
1. परिचय
मुझे हमेशा से ही कोर्टरूम की कार्यवाही में दिलचस्पी रही है. मैं हमेशा से ही यह कल्पना करता रहा हूं कि मैं कोर्टरूम की जटिलताओं को आसानी से समझ पाऊंगा और दमदार तरीके से फ़ैसले के पक्ष में अपनी दलीलें रख पाऊंगा. हालाँकि, अब मैं वकालत नहीं करता, लेकिन मुझे यह बताते हुए खुशी हो रही है कि एआई की मदद से, हम सभी का कोर्टरूम में बहस करने का सपना पूरा हो सकता है.

आज हम Google के एआई टूल इस्तेमाल करने का तरीका जानेंगे. जैसे, Vertex AI, Firestore, और Cloud Run Functions. इनकी मदद से, कानूनी डेटा को प्रोसेस और समझा जा सकता है. साथ ही, बहुत तेज़ी से खोज की जा सकती है. इसके अलावा, हो सकता है कि इनकी मदद से, अपने काल्पनिक क्लाइंट (या खुद) को मुश्किल स्थिति से बाहर निकाला जा सके.
आपको किसी गवाह से जिरह नहीं करनी है, लेकिन हमारे सिस्टम की मदद से, आपको ढेर सारी जानकारी को आसानी से समझने, साफ़ तौर पर जवाब जनरेट करने, और कुछ ही सेकंड में सबसे काम का डेटा पेश करने में मदद मिलेगी.
2. आर्किटेक्चर
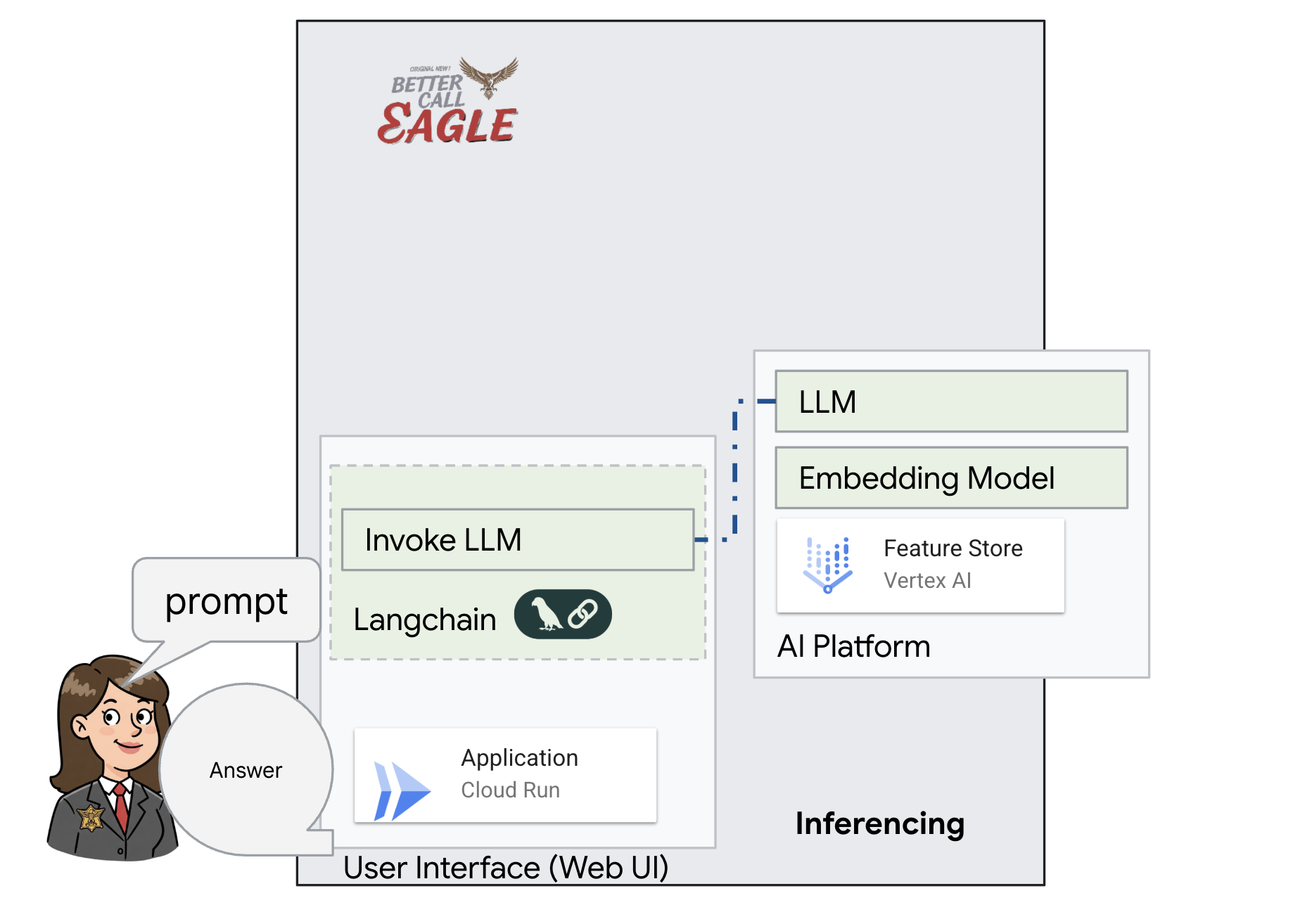
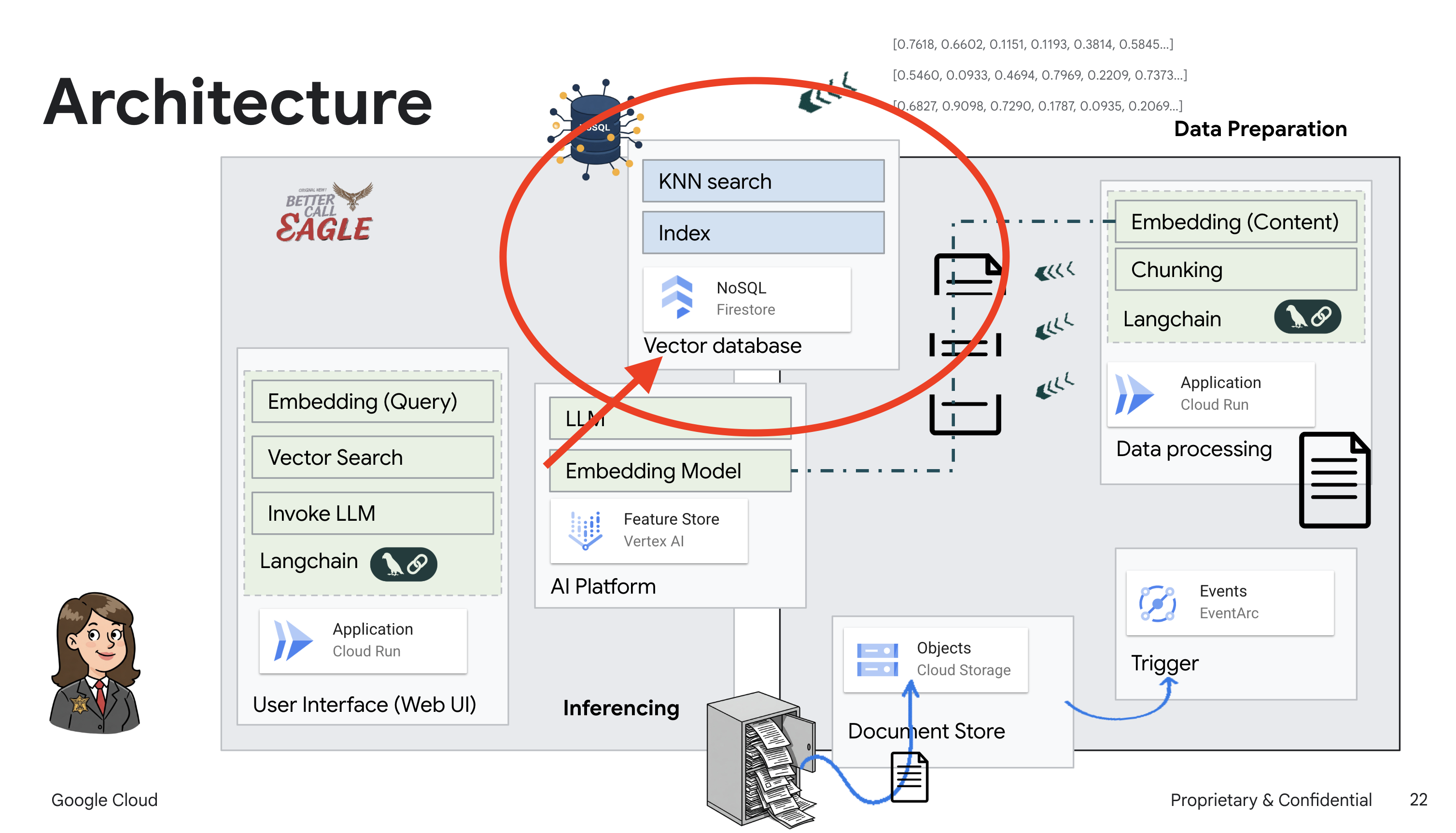
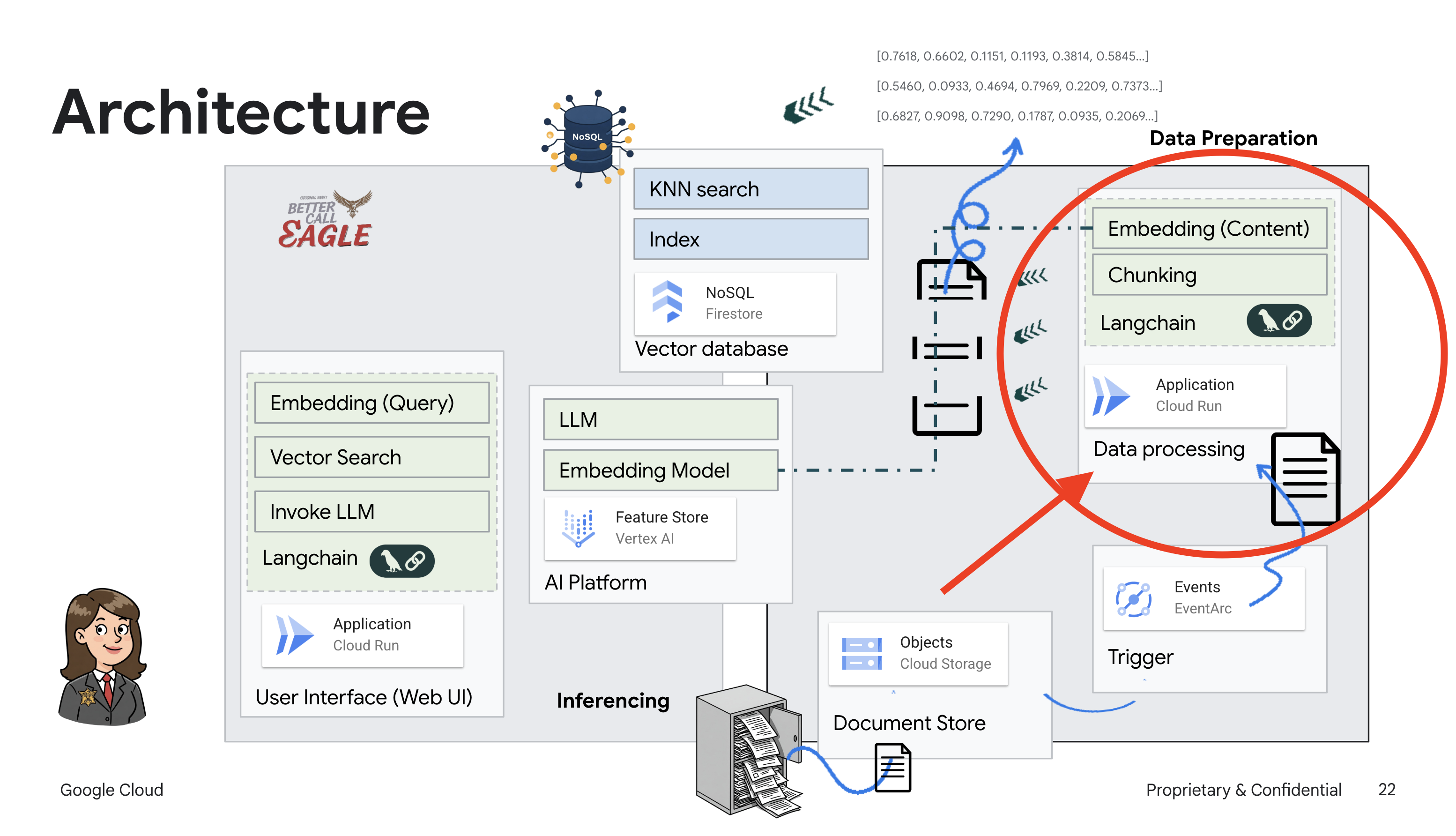
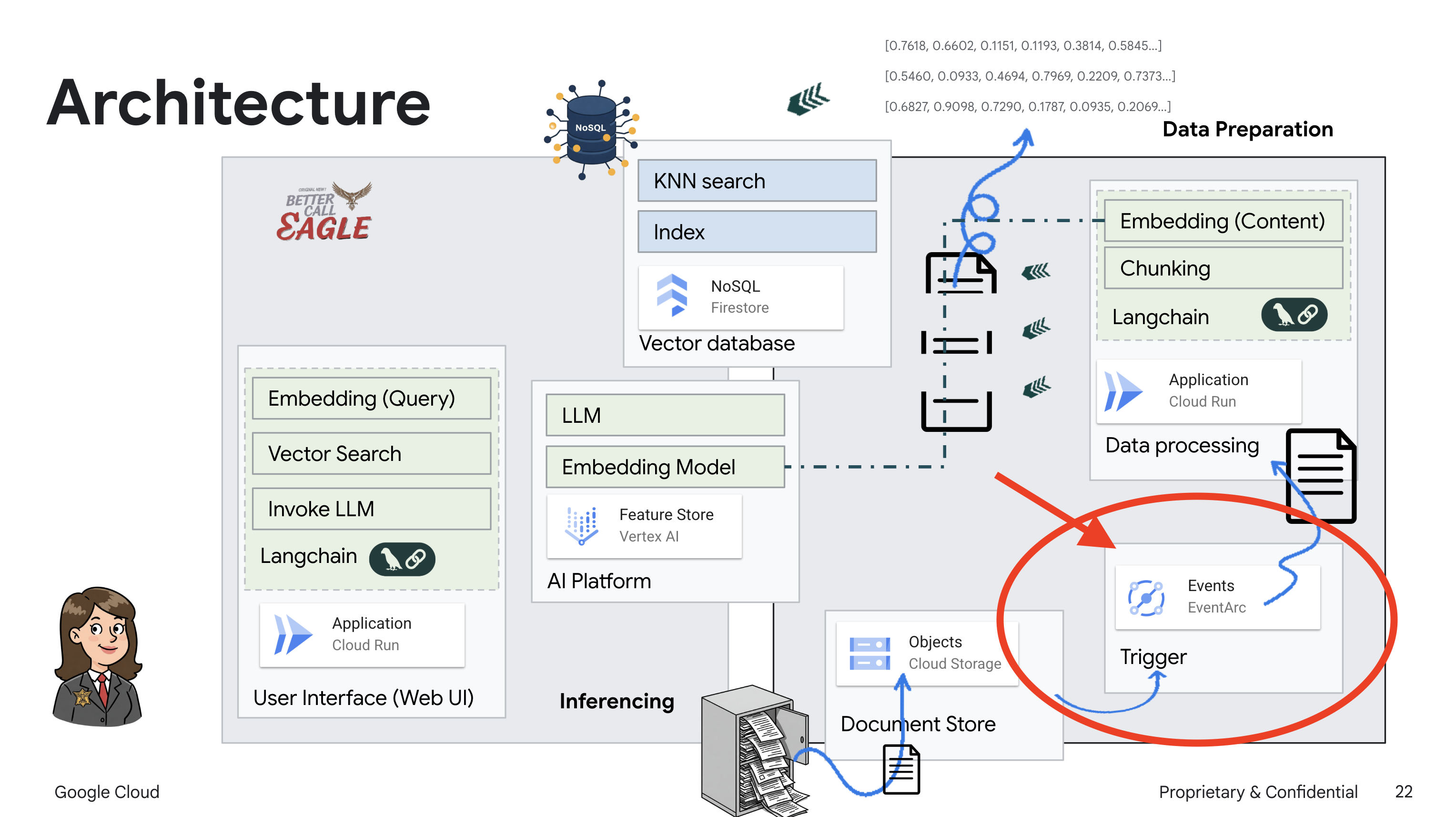
इस प्रोजेक्ट में, Google Cloud के एआई टूल का इस्तेमाल करके कानूनी मामलों में मदद करने वाला एक टूल बनाया गया है. इसमें इस बात पर ज़ोर दिया गया है कि कानूनी डेटा को कैसे प्रोसेस किया जाए, उसे कैसे समझा जाए, और उसे कैसे खोजा जाए. इस सिस्टम को इस तरह से डिज़ाइन किया गया है कि यह बहुत सारी जानकारी को आसानी से समझ सकता है, खास जानकारी जनरेट कर सकता है, और काम का डेटा तेज़ी से दिखा सकता है. कानूनी मामलों में मदद करने वाले एआई के आर्किटेक्चर में कई मुख्य कॉम्पोनेंट शामिल होते हैं:
