
1. Introduction
J'ai toujours été fasciné par l'intensité des tribunaux, m'imaginant naviguer avec aisance dans leurs complexités et prononcer des plaidoiries percutantes. Bien que ma carrière m'ait mené ailleurs, je suis ravi de vous annoncer qu'avec l'aide de l'IA, nous pourrions tous être plus près de réaliser ce rêve de tribunal.

Aujourd'hui, nous allons voir comment utiliser les puissants outils d'IA de Google, comme Vertex AI, Firestore et Cloud Run Functions, pour traiter et comprendre les données juridiques, effectuer des recherches ultra-rapides et, peut-être, aider votre client imaginaire (ou vous-même) à se sortir d'une situation délicate.
Vous n'interrogez peut-être pas un témoin, mais notre système vous permet de passer au crible des montagnes d'informations, de générer des résumés clairs et de présenter les données les plus pertinentes en quelques secondes.
2. Architecture
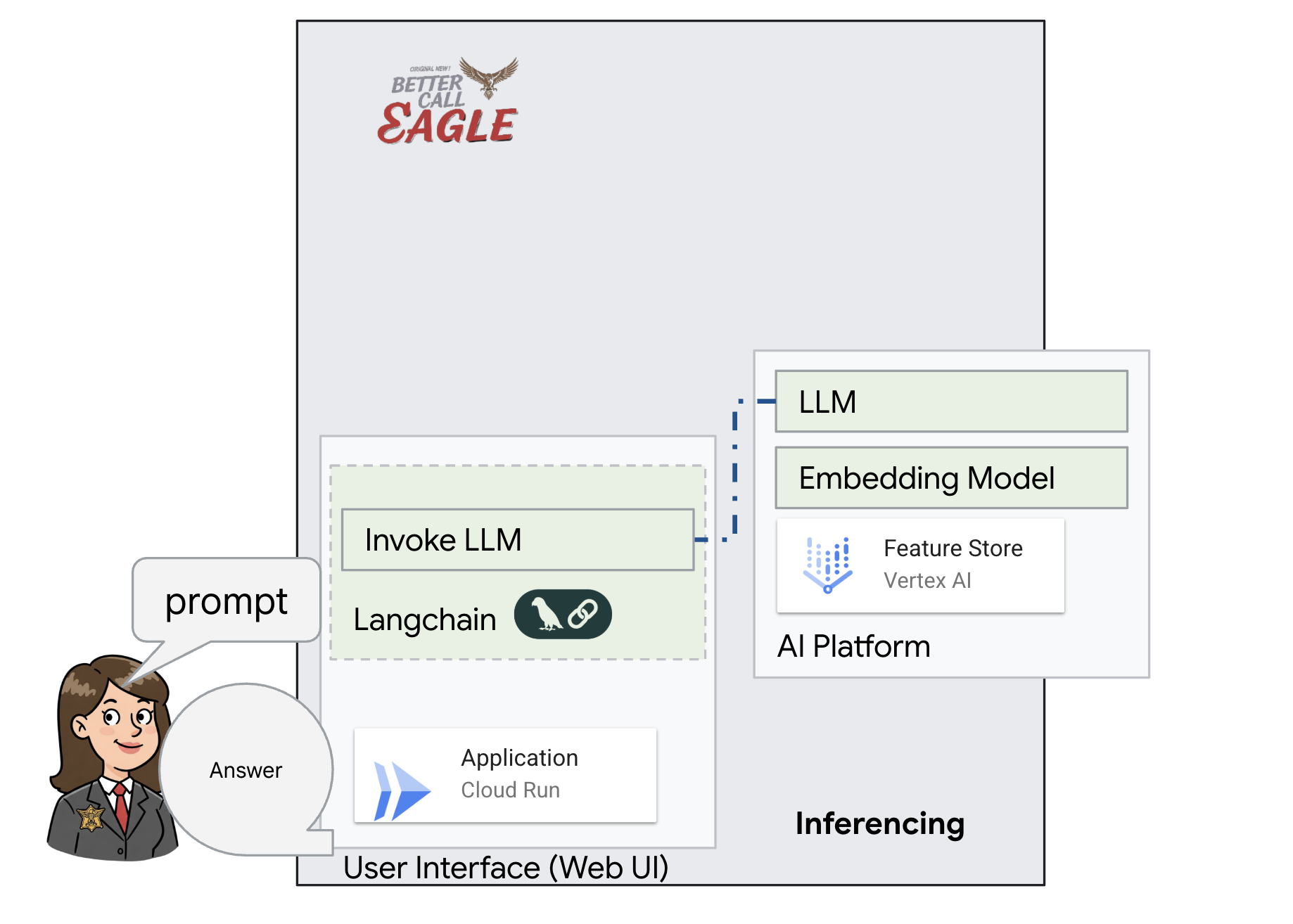
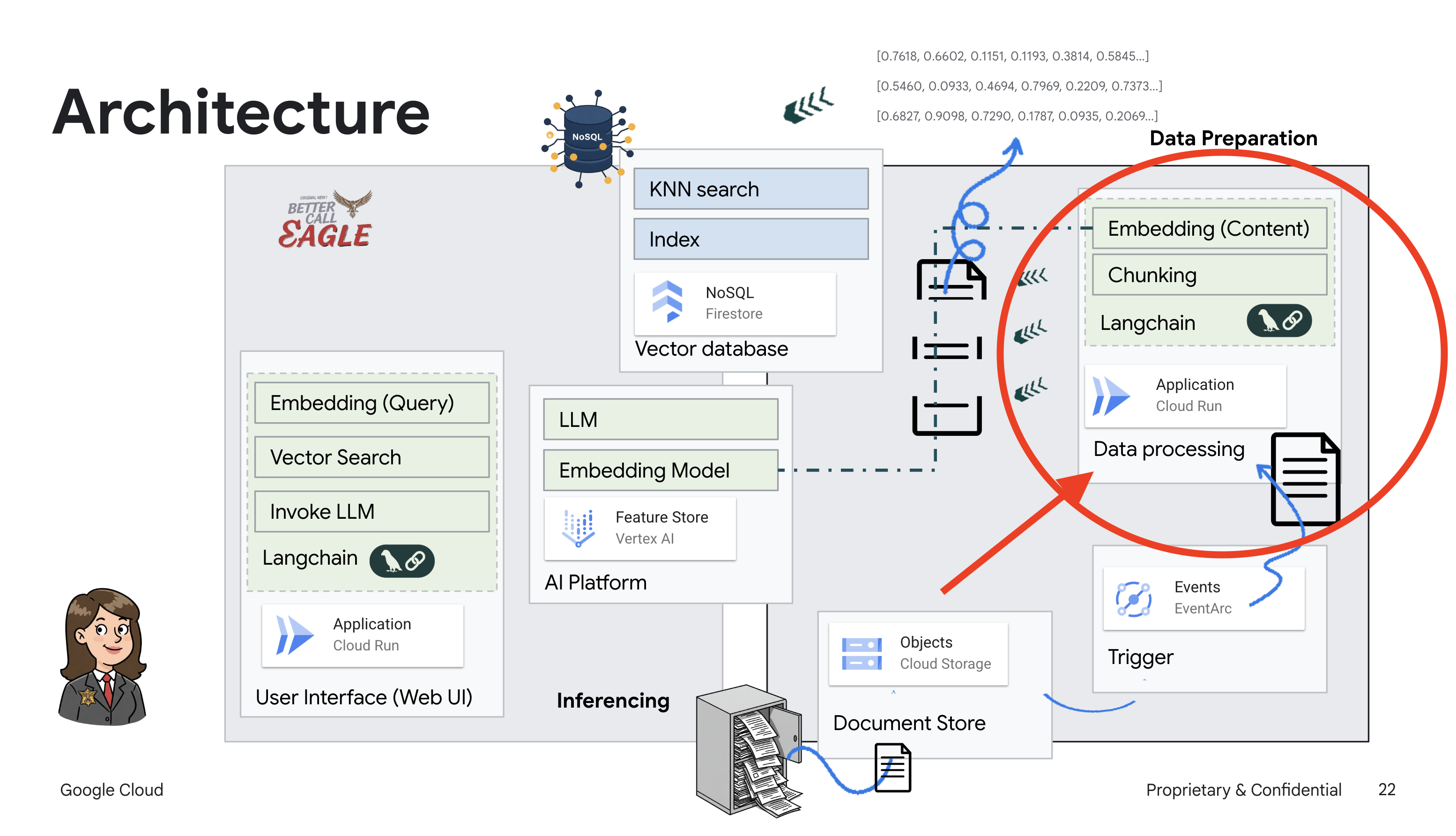
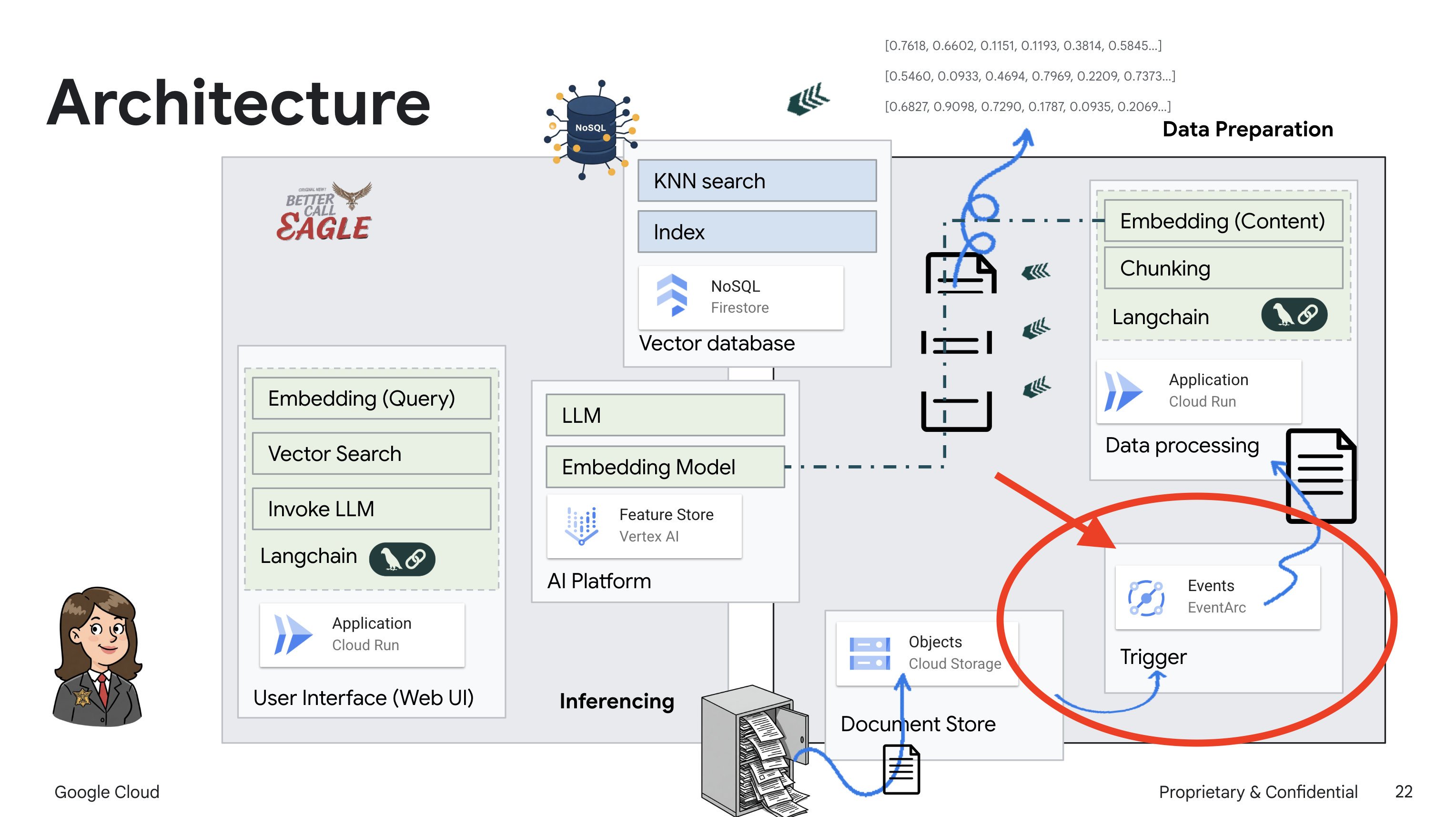
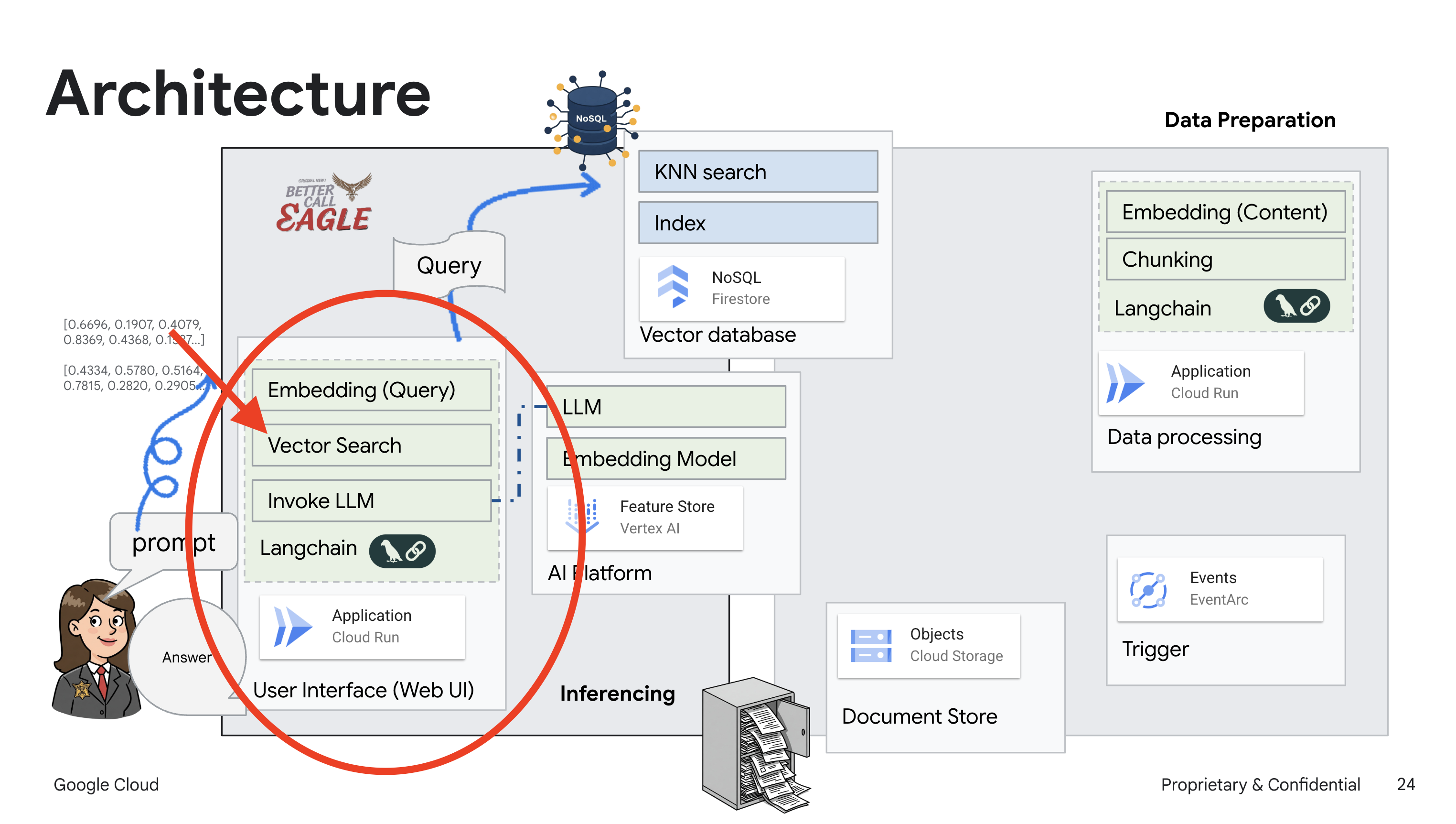
Ce projet se concentre sur la création d'un assistant juridique à l'aide des outils d'IA Google Cloud. Il met l'accent sur le traitement, la compréhension et la recherche de données juridiques. Le système est conçu pour passer au crible de grandes quantités d'informations, générer des résumés et présenter rapidement les données pertinentes. L'architecture de l'assistant juridique implique plusieurs composants clés :
Créer une base de connaissances à partir de données non structurées : Google Cloud Storage (GCS) est utilisé pour stocker des documents juridiques. Firestore, une base de données NoSQL, fonctionne comme un magasin de vecteurs, contenant des blocs de documents et leurs