
1. מבוא
תמיד נמשכתי לדרמה שמתרחשת באולם בית המשפט, ודמיינתי את עצמי מתמרן בחוכמה בין המורכבויות ומציג טיעוני סיום משכנעים. הקריירה שלי הובילה אותי למקום אחר, אבל אני שמח לשתף שבזכות AI, יכול להיות שכולנו נהיה קרובים יותר להגשמת החלום הזה.

היום נסביר איך להשתמש בכלי ה-AI המתקדמים של Google – כמו Vertex AI, Firestore ו-Cloud Run Functions – כדי לעבד ולהבין נתונים משפטיים, לבצע חיפושים מהירים במיוחד, ואולי, רק אולי, לעזור ללקוח הדמיוני שלכם (או לכם) לצאת ממצב בעייתי.
יכול להיות שלא תחקרו עדים, אבל בעזרת המערכת שלנו תוכלו לסנן כמויות עצומות של מידע, ליצור סיכומים ברורים ולהציג את הנתונים הרלוונטיים ביותר תוך שניות.
2. ארכיטקטורה
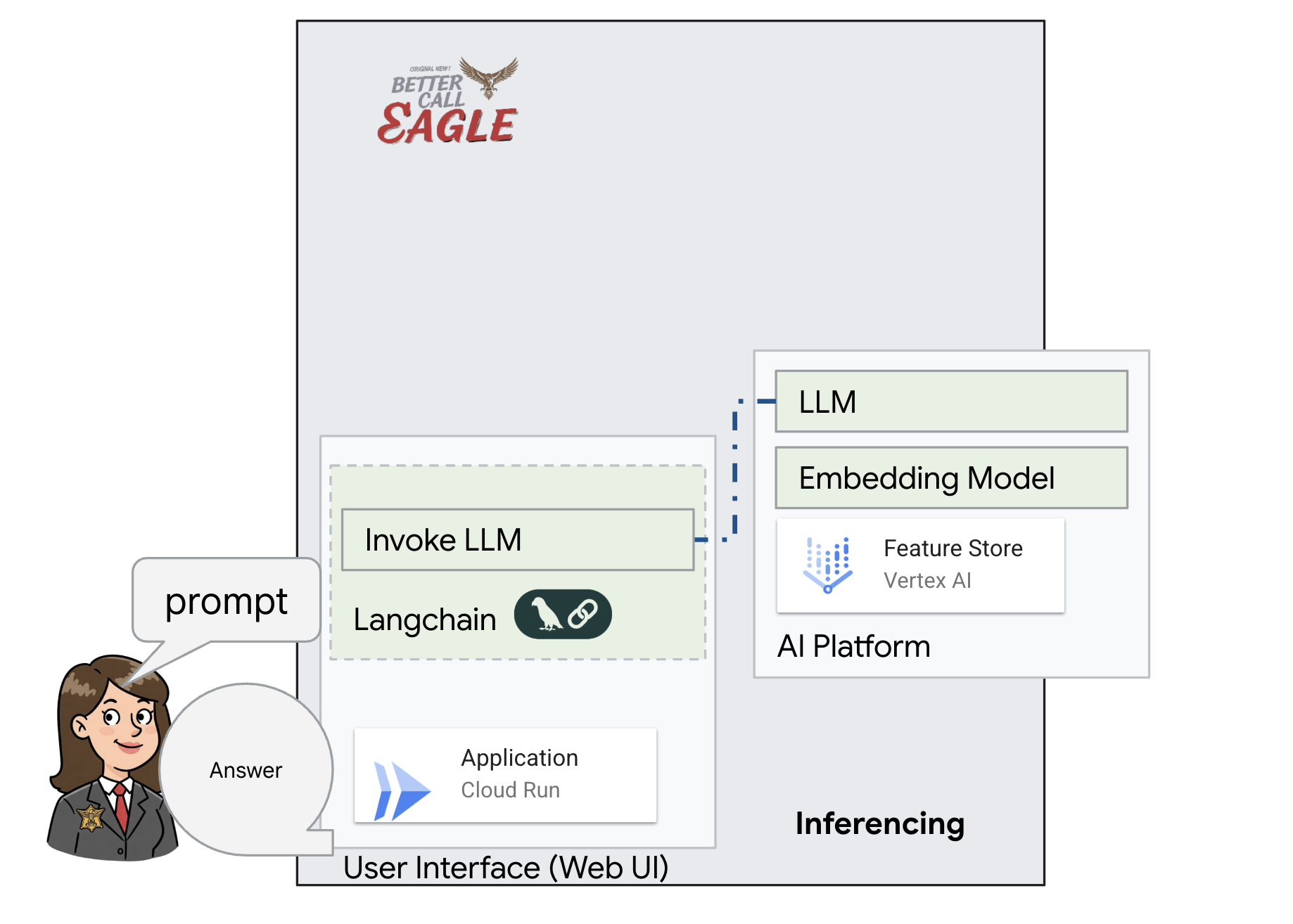
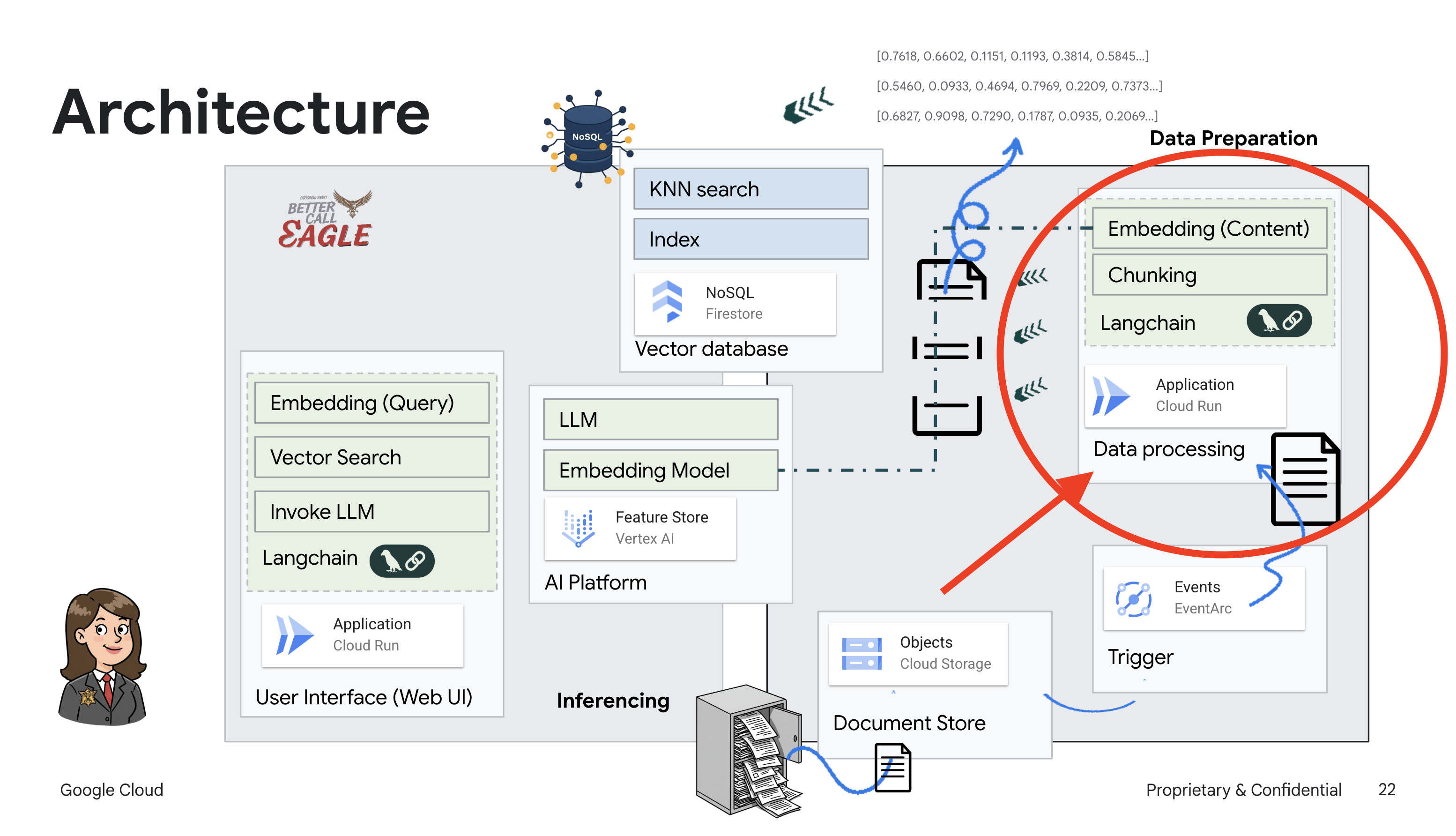
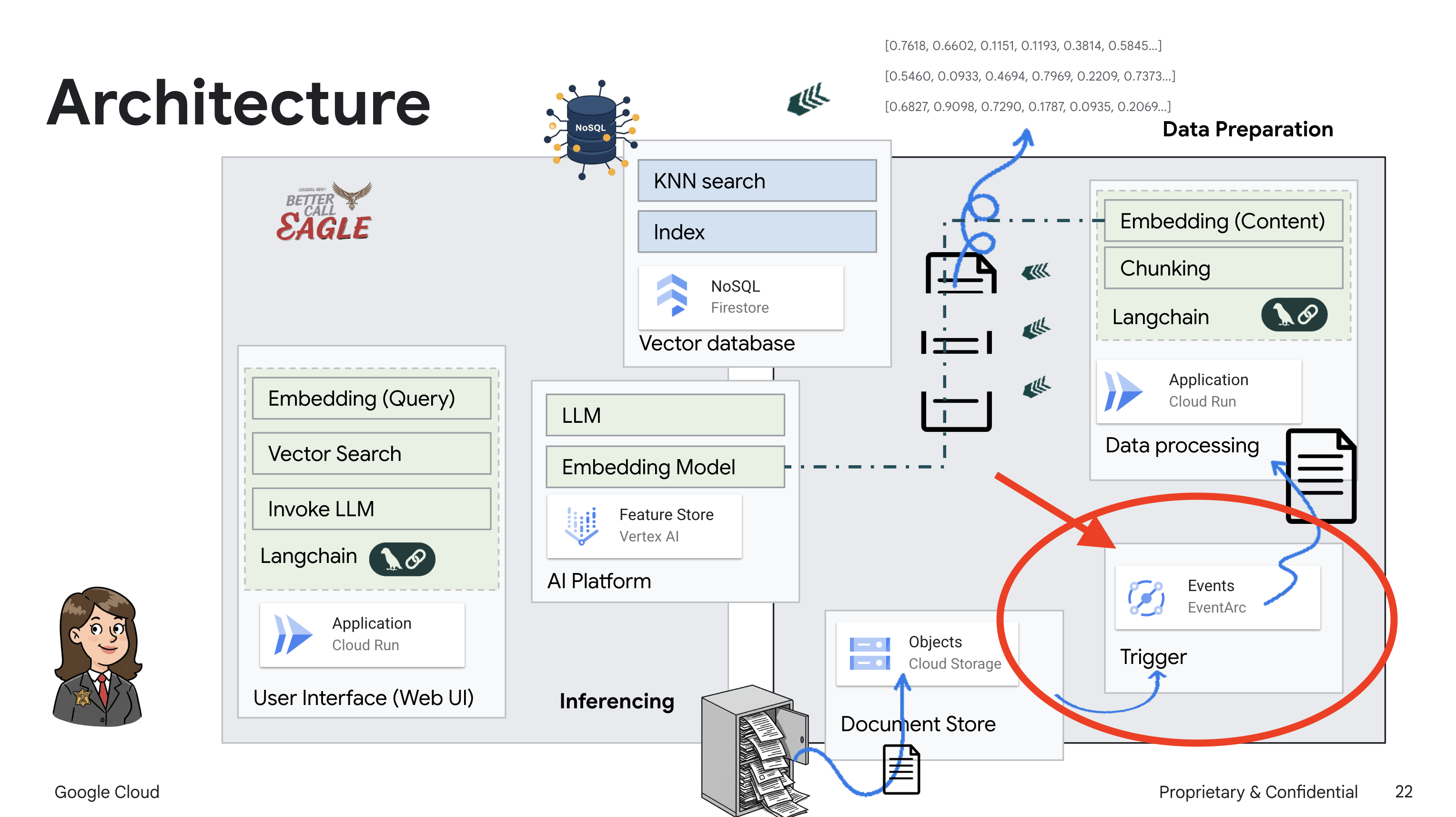
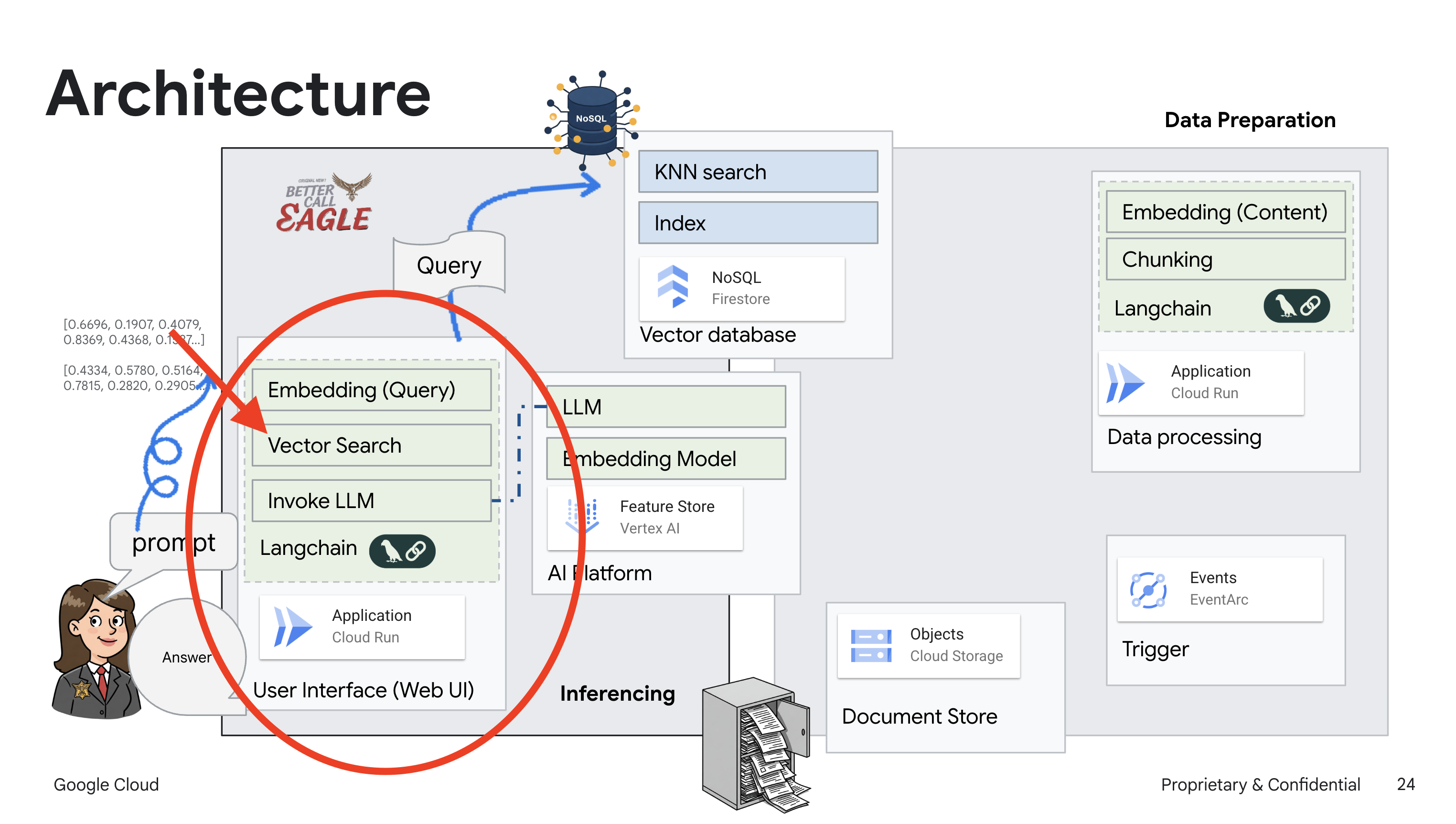
הפרויקט הזה מתמקד בבניית עוזר משפטי באמצעות כלי AI ב-Google Cloud, ומתמקד בהסבר על עיבוד, הבנה וחיפוש של נתונים משפטיים. המערכת נועדה לסנן כמויות גדולות של מידע, ליצור סיכומים ולהציג נתונים רלוונטיים במהירות. הארכיטקטורה של העוזר המשפטי כוללת כמה רכיבים מרכזיים:
