کرد. این زمینه بازیابی شده همان چیزی است که RAG از آن استفاده میکند تا پاسخهایی به شما بدهد که ریشه در اطلاعات حقوقی واقعی دارند، نه فقط تخیل LLM!
👉 در یک برگه/پنجره جدید، به Firestore در کنسول Google Cloud بروید.
👉 روی ایجاد پایگاه داده کلیک کنید
👉 Native mode و نام پایگاه داده را به عنوان (default) انتخاب کنید.
👉 یک region واحد را انتخاب کنید: us-central1 و روی « ایجاد پایگاه داده» کلیک کنید. Firestore پایگاه دادهی شما را آمادهسازی خواهد کرد که ممکن است چند لحظه طول بکشد.
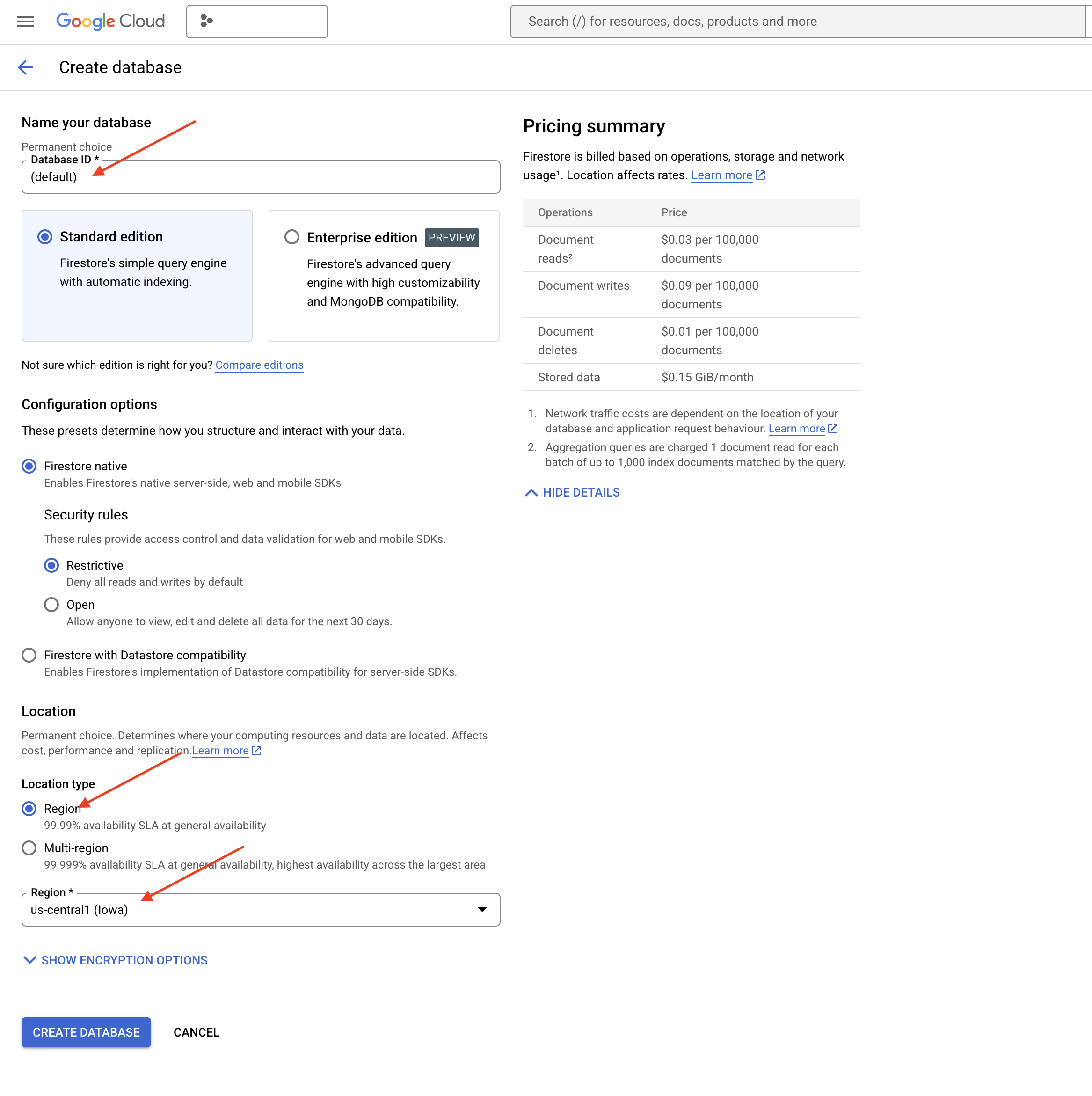
👉 به ترمینال Cloud IDE برگردید - یک Vector Index در فیلد embedding_vector ایجاد کنید تا جستجوی برداری در مجموعه legal_documents شما فعال شود.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
فایراستور شروع به ایجاد شاخص برداری میکند. ایجاد شاخص میتواند کمی زمان ببرد، مخصوصاً برای مجموعه دادههای بزرگتر. شاخص را در حالت "ایجاد" خواهید دید و پس از ساخت، به حالت "آماده" منتقل میشود. 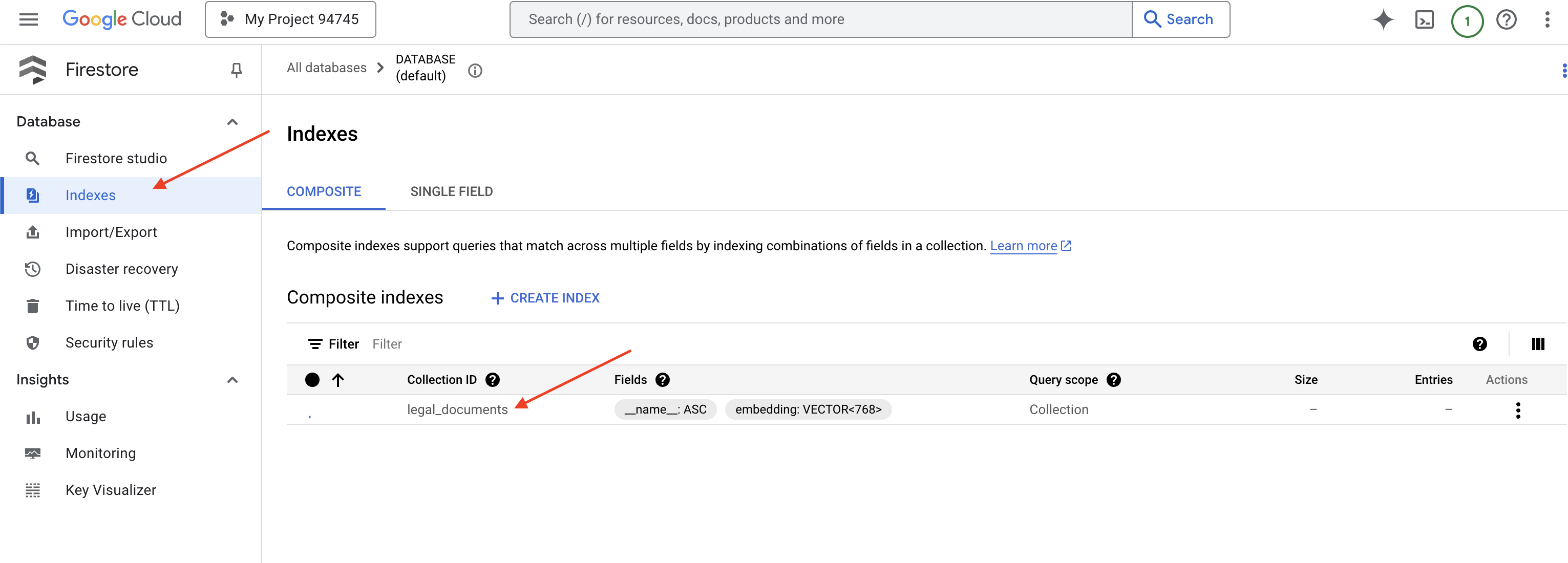
۷. بارگذاری دادهها در فروشگاه وکتور
حالا که RAG و مخزن برداریمان را درک کردیم، وقت آن رسیده که موتوری بسازیم که کتابخانه حقوقی ما را پر کند! خب، چطور میتوانیم اسناد حقوقی را «قابل جستجو بر اساس معنی» کنیم؟ جادو در جاسازیهاست! جاسازیها را به عنوان تبدیل کلمات، جملات یا حتی کل اسناد به بردارهای عددی - فهرستهایی از اعداد که معنای معنایی آنها را در بر میگیرند - در نظر بگیرید. مفاهیم مشابه، بردارهایی را به دست میآورند که در فضای برداری «نزدیک» به یکدیگر هستند. ما از مدلهای قدرتمندی (مانند مدلهای Vertex AI) برای انجام این تبدیل استفاده میکنیم.
