
1. Pengantar
Saya selalu terpesona dengan intensitas ruang sidang, membayangkan diri saya dengan cekatan menangani kerumitannya dan menyampaikan argumen penutup yang kuat. Meskipun jalur karier saya telah membawa saya ke tempat lain, saya senang untuk menyampaikan bahwa dengan bantuan AI, kita semua mungkin akan lebih dekat untuk mewujudkan impian ruang sidang tersebut.

Hari ini, kita akan mempelajari cara menggunakan alat AI canggih Google—seperti Vertex AI, Firestore, dan Cloud Run Functions untuk memproses dan memahami data hukum, melakukan penelusuran secepat kilat, dan mungkin, membantu klien imajiner Anda (atau diri Anda sendiri) keluar dari situasi sulit.
Anda mungkin tidak sedang menginterogasi saksi, tetapi dengan sistem kami, Anda dapat menyaring banyak informasi, membuat ringkasan yang jelas, dan menyajikan data yang paling relevan dalam hitungan detik.
2. Arsitektur
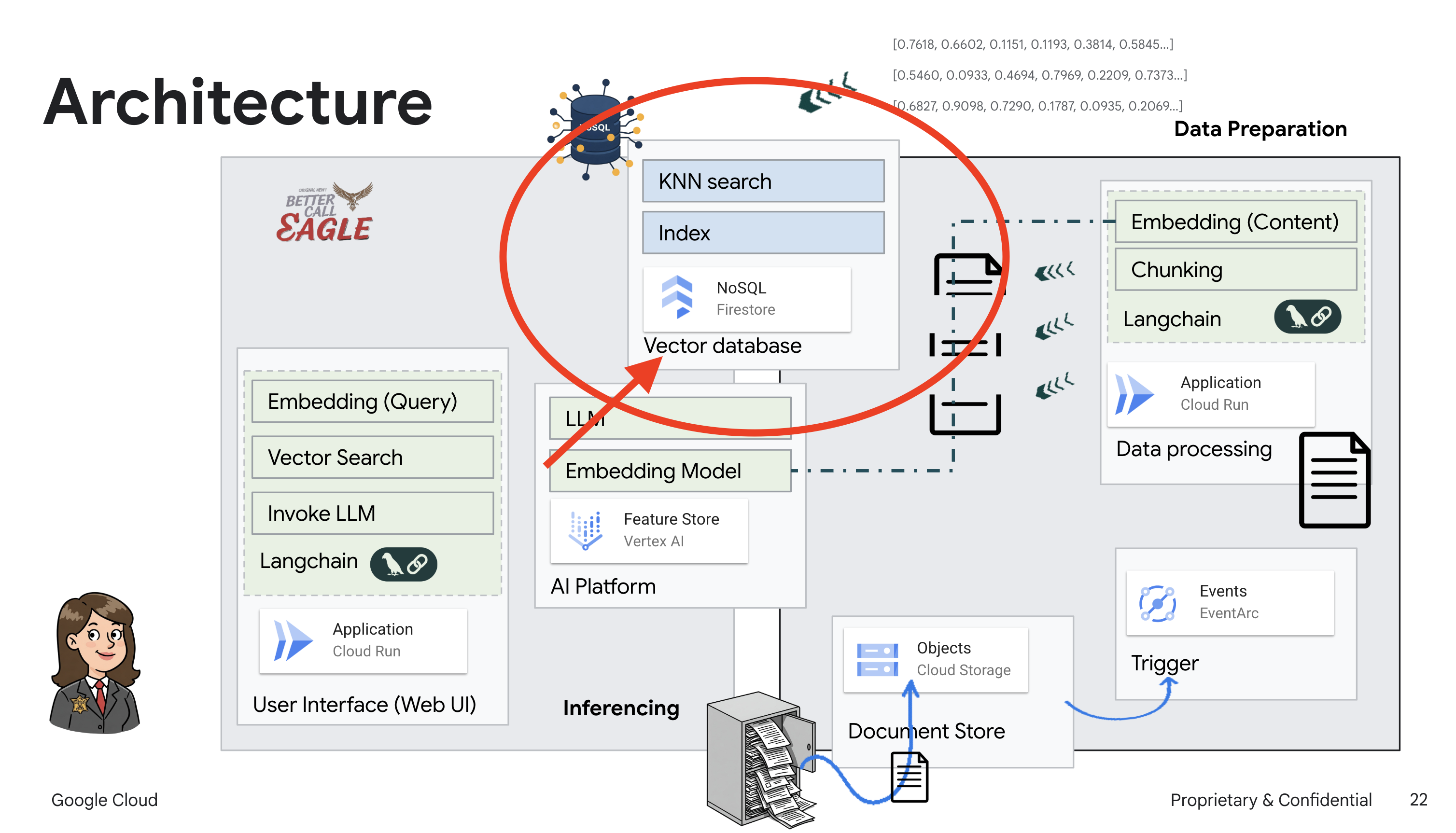
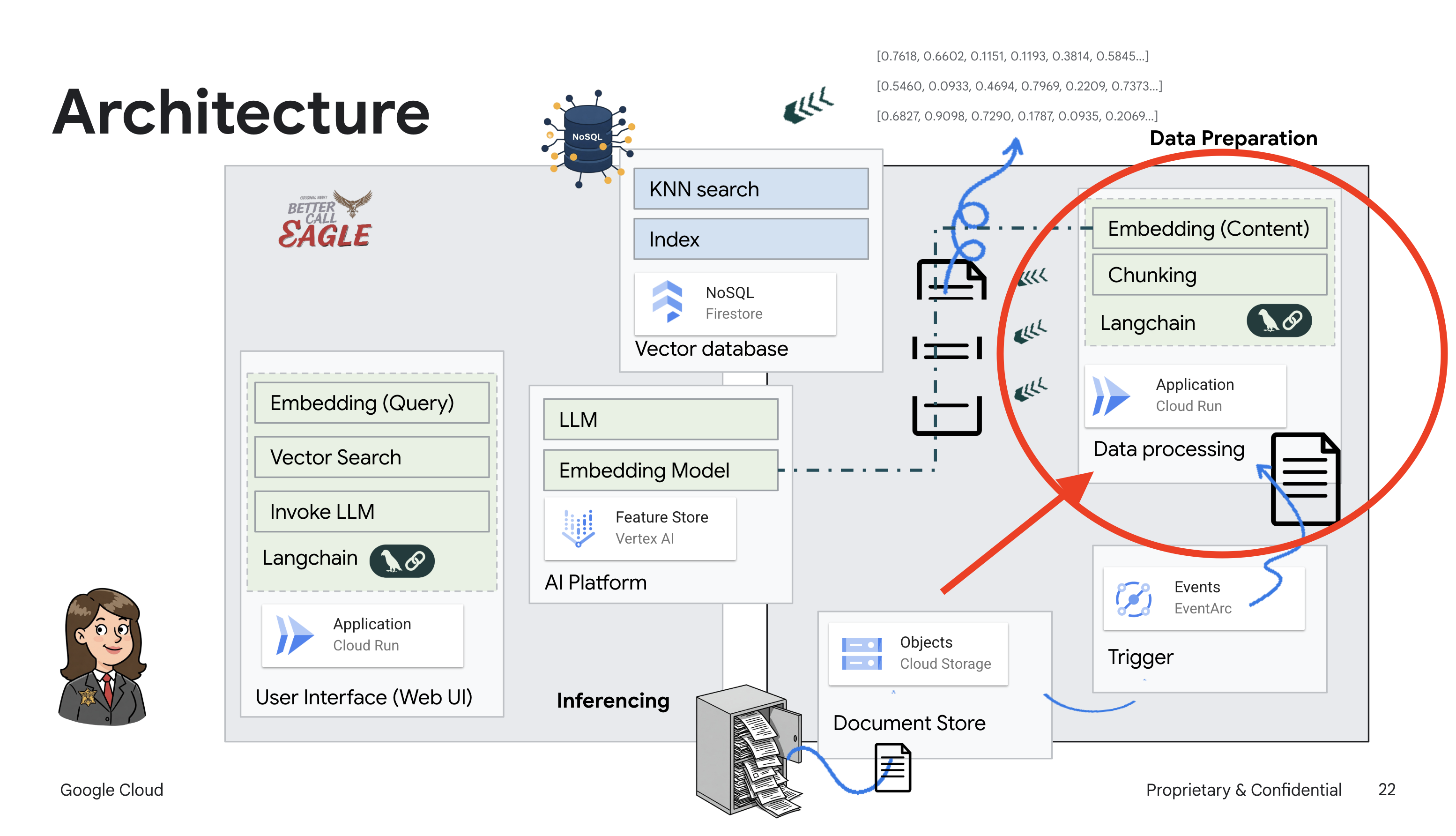
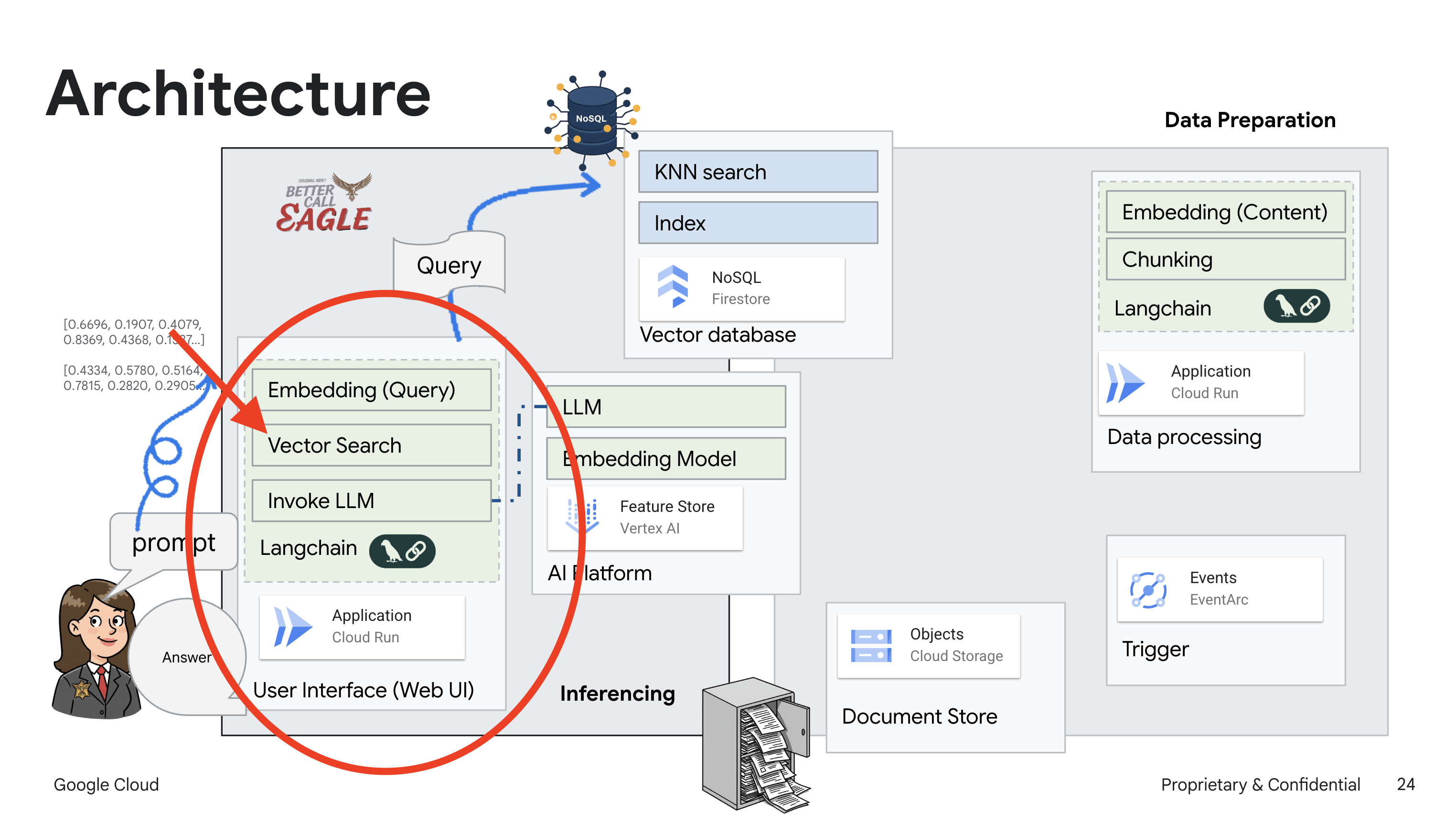
Project ini berfokus pada pembuatan asisten hukum menggunakan alat AI Google Cloud, dengan menekankan cara memproses, memahami, dan menelusuri data hukum. Sistem ini dirancang untuk menyaring sejumlah besar informasi, membuat ringkasan, dan menyajikan data yang relevan dengan cepat. Arsitektur asisten hukum melibatkan beberapa komponen utama:
Membangun Basis pengetahuan dari data tidak terstruktur: Google Cloud Storage (GCS) digunakan untuk menyimpan dokumen hukum. Firestore, database NoSQL, berfungsi sebagai penyimpanan vektor, yang menyimpan potongan dokumen dan sematan yang sesuai. Vector Search diaktifkan di Firestore untuk memungkinkan penelusuran kemiripan. Saat dokumen hukum baru diupload ke GCS, Eventarc akan memicu fungsi Cloud Run. Fungsi ini memproses dokumen dengan membaginya menjadi beberapa bagian dan membuat embedding untuk setiap bagian menggunakan model embedding teks Vertex AI. Embedding ini kemudian disimpan di Firestore bersama dengan potongan teks. 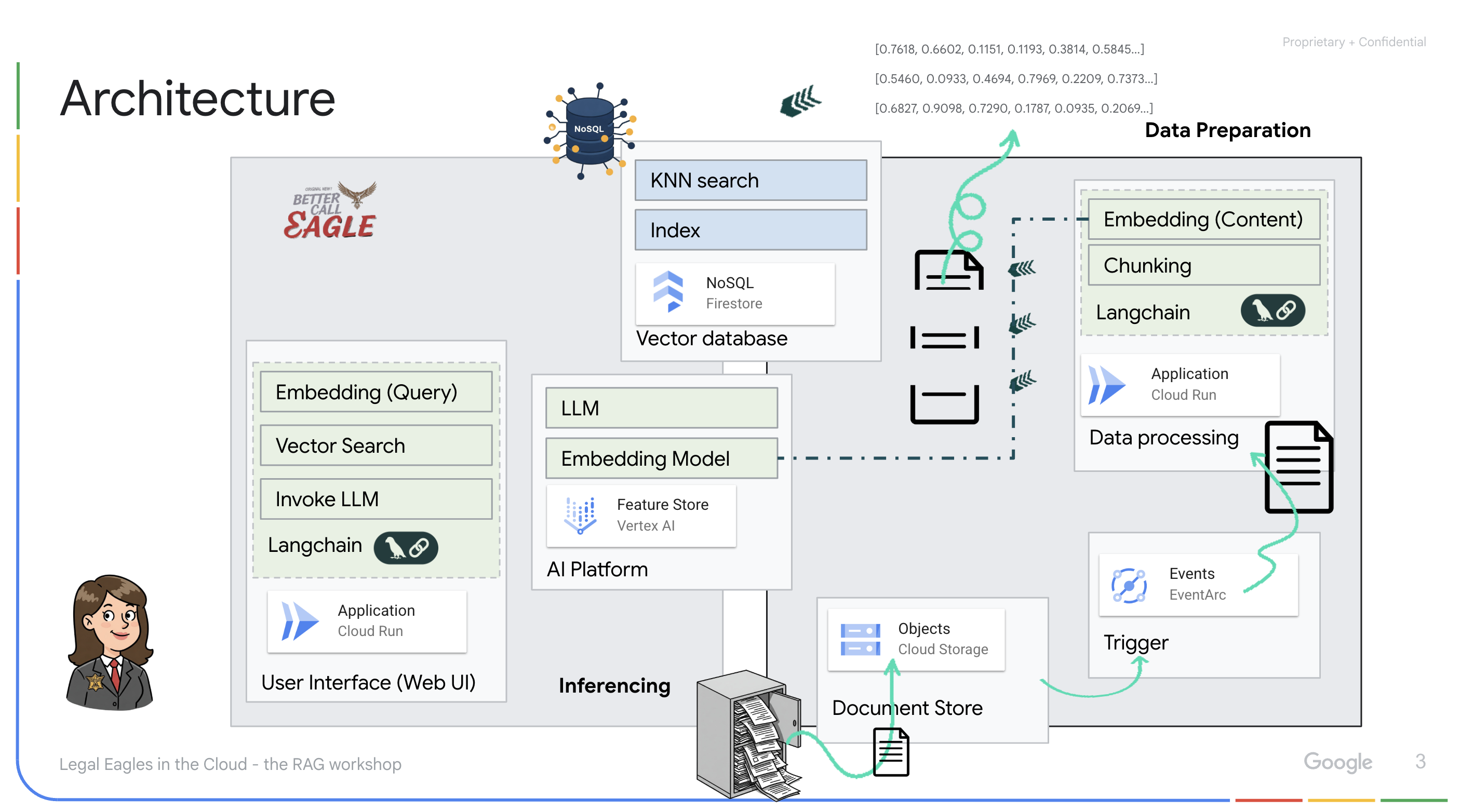