בניית מאגר ידע מנתונים לא מובְנים: נעשה שימוש ב-Google Cloud Storage (GCS) לאחסון מסמכים משפטיים. Firestore, מסד נתונים NoSQL, פועל כמאגר וקטורים שמכיל נתחים של מסמכים והטמעות תואמות. חיפוש וקטורי מופעל ב-Firestore כדי לאפשר חיפושים של דמיון. כשמסמך משפטי חדש מועלה ל-GCS, Eventarc מפעיל פונקציית Cloud Run. הפונקציה הזו מעבדת את המסמך על ידי פיצול שלו לחלקים ויצירת הטמעות לכל חלק באמצעות מודל הטמעת הטקסט של Vertex AI. ההטמעות האלה מאוחסנות ב-Firestore לצד חלקי הטקסט. 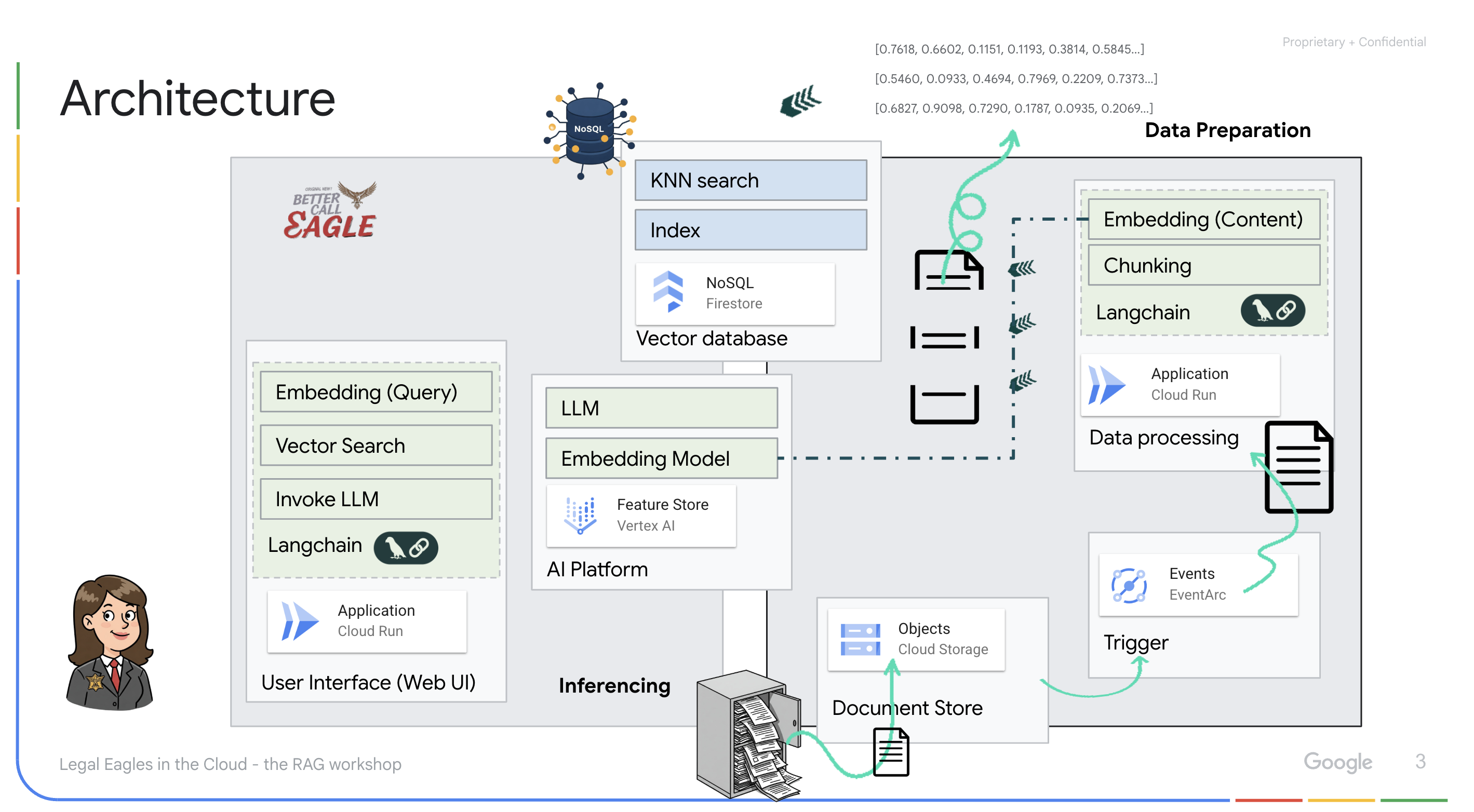
אפליקציה שמבוססת על LLM ו-RAG : הליבה של מערכת השאלות והתשובות היא הפונקציה ask_llm, שמשתמשת בספריית langchain כדי ליצור אינטראקציה עם מודל שפה גדול (LLM) של Gemini ב-Vertex AI. הוא יוצר HumanMessage מהשאילתה של המשתמש, וכולל SystemMessage שמורה ל-LLM לפעול כעוזר משפטי מועיל. המערכת משתמשת בגישה של יצירה מוגברת של אחזור (RAG), שבה, לפני מתן תשובה לשאילתה, המערכת משתמשת בפונקציה search_resource כדי לאחזר הקשר רלוונטי ממאגר הווקטורים של Firestore. ההקשר הזה נכלל בהודעה מהמערכת כדי שהתשובה של ה-LLM תתבסס על המידע המשפטי שסופק. 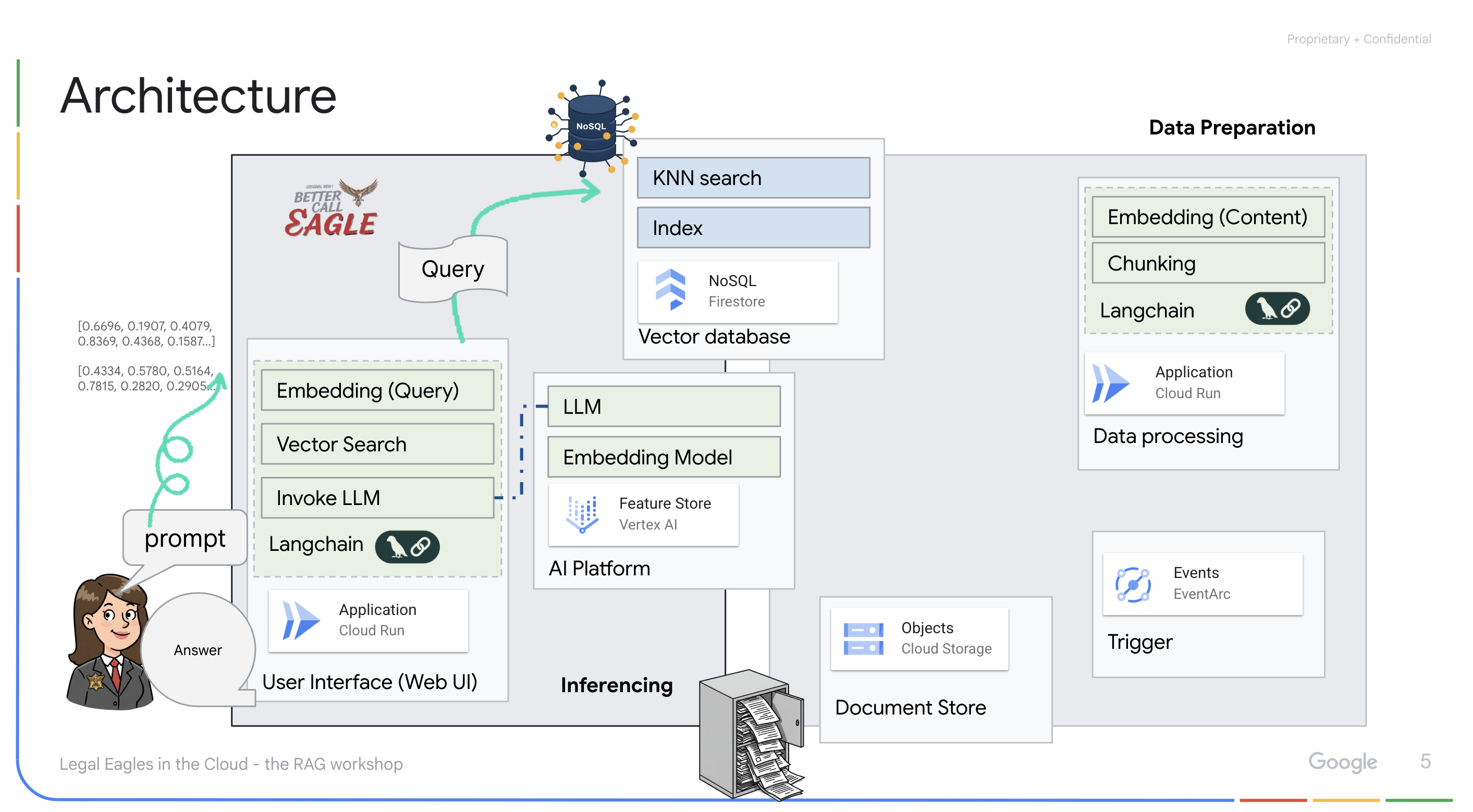
מטרת הפרויקט היא להתרחק מ"פרשנויות יצירתיות" של מודלים גדולים של שפה (LLM) באמצעות RAG, שקודם שולף מידע רלוונטי ממקור משפטי מהימן לפני שהוא יוצר תשובה. כך מתקבלות תשובות מדויקות ומושכלות יותר שמבוססות על מידע משפטי אמיתי. המערכת מבוססת על שירותים שונים של Google Cloud, כמו Google Cloud Shell, Vertex AI, Firestore, Cloud Run ו-Eventarc.