و برای خودکارسازی بارگذاری اسناد، از توابع Cloud Run و Eventarc استفاده خواهیم کرد. Cloud Run Functions یک کانتینر سبک و بدون سرور است که کد شما را فقط در صورت نیاز اجرا میکند. ما اسکریپت پایتون پردازش اسناد خود را در یک کانتینر بستهبندی کرده و آن را به عنوان یک تابع Cloud Run مستقر خواهیم کرد.
👉 در یک برگه/پنجره جدید، به فضای ذخیرهسازی ابری بروید.
👉 در منوی سمت چپ روی «سطلها» کلیک کنید.
👉 روی دکمهی «+ ایجاد» در بالا کلیک کنید.
👉 پیکربندی سطل خود (تنظیمات مهم):
- نام سطل : 'yourprojectID' -doc-bucket (باید پسوند -doc-bucket را در انتها داشته باشید)
- region : منطقهی
us-central1را انتخاب کنید. - کلاس ذخیرهسازی : "استاندارد". استاندارد برای دادههایی که مرتباً به آنها دسترسی پیدا میشود مناسب است.
- کنترل دسترسی : گزینه پیشفرض "کنترل دسترسی یکنواخت" را انتخاب کنید. این گزینه، کنترل دسترسی یکپارچه و در سطح سطل را فراهم میکند.
- گزینههای پیشرفته : برای این آموزش، تنظیمات پیشفرض معمولاً کافی است.
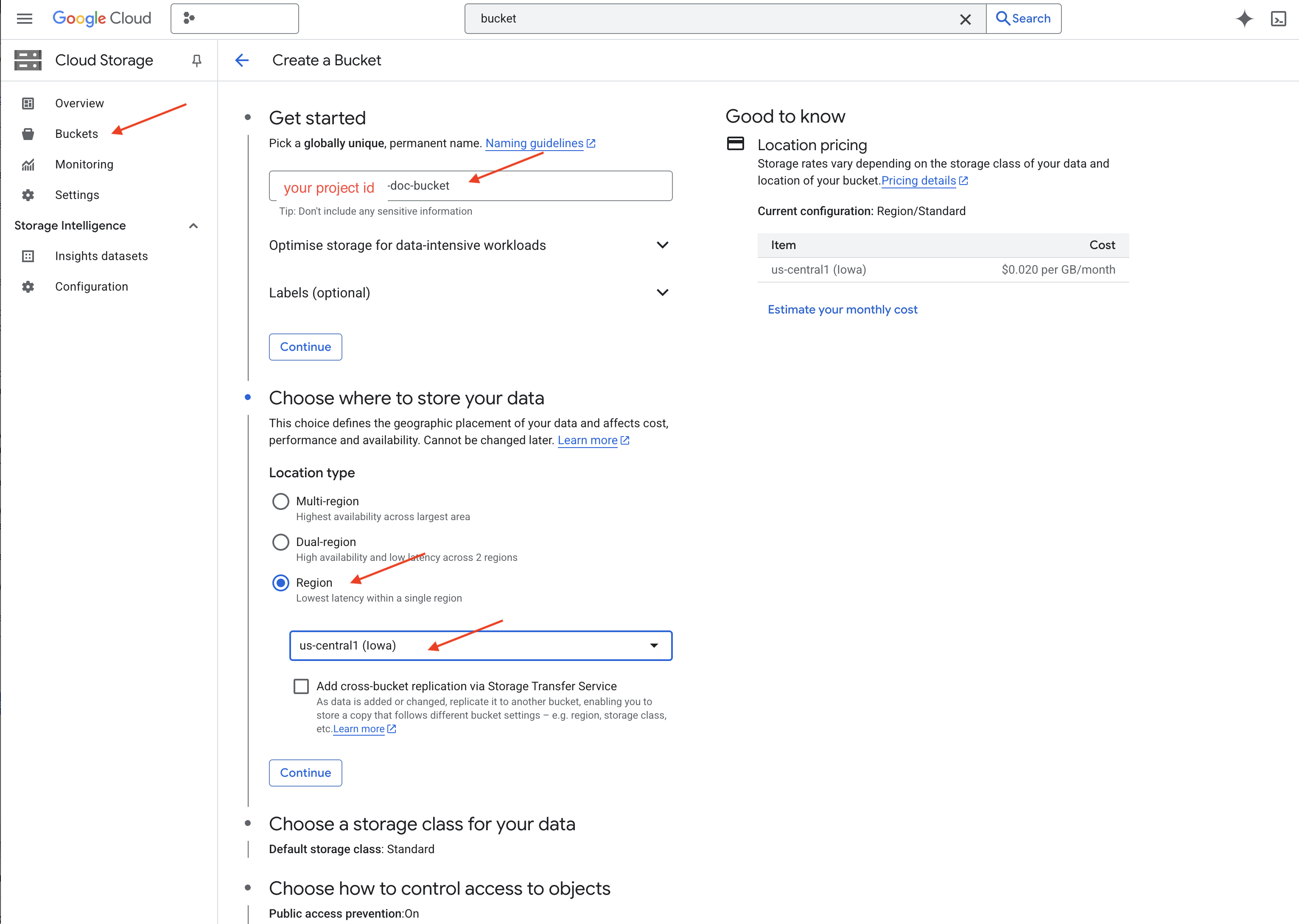
👉 برای ایجاد سطل خود، روی دکمه CREATE کلیک کنید.
👉 ممکن است پنجرهای با مضمون جلوگیری از دسترسی عمومی مشاهده کنید. کادر مربوطه را علامت بزنید و روی «تأیید» کلیک کنید.
اکنون سطل تازه ایجاد شده خود را در لیست سطلها مشاهده خواهید کرد. نام سطل خود را به خاطر بسپارید، بعداً به آن نیاز خواهید داشت.