बिना स्ट्रक्चर वाले डेटा से नॉलेज बेस बनाना: Google Cloud Storage (GCS) का इस्तेमाल, कानूनी दस्तावेज़ों को सेव करने के लिए किया जाता है. Firestore, एक NoSQL डेटाबेस है. यह वेक्टर स्टोर के तौर पर काम करता है. इसमें दस्तावेज़ के चंक और उनसे जुड़ी एम्बेडिंग होती हैं. Firestore में वेक्टर सर्च की सुविधा चालू होती है, ताकि मिलती-जुलती चीज़ों को खोजा जा सके. जब GCS पर कोई नया कानूनी दस्तावेज़ अपलोड किया जाता है, तो Eventarc, Cloud Run फ़ंक्शन को ट्रिगर करता है. यह फ़ंक्शन, दस्तावेज़ को प्रोसेस करता है. इसके लिए, दस्तावेज़ को छोटे-छोटे हिस्सों में बांटा जाता है. इसके बाद, Vertex AI के टेक्स्ट एम्बेडिंग मॉडल का इस्तेमाल करके, हर हिस्से के लिए एम्बेडिंग जनरेट की जाती है. इसके बाद, इन एम्बेडिंग को टेक्स्ट के हिस्सों के साथ Firestore में सेव किया जाता है. 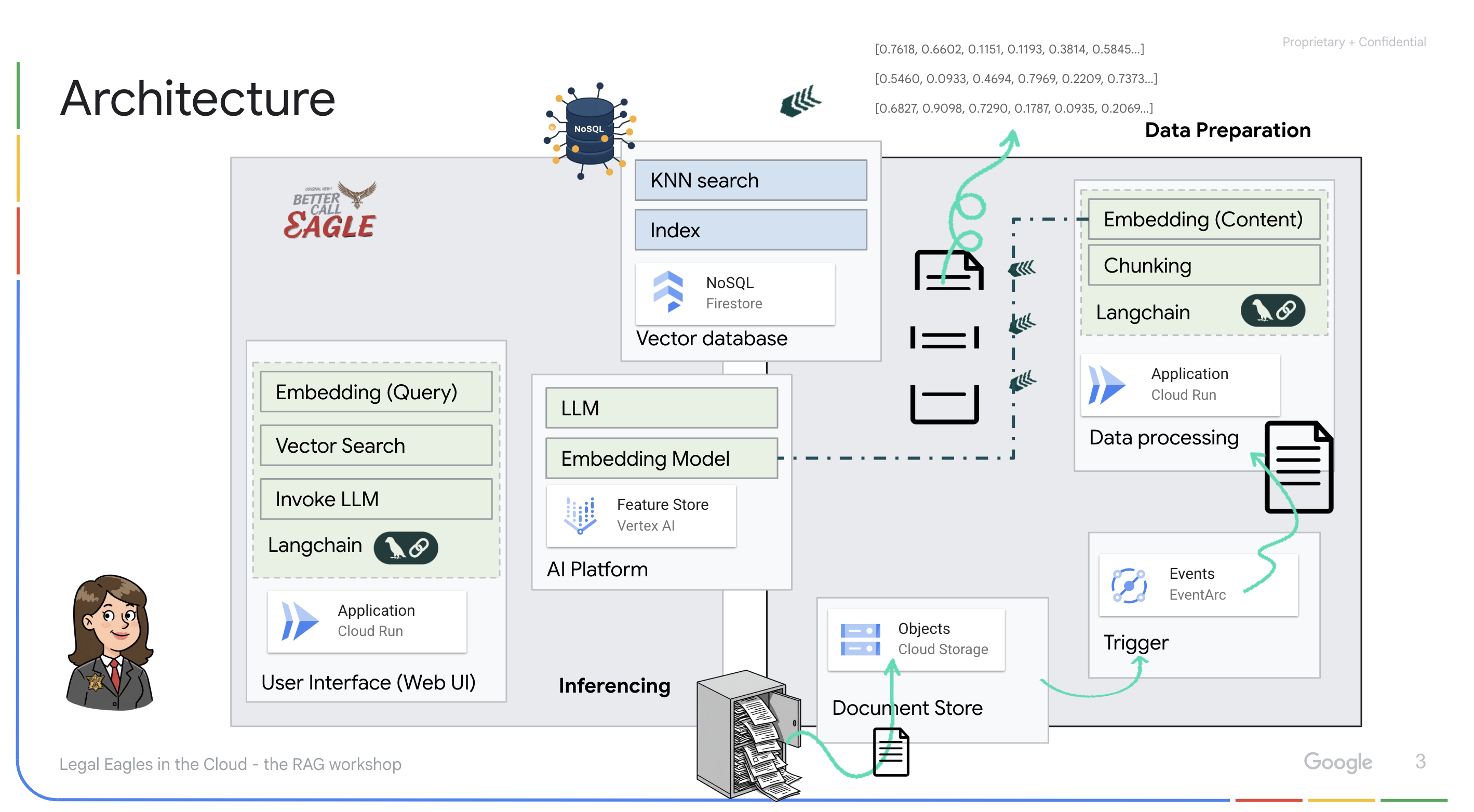
एलएलएम और आरएजी की मदद से काम करने वाला ऐप्लिकेशन : सवाल-जवाब वाले सिस्टम का मुख्य हिस्सा ask_llm फ़ंक्शन है. यह langchain लाइब्रेरी का इस्तेमाल करके, Vertex AI Gemini लार्ज लैंग्वेज मॉडल के साथ इंटरैक्ट करता है. यह उपयोगकर्ता की क्वेरी से एक HumanMessage बनाता है. इसमें एक SystemMessage भी शामिल होता है, जो एलएलएम को मददगार कानूनी सहायक के तौर पर काम करने का निर्देश देता है. सिस्टम, जानकारी पाने के लिए जनरेटिव एआई (आरएजी) का इस्तेमाल करता है. इसमें, किसी क्वेरी का जवाब देने से पहले, सिस्टम search_resource फ़ंक्शन का इस्तेमाल करके, Firestore वेक्टर स्टोर से काम का कॉन्टेक्स्ट पाता है. इसके बाद, इस कॉन्टेक्स्ट को SystemMessage में शामिल किया जाता है, ताकि एलएलएम का जवाब, दी गई कानूनी जानकारी पर आधारित हो. 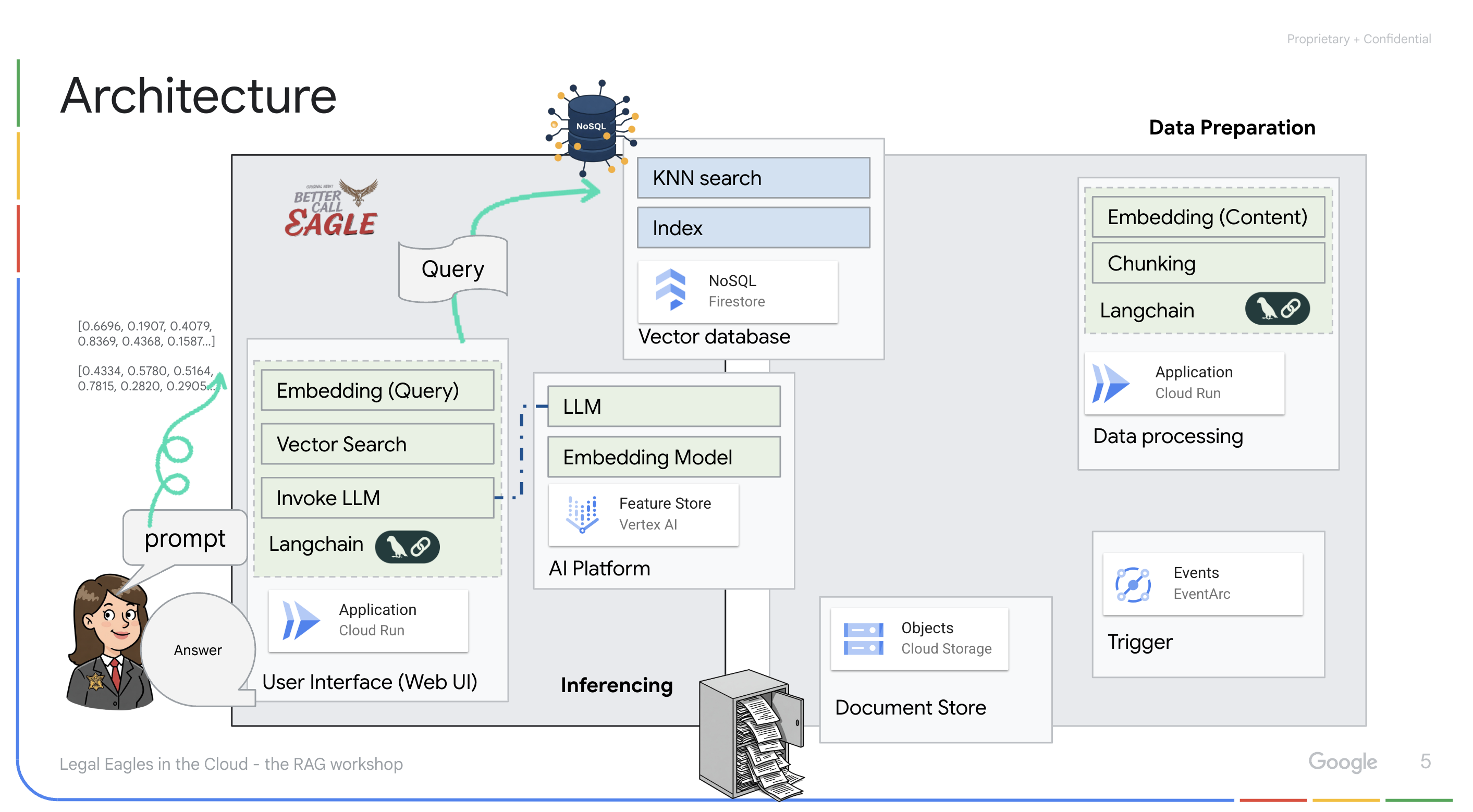
इस प्रोजेक्ट का मकसद, एलएलएम की "क्रिएटिव इंटरप्रिटेशन" से दूर जाना है. इसके लिए, RAG का इस्तेमाल किया जाता है. यह जवाब जनरेट करने से पहले, भरोसेमंद कानूनी सोर्स से काम की जानकारी हासिल करता है. इससे, कानूनी जानकारी के आधार पर ज़्यादा सटीक और भरोसेमंद जवाब मिलते हैं. इस सिस्टम को Google Cloud की कई सेवाओं का इस्तेमाल करके बनाया गया है. जैसे, Google Cloud Shell, Vertex AI, Firestore, Cloud Run, और Eventarc.