3. לפני שמתחילים
במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud. הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. איך בודקים אם החיוב מופעל בפרויקט
הפעלת Gemini Code Assist ב-Cloud Shell IDE
👉 במסוף Google Cloud, עוברים אל Gemini Code Assist Tools, מסכימים לתנאים ולהגבלות ומפעילים את Gemini Code Assist ללא עלות.
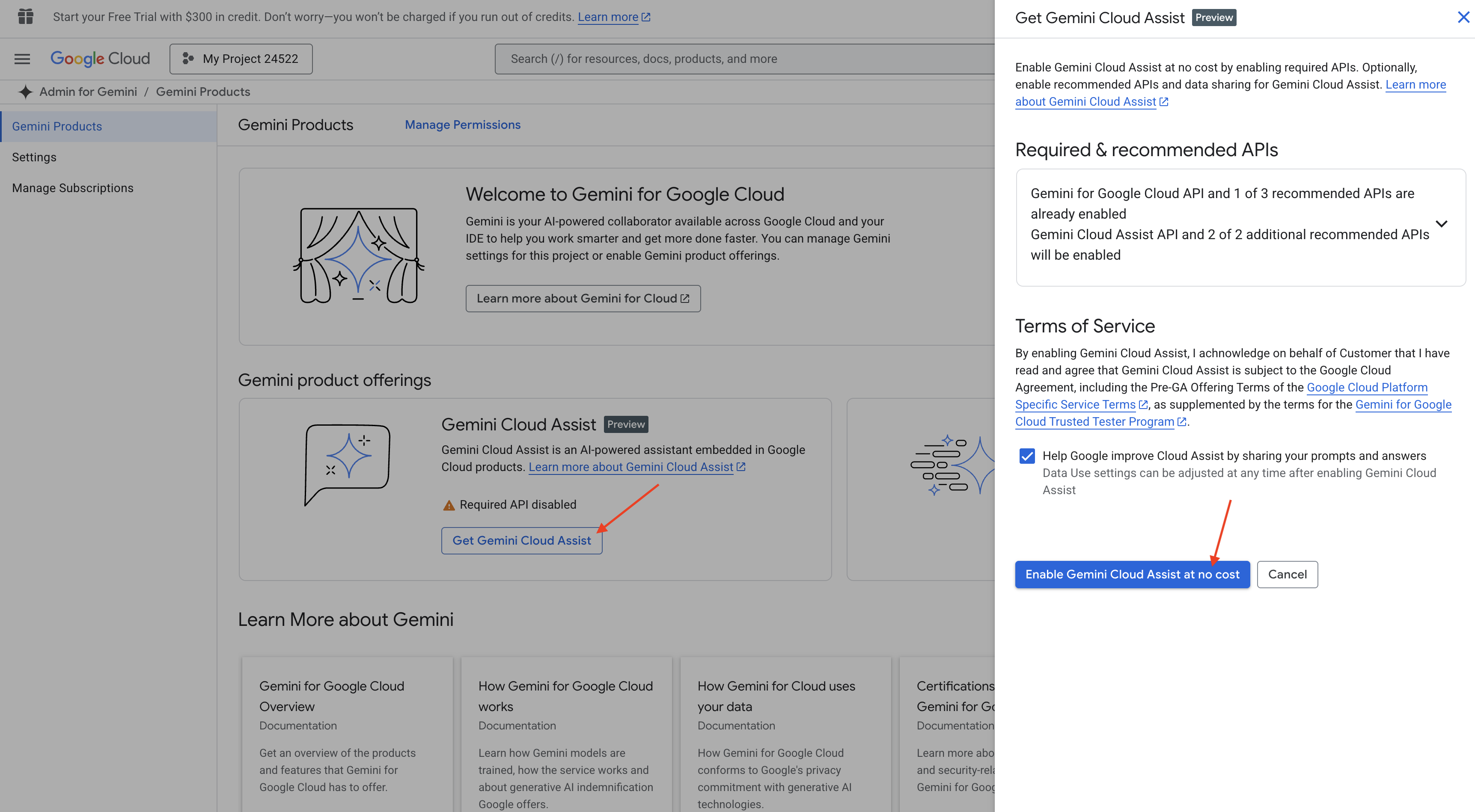
אפשר להתעלם מהגדרת ההרשאות ולצאת מהדף הזה.
עבודה ב-Cloud Shell Editor
👈 לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud (זהו סמל בצורת טרמינל בחלק העליון של חלונית Cloud Shell).
👈 לוחצים על הלחצן 'פתיחת כלי העריכה' (הוא נראה כמו תיקייה פתוחה עם עיפרון). ייפתח חלון של Cloud Shell Editor. בצד שמאל יופיע סייר הקבצים.

👈 לוחצים על הלחצן Cloud Code Sign-in (כניסה באמצעות קוד בענן) בשורת הסטטוס התחתונה, כמו שמוצג. נותנים הרשאה לפלאגין לפי ההוראות. אם בסרגל הסטטוס מופיע הכיתוב Cloud Code - no project, בוחרים באפשרות הזו, ואז בתפריט הנפתח 'Select a Google Cloud Project' בוחרים את הפרויקט הספציפי ב-Google Cloud שרוצים לעבוד איתו.
👈 פותחים את הטרמינל בסביבת הפיתוח המשולבת (IDE) בענן, 
👈 בטרמינל החדש, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list
👈 לוחצים על Activate Cloud Shell (הפעלת Cloud Shell) בחלק העליון של מסוף Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 מריצים את הפקודה הבאה כדי להפעיל את ממשקי Google Cloud API הנדרשים:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
בסרגל הכלים של Cloud Shell (בחלק העליון של חלונית Cloud Shell), לוחצים על הלחצן Open Editor (פתיחת העורך) (הוא נראה כמו תיקייה פתוחה עם עיפרון). ייפתח חלון עם Cloud Shell Code Editor. בצד שמאל יופיע סייר הקבצים.
👉 במסוף, מורידים את פרויקט Bootstrap Skeleton:
git clone https://github.com/weimeilin79/legal-eagle.git
אופציונלי: גרסה בספרדית
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
אחרי שמריצים את הפקודה הזו בטרמינל Cloud Shell, נוצרת תיקייה חדשה עם שם המאגר legal-eagle בסביבת Cloud Shell.
4. כתיבת אפליקציית ההסקה באמצעות Gemini Code Assist
בקטע הזה נתמקד בבניית הליבה של העוזר המשפטי שלנו – אפליקציית האינטרנט שמקבלת שאלות ממשתמשים ומתקשרת עם מודל ה-AI כדי ליצור תשובות. נשתמש ב-Gemini Code Assist כדי לכתוב את קוד ה-Python לחלק הזה של ההסקה.
בתחילה, ניצור אפליקציית Flask שמשתמשת בספריית LangChain כדי לתקשר ישירות עם מודל Gemini ב-Vertex AI. הגרסה הראשונה הזו תפעל כעוזר משפטי מועיל שמבוסס על הידע הכללי של המודל, אבל עדיין לא תהיה לו גישה למסמכים ספציפיים של תיקים משפטיים שלנו. כך נוכל לראות את ביצועי הבסיס של מודל ה-LLM לפני שנשפר אותו באמצעות RAG בהמשך.
בחלונית Explorer של Cloud Code Editor (בדרך כלל בצד שמאל), אמורה להופיע התיקייה שנוצרה כששיבטתם את מאגר Git legal-eagle, פותחים את תיקיית הבסיס של הפרויקט ב-Explorer. תופיע תיקיית משנה webapp, צריך לפתוח גם אותה. 
👈 כדי לערוך קובץ legal.py בעורך הקוד של Cloud Code, אפשר להשתמש בשיטות שונות כדי לתת הנחיות ל-Gemini Code Assist.
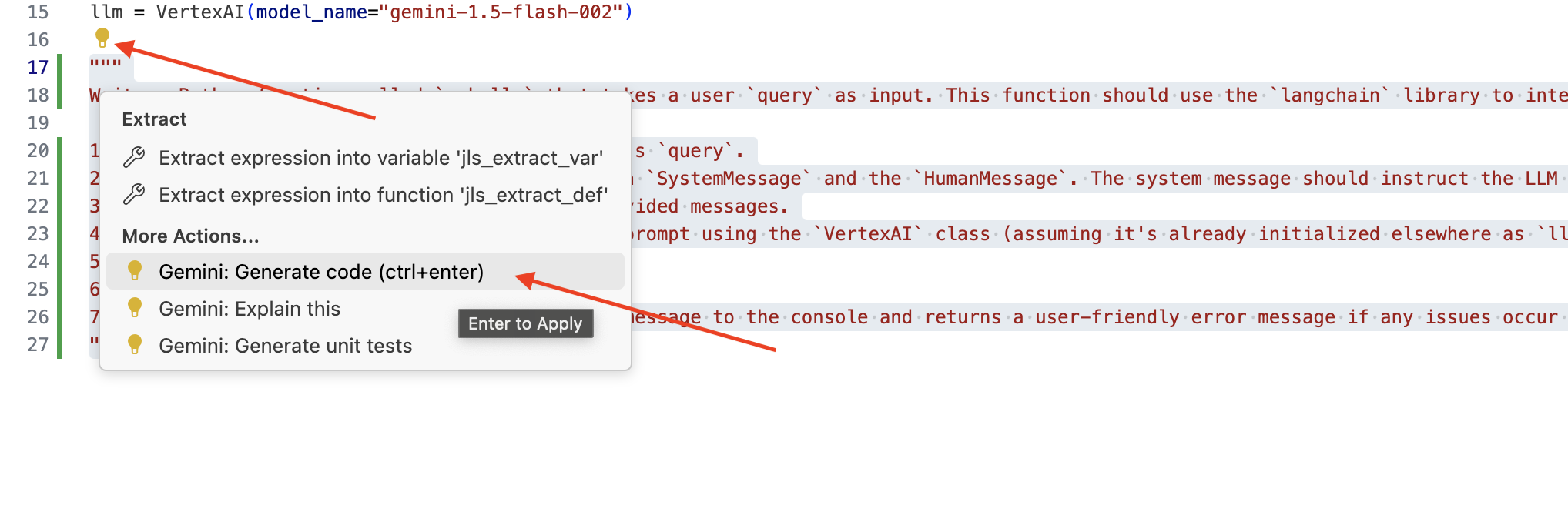
👉 מעתיקים את ההנחיה הבאה לחלק התחתון של legal.py, מתארים בבירור מה רוצים ש-Gemini Code Assist ייצור, לוחצים על סמל הנורה 💡 שמופיע ובוחרים באפשרות Gemini: Generate Code (יכול להיות שפריט התפריט המדויק יהיה שונה מעט בהתאם לגרסה של Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
בדיקה מדוקדקת של הקוד שנוצר
- האם הוא פועל בערך לפי השלבים שציינת בתגובה?
- האם הוא יוצר
ChatPromptTemplateעםSystemMessageועםHumanMessage? - האם הוא כולל טיפול בסיסי בשגיאות (
try...except)?
אם הקוד שנוצר טוב וברובו נכון, אפשר לאשר אותו (מקישים על Tab או על Enter כדי לאשר הצעות מוטבעות, או לוחצים על 'אישור' כדי לאשר בלוקים גדולים יותר של קוד).
אם הקוד שנוצר לא בדיוק מה שרציתם, או שיש בו שגיאות, אל דאגה! Gemini Code Assist הוא כלי שיעזור לכם, ולא כלי שיכתוב קוד מושלם בניסיון הראשון.
עורכים ומשנים את הקוד שנוצר כדי לשפר אותו, לתקן שגיאות ולהתאים אותו טוב יותר לדרישות שלכם. כדי להנחות את Gemini Code Assist בצורה נוספת, אפשר להוסיף עוד הערות או לשאול שאלות ספציפיות בחלונית הצ'אט של Code Assist.
אם אתם עדיין חדשים ב-SDK, הנה דוגמה מעשית.
👈 מעתיקים ומדביקים ומחליפים את הקוד הבא ב-legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 אופציונלי: גרסה בספרדית
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
לאחר מכן, יוצרים פונקציה לטיפול במסלול שיגיב לשאלות של המשתמשים.
פותחים את הקובץ main.py ב-Cloud Shell Editor. בדומה לאופן שבו יצרתם את ask_llm ב-legal.py, השתמשו ב-Gemini Code Assist כדי ליצור את Flask Route ואת הפונקציה ask_question. מקלידים את ההנחיה הבאה כתגובה ב-main.py: (חשוב להוסיף אותה לפני שמפעילים את אפליקציית Flask ב-if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
מאשרים רק אם הקוד שנוצר טוב וברובו נכון. אם אתם לא מכירים את Python, הנה דוגמה פעילה.העתיקו והדביקו את הקוד הזה אל main.py מתחת לקוד שכבר נמצא שם.