۸. یک قابلیت اجرای ابری راهاندازی کنید
👉 در ویرایشگر کد Cloud Shell، به دایرکتوری کاری legal-eagle بروید: از دستور cd در ترمینال Cloud Editor برای ایجاد پوشه استفاده کنید.
cd ~/legal-eagle
mkdir loader
cd loader
👉 فایلهای main.py ، requirements.txt و Dockerfile را ایجاد کنید. در ترمینال Cloud Shell، از دستور touch برای ایجاد فایلها استفاده کنید:
touch main.py requirements.txt Dockerfile
پوشهی تازه ایجاد شده به نام *loader و سه فایل را مشاهده خواهید کرد.
👉 main.py در پوشه loader ویرایش کنید. در پنجره فایل اکسپلورر سمت چپ، به دایرکتوری که فایلها را در آن ایجاد کردهاید بروید و روی main.py دوبار کلیک کنید تا در ویرایشگر باز شود.
کد پایتون زیر را در main.py قرار دهید:
این برنامه فایلهای جدید آپلود شده در سطل GCS را پردازش میکند، متن را به تکههایی تقسیم میکند، برای هر تکه جاسازیهایی ایجاد میکند و تکهها و جاسازیهای آنها را در Firestore ذخیره میکند.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
requirements.txt را ویرایش کنید. خطوط زیر را در فایل قرار دهید:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
۹. تست و ساخت تابع Cloud Run
👉 ما این را در یک محیط مجازی اجرا خواهیم کرد و کتابخانههای پایتون لازم برای عملکرد Cloud Run را نصب خواهیم کرد.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 یک شبیهساز محلی برای تابع Cloud Run راهاندازی کنید
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 ترمینال قبلی را در حال اجرا نگه دارید، یک ترمینال جدید باز کنید و دستور آپلود فایل به سطل را اجرا کنید.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 در حالی که شبیهساز در حال اجرا است، میتوانید CloudEvents آزمایشی را به آن ارسال کنید. برای این کار به یک ترمینال جداگانه در IDE نیاز دارید.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
باید مقدار OK را برگرداند.
👉 شما دادهها را در Firestore تأیید خواهید کرد، به کنسول Google Cloud بروید و به «Databases» و سپس «Firestore» بروید و تب «Data» و سپس مجموعه legal_documents را انتخاب کنید. خواهید دید که اسناد جدیدی در مجموعه شما ایجاد شدهاند که هر کدام نشاندهنده بخشی از متن فایل آپلود شده هستند. 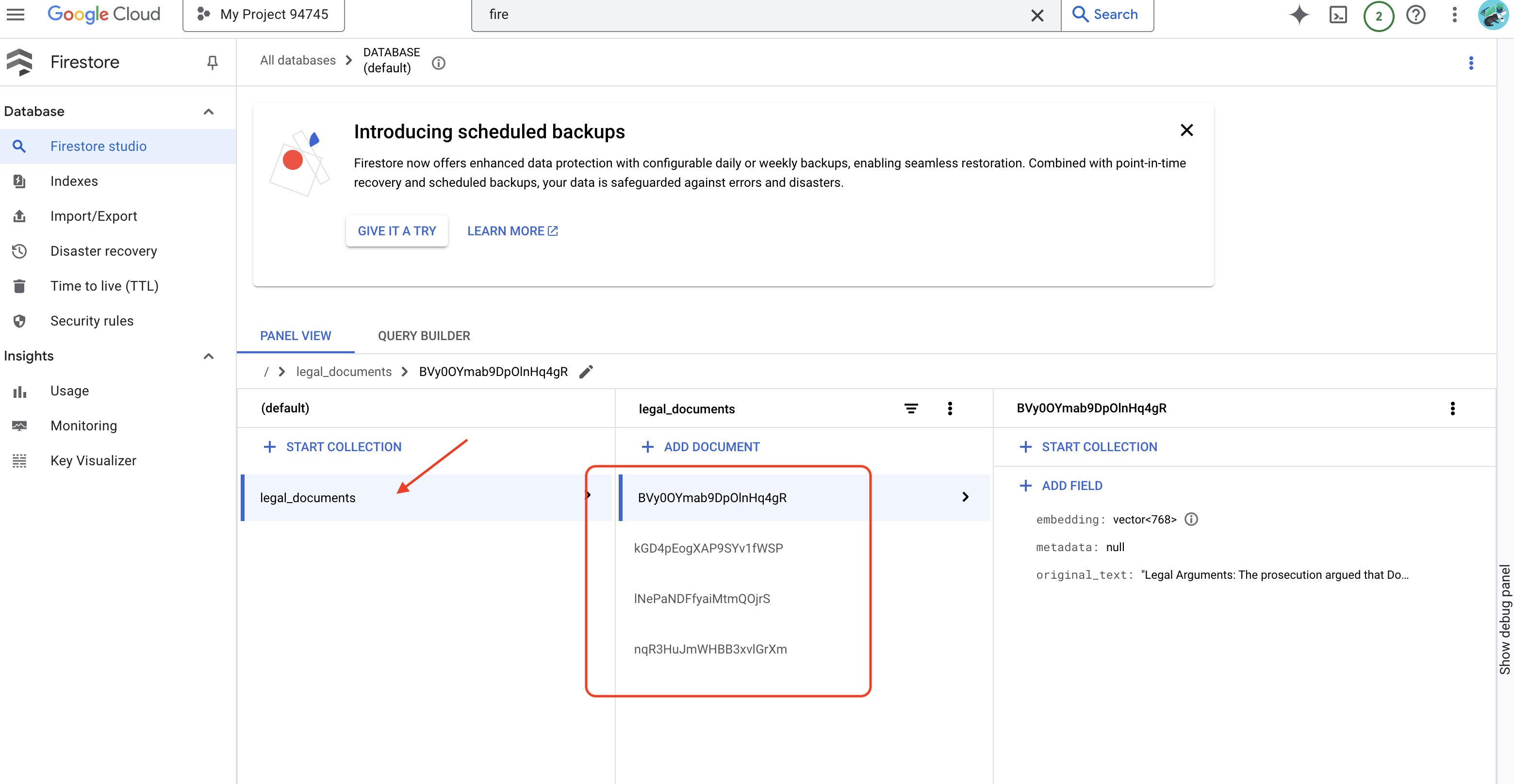
👉 در ترمینالی که شبیهساز را اجرا میکند، برای خروج Ctrl+C را تایپ کنید. و ترمینال دوم را ببندید.
👉 برای خروج از محیط مجازی، دستور deactivate را اجرا کنید.