embeddings correspondants. La recherche vectorielle est activée dans Firestore pour permettre les recherches de similarités. Lorsqu'un nouveau document juridique est importé dans GCS, Eventarc déclenche une fonction Cloud Run. Cette fonction traite le document en le divisant en blocs et en générant des embeddings pour chaque bloc à l'aide du modèle d'embedding de texte de Vertex AI. Ces embeddings sont ensuite stockés dans Firestore avec les blocs de texte. 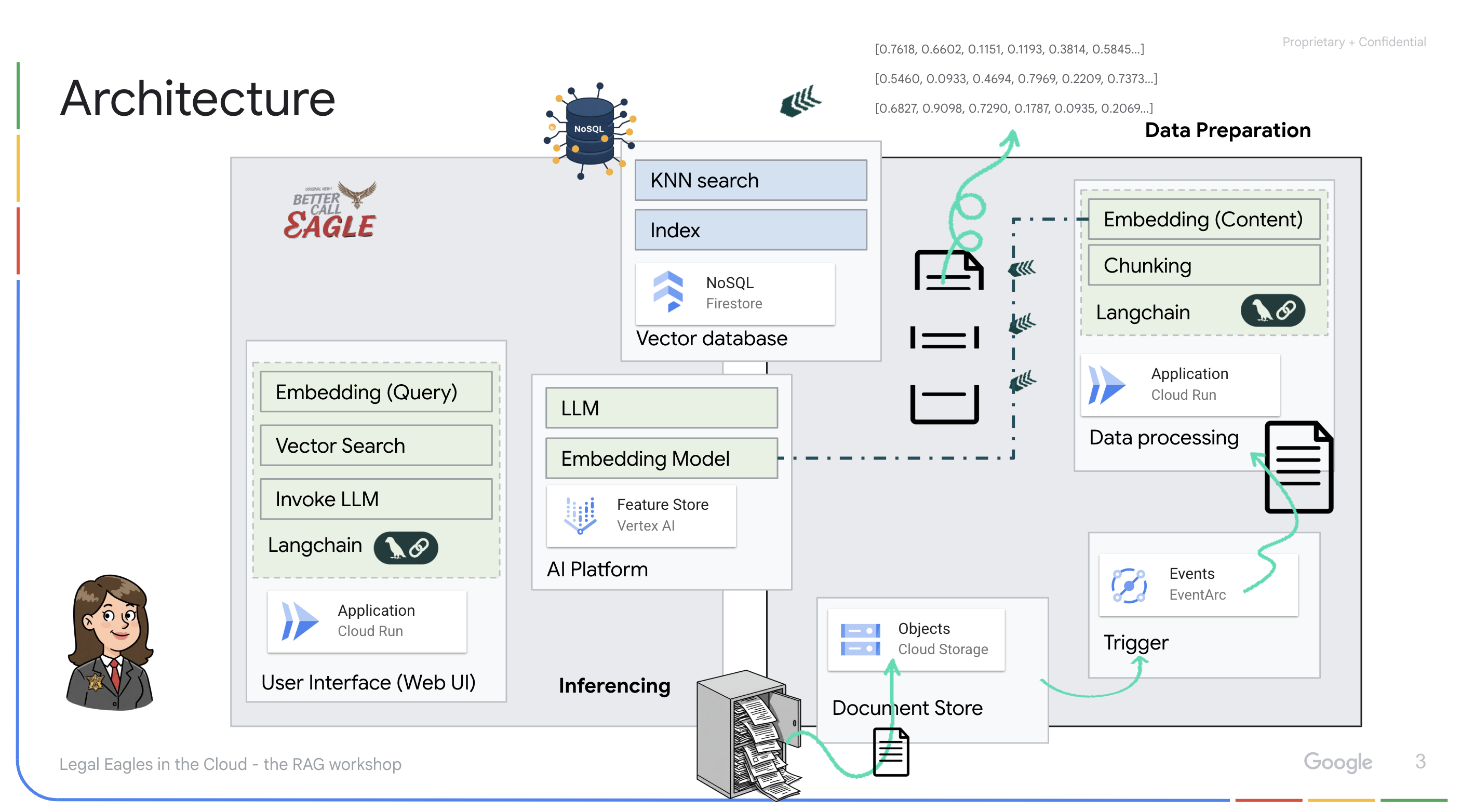
Application optimisée par LLM et RAG : le cœur du système de questions-réponses est la fonction ask_llm, qui utilise la bibliothèque Langchain pour interagir avec un grand modèle de langage Gemini Vertex AI. Il crée un HumanMessage à partir de la requête de l'utilisateur et inclut un SystemMessage qui demande au LLM d'agir en tant qu'assistant juridique utile. Le système utilise une approche de génération augmentée par récupération (RAG, Retrieval-Augmented Generation). Avant de répondre à une requête, il utilise la fonction search_resource pour récupérer le contexte pertinent à partir du magasin de vecteurs Firestore. Ce contexte est ensuite inclus dans le SystemMessage pour ancrer la réponse du LLM dans les informations juridiques fournies. 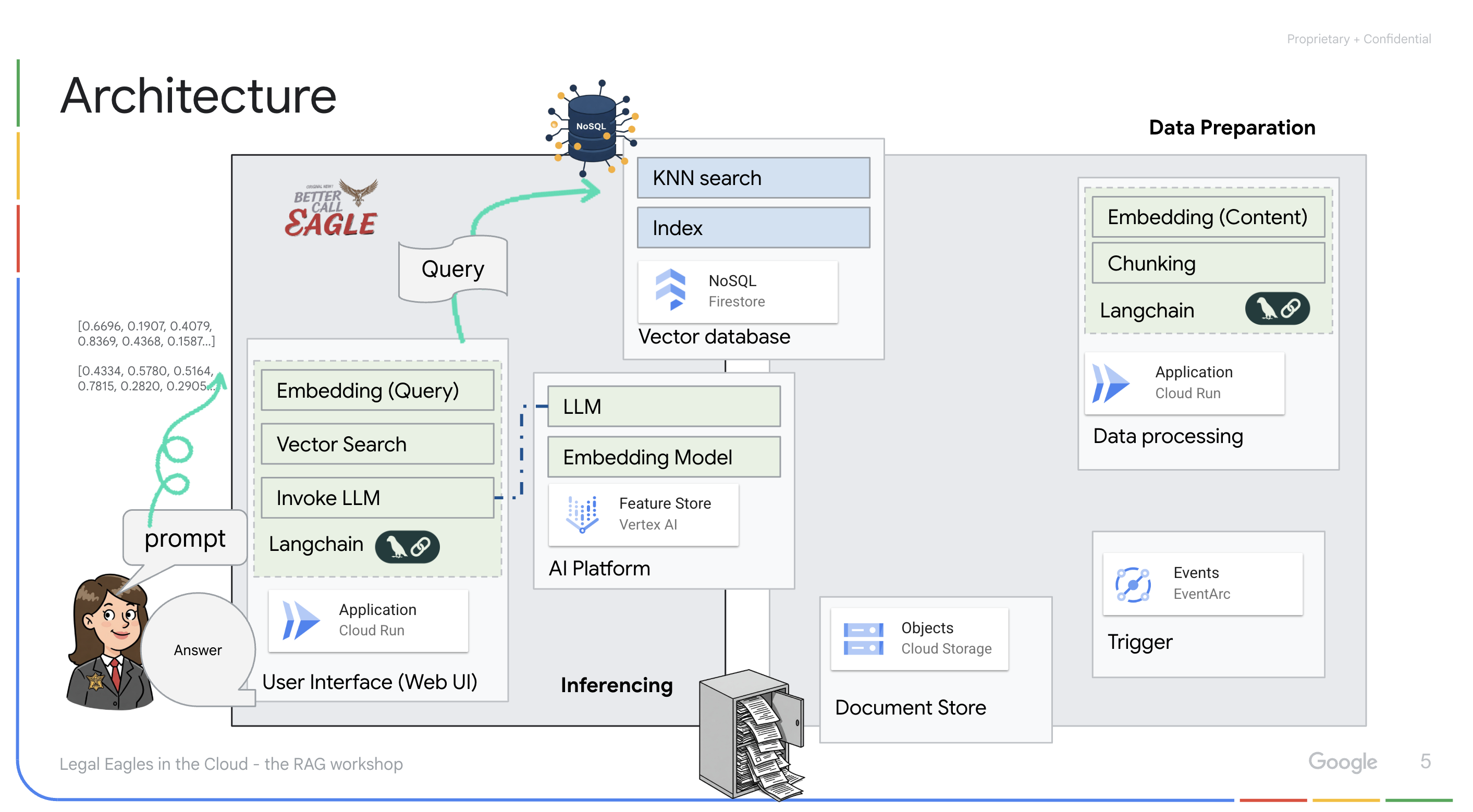
Le projet vise à s'éloigner des "interprétations créatives" des LLM en utilisant le RAG, qui récupère d'abord des informations pertinentes à partir d'une source juridique fiable avant de générer une réponse. Vous obtenez ainsi des réponses plus précises et plus éclairées, basées sur des informations juridiques réelles. Le système est conçu à l'aide de divers services Google Cloud, tels que Google Cloud Shell, Vertex AI, Firestore, Cloud Run et Eventarc.