3. शुरू करने से पहले
Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं. पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. यह देखने का तरीका जानें कि किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
Cloud Shell IDE में Gemini Code Assist को चालू करना
👉 Google Cloud Console में, Gemini Code Assist के टूल पर जाएं. इसके बाद, बिना किसी शुल्क के Gemini Code Assist को चालू करें. इसके लिए, आपको शर्तों से सहमत होना होगा.
अनुमति सेटअप करने की प्रोसेस को अनदेखा करें और इस पेज को छोड़ दें.
Cloud Shell Editor पर काम करना
👉 Google Cloud Console में सबसे ऊपर, Cloud Shell चालू करें पर क्लिक करें. यह Cloud Shell पैनल में सबसे ऊपर मौजूद, टर्मिनल के आकार का आइकॉन है
👉 "एडिटर खोलें" बटन पर क्लिक करें. यह बटन, पेंसिल वाले खुले फ़ोल्डर की तरह दिखता है. इससे विंडो में Cloud Shell Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा.

👉 नीचे दिए गए स्टेटस बार में, क्लाउड कोड से साइन इन करें बटन पर क्लिक करें. निर्देशों के मुताबिक, प्लगिन को अनुमति दें. अगर आपको स्टेटस बार में Cloud Code - no project दिखता है, तो उसे चुनें. इसके बाद, ड्रॉप-डाउन में ‘Select a Google Cloud Project' को चुनें. इसके बाद, प्रोजेक्ट की सूची में से वह Google Cloud प्रोजेक्ट चुनें जिस पर आपको काम करना है.
👉 क्लाउड आईडीई में टर्मिनल खोलें, 
👉 नए टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
👉 Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
gcloud config set project <YOUR_PROJECT_ID>
👉 ज़रूरी Google Cloud API चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Cloud Shell टूलबार (Cloud Shell पैन के सबसे ऊपर) में, "Open Editor" बटन पर क्लिक करें. यह बटन, पेंसिल वाले खुले फ़ोल्डर की तरह दिखता है. इससे विंडो में Cloud Shell Code Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा.
👉 टर्मिनल में, Bootstrap Skeleton Project डाउनलोड करें:
git clone https://github.com/weimeilin79/legal-eagle.git
ज़रूरी नहीं: स्पैनिश वर्शन
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Cloud Shell टर्मिनल में यह कमांड चलाने के बाद, आपके Cloud Shell एनवायरमेंट में legal-eagle नाम का एक नया फ़ोल्डर बन जाएगा.
4. Gemini Code Assist की मदद से, अनुमान लगाने वाला ऐप्लिकेशन लिखना
इस सेक्शन में, हम अपने कानूनी सहायक के मुख्य हिस्से को बनाने पर फ़ोकस करेंगे. यह एक वेब ऐप्लिकेशन है, जो उपयोगकर्ता के सवालों को लेता है और जवाब जनरेट करने के लिए एआई मॉडल के साथ इंटरैक्ट करता है. हम इस अनुमान वाले हिस्से के लिए Python कोड लिखने में, Gemini Code Assist की मदद लेंगे.
शुरुआत में, हम एक Flask ऐप्लिकेशन बनाएँगे. यह ऐप्लिकेशन, LangChain लाइब्रेरी का इस्तेमाल करके सीधे तौर पर Vertex AI Gemini मॉडल से कम्यूनिकेट करेगा. यह पहला वर्शन, मॉडल की सामान्य जानकारी के आधार पर कानूनी मामलों में मदद करने वाले असिस्टेंट के तौर पर काम करेगा. हालांकि, फ़िलहाल इसके पास हमारे कोर्ट केस से जुड़े दस्तावेज़ों का ऐक्सेस नहीं होगा. इससे हमें एलएलएम की बेसलाइन परफ़ॉर्मेंस का पता चलेगा. इसके बाद, हम इसे आरएजी की मदद से बेहतर बना पाएंगे.
Cloud Code Editor के एक्सप्लोरर पैन (आम तौर पर बाईं ओर) में, अब आपको वह फ़ोल्डर दिखेगा जो Git रिपॉज़िटरी को क्लोन करते समय बनाया गया था legal-eagle, एक्सप्लोरर में अपने प्रोजेक्ट का रूट फ़ोल्डर खोलें. आपको इसमें webapp सबफ़ोल्डर दिखेगा. इसे भी खोलें. 
👉 Cloud Code Editor में legal.py फ़ाइल में बदलाव करें. Gemini Code Assist को प्रॉम्प्ट करने के लिए, अलग-अलग तरीकों का इस्तेमाल किया जा सकता है.
👉 नीचे दिए गए प्रॉम्प्ट को legal.py के सबसे नीचे कॉपी करें. इसमें साफ़ तौर पर बताया गया है कि आपको Gemini Code Assist से क्या जनरेट करवाना है. इसके बाद, लाइट बल्ब 💡 आइकॉन पर क्लिक करें और Gemini: कोड जनरेट करें को चुनें. मेन्यू आइटम का नाम, Cloud Code के वर्शन के हिसाब से थोड़ा अलग हो सकता है.
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
जनरेट किए गए कोड की ध्यान से समीक्षा करना
- क्या जवाब में, टिप्पणी में बताए गए तरीके का पालन किया गया है?
- क्या इससे
SystemMessageऔरHumanMessageके साथChatPromptTemplateबन जाता है? - क्या इसमें गड़बड़ी ठीक करने की बुनियादी सुविधा (
try...except) शामिल है?
अगर जनरेट किया गया कोड अच्छा है और ज़्यादातर सही है, तो उसे स्वीकार किया जा सकता है. इसके लिए, इनलाइन सुझावों के लिए Tab या Enter दबाएं या बड़े कोड ब्लॉक के लिए "स्वीकार करें" पर क्लिक करें.
अगर जनरेट किया गया कोड आपकी ज़रूरत के मुताबिक नहीं है या उसमें गड़बड़ियां हैं, तो चिंता न करें! Gemini Code Assist एक ऐसा टूल है जो आपकी मदद करता है. यह पहली बार में ही सही कोड लिखने के लिए नहीं है.
जनरेट किए गए कोड में बदलाव करें और उसे बेहतर बनाएं. साथ ही, उसमें मौजूद गड़बड़ियों को ठीक करें और अपनी ज़रूरतों के हिसाब से उसे ढालें. Code Assist चैट पैनल में ज़्यादा टिप्पणियां जोड़कर या खास सवाल पूछकर, Gemini Code Assist को और प्रॉम्प्ट दिए जा सकते हैं.
अगर आपको एसडीके के बारे में ज़्यादा जानकारी नहीं है, तो यहां एक उदाहरण दिया गया है.
👉 यहां दिए गए कोड को अपनी legal.py में कॉपी करके चिपकाएं और बदलें:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ज़रूरी नहीं: स्पैनिश वर्शन
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
इसके बाद, एक ऐसा फ़ंक्शन बनाएं जो उपयोगकर्ता के सवालों के जवाब दे सके.
Cloud Shell Editor में main.py खोलें. legal.py में ask_llm जनरेट करने के तरीके की तरह ही, Gemini Code Assist का इस्तेमाल करके Flask Route और ask_question फ़ंक्शन जनरेट करें. main.py में टिप्पणी के तौर पर यह प्रॉम्प्ट टाइप करें: (पक्का करें कि इसे if __name__ == "__main__": पर Flask ऐप्लिकेशन शुरू करने से पहले जोड़ा गया हो)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
सिर्फ़ तब स्वीकार करें, जब जनरेट किया गया कोड अच्छा हो और ज़्यादातर सही हो. अगर आपको Python के बारे में जानकारी नहीं है, तो यहां एक उदाहरण दिया गया है. इसे कॉपी और चिपकाएं. इसके बाद, इसे main.py में मौजूद कोड के नीचे चिपकाएं.
👉 पक्का करें कि आपने वेब ऐप्लिकेशन शुरू होने से पहले, यहां दिया गया कोड चिपका दिया हो (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
यह तरीका अपनाकर, Gemini Code Assist को चालू किया जा सकता है. साथ ही, अपने प्रोजेक्ट को सेट अप किया जा सकता है और इसका इस्तेमाल करके, अपनी main.py फ़ाइल में ask फ़ंक्शन जनरेट किया जा सकता है.
5. Cloud Editor में लोकल टेस्टिंग की सुविधा
👉 एडिटर के टर्मिनल में,डिपेंडेंट लाइब्रेरी इंस्टॉल करें और वेब यूज़र इंटरफ़ेस को स्थानीय तौर पर शुरू करें.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Cloud Shell टर्मिनल के आउटपुट में स्टार्टअप मैसेज देखें. Flask आम तौर पर ऐसे मैसेज प्रिंट करता है जिनसे पता चलता है कि यह चल रहा है और किस पोर्ट पर चल रहा है.
- http://127.0.0.1:8080 पर चल रहा है
अनुरोधों को पूरा करने के लिए, ऐप्लिकेशन का चालू रहना ज़रूरी है.
👉 "वेब प्रीव्यू" मेन्यू में जाकर,पोर्ट 8080 पर झलक देखें को चुनें. Cloud Shell, आपके ऐप्लिकेशन की वेब झलक के साथ एक नया ब्राउज़र टैब या विंडो खोलेगा. 
👉 ऐप्लिकेशन के इंटरफ़ेस में, कानूनी केस के रेफ़रंस से जुड़े कुछ सवाल टाइप करें और देखें कि एलएलएम कैसे जवाब देता है. उदाहरण के लिए, ये काम किए जा सकते हैं:
- माइकल ब्राउन को कितने साल की जेल की सज़ा सुनाई गई थी?
- जेन स्मिथ की कार्रवाइयों की वजह से, बिना अनुमति के लिए गए शुल्क के तौर पर कितना रेवेन्यू जनरेट हुआ?
- एमिली व्हाइट के मामले की जांच में, पड़ोसियों की गवाही की क्या भूमिका थी?
👉 ज़रूरी नहीं: स्पैनिश वर्शन
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿एमिली व्हाइट के मामले की जांच में, पड़ोसियों के बयानों की क्या भूमिका थी?
जवाबों को ध्यान से देखने पर, आपको पता चलेगा कि मॉडल गलत जानकारी दे सकता है, अस्पष्ट या सामान्य जवाब दे सकता है. साथ ही, कभी-कभी आपके सवालों का गलत मतलब निकाल सकता है. ऐसा इसलिए होता है, क्योंकि मॉडल के पास अब तक कुछ खास कानूनी दस्तावेज़ों का ऐक्सेस नहीं है.
👉 आगे बढ़ें और Ctrl+C दबाकर स्क्रिप्ट को रोकें.
👉 वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, टर्मिनल में यह कमांड चलाएं:
deactivate
6. वेक्टर स्टोर सेट अप करना
अब एलएलएम के, कानून की ‘क्रिएटिव व्याख्याओं' को खत्म करने का समय आ गया है.यहीं पर, जानकारी खोजकर जवाब देने की सुविधा (आरएजी) काम आती है! इसे ऐसे समझें कि आपके सवालों के जवाब देने से ठीक पहले, हम अपने एलएलएम को कानूनी मामलों से जुड़ी एक बेहतरीन लाइब्रेरी का ऐक्सेस देते हैं. RAG, सिर्फ़ अपनी सामान्य जानकारी पर भरोसा करने के बजाय, सबसे पहले भरोसेमंद सोर्स से काम की जानकारी इकट्ठा करता है. हमारे मामले में, यह सोर्स कानूनी दस्तावेज़ हैं. इसके बाद, RAG इस जानकारी का इस्तेमाल करके, ज़्यादा सटीक और सही जवाब जनरेट करता है. RAG की सामान्य जानकारी, मॉडल के हिसाब से धुंधली या पुरानी हो सकती है. यह कुछ ऐसा है जैसे एलएलएम, कोर्टरूम में जाने से पहले अपना होमवर्क कर रहा हो!