👈 חשוב להקפיד להדביק את הקוד הבא לפני תחילת אפליקציית האינטרנט (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
אם תפעלו לפי השלבים האלה, תוכלו להפעיל את Gemini Code Assist, להגדיר את הפרויקט ולהשתמש בו כדי ליצור את הפונקציה ask בקובץ main.py.
5. בדיקה מקומית ב-Cloud Editor
👈 במסוף של העורך,מתקינים ספריות תלויות ומפעילים את ממשק האינטרנט באופן מקומי.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
מחפשים הודעות הפעלה בפלט של הטרמינל ב-Cloud Shell. בדרך כלל, Flask מדפיס הודעות שמציינות שהוא פועל ובאיזה יציאה.
- הפעלה בכתובת http://127.0.0.1:8080
האפליקציה צריכה להמשיך לפעול כדי לטפל בבקשות.
👈 בתפריט 'תצוגה מקדימה באינטרנט', בוחרים באפשרות תצוגה מקדימה ביציאה 8080. ב-Cloud Shell תיפתח כרטיסייה חדשה בדפדפן או חלון חדש עם תצוגה מקדימה של האפליקציה באינטרנט. 
👉 בממשק של האפליקציה, מקלידים כמה שאלות שקשורות באופן ספציפי להפניות למקרים משפטיים, ובודקים איך ה-LLM מגיב. לדוגמה, תוכלו לנסות:
- כמה שנים במאסר נשפט מייקל בראון?
- כמה כסף בחיובים לא מורשים נוצר כתוצאה מהפעולות של דנה כהן?
- איזה תפקיד מילאו העדויות של השכנים בחקירת המקרה של אמילי וייט?
👉 אופציונלי: גרסה בספרדית
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
אם תתבוננו בתשובות, סביר להניח שתשימו לב שהמודל עלול להמציא תשובות, להיות מעורפל או כללי, ולפעמים לפרש לא נכון את השאלות שלכם, במיוחד כי עדיין אין לו גישה למסמכים משפטיים ספציפיים.
👉 מומלץ להפסיק את הסקריפט על ידי הקשה על Ctrl+C.
👈 כדי לצאת מהסביבה הווירטואלית, מריצים את הפקודה הבאה במסוף:
deactivate
6. הגדרת מאגר וקטורים
הגיע הזמן לשים סוף ל'פרשנויות היצירתיות' של החוק שנוצרות על ידי מודלים גדולים של שפה (LLM). כאן נכנס לתמונה דור משופר של אחזור (RAG). אפשר לחשוב על זה כאילו אנחנו נותנים למודל השפה הגדול שלנו גישה לספרייה משפטית עוצמתית במיוחד, ממש לפני שהוא עונה על השאלות שלכם. במקום להסתמך רק על הידע הכללי שלה (שיכול להיות לא מדויק או מיושן, בהתאם למודל), טכנולוגיית RAG מאחזרת קודם מידע רלוונטי ממקור מהימן – במקרה שלנו, מסמכים משפטיים – ואז משתמשת בהקשר הזה כדי ליצור תשובה מושכלת ומדויקת הרבה יותר. זה כמו שמודל ה-LLM עושה את שיעורי הבית שלו לפני שהוא נכנס לאולם בית המשפט.
כדי לבנות את מערכת ה-RAG שלנו, אנחנו צריכים מקום לאחסן בו את כל המסמכים המשפטיים האלה, וחשוב מכך, לאפשר חיפוש שלהם לפי משמעות. כאן נכנס לתמונה Firestore. Firestore הוא מסד נתונים גמיש, ניתן להרחבה ולא רלציוני (NoSQL) של מסמכים ב-Google Cloud.
נשתמש ב-Firestore בתור מאגר הווקטורים שלנו. נאחסן קטעים ממסמכים משפטיים ב-Firestore, ולכל קטע נאחסן גם את ההטמעה שלו – הייצוג המספרי של המשמעות שלו.
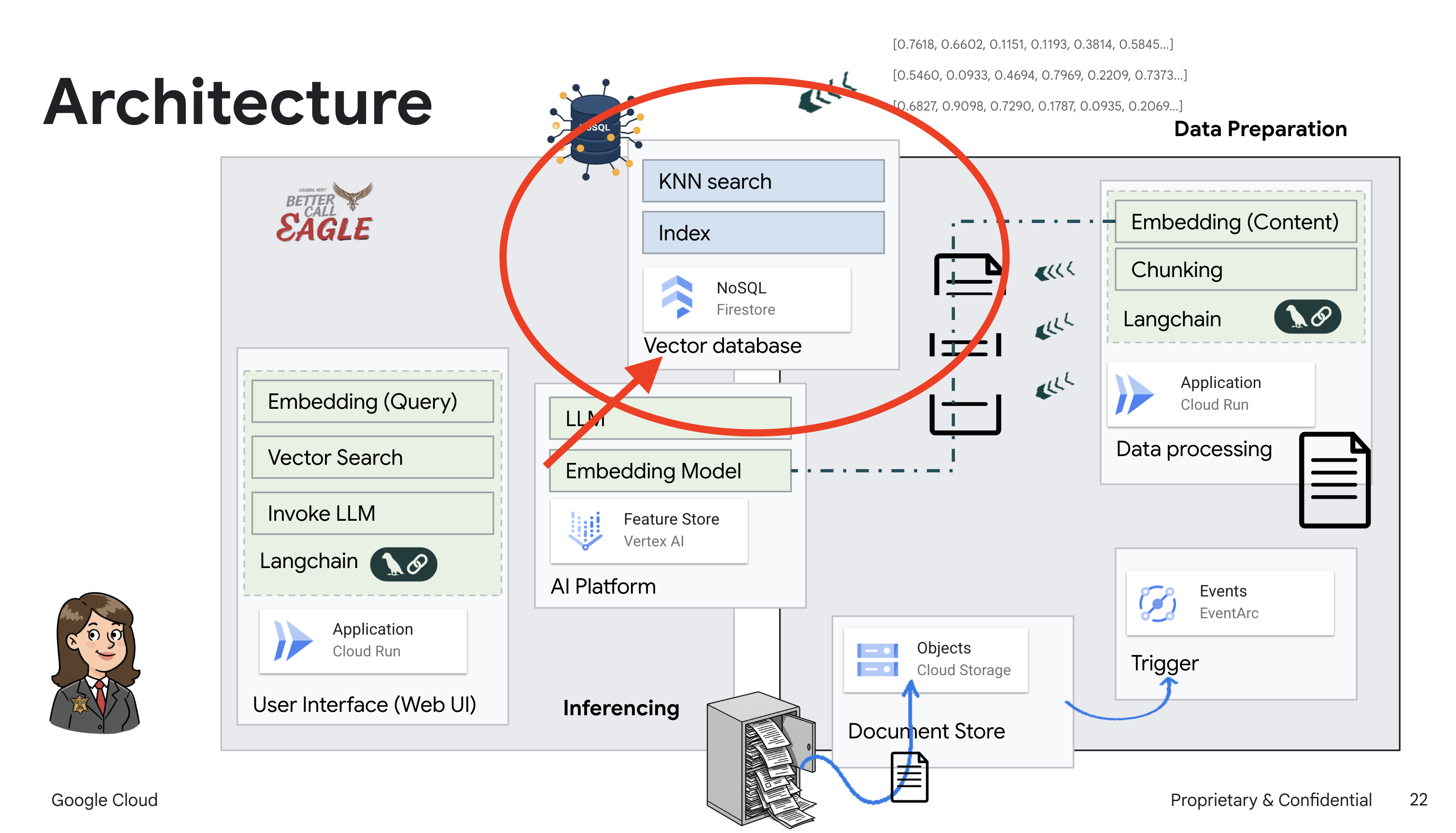
לאחר מכן, כששואלים את Legal Eagle שאלה, אנחנו משתמשים בחיפוש וקטורי של Firestore כדי למצוא את חלקי הטקסט המשפטי שהכי רלוונטיים לשאילתה. ההקשר הזה הוא מה ש-RAG משתמש בו כדי לתת לכם תשובות שמבוססות על מידע משפטי אמיתי, ולא רק על הדמיון של ה-LLM.
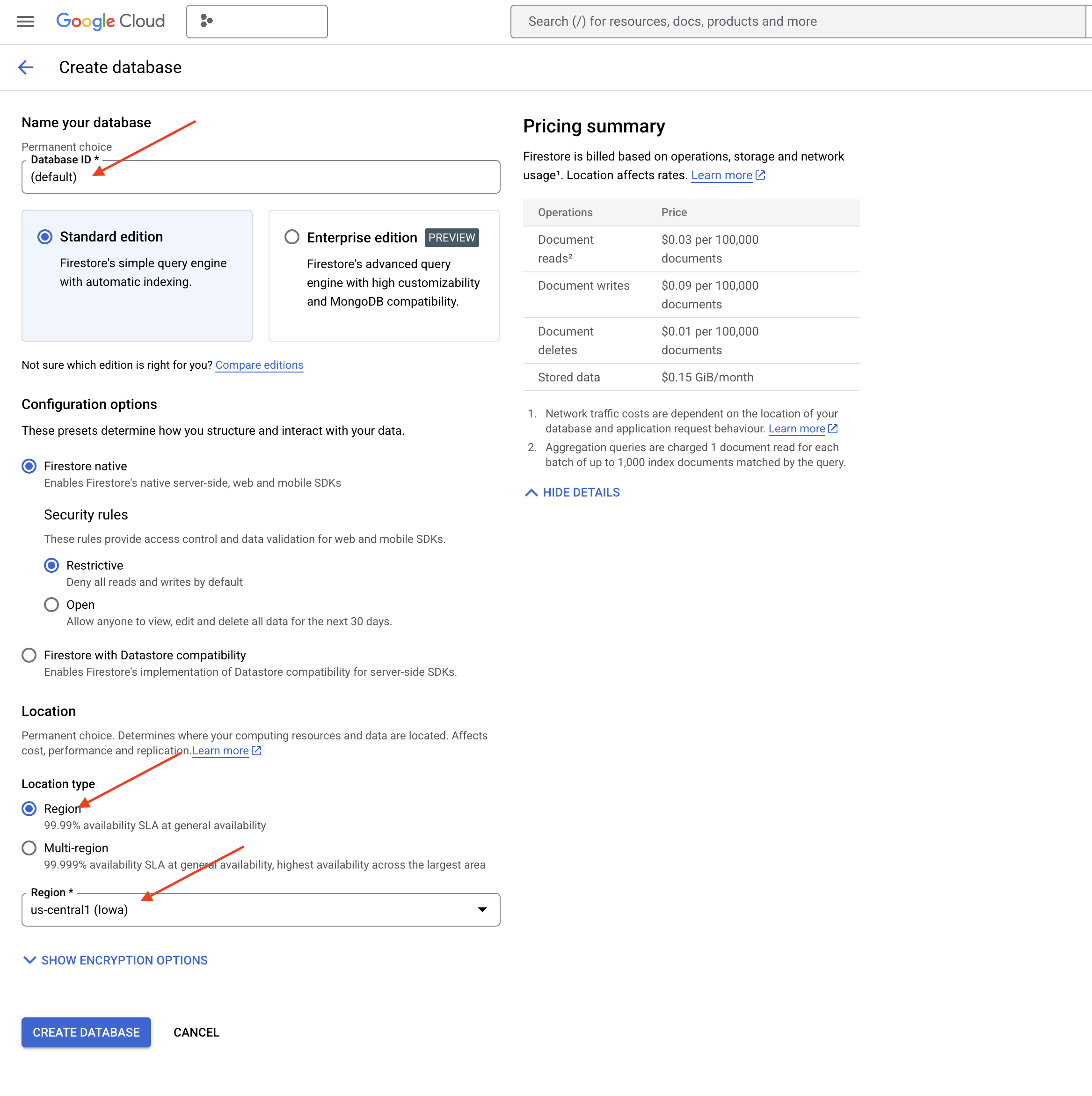
👈 בכרטיסייה או בחלון חדשים, נכנסים ל-Firestore במסוף Google Cloud.
👈 לוחצים על יצירת מסד נתונים.
👈 בוחרים באפשרות Native mode ומזינים את שם מסד הנתונים (default).
👈 בוחרים באפשרות region: us-central1 , ולוחצים על יצירת מסד נתונים. מערכת Firestore תקצה את מסד הנתונים, והתהליך הזה עשוי להימשך כמה רגעים.