3. Avant de commencer
Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud. Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Activer Gemini Code Assist dans Cloud Shell IDE
👉 Dans la console Google Cloud, accédez à Outils Gemini Code Assist, puis activez Gemini Code Assist sans frais en acceptant les conditions d'utilisation.
Ignorez la configuration des autorisations et quittez cette page.
Travailler dans l'éditeur Cloud Shell
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell).
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche.

👉 Cliquez sur le bouton Cloud Code – Se connecter dans la barre d'état inférieure (voir ci-dessous). Autorisez le plug-in comme indiqué. Si Cloud Code – Aucun projet est affiché dans la barre d'état, cliquez dessus. Dans le menu déroulant "Sélectionner un projet Google Cloud", sélectionnez le projet Google Cloud que vous comptez utiliser.
👉 Ouvrez le terminal dans l'IDE cloud,  .
.
👉 Dans le nouveau terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
👉 Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Exécutez la commande suivante pour activer les API Google Cloud nécessaires :
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Dans la barre d'outils Cloud Shell (en haut du volet Cloud Shell), cliquez sur le bouton "Ouvrir l'éditeur" (il ressemble à un dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche.
👉 Dans le terminal, téléchargez le projet squelette Bootstrap :
git clone https://github.com/weimeilin79/legal-eagle.git
FACULTATIF : VERSION ESPAGNOLE
👉 Une version alternative en espagnol est disponible. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Après avoir exécuté cette commande dans le terminal Cloud Shell, un nouveau dossier portant le nom du dépôt legal-eagle sera créé dans votre environnement Cloud Shell.
4. Écrire l'application d'inférence avec Gemini Code Assist
Dans cette section, nous allons nous concentrer sur la création du cœur de notre assistant juridique : l'application Web qui reçoit les questions des utilisateurs et interagit avec le modèle d'IA pour générer des réponses. Nous allons utiliser Gemini Code Assist pour nous aider à écrire le code Python de cette partie d'inférence.
Dans un premier temps, nous allons créer une application Flask qui utilise la bibliothèque LangChain pour communiquer directement avec le modèle Gemini de Vertex AI. Cette première version servira d'assistant juridique utile basé sur les connaissances générales du modèle, mais elle n'aura pas encore accès à nos documents spécifiques sur les affaires judiciaires. Cela nous permettra de voir les performances de base du LLM avant de l'améliorer avec la RAG plus tard.
Dans le volet "Explorateur" de l'éditeur Cloud Code (généralement à gauche), vous devriez maintenant voir le dossier créé lorsque vous avez cloné le dépôt Git legal-eagle. Ouvrez le dossier racine de votre projet dans l'explorateur. Vous y trouverez un sous-dossier webapp. Ouvrez-le également. 
👉 Pour modifier le fichier legal.py dans l'éditeur Cloud Code, vous pouvez utiliser différentes méthodes pour solliciter Gemini Code Assist.
👉 Copiez le prompt suivant en bas de legal.py, qui décrit clairement ce que vous souhaitez que Gemini Code Assist génère, cliquez sur l'icône en forme d'ampoule 💡, puis sélectionnez Gemini: Generate Code (Gemini : générer du code). L'intitulé exact de l'élément de menu peut varier légèrement selon la version de Cloud Code.
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Examinez attentivement le code généré.
- Suit-il à peu près les étapes que vous avez décrites dans le commentaire ?
- Crée-t-il un
ChatPromptTemplateavecSystemMessageetHumanMessage? - Inclut-il la gestion des erreurs de base (
try...except) ?
Si le code généré est correct, vous pouvez l'accepter (appuyez sur la touche Tabulation ou Entrée pour les suggestions intégrées, ou cliquez sur "Accepter" pour les blocs de code plus volumineux).
Si le code généré ne correspond pas exactement à ce que vous attendiez ou comporte des erreurs, ne vous inquiétez pas. Gemini Code Assist est un outil qui vous aide, et non qui écrit du code parfait du premier coup.
Modifiez le code généré pour l'affiner, corriger les erreurs et mieux répondre à vos besoins. Vous pouvez affiner votre requête Gemini Code Assist en ajoutant des commentaires ou en posant des questions spécifiques dans le panneau de chat Code Assist.
Si vous débutez avec le SDK, voici un exemple fonctionnel.
👉 Copiez et collez le code suivant en le REMPLAÇANT dans votre legal.py :
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 FACULTATIF : VERSION ESPAGNOLE
Remplace le texte suivant comme indiqué : You are a helpful assistant, par You are a helpful assistant that speaks Spanish,
Ensuite, créez une fonction pour gérer une route qui répondra aux questions des utilisateurs.
Ouvrez main.py dans l'éditeur Cloud Shell. De la même manière que vous avez généré ask_llm dans legal.py, utilisez Gemini Code Assist pour générer la fonction Flask Route et ask_question. Saisissez le PROMPT suivant en tant que commentaire dans main.py : (assurez-vous de l'ajouter avant de démarrer l'application Flask à if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
N'accepte la réponse que si le code généré est bon et globalement correct. Si vous ne connaissez pas Python, voici un exemple fonctionnel.Copiez et collez ce code dans votre main.py, sous le code déjà présent.
👉 Assurez-vous de coller ce qui suit AVANT le début de l'application Web (if name == "main")
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
En suivant ces étapes, vous devriez pouvoir activer Gemini Code Assist, configurer votre projet et l'utiliser pour générer la fonction ask dans votre fichier main.py.
5. Tests locaux dans l'éditeur Cloud
👉 Dans le terminal de l'éditeur,installez les bibliothèques dépendantes et démarrez l'interface utilisateur Web en local.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Recherchez les messages de démarrage dans la sortie du terminal Cloud Shell. Flask affiche généralement des messages indiquant qu'il est en cours d'exécution et sur quel port.
- Running on http://127.0.0.1:8080
L'application doit continuer à s'exécuter pour traiter les requêtes.
👉 Dans le menu "Aperçu sur le Web", sélectionnez Prévisualiser sur le port 8080. Cloud Shell ouvre un nouvel onglet ou une nouvelle fenêtre de navigateur avec l'aperçu Web de votre application. 
👉 Dans l'interface de l'application, saisissez quelques questions spécifiques liées à des références de procédures judiciaires et voyez comment le LLM répond. Par exemple, vous pouvez essayer :
- À combien d'années de prison Michael Brown a-t-il été condamné ?
- Quel montant de frais non autorisés a été généré par les actions de Jane Smith ?
- Quel rôle les témoignages des voisins ont-ils joué dans l'enquête sur l'affaire Emily White ?
👉 FACULTATIF : VERSION ESPAGNOLE
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Si vous examinez attentivement les réponses, vous remarquerez probablement que le modèle peut halluciner, être vague ou générique, et parfois mal interpréter vos questions, d'autant plus qu'il n'a pas encore accès à des documents juridiques spécifiques.
👉 Arrêtez le script en appuyant sur Ctrl+C.
👉 Pour quitter l'environnement virtuel, exécutez la commande suivante dans le terminal :
deactivate
6. Configurer le magasin de vecteurs
Il est temps de mettre fin à ces "interprétations créatives" de la loi par les LLM.C'est là que la génération augmentée par récupération (RAG) entre en jeu ! C'est comme si vous donniez à notre LLM un accès à une bibliothèque juridique super puissante juste avant qu'il réponde à vos questions. Au lieu de s'appuyer uniquement sur ses connaissances générales (qui peuvent être floues ou obsolètes selon le modèle), le RAG récupère d'abord des informations pertinentes à partir d'une source fiable (dans notre cas, des documents juridiques), puis utilise ce contexte pour générer une réponse beaucoup plus éclairée et précise. C'est comme si le LLM faisait ses devoirs avant d'entrer dans la salle d'audience !
Pour créer notre système RAG, nous avons besoin d'un endroit où stocker tous ces documents juridiques et, surtout, de les rendre consultables par signification. C'est là que Firestore entre en jeu. Firestore est la base de données de documents NoSQL flexible et évolutive de Google Cloud.
Nous allons utiliser Firestore comme magasin de vecteurs. Nous allons stocker des blocs de nos documents juridiques dans Firestore. Pour chaque bloc, nous allons également stocker son embedding, c'est-à-dire la représentation numérique de sa signification.
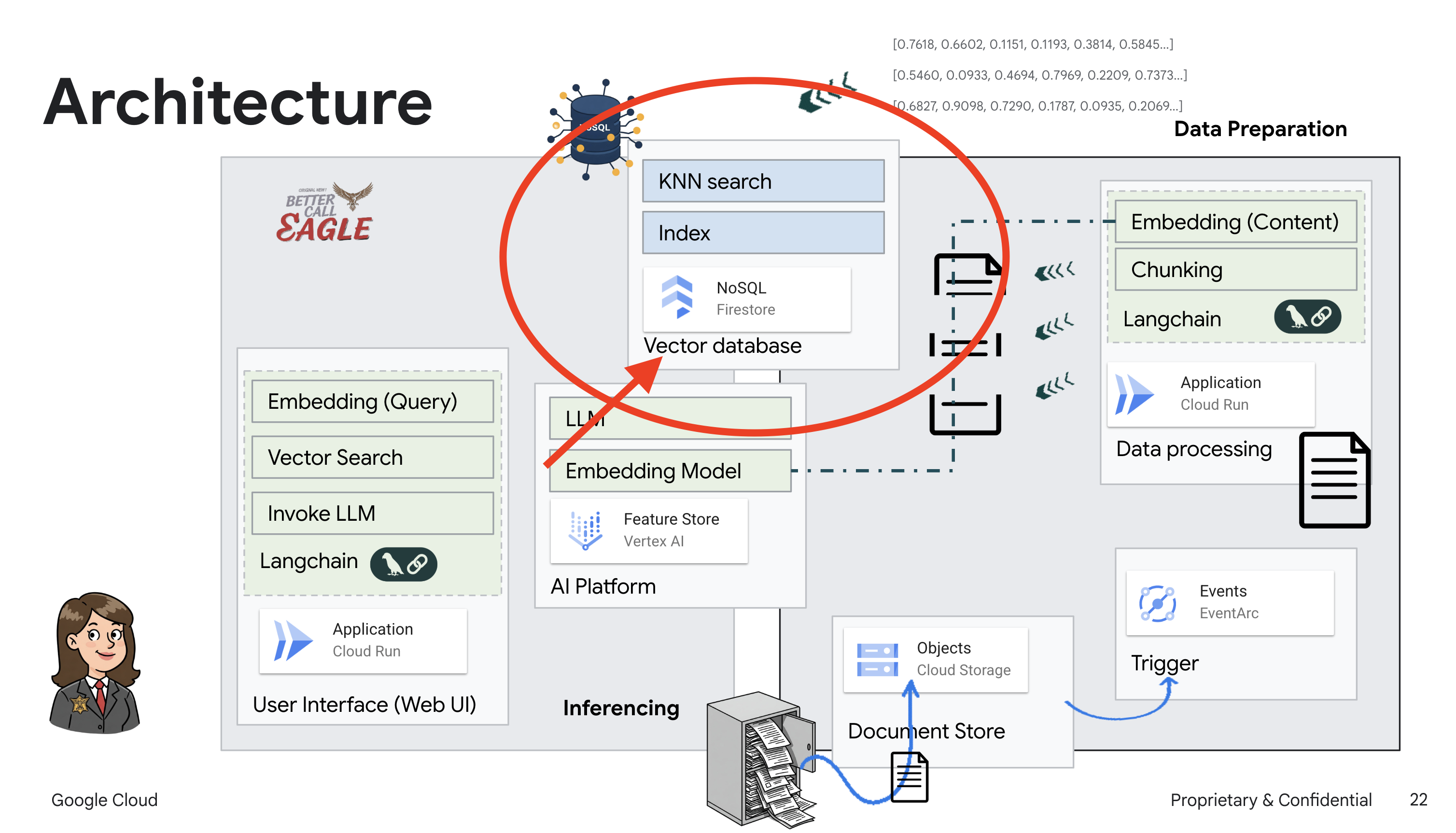
Ensuite, lorsque vous posez une question à notre Aigle juridique, nous utilisons la recherche vectorielle de Firestore pour trouver les blocs de texte juridique les plus pertinents pour votre requête. C'est ce contexte récupéré que le RAG utilise pour vous fournir des réponses ancrées dans des informations juridiques réelles, et non dans l'imagination des LLM.