deactivate
۱۰. ساخت ایمیج کانتینر و ارسال آن به مخازن Artifacts
👉 وقت آن رسیده که این را در فضای ابری مستقر کنید. در فایل اکسپلورر، روی Dockerfile دوبار کلیک کنید. از Gemini بخواهید که فایل docker را برای شما تولید کند، Gemini Code Assist را باز کنید و از دستور زیر برای تولید فایل استفاده کنید.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
برای بهترین روش، توصیه میشود روی Diff with Open File (دو فلش با جهتهای مخالف) کلیک کنید و تغییرات را بپذیرید. 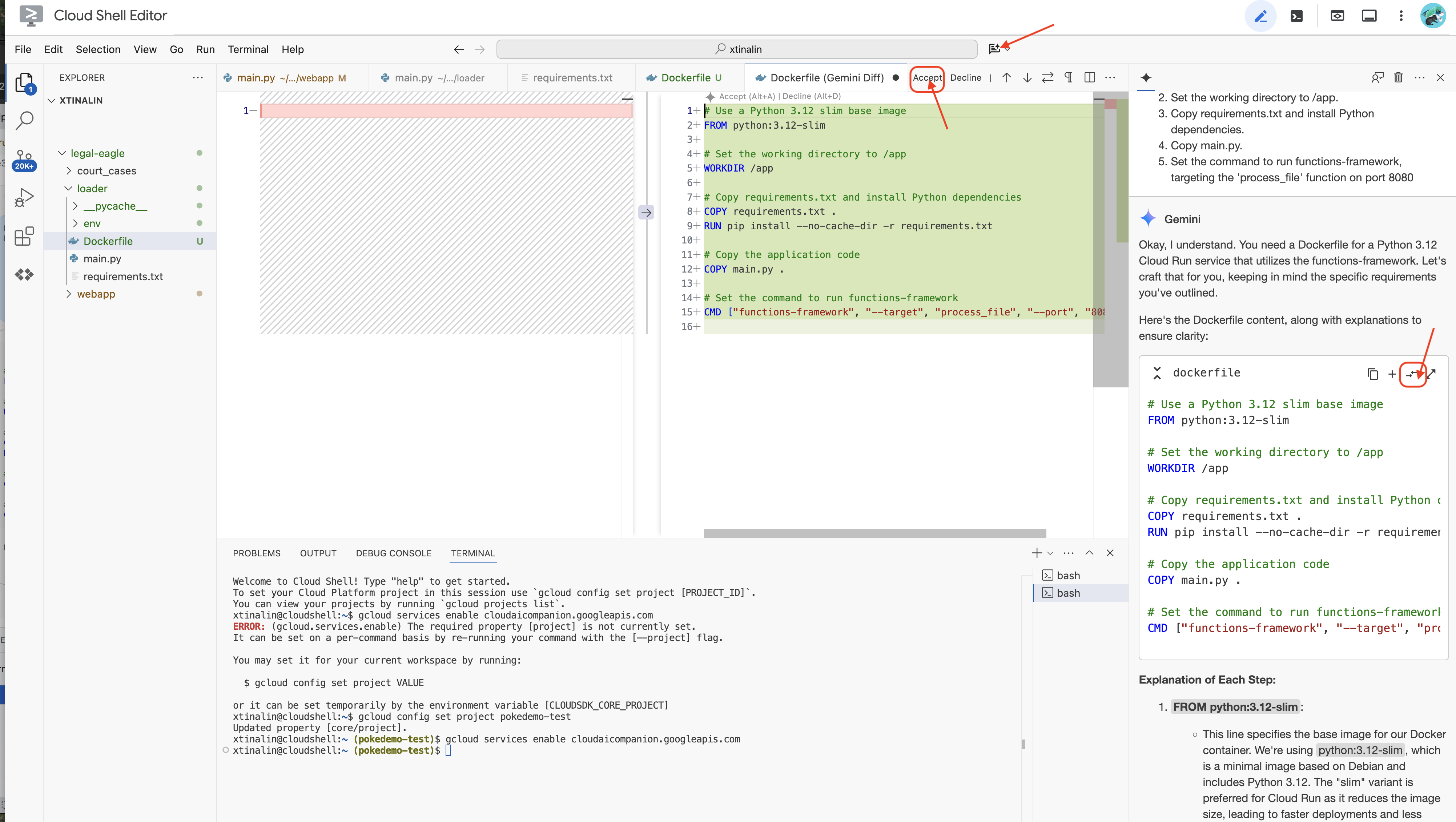
👉 اگر با کانتینرها تازهکار هستید، در اینجا یک مثال کاربردی آورده شده است:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 در ترمینال، یک مخزن مصنوعات ایجاد کنید تا ایمیج داکری که قرار است بسازیم را در آن ذخیره کنید.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
شما باید مخزن ایجاد شده [my-repository] را ببینید.
👉 دستور زیر را برای ساخت ایمیج داکر اجرا کنید.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 حالا آن را به رجیستری اضافه میکنید
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
ایمیج داکر اکنون در my-repository ، مخزن مصنوعات، موجود است.
۱۱. تابع Cloud Run را ایجاد کنید و تریگر Eventarc را تنظیم کنید.
قبل از پرداختن به جزئیات پیادهسازی بارگذاریکننده اسناد حقوقی، بیایید بهطور خلاصه اجزای مربوطه را درک کنیم: Cloud Run یک پلتفرم کاملاً مدیریتشده بدون سرور است که به شما امکان میدهد برنامههای کانتینر شده را به سرعت و به راحتی پیادهسازی کنید. این پلتفرم مدیریت زیرساخت را کنار میگذارد و به شما امکان میدهد روی نوشتن و پیادهسازی کد خود تمرکز کنید.
ما بارگذار سند خود را به عنوان یک سرویس Cloud Run مستقر خواهیم کرد. اکنون، بیایید با تنظیم تابع Cloud Run خود ادامه دهیم:
👉 در کنسول گوگل کلود، به Cloud Run بروید.
👉 به Deploy Container بروید و در منوی کشویی روی SERVICE کلیک کنید.
👉 سرویس Cloud Run خود را پیکربندی کنید:
- تصویر کانتینر : در قسمت URL روی "Select" کلیک کنید. URL تصویری را که به Artifact Registry ارسال کردهاید (مثلاً us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage) پیدا کنید.
- نام سرویس :
legal-eagle-loader - منطقه : منطقه
us-central1را انتخاب کنید. - احراز هویت : برای اهداف این کارگاه، میتوانید «اجازه دادن به فراخوانیهای احراز هویت نشده» را فعال کنید. برای محیط عملیاتی، احتمالاً میخواهید دسترسی را محدود کنید.
- کانتینر، شبکه، امنیت : پیشفرض.