Aplikasi yang didukung oleh LLM & RAG : Inti dari sistem question-answering adalah fungsi ask_llm, yang menggunakan library langchain untuk berinteraksi dengan Model Bahasa Besar Gemini Vertex AI. Fungsi ini membuat HumanMessage dari kueri pengguna, dan menyertakan SystemMessage yang menginstruksikan LLM untuk bertindak sebagai asisten hukum yang bermanfaat. Sistem menggunakan pendekatan Retrieval-Augmented Generation (RAG), di mana, sebelum menjawab kueri, sistem menggunakan fungsi search_resource untuk mengambil konteks yang relevan dari penyimpanan vektor Firestore. Konteks ini kemudian disertakan dalam SystemMessage untuk mendasarkan jawaban LLM pada informasi hukum yang diberikan. 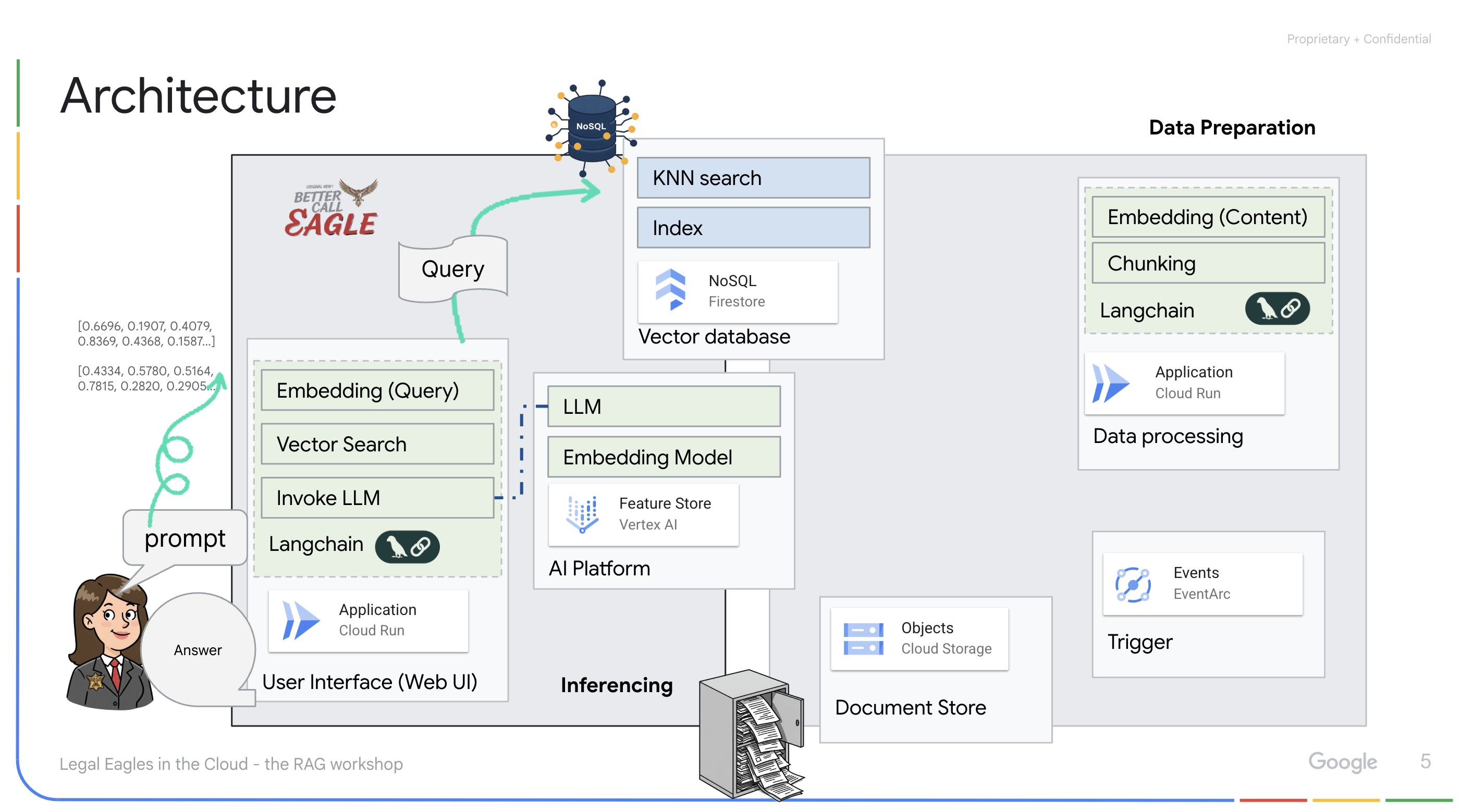
Project ini bertujuan untuk menghindari "interpretasi kreatif" LLM dengan menggunakan RAG, yang terlebih dahulu mengambil informasi yang relevan dari sumber hukum tepercaya sebelum menghasilkan jawaban. Hal ini menghasilkan respons yang lebih akurat dan tepat berdasarkan informasi hukum yang sebenarnya. Sistem ini dibangun menggunakan berbagai layanan Google Cloud, seperti Google Cloud Shell, Vertex AI, Firestore, Cloud Run, dan Eventarc.
3. Sebelum memulai
Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud. Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mengaktifkan Gemini Code Assist di Cloud Shell IDE
👉 Di konsol Google Cloud, buka Alat Gemini Code Assist, aktifkan Gemini Code Assist tanpa biaya dengan menyetujui persyaratan dan ketentuan.
Abaikan penyiapan izin, tutup halaman ini.
Bekerja di Cloud Shell Editor
👉 Klik Activate Cloud Shell di bagian atas konsol Google Cloud (Ikon berbentuk terminal di bagian atas panel Cloud Shell)
👉 Klik tombol "Open Editor" (terlihat seperti folder terbuka dengan pensil). Tindakan ini akan membuka Cloud Shell Editor di jendela. Anda akan melihat file explorer di sisi kiri.