अपने RAG सिस्टम को बनाने के लिए, हमें उन सभी कानूनी दस्तावेज़ों को सेव करने की जगह चाहिए. साथ ही, यह भी ज़रूरी है कि उन्हें उनके मतलब के हिसाब से खोजा जा सके. ऐसे में, Firestore आपकी मदद कर सकता है! Firestore, Google Cloud का एक ऐसा NoSQL दस्तावेज़ डेटाबेस है जिसे ज़रूरत के हिसाब से बदला जा सकता है और बढ़ाया जा सकता है.
हम Firestore को वेक्टर स्टोर के तौर पर इस्तेमाल करने जा रहे हैं. हम अपने कानूनी दस्तावेज़ों के कुछ हिस्सों को Firestore में सेव करेंगे. साथ ही, हर हिस्से के लिए हम उसकी एम्बेडिंग भी सेव करेंगे. एम्बेडिंग, उसके मतलब का संख्यात्मक प्रतिनिधित्व होता है.
इसके बाद, जब आप हमारे लीगल ईगल से कोई सवाल पूछते हैं, तो हम Firestore की वेक्टर सर्च सुविधा का इस्तेमाल करके, कानूनी टेक्स्ट के उन हिस्सों को ढूंढेंगे जो आपकी क्वेरी के लिए सबसे ज़्यादा काम के हैं. इसी कॉन्टेक्स्ट का इस्तेमाल RAG करता है, ताकि आपको ऐसे जवाब मिल सकें जो सिर्फ़ एलएलएम की कल्पना पर आधारित न हों, बल्कि असल कानूनी जानकारी पर आधारित हों!
👉 नए टैब/विंडो में, Google Cloud Console में Firestore पर जाएं.
👉 डेटाबेस बनाएं पर क्लिक करें
👉 Native mode और डेटाबेस का नाम (default) के तौर पर चुनें.
👉 एक ही region चुनें: us-central1 और डेटाबेस बनाएं पर क्लिक करें. Firestore आपके डेटाबेस को उपलब्ध कराएगा. इसमें कुछ समय लग सकता है.
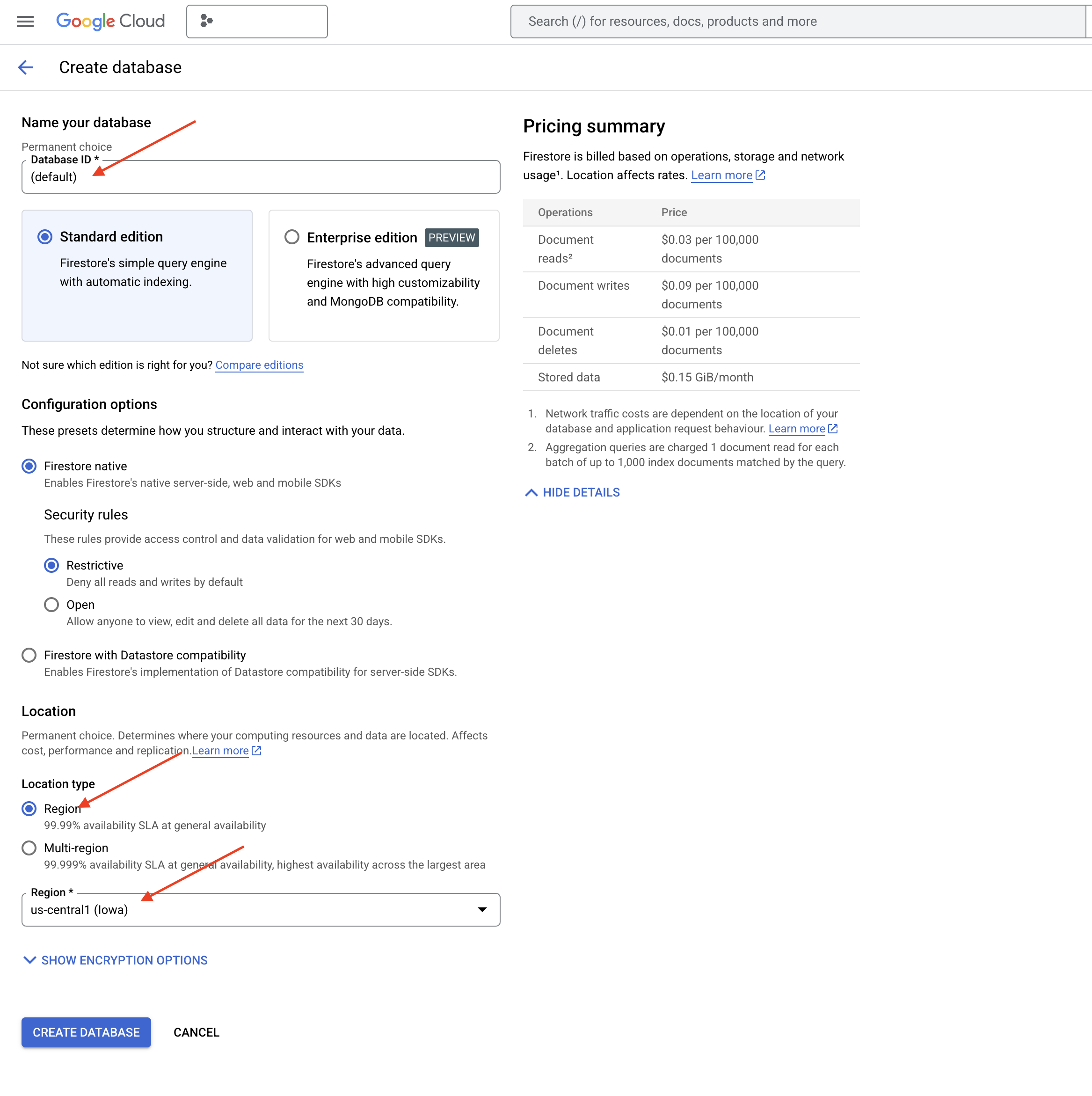
👉 Cloud IDE के टर्मिनल पर वापस जाएं. इसके बाद, embedding_vector फ़ील्ड पर एक वेक्टर इंडेक्स बनाएं, ताकि आपके legal_documents कलेक्शन में वेक्टर सर्च की सुविधा चालू की जा सके.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore, वेक्टर इंडेक्स बनाना शुरू कर देगा. इंडेक्स बनाने में कुछ समय लग सकता है. खास तौर पर, बड़े डेटासेट के लिए. आपको इंडेक्स "बनाया जा रहा है" स्टेटस में दिखेगा. इंडेक्स बनने के बाद, इसका स्टेटस "तैयार है" में बदल जाएगा. 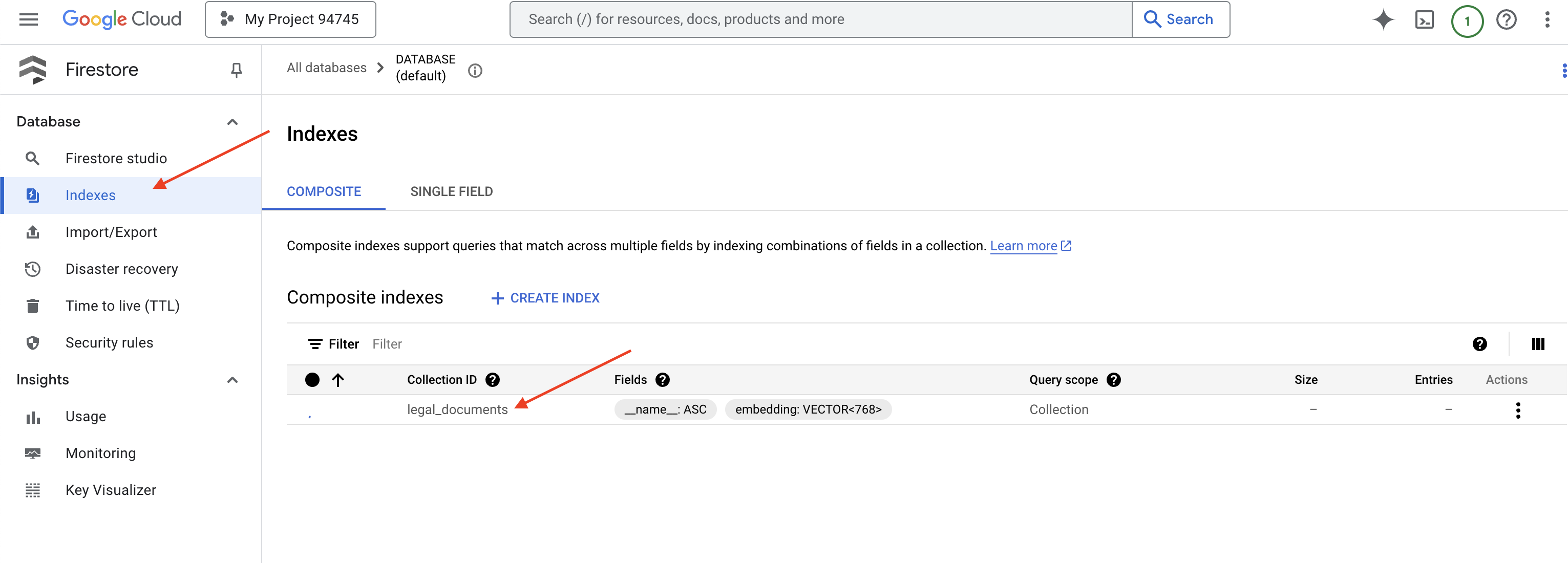
7. वेक्टर स्टोर में डेटा लोड करना
अब जब हम RAG और अपने वेक्टर स्टोर के बारे में जान चुके हैं, तो अब हमें ऐसा इंजन बनाना है जो हमारी कानूनी लाइब्रेरी को भर सके! तो हम कानूनी दस्तावेज़ों को 'मतलब के हिसाब से खोजे जाने लायक' कैसे बनाते हैं? असल बात तो एंबेड करने में छिपी है! एंबेडिंग को शब्दों, वाक्यों या पूरे दस्तावेज़ों को संख्या वाले वेक्टर में बदलने की प्रोसेस के तौर पर देखा जा सकता है. ये संख्याओं की ऐसी सूचियां होती हैं जो उनके सिमैंटिक मतलब को कैप्चर करती हैं. मिलते-जुलते कॉन्सेप्ट को वेक्टर स्पेस में ऐसे वेक्टर मिलते हैं जो एक-दूसरे के 'करीब' होते हैं. हम इस कन्वर्ज़न को पूरा करने के लिए, Vertex AI जैसे बेहतर मॉडल का इस्तेमाल करते हैं.
दस्तावेज़ लोड करने की प्रोसेस को ऑटोमेट करने के लिए, हम Cloud Run फ़ंक्शन और Eventarc का इस्तेमाल करेंगे. Cloud Run Functions एक हल्का और सर्वरलेस कंटेनर है. यह आपके कोड को सिर्फ़ तब चलाता है, जब इसकी ज़रूरत होती है. हम दस्तावेज़ प्रोसेस करने वाली Python स्क्रिप्ट को कंटेनर में पैकेज करेंगे और उसे Cloud Run फ़ंक्शन के तौर पर डिप्लॉय करेंगे.