👈 בחזרה במסוף של Cloud IDE – יוצרים אינדקס וקטורי בשדה embedding_vector, כדי להפעיל חיפוש וקטורי בקולקציית legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore יתחיל ליצור את אינדקס הווקטורים. יצירת האינדקס יכולה לקחת זמן, במיוחד כשמדובר במערכי נתונים גדולים. האינדקס יופיע במצב 'יצירה', וכשהוא יהיה מוכן הוא יעבור למצב 'מוכן'. 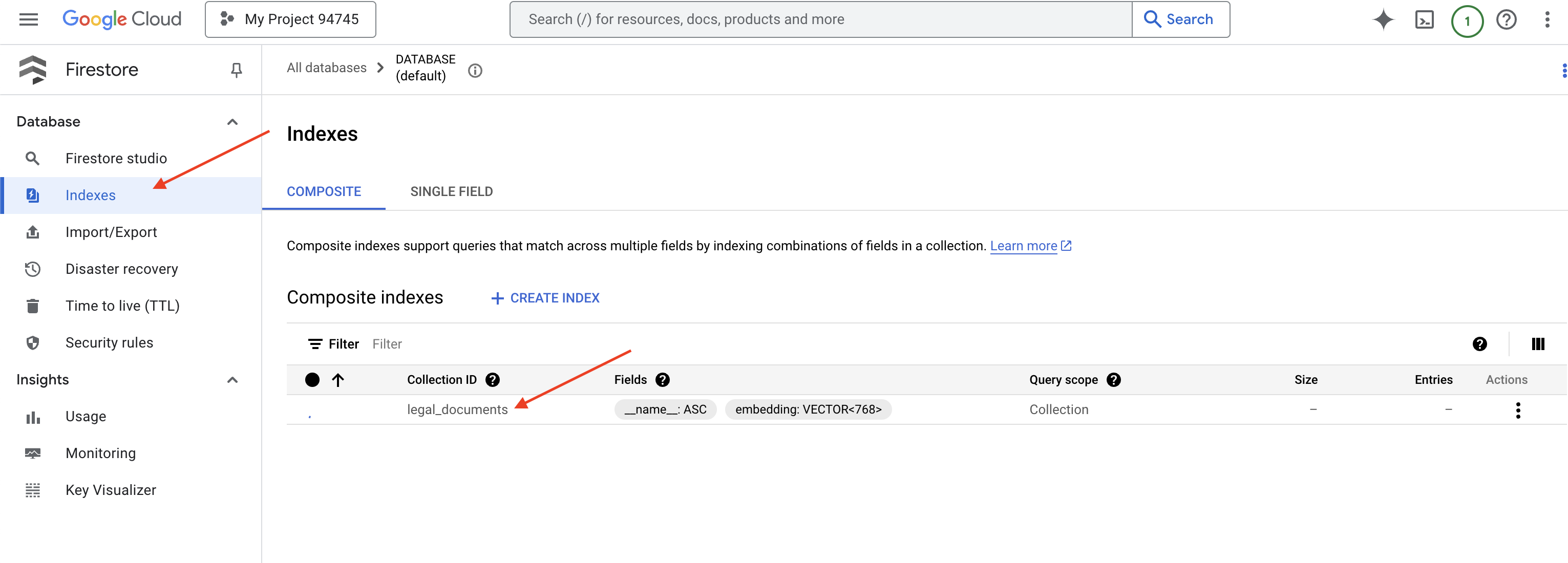
7. טעינת נתונים למאגר הווקטורים
אחרי שהבנו מה זה RAG ומה זה מאגר וקטורים, הגיע הזמן לבנות את המנוע שממלא את הספרייה המשפטית שלנו! אז איך אפשר להפוך מסמכים משפטיים ל'ניתנים לחיפוש לפי משמעות'? הקסם נמצא בהטמעות! אפשר לחשוב על הטמעות כהמרת מילים, משפטים או אפילו מסמכים שלמים לווקטורים מספריים – רשימות של מספרים שמייצגות את המשמעות הסמנטית שלהם. מושגים דומים מקבלים וקטורים שקרובים זה לזה במרחב הווקטורי. אנחנו משתמשים במודלים מתקדמים (כמו אלה מ-Vertex AI) כדי לבצע את ההמרה הזו.
כדי להפוך את טעינת המסמכים לאוטומטית, נשתמש בפונקציות Cloud Run וב-Eventarc. פונקציות Cloud Run הוא קונטיינר קל משקל ללא שרת שמריץ את הקוד רק כשצריך. אנחנו נארוז את סקריפט Python לעיבוד מסמכים בקונטיינר ונפרוס אותו כפונקציית Cloud Run.
👈 בכרטיסייה או בחלון חדשים, עוברים אל Cloud Storage.
👈 בתפריט הימני, לוחצים על 'מאגרי נתונים'.
👈 לוחצים על הכפתור '+ יצירה' בחלק העליון.
👉 הגדרת קטגוריה (הגדרות חשובות):
- bucket name: ‘yourprojectID'-doc-bucket (חובה להוסיף את הסיומת -doc-bucket בסוף)
- region: בוחרים את האזור
us-central1. - סוג אחסון: Standard. Standard מתאים לנתונים שניגשים אליהם לעיתים קרובות.
- בקרת גישה: משאירים את ברירת המחדל 'בקרת גישה אחידה' מסומנת. כך מתקבלת בקרת גישה עקבית ברמת הקטגוריה.
- אפשרויות מתקדמות: בדרך כלל הגדרות ברירת המחדל מספיקות ללימוד הזה.
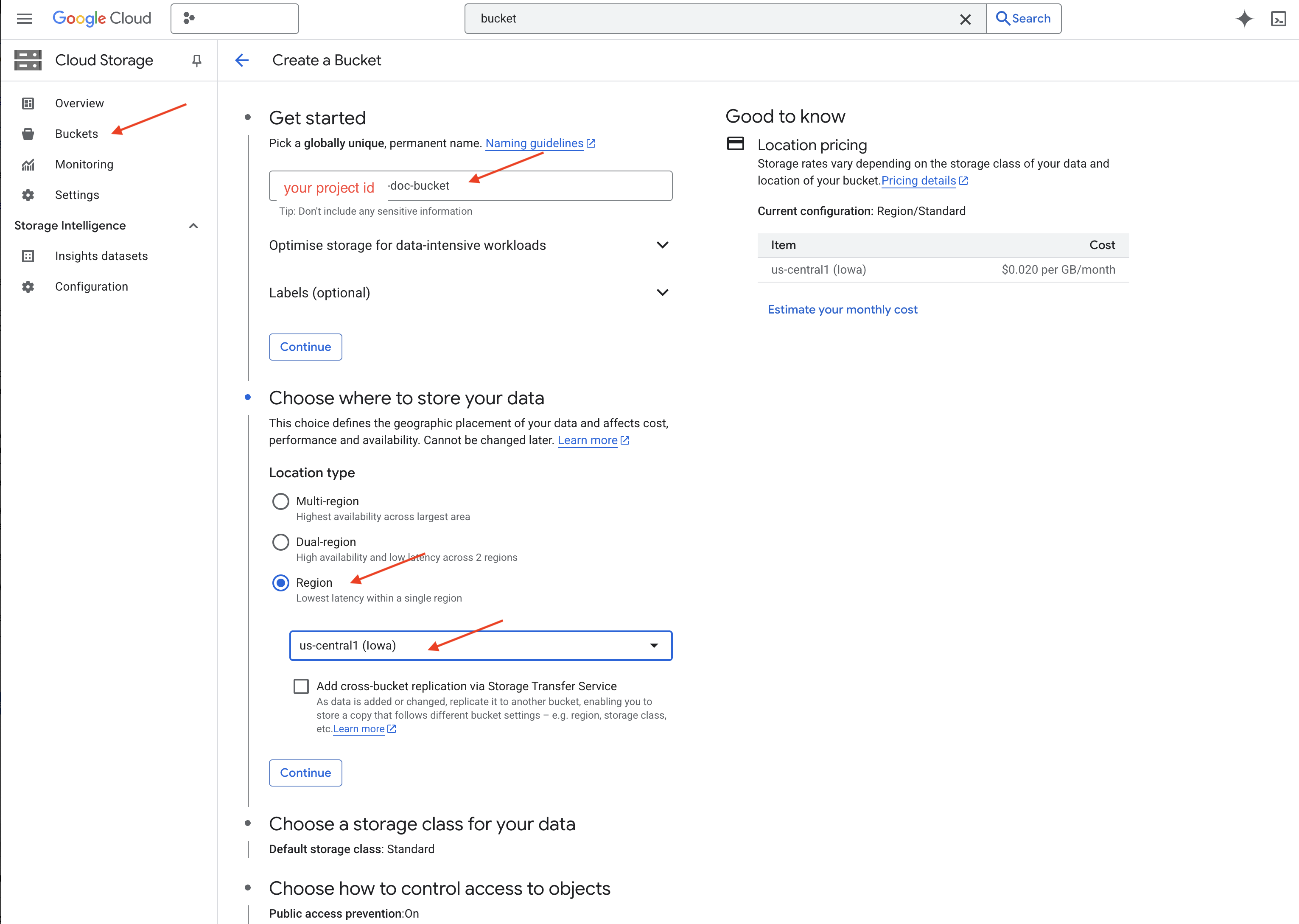
👉 לוחצים על הלחצן CREATE כדי ליצור את הקטגוריה.
👈 יכול להיות שיופיע חלון קופץ לגבי מניעת גישה ציבורית. משאירים את התיבה מסומנת ולוחצים על 'אישור'.
עכשיו הקטגוריה החדשה שיצרתם תופיע ברשימת הקטגוריות. חשוב לזכור את שם הקטגוריה, כי תצטרכו אותו בהמשך.
8. הגדרת פונקציית Cloud Run
👈 ב-Cloud Shell Code Editor, עוברים לספריית העבודה legal-eagle: משתמשים בפקודה cd בטרמינל של Cloud Editor כדי ליצור את התיקייה.
cd ~/legal-eagle
mkdir loader
cd loader
👈 יוצרים קבצים ב-main.py,requirements.txt ו-Dockerfile. בטרמינל של Cloud Shell, משתמשים בפקודה touch כדי ליצור את הקבצים:
touch main.py requirements.txt Dockerfile
תוצג התיקייה החדשה שנוצרה בשם *loader ושלושת הקבצים.
👈 עורכים את main.py בתיקייה loader. בסייר הקבצים בצד ימין, עוברים אל הספרייה שבה יצרתם את הקבצים ולוחצים לחיצה כפולה על main.py כדי לפתוח אותה בעורך.
מדביקים את קוד Python הבא ב-main.py:
האפליקציה הזו מעבדת קבצים חדשים שמועלים לקטגוריה ב-GCS, מפצלת את הטקסט לחלקים, יוצרת הטמעות לכל חלק ומאחסנת את החלקים וההטמעות שלהם ב-Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
עורכים את requirements.txt.מדביקים את השורות הבאות בקובץ:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. בדיקה ויצירה של פונקציית Cloud Run
👈 נריץ את הפקודה הזו בסביבה וירטואלית ונתקין את ספריות Python הנדרשות לפונקציית Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👈 הפעלת אמולטור מקומי לפונקציית Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👈 משאירים את הטרמינל האחרון פתוח, פותחים טרמינל חדש ומריצים את הפקודה להעלאת קובץ לקטגוריה.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👈 בזמן שהאמולטור פועל, אפשר לשלוח אליו CloudEvents לבדיקה. לצורך הפעולה הזו, תצטרכו טרמינל נפרד בסביבת הפיתוח המשולבת.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
התשובה צריכה להיות OK.
👈 כדי לאמת את הנתונים ב-Firestore, עוברים אל מסוף Google Cloud, אל Databases (מסדי נתונים) ואז אל Firestore, בוחרים בכרטיסייה Data (נתונים) ואז באוסף legal_documents. תראו שנוצרו מסמכים חדשים באוסף, כל אחד מהם מייצג חלק מהטקסט בקובץ שהועלה. 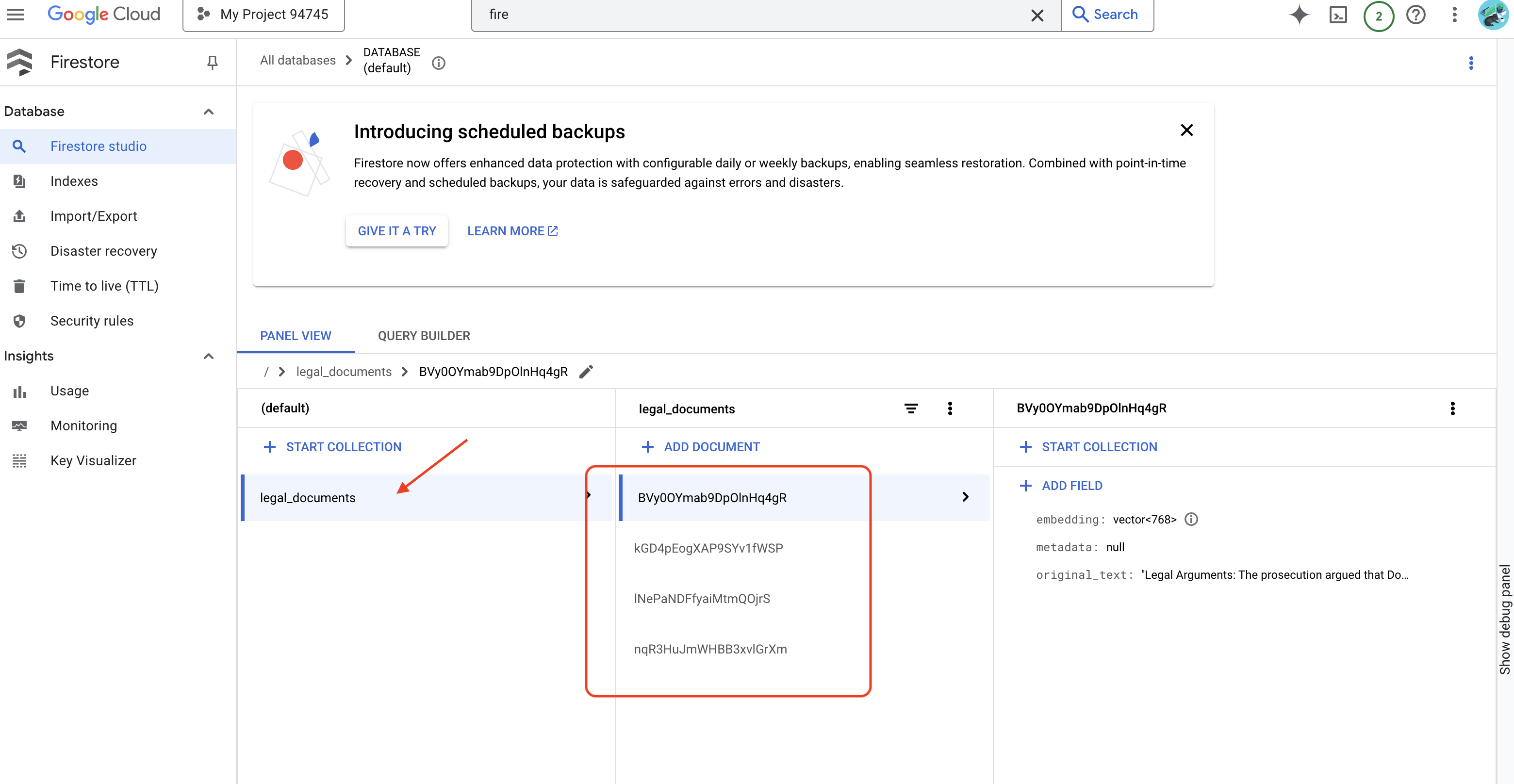
👈 בטרמינל שבו פועל האמולטור, מקלידים Ctrl+C כדי לצאת. וסוגרים את הטרמינל השני.