👉 Dans un nouvel onglet ou une nouvelle fenêtre, accédez à Firestore dans la console Google Cloud.
👉 Cliquez sur Créer une base de données.
👉 Choisissez Native mode et le nom de la base de données (default).
👉 Sélectionnez region us-central1 , puis cliquez sur Créer une base de données. Firestore provisionne votre base de données, ce qui peut prendre quelques instants.
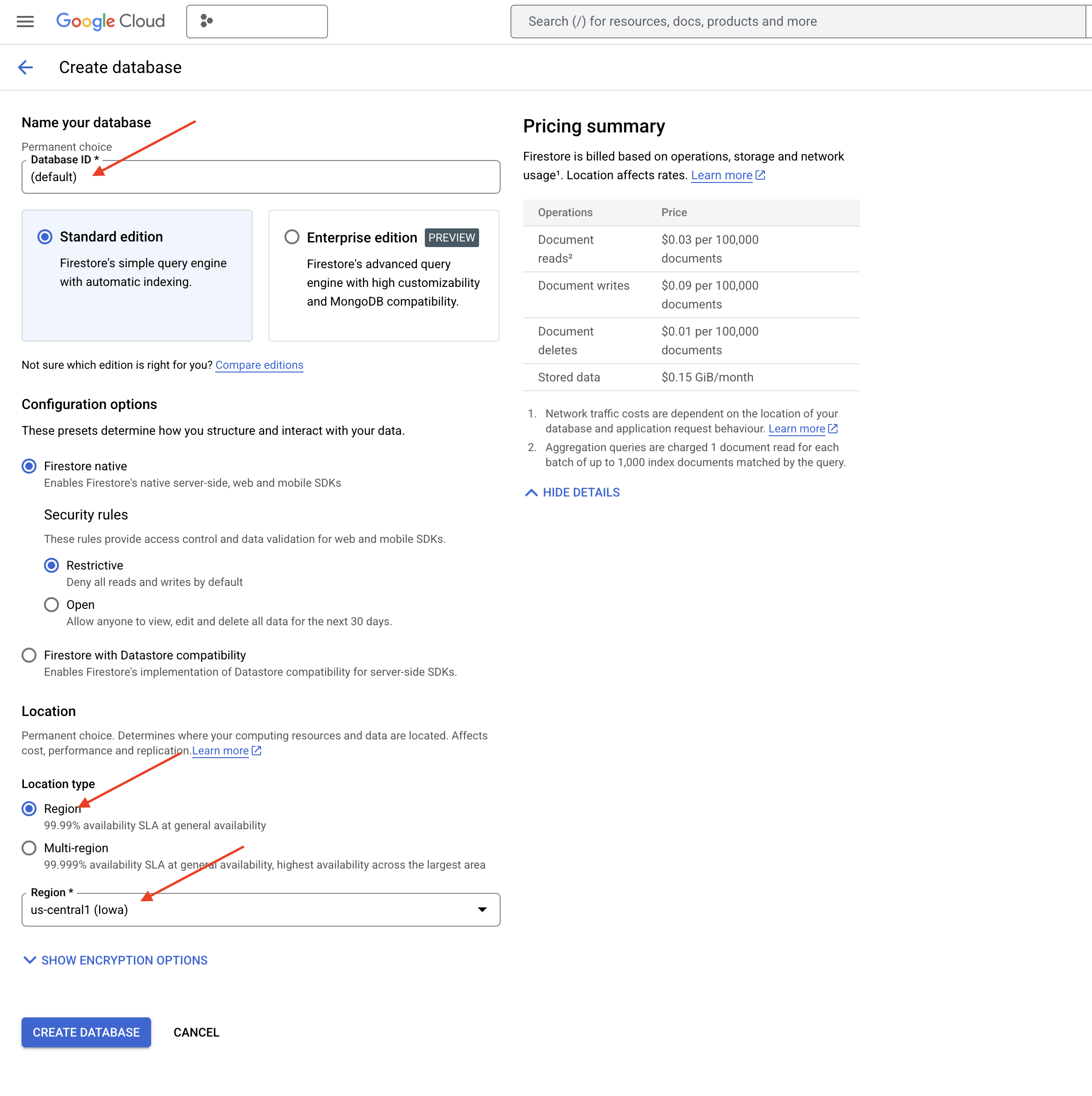
👉 De retour dans le terminal de l'IDE Cloud, créez un index vectoriel sur le champ "embedding_vector" pour activer la recherche vectorielle dans votre collection "legal_documents".
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore commence à créer l'index vectoriel. La création d'un index peut prendre un certain temps, en particulier pour les ensembles de données volumineux. L'index s'affiche à l'état "Création", puis passe à l'état "Prêt" une fois qu'il est créé. 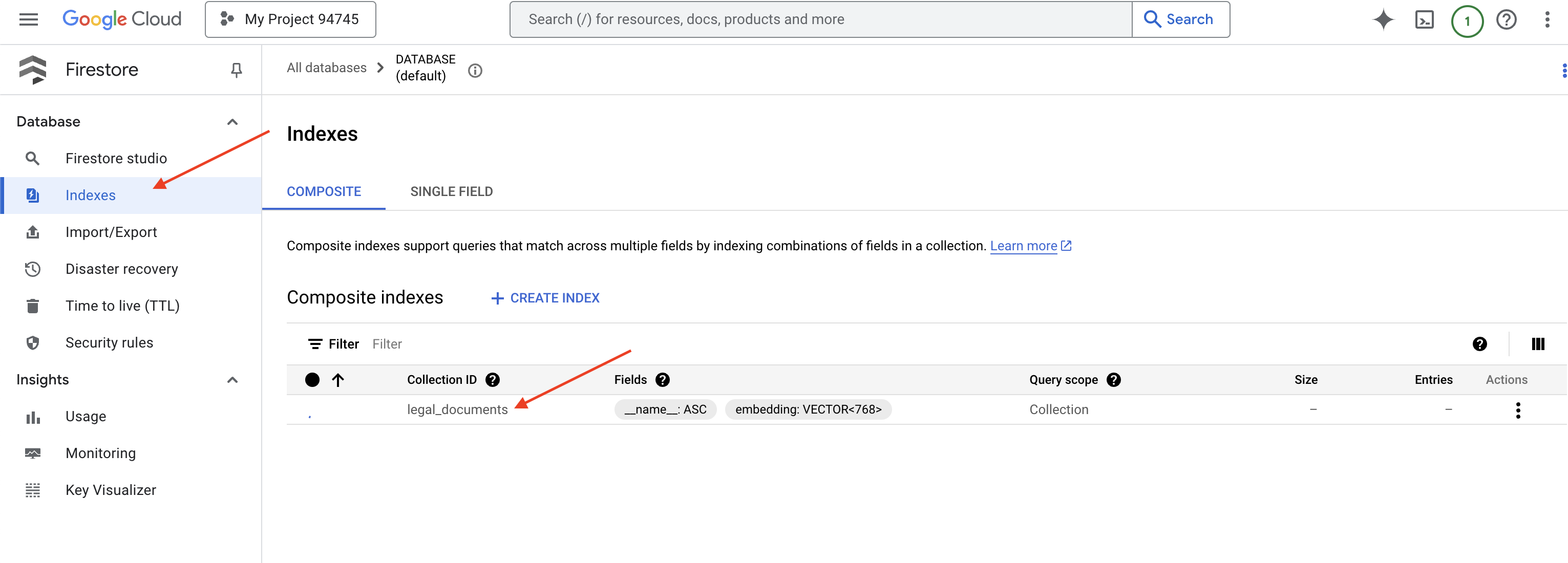
7. Charger des données dans le Vector Store
Maintenant que nous comprenons le RAG et notre magasin de vecteurs, il est temps de créer le moteur qui alimente notre bibliothèque juridique. Alors, comment rendre les documents juridiques "recherchables par signification" ? La magie réside dans les embeddings ! Les embeddings permettent de convertir des mots, des phrases ou même des documents entiers en vecteurs numériques (listes de nombres qui capturent leur signification sémantique). Les concepts similaires obtiennent des vecteurs "proches" les uns des autres dans l'espace vectoriel. Nous utilisons des modèles puissants (comme ceux de Vertex AI) pour effectuer cette conversion.
Pour automatiser le chargement de nos documents, nous utiliserons Cloud Run Functions et Eventarc. Cloud Run Functions est un conteneur léger sans serveur qui exécute votre code uniquement lorsque cela est nécessaire. Nous allons empaqueter notre script Python de traitement de documents dans un conteneur et le déployer en tant que fonction Cloud Run.
👉 Dans un nouvel onglet ou une nouvelle fenêtre, accédez à Cloud Storage.
👉 Cliquez sur "Buckets" (Paliers) dans le menu de gauche.
👉 Cliquez sur le bouton "+ CRÉER" en haut de l'écran.
👉 Configurez votre bucket (paramètres importants) :
- Nom du bucket : yourprojectID-doc-bucket (vous DEVEZ ajouter le suffixe -doc-bucket à la fin).
- region : sélectionnez la région
us-central1. - Classe de stockage : "Standard". Le stockage standard convient aux données auxquelles vous accédez fréquemment.
- Contrôle des accès : laissez l'option par défaut "Contrôle des accès uniforme" sélectionnée. Cela permet un contrôle des accès cohérent au niveau du bucket.
- Options avancées : pour ce tutoriel, les paramètres par défaut sont généralement suffisants.