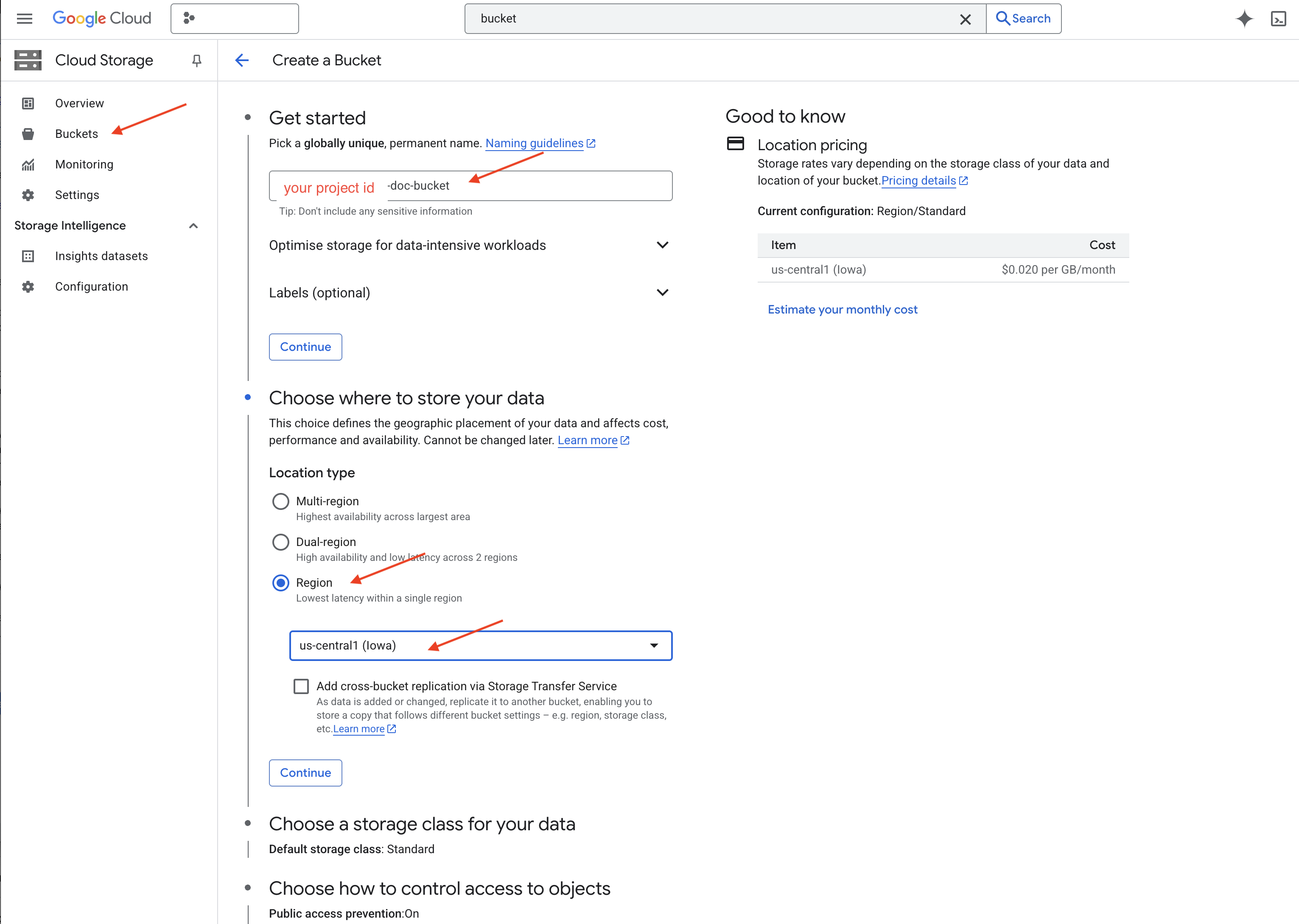
👉 नए टैब/विंडो में, Cloud Storage पर जाएं.
👉 बाईं ओर मौजूद मेन्यू में, "बकेट" पर क्लिक करें.
👉 सबसे ऊपर मौजूद, "+ बनाएं" बटन पर क्लिक करें.
👉 अपने बकेट को कॉन्फ़िगर करें (ज़रूरी सेटिंग):
- बकेट का नाम: ‘yourprojectID'-doc-bucket (आखिर में -doc-bucket सफ़िक्स होना ज़रूरी है)
- region:
us-central1क्षेत्र चुनें. - स्टोरेज क्लास: "स्टैंडर्ड". स्टैंडर्ड, अक्सर ऐक्सेस किए जाने वाले डेटा के लिए सही है.
- ऐक्सेस कंट्रोल: डिफ़ॉल्ट रूप से चुने गए "यूनिफ़ॉर्म ऐक्सेस कंट्रोल" को ही चुने रहने दें. इससे बकेट के लेवल पर ऐक्सेस कंट्रोल एक जैसा होता है.
- ऐडवांस विकल्प: इस ट्यूटोरियल के लिए, डिफ़ॉल्ट सेटिंग आम तौर पर काफ़ी होती हैं.
👉 बकेट बनाने के लिए, बनाएं बटन पर क्लिक करें.
👉 आपको सार्वजनिक ऐक्सेस को रोकने के बारे में एक पॉप-अप दिख सकता है. बॉक्स पर सही का निशान लगा रहने दें और ‘पुष्टि करें' पर क्लिक करें.
अब आपको 'बकेट' सूची में, अपनी नई बकेट दिखेगी. अपने बकेट का नाम याद रखें. आपको इसकी ज़रूरत बाद में पड़ेगी.
8. Cloud Run फ़ंक्शन सेट अप करना
👉 Cloud Shell Code Editor में, वर्किंग डायरेक्ट्री legal-eagle पर जाएं: फ़ोल्डर बनाने के लिए, Cloud Editor टर्मिनल में cd कमांड का इस्तेमाल करें.
cd ~/legal-eagle
mkdir loader
cd loader
👉 main.py,requirements.txt, और Dockerfile फ़ाइलें बनाएं. Cloud Shell टर्मिनल में, फ़ाइलें बनाने के लिए touch कमांड का इस्तेमाल करें:
touch main.py requirements.txt Dockerfile
आपको *loader नाम का नया फ़ोल्डर और तीन फ़ाइलें दिखेंगी.
👉 loader फ़ोल्डर में जाकर, main.py में बदलाव करें. बाईं ओर मौजूद फ़ाइल एक्सप्लोरर में, उस डायरेक्ट्री पर जाएं जहां आपने फ़ाइलें बनाई हैं. इसके बाद, main.py पर दो बार क्लिक करके, उसे एडिटर में खोलें.
नीचे दिए गए Python कोड को main.py में चिपकाएं:
यह ऐप्लिकेशन, GCS बकेट में अपलोड की गई नई फ़ाइलों को प्रोसेस करता है. साथ ही, टेक्स्ट को हिस्सों में बांटता है, हर हिस्से के लिए एंबेडिंग जनरेट करता है, और हिस्सों और उनकी एंबेडिंग को Firestore में सेव करता है.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
requirements.txt में बदलाव करें.फ़ाइल में ये लाइनें चिपकाएं:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Cloud Run फ़ंक्शन को टेस्ट करना और बनाना
👉 हम इसे वर्चुअल एनवायरमेंट में चलाएंगे और Cloud Run फ़ंक्शन के लिए ज़रूरी Python लाइब्रेरी इंस्टॉल करेंगे.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Cloud Run फ़ंक्शन के लिए लोकल एम्युलेटर शुरू करना
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 आखिरी टर्मिनल को चालू रखें, एक नया टर्मिनल खोलें, और बकेट में कोई फ़ाइल अपलोड करने के लिए कमांड चलाएं.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 एम्युलेटर चालू होने पर, उस पर CloudEvents को टेस्ट के तौर पर भेजा जा सकता है. इसके लिए, आपको IDE में एक अलग टर्मिनल की ज़रूरत होगी.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
इससे OK रिस्पॉन्स मिलना चाहिए.
👉 आपको Firestore में डेटा की पुष्टि करनी होगी. इसके लिए, Google Cloud Console पर जाएं और "डेटाबेस" फिर "Firestore" पर जाएं. इसके बाद, "डेटा" टैब और फिर legal_documents कलेक्शन चुनें. आपको दिखेगा कि आपके कलेक्शन में नए दस्तावेज़ बनाए गए हैं. इनमें से हर दस्तावेज़, अपलोड की गई फ़ाइल के टेक्स्ट के एक हिस्से को दिखाता है. 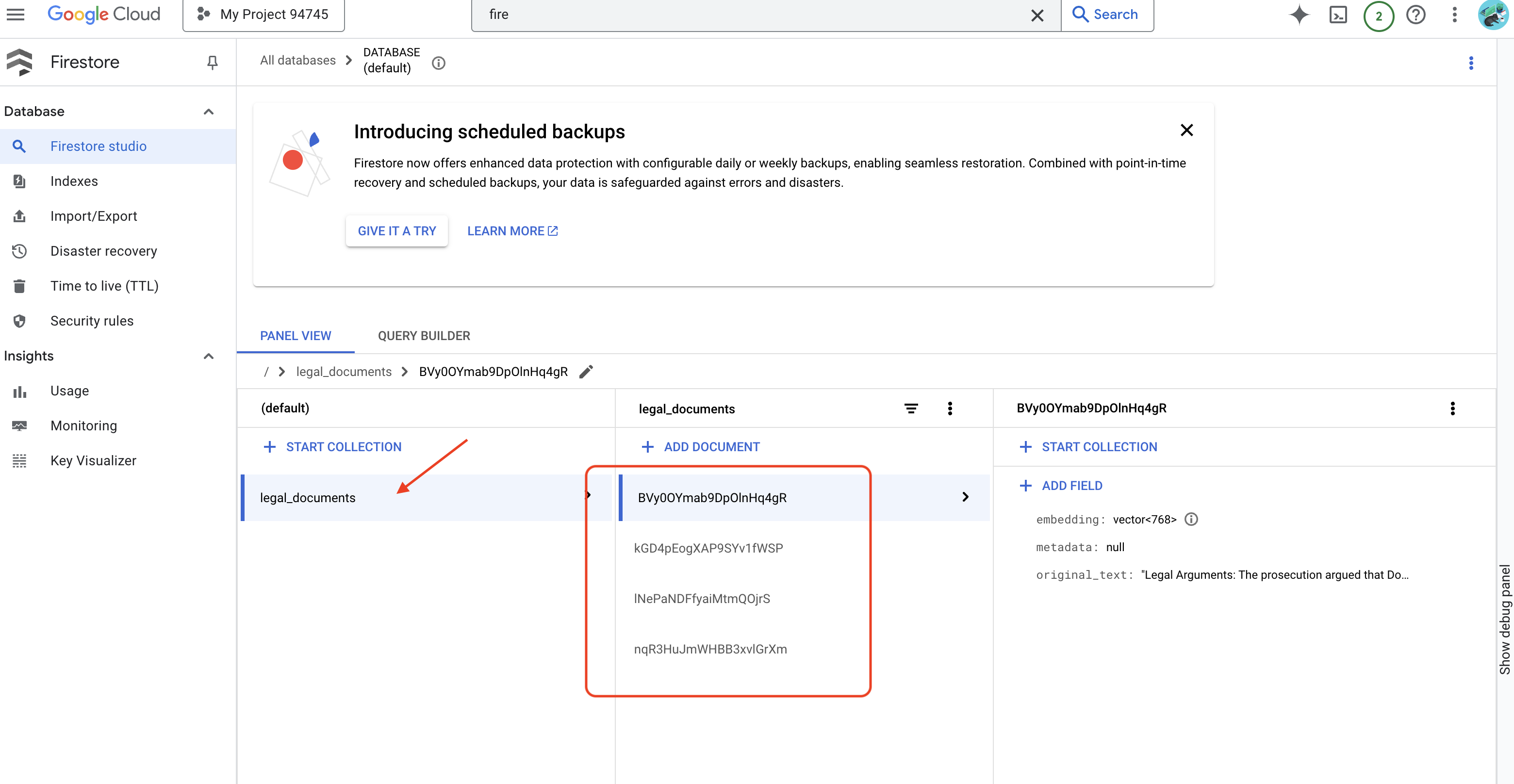
👉 एम्युलेटर चलाने वाले टर्मिनल में, बाहर निकलने के लिए Ctrl+C टाइप करें. इसके बाद, दूसरे टर्मिनल को बंद करें.
👉 वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, deactivate कमांड चलाएं.
deactivate
10. कंटेनर इमेज बनाना और उसे Artifacts रिपॉज़िटरी में पुश करना
👉 अब इसे क्लाउड पर डिप्लॉय करने का समय है. फ़ाइल एक्सप्लोरर में, Dockerfile पर दो बार क्लिक करें. Gemini से आपके लिए dockerfile जनरेट करने के लिए कहें. इसके लिए, Gemini Code Assist खोलें और फ़ाइल जनरेट करने के लिए, यहां दिया गया प्रॉम्प्ट इस्तेमाल करें.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
सबसे सही तरीके के लिए, हमारा सुझाव है कि आप खुली हुई फ़ाइल से अंतर(विपरीत दिशाओं वाले दो ऐरो) पर क्लिक करें और बदलावों को स्वीकार करें. 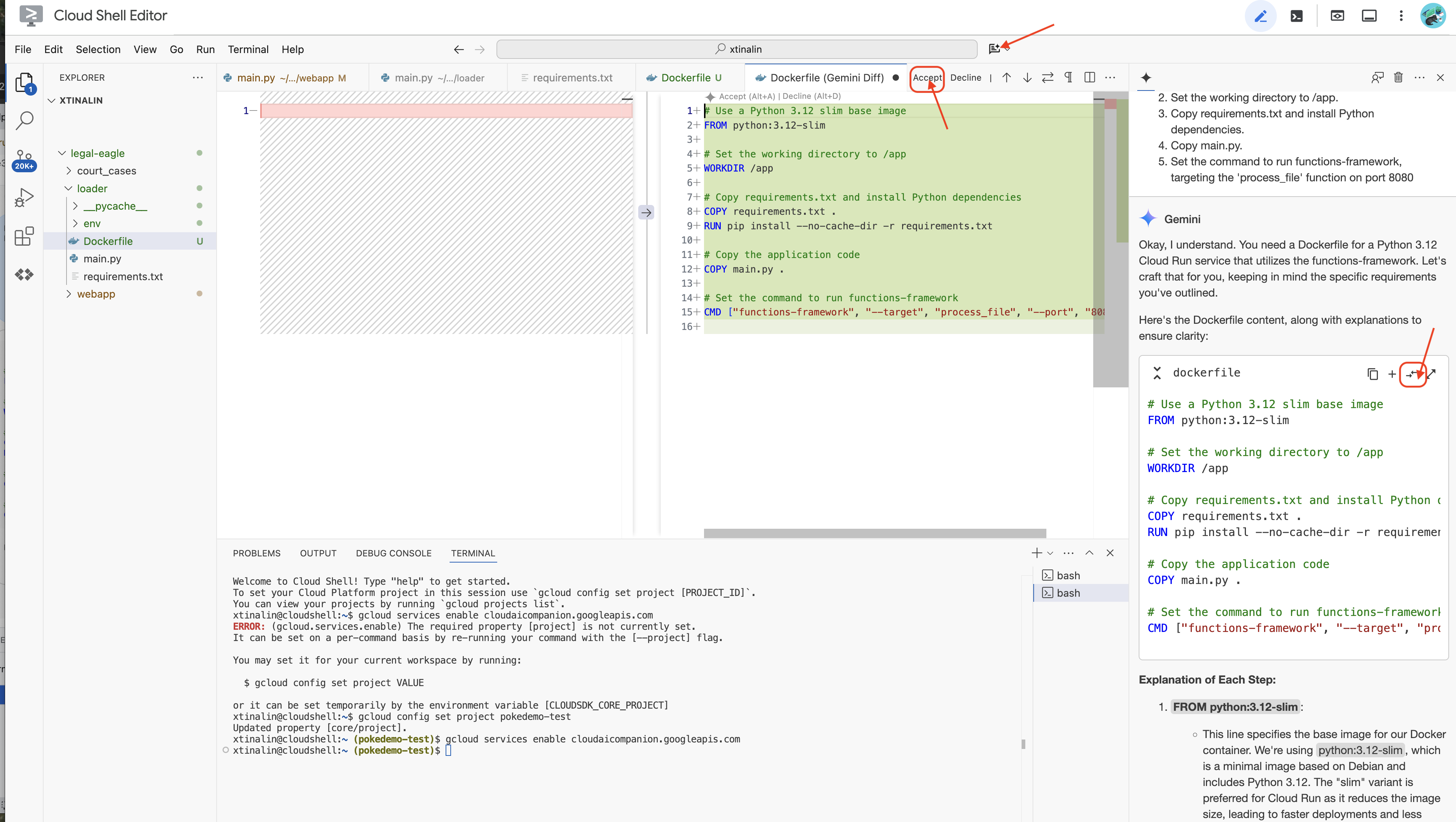
👉 अगर आपको कंटेनर के बारे में ज़्यादा जानकारी नहीं है, तो यहां एक उदाहरण दिया गया है:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 टर्मिनल में, आर्टफ़ैक्ट रिपॉज़िटरी बनाएं. इसमें हम डॉकर इमेज को सेव करेंगे.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
आपको [my-repository] नाम का डेटाबेस बनाया गया दिखेगा.