👉 روی CREATE کلیک کنید. Cloud Run سرویس شما را مستقر خواهد کرد. 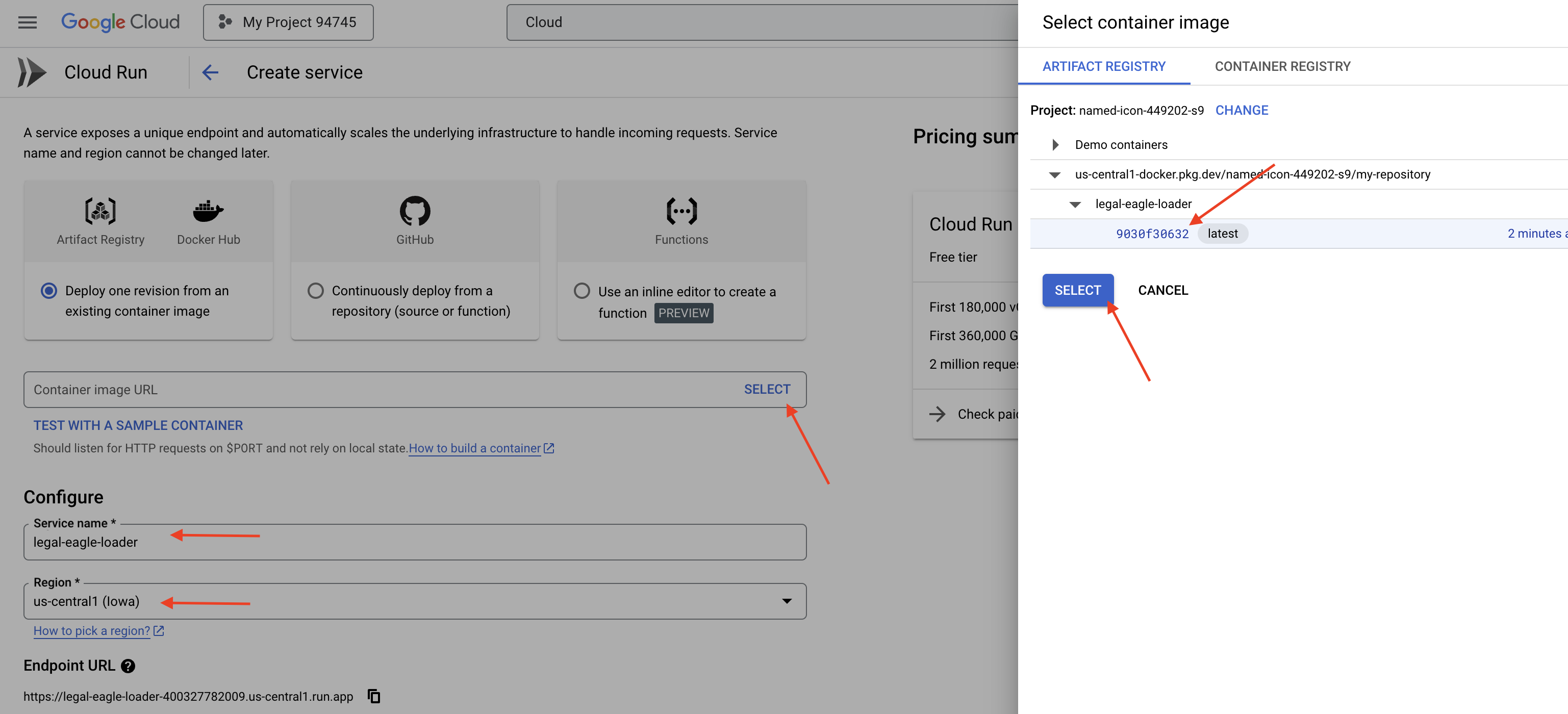
برای فعال کردن خودکار این سرویس هنگام اضافه شدن فایلهای جدید به مخزن ذخیرهسازی، از Eventarc استفاده خواهیم کرد. Eventarc به شما امکان میدهد با مسیریابی رویدادها از منابع مختلف به سرویسهای خود، معماریهای مبتنی بر رویداد ایجاد کنید.
با راهاندازی Eventarc، سرویس Cloud Run ما به محض آپلود شدن، اسناد تازه اضافه شده را به طور خودکار در Firestore بارگذاری میکند و بهروزرسانیهای دادهها را در زمان واقعی برای برنامه RAG ما امکانپذیر میسازد.
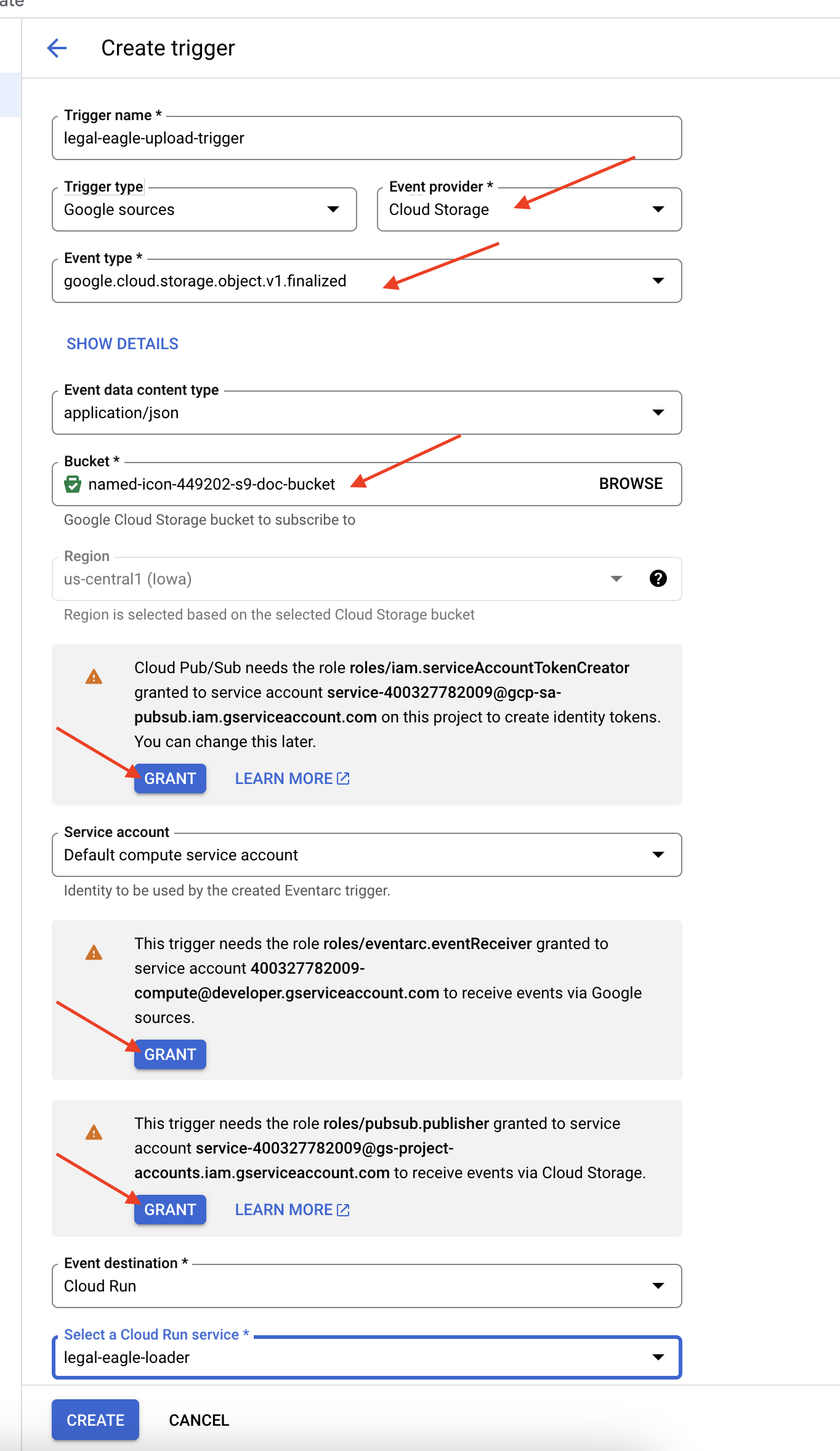
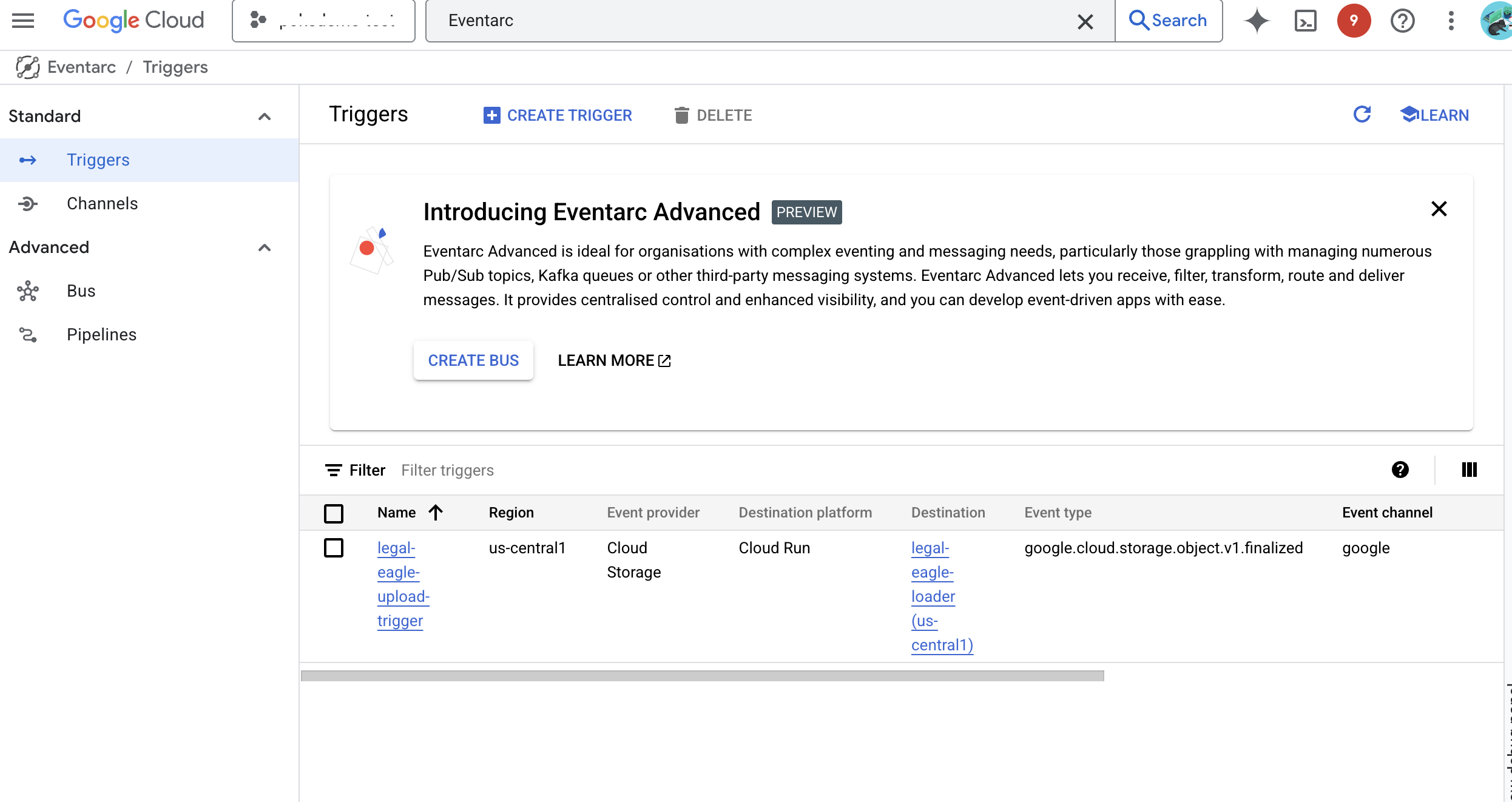
👉 در کنسول گوگل کلود، در بخش EventArc به بخش Triggers بروید. روی "+ CREATE TRIGGER" کلیک کنید. 👉 پیکربندی Eventarc Trigger:
- نام تریگر:
legal-eagle-upload-trigger. - نوع محرک: منابع گوگل
- ارائهدهنده رویداد: فضای ذخیرهسازی ابری را انتخاب کنید.
- نوع رویداد:
google.cloud.storage.object.v1.finalizedرا انتخاب کنید - مخزن ذخیرهسازی ابری: مخزن GCS خود را از منوی کشویی انتخاب کنید.
- نوع مقصد: "سرویس Cloud Run".
- سرویس:
legal-eagle-loaderرا انتخاب کنید. - منطقه:
us-central1 - مسیر: فعلاً این را خالی بگذارید.
- تمام مجوزهایی که در صفحه درخواست شده است را اعطا کنید
👉 روی CREATE کلیک کنید. Eventarc اکنون تریگر را تنظیم میکند.
سرویس Cloud Run برای خواندن فایلها از اجزای مختلف به مجوز نیاز دارد. ما باید مجوز حساب کاربری سرویس مورد نیاز را به آن اعطا کنیم.
۱۲. اسناد قانونی را در سطل GCS بارگذاری کنید
👉 فایل دادگاه را در سطل GCS خود آپلود کنید. به یاد داشته باشید که نام سطل خود را جایگزین کنید.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
برای نظارت بر گزارشهای سرویس Cloud Run، به Cloud Run -> سرویس خود، legal-eagle-loader -> "گزارشها" بروید. گزارشها را برای پیامهای پردازش موفقیتآمیز، از جمله موارد زیر، بررسی کنید:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