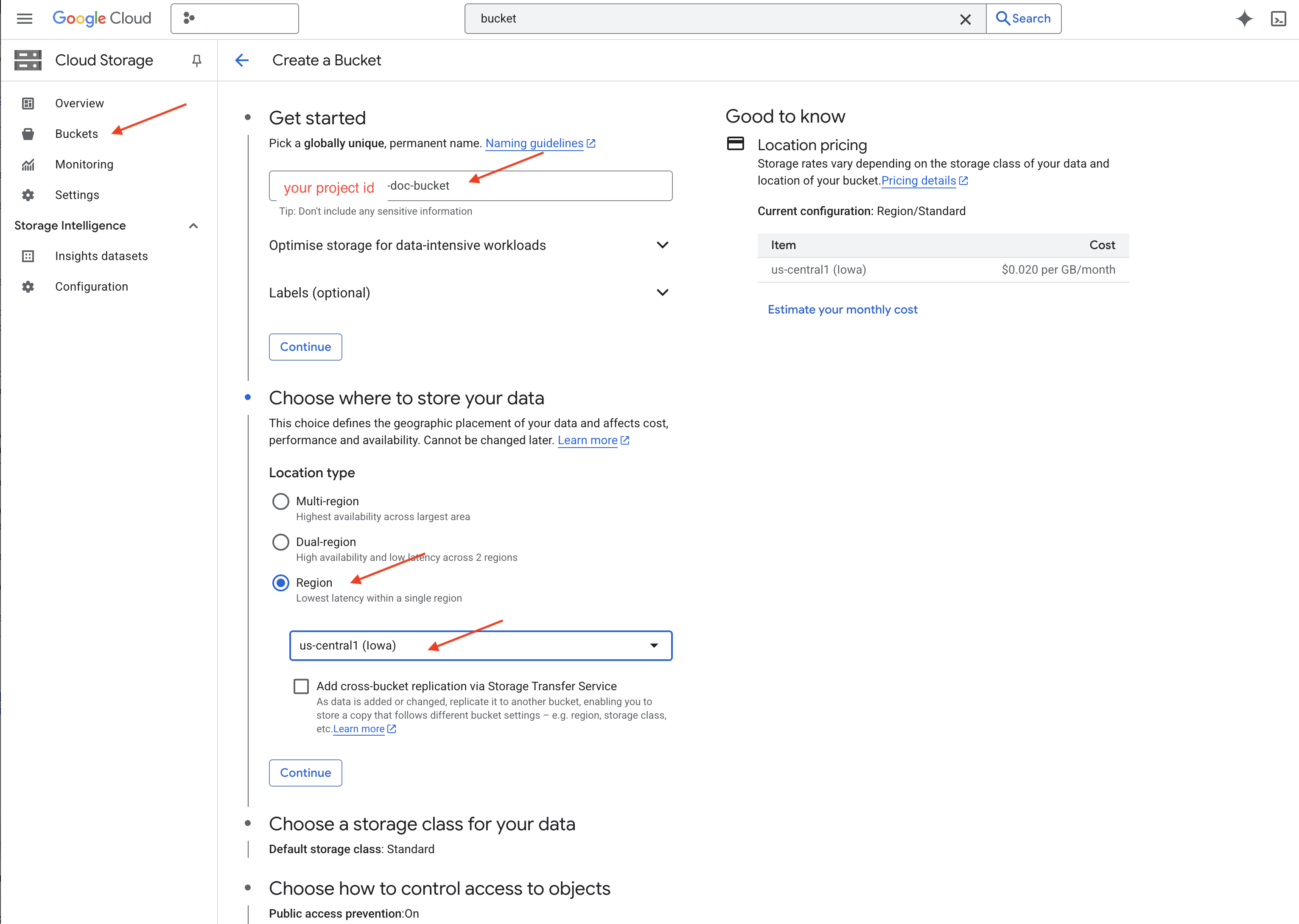
👉 Cliquez sur le bouton CRÉER pour créer votre bucket.
👉 Un pop-up concernant la protection contre l'accès public peut s'afficher. Laissez la case cochée et cliquez sur "Confirmer".
Vous devriez maintenant voir le bucket que vous venez de créer dans la liste des buckets. Notez le nom de votre bucket, car vous en aurez besoin plus tard.
8. Configurer une fonction Cloud Run
👉 Dans l'éditeur de code Cloud Shell, accédez au répertoire de travail legal-eagle : utilisez la commande cd dans le terminal de l'éditeur Cloud pour créer le dossier.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Créez les fichiers main.py, requirements.txt et Dockerfile. Dans le terminal Cloud Shell, utilisez la commande touch pour créer les fichiers :
touch main.py requirements.txt Dockerfile
Vous verrez le dossier *loader que vous venez de créer et les trois fichiers.
👉 Modifiez main.py dans le dossier loader. Dans l'explorateur de fichiers à gauche, accédez au répertoire dans lequel vous avez créé les fichiers, puis double-cliquez sur main.py pour l'ouvrir dans l'éditeur.
Collez le code Python suivant dans main.py :
Cette application traite les nouveaux fichiers importés dans le bucket GCS, divise le texte en blocs, génère des embeddings pour chaque bloc et stocke les blocs et leurs embeddings dans Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Modifiez requirements.txt.Collez les lignes suivantes dans le fichier :
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Tester et créer une fonction Cloud Run
👉 Nous allons exécuter cette commande dans un environnement virtuel et installer les bibliothèques Python nécessaires pour la fonction Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Démarrez un émulateur local pour la fonction Cloud Run.
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Laissez le dernier terminal en cours d'exécution, ouvrez-en un nouveau et exécutez la commande permettant d'importer un fichier dans le bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Lorsque l'émulateur est en cours d'exécution, vous pouvez lui envoyer des CloudEvents de test. Pour cela, vous aurez besoin d'un terminal distinct dans l'IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
La réponse doit être "OK".
👉 Pour vérifier les données dans Firestore, accédez à la console Google Cloud, puis à "Bases de données " et"Firestore ". Sélectionnez ensuite l'onglet "Données", puis la collection legal_documents. Vous verrez que de nouveaux documents ont été créés dans votre collection. Chacun représente un bloc de texte du fichier importé. 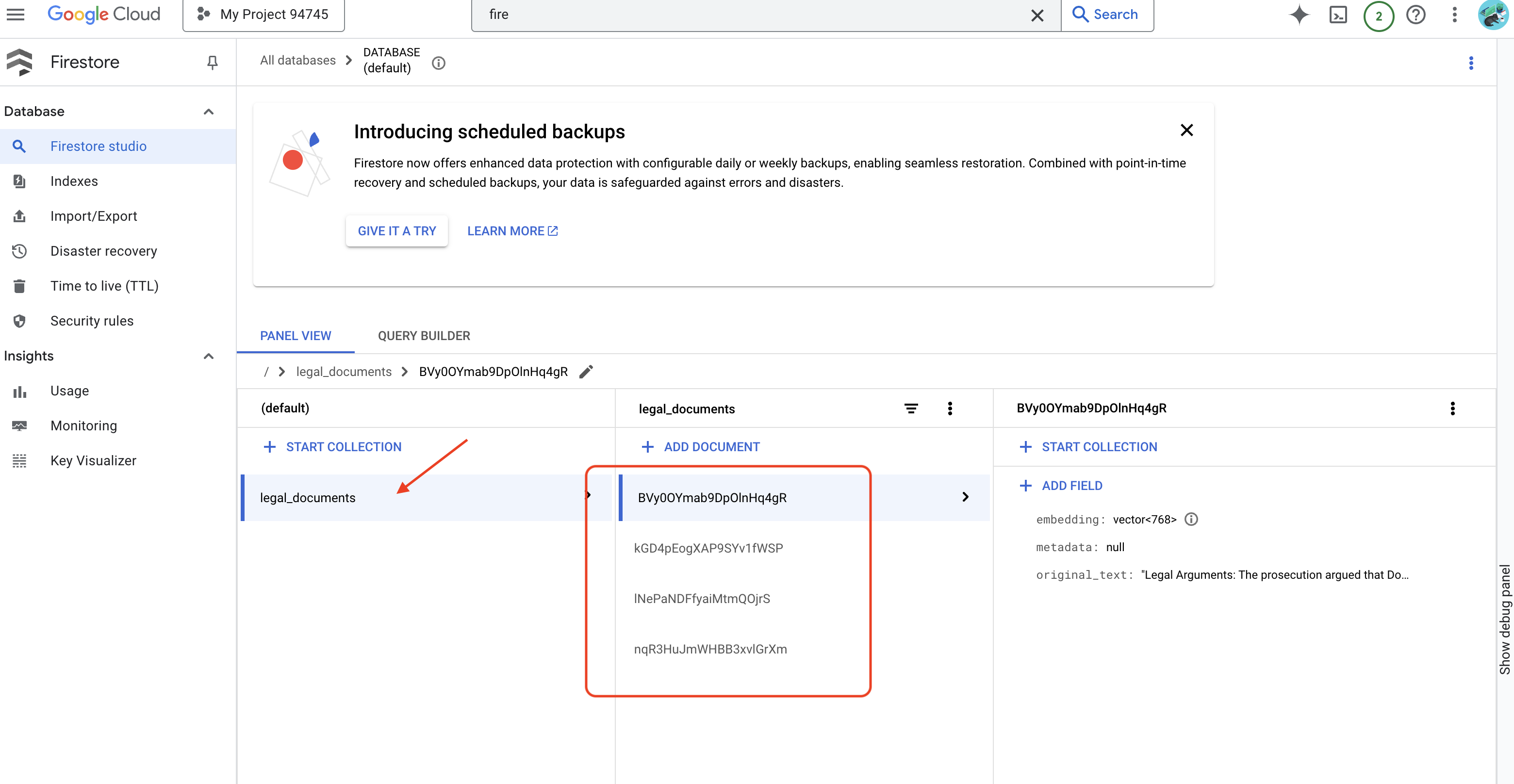
👉 Dans le terminal exécutant l'émulateur, saisissez Ctrl+C pour quitter. Fermez le deuxième terminal.
👉 Exécutez la commande "deactivate" pour quitter l'environnement virtuel.
deactivate
10. Créer une image de conteneur et la transférer vers les dépôts d'artefacts
👉 Il est temps de déployer cela dans le cloud. Dans l'explorateur de fichiers, double-cliquez sur Dockerfile. Demandez à Gemini de générer le fichier Dockerfile pour vous. Ouvrez Gemini Code Assist et utilisez le prompt suivant pour générer le fichier.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Pour suivre les bonnes pratiques, nous vous recommandons de cliquer sur Afficher les différences avec le fichier ouvert(deux flèches dans des directions opposées) et d'accepter les modifications. 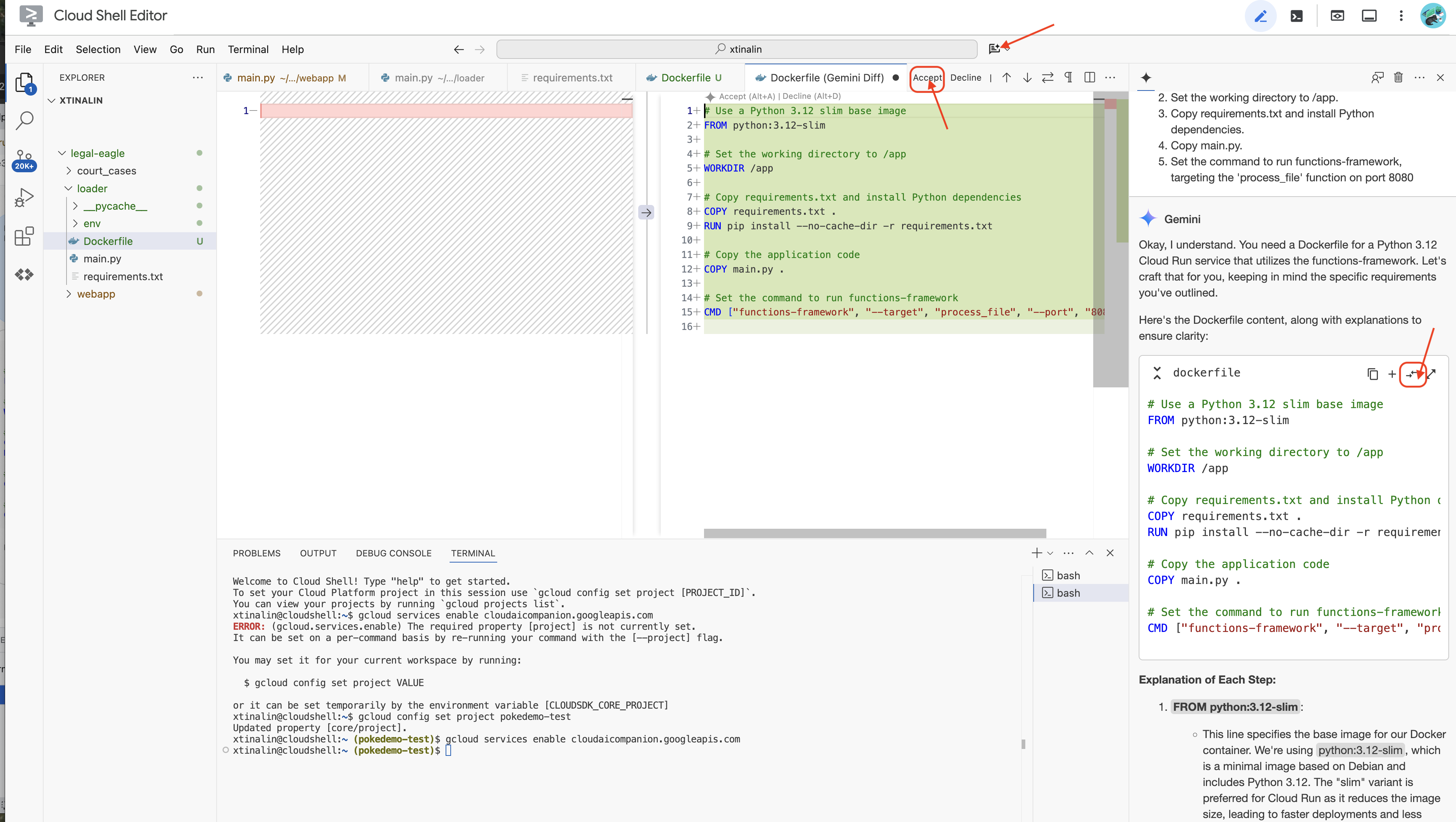
👉 Si vous débutez avec les conteneurs, voici un exemple pratique :
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 Dans le terminal, créez un dépôt d'artefacts pour stocker l'image Docker que nous allons créer.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Le message Dépôt [my-repository] créé doit s'afficher.