👉 Klik tombol Cloud Code Sign-in di status bar bawah seperti yang ditunjukkan. Otorisasi plugin seperti yang ditunjukkan. Jika Anda melihat Cloud Code - no project di status bar, pilih opsi tersebut, lalu di drop-down 'Select a Google Cloud Project', pilih Project Google Cloud tertentu dari daftar project yang akan dikerjakan.
👉 Buka terminal di IDE cloud, 
👉 Di terminal baru, verifikasi bahwa Anda sudah diautentikasi dan project ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
👉 Klik Activate Cloud Shell di bagian atas konsol Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Jalankan perintah berikut untuk mengaktifkan Google Cloud API yang diperlukan:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Di toolbar Cloud Shell (di bagian atas panel Cloud Shell), klik tombol "Open Editor" (terlihat seperti folder terbuka dengan pensil). Tindakan ini akan membuka Editor Kode Cloud Shell di jendela. Anda akan melihat file explorer di sisi kiri.
👉 Di terminal, download Project Kerangka Bootstrap:
git clone https://github.com/weimeilin79/legal-eagle.git
OPSIONAL: VERSI SPANYOL
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Setelah menjalankan perintah ini di terminal Cloud Shell, folder baru dengan nama repositori legal-eagle akan dibuat di lingkungan Cloud Shell Anda.
4. Menulis Aplikasi Inferensi dengan Gemini Code Assist
Di bagian ini, kita akan berfokus pada pembangunan inti asisten hukum kita – aplikasi web yang menerima pertanyaan pengguna dan berinteraksi dengan model AI untuk menghasilkan jawaban. Kita akan memanfaatkan Gemini Code Assist untuk membantu kita menulis kode Python untuk bagian inferensi ini.
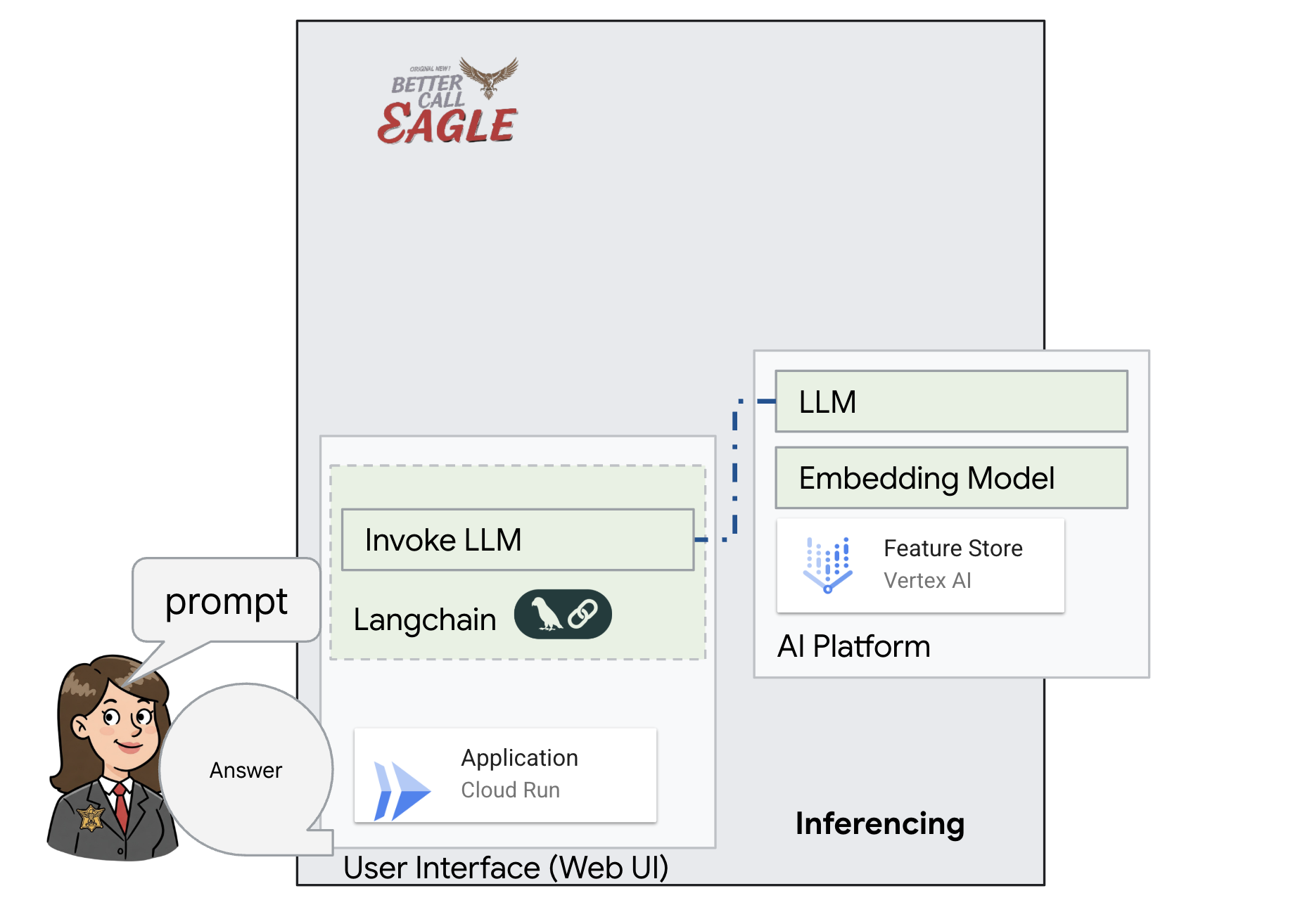
Awalnya, kita akan membuat aplikasi Flask yang menggunakan library LangChain untuk berkomunikasi langsung dengan model Vertex AI Gemini. Versi pertama ini akan bertindak sebagai asisten hukum yang berguna berdasarkan pengetahuan umum model, tetapi belum memiliki akses ke dokumen kasus pengadilan spesifik kami. Hal ini akan memungkinkan kita melihat performa dasar LLM sebelum kita meningkatkannya dengan RAG nanti.
Di panel Explorer Editor Cloud Code (biasanya di sisi kiri), Anda sekarang akan melihat folder yang dibuat saat Anda meng-clone repositori Git legal-eagle. Buka folder root project Anda di Explorer. Anda akan menemukan subfolder webapp di dalamnya, buka juga subfolder tersebut. 
👉 Edit file legal.py di Cloud Code Editor, Anda dapat menggunakan berbagai metode untuk meminta Gemini Code Assist.
👉 Salin perintah berikut ke bagian bawah legal.py yang menjelaskan dengan jelas apa yang Anda inginkan untuk dibuat oleh Gemini Code Assist, klik ikon bohlam 💡 yang muncul, lalu pilih Gemini: Generate Code (item menu yang tepat mungkin sedikit berbeda, bergantung pada versi Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Tinjau kode yang dihasilkan dengan cermat
- Apakah langkah-langkahnya kurang lebih sama dengan yang Anda uraikan dalam komentar?
- Apakah ini membuat
ChatPromptTemplatedenganSystemMessagedanHumanMessage? - Apakah kode tersebut menyertakan penanganan error dasar (
try...except)?
Jika kode yang dihasilkan sudah bagus dan sebagian besar benar, Anda dapat menerimanya (Tekan Tab atau Enter untuk saran inline, atau dengan mengklik "Terima" untuk blok kode yang lebih besar).
Jika kode yang dihasilkan tidak sesuai dengan yang Anda inginkan, atau memiliki error, jangan khawatir. Gemini Code Assist adalah alat untuk membantu Anda, bukan untuk menulis kode yang sempurna pada percobaan pertama.
Edit dan ubah kode yang dihasilkan untuk menyempurnakannya, memperbaiki kesalahan, dan lebih sesuai dengan persyaratan Anda. Anda dapat memberikan perintah lebih lanjut kepada Gemini Code Assist dengan menambahkan lebih banyak komentar atau mengajukan pertanyaan spesifik di panel chat Code Assist.
Jika Anda masih baru menggunakan SDK, berikut contoh yang berfungsi.
👉 Salin & tempel dan GANTI kode berikut ke dalam legal.py Anda:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPSIONAL: VERSI SPANYOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
Selanjutnya, buat fungsi untuk menangani rute yang akan merespons pertanyaan pengguna.
Buka main.py di Cloud Shell Editor. Mirip dengan cara Anda membuat ask_llm di legal.py, gunakan Gemini Code Assist untuk Membuat Rute Flask dan Fungsi ask_question. Ketik PROMPT berikut sebagai komentar di main.py: (Pastikan PROMPT ditambahkan sebelum Anda memulai aplikasi Flask di if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Terima HANYA jika kode yang dihasilkan sudah bagus dan sebagian besar benar. Jika Anda tidak terbiasa dengan Python.Berikut contoh yang berfungsi, salin & tempel ini ke main.py Anda di bawah kode yang sudah ada.
👉 Pastikan Anda menempelkan kode berikut SEBELUM memulai aplikasi web (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Dengan mengikuti langkah-langkah ini, Anda akan dapat berhasil mengaktifkan Gemini Code Assist, menyiapkan project, dan menggunakannya untuk membuat fungsi ask dalam file main.py.
5. Pengujian Lokal di Cloud Editor
👉 Di terminal editor,instal library dependen dan mulai UI Web secara lokal.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Cari pesan startup di output terminal Cloud Shell. Flask biasanya mencetak pesan yang menunjukkan bahwa Flask sedang berjalan dan di port mana.
- Berjalan di http://127.0.0.1:8080
Aplikasi harus terus berjalan untuk menayangkan permintaan.
👉 Dari menu "Web preview", pilih Preview on port 8080. Cloud Shell akan membuka tab atau jendela browser baru dengan pratinjau web aplikasi Anda. 
👉 Di antarmuka aplikasi, ketik beberapa pertanyaan yang secara khusus terkait dengan referensi kasus hukum dan lihat cara LLM merespons. Misalnya, Anda dapat mencoba:
- Berapa tahun hukuman penjara yang dijatuhkan kepada Michael Brown?
- Berapa banyak uang dalam tagihan tidak sah yang dihasilkan sebagai akibat dari tindakan Jane Smith?
- Apa peran kesaksian tetangga dalam penyelidikan kasus Emily White?
👉 OPSIONAL: VERSI SPANYOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Jika Anda mencermati jawabannya, Anda mungkin akan melihat bahwa model dapat berhalusinasi, tidak jelas atau umum, dan terkadang salah menafsirkan pertanyaan Anda, terutama karena model belum memiliki akses ke dokumen hukum tertentu.
👉 Lanjutkan dan hentikan skrip dengan menekan Ctrl+C.
👉 Keluar dari lingkungan virtual, jalankan perintah berikut di terminal:
deactivate
6. Menyiapkan Penyimpanan Vektor
Saatnya menghentikan'interpretasi kreatif' LLM terhadap hukum. Di sinilah Retrieval-Augmented Generation (RAG) hadir untuk menyelamatkan situasi. Anggap saja seperti memberi LLM kami akses ke perpustakaan hukum yang sangat canggih tepat sebelum LLM menjawab pertanyaan Anda. Daripada hanya mengandalkan pengetahuan umumnya (yang bisa jadi tidak jelas atau sudah usang, bergantung pada modelnya), RAG terlebih dahulu mengambil informasi yang relevan dari sumber tepercaya – dalam kasus kami, dokumen hukum – lalu menggunakan konteks tersebut untuk menghasilkan jawaban yang jauh lebih akurat dan tepat. Ini seperti LLM yang mengerjakan PR-nya sebelum masuk ke ruang sidang.