و بسته به سرعت راهاندازی ثبت وقایع، جزئیات بیشتری از وقایع را نیز در اینجا مشاهده خواهید کرد.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
در گزارشها به دنبال هرگونه پیام خطایی باشید و در صورت لزوم آن را عیبیابی کنید. 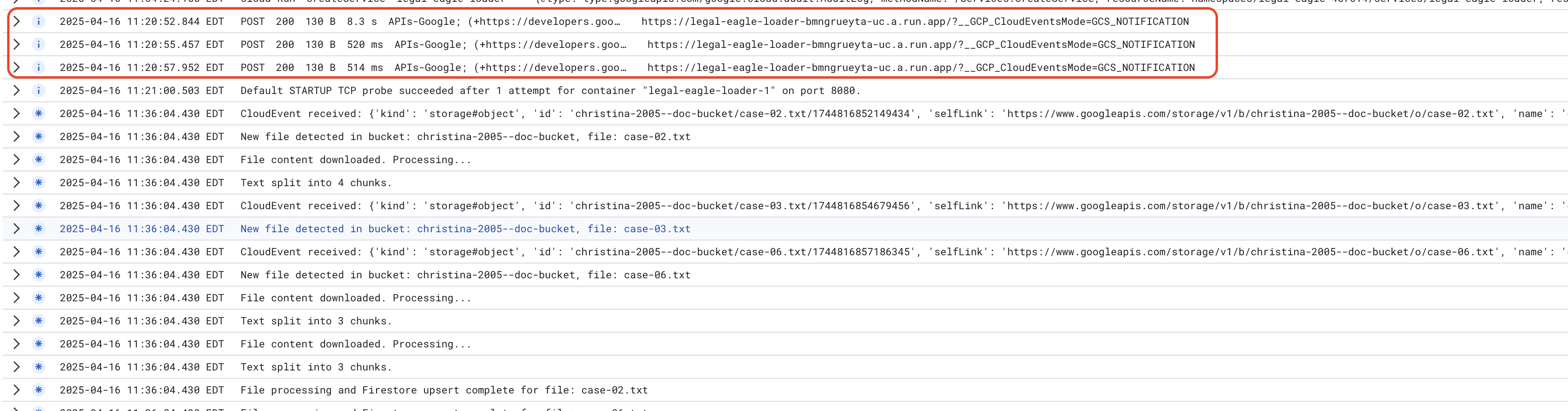
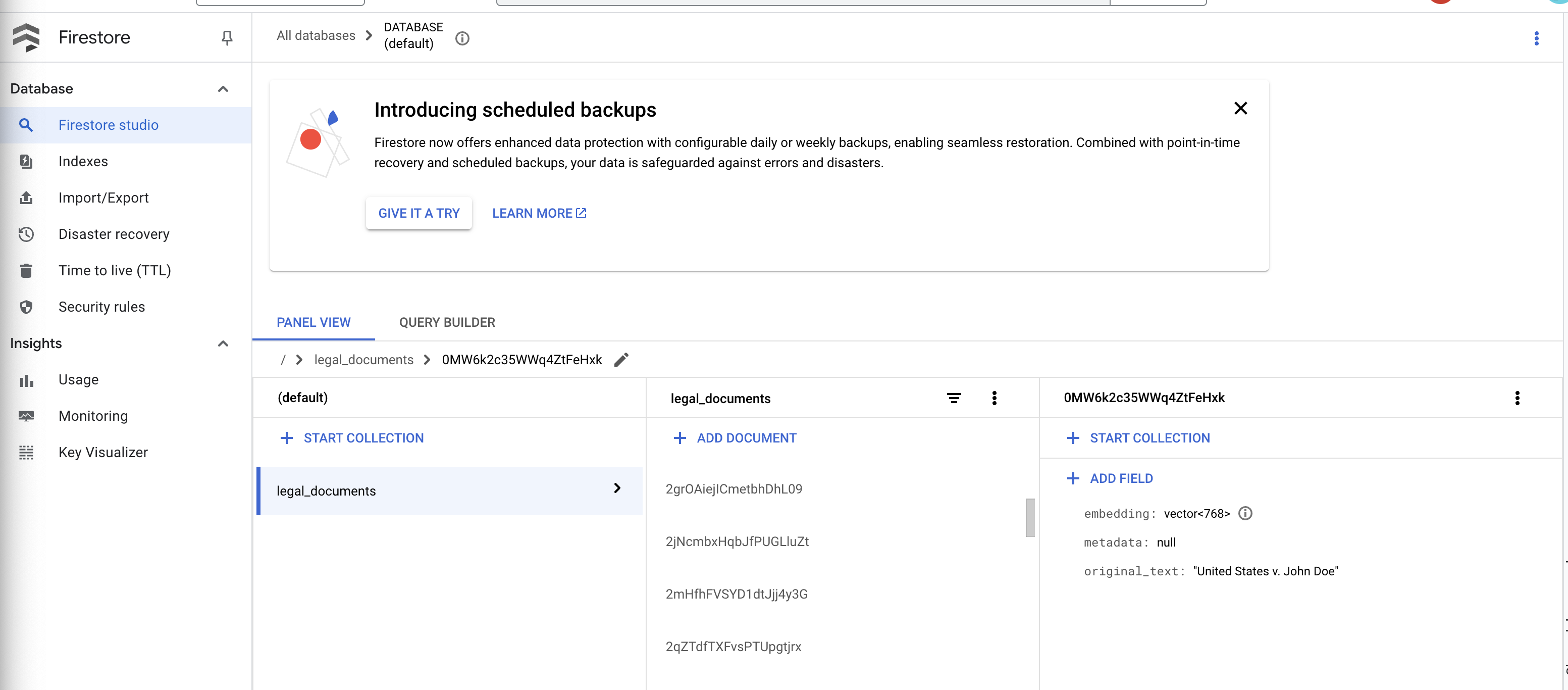
👉 دادهها را در Firestore تأیید کنید. و مجموعه اسناد قانونی خود را باز کنید.
👉 شما باید اسناد جدیدی را که در مجموعه شما ایجاد شدهاند، ببینید. هر سند نشاندهنده بخشی از متن فایلی است که آپلود کردهاید و شامل موارد زیر خواهد بود:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
۱۳. پیادهسازی RAG
LangChain یک چارچوب قدرتمند است که برای سادهسازی توسعه برنامههای کاربردی مبتنی بر مدلهای زبانی بزرگ (LLM) طراحی شده است. LangChain به جای اینکه مستقیماً با پیچیدگیهای APIهای LLM، مهندسی سریع و مدیریت دادهها دست و پنجه نرم کند، یک لایه انتزاعی سطح بالا ارائه میدهد. این چارچوب، اجزا و ابزارهای از پیش ساخته شدهای را برای کارهایی مانند اتصال به LLMهای مختلف (مانند مدلهای OpenAI، Google یا دیگران)، ساخت زنجیرههای پیچیده عملیات (مثلاً بازیابی دادهها و به دنبال آن خلاصهسازی) و مدیریت حافظه محاورهای ارائه میدهد.
به طور خاص برای RAG، ذخیرهسازیهای برداری در LangChain برای فعال کردن جنبه بازیابی RAG ضروری هستند. آنها پایگاههای داده تخصصی هستند که برای ذخیره و جستجوی کارآمد جاسازیهای برداری طراحی شدهاند، که در آنها قطعات متنی از نظر معنایی مشابه به نقاط نزدیک به هم در فضای برداری نگاشت میشوند. LangChain از لولهکشی سطح پایین مراقبت میکند و به توسعهدهندگان اجازه میدهد تا بر منطق اصلی و عملکرد برنامه RAG خود تمرکز کنند. این امر به طور قابل توجهی زمان و پیچیدگی توسعه را کاهش میدهد و به شما امکان میدهد تا به سرعت برنامههای مبتنی بر RAG را نمونهسازی و مستقر کنید و در عین حال از استحکام و مقیاسپذیری زیرساخت Google Cloud بهره ببرید.