👉 Docker इमेज बनाने के लिए, यह कमांड चलाएं.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
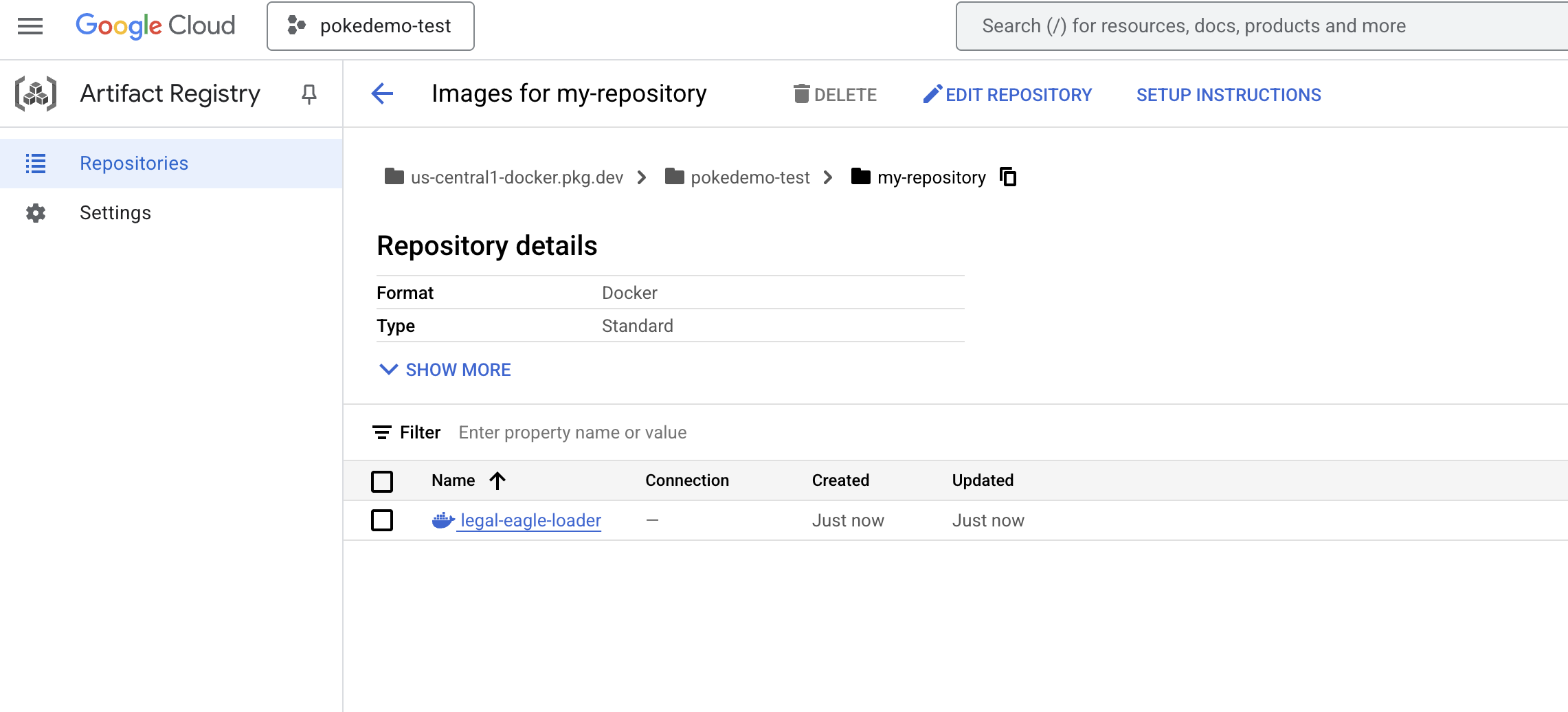
👉 अब आपको उस इमेज को रजिस्ट्री में पुश करना होगा
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
Docker इमेज अब my-repository Artifacts Repository में उपलब्ध है.
11. Cloud Run फ़ंक्शन बनाना और Eventarc ट्रिगर सेट अप करना
कानूनी दस्तावेज़ लोड करने वाले हमारे टूल को डिप्लॉय करने के बारे में ज़्यादा जानकारी देने से पहले, आइए इसमें शामिल कॉम्पोनेंट के बारे में संक्षेप में जानते हैं: Cloud Run, पूरी तरह से मैनेज किया गया सर्वरलेस प्लैटफ़ॉर्म है. इसकी मदद से, कंटेनर वाले ऐप्लिकेशन को आसानी से और तेज़ी से डिप्लॉय किया जा सकता है. यह इन्फ़्रास्ट्रक्चर मैनेजमेंट को अलग कर देता है, ताकि आप कोड लिखने और उसे डिप्लॉय करने पर फ़ोकस कर सकें.
हम अपने दस्तावेज़ लोडर को Cloud Run सेवा के तौर पर डिप्लॉय करेंगे. अब, Cloud Run फ़ंक्शन सेट अप करने के लिए आगे बढ़ते हैं:
👉 Google Cloud Console में, Cloud Run पर जाएं.
👉 Deploy Container पर जाएं और ड्रॉप-डाउन में SERVICE पर क्लिक करें.
👉 Cloud Run सेवा को कॉन्फ़िगर करें:
- कंटेनर इमेज: यूआरएल फ़ील्ड में "चुनें" पर क्लिक करें. Artifact Registry में पुश की गई इमेज का यूआरएल ढूंढें. उदाहरण के लिए, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage.
- सेवा का नाम:
legal-eagle-loader - क्षेत्र:
us-central1क्षेत्र चुनें. - पुष्टि करना: इस वर्कशॉप के लिए, "बिना पुष्टि किए गए अनुरोधों को अनुमति दें" विकल्प को चुना जा सकता है. प्रोडक्शन के लिए, आपको ऐक्सेस को सीमित करना पड़ सकता है.
- कंटेनर, नेटवर्किंग, सुरक्षा : डिफ़ॉल्ट.
👉 बनाएं पर क्लिक करें. Cloud Run आपकी सेवा को डिप्लॉय करेगा. 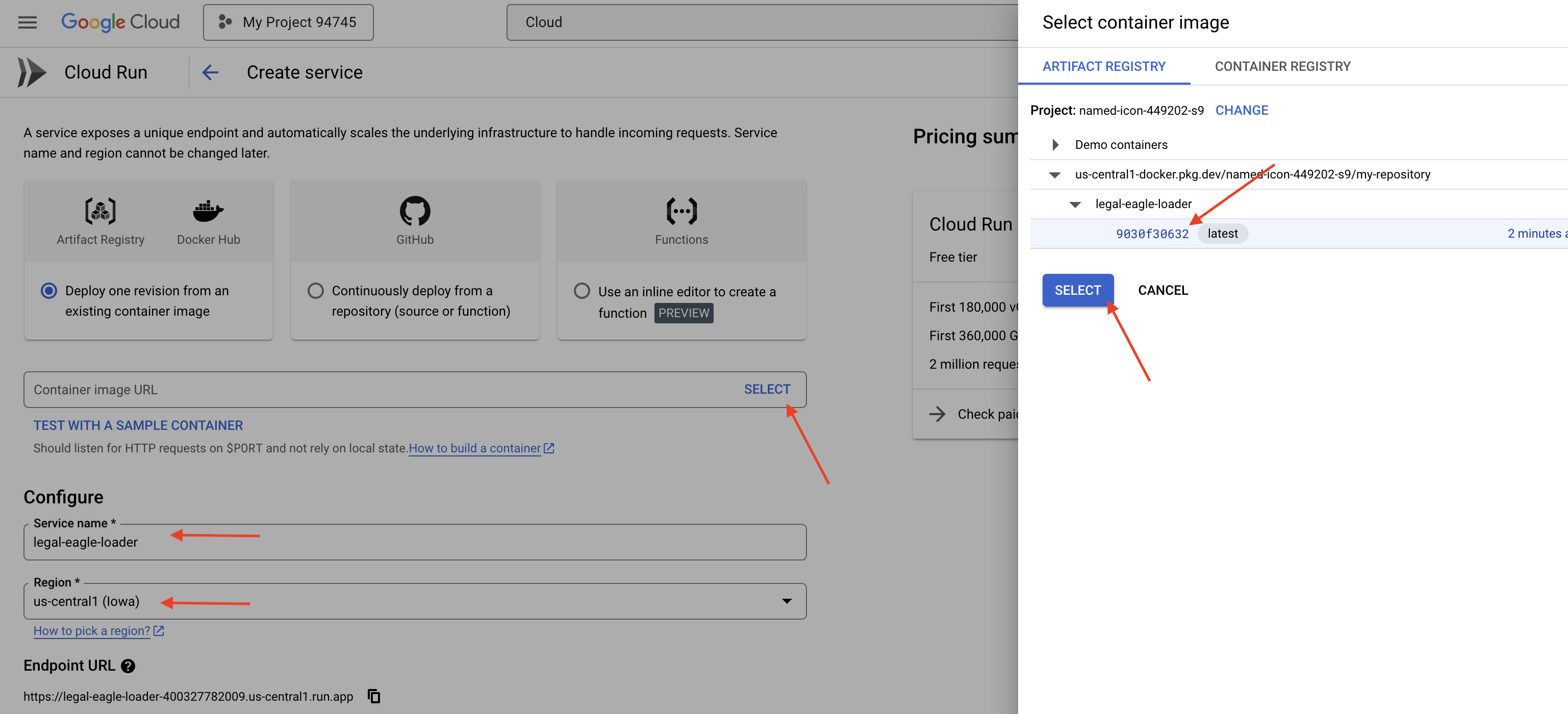
जब हमारे स्टोरेज बकेट में नई फ़ाइलें जोड़ी जाती हैं, तो इस सेवा को अपने-आप ट्रिगर करने के लिए, हम Eventarc का इस्तेमाल करेंगे. Eventarc की मदद से, इवेंट पर आधारित आर्किटेक्चर बनाए जा सकते हैं. इसके लिए, अलग-अलग सोर्स से इवेंट को अपनी सेवाओं पर रूट किया जाता है.
Eventarc सेट अप करने पर, हमारी Cloud Run सेवा, अपलोड किए गए नए दस्तावेज़ों को Firestore में अपने-आप लोड कर देगी. इससे हमारे RAG ऐप्लिकेशन के लिए, रीयल-टाइम में डेटा अपडेट करने की सुविधा चालू हो जाएगी.