👉 Exécutez la commande suivante pour créer l'image Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Vous allez maintenant envoyer cette image au registre.
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
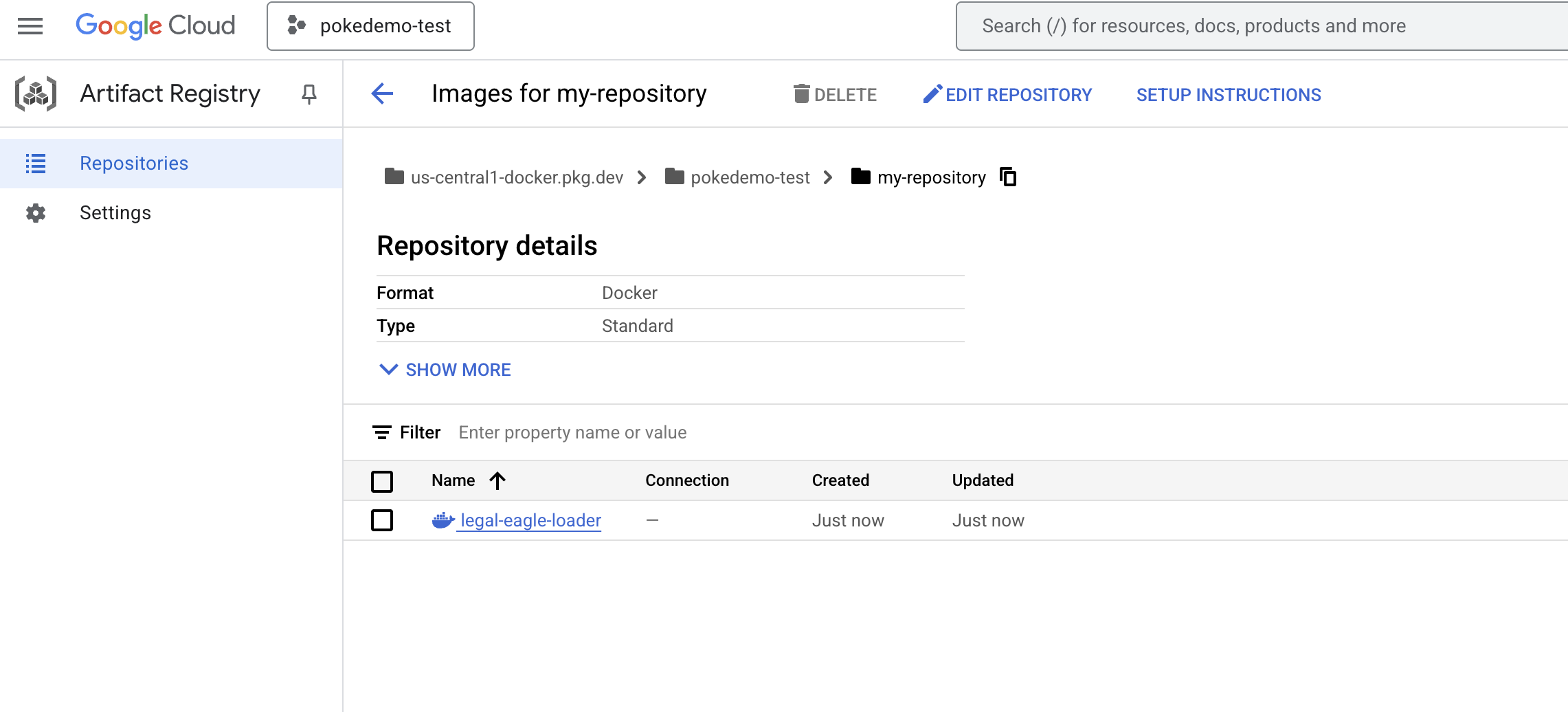
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
L'image Docker est désormais disponible dans le dépôt d'artefacts my-repository.
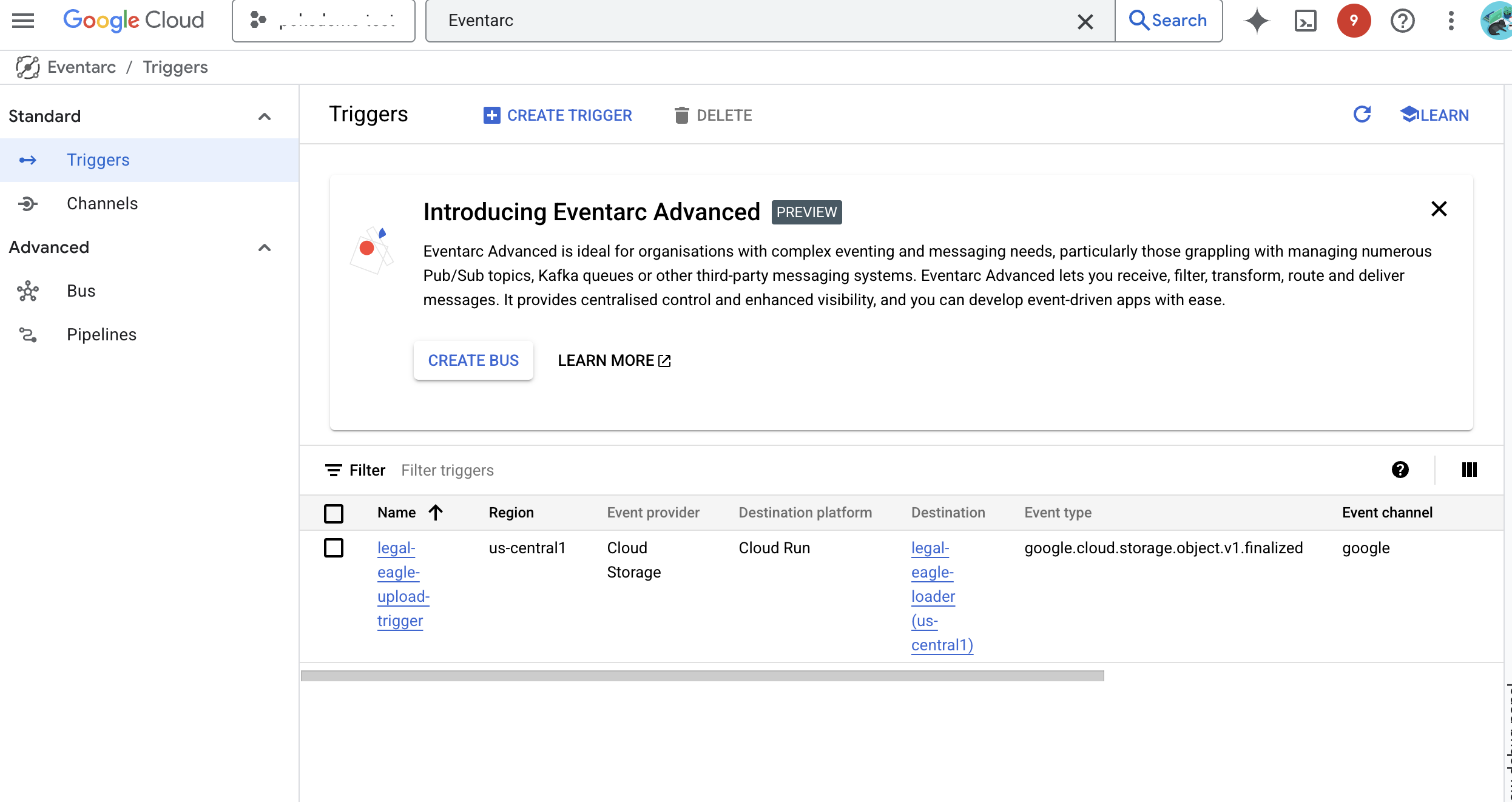
11. Créer la fonction Cloud Run et configurer le déclencheur Eventarc
Avant de nous pencher sur les spécificités du déploiement de notre chargeur de documents juridiques, examinons brièvement les composants impliqués : Cloud Run est une plate-forme sans serveur entièrement gérée qui vous permet de déployer des applications conteneurisées rapidement et facilement. Elle élimine la gestion de l'infrastructure, ce qui vous permet de vous concentrer sur l'écriture et le déploiement de votre code.
Nous allons déployer notre chargeur de documents en tant que service Cloud Run. Nous allons maintenant configurer notre fonction Cloud Run :
👉 Dans la console Google Cloud, accédez à Cloud Run.
👉 Accédez à Déployer un conteneur, puis cliquez sur SERVICE dans le menu déroulant.
👉 Configurez votre service Cloud Run :
- Image de conteneur : cliquez sur "Sélectionner" dans le champ de l'URL. Recherchez l'URL de l'image que vous avez transférée vers Artifact Registry (par exemple, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Service name (Nom du service) :
legal-eagle-loader - Région : sélectionnez la région
us-central1. - Authentification : pour cet atelier, vous pouvez autoriser les appels non authentifiés. Pour la production, vous souhaiterez probablement restreindre l'accès.
- Conteneur, mise en réseau, sécurité : par défaut.