Untuk membangun sistem RAG kami, kami memerlukan tempat untuk menyimpan semua dokumen hukum tersebut dan, yang penting, membuatnya dapat dicari berdasarkan maknanya. Di sinilah Firestore berperan. Firestore adalah database dokumen NoSQL yang fleksibel dan skalabel dari Google Cloud.
Kita akan menggunakan Firestore sebagai penyimpanan vektor. Kita akan menyimpan potongan dokumen hukum di Firestore, dan untuk setiap potongan, kita juga akan menyimpan embedding-nya – representasi numerik dari maknanya.
Kemudian, saat Anda mengajukan pertanyaan kepada Legal Eagle kami, kami akan menggunakan penelusuran vektor Firestore untuk menemukan potongan teks hukum yang paling relevan dengan kueri Anda. Konteks yang diambil ini adalah yang digunakan RAG untuk memberikan jawaban yang didasarkan pada informasi hukum yang sebenarnya, bukan hanya imajinasi LLM.
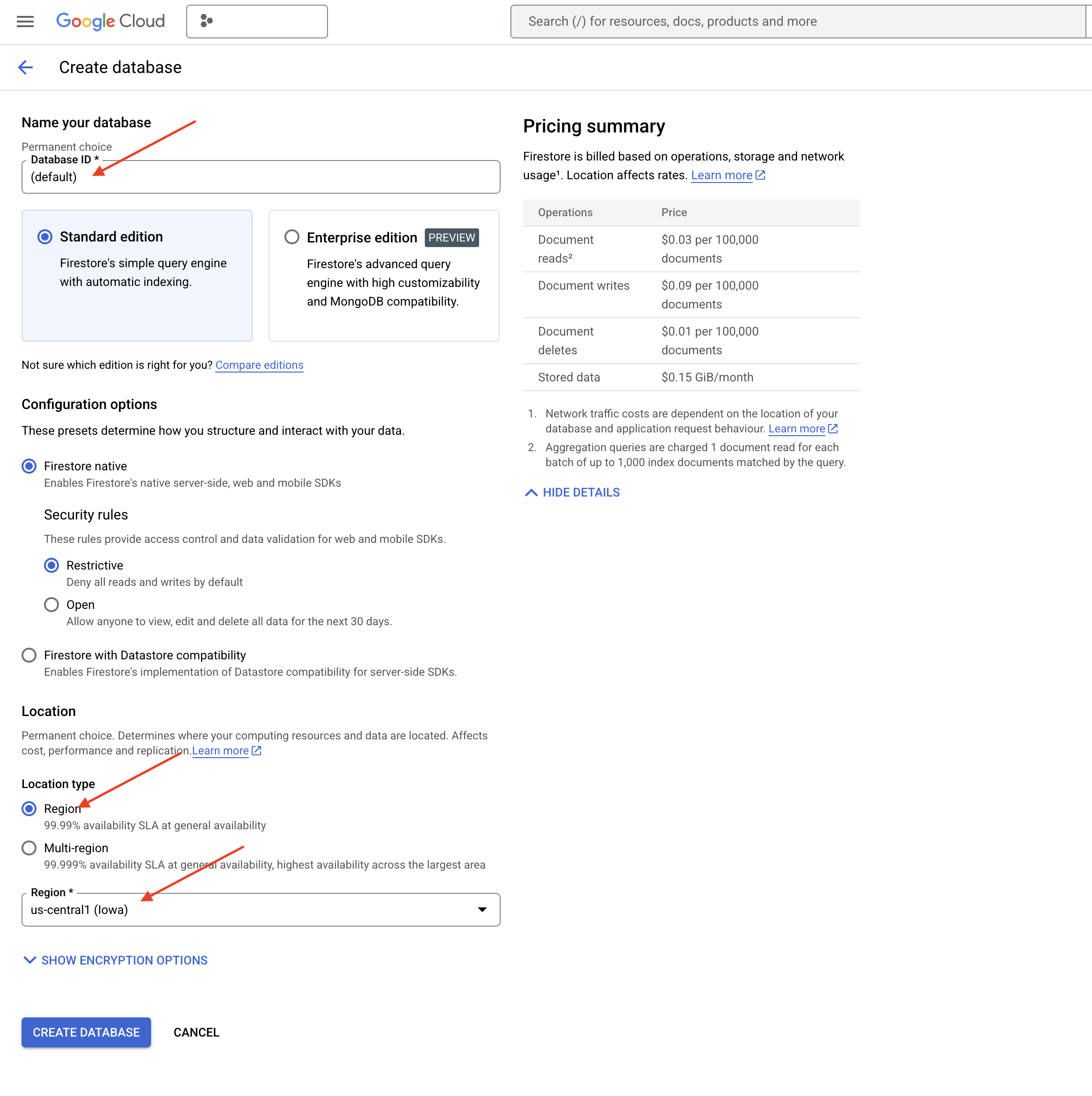
👉 Di tab/jendela baru, buka Firestore di Konsol Google Cloud.
👉 Klik Buat Database
👉 Pilih Native mode dan nama database sebagai (default).
👉 Pilih region tunggal: us-central1 , lalu klik Buat Database. Firestore akan menyediakan database Anda, yang mungkin memerlukan waktu beberapa saat.
👉 Kembali di terminal Cloud IDE - buat Indeks Vektor di kolom embedding_vector, untuk mengaktifkan penelusuran vektor di koleksi legal_documents Anda.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore akan mulai membuat indeks vektor. Pembuatan indeks dapat memerlukan waktu beberapa saat, terutama untuk set data yang lebih besar. Anda akan melihat indeks dalam status "Membuat", dan indeks akan bertransisi ke "Siap" saat dibuat. 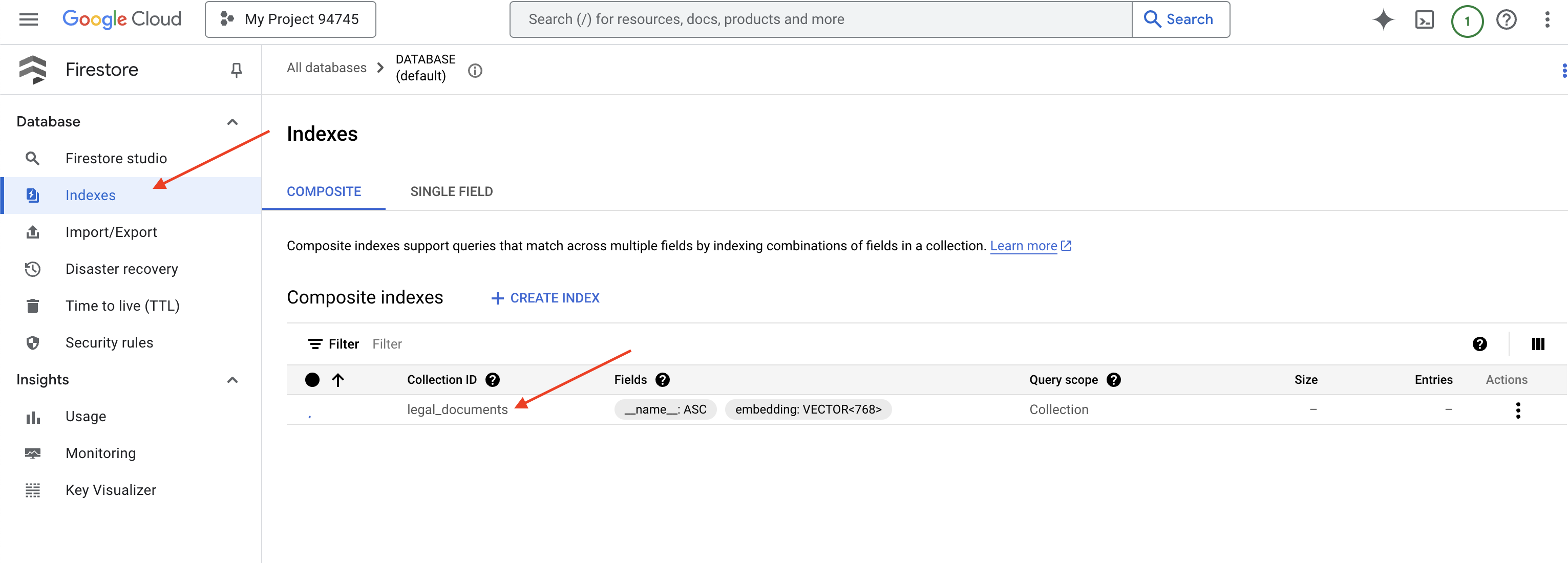
7. Memuat Data ke dalam Penyimpanan Vektor
Setelah memahami RAG dan penyimpanan vektor, kini saatnya membangun mesin yang mengisi koleksi hukum kita. Jadi, bagaimana cara membuat dokumen hukum 'dapat ditelusuri berdasarkan makna'? Keajaibannya ada di embedding! Anggap embedding sebagai proses mengonversi kata, kalimat, atau bahkan seluruh dokumen menjadi vektor numerik – daftar angka yang menangkap makna semantiknya. Konsep serupa akan mendapatkan vektor yang 'berdekatan' satu sama lain di ruang vektor. Kami menggunakan model canggih (seperti model dari Vertex AI) untuk melakukan konversi ini.
Untuk mengotomatiskan pemuatan dokumen, kita akan menggunakan Cloud Run Functions dan Eventarc. Cloud Run Functions adalah container serverless ringan yang menjalankan kode Anda hanya saat diperlukan. Kita akan mengemas skrip Python pemrosesan dokumen ke dalam container dan men-deploy-nya sebagai Fungsi Cloud Run.