👈 מריצים את הפקודה deactivate כדי לצאת מהסביבה הווירטואלית.
deactivate
10. יצירת קובץ אימג' של קונטיינר והעברה בדחיפה למאגרי Artifacts
👈 הגיע הזמן לפרוס את זה בענן. בסייר הקבצים, לוחצים לחיצה כפולה על Dockerfile. מבקשים מ-Gemini ליצור את קובץ ה-Dockerfile, פותחים את Gemini Code Assist ומשתמשים בהנחיה הבאה כדי ליצור את הקובץ.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
מומלץ ללחוץ על השוואה עם קובץ פתוח(שני חצים בכיוונים מנוגדים) ולאשר את השינויים. 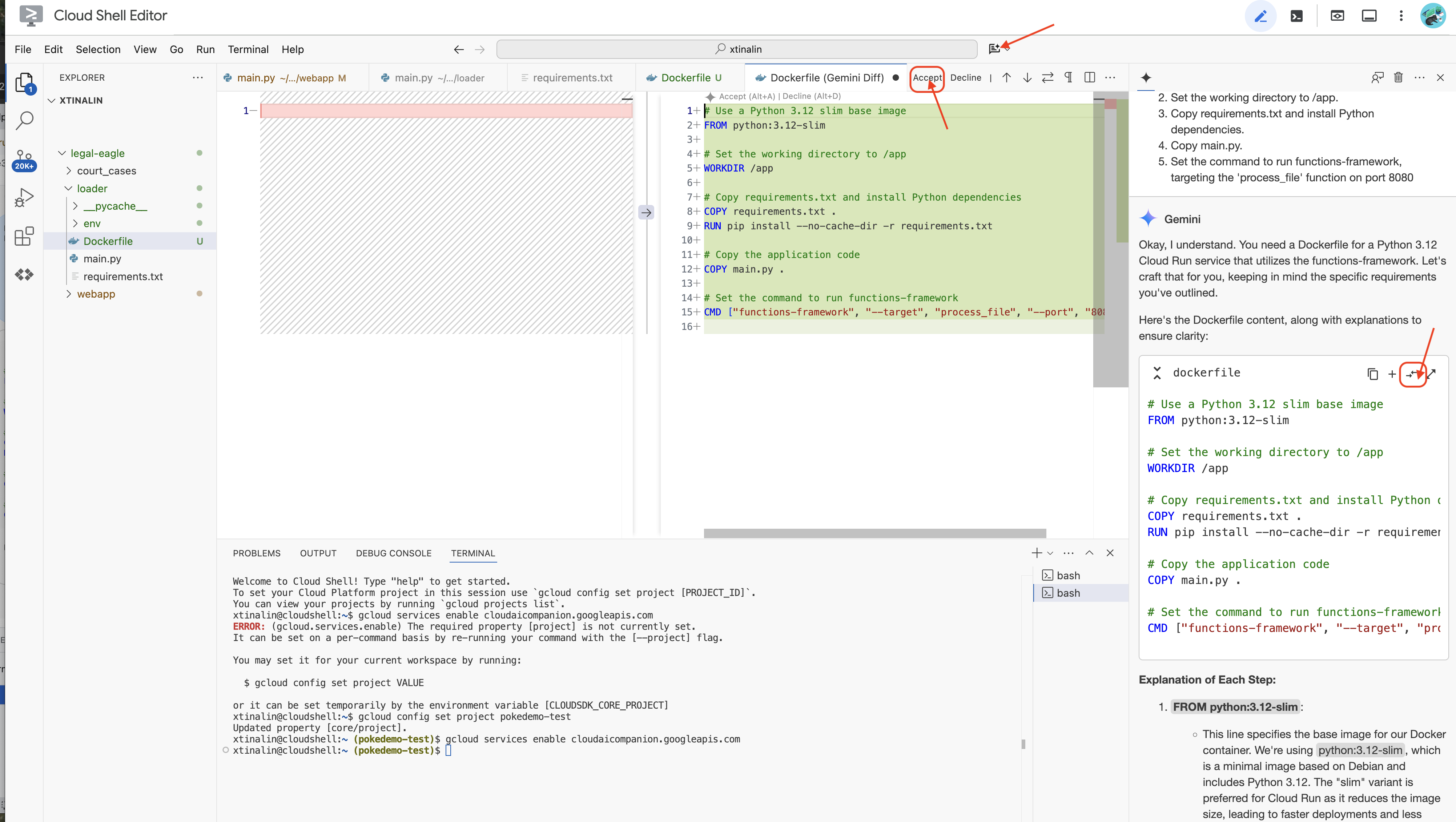
👈 אם אין לכם ניסיון עם מאגרי תגים, הנה דוגמה מעשית:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👈 בטרמינל, יוצרים מאגר ארטיפקטים לאחסון תמונת ה-Docker שאנחנו הולכים ליצור.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
אמור להופיע הכיתוב נוצר מאגר [my-repository].
👈 מריצים את הפקודה הבאה כדי ליצור את קובץ האימג' של Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👈 עכשיו צריך להעביר את זה למרשם
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
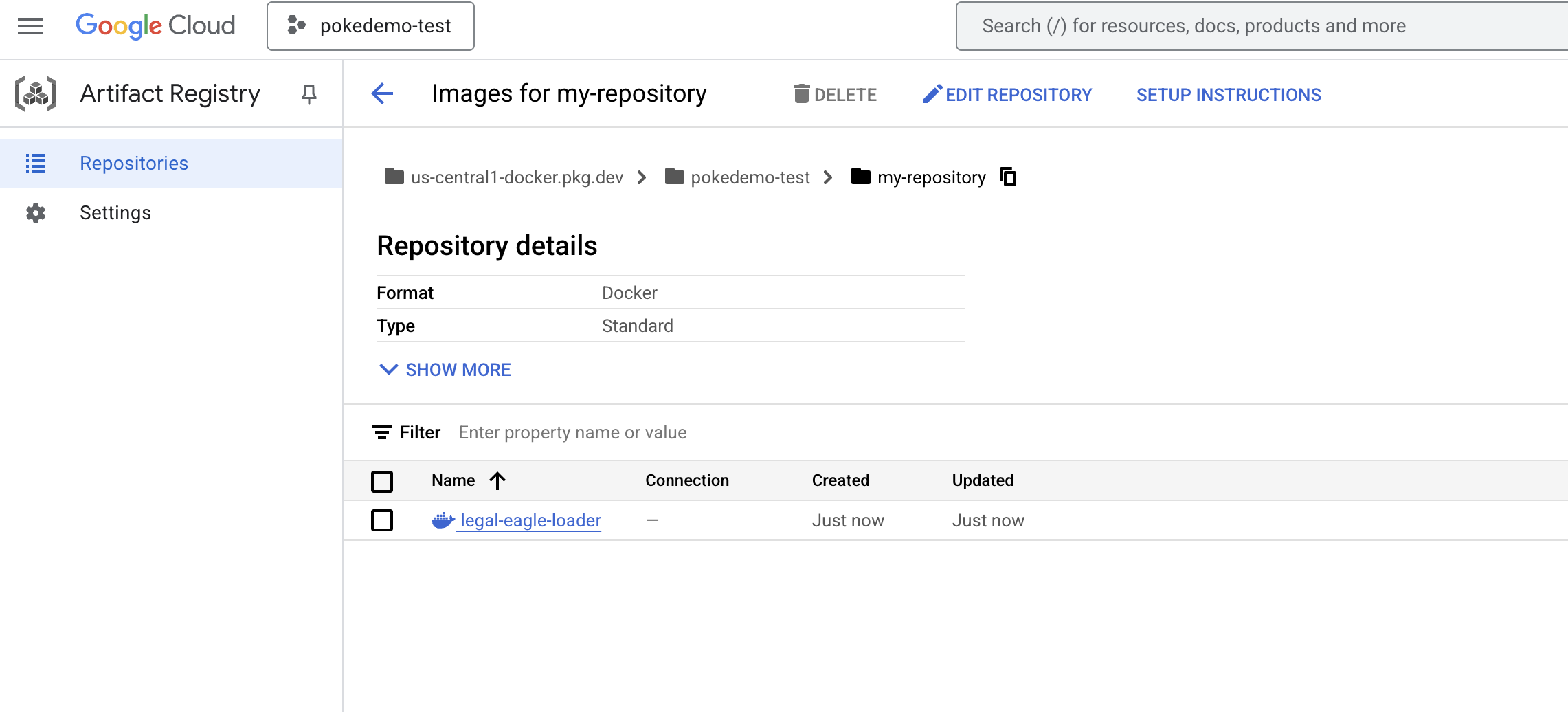
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
קובץ אימג' של Docker זמין עכשיו ב-my-repository Artifacts Repository.
11. יצירת פונקציית Cloud Run והגדרת טריגר Eventarc
לפני שנעמיק בפרטים של פריסת טוען המסמכים המשפטיים שלנו, נסביר בקצרה על הרכיבים שמעורבים בתהליך: Cloud Run היא פלטפורמה מנוהלת ללא שרת (serverless) שמאפשרת לפרוס אפליקציות בקונטיינרים במהירות ובקלות. הוא מסתיר את ניהול התשתית, ומאפשר לכם להתמקד בכתיבה ובפריסה של הקוד.
נפרוס את טוען המסמכים שלנו כשירות Cloud Run. עכשיו נמשיך להגדיר את פונקציית Cloud Run:
👈 ב-Google Cloud Console, עוברים אל Cloud Run.
👈 עוברים אל Deploy Container (פריסת מאגר תגים) ובתפריט הנפתח לוחצים על SERVICE (שירות).
👈 מגדירים את שירות Cloud Run:
- קובץ אימג' של קונטיינר: לוחצים על 'בחירה' בשדה כתובת ה-URL. מאתרים את כתובת ה-URL של התמונה שדחפתם ל-Artifact Registry (לדוגמה, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- שם השירות:
legal-eagle-loader - אזור: בוחרים את האזור
us-central1. - אימות: לצורך הסדנה הזו, אפשר לאפשר 'הפעלת קריאות לא מאומתות'. בסביבת ייצור, כדאי להגביל את הגישה.
- Container, Networking, Security (קונטיינר, רשת, אבטחה): ברירת מחדל.