👉 Cliquez sur CRÉER. Cloud Run déploie votre service. 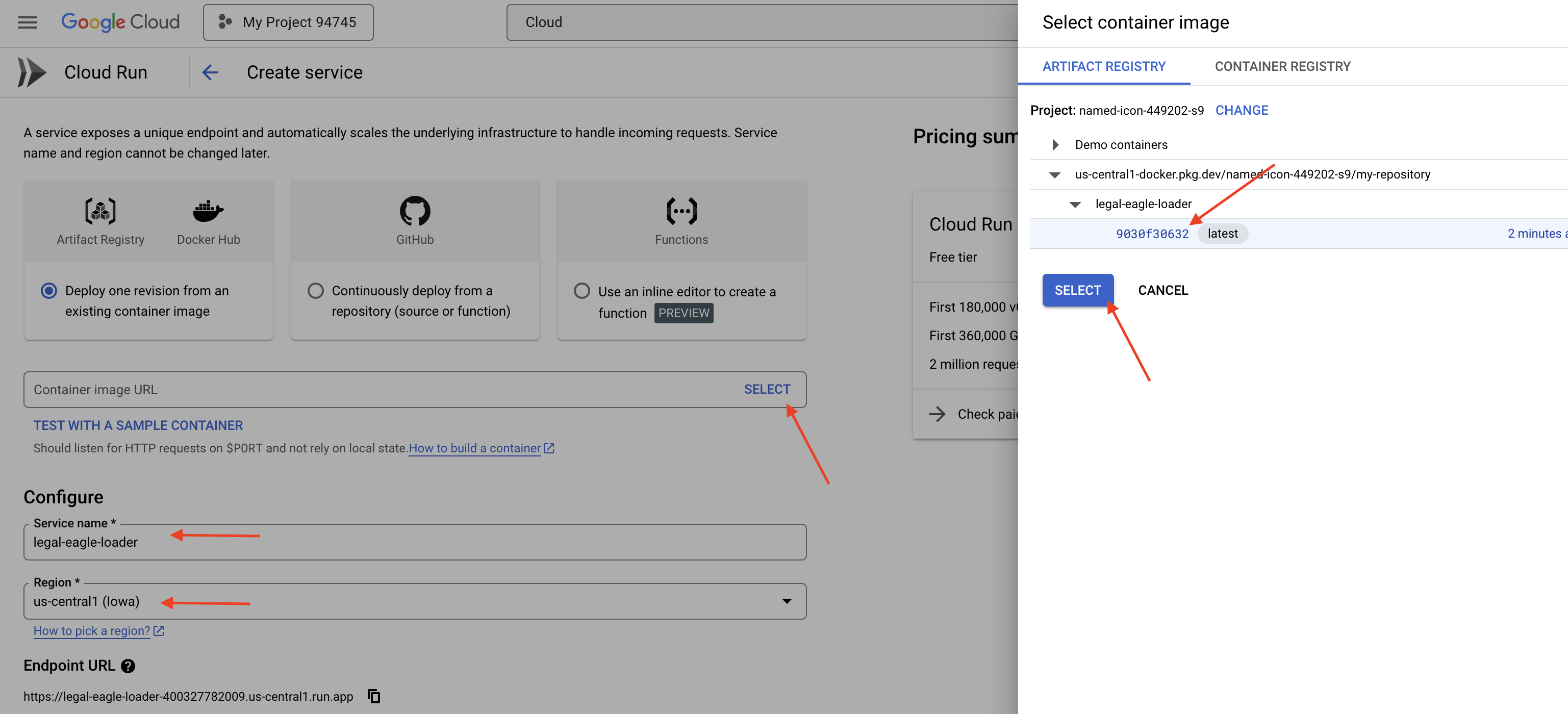
Pour déclencher automatiquement ce service lorsque de nouveaux fichiers sont ajoutés à notre bucket de stockage, nous allons utiliser Eventarc. Eventarc vous permet de créer des architectures basées sur des événements en acheminant les événements de différentes sources vers vos services.
En configurant Eventarc, notre service Cloud Run chargera automatiquement les documents nouvellement ajoutés dans Firestore dès qu'ils seront importés, ce qui permettra de mettre à jour les données en temps réel pour notre application RAG.
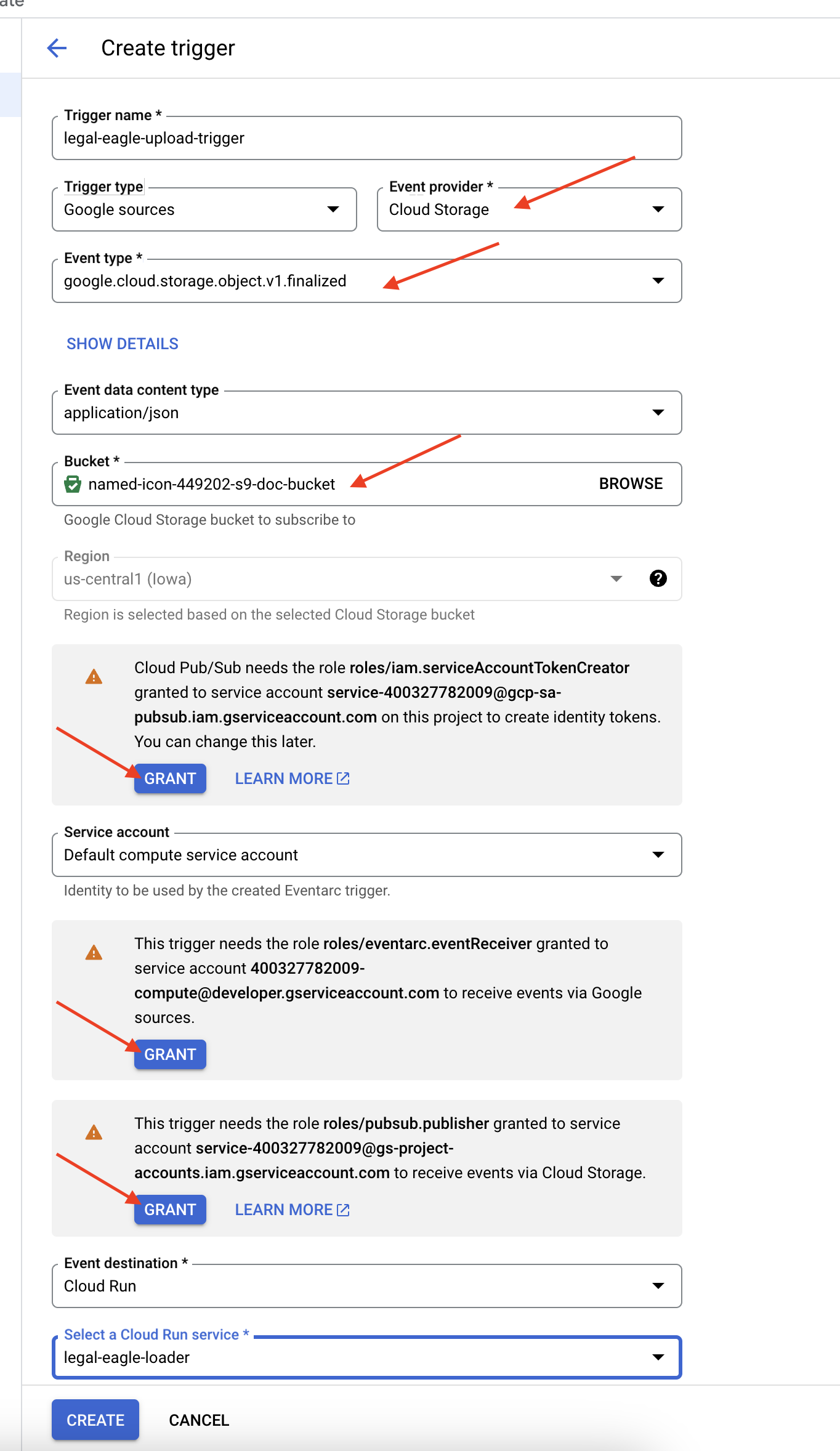
👉 Dans la console Google Cloud, accédez à Déclencheurs sous Eventarc. Cliquez sur "+ CRÉER UN DÉCLENCHEUR". 👉 Configurez le déclencheur Eventarc :
- Nom du déclencheur :
legal-eagle-upload-trigger. - TriggerType : sources Google
- Fournisseur d'événements : sélectionnez Cloud Storage.
- Type d'événement : sélectionnez
google.cloud.storage.object.v1.finalized. - Bucket Cloud Storage : sélectionnez votre bucket GCS dans le menu déroulant.
- Type de destination : "Service Cloud Run".
- Service : sélectionnez
legal-eagle-loader. - Région :
us-central1 - Chemin d'accès : laissez ce champ vide pour le moment .
- Accorder toutes les autorisations demandées sur la page
👉 Cliquez sur CRÉER. Eventarc va maintenant configurer le déclencheur.
Le service Cloud Run a besoin d'une autorisation pour lire les fichiers de différents composants. Nous devons accorder au compte de service du service les autorisations dont il a besoin.
12. Importer des documents juridiques dans le bucket GCS
👉 Importez le fichier de la procédure judiciaire dans votre bucket GCS. N'oubliez pas de remplacer le nom de votre bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Surveillez les journaux du service Cloud Run en accédant à Cloud Run > votre service legal-eagle-loader > "Journaux". Vérifiez les journaux pour les messages de traitement réussi, y compris :
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
En fonction de la rapidité de la configuration de la journalisation, vous verrez également des journaux plus détaillés ici.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Recherchez les éventuels messages d'erreur dans les journaux et résolvez les problèmes si nécessaire. 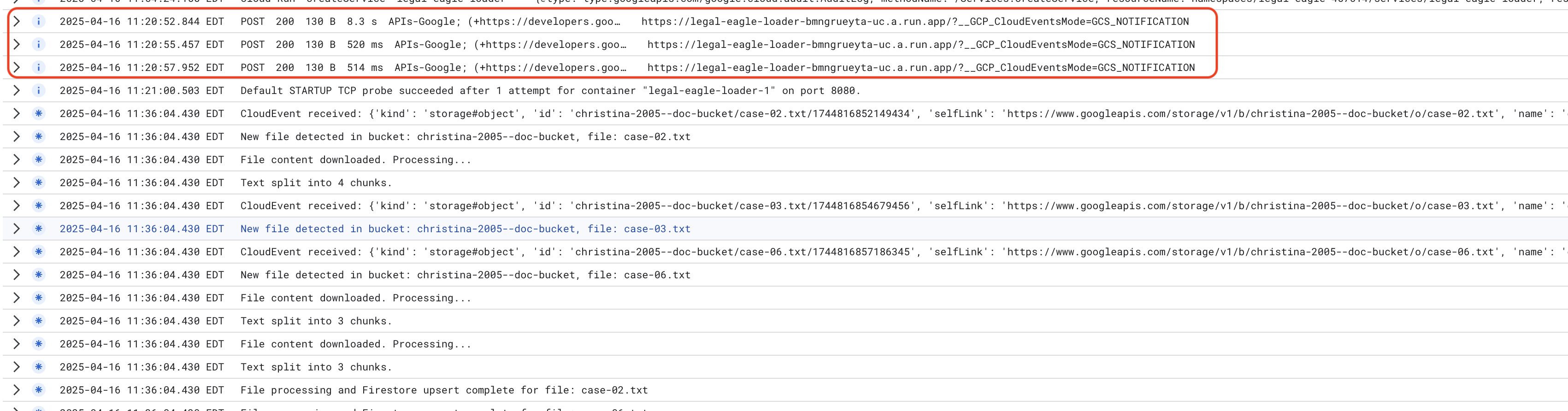
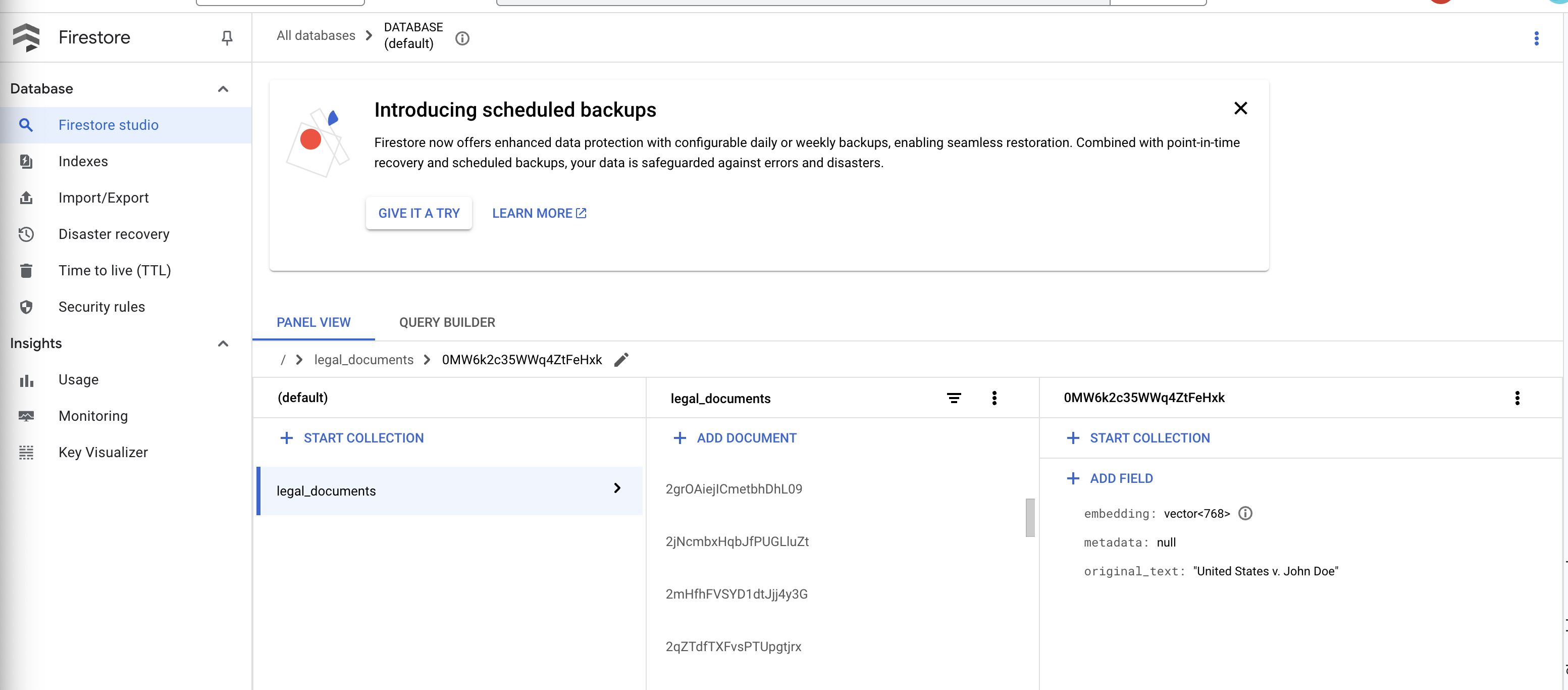
👉 Vérifiez les données dans Firestore. Ouvrez votre collection legal_documents.