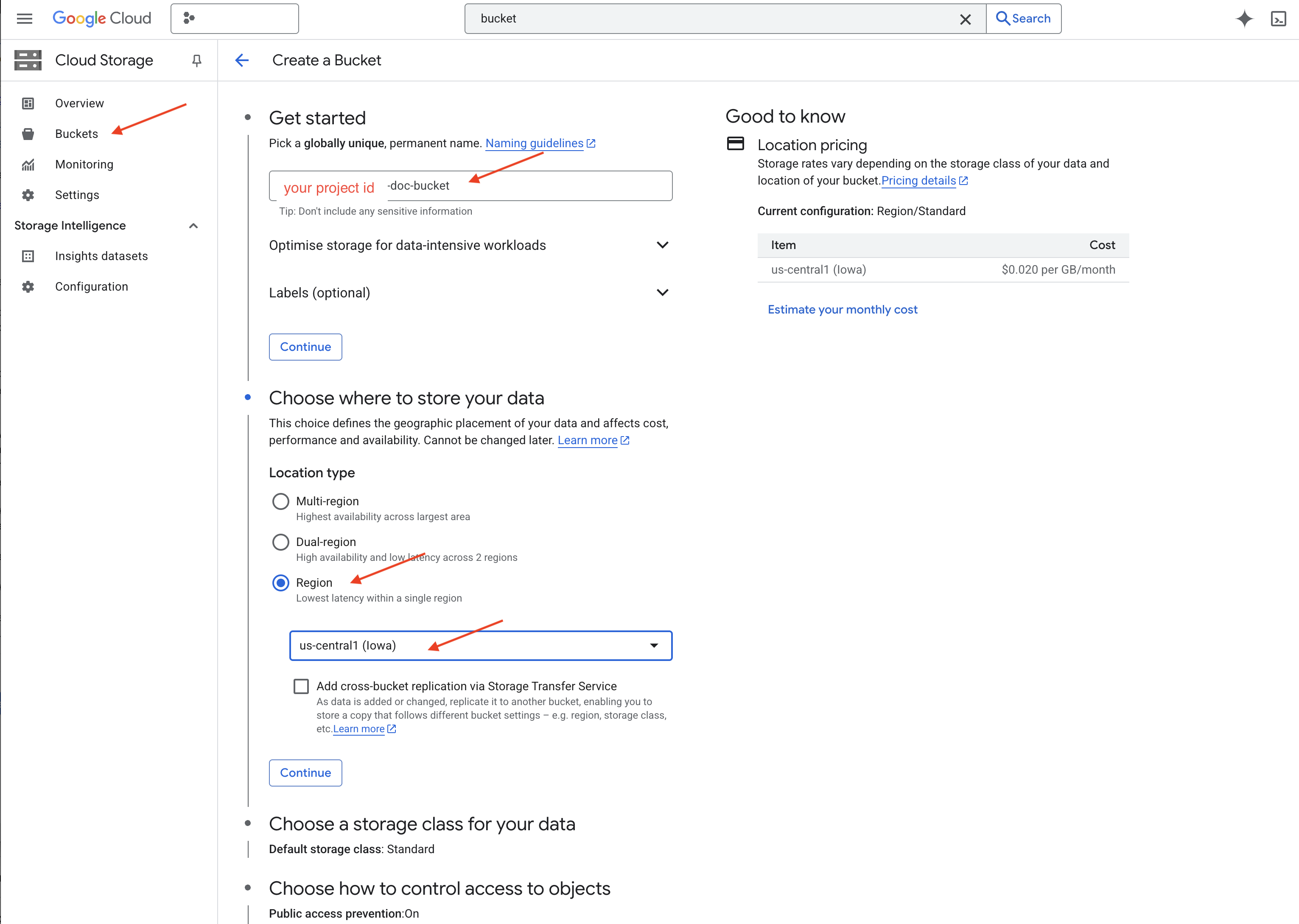
👉 Di tab/jendela baru, buka Cloud Storage.
👉 Klik "Bucket" di menu sebelah kiri.
👉 Klik tombol "+ BUAT" di bagian atas.
👉 Konfigurasi bucket Anda (Setelan penting):
- bucket name: ‘yourprojectID'-doc-bucket (ANDA HARUS memiliki akhiran -doc-bucket di bagian akhir)
- region: Pilih wilayah
us-central1. - Kelas penyimpanan: "Standard". Standard cocok untuk data yang sering diakses.
- Access control: Biarkan "Uniform access control" dipilih secara default. Tindakan ini memberikan kontrol akses level bucket yang konsisten.
- Opsi lanjutan: Untuk tutorial ini, setelan default biasanya sudah cukup.
👉 Klik tombol CREATE untuk membuat bucket Anda.
👉 Anda mungkin melihat pop-up tentang pencegahan akses publik. Biarkan kotak dicentang, lalu klik 'Konfirmasi'.
Sekarang Anda akan melihat bucket yang baru dibuat dalam daftar Bucket. Ingat nama bucket Anda, Anda akan memerlukannya nanti.
8. Menyiapkan Cloud Run Function
👉 Di Editor Kode Cloud Shell, buka direktori kerja legal-eagle: Gunakan perintah cd di terminal Cloud Editor untuk membuat folder.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Buat file main.py,requirements.txt, dan Dockerfile. Di terminal Cloud Shell, gunakan perintah touch untuk membuat file:
touch main.py requirements.txt Dockerfile
Anda akan melihat folder yang baru dibuat bernama *loader dan tiga file.
👉 Edit main.py di folder loader. Di file explorer di sebelah kiri, buka direktori tempat Anda membuat file, lalu klik dua kali main.py untuk membukanya di editor.
Tempelkan kode Python berikut ke main.py:
Aplikasi ini memproses file baru yang diupload ke bucket GCS, membagi teks menjadi beberapa bagian, membuat penyematan untuk setiap bagian, dan menyimpan bagian serta penyematannya di Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Edit requirements.txt.Tempel baris berikut ke dalam file:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Menguji dan membangun Cloud Run Function
👉 Kita akan menjalankan ini di lingkungan virtual dan menginstal library Python yang diperlukan untuk fungsi Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Mulai emulator lokal untuk fungsi Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Biarkan terminal terakhir tetap berjalan, buka terminal baru, lalu jalankan perintah untuk mengupload file ke bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Saat emulator berjalan, Anda dapat mengirim CloudEvent pengujian ke emulator. Anda memerlukan terminal terpisah di IDE untuk melakukan hal ini.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Tindakan ini akan menampilkan OK.
👉 Anda akan memverifikasi Data di Firestore, membuka Konsol Google Cloud, lalu membuka "Databases", lalu "Firestore", lalu memilih tab "Data", lalu koleksi legal_documents. Anda akan melihat dokumen baru telah dibuat dalam koleksi Anda, yang masing-masing mewakili potongan teks dari file yang diupload. 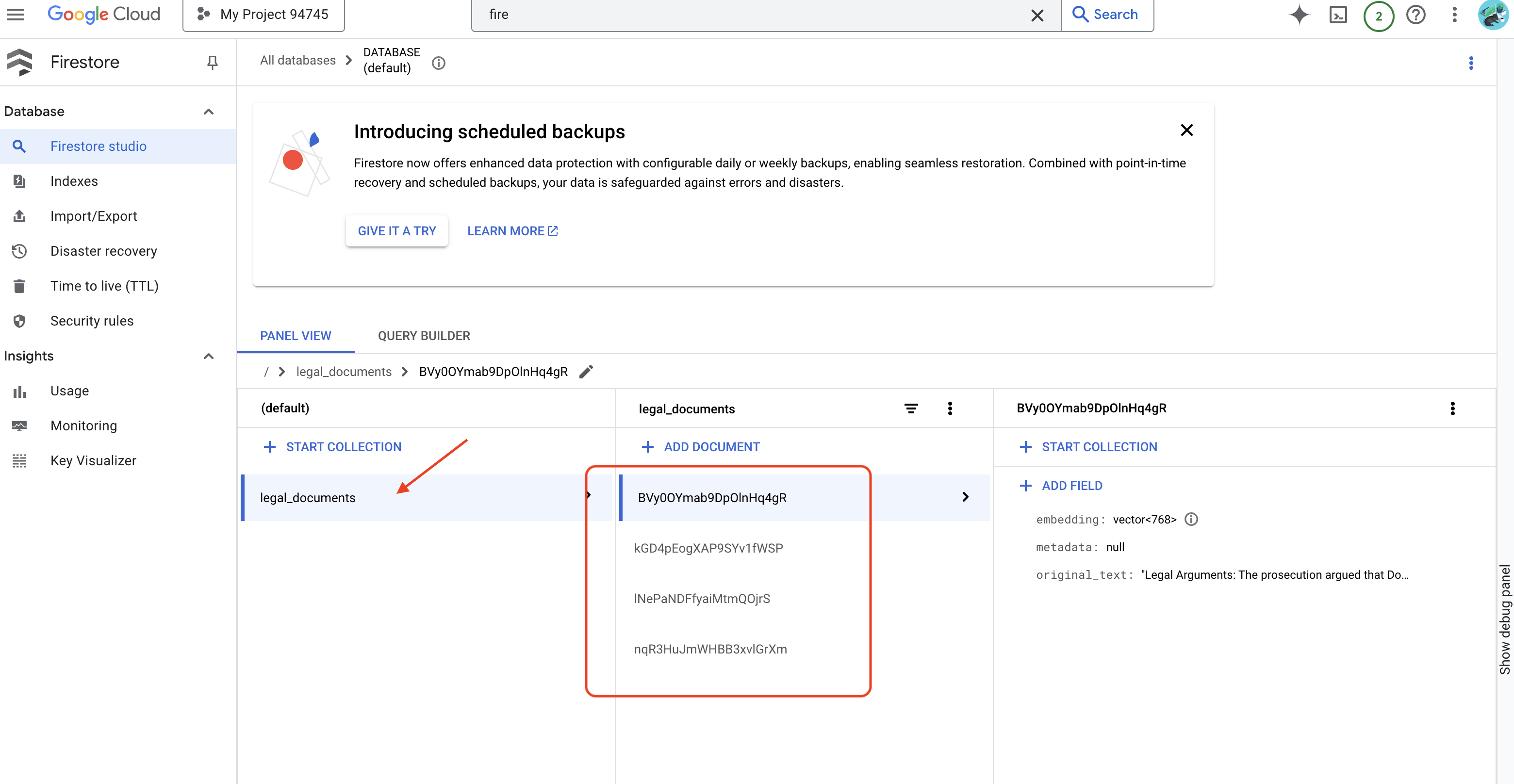
👉 Di terminal yang menjalankan emulator, ketik Ctrl+C untuk keluar. Kemudian, tutup terminal kedua.
👉 Jalankan deactivate untuk keluar dari lingkungan virtual.
deactivate
10. Membangun image container dan mengirimkannya ke repositori Artifacts
👉 Saatnya men-deploy ini ke cloud. Di file explorer, klik dua kali Dockerfile. Minta Gemini untuk membuat dockerfile bagi Anda, buka Gemini Code Assist, lalu gunakan perintah berikut untuk membuat file.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Sebagai praktik terbaik, sebaiknya klik Diff with Open File(dua panah dengan arah berlawanan, dan terima perubahan). 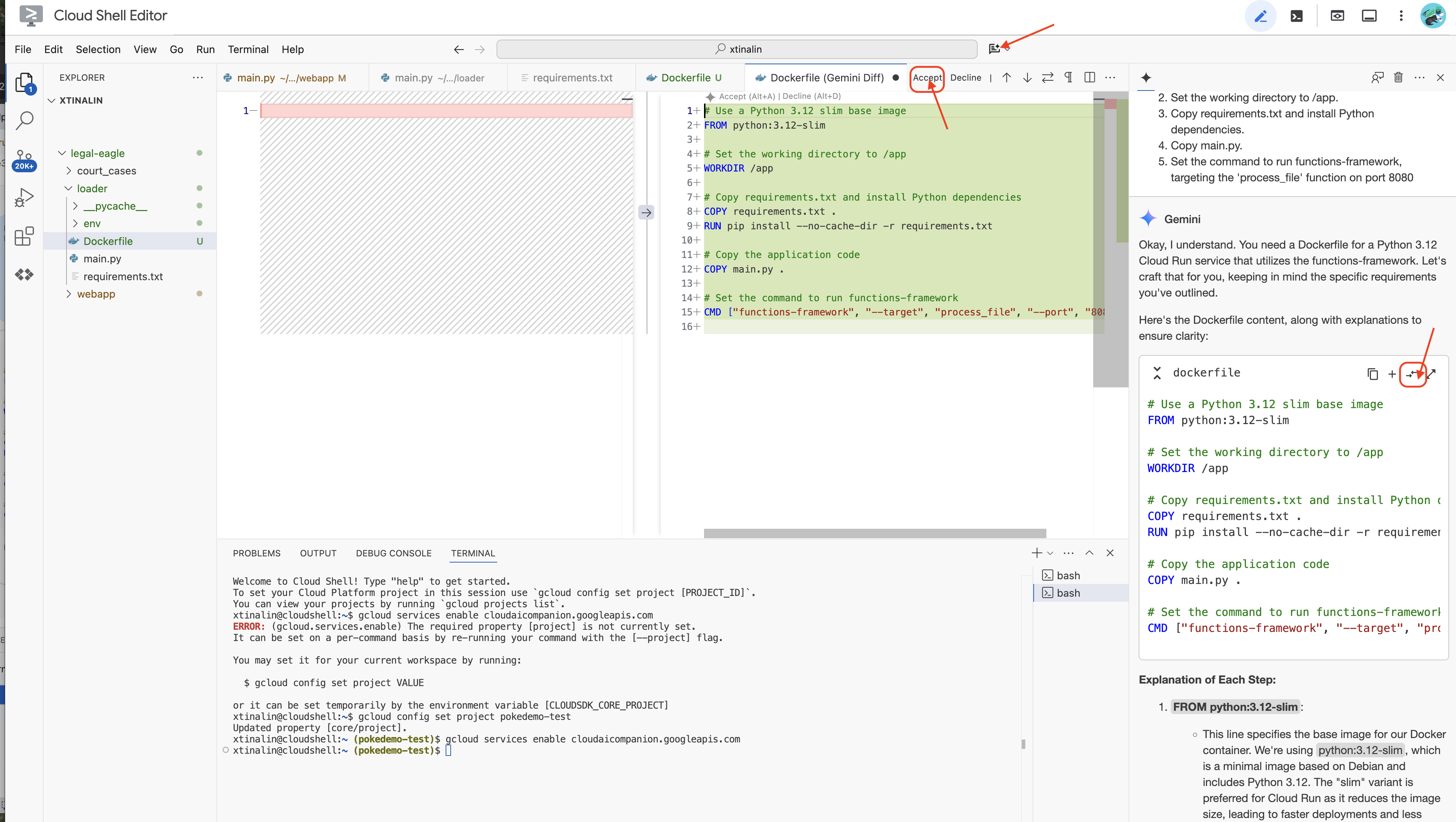
👉 Jika Anda baru menggunakan Container, berikut contoh cara kerjanya:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 Di terminal, buat repositori artefak untuk menyimpan image Docker yang akan kita bangun.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Anda akan melihat Created repository [my-repository].