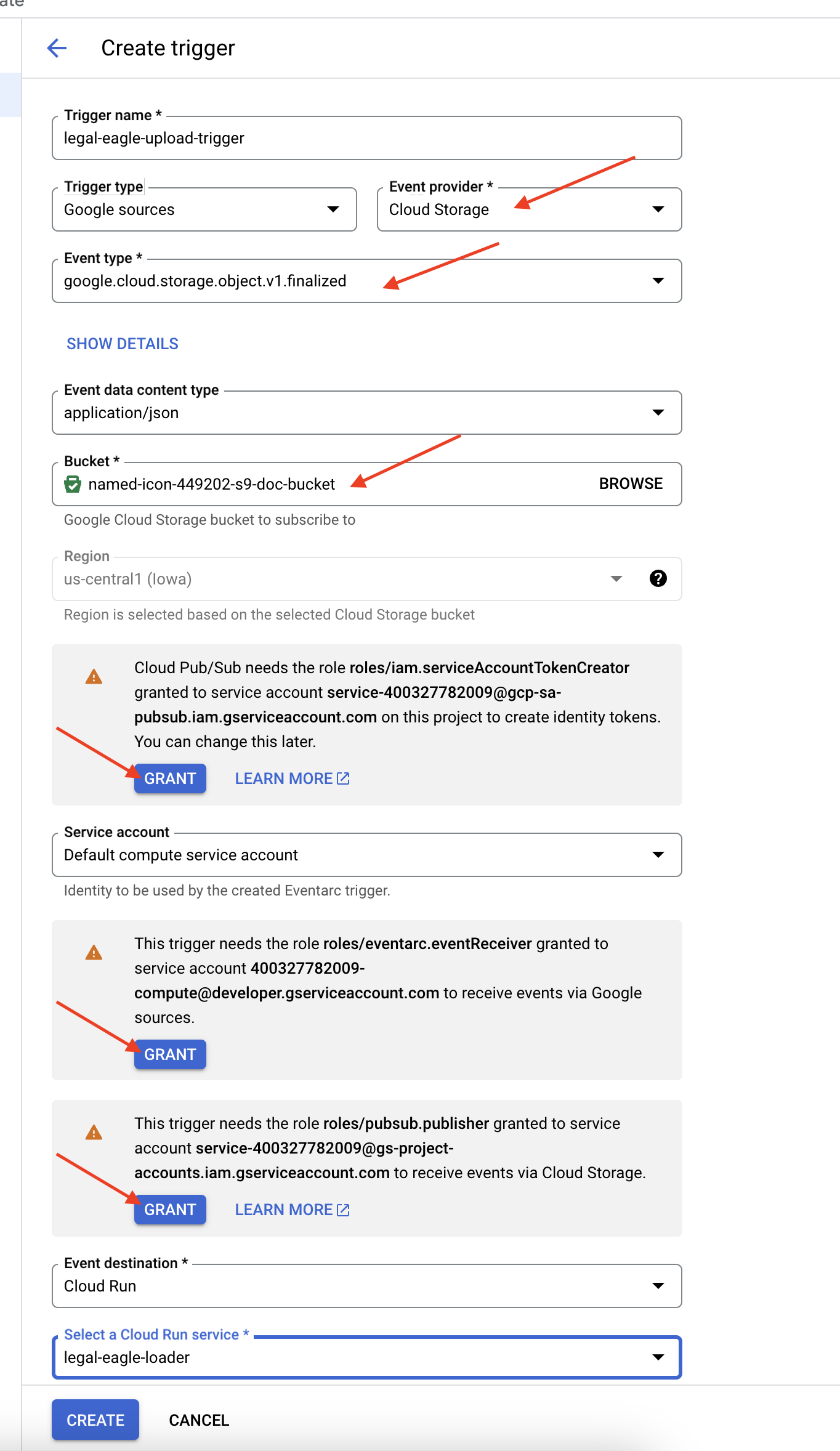
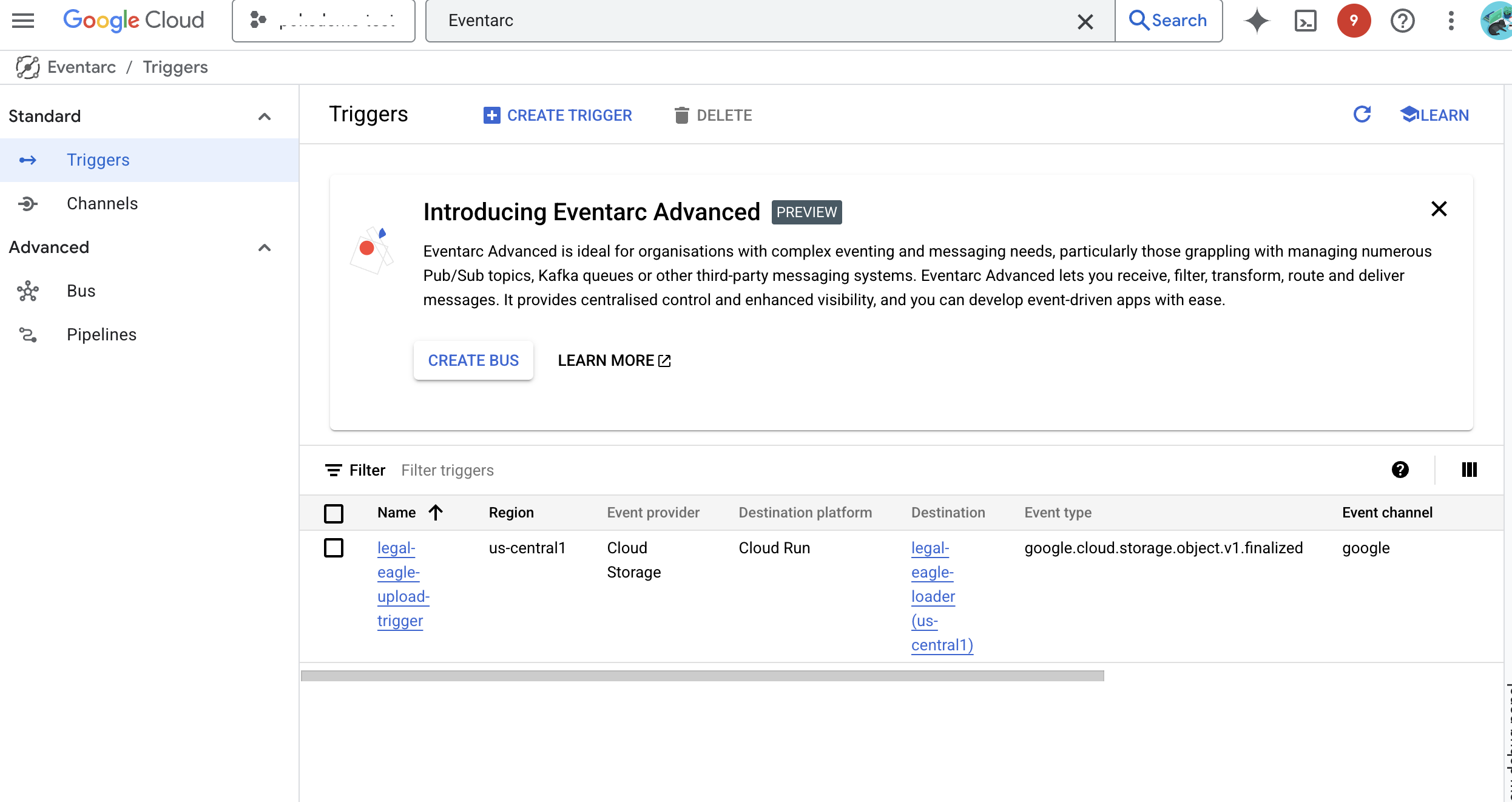
👉 Google Cloud Console में, EventArc में जाकर ट्रिगर पर जाएं. "+ ट्रिगर बनाएं" पर क्लिक करें. 👉 Eventarc ट्रिगर कॉन्फ़िगर करें:
- ट्रिगर का नाम:
legal-eagle-upload-trigger. - TriggerType: Google Sources
- इवेंट प्रोवाइडर: Cloud Storage को चुनें.
- इवेंट का टाइप:
google.cloud.storage.object.v1.finalizedचुनें - Cloud Storage बकेट: ड्रॉपडाउन से अपना GCS बकेट चुनें.
- डेस्टिनेशन का टाइप: "Cloud Run सेवा".
- सेवा:
legal-eagle-loaderको चुनें. - क्षेत्र:
us-central1 - पाथ: इसे फ़िलहाल खाली छोड़ दें .
- पेज पर दिखने वाली सभी अनुमतियां दें
👉 बनाएं पर क्लिक करें. Eventarc अब ट्रिगर सेट अप करेगा.
Cloud Run सेवा को अलग-अलग कॉम्पोनेंट से फ़ाइलें पढ़ने की अनुमति चाहिए. हमें सेवा के सेवा खाते को ज़रूरी अनुमति देनी होगी.
12. GCS बकेट में कानूनी दस्तावेज़ अपलोड करें
👉 अदालत के मामले की फ़ाइल को अपने GCS बकेट में अपलोड करें. बकेट का नाम बदलने के लिए, यह तरीका अपनाएं.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Cloud Run सेवा के लॉग की निगरानी करें. इसके लिए, Cloud Run -> आपकी सेवा legal-eagle-loader -> "लॉग" पर जाएं. प्रोसेस होने के मैसेज के लॉग देखें. इनमें ये शामिल हैं:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
साथ ही, लॉगिंग को कितनी तेज़ी से सेट अप किया गया था, इसके आधार पर आपको यहां ज़्यादा जानकारी वाले लॉग भी दिखेंगे
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
लॉग में गड़बड़ी के मैसेज देखें और अगर ज़रूरी हो, तो समस्या हल करें. 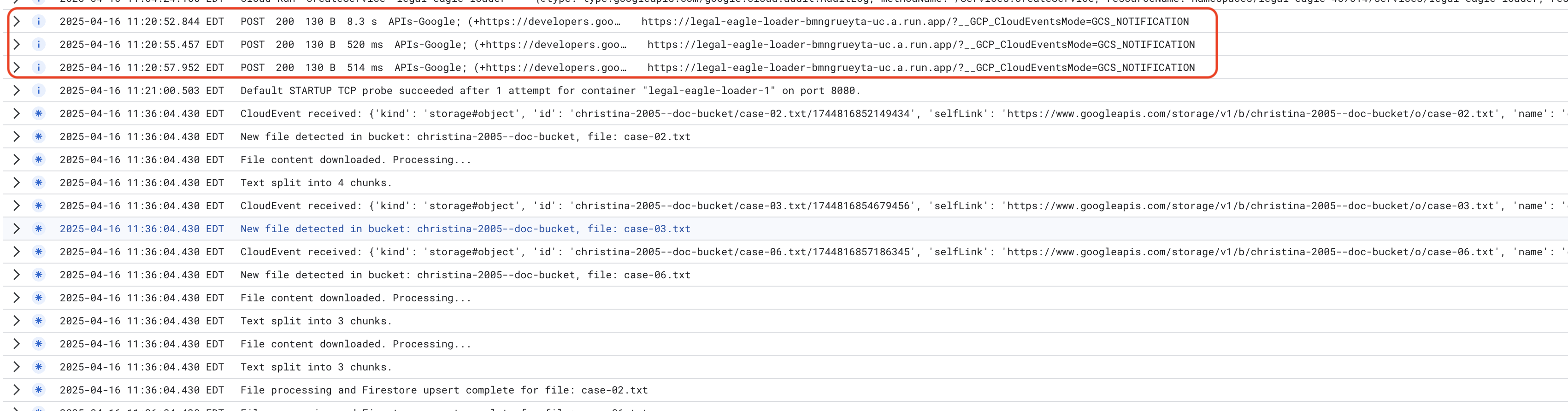
👉 Firestore में डेटा की पुष्टि करें. इसके बाद, legal_documents कलेक्शन खोलें.