با توضیح LangChain، اکنون باید فایل legal.py خود را در پوشه webapp برای پیادهسازی RAG بهروزرسانی کنید. این کار به LLM اجازه میدهد تا قبل از ارائه پاسخ، اسناد مرتبط را در Firestore جستجو کند.
👉 ماژولهای FirestoreVectorStore و سایر ماژولهای مورد نیاز را از langchain و vertexai وارد کنید. موارد زیر را به legal.py فعلی اضافه کنید.
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 هوش مصنوعی Vertex و مدل جاسازی را مقداردهی اولیه کنید. شما از text-embedding-004 استفاده خواهید کرد. کد زیر را درست پس از وارد کردن ماژولها اضافه کنید.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 یک FirestoreVectorStore ایجاد کنید که به مجموعه legal_documents اشاره میکند و از مدل جاسازی اولیه شده استفاده میکند و فیلدهای محتوا و جاسازی را مشخص میکند. این کد را درست بعد از کد مدل جاسازی قبلی اضافه کنید.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 تابعی به نام search_resource تعریف کنید که یک کوئری را دریافت میکند، با استفاده از vector_store.similarity_search جستجوی شباهت انجام میدهد و نتایج ترکیبی را برمیگرداند.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 تابع ask_llm جایگزین کنید و از تابع search_resource برای بازیابی زمینه مرتبط بر اساس جستجوی کاربر استفاده کنید.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 اختیاری: نسخه اسپانیایی
Sustituye el siguiente texto como se indica: You are a helpful assistant, به You are a helpful assistant that speaks Spanish,
👉 پس از پیادهسازی RAG در legal.py، باید قبل از استقرار، آن را به صورت محلی آزمایش کنید، برنامه را با دستور زیر اجرا کنید:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 برای دسترسی به برنامه از webpreview استفاده کنید، با دستیار صحبت کنید و برای خروج از فرآیندی که به صورت محلی اجرا میشود، ctrl+c را تایپ کنید. و برای خروج از محیط مجازی، deactivate را اجرا کنید.