👈 לוחצים על יצירה. השירות ייפרס ב-Cloud Run. 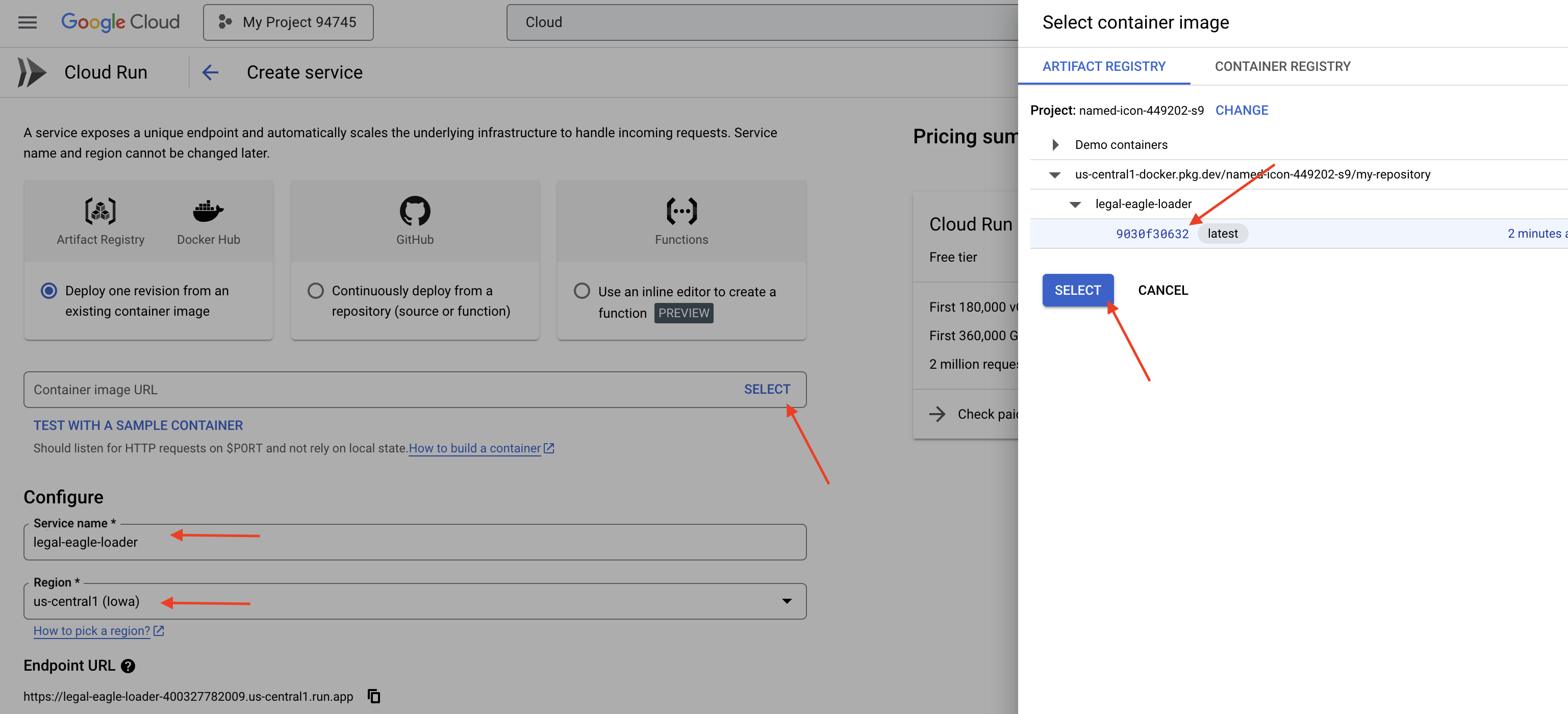
כדי להפעיל את השירות הזה באופן אוטומטי כשמוסיפים קבצים חדשים לקטגוריית האחסון, נשתמש ב-Eventarc. Eventarc מאפשר לכם ליצור ארכיטקטורות מבוססות-אירועים על ידי ניתוב אירועים ממקורות שונים לשירותים שלכם.
הגדרנו את Eventarc, ולכן השירות שלנו ב-Cloud Run יטען באופן אוטומטי את המסמכים החדשים שנוספו ל-Firestore ברגע שהם יועלו. כך אפשר לעדכן את הנתונים בזמן אמת באפליקציית ה-RAG שלנו.
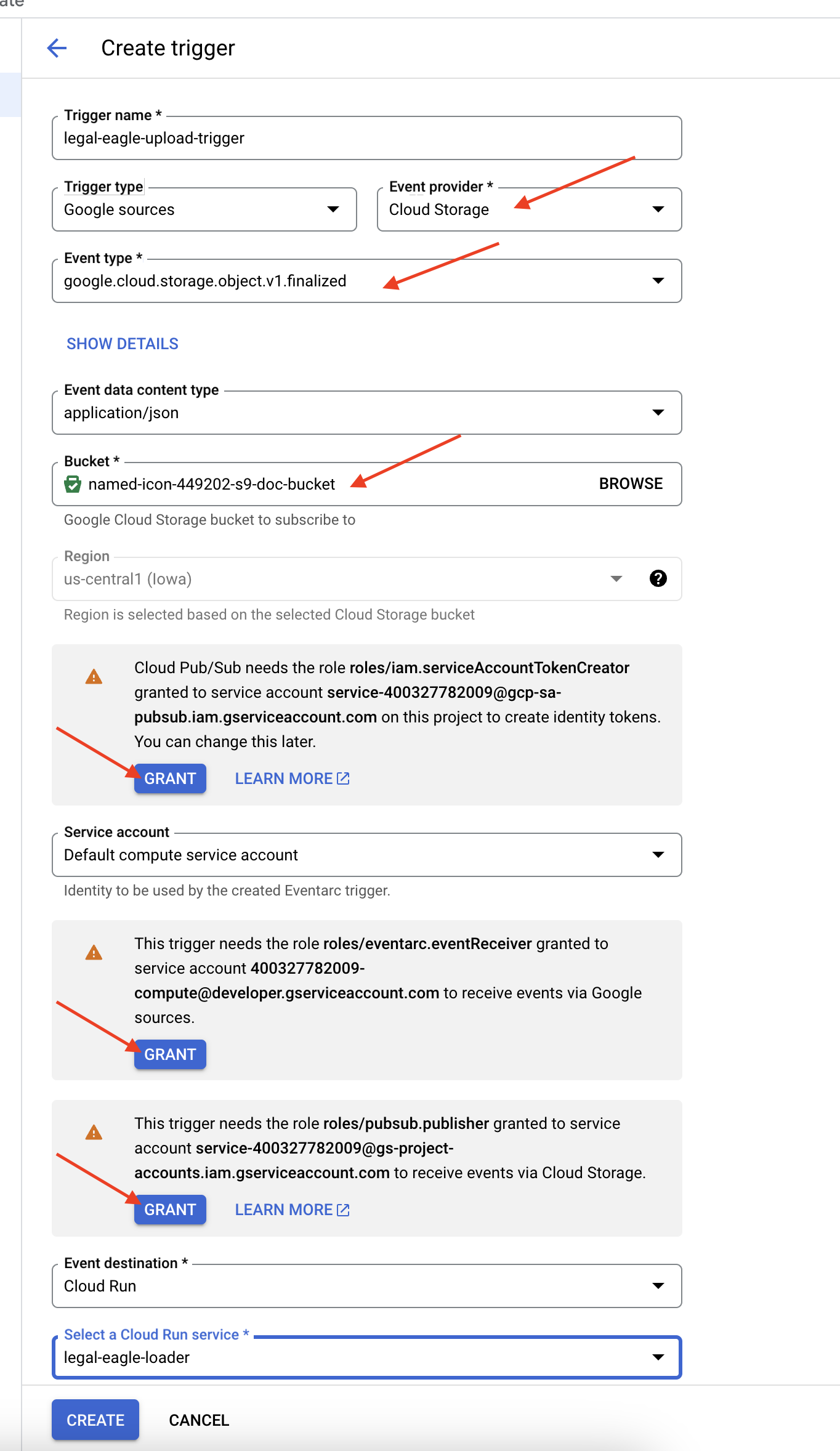
👈 במסוף Google Cloud, עוברים אל Triggers בקטע EventArc. לוחצים על '+ יצירת טריגר'. 👉 הגדרת טריגר Eventarc:
- שם הטריגר:
legal-eagle-upload-trigger. - TriggerType: Google Sources
- ספק האירועים: בוחרים באפשרות Cloud Storage.
- סוג האירוע: בוחרים באפשרות
google.cloud.storage.object.v1.finalized - קטגוריה של Cloud Storage: בוחרים את הקטגוריה של GCS מהתפריט הנפתח.
- סוג היעד: Cloud Run service (שירות Cloud Run).
- שירות: בוחרים באפשרות
legal-eagle-loader. - אזור:
us-central1 - נתיב: כרגע משאירים את השדה הזה ריק .
- נותנים את כל ההרשאות שהוצגו בדף
👈 לוחצים על יצירה. מערכת Eventarc תגדיר עכשיו את הטריגר.
לשירות Cloud Run דרושה הרשאה לקרוא קבצים מרכיבים שונים. צריך להעניק לחשבון השירות של השירות את ההרשאה שהוא צריך.
12. העלאת מסמכים משפטיים לקטגוריית GCS
👈 מעלים את קובץ התיק המשפטי לקטגוריה ב-GCS. חשוב לזכור להחליף את שם הקטגוריה.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
כדי לעקוב אחרי יומני שירות של Cloud Run, עוברים אל Cloud Run -> השירות שלכם legal-eagle-loader -> 'יומנים'. בודקים ביומנים אם יש הודעות על עיבוד מוצלח, כולל:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
בהתאם למהירות ההגדרה של הרישום ביומן, תוכלו לראות כאן גם יומנים מפורטים יותר
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
מחפשים הודעות שגיאה ביומנים ומבצעים פתרון בעיות אם יש צורך. 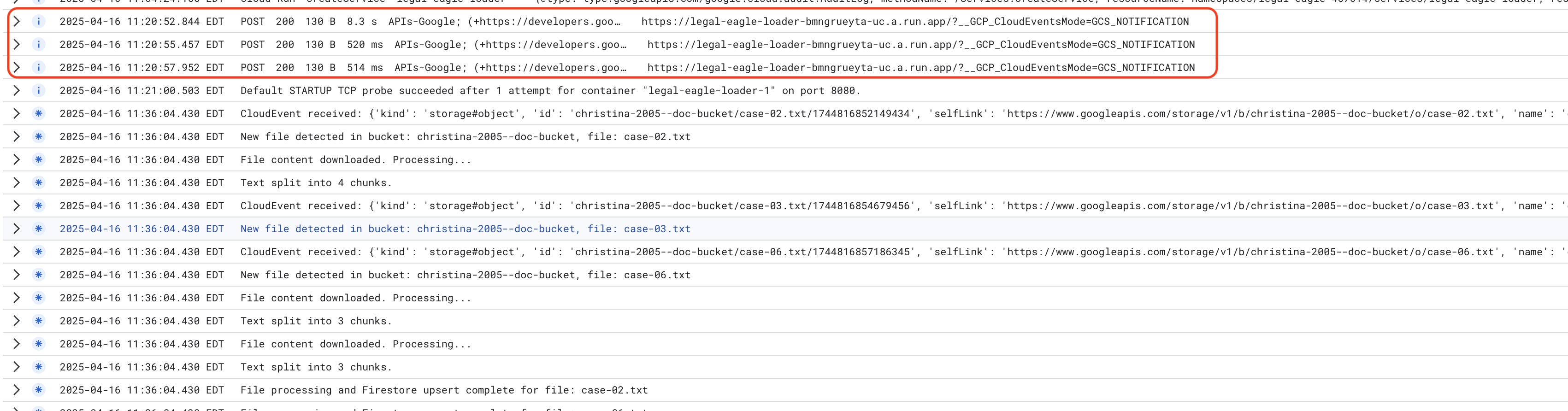
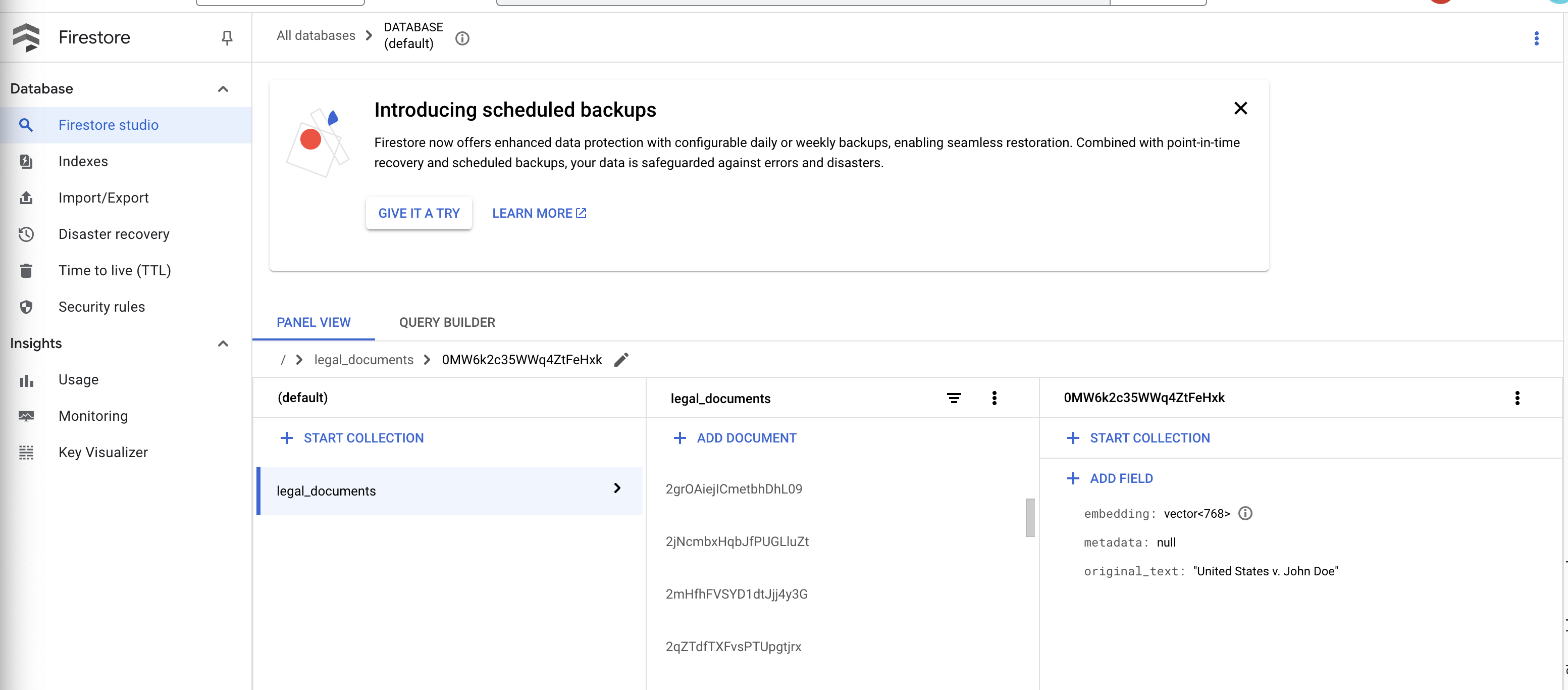
👈 מאמתים את הנתונים ב-Firestore. פותחים את האוסף legal_documents.