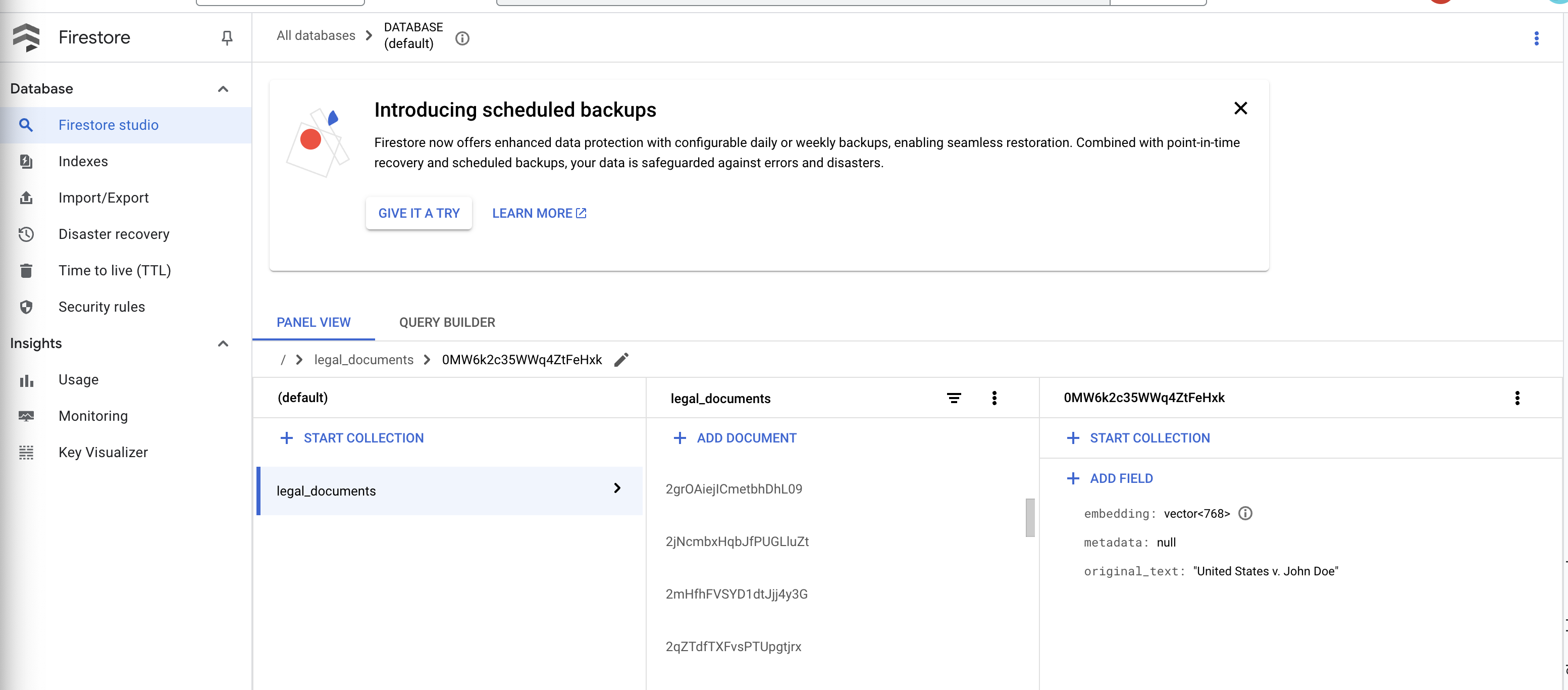
👉 आपको अपने कलेक्शन में बनाए गए नए दस्तावेज़ दिखने चाहिए. हर दस्तावेज़ में, अपलोड की गई फ़ाइल के टेक्स्ट का एक हिस्सा होगा. इसमें यह जानकारी शामिल होगी:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. आरएजी लागू करना
LangChain एक बेहतरीन फ़्रेमवर्क है. इसे लार्ज लैंग्वेज मॉडल (एलएलएम) की मदद से काम करने वाले ऐप्लिकेशन को आसानी से बनाने के लिए डिज़ाइन किया गया है. LangChain, एलएलएम एपीआई, प्रॉम्प्ट इंजीनियरिंग, और डेटा हैंडलिंग की जटिलताओं से सीधे तौर पर निपटने के बजाय, एक हाई-लेवल ऐब्स्ट्रैक्शन लेयर उपलब्ध कराता है. इसमें पहले से बने कॉम्पोनेंट और टूल उपलब्ध होते हैं. इनका इस्तेमाल कई तरह के एलएलएम (जैसे कि OpenAI, Google या अन्य) से कनेक्ट करने, जटिल ऑपरेशन की चेन बनाने (जैसे, डेटा वापस पाने के बाद खास जानकारी तैयार करना) और बातचीत की मेमोरी को मैनेज करने जैसे कामों के लिए किया जा सकता है.
खास तौर पर, RAG के लिए LangChain में वेक्टर स्टोर ज़रूरी होते हैं. इनसे RAG के डेटा को वापस पाने की सुविधा चालू की जा सकती है. ये खास डेटाबेस होते हैं. इन्हें वेक्टर एम्बेडिंग को कुशलता से सेव करने और क्वेरी करने के लिए डिज़ाइन किया गया है. इनमें सिमैंटिक रूप से मिलते-जुलते टेक्स्ट को वेक्टर स्पेस में एक-दूसरे के नज़दीक मौजूद पॉइंट पर मैप किया जाता है. LangChain, लो-लेवल प्लंबिंग का ध्यान रखता है. इससे डेवलपर, अपने आरएजी ऐप्लिकेशन के मुख्य लॉजिक और फ़ंक्शन पर फ़ोकस कर पाते हैं. इससे डेवलपमेंट में लगने वाला समय और जटिलता काफ़ी कम हो जाती है. साथ ही, आपको Google Cloud के मज़बूत और स्केलेबल इंफ़्रास्ट्रक्चर का फ़ायदा मिलता है. इससे, RAG पर आधारित ऐप्लिकेशन के प्रोटोटाइप को तेज़ी से बनाया और डिप्लॉय किया जा सकता है.
LangChain के बारे में जानकारी मिलने के बाद, अब आपको RAG को लागू करने के लिए, webapp फ़ोल्डर में मौजूद legal.py फ़ाइल को अपडेट करना होगा. इससे एलएलएम, जवाब देने से पहले Firestore में मौजूद ज़रूरी दस्तावेज़ों को खोज पाएगा.
👉 langchain और vertexai से FirestoreVectorStore और अन्य ज़रूरी मॉड्यूल इंपोर्ट करें. मौजूदा legal.py में ये जोड़ें
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Vertex AI और एम्बेडिंग मॉडल को शुरू करें.आपको text-embedding-004 का इस्तेमाल करना होगा. मॉड्यूल इंपोर्ट करने के तुरंत बाद, यह कोड जोड़ें.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 कानूनी दस्तावेज़ों के कलेक्शन की ओर इशारा करने वाला FirestoreVectorStore बनाएं. इसके लिए, शुरू किए गए एम्बेडिंग मॉडल का इस्तेमाल करें. साथ ही, कॉन्टेंट और एम्बेडिंग फ़ील्ड तय करें. इसे पिछले एम्बेडिंग मॉडल कोड के ठीक बाद जोड़ें.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 search_resource नाम का एक फ़ंक्शन तय करें. यह फ़ंक्शन, क्वेरी लेता है. साथ ही, vector_store.similarity_search का इस्तेमाल करके, मिलती-जुलती क्वेरी खोजता है और मिले-जुले नतीजे दिखाता है.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 ask_llm फ़ंक्शन को बदलें और उपयोगकर्ता की क्वेरी के आधार पर, काम का कॉन्टेक्स्ट पाने के लिए search_resource फ़ंक्शन का इस्तेमाल करें.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ज़रूरी नहीं: स्पैनिश वर्शन
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 legal.py में RAG को लागू करने के बाद, आपको इसे डिप्लॉय करने से पहले स्थानीय तौर पर इसकी जांच करनी चाहिए. इसके लिए, इस कमांड का इस्तेमाल करके ऐप्लिकेशन चलाएं:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 ऐप्लिकेशन को ऐक्सेस करने के लिए, webpreview का इस्तेमाल करें. सहायता टीम से बात करें और ctrl+c टाइप करके, स्थानीय तौर पर चल रही प्रोसेस से बाहर निकलें. साथ ही, वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, deactivate का इस्तेमाल करें.
deactivate
👉 वेब ऐप्लिकेशन को Cloud Run पर डिप्लॉय करने के लिए, यह लोडर फ़ंक्शन की तरह ही होगा. आपको Docker इमेज को Artifact Registry में बनाना, टैग करना, और पुश करना होगा:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 अब वेब ऐप्लिकेशन को Google Cloud पर डिप्लॉय करने का समय आ गया है. टर्मिनल में ये कमांड चलाएं:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Google Cloud Console में Cloud Run पर जाकर, डिप्लॉयमेंट की पुष्टि करें.आपको legal-eagle-webapp नाम की एक नई सेवा दिखेगी.
ज़्यादा जानकारी वाले पेज पर जाने के लिए, सेवा पर क्लिक करें. आपको सबसे ऊपर डिप्लॉय किया गया यूआरएल दिखेगा. 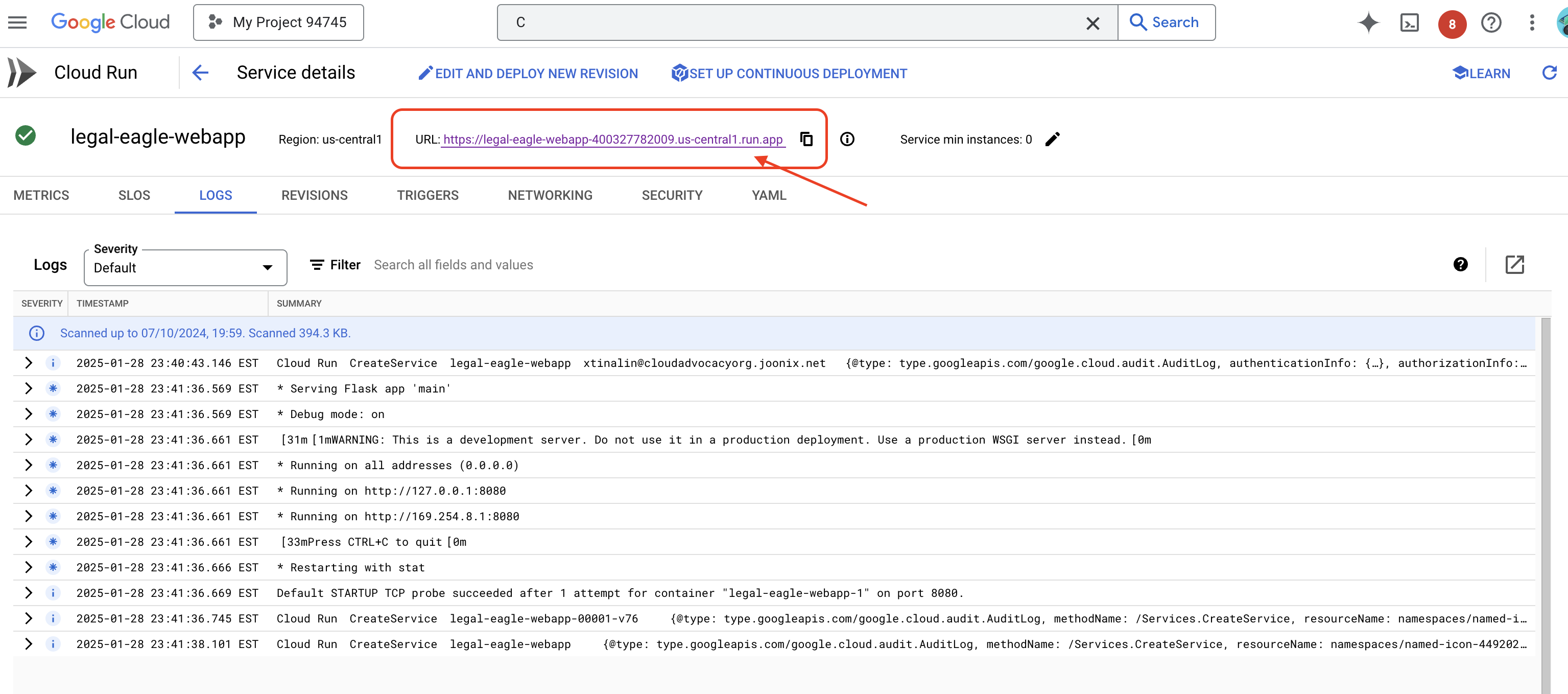
👉 अब, डिप्लॉय किए गए यूआरएल को ब्राउज़र के नए टैब में खोलें. कानूनी मामलों में मदद करने वाले एआई से इंटरैक्ट किया जा सकता है. साथ ही, उन अदालती मामलों से जुड़े सवाल पूछे जा सकते हैं जिन्हें आपने court_cases फ़ोल्डर में लोड किया है:
- माइकल ब्राउन को कितने साल की जेल की सज़ा सुनाई गई थी?
- जेन स्मिथ की कार्रवाइयों की वजह से, बिना अनुमति के लिए गए शुल्क के तौर पर कितना रेवेन्यू जनरेट हुआ?
- एमिली व्हाइट के मामले की जांच में, पड़ोसियों की गवाही की क्या भूमिका थी?
👉 ज़रूरी नहीं: स्पैनिश वर्शन
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
आपको यह जानकर खुशी होगी कि अब जवाब ज़्यादा सटीक और अपलोड किए गए कानूनी दस्तावेज़ों के कॉन्टेंट पर आधारित हैं. इससे RAG की क्षमता का पता चलता है!
वर्कशॉप पूरी करने के लिए बधाई!! आपने एलएलएम, LangChain, और Google Cloud का इस्तेमाल करके, कानूनी दस्तावेज़ों का विश्लेषण करने वाला ऐप्लिकेशन बना लिया है और उसे डिप्लॉय कर दिया है. आपने कानूनी दस्तावेज़ों को शामिल करने और उन्हें प्रोसेस करने का तरीका सीखा. साथ ही, RAG का इस्तेमाल करके, एलएलएम के जवाबों में काम की जानकारी जोड़ने और अपने ऐप्लिकेशन को सर्वरलेस सेवा के तौर पर डिप्लॉय करने का तरीका सीखा. इस जानकारी और बनाए गए ऐप्लिकेशन से, आपको कानूनी कामों के लिए एलएलएम की क्षमताओं के बारे में ज़्यादा जानने में मदद मिलेगी. बहुत बढ़िया!"
14. चुनौती
अलग-अलग तरह के मीडिया::
कोर्ट के वीडियो और ऑडियो रिकॉर्डिंग जैसे अलग-अलग तरह के मीडिया को कैसे शामिल किया जाए और प्रोसेस किया जाए. साथ ही, काम का टेक्स्ट कैसे निकाला जाए.
ऑनलाइन ऐसेट:
वेब पेज जैसी ऑनलाइन ऐसेट को लाइव प्रोसेस करने का तरीका.