👉 Jalankan perintah berikut untuk membuat image Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Sekarang Anda akan mengirimkannya ke registry
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
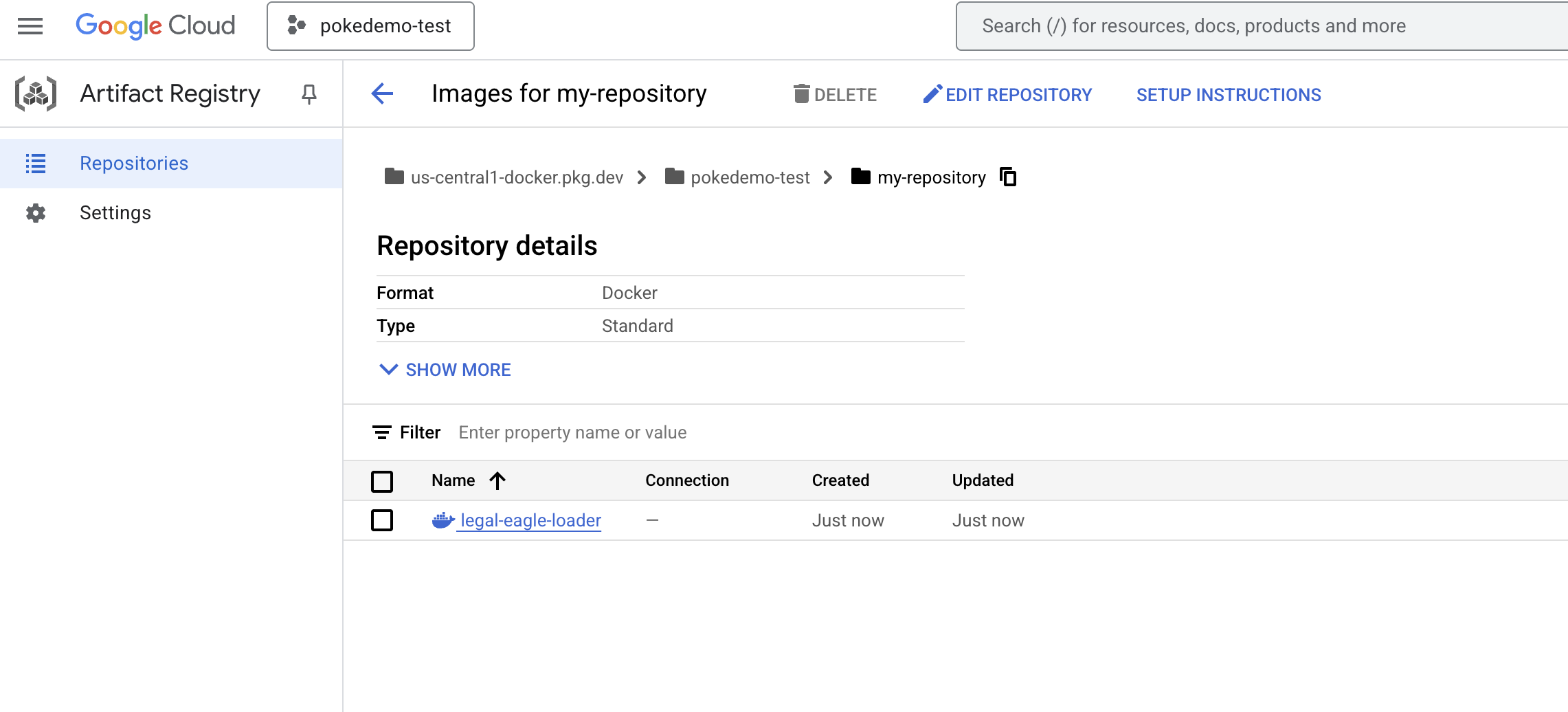
Image Docker kini tersedia di my-repository Artifacts Repository.
11. Buat fungsi Cloud Run dan siapkan pemicu Eventarc
Sebelum mempelajari secara spesifik cara men-deploy pemuat dokumen hukum kita, mari kita pahami secara singkat komponen yang terlibat: Cloud Run adalah platform serverless terkelola sepenuhnya yang memungkinkan Anda men-deploy aplikasi dalam container dengan cepat dan mudah. Cloud Run mengabstraksi pengelolaan infrastruktur, sehingga Anda dapat berfokus pada penulisan dan deployment kode.
Kita akan men-deploy pemuat dokumen sebagai layanan Cloud Run. Sekarang, mari kita lanjutkan dengan menyiapkan fungsi Cloud Run:
👉 Di Konsol Google Cloud, buka Cloud Run.
👉 Buka Deploy Container, lalu klik SERVICE di menu drop-down.
👉 Konfigurasi layanan Cloud Run Anda:
- Container image: Klik "Pilih" di kolom URL. Temukan URL image yang Anda kirim ke Artifact Registry (misalnya, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Service name:
legal-eagle-loader - Region: Pilih region
us-central1. - Authentication: Untuk tujuan workshop ini, Anda dapat mengizinkan "Allow unauthenticated invocations". Untuk produksi, Anda mungkin ingin membatasi akses.
- Container, Networking, Security : default.
👉 Klik BUAT. Cloud Run akan men-deploy layanan Anda. 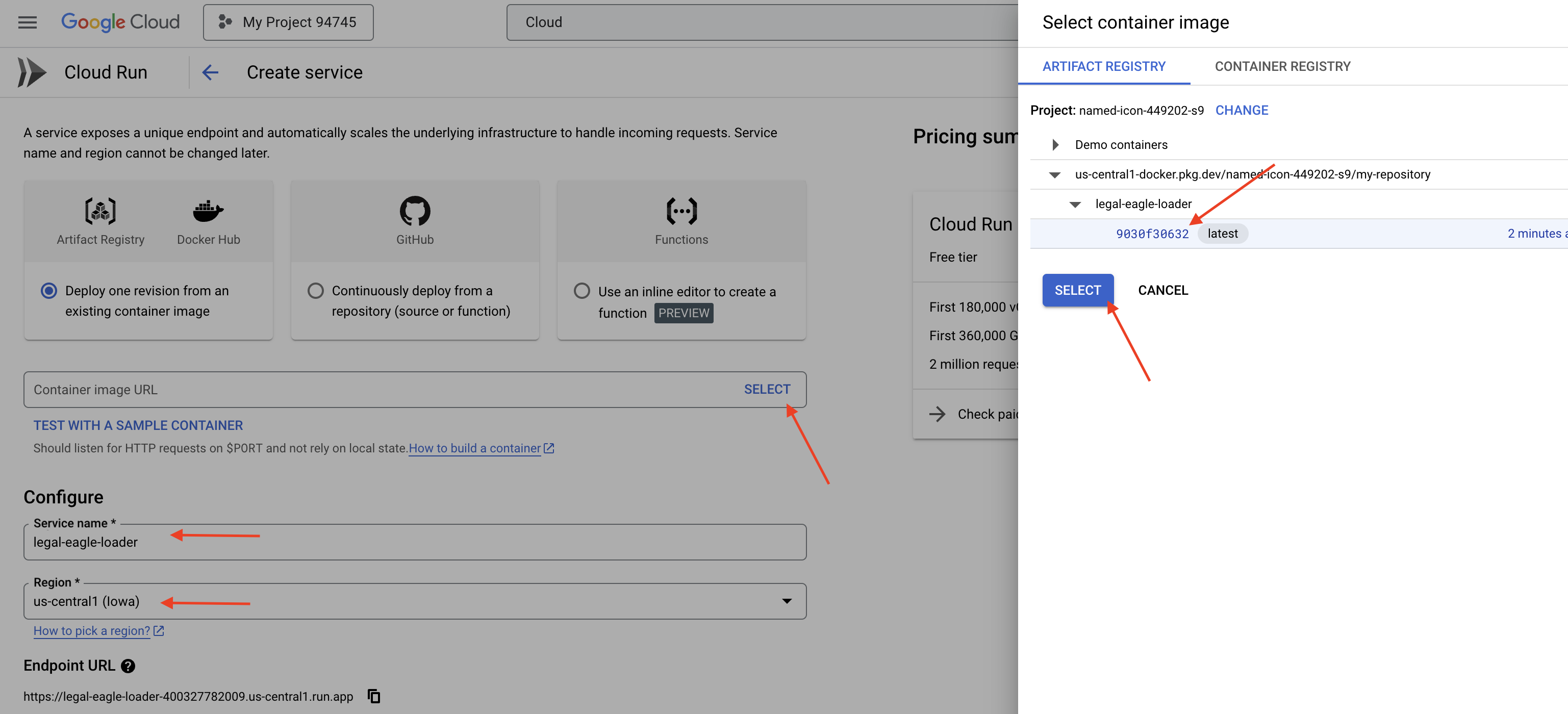
Untuk memicu layanan ini secara otomatis saat file baru ditambahkan ke bucket penyimpanan, kita akan menggunakan Eventarc. Eventarc memungkinkan Anda membuat arsitektur berbasis peristiwa dengan merutekan peristiwa dari berbagai sumber ke layanan Anda.