👉 De nouveaux documents devraient s'afficher dans votre collection. Chaque document représente un bloc de texte du fichier que vous avez importé et contient les éléments suivants :
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Implémenter le RAG
LangChain est un framework puissant conçu pour simplifier le développement d'applications basées sur des grands modèles de langage (LLM). Au lieu de se débattre directement avec les subtilités des API LLM, de l'ingénierie des requêtes et de la gestion des données, LangChain fournit une couche d'abstraction de haut niveau. Il propose des composants et des outils prédéfinis pour des tâches telles que la connexion à différents LLM (comme ceux d'OpenAI, de Google ou d'autres), la création de chaînes d'opérations complexes (par exemple, la récupération de données suivie d'un résumé) et la gestion de la mémoire conversationnelle.
Pour le RAG en particulier, les magasins de vecteurs dans LangChain sont essentiels pour activer l'aspect récupération du RAG. Il s'agit de bases de données spécialisées conçues pour stocker et interroger efficacement les embeddings de vecteurs, où les textes sémantiquement similaires sont mappés sur des points proches les uns des autres dans l'espace vectoriel. LangChain s'occupe des détails techniques de bas niveau, ce qui permet aux développeurs de se concentrer sur la logique et les fonctionnalités de base de leur application RAG. Cela réduit considérablement le temps et la complexité du développement, ce qui vous permet de prototyper et de déployer rapidement des applications basées sur la RAG tout en tirant parti de la robustesse et de l'évolutivité de l'infrastructure Google Cloud.
Maintenant que vous avez compris LangChain, vous devez mettre à jour votre fichier legal.py dans le dossier webapp pour l'implémentation RAG. Cela permettra au LLM de rechercher des documents pertinents dans Firestore avant de fournir une réponse.
👉 Importez FirestoreVectorStore et les autres modules requis depuis langchain et vertexai. Ajoutez les éléments suivants au legal.py actuel.
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Initialisez Vertex AI et le modèle d'embedding.Vous utiliserez text-embedding-004. Ajoutez le code suivant juste après l'importation des modules.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Créez un FirestoreVectorStore pointant vers la collection legal_documents, en utilisant le modèle d'embedding initialisé et en spécifiant les champs de contenu et d'embedding. Ajoutez ce code juste après le code du modèle d'embedding précédent.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Définissez une fonction appelée search_resource qui prend une requête, effectue une recherche de similarité à l'aide de vector_store.similarity_search et renvoie les résultats combinés.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 Remplacez la fonction ask_llm et utilisez la fonction search_resource pour récupérer le contexte pertinent en fonction de la requête de l'utilisateur.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 FACULTATIF : VERSION ESPAGNOLE
Remplace le texte suivant comme indiqué : You are a helpful assistant, par You are a helpful assistant that speaks Spanish,
👉 Après avoir implémenté RAG dans legal.py, vous devez le tester en local avant de le déployer. Pour ce faire, exécutez l'application avec la commande suivante :
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Utilisez webpreview pour accéder à l'application, parlez à l'assistance et saisissez ctrl+c pour quitter le processus exécuté en local, puis exécutez "deactivate" pour quitter l'environnement virtuel.
deactivate
👉 Pour déployer l'application Web sur Cloud Run, la procédure est semblable à celle de la fonction de chargement. Vous allez créer l'image Docker, lui ajouter un tag et la transférer vers Artifact Registry :
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Il est temps de déployer l'application Web sur Google Cloud. Dans le terminal, exécutez les commandes suivantes :
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Vérifiez le déploiement en accédant à Cloud Run dans la console Google Cloud.Un nouveau service nommé legal-eagle-webapp devrait s'afficher.
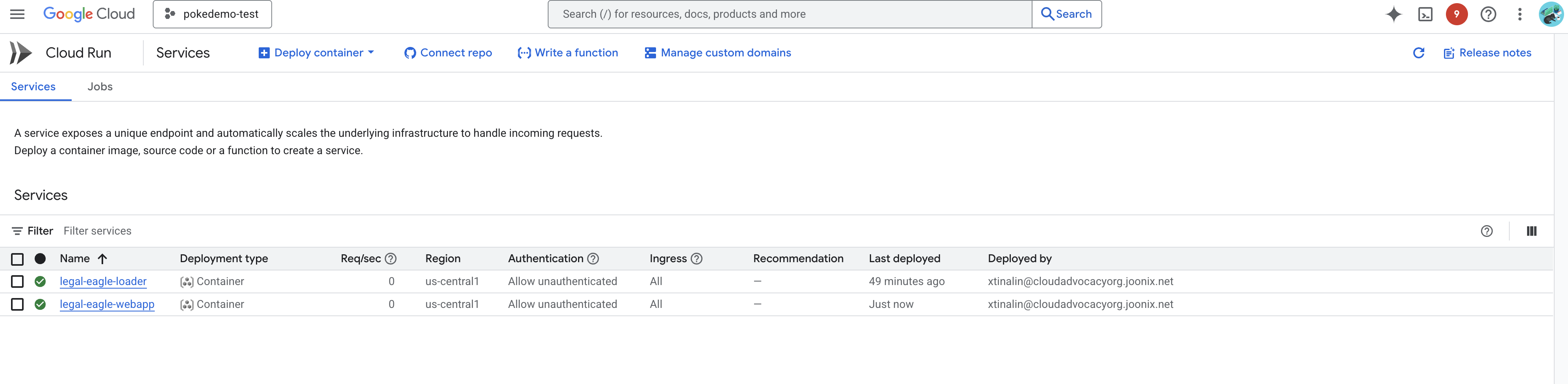
Cliquez sur le service pour accéder à sa page d'informations. L'URL déployée est disponible en haut de la page. 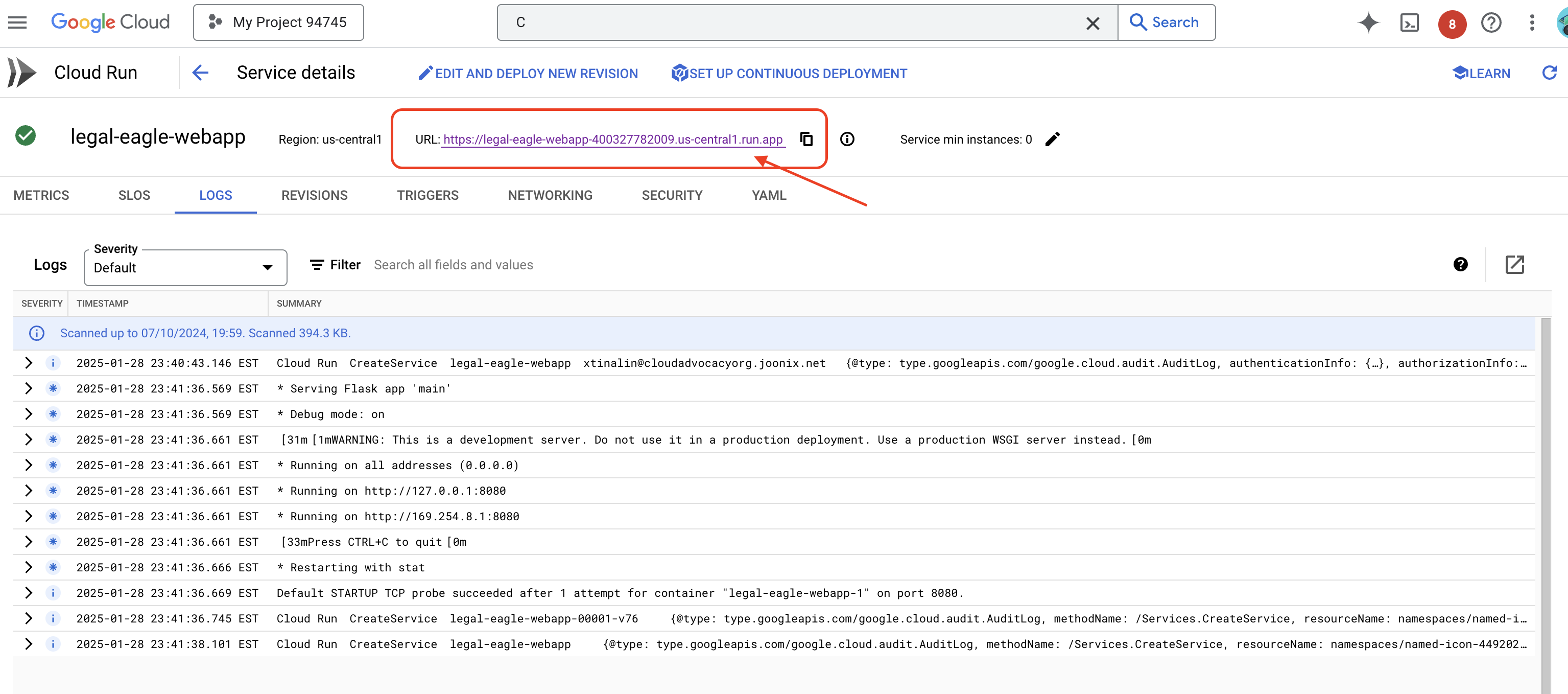
👉 Ouvrez maintenant l'URL déployée dans un nouvel onglet de navigateur. Vous pouvez interagir avec l'assistant juridique et lui poser des questions sur les affaires judiciaires que vous avez chargées(dans le dossier "court_cases") :
- À combien d'années de prison Michael Brown a-t-il été condamné ?
- Quel montant de frais non autorisés a été généré par les actions de Jane Smith ?
- Quel rôle les témoignages des voisins ont-ils joué dans l'enquête sur l'affaire Emily White ?
👉 FACULTATIF : VERSION ESPAGNOLE
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Vous devriez remarquer que les réponses sont désormais plus précises et ancrées dans le contenu des documents juridiques que vous avez importés, ce qui illustre la puissance de la RAG.
Félicitations, vous avez terminé l'atelier ! Vous avez créé et déployé une application d'analyse de documents juridiques à l'aide de LLM, de LangChain et de Google Cloud. Vous avez appris à ingérer et à traiter des documents juridiques, à enrichir les réponses des LLM avec des informations pertinentes à l'aide de la méthode RAG et à déployer votre application en tant que service sans serveur. Ces connaissances et l'application créée vous aideront à explorer plus en détail la puissance des LLM pour les tâches juridiques. Bravo !"
14. Défi
Types de contenus variés :
Ingérer et traiter différents types de contenus multimédias, tels que des vidéos et des enregistrements audio de tribunaux, et extraire le texte pertinent
Composants en ligne :
Traiter des composants en ligne tels que des pages Web en direct