👈 אמורים להופיע מסמכים חדשים שנוצרו באוסף. כל מסמך ייצג חלק מהטקסט בקובץ שהעליתם ויכלול:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. הטמעה של RAG
LangChain הוא framework רב-עוצמה שנועד לייעל את הפיתוח של אפליקציות שמבוססות על מודלים גדולים של שפה (LLM). במקום להתמודד ישירות עם המורכבות של ממשקי LLM API, הנדסת הנחיות וטיפול בנתונים, LangChain מספקת שכבת הפשטה ברמה גבוהה. הוא מציע רכיבים וכלים מוכנים מראש למשימות כמו חיבור למודלים שונים של שפה גדולה (LLM) (כמו אלה של OpenAI, Google או אחרים), בניית שרשראות מורכבות של פעולות (למשל, אחזור נתונים ואחריו סיכום) וניהול זיכרון שיחות.
במקרה של RAG, מאגרי וקטורים ב-LangChain חיוניים להפעלת ההיבט של אחזור המידע ב-RAG. אלה מסדי נתונים ייעודיים שנועדו לאחסן ולשאילתות הטמעה של וקטורים בצורה יעילה, שבה קטעי טקסט דומים מבחינה סמנטית ממופים לנקודות קרובות במרחב וקטורי. LangChain מטפל בפרטים הטכניים ברמה הנמוכה, ומאפשר למפתחים להתמקד בלוגיקה ובפונקציונליות העיקריות של אפליקציית ה-RAG שלהם. השימוש ב-Vertex AI Search מקצר משמעותית את זמן הפיתוח ומפשט את התהליך, ומאפשר לכם ליצור אב טיפוס ולפרוס במהירות אפליקציות מבוססות RAG, תוך ניצול העמידות והמדרגיות של תשתית הענן של Google Cloud.
אחרי ההסבר על LangChain, צריך לעדכן את הקובץ legal.py בתיקייה webapp של הטמעת ה-RAG. כך מודל ה-LLM יוכל לחפש מסמכים רלוונטיים ב-Firestore לפני שיספק תשובה.
👈 מייבאים את FirestoreVectorStore ומודולים נדרשים אחרים מ-langchain ומ-vertexai. מוסיפים את הטקסט הבא לקובץ legal.py הנוכחי:
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👈 מאתחלים את Vertex AI ואת מודל ההטמעה.תשתמשו ב-text-embedding-004. מוסיפים את הקוד הבא מיד אחרי ייבוא המודולים.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 יוצרים FirestoreVectorStore שמפנה לקולקציית legal_documents, באמצעות מודל ההטמעה שאותחל ומציינים את שדות התוכן וההטמעה. מוסיפים את הקוד הזה מיד אחרי הקוד של מודל ההטמעה הקודם.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👈 מגדירים פונקציה בשם search_resource שמקבלת שאילתה, מבצעת חיפוש דמיון באמצעות vector_store.similarity_search ומחזירה את התוצאות המשולבות.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 מחליפים את הפונקציה ask_llm ומשתמשים בפונקציה search_resource כדי לאחזר הקשר רלוונטי על סמך השאילתה של המשתמש.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 אופציונלי: גרסה בספרדית
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👈 אחרי שמטמיעים את RAG בקובץ legal.py, צריך לבדוק אותו באופן מקומי לפני הפריסה. מריצים את האפליקציה באמצעות הפקודה:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👈 משתמשים ב-webpreview כדי לגשת לאפליקציה, מדברים עם העוזר הווירטואלי ומקלידים ctrl+c כדי לצאת מהתהליך שמופעל באופן מקומי. מריצים את הפקודה deactivate כדי לצאת מהסביבה הווירטואלית.
deactivate
👈 כדי לפרוס את אפליקציית האינטרנט ב-Cloud Run, התהליך דומה לפריסה של פונקציית הטעינה. תבנו את קובץ האימג' של Docker, תתייגו אותו ותעבירו אותו בדחיפה ל-Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👈 הגיע הזמן לפרוס את אפליקציית האינטרנט ב-Google Cloud. במסוף, מריצים את הפקודות הבאות:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
כדי לוודא שהפריסה בוצעה, עוברים אל Cloud Run במסוף Google Cloud.אמור להופיע שירות חדש בשם legal-eagle-webapp.
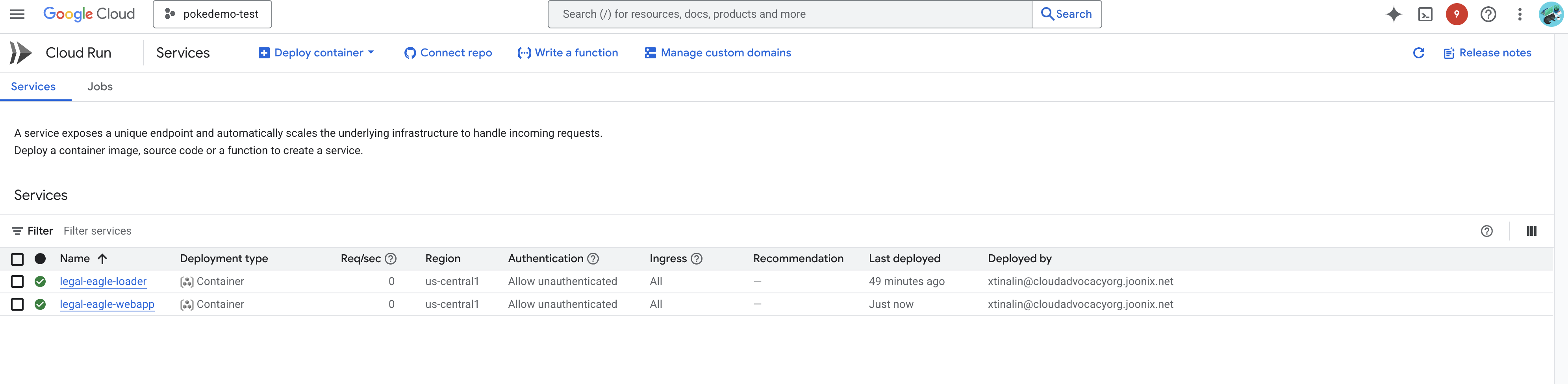
לוחצים על השירות כדי לעבור לדף הפרטים שלו. כתובת ה-URL שנפרסה מופיעה בחלק העליון של הדף. 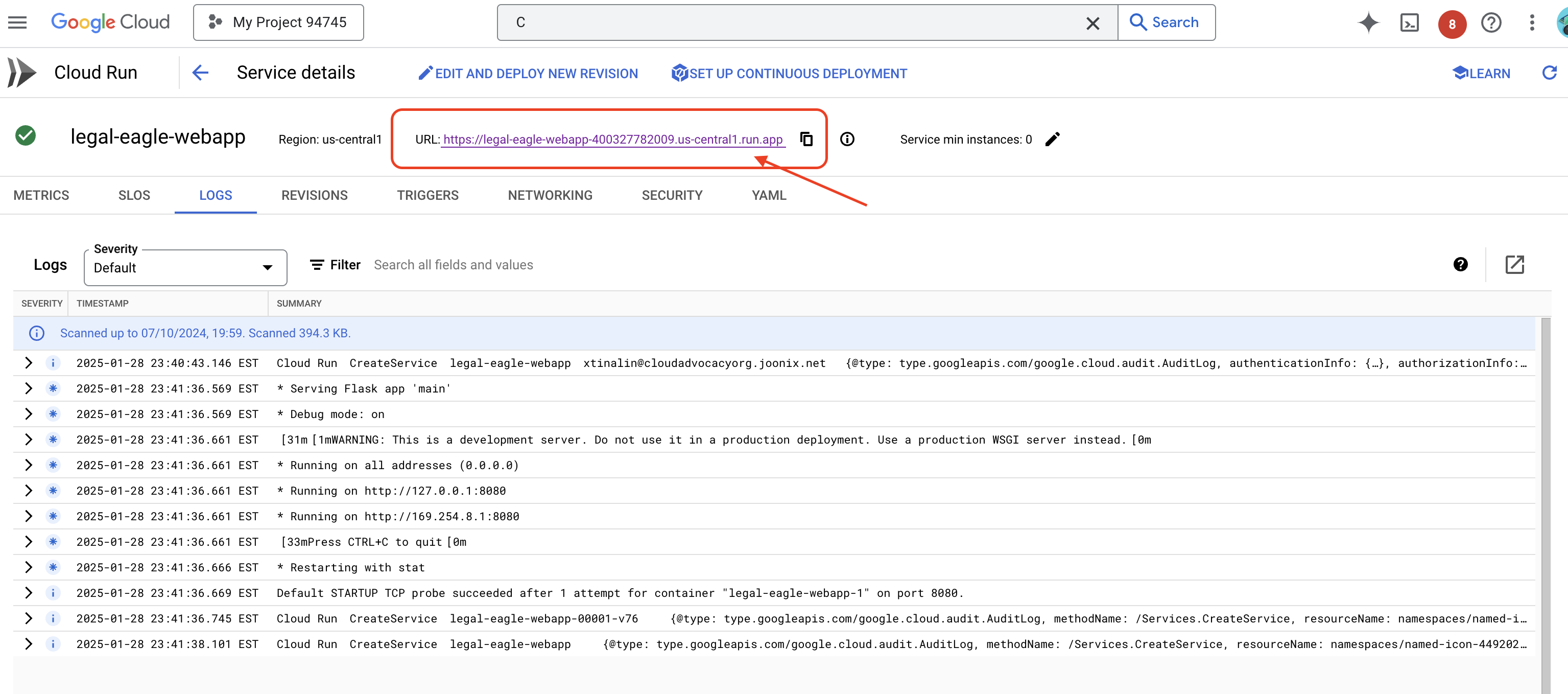
👈 עכשיו, פותחים את כתובת ה-URL שנפרסה בכרטיסייה חדשה בדפדפן. אתם יכולים לקיים אינטראקציה עם העוזר המשפטי ולשאול שאלות שקשורות לתיקי בית המשפט שהעליתם(בתיקייה court_cases):
- כמה שנים במאסר נשפט מייקל בראון?
- כמה כסף בחיובים לא מורשים נוצר כתוצאה מהפעולות של דנה כהן?
- איזה תפקיד מילאו העדויות של השכנים בחקירת המקרה של אמילי וייט?
👉 אופציונלי: גרסה בספרדית
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
אפשר לראות שהתשובות עכשיו מדויקות יותר ומבוססות על התוכן של המסמכים המשפטיים שהעליתם. זהו כוחו של RAG!
כל הכבוד על השלמת הסדנה!! יצרתם ופרסתם בהצלחה אפליקציה לניתוח מסמכים משפטיים באמצעות מודלים גדולים של שפה (LLM), LangChain ו-Google Cloud. למדתם איך להטמיע ולעבד מסמכים משפטיים, להוסיף מידע רלוונטי לתשובות של מודלים גדולים של שפה (LLM) באמצעות RAG, ולפרוס את האפליקציה כשירות ללא שרת. הידע הזה והאפליקציה שתיבנו יעזרו לכם לחקור לעומק את היכולות של מודלים גדולים של שפה (LLM) למשימות משפטיות. כל הכבוד!"
14. האתגר
סוגי מדיה מגוונים::
איך להטמיע ולעבד סוגי מדיה שונים, כמו סרטונים מהמשפט והקלטות אודיו, ולחלץ טקסט רלוונטי.
נכסים אונליין:
איך מעבדים נכסים אונליין כמו דפי אינטרנט בזמן אמת.