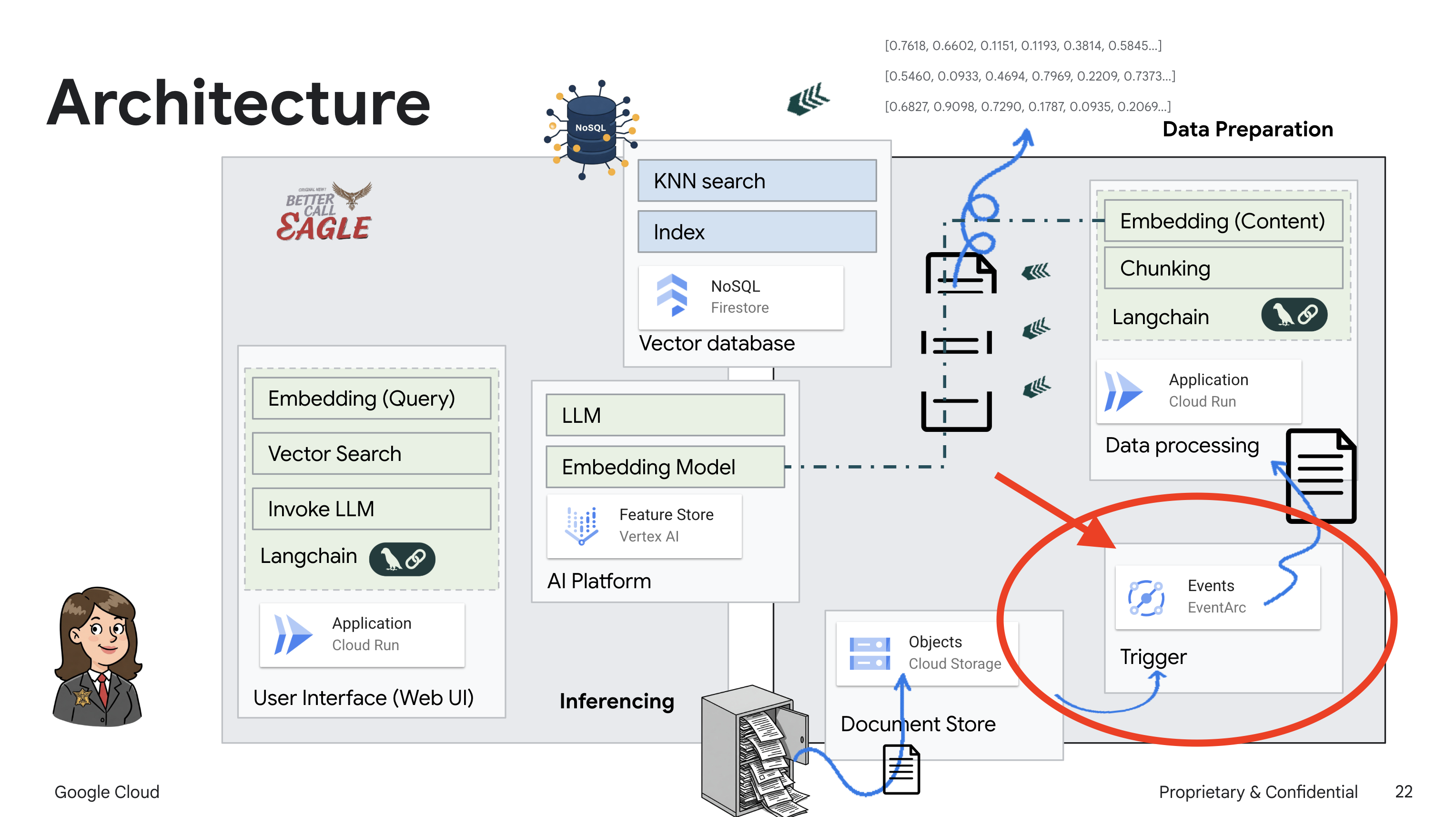
Dengan menyiapkan Eventarc, layanan Cloud Run kami akan otomatis memuat dokumen yang baru ditambahkan ke Firestore segera setelah diupload, sehingga memungkinkan pembaruan data real-time untuk aplikasi RAG kami.
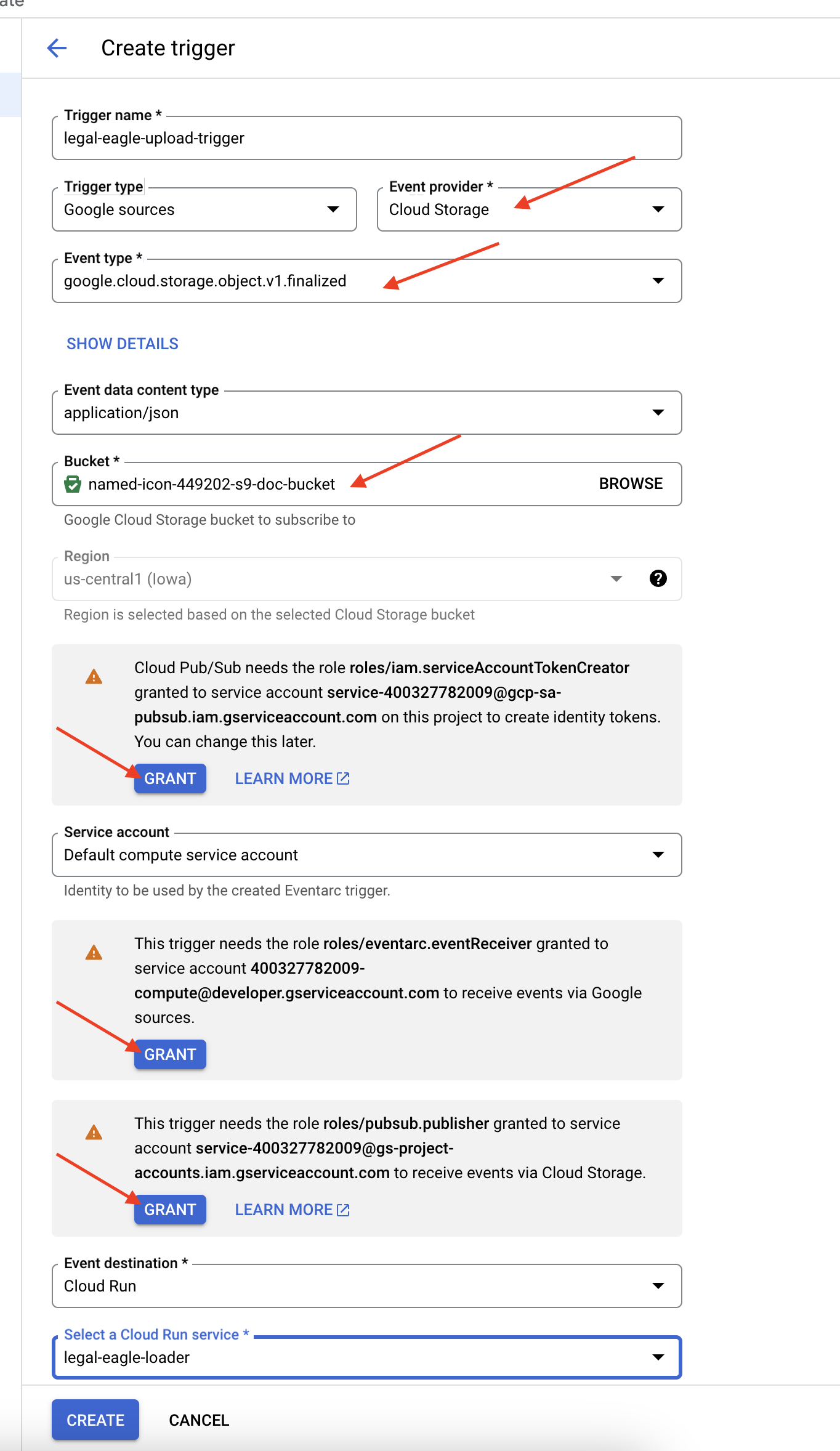
👉 Di Konsol Google Cloud, buka Triggers di bagian EventArc. Klik "+ BUAT Pemicu". 👉 Konfigurasi Pemicu Eventarc:
- Nama pemicu:
legal-eagle-upload-trigger. - TriggerType: Sumber Google
- Penyedia peristiwa: Pilih Cloud Storage.
- Jenis acara: Pilih
google.cloud.storage.object.v1.finalized - Bucket Cloud Storage: Pilih bucket GCS Anda dari dropdown.
- Jenis tujuan: "Layanan Cloud Run".
- Layanan: Pilih
legal-eagle-loader. - Region:
us-central1 - Jalur: Kosongkan bagian ini untuk saat ini .
- Berikan semua izin yang diminta di halaman
👉 Klik BUAT. Eventarc kini akan menyiapkan pemicu.
Layanan Cloud Run memerlukan izin untuk membaca file dari berbagai komponen. Kita perlu memberikan izin yang diperlukan akun layanan layanan.
12. Mengupload dokumen hukum ke bucket GCS
👉 Upload file kasus pengadilan ke bucket GCS Anda. Ingat, untuk mengganti nama bucket Anda.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Pantau Log Layanan Cloud Run, buka Cloud Run -> layanan Anda legal-eagle-loader -> "Logs". Periksa log untuk pesan pemrosesan yang berhasil, termasuk:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
Bergantung pada seberapa cepat penyiapan logging, Anda juga akan melihat log detail lainnya di sini
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Cari pesan error di log dan pecahkan masalah jika perlu. 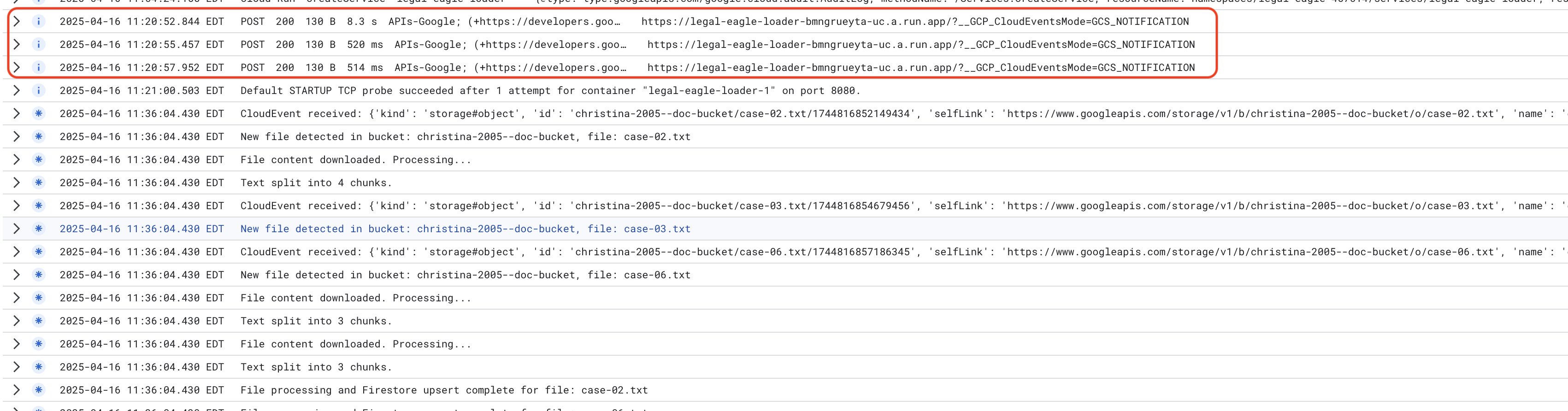
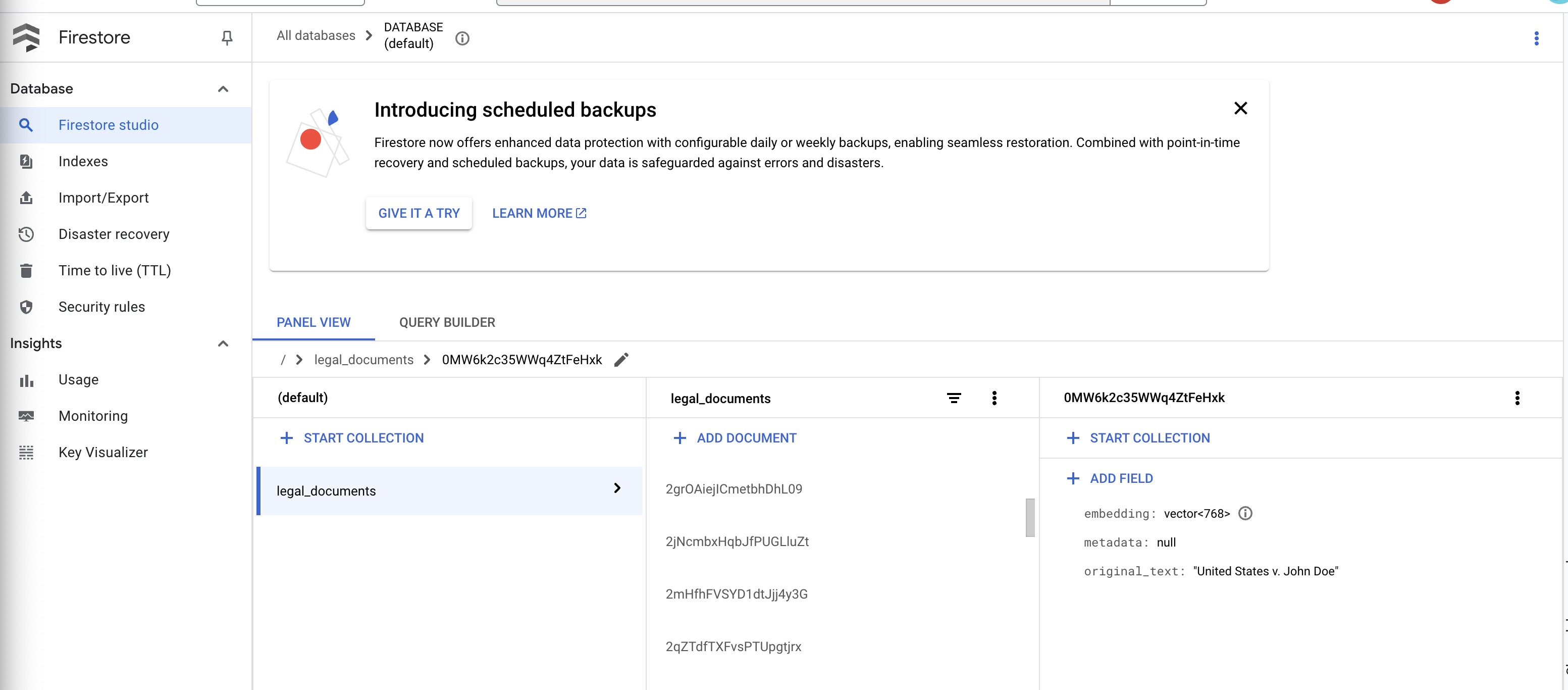
👉 Verifikasi Data di Firestore. Kemudian, buka koleksi legal_documents Anda.