deactivate
👉 برای استقرار برنامه وب در Cloud Run، مشابه تابع loader عمل میکند. شما تصویر Docker را میسازید، برچسبگذاری میکنید و به Artifact Registry ارسال میکنید:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 وقت آن است که برنامه وب را در Google Cloud مستقر کنید. در ترمینال، این دستورات را اجرا کنید:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
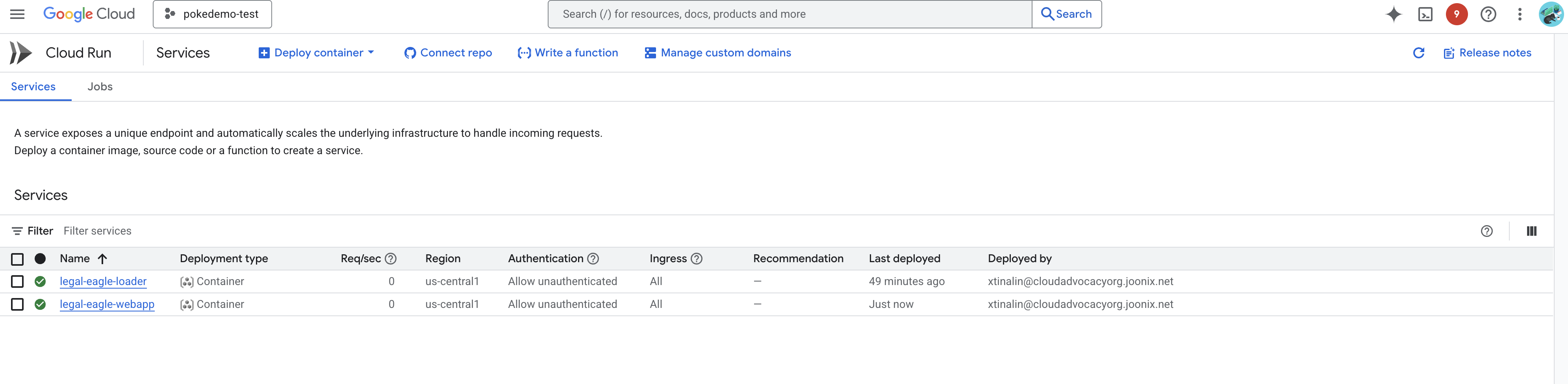
با رفتن به Cloud Run در کنسول Google Cloud، استقرار را تأیید کنید. باید سرویس جدیدی با نام legal-eagle-webapp در فهرست مشاهده کنید.
روی سرویس کلیک کنید تا به صفحه جزئیات آن برسید، میتوانید URL مستقر شده را در بالا پیدا کنید. 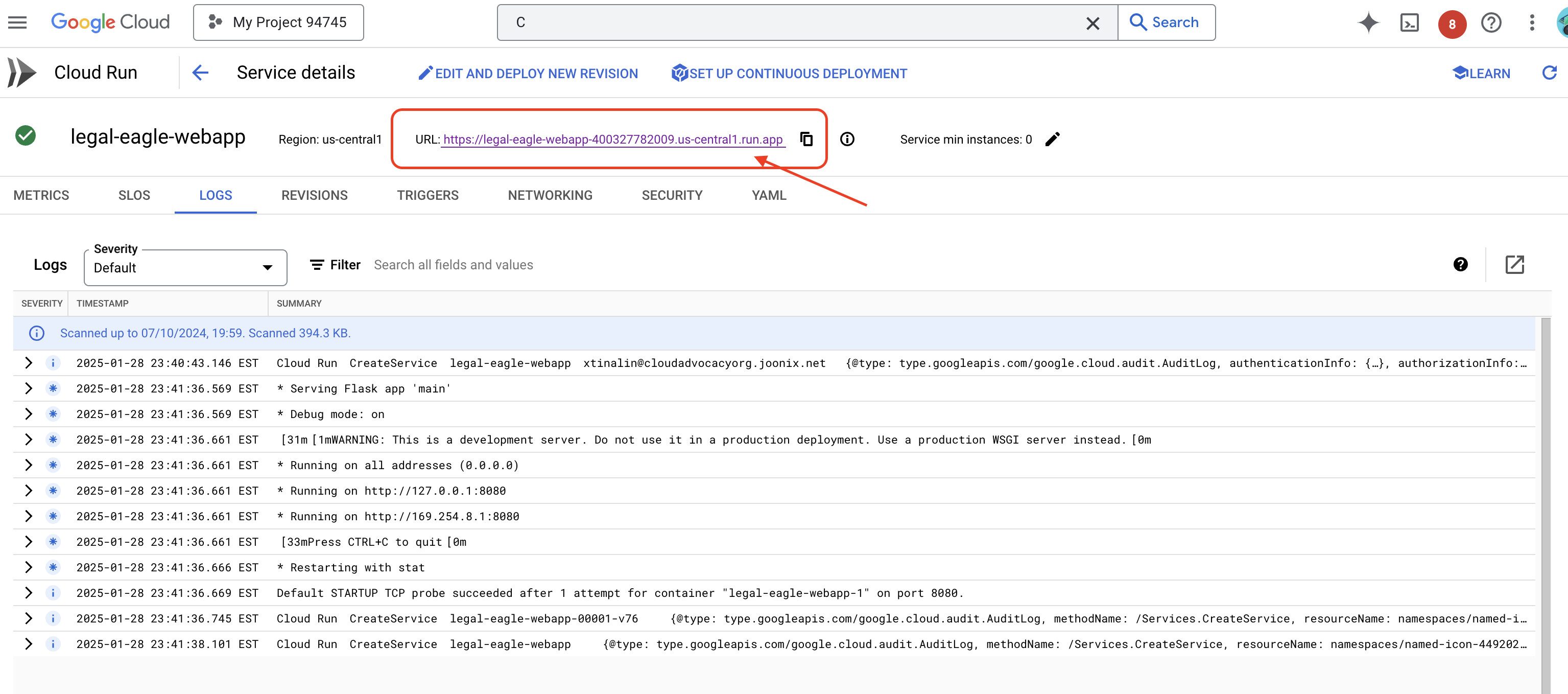
👉 اکنون، URL باز شده را در یک برگه مرورگر جدید باز کنید. میتوانید با دستیار حقوقی تعامل داشته باشید و سوالات مربوط به پروندههای دادگاهی که بارگذاری کردهاید (در پوشه court_cases) را بپرسید:
- مایکل براون به چند سال زندان محکوم شد؟
- در نتیجه اقدامات جین اسمیت، چه مقدار پول از طریق برداشتهای غیرمجاز به دست آمد؟
- شهادت همسایهها چه نقشی در تحقیقات پرونده امیلی وایت داشت؟
👉 اختیاری: نسخه اسپانیایی
- ¿A cuántos años de prisión fue sentenciado Michael Brown؟
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith؟
- ¿Qué papel jugaron los testimonios de los vecinos en la investigation del caso de Emily White؟
باید توجه داشته باشید که پاسخها اکنون دقیقتر و مبتنی بر محتوای اسناد قانونی آپلود شده شما هستند که قدرت RAG را نشان میدهد!
تبریک بابت اتمام کارگاه!! شما با موفقیت یک برنامه تحلیل اسناد حقوقی را با استفاده از LLMها، LangChain و Google Cloud ساختید و مستقر کردید. شما یاد گرفتهاید که چگونه اسناد حقوقی را دریافت و پردازش کنید، پاسخهای LLM را با اطلاعات مرتبط با استفاده از RAG تقویت کنید و برنامه خود را به عنوان یک سرویس بدون سرور مستقر کنید. این دانش و برنامه ساخته شده به شما کمک میکند تا قدرت LLMها را برای کارهای حقوقی بیشتر بررسی کنید. آفرین!
۱۴. چالش
انواع رسانههای متنوع: :
نحوه دریافت و پردازش انواع رسانههای متنوع مانند ویدیوهای دادگاه و ضبط صدا و استخراج متن مرتبط.
داراییهای آنلاین :
نحوه پردازش داراییهای آنلاین مانند صفحات وب به صورت زنده.