👉 Anda akan melihat dokumen baru yang dibuat di koleksi Anda. Setiap dokumen akan merepresentasikan potongan teks dari file yang Anda upload dan akan berisi:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Menerapkan RAG
LangChain adalah framework canggih yang dirancang untuk menyederhanakan pengembangan aplikasi yang didukung oleh model bahasa besar (LLM). Daripada berurusan langsung dengan kerumitan API LLM, rekayasa perintah, dan penanganan data, LangChain menyediakan lapisan abstraksi tingkat tinggi. Vertex AI menawarkan komponen dan alat bawaan untuk tugas-tugas seperti menghubungkan ke berbagai LLM (seperti dari OpenAI, Google, atau lainnya), membangun rantai operasi yang kompleks (misalnya, pengambilan data yang diikuti dengan peringkasan), dan mengelola memori percakapan.
Khusus untuk RAG, penyimpanan Vektor di LangChain sangat penting untuk mengaktifkan aspek pengambilan RAG. Database ini adalah database khusus yang dirancang untuk menyimpan dan membuat kueri embedding vektor secara efisien, di mana potongan teks yang serupa secara semantik dipetakan ke titik-titik yang berdekatan dalam ruang vektor. LangChain menangani proses tingkat rendah, sehingga developer dapat berfokus pada logika dan fungsi inti aplikasi RAG mereka. Hal ini secara signifikan mengurangi waktu dan kompleksitas pengembangan, sehingga Anda dapat membuat prototipe dan men-deploy aplikasi berbasis RAG dengan cepat sekaligus memanfaatkan keandalan dan skalabilitas infrastruktur Google Cloud.
Setelah LangChain dijelaskan, Anda sekarang perlu memperbarui file legal.py di folder webapp untuk penerapan RAG. Hal ini akan memungkinkan LLM menelusuri dokumen yang relevan di Firestore sebelum memberikan jawaban.
👉 Impor FirestoreVectorStore dan modul lain yang diperlukan dari langchain dan vertexai. Tambahkan kode berikut ke legal.py saat ini
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Lakukan inisialisasi Vertex AI dan model penyematan.Anda akan menggunakan text-embedding-004. Tambahkan kode berikut tepat setelah mengimpor modul.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Buat FirestoreVectorStore yang mengarah ke koleksi legal_documents, menggunakan model embedding yang diinisialisasi dan menentukan kolom konten dan embedding. Tambahkan kode ini tepat setelah kode model penyematan sebelumnya.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Tentukan fungsi bernama search_resource yang mengambil kueri, melakukan penelusuran kemiripan menggunakan vector_store.similarity_search, dan menampilkan hasil gabungan.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 GANTI fungsi ask_llm dan gunakan fungsi search_resource untuk mengambil konteks yang relevan berdasarkan kueri pengguna.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPSIONAL: VERSI SPANYOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 Setelah menerapkan RAG di legal.py, Anda harus mengujinya secara lokal sebelum men-deploy, jalankan aplikasi dengan perintah:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Gunakan webpreview untuk mengakses aplikasi, berbicara dengan asisten, dan ketik ctrl+c untuk keluar dari proses yang dijalankan secara lokal. Jalankan deactivate untuk keluar dari lingkungan virtual.
deactivate
👉 Untuk men-deploy aplikasi web ke Cloud Run, caranya mirip dengan fungsi loader. Anda akan membangun, memberi tag, dan mengirim image Docker ke Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Saatnya men-deploy aplikasi web ke Google Cloud. Di terminal, jalankan perintah berikut:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Verifikasi deployment dengan membuka Cloud Run di Konsol Google Cloud.Anda akan melihat layanan baru bernama legal-eagle-webapp tercantum.
Klik layanan untuk membuka halaman detailnya. Anda dapat menemukan URL yang di-deploy di bagian atas. 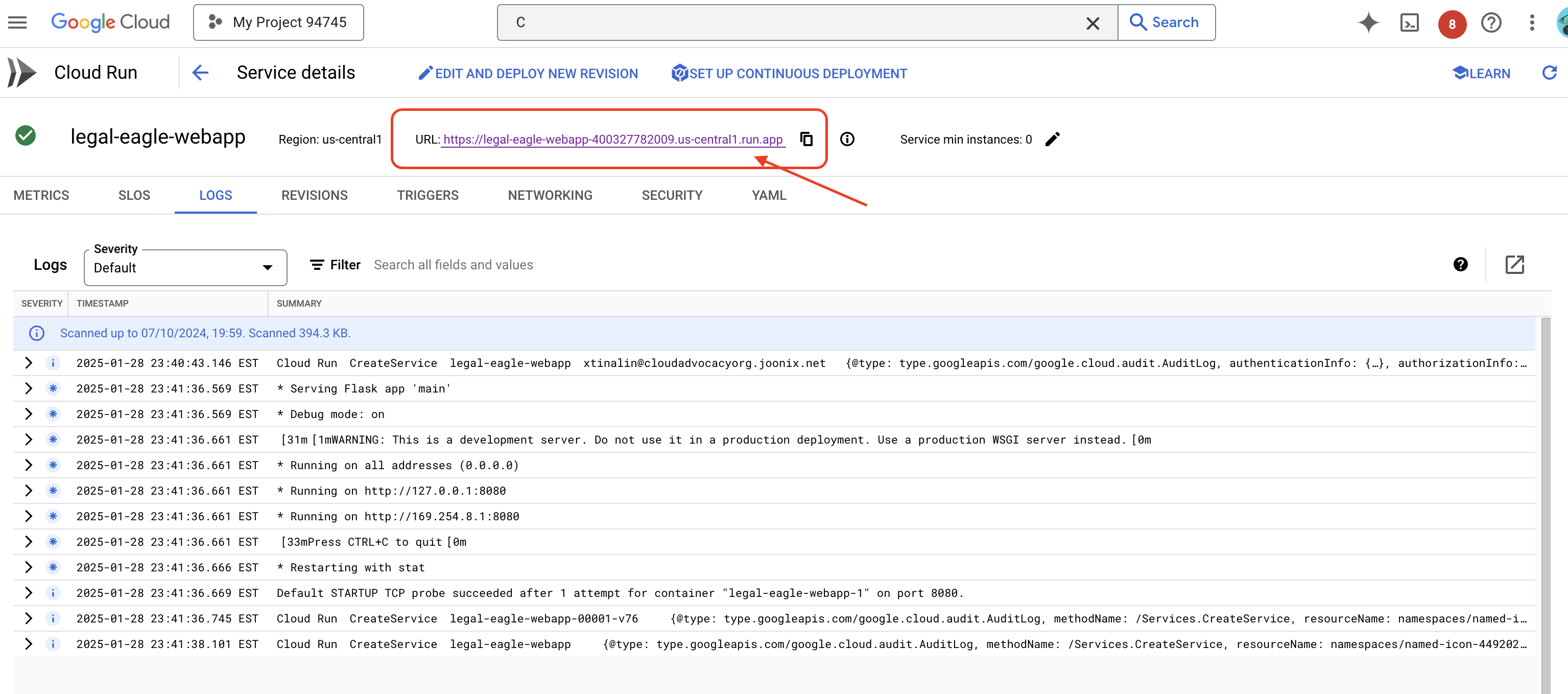
👉 Sekarang, buka URL yang di-deploy di tab browser baru. Anda dapat berinteraksi dengan asisten hukum dan mengajukan pertanyaan terkait kasus pengadilan yang telah Anda muat(di folder court_cases):
- Berapa tahun hukuman penjara yang dijatuhkan kepada Michael Brown?
- Berapa banyak uang dalam tagihan tidak sah yang dihasilkan sebagai akibat dari tindakan Jane Smith?
- Apa peran kesaksian tetangga dalam penyelidikan kasus Emily White?
👉 OPSIONAL: VERSI SPANYOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Anda akan melihat bahwa respons kini lebih akurat dan didasarkan pada konten dokumen hukum yang telah Anda upload, yang menunjukkan keunggulan RAG.
Selamat telah menyelesaikan workshop ini. Anda telah berhasil membangun dan men-deploy aplikasi analisis dokumen hukum menggunakan LLM, LangChain, dan Google Cloud. Anda telah mempelajari cara menyerap dan memproses dokumen hukum, meningkatkan kualitas respons LLM dengan informasi yang relevan menggunakan RAG, dan men-deploy aplikasi Anda sebagai layanan tanpa server. Pengetahuan ini dan aplikasi yang dibuat akan membantu Anda lebih lanjut menjelajahi kemampuan LLM untuk tugas hukum. Bagus!"
14. Tantangan
Berbagai Jenis Media::
Cara menyerap dan memproses berbagai jenis media seperti video pengadilan dan rekaman audio, serta mengekstrak teks yang relevan.
Aset Online:
Cara memproses aset online seperti halaman web secara